前言
可以通过长按二维码关注我的公众号,不过会先在掘金更新后同步过去。

PC端的这个右侧的目录找东西确实好找点,我每次写也非常注意看这块排版工不工整🤣,用这里去直接跳到对应的内容真的还算方便,所以就想着做个目录,以后如果写了新的,也会在这篇写上标题。
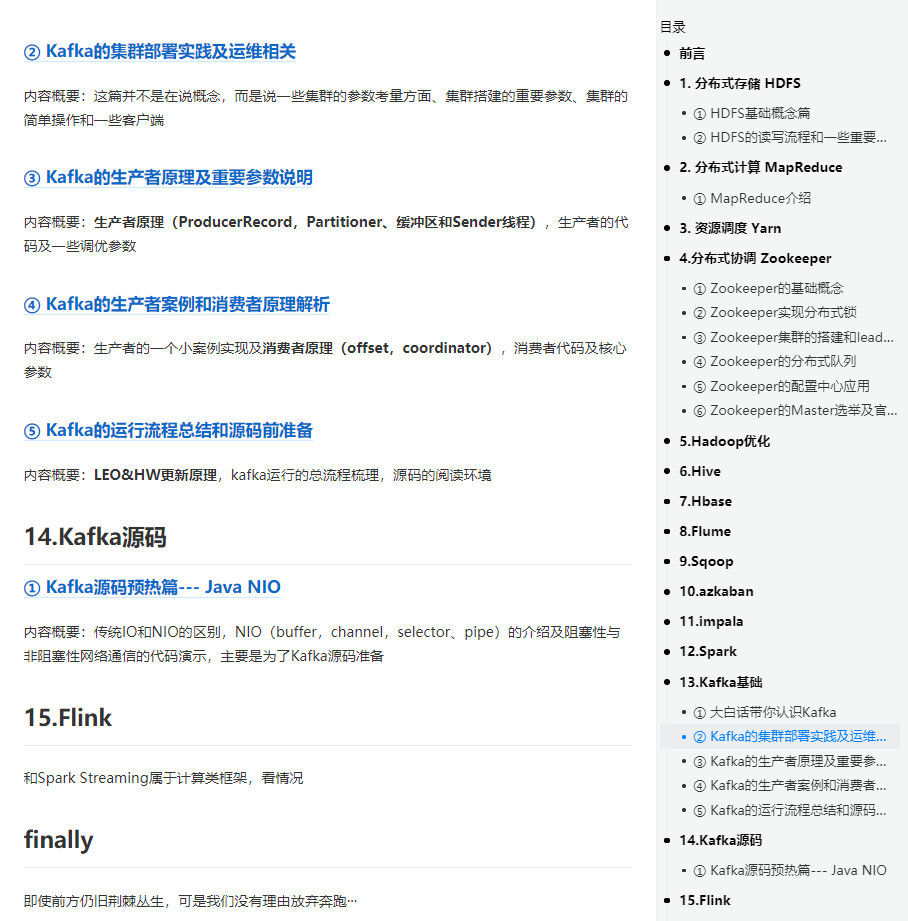
按照不同技术框架的划分形式。已经有写过的就写上,没写过的就先空着。
1. 分布式存储 HDFS
① HDFS基础概念篇
内容概要:block的概念与副本、机架存储策略、三大组件:NameNode,DataNode,SecondaryNamenode、元数据metaData、心跳机制和负载均衡机制
② HDFS的读写流程和一些重要策略
内容概要:HDFS的读写流程,hadoop HA高可用,联邦,存储小文件时的HAR和Sequence File
③ HDFS的基础总结及架构演进
内容概要:对前面两篇的一些总结及补充
2. 分布式计算 MapReduce
① MapReduce介绍
内容概要:mapper和reducer代码、shuffle、二排、数据倾斜的判断和减缓
3. 资源调度 Yarn
① 带你入坑大数据(四)--- 资源调度框架Yarn
内容概要:全是理论性的东西。yarn的应用场景、核心组件、应用调度过程、yarn的典型应用
4.分布式协调 Zookeeper
zookeeper写的时候姑且是按照Java的套路去写的,和大数据的操作扯不上关系,之后可能会进行相应的补充
① Zookeeper的基础概念
内容概要:包括zookeeper的简介和特征,会话机制、znode的数据构成和节点类型,还有zk的监听机制
② Zookeeper实现分布式锁
内容概要:锁的特征,zkClient的使用、使用节点不可重名+watch机制实现分布式锁、使用取号 + 最小号取lock + watch原理实现分布式锁
③ Zookeeper集群的搭建和leader选举
内容概要:伪集群形式的zookeeper的集群搭建,集群连接和监控,paxos算法的解释说明、zookeeper的leader选举机制
④ Zookeeper的分布式队列
内容概要:ZAB协议的介绍,数据同步,丢弃事务,leader崩溃恢复、zookeeper的分布式队列的实现逻辑及代码实现
⑤ Zookeeper的配置中心应用
内容概要:配置中心的介绍,数据结构,代码实现
⑥ Zookeeper的Master选举及官网小览
内容概要:master选举和zookeeper的相关实现、官网自己的一个浏览过程
5.Hadoop源码及优化
前置两篇RPC基础
从零开始的高并发(七)--- RPC的介绍,协议及框架
内容概要:简单过了一遍RPC是什么,三个过程,为什么我们需要它,它的特性和适用场景,RPC的流程及协议定义还有它的框架的一些小知识
从零开始的高并发(八)--- RPC框架的简单实现
内容概要:RPC的流程和任务分析及代码实现,附带过程优化,优化部分推荐先直接跳转总图查看
① Hadoop源码篇 --- NameNode的启动流程解析
内容概要:如题,NameNode启动流程分析,思路为验证NameNode是不是一个RPC的服务端
② Hadoop源码篇 --- DataNode的初始化与注册流程
内容概要:如题,DataNode启动流程分析,思路也是验证它是否是RPC的客户端,还有Hadoop HA高可用方案原理
③ Hadoop源码篇 --- 面试常问的Namenode元数据管理及双缓冲机制
内容概要:如题
6.Hive
7.Hbase
① MySQL同步数据到HBase
内容概要:如题,还有一些细节说明
8.Flume
9.Sqoop
10.azkaban
11.impala
12.Spark
① 从零开始认识 Spark
内容概要:Spark 的四大特性,基础架构,安装及任务提交的一些内容
② 一文带你过完Spark RDD的基础概念
内容概要:RDD 的五大特性说明,算子说明,RDD 的依赖关系,血缘,缓存机制,checkpoint机制,DAG 的生成及 stage 的划分
③ 关于Spark基础的一些小问题补充
内容概要:补充一些前两篇没提到的知识点,比如广播变量,任务调度,序列化的问题
④ 一文带你理清Spark Core调优的方方面面
内容概要:参考美团之前的Spark文章,提及 Spark 的十大开发原则及 Spark 的运行流程,还有内存模型调优及数据倾斜处理
⑤ Spark Streaming 的容错机制
内容概要:顾名思义,Executor 和 Driver 的容错
⑥ 完成你的第一个Spark Streaming程序
内容概要:顾名思义,运行流程说明及 BlockInterval 和 BatchInterval 的说明,setMaster 的理解补充
13.Kafka基础
① 大白话带你认识Kafka
内容概要:Kafka中的一些基础角色的介绍,topic,partition,producer,consumer,message,副本,消费者组,controller、kafka和zookeeper的配合,kafka的顺序写和零拷贝,日志分段存储机制和kafka的三层网络模型
② Kafka的集群部署实践及运维相关
内容概要:这篇并不是在说概念,而是说一些集群的参数考量方面、集群搭建的重要参数、集群的简单操作和一些客户端
③ Kafka的生产者原理及重要参数说明
内容概要:生产者原理(ProducerRecord,Partitioner、缓冲区和Sender线程),生产者的代码及一些调优参数
④ Kafka的生产者案例和消费者原理解析
内容概要:生产者的一个小案例实现及消费者原理(offset,coordinator),消费者代码及核心参数
⑤ Kafka的运行流程总结和源码前准备
内容概要:LEO&HW更新原理,kafka运行的总流程梳理,源码的阅读环境
14.Kafka源码
① Kafka源码预热篇--- Java NIO
内容概要:传统IO和NIO的区别,NIO(buffer,channel,selector、pipe)的介绍及阻塞性与非阻塞性网络通信的代码演示,主要是为了Kafka源码准备
② Kafka源码篇 --- 你一定能get到的Producer的初始化及元数据获取流程
内容概要:通过源码中自带的Producer.java例子分析 KafkaProducer 的初始化过程及发送流程,还有元数据管理及 waitOnMetadata 的工作逻辑
③ Kafka源码篇 --- 可能是你看过最详细的RecordAccumulator解读
内容概要:如题,缓冲区RecordAccumulator的源码解读
15.Flink
① Flink 基础入门
内容概要:Flink 的四大特性及案例说明,不同模式下的安装提交
② Flink算子操作
内容概要:Flink shell 的使用,数据源及常用算子的示例说明
③ 过一下Flink的各种State
内容概要:Flink 的 state 代码示例,按照官方示例展示
④ Flink的checkPoint机制
内容概要:之前程序的 checkpoint 改造,checkpoint机制的说明及如何使用
16.ELK
① Elk环境篇 --- 本地快速搭建你的ElasticSearch及Kibana
内容概要:本地搭建 ElasticSearch 和 Kibana(提供安装包),及 ES 的一些简单操作
finally
即使前方仍旧荆棘丛生,可是我们没有理由放弃奔跑···
这个flag无论对于你我来说都是一个考验,在第一篇HDFS的时候,就说过了这虽然是类似于一份学习笔记,可是绝对有头有尾,会用最清晰明了的语言来描述知识点,希望大家也能有所收获。以这个目录为证,相信我一定能说到做到。
现在有在经营自己的知识星球,免费但不代表会没有收获。对大数据方向感兴趣的同学可以关注一下