

前言
ELK的基本介绍
ELK是三个软件产品的首字母缩写,Elasticsearch,Logstash 和 Kibana。这三款软件都是开源软件,通常是配合使用,而且又先后归于 Elastic.co 公司名下,故被简称为 ELK 协议栈
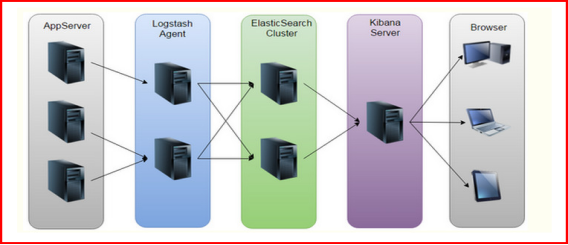
左边我们部署了多台服务器,然后我们通过logstash来采集数据,采集完成我们发送到ES集群中存起来,然后通过Kibana去展示到我们的浏览器中,就是这么一个简单的套路
Elasticsearch是个开源分布式搜索引擎,它的特点有:开箱即用,分布式,零配置,自动发现,索引自动分片,索引副本机制,RESTful风格接口,多数据源,自动搜索负载等。
Logstash是一个完全开源的工具,他可以对你的日志进行收集、过滤,并将其存储供以后使用(比如供ES来进行搜索)。
Kibana 也是一个开源和免费的工具,它Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
ELK的实现介绍
| ELK | 实现语言 | 简介 |
|---|---|---|
| ElasticSearch | Java | 实时的分布式搜索和分析引擎,可用于全文检索,结构化搜索以及分析,基层基于Lucene。类似于Solr |
| Logstash | JRuby | 具有实时渠道能力的数据收集引擎,包含输入、过滤、输出模块,一般在过滤模块中做日志格式化的解析工作 |
| Kibana | JavaScript | 为ElasticSerach提供分析平台和可视化的Web平台。他可以ElasticSerach的索引中查找,呼唤数据,并生成各种维度的表图 |
ELK的参考资料
ELK官网:https://www.elastic.co/
ELK官网文档:https://www.elastic.co/guide/index.html
ELK中文手册:https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
ELK中文社区:https://elasticsearch.cn/
一、Elasticsearch的部署
1.1 简介
ElaticSearch,简称为ES, ES是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。ES也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
下面是搜索引擎提供的一些使用的案例
GayHub:
2013年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索。它使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码”
Wiki:
维基百科:启动以elasticsearch为基础的核心搜索架构
SoundCloud:
SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务
Baidu:
百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括Casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据
Sina:使用ElasticSearch分析处理32亿条实时日志
Alibaba:使用ElasticSearch构建挖财自己的日志采集和分析体系
1.2 使用准备
我把我用到的安装包都上传到百度云了,有需要的可以自提,避免网络的尴尬🤣
链接:https://pan.baidu.com/s/17m0LmmRcffQbfhjSikIHhA
提取码:l1lj
首先我们得注意的是,ES是不能通过root用户来进行启动的,必须通过普通用户来安装启动,这里我们使用一个新建的用户
解决方案也可以直接参考这个 https://www.cnblogs.com/gcgc/p/10297563.html
首先是下安装包,然后再解压一下即可,操作比较简单这里就不说明了
之后我们创建两个文件夹,都在ES的目录下创建即可
mkdir -p /usr/local/elasticsearch-6.7.0/logs/
mkdir -p /usr/local/elasticsearch-6.7.0/datas
就是创建了一个数据文件和一个日志的存储文件夹而已
之后修改一下配置文件,在config文件夹中 vim elasticsearch.yml
cluster.name: myes
node.name: node3
path.data: 自己的安装路径/elasticsearch-6.7.0/datas
path.logs: 自己的安装路径/elasticsearch-6.7.0/logs
network.host: 自己节点的地址
http.port: 9200
discovery.zen.ping.unicast.hosts: ["node1", "node2", "node3"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: "*"
cluster.name --- 集群的名字,默认ElasticSearch
node.name --- 节点名
path.data --- 数据文件存放路径
path.logs --- 日志文件存放路径
http.port --- 访问端口号
discovery.zen.ping.unicast.hosts: 集群自动发现功能
bootstrap.system_call_filter:
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: "*"
这里要注意path.data 和 path.logs记得路径前要/,比如我的就是 path.data: /usr/local/elasticsearch-6.7.0/datas,当然大家都是聪明的孩子,估计是不会忘的
我们还可以设置一下最大和最小堆内存,在jvm.option配置文件中,修改完之后分发到另外的节点上去即可,当然另外两个节点的那个配置文件也是按照上方的套路去改就好了。
cd /usr/local
scp -r elasticsearch-6.7.0/ node2:$PWD
scp -r elasticsearch-6.7.0/ node3:$PWD
由于我的前两台虚拟机不知道咋地就崩掉了,本身自己的电脑内存就不足。所以我就单节点了🤣
1.3 修改一些系统配置
1.3.1 普通用户打开文件的最大数限制
问题错误信息描述:
max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
解决方案:解除普通用户打开文件的最大数限制,不然ES启动时可能会报错
sudo vi /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
这四行粘贴上去即可
1.3.2 普通用户启动线程数限制
sudo vi /etc/sysctl.conf
添加下面两行
vm.max_map_count=655360
fs.file-max=655360
执行 sudo sysctl -p,使得配置生效

注意:以上两个问题修改完成之后,一定要重新连接linux生效。关闭secureCRT或者XShell工具,然后重新打开工具连接linux即可
1.3.3 重新连接工具后的行动
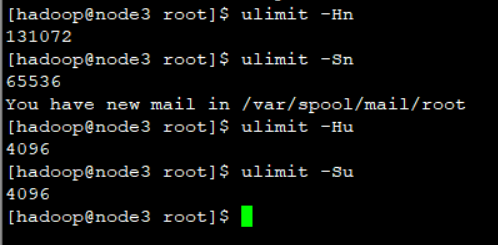
执行下面4个命令,没问题即可
[hadoop@node01 ~]$ ulimit -Hn
131072
[hadoop@node01 ~]$ ulimit -Sn
65536
[hadoop@node01 ~]$ ulimit -Hu
4096
[hadoop@node01 ~]$ ulimit -Su
4096
1.3.4 启动ES集群
nohup /usr/local/elasticsearch-6.7.0/bin/elasticsearch 2>&1 &
启动成功之后jsp即可看到es的服务进程,并且访问页面
http://node3:9200/?pretty
注意:如果哪一台机器服务启动失败,那么就到哪一台机器的logs去查看错误日志即可
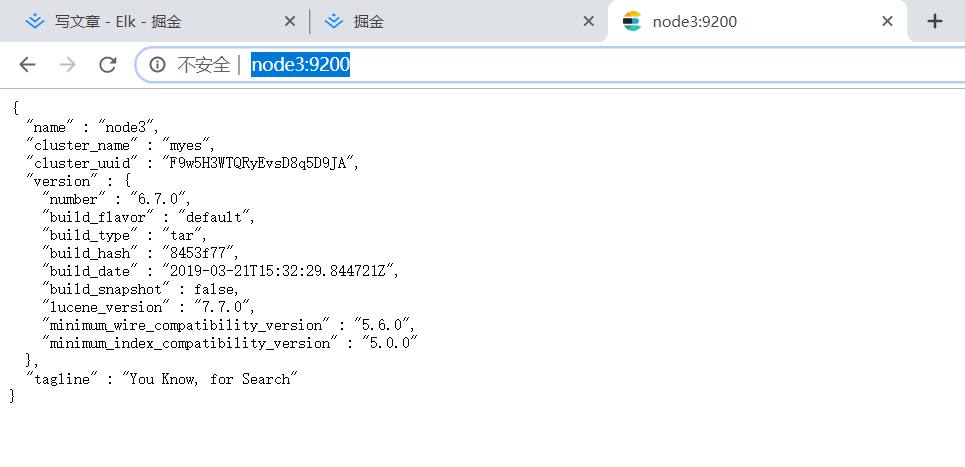
出现这个页面,就是已经启动了,非常丑陋
1.3.5 elasticsearch-head插件
由于es服务启动之后,访问界面比较丑陋,为了更好的查看索引库当中的信息,我们可以通过安装elasticsearch-head这个插件来实现,这个插件可以更方便快捷的看到es的管理界面
首先安装一下node.js
1.3.6 Node.js
Node.js是一个基于 Chrome V8 引擎的 JavaScript 运行环境。
Node.js是一个Javascript运行环境(runtime environment),发布于2009年5月,由Ryan Dahl开发,实质是对Chrome V8引擎进行了封装。Node.js 不是一个 JavaScript 框架,不同于CakePHP、Django、Rails。Node.js 更不是浏览器端的库,不能与 jQuery、ExtJS 相提并论。Node.js 是一个让 JavaScript 运行在服务端的开发平台,它让 JavaScript 成为与PHP、Python、Perl、Ruby 等服务端语言平起平坐的脚本语言。
安装步骤参考:https://www.cnblogs.com/kevingrace/p/8990169.html
下载好安装包之后,我们解压,进行些配置即可
sudo ln -s /usr/local/node-v8.1.0-linux-x64/lib/node_modules/npm/bin/npm-cli.js /usr/local/bin/npm
sudo ln -s /usr/local/node-v8.1.0-linux-x64/bin/node /usr/local/bin/node
然后修改环境变量
sudo vim .bash_profile
export NODE_HOME=/usr/local/node-v8.1.0-linux-x64
export PATH=:$PATH:$NODE_HOME/bin
然后source一下
出现以上的这个node和npm的版本即可
1.3.7 elasticsearch-head插件的安装
在线安装的话不太推荐,因为大家的网速都(你懂的),当然像我这种提前准备好了安装包的就不一样了
这时候我们把它解压,然后修改一下Gruntfile.js
cd /usr/local/elasticsearch-head
vim Gruntfile.js
你可以直接先shift+:,转到命令模式,使用/hostname来找到这个参数,hostname: '你自己的节点ip'
之后
cd /usr/local/elasticsearch-head/_site
vim app.js
和上面同样的套路,先找http://这个关键字,然后把localhost改成自己的节点ip
之后我们就可以开启服务了
cd /usr/local/elasticsearch-head/node_modules/grunt/bin/
nohup ./grunt server >/dev/null 2>&1 &
之后访问 http://你的节点ip:9100/即可访问,当然也是一个好看不到哪去的页面,还有就是,我这里有两个虚拟机傻了,所以没办法就启动了个单节点的

1.3.8 如何关闭
执行以下命令找到elasticsearch-head的插件进程,然后使用kill -9 杀死进程即可

sudo yum install net-tools
netstat -nltp | grep 9100
kill -9 88297
1.3.9 Kibana的安装
这个东西基本就是解压就能用了
先准备个安装包,然后解压出来
cd /usr/local/kibana-6.7.0-linux-x86_64/config/
vi kibana.yml
配置内容如下:
server.host: "node3"
elasticsearch.hosts: ["http://node3:9200"]
然后我们就可以开始启动了
cd /usr/local/kibana-6.7.0-linux-x86_64
nohup bin/kibana >/dev/null 2>&1 &

这种时候需要的就是等待即可

额,我们再等一小下😂

这里说它通知你你的集群里面啥数据都没有,这时候随便点第一个就是了
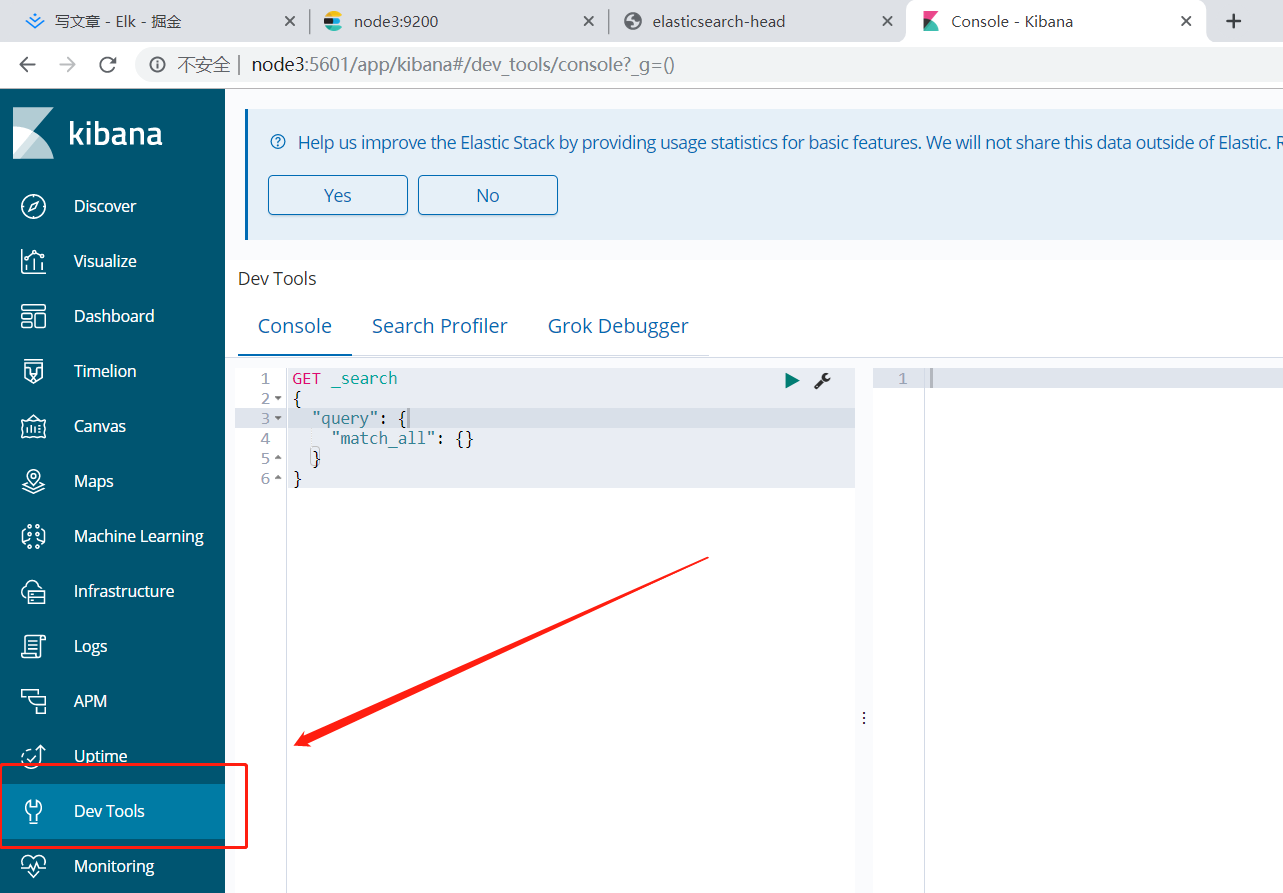
这种时候就算是安装完成了。之后我们的交互方式就是DEV tools---开发者工具那里去进行和ES的交互
二、简单操作一下ElasticSearch
2.1 ES的一些概念
我们使用传统的关系型数据库来类比一下
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
我们平时接触的比如MySQL,它是不是有多个数据库,每个数据库中有多张表table,每张表都有很多条数据Rows,然后数据又有字段 Columns
而一个ES下面有很多个索引库Indices,而它下面又有很多的Types,类似于table的东西,每一条数据都是documents,然后字段就是Fields
2.2 一些专有名词的解释
2.2.1、索引 index
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。
2.2.2、类型 type
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由我们来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
2.2.3、字段Field
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
2.2.4、映射 mapping
其实就是类似于JavaBean一样的东西。mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
2.2.5、文档 document
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。
在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。
2.2.6、接近实时 NRT
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒以内)
2.2.7、分片和副本 shards & replicas
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。分片很重要,主要有两方面的原因:
允许你水平分割/扩展你的内容容量。
允许你在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
在一个网络环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做 replicas,或者中文翻译过来可能叫副本。
replicas之所以重要,有两个主要原因:
在分片/节点失败的情况下,提供了高可用性。因为这个原因,复制分片从不与原/主要(original/primary)分片置于同一节点上。扩展你的搜索量/吞吐量,因为搜索可以在所有的 replicas 上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。shards & replicas 的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变 replicas 的数量,但是你事后不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个replicas,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
2.2.8、一个管理工具
curl是利用URL语法在命令行方式下工作的开源文件传输工具,使用curl可以简单实现常见的get/post请求。简单的认为是可以在命令行下面访问url的一个工具。在centos的默认库里面是有curl工具的,如果没有yum安装即可。
yum -y install curl
curl
-X 指定http的请求方法 有HEAD GET POST PUT DELETE
-d 指定要传输的数据
-H 指定http请求头信息
2.3 使用 Xput创建索引
2.3.1 创建索引
此时我们的索引中是仅有Kibana默认帮我们创建的索引的
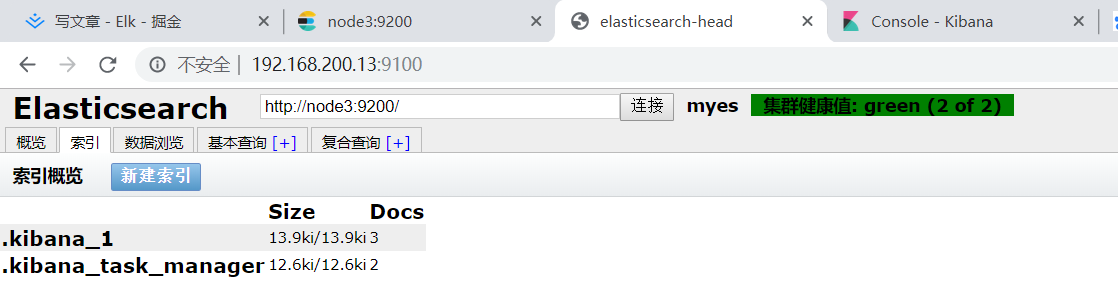
在我们的kibana的dev tools当中执行以下语句
curl -XPUT http://node3:9200/blog01/?pretty
kibana会自动帮我们进行一些格式的调整
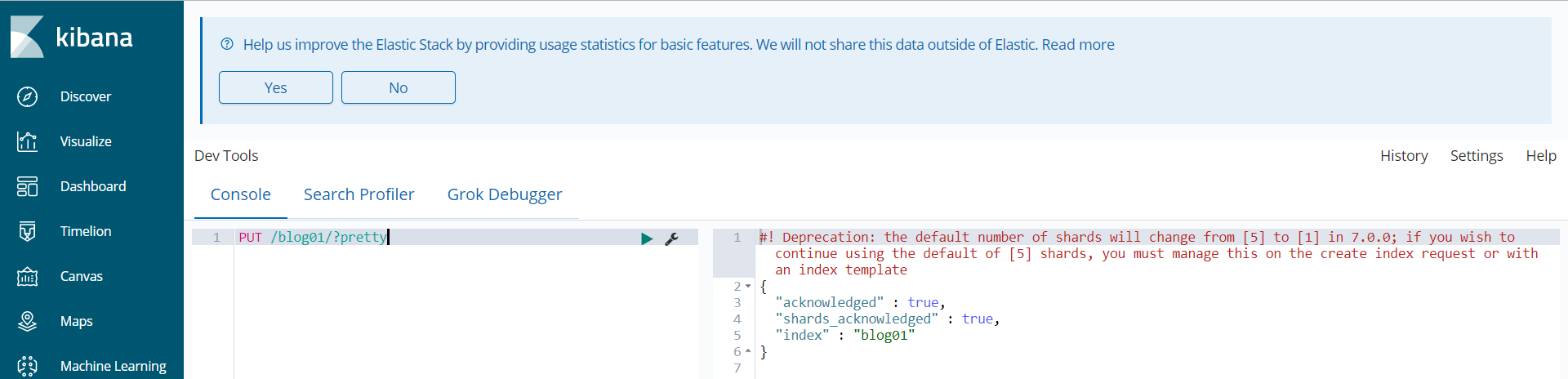
执行成功后,此时我们又能看到所谓好看的页面了🤣
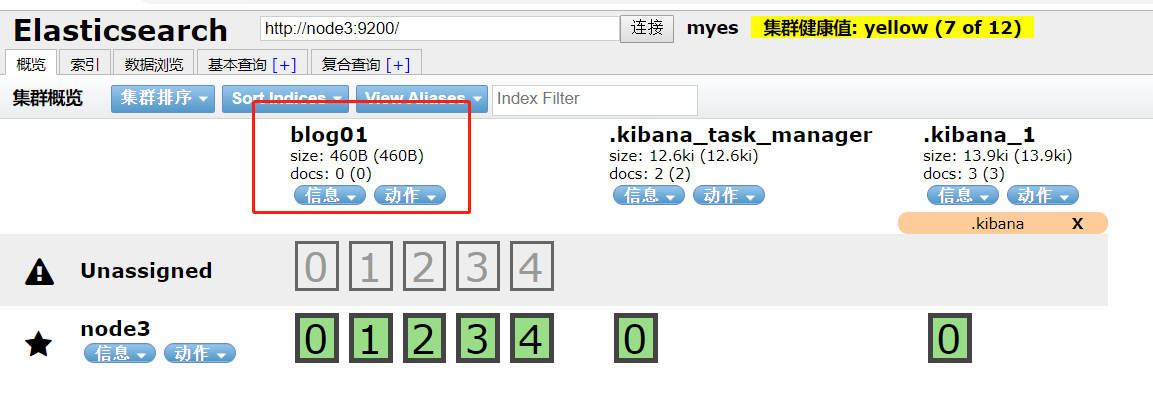
2.3.2 插入一条数据
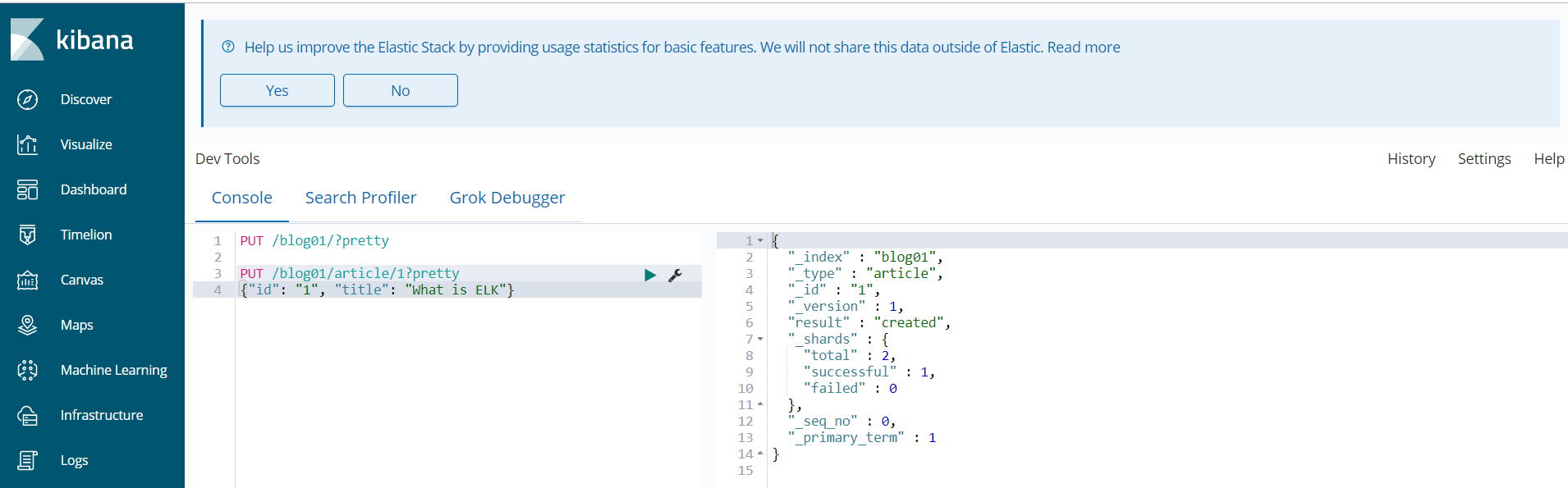
curl -XPUT http://node3:9200/blog01/article/1?pretty -d '{"id": "1", "title": "What is ELK"}'
使用 PUT 动词将一个文档添加到 /article(文档类型),并为该文档分配 ID 为1。URL 路径显示为index/doctype/ID(索引/文档类型/ID)。
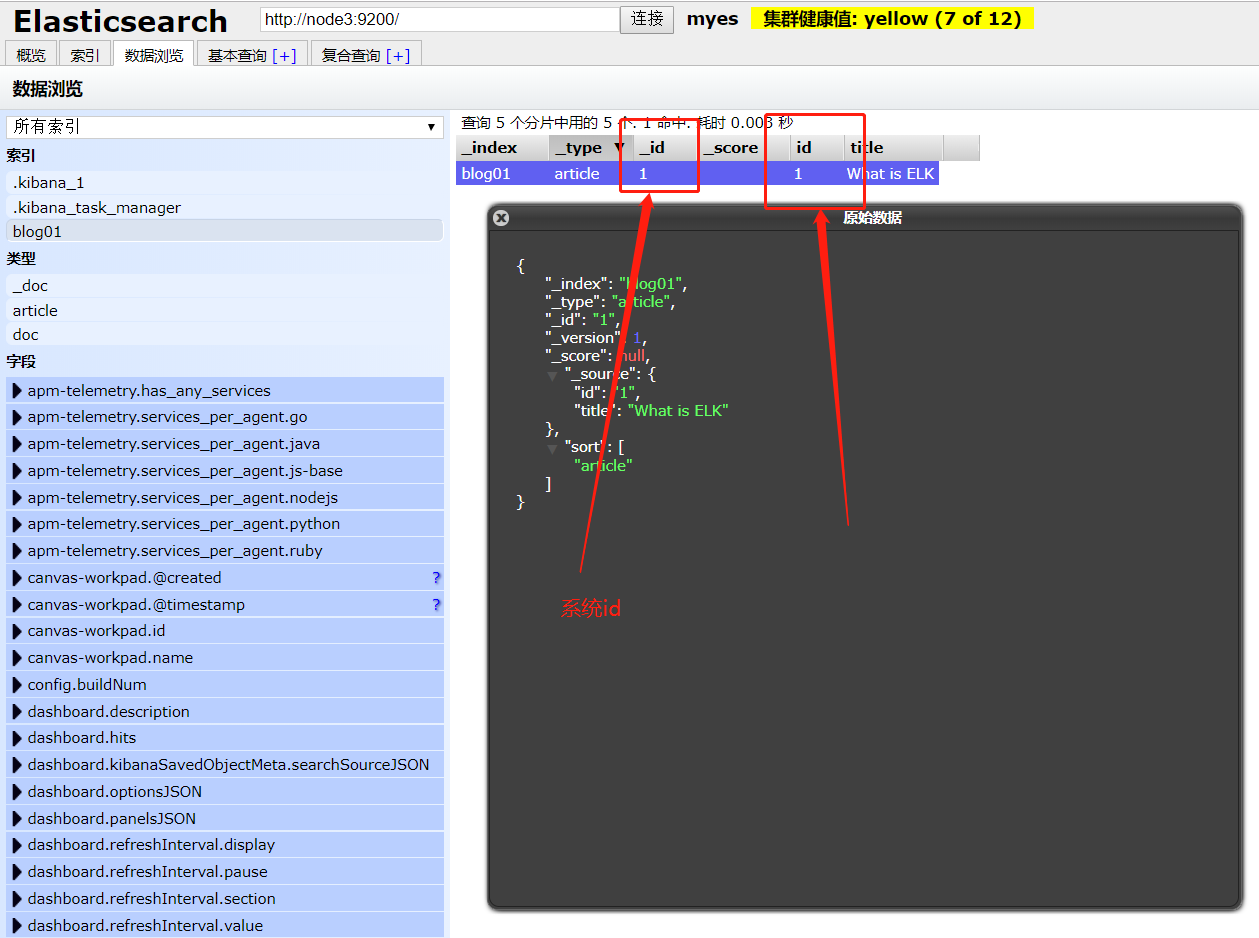
我们可以在数据浏览模块点击blog01进行查看
如果出现问题:Content-Type header [application/x-www-form-urlencoded] is not supported
此原因时由于ES增加了安全机制, 进行严格的内容类型检查,严格检查内容类型也可以作为防止跨站点请求伪造攻击的一层保护。 官网解释
http.content_type.required
2.3.3 查询数据
curl -XGET http://node3:9200/blog01/article/1?pretty
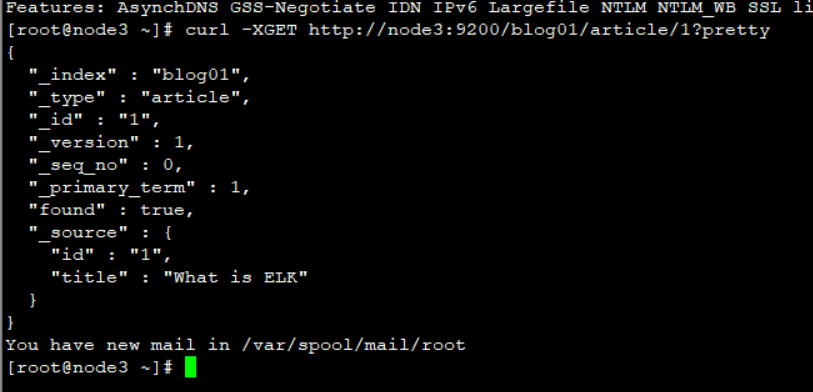
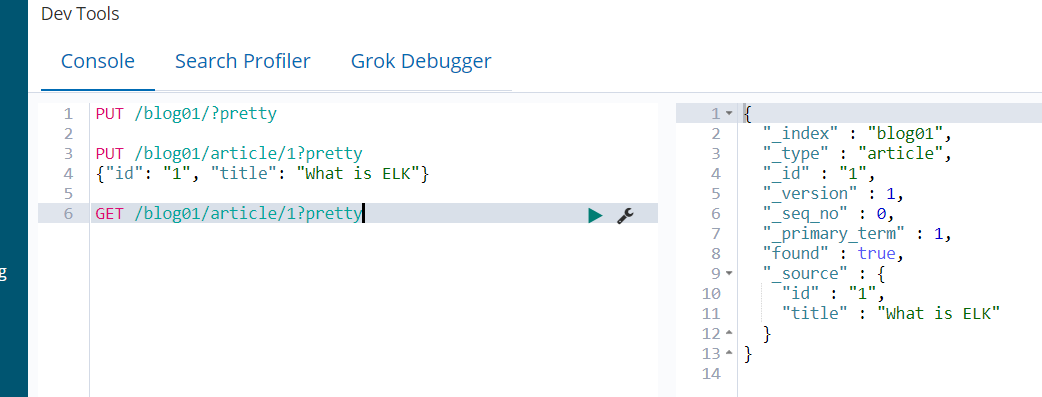
这个命令可以在Kibana执行,也可以在集群执行
2.3.4 更新文档
更新操作和插入基本一致,因为就是有id就更新,无id就插入,和Java那块的操作比较像
curl -XPUT http://node3:9200/blog01/article/1?pretty -d '{"id": "1", "title": " What is elasticsearch"}'
图就不贴啦,玩玩就好
2.3.5 搜索文档
curl -XGET "http://node3:9200/blog01/article/_search?q=title:elasticsearch"
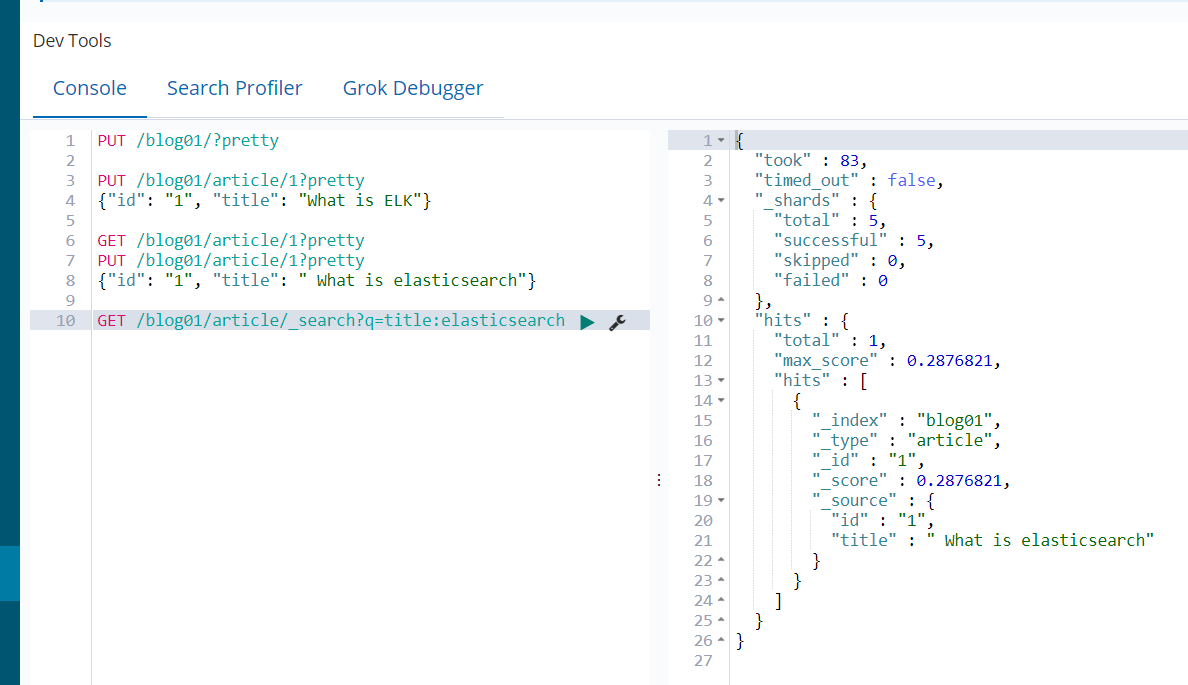
2.3.6 删除文档及索引
删除文档
curl -XDELETE "http://node3:9200/blog01/article/1?pretty"
删除索引
curl -XDELETE http://node3:9200/blog01?pretty
执行就会删除了,这里我就不执行了
2.4 ES的条件查询
这里先模拟一些数据出来
POST /school/student/_bulk
{ "index": { "_id": 1 }}
{ "name" : "tellYourDream", "age" : 25 , "sex": "boy", "birth": "1995-01-01" , "about": "i like bigdata" }
{ "index": { "_id": 2 }}
{ "name" : "guanyu", "age" : 21 , "sex": "boy", "birth": "1995-01-02" , "about": "i like diaocan" }
{ "index": { "_id": 3 }}
{ "name" : "zhangfei", "age" : 18 , "sex": "boy", "birth": "1998-01-02" , "about": "i like travel" }
{ "index": { "_id": 4 }}
{ "name" : "diaocan", "age" : 20 , "sex": "girl", "birth": "1996-01-02" , "about": "i like travel and sport" }
{ "index": { "_id": 5 }}
{ "name" : "panjinlian", "age" : 25 , "sex": "girl", "birth": "1991-01-02" , "about": "i like travel and wusong" }
{ "index": { "_id": 6 }}
{ "name" : "caocao", "age" : 30 , "sex": "boy", "birth": "1988-01-02" , "about": "i like xiaoqiao" }
{ "index": { "_id": 7 }}
{ "name" : "zhaoyun", "age" : 31 , "sex": "boy", "birth": "1997-01-02" , "about": "i like travel and music" }
{ "index": { "_id": 8 }}
{ "name" : "xiaoqiao", "age" : 18 , "sex": "girl", "birth": "1998-01-02" , "about": "i like caocao" }
{ "index": { "_id": 9 }}
{ "name" : "daqiao", "age" : 20 , "sex": "girl", "birth": "1996-01-02" , "about": "i like travel and history" }
直接copy到kibana下面执行即可
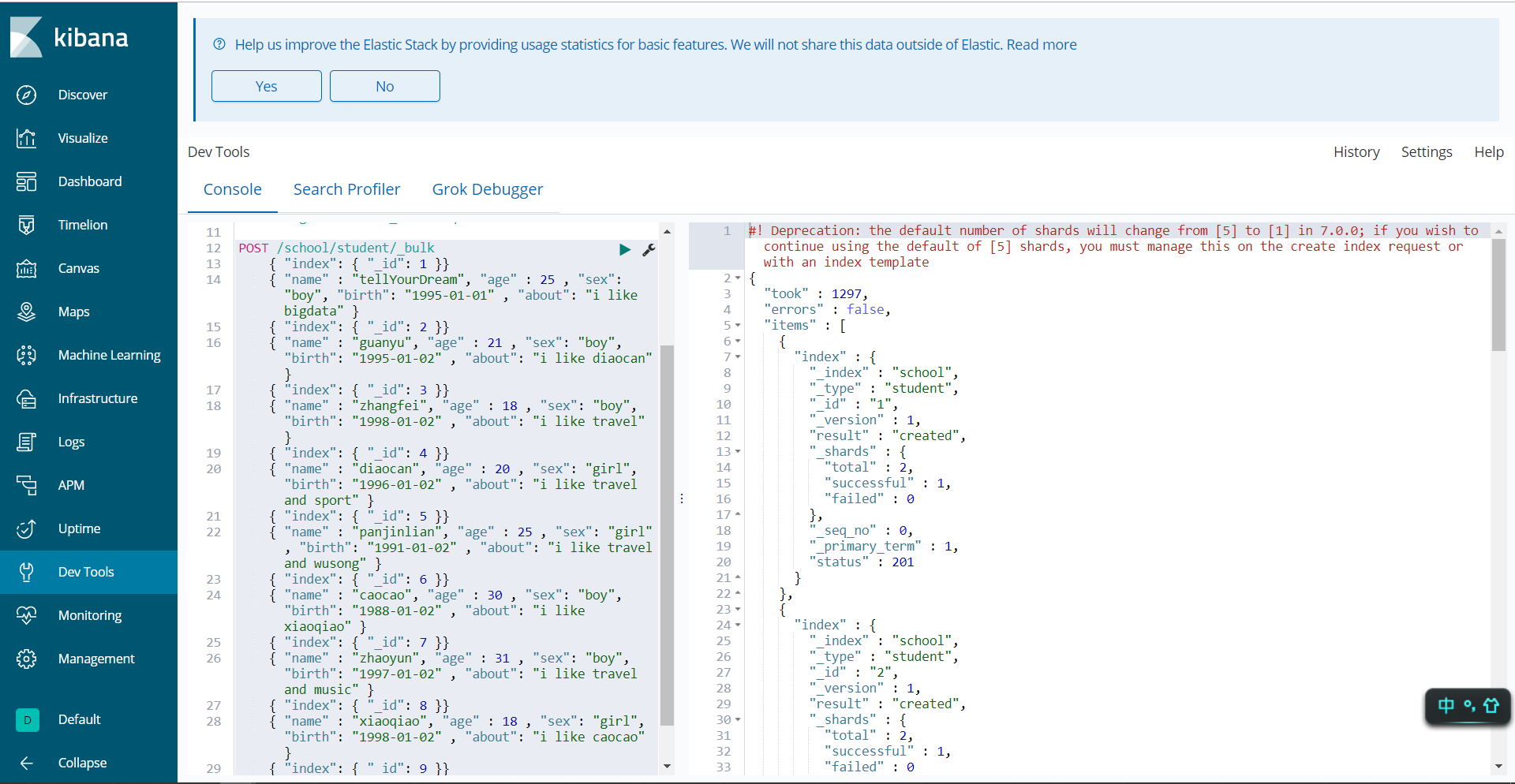
此时在ES-head这边也能看的见
2.4.1 1、使用match_all做查询
GET /school/student/_search?pretty
{
"query": {
"match_all": {}
}
}
问题:通过match_all匹配后,会把所有的数据检索出来,但是往往真正的业务需求并非要找全部的数据,而是检索出自己想要的;并且对于es集群来说,直接检索全部的数据,很容易造成GC现象。所以,我们要学会如何进行高效的检索数据
2.4.2 通过关键字段进行查询
GET /school/student/_search?pretty
{
"query": {
"match": {"about": "travel"}
}
}
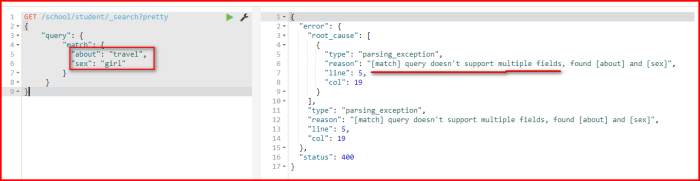
如果此时想查询喜欢旅游的,并且不能是男孩的,怎么办?
【这种方式是错误的,因为一个match下,不能出现多个字段值[match] query doesn't support multiple fields】,需要使用复合查询
2.4.3 bool的复合查询
当出现多个查询语句组合的时候,可以用bool来包含。bool合并聚包含:must,must_not或者should, should表示or的意思
例子:查询非男性中喜欢旅行的人
GET /school/student/_search?pretty
{
"query": {
"bool": {
"must": { "match": {"about": "travel"}},
"must_not": {"match": {"sex": "boy"}}
}
}
}
2.4.4、bool的复合查询中的should
should表示可有可无的(如果should匹配到了就展示,否则就不展示)
例子:
查询喜欢旅行的,如果有男性的则显示,否则不显示
GET /school/student/_search?pretty
{
"query": {
"bool": {
"must": { "match": {"about": "travel"}},
"should": {"match": {"sex": "boy"}}
}
}
}
2.4.5、term匹配
使用term进行精确匹配(比如数字,日期,布尔值或 not_analyzed的字符串(未经分析的文本数据类型))
语法
{ "term": { "age": 20 }}
{ "term": { "date": "2018-04-01" }}
{ "term": { "sex": “boy” }}
{ "term": { "about": "travel" }}
例子:查询喜欢旅行的
GET /school/student/_search?pretty
{
"query": {
"bool": {
"must": { "term": {"about": "travel"}},
"should": {"term": {"sex": "boy"}}
}}
}
2.4.6、使用terms匹配多个值
GET /school/student/_search?pretty
{
"query": {
"bool": {
"must": { "terms": {"about": ["travel","history"]}}
}
}
}
2.4.7、Range过滤
Range过滤允许我们按照指定的范围查找一些数据:操作范围:
gt: --- 大于
gae: --- 大于等于
lt: --- 小于
lte: --- 小于等于
例子:查找出大于20岁,小于等于25岁的学生
GET /school/student/_search?pretty
{
"query": {
"range": {
"age": {"gt":20,"lte":25}
}
}
}
2.4.8、exists和 missing过滤
exists和missing过滤可以找到文档中是否包含某个字段或者是没有某个字段
例子:
查找字段中包含age的文档
GET /school/student/_search?pretty
{
"query": {
"exists": {
"field": "age"
}
}
}
2.4.9、bool的多条件过滤
用bool也可以像之前match一样来过滤多行条件:
must: --- 多个查询条件的完全匹配,相当于 and 。
must_not: --- 多个查询条件的相反匹配,相当于 not 。
should: --- 至少有一个查询条件匹配, 相当于 or
例子:
过滤出about字段包含travel并且年龄大于20岁小于30岁的同学
GET /school/student/_search?pretty
{
"query": {
"bool": {
"must": [
{"term": {
"about": {
"value": "travel"
}
}},{"range": {
"age": {
"gte": 20,
"lte": 30
}
}}
]
}
}
}
2.4.10、查询与过滤条件合并
通常复杂的查询语句,我们也要配合过滤语句来实现缓存,用filter语句就可以来实现
例子:查询出喜欢旅行的,并且年龄是20岁的文档
GET /school/student/_search?pretty
{
"query": {
"bool": {
"must": {"match": {"about": "travel"}},
"filter": [{"term":{"age": 20}}]
}
}
}
2.5 ES 中的重要概念Mappings & Settings
Mappings主要用于定义ES中的字段类型,在es当中,每个字段都会有默认的类型,根据我们第一次插入数据进去,es会自动帮我们推断字段的类型,当然我们也可以通过设置mappings来提前自定义我们字段的类型
DELETE document
PUT document
{
"mappings": {
"article" : {
"properties":
{
"title" : {"type": "text"} ,
"author" : {"type": "text"} ,
"titleScore" : {"type": "double"}
}
}
}
}
之后可以使用get document/article/_mapping来查看
Settings 主要用于定义分片数及副本数。
DELETE document
PUT document
{
"mappings": {
"article" : {
"properties":
{
"title" : {"type": "text"} ,
"author" : {"type": "text"} ,
"titleScore" : {"type": "double"}
}
}
}
}
GET /document/_settings
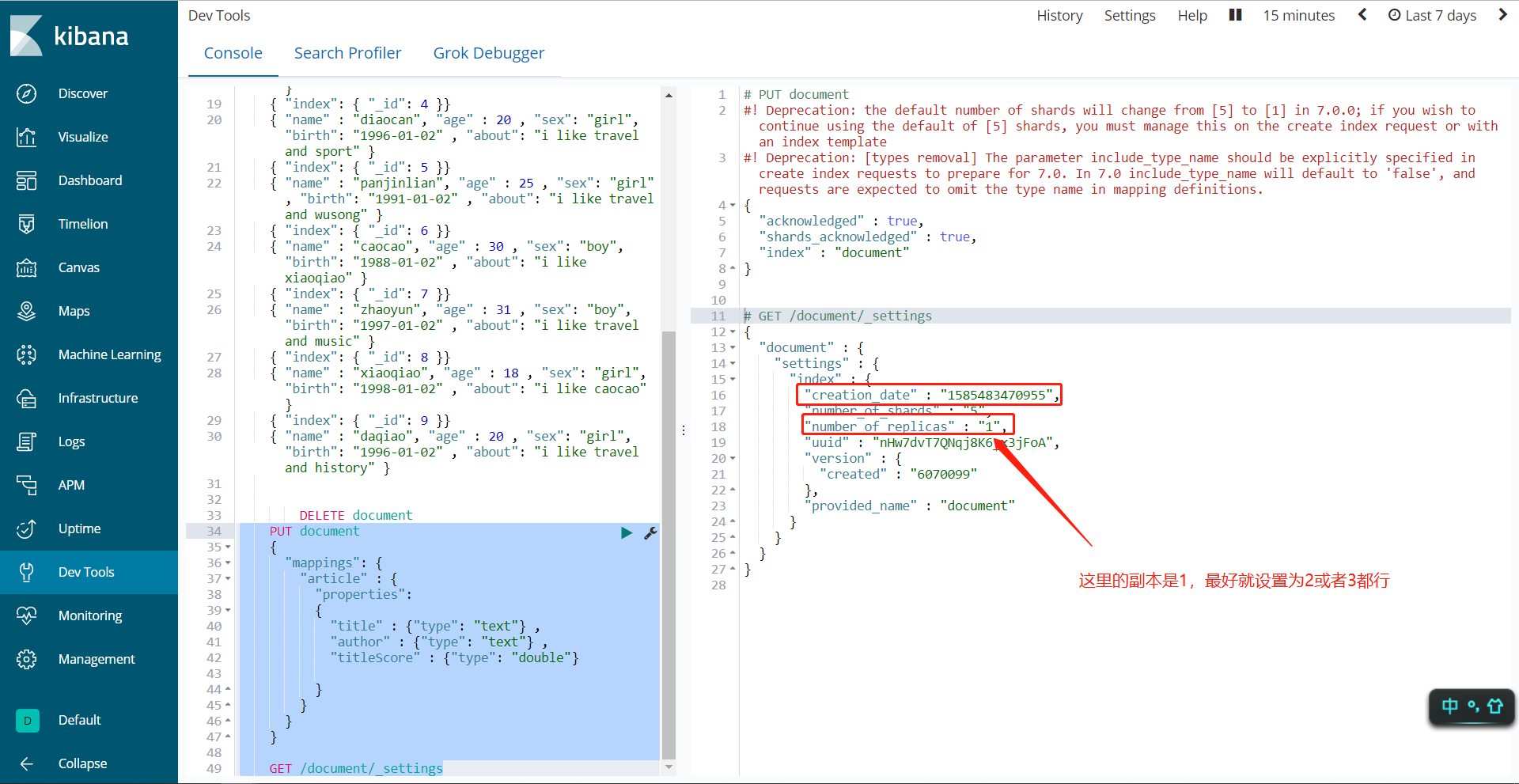
因为我的节点就只有一个,就不截图ES-head那边的图了,没啥用😂
三、ES的分页解决方案
模拟一些数据再说,直接复制上去Kibana执行即可
DELETE us
POST /_bulk
{ "create": { "_index": "us", "_type": "tweet", "_id": "1" }}
{ "email" : "john@smith.com", "name" : "John Smith", "username" : "@john" }
{ "create": { "_index": "us", "_type": "tweet", "_id": "2" }}
{ "email" : "mary@jones.com", "name" : "Mary Jones", "username" : "@mary" }
{ "create": { "_index": "us", "_type": "tweet", "_id": "3" }}
{ "date" : "2014-09-13", "name" : "Mary Jones", "tweet" : "Elasticsearch means full text search has never been so easy", "user_id" : 2 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "4" }}
{ "date" : "2014-09-14", "name" : "John Smith", "tweet" : "@mary it is not just text, it does everything", "user_id" : 1 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "5" }}
{ "date" : "2014-09-15", "name" : "Mary Jones", "tweet" : "However did I manage before Elasticsearch?", "user_id" : 2 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "6" }}
{ "date" : "2014-09-16", "name" : "John Smith", "tweet" : "The Elasticsearch API is really easy to use", "user_id" : 1 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "7" }}
{ "date" : "2014-09-17", "name" : "Mary Jones", "tweet" : "The Query DSL is really powerful and flexible", "user_id" : 2 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "8" }}
{ "date" : "2014-09-18", "name" : "John Smith", "user_id" : 1 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "9" }}
{ "date" : "2014-09-19", "name" : "Mary Jones", "tweet" : "Geo-location aggregations are really cool", "user_id" : 2 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "10" }}
{ "date" : "2014-09-20", "name" : "John Smith", "tweet" : "Elasticsearch surely is one of the hottest new NoSQL products", "user_id" : 1 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "11" }}
{ "date" : "2014-09-21", "name" : "Mary Jones", "tweet" : "Elasticsearch is built for the cloud, easy to scale", "user_id" : 2 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "12" }}
{ "date" : "2014-09-22", "name" : "John Smith", "tweet" : "Elasticsearch and I have left the honeymoon stage, and I still love her.", "user_id" : 1 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "13" }}
{ "date" : "2014-09-23", "name" : "Mary Jones", "tweet" : "So yes, I am an Elasticsearch fanboy", "user_id" : 2 }
{ "create": { "_index": "us", "_type": "tweet", "_id": "14" }}
{ "date" : "2014-09-24", "name" : "John Smith", "tweet" : "How many more cheesy tweets do I have to write?", "user_id" : 1 }
3.1 size+from浅分页
按照一般的查询流程来说,如果我想查询前10条数据:
- 客户端请求发给某个节点
- 节点转发给个个分片,查询每个分片上的前10条
- 结果返回给节点,整合数据,提取前10条
- 返回给请求客户端
from定义了目标数据的偏移值,size定义当前返回的事件数目
查询前5条的数据
GET /us/_search?pretty
{
"from" : 0 , "size" : 5
}
从第5条开始算,查询5条
GET /us/_search?pretty
{
"from" : 5 , "size" : 5
}
之后我们在Java API当中就是这样来查询我们ES的数据,不过这种浅分页只适合少量数据,因为随from增大,查询的时间就会越大,而且数据量越大,查询的效率指数下降
优点:from+size在数据量不大的情况下,效率比较高
缺点:在数据量非常大的情况下,from+size分页会把全部记录加载到内存中,这样做不但运行速递特别慢,而且容易让ES出现内存不足而挂掉
3.2 深分页scroll
对于上面介绍的浅分页,当Elasticsearch响应请求时,它必须确定docs的顺序,排列响应结果。
如果请求的页数较少(假设每页20个docs), Elasticsearch不会有什么问题,但是如果页数较大时,比如请求第20页,Elasticsearch不得不取出第1页到第20页的所有docs,再去除第1页到第19页的docs,得到第20页的docs。
解决的方式就是使用scroll,scroll就是维护了当前索引段的一份快照信息--缓存(这个快照信息是你执行这个scroll查询时的快照)。
可以把 scroll 分为初始化和遍历两步: 1、初始化时将所有符合搜索条件的搜索结果缓存起来,可以想象成快照; 2、遍历时,从这个快照里取数据;
初始化
GET us/_search?scroll=3m
{
"query": {"match_all": {}},
"size": 3
}
初始化的时候就像是普通的search一样,其中的scroll=3m代表当前查询的数据缓存3分钟。Size:3 代表当前查询3条数据
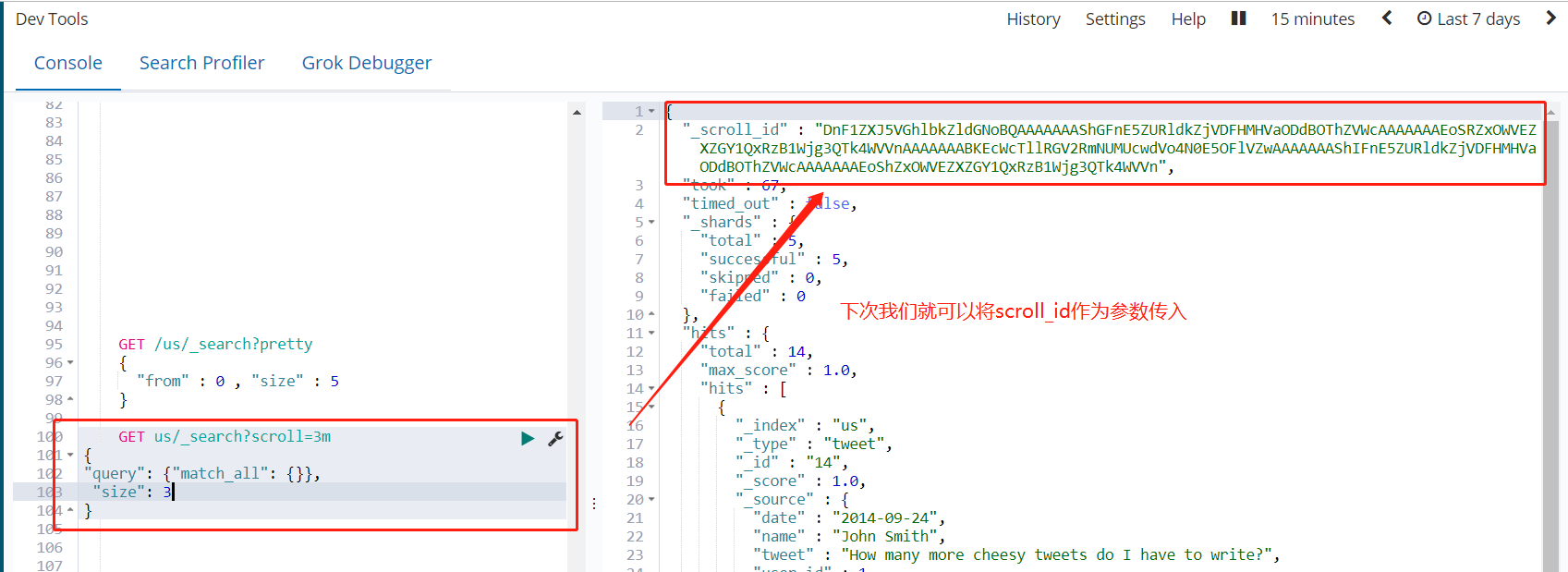
在遍历时候,拿到上一次遍历中的scrollid,然后带scroll参数,重复上一次的遍历步骤,知道返回的数据为空,就表示遍历完成
GET /_search/scroll
{
"scroll" : "1m",
"scroll_id" : "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAShGFnE5ZURldkZjVDFHMHVaODdBOThZVWcAAAAAAAEoSRZxOWVEZXZGY1QxRzB1Wjg3QTk4WVVnAAAAAAABKEcWcTllRGV2RmNUMUcwdVo4N0E5OFlVZwAAAAAAAShIFnE5ZURldkZjVDFHMHVaODdBOThZVWcAAAAAAAEoShZxOWVEZXZGY1QxRzB1Wjg3QTk4WVVn"
}
注意:每次都要传参数scroll,刷新搜索结果的缓存时间,另外不需要指定index和type(不要把缓存的时时间设置太长,占用内存)
对比:
浅分页,每次查询都会去索引库(本地文件夹)中查询pageNum*page条数据,然后截取掉前面的数据,留下最后的数据。 这样的操作在每个分片上都会执行,最后会将多个分片的数据合并到一起,再次排序,截取需要的。
深分页,可以一次性将所有满足查询条件的数据,都放到内存中。分页的时候,在内存中查询。相对浅分页,就可以避免多次读取磁盘。
四、ES的中文分词器IK
ES默认对英文文本的分词器支持较好,但和lucene一样,如果需要对中文进行全文检索,那么需要使用中文分词器,同lucene一样,在使用中文全文检索前,需要集成IK分词器。那么我们接下来就来安装IK分词器,以实现中文的分词
4.1 下载
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.7.0/elasticsearch-analysis-ik-6.7.0.zip
然后在ES的目录中新建一个目录存放这个插件
mkdir -p /usr/local/elasticsearch-6.7.0/plugins/analysis-ik
unzip elasticsearch-analysis-ik-6.7.0.zip -d /usr/local/elasticsearch-6.7.0/plugins/analysis-ik/
然后你再分发到其它的机器即可
cd /usr/local/elasticsearch-6.7.0/plugins
scp -r analysis-ik/ node2:$PWD
之后你需要重启ES的服务
ps -ef|grep elasticsearch | grep bootstrap | awk '{print $2}' |xargs kill -9
nohup /kkb/install/elasticsearch-6.7.0/bin/elasticsearch 2>&1 &
4.2 体验一把
在kibana中创建索引库并配置IK分词器
delete iktest
PUT /iktest?pretty
{
"settings" : {
"analysis" : {
"analyzer" : {
"ik" : {
"tokenizer" : "ik_max_word"
}
}
}
},
"mappings" : {
"article" : {
"dynamic" : true,
"properties" : {
"subject" : {
"type" : "text",
"analyzer" : "ik_max_word"
}
}
}
}
}
在创建索引库的时候,我们指定分词方式为ik_max_word,会对我们的中文进行最细粒度的切分,现在来看下效果

这里你可以看到,我的id被分成了好几块
你还可以用下面的语法对你的查询进行高亮,比如这个效果
POST /iktest/article/_search?pretty
{
"query" : { "match" : { "subject" : "抗击肺炎" }},
"highlight" : {
"pre_tags" : ["<font color=red>"],
"post_tags" : ["</font>"],
"fields" : {
"subject" : {}
}
}
}

4.3 配置热词更新
我们可以发现我的ID是被分割成好几块的,因为在插件它的视角中“说出你的愿望吧”并不是个热词,但是我们可以告诉它我这是个热词🤣

比如现在,影流之主,蔡徐坤,都是被分掉的,那我们怎么配置呢?就需要我们经常能够实时的更新我们的网络热词,我们可以通过tomcat来实现远程词库来解决这个问题。
4.4 安装一个tomcat
安装tomcat就随便来一个就好了
然后你需要去到它的ROOT路径下,比如我的是
cd /usr/local/apache-tomcat-8.5.34/webapps/ROOT
然后new一个file出来
vi hot.dic

然后保存退出即可
接下来启动你的tomcat,要是启动成功就会能看到一个bootstrap服务

能访问到hot.dic即可

4.5 修改一下分词器的配置
其实就是修改这个文件

点进来有一些中文注释,然后你看到这个
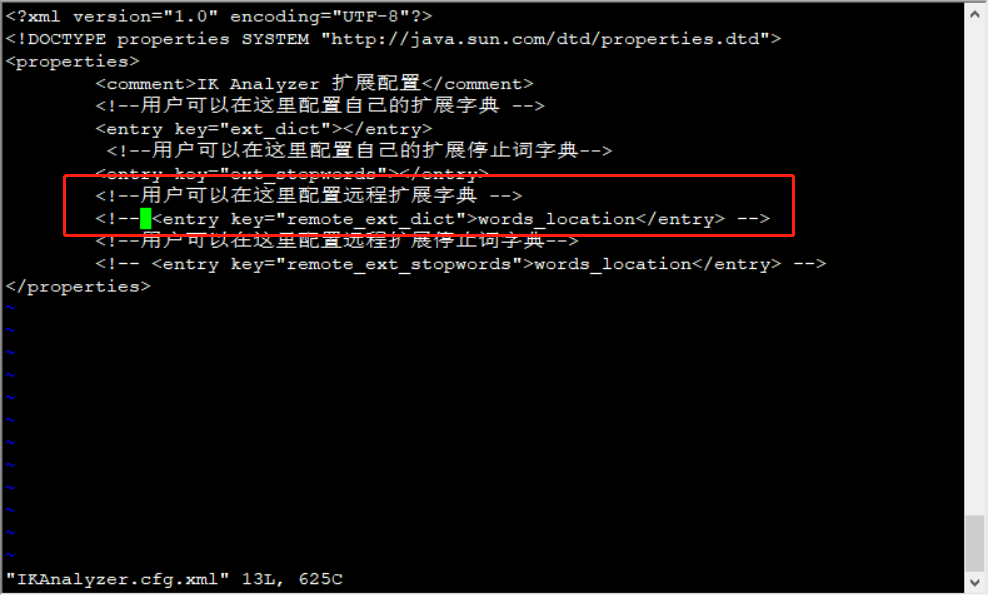
把这一行的注释去掉,然后就配置上我们刚刚可以访问到的tomcat的词的路径,也就是 http://192.168.200.11:8080/hot.dic 即可
然后把这个配置文件也分发到另外两个节点上
然后我们重启一下ES即可,现在再进行分词,就会有关键字了

finally
这篇主要就是部署了,后面会涉及操作一些api啥的,篇幅就不搞这么长啦😶
