

前言
前情概要
距离上一篇的更新也是好一段日子了,期间也是有小伙伴催更可是因为一些琐事一直没处理好,接下来会恢复周更
有小伙伴的反馈中说到标题都是经典应用,太过笼统所以没法通过标题得知对应内容的问题,在此也是进行了改进
第四篇:Zookeeper的经典应用场景---标题修改为---Zookeeper的分布式队列
第五篇:Zookeeper的经典应用场景2---标题修改为---Zookeeper的配置中心应用
以往链接
从零开始的高并发(二)--- Zookeeper实现分布式锁
从零开始的高并发(三)--- Zookeeper集群的搭建和leader选举
从零开始的高并发(四)--- Zookeeper的分布式队列
从零开始的高并发(五)--- Zookeeper的配置中心应用
内容一:简单谈谈Zookeeper的Master选举
1.什么是Master选举
在分布式架构中经常采用的结构就是一主多从,主节点祈使句就是负责协调管理集群用的。我们可以借用这个场景去展开。
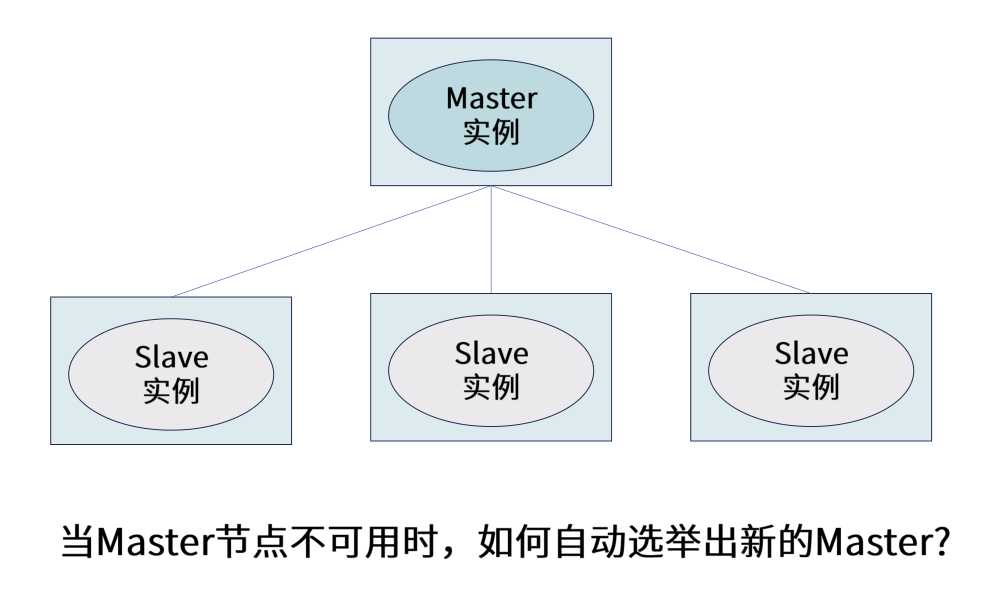
2.zookeeper如何去实现master选举
为什么我们要采用临时节点,以为考虑到master节点可能负载较高,挂掉了,这时我们要保证其他下面的servers服务都能够得到通知,
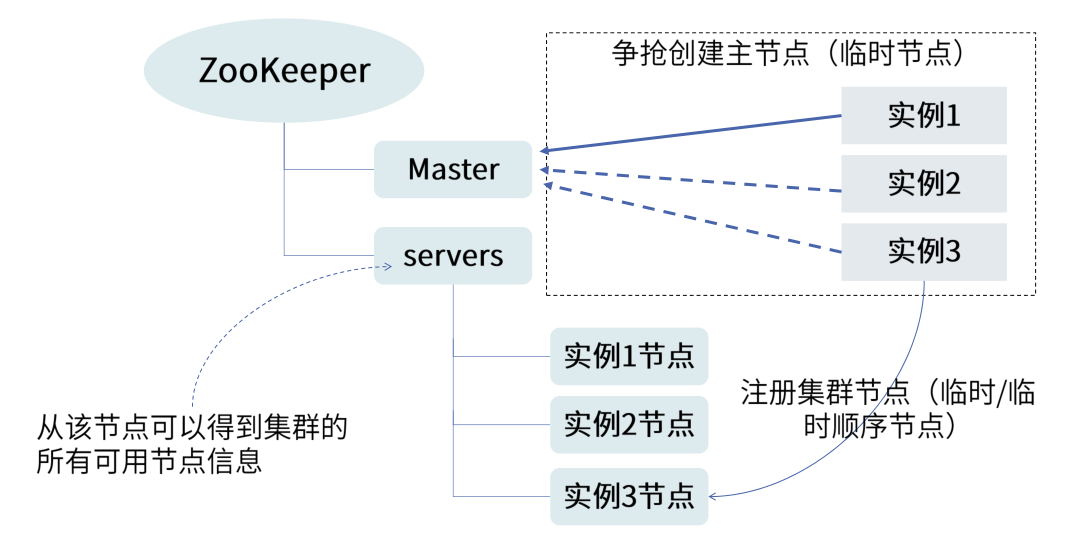
其实我们也可以通过最小节点方式来实现,就谁排在前面,谁就有权利去获得master
3.代码实现
① 需要使用到的变量
首先我们需要有一个master节点,然后cluster代表的是集群的名字,name是指服务名,address是指服务的地址。masterPath是指master的znode目录,value是用来记录上面的name加address的,ZkClient不用多说了,从第二篇开始用这货用到现在了
private String cluster, name, address;
private final String masterPath, value;
private String master;
private ZkClient client;
② 构造器
public Server(String cluster, String name, String address) {
super();
this.cluster = cluster;
this.name = name;
this.address = address;
masterPath = "/" + this.cluster + "/master";
value = "name:" + this.name + " address:" + this.address;
client = new ZkClient("localhost:2181");
client.setZkSerializer(new MyZkSerializer());
String serversPath = "/" + this.cluster + "/servers";
client.createPersistent(serversPath, true);
String serverPath = serversPath + "/" + name;
client.createEphemeral(serverPath, value);
new Thread(new Runnable() {
@Override
public void run() {
electionMaster(client);
}
}).start();
}
进来时你要先告诉我,你是属于哪个集群的啊,你的名字,还有你的对应地址是什么,然后我们的masterPath就定义在这个集群的master目录下,这种方式让我们方便记录多个不同的集群。
serversPath是指集群中所有服务信息存放的znode根目录路径,serverPath是一个具体的服务,是刚刚的根目录+这个服务的名字,这个服务我们是要存放于临时节点(createEphemeral()方法)上的,刚刚的根目录我们是创建了持久节点(createPersistent()方法),为什么我们现在要使用临时节点了呢,因为我们刚刚也提到了,master节点是可以挂掉的,而且我们之后也会进行master节点挂掉的模拟,value是用来记录name和address的,在之后的执行结果中会打印出来
最后通过一个线程去执行这个master的选举,我们在master的选举中要不停地监听我们的master,在master被抢到了以后,我需要对这个线程进行阻塞操作,可是如果这时候主线程阻塞了,整个程序就不跑了,所以我们必须通过一个子线程去帮我们去抢master,此时就算我抢不到master,也能保证整个程序可以继续往下执行。
③ 选举的方法实现
public void electionMaster(ZkClient client) {
try {
//尝试去获取master
client.createEphemeral(masterPath, value);
//如果成功,记录master节点信息
//在这里我们记录master信息并作为缓存,方便得知这个集群的master是谁
//这样就可以不再使用zookeeper去查master了
master = client.readData(masterPath);
System.out.println(value + "创建节点成功,成为Master");
} catch (ZkNodeExistsException e) {
//没有抢到master的情况下,我们把现在master的信息读到自己的服务里面
master = client.readData(masterPath);
System.out.println("Master为:" + master);
}
// 为阻塞自己等待而用
CountDownLatch cdl = new CountDownLatch(1);
// 注册watcher
IZkDataListener listener = new IZkDataListener() {
@Override
public void handleDataDeleted(String dataPath) throws Exception {
System.out.println("-----监听到节点被删除");
cdl.countDown();
}
@Override
public void handleDataChange(String dataPath, Object data) throws Exception {
}
};
client.subscribeDataChanges(masterPath, listener);
// 让自己阻塞
if (client.exists(masterPath)) {
try {
cdl.await();
} catch (InterruptedException e1) {
e1.printStackTrace();
}
}
// 醒来后,取消watcher
client.unsubscribeDataChanges(masterPath, listener);
// 递归调自己(下一次选举)
electionMaster(client);
}
public void close() {
client.close();
}
}
我们监听节点的删除事件,一旦master节点被释放掉了,我们会立即唤醒自己的线程去参与争抢。在最后还进行了一个if (client.exists(masterPath))的判断,确定是已经有节点成为了master了,我们就会通过await方法让自己阻塞,如果不存在master,那就重新调用自身争抢master的方法
最后的close()方法是为了模拟机器挂掉而使用的,与代码本身的逻辑无关
④ 场景测试
我们使用线程来代替进程,ScheduledThreadPoolExecutor是一个定时任务,5秒后我会关闭s1,10秒后关闭s2以此类推。
public static void main(String[] args) {
// 测试时,依次开启多个Server实例java进程,然后停止获取的master的节点,看谁抢到Master
Server s1 = new MasterElectionDemo().new Server("cluster1", "server1", "192.168.1.11:8991");
Server s2 = new MasterElectionDemo().new Server("cluster1", "server2", "192.168.1.11:8992");
Server s3 = new MasterElectionDemo().new Server("cluster1", "server3", "192.168.1.11:8993");
Server s4 = new MasterElectionDemo().new Server("cluster1", "server4", "192.168.1.11:8994");
ScheduledThreadPoolExecutor scheduled = new ScheduledThreadPoolExecutor(1);
scheduled.schedule(()->{
System.out.println("关闭s1");
s1.close();
}, 5, TimeUnit.SECONDS);
scheduled.schedule(()->{
System.out.println("关闭s2");
s2.close();
}, 10, TimeUnit.SECONDS);
scheduled.schedule(()->{
System.out.println("关闭s3");
s3.close();
}, 15, TimeUnit.SECONDS);
try {
Thread.currentThread().join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
⑤ 结果分析

因为我们s1是第一个被创建的,所以它成为master的可能性当然是最大的

此时我们5秒后关闭s1,这时监听到master节点没了,大家都被唤醒去抢master,然后s4抢到了,成为了master

此时我们再删除s2和s3,就会发现和上面不一样了,因为s4是master,所以我删除s2,或者s3都没关系,都不像删除s1的时候会再触发master的选举,假设我们下次不是s4抢到,而是s3抢到了master,那我们在关闭s3的时候,就会像s1关闭时那样重新触发选举了,不过此时就仅仅还剩s4了而已
内容二:zookeeper的官网
1.为什么要普及一下官网
在自己还是0基础的时候,如何来通过官网去学习,虽然现在网上关于各大框架的知识确实已经很多了,可是我们还是有必要去浏览这些开源框架的官网,因为无论网上的说法再参差不齐众说纷纭,但官网是代表着绝对权威的
而且官网所提到的知识一般也是基础的应用,不会说涉及很多复杂的业务场景,从官网上去了解一个新的框架是最好的,也不会存在带有误导性的demo和总结,在大致了解之后,想看看具体的业务中使用,则可以使用百度,去看看别人写的一些应用,就没有问题。
如果官网都会出错,那就只能自己看源码了,过程则会非常痛苦(摊手)
2.如何去大致地浏览官网
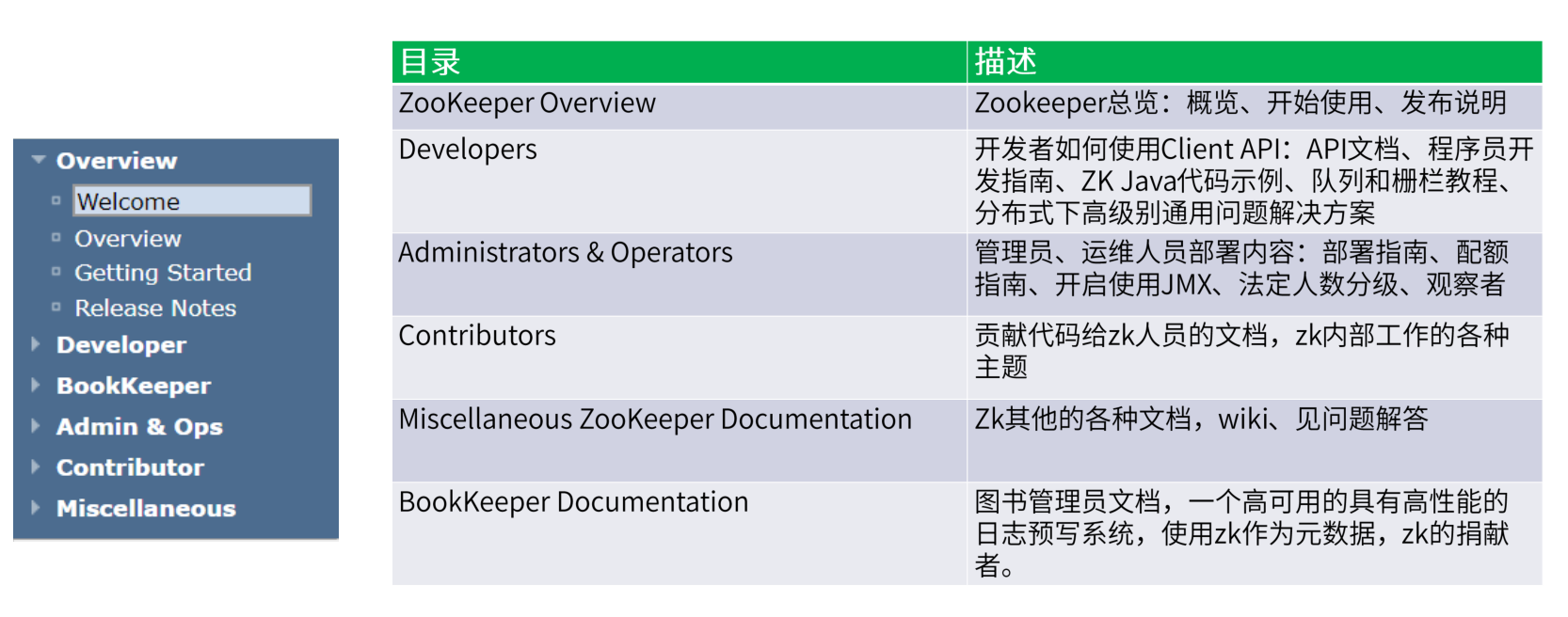
基本会按照之前写的章节的内容去大致说明,就是以前章节提到的内容在官网中哪里可以找到
这是zookeeper官网的目录结构,整个zookeeper的骨架都会列出来
① 欢迎页
这里其实就是介绍了每个栏目分别都存在了什么东西,上面的图其实也大致翻译了这些内容
② 我们最关心的Programmer's Guide

Developing Distributed Applications that use ZooKeeper
Introduction---这个模块的简介
The ZooKeeper Data Model---zookeeper的数据模型
ZNodes---znode的介绍
Watches---监听机制的介绍
Data Access---之前谈到额ACL
Ephemeral Nodes---临时节点的介绍
Sequence Nodes -- Unique Naming---顺序节点的介绍及命名唯一规则
这俩是3.5.3的新加入的节点类型,我们使用的版本并未涉及
Container Nodes
TTL Nodes
Time in ZooKeeper---zookeeper的时间定义
ZooKeeper Stat Structure---节点的元数据,zxid那些
ZooKeeper Sessions---session相关
ZooKeeper Watches---watch想关及watch怎样用
Semantics of Watches---watch的意义
Remove Watches---移除
What ZooKeeper Guarantees about Watches---watch的机制
Things to Remember about Watches---使用注意的事项
以下也不一一翻译了,就是各个方面相关的知识呗
ZooKeeper access control using ACLs
ACL Permissions
Builtin ACL Schemes
ZooKeeper C client API
Pluggable ZooKeeper authentication
Consistency Guarantees---特性
Bindings---客户端使用方面的
Java Binding
Client Configuration Parameters
C Binding
Installation
Building Your Own C Client
Building Blocks: A Guide to ZooKeeper Operations
Handling Errors
Connecting to ZooKeeper
Read Operations
Write Operations
Handling Watches
Miscelleaneous ZooKeeper Operations
Program Structure, with Simple Example
Gotchas: Common Problems and Troubleshooting
③ java example

ZooKeeper Java Example
A Simple Watch Client
Requirements
Program Design
The Executor Class
The DataMonitor Class
Complete Source Listings
在program design中会介绍这个程序所要达成的目的

④ Barrier and Queue Tutorial和Recipes
这里提到了栅栏和队列的实现,不过在之前的文章中实现的方式和官网的不同
Recipes上面的是一些更为高级的使用,双栅栏,权重队列,共享锁,对leader选举的补充等等
⑤ Admin & Ops
这里涉及到一些运维和管理员的使用文档,比如怎么去搭建集群等,在这里只贴部分,在之前的文章也有提到

dataLogDir也是通过log4j来进行管理的
JMX:zookeeper默认实现了JMX接口,内容也包括了之前我们提到的jconsole
Observers Guide:观察者,其实它的职责就是服务集群,可以用来分担读请求的负载,还可以让leader选举的时候更加快速,在集群数较多的时候,进行leader选举是一个非常耗时的过程,比如我只让几个节点来参与leader选举,其余的只是作为观察者,不参与投票而仅同步数据。
⑥ contributor
开票就提到了我们说过的原子广播协议

wiki中有关于zab的介绍,包括paxos算法的介绍也有
⑦ 支持的客户端
⑧ 一些有用的工具
keptCollections

curator
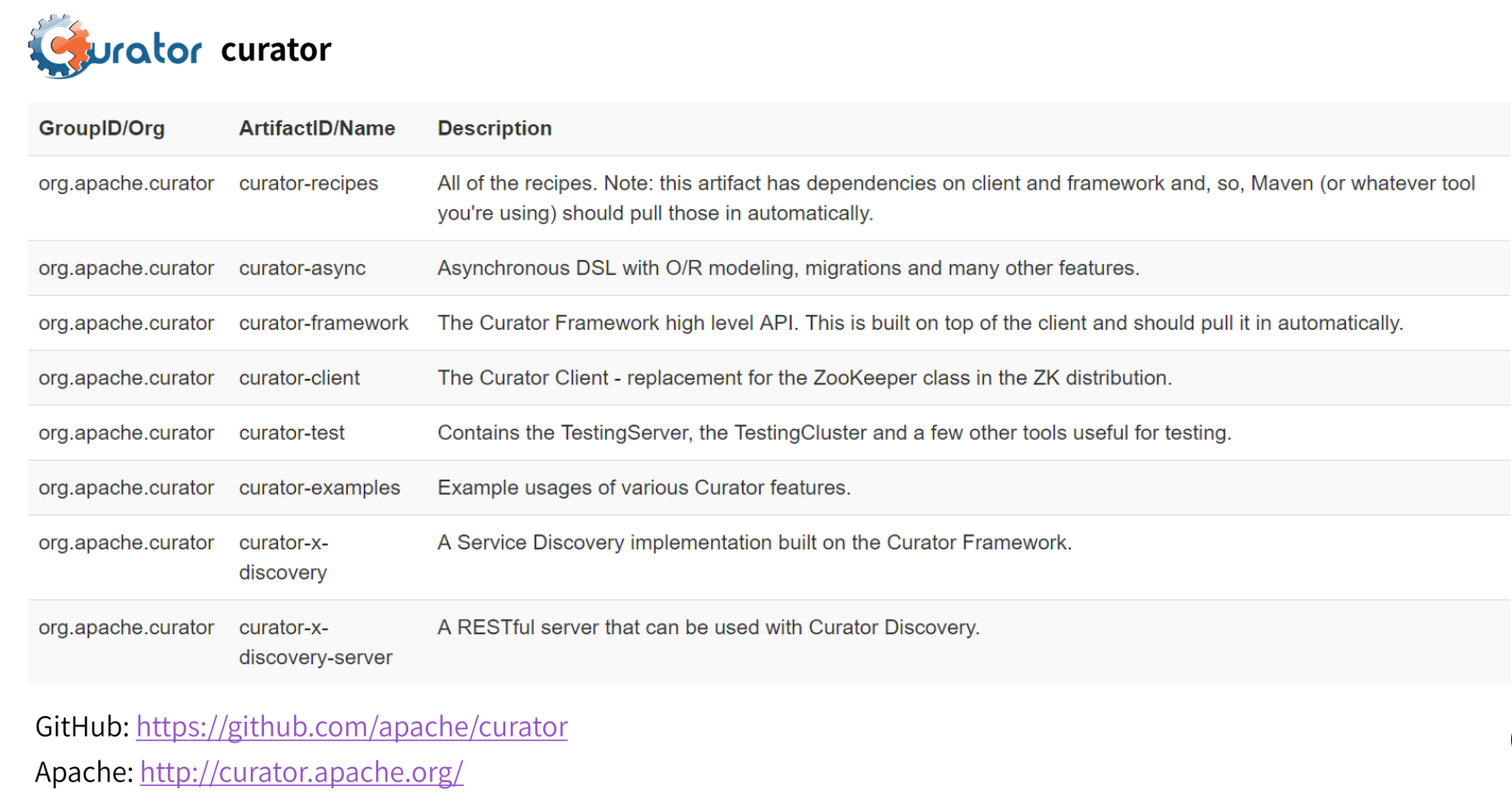
curator的一种比较优雅的链式编程
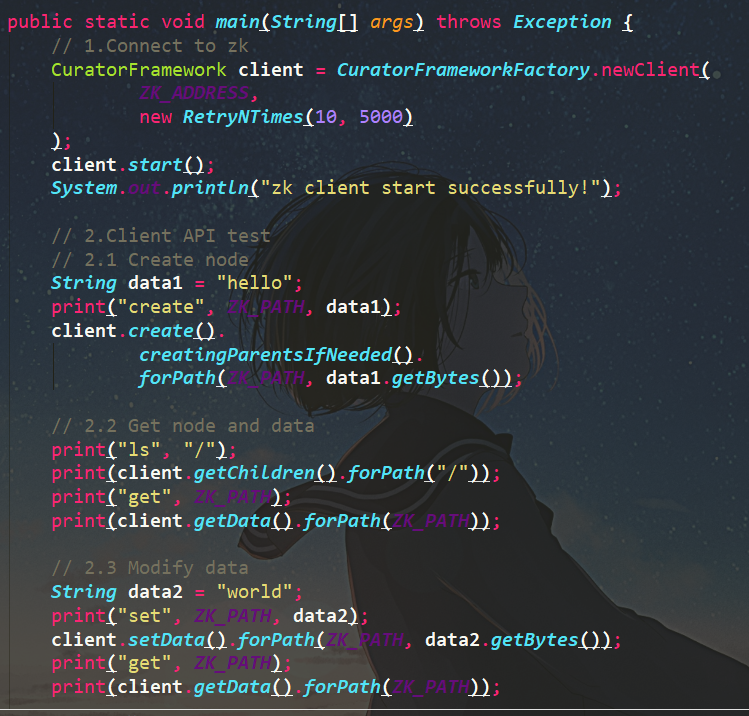
curator自身实现了leader选举和分布式锁等功能,leader选举中Curator提供了LeaderSelector监听器实现Leader选举功能,同一时刻,只有一个Listener会进入takeLeadership()方法,说明它是当前的Leader。不过如果不清楚这个机制的话代码走起来说真的其实有点懵。而分布式锁呢curator是通过一个InterProcessMutexDemo类来实现的,这里就不展开了。
finally
到这篇为止zookeeper的东西就差不多了,也算是填了一个坑吧,代码从二到六也算是敲的不少,而且基本都是完整地贴出来了,有兴趣想跑一下验证的话直接ctrl+c/v即可。之后应该是循序渐进,RPC再到dubbo的一个路线
下一篇:从零开始的高并发(七)--- RPC的介绍,协议及框架
