

前言
Spark的知识点很多,决定分多P来慢慢讲🤣,比较关键的RDD算子其实已经写了大半,奈何内容还是太多了就不和这篇扯皮的放一起了。
老套路,我们点开官网来see see先吧
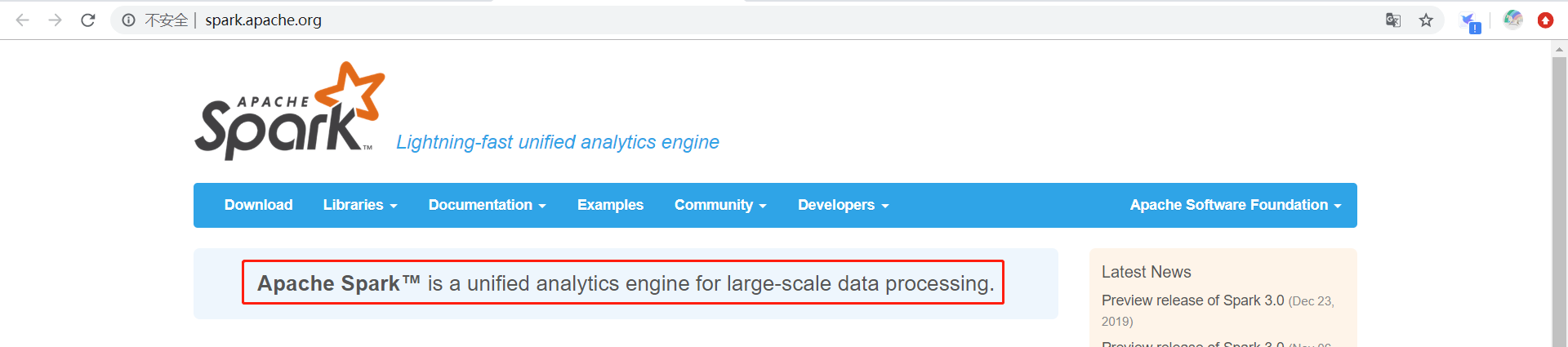
把这句话翻译一下

spark是在Hadoop基础上的改进,是 UC Berkeley AMP lab 所开源的类 Hadoop MapReduce 的通用的并行计算框架,Spark 基于 mapReduce 算法实现的分布式计算,它拥有 Hadoop MapReduce 所具有的优点。
但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写 HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的mapReduce的算法。但是它仅仅只是涉及到计算,并没有涉及到数据的存储,后期需要使用spark对接外部的数据源,比如 Hadoop 中的 HDFS。
一、Spark 基础
1.1 Spark 的四大特性
其实就是官网主页以下的内容
1.1.1 速度快

把内容丢到百度翻译中去

先不管什么DAG调度,查询优化···等等诸如此类的专业术语,就看那张柱形图那个百来倍速度我们就知道它很快就是了,MapReduce 需要 110s 的事情它 0.9s 就完成了
1.1.2 Spark 为啥比 MapReduce 快这么多
大概可以分为两个方面
1.基于内存:mapreduce任务在计算的时候,每一个job的输出结果会落地到磁盘,后续有其他的job需要依赖于前面job的输出结果,这个时候就需要进行大量的磁盘io操作,性能就比较低。而spark任务在计算的时候,job的输出结果可以保存在内存中,后续有其他的job需要依赖于前面job的输出结果,这个时候就直接从内存中获取,避免了磁盘io操作,所以性能就得以提升。
2.进程与线程方面:mapreduce任务以进程的方式运行在yarn集群中,比如程序中有100个MapTask,一个task就需要一个进程,这些task要运行就需要开启100个进程。
spark任务以线程的方式运行在进程中,比如程序中有100个MapTask,后期一个task就对应一个线程,这里就不在是进程,这些task需要运行,这里如果极端一点:只需要开启1个进程,在这个进程中启动100个线程就可以了。进程中可以启动很多个线程,而开启一个进程与开启一个线程需要的时间和调度代价是不一样。开启一个进程需要的时间远远大于开启一个线程。
1.1.3 易用性


这个就没有啥好展开的了,就是可以通过 java/scala/python/R/SQL 等不同语言快速去编写 spark 程序
1.1.4 通用性
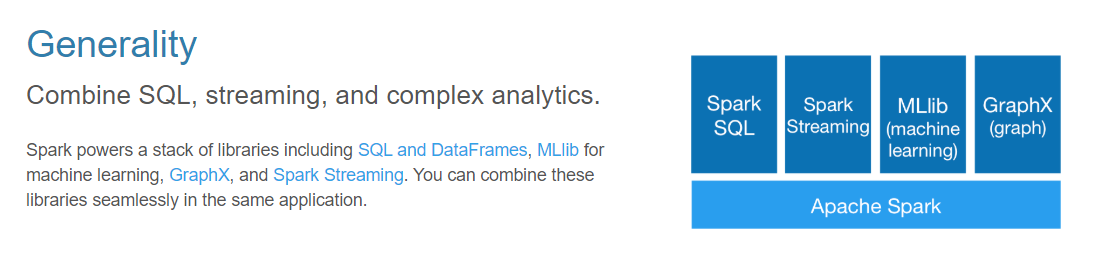
其实可以理解为 Spark 已经形成了自己的一个生态,其内部包含了许多模块
SparkSQL:通过sql去做离线分析
SparkStreaming:解决实时计算用的
Mlib:机器学习的算法库
Graphx:图计算方面的
1.1.5 兼容性

spark程序就是一个计算逻辑程序,这个任务要运行就需要计算资源(内存、cpu、磁盘),哪里可以给当前这个任务提供计算资源,就可以把spark程序提交到哪里去运行
1.2 Spark 的架构
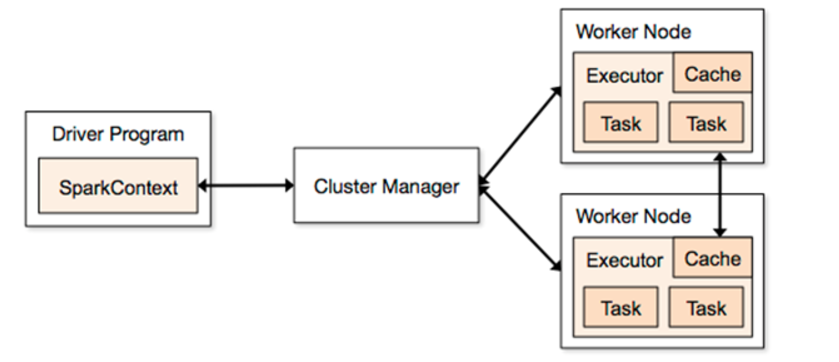
1.2.1 Driver
它会执行客户端写好的main方法,它会构建一个名叫 SparkContext 对象。该对象 是所有spark程序的执行入口
1.2.2 Cluster Manager
给 Spark 程序提供外部计算资源的服务,一般来说有以下3种
- standAlone:Spark 自带的集群模式,整个任务的资源分配由 Spark 集群的老大 master 负责
- Yarn:可以把 Spark 提交到 Yarn 中运行,此时资源分配由 Yarn 中的老大 ResourceManager 负责
- mesos:Apache开源的一个类似于 Yarn 的资源调度平台
正常来说我们都会使用 Yarn 去进行管理
1.2.3 Worker Node
Master是整个spark集群的老大,负责任务资源的分配。也就是 Spark 集群中负责干活的小弟,是负责任务计算的节点
1.2.4 Executor
Executor 是一个进程,它会在worker节点启动该进程(计算资源)
1.2.5 Task
spark任务是以task线程的方式运行在worker节点对应的executor进程中
1.3 Spark 的安装部署
一笔带过。简单点来说就是下好安装包丢到服务器,解压下来去到conf文件夹 vim spark-env.sh,配一下 Java 的环境变量和 zookeeper,然后 vim slaves 去配置 worker 节点。然后修改 Spark 的环境变量并且分发到 worker 中,然后 source /etc/profile 即可。
需要注意的是我们一般为了 Spark 集群的高可用会有多个master(Hadoop HA的套路),一般来说会这样配置
#配置zk相关信息
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181
-Dspark.deploy.zookeeper.dir=/spark"
上面其实就是 -D 然后带上3个参数,参数和参数之间用空格隔开即可
spark.deploy.recoveryMode 是高可用方案依赖于zookeeper进行恢复,第二个 spark.deploy.zookeeper.url 指定了zookeeper的地址,第三个 spark.deploy.zookeeper.dir 是指这个zookeeper节点负责接收 Spark 产生的元数据(目录就是一个字符串)
1.4 spark集群的启动和停止
先启动zk再启动spark集群
可以在任意一台服务器来执行(条件:需要任意2台机器之间实现ssh免密登录)
$SPARK_HOME/sbin/start-all.sh
在哪里启动这个脚本,就在当前该机器启动一个Master进程
整个集群的worker进程的启动由slaves文件控制
后期可以在其他机器单独再启动master
$SPARK_HOME/sbin/start-master.sh
如果部署成功,是可以通过
http://master主机名:8080
来访问一个web界面的,各种各样的集群信息都能看得到,大致包括
整个spark集群的详细信息
整个spark集群总的资源信息
整个spark集群已经使用的资源信息
整个spark集群还剩的资源信息
整个spark集群正在运行的任务信息
整个spark集群已经完成的任务信息
补充一句,备用的master节点的话,status 的值就会是 standby
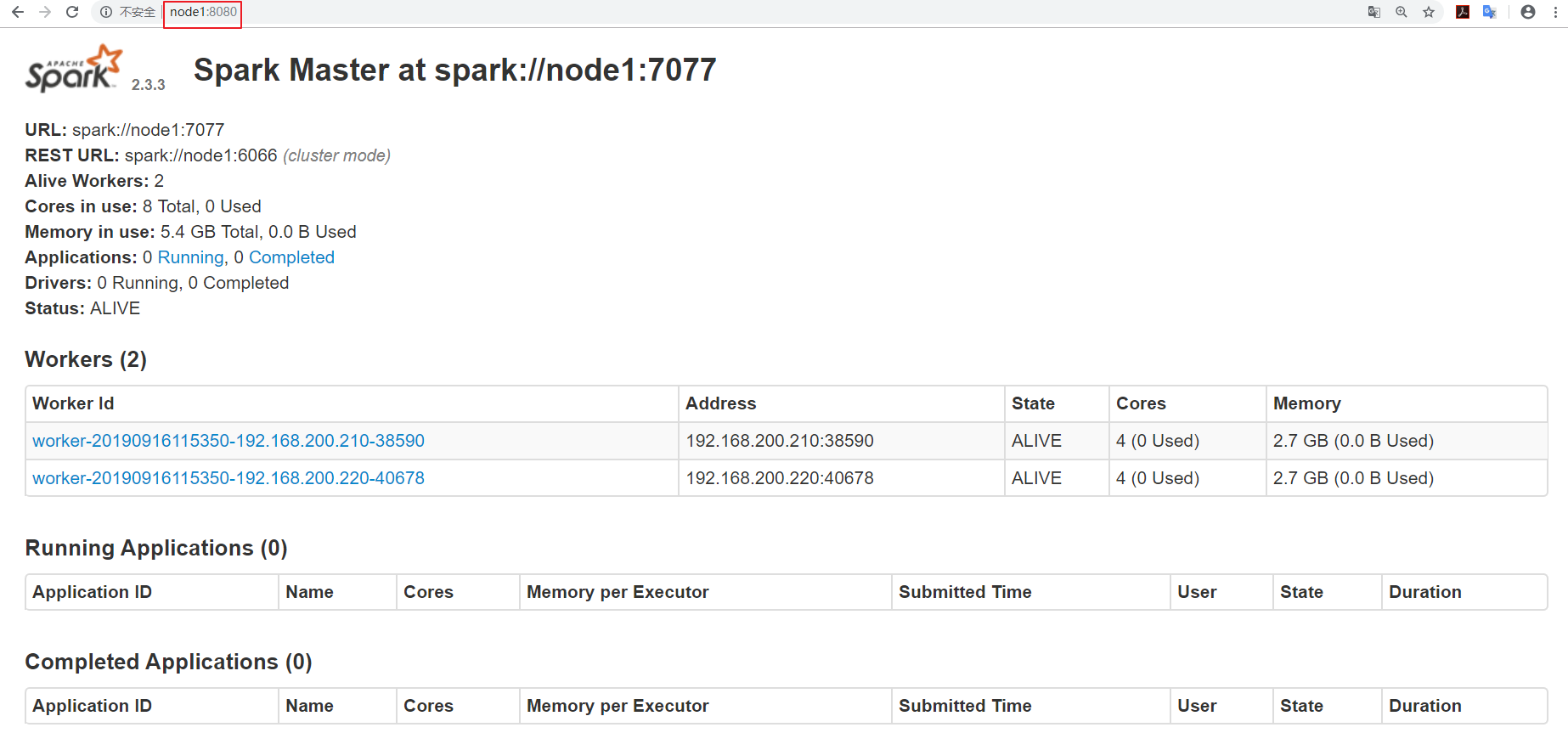
上面的信息英文都不难理解,这里就不一一说明了。
1.5 如何恢复到上一次活着master挂掉之前的状态?
在高可用模式下,整个spark集群就有很多个master,其中只有一个master被zk选举成活着的master,其他的多个master都处于standby,同时把整个spark集群的元数据信息通过zk中节点进行保存。
后期如果活着的master挂掉。首先zk会感知到alive的master挂掉,下面开始在多个处于standby中的master进行选举,再次产生一个alive的master,这个alive的master会 读取保存在zk节点中的spark集群元数据信息 ,恢复到上一次master的状态。整个过程在恢复的时候经历过了很多个不同的阶段,每个阶段都需要一定时间,最终恢复到上个alive的master的转态,整个恢复过程一般需要1-2分钟。
1.6 在master的恢复阶段对任务的影响?
- 对已经运行的任务是没有任何影响。由于该任务正在运行,说明它 已经拿到了计算资源,这个时候就不需要master
- 对即将要提交的任务是有影响。由于该任务需要有计算资源,这个时候会找活着的master去申请计算资源,由于没有一个活着的master,该任务是 获取不到计算资源,也就是任务无法运行。
1.7 Spark程序的提交
1.7.1 普通模式下
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node1:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
examples/jars/spark-examples_2.11-2.3.3.jar \
10
参数说明:
--class:指定包含main方法的主类
--master:指定spark集群master地址
--executor-memory:指定任务在运行的时候需要的每一个executor内存大小
--total-executor-cores: 指定任务在运行的时候需要总的cpu核数
1.7.2 高可用模式提交 (集群有多个master)
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node1:7077,node2:7077,node3:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
examples/jars/spark-examples_2.11-2.3.3.jar \
10
其实没有太多的变化。spark集群中有很多个master,并不知道哪一个master是活着的master,即使你知道哪一个master是活着的master,它也有可能下一秒就挂掉,这里就可以把所有master都罗列出来
--master spark://node1:7077,node2:7077,node3:7077
后期程序会轮询整个master列表,最终找到活着的master,然后向它申请计算资源,最后运行程序。
1.8 Spark-shell
···
finally
本来也是打算写一个scala的,但是想到这东西也不算难,而且大家也可以通过各类的搜索引擎去学习,所以就丢到草稿里面了(其实就是懒了没写完😂)
这篇其实只是一个概念入门,下一篇我们开始扯 RDD 。有兴趣的朋友可持续关注哦!公众号:说出你的愿望吧

