一、背景
1.概述
SVM PLALDA}←硬分类→软⎩⎨⎧(概率判别模型,对P(y∣x)建模)LogisticRegression⇒MaxEntropyModel(概率生成模型,对P(x,y)建模)NaiveBayes⇒HiddenMarkovModel⎭⎬⎫→MEMM→CRF
如上所示,分类问题分为硬分类和软分类两种。
硬分类问题指的是分类结果非此即彼的模型,包括SVM、PLA、LDA等。软分类问题将概率作为分类的依据,分为概率判别模型和概率生成模型两种。
概率判别模型是一种对概率P(y∣x)进行建模的方法,其中最典型的算法是逻辑回归(Logistic Regression,LR)。LR的损失函数采用的是交叉熵损失函数,因此这类模型也被称为对数线性模型,或者更一般地,最大熵模型(Max Entropy Model)。这类模型的概率假设与指数族分布是一致的。另一方面,朴素贝叶斯算法(Naive Bayes)是概率生成模型的一种。如果我们将朴素贝叶斯中的单元素条件独立性推广到一系列隐变量,我们就可以得到动态模型,如隐马尔可夫模型(Hidden Markov Model,HMM)。从概率的角度来看,HMM可以被视为高斯混合模型(Gaussian Mixture Model,GMM)在时序上的推广。
2.HMM vs. MEMM
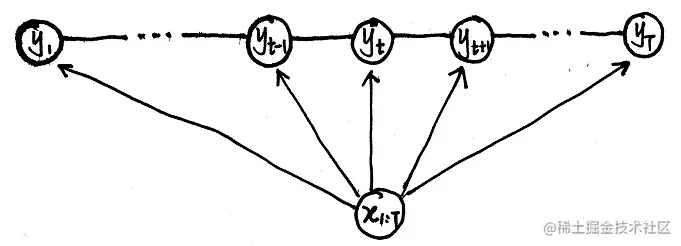
如果将最大熵模型和HMM相结合,就得到了最大熵马尔可夫模型(Max Entropy Markov Model)。MEMM的概率图如下:
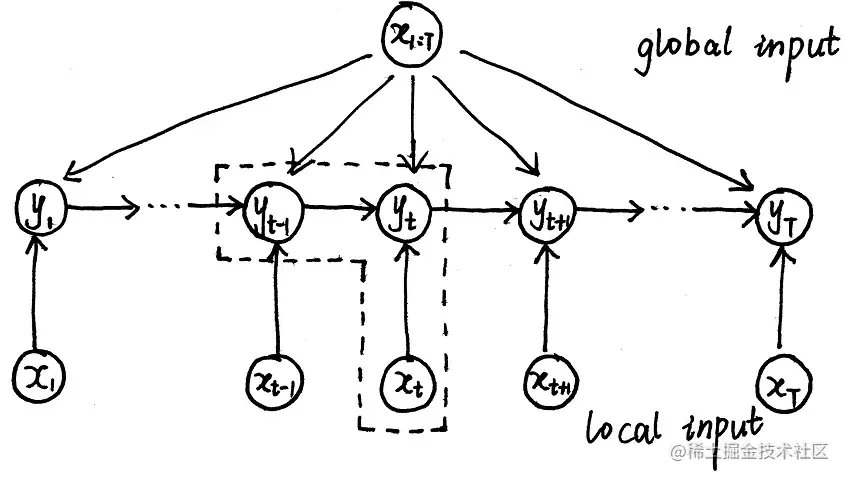
这个概率图就是将HMM的概率图观测变量和隐变量的边反向,这样的话HMM中的观测独立假设就不成立了,也因此X对Y的影响包括局部和全局两种。
HMM的观测独立假设是一个很强的假设,如果我们有一个文本样本,那么观测独立假设就意味着样本之中的每个词之间没有任何关系,这显然是不合理的,因此打破这个假设是更加合理的。
HMM的概率图如下:
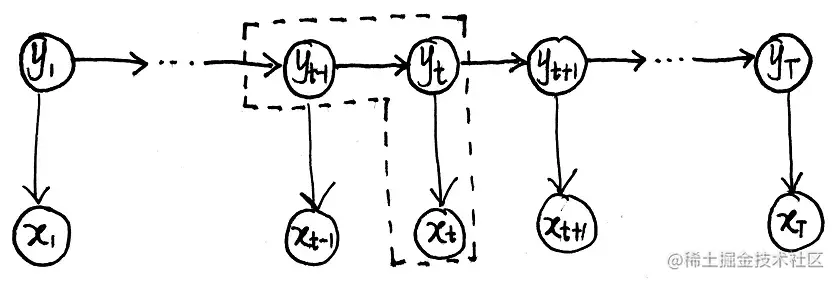
HMM是一个概率生成模型,其建模对象是P(X,Y∣λ),可以将HMM的看做是由图中画虚线的部分所组成的,结合其两个假设,可以写出其概率公式为:
P(X,Y∣λ)=i=1∏TP(xt,yt∣yt−1,λ)=i=1∏TP(yt∣yt−1,λ)P(xt∣yt,λ)
在MEMM的概率图中,xt、xt+1、yt+1之间是head-to-head的结构,它们是不独立的,因此打破了观测独立假设,X的作用分为global和local两种。MEMM是概率判别模型,其建模对象是P(Y∣X,λ),其概率图可以认为是由图中画虚线的部分组成,因此其概率公式为:
P(Y∣X,λ)=i=1∏TP(yt∣yt−1,x1:T,λ)
MEMM的缺陷是其必须满足局部的概率归一化(也就是Label Bias Problem),对于这个问题,我们将y之间的箭头转为直线从而得到无向图(线性链条件随机场),这样就只要满足全局归一化了(破坏了齐次马尔可夫假设)。
3.标注偏置问题
标注偏置问题(Label Bias Problem)是MEMM存在的一个局限性,这也是决定它不流行的主要原因,条件随机场(Conditional Random Field,CRF)通过使用无向图解决了这个问题。
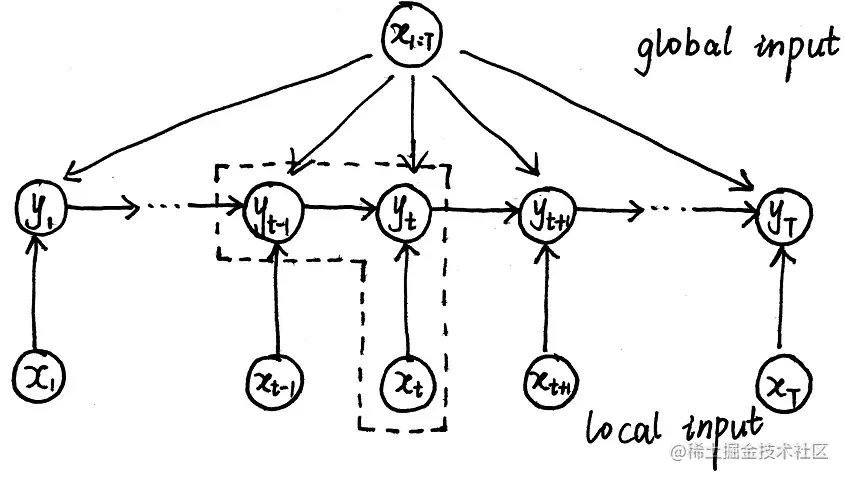
对于MEMM,上面的概率图由于存在齐次马尔可夫假设可以认为是由一个个方框中的部分组成的,因此有概率公式如下:
P(Y∣X,λ)=i=1∏TP(yt∣yt−1,x1:T,λ)
对于每一个方框中的组件,我们可以看做一个函数,叫做mass score,这个函数对外是有一定能量的,但这个mass score同时必须是一个概率P(yt∣yt−1,x1:T,λ),因此被归一化了,叫做局部归一化,这就是导致标注偏置问题的根本原因所在。
而CRF采用无向图的结构,其天然地满足全局归一化,也就打破了齐次马尔可夫假设,从而解决了标注偏置问题。
局部归一化造成了标注偏置问题,这一问题造成的现象可以通过以下例子来解释。
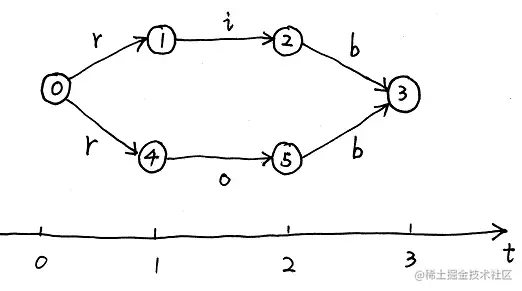
对于上图中训练得到的MEMM模型,节点表示时刻的状态yt,边表示观测xt。可以看出,上述状态从1到2,2到3,4到5,5到3全部都只有一个状态转移的选择,这也就导致无论观测xt是多少,yt都不关心而只会向确定的一个状态进行转移。
上述状况显然表明训练得到的模型是不合理的,举个更具体的例子,如果对“小明 爱 中国”进行词性标注,模型会根据“小明”和“爱”的词性直接标注“中国”的词性,根本不关心观测“中国”本身。
上述MEMM模型是根据训练数据训练得到的,比如在训练数据中一共有3个rob,1个rib,这样的训练数据得到的模型概率如下图所示:
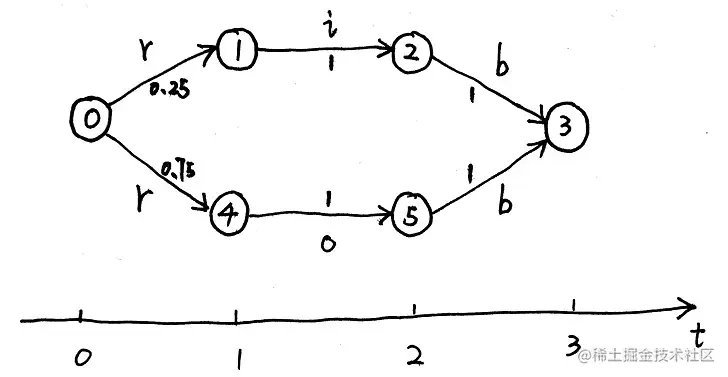
可以看出由于局部归一化从1到2,2到3,4到5,5到3的状态转移概率全部都是1,这样会造成求解Decoding问题时的标注偏置问题,也就是在观测为rib的条件下,求解最可能的标准序列Y^时会得到以下结果:
Y^=y1,y2,y3argmaxP(y1,y2,y3∣rib)=0→4→5→3
也就是说解得的结果反而是0→4→5→3,这是因为概率0.75×1×1>0.25×1×1所致。
二、条件随机场
1.条件随机场的概率密度函数
CRF中条件代表这是一个判别式模型,随机场表示其是一个无向图模型。CRF的概率图如下:
对于无向图的因子分解,可以参考以前的文章中的讲解:9.概率图模型。
简单来说,无向图的概率分布可以分解为图中所有最大团的势函数的乘积。给定概率无向图模型,Ci,i=1,2,⋯,K为无向图模型上的最大团,则x的联合概率分布P(x)可以写为:
P(x)=Z1i=1∏Kψ(xCi)Ci:最大团xCi:最大团随机变量集合ψ(xCi):势函数,必须为正Z=x∑i=1∏Kψ(xCi)=x1∑x2∑⋯xp∑i=1∏Kψ(xCi)
Z是归一化因子,通常使用势函数ψ(xCi)=exp{−E(xCi)}(这里的E(xCi)叫做能量函数),也就是说:
P(x)=Z1i=1∏Kψ(xCi)=Z1i=1∏Kexp{−Ei(xCi)}=Z1exp{i=1∑K−Ei(xCi)}=Z1exp{i=1∑KFi(xCi)}=Z1exp{i=1∑KF(xCi)}
为方便起见,这里把−Ei(xCi)写作Fi(xCi)只是为了简化形式,并且不同最大团之间使用的是同一个F函数。在CRF中对于P(Y∣X)也就有:
P(Y∣X)=Z1exp{i=1∑KF(yCi)}=Z1exp{t=1∑TF(yt−1,yt,x1:T)}
这里为了方便起见,在y1前添加y0节点,因此对于CRF这个线性链,其中一共有T个最大团。
对于函数F(yt−1,yt,x1:T),我们可以把它写作三部分:
F(yt−1,yt,x1:T)=Δyt−1,x1:T+Δyt,x1:T+Δyt−1,yt,x1:T
其中 Δyt−1,x1:T 和 Δyt,x1:T 称为状态函数, Δyt−1,yt,x1:T 称为转移函数。由于在∑t=1TF(yt−1,yt,x1:T) 中每个 Δyt,x1:T 都出现了两次,并且我们还需要做归一化,因此在每个 F 中省略 Δyt−1,x1:T 这一项即可,也就是说我们采用的 F 为:
F(yt−1,yt,x1:T)=Δyt,x1:T+Δyt−1,yt,x1:T
我们定义 Δyt,x1:T 和 Δyt−1,yt,x1:T 如下:
Δyt−1,yt,x1:T=k=1∑Kλkfk(yt−1,yt,x1:T)Δyt,x1:T=l=1∑Lηlgl(yt,x1:T)
上式中fk和gl是给定的特征函数(或者指数函数),λk和ηl是参数。特征函数的取值是人为给定的,取值只能是0或1,fk称为转移特征,gl称为状态特征,只有在满足特征条件时特征函数取值才为1,否则为0,比如我们可以规定:
f1(yt−1,yt,x1:T)={1,yi−1=1,yi=1,x1:T(i=2,3)0,otherwise
总而言之,P(Y∣X)的概率密度函数可以表示为:
P(Y∣X)=Z1exp{t=1∑T[k=1∑Kλkfk(yt−1,yt,x1:T)+l=1∑Lηlgl(yt,x1:T)]}
2.概率密度函数的向量形式
为了更方便地使用概率密度函数进行后续求导等一系列操作,我们需要对上述概率密度函数进行整理和简化,从而取得其向量的表示形式。
对于归一化因子Z,其只和x,λ,η有关,而与y无关,这是因为y被积分积掉了,因此可以写成以下形式:
Z=Z(x,λ,η)
接着我们定义以下向量:
y=⎝⎛y1y2⋮yT⎠⎞,x=⎝⎛x1x2⋮xT⎠⎞,λ=⎝⎛λ1λ2⋮λK⎠⎞,η=⎝⎛η1η2⋮ηL⎠⎞f=f(yt−1,yt,x)=⎝⎛f1f2⋮fK⎠⎞,g=g(yt,x)=⎝⎛g1g2⋮gL⎠⎞
则此时我们将概率密度函数写作以下向量相乘的形式:
P(Y=y∣X=x)=Z(x,λ,η)1exp{t=1∑T[λT⋅f(yt−1,yt,x)+ηT⋅g(yt,x)]}
此时式子中还剩下一个关于t的连加号,而与t有关的只有f和g,于是我们考虑可以将这个连加号放到括号里面:
P(Y=y∣X=x)=Z(x,λ,η)1exp{λT⋅t=1∑Tf(yt−1,yt,x)+ηT⋅t=1∑Tg(yt,x)}
接着继续定义如下两个向量:
θ=(λη)K+L,H=(∑t=1Tf(yt−1,yt,x)∑t=1Tg(yt,x))K+L
于是最终可以将概率密度函数写成如下形式:
P(Y=y∣X=x)=Z(x,θ)1exp{θT⋅H}
三、参数估计和推断
1.条件随机场要解决的问题
Learning: 也就是参数估计问题,对于给定的训练数据 {(x(i),y(i))}i=1N,x,y 均是 T 维向量,需要估计参数 θ^=argmax∏i=1NP(y(i)∣x(i)) 。
Inference:
- ①边缘概率: 求 P(yt∣x) ;
- ②条件概率: 一般在生成模型中较为关注,条件随机场不关注;
- ③MAP推断:也就是Decoding问题,即 y^=argmaxP(y∣x) 。
2.求解边缘概率
求解边缘概率的问题就是给定概率分布 P(Y=y∣X=x) ,求解 P(yt=i∣x) 。对于 P(y∣x) ,其概率分布为:
P(y∣x)=Z1t=1∏Tϕt′(yt′−1,yt′,x)
因此我们要求解的概率分布为:
P(yt=i∣x)=y1:t−1,yt+1:T∑P(y∣x)=y1:t−1∑yt+1:T∑Z1t=1∏Tϕt′(yt′−1,yt′,x)
假设yt的取值集合为S。直接计算上式的复杂度非常高,因为求和的复杂度是O(∣S∣T),求积的复杂度是O(T),因此整体的复杂度是O(T∣S∣T)。为了降低复杂度,我们的解决方案是调整求和符号的位置,这实际上就是我们之前讨论过的变量消除方法。
我们将t时刻左右两边的势函数连同积分号拆成两部分Δ左和Δ右:
P(yt=i∣x)=Z1Δ左Δ右Δ左=y1:t−1∑ϕ1(y0,y1,x)ϕ2(y1,y2,x)⋯ϕt−1(yt−2,yt−1,x)ϕt(yt−1,yt=i,x)Δ右=yt+1:T∑ϕt+1(yt=i,yt+1,x)ϕt+2(yt+1,yt+2,x)⋯ϕT(yT−1,yT,x)
对于Δ左,我们按照变量消除法的思路来调整加和符号的位置:
Δ左=yt−1∑ϕt(yt−1,yt=i,x)yt−2∑ϕt−1(yt−2,yt−1,x)⋯y1∑ϕ2(y1,y2,x)y0∑ϕ1(y0,y1,x)
按照从右往左积分的方式可以降低计算的复杂度,也就是一个一个地进行积分,并且上式为了看起来方便省略了括号。这里的y0是为了表达方便才加上去的一个随机变量,可以认为它的值只能取start这一个值。
接下来我们将上式写成递推式的形式,我们定义:
αt(i)=Δ左
则递推式为:
αt(i)=j∈S∑ϕt(yt−1=j,yt=i,x)αt−1(j)
类似地,对Δ右的积分方式为:
Δ右=yt+1∑ϕt+1(yt=i,yt+1,x)yt+2∑ϕt+2(yt+1,yt+2,x)⋯yT−1∑ϕT(yT−2,yT−1,x)yT∑ϕT(yT−1,yT,x)
同样地这里也省略一系列括号,顺序也是从右往左进行积分。我们定义:
βt(i)=Δ右
递推式为:
βt(i)=j∈S∑ϕt+1(yt=i,yt+1=j,x)βt+1(j)
因此,最终的结论也就是:
P(yt=i∣x)=Z1αt(i)βt(i)
这个方法类似于HMM中的前向后向算法,其实也就是概率图模型中精确推断的变量消除法(信念传播),相关参考链接为:10.概率图推断
3.参数估计
对于概率密度函数的以下形式:
P(Y=y∣X=x)=Z(x,θ)1exp{θT⋅H}
这里可以看出这个概率密度函数就是一个指数族分布,其中参数向量就是上面的θ,充分统计量也就是H。有关指数族分布的讲解可以参考这个链接:8.指数族分布
CRF的参数估计问题就是在似然上做梯度上升来求得最优解,而我们用来求导的概率密度函数使用以下形式:
P(Y=y∣X=x)=Z(x,λ,η)1exp{t=1∑T[λT⋅f(yt−1,yt,x)+ηT⋅g(yt,x)]}
按照极大似然估计的思路,写出公式如下:
θ^=θargmaxi=1∏NP(y(i)∣x(i))=θargmaxi=1∑NlogP(y(i)∣x(i))=θargmax记作L(λ,η)i=1∑N[−logZ(x(i),λ,η)+t=1∑T[λT⋅f(yt−1(i),yt(i),x(i))+ηT⋅g(yt(i),x(i))]]=θargmaxL(λ,η)
然后需要对λ和η求导,以λ为例。等号右边的部分对λ求导较为简单。
从指数族分布的角度来看,Z(x(i),λ,η)就是配分函数,logZ(x(i),λ,η)也就是log配分函数。套用指数族分布中第三部分的结论,我们可以知道:
∇θ(logZ(x(i),θ))=EP(y∣x(i))[H]=EP(y∣x(i))[(∑t=1Tf(yt−1,yt,x(i))∑t=1Tg(yt,x(i)))]
类似的对于θ的一部分λ进行求导我们可以知道:
∇λ(logZ(x(i),λ,η))=EP(y∣x(i))[t=1∑Tf(yt−1,yt,x(i))]=y∑[P(y∣x(i))t=1∑Tf(yt−1,yt,x(i))]
这个结论和指数族分布中第三部分的推导过程类似,这里我们就不再重复。
对于上述式子,我们可以调整加和符号的位置:
t=1∑T[y∑P(y∣x(i))f(yt−1,yt,x(i))]=t=1∑T[y1:t−2∑yt−1∑yt∑yt+1:T∑P(y∣x(i))f(yt−1,yt,x(i))]=t=1∑T[yt−1∑yt∑P(yt−1,yt∣x(i))f(yt−1,yt,x(i))]
对于概率P(yt−1,yt∣x(i)),这显然是一个边缘概率,我们可以利用前向后向算法来求解这个边缘概率,然后就能得到这个导数。对于边缘概率P(yt∣x(i)),我们可以将1到t的势函数记作Δ∗左,将t+1到T的势函数记作Δ∗右。类似地,在求解P(y∗t−1,y∗t∣x(i))时,我们可以将1到t−1部分的势函数记作Δ左,将t+1到T的势函数记作Δ右。总的来说,求解的过程是类似的。
因此,最终我们得到的log似然对λ的导数为:
∇λL(λ,η)=∑i=1N∑t=1T[f(yt−1(i),yt(i),x(i))−∑yt−1∑ytP(yt−1,yt∣x(i))f(yt−1,yt,x(i))]
然后按照梯度上升的方式来更新参数即可,η的处理也类似:
{λ(m+1)=λ(m)+step⋅∇λ(m)L(λ(m),η(m))η(m+1)=η(m)+step⋅∇η(m)L(λ(m),η(m))
4.Decoding问题
Decoding问题和HMM中的Viterbi算法类似,同样采样动态规划的思想⼀层⼀层求解最大值,求解方法很类似,这里就不再重复,参考链接:16.隐马尔可夫链,更具体的可以参考李航老师的《统计学习方法》中关于CRF的讲解。
“本文正在参加 人工智能创作者扶持计划 ”


