

一、栈
1.定义
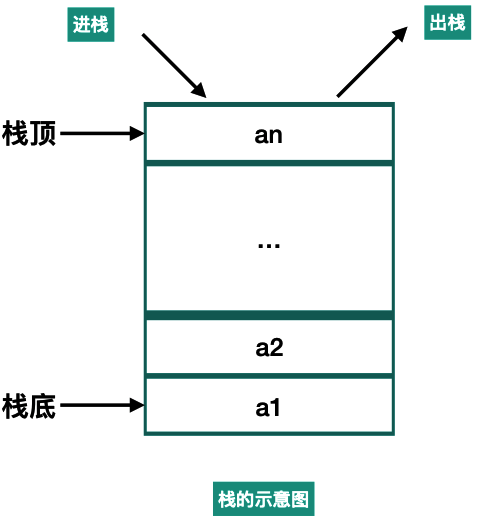
栈是一种特殊的线性表,仅允许在表的一端进行插入和删除运算。这一端被称为栈顶(top),相对地,把另一端称为栈底(bottom)。向一个栈插入新元素又称作进栈、入栈或压栈(push),它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;从一个栈删除元素又称作出栈或退栈(pop),它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。所以栈具有“后入先出”的特点(LIFO)。
2.顺序栈(静态栈)
顺序栈,即用顺序表实现栈的存储结构
1.结构
#include "stdio.h"
#include "stdlib.h"
#include "math.h"
#include "time.h"
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
#define MAXSIZE 20 /* 存储空间初始分配量 */
typedef int Status;
typedef int SElemType; /* SElemType类型根据实际情况而定,这里假设为int */
typedef struct {
SElemType data[MAXSIZE];
int top; /* 用于栈顶指针 */
}SqStack;
2.构建空栈
Status InitStack(SqStack *S){
S->top = -1;
return OK;
}
3.将栈置空
Status ClearStack(SqStack *S){
//疑问: 将栈置空,需要将顺序栈的元素都清空吗?
//不需要,只需要修改top标签就可以了.
S->top = -1;
return OK;
}
4.判断顺序栈是否为空
Status StackEmpty(SqStack S){
if (S.top == -1)
return TRUE;
else
return FALSE;
}
5.返回栈的长度
int StackLength(SqStack S){
return S.top + 1;
}
6.获取栈顶
Status GetTop(SqStack S,SElemType *e){
if (S.top == -1)
return ERROR;
else
*e = S.data[S.top];
return OK;
}
7.插入元素e为新栈顶元素
Status PushData(SqStack *S, SElemType e){
//栈已满
if (S->top == MAXSIZE -1) {
return ERROR;
}
//栈顶指针+1;
S->top ++;
//将新插入的元素赋值给栈顶空间
S->data[S->top] = e;
// 可以合并成 S->data[++ S->top] = e;
return OK;
}
8.删除S栈顶元素,并且用e带回
Status Pop(SqStack *S,SElemType *e){
//空栈,则返回error;
if (S->top == -1) {
return ERROR;
}
//将要删除的栈顶元素赋值给e
*e = S->data[S->top];
//栈顶指针--;
S->top--;
// *e = S->data[S->top--];
return OK;
}
9.从栈底到栈顶依次对栈中的每个元素打印
Status StackTraverse(SqStack S){
int i = 0;
printf("此栈中所有元素");
while (i<=S.top) {
printf("%d ",S.data[i++]);
}
printf("\n");
/*
int i = S.top;
while (i >= 0) {
printf("%d ",S.data[i--]);
}
printf("\n");
*/
return OK;
}
3.链式栈(动态栈)
链栈的实现思路同顺序栈类似,顺序栈是将顺序表(数组)的一端作为栈底,另一端为栈顶;链栈也如此,通常我们将链表的头部作为栈顶,尾部作为栈底
将链表头部作为栈顶的一端,可以避免在实现数据 "入栈" 和 "出栈" 操作时做大量遍历链表的耗时操作。
链表的头部作为栈顶,意味着:
- 在实现数据"入栈"操作时,需要将数据从链表的头部插入;
- 在实现数据"出栈"操作时,需要删除链表头部的首元节点;
因此,链栈实际上就是一个只能采用头插法插入或删除数据的链表。
1.结构
#include "stdio.h"
#include "stdlib.h"
#include "math.h"
#include "time.h"
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
#define MAXSIZE 20 /* 存储空间初始分配量 */
typedef int Status;
typedef int SElemType; /* SElemType类型根据实际情况而定,这里假设为int */
链栈结构
//链栈中节点结构
typedef struct StackNode {
SElemType data;
struct StackNode *next;
}StackNode,*LinkStackPtr;
//链栈结构
typedef struct {
LinkStackPtr top;
int count;
}LinkStack;
2.构造空栈
Status InitStack(LinkStack *S) {
S->top=NULL;
S->count=0;
return OK;
}
3.置为空栈
Status ClearStack(LinkStack *S){
LinkStackPtr p,q;
p = S->top;
while (p) {
q = p;
p = p->next;
free(q);
}
S->count = 0;
return OK;
}
4.判断空栈
Status StackEmpty(LinkStack S){
if (S.count == 0)
return TRUE;
else
return FALSE;
}
5.长度
int StackLength(LinkStack S){
return S.count;
}
6.获取栈顶元素
Status GetTop(LinkStack S,SElemType *e){
if(S.top == NULL)
return ERROR;
else
*e = S.top->data;
return OK;
}
7.进栈(头插法)
Status Push(LinkStack *S, SElemType e){
//创建新结点temp
LinkStackPtr temp = (LinkStackPtr)malloc(sizeof(StackNode));
//赋值
temp->data = e;
//把当前的栈顶元素赋值给新结点的直接后继, 参考图例第①步骤;
temp->next = S->top;
//将新结点temp 赋值给栈顶指针,参考图例第②步骤;
S->top = temp;
S->count++;
return OK;
}
8.出栈
Status Pop(LinkStack *S,SElemType *e){
LinkStackPtr p;
if (StackEmpty(*S)) {
return ERROR;
}
//将栈顶元素赋值给*e
*e = S->top->data;
//将栈顶结点赋值给p,参考图例①
p = S->top;
//使得栈顶指针下移一位, 指向后一结点. 参考图例②
S->top= S->top->next;
//释放p
free(p);
//个数--
S->count--;
return OK;
}
9.遍历链栈
Status StackTraverse(LinkStack S){
LinkStackPtr p;
p = S.top;
while (p) {
printf("%d ",p->data);
p = p->next;
}
printf("\n");
return OK;
}
二、递归
什么是递归?若在一个函数,过程或数据结构定义的内部又直接(或间接)出现定义本身的应用;则称为他们是 递归的.或者是递归定义.
哪些问题能采用递归来解决呢?下面3种情况,一班用递归来解决
1.定义是递归的
比如很多数学定义本身就是递归定义;例如大家非常熟悉的阶乘,斐波拉契数列等;
阶乘Fact(n)
(1)若 n=0,则返回1;
(2)若 n>1,则返回n*Fact(n);
long Fact(Long n){
if(n=0) return 1;
else return n * Fact(n-1);
}
二阶斐波拉契数列Fib(n)
(1)若 n=1 或 n=2,则返回1;
(2)若 n>2,则返回 Fib(n-1)+Fib(n-2);
long Fib(Long n){
if(n == 1 || n == 2) return 1;
else return Fib(n-1)+Fib(n-2);
}
对于类似这种复杂问题,若能够分解成几个简单且解法相同或类似的子问题,来求解,便称为递归求解.
例如,在求解4!时先求解3!,然后再进一步分解进行求解,这种求解方式叫做"分治法"。
采取"分治法"进行递归求解的问题需满足以下三个条件:
- 1.能将一个问题转换变成一个小问题,而新问题和原问题解法相同或类同.不同的仅仅是处理的对象,并且 这些处理更小且变化有规律的.
- 2.可以通过上述转换而使得问题简化
- 3.必须有一个明确的递归出口,或称为递归边界.
void p(参数表){
if (递归结束条件成立)可直接求解; //递归终止条件
else p(较小的参数); //递归步骤
}
2.数据结构是递归的
其数据结枸本身具有递归的特性
例如,对于链表,其结点 Node 的定义由数据域 data 和指针域 next 组成,而指针域 next 是一种指向 Node 类型的指针,即 Node 的定义中又用到了其自身。所以链表是一种递归的数据结构
递归法遍历链表
void foreachList(LinkList p){
//递归结束
if(p == NULL) return;
else{
printf("%d",p->data);
foreachList(p->next);
}
}
在递归算法中,如果递归结束条件成立,只执行 return 操作时,分治法求解递归问题算法一般形式可简化为:
void p(参数表){
if(递归条件不成立)
p(较小参数);
}
void foreachList(LinkList p){
if(p){
printf("%d",p->data);
foreachList(p->next);
}
}
3.问题的解法是递归的
有一类问题,虽然问题本身并没有明显的递归结枸,但是采样递归求解比迭代求解更简单,如汉诺塔问题,八皇后问题,迷宫问题
三、递归与栈的关系
一个递归函数,在函数的执行过程中,需要多次进行自我调用,那么是如何执行的?
在了解归函数是如何执行之前,先来了解一下任何的 2 个函数之间调用过程
在高级语言的程序中,调用函数和被调用的函数之间的链接与信息交换都是通过钱来进行的
通常,当在一个函数的运行期间调用另一个函数时,在运行被调用函数之前,系统需要先完成 3 件事情
- 1.将所有的实参,返回地址等信息调用传递被调用函数保存
- 2.为被调用函数的局部变量分配存储空间
- 3.将控制转移到被调函数入口
而从被调用函数返回调用函数之前,系統同样需要完成 3 件事
- 1.保存被调用函数的计算结果;
- 2.释放被调用函数的数据区
- 3.依照被调用函数保存的返回地址将控制移动到调用函数
当多个函数构成嵌套调用时,按照“先调用后返回“的原则,上述函数之间的信息传递和控制转移必须通过”栈”来实现。即系统将整个程序运行时的所需要的数据空间都安排在一个栈中,每当调用一个函数时,就在它的栈顶分配一个存储区,每当这个函数退出时,就释放它的存储区。则当前运行时的函数的数据区必在栈顶
递归函数的运行过程类似多个函数嵌套调用;只是调用函数和被调用函数是同一个函数。因此,和每次调用相关的一个重要概念是递归函数运行的“层次“,假设调用该递归函数的主函数为第 0 层,则从主函数调用递归函数进入第 1 层,从第i层递归调用本函数为进入下一层。即第 i+1 层。反正退出第 i 层递归应返回上一层,即i-1层
为了保证递归函数正确执行,系统需要设立ー个“递归工作栈“作为整个递归函数运行期间使用的数据存储区。每一层递归所需信息构成一个工作记录,其中包括所有的实参,所有的局部变量以及上一层的返回地址 每进入一层递归,就产生一个新的工作记录压入栈顶。每退出一个递归就从栈顶弹出一个工作记录,则当前执行层的工作记录必须是递归工作栈栈顶的工作记录,称为”活动记录“
四、汉诺塔问题
Hanoi 塔问题: 问题描述: 假如有3个分别命名为A,B,C的塔座,在塔座A上插有n个直接⼤大⼩小各不不相同的,从小到大的 编号为1,2,3...n的圆盘. 现在要求将塔座A上的n个圆盘移动到塔座C上. 并仍然按照同样的顺序叠排. 圆盘移动时必须按照以下的规则:
- 每次只能移动⼀一个圆盘;
- 圆盘可以插在A,B,C的任⼀一塔座上;
- 任何时刻都不不能将⼀个较大的圆盘压在小的圆盘之上.
汉诺塔问题是一个经典的问题。汉诺塔(Hanoi Tower),又称河内塔,源于印度一个古老传说。大梵天创造世界的时候做了三根金刚石柱子,在一根柱子上从下往上按照大小顺序摞着64片黄金圆盘。大梵天命令婆罗门把圆盘从下面开始按大小顺序重新摆放在另一根柱子上。并且规定,任何时候,在小圆盘上都不能放大圆盘,且在三根柱子之间一次只能移动一个圆盘。问应该如何操作?
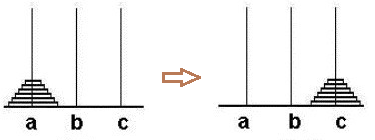
一股脑地考虑每一步如何移动很困难,我们可以换个思路。先假设除最下面的盘子之外,我们已经成功地将上面的64个盘子移到了b柱,此时只要将最下面的盘子由a移动到c即可。如图
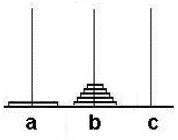
当最大的盘子由a移到c后,b上是余下的63个盘子,a为空。因此现在的目标就变成了将这63个盘子由b移到c。这个问题和原来的问题完全一样,只是由a柱换为了b柱,考虑用递归思想
当盘子只有一个是,即N=1,只有一个动作,从A移动到C即结束
当有N个盘子时:
上半部分: 移动一定和n-1盘子移动时的动作相同。出发地都是A,只不过,n-1个盘子移动的目的是B,而不是C。这样方便取出最后一个盘子
中间部分: 一定是由A移动到C
下半部分: 此时等待移动的盘子已经都在B上,而不是A上,移动步骤类似于n-1个盘子的移动。出发地是B,目的地是C
//n为当前盘子编号. ABC为塔盘z
void Hanoi(int n ,char A,char B,char C){
//只有一个时,直接移动到C
if(n==1){
moves(A, 1, C);
return;
}
//将n-1个盘子由A移动到B,以C为辅助
Hanoi(n-1, A, C, B);
//将A上最大圆盘移动到C上
moves(A, n, C);
//将n-1个盘子由B移动到C,以A为辅助
Hanoi(n-1, B, A, C);
}
int m = 0;
void moves(char X,int n,char Y){
m++;
printf("%d: from %c ——> %c \n",n,X,Y);
}
int main(int argc, const char * argv[]) {
Hanoi(3, 'A', 'B', 'C');
printf("盘子数量为3:一共实现搬到次数:%d\n",m);
return 0;
}
