

--本文采自本人公众号《猴哥别瞎说》
为什么要有深拷贝和浅拷贝?
回答这个问题之前,我们先来看看 JavaScript 中的数据类型吧。
JavaScript 语言的每一个值都属于某一种数据类型。JavaScript 语言一共规定了 7 种数据类型,分别是:Undefined、Null、Boolean、String、Number、Symbol、Object。
这其中又可以分为两大类:基本数据类型与引用数据类型。
基本数据类型
- 定义:基本数据类型指的是简单的数据段。基本类型是按值访问的,因为可以操作保存在变量中的实际值。
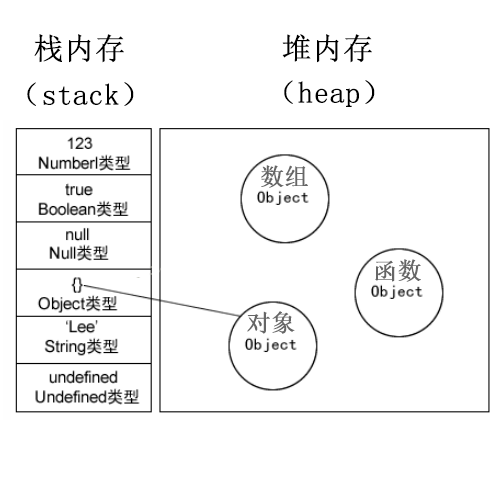
- 存储方式:基本类型的值在内存中占据固定大小的空间,被保存在栈内存中。从一个变量向另一个变量复制基本类型的值,会创建这个值的一个副本。
- 用法:不能给基本类型的值添加属性。
Undefined、Null、Boolean、String、Number、Symbol属于基本数据类型。
引用数据类型
- 定义:引用类型值是指那些可以由多个值构成的对象。javaScript 不允许直接访问内存中的位置,也就是不能直接访问操作对象的内存空间。在操作对象时,实际上是在操作对象的引用而不是实际的对象。
- 存储方式:引用类型的值是对象,保存在堆内存中,包含引用类型值的变量实际上包含的并不是对象本身,而是一个指向该对象的指针。从一个变量向另一个变量复制引用类型的值,复制的其实是指针,因此两个变量最终都指向同一个对象。
- 用法:对于引用类型的值,可以为其添加属性和方法,也可以改变和删除其属性和方法。
除了上面提到的 6 种基本数据类型外,剩下的就是引用类型了,统称为 Object 类型。细分的话,有:Object 类型、Array 类型、Date 类型、RegExp 类型、Function 类型 等。更详细的类型分类可以看这里:你知道所有的类型对象么?
上图说话:
需要深浅拷贝的原因
正因为引用类型的这种机制, 当我们从一个变量向另一个变量复制引用类型的值时,实际上是将这个引用类型在栈内存中的引用地址复制了一份给新的变量,其实就是一个指针。因此当操作结束后,这两个变量实际上指向的是同一个在堆内存中的对象,改变其中任意一个对象,另一个对象也会跟着改变。
在某些时候,我们不希望出现“改变其中任意一个对象,另一个对象也会跟着改变”这种情况,于是就有了深浅拷贝。
这里需要明确的一点是:深拷贝和浅拷贝只发生在引用类型中。
深拷贝与浅拷贝的区别
那么深拷贝和浅拷贝的区别是什么呢?
层次
- 浅拷贝:只将对象的各个属性进行依次复制,不会进行递归复制,也就是说浅拷贝只会赋值目标对象的第一层属性。
- 深拷贝:不仅仅拷贝目标对象的第一层属性,而是递归拷贝目标对象的所有属性。
是否开辟新的内存
- 浅拷贝 对于目标对象第一层为基本数据类型的数据,就是直接赋值,即「传值」。而对于目标对象第一层为引用数据类型的数据,就是直接赋存于栈内存中的堆内存地址,即「传址」, 并没有开辟新的内存。复制的结果是两个对象指向同一个地址,修改其中一个对象的属性,则另一个对象的属性也会改变,
- 深拷贝 而深复制则是开辟新的内存,两个对象对应两个不同的地址,修改其中一个对象的属性,不会改变另一个对象的属性。
浅拷贝的实现
常见的浅拷贝的实现方式有如下几种:
- 针对普通对象:Object.assign()。备注:这是 ES6 新增的语法。
- 针对数组对象:Array.prototype.concat(),Array.prototype.slice()。
- 小技巧:ES6 的展开语法(...)也可以用用于浅拷贝哦。
浅拷贝的实现方式较为简单,上面提到的几种方式都不做展开讲解。这里只写下一个不局限于 ES6 与数组对象的通用方式:
function shallowClone(source) {
var target = {};
for (var key in source) {
if (Object.prototype.hasOwnProperty.call(source, key)) {
target[key] = source[key];
}
}
return target;
}
上面代码中的 hasOwnProperty 与 for ... in 的区别主要在于是否查找 [[Prototype]] 链:
for ... in 循环遍历出所有可枚举的自有属性,包括自身对象及其 [[Prototype]] 原型链中。相比之下,hasOwnProperty 只会检查属性是否在对象上,不会检查 [[Prototype]] 原型链。
深拷贝的实现
关于深拷贝的实现,我们先来看具体的实现方式,再来说说其必要性。
写逻辑实现前,一个好的习惯是:先写下验证逻辑可行性的测试代码。那么在此处,写下一个常见的测试案例为:
var testSample = {
name: "frank shaw",
work: {
job: "FEer",
location: "SZ"
},
a1: undefined,
a2: null,
a3: 123
}
第一步:简单实现
简单实现的想法呢,也非常直接明了:浅拷贝+递归嘛。可以借用上文的通用浅拷贝的代码,再加上递归,就可以有一个简单实现版本了:
//版本一
function deepClone1(source) {
var target = {};
for (var key in source) {
if (Object.prototype.hasOwnProperty.call(source, key)) {
if(typeof source[key] == 'object'){
//拷贝目标是对象,执行递归操作
target[key] = deepClone1(source[key]);
} else {
target[key] = source[key];
}
}
}
return target;
}
我们来看版本一的实现,它是粗糙的。有如下显而易见的缺陷:
1、没有对传入参数进行校验,传入 null 时应该返回 null 而不是 {};
2、对于对象的判断逻辑不严谨,判断依据 typeof null === 'object' 过于粗糙;
3、没有考虑数组的兼容;
我们来考虑改进的版本。
第二步:拷贝数组
首先增加一个判断是否是对象的函数:
function isObject(obj){
return typeof obj === 'object' && obj != null;
}
因为 typeof null === 'object',所以在上面的代码中增加了一个&&判断。
判断是否是数组的方法也很简单,直接使用内置类型Array的方法 Array.prototype.isArray 即可。
完善后的版本代码如下:
//版本二
function deepClone2(source) {
//对于非对象类型,直接返回,参考上文的基本类型与引用类型
if(!isObject(source)) return source;
//考虑数组的情况
var target = Array.isArray(source) ? [] : {};
for (var key in source) {
if (Object.prototype.hasOwnProperty.call(source, key)) {
if(isObject(source[key])){
//拷贝目标是对象,执行递归操作
target[key] = deepClone2(source[key]);
} else {
target[key] = source[key];
}
}
}
return target;
}
第三步:循环引用
一个循环引用的栗子,可以给我们的测试用例 testSample 增加一个变量 circleLink ,让其引用 testSample 自身。这种情况若处理不得当,有可能导致无限循环,该怎么解决呢?
其实,解决循环引用的通用办法就是使用一个容器将之前使用过的变量保存起来。在判断是否有可能导致循环引用的时候,去问对应的容器是否包含特定变量即可。若容器包含,那么就使用容器的变量即可;若不包含,那么让容器将其记录下来。
这里使用 JavaScript 自带的 WeakMap 来作为容器(当然 WeakMap 是 ES6 新增的,在 ES5 的时候可以选择数组作为容器)。代码如下:
//版本三
function deepClone3(source, bucket = new WeakMap()) {
if(!isObject(source)) return source;
//判断容器是否存在变量source
if(bucket.has(source)) return bucket.get(source);
var target = Array.isArray(source) ? [] : {};
//容器中增加对应记录
bucket.set(source,target);
for (var key in source) {
if (Object.prototype.hasOwnProperty.call(source, key)) {
if(isObject(source[key])){
//递归,将bucket容器传入
target[key] = deepClone3(source[key], bucket);
} else {
target[key] = source[key];
}
}
}
return target;
}
使用以上方法,在解决了循环引用问题的时候,也一并将“引用丢失”问题解决了。Great~
第四步:破解递归爆栈
当递归的层级过深的时候,会出现栈溢出的危险(即爆栈),一般我们考虑使用循环来代替递归来解决栈溢出的问题。那么怎么做呢?
我们可以将多层嵌套的数据结构看成一棵树。举个栗子:
var a = {
a1: 1,
a2: {
b1: 1,
b2: {
c1: 1
}
}
}
将其想象为一棵树,是这个样子的:
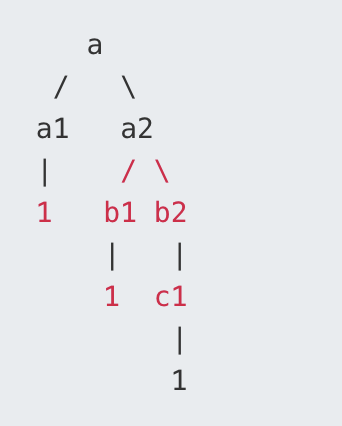
树上的每个结点的结构为:
let Node = {
parent, //父结点
key, //key部分
data //value部分
}
用循环遍历一棵树,需要借助一个栈。当栈为空时就遍历完了,栈顶存储的是下一个需要拷贝的节点。
//版本四
function deepClone4(source) {
if(!isObject(source)) return source;
//容器,解决循环应用问题
let bucket = new WeakMap();
//返回的是一颗新树(全新的root结点)
let root = Array.isArray(source) ? [] : {};
// 栈数组的初始化,放入source元素
const stack = [
{
parent: root,
key: undefined,
data: source,
}
];
while(stack.length) {
// 广度优先算法
const node = stack.pop();
const parent = node.parent;
const key = node.key;
const data = node.data;
// 初始化赋值目标,key为undefined则拷贝到父元素,否则拷贝到子元素
let target = parent;
if (typeof key !== 'undefined') {
target = parent[key] = Array.isArray(data) ? [] : {};
}
//判断每个Object对象是否出现在bucket容器中
if(isObject(data)){
if(bucket.has(data)){
parent[key] = bucket.get(data);
continue;//中断本次循环
}
bucket.set(data, target);
}
for(let k in data) {
if (Object.prototype.hasOwnProperty.call(data, k)) {
if (isObject(data[k])) {
// 下一次循环
stack.push({
parent: target,
key: k,
data: data[k],
});
} else {
target[k] = data[k];
}
}
}
}
return root;
}
代码逻辑不算难。这个简单实现的版本是可以run起来的。
总结
这就是关于深浅拷贝的探讨啦。其实,上面实现的代码中,实现的都是非常基本的功能(数组、循环引用、递归爆栈)。
更多的考虑点,如对于Symbol类型、Map类型、Buffer类型、原型链以及DOM元素的拷贝,都没有考虑进去。网络上著名的Lodash库中的cloneDeep()、jQuery.extend()都是极好的深浅拷贝的最佳实现。有兴趣的可以去看看。
最后,想要聊聊的一个小的点是:深拷贝是否必要?
深拷贝的必要性
我们都知道,JavaScript 在语言层提供给到我们的可以直接使用的深拷贝的方法是 JSON.parse(JSON.stringify(obj))。这个针对JSON字符串的序列化操作,实际上可以使用的范围是非常有限的。
那么为什么 JavaScript 官方不给我们提供一个直接可以使用的深拷贝方法,而是需要我们自己来实现呢?
根本原因在于:如果官方实现一个可以任意使用的深拷贝方法,那么需要考虑的类型对象太多了(关于类型对象,可以看这里:你知道所有的类型对象么?),性能必然不好。这是一个吃力不讨好的工作。
实际上,在我们日常开发工作中,绝大多数的工作都不是必须使用深拷贝不可的。而且,使用深拷贝方法(即使是网络上开源库的方法),其在背后做的操作你若不清楚的话,极有可能会带来无法预期的性能问题。
于是,在此建议:能不用深拷贝就别用。
JavaScript 深入系列文章:
