

--本文采自本人公众号《猴哥别瞎说》
从 JavaScript 的执行过程说起
对于常见编译型语言(例如:Java)来说,编译步骤分为:词法分析->语法分析->语义检查->代码优化和字节码生成。
而 JavaScript 有点不一样。它的过程是:词法分析 -> 语法分析 -> 语法树,紧接着就开始解释执行了。
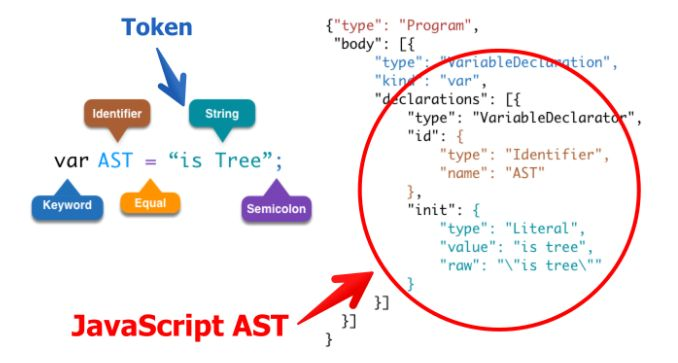
本文重点来看看上面流程中提到的 JavaScript 中的词法分析部分。
词法分析概述
何谓词法分析呢?词法分析是将输入的字符流转换为 token 流。这个 token,是 JavaScript 词法规定的语言最小语义单元。token 可以翻译成“标记”或者“词”。在本文中,笔者统一把 token 翻译成词。
从字符到词的整个过程是没有结构的,只要符合词的规则,就构成词(一般来说,词法设计不会包含冲突)。也就是说,词法分析的过程就是这样一个过程:假设我们有了一段字符串的输入,这些字符串会被词法规则转变成 token 集合。
既然词法分析有对应的规则,那么我们就来分析一下这些规则是怎样的。
首先,对我们的 JavaScript 源代码输入做一个对应的词法分类。如下图:
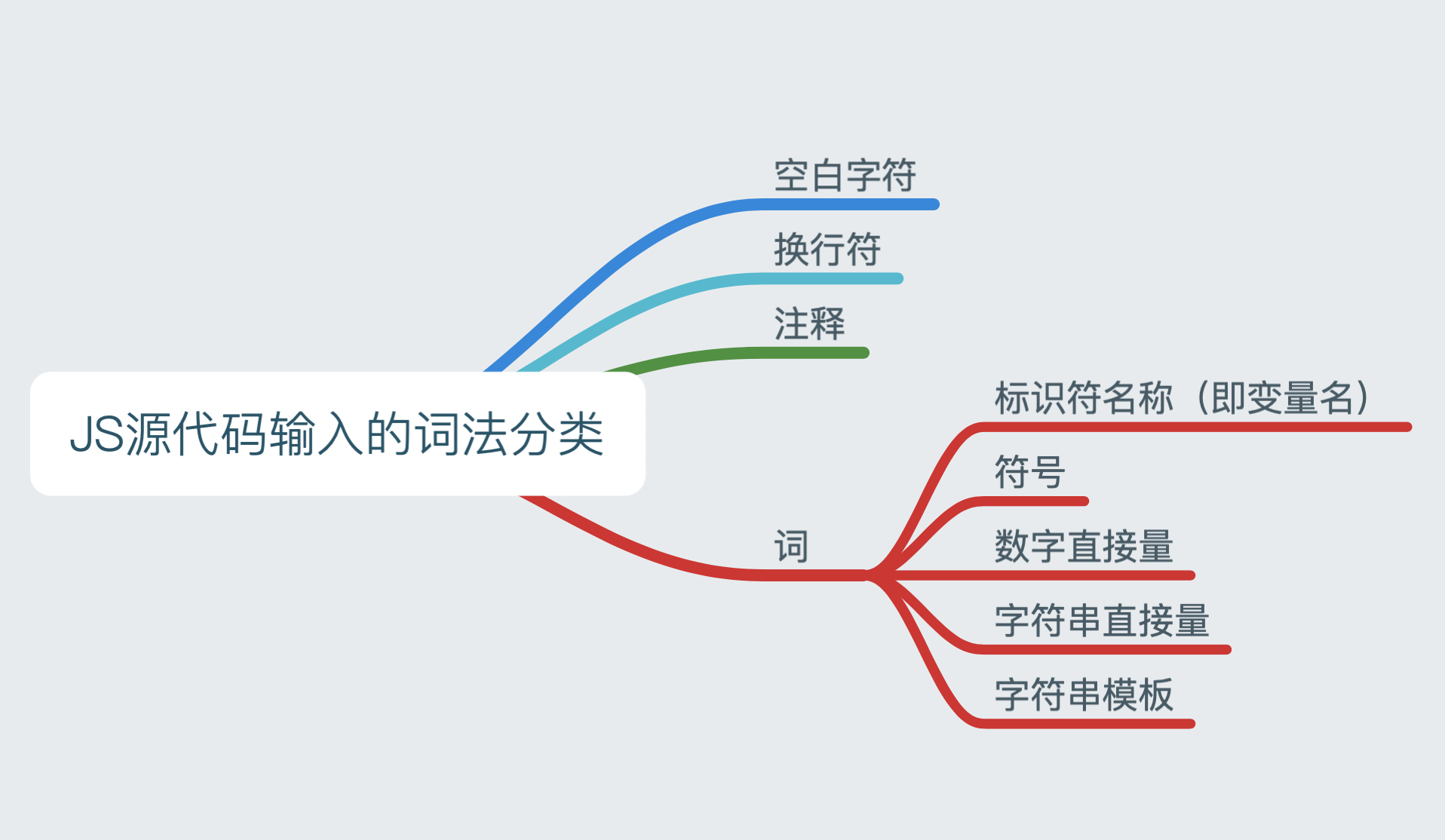
可以看到,JavaScript 有些与一般语言的词法分析过程不同的地方在于:它将换行符与注释都算入到此法规则中。 对 JavaScript 而言,换行符和注释还会影响语法分析过程。
下面我们来细看这些规则并尝试对其进行解读。
空白符号
说起空白符号,想必给大家留下的印象就是空格,但是实际上,JavaScript 可以支持更多空白符号。
<HT>(或称<TAB>) 是 U+0009,是缩进 TAB 符,也就是字符串中写的\t。<VT>是 U+000B,也就是垂直方向的 TAB 符\v,这个字符在键盘上很难打出来,所以很少用到。<FF>是 U+000C,Form Feed,分页符,字符串直接量中写作\f,现代已经很少有打印源程序的事情发生了,所以这个字符在 JavaScript 源代码中很少用到。<SP>是 U+0020,就是最普通的空格了。<NBSP>是 U+00A0,非断行空格,它是 SP 的一个变体,在文字排版中,可以避免因为空格在此处发生断行,其它方面和普通空格完全一样。多数的 JavaScript 编辑环境都会把它当做普通空格(因为一般源代码编辑环境根本就不会自动折行……)。HTML 中,很多人喜欢用的 最后生成的就是它了。<ZWNBSP>(旧称BOM) 是 U+FEFF,这是 ES5 新加入的空白符,是 Unicode 中的零宽非断行空格,在以 UTF 格式编码的文件中,常常在文件首插入一个额外的 U+FEFF,解析 UTF 文件的程序可以根据 U+FEFF 的表示方法猜测文件采用哪种 UTF 编码方式。这个字符也叫做“bit order mark”。
换行符
接下来我们来看看换行符。JavaScript 中只提供了 4 种字符作为换行符。
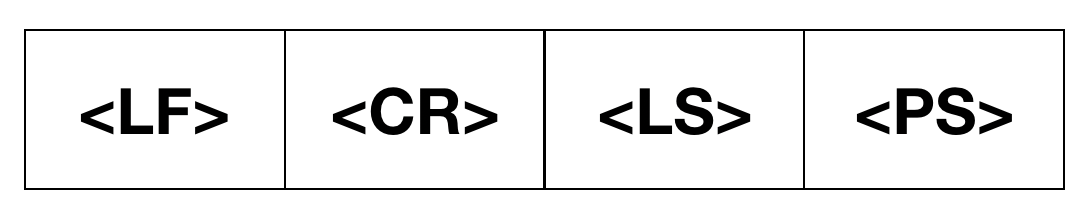
其中,<LF>是 U+000A,就是最正常换行符,在字符串中的\n。
<CR>是 U+000D,这个字符真正意义上的“回车”,在字符串中是\r,在一部分 Windows 风格文本编辑器中,换行是两个字符\r\n。
<LS>是 U+2028,是 Unicode 中的行分隔符。<PS>是 U+2029,是 Unicode 中的段落分隔符。
大部分换行符在被词法分析器扫描出之后,会被语法分析器丢弃,但是换行符会影响 JavaScript 的两个重要语法特性:自动插入分号和“no line terminator”规则。在此留意即可,之后会有详细文章进行介绍。
注释
JavaScript 的注释分为单行注释和多行注释两种:
/* MultiLineCommentChars */
// SingleLineCommentChars
多行注释中允许自由地出现除了*之外的所有字符。而每一个*之后,不能出现正斜杠符/。除了四种 LineTerminator 之外,所有字符都可以作为单行注释。
词
标识符名称(即变量名)
标识符名称可以以美元符“$”、下划线“_”或者 Unicode 字母开始,除了开始字符以外,标识符名称中还可以使用 Unicode 中的连接标记、数字、以及连接符号。
标识符名称的任意字符可以使用 JavaScript 的 Unicode 转义写法,使用 Unicode 转义写法时,没有任何字符限制。
限制情况
当然,也有限制情况:标识符名称不能是 保留字。 保留字在 JavaScript 中很多,其中,就有 关键字:
await break case catch class const continue debugger default delete do else export extends finally for function if import ininstance of new return super switch this throw try typeof var void while with yield
还有,NullLiteral(null)和BooleanLiteral(true false)也是保留字,不能用做标识符名称。
除了上述内容,还有一些额外的为未来使用而保留的关键字:
enum implements package protected interface private public
符号
在这里,列出所有的符号:
{ ( ) [ ] . ... ; , < > <= >= == != === !== + - * % ** ++ -- << >> >>> & | ^ ! ~ && || ? : = += -= *= %= **= <<= >>= >>>= &= |= ^= => / /= }
数字直接量
我们来看看今天标题提出的问题。
JavaScript 规范中规定的数字直接量可以支持四种写法:十进制数、二进制整数、八进制整数和十六进制整数。
十进制
十进制的 Number 可以带小数,小数点前后部分都可以省略,但是不能同时省略,看几个合法的数字直接量的例子:
.01
24.
24.01
这里就有一个问题,也是我们标题提出的问题。我们看一段代码:
24.toString()
这时候24.会被当做省略了小数点后面部分的数字而看成一个整体,所以我们要想让点单独成为一个 token,就要加入空格或者再增加一个小数点,这样写:
24 .toString()
24..toString()
数字直接量还支持科学计数法(这里 e 后面的部分,只允许使用整数),例如:
10.24E+2
10.24e-2
10.24e2
更多进制
当以0x 0b 或者0o 开头时,表示特定进制的整数:
0xFA
0o73
0b10000
上面这几种进制都不支持小数,也不支持科学计数法。
字符串直接量
JavaScript 中的 StringLiteral 支持单引号和双引号两种写法。
" DoubleStringCharacters "
' SingleStringCharacters '
单双引号的区别仅仅在于写法,在双引号字符串直接量中,双引号必须转义,在单引号字符串直接量中,单引号必须转义。字符串中其他必须转义的字符是\和所有换行符。
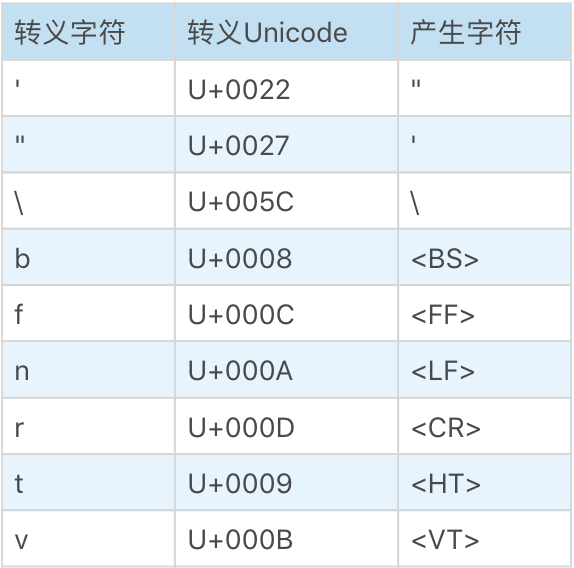
关于单字符转义(即一个反斜杠\后面跟一个字符这种形式),这里整合了所有有意义的转义字符。如下:
字符串模板
从语法结构上,字符串模板是个整体,其中的$ { }是并列关系。
但是实际上,在 JavaScript 词法中,包含$ { }的 字符串模板,是被拆开分析的,如:
`a${b}c${d}e`
它在 JavaScript 中被认为是:
`a${
b
}c${
d
}e`
它被拆成了五个部分:
- `a${ 这个被称为模板头
- }c${ 被称为模板中段
- }e` 被称为模板尾
- b 和 d 都是普通标识符
实际上,这里的词法分析过程已经跟语法分析深度耦合了。
总结
我们一起学习 JavaScript 的词法部分,这部分的内容包括了空白符号、换行符、注释、标识符名称、符号、数字直接量、字符串直接量、字符串模板。其中的词法规则就解释了文章标题的疑问。掌握这些词法规则对我们平时调试代码至关重要。
JavaScript 深入系列文章:
