首页
沸点
课程
数据标注
HOT
AI Coding
更多
直播
活动
APP
插件
直播
活动
APP
插件
搜索历史
清空
创作者中心
写文章
发沸点
写笔记
写代码
草稿箱
创作灵感
查看更多
登录
注册
确定删除此收藏集吗
删除后此收藏集将被移除
取消
确定删除
确定删除此文章吗
删除后此文章将被从当前收藏集中移除
取消
确定删除
编辑收藏集
名称:
描述:
0
/100
公开
当其他人关注此收藏集后不可再更改为隐私
隐私
仅自己可见此收藏集
取消
确定
Spark SQL
订阅
wen酱110586
更多收藏集
微信扫码分享
微信
新浪微博
QQ
27篇文章 · 0订阅
Spark 系列(十二)—— Spark SQL JOIN 操作
本文主要介绍 Spark SQL 的多表连接,需要预先准备测试数据。分别创建员工和部门的 Datafame,并注册为临时视图,代码如下: Cross (or Cartesian) Join : 交叉 (或笛卡尔) 连接。 自然连接是在两张表中寻找那些数据类型和列名都相同的字段,…
Spark 系列(十)—— Spark SQL 外部数据源
Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景。 CSV 是一种常见的文本文件格式,其中每一行表示一条记录,记录中的每个字段用逗号分隔。 为节省主文篇幅,所有读写配置项见文末 9.1 小节。 需要注意的是:…
Spark 系列(八)—— Spark SQL 之 DataFrame 和 Dataset
Spark SQL 是 Spark 中的一个子模块,主要用于操作结构化数据。它具有以下特点: 支持扩展并能保证容错。 为了支持结构化数据的处理,Spark SQL 提供了新的数据结构 DataFrame。DataFrame 是一个由具名列组成的数据集。它在概念上等同于关系数据库…
教你从0到1搭建本地Hadoop 及Spark 分布式HA运行环境
工欲善其事必先利其器,在深入学习大数据相关技术之前,先手动从0到1搭建一个属于自己的本地Hadoop和Spark运行环境,对于继续研究大数据生态圈各类技术具有重要意义。本文旨在站
Spark 系列(十一)—— Spark SQL 聚合函数 Aggregations
通常在使用大型数据集时,你可能关注的只是近似值而不是准确值,这时可以使用 approx_count_distinct 函数,并可以使用第二个参数指定最大允许误差。 获取 DataFrame 中指定列的第一个值或者最后一个值。 获取 DataFrame 中指定列的最小值或者最大值…
Spark 系列(十)—— Spark SQL 外部数据源
Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景。 CSV 是一种常见的文本文件格式,其中每一行表示一条记录,记录中的每个字段用逗号分隔。 为节省主文篇幅,所有读写配置项见文末 9.1 小节。 需要注意的是:…
Spark 系列(九)—— Spark SQL 之 Structured API
Spark 中所有功能的入口点是 SparkSession,可以使用 SparkSession.builder() 创建。创建后应用程序就可以从现有 RDD,Hive 表或 Spark 数据源创建 DataFrame。示例如下: 1. 由外部数据集创建 2. 由内部数据集创建 …
Spark 系列(八)—— Spark SQL 之 DataFrame 和 Dataset
Spark SQL 是 Spark 中的一个子模块,主要用于操作结构化数据。它具有以下特点: 支持扩展并能保证容错。 为了支持结构化数据的处理,Spark SQL 提供了新的数据结构 DataFrame。DataFrame 是一个由具名列组成的数据集。它在概念上等同于关系数据库…
技术干货|为什么越来越多企业放弃 Flink/Spark,用 AutoMQ 替代传统 ETL?
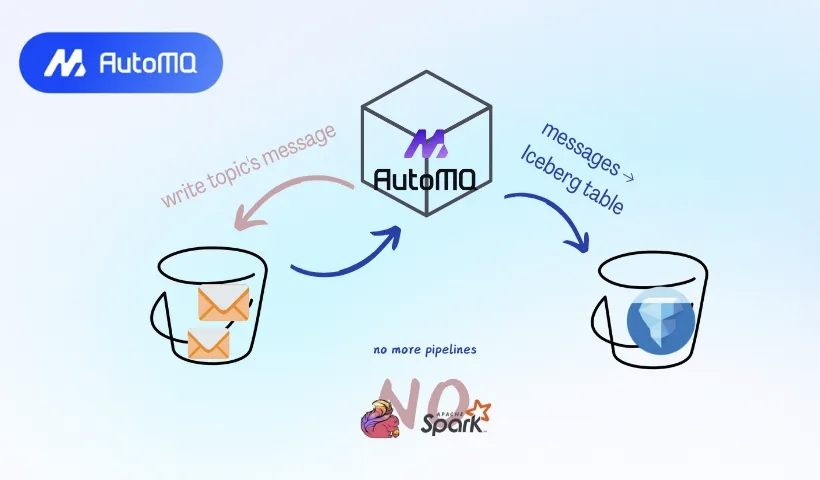 **文章导读** 在云原生架构逐渐成为主流的今天
从数据库系统到Spark SQL (四)
从数据库系统到Spark SQL (二) 中由于篇幅过长,所以与Spark SQL的部分放到这一章来论述。在第二篇中有提到这样一句话: 这里为什么可以减少磁盘寻道呢?其实这跟Spark的Tungsten优化机制有点像。下面就来介绍一下databricks引进的这一功能 Tung…




