兄弟们好,今天我用一块 ESP32 开发板,搭了个延迟拉满的 “慢半拍” AI 聊天机器人:语音识别和合成靠讯飞云,大脑用 Deepseek,虽然反应慢得像没睡醒,但从录音、转文字、生成回复到语音播放的全链路都跑通了,当个会讲故事的 “电子宠物” 玩还挺有意思。
先给大家捋捋这个 “慢半拍” 机器人的整体架构,我把它拆成了四层,从下到上分别是硬件层、驱动层、服务层和应用层,项目整体架构如下:
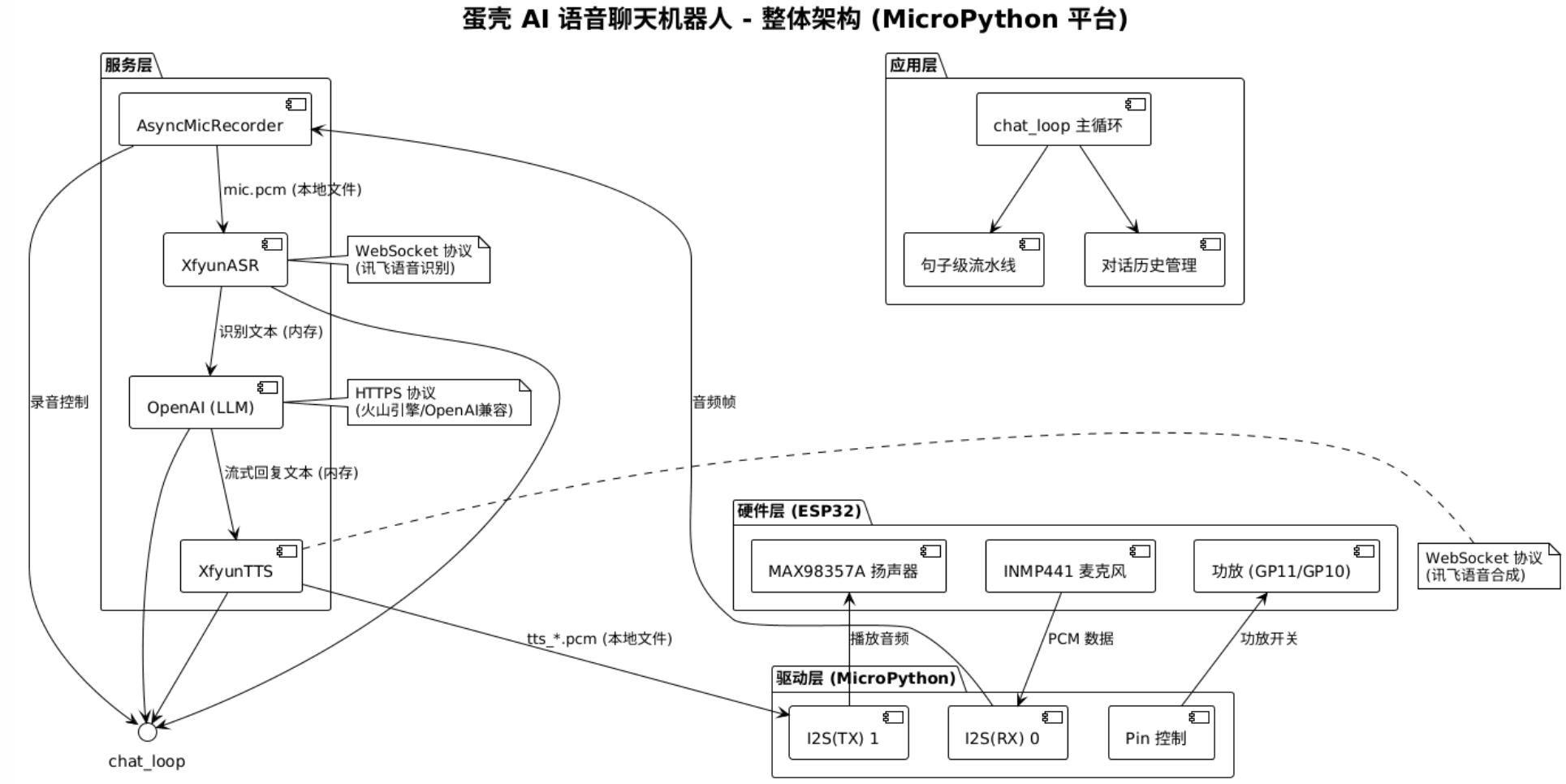
最底层是硬件层,核心就是 ESP32 开发板,外接了 INMP441 I2S 麦克风用来录音,MAX98357A 功放模块带小喇叭用来放音,还有两个引脚控制功放开关和增益 —— 毕竟嵌入式设备底噪大,不用的时候把功放关掉能安静不少。
往上是驱动层,用 MicroPython 的 machine.I2S 驱动麦克风和喇叭,把采集到的声音和要播放的音频转成 PCM 数据,还有用 Pin 控制功放的开关,代码里初始化的时候就把功放默认关了,避免上电的电流噪音。
再往上是服务层,也是整个项目的核心:录音用 AsyncMicRecorder,带 VAD 语音检测,不用手动控制录音起止;转文字靠讯飞云的 ASR,通过 WebSocket 协议传音频;大脑是 Deepseek 的 LLM,用 OpenAI 兼容的接口请求,流式返回回复;最后再把文字丢给讯飞云的 TTS,合成成语音文件,整个服务层都是靠网络请求撑起来的,这也是延迟的主要来源之一。
最上层是应用层,就是那个 chat_loop 主循环,管着对话的整个流程,还有对话历史管理,只保留最近 3 轮对话,避免上下文太长导致请求超时,还有那个 “句子级流水线”,把 LLM 的回复按标点拆成句子,合成一句播一句,不用等完整回复生成完再放。
整个机器人的运行流程,从开机到对话,其实就是一套固定的闭环,我用流程图把它拆成了初始化、录音识别、LLM 推理 + TTS 播放三个阶段,整体工作流程如下:
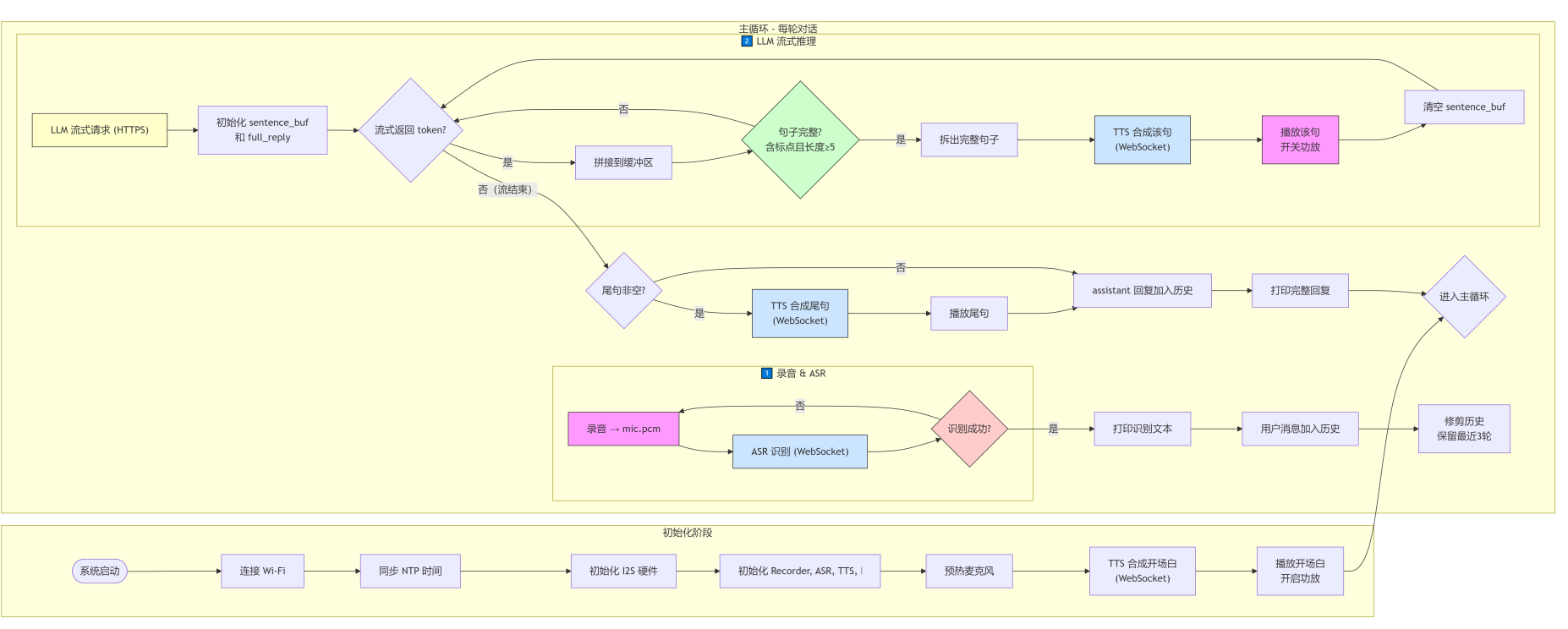
初始化阶段很简单,开机先连 WiFi,同步 NTP 时间,然后初始化 I2S 硬件、麦克风、ASR、TTS 和 LLM 的实例,预热麦克风之后,先合成一段开场白播出来,告诉你 “我准备好了”,这部分代码里都写得很清楚,connect_wifi 函数处理 WiFi 连接,还有个循环会自动切换 NTP 服务器,避免同步失败。
然后就是每轮对话的 “录音 & ASR” 阶段,主循环里先调用 recorder.listen(),等你说话,VAD 检测到语音就开始录音,结束后保存成 mic.pcm 文件,丢给讯飞云 ASR 转成文字,如果识别失败就重新监听,代码里用 if not text 处理了这种情况,不会直接崩掉。
接下来就是最 “慢” 的部分 ——LLM 流式推理 + 句子级 TTS 流水线。这里我用了个小技巧,不是等 LLM 把完整回复生成完再去合成语音,而是用流式请求,每收到一段内容就拼到 sentence_buf 里,一旦遇到句号、感叹号这些标点,而且句子长度够 5 个字符,就立刻把这句话丢给 TTS 合成,合成完直接播放,同时清空缓冲区,继续等下一句。这样做的好处是不用等完整回复,能 “边生成边播放”,但坏处就是每一句都要请求一次 TTS,叠加起来延迟就更高了,也是 “慢半拍” 的罪魁祸首之一。
等 LLM 流结束之后,还要处理一下没标点的尾句,避免最后一段文字被漏掉,播完之后把回复加到对话历史里,再修剪一下,保留最近 3 轮,避免越攒越多。
我们需要的配件如下:
- ESP32 开发板(核心主控,运行 MicroPython)
- INMP441 I2S 数字麦克风模块(语音采集)
- MAX98357A I2S 音频功放模块(语音播放驱动)
- 小型无源扬声器(搭配功放输出声音)
- 杜邦线(公对母 / 公对公,用于模块接线)
- 5V USB 供电线(为 ESP32 及音频模块供电)
接线情况如下:
- INMP441 麦克风模块接线:
- VCC 接 ESP32 3.3V
- GND 接 ESP32 GND
- SCK 接 ESP32 GPIO5
- WS 接 ESP32 GPIO4
- SD 接 ESP32 GPIO6
- MAX98357A 功放模块接线:
- VIN 接 ESP32 3.3V
- GND 接 ESP32 GND
- BCLK 接 ESP32 GPIO12
- LRCLK 接 ESP32 GPIO14
- DIN 接 ESP32 GPIO13
- 功放控制引脚接线:
- SD 接 ESP32 GPIO11
- GAIN 接 ESP32 GPIO10
- 扬声器接线:
- 正极接 MAX98357A SPK+
- 负极接 MAX98357A SPK
这里,我们首先需要下载安装以下驱动包(upypi搜索复制安装命令即可):
接着,复制下面的main.py烧录到单片机中运行即可:
# Python env : MicroPython v1.23.0
# -*- coding: utf-8 -*-
# @Time : 2026/04/20
# @Author : leeqingsui
# @File : main.py
# @Description : XiaoZhi AI voice chatbot — mic -> ASR -> LLM -> TTS -> speaker
# ======================================== 导入相关模块 =========================================
from machine import I2S, Pin
import asyncio
import time
import ntptime
import network
import urandom
from async_mic_recorder import AsyncMicRecorder
from xfyun_asr import XfyunASR
from xfyun_tts import XfyunTTS
from uopenai import OpenAI
# ======================================== 全局变量 ============================================
# Wi-Fi 配置
WIFI_SSID = "Y/OURSPACE"
WIFI_PASSWORD = "qc123456789"
# 讯飞 ASR 配置
ASR_APPID = ""
ASR_KEY = ""
ASR_SECRET = ""
# 讯飞 TTS 配置
TTS_APPID = ""
TTS_KEY = ""
TTS_SECRET = ""
# LLM 配置(OpenAI 兼容接口)
LLM_KEY = ""
LLM_URL = ""
LLM_MODEL = "deepseek-v3-2-251201"
LLM_SYSTEM = "你是蛋壳,一个AI电子宠物,请可爱的回复我"
# 对话历史保留轮数(每轮 = 1 user + 1 assistant)
MAX_ROUNDS = 3
# 临时音频文件路径
MIC_PCM = "mic.pcm"
TTS_PCM = "tts.pcm"
# 思考提示语(VAD 完成后随机播放,启动时预合成)
THINKING_PHRASES = [
"好的,蛋壳知道了,让蛋壳仔细想想,蛋壳脑袋有点慢慢的哦",
"嗯嗯,蛋壳听到啦,稍等一下下,蛋壳在认真想呢",
"收到收到,蛋壳的小脑袋瓜转起来啦,马上马上",
"哦哦哦,蛋壳明白了,让蛋壳想一想,别着急哟",
"好哒,蛋壳在想了,脑袋瓜有点小,请稍等一秒秒",
]
THINKING_PCMS = ["thinking_{}.pcm".format(i) for i in range(len(THINKING_PHRASES))]
# ======================================== 功能函数 ============================================
def timed_function(f: callable, *args: tuple, **kwargs: dict) -> callable:
"""
计时装饰器,用于计算并打印函数/方法运行时间。
Args:
f (callable): 需要传入的函数/方法
args (tuple): 函数/方法 f 传入的任意数量的位置参数
kwargs (dict): 函数/方法 f 传入的任意数量的关键字参数
Returns:
callable: 返回计时后的函数
"""
myname = str(f).split(' ')[1]
def new_func(*args: tuple, **kwargs: dict) -> any:
t: int = time.ticks_us()
result = f(*args, **kwargs)
delta: int = time.ticks_diff(time.ticks_us(), t)
print('Function {} Time = {:6.3f}ms'.format(myname, delta / 1000))
return result
return new_func
def connect_wifi():
print("[WiFi] 正在连接:", WIFI_SSID)
sta = network.WLAN(network.STA_IF)
if not sta.isconnected():
sta.active(True)
sta.connect(WIFI_SSID, WIFI_PASSWORD)
while not sta.isconnected():
time.sleep(0.5)
print("[WiFi] 连接成功,IP:", sta.ifconfig()[0])
def trim_history(messages: list, max_rounds: int) -> list:
"""保留 system prompt + 最近 max_rounds 轮对话"""
system = [m for m in messages if m["role"] == "system"]
dialog = [m for m in messages if m["role"] != "system"]
if len(dialog) > max_rounds * 2:
dialog = dialog[-(max_rounds * 2):]
return system + dialog
def on_energy(e):
print("能量:", e, end="\r")
def on_event(msg):
if msg == "ready":
print("[麦克风] 预热完成,开始监听...")
elif msg == "voice_start":
print("\n[麦克风] 检测到语音,录音中...")
elif msg == "too_short":
print("\n[麦克风] 语音过短,继续监听...")
elif msg.startswith("saved:"):
_, path, size = msg.split(":")
print("[麦克风] 录音保存 -> {} ({} 字节)".format(path, size))
async def play_pcm(audio_out, amp_sd, filepath: str, rate: int = 16000) -> None:
"""播放 PCM 文件,等待 I2S 缓冲区播完后关闭功放"""
print("[播放] 开始播放:", filepath)
amp_sd.value(1)
total = 0
with open(filepath, "rb") as f:
while True:
chunk = f.read(2048)
if not chunk:
break
audio_out.write(chunk)
total += len(chunk)
print("[播放] 已写入 {} 字节,等待缓冲区播完...".format(total))
ibuf_ms = 40000 * 1000 // (rate * 2)
await asyncio.sleep_ms(ibuf_ms + 200)
amp_sd.value(0)
print("[播放] 播放完成,功放已关闭")
await asyncio.sleep_ms(300)
async def chat_loop(recorder, asr, llm, tts, audio_out, amp_sd):
import json as _json
messages = [{"role": "system", "content": LLM_SYSTEM}]
round_num = 0
# 预合成思考提示音(仅首次启动时执行)
print("[系统] 预合成思考提示音...")
for i, phrase in enumerate(THINKING_PHRASES):
fname = THINKING_PCMS[i]
try:
import os
os.stat(fname)
print("[预热] {} 已存在,跳过".format(fname))
except OSError:
print("[预热] 合成: {}".format(phrase))
await tts.synthesize(phrase, fname)
print("[系统] 提示音预热完成")
print("[系统] 麦克风预热中...")
await recorder.start()
# 开场白
await tts.synthesize_and_play("你好,我是蛋壳,有什么可以帮你的?", audio_out, amp_sd)
print("[系统] 蛋壳已就绪,请开始说话!")
while True:
round_num += 1
print("\n========== 第 {} 轮对话 ==========".format(round_num))
# 1. 录音
t0 = time.ticks_us()
await recorder.listen(MIC_PCM)
print("[计时] 录音 {:6.3f}ms".format(time.ticks_diff(time.ticks_us(), t0) / 1000))
# 2. 立即播放思考提示音
thinking_pcm = THINKING_PCMS[urandom.randint(0, len(THINKING_PCMS) - 1)]
print("[提示] 播放:", thinking_pcm)
await play_pcm(audio_out, amp_sd, thinking_pcm)
# 3. ASR
t0 = time.ticks_us()
text = await asr.recognize(MIC_PCM)
print("[计时] ASR {:6.3f}ms".format(time.ticks_diff(time.ticks_us(), t0) / 1000))
if not text:
print("[ASR] 未识别,重新监听")
round_num -= 1
continue
print("[ASR]", text)
# 4. LLM 流式 + 句子级 TTS 边收边播
messages.append({"role": "user", "content": text})
messages = trim_history(messages, MAX_ROUNDS)
print("[LLM] 流式推理,messages:", len(messages))
t0 = time.ticks_us()
resp = await llm.chat.completions.create(
model=LLM_MODEL, messages=messages, stream=True
)
full_reply = ""
sentence_buf = ""
sentence_idx = 0
SENT_ENDS = "。!?!?\n"
MIN_SENT_LEN = 5
async for line in resp.iter_lines():
line = line.strip()
if not line:
continue
if line == b"data: [DONE]":
break
if line.startswith(b"data: "):
try:
chunk = _json.loads(line[6:])
except Exception:
continue
token = chunk.get("choices", [{}])[0].get("delta", {}).get("content", "")
if not token:
continue
sentence_buf += token
full_reply += token
if any(c in sentence_buf for c in SENT_ENDS) and len(sentence_buf) >= MIN_SENT_LEN:
sentence_idx += 1
print("[TTS] 第{}句: {}".format(sentence_idx, sentence_buf))
await tts.synthesize_and_play(sentence_buf, audio_out, amp_sd)
sentence_buf = ""
# 尾句(无标点结尾)
if sentence_buf.strip():
sentence_idx += 1
print("[TTS] 尾句: {}".format(sentence_buf))
await tts.synthesize_and_play(sentence_buf, audio_out, amp_sd)
print("[计时] LLM+TTS+播放 {:6.3f}ms".format(time.ticks_diff(time.ticks_us(), t0) / 1000))
messages.append({"role": "assistant", "content": full_reply})
print("[LLM] 完整回复:", full_reply)
# ======================================== 自定义类 ============================================
# ======================================== 初始化配置 ===========================================
time.sleep(3)
print("FreakStudio: DShell AI voice chatbot starting")
# Wi-Fi 连接 + NTP 时间同步
connect_wifi()
print("[NTP] 正在同步时间...")
for _ntp_host in ("ntp.aliyun.com", "pool.ntp.org", "time.cloudflare.com"):
try:
ntptime.host = _ntp_host
ntptime.settime()
print("[NTP] 时间同步完成,服务器:", _ntp_host)
break
except Exception as _e:
print("[NTP] {} 失败: {},尝试下一个...".format(_ntp_host, _e))
else:
print("[NTP] 所有服务器均失败,使用本地时间继续")
# I2S 麦克风(INMP441)
print("[I2S] 初始化麦克风 INMP441...")
audio_in = I2S(
0,
sck=Pin(5), ws=Pin(4), sd=Pin(6),
mode=I2S.RX,
bits=16,
format=I2S.MONO,
rate=16000,
ibuf=40000,
)
print("[I2S] 麦克风就绪")
# I2S 扬声器(MAX98357A)
print("[I2S] 初始化扬声器 MAX98357A...")
audio_out = I2S(
1,
sck=Pin(12), ws=Pin(14), sd=Pin(13),
mode=I2S.TX,
bits=16,
format=I2S.MONO,
rate=16000,
ibuf=40000,
)
print("[I2S] 扬声器就绪")
# 功放控制引脚
amp_sd = Pin(11, Pin.OUT)
amp_gain = Pin(10, Pin.OUT)
amp_sd.value(0)
amp_gain.value(0)
print("[功放] SD=GP11 GAIN=GP10,默认关闭,增益 12dB")
# 驱动实例化
print("[驱动] 初始化各模块...")
recorder = AsyncMicRecorder(
audio_in,
rate=16000,
threshold=350,
silence_frames=10,
min_voice_frames=5,
frame_bytes=2048,
max_seconds=30,
warmup_frames=15,
on_energy=on_energy,
on_event=on_event,
)
asr = XfyunASR(ASR_APPID, ASR_KEY, ASR_SECRET, sample_rate=16000)
tts = XfyunTTS(TTS_APPID, TTS_KEY, TTS_SECRET, auf="audio/L16;rate=16000")
llm = OpenAI(api_key=LLM_KEY, base_url=LLM_URL)
print("[驱动] 全部初始化完成")
# ======================================== 主程序 ===========================================
asyncio.run(chat_loop(recorder, asr, llm, tts, audio_out, amp_sd))
关于API Key相关配置可看之前的博客: mp.weixin.qq.com/s/BjIyOru3O… mp.weixin.qq.com/s/FjLpAYmev… mp.weixin.qq.com/s/ICCfzNvTy… mp.weixin.qq.com/s/FWLETNzlI… mp.weixin.qq.com/s/ThA0dkDcE…
运行结果如下:
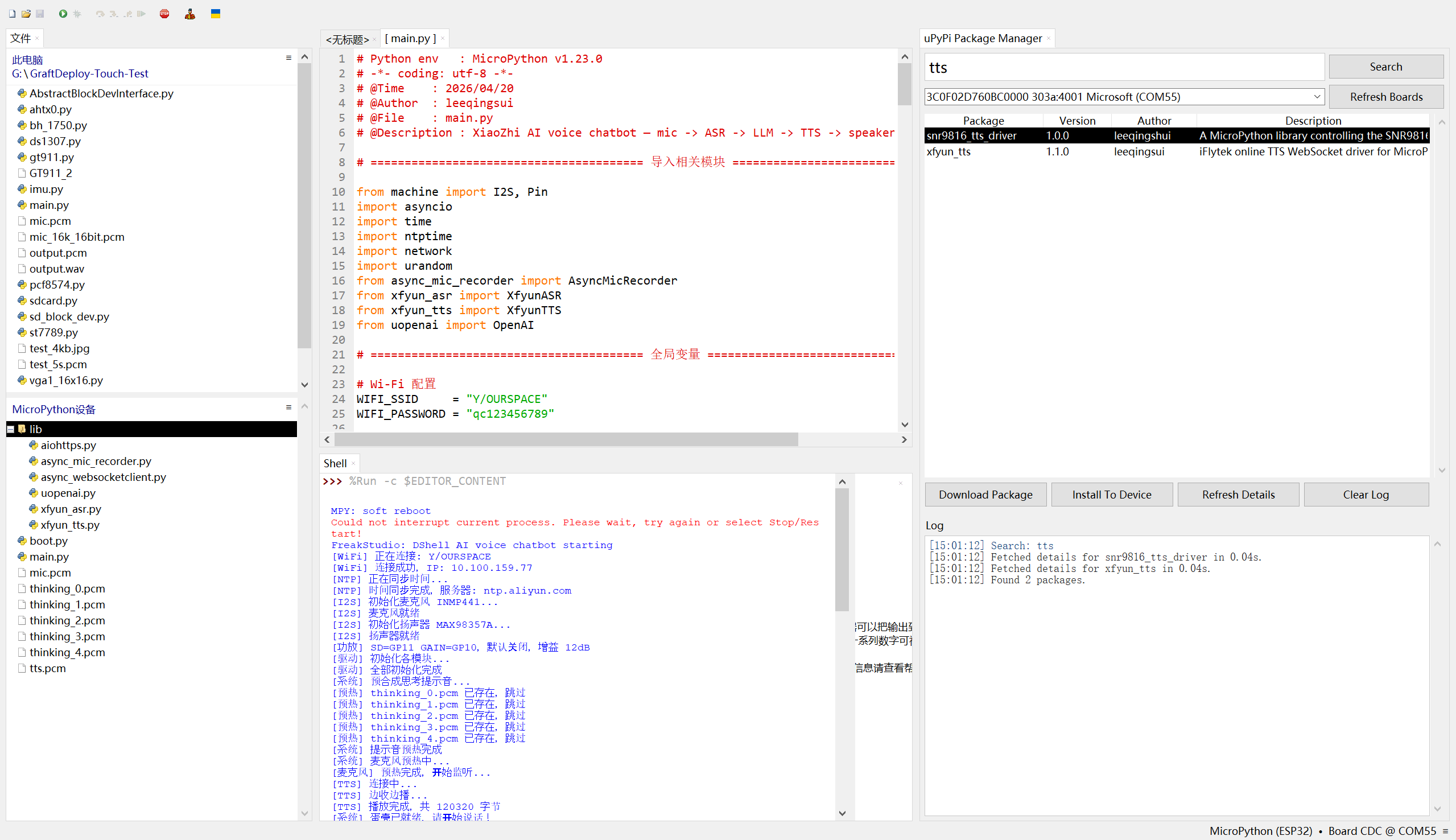
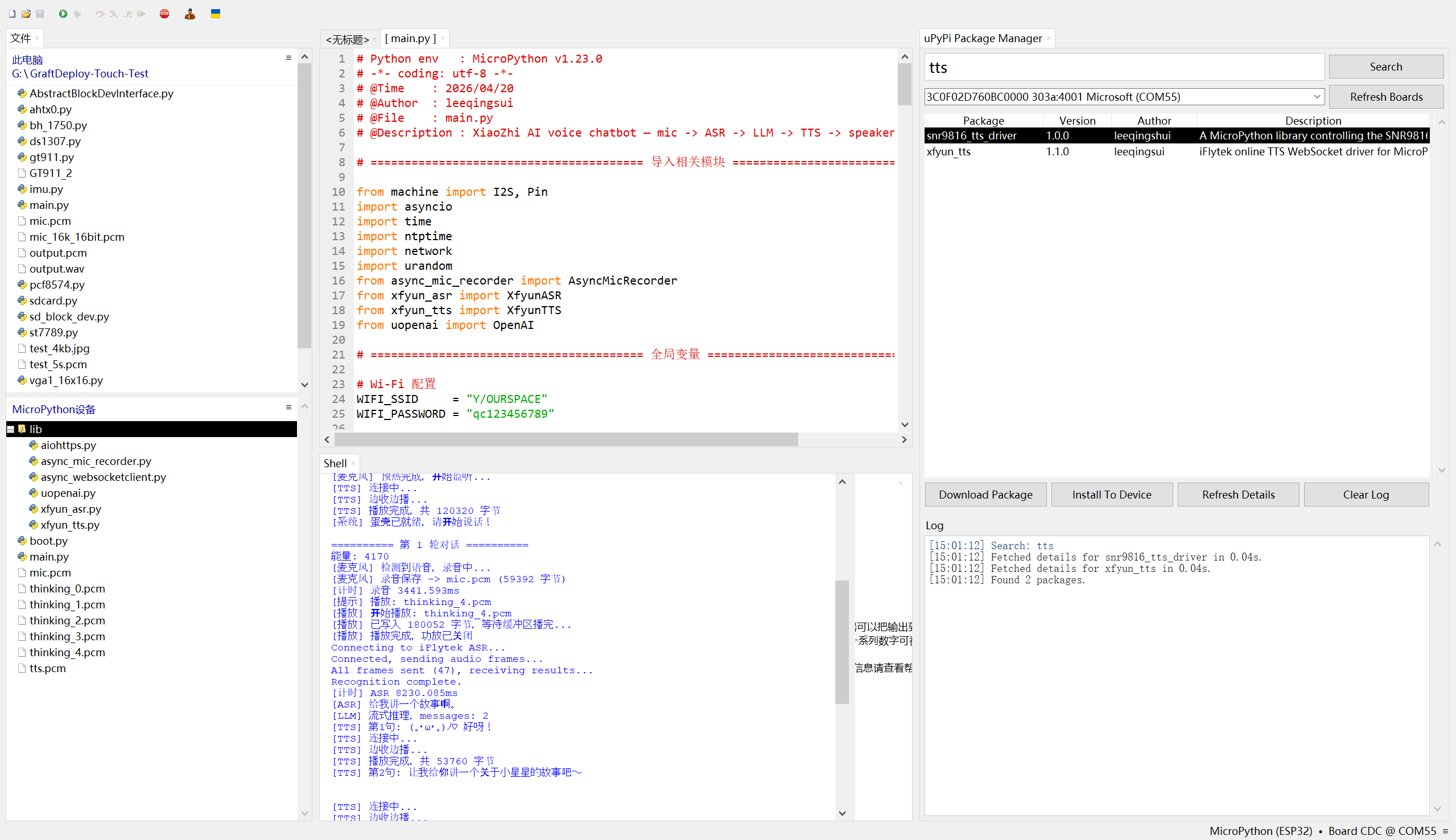
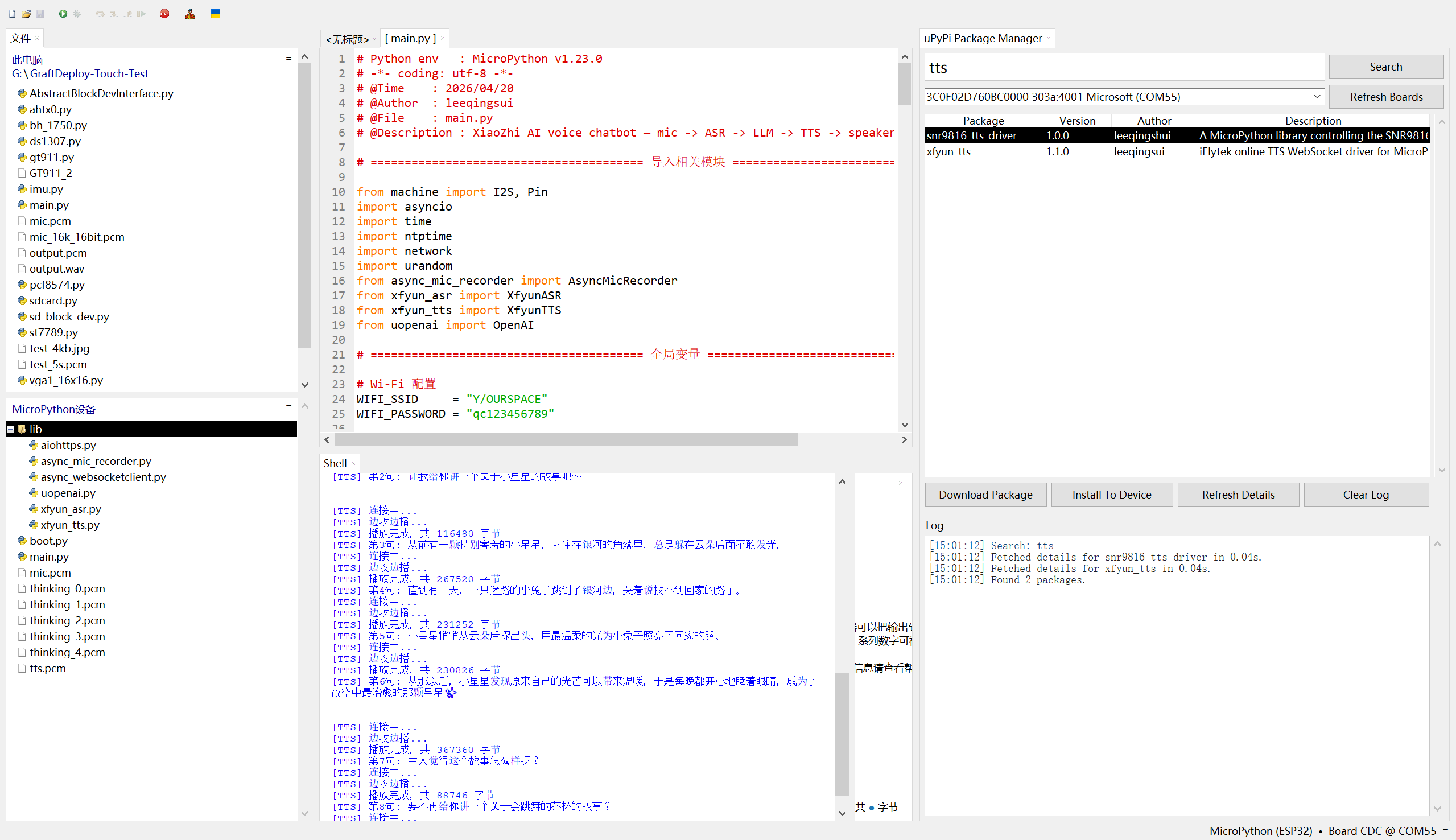

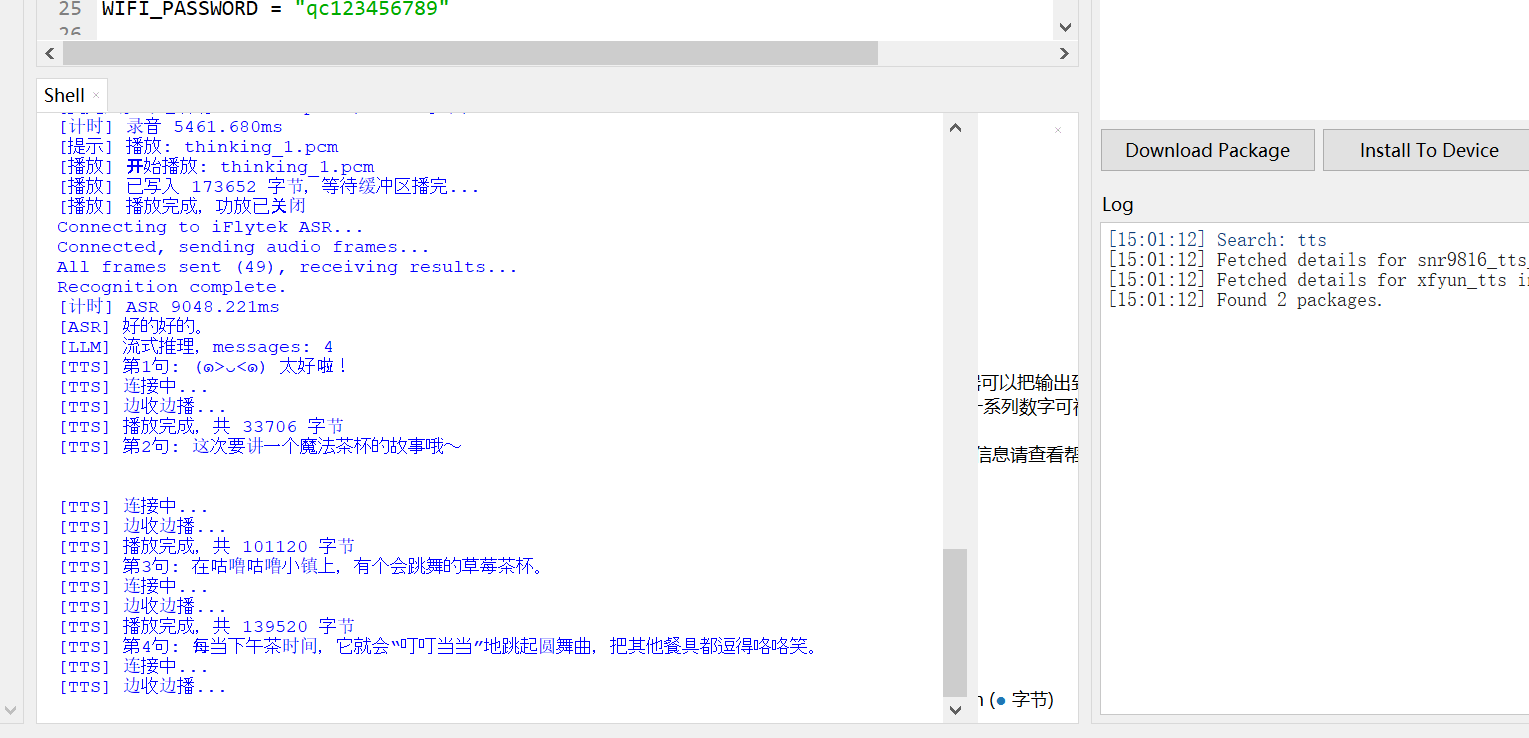
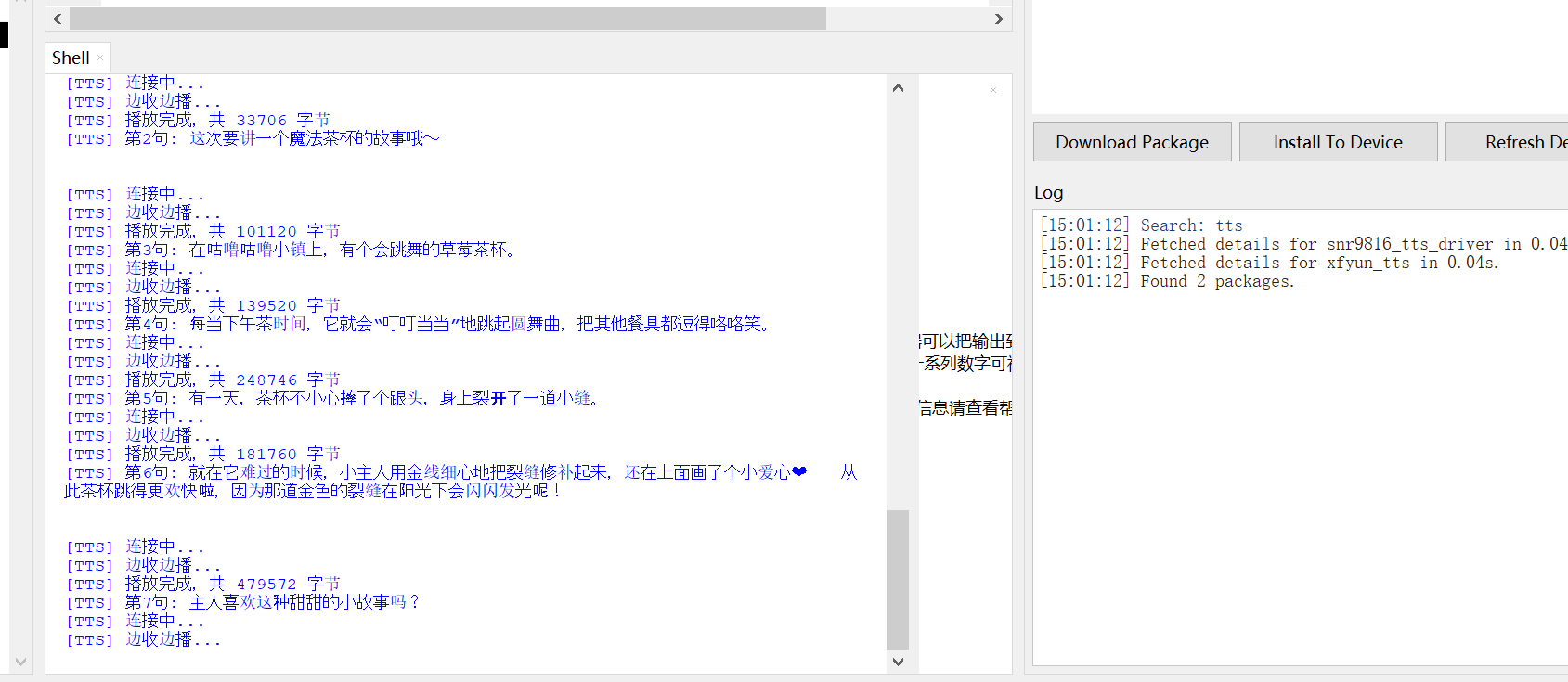
实际跑起来是什么样?说真的,慢得很有仪式感。比如我对着麦克风说 “给我讲个故事”,它先录个几秒钟,然后 ASR 识别要等一会儿,接着 LLM 开始生成回复,串口里会一句一句打印 “第 1 句:xxx”,然后 TTS 合成完,喇叭才会慢慢悠悠地说出第一句话,然后等几秒,再说出第二句,讲个完整的小故事要等好几轮 TTS 合成,全程下来能等一两分钟。但架不住它能跑通啊,串口日志里能清楚看到每个环节的状态:麦克风预热、检测到语音、录音保存、ASR 识别完成、LLM 流式推理、TTS 合成、播放完成,功放开关的日志也都有,没有崩溃,没有乱码,多轮对话也能记住上下文,比如我问 “这个故事里的小兔子后来怎么样了”,它能接着之前的故事往下说,虽然等得久,但交互逻辑是完整的,而且那个 “蛋壳” 的设定也生效了,回复都是软乎乎的可爱语气,还挺有电子宠物那味儿的。
我们可以看到:程序启动后整体运行流程完整且顺畅,WiFi 成功连接并获取 IP,NTP 时间同步可自动切换服务器完成校准,I2S 麦克风、功放扬声器等硬件模块均正常初始化,功放引脚也按逻辑完成默认配置,各驱动模块实例化无误后,系统会自动播放开场白进入语音监听状态,后续每轮对话都能稳定走完录音、识别、推理、合成播放的全链路,没有出现流程中断的情况。 核心功能模块均表现正常,麦克风的 VAD 语音检测能实时反馈能量值并精准触发录音,讯飞 ASR 可稳定将语音转写为文本,未出现识别失效问题;DeepSeek 大模型能保留对话上下文并实现流式推理,按句子拆分回复内容,讯飞 TTS 配合功放模块可完成逐句语音播放,且功放能在播放前后自动开关,底噪和功耗控制逻辑生效。 每轮对话均完整执行「录音 →ASR→LLM 流式推理 → 句子级 TTS→ 边收边播」的链路:
- 麦克风检测到语音后自动录音,保存为
mic.pcm; - 讯飞 ASR 识别音频并返回文本结果(如第一轮识别 “给我讲一个故事啊”,第二轮识别 “好的好的”);
- DeepSeek LLM 流式生成回复,按标点拆分句子;
- 讯飞 TTS 逐句合成语音并播放,实现 “边收边播” 的实时交互体验。
我们可以看到,单轮 ASR 耗时约 3-9 秒(如第一轮 3441.593ms,第二轮 9048.221ms)。
为什么慢?实际上瓶颈在 ASR 和 TTS: 核心问题:先发完所有帧,再收结果,串行设计。
- 发帧循环:每帧 1280 bytes,每帧强制 sleep 40ms
- → 10秒音频 = 10s × 16000 × 2 / 1280 = 250帧
- → 250帧 × 40ms = 10秒 光发帧就要10秒!
这个 40ms 间隔是模拟实时发送节奏,但代价是:音频多长,发帧就多久,这是讯飞云Web API相关的要求,我们无法调整。
TTS 瓶颈(xfyun_tts.py):synthesize_and_play 已经做了流式优化(收到 chunk 立即写 I2S),但还有两个隐性延迟:
- 每句话独立建立 WebSocket 连接:handshake 一次 TLS 握手 ~500ms-1s
- 句子级切割:LLM 流式输出,每遇到句号才触发一次 TTS,短句也要走完整的连接→合成→播放流程
# main.py 里的逻辑
if any(c in sentence_buf for c in SENT_ENDS) and len(sentence_buf) >= MIN_SENT_LEN:
await tts.synthesize_and_play(sentence_buf, ...) # 每句都重新握手
延迟叠加路径(一次完整对话)如下:
VAD录音结束
→ ASR发帧等待(音频时长 × 1倍) ← 最大瓶颈
→ ASR云端识别返回 ~500ms
→ 播放思考提示音 ~3s
→ LLM首token ~1s
→ TTS握手 ~500ms
→ TTS首chunk到I2S ~200ms
─────────────────────────────────
总计:说5秒话 → 等待约 10-12秒
瓶颈不是"网络慢",是协议设计决定的串行等待:讯飞 ASR 的 WebSocket 协议要求模拟实时发帧节奏,MicroPython 单线程又不能边发边收,两个约束叠加,延迟就是音频时长的函数。
其实做这个项目,本来就是想练手嵌入式 AI 语音的全链路,没想着要做个秒回的助手,结果反而意外 get 到了 “慢半拍” 的乐趣,不用焦虑秒回,等着机器人慢慢悠悠地讲故事,反而有种久违的松弛感。而且整个项目的代码都是模块化的,ASR、TTS、LLM 都是独立的模块,想换服务商也很方便,比如把讯飞云换成百度的,或者把 Deepseek 换成其他兼容 OpenAI 接口的模型,都不用大改。如果你也想玩一玩嵌入式 AI 语音,这个项目的代码和架构应该能给你点参考,哪怕最后做出来也是个慢半拍的机器人,也挺有意思的,毕竟谁规定 AI 助手必须快呢?