

day13 学习日记: 一天内把一个建议RAG项目初版跑通(RAG + 日期检索救火)
一天内完成了一个“能跑、可用、可迭代”的初步落地。这篇就按当天的真实节奏,把关键步骤、坑点、以及当时的体感记录下来——以后再遇到类似“明明有数据但检索不到”的问题,可以直接按这份清单排查。
我当天反复验证到的几个结论:
- 确定性检索要有“硬锚点”:像日期这种查询,不能只靠向量相似度。
- AI/向量逻辑优先放 Python:文本处理、入库流水线、检索策略在 Python 里更顺手,也更容易做成单一事实来源。
- 线上问题往往是环境/网络:代理、环境变量作用域(Preview vs Production)、Serverless 出站网络,都会伪装成“模型不行”。
当天的落地历程(按时间线拆解)
1)目标确认:先把“能用的 RAG”跑起来
我给自己定的验收标准很简单:
- 能流式对话(体验像“打字机”一样顺滑)
- 能从 Supabase 向量库检索到上下文并回答
- 能按日期准确命中(例如:问 4-9 必须能明确找到
2026-4-09.md)
2)第一轮实现:RAG 通了,但日期查询会漂移
现象
库里确实有
2026-4-09.md 的切片,但问“4-9 写了什么”时,经常出现:
- 找不到相关内容
- 或命中的是主题相近、日期不对的日记
原因
向量检索对“日期”这类强结构信息不敏感,属于软信号;而文件名/slug 才是硬锚点。
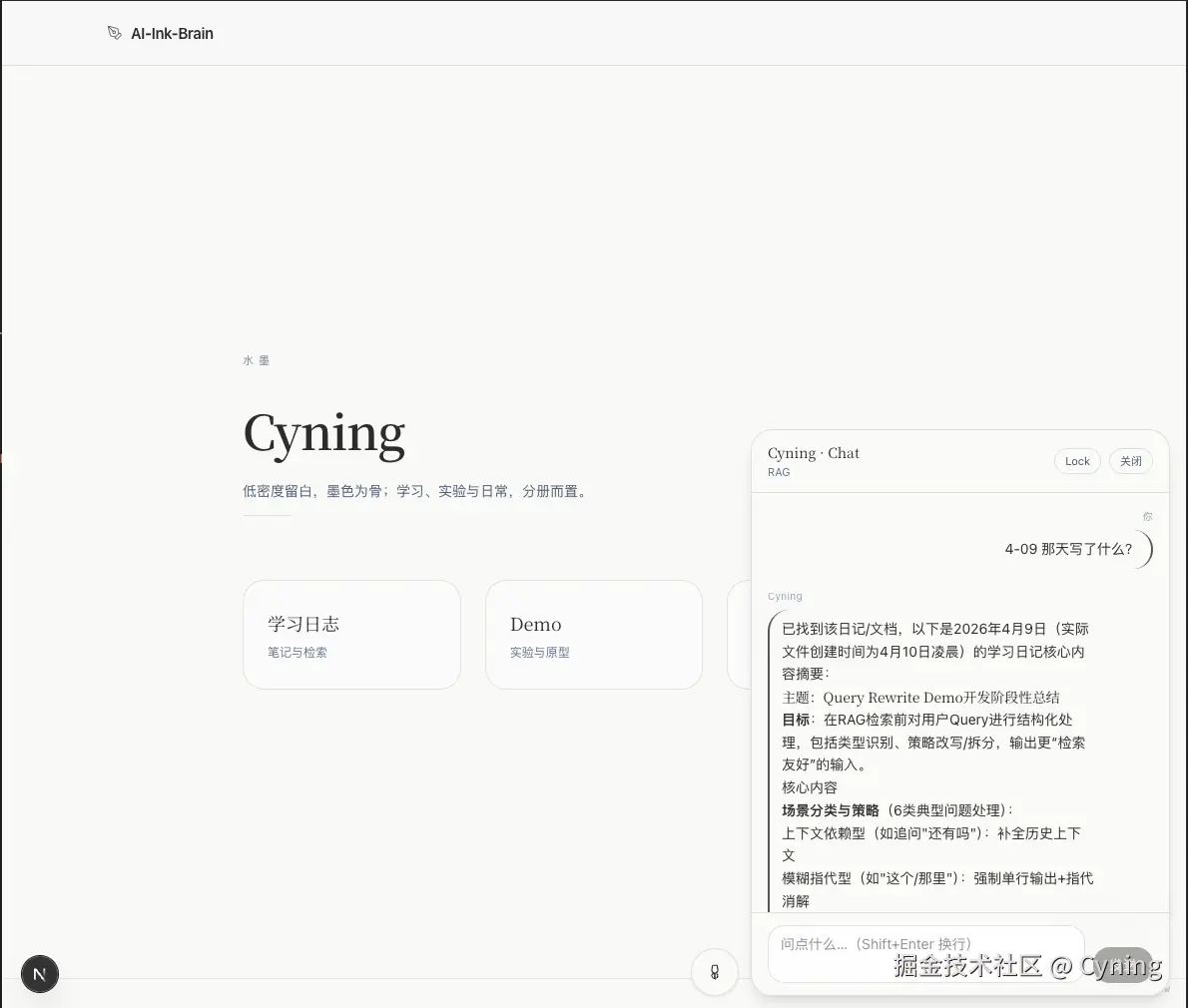
3)救火方案:Query Rewrite + Anchors First(确定性路径置顶)
当天最终跑通的策略是“双路”:
- 语义路径:仍然保留向量 Top-K(处理模糊主题问题)
- 确定性路径:只要问题里出现日期,就把对应文件的切片硬拉出来并置顶
核心动作(按落地顺序):
- 日期提取器:用正则把
4-09/24-4-09/2026-4-09等变体统一解析成候选文件名列表(例如2026-4-09.md、2026-04-09.md)。 - Query Augmentation:embedding 前把
TitleAnchor: 2026-4-09.md追加到 query,让向量更靠近目标日记的“Title”上下文。 - Anchors First:再从 Supabase 直接按
metadata.slug=2026-4-09(或content里Title: 2026-4-09.md)把切片拉出来,排在向量结果前面。
体感
这一招非常“工程化”,但有效:RAG 的稳定性从“看运气”变成“可解释、可复现”。
4)工程落地:把 AI/向量逻辑迁到 Python,并保持前端体验
当天的关键决定是:AI 交互链路优先走 Python,前端只做同源代理和 UI。
- Python(FastAPI)负责:embedding、Supabase
match_documents、日期锚点、流式输出 - Next.js 负责:
/api/py/chat作为 BFF 代理,前端继续用水墨风 UI 做流式渲染
这一步的价值是把“复杂度”从前端移走:以后不管换模型、换维度、改检索策略,都集中在 Python 侧改。
当天的收获
我觉得这一天最重要的不是“把功能做出来”,而是把项目从一堆散点,变成一个可以长期演进的形态:
- 检索策略可解释(为什么命中/为什么不命中)
- 链路可排障(日志能定位 threshold、Top-K、锚点注入、网络/代理)
- 架构优先级清晰(AI/向量在 Python;纯交互/代理在 TS)
最后的碎碎念:
“RAG 的问题不在于模型聪不聪明,而在于你有没有把‘必须确定的东西’变成确定的。”
