

CC 源码解读系列
- #1 Claude Code 为什么不用 RAG? ← 本文
- #2 记忆系统为什么不用向量数据库?
- #3 Agent Teams 团队调度系统(即将发布)
本文基于 Claude Code 开源仓库的实际源码分析,代码路径来自
src/目录。
最近在阅读 Claude Code(CC)的开源源码,发现一个有意思的设计决策:CC 完全没有 RAG(Retrieval Augmented Generation),没有 embedding,没有向量数据库,没有语义检索。
但它能精准地在一个大型代码库里找到相关文件、记住你上周说过的事情、并且在复杂探索任务里自动派遣子 Agent。
这是怎么做到的?翻源码之后发现,CC 用了一套完全不同的路子。
一、起点:让 AI 自己搜代码
RAG 的核心思路是:先把文档 embedding 成向量,然后用相似度检索找相关片段,塞进 prompt。
CC 完全不这样做。它的策略更"野蛮"——直接给 Claude 一堆搜索工具,让它自己决定搜什么:
Grep:正则搜代码内容Glob:文件名模式匹配Read:读具体文件Bash:跑git log、find等系统命令
这就像把 Claude 变成了一个有 shell 权限的工程师,而不是一个查文档的问答机器人。
优点是精准——Grep 找到的就是真实代码,不存在语义偏差。缺点也很明显:项目大了之后,Grep 扛不住。
二、问题来了:精准但没有排序
想象一个 5 万文件的 monorepo,你搜 handle,Grep 可能返回 200 个匹配。每个都是"精确"结果,但 Claude 的 context window 是有限的,200 个结果全塞进去既浪费 token 又干扰判断。
RAG 至少还有个相关性排序。Grep 的输出是按文件路径字母序排的——完全没有"哪个更重要"的概念。
CC 怎么解决这个问题?不是引入向量检索,而是 5 层策略的组合。
三、CC 的 5 层策略
第 1 层:CLAUDE.md — 人工项目地图
最简单粗暴也最有效的一层:让开发者手写项目的关键信息,放进 CLAUDE.md。
CC 会在每次会话加载这个文件,相当于给 Claude 一份"项目导览"。实质上是手动索引——开发者用自然语言告诉 Claude 哪些文件重要、架构是什么、哪些目录干什么用。
关于 CLAUDE.md 的写法和最佳实践,可以参考我之前的文章:CLAUDE.md 到底该怎么写?从「给 AI 的交接文档」说起。这里重点从源码角度看 CC 是怎么加载和使用它的。
源码 utils/claudemd.ts 的注释清楚地写出了 4 层加载逻辑:
/**
* Files are loaded in the following order:
*
* 1. Managed memory (/etc/claude-code/CLAUDE.md) - Global for all users
* 2. User memory (~/.claude/CLAUDE.md) - Private global for all projects
* 3. Project memory (CLAUDE.md, .claude/CLAUDE.md, .claude/rules/*.md) - Checked into codebase
* 4. Local memory (CLAUDE.local.md) - Private project-specific instructions
*
* Files are loaded in reverse order of priority — the latest files are highest priority
* with the model paying more attention to them.
*/
越靠近当前目录的配置优先级越高,文件路径越深越重要。支持 @include 指令做文件嵌套——你可以把大型项目的文档拆成多个文件,按需 include。
本质:这是一个人工维护的语义索引,代替了 embedding 的"自动理解"。代价是需要开发者维护,收益是零幻觉、零延迟。
第 2 层:FileIndex — 文件名模糊搜索 + nucleo 算法评分
当 Claude 不知道具体文件在哪、只有模糊印象时(比如"有个处理权限的文件"),CC 提供了 FileIndex。
源码在 src/native-ts/file-index/index.ts,注释说明这是对 Rust NAPI 模块(基于 Helix 编辑器的 nucleo)的纯 TypeScript 重写。
下面这张流程图展示了 FileIndex 从收集文件到返回排序结果的完整过程:
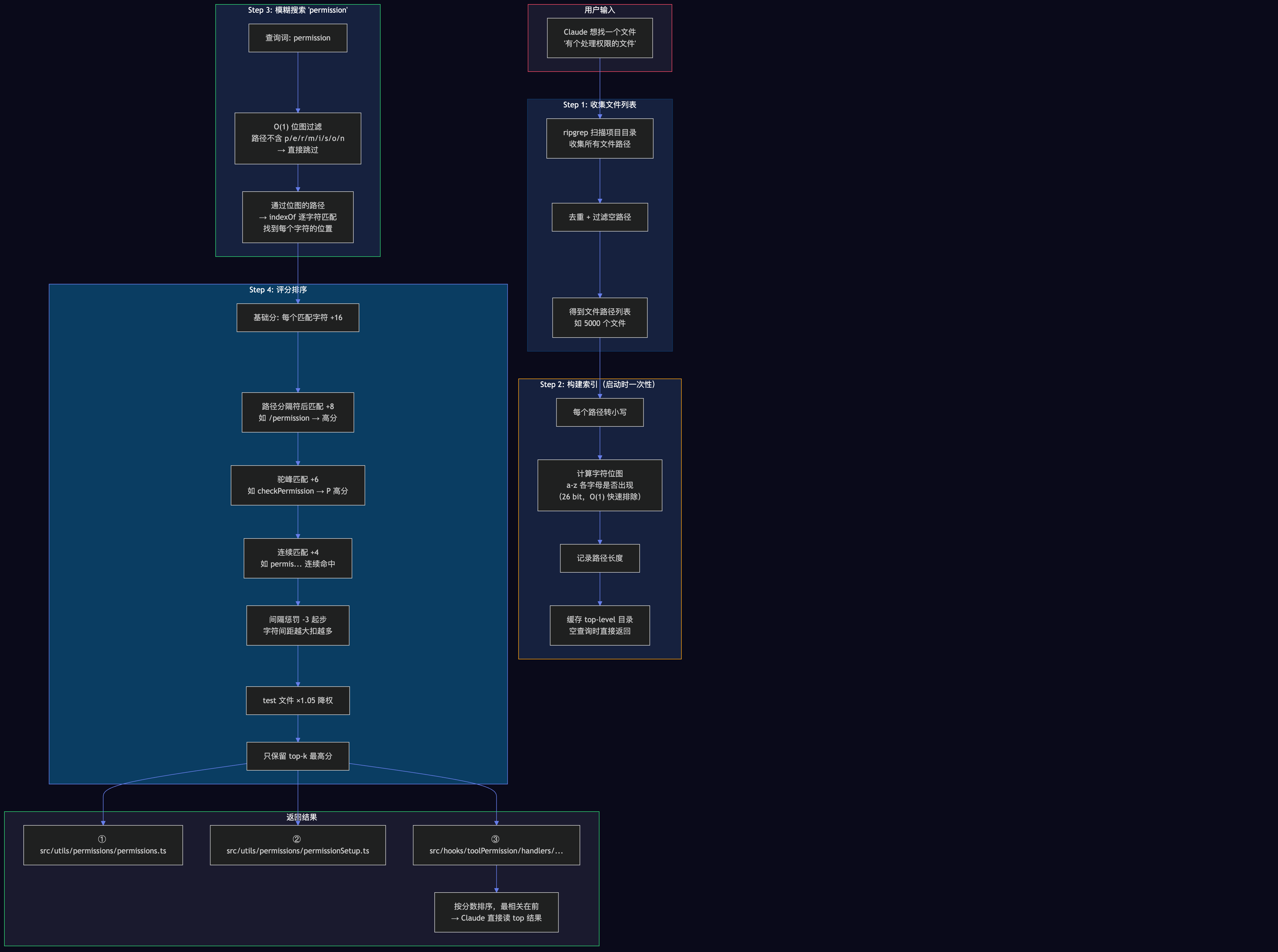
整个流程分 4 步:ripgrep 收集文件列表 → 构建位图索引(26bit 字符位图实现 O(1) 快速排除)→ 模糊匹配 → 多维度评分排序返回 top-k。
核心评分常量:
// nucleo-style scoring constants (approximating fzf-v2 / nucleo bonuses)
const SCORE_MATCH = 16
const BONUS_BOUNDARY = 8 // 路径边界处匹配(/ \ - _ . 空格)
const BONUS_CAMEL = 6 // 驼峰命名边界
const BONUS_CONSECUTIVE = 4 // 连续字符匹配
const BONUS_FIRST_CHAR = 8 // 首字符匹配
const PENALTY_GAP_START = 3
const PENALTY_GAP_EXTENSION = 1
性能优化有几个亮点:
① Bitmap 预过滤(O(1) 拒绝)
每个文件路径在索引时预计算一个 26-bit bitmap,对应 a-z 每个字母是否出现:
private indexPath(i: number): void {
const lp = this.paths[i]!.toLowerCase()
this.lowerPaths[i] = lp
let bits = 0
for (let j = 0; j < len; j++) {
const c = lp.charCodeAt(j)
if (c >= 97 && c <= 122) bits |= 1 << (c - 97)
}
this.charBits[i] = bits
}
搜索时先用 (charBits[i] & needleBitmap) !== needleBitmap 做 O(1) 位运算过滤。注释说"broad queries like 'test' → 10%+ free win; 90%+ rejection for rare chars"。
② 异步分块构建,不阻塞主线程
const CHUNK_MS = 4 // 每次处理 ~4ms,然后 yield 给 event loop
// 5万文件 ~2ms on M-series,可能 15ms+ on older Windows hardware
// Chunk sizes are time-based (not count-based) so slow machines get smaller chunks
③ Top-K 维护,不全量排序
不是搜完所有文件再 sort,而是维护一个大小为 limit 的升序数组,用二分插入保持有序——只在找到更好匹配时才更新:
} else if (score > threshold) {
let lo = 0, hi = topK.length
while (lo < hi) {
const mid = (lo + hi) >> 1
if (topK[mid]!.fuzzScore < score) lo = mid + 1
else hi = mid
}
topK.splice(lo, 0, { path, fuzzScore: score })
topK.shift()
threshold = topK[0]!.fuzzScore
}
④ test 文件轻微降权
const finalScore = path.includes('test')
? Math.min(positionScore * 1.05, 1.0)
: positionScore
测试文件在大多数搜索场景下不是首要结果,加 5% 惩罚。细节但体贴。
智能大小写:
// Smart case: lowercase query → case-insensitive; any uppercase → case-sensitive
const caseSensitive = query !== query.toLowerCase()
和 vim / fzf 行为一致——全小写搜索忽略大小写,有大写字母就区分大小写。
第 3 层:Grep + Read — 在缩小范围内精确搜索
FileIndex 缩小了候选文件集,Grep 在这些文件里做精确内容搜索,Read 读取完整文件。
这一层没有特别的算法,但有个重要原则:Claude 自己决定搜什么、怎么搜、搜多深。这是 Agentic 模式的核心——不是预先计算好"相关文档"再喂给模型,而是让模型在搜索过程中动态调整策略。
第 4 层:Explore Subagent — 复杂探索时自动派遣子 Agent
对于更复杂的探索任务,CC 有一个内置的 Explore Agent。当主 Agent 判断需要深度探索代码库时,会自动 spawn 这个子 Agent。
源码 src/tools/AgentTool/built-in/exploreAgent.ts:
export const EXPLORE_AGENT: BuiltInAgentDefinition = {
agentType: 'Explore',
// Ants get inherit to use the main agent's model;
// external users get haiku for speed
model: process.env.USER_TYPE === 'ant' ? 'inherit' : 'haiku',
// Explore is a fast read-only search agent — it doesn't need commit/PR/lint
// rules from CLAUDE.md. The main agent has full context and interprets results.
omitClaudeMd: true,
...
}
几个设计细节:
使用 Haiku 而不是 Sonnet:探索任务是读多写少,用便宜快速的 Haiku(外部用户)降低成本。Anthropic 内部员工(ant)用 inherit 继承主 Agent 的模型。
omitClaudeMd: true:Explore Agent 不加载项目的 CLAUDE.md——它只需要搜索能力,不需要了解项目的 commit 规范、PR 流程之类的。主 Agent 负责解读结果。
严格只读:禁用了 Edit、Write、NotebookEdit 工具,系统提示里用全大写强调:
=== CRITICAL: READ-ONLY MODE - NO FILE MODIFICATIONS ===
并行搜索:提示词明确要求"spawn multiple parallel tool calls for grepping and reading files",通过并行 IO 提高探索速度。
第 5 层:Compaction — 旧搜索结果压缩清理
随着对话进行,之前的搜索结果会越来越多,占用 context window。CC 有 Compaction 机制,将历史轮次压缩成摘要,清理不再需要的搜索结果。
这层解决的不是"怎么找到相关信息",而是"如何保持 context 干净"——本质上是另一种形式的"索引维护"。
四、记忆系统也不用 Embedding
CC 有一个基于文件的记忆系统(~/.claude/projects/*/memory/),存储跨会话的上下文。有意思的是,它的记忆检索也不用 embedding。
源码 src/memdir/findRelevantMemories.ts:
const SELECT_MEMORIES_SYSTEM_PROMPT = `You are selecting memories that will be useful
to Claude Code as it processes a user's query. You will be given the user's query
and a list of available memory files with their filenames and descriptions.
Return a list of filenames for the memories that will clearly be useful
to Claude Code (up to 5). Only include memories that you are certain will be helpful.`
export async function findRelevantMemories(
query: string,
memoryDir: string,
signal: AbortSignal,
recentTools: readonly string[] = [],
alreadySurfaced: ReadonlySet<string> = new Set(),
): Promise<RelevantMemory[]> {
const memories = await scanMemoryFiles(memoryDir, signal)
const selectedFilenames = await selectRelevantMemories(
query, memories, signal, recentTools,
)
// ...
}
机制很简单:Sonnet 做 side query,输入是用户的 query + 所有记忆文件的 frontmatter(文件名 + description 字段),输出是最多 5 个相关文件名。
const result = await sideQuery({
model: getDefaultSonnetModel(), // Sonnet
system: SELECT_MEMORIES_SYSTEM_PROMPT,
messages: [{ role: 'user', content: `Query: ${query}\n\nAvailable memories:\n${manifest}` }],
max_tokens: 256, // 只需要返回文件名列表,非常轻量
output_format: { type: 'json_schema', ... },
})
一个有趣的细节:如果 Claude 最近在用某个工具(比如 mcp__X__spawn),记忆选择会主动过滤掉这个工具的"使用文档"类记忆:
// When Claude Code is actively using a tool (e.g. mcp__X__spawn),
// surfacing that tool's reference docs is noise — the conversation
// already contains working usage.
// DO still select memories containing warnings, gotchas, or known issues
// about those tools — active use is exactly when those matter.
const toolsSection = recentTools.length > 0
? `\n\nRecently used tools: ${recentTools.join(', ')}`
: ''
逻辑:你都在用这个工具了,再给你这个工具的使用说明是噪声。但如果记忆里有"这个工具的已知坑",反而应该优先展示。
记忆保鲜期
src/memdir/memoryAge.ts 有个精妙的设计——记忆文件会带着年龄信息展示给主模型:
export function memoryFreshnessText(mtimeMs: number): string {
const d = memoryAgeDays(mtimeMs)
if (d <= 1) return ''
return (
`This memory is ${d} days old. ` +
`Memories are point-in-time observations, not live state — ` +
`claims about code behavior or file:line citations may be outdated. ` +
`Verify against current code before asserting as fact.`
)
}
注释说明了动机:"user reports of stale code-state memories (file:line citations to code that has since changed) being asserted as fact — the citation makes the stale claim sound more authoritative, not less."
这是一个真实踩坑后的修复。记忆里写着"AuthService 在 src/auth.ts:142 处理登录",但那个文件早就重构了,Claude 还一本正经地引用这个"出处"。解法不是引入更复杂的记忆管理,而是直接告诉模型"这条记忆 47 天前写的,信之前自己核实一下"。
五、边界:什么场景必须用 RAG
CC 的方案不是万能的,几个场景下 RAG 仍然是更好的选择:
1. 超大非结构化文档库:如果你有 10 万篇 Confluence 页面需要检索,让 AI 用 Grep 搜不现实。RAG 的向量索引在这个规模下有明显优势。
2. 语义相似而非关键词匹配:搜"用户登录相关的代码",Grep 能找到,但"身份验证"、"session 管理"、"OAuth 流程"这些语义相关但关键词不同的内容,向量检索更擅长。
3. 多语言混合文档:中文查询匹配英文文档,RAG 的向量空间天然支持跨语言语义对齐。
4. 无法给 AI 工具权限的场景:如果你的系统无法给 AI 直接执行搜索命令的权限(安全限制),RAG 是合理的替代。
CC 的场景是:代码库 + 有工具执行权限的 Agent。在这个场景下,精确搜索 + 分层策略比 embedding 检索更直接、更可控、更省成本。
总结
CC 不用 RAG 的根本原因是:它不需要。
RAG 解决的问题是"如何从大量文档里找到相关片段,塞进有限的 context window"。CC 换了个思路——不预先计算相关性,而是让模型带着搜索工具自己探索,用 FileIndex 做模糊排序,用 CLAUDE.md 做手动索引,用 Compaction 管理 context 大小,用 Haiku 子 Agent 分担搜索负担。
每一层都很简单,但组合在一起,覆盖了代码库探索的大部分场景。
这让我想到一个更广泛的设计原则:不要为了用技术而用技术。Embedding + 向量数据库是一套完整的基础设施,引入它就要维护它、监控它、调 retrieval 参数。在能用更简单方案解决问题的情况下,复杂方案只是债务。
预告:下一篇
CC 开源源码解读(二):上下文压缩是怎么做的?
CC 的 Compaction 机制非常有意思——不是简单的截断,而是一套分层压缩策略。在长对话中,CC 如何判断什么信息可以丢弃、什么必须保留?如何在压缩信息量和保持 Agent 连贯性之间取得平衡?
源码层面深挖,下篇见。
如果你也在研究 CC 源码,欢迎评论区交流。
源码仓库:claude-code GitHub
