

社交圈里偶尔冒出一种半开玩笑的说法:Google Research 一篇讲 KV 与向量极端压缩的博文,「把内存相关股价都带崩了」。笔者未核实任何单日行情与因果链——股价受利率、库存、产能、风险偏好等一堆变量支配,把涨跌归因到一篇算法研究推介,多半是过度简化甚至段子;下面的文字也不是投资建议,更不是在替「内存股」做叙事。[1][2]
但这类传言之所以听起来像真的,恰恰说明大家已经默认:大模型推理里,DRAM / HBM 与 KV cache 的体积是绑在一起的——谁能让同样效果吃更少比特,谁就能在叙事上动到「内存要不要再买那么多」的想象。技术读者若真关心这件事,该打开的是 arXiv PDF 里的假设与失真界,而不是 K 线;笔者读 Google Research 博文、再对照 arXiv:2504.19874 的动机,和当年读 量化 从 JPEG 走到 神经网络 时类似:先看失真—比特率这条主线有没有讲清楚,再谈「快了多少倍」的 headline。[1][2]
一句话:TurboQuant 是一套面向高维向量的向量量化(vector quantization) 流程——博文将其定位为缓解 LLM(大语言模型,Large Language Model)键值缓存(KV cache) 与向量检索内存瓶颈的工具;技术上有两块可单独命名的砖:PolarQuant(极坐标视角做高质量压缩)与 QJL(Quantized Johnson–Lindenstrauss,在残差上补 1 bit 以纠偏内积估计)。同一主题在 ICLR 2026(TurboQuant)与 AISTATS 2026(QJL、PolarQuant)会议投稿脉络下公开;更硬的定理与比特率表述见研究论文arXiv:2504.19874。[1][2]
KV cache:推理时缓存历史 token 对应的键值张量,避免每一步重算整段上下文;体积一大,内存与带宽先顶不住。
向量量化:把连续向量映射到离散码字,用更少比特表示,代价是失真(distortion) ;传统分块量化常要额外存每块量化常数,带来博文所说的「memory overhead」,部分抵消压缩收益。[1]
下文按「问题 → 两条算法线 → 博文实验叙事 → 研究论文与博文的细部对照 → 意义与边界」组织;营销式措辞与可核对陈述分开写。[1][2]
读前先看:博文与论文各管哪一段
- 读博文:快速建立直觉——PolarQuant 的几何图景、QJL 的「1 bit 纠偏」、以及 LongBench / needle-in-a-haystack 等任务上相对 KIVI 等基线的图表结论。[1]
- 读 arXiv PDF:核对失真率、信息论下界、以及「每通道 3.5 bit / 2.5 bit」这类论文摘要里的定量句——与博文「3 bit KV、零精度损失」等 headline 级表述不必逐字对齐,以 PDF 为准做产品/工程决策。[2]
- 落地:同一套方法同时讲 KV 与近邻检索;Gemini 级产品与你的本地部署差很远,别混成一张表。
一、为什么高维向量会同时卡住「生成」和「搜索」
向量是当代 AI 表示语义与特征的基本载体;维度一高,内存与带宽开销陡增。对 Transformer 类模型,KV cache 像高速「备忘」:把常用键值放在手可及处,支撑长上下文与快速 attention;瓶颈一出,相似度检索(向量搜索)也会拖慢索引构建与查询。[1]
向量量化老早就存在,但经典做法往往要为每个小块额外存全精度的缩放/偏置类常数——博文用 1~2 bit/数 量级形容这类 overhead,会部分抵消压缩初衷。[1]
二、TurboQuant 的两段式:先 PolarQuant「塑形」,再 QJL「收口误差」
博文把 TurboQuant 拆成两步(以下为意译,细节以论文为准):[1]
- 高质量压缩(PolarQuant) :先对数据向量做随机旋转,让几何结构更易吃标量量化;这一阶段用掉大部分比特预算,抓住向量的「主能量与主方向」。极坐标叙事里,把「沿轴距离」换成「半径 + 方向角」的表述,用来解释为何能省掉某些昂贵的归一化/边界处理——直觉是:角分布更集中时,网格更可预期。[1]
- 消除隐性偏差(QJL) :第一阶段后会剩一点残差;再用约 1 bit 的预算对残差做 QJL。Johnson–Lindenstrauss(JL) 类变换擅长在降维时保持距离关系;这里把数值压到符号位(±1) 量级,并配合特殊估计器在低精度数据 + 高精度查询之间做平衡,以保证 attention 里用到的内积/相似度仍可算准。[1]
通俗一点想(仅为直觉,不等于实现细节):更像搬家装箱——先把大件摆顺(PolarQuant 用掉大部分比特预算,把「主形状」稳住),墙角缝隙再用薄盒子填(QJL 在残差上花约 1 bit,专治「大头摆完还剩的小偏差」),避免 attention 里内积整体跑偏。它和JPEG 里常说的「先换一套表示再量化」同属一条思路,但这里压的是高维向量、盯的是相似度能不能扛住,不是把照片压成 .jpg。物理课里换坐标系也会用到旋转——和这里的随机旋转在换基、换姿态上同源;差别在于本文要证明的是失真—比特率,不是轨迹与动力学。[1]
博文单独设小节介绍 QJL 与 PolarQuant,并配有示意视频/图(发布时建议直接打开原文页看图,比文字省一半时间)。[1]
三、材料勘读:博文里的结果句,哪些能直接当真?
下列条目转述自 Google Research 博文的实验段落,不是替你复现实验的承诺;图均为截图自官方博文页,版权归 Google / 出版方。[1]
博文在多项任务上点名 LongBench、needle-in-a-haystack、ZeroSCROLLS、RULER、L-Eval 等,并涉及 Gemma、Mistral 等模型;下面几张图分别对应「长上下文条形图」「Haystack 热图」「KV 内算 logits 的加速」「GloVe 检索」——读这节时扫一眼即可,数字以原图为准。[1]
LongBench:Llama-3.1-8B-Instruct 上的条形对比
- 长上下文条形图:在 LongBench 上,Llama-3.1-8B-Instruct 与 KIVI、TurboQuant、PolarQuant、Full Cache 等对比;bitwidth 括号以原图为准。[1]
Needle-in-a-haystack:六格热图
- Haystack 类任务:博文称 TurboQuant 在展示的结果里达到「完美下游表现」,同时 KV 体积至少约 6× 压缩(措辞以英文原文为准)。[1]
KV 内 attention logits:相对优化基线的加速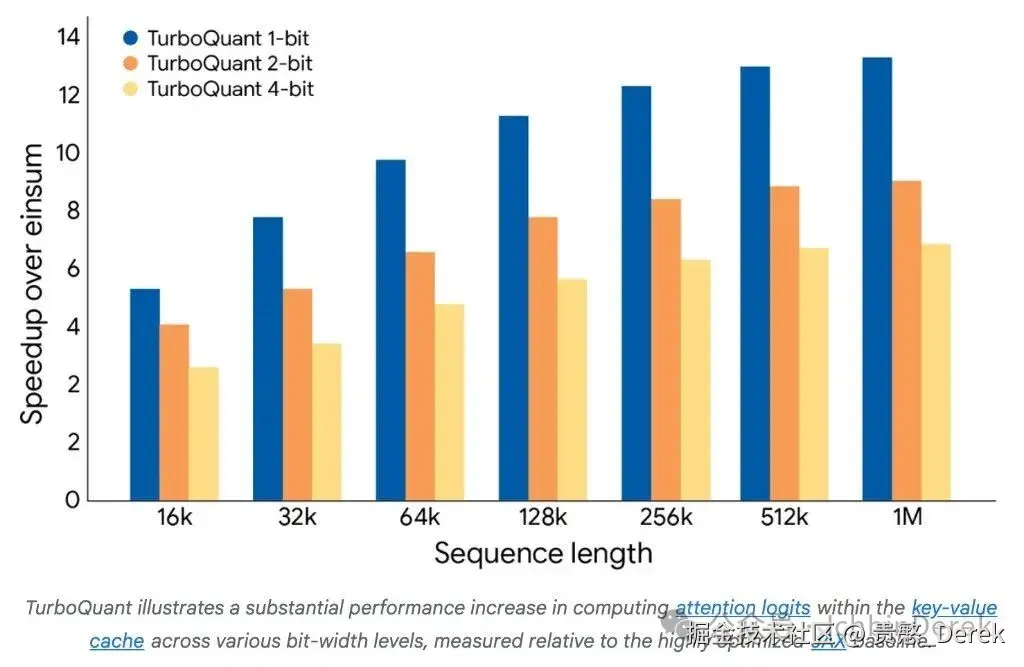
- 比特与速度:博文称可将 KV cache 压到约 3 bit 而无需训练/微调、不牺牲精度、且相对原始 LLM 运行更快;又称 4 bit TurboQuant 在 H100 上相对 32 bit 未量化 key 计算 attention logits 可高达约 8× 加速(以原图与脚注为准;上图与「8×」句可能对应不同设定,请对照原文)。[1]
GloVe 向量检索:Recall@1@k
- 向量检索:与 PQ、RabitQ 等对比 GloVe(d=200)上的 1@k recall;博文称 TurboQuant recall 更优且更省「大码本/数据特调」之类成本。[1]
标注推断:「Redefining」「transformative」属于宣传语气;是否「重新定义」取决于你的评价指标是 吞吐、召回还是端到端业务成本——读者应回到 PDF 的条件与假设。[1]
四、研究论文里多出来的「硬句子」(arXiv:2504.19874)
研究论文摘要把问题放在 Shannon 源编码传统下的向量量化:同时关心 MSE 与内积失真,并声称 data-oblivious、适合 online 的算法在比特宽与维度上达到接近最优失真率(与信息论下界差一个小常数,文中给出约 2.7 倍因子量级——以 PDF 为准)。[2]
内积误差、MSE 与比特宽度下的理论界(论文图示)
实验摘要句(直接转述 arXiv 摘要):KV cache 量化在 3.5 bits per channel 下「absolute quality neutrality」;2.5 bits per channel 下「marginal quality degradation」;近邻检索上相对积量化类方法 recall 更优且索引时间近乎为零。[2]
与博文 headline 的对照:博文强调「3 bit」「zero accuracy loss」等更易传播的短句;论文摘要用 3.5 / 2.5 bits per channel 与「neutrality / marginal degradation」的更细粒度描述——以论文为严谨口径,博文作传播层阅读。[1][2]
五、结语:为什么值得同时打开 arXiv 与博文
若问 TurboQuant 这条线的意义,不在于多一个新缩写,而在于把「KV/向量检索都要吃内存」的问题,放进可证明的失真率与可测的吞吐/召回里一起谈——让读者知道该去 arXiv PDF 对公式与假设,再去 Google Research 博文 看图与场景叙事。[1][2]
笔者理解若有与 PDF 最新版本不一致之处,以 arXiv 与官方博文更新为准;工程落地前请用你的模型与数据复现关键曲线。
工程边界(回应「没有代码怎么信」一类质疑):截至本文整理日,研究论文与 Google Research 博文侧重方法与定理、实验曲线;未在文内给出与论文一一对应的官方开源仓库链接。网上检索 turboquant 可能命中同名无关项目(例如量化交易类仓库),勿凭仓库名当论文实现。与文中多次出现的基线 KIVI 等对读时,后者有公开的 GitHub 与 arXiv,复现门槛不对称——更适合把 TurboQuant 先当「论文 + 官方图表」读,再决定是否投入自研复现。[1][2]
吞吐口径:博文中的 H100、8× 等表述多针对 KV 内 attention logits 计算或图示设定;不等于直接承诺你业务里端到端的 token/s 提升——落地请以你的框架与批大小实测为准。[1]
参考文献与延伸阅读
- Amir Zandieh、Vahab Mirrokni 等,TurboQuant: Redefining AI efficiency with extreme compression,Google Research Blog,research.google/blog/turboq… 2026-03-24;访问日 2026-03-26)
- Amir Zandieh、Majid Daliri、Majid Hadian、Vahab Mirrokni,TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate,arXiv:2504.19874,arxiv.org/abs/2504.19… 2025-04-28);PDF:arxiv.org/pdf/2504.19…
- ICLR 2026 投稿页(OpenReview):openreview.net/forum?id=tO… — 与会议录用信息、评审讨论互证(以页面为准)。
- KIVI 基线(文中对比对象):Liu 等,KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache,arXiv:2402.02750,arxiv.org/abs/2402.02…;代码:github.com/jy-yuan/KIV…。
- 论文元数据聚合(Hugging Face Papers):huggingface.co/papers/2504… — 便于跟踪引用与社区讨论,非替代 PDF。
