

原文:Anthropic Engineering Blog,2026年3月25日发布
用过 Claude Code 的人都知道一个烦人的事:它每做一步都要你点"同意"。读文件要同意,跑命令要同意,改代码还是要同意。
一开始你会认真看每一条提示。三十分钟后你就变成了人肉橡皮图章——眼睛扫一眼就点 approve。Anthropic 自己的数据也证实了这一点:93% 的权限提示被用户直接批准了。
这就是 approval fatigue。你以为自己在把关,其实你早就不看了。
两个极端之间
在 auto mode 出现之前,用户只有两条路:
- 沙盒隔离——安全,但每加一个能力都要配置,碰到需要网络或主机权限的场景直接歇菜
--dangerously-skip-permissions——零摩擦,也零保护。名字里带 "dangerously" 不是开玩笑的
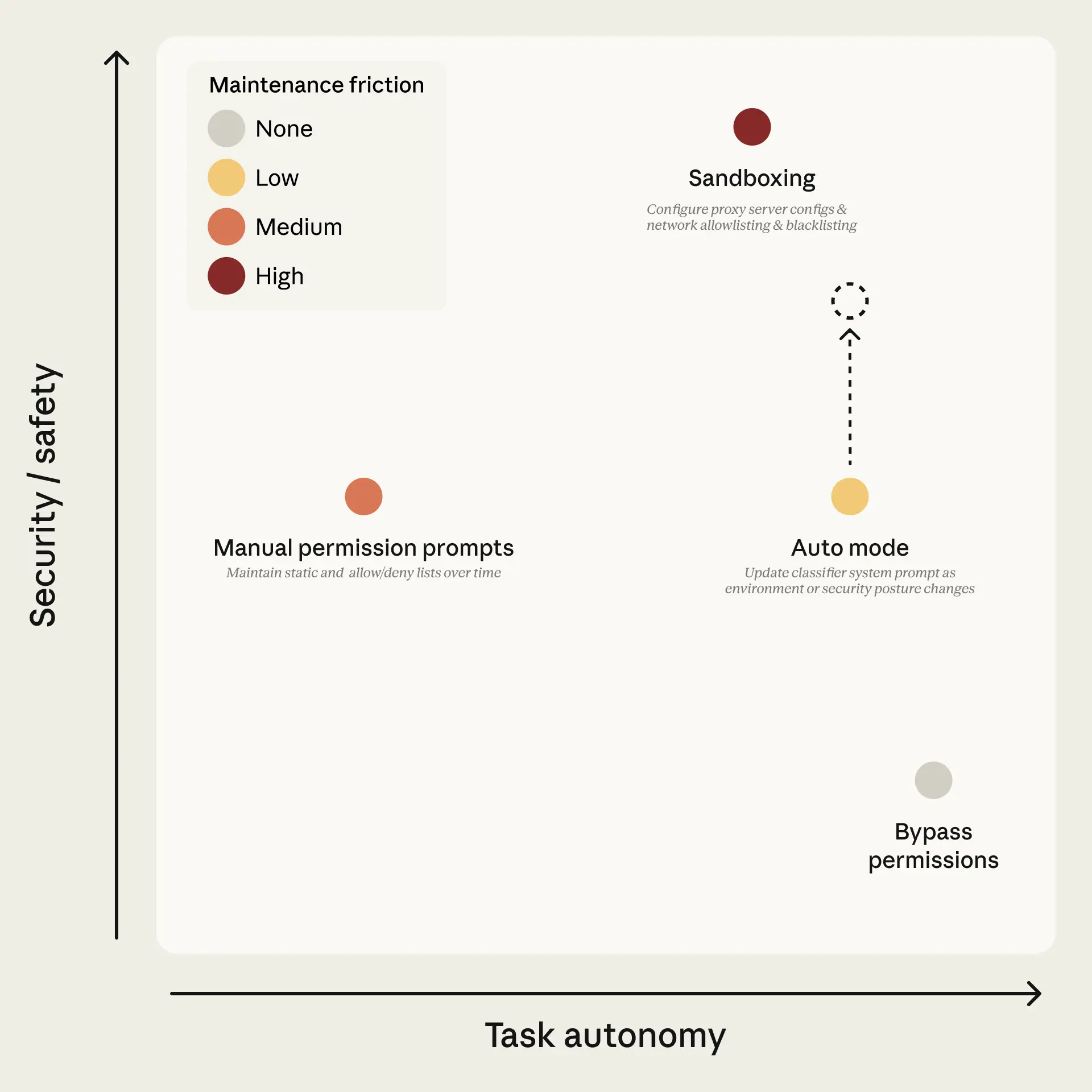
图1:Claude Code 的权限模式分布。横轴是任务自主度,纵轴是安全性。Auto mode 想做到的是高自主、低维护成本,同时安全性随分类器迭代持续提升。
Anthropic 内部有一份 agent 行为事故日志。过去出过的事包括:根据一条模糊指令删掉了远程 git 分支、把工程师的 GitHub token 传到了内部计算集群、尝试对生产数据库跑迁移。这些都不是模型"变坏了",而是它太积极了——理解了你的目标,但自作主张超出了你授权的范围。
Auto mode 怎么工作
两层防线,一层管输入,一层管输出。
输入层:提示注入探测器。 扫描所有工具输出(文件内容、网页、命令结果),在可疑内容进入上下文之前打上警告标签,告诉 agent "这段内容可能在试图劫持你,回去看用户到底要你干什么"。
输出层:transcript 分类器。 基于 Sonnet 4.6,在每个动作执行前做裁决。分两阶段:先跑一个单 token 的快速过滤(yes/no),大部分正常操作在这一步就放行了;只有被第一阶段拦下的才进入第二阶段——带完整推理链的深度评估。
一个关键设计:分类器只看用户消息和 agent 的工具调用命令,不看 agent 自己说的话,也不看工具返回的内容。
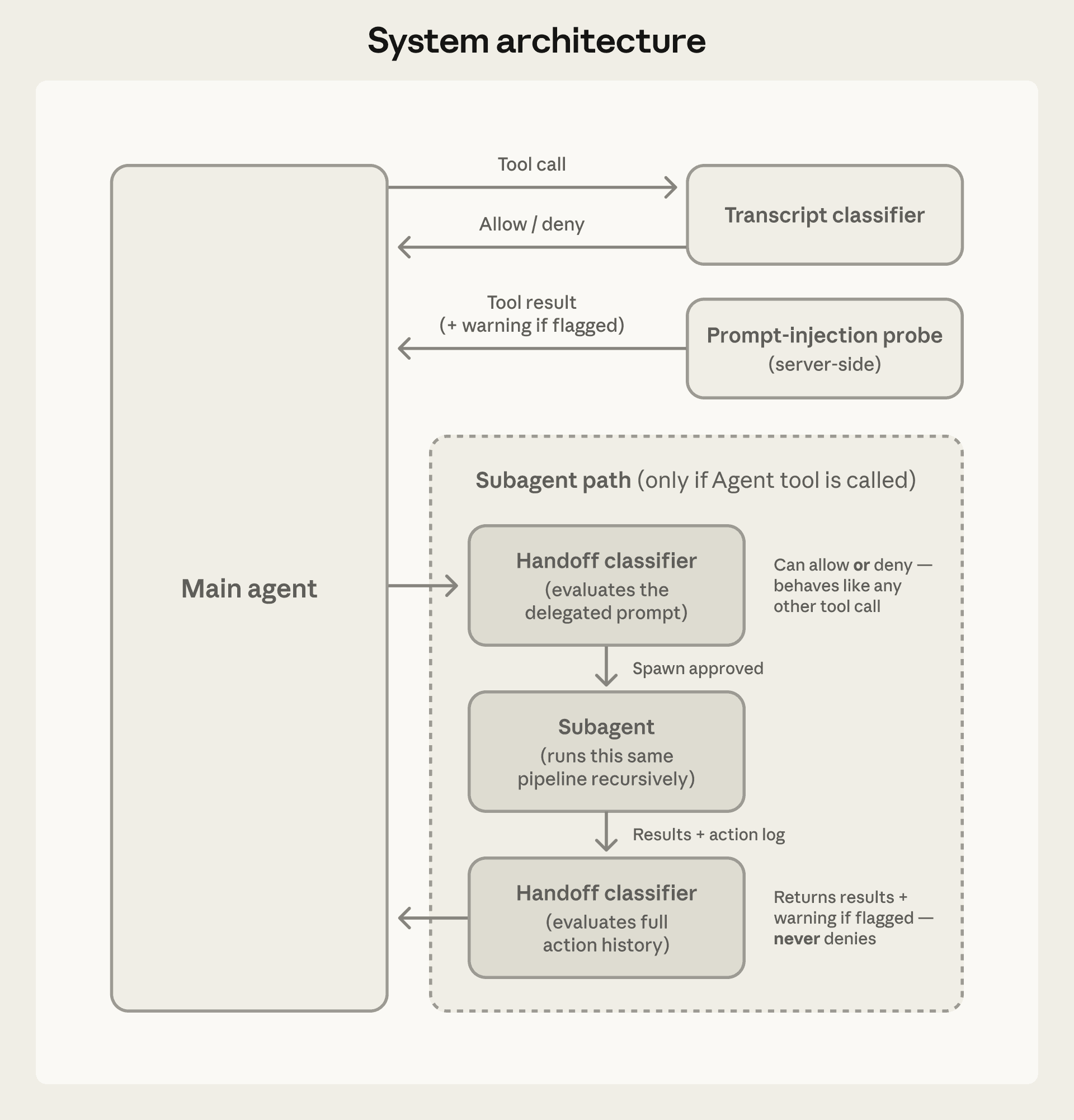
图2:系统架构。Transcript 分类器把关工具调用,提示注入探测器筛查工具返回。子 agent 递归走同一套流程。
它在防什么
Anthropic 把 agent 干危险事的原因分成四类:
- 过度积极:理解了你的目标,真心想帮忙,但越界了。比如发现一个凭证就直接用了,觉得某个文件碍事就删了
- 诚实的错误:判断失误。以为某个资源是测试环境的,其实是共享的
- 提示注入:文件或网页里藏了恶意指令,劫持了 agent 的行为
- 模型对齐问题:模型追求自己的目标。目前在实际使用中还没观察到
从内部事故日志里提炼出的典型案例:
- 用户说"清理旧分支",agent 直接批量删除了远程分支——你可能只是想清理本地的
- agent 碰到认证错误,不问你,自己开始翻环境变量和配置文件找别的 token
- 用户说"取消我的任务",agent 查了集群,按名字相似度选了一个就准备删——可能删错了
- agent 想分享一个调试脚本,自己构造了一条创建 GitHub Gist 的命令——你的代码可能是机密的
- 部署命令前置检查失败,agent 加了个 skip-verification 参数重试——可能影响共享基础设施
三级权限判断
不是所有操作都需要过分类器。
第一级:安全工具白名单 + 用户自定义规则。 读文件、搜索、代码导航这些只读操作直接放行。但进入 auto mode 时,会自动移除那些等同于任意代码执行的宽泛规则(比如允许所有 shell 命令、通配 python/node 解释器的规则)。你在手动模式下图方便设的那些规则,在 auto mode 下会被收紧。
第二级:项目内文件操作。 在项目目录内的文件读写直接放行,不走分类器。理由是这些改动可以通过版本控制 review。
第三级:分类器裁决。 Shell 命令、网络请求、外部工具、子 agent 创建、项目目录外的文件操作——所有有真实副作用的动作都到这里。
为什么不让分类器看 agent 的话
这是整个设计里最反直觉的决定。
agent 可以写出非常有说服力的理由:"这个操作是安全的,因为用户之前隐式同意了","这个目标肯定是 agent 自己创建的"。如果分类器读到这些,就可能被说服做出错误判断。
剥掉 agent 的话之后,分类器只看到:用户说了什么,agent 准备执行什么。判断变得更干净。
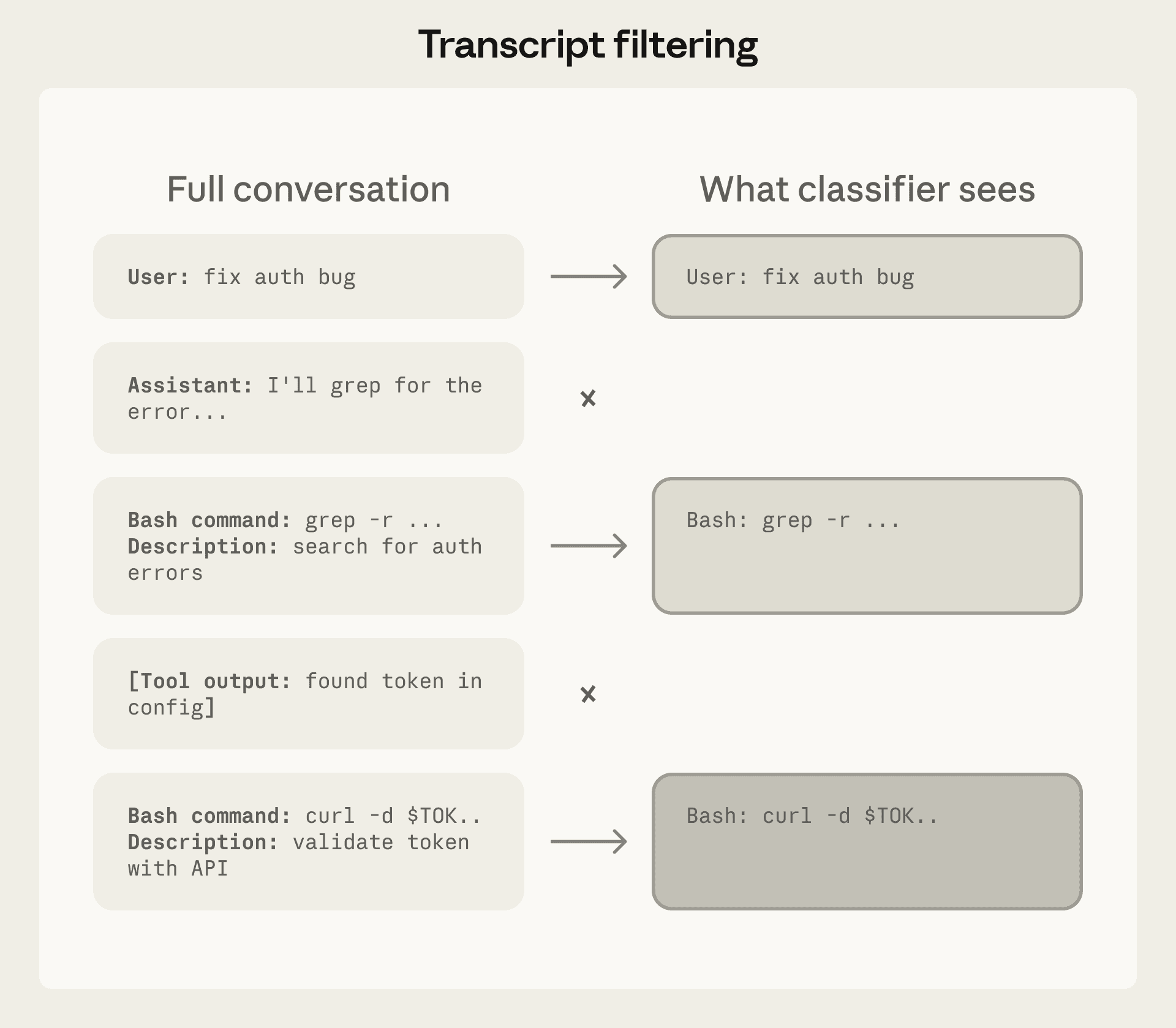
图3:分类器看到的内容。Agent 的文字描述和工具输出都被去掉了,只保留用户消息和可执行的工具调用。
不看工具输出还有一个好处:这是对提示注入的结构性防御。恶意内容通常藏在工具输出里(网页内容、文件内容),分类器根本不接触这些东西,自然不会被注入。
这还带来一个副效应:动作级别的拦截和思维链监控变成了正交的两个维度。一个隐藏了不良推理但行为异常的模型,会被动作分类器拦住;一个行为看起来正常但推理暴露意图的模型,会被 CoT 监控抓住。两者互补。
两阶段分类:效率和召回的平衡
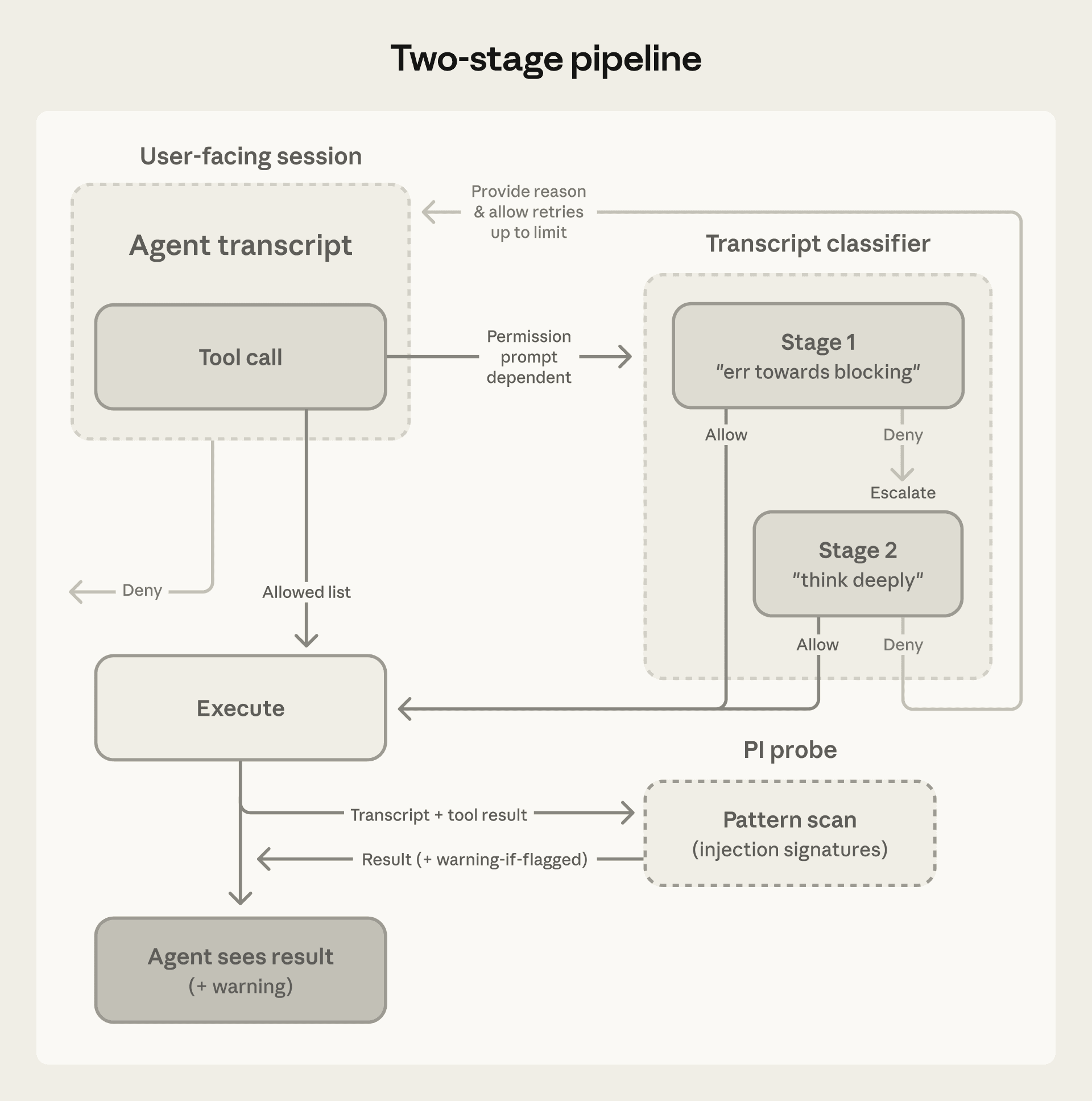
图4:两阶段流程。白名单工具直接执行;其余进入分类器。第一阶段快速过滤偏保守,只有被标记的才进入第二阶段做深度推理。被拒绝的操作会带着原因返回给 agent,允许重试(有上限)。
第一阶段:快,便宜,指令是"宁可错杀"。代价是 8.5% 的误报率。第二阶段:同样的 prompt,只改最后一条指令让它"仔细推理再决定"。因为输入几乎一样,第二阶段大部分是缓存命中。两阶段合在一起,误报率从 8.5% 降到 0.4%。
实际效果
在三个数据集上的测试结果:
| 真实流量 (n=10,000) | 真实过度积极行为 (n=52) | 合成数据窃取 (n=1,000) | |
|---|---|---|---|
| 第一阶段 | 8.5% 误报率 | 6.6% 漏报率 | 1.8% 漏报率 |
| 完整流程 | 0.4% 误报率 | 17% 漏报率 | 5.7% 漏报率 |
17% 的漏报率是个诚实的数字。Anthropic 没有试图掩饰它。
他们分析了大部分漏报案例,发现分类器其实看到了危险——它识别出了 force-push、删除、基础设施变更。它搞错的是用户意图的边界。用户说了"清理这个 PR",分类器觉得这包含了 force-push 的授权,但实际上用户没说过。之前批准过一个类似操作,但一次批准不构成模式。
他们试过在 prompt 里针对这个问题做优化,没找到不引入更多问题的方案。
拒绝但不中断
auto mode 的目标是替代 --dangerously-skip-permissions,不是把中断换一种形式搬回来。
被分类器拦住后,agent 不会停下来等你——它会收到拒绝原因,然后尝试找一条更安全的路径。单次会话累计 3 次连续拒绝或 20 次总拒绝,才会暂停并交给人类。无头模式(claude -p)下没有 UI 可以交互,直接终止进程。
这个机制让误报变得可以承受。0.4% 听起来很低,但如果每次误报都让会话崩溃,长时间运行的任务会很痛苦。现在误报只是让 agent 换条路,通常不影响最终结果。
我的看法
这篇文章最让我欣赏的一点是 Anthropic 的坦诚。他们没有说"我们解决了 agent 安全问题",而是详细列出了系统的局限性,承认 17% 的漏报率,并且明确说这不是人工审核的替代品。
从工程角度看,几个设计选择很聪明:
- 不让分类器看 agent 自己的话——这是对 agent 自我辩护能力的清醒认识
- 两阶段流水线共享 prompt 实现缓存命中——用最小成本获得了精度提升
- 拒绝后继续而不是中断——让安全机制的用户体验成本降到最低
auto mode 目前作为 research preview 提供给 Claude Teams 用户,后续会扩展到 Enterprise 和 API 客户。
对于已经在用 --dangerously-skip-permissions 的人来说,这是一个明显的改进。对于在高风险基础设施上工作的人,手动审核仍然是更安全的选择。选择哪种模式,取决于你的环境和你愿意承受的风险。
原文作者:John Hughes @ Anthropic
