

1. 问题描述
A 同学训完一阶段浮点模型 P_model_float,将模型提供给 B 同学,B 同学固定 P_model_float 权重后(用一阶段浮点输出),分别用不同数据分开去训练二阶段 prediction、planning 两个分支,最后拼到一起成 float_model_all 提供给 C 同学用于量化部署。
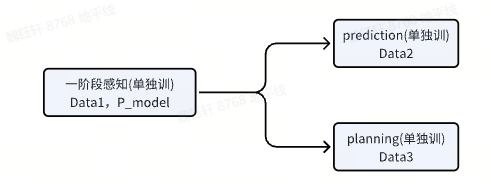
C 同学使用 P_model_float 在 Data1 上进行 calib/qat,生成 qat 达标模型 P_model_qat,然后冻结 P_model_qat 模型权重与 scale,用 P_model_out_qat 与 Data2/Data3 分别去单独 calib/qat 对应 head。
P_model_qat 在 Data1 上指标达标,在 Data2 上 P_model_qat + prediction_float-calib 的 obstacle 指标,相比于 P_model_float-calib + prediction_float-calib 在 Data2 上的要差 2 个点。
说明 P_model_qat 得到的权重虽然在 Data1 上指标满足,但泛化性不如 P_model_float,本质是 stage1 data 和 stage2 data 数据分布不同,stage1 data 校准 scale 不适用于 state2 data。
此时可以将 Data2 加入到 Data1 中进行 calib(不使用 Data2 数据 进行 qat 一阶段的 P_model),让 calib 得到的 scale 更合理,避免一阶段模型 P_model 在 Data2 上产生截断误差,eval 评测 P_model 指标时,需要将 Data1_eval 和 Data2_eval 都评测,让一阶段 P_model_qat 在 Data1 和 Data2 指标都接近 float,增强一阶段 P_model_qat 的泛化性(接近 P_model_float)。
2. 推荐解决方案
问题描述章节的处理方案肯定不是推荐的链路,因为一阶段 P_model_qat 后,模型的权重 P_model_qat-weight 会发生变化,此时去接二阶段模型,交接处是存在匹配误差的。
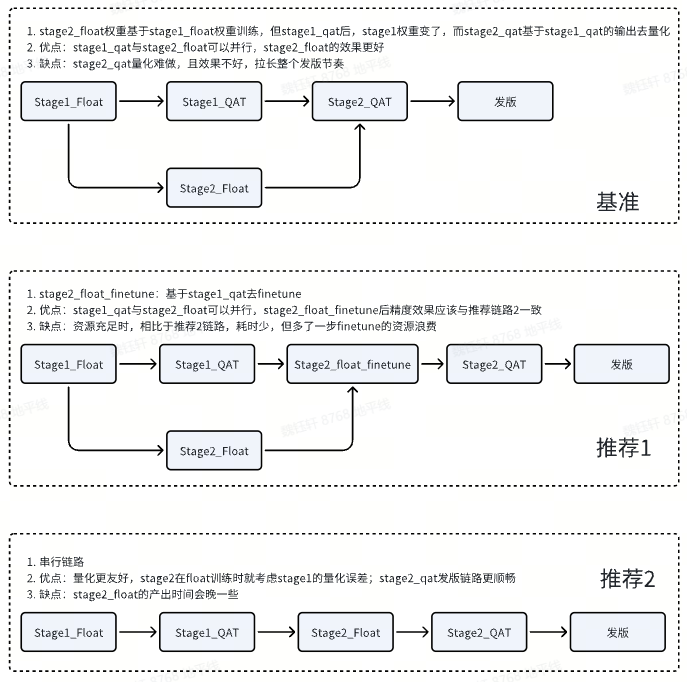
2.1 方案推荐 1
使用 P_model_qat 的 float 输出,结合 Data2,finetune float prediction head,让 prediction float head 权重结合一阶段 qat 输出在 Data2 上效果更优,然后再进行二阶段 prediction_float_new 的 calib/qat。
2.2 方案推荐 2
一阶段 P_model_float -> P_model_calib/qat -> 用 P_model_qat_out 去训练 prediction_float -> prediction_calib/qat,可以减少训练资源浪费,且调优更简单。
3.代码实践
要求代码做好模块化管理
- 一阶段已经 qat 好,二阶段基于一阶段 qat 后的结果进行的 float_finetune(float_train)
# float_model 二阶段head 加载float预训练权重
float_model.load_state_dict(float_state_dict)
# 对整个float_model进行prepare
# stage1输出加dequant,让stage2接收float输出 进行stage2 float训练
stage1qat_stage2float_model = prepare(float_model.eval(), example_input,
qconfig_setter=(
calibration_8bit_weight_16bit_act_qconfig_setter,
),
)
# 加载qat训好的stage1_qat权重
- 一阶段已经 qat 好,加载 stage2float 权重,仅 calib stage2 head
# float_model 二阶段head 加载float权重
float_model.load_state_dict(float_state_dict)
# 对整个float_model进行prepare
# stage1输出去掉dequant
calib_model = prepare(float_model.eval(), example_input,
qconfig_setter=(
calibration_8bit_weight_16bit_act_qconfig_setter,
),
)
# 加载stage1 qat训好的权重
- 一阶段已经 qat 好,stage2 calib 后,仅 qat stage2 head
# 对整个float_model进行prepare
# stage1输出去掉dequant
stage1qat_stage2qat_model = prepare(float_model.eval(), example_input,
qconfig_setter=(
calibration_8bit_weight_16bit_act_qconfig_setter,
),
)
# 加载qat训好的stage1_qat权重
stage1qat_stage2qat_model.load_state_dict(calib_state_dict)
- debug 分析:stage1_qat_stage2_float vs stage1_qat_stage2_calib
from horizon_plugin_profiler import QuantAnalysis
# float.pt和calib.pt跑一致性敏感度和逐层对比
# 参考前面去准备stage1_qat_stage2_float与stage1_qat_stage2_calib 模型准备与加载对应部分的权重
qa = QuantAnalysis(stage1_qat_stage2_float, stage1_qat_stage2_calib, "fake_quant", out_dir="./stage2_float_vs_calib")
qa.set_bad_case(bad_example_input) # 整个模型输入
qa.run()
qa.compare_per_layer() # 整个都跑,stage1两个都是qat状态去跑逐层
# 仅针对map head跑敏感度
qa.sensitivity(metric="ATOL", prefixes=("model.map_head",))
