

前言:
AI时代,前端转型势在必行,或者说环境已经开始逐步在强制你转型了,从前两年的与AI共同编程,到现在AI已经开始完成大多数的工作了。那么前端如何定位自己的角色就更显得重要了。作者就是从一名前端,逐步转成了一个AI开发者,不在局限在前端领域,而是多语言的开发者,或者说是AI工具或者AI驱动的项目开发者。
本文而是作者在多个真实项目中,通过不断试错、总结、优化 Prompt 和工程流程后,沉淀出的一些经验(可能有不准确的地方,完全是根据自身工程经验的总结)。
如何让AI写出一个完整的项目,并且这个项目还能做到符合预期且代码健壮稳定。
目标只有一个:
如何让 AI 写出一个完整、可维护、符合预期,并且足够稳定的真实项目。
我大概总结了几个部分
1. 提示词
-
清晰的输入源
你应该知道你的上游是什么,输出是什么。如果有,要如何处理,避免这些影响的自己的上下文。
-
prompt如何写
也就是你如何组织自己的prompt。很多人觉得 AI “不稳定”“经常胡写”“代码质量不行”,但实际项目中你会发现:80% 的问题,出在输入,而不是模型。
我总结了很重要的一点就是结构化
结构化是指两个方面,一个是你描述的需求要有明确的结构层级。 如:
- 角色定义
- 目标描述
- 输入说明
- 输出要求
- 约束条件
- 失败处理规则
那么你的输入应该类似这样: ::: block-1 你是一个资深前端 + AI 工程师
你的目标是将 Figma 原型转换为 React 项目
输入包含:原型图片 + Figma 节点数据
输出必须是可运行的 React 项目
不允许留下 TODO
不允许修改已有文件
:::第二点就是对输入输出的结构化要求,也就是大模型比较容易理解的如XML结构
这一点是因为在大模型的训练过程中,接收了大量的Xml的结构化数据,所以它天然的对这种结构敏感。这个在claude文档中曾经提到过。如去年爆火的bolt.new的开源版本里面,它的prompt可以看到大量的结构化提示词

可看到很多的结构化指令
-
分层次,反向提示 不要一次性让 AI 干所有事。
错误方式:
根据这些内容,帮我生成一个完整项目
正确方式:
第一步: 只让AI分析
第一步: 只让AI给方案
第三步:只让AI生成代码
第四步:只让AI修复问题
并且加入反向提示:
如果信息不足,必须明确指出 不允许自行假设 不允许使用未声明的库
这一步能极大减少“看似合理、实际不可用”的幻觉代码
-
提示词不要怕多,把你想到的边界情况都写上也不无不可, 毕竟现在模型的理解能力和上下文长度已经有了很大的提升。
2. 工程化
真正能落地的 AI 开发,一定是工程化的,而不是聊天式的。
过程可控、分步骤,而不是一次性生成
你可以把 AI 看成一个不太聪明但执行力极强的工程师,
前提是你要拆好任务
例如一个真实项目流程:
初始化项目结构
锁定技术栈
生成页面骨架/路由等
其它部分
代码自检与修复
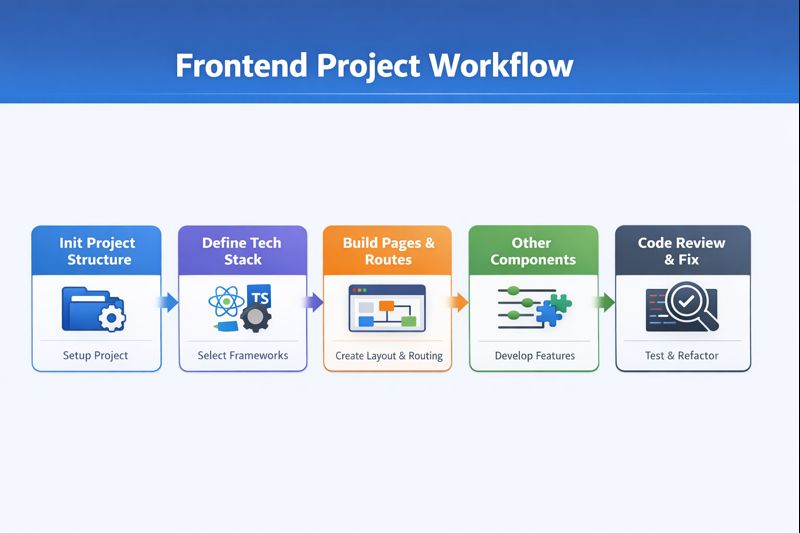
每一步都有明确输入和输出
如果拆的足够细致,那么每一步的产出其实都可以用我们工程化的方式来解决,对产物的检查会大幅度的减少AI的乱写的情况,同时还能给我们节省很多不必要的token浪费
增加模版
模版是限制AI发散的非常有效的方式。在很多优秀的开源项目中也都是提供了大量的模版来实现。
想象一个让AI在一个圈子里面发挥,和让AI无边界的发挥哪一种会更加的稳定。毕竟我们需要的是一个生产项目,而不是一个聊天机器人。
mcp
其实这个更多的是为了让产品更加的看起来像 "产品"。
毕竟让AI生成一个城市的实时天气情况,它最后给你的是一堆假的数据摆在那,也很让人出戏。
模型选择
这个没有太多选择,就是claude系,对指令的遵循非常好。
gemini3最近也挺火,试了一下,试图能力确实比claude要好,但是说指令遵循,自我感觉没有claude更好。
其它
整个过程也遇到了一些问题,比如最大的问题就是AI编写速度这个。
也尝试过并发处理,其实就是用空间换时间,如果能做到当然很好,没有去做特别深入的尝试。但是可想而知会有一个问题就是上下文同步的问题,怎么保证每个session之间的上下文是有关联的,比如我们的路由,点击跳转,状态管理等等。
或者是父子session的方式,但是又该如何划分职责,以及记忆管理都会比较复杂。
但终归是有办法解决的,但同时也可以有另一个反思就是既然我们做的是一个完备的可上线的东西,那么对应的时间耗费是否也是可以接受的。
从稳定性和上下文管理的角度来说,业界已经出了对应的agent产品来解决,claude code和gemini cli都是帮你解决这些问题的。它们可以帮助你解决上下文自动压缩的问题,工具使用,文件查找等等以前需要我们手动的补全的能力。
而且claude code真心好用,有了它之后我们之前的代码可以节省70%,它做到了一个真正的agent能做到的事情。但是即使用了这个agent的产品,也会面临很多情况,比如我们就遇到了一些情况。
一个是频繁对话以及一些输入过大的情况,最终会撑爆上下文。或者它自身记忆的问题导致它不记得的cwd目录,导致它自己去寻找目录写入文件。
目前它也提供了一些好的方式去解决。比如subagent, 读写钩子或者Skill等能力。
这里很多步骤的细节没有很具体的写,涉及到的问题会很多,感觉每一个细节都可以详细的出一篇文章的地步。
虽然上文说到了工程化去解决一些问题,实践中其实大家都感觉到了一点就是人为的干预在越来越少。也就是大模型的能力始终在进步。我们目前的一切操作,似乎都是在给过渡阶段打补丁。
