

1.前言
在模型板端部署过程中,开发者主要关心图像如何获取,模型性能如何评测以及如何优化模型等问题。对于图像的获取,地平线提供了 Pyramid 硬件,其不但可以获取多尺寸图像,且利用内存共享机制可将内存给到 BPU 直接进行推理。针对耗时,内存占用,DDR 带宽占用等指标进行评测和优化,地平线提供了诸如 Trace,hrt_ucp_monitor 等一系列性能分析工具用于性能监测,使得开发者能够清晰掌握模型运行时的资源占用和硬件效率。最后,地平线提供 VP,HPL 以及 DSP 多种模块用于前后处理环节的算法开发。本文将结合实例说明模型如何进行部署,性能分析以及常见的问题解析。
2.UCP 简介
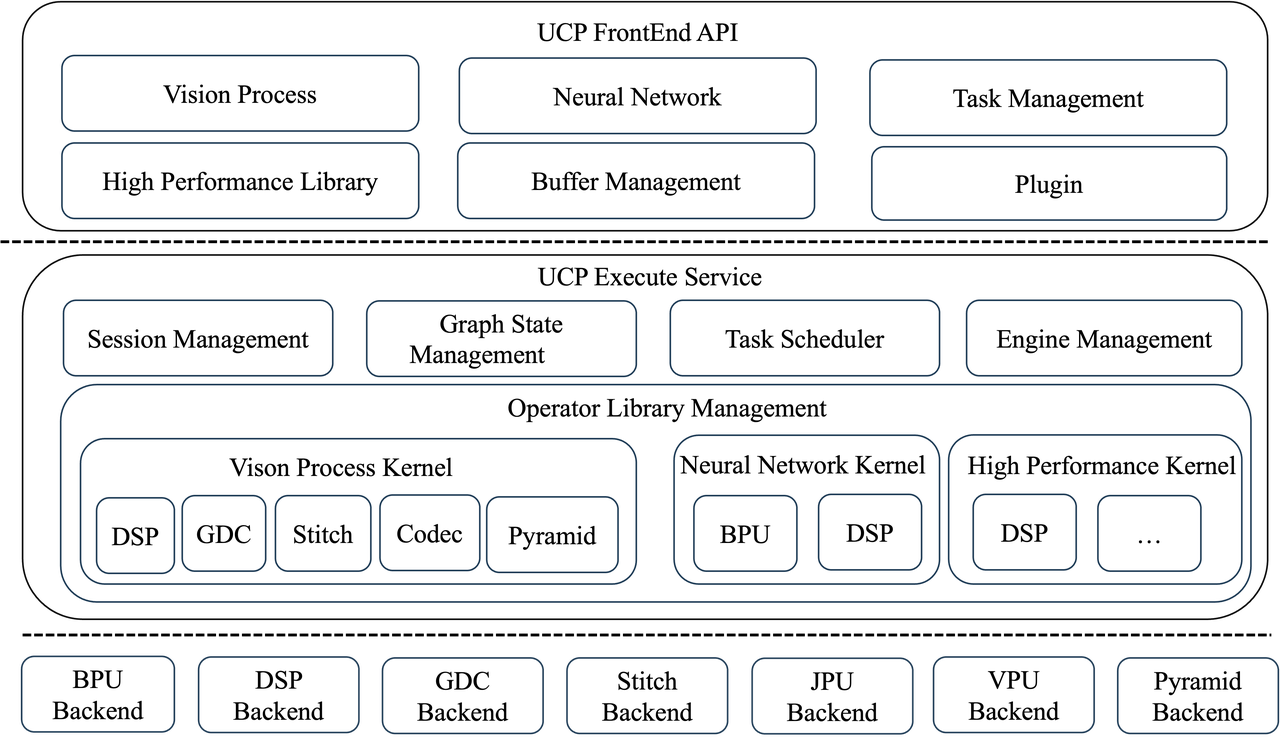
征程 6 工具链在应用部署端新引入了统一计算平台(Unify Compute Platform,以下简称 UCP)。UCP 面向应用层,属于嵌入式应用开发(runtime)范畴,提供视觉处理(Vision Process,以下简称 VP)、模型推理(Neural Network,以下简称 NN)、高性能计算库(High Performance Library,以下简称 HPL)等功能。
UCP 还定义了一套统一的异构编程接口,支持对 SoC 上各后端硬件资源的调用,包括 BPU、DSP、ISP、GDC、STITCH、JPU、VPU、PYRAMID 等,以完成 SoC 上任务的统一调度。
UCP 的架构图如下所示:

3.模型推理
3.1 快速上手
以下面的代码为例,说明 DNN 和 UCP 接口的使用方式,整体包含 5 个主要步骤,详细信息可参考用户手册《统一计算平台-模型推理开发》,《模型部署实践指导-模型部署实践指导实例》,《UCP 通用 API 介绍》等相关章节:

int main(int argc, char **argv) {
... // 解析命令行参数
hbDNNPackedHandle_t packed_dnn_handle;
hbDNNHandle_t dnn_handle;
const char **model_name_list;
auto modelFileName = FLAGS_model_file.c_str();
int model_count = 0;
//1. 加载模型并获取模型名称列表以及Handle
{
hbDNNInitializeFromFiles(&packed_dnn_handle, &modelFileName, 1);
hbDNNGetModelNameList(&model_name_list, &model_count, packed_dnn_handle);
hbDNNGetModelHandle(&dnn_handle, packed_dnn_handle, model_name_list[0]);
}
std::vector<hbDNNTensor> input_tensors;
std::vector<hbDNNTensor> output_tensors;
int input_count = 0;
int output_count = 0;
//2. 根据模型的输入输出准备张量
{
hbDNNGetInputCount(&input_count, dnn_handle);
hbDNNGetOutputCount(&output_count, dnn_handle);
input_tensors.resize(input_count);
output_tensors.resize(output_count);
prepare_tensor(input_tensors.data(), output_tensors.data(), dnn_handle);
}
//3. 准备输入数据并填入到对应的张量中
read_image_2_tensor_as_nv12(FLAGS_image_file, input_tensors.data());
// 确保更新输入后进行Flush操作以确保BPU使用正确的数据
for (int i = 0; i < input_count; i++) {
hbUCPMemFlush(&input_tensors[i].sysMem[0], HB_SYS_MEM_CACHE_CLEAN);
}
//4. 创建任务并进行推理
hbUCPTaskHandle_t task_handle{nullptr};
hbDNNTensor *output = output_tensors.data();
{
hbDNNInferV2(&task_handle, output, input_tensors.data(), dnn_handle);
hbUCPSchedParam ctrl_param;
HB_UCP_INITIALIZE_SCHED_PARAM(&ctrl_param);
ctrl_param.backend = HB_UCP_BPU_CORE_ANY;
hbUCPSubmitTask(task_handle, &ctrl_param);
hbUCPWaitTaskDone(task_handle, 0);
}
//5. 处理输出数据
for (int i = 0; i < output_count; i++) {
hbUCPMemFlush(&output_tensors[i].sysMem[0], HB_SYS_MEM_CACHE_INVALIDATE);
}
//6: 释放资源
{
hbUCPReleaseTask(task_handle);
for (int i = 0; i < input_count; i++) {
hbUCPFree(&(input_tensors[i].sysMem[0]));
}
for (int i = 0; i < output_count; i++) {
hbUCPFree(&(output_tensors[i].sysMem[0]));
}
// 释放模型
hbDNNRelease(packed_dnn_handle);
}
return 0;
}
⚠️ 上面的例子仅为 demo,实际使用时,需要注意以下几点:
- 图像可以直接从 Pyramid 接口直接获取 nv12 的输出,无需进行拷贝,可直接传递给 BPU 进行推理
- 输入输出内存的大小和对齐 stride,详见第 5.3 节说明
- 接口进行返回值检查,以保证函数的正确执行
3.2 实用技巧
3.2.1 添加 desc
有的时候,为了方便自动化作业,需要给不同的模型,输入和输出打上标签以区分他们。
需要注意的是,如果是为输入添加描述信息,由于 pyramid 和 resizer 节点会改变 bc 的输入节点数,因此需要给对应每个节点都添加对应的信息。
比较推荐的做法是在 compile 之前再添加:
from hbdk4.compiler import load
quantized_bc = load("xxx.bc")
func = quantized_bc[0]
func.desc = "xxx model" #模型的描述
func.inputs[0].desc = "xxx input" #模型输入的描述
func.outputs[0].desc = "xxx output" #模型输出的描述
模型部署时,通过下面的接口来获取描述信息:
//模型的描述信息
int32_t hbDNNGetModelDesc(char const **desc, uint32_t *size, int32_t *type,
hbDNNHandle_t dnnHandle);
//输入的描述信息
int32_t hbDNNGetInputDesc(char const **desc, uint32_t *size, int32_t *type,
hbDNNHandle_t dnnHandle, int32_t inputIndex);
//输出的描述信息
int32_t hbDNNGetOutputDesc(char const **desc, uint32_t *size, int32_t *type,
hbDNNHandle_t dnnHandle, int32_t outputIndex);
3.2.2 模型打包
模型打包功能,可以将多个模型打包进一个 hbm 文件中,对于共享任务可以节省模型的空间,具体 api 介绍可见《HBDK Tool API Reference》:
from horizon_plugin_pytorch.quantization.hbdk4 import export
from hbdk4.compiler import load, convert, compile, link
# export 阶段记得配置 name
qat_bcA = export(qat_model_A, example_input, name="backbone_head1_head2")
quantized_modelA = convert(qat_bcA, "nash-m")
# 注意:此时compile生成的模型后缀名为.hbo
hbo_nameA = "nameA_compiled.hbo"
hboA = compile(quantized_modelA, path=hbo_nameA, march="nash-m")
qat_bcB = export(qat_model_B, example_input, name="backbone_head1")
quantized_modelB = convert(qat_bcB, "nash-m")
hbo_nameB = "nameB_compiled.hbo"
hboB = compile(quantized_modelB, path=hbo_nameB, march="nash-m", opt=2)
# link生成打包模型,后缀名为.hbm
hbm_name = "compiled.hbm"
hbm = link([hboA, hboB], hbm_name)
在生成 hbm 文件后,上板运行使用 hrt_model_exec 查看模型可以看到:
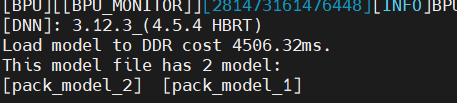
推理测试时,用 model_file 指定 hbm 路径,model_name 指定具体哪一个模型

3.2.3 小模型批处理
由于 BPU 为资源独占型硬件,对于那些耗时较短的小模型,其框架调度耗时开销可能大于其模型运行时间,为了缓解这个问题。在征程 6 平台,UCP 支持通过复用 task_handle 方式来一次将多个模型下发,全部执行完成后再一次性返回,从而将 N 次开销合并为一次:
// 获取模型指针并存储
std::vector<hbDNNHandle_t> model_handles;
// 准备各个模型的输入输出,准备过程省略
std::vector<std::vector<hbDNNTensor>> inputs;
std::vector<std::vector<hbDNNTensor>> outputs;
// 创建任务并进行推理
{
// 创建并添加任务,复用task_handle
hbUCPTaskHandle_t task_handle{nullptr};
for(size_t task_id{0U}; task_id < inputs.size(); task_id++){
hbDNNInferV2(&task_handle, outputs[task_id].data(), inputs[task_id].data(), model_handles[i]);
}
// 提交任务
hbUCPSchedParam sche_param;
HB_UCP_INITIALIZE_SCHED_PARAM(&sche_param);
sche_param.backend = HB_UCP_BPU_CORE_ANY;
hbUCPSubmitTask(task_handle, &sche_param);
// 等待任务完成
hbUCPWaitTaskDone(task_handle, 0);
}
3.2.4 优先级抢占
在征程 6 计算平台上,BPU 硬件本身没有抢占功能,对于一个计算任务其一旦进入 BPU 后,就无法被打断,其他计算任务只能等待当前计算任务完成退出后才能运行。
此时很容易出现 BPU 计算资源被一个大模型任务独占,进而影响其他高优先级模型任务的执行,针对这个问题,工具链采用 cpu 调度的机制来优化 BPU 资源:
- hbm 模型在 BPU 推理表现为一个或多个 function-call,function-call 为 BPU 最小的执行单元。当一个模型的所有 function-call 都执行完成时,这个模型也就执行完成了
- BPU 模型任务抢占粒度设计为 function-all,如果一个模型只有一个 function-call 那么其无法被抢占,如果一个模型有多个 function-call 可能出现这个模型完成部分 function-call 后,BPU 挂起当前模型,然后切换执行其他模型
UCP 支持任务优先级调度和抢占,可通过 hbUCPSchedParam 结构体进行配置:
typedef struct hbUCPSchedParam {int32_t priority;int64_t customId;uint64_t backend;uint32_t deviceId;} hbUCPSchedParam;
- priority:任务优先级,支持[0, 255]之间的数值,对于模型任务而言:
- [0, 253]普通优先级,不可抢占其他任务,但在未执行时支持按优先级进行排队
- 254:为 high 优先级,支持抢占普通任务
- 255:为 urgent 优先级,支持抢占普通任务和 high 任务
- 可被中断抢占的任务,需要在模型编译阶段配置 max_time_per_fc 进行模型拆分
- customId:自定义优先级
- backend:任务硬件 id
- deviceId:设备 ID 比如,有下面的两个模型,一个单线程耗时 20.9 ms,一个单线程耗时 8.3ms:
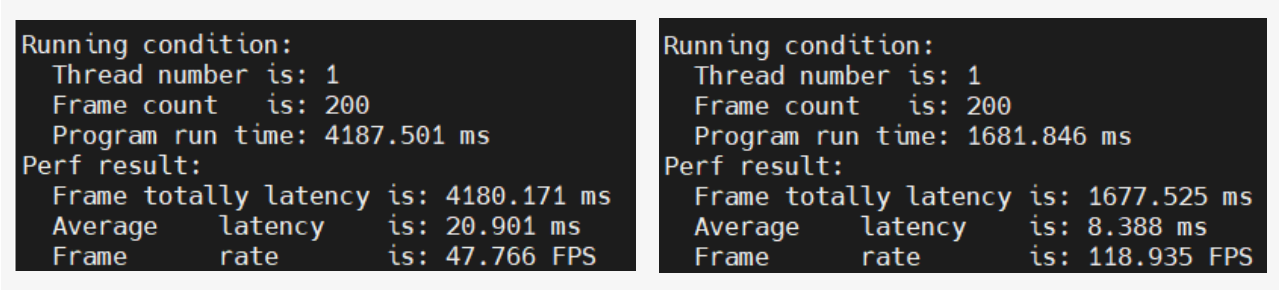
让这两个模型同时运行,且设置 max_time_per_fc=2000,两个模型的优先级均为普通优先级时 UCP trace 耗时如下:

当将模型 2 的优先级设为 high,模型 1 仍为普通优先级时:
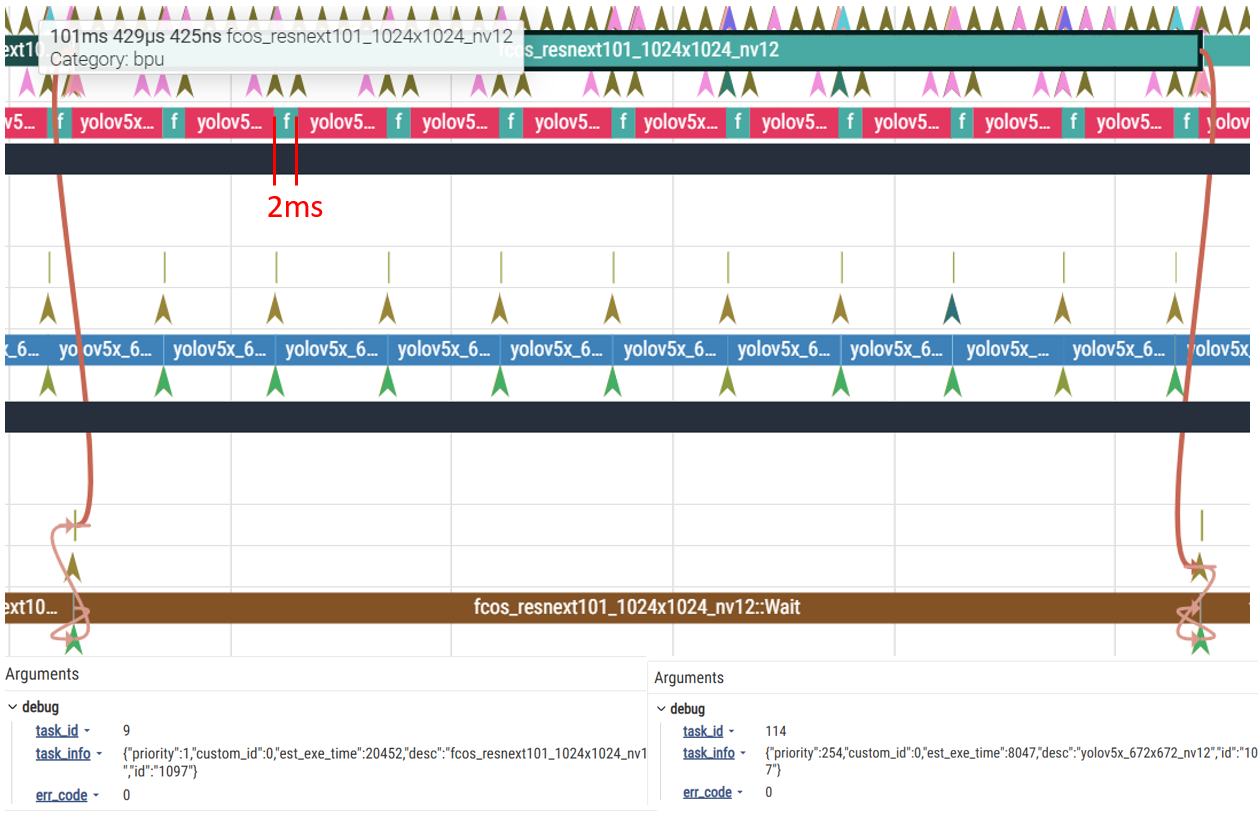
可以看到,在下面的模型一次 infer 过程中,模型被切分为多个 2ms 运行的 function-call 运行,中间插入了很多 high 优先级模型,导致一次模型前向耗时大大增加。
3.2.5 LRU 内存优化
LRU(Least Recently Used)算法是用于优化内存页的调度算法。BPU 内存在 BPU 实际使用前,NN 模块内部需要对该块内存进行特殊处理才能够正常使用,如果频繁对模型及其依赖申请释放会导致 CPU 负载变大,从而可能会引发性能问题。 如果确实有频繁申请释放的需求,推理库提供了内存 LRU 缓存功能,通过设置环境变量 HB_NN_ENABLE_MEM_LRU_CACHE 为 true 来使用。设置方式如下:
export HB_NN_ENABLE_MEM_LRU_CACHE=true
开启了这个功能之后,对模型的输入输出不是实时申请和释放的,会在一开始就申请好并进行循环复用。所以如果用户在模型跑完推理后就立刻执行内存释放操作,实际不会立刻释放,UCP 这一层会等一段时间后才执行(默认至少 1s),所以可能会有内存泄漏的风险,建议是模型推理的内存块不要释放,且模型每次输入输出的虚拟地址是复用的。
3.3 输入输出处理
3.3.1 Crop 裁剪
Crop 主要思想是利用地址偏移,并通过 stride 将图像多余的部分进行屏蔽从而送入准备好的模型输入。这种 Crop 方式不引入 memory copy,减少 IO 开销。
限制:
- 图像输入大小要大于模型实际输入大小,w_stride 要 32(E/M)/64(P/H)字节对齐
- 模型的 validShape 为固定值,stride 为动态值
- 裁剪偏移的输入首地址要 32 对齐
详细示例可以参考《基础示例包使用说明》中 advanced_samples 的 crop 示例
3.3.2 Resizer
Resizer 主要是指具有 nv12 图像输入和 ROI 输入的模型,编译器支持通过 JIT 动态指令的方式,从 nv12 图像上完成抠图 +Resize 功能。其不仅仅是图像 stride 为动态,输入的 H,W 也为动态,w_stride 也同样需要满足 32(E/M)/64(P/H)字节对齐,roi 不需要进行对齐:
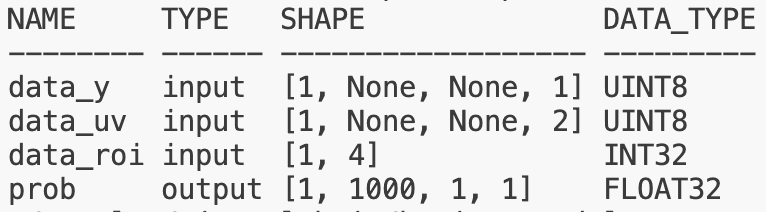
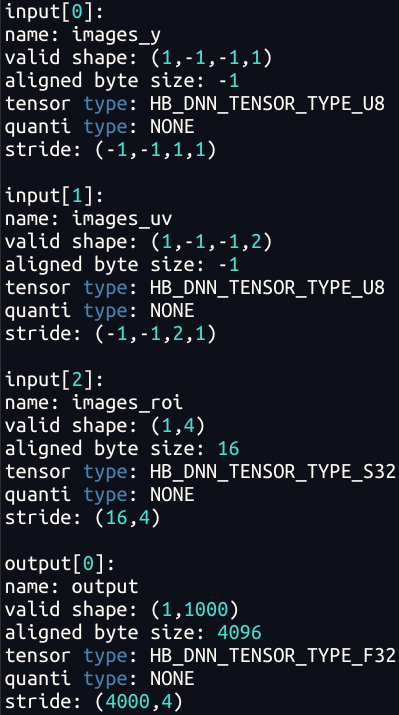
3.3.3 图像 tensor 对齐
在征程 6 芯片,有一块叫 Pyramid 的金字塔硬件处理模块,可提供 Camera 输入图像的缩放及 ROI 抠图能力,其输出为 nv12 类型的图像数据,并可基于共享内存机制直接给到 BPU 进行模型推理,因此在征程 6 工具链中:
- Pyramid 模型是指具有 nv12 图像输入的模型
- Resizer 模型指的是具有 nv12 图像输入和 ROI 输入的模型,编译器支持通过 JIT 动态指令的方式,从 nv12 图像上完成 ROI 抠图 +Resize 功能 征程 6P/H 要求 nv12 stride 满足 64 对齐,征程 6E/M/B 是 32 对齐。 Pyramid 的输入 stride 为动态,比如模型输入为 224x224 的 nv12 图像,其格式为:
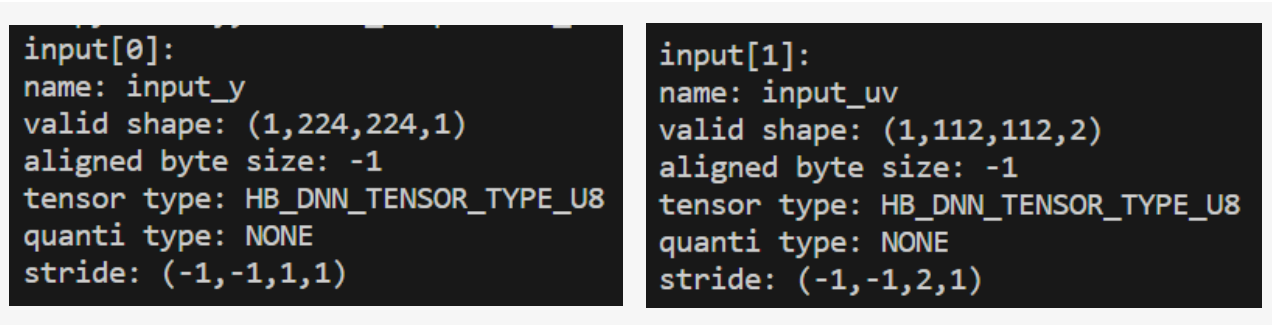
其中,-1 为占位符,表示为动态,Pyramid 输入的 stride 为动态。那么此时我们就需要通过手动计算方式来获取了:
#define ALIGN_SIZE(size,align_byte) (((size)+(align_byte-1))&~(align_byte-1))
HBDNNTensor* input;
auto dim_len = input[i].properties.validShape.numDimensions;
for(int dim_i = dim_len-1;dim_i>=0;dim_i--){
if(input[i].properties.stride[dim_i]==-1){
auto cur_stride = input[i].properties.stride[dim_i+1] *
input[i].properties.validShape.dimensionSize[dim_i+1];
input[i].properties.stride[dim_i] = ALIGN_SIZE(cur_stride,NUM);
}
}
int input_memSize = input[i].properties.stride[0] * input[i].properties.validShape.dimensinoSize[0];
对于非 nv12 类型的其他输入,以 rgb 输入 input 作为例子,1x224x224x3 的 rgb 图像如下所示:
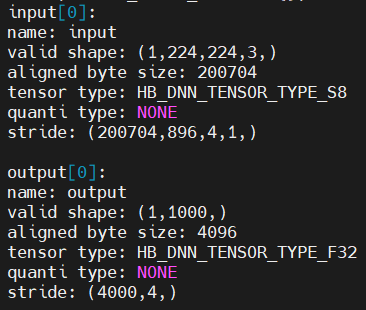
输入申请的大小可以通过 aligned byte size 来获取:
int input_memSize = input[i].properties.alignedByteSize;
3.3.4 内存单元对齐
BPU 中的内存单元也是遵循向量化对齐的原则,类似于 avx/neon 等,需要内存对齐。所以对于不满足对齐最小字节的内存要被强制对齐到最小的内存字节上。
征程 6H/P tensor 最小申请内存是 256 字节,征程 6E/M 是 64 字节,征程 6B 是 128 字节,这个差异会体现在模型的 aligned byte size 和 stride 属性上。
举个例子:
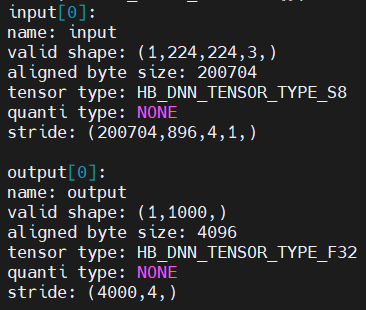
上面模型的 stride=4000,output 需要申请的内存为 4000Byte,但由于内存需要对齐,所以实际上的需要申请的内存大小为((4000+(256-1))&~(256-1))=4096Byte。 在模型实际部署中,非图像输入/输出节点所需申请的内存大小均可以从模型节点属性的结构体中读取到,因此无需特别关注:
hbDNNTensor* output;
int output_memSize = output[i].properties.alignedByteSize;
3.3.5 padding
由于内存单元对齐的影响,feature 申请的大小和拷贝需要根据 stride 和 alignedByteSize 来进行。用户侧需要手动处理这些 padding,可能对前处理和后处理的代码有较大的变动。这里地平线提供了一种优化方案:input_no_padding/ouput_no_padding,在开启这两个选项后,可以直接将输入/出实际大小的内存送入接口,接口内部会自行处理对齐,无需用户侧修改代码。但开启这个参数后,可能会对模型延时产生微小影响。
- input_no_padding:对所有非图像的输入去 padding
- output_no_padding:对模型所有的输出去 padding 若编译时配置了 input_no_padding=True,output_no_padding=True,无需关注非图像的对齐问题:
#PTQ配置方式,在yml中
compiler_parameters:
extra_params: {"input_no_padding": True, "output_no_padding": True}
#QAT配置方式
from hbdk4.compiler import compile
compile(quantized_bc,march,path,input_no_padding=True,output_no_padding=True)
举个例子,比如一个模型的输出 shape 为 1x21x21x255,其 output_no_padding=False 和 output_no_padding=True 的结果如下图所示:
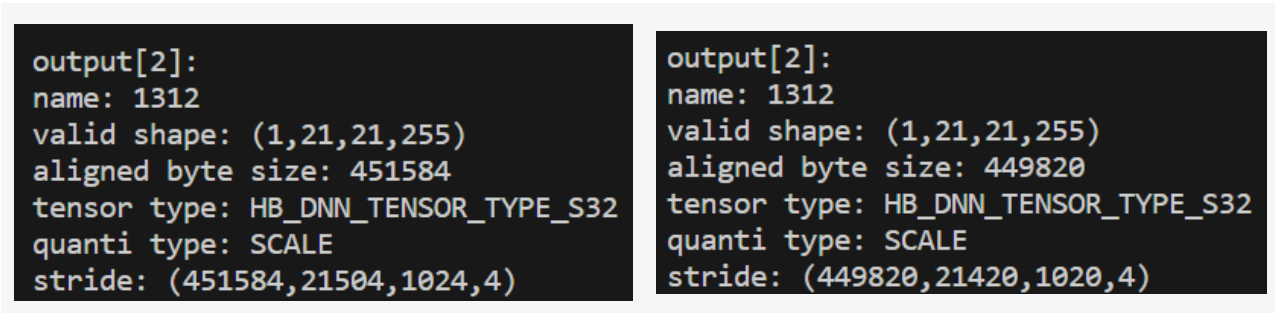
4.性能分析
4.1 模型性能分析
如果开发者没有实体板子,只有 hbm 模型,可以使用 hbdk4 中的 hbm_perf 接口获取静态性能评估文件(html,json 格式)以及模型耗时:
from hbdk4.compiler import hbm_perf
hbm_perf(xxx.hbm)
模型中如果有 CPU 算子,则会影响 perf 的结果,建议去除 CPU 算子之后再进行分析。CPU 算子一般可以通过以下两种方式查看到:
- convert 之后的模型可视化,然后查询是否有 hbtl 类型算子
- 利用 statistics 接口统计 bc 模型算子类型
如果有与开发环境直连的板子可以使用下面的方式进行测试,与实测偏差会更小:
from hbdk4.compiler import hbm_perf
hbm_perf(xxx.hbm,remote_ip="xxx")
或按照用户手册《统一计算平台-模型推理工具介绍》使用 hrt_model_exec 工具在板端进行性能测试:
hrt_model_exec perf --model_file=xxx.hbm --frame_count=200
4.1.1 带宽占用
静态评测时,带宽信息可以从模型编译过程中生成的 xxx.html/xxx.json 中文件获取,在 ptq 中会自动生成这两个文件,在 qat 中,可以通过生成 hbm 模型后,使用 hbm_perf 接口来生成这两个文件。
平均带宽
平均带宽(GB/s) = DDR bytes per second( for n FPS)/n * 设计帧率/2^30,以下面的模型为例,实际需求帧率为 30FPS,那么该模型所需的平均带宽为:12293553099/57.12 * 30/2^30 = 6.01GB/s:

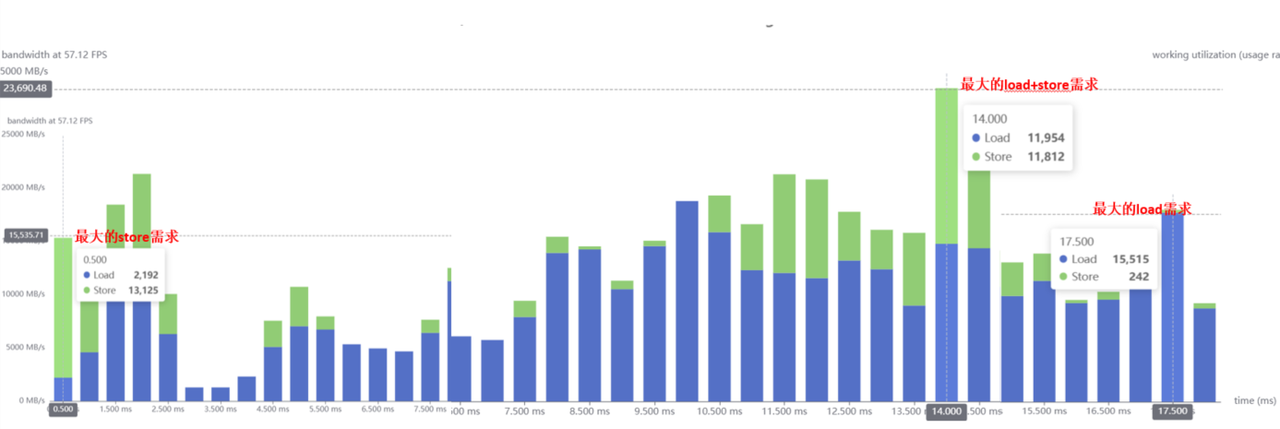
峰值带宽
峰值带宽可以通过推理带宽柱状图来进行分析,最高的柱子即最大的 load/strore 带宽。比如下面这个图,该模型的最大 load 需求为 15515MB/s=15.15GB/s,最大的 store 需求为 13125MB/s=12.82GB/s,最大的 load+store 需求为 11954+11812=23766MB/s=23.21GB/s
4.1.2 带宽优化
在实际应用中,模型的推理耗时可能出现比正常评测要更长的现象,主要原因往往来源于 BPU 的等待耗时以及带宽资源不足的影响。这里主要针对带宽问题进行说明。
BPU 模型的带宽消耗主要集中在模型加载、推理时的 featuremap 读写,输出写回,优化策略如下:
- 使用 balance 参数来平衡带宽和延时
compile(balance=x) # 0=优先ddr优化,100=优先延迟优化,默认balance=100,推荐balance=2
ptq 时,修改配置文件中的 compile_mode:
compile_mode: 'balance'
balance_factor: 2
- 对于小模型使用多 batch 推理模式,可以减少 weight 的加载次数
- 减少模型抢占调用:优先级 255 的抢占任务会刷新整个 SRAM,导致大量带宽开销,建议通过任务编排方式运行模型,而不是优先级抢占
- Batch 拆分:若模型需要 concat 多路输入(比如 BEV 类模型),将 batch mode 拆分,每一路单独提取特征,牺牲很少的延时来降低峰值带宽
4.1.3 内存占用
模型所需的内存可以通过 Summary 查看到:
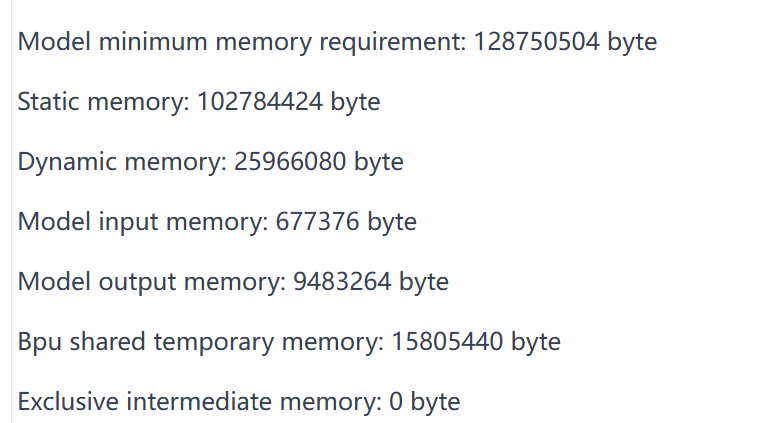

Shared temporary memory 共享临时内存,主要目的是用于相同优先级模型共享内存,优化模型推理内存的使用。对于相同优先级的模型,会共享 temporary memory。该功能的约束条件:
- 跨 BPU Core 不可用
- 跨优先级不可用,0-253 的优先级之间的都可以共享,254 只能和其他 254 共享,255 只能与其他 255 共享
- 跨进程不可用
当开发人员对模型运行时所需内存进行评测时,可先通过 Summary 的内容先进行静态数据评估,模型的内存占用=Static Memory + Dynamic Memory。
4.2 动态性能分析
在模型的部署和运行过程中,我们比较关注模型的推理耗时,bpu/cpu 占用,DDR 读写带宽以及内存占用。这些信息可以通过以下工具来获取:
4.2.1 hrt_model_exec
hrt_model_exec 是一个模型执行工具,可直接用于在开发板上评测模型的推理性能,获取模型信息。工具源码路径在 samples/ucp_tutorial/tools/hrt_model_exec。
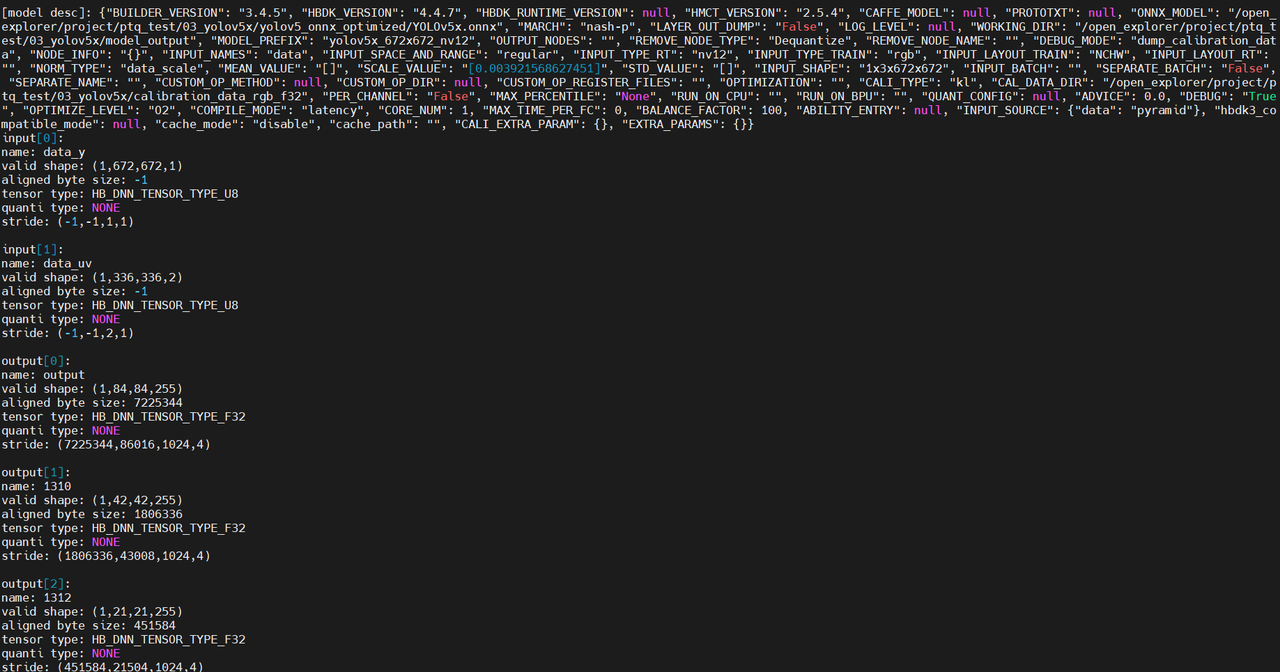
模型输入输出信息:
hrt_model_exec model_info --model_file xxx.hbm
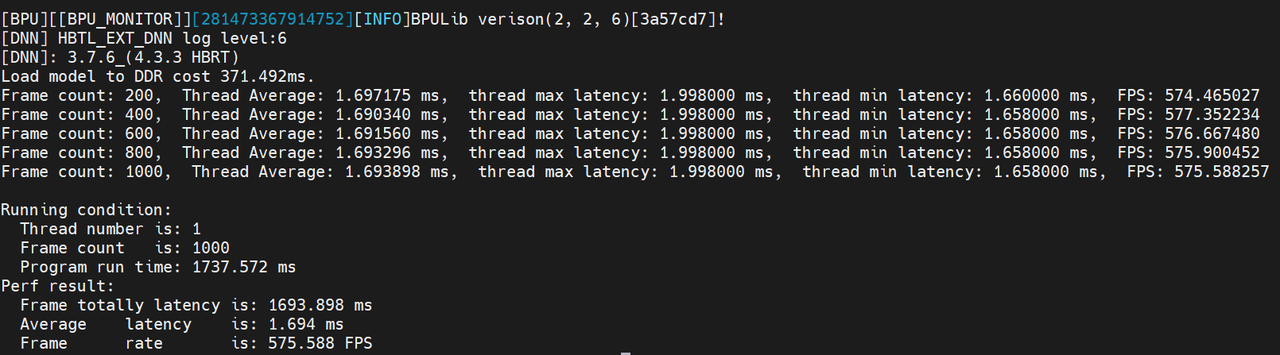
模型单线程耗时:
hrt_model_exec perf --model_file xxx.hbm --frame_count 1000 --thread_num 1
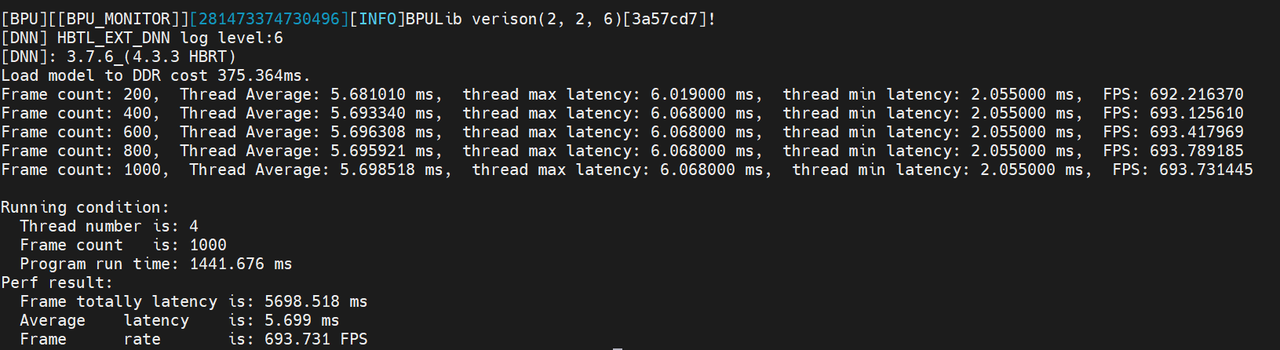
模型多线程耗时:
hrt_model_exec perf --model_file xxx.hbm --frame_count 1000 --thread_num 4
指定优先级运行:
hrt_model_exec perf --model_file xxx.hbm --frame_count 1000 --thread_num 1 --task_priority 1
更多的 hrt_model_exec 命令可以在《统一计算平台-模型推理工具介绍-hrt_model_exec》中查看。
4.2.1.1 单线程和多线程差异
在单线程下,工具按照单核单线程的串行逻辑运行,统计的性能可以理解为单帧处理的平均时间(包括调度开销,BPU 执行时间以及 CPU 执行时间)。
在多线程下,工具会启动多个线程进行模型推理,统计得到的 FPS 表示充分使用资源情况下模型的吞吐量,主要用于评测高并发情况下的模型处理能力。
- 为什么单线程模型运行耗时比多线程耗时短? 答:由于 BPU 本身是一种独占硬件,同一时间只能运行一个任务,多个线程同时提交任务时,只能按一定顺序执行,因此多线程模式下,模型的 Latency 耗时的增大,主要来源于任务下发后的等待时间。
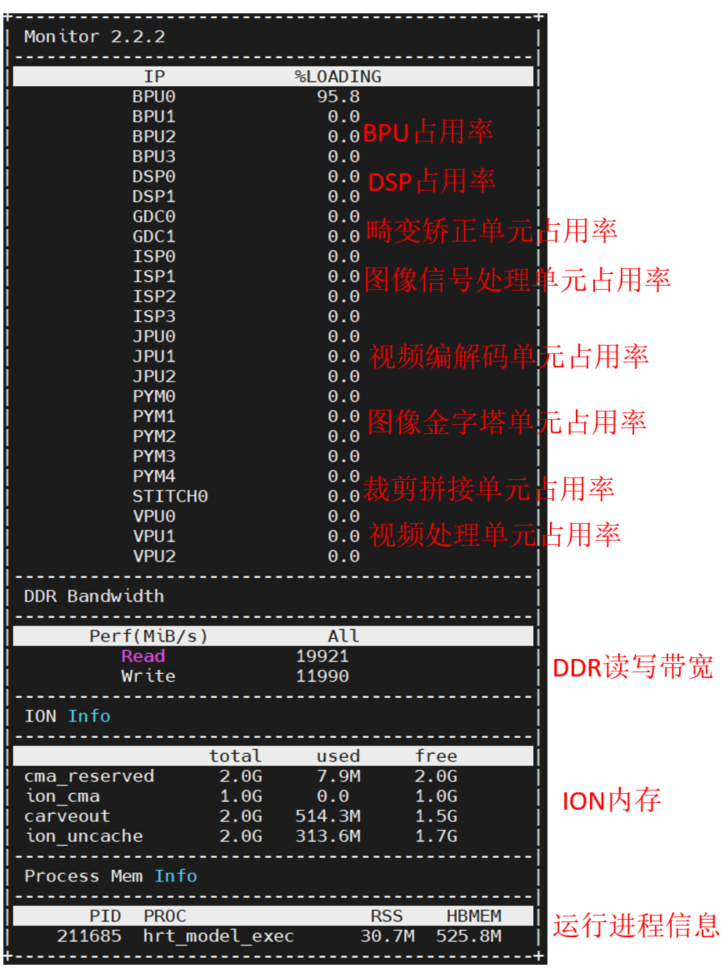
4.2.2 hrt_ucp_monitor
工具 hrt_ucp_monitor 是一个关于监控硬件 IP 占用率和内存信息的工具。hrt_ucp_monitor 工具位于 samples/ucp_tutorial/tools 中。 hrt_ucp_moitor 支持的内存信息包括 DDR 读写带宽,ION 内存,进程内存,默认为每秒采样 500 次,详细的运行参数请参考《统一计算平台-UCP 性能分析工具》。在终端运行命令 hrt_ucp_monitor 即可看到对应的监控信息:
rss 查看可以通过以下命令查看:
ps -aux //RSS指标
top //RES指标


HBMEM 为应用进程申请的总 ION 大小:
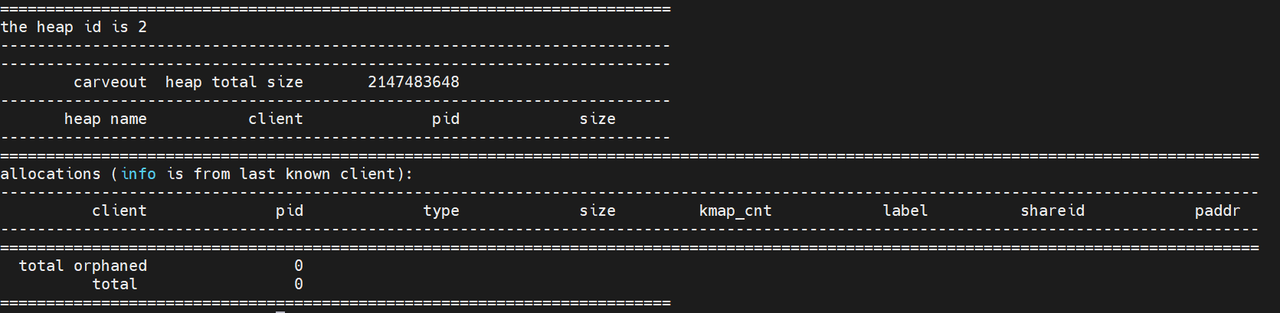
ION:ION 是为了解决内存碎片化而引入的通用内存管理器,一共有三种:ion(上面的 ion_cam),reserve(上面的 cma_reserved)和 carveout(上面的 carveout)。ion 是主要类型,用于一般的内存分配。reserve 本质上也是 carveout,区分的主要目的是 DDR 支持多个 bank。对于 BPU 模型来说,其优先在 carveout 上分配内存。可以通过观察 /sys/kernel/debug/ion/heaps/carveout 来测试内存占用:
上图为未加载时,carveout 的状态
!
模型加载后,carveout 的状态
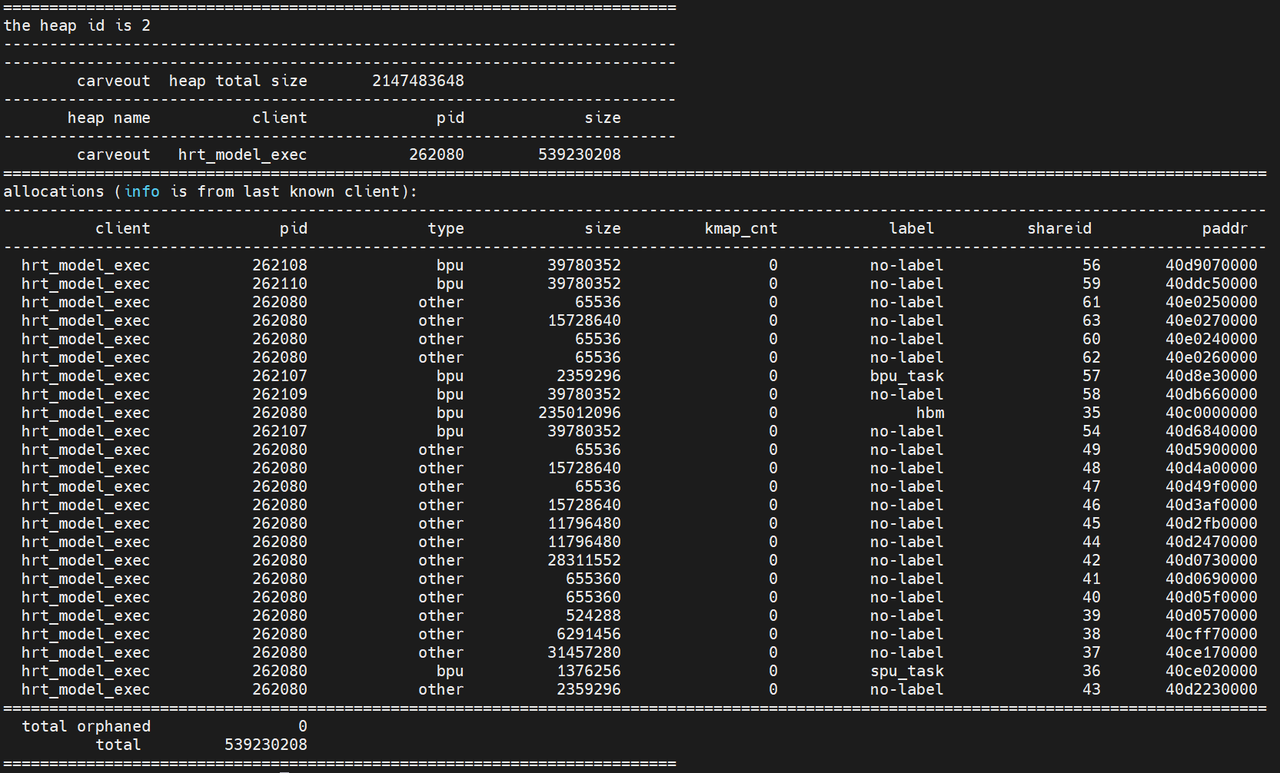
4.2.3 hrut_ddr
带宽占用主要使用 hrut_ddr 来进行分析:
Usage: hrut_ddr [OPTION]...
Show and calculate memory throughput through AIX bus in each period.
Mandatory arguments to long options are mandatory for short options too.
-t, --type The type of monitoring range. Supported
values for type are(case-insensitive)
when multiple type specified, Enclose in quotation marks
e.g. -t "mcu cpu"
If the types exceeds 1, a RoundRobin method is used.
For accuracy, set as less types as possible
e.g. In the first period the mcu data is read, second period the cpu data is read.
The elapsed time get averaged, and each type result in one round put into one table
slc vdo cam cpe0 cpe1 cpe2 cpe3 cpelite
idu gpu vdsp peri his sram bpu_p0 bpu_p1
bpu_p2 mcu cpu secland
cpu only monitor the throughput of CPU master range
bpu only monitor the throughput of BPU master range
cam only monitor the throughput of Camera master range
J6P Note: cam contains cpe, cpelite, idu. bpu id range: bpu_p0, bpu_p1(only in vm), bpu_p2(only in vm)
rr_all RoundRobin between all range types
-p, --period The sample period for monitored range. (unit: us, default: 1000, range:[1000, 2000000])
-d, --device The char device of DDR Perf Monitor. [0~5] 0: ddrsys0 mon0, 2 ddrsys1_mon0
J6P: [0~15]
-n, --number The sampling period times for monitored range before copying to userspace. (0~400] default: 100
!!!When in roundrobin mode, this is forcely set to 1
-N, --over_all Over_all read times. i.e. Approximately how much tables you get in commands line
-f, --filename the csv output filename
-r, --raw Output raw data, hexadecimal format, without conversion. Decimal by default
-c, --csv Output csv format data
-D, --dissh Disable shell output
Example:
hrut_ddr -t cpu -p 1000 -d 0
hrut_ddr -t cpu -p 1000 -r
hrut_ddr -t cpu -p 1000
hrut_ddr -t "cpu mcu" -p 1000 -c -f "mon0.csv"
hrut_ddr -d "0 1" -p 1000
根据 hrut_ddr 工具的 log,获取 BPU 带宽占用和系统带宽占用,Read+Write 的值即为总带宽:
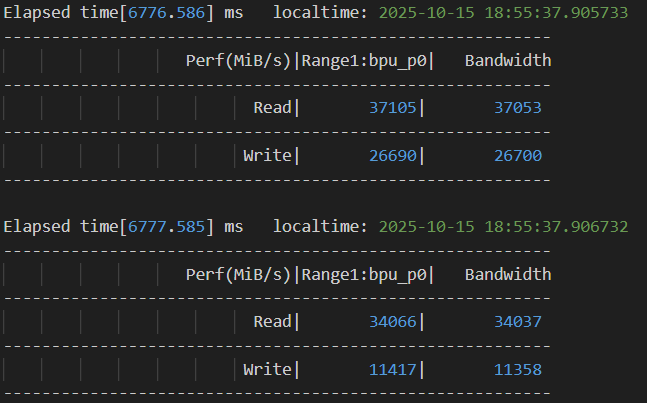
4.3 问题
在实际的运行中,可能会出现与上面带宽评测结果差距较大的情况。这是由于在实际中不仅仅是模型的运行需要带宽,cam 和 cpu 也是需要带宽的。根据过往的经验,可以根据峰值带宽和均值带宽来提前判断是否存在风险,高于理论带宽的 75% 以上,就需要进行测试验证了。
5.推理典型问题处理
5.1 timeout 问题
5.1.1 模型 timeout 时间是否设置合理
如果模型是异步推理的,模型本身执行的时间较长,而异步等待接口设置的超时时间不足也可能造成 timeout。
hbUCPWaitTaskDone(hbUCPTaskHandle_t taskHandle, int32_t timeout);
timeout 的耗时可以设置为模型正常推理时间的一倍即可。
5.1.2 CPU 负载是否过高
由于模型的运行调度是由 CPU 来处理的,如果调度线程一直获取不到时间片,即使任务完成也无法及时同步到用户接口,导致推理延时。
在运行过程中,可以使用 top/htop 等监视 CPU 利用率,如果 CPU 负载超过 90%,可能出现系统异常,这个必须得到解决
5.1.3 内存泄漏
当存在内存泄漏时,在系统内存不足的情况下,内存申请缓慢,可能会导致推理超时。可以在编译时添加检测:
target_compile_options(testbed PRIVATE -fsanitize=address)
target_link_options(testbed PRIVATE -fsanitize=address)
或在单元测试时,利用 getpid()获取当前进程的 pid,再查看/proc/pid/status 中的 VmRSS。
5.2 推理 hang
模型指令原因导致的底层运行错误,错误没有上报,导致 hang 住。此时,可通过 cat/sys/devices/system/bpu/bpu0/task_running 对 bpu 任务情况进行查看,如下图所示: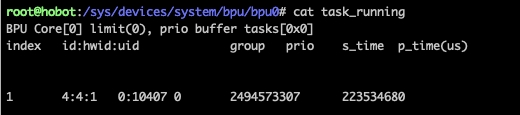
s_time 不为空表示任务已经正常开始,而 p_time 一直增加没有减少,即可认为 BPU 任务 hang 住了, 可以使用 watch 命令来记录 bpu 任务情况:
watch -n 2 'cat /sys/devices/system/bpu/bpu0/task_running|tee -a bpu.log'
如果发生此类问题,可以提供 bpu log 给地平线技术支持人员分析,log 的地址在:/log/bpux/message 中。
5.3 log 获取
在遇到上面的问题的时候,我们可以通过分析日志来获取问题原因,需要的是 UCP 日志以及系统日志:
5.3.1 UCP 日志
在程序运行时可以看到各种 log 的等级:
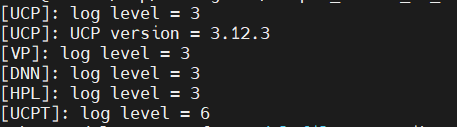
在发生上面的问题后,为了获取具体的问题原因,可以修改 log 等级来抓取不同等级的日志,配置方式如下:
UCP log 设置主要通过以下环境变量:
- HB_UCP_LOG_LEVEL:ucp 模块 log 等级(等级从 0 到 6,分别为 trace, debug, info, warn, error, critical, never, 默认为 warn)
- HB_NN_LOG_LEVEL:nn 模块 log 等级
- HB_UCP_LOG_PATH: ucp 日志存储路径
export HB_UCP_LOG_LEVEL=3
export HB_UCP_LOG_PATH=xxx
更详细的环境变量和说明可以参考《统一计算平台-UCP 通用 API 介绍-环境变量》
5.3.2 系统日志
系统日志获取:
dmesg:在 Linux 系统中用于显示或控制内核环形缓冲区的内容更,允许查看或操作内核消息。
dmesg >dmesg.log
logcat:可以用于打印设备的系统日志
logcat >logcat.log
6.UCP Trace 使用
征程 6 算法工具链提供了一套板端实测性能工具 UCP Trace,通过在 UCP 执行的关键路径上嵌入 trace 记录,进而深入分析 UCP 应用调度逻辑,具体可以参考《统一计算平台-UCP 性能分析工具》一节。 UCP Tracer 记录点:UCP 记录点包括任务 trace 记录点和算子 trace 记录点
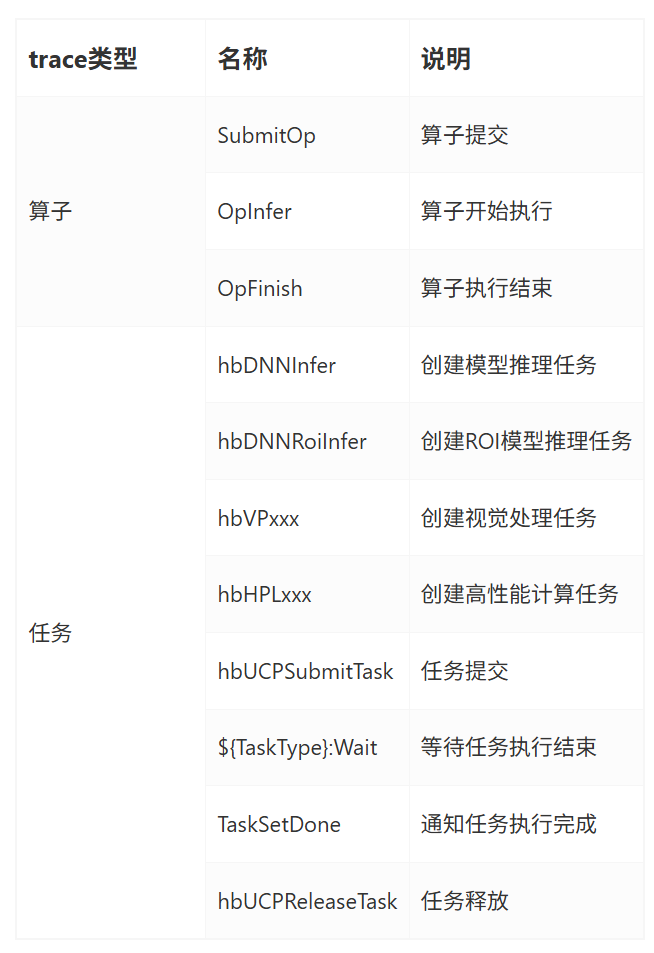
6.1 in_process 模式
6.1.1 运行实例
in_process 模式下只能抓取 UCP 进程内的 trace,无需启动 prefetto 的后台进程
启动步骤:
export HB_UCP_PERFETTO_CONFIG_PATH=ucp_in_process.json
export HB_UCP_ENABLE_PERFETTO=true
- ucp_in_process.json
{
"backend": "in_process", #backend可选
"trace_config": "ucp_in_process.cfg" #perfetto的配置文件路径,仅在in_process下有效
}
- ucp_in_process.cfg
# Enable periodic flushing of the trace buffer into the output file.
write_into_file: true
# Output file path
output_path: "ucp.pftrace" #保存trace文件的路径
# Sampling duration: 10s
duration_ms: 10000 #0表示持续抓取
# Writes the userspace buffer into the file every 2.5 seconds.
file_write_period_ms: 2500 #控制buffer写文件,不是覆盖,相当于控制罗盘,一般不需要特殊指定
buffers {
# buffer size
size_kb: 65535 #如果出现数据丢失可设置大一些
# DISCARD: no new sampling data will be stored when the storage is full.
# RING_BUFFER: old sampling data will be discarded and new data will be stored when the storage is full.
fill_policy: RING_BUFFER
}
# UCP data source
data_sources: {
config {
name: "track_event"
track_event_config {
enabled_categories: "dnn"
}
}
}
在该目录下会生成 trace 文件:文件名为 output_path 中配置的文件名:

1.Perfetto 不支持自动覆盖,如果设置路径中有之前的 ptrace 文件会报错
2.ucp_in_process.json 中指定的文件路径是相对路径,需要配置文件和脚本放在同一个路径下

6.1.2 结果解析
生成的 ucp.pftrace 就是我们要分析的文件,使用 Perfetto UI 打开:
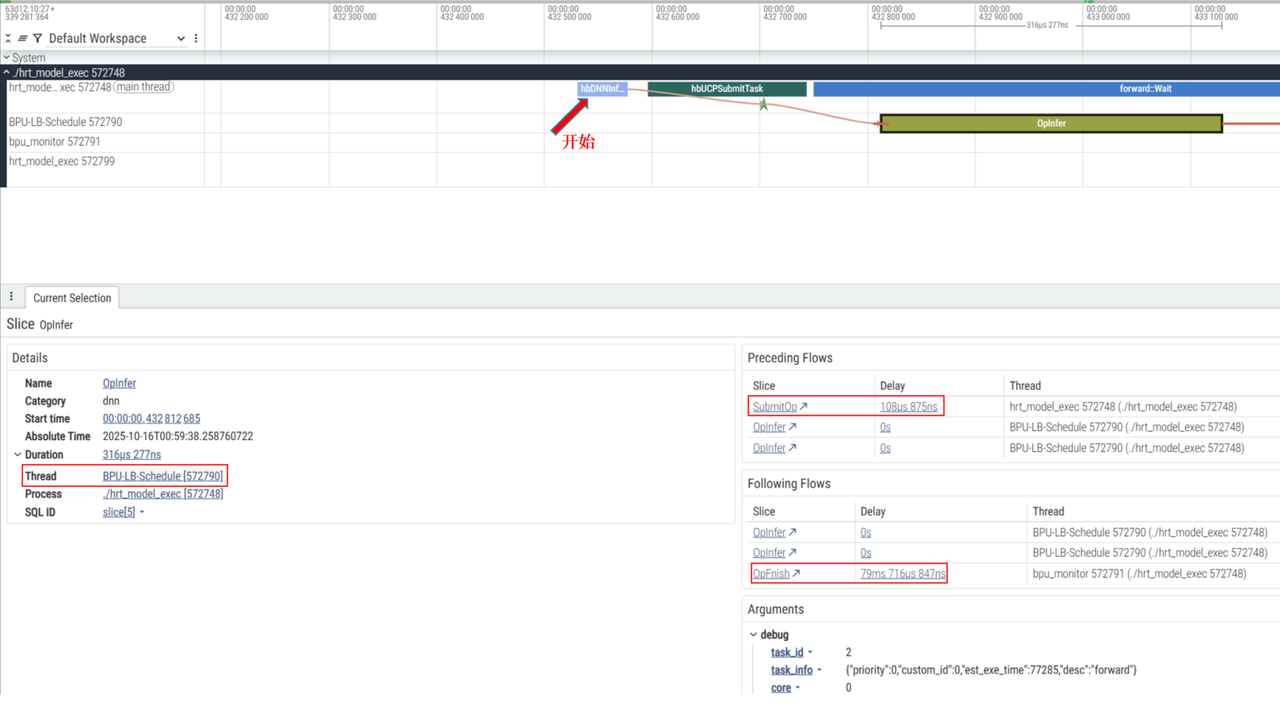
选择生成的 ucp.pftrace 文件,选中一个带有 forward::Wait 字样的一块,如下图所示:
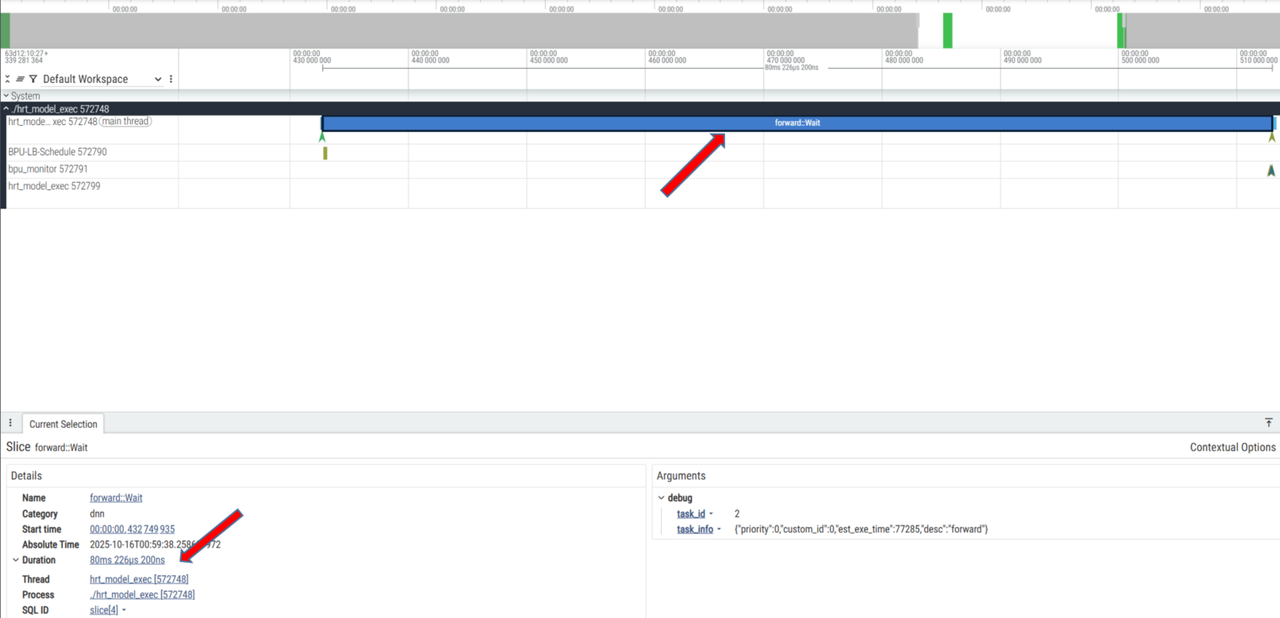
可以看到等待部分耗时大约为 80.xms,也可以看到线程和进程的信息(Wait 部分)
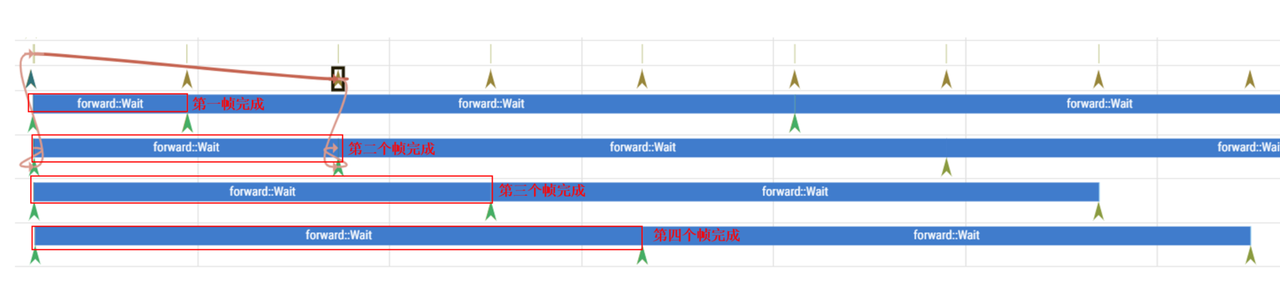
- 单线程 + 多帧
hrt_model_exec perf --model_file xxx.hbm --frame_count 4

- 多线程 + 多帧
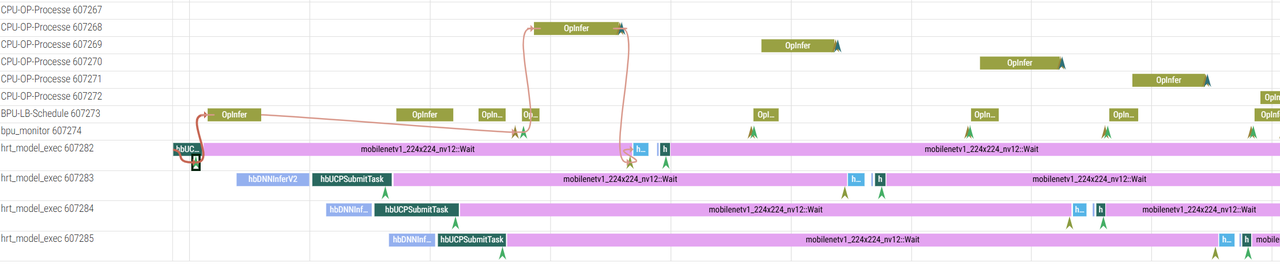
hrt_model_exec perf --model_file xxx.hbm --frame_count 10 --thread_num 4
如何分析:
- 查看 UCP 内部调度是否正常例如哪块耗时明显高于预期
- 观察 BPU 是否持续在使用:例如两个 BPU Opfinish 之间的耗时是否符合预期,继而判断任务编排是否合理,任务下发是否及时
- 多线程 + 多帧 +CPU 结果
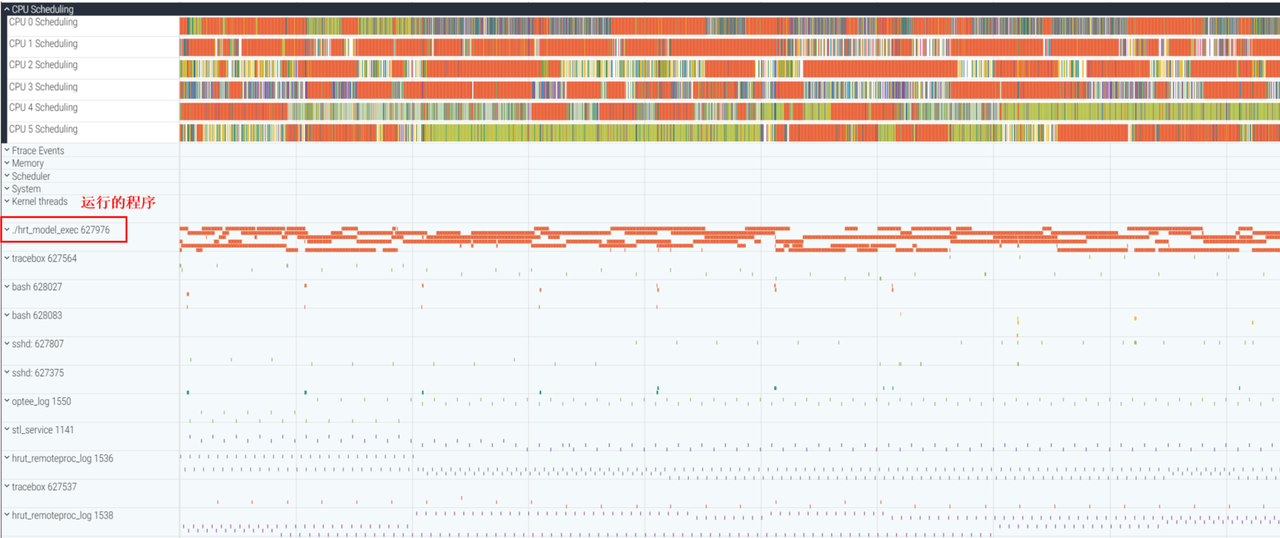
6.2 system 模式
在 system 模式下,UCP trace 只是其中一个数据源,因此需要运行 Perfetto 的后台进程来完成 trace 捕获。
- 运行 Perfetto 后台进程
tracebox traced --background
tracebox traced_probes --background --reset-ftrace
tracebox perfetto -c ucp_system.cfg -o ucp.pftrace
请注意,为了能够获取完整的数据,需要确保 hrt_model_exec 执行结束前,perfetto 进程未退出。可以适当增加 ucp_system.cfg 中的 duration_ms,当前默认为 10000ms
- 开启一个新终端,设置环境变量和运行程序
export HB_UCP_PERFETTO_CONFIG_PATH=ucp_system.json
export HB_UCP_ENABLE_PERFETTO=true
- 运行程序,比如运行 hrt_model_exec 命令,并将获取到的 ucp.pftrace 解析:
7.视觉处理/高性能算子
UCP 提供了视觉处理和高性能算子两大方向的多种接口:
- 视觉处理主要针对视频编/解码,光流,AVM 拼接等常规视觉算法
- 高性能算子依赖于 DSP 的实现,主要用于 fft 和 ifft 的加速 更多信息可以参考用户手册《统一计算平台》的相关章节。
8.DSP 使用
征程 6 的 dsp 使用了 Cadence 的 Tensilica Vision Q8 DSP IP(征程 6B 为 Vision 130)。支持 int8/int16/int32/float32/double 的浮点计算。 当前 DSP 可以用于加速模型前后处理比如点云体素化,模型量化反量化等操作,模型中间的算子加速暂不支持。更详细的说明,请参照《[DSP 算子开发](https
