

为什么现在越来越多的后端,开始学习向量数据库和 RAG,因为你不学,就意味着你的价值正在消失,正在被淘汰😄。

RAG 是什么?
RAG(检索增强生成,Retrieval-Augmented Generation)是一种结合检索与生成的 AI 架构模式,先从外部知识库检索相关信息,然后把这些信息作为上下文再由大语言模型生成答案,从而显著提高回答的准确性、实时性和相关性。
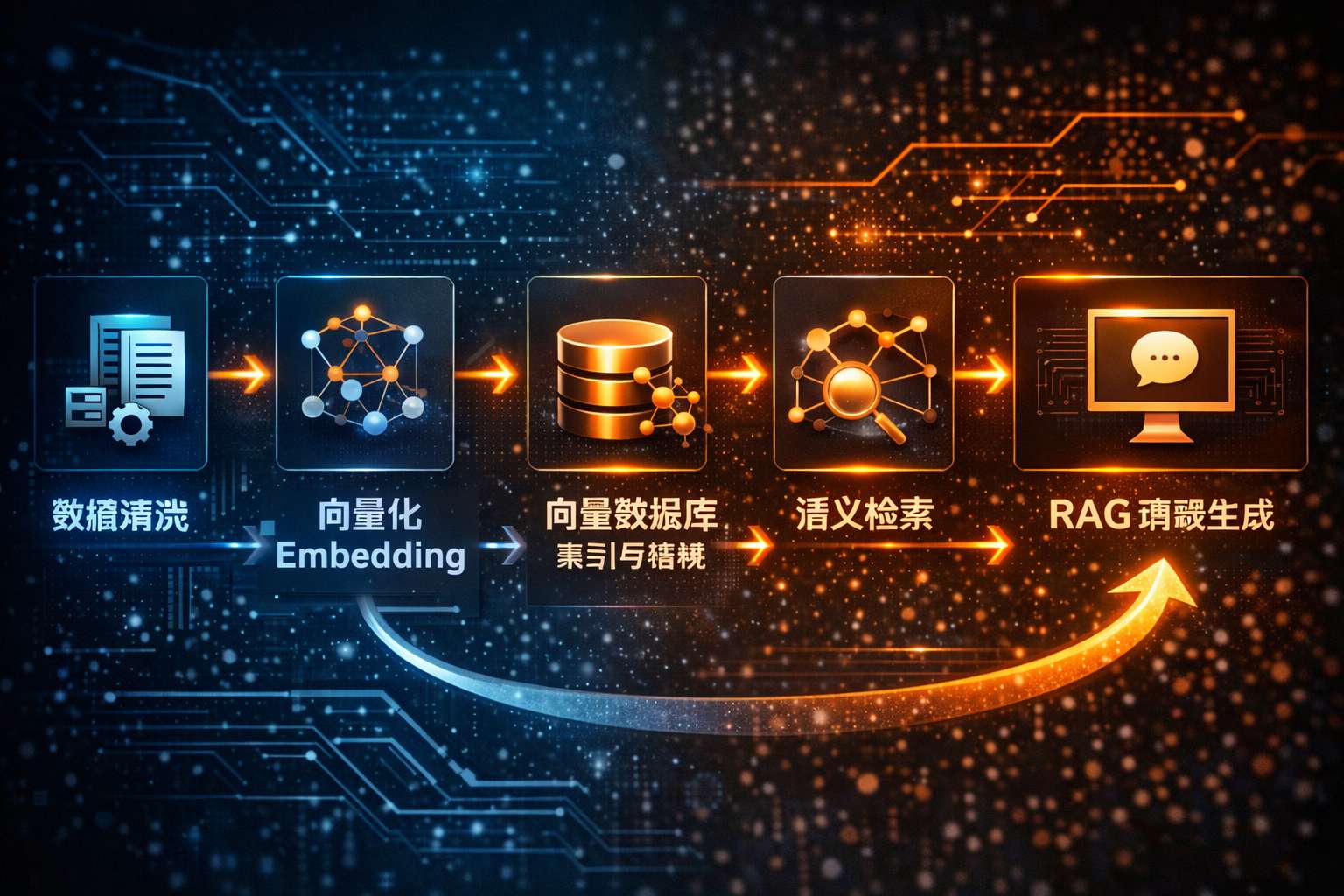
RAG 的工作流程大致分为三个核心步骤:
-
从数据源中提取信息并向量化
-
使用向量数据库进行语义检索
-
把检索到的信息注入模型进行生成
这让 RAG 的回答既“有依据”又比普通大模型响应更稳定、更可信。
向量数据库:RAG 的真正引擎
所谓向量数据库,是一种专门存储和检索高维 语义向量 的数据库。它通过向量搜索(semantic search)来判断文本之间的语义相似度,而不是传统的关键词匹配。
向量数据库对 RAG 至关重要,因为它负责:
-
存储模型生成的向量(Embedding)
-
对海量语义向量进行高效检索
-
支持元数据过滤、扩容和高并发查询
没有向量数据库,RAG 的“检索”这一核心步骤就无法高效实现。
RAG 工程链路:向量化 → 向量数据库 → 检索 → 生成
为什么越来越多后端开始学它?
1. RAG 不只是“AI 玩法”,而是工程架构
很多团队最初认为 AI 只是“Prompt + 模型”就足够。但在真实的工程环境中,仅凭模型无法解决以下问题:
-
模型输出不稳定或错误
-
私有业务数据无法直接接入
-
权限控制与审计难以实现
RAG 通过引入检索步骤,把语义相关内容送入生成链路,使答案更准确、可控、可审计。
同时,RAG 允许系统利用私有数据而不需要再训练原始模型本身,这对于企业应用至关重要。
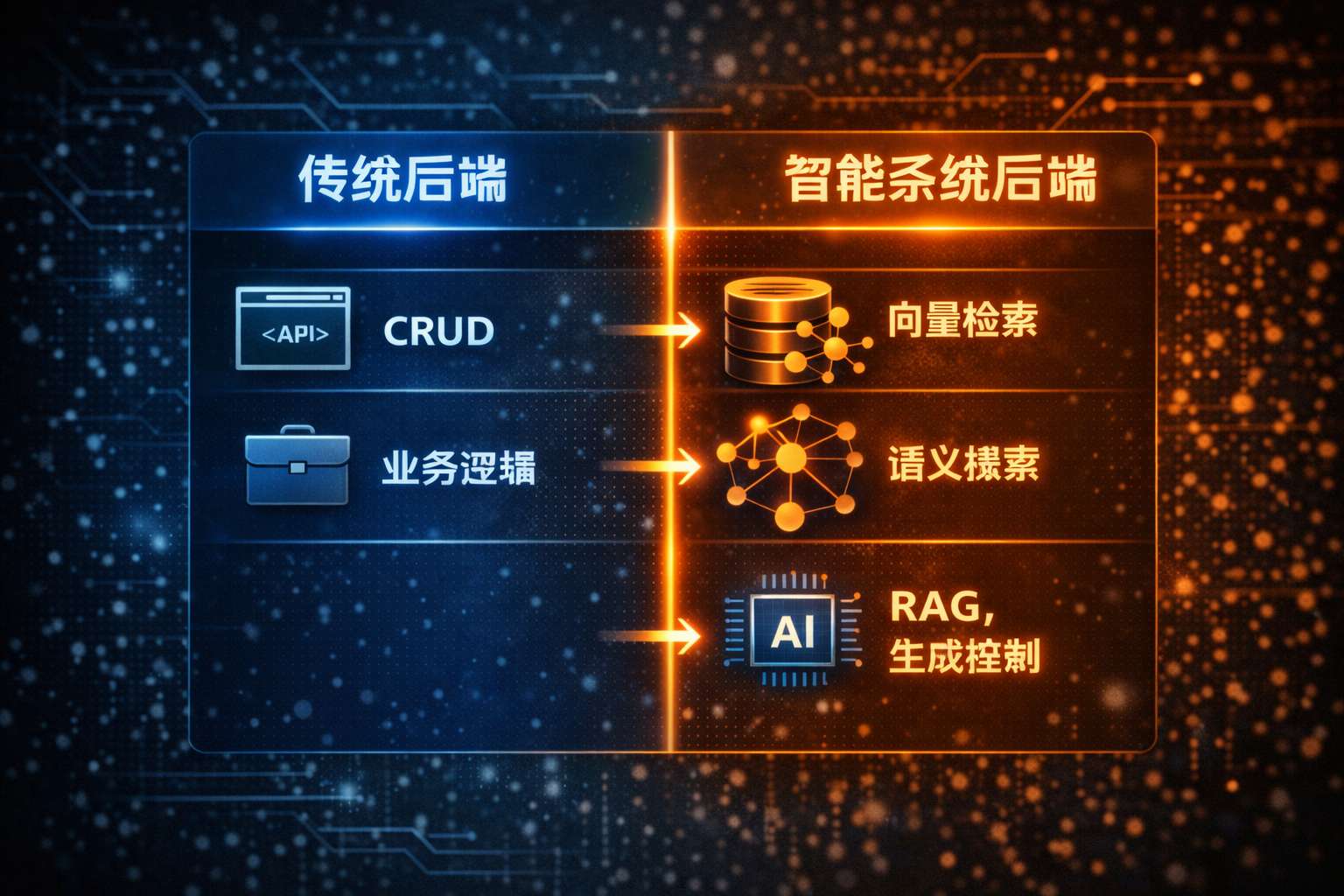
2. 向量数据库正在成为后端工程的新基座
向量数据库不是“学 AI 的可选项”,而是支持大规模语义搜索与检索的基础设施,它的能力包括:
-
高维向量索引与快速相似性搜索
-
支持海量数据的扩容与负载
-
元数据过滤、权限控制与多租户隔离
这些能力让向量数据库在许多实际工程场景(如智能客服、知识搜索、推荐引擎)中成为必需品,而不仅仅是“AI 技术栈的一部分”。
传统后端和AI后端能力对比
3. 这不是“AI热潮”,而是工程现实
现在的后端必须考虑:
-
向量数据库的选型与调优
-
向量检索的性能与扩容策略
-
RAG 架构的工程化实现
-
动态更新语义数据的机制
这些问题本质上是工程设计问题,不是简单的模型调参。
因此,越来越多后端工程师不得不掌握这些技术,因为它直接决定一个智能系统能否稳定上线、规模化运行与可控迭代。
后端学向量数据库和 RAG,不仅仅为了学AI,而更重要的是让自己更有价值。
