

Sonar分析AI代码质量、安全与可维护性。LLM通过率高但复杂性和冗余度增加。Gemini 3 Pro高效,GPT-5.2安全最佳但代码量大,Claude Sonnet有漏洞和泄漏问题。
译自:New data on code quality: GPT-5.2 high, Opus 4.5, Gemini 3, and more
作者:Prasenjit Sarkar
功能性基准仍然是评估AI模型的标准,它能有效衡量生成的代码是否能通过测试用例。随着LLM的发展,它们在解决这些功能性挑战方面变得越来越熟练。然而,对于将这些代码部署到生产环境的工程领导者来说,功能正确性只是等式的一半。
为了了解AI编码模型的真正有效性,我们还需要了解其结构质量、安全性以及可维护性。值得庆幸的是,Sonar在进行这项工作方面处于有利地位,因为我们每天分析超过7500亿行代码。
几个月前,我们开始分析使用领先LLM创建的代码的质量、安全性和可维护性,方法是使用SonarQube静态分析引擎,在超过4,000个不同的Java编程任务上对其进行测试。
今天,我们将在新的Sonar LLM 排行榜中公布所有评估结果,并分享我们关于GPT-5.2 High、GPT-5.1 High、Gemini 3.0 Pro、Opus 4.5 Thinking和Claude Sonnet 4.5的最新发现。
可视化权衡
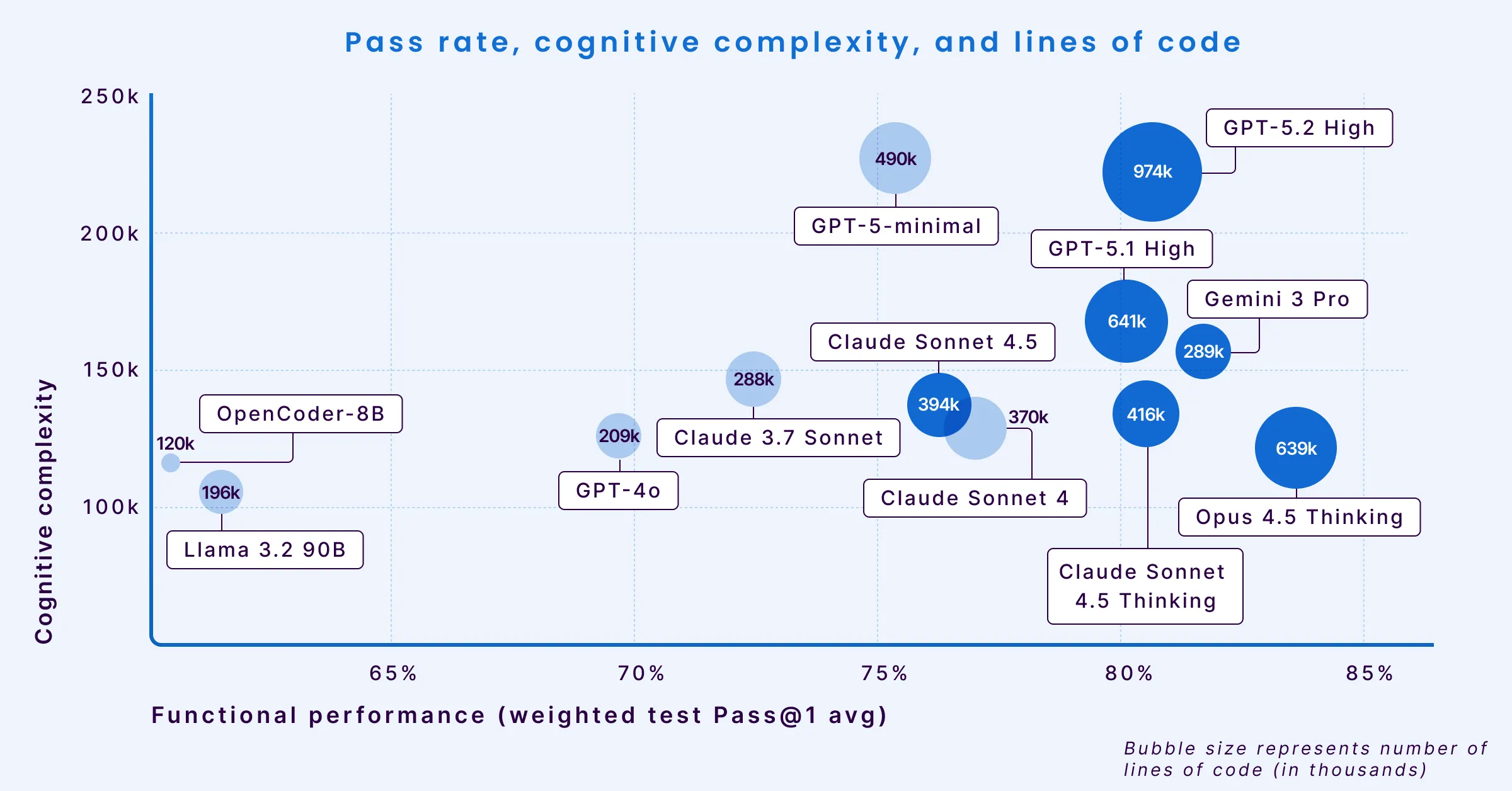
为了理解不同模型的权衡和行为,我们从三个关键维度绘制了它们:通过率(X轴)、认知复杂度(Y轴)和冗长性(气泡大小)。
随着模型变得更“高性能”并向右移动,它们的输出往往会变得更加冗长和复杂,给审查和使用代码的工程师带来更高的负担。
复杂性关联
我们的研究强调了模型推理能力与代码复杂性之间的关联。当模型尝试用复杂的、有状态的解决方案来解决更难的问题时,它们往往会偏离简单的代码。这种转变带来了比简单语法错误更难检测的工程挑战。
例如:
- Opus 4.5 Thinking 在功能性能方面领先,通过率达到83.62%(因此在上方图表中它最靠右)。然而,这种性能伴随着高冗长性,为解决基准测试生成了639,465行代码(LOC)(这就是为什么它是图表中最大的气泡之一)。这比不那么冗长的模型多出一倍以上。
- Gemini 3 Pro 作为效率的例外脱颖而出。它实现了可比较的81.72%通过率,同时保持了低认知复杂度和低冗长性(小气泡大小)。这种组合表明它具有用简洁、可读的代码解决复杂问题的独特能力。但与其他最新模型相比,Gemini 的问题密度最高。
- GPT 5.2 High 在功能性能方面排名第三(80.66%),落后于Opus 4.5和Gemini 3 Pro。尽管通过率很高,但它生成了同批模型中最高的代码量(974,379行代码)。与其前身(GPT 5.1 High)相比,GPT 5.2 的可维护性下降,并且所有严重程度的错误密度都有所增加,尽管它在整体安全性和阻断级别漏洞方面略有改善。
- GPT-5.1 High 也达到了80%的通过率,但认知复杂度有所增加(在Y轴上位置较高)。这表明尽管它解决了问题,但它生成的逻辑在结构上更难阅读和维护。
工程规范和可靠性
虽然模型展示了强大的逻辑能力,但我们的分析揭示了它们在处理资源管理和线程安全等软件工程基础方面存在的明显模式。将这些数字情境化后,揭示了通过率相似的模型之间在可靠性方面存在的显著差异。
1. 并发挑战: GPT-5.2 High 展示了强大的推理能力,但比其同类模型更容易出现并发错误。它每百万行代码(MLOC)生成470个并发问题——这一比率几乎是次接近模型的两倍,比Gemini 3 Pro高出6倍以上。
| 模型 | 每百万行代码的并发问题数 |
|---|---|
| GPT 5.2 High | 470 |
| GPT-5.1 High | 241 |
| Opus 4.5 Thinking | 133 |
| Claude Sonnet 4.5 | 129 |
| Gemini 3 Pro | 69 |
2. 资源管理: Claude Sonnet 4.5 显示出更高的资源管理泄漏率,每百万行代码生成195个泄漏。相比之下,GPT-5.1 High 在相同的任务中每百万行代码仅产生51个泄漏。
| 模型 | 每百万行代码的资源泄漏数 |
|---|---|
| Claude Sonnet 4.5 | 195 |
| GPT 5.2 High | 86 |
| Opus 4.5 Thinking | 84 |
| Gemini 3 Pro | 79 |
| GPT-5.1 High | 51 |
3. 控制流精度: Gemini 3 Pro 的控制流错误率最高(每百万行代码200个),几乎是Opus 4.5 Thinking(每百万行代码55个)的4倍。GPT 5.2 High 表现出高精度,在同批模型中实现了最低的错误率,每百万行代码仅有22个控制流错误。
| 模型 | 每百万行代码的控制流错误数 |
|---|---|
| Gemini 3 Pro | 200 |
| Claude Sonnet 4.5 | 152 |
| GPT-5.1 High | 98 |
| Opus 4.5 Thinking | 55 |
| GPT 5.2 High | 22 |
安全验证
安全性仍然是验证的关键领域。我们的分析证实,模型并非总能可靠地从源头到目标跟踪不受信任的用户输入。
Claude Sonnet 4.5 每百万行代码记录了198个阻断严重性漏洞,包括路径遍历和注入缺陷。这一比率高于其同类其他模型。Opus 4.5 Thinking 的表现明显更好,每百万行代码仅有44个阻断漏洞,这表明其“思考”过程可能允许在生成输出之前更好地验证安全约束。GPT 5.2 High 在同批模型中实现了最佳安全态势,每百万行代码仅有16个阻断漏洞。尽管其他指标显示该模型在代码量和通用错误密度方面表现不佳,但其对关键安全热点的处理目前是同类最佳。
| 模型 | 每百万行代码的阻断漏洞数 |
|---|---|
| Claude Sonnet 4.5 | 198 |
| Gemini 3 Pro | 66 |
| GPT-5.1 High | 53 |
| Opus 4.5 Thinking | 44 |
| GPT 5.2 High | 16 |
可维护性的挑战
除了关键错误之外,可维护性仍然是AI代码总拥有成本的主要因素。“代码异味”问题会降低可维护性,在所评估的模型中,这些问题占所有检测到问题的92%到96%。
GPT-5.1 High 每百万行代码生成了超过4,400个通用异味。
| 模型 | 每百万行代码的通用异味数 |
|---|---|
| GPT-5.1 High | 4426 |
| GPT 5.2 High | 3453 |
| Gemini 3 Pro | 3044 |
| Claude Sonnet 4.5 | 2551 |
| Opus 4.5 Thinking | 2225 |
Claude Sonnet 4.5 绕过了更多的设计最佳实践。
| 模型 | 每百万行代码的设计最佳实践违规数 |
|---|---|
| Claude Sonnet 4.5 | 4316 |
| Gemini 3 Pro | 3824 |
| Opus 4.5 Thinking | 2494 |
| GPT 5.2 High | 2293 |
| GPT-5.1 High | 1840 |
关于 Sonar LLM 排行榜
我们创建 Sonar LLM 排行榜是为了提供模型如何构建代码的透明度,而不仅仅是它们构建了什么。通过将数千个AI生成的解决方案运行通过 SonarQube,我们根据对工程领导者重要的指标来评估模型:安全性、可靠性、可维护性和复杂性。
在Sonar LLM 排行榜上探索完整数据集。
