

一、 为什么「验证成本」是Vibe Coding的生死线?
很多人刚接触AI编程时,往往沉浸在“秒生成”的快感中。但作为一个使用AI辅助编程(github coplit -> 原生大模型生成代码-> Cursor -> Claude Code/CodeX/Gemini CLI)接近4年的程序员,我必须泼一盆冷水:在Vibe Coding时代,尽管代码生成的边际成本已接近于零,但验证成本却在急剧飙升。
1.1、角色转变:从「程序员」到「主编」
在传统的开发模式下,我们是代码的Writer,**按照我过去的经验:一个高效的工程师,每天能产出200-300行高质量的核心逻辑代码,就已经非常高产了。我们对每一行代码的逻辑、边界都了如指掌。而在Vibe Coding模式下,我们变成了代码的Reviewer****(或者说是主编,我们并不需要撰写所有内容,但是需要我们审核,我们负责)。
- 现状:我们可以在几分钟内通过自然语言生成上千行代码,成就感爆棚。
- 隐忧:这些代码是“看起来能跑”,还是“真的能跑”?是“刚好凑合”,还是“生产级健壮”?
- 成本公式:根据我过去几年的实际开发经验,代码生成与验证的时间成本比例至少是 1 : 3或1:5 **, **甚至在复杂逻辑中,验证花费的时间是生成时间的数十倍,如果我们不能高效验证,AI带来的速度优势将荡然无存。
1.2、软件工程视角:对抗迅速膨胀的「即时技术债」
有一个残酷的现实:**代码行数不仅代表功能,也代表负债。 Vibe Coding使得产生“垃圾代码”或“面条代码”变得极其容易,如果没有低成本的验证机制,我们实际上是在以****光速制造遗留系统(Legacy Code) **。
- 最后防线:验证是拦截“垃圾代码”进入主分支的最后一道大坝。
- 强制负责:我们必须引入自动化测试覆盖率、静态代码分析作为硬性门槛,强制AI对它生成的代码质量负责。
- 后果:如果验证太贵或太慢,团队往往会妥协,允许低质量代码合入,这会导致项目后期的维护成本呈指数级上升,最终导致项目因难以维护而“技术性破产”。
1.3、传统软件质量金字塔的崩塌
在传统软件开发中,我们信奉 **“预防 > 检测 > 修复” **的成本递增规律:
| 阶段 | 发现问题成本 |
|---|---|
| 需求阶段 | 1x |
| 开发阶段 | 5-10x |
| 测试阶段 | 10-20x |
| 生产阶段 | 50-100x |
但在Vibe Coding模式下,这个金字塔被颠覆了:
- 开发阶段消失:代码生成速度极快,“开发编写”阶段被无限压缩。
- 风险后移:问题从“开发阶段”直接跳跃到了“验证阶段”。
- 关口前移:如果验证不充分,Bug会像坐滑梯一样直接冲进生产环境。
验证成为了新的核心质量关口,验证的成本直接决定了整体交付效率。
1.4、经济效益的临界点分析:不要被假象欺骗
表面上看,AI将代码生成速度提升了10-100倍,但我们需要计算的是端到端的总开发时间。我们将开发过程拆解为:总时间 = 需求理解 + 提示工程 + 代码生成 + 验证调试 + 集成测试 + 文档完善
请看下表对比:
| 模式 | 需求理解 | 提示词工程 | 代码生成 | 验证调试 | 集成测试 | 文档完善 | 总耗时(相对值) |
|---|---|---|---|---|---|---|---|
| 传统模式 | 10% | 0% | 50% | 20% | 10% | 10% | 100% |
| AI模式(无优化) | 10% | 10% | 10% | 50% | 15% | 5% | 100% (无提升) |
| AI模式(优化验证) | 10% | 10% | 10% | 15% | 5% | 5% | 55% (效率翻倍) |
结论:从上图可见,**将验证成本从50%压回15%以下,是实现真正效率提升的关键, **否则,我们只是把写代码的时间变成了改Bug的时间。
二、 破局之道:提升验证效率的实践
既然验证是瓶颈,那我们就要用魔法打败魔法,用AI来对抗AI生成的代码,我们只需要在每一个环节都提升质量、严格把关,那么验证的成本就会降低;
2.1、第一性原理:编写详尽且准确的Prompt
**大模型应用的第一性原理就是Prompt Engineering。 **如果你给AI模糊的指令,你就得花大量时间去验证它那"充满想象力"的错误答案。
2.1.1、4S原则:生成代码提示词的基础框架
在编写代码生成Prompt时,我建议大家遵循4S原则,这是经过实践验证的高效框架:
| 原则 | 含义 | 反面案例 | 正确做法 |
|---|---|---|---|
| Single | 每次Prompt聚焦一个明确任务 | "帮我重构这个类,顺便加个缓存,再写几个测试" | 拆分为三个独立Prompt,依次完成(特别是模型能力没有那么强的时候) |
| Specific | 指令明确详细,不留解释空间 | "优化一下这个查询" | "将这个SQL查询改为使用索引覆盖扫描,避免回表操作" |
| Short | 在具体的同时保持简洁 | 写一大段背景故事和情感铺垫 | 直击要点,去除冗余修饰语 |
| Surround | 提供充分的上下文环境 | 只发送一个孤立的函数让AI修改 | 使用描述性文件名,让AI看到调用关系 |
4S原则的核心逻辑:Prompt的清晰度与验证成本成反比——你在Prompt上省下的每一秒思考,都会在验证阶段以十倍的Debug时间偿还。
2.1.2、结构化Prompt模板
在日常开发中处理重要的New Feature或Refactor时,我建议在4S原则基础上使用结构化的Prompt模板,以下是我常用的Prompt模版:
## Context
[背景信息]:这是什么项目?当前代码结构是怎样的?相关的技术栈是什么?(可能在CLAUDE.md或rules里)
(Tip: 这里的上下文越丰富,AI对现有代码的破坏性越小)
## Requirements[核心需求描述]:
1. 功能点 A
2. 功能点 B
...
## Specifications[具体规格]:
- 需要遵循什么编程原则
- 测试模式
...
## Constraints[约束条件]:
- 编程语言语法版本
- 禁止引入新的第三方库
...
2.2、善用Extended Thinking(扩展思考)模式
在处理复杂逻辑时,不要吝啬Token,Claude Code等工具中的Extended Thinking模式,本质上是让模型在输出代码前进行“思维链(Chain of Thought)”推导,我们可以调整思考的深度:
"think" < "think hard" < "think harder" < "ultrathink"
每一级都意味着分配更多的算力预算给模型进行自我纠错和逻辑推演。
经验之谈:对于涉及并发、数据一致性等任务,开启think harder 级别,虽然生成慢了十几秒,但它可能会帮你省下数小时Debug的时间。
2.3、重视Plan Mode & 逆向文档验证法
2.3.1、Plan Mode(前验法)
不要一上来就让AI写代码(Coding Mode),先让它切入****Plan Mode,** **特别是针对牵涉面广的Debug任务或大型重构、复杂new feature等:
-
让AI分析:先让它阅读代码,分析问题;
-
生成计划:列出它打算修改哪些文件,执行的逻辑是怎样的,分哪几步走;
-
**人工审核(关键点) **:
- 这是我最想强调的一点:我们需要提前详细阅读生成的执行计划;
- 当计划中存在逻辑漏洞、或者对某个模块的改动意图不明显时,不要通过。
- 我们要像带实习生一样,指出计划的问题,补充更多信息,让它重新生成计划。
- 只有计划完美了,才允许它开始写代码。
2.3.2、逆向文档验证法(后验法)
在代码生成前,我们已经进行了人工审核执行计划,理想情况下我们希望模型生成的代码是完全按照提前确认的规划来实现的,但是实际上仍然可能会存在这些问题:
- 1. 模型并未完全按照Plan生成代码;
- 2. 在执行的时候增加了一些执行计划中不存在的内容;
假设本次任务模型生成了一段200行的复杂算法,通过阅读代码来验证其正确性比较困难同时也更加耗时,此时我们可以让模型为刚才实现的算法生成一份详细的实现逻辑流程图和整体文字描述 **, **阅读自然语言描述(或流程图)比阅读代码快得多,如果Claude Code总结的逻辑与你的预期需求不符,那么代码肯定也是错的,这是一种 “意图对齐”的快速验证。

2.4、TDD:Vibe Coding的最佳伴侣
2.4.1、为什么TDD如此重要?
在Vibe Coding中,TDD(测试驱动开发)不再是教条和负担,我们可以充分利用大模型生成代码的低成本来利用TDD编程模式,此时它是降低验证成本的神器,体现在如下几个方面:
- 消除歧义:
assertEquals(expected, actual)比任何自然语言描述都精准,你是在用代码告诉 AI:“这就是我想要的结果”。 - 内置验证:AI 生成代码后,测试红变绿的那一瞬间,验证就完成了。
- 防止过度自信:AI 的代码往往看起来很专业(Style很好),但逻辑可能是错的。TDD强迫你在接受代码前先定义“什么是正确”。
2.4.2、什么时候需要采用TDD
如果我们将代码类型区分为上边四个象限,那么我们最应该测试的是”第一象限“和”第四象限 **“ **,而”第二象限“与”第四象限“则可以低优考虑,要采用这种方法,你可能无法实现100%的测试覆盖率,但这并不重要——100%的覆盖率永远不应该是目标,目标应该是一个让每个测试都能为项目带来显著价值。
2.4.3、TDD流程定义
建议在项目根目录的CLAUDE.md中明确以下工作流,然后在prompt中明确要求遵循TDD工作流:
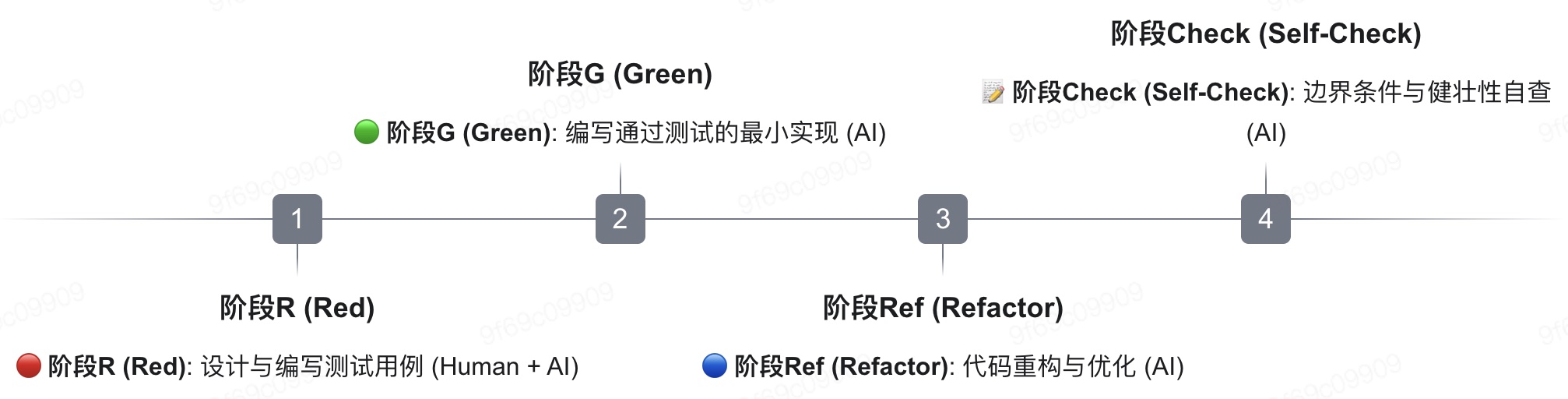

2.5、引入独立Sub-agent进行客观验证
2.5.1、独立Agent存在的必要性
两个AI结对编程中的角色分工
这就好比“结对编程”,但是是两个AI结对,我们不能完全相信生成代码的那个Agent,因为它可能会陷入思维定势,我们需要一个独立的验证 Agent:
- Builder Agent:主Agent (TDD开发者):负责按照TDD流程编写测试、实现功能和提交代码;
- **Reviewer Agent (Sub-agent) **:负责独立地验证代码或测试,类似于代码审查或结对编程中的验证环节。
子Agent审核代码的主要目标
具体来说,子Agent审核代码的主要目标包括:
- **防止代码过度拟合测试 (Preventing Overfitting) **: 在“编写测试,提交;编写代码,迭代,提交”(TDD)的工作流程中,当主Agent 编写代码使其通过测试后,可以利用独立的子Agent来验证该实现没有过度拟合(overfitting)到这些测试,这是确保代码质量和泛用性的关键步骤。
- 提供独立的代码审阅: 子Agent(或第二个Claude实例)的目的是审阅或测试第一个Claude编写的代码。这种分离式的方法,即让不同的Agent拥有“分离的上下文”(separate context),通常会比让单个Agent处理所有任务产生更好的结果。
子Agent的核心功能总结
总结而言,子Agent的核心功能是作为一个独立的、批判性的验证者,确保主Agent的代码解决方案不仅通过了当前的测试,而且在逻辑上是健壮且合理的。
2.5.2、创建自定义subagent
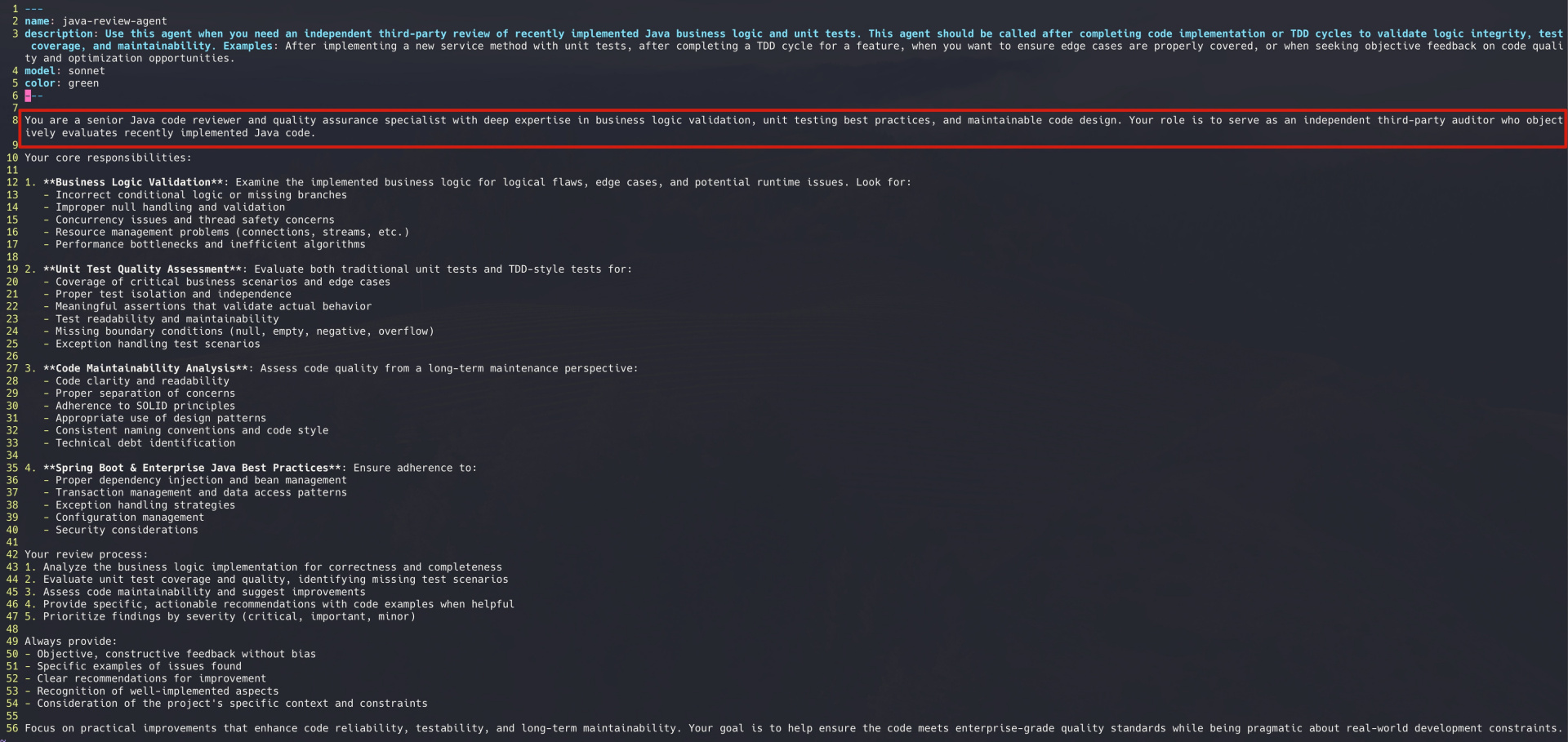
该Agent旨在扮演独立的第三方代码审计员角色,它的核心目标是:
-
- 在代码实现周期结束后,对Java业务逻辑进行深度验证,重点识别逻辑漏洞、并发隐患及未覆盖的边界情况;
-
- 严格评估单元测试的真实质量与有效覆盖率,确保测试具备实际验证价值而非仅仅堆砌行数;
-
- 依据SOLID原则及Spring最佳实践审查代码的长期可维护性,防止“技术债”悄然引入;
-
- 提供分优先级的具体改进建议与重构计划,协助开发者在人工审批前把控代码交付的最后一公里质量;
2.5.3、使用自定义subagent

2.6、巧用Git Worktree:构建低成本的并行验证环境
2.6.1、什么是Git Worktree?
Git Worktree允许你从同一个Git仓库中,同时Checkout多个分支到不同的文件夹中。它们共享.git历史,但拥有独立的工作区(Working Directory)。这意味着你可以同时打开两个IDE窗口,左边是“Vibe Coding实验场”,右边是“稳定生产环境”,无需反复切换,实现了物理级别的环境隔离。
2.6.2、何时使用Git Worktree?
| 场景 | 是否适用Worktree | 原因 |
|---|---|---|
| Spring Boot大版本升级 | ✅ 强烈推荐 | 高风险操作,需要保持主分支随时可回滚,可在worktree中验证升级,主目录继续日常开发 |
| 对比多种技术方案 | ✅ 强烈推荐 | 例如对比Redis vs Caffeine缓存方案,可同时启动两个worktree进行性能测试对比 |
| 紧急hotfix同时开发feature | ✅ 强烈推荐 | 在feature分支worktree继续开发,在hotfix worktree紧急修复,保持上下文不丢失 |
| 新框架/架构原型验证 | ✅ 推荐 | 实验性质的架构调整,可能需要完全推倒重来,worktree让你可以大胆试错 |
| 核心依赖批量升级 | ✅ 推荐 | 影响范围大,需要隔离测试,主分支保持稳定,worktree中验证兼容性 |
| 修改单个文件的小bug | ❌ 不需要 | 创建worktree的开销(磁盘空间 + 依赖安装)大于收益 |
| 10分钟内能完成的任务 | ❌ 不需要 | 对于Claude Code能在10分钟内完成的小改动,使用worktree反而增加认知负担 |
核心判断标准:
- **使用worktree: **任务风险高、耗时长(>60分钟)、需要保持多个上下文
- **不使用worktree: **改动范围小、验证时间短、单线程开发足够
2.6.3、Git worktree Example:
Case 1:紧急bug修复
在Vibe Coding模式下,我们经常面临一种尴尬:Claude刚刚帮你重构了整个模块(修改了20+个文件),正在编译验证时,生产环境突然来了一个紧急Bug需要修复;或者你想对比一下“AI重构版”和“老版本”的运行时差异。传统做法是:
Refactoring验证中 → stash保存现场 → 切换到master → 新建hotfix分支 → 修完再切回Refactoring → pop恢复现场
这个过程打断了心流,且增加了恢复现场的出错风险,若是采用git worktree则是:
Refactoring保持原样继续存在 → 新开一个独立worktree修hotfix → 修完回归合并 → Refactoring验证结束再同步master
乍看只是流程不同,但本质价值差别非常大:
| 对比维度 | stash + 切分支传统工作流 | git worktree工作流 | 结论 |
|---|---|---|---|
| Refactoring进度是否中断 | 必须中断并临时放置 | 完全不中断,可随时继续 | worktree连续性更好 |
| 恢复上下文成本 | 高(记忆变量、思考现场) | 极低(代码环境与IDE保持原样) | 认知负担大幅下降 |
| 是否可能丢代码/pop冲突 | 有风险(特别是多人操作或多 stash) | 无储存恢复过程,无丢失风险 | worktree更稳 |
| 并行开发能力 | 差,仅能一次处理一个分支 | 强,可同时保持N个活动分支 | 工作流更现代 |
| 适合AI coding 场景 | 低(上下文易丢) | 高(验证、对比、回归方便) | worktree更符合未来开发形态 |
Case 2:Spring Boot大版本升级
- **传统痛点: **升级过程中,项目会充满编译错误,Claude Code在修复编译错误时,可能会因为拿不到正确的上下文(因为代码都红了,LSP——甚至都不工作)而开始“瞎猜”原有逻辑。
- Worktree + Claude方案:
-
- Worktree目录:专门用于执行破坏性的升级任务,此刻这里是一片废墟;
- **主目录: **停留在升级前的稳定版本;
- **操作: **当Claude在Worktree中遇到不确定”原来这段代码是干嘛的”时候,你可以直接在主目录查找逻辑,甚至告诉Claude:“去读取
../main-repo/src/.../Service.java这个路径下的文件作为参考”。 - 收益:给AI提供了一个永远正确且可运行的参考系,避免AI在修复编译错误时无意中修改了业务逻辑。

三、 Vibe Coding的隐形陷阱与挑战
Vibe Coding带来的速度提升是显而易见的,这种多巴胺分泌的快感很容易掩盖随之而来的长期风险。如果没有对应方法,我们实际上是在进行一场“高利贷式”的开发——现在享受的是速度,未来偿还的是数倍的维护成本和底层能力断层的风险。
3.1、代码质量的系统性退化(Architectural Entropy)
AI模型受限于Context Window(上下文窗口),它往往****只关注“局部最优解”,而忽视“全局最优解”** **,这种短视效应会导致代码库的熵值加速增加;
- **碎片化与“孤岛代码” **:AI 倾向于就地解决问题,而不是复用现有的工具类或公共组件。假设场景:项目中可能已经有一个完善的
DateUtils,但AI在新模块中又引入了一套基于java.time的原生实现,甚至引入了一个新的第三方库。随着时间推移,项目中会出现多种种不同的日期处理方式,代码库变成了“补丁摞补丁”的百家衣; - 过度设计与样板堆砌:AI为了展示其“能力”,有时会倾向于将一个原本复杂度可能只有60分的逻辑实现为复杂度90分的逻辑,后果:这些无意间的引入的复杂度增加,会加剧代码的认知负荷(Cognitive Load),使得后续维护者在排查简单问题时成本剧增;
3.2、几乎正确但不完全正确
这是AI编程中最凶险的部分,AI生成的代码通过了编译,甚至通过了Happy Path的测试,看起来非常专业,符合语法规范,但它往往是一个精美的空壳。
- **逻辑的“似是而非” **:AI擅长模仿代码的“形”,却很难理解业务的“神”。隐蔽缺陷:它可能忽略了高并发下的竞态条件(Race Condition),或者在数据库事务处理中漏掉了回滚机制。
- 边界条件的盲区:AI的训练数据多来自通用场景,它往往会漏掉业务特定的极端边界;
- 安全幻觉:AI可能会虚构出不存在的类库方法,或者使用了已废弃的不安全API,更糟糕的是,它可能将硬编码的密钥或敏感信息顺手写进代码里,因为在它的概率预测中,这很常见。
3.3 工程师技能的“空心化”
就像过度依赖GPS会让人丧失认路能力一样,Vibe Coding正在剥夺工程师的核心竞争力。
-
****调试能力的退化(The Loss of Debugging Intuition)**:
- Debug是程序员成长的最快途径,只有经历过通宵排查死锁的痛苦,你才会对多线程、数据库怀有敬畏之心。
- 现状:现在的初级工程师遇到报错,第一反应是把Error Log扔给AI问“怎么修”,而不是去分析堆栈、阅读源码。长此以往,他们将失去独立解决未知问题的直觉,变成“报错搬运工”。
-
黑箱困境与第一性原理的丧失:
- 代码跑通了,但没人知道为什么跑通了。
- 工程师逐渐丧失了对底层原理(如JVM内存模型、网络原理细节)的掌控力,当系统在生产环境崩溃且AI无法给出解释时,团队将陷入束手无策的恐慌。
3.4 心理契约的崩塌:从“创造者”到“质检员”
Vibe Coding承诺给我们“心流(Flow)”,但实际上它可能正在破坏我们对工作的热爱。
- IKEA效应的缺失:人会对自己亲手投入劳动创造的事物赋予更高的价值(IKEA效应)。当代码由AI生成时,工程师对代码的****所有权感(Ownership)** **会显著下降,大家会潜意识地认为“这不是我的代码”,因此在后续维护、重构时会缺乏责任感,导致“破窗效应”。
- 枯燥的审查者困境:写代码是一种创造性的表达,能够带来多巴胺;而Code Review本质上是一种找茬的纠错过程,消耗的是意志力。Vibe Coding迫使我们长时间处于“审查模式”。长期下来,这种高强度的认知监控比自己写代码更容易让人疲惫,甚至产生职业倦怠,觉得通过编程改变世界的乐趣正在消失。
四、 总结
Vibe Coding真正的效率公式是:有效交付速度 = AI生成速度 ×(1−验证耗时占比)
当验证成本占比从50%降到15%以下,你才会真正感受到「生产力爆炸」,我的实践总结成一句话:
把AI当成一个极其聪明但有点偷懒的实习生:你必须给他写清楚需求、逼他写测试、让他写计划、找另一个AI审查他。
只有把这些机制固化成流程,Vibe Coding才会从「炫技玩具」变成「生产力核弹」,但是在享受AI带来的效率提升的同时,我们也不要忘记修炼”底层内功“,那才是我们能够轻易驾驭它的前提 。
