论文地址:《OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment》。本文是对该篇论文的阅读笔记,如有不足之处,请指正。
引言
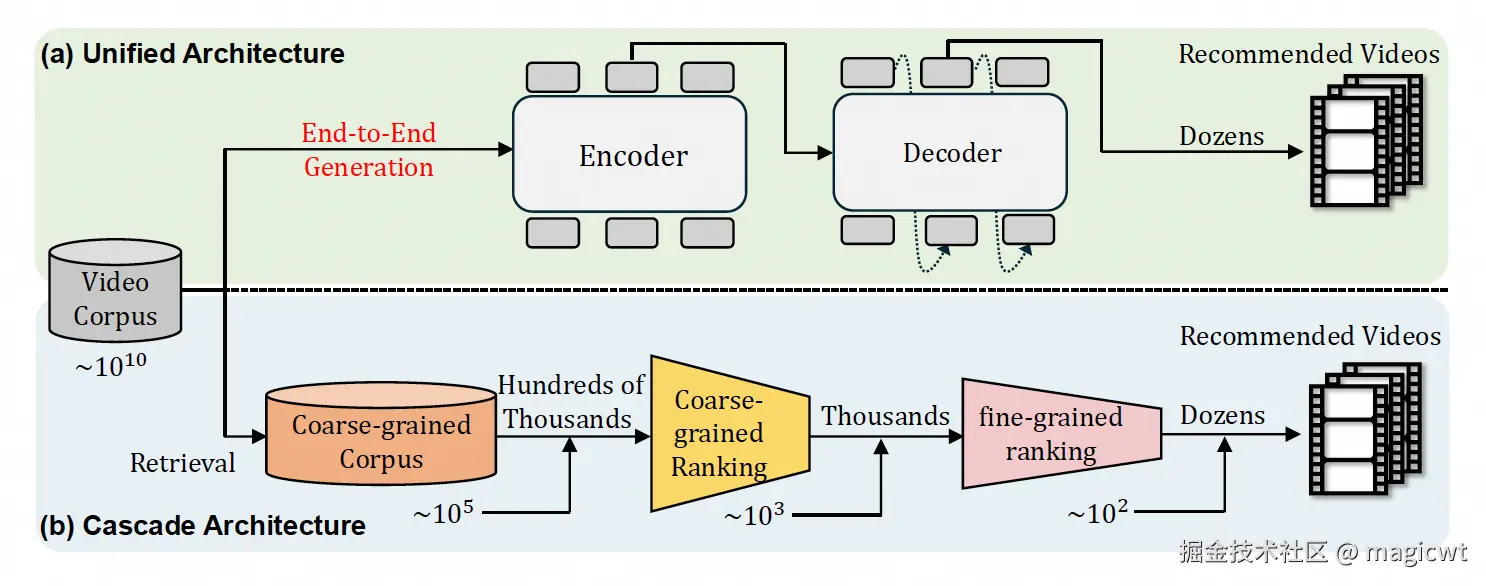
传统推荐系统普遍采用多阶段级联架构,如图1下方所示,典型流程包含三个阶段:召回、粗排和精排。尽管高效,但各阶段独立优化,限制了整体性能上限。
生成式推荐将候选物品标识符的生成视为自回归序列任务,通过语义ID编码物品语义,具备更强的语义表达与多样性生成能力。但当前生成式推荐仅用于召回阶段。论文提出OneRec,一种单阶段的端到端的生成式推荐架构,如图1上方所示,其核心组件包括:
- 编码器-解码器架构,编码用户行为序列,并解码得到用户可能感兴趣的视频;
- 会话级列表生成,替代传统逐个物品预测;
- 迭代偏好对齐,构建偏好配对,采用DPO算法对齐偏好,增强生成质量;
方法
数据准备
OneRec的输入是用户正向历史行为序列Hu={v1h,v2h,...,vnh},其中,v表示用户有效观看或感兴趣(喜欢、关注、分享)的视频,n表示行为序列长度。OneRec的输出是一个会话下的推荐视频列表S={v1,v2,...,vm}。每个视频vi,使用其多模态嵌入ei∈Rd进行描述。论文采用残差K均值量化算法将ei转换为平衡的语义ID,如图2所示。
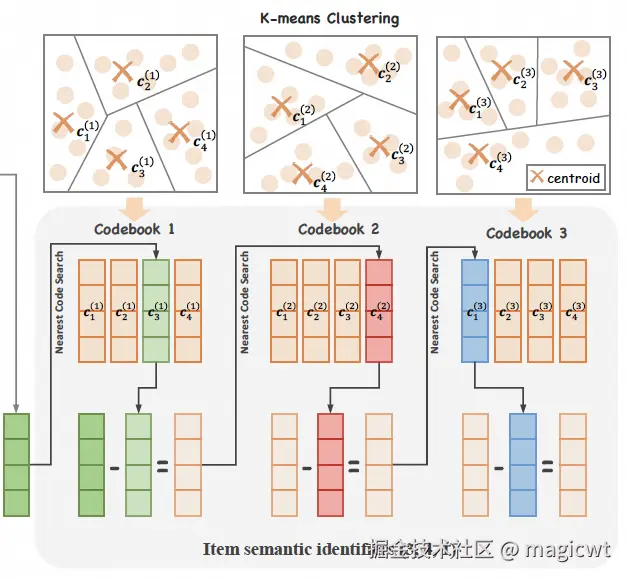
令语义ID的总层数为L。在第一层,令初始残差ri1=ei。在第l层,令该层的码本Cl={c1l,...,cKl},其中,K表示码本的大小。则ei的语义ID的层级索引由下式计算:
si1=argkmin∥ri1−ck1∥22,ri2=ri1−csi11si2=argkmin∥ri2−ck2∥22,ri3=ri2−csi22⋮siL=argkmin∥riL−ckL∥22
为了构建平衡的码本Cl,解决被称为“沙漏”现象的问题(中间层集中映射至某个索引上),论文使用如图3所示的平衡K均值聚类算法进行码本的构建,确保每个聚类包含等量视频。对于给定的视频集合V,该算法将其划分为K个聚类,每个聚类均包含w=∣V∣/K个视频。在迭代计算的每步中,每个聚类依次被分配w个距离最近的视频,然后对分配的w个视频计算平均向量,对聚类中心进行修正,如此迭代直至算法收敛,得到最终的码本Cl。

会话级列表生成
不同于传统的逐个物品预测的推荐系统,仅预测下一个视频,会话级列表生成基于用户历史交互序列生成列表。会话表示多个(一般5到10个)视频构成的列表。
论文定义高质量的会话标准:
- 一个会话中用户观看的视频数要达到或超过5个;
- 一个会话中用户观看的视频总时长要超过某个阈值;
- 一个会话中用户有交互行为,比如点赞、分享视频等。
令M表示会话级列表生成模型,其目标可用下式表示:
S:=M(Hu)(1)
其中,模型的输入Hu表示用户历史交互序列,由历史交互的多个视频的语义ID构成,即Hu={(s11,s12,...,s1L),(s21,s22,...,s2L),...,(sn1,sn2,...,snL)},模型的输出S表示会话,也是由多个视频的语义ID构成,即S={(s11,s12,...,s1L),(s21,s22,...,s2L),...,(sm1,sm2,...,smL)}。
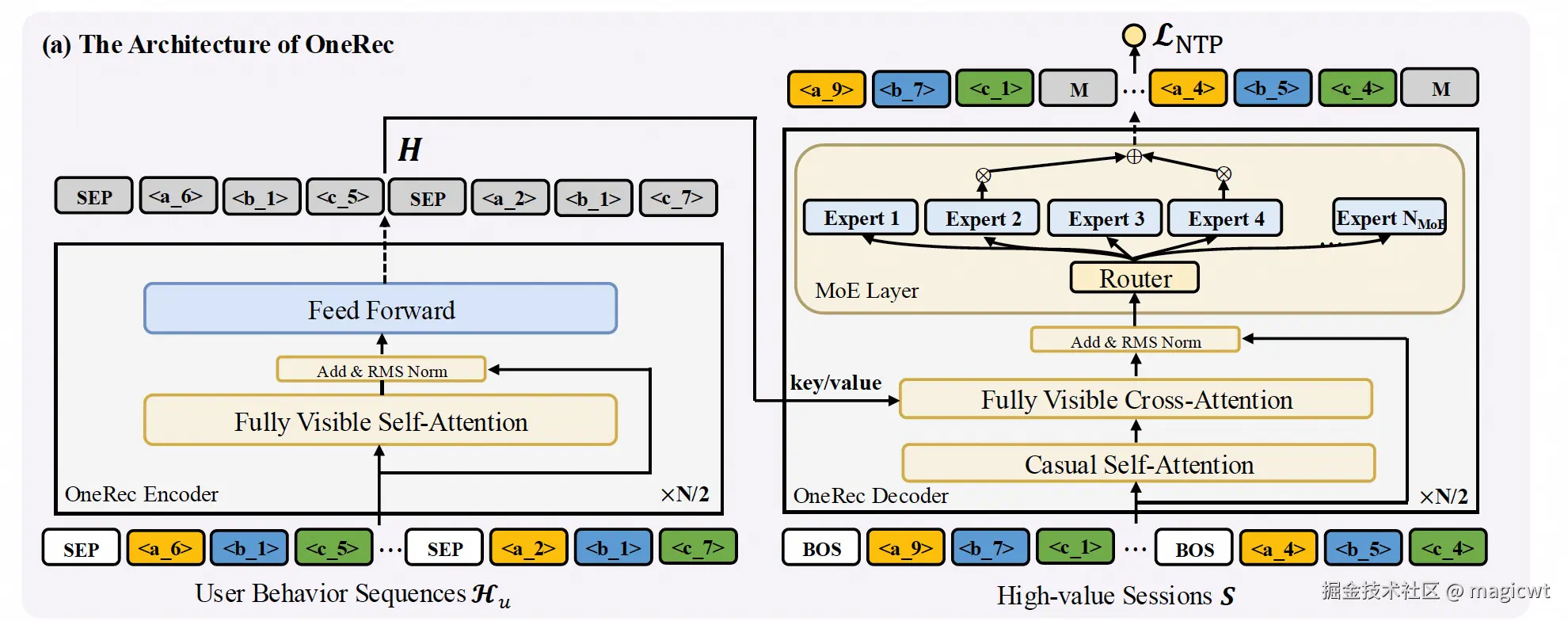
OneRec的模型结构如图4所示。和T5一致,OneRec也是一个比较典型的基于Transformer的网络结构,包括编码器和解码器两个部分。编码器用于建模用户历史交互序列,解码器用于生成会话。
编码器包含多层,每层由多头自注意力和前馈神经网络构成,编码器可表示为H=Encoder(Hu),其中,H表示编码器输出的用户历史交互序列的表征向量。
解码器是自回归的方式,输入包含已生成会话中的视频语义ID列表。解码器也包含多层,每层由多头交叉注意力和MoE(Mixture of Experts)架构的前馈神经网络构成。多头交叉注意力中,查询是会话,键和值是编码器输出的用户历史交互序列的表征向量。
为了实现较低的计算成本,解码器中的前馈神经网络采用MoE架构,这样在计算时,通过路由,每次只有部分专家网络被激活,从而能够减少计算的参数量。解码器中第l层前馈神经网络可由下式表示:
Htl+1gi,tsi,t=i=1∑NMoE(gi,tFFNi(Htl))+Htl={si,t,0,si,t∈Topk({sj,t∣1≤j≤N},KMoE),otherwise,=Softmaxi(HtlTeil)(2)
其中,NMoE表示专家网络的数量,FFNi(⋅)表示第i个专家网络,gi,t表示第i个专家网络的门控值,通过该值,每次仅门控值靠前的KMoE个专家网络被激活。
训练时,论文还会在每个视频的语义ID前增加一个特殊的表示开始的token——s[BOS],构成解码器的输入:
Sˉ={s[BOS],s11,s12,...,s1L,s[BOS],s21,s22,...,s2L,...,s[BOS],sm1,sm2,...,smL}(3)
训练目标采用预测下一个token的交叉熵损失函数:
LNTP=−i=1∑mj=1∑LlogP(sij+1∣[s[BOS],s11,s12,...,s1L,...,s[BOS],si1,si2,...,sij];Θ)(4)
基于奖励模型的迭代偏好对齐
论文对上一节得到的模型进行微调以对齐人类偏好。论文具体使用DPO算法对模型进行微调,以进一步增强模型能力。在自然语言处理中,偏好数据由人工标注,但是推荐系统中,偏好对齐的一个挑战是用户和物品交互数据的稀疏,因此需要构建一个奖励模型生成偏好数据。
奖励模型训练
令R(u,S)表示奖励模型。奖励模型的输出r表示用户u对于会话 S={v1,v2,...,vm}的偏好奖励。
论文首先对于会话S中的每个物品vi,提取其目标感知(target-aware)表征ei=vi⊙u,其中,⊙表示目标感知操作,例如针对用户历史交互序列的目标注意力(target attention),最终获得会话S的目标感知表征h={e1,e2,...,em}。
论文进一步对h中的各个物品,通过自注意力进行交互,融合各个物品的信息:
hf=SelfAttention(hWsQ,hWsK,hWsV)(5)
然后使用不同的塔分别预测会话在各种业务目标下的偏好奖励
r^swt=Towerswt(Sum(hf)),r^vtr=Towervtr(Sum(hf))r^wtr=Towerwtr(Sum(hf)),r^ltr=Towerltr(Sum(hf))where Tower(⋅)=Sigmoid(MLP(⋅))(6)
每个塔的结构均是在多层神经网络基础上,增加一个Sigmoid的输出头,输出某个业务指标的偏好奖励,这些业务指标包括:
- swt,session watch time,观看时长;
- vtr,view probability,观看概率;
- wtr,follow probability,关注概率;
- ltr,like probability,点赞概率。
对于每个会话,每个塔输出某个业务指标的偏好奖励r^swt,...,并令yswt,...表示这个会话某个业务指标的真实值。论文使用最小化交叉熵损失函数作为训练目标训练奖励模型,损失函数的定义如下:
LRM=−swt,...∑xtr(yxtrlog(r^xtr)+(1−yxtr)log(1−r^xtr))(7)
迭代偏好对齐
论文基于奖励模型R(u,S)和当前的OneRec模型Mt,首先对于某个用户以beam search的方式生成N个会话:
Sun∼Mt(Hu) for all u∈U and n∈[N](8)
其中,[N]表示{1,2,...,N}。
然后使用奖励模型R(u,S)计算上述OneRec模型输出的某个用户的多个会话的偏好奖励run:
run=R(u,Sun)(9)
并从中选择偏好奖励最高的会话(Suw,Hu)和偏好奖励最低的奖励(Sul,Hu),构建偏好配对Dtpairs=(Suw,Sul,Hu)。将这些偏好配对作为训练样本,微调Mt得到新模型Mt+1,微调时在损失函数中增加DPO损失,以对齐偏好,使模型倾向输出偏好奖励高的会话:
LDPO=LDPO(Suw,Sul∣Hu)=−logσ(βlogMt(Suw∣Hu)Mt+1(Suw∣Hu)−βlogMt(Sul∣Hu)Mt+1(Sul∣Hu))(10)
偏好对齐是个持续迭代的过程,迭代多步,每步中的过程如上所述,如图5所示。

整个迭代过程的算法如图6所示,迭代多次,得到多个模型Mt,...,MT。每步迭代中,为了减少beam search的计算量,论文进行随机采样,只采样1%的数据进行偏好对齐的计算。

系统部署
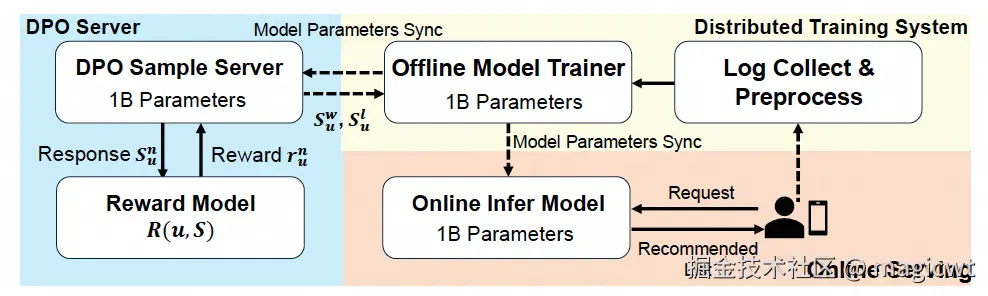
系统部署如图7所示,其包含三个部分:训练系统,在线服务系统和DPO采样服务。系统收集在线交互日志作为训练样本,训练基座模型,训练目标是预测下一个token(next token prediction),损失函数是LNTP,然后,再在损失函数中增加LDPO进行模型微调,对齐偏好。训练后的模型参数同步至在线服务系统和DPO采样服务,分别用于在线推理和偏好对齐训练样本生成。
实验
离线评估
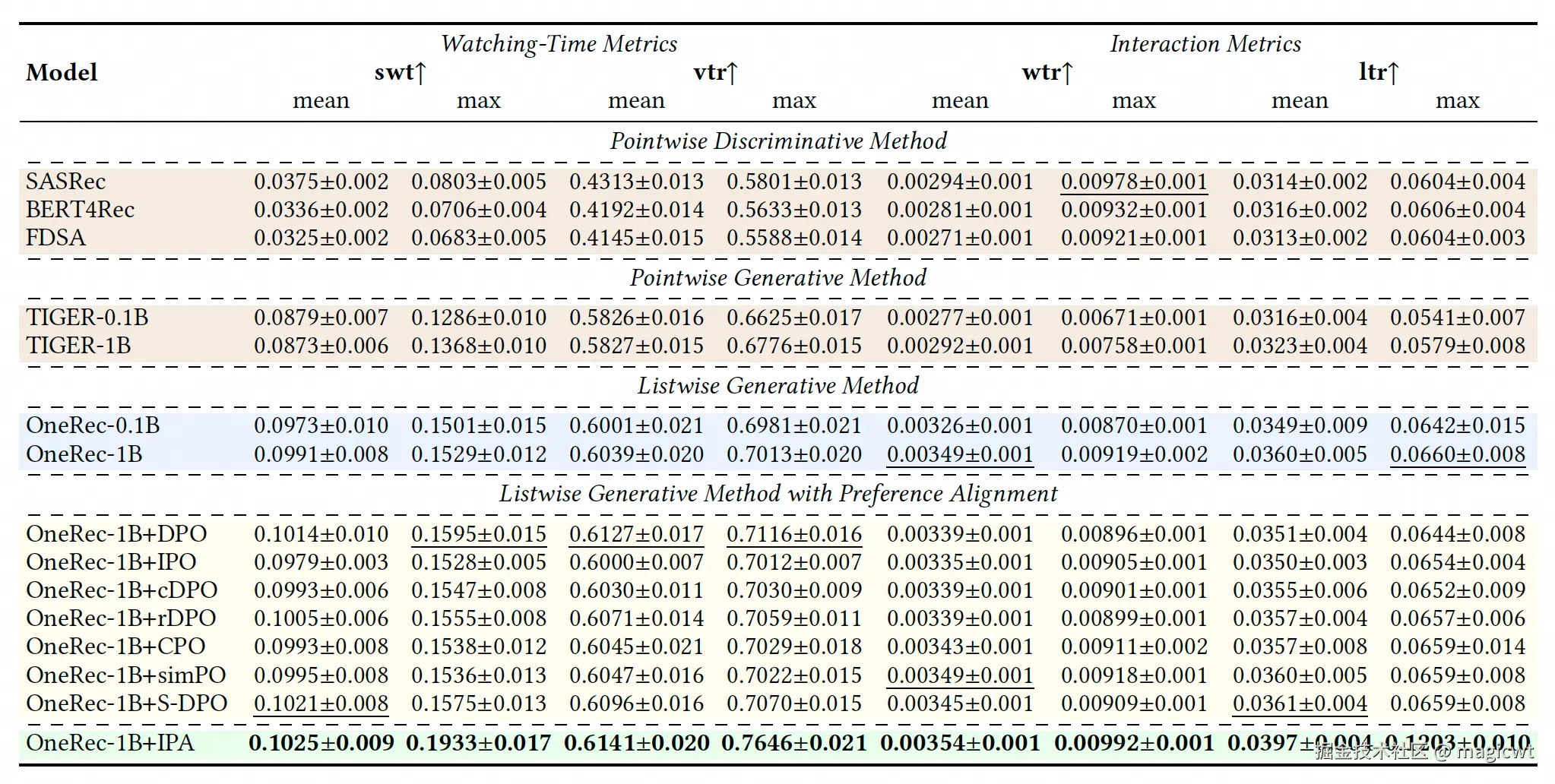
论文首先通过离线评估比较OneRec和其他基线模型,评估指标包括观看时长指标(swt和vtr)和交互指标(wtr和ltr),基线模型既包括以point-wise方式生成单个推荐结果的模型(判别式的模型包括SASRec、BERT4Rec、FDSA,生成式的模型包括TIGER-0.1B、TIGER-1B),也包括基于OneRec、但偏好对齐采用其他DPO算法变体的模型。
离线评估结果如图8所示。结论有三个:
- 以session-wise方式生成多个推荐结果优于以point-wise方式生成单个推荐结果(例如TIGER);
- 少量偏好对齐训练可以提升模型性能,OneRec-1B+IPA相比OneRec-1B在swt和ltr上分别有4.04%和5.43%的提升;
- IPA优于其他DPO算法变体。
消融实验
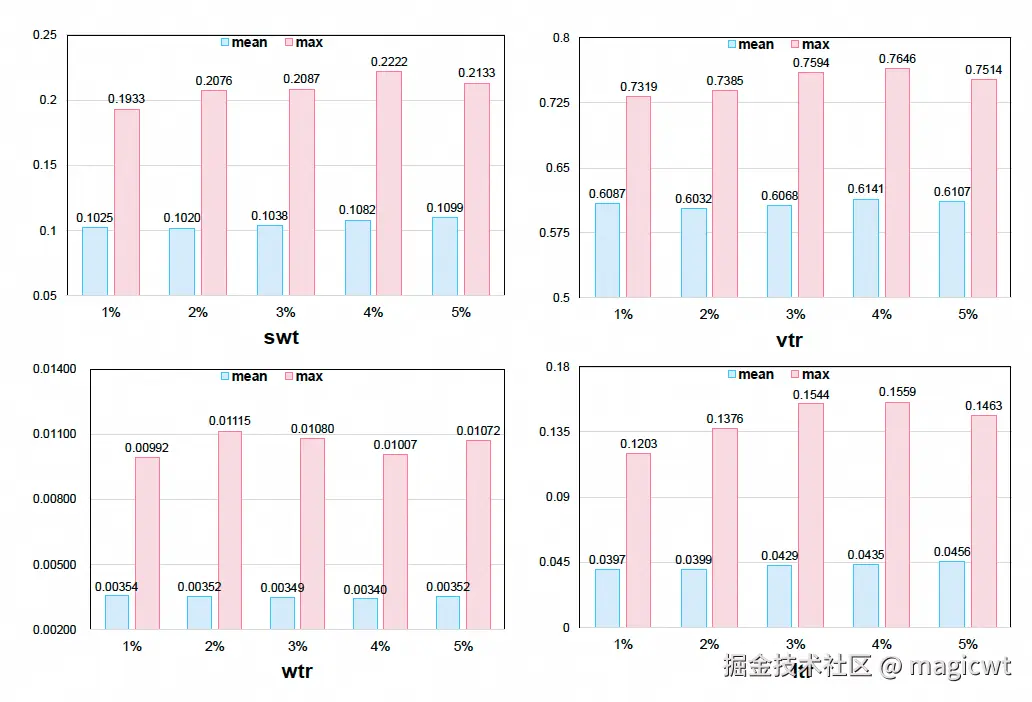
论文对DPO的采样比例进行消融实验,采样比例分别是1%、2%、3%、4%、5%时,各业务指标的平均值和最大值如图9所示,从中可以看到,随着采样比例增加,业务指标有一定的增长,但不明显,而计算量会随着采样比例线性增长,所以论文指出,综合权衡模型性能和计算成本,采用1%的采样比例。
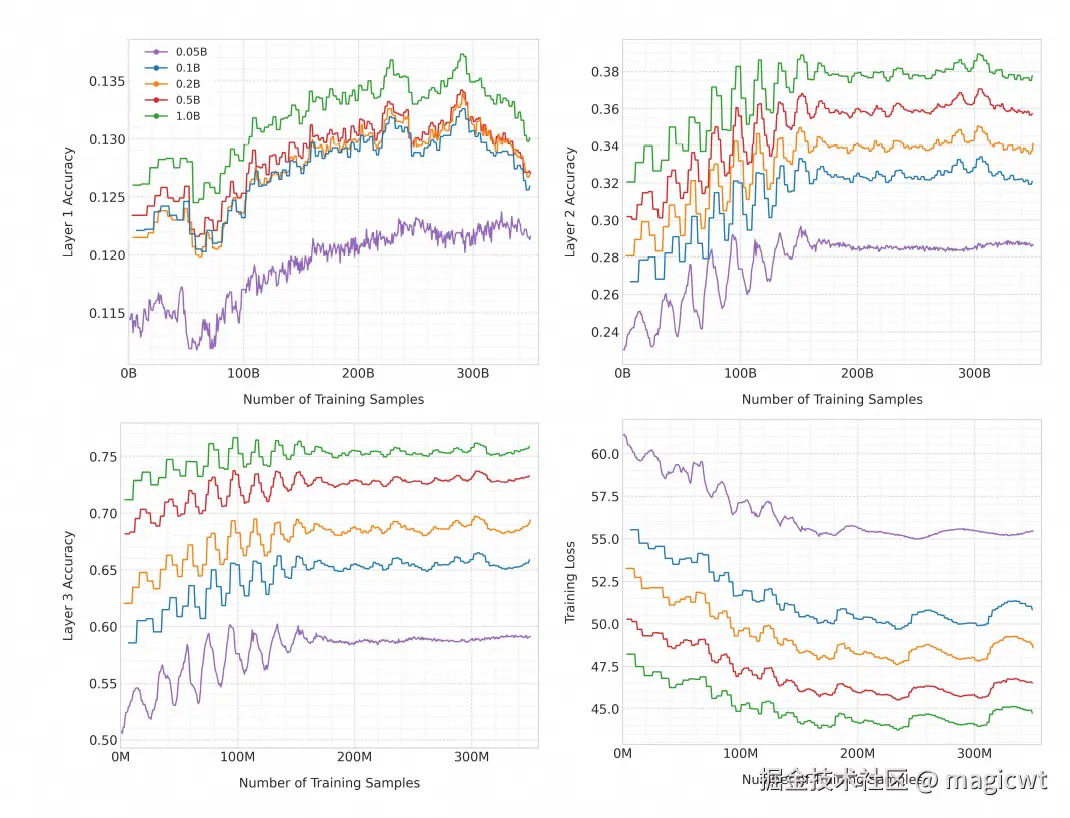
论文还对模型大小进行消融实验,模型大小分别是0.05B、0.1B、0.2B、0.5B、1.0B时,准确度和训练损失随着训练样本增加的变化趋势如图10所示,从中可以看出1.0B最优,这论证了大模型在推荐领域也符合scaling law,即模型越大,效果越好。
Prediction Dynamics
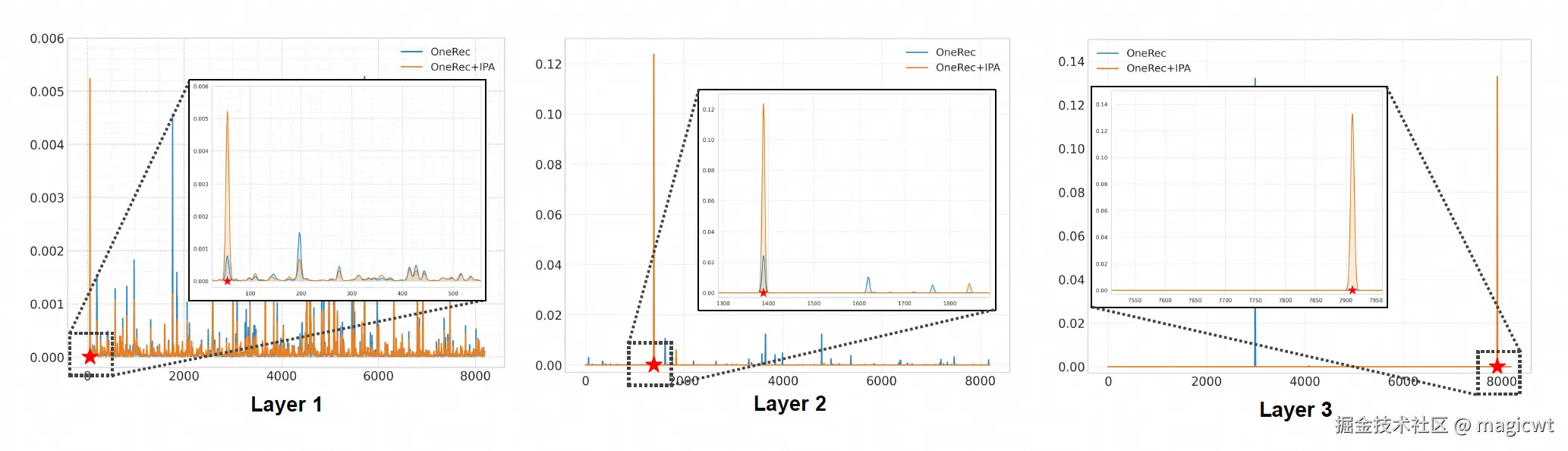
论文使用OneRec和OneRec+IPA分别对8192个物品的语义ID(分3层)进行预测,概率分布如图11所示,其中红星表示偏好奖励最高的物品的语义ID,说明OneRec+IPA相对OneRec,更倾向生成偏好对齐的结果。
在线AB实验
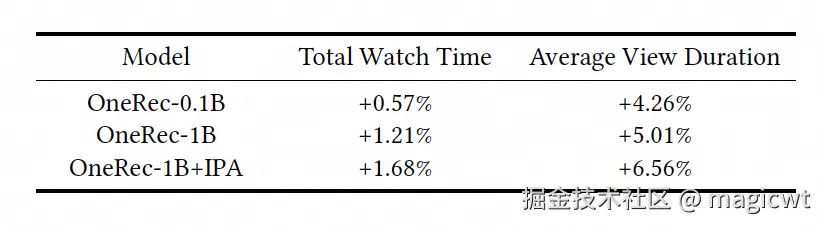
论文还进行了在线AB实验,OneRec-1B+IPA相比原先的多阶段推荐系统,在总观看时长和平均每个视频的观看时长上分别有1.68%和6.56%的提升。
结论
论文提出工业级单阶段生成式推荐解决方案OneRec,其贡献包括:
- 采用 MoE 架构高效扩展模型参数,为大规模工业级推荐提供可扩展蓝图;
- 证明会话级生成能更好捕捉用户偏好动态,优于孤立的物品级建模;
- 提出迭代偏好对齐策略,提升模型在多样用户偏好下的泛化能力。
离线评估与在线AB实验验证了OneRec的有效性与高效性。分析发现模型在点赞等互动指标上仍有局限,未来将增强端到端生成式推荐的多目标建模能力以优化用户体验。


