

TPOT 自动机器学习(二)
原文:
annas-archive.org/md5/19eaa1d0c8545e21eea1290b4c7ec6c1译者:飞龙
第五章:使用 TPOT 和 Dask 进行并行训练
在本章中,你将深入探讨一个更高级的话题;那就是自动化机器学习。你将学习如何通过在 Dask 集群上分配工作来以并行方式处理机器学习任务。本章将比前两章更具理论性,但你仍然会学到许多有用的东西。
我们将涵盖 Python 并行背后的基本主题和思想,你将学习以几种不同的方式实现并行。然后,我们将深入探讨 Dask 库,探索其基本功能,并了解如何将其与 TPOT 结合使用。
本章将涵盖以下主题:
-
Python 并行编程简介
-
Dask 库简介
-
使用 TPOT 和 Dask 训练机器学习模型
让我们开始吧!
技术要求
在阅读和理解这一章之前,你不需要有任何关于 Dask 或甚至并行编程的经验。虽然将如此大的概念压缩到几页纸上几乎是不可能的,但你应该仍然能够跟上并完全理解这里所写的一切,因为所有概念都将得到解释。
你可以在此处下载本章的源代码和数据集:github.com/PacktPublishing/Machine-Learning-Automation-with-TPOT/tree/main/Chapter05。
Python 并行编程简介
在某些情况下,需要按顺序执行任务(即第二个任务在第一个任务完成后开始)。例如,第二个函数的输入可能依赖于第一个函数的输出。如果是这样,这两个函数(进程)不能同时执行。
但大多数情况下并非如此。想象一下,在仪表盘显示之前,你的程序正在连接到三个不同的 API 端点。第一个 API 返回当前的天气状况,第二个返回股票价格,最后一个返回今天的汇率。一个接一个地调用 API 没有意义。它们之间没有依赖关系,所以按顺序运行它们会浪费大量时间。
不仅如此,这还会浪费 CPU 核心。大多数现代电脑至少有四个 CPU 核心。如果你是按顺序运行任务的,你只在使用一个核心。为什么不能使用所有这些核心呢?
在 Python 中实现并行的一种方式是使用多进程。这是一种基于进程的并行技术。正如你所想象的那样,Python 内置了一个 multiprocessing 库,本节将教你如何使用它。从 Python 3.2 及更高版本开始,这个库不再被推荐用于在应用程序中实现多进程。有一个新的库出现了,它的名字叫 concurrent.futures。这又是另一个你将在本节中学习如何使用的内置库。
解释和理解多进程的最简单方式是使用 Python 的内置 time 库。你可以用它来跟踪时间差异,以及故意暂停程序执行等。这正是我们所需要的,因为我们可以在它们之间插入一些时间间隔的打印语句,然后观察程序在顺序执行和并行执行时的行为。
你将通过几个动手实例了解 Python 中多进程的工作方式。
首先,请查看以下代码片段。在这个片段中,已经声明了 sleep_func() 函数。它的任务是打印一条消息,暂停程序执行 1 秒,然后在函数完成时打印另一条消息。我们可以监控这个函数运行任意次数(比如说五次)并打印出执行时间。代码片段如下:
import time
def sleep_func():
print('Sleeping for a 1 second')
time.sleep(1)
print('Done.')
if __name__ == '__main__':
time_start = time.time()
# Run the function 5 times
sleep_func()
sleep_func()
sleep_func()
sleep_func()
sleep_func()
time_stop = time.time()
print(f'Took {round(time_stop - time_start, 2)} seconds to execute!')
相应的输出如下所示:
Sleeping for a 1 second
Done.
Sleeping for a 1 second
Done.
Sleeping for a 1 second
Done.
Sleeping for a 1 second
Done.
Sleeping for a 1 second
Done.
Took 5.02 seconds to execute!
那么,这里发生了什么?至少说,没有什么意外。sleep_func() 函数按顺序执行了五次。执行时间大约为 5 秒。你也可以以下面的方式简化前面的代码片段:
import time
def sleep_func():
print('Sleeping for a 1 second')
time.sleep(1)
print('Done.')
if __name__ == '__main__':
time_start = time.time()
# Run the function 5 times in loop
for _ in range(5):
sleep_func()
time_stop = time.time()
print(f'Took {round(time_stop - time_start, 2)} seconds to execute!')
结果与你预期的一样:
Sleeping for a 1 second
Done.
Sleeping for a 1 second
Done.
Sleeping for a 1 second
Done.
Sleeping for a 1 second
Done.
Sleeping for a 1 second
Done.
Took 5.01 seconds to execute!
这种方法有什么问题吗?嗯,是的。我们浪费了时间和 CPU 核心。这些函数在某种程度上并不依赖,那么我们为什么不在并行中运行它们呢?正如我们之前提到的,有两种方法可以做到这一点。让我们首先检查通过 multiprocessing 库的老方法。
这种方法有点繁琐,因为它需要声明一个进程、启动它并加入它。如果你只有几个进程,这并不那么麻烦,但如果你程序中有成百上千个进程呢?这很快就会变得繁琐。
以下代码片段演示了如何并行运行 sleep_func() 函数三次:
import time
from multiprocessing import Process
def sleep_func():
print('Sleeping for a 1 second')
time.sleep(1)
print('Done.')
if __name__ == '__main__':
time_start = time.time()
process_1 = Process(target=sleep_func)
process_2 = Process(target=sleep_func)
process_3 = Process(target=sleep_func)
process_1.start()
process_2.start()
process_3.start()
process_1.join()
process_2.join()
process_3.join()
time_stop = time.time()
print(f'Took {round(time_stop - time_start, 2)} seconds to execute!')
输出如下所示:
Sleeping for a 1 second
Sleeping for a 1 second
Sleeping for a 1 second
Done.
Done.
Done.
Took 1.07 seconds to execute!
如你所见,三个进程都是独立且并行启动的,因此它们都成功地在同一秒内完成了任务。
Process() 和 start() 都是显而易见的,但 join() 函数在做什么呢?简单来说,它告诉 Python 等待进程完成。如果你在所有进程中调用 join(),则最后两行代码不会执行,直到所有进程都完成。为了好玩,尝试移除 join() 调用;你会立即明白其含义。
你现在对多进程有了基本的直觉,但故事还没有结束。Python 3.2 引入了一种新的、改进的并行执行任务的方法。concurrent.futures 库是目前最好的库,你将学习如何使用它。
使用它,你不需要手动管理进程。每个执行过的函数都会返回一些东西,在我们的sleep_func()函数中是None。你可以通过返回最后一个语句而不是打印它来改变它。此外,这种新的方法使用ProcessPoolExecutor()来运行。你不需要了解任何关于它的东西;只需记住,它用于同时执行多个进程。从代码的角度来看,简单地将你想要并行运行的所有内容放在里面。这种方法解锁了两个新的函数:
-
submit(): 用于并行运行函数。返回的结果将被追加到列表中,这样我们就可以在下一个函数中打印它们(或做任何其他事情)。 -
result(): 用于从函数中获取返回值。我们只需简单地打印结果,但你也可以做任何其他事情。
总结一下,我们将结果追加到列表中,然后在函数执行完毕后打印它们。以下代码片段展示了如何使用最新的 Python 方法实现多进程:
import time
import concurrent.futures
def sleep_func():
print('Sleeping for a 1 second')
time.sleep(1)
return 'Done.'
if __name__ == '__main__':
time_start = time.time()
with concurrent.futures.ProcessPoolExecutor() as ppe:
out = []
for _ in range(5):
out.append(ppe.submit(sleep_func))
for curr in concurrent.futures.as_completed(out):
print(curr.result())
time_stop = time.time()
print(f'Took {round(time_stop - time_start, 2)} seconds to execute!')
结果如下所示:
Sleeping for a 1 second
Sleeping for a 1 second
Sleeping for a 1 second
Sleeping for a 1 second
Sleeping for a 1 second
Done.
Done.
Done.
Done.
Done.
Took 1.17 seconds to execute!
如你所见,程序的行为与我们之前所做的一样,增加了一些好处——你不需要自己管理进程,而且语法更加简洁。
我们目前遇到的一个问题是缺少函数参数。目前,我们只是调用一个不接受任何参数的函数。这种情况在大多数时候都不会发生,因此尽早学习如何处理函数参数是很重要的。
我们将向sleep_func()函数引入一个参数,允许我们指定执行将被暂停多长时间。函数内的打印语句相应地更新。暂停时间在sleep_seconds列表中定义,并在每次迭代中将该值作为第二个参数传递给append()。
整个代码片段如下所示:
import time
import concurrent.futures
def sleep_func(how_long: int):
print(f'Sleeping for a {how_long} seconds')
time.sleep(how_long)
return f'Finished sleeping for {how_long} seconds.'
if __name__ == '__main__':
time_start = time.time()
sleep_seconds = [1, 2, 3, 1, 2, 3]
with concurrent.futures.ProcessPoolExecutor() as ppe:
out = []
for sleep_second in sleep_seconds:
out.append(ppe.submit(sleep_func, sleep_second))
for curr in concurrent.futures.as_completed(out):
print(curr.result())
time_stop = time.time()
print(f'Took {round(time_stop - time_start, 2)} seconds to execute!')
结果如下所示:
Sleeping for 1 seconds
Sleeping for 2 seconds
Sleeping for 3 seconds
Sleeping for 1 seconds
Sleeping for 2 seconds
Sleeping for 3 seconds
Finished sleeping for 1 seconds.
Finished sleeping for 1 seconds.
Finished sleeping for 2 seconds.
Finished sleeping for 2 seconds.
Finished sleeping for 3 seconds.
Finished sleeping for 3 seconds.
Took 3.24 seconds to execute!
这样你就可以在并行处理中处理函数参数了。请记住,每个机器上的执行时间可能不会完全相同,因为运行时间将取决于你的硬件。一般来说,你应该看到与脚本的非并行版本相比的速度提升。你现在已经了解了并行处理的基础。在下一节中,你将了解 Python 的 Dask 库是如何进入画面的,在接下来的章节中,你将结合并行编程、Dask 和 TPOT 来构建机器学习模型。
Dask 库简介
你可以将 Dask 视为数据规模处理中最革命的 Python 库之一。如果你是常规的 pandas 和 NumPy 用户,你会喜欢 Dask。这个库允许你处理 NumPy 和 pandas 不允许的数据,因为它们不适合 RAM。
Dask 支持 NumPy 数组和 pandas DataFrame 数据结构,所以你将很快熟悉它。它可以在你的电脑或集群上运行,这使得扩展变得更加容易。你只需要编写一次代码,然后选择你将运行它的环境。就这么简单。
另有一点需要注意,Dask 允许你通过最小的改动并行运行代码。正如你之前看到的,并行处理事物意味着执行时间减少,这是我们通常希望的行为。稍后,你将学习 Dask 中的并行性是如何通过 dask.delayed 实现的。
要开始,你必须安装这个库。确保正确的环境被激活。然后,从终端执行以下命令:
pipenv install "dask[complete]"
有其他安装选项。例如,你可以只安装数组或 DataFrames 模块,但最好从一开始就安装所有内容。不要忘记在库名称周围加上引号,否则会导致错误。
如果你已经安装了所有东西,你将能够访问三个 Dask 集合——数组、DataFrames 和 bags。所有这些都可以存储比你的 RAM 大的数据集,并且它们都可以在 RAM 和硬盘之间分区数据。
让我们从 Dask 数组开始,并与 NumPy 的替代品进行比较。你可以在 Notebook 环境中执行以下代码单元,创建一个具有 1,000x1,000x1,000 维度的 NumPy 单位数组。%%time 魔法命令用于测量单元格执行完成所需的时间:
%%time
import numpy as np
np_ones = np.ones((1000, 1000, 1000))
构建比这个更大的数组会导致我的机器出现内存错误,但这对比较来说已经足够了。相应的输出如下所示:
CPU times: user 1.86 s, sys: 2.21 s, total: 4.07 s
Wall time: 4.35 s
如你所见,创建这个数组花费了 4.35 秒。现在,让我们用 Dask 来做同样的事情:
%%time
import dask.array as da
da_ones = da.ones((1000, 1000, 1000))
如你所见,唯一的变化在于库导入名称。如果你第一次遇到 Dask 库,执行时间的结果可能会让你感到惊讶。它们在这里展示:
CPU times: user 677 µs, sys: 12 µs, total: 689 µs
Wall time: 696 µs
是的,你确实在读这段话。Dask 创建了一个具有相同维度的数组,耗时 696 微秒,这比之前快了 6,250 倍。当然,你不应该期望在现实世界中执行时间会有这么大的减少,但差异仍然应该相当显著。
接下来,让我们看看 Dask DataFrames。语法应该再次感觉非常相似,所以你不需要花太多时间来学习这个库。为了完全展示 Dask 的功能,我们将创建一些大型数据集,这些数据集将无法适应单个笔记本电脑的内存。更准确地说,我们将创建 10 个基于时间序列的 CSV 文件,每个文件代表一年的数据,按秒聚合并通过五个不同的特征进行测量。这有很多,创建它们肯定需要一些时间,但最终你应该会有 10 个数据集,每个数据集大约有 1 GB 的大小。如果你像我一样有一个 8 GB RAM 的笔记本电脑,你根本无法将其放入内存中。
以下代码片段创建了这些数据集:
import pandas as pd
from datetime import datetime
for year in np.arange(2010, 2020):
dates = pd.date_range(
start=datetime(year=year, month=1, day=1),
end=datetime(year=year, month=12, day=31),
freq='S'
)
df = pd.DataFrame()
df['Date'] = dates
for i in range(5):
df[f'X{i}'] = np.random.randint(low=0, high=100, size=len(df))
df.to_csv(f'data/{year}.csv', index=False)
!ls data/
只需确保你的笔记本位于这个/data文件夹中,你就可以顺利开始了。另外,如果你要跟进度,请确保你有 10 GB 的磁盘空间。最后一行,!ls data/,列出了data文件夹中所有文件。你应该看到以下内容:
2010.csv 2012.csv 2014.csv 2016.csv 2018.csv
2011.csv 2013.csv 2015.csv 2017.csv 2019.csv
现在,让我们看看 pandas 读取单个 CSV 文件并执行简单聚合操作需要多少时间。更精确地说,数据集按月份分组,并提取总和。以下代码片段演示了如何进行此操作:
%%time
df = pd.read_csv('data/2010.csv', parse_dates=['Date'])
avg = df.groupby(by=df['Date'].dt.month).sum()
结果在这里显示:
CPU times: user 26.5 s, sys: 9.7 s, total: 36.2 s
Wall time: 42 s
如你所见,pandas 执行这个计算需要 42 秒。这并不算太糟糕,但如果你绝对需要加载所有数据集并执行计算呢?让我们接下来探索这个问题。
你可以使用glob库来获取指定文件夹中所需文件的路径。然后你可以单独读取它们,并使用 pandas 的concat()函数将它们堆叠在一起。聚合操作以相同的方式进行:
%%time
import glob
all_files = glob.glob('data/*.csv')
dfs = []
for fname in all_files:
dfs.append(pd.read_csv(fname, parse_dates=['Date']))
df = pd.concat(dfs, axis=0)
agg = df.groupby(by=df['Date'].dt.year).sum()
这里没有太多可说的——笔记本只是简单地崩溃了。将 10 GB+的数据存储到 8 GB RAM 的机器中是不切实际的。你可以通过分块加载数据来解决这个问题,但这又是一个头疼的问题。
Dask 能做些什么来帮助呢?让我们学习如何使用 Dask 加载这些 CSV 文件并执行相同的聚合操作。你可以使用以下代码片段来完成:
%%time
import dask.dataframe as dd
df = dd.read_csv('data/*.csv', parse_dates=['Date'])
agg = df.groupby(by=df['Date'].dt.year).sum().compute()
结果将再次让你感到惊讶:
CPU times: user 5min 3s, sys: 1min 11s, total: 6min 15s
Wall time: 3min 41s
这是正确的——在不到 4 分钟内,Dask 成功地将超过 10 GB 的数据读取到 8 GB RAM 的机器上。仅此一点就足以让你重新考虑 NumPy 和 pandas,尤其是如果你正在处理大量数据或者你预计在不久的将来会处理数据。
最后,还有 Dask 的 bags。它们用于存储和处理无法放入内存的通用 Python 数据类型——例如,日志数据。我们不会探索这个数据结构,但了解它的存在是很好的。
另一方面,我们将使用 Dask 来探索并行处理的概念。在上一节中,你已经了解到没有有效的理由要按顺序处理数据或执行任何其他操作,因为一个操作的输入并不依赖于另一个操作的输出。
Dask 延迟允许并行执行。当然,你仍然可以依赖我们之前学到的多进程概念,但为什么还要这样做呢?这可能是一个繁琐的方法,而 Dask 有更好的解决方案。使用 Dask,你不需要改变编程语法,就像纯 Python 那样。你只需要使用@dask.delayed装饰器来注释你想并行化的函数,然后就可以开始了!
你可以将多个函数并行化,然后将它们放入计算图中。这正是我们接下来要做的。
以下代码片段声明了两个函数:
-
cube(): 返回一个数字的立方 -
multiply(): 将列表中的所有数字相乘并返回乘积
这里是你需要的库导入:
import time
import dask
import math
from dask import delayed, compute
让我们在五个数字上运行第一个函数,并在结果上调用第二个函数,看看会发生什么。注意cube()函数内部的time.sleep()调用。这将使我们在并行化和非并行化函数之间发现差异变得容易得多:
%%time
def cube(number: int) -> int:
print(f'cube({number}) called!')
time.sleep(1)
return number ** 3
def multiply(items: list) -> int:
print(f'multiply([{items}]) called!')
return math.prod(items)
numbers = [1, 2, 3, 4, 5]
graph = multiply([cube(num) for num in numbers])
print(f'Total = {graph}')
这就是您的常规(顺序)数据处理。这没有什么问题,尤其是在操作如此少且简单的情况下。相应的输出如下:
cube(1) called!
cube(2) called!
cube(3) called!
cube(4) called!
cube(5) called!
multiply([[1, 8, 27, 64, 125]]) called!
Total = 1728000
CPU times: user 8.04 ms, sys: 4 ms, total: 12 ms
Wall time: 5.02 s
如预期的那样,由于顺序执行,代码单元运行了大约 5 秒钟。现在,让我们看看您需要对这些函数进行哪些修改以实现并行化:
%%time
@delayed
def cube(number: int) -> int:
print(f'cube({number}) called!')
time.sleep(1)
return number ** 3
@delayed
def multiply(items: list) -> int:
print(f'multiply([{items}]) called!')
return math.prod(items)
numbers = [1, 2, 3, 4, 5]
graph = multiply([cube(num) for num in numbers])
print(f'Total = {graph.compute()}')
因此,只需要@delayed装饰器和在图上调用compute()。结果如下所示:
cube(3) called!cube(2) called!cube(4) called!
cube(1) called!
cube(5) called!
multiply([[1, 8, 27, 64, 125]]) called!
Total = 1728000
CPU times: user 6.37 ms, sys: 5.4 ms, total: 11.8 ms
Wall time: 1.01 s
如预期的那样,由于并行执行,整个过程仅用了不到一秒钟。之前声明的计算图还有一个方便的特性——它很容易可视化。您需要在您的机器上安装GraphViz,并将其作为 Python 库。对于每个操作系统,安装过程都不同,所以我们在这里不详细说明。快速 Google 搜索会告诉您如何安装它。一旦完成安装,您可以执行以下代码行:
graph.visualize()
对应的可视化显示如下:
![图 5.1 – Dask 计算图的可视化
图 5.1 – Dask 计算图的可视化
如您从图中所见,cube()函数被并行调用五次,其结果存储在上面的桶中。然后,使用这些值调用multiply()函数,并将乘积存储在顶部的桶中。
关于 Dask 的基本知识,您需要了解的就是这些。您已经学会了如何使用 Dask 数组和数据框,以及如何使用 Dask 并行处理操作。不仅如此,您还了解了 Dask 在现代数据科学和机器学习中的关键作用。数据集的大小通常超过可用内存,因此需要现代解决方案。
在下一节中,您将学习如何使用 Dask 训练 TPOT 自动化机器学习模型。
使用 TPOT 和 Dask 训练机器学习模型
优化机器学习管道是首要的任务,这是一个耗时的过程。我们可以通过并行运行来显著缩短它。当与 TPOT 结合使用时,Dask 和 TPOT 工作得很好,本节将教会您如何在 Dask 集群上训练 TPOT 模型。不要让“集群”这个词吓到您,因为您的笔记本电脑或 PC 就足够了。
您需要安装一个额外的库才能继续,它被称为dask-ml。正如其名所示,它用于使用 Dask 进行机器学习。从终端执行以下命令来安装它:
pipenv install dask-ml
完成这些后,您可以打开 Jupyter Lab 或您喜欢的 Python 代码编辑器并开始编码。让我们开始:
-
让我们从库导入开始。我们还会在这里做出数据集的决定。这次,我们不会在数据清洗、准备或检查上花费任何时间。目标是尽快准备好数据集。scikit-learn 中的
load_digits()函数很有用,因为它旨在获取许多 8x8 像素的数字图像以进行分类。由于一些库经常用不必要的警告填满你的屏幕,我们将使用
warnings库来忽略它们。有关所有库导入的参考,请参阅以下代码片段:import tpot from tpot import TPOTClassifier from sklearn.datasets import load_digits from sklearn.model_selection import train_test_split from dask.distributed import Client import warnings warnings.filterwarnings('ignore')这里唯一的新事物是来自
dask.distributed的Client类。它用于与 Dask 集群(在这种情况下是你的计算机)建立连接。 -
你现在将创建一个客户端实例。这将立即启动 Dask 集群并使用你所有可用的 CPU 核心。以下是创建实例和检查集群运行位置的代码:
client = Client() client执行后,你应该看到以下输出:
![Figure 5.2 – Dask 集群信息]
![img/B16954_05_002.jpg]
![Figure 5.2 – Dask 集群信息]
你可以点击仪表板链接,它将带你到 http://127.0.0.1:8787/status。以下截图显示了仪表板首次打开时的样子(没有运行任务):
![Figure 5.3 – Dask 集群仪表板(无运行任务)]
![img/B16954_05_003.jpg]
图 5.3 – Dask 集群仪表板(无运行任务)
一旦开始训练模型,仪表板将变得更加多彩。我们将在下一步进行必要的准备。
-
你可以调用
load_digits()函数来获取图像数据,然后使用train_test_split()函数将图像分割成训练和测试子集。在这个例子中,训练/测试比例是 50:50,因为我们不想在训练上花费太多时间。在几乎任何情况下,训练集的比例都应该更高,所以请确保记住这一点。分割完成后,你可以对子集调用
.shape来检查它们的维度。以下是整个代码片段:digits = load_digits() X_train, X_test, y_train, y_test = train_test_split( digits.data, digits.target, test_size=0.5, ) X_train.shape, X_test.shape相应的输出在以下图中显示:
![Figure 5.4 – 训练和测试子集的维度]
![img/B16954_05_004.jpg]
图 5.4 – 训练和测试子集的维度
下一个目标 – 模型训练。
-
你现在拥有使用 TPOT 和 Dask 训练模型所需的一切。你可以以与之前非常相似的方式这样做。这里的关键参数是
use_dask。如果你想使用 Dask 进行训练,你应该将其设置为True。其他参数都是众所周知的:estimator = TPOTClassifier( n_jobs=-1, random_state=42, use_dask=True, verbosity=2, max_time_mins=10 )现在,你已准备好调用
fit()函数并在训练子集上训练模型。以下是执行此操作的代码行:estimator.fit(X_train, y_train)一旦开始训练模型,Dask 仪表板的界面将立即改变。以下是过程进行几分钟后的样子:
![Figure 5.5 – 训练期间的 Dask 仪表板]
![img/B16954_05_005.jpg]
图 5.5 – 训练期间的 Dask 仪表板
10 分钟后,TPOT 将完成管道优化,你将在你的笔记本中看到以下输出:
图 5.6 – TPOT 优化输出
要将 TPOT 和 Dask 结合起来,你需要做的是所有这些。
你现在知道如何在 Dask 集群上训练模型,这是处理更大数据集和更具挑战性问题的推荐方法。
摘要
本章不仅包含了关于 TPOT 和以并行方式训练模型的信息,还包含了关于并行性的通用信息。你已经学到了很多——从如何并行化只做了一段时间休眠的基本函数,到并行化带有参数的函数和 Dask 基础知识,再到在 Dask 集群上使用 TPOT 和 Dask 训练机器学习模型。
到现在为止,你已经知道了如何以自动化的方式解决回归和分类任务,以及如何并行化训练过程。接下来的章节,第六章*,深度学习入门 – 神经网络速成课,将为你提供关于神经网络所需的知识。这将构成第七章**,使用 TPOT 的神经网络分类器的基础,我们将深入探讨使用最先进的神经网络算法训练自动化机器学习模型。
和往常一样,请随意练习使用 TPOT 解决回归和分类任务,但这次,尝试使用 Dask 并行化这个过程。
问答
-
定义“并行性”这个术语。
-
解释哪些类型的任务可以并行化,哪些不可以。
-
列出并解释在应用程序中实现并行化的三种选项(所有这些都在本章中列出)。
-
Dask 是什么?它为什么比 NumPy 和 pandas 在处理更大数据集时更优越?
-
名称并解释在 Dask 中实现的三种基本数据结构。
-
Dask 集群是什么?
-
你需要做什么来告诉 TPOT 它应该使用 Dask 进行训练?
第三部分:TPOT 中的高级示例和神经网络
本节面向更高级的用户。介绍了如神经网络等主题,并在 TPOT 中构建神经网络分类器。最后,将预测模型作为 REST API 部署到本地和云端,并用于实时预测。
本节包含以下章节:
-
第六章, 深度学习入门——神经网络速成课程
-
第七章, 使用 TPOT 的神经网络分类器
-
第八章, TPOT 模型部署
-
第九章, 在生产中使用部署的 TPOT 模型
第六章:深度学习入门:神经网络快速课程
在本章中,你将学习深度学习和人工神经网络的基础知识。你将了解这些主题背后的基本思想和理论,以及如何使用 Python 训练简单的神经网络模型。本章将为后续章节提供一个极好的入门,在这些章节中,管道优化和神经网络的理念将结合在一起。
我们将涵盖深度学习背后的基本主题和思想,为什么它在过去几年中变得流行,以及神经网络比传统机器学习算法表现更好的案例。你还将获得实际操作经验,从零开始编写自己的神经网络,以及通过预制的库来实现。
本章将涵盖以下主题:
-
深度学习概述
-
介绍人工神经网络
-
使用神经网络对手写数字进行分类
-
比较回归和分类中的神经网络
技术要求
在深度学习和神经网络方面没有先前的经验是必要的。你应该能够仅从本章中理解基础知识。先前的经验是有帮助的,因为深度学习不是一次就能学会的。
你可以在此处下载本章的源代码和数据集:github.com/PacktPublishing/Machine-Learning-Automation-with-TPOT/tree/main/Chapter06。
深度学习概述
深度学习是机器学习的一个子领域,它专注于神经网络。神经网络作为一个概念并不新鲜——它们在 20 世纪 40 年代就被引入了,但直到它们开始在数据科学竞赛中获胜(大约在 2010 年左右),才获得了更多的流行。
深度学习和人工智能可能最有成效的一年是 2016 年,这一切都归功于一个单一事件。AlphaGo,一个玩围棋的计算机程序,击败了世界排名第一的选手。在此事件之前,围棋被认为是一种计算机无法掌握的游戏,因为存在如此多的潜在棋盘配置。
如前所述,深度学习基于神经网络。你可以将神经网络想象成有向无环图 – 由顶点(节点)和边(连接)组成的图。输入层(最左侧的第一层)接收来自数据集的原始数据,通过一个或多个隐藏层传递,并构建输出。
你可以在以下图表中看到神经网络的一个示例架构:
图 6.1 – 一个示例神经网络架构
最左侧的小黑点表示输入数据——直接来自你的数据集的数据。然后这些值通过各自的权重和偏差与隐藏层连接。这些权重和偏差的常见称呼是可调参数。我们将在下一节中讨论这个术语并展示如何计算它们。
神经网络中的每个节点都称为神经元。让我们看看单个神经元的架构:
图 6.2 – 单个神经元
X 值对应于输入层或前一隐藏层的值。这些值相乘(x1 * w1,x2 * w2)然后相加(x1w1 + x2w2)。在求和之后,添加一个偏差项,最后,所有内容都通过一个激活函数。这个函数决定神经元是否会“激活”。用最简单的话说,就像一个开关。
这里展示了权重和偏差的简要说明:
-
权重:
a) 与前一层的值相乘
b) 可以改变幅度或完全将值从正变为负
c) 在函数术语中——调整权重会改变函数的斜率
-
偏差:
a) 解释为函数的偏移
b) 偏差的增加会导致函数向上移动
c) 偏差的减少会导致函数向下移动
除了人工神经网络之外,还有许多类型的神经网络架构,这里将讨论它们:
-
卷积神经网络(CNNs)——一种最常见的神经网络类型,用于分析图像。它们基于卷积操作——两个矩阵之间的操作,其中一个矩阵在另一个矩阵上滑动(卷积)并计算逐元素乘积。这个操作的目标是找到一个滑动的矩阵(核)可以从输入图像中提取正确的特征,从而简化图像分类任务。
-
循环神经网络(RNNs)——一种最常见的神经网络类型,用于处理序列数据。如今,这些网络被应用于许多任务,如手写识别、语音识别、机器翻译和时间序列预测。RNN 模型一次处理序列中的单个元素。处理完毕后,新的更新单元的状态传递到下一个时间步。想象一下根据前 n 个字符预测单个字符;这就是一般的概念。
-
生成对抗网络(GANs)——一种最常见的神经网络类型,用于在从真实数据学习后创建新的样本。GAN 架构由两个独立的模型组成——生成器和判别器。生成器模型的任务是生成假图像并将其发送到判别器。判别器的工作就像一个法官,试图判断图像是否为假。
-
自编码器 – 无监督学习技术,旨在学习高维数据集的低维表示。从某种意义上说,它们的工作方式类似于主成分分析(PCA)。
这四个深度学习概念不会在本书中介绍。我们将只关注人工神经网络,但了解它们的存在是有好处的,以防你想要自己深入研究。
下一节将探讨人工神经网络,并展示如何在 Python 中实现它们,无论是从头开始还是使用数据科学库。
介绍人工神经网络
人工神经网络的基本构建块是神经元。单独来看,一个神经元是无用的,但当它组合成一个更复杂的网络时,它可以具有强大的预测能力。
如果你不能理解其中的原因,想想你的大脑以及它是如何工作的。就像人工神经网络一样,它也是由数百万个神经元组成的,只有当它们之间有通信时才会工作。由于人工神经网络试图模仿人脑,它们需要以某种方式复制大脑中的神经元及其之间的连接(权重)。这一关联将在本节中逐步变得不那么抽象。
今天,人工神经网络可以用来解决常规机器学习算法可以解决的任何问题。简而言之,如果你可以用线性或逻辑回归解决问题,你也可以用神经网络解决。
在我们能够探索整个网络的复杂性和内部工作原理之前,我们必须从简单开始——从单个神经元的理论开始。
单个神经元的理论
使用 Python 模拟单个神经元很容易。例如,假设一个神经元从五个其他神经元(输入,或 X)接收值。在将其实现为代码之前,我们先从视觉上考察这种行为。以下图表显示了单个神经元在接收来自前一层五个神经元的值时的样子(我们正在模拟右侧的神经元):
图 6.3 – 模拟单个神经元
X 代表输入特征,这些特征可能来自原始数据或前一个隐藏层。每个输入特征都分配有一个权重,用 W 表示。相应的输入值和权重相乘并求和,然后在结果上加上偏置项(b)。
计算我们神经元输出值的公式如下:
让我们用具体的数值来使这个概念更清晰。以下图表看起来与图 6.3 相同,但用实际的数字代替了变量:
图 6.4 – 神经元值计算
我们可以直接将这些值代入前面的公式来计算值:
实际上,单个神经元可以从前一层可能成千上万的神经元中获得其值,因此手动计算值并直观表达是不切实际的。
即使你决定这样做,那也只是一个前向传递。神经网络在反向传递中学习,手动计算这个传递要复杂得多。
编码单个神经元
接下来,让我们看看如何使用 Python 半自动化地计算神经元值:
-
首先,让我们声明输入值、它们各自的权重以及偏置项的值。前两者是列表,而偏置项只是一个数字:
inputs = [5, 4, 2, 1, 6] weights = [0.1, 0.3, 0.05, 0.4, 0.9] bias = 4这就是计算输出值所需的所有内容。接下来,让我们看看你的选择有哪些。
-
计算神经元输出值有三种简单的方法。第一种是最手动的方法,即明确地乘以相应的输入和权重,然后将它们与偏置项相加。
下面是一个 Python 实现:
output = (inputs[0] * weights[0] + inputs[1] * weights[1] + inputs[2] * weights[2] + inputs[3] * weights[3] + inputs[4] * weights[4] + bias) output执行此代码后,你应该会看到一个
11.6的值打印出来。更精确地说,这个值应该是11.600000000000001,但不用担心这个计算误差。下一种方法稍微更可扩展一些,它归结为同时迭代输入和权重,并递增之前声明的输出变量。循环结束后,添加偏置项。下面是如何实现这种计算方法的:
output = 0 for x, w in zip(inputs, weights): output += x * w output += bias output输出仍然是相同的,但你可以立即看到这个选项的可扩展性有多高。想象一下,如果前一个网络层有 1,000 个神经元,使用第一个选项——这甚至都不方便。
第三种也是首选的方法是使用科学计算库,例如 NumPy。有了它,你可以计算向量点积并添加偏置项。下面是如何操作的:
import numpy as np output = np.dot(inputs, weights) + bias output这个选项既易于编写也易于执行,所以是首选的。
你现在知道如何编码单个神经元——但神经网络使用的是神经元层。你将在下一节中了解更多关于层的内容。
单层的理论
为了简化问题,可以将层想象成向量或简单的组。层并不是一些复杂或抽象的数据结构。在代码术语中,你可以将它们视为列表。它们包含一定数量的神经元。
编码单个神经层与编码单个神经元相当相似。我们仍然有相同的输入,因为它们要么来自前一个隐藏层,要么来自输入层。变化的是权重和偏置。在代码术语中,权重不再被视为列表,而是列表的列表(或矩阵)。同样,偏置现在是一个列表而不是标量值。
简单来说,你的权重矩阵将会有与新层中神经元数量一样多的行,以及与前一层的神经元数量一样多的列。让我们通过一个示例图来使这个概念更加具体化:
图 6.5 – 神经层
权重值故意没有放在之前的图中,因为它看起来会很杂乱。要在代码中实现这一层,你需要以下结构:
-
输入向量(1 行,5 列)
-
权重矩阵(2 行,5 列)
-
偏置向量(1 行,2 列)
线性代数中的一个矩阵乘法规则指出,两个矩阵需要具有形状(m, n)和(n, p),以便在乘法后产生一个(m, p)矩阵。考虑到这一点,你可以通过转置权重矩阵轻松地进行矩阵乘法。
从数学上讲,这是你可以用来计算输出层值的公式:
在这里,以下适用:
-
是输入向量。
-
是权重矩阵。
-
是偏置向量。
让我们为所有这些声明值,并看看如何计算输出层的值:
之前提到的公式现在可以用来计算输出层的值:
这基本上就是你可以计算整个层的输出的方法。对于实际的神经网络,计算量会增长,因为每一层有数千个神经元,但数学背后的逻辑是相同的。
你可以看到手动计算层输出是多么繁琐。你将在下一节中学习如何在 Python 中计算这些值。
编码单层
现在我们来探讨三种计算单层输出值的方法。与单个神经元一样,我们将从手动方法开始,并以 NumPy 的一行代码结束。
你必须首先声明输入、权重和偏置的值,所以下面是如何做的:
inputs = [5, 4, 2, 1, 6]
weights = [
[0.1, 0.3, 0.05, 0.4, 0.9],
[0.3, 0.15, 0.4, 0.7, 0.2]
]
biases = [4, 2]
让我们继续计算输出层的值:
-
让我们从手动方法开始。不,我们不会像处理神经元那样进行相同的程序。当然,你可以这样做,但看起来会太杂乱且不实用。相反,我们将立即使用
zip()函数遍历weights矩阵和biases数组,并计算单个输出神经元的值。这个过程会重复进行,直到有那么多神经元,每个输出神经元都会被添加到一个表示输出层的列表中。
这是整个代码片段:
layer = [] for n_w, n_b in zip(weights, biases): output = 0 for x, w in zip(inputs, n_w): output += x * w output += n_b layer.append(output) layer结果是一个包含值
[11.6, 6.8]的列表,这与我们之前手动计算得到的结果相同。虽然这种方法可行,但仍然不是最优的。让我们看看如何改进。
-
你现在将通过将输入值与
weights矩阵的每一行进行向量点积来计算输出层的值。在完成此操作后,将添加偏置项。让我们看看它是如何实际工作的:
import numpy as np layer = [] for n_w, n_b in zip(weights, biases): layer.append(np.dot(inputs, n_w) + n_b) layer层的值仍然是相同的——
[11.6, 6.8],这种方法比之前的方法稍微可扩展一些。它还可以进一步改进。让我们看看下一步如何操作。 -
你可以使用一行 Python 代码在输入和转置权重之间执行矩阵乘法,并添加相应的偏差。下面是如何操作的:
layer = np.dot(inputs, np.transpose(weights)) + biases layer如果出于某种原因,你想手动计算输出,这是推荐的方法。NumPy 可以完全处理它,因此它也是最快的。
现在,你已经知道了如何计算单个神经元和神经网络单层的输出值。到目前为止,我们还没有涵盖神经网络中的一个关键概念,它决定了神经元是否会“触发”或“激活”。这些被称为激活函数,我们将在下一节中介绍。
激活函数
激活函数对于神经网络输出,以及深度学习模型的输出至关重要。它们不过是数学方程,而且相对简单。激活函数是决定神经元是否“激活”的函数。
另一种思考激活函数的方式是将其视为一种门控,它位于当前神经元接收到的输入和其输出(传递到下一层)之间。激活函数可以像阶跃函数(开启或关闭神经元)那样简单,或者稍微复杂一些且非线性。在学习和提供准确预测的复杂数据中,非线性函数非常有用。
接下来,我们将介绍一些最常用的激活函数。
阶跃函数
阶跃函数基于一个阈值。如果输入的值高于阈值,则神经元被激活。这就是为什么我们可以说阶跃函数充当开/关开关——中间没有值。
你可以使用 Python 和 NumPy 轻松地声明和可视化一个基本的阶跃函数。过程如下:
-
首先,你必须定义一个阶跃函数。典型的阈值是 0,因此只有当传递给函数的值大于 0(输入值是前一个输入的总和乘以权重并加上偏差)时,神经元才会激活。
这种逻辑在 Python 中实现起来非常简单:
def step_function(x): return 1 if x > 0 else 0 -
现在,你可以声明一个值列表,这些值将作为该函数的输入,然后对列表应用
step_function()。以下是一个示例:xs = np.arange(-10, 10, step=0.1) ys = [step_function(x) for x in xs] -
最后,你只需两行代码就可以使用 Matplotlib 库可视化该函数:
plt.plot(xs, ys, color='#000000', lw=3) plt.title('Step activation function', fontsize=20)你可以在以下图表中直观地看到函数的工作方式:
图 6.6 – 阶跃激活函数
阶跃函数的最大问题是它不允许有多个输出——只有两个。接下来,我们将深入研究一系列非线性函数,你将看到它们的不同之处。
Sigmoid 函数
Sigmoid 激活函数通常被称为逻辑函数。它在神经网络和深度学习的领域中非常受欢迎。它本质上将输入转换为一个介于 0 和 1 之间的值。
你将在后面看到函数的工作方式,你将立即注意到它相对于阶梯函数的优势 – 梯度是平滑的,所以输出值中没有跳跃。例如,如果值略有变化(例如,从-0.000001 到 0.0000001),你不会从 0 跳到 1。
Sigmoid 函数在深度学习中确实存在一个常见问题 – 梯度消失。这是一个在反向传播(神经网络学习过程中的一个过程,远超本章范围)中经常出现的问题。简单来说,梯度在反向传递过程中“消失”,使得网络无法学习(调整权重和偏差),因为建议的调整太接近于零。
你可以使用 Python 和 NumPy 轻松声明和可视化 Sigmoid 函数。过程如下:
-
首先,你需要定义 Sigmoid 函数。其公式已经相当成熟:(1 / (1 + exp(-x))),其中x是输入值。
下面是如何在 Python 中实现此公式的示例:
def sigmoid_function(x): return 1 / (1 + np.exp(-x)) -
现在,你可以声明一个值列表,该列表将作为此函数的输入,然后应用
sigmoid_function()到这个列表上。以下是一个示例:xs = np.arange(-10, 10, step=0.1) ys = [step_function(x) for x in xs] -
最后,你只需两行代码就可以使用 Matplotlib 库可视化该函数:
plt.plot(xs, ys, color='#000000', lw=3) plt.title(Sigmoid activation function', fontsize=20)你可以在以下图表中看到函数的视觉工作方式:
![Figure 6.7 – Sigmoid 激活函数
图 6.7 – Sigmoid 激活函数
一个很大的缺点是 sigmoid 函数返回的值不是围绕零中心分布的。这是一个问题,因为对高度负值或高度正值输入的建模变得更加困难。双曲正切函数解决了这个问题。
双曲正切函数
双曲正切函数(或 TanH)与 Sigmoid 函数密切相关。它也是一种激活函数,也受到梯度消失问题的影响,但其输出值围绕零中心分布 – 函数的范围从-1 到+1。
这使得对高度负值或高度正值输入的建模变得容易得多。你可以使用 Python 和 NumPy 轻松声明和可视化双曲正切函数。过程如下:
-
首先,你需要定义双曲正切函数。你可以使用 NumPy 的
tanh()函数来实现。下面是如何在 Python 中实现它的示例:
def tanh_function(x): return np.tanh(x) -
现在,你可以声明一个值列表,该列表将作为此函数的输入,然后应用
tanh_function()到这个列表上。以下是一个示例:xs = np.arange(-10, 10, step=0.1) ys = [step_function(x) for x in xs] -
最后,你只需两行代码就可以使用 Matplotlib 库可视化该函数:
plt.plot(xs, ys, color='#000000', lw=3) plt.title(Tanh activation function', fontsize=20)你可以在以下图表中看到函数的视觉工作方式:
![Figure 6.8 – 双曲正切激活函数
图 6.8 – 双曲正切激活函数
为了有效地训练和优化神经网络,您需要一个充当线性函数但本质上是非线性的激活函数,以便网络能够学习数据中的复杂关系。这就是本节最后一个激活函数的作用所在。
矩形线性单元函数
矩形线性单元(或 ReLU)函数是您在大多数现代深度学习架构中都能看到的激活函数。简单来说,它返回 0 和 x 之间的两个值中的较大值,其中 x 是输入值。
ReLU 是最具计算效率的函数之一,它允许相对快速地找到收敛点。您将在下一节中看到如何在 Python 中实现它:
-
首先,您必须定义 ReLU 函数。这可以从头开始完成,也可以使用 NumPy 完成,因为您只需要找到两个值(0 和 x)中的较大值。
这是 Python 中实现 ReLU 的方法:
def relu_function(x): return np.maximum(0, x) -
您现在可以声明一个值列表,该列表将作为此函数的输入,然后应用
relu_function()到此列表。以下是一个示例:xs = np.arange(-10, 10, step=0.1) ys = [step_function(x) for x in xs] -
最后,您可以使用 Matplotlib 库仅用两行代码来可视化该函数:
plt.plot(xs, ys, color='#000000', lw=3) plt.title(ReLU activation function', fontsize=20)您可以在以下图表中直观地看到该函数的工作原理:
![图 6.9 – ReLU 激活函数
图 6.9 – ReLU 激活函数
这就是 ReLU 的概述。您可以使用默认版本或任何变体(例如,泄漏 ReLU 或参数 ReLU),具体取决于用例。
您现在已经了解了足够的理论,可以使用 Python 编写一个基本的神经网络。我们还没有涵盖所有的理论主题,所以像损失、梯度下降、反向传播等术语可能仍然感觉抽象。我们将在接下来的动手示例中尝试解开这些谜团。
使用神经网络对手写数字进行分类
深度学习的“hello world”是训练一个能够对手写数字进行分类的模型。这正是本节要做的。使用 TensorFlow 库实现它只需要几行代码。
在您继续之前,您必须安装 TensorFlow。根据您是在 Windows、macOS 还是 Linux 上,以及您是否有 CUDA 兼容的 GPU,安装过程会有所不同。您可以参考官方安装说明:www.tensorflow.org/install。本节其余部分假设您已安装 TensorFlow 2.x。以下是需要遵循的步骤:
-
首先,您必须导入 TensorFlow 库以及一些额外的模块。
datasets模块使您能够直接从笔记本中下载数据。layers和models模块将在以后用于设计神经网络的架构。这是导入代码片段:
import tensorflow as tf from tensorflow.keras import datasets, layers, models -
现在,您可以继续进行数据收集和准备。调用
datasets.mnist.load_data()将下载训练和测试图像以及相应的训练和测试标签。这些图像是灰度的,大小为 28x28 像素。这意味着您将有一系列 28x28 的矩阵,其值范围从 0(黑色)到 255(白色)。然后,您可以通过重新缩放图像来进一步准备数据集 – 将值除以 255,将所有内容转换为 0 到 1 的范围:
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data() train_images, test_images = train_images / 255.0, test_images / 255.0在您的笔记本中应该看到以下内容:
图 6.10 – 下载 MNIST 数据集
-
此外,您还可以检查图像中的一个矩阵值,看看您是否能在其中找到模式。
以下代码行使检查矩阵变得容易 – 它打印它们并将所有浮点数四舍五入到一个小数点:
print('\n'.join([''.join(['{:4}'.format(round(item, 1)) for item in row]) for row in train_images[0]]))结果如下截图所示:
图 6.11 – 检查单个图像矩阵
您是否注意到在图像中很容易找到数字 5?您可以通过执行
train_labels[0]来验证。 -
您可以继续布局神经网络架构。如前所述,输入图像的大小为 28x28 像素。人工神经网络不能直接处理矩阵,因此您必须将这个矩阵转换为向量。这个过程被称为
layers.Dense()来构建一个层。这个隐藏层也需要一个激活函数,因此可以使用 ReLU。
最后,您可以添加最终的(输出)层,该层需要与不同类别的数量一样多的神经元 – 在这个例子中是 10 个。
这是网络架构的整个代码片段:
model = models.Sequential([ layers.Flatten(input_shape=(28, 28)), layers.Dense(128, activation='relu'), layers.Dense(10) ])models.Sequential函数允许您将层一个接一个地堆叠起来,并且,嗯,从单个层中构建一个网络。您可以通过在模型上调用
summary()方法来查看模型的架构:model.summary()结果如下截图所示:
图 6.12 – 神经网络架构
-
在模型训练之前,您还需要做一件事,那就是编译模型。在编译过程中,您需要指定优化器、损失函数和优化指标的具体值。
这些内容在本章中尚未涉及,但下面将简要解释每个部分:
-
优化器 – 用于改变神经网络属性以减少损失值的算法。这些属性包括权重、学习率等。
-
损失 – 一种用于计算梯度的方法,然后使用这些梯度来更新神经网络中的权重。
-
指标 – 您正在优化的指标(例如,准确率)。
深入探讨这些主题超出了本书的范围。有很多资源可以帮助您了解深度学习背后的理论。本章仅旨在介绍基本概念。
你可以通过执行以下代码来编译你的神经网络:
model.compile( optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'] )
-
-
现在,你已经准备好训练模型了。训练子集将被用来训练网络,测试子集将被用来评估。网络将训练 10 个 epoch(即 10 次完整遍历整个训练数据)。
你可以使用以下代码片段来训练模型:
history = model.fit( train_images, train_labels, epochs=10, validation_data=(test_images, test_labels) )执行前面的代码将启动训练过程。所需时间取决于你的硬件配置以及你是否使用了 GPU 或 CPU。你应该会看到以下类似的屏幕截图:
图 6.13 – MNIST 模型训练
经过 10 个 epoch 后,验证集上的准确率达到了 97.7%——如果我们考虑到常规神经网络在图像处理上表现不佳的话,这已经是非常出色的了。
-
要在新的实例上测试你的模型,你可以使用
predict()方法。它返回一个数组,告诉你对于给定类别的预测是否正确。这个数组将有 10 个项,因为共有 10 个类别。然后,你可以调用
np.argmax()来获取值最高的项:import numpy as np prediction = model.predict(test_images[0].reshape(-1, 784)) print(f'True digit = {test_labels[0]}') print(f'Predicted digit = {np.argmax(prediction)}')结果将在下面的屏幕截图中展示:
图 6.14 – 测试 MNIST 模型
如你所见,预测是正确的。
就是这样简单,使用 TensorFlow 等库训练神经网络。请记住,在现实世界中,我们不建议使用这种方式处理图像分类,因为我们已经将 28x28 的图像展平,立即丢失了所有的二维信息。对于图像分类,CNN(卷积神经网络)会是一个更好的方法,因为它们可以从二维数据中提取有用的特征。我们的人工神经网络在这里表现良好,因为 MNIST 是一个简单且干净的数据库集——这不是你在工作中会遇到的很多情况。
在下一节中,你将了解使用神经网络处理分类和回归任务的差异。
回归与分类中的神经网络
如果你使用过 scikit-learn 进行过任何机器学习,你就会知道,对于回归和分类数据集,都有专门的类和模型。例如,如果你想将决策树算法应用于分类数据集,你会使用DecisionTreeClassifier类。同样,对于回归任务,你会使用DecisionTreeRegressor类。
但你该如何使用神经网络呢?没有专门用于分类和回归任务的类或层。
相反,你可以通过调整输出层中的神经元数量来适应。简单来说,如果你处理的是回归任务,输出层中必须只有一个神经元。如果你处理的是分类任务,输出层中的神经元数量将与目标变量中的不同类别数量相同。
例如,你看到了上一节中的神经网络在输出层有 10 个神经元。原因是存在从零到九的 10 个不同的数字。如果你预测的是某物的价格(回归),输出层将只有一个神经元。
神经网络的任务是学习适当的参数值(权重和偏置),以产生最佳输出值,无论你正在解决什么类型的问题。
摘要
如果这是您第一次接触深度学习和神经网络,那么这一章可能难以理解。反复阅读材料可能会有所帮助,但这还不足以完全理解这个主题。关于深度学习,甚至关于深度学习的小子集,已经写出了整本书。因此,在一章中涵盖所有内容是不可能的。
尽管如此,您应该了解神经元、层和激活函数概念背后的基本理论,并且您可以随时自学更多。下一章,第七章*,TPOT 神经网络分类器*,将向您展示如何连接神经网络和管道优化,这样您就可以完全自动地构建最先进的模型。
和往常一样,请随时探索深度学习和神经网络的理沦和实践。这绝对是一个值得进一步研究的学术领域。
Q&A
-
你将如何定义“深度学习”这个术语?
-
传统机器学习算法与深度学习中使用的算法有什么区别?
-
列出并简要描述五种类型的神经网络。
-
你能想出如何根据每层的神经元数量来计算网络中的可训练参数数量吗?例如,具有架构[10, 8, 8, 2]的神经网络总共有 178 个可训练参数(160 个权重和 18 个偏置)。
-
列出四种不同的激活函数,并简要解释它们。
-
用你自己的话描述神经网络中的损失。
-
解释为什么用常规人工神经网络来建模图像分类模型不是一个好主意。
第七章:使用 TPOT 的神经网络分类器
在本章中,你将学习如何以自动化的方式构建你的深度学习分类器——通过使用 TPOT 库。假设你已了解人工神经网络的基本知识,因此诸如神经元、层、激活函数和学习率等术语应该听起来很熟悉。如果你不知道如何简单地解释这些术语,请回顾第六章,深度学习入门:神经网络快速入门。
在本章的整个过程中,你将了解到构建基于神经网络的简单分类器是多么容易,以及你如何调整神经网络以更好地满足你的需求和训练数据。
本章将涵盖以下主题:
-
探索数据集
-
探索训练神经网络分类器的选项
-
训练神经网络分类器
技术要求
你不需要有深度学习和神经网络的实际操作经验。然而,了解一些基本概念和术语是必须的。如果你对这个主题完全陌生,请回顾第六章,深度学习入门:神经网络快速入门。
你可以在此处下载本章的源代码和数据集:github.com/PacktPublishing/Machine-Learning-Automation-with-TPOT/tree/main/Chapter07。
探索数据集
没有必要对数据集进行过度探索。仅仅因为我们可以用 TPOT 训练神经网络模型,并不意味着我们应该花费 50 多页来无谓地探索和转换复杂的数据集。
因此,在本章中,你将使用 scikit-learn 内置的数据集——乳腺癌数据集。这个数据集不需要从网络上下载,因为它已经内置在 scikit-learn 中。让我们先加载并探索它:
-
首先,你需要加载几个库。我们导入 NumPy、pandas、Matplotlib 和 Seaborn,以便于数据分析和可视化。此外,我们还从
sklearn.datasets模块导入load_breast_cancer函数。这是将数据集加载进来的函数。最后,从 Matplotlib 导入rcParams模块,以便使默认样式更容易看清楚:import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.datasets import load_breast_cancer from matplotlib import rcParams rcParams['figure.figsize'] = (14, 7) rcParams['axes.spines.top'] = False rcParams['axes.spines.right'] = False -
你现在可以使用
load_breast_cancer函数来加载数据集。该函数返回一个字典,因此我们可以使用keys()方法来打印键:data = load_breast_cancer() data.keys()结果如下所示:
图 7.1 – 乳腺癌数据集的字典键
-
您现在可以使用这个字典来提取感兴趣的属性。目前最重要的是
data和target键。您可以将它们的值存储到单独的变量中,然后从它们中构建一个数据框对象。使用原始值是可能的,但 pandas 数据框数据结构将允许更轻松的数据操作、转换和探索。这里是如何将这些数据转换为 pandas 数据框的:
features = data.data target = data.target df =\ pd.DataFrame(data=features,columns=data.feature_names) df['target'] = target df.sample(8)结果如下表所示:
图 7.2 – 乳腺癌数据集的八行样本
-
在分析方面,您首先想要做的是检查缺失数据。Pandas 内置了一个
isnull()方法,它为数据集中的每个值返回布尔值。然后,您可以在这些结果上调用sum()方法来获取每列的缺失值计数:df.isnull().sum()结果如下所示:
图 7.3 – 每列的缺失值计数
如您所见,没有缺失值。
-
在探索阶段,下一步是熟悉您的数据集。数据可视化技术可以提供一种极好的方式来完成这项工作。
例如,您可以声明一个名为
make_count_chart()的函数,它接受任何分类属性并可视化其分布。下面是这个函数的代码示例:def make_count_chart(column, title, ylabel, xlabel, y_offset=0.12, x_offset=700): ax = df[column].value_counts().plot(kind='bar', fontsize=13, color='#4f4f4f') ax.set_title(title, size=20, pad=30) ax.set_ylabel(ylabel, fontsize=14) ax.set_xlabel(xlabel, fontsize=14) for i in ax.patches: ax.text(i.get_x() + x_offset, i.get_height()\ + y_offset, f'{str(round(i.get_height(), 2))}',\ fontsize=15) return ax您现在可以使用以下代码片段来可视化目标变量,以找出有多少实例是良性的,有多少是恶性的:
make_count_chart( column='target', title=\ 'Number of malignant (1) vs benign (0) cases', ylabel='Malignant? (0 = No, 1 = Yes)', xlabel='Count', y_offset=10, x_offset=0.22 )结果如下所示:
图 7.4 – 恶性和良性病例数量
如您所见,恶性病例的数量要多得多,所以类别并不完全平衡。类别不平衡可能导致高度准确但不可用的模型。想象一下,您正在对罕见事件进行分类。在每 10,000 笔交易中,只有一笔被分类为异常。显然,机器学习模型没有多少机会学习使异常与其他事件不同的原因。
此外,总是预测交易是正常的会导致一个 99.99% 准确的模型。这是一个最先进的准确率,但模型不可用。
处理不平衡数据集有许多技术,但这些超出了本书的范围。
-
下一个步骤是相关性分析。这一步的目标是看看哪些特征对目标变量影响最大。换句话说,我们想要确定特征方向变化与目标类之间的相关性。在 30+ 列的数据集上可视化整个相关性矩阵并不是最好的主意,因为这需要一个太大而无法舒适地放在单页上的图。相反,我们可以计算特征与目标变量之间的相关性。
这里是如何为
平均面积特征进行此操作的示例——通过从 NumPy 调用corrcoeff()方法:np.corrcoef(df['mean area'], df['target'])[1][0]结果如下所示:
corr_with_target = [] for col in df.columns[:-1]: corr = np.corrcoef(df[col], df['target'])[1][0] corr_with_target.append({'Column': col, 'Correlation': corr}) corr_df = pd.DataFrame(corr_with_target) corr_df = \ corr_df.sort_values(by='Correlation', ascending=False)请注意循环开始处的
[:-1]。由于目标变量是最后一列,我们可以使用上述切片技术排除目标变量,从而不将其包含在相关性计算中。目标变量与非目标变量之间的相关系数将为 1,这对我们来说并不特别有用。您现在可以使用以下代码来绘制与目标变量的相关性水平条形图:
plt.figure(figsize=(10, 14)) plt.barh(corr_df['Column'], corr_df['Correlation'], color='#4f4f4f') plt.title('Feature correlation with the target variable', fontsize=20) plt.xlabel('Feature', fontsize=14) plt.ylabel('Correlation', fontsize=14) plt.show()结果如下所示:
图 7.6 – 特征与目标变量的相关性
如您所见,大多数特征与目标变量具有高度负相关性。负相关性意味着当一个变量增加时,另一个变量会减少。在我们的例子中,特征数量的减少会导致目标变量的增加。
-
您还可以根据目标变量的值可视化每个数值列的分布。更准确地说,这意味着在单个图表上绘制两个单独的直方图,每个直方图只显示相应目标值子集的分布。
例如,这意味着一个直方图将显示每个变量的恶性实例的分布,另一个直方图将显示良性实例的分布。
您即将看到的代码片段声明了一个
draw_histogram()函数,该函数遍历数据集中的每一列,根据目标变量的不同类别绘制直方图,并将此直方图附加到图上。一旦所有直方图都被附加,该图将显示给用户。用户还必须指定他们想要的行数和列数,这为设计可视化提供了一些额外的自由度。
这是绘制此直方图网格的代码片段:
def draw_histogram(data, columns, n_rows, n_cols): fig = plt.figure(figsize=(12, 18)) for i, var_name in enumerate(columns): ax = fig.add_subplot(n_rows, n_cols, i + 1) sns.histplot(data=data, x=var_name, hue='target') ax.set_title(f'Distribution of {var_name}') fig.tight_layout() plt.show() draw_histogram(df, df.columns[:-1], 9, 4)这将是一个非常大的数据可视化,包含 9 行和 4 列。最后一行将只有 2 个直方图,因为总共有 30 个连续变量。
结果如下所示:
图 7.7 – 每个连续变量的直方图
如您所见,大多数情况下存在明显的分离,因此我们的模型在类之间进行合理的分离时不应有太多困难。
那就是我们在探索性数据分析方面要做的所有事情。您可以,并且被鼓励去做更多,特别是对于自定义和更复杂的数据集。下一节将向您介绍您用于训练自动神经网络分类器的选项。
探索训练神经网络分类器的选项
当使用 TPOT 训练神经网络模型时,你有许多选项。整个神经网络的故事在 TPOT 中仍然是新的和实验性的,需要比常规的 scikit-learn 估计器更多的手动工作。
默认情况下,TPOT 不会使用神经网络模型,除非你明确指定它必须使用。这种指定是通过选择一个包含一个或多个神经网络估计器的适当配置字典来完成的(你也可以手动编写这些字典)。
更方便的选项是从tpot/config/classifier_nn.py文件中导入配置字典。该文件包含两个 PyTorch 分类器配置,如下面的图所示:
图 7.8 – TPOT PyTorch 分类器配置
从前面的图中,你可以看到 TPOT 目前可以处理基于深度学习库的两种不同类型的分类器:
-
逻辑回归:在
tpot.builtins.PytorchLRClassifier中展示 -
多层感知器:在
tpot.builtins.PytorchMLPClassifier中展示
你可以选择导入此文件或手动编写配置。此外,你还可以指定自己的配置字典,这些字典以某种方式修改了现有的配置。例如,你可以使用以下代码来使用基于 PyTorch 的逻辑回归估计器:
tpot_config = {
'tpot.nn.PytorchLRClassifier': {
'learning_rate': [1e-3, 1e-2, 1e-1, 0.5, 1.]
}
}
在本章后面,当我们开始实现神经网络分类器时,将讨论自定义配置。
你应该记住,使用 TPOT 训练神经网络分类器是一个耗时的任务,通常比 scikit-learn 估计器训练时间要长得多。一般来说,你应该预计神经网络训练时间要慢几个数量级。这是因为神经网络架构可以有数百万个可训练和可调整的参数,找到所有这些参数的正确值需要时间。
考虑到这一点,你应该首先考虑更简单的选项,因为 TPOT 很可能在默认的 scikit-learn 估计器上为你提供一个性能优异的管道。
下一节将继续从上一节停止的地方继续训练神经网络分类器,并展示如何使用不同的训练配置来训练你的模型。
训练神经网络分类器
到目前为止,我们已经加载了数据集并进行了基本的数据探索性分析。本章的这一部分将专注于通过不同的配置来训练模型:
-
在我们开始模型训练之前,我们需要将我们的数据集分成训练集和测试集。这样做将允许我们有一个模型从未见过的数据样本,并且可以稍后用于评估。
以下代码片段将以 75:25 的比例分割数据:
from sklearn.model_selection import train_test_split X = df.drop('target', axis=1) y = df['target'] X_train, X_test, y_train, y_test =train_test_split(\ X, y, test_size=0.25, random_state=42)我们可以开始训练了。
-
像往常一样,让我们从训练一个基线模型开始。这将作为神经网络分类器必须超越的最小可行性能。
最简单的二元分类算法是逻辑回归。以下代码片段从 scikit-learn 中导入它,以及一些评估指标,如混淆矩阵和准确率。此外,该片段实例化了模型,进行了训练,在保留集上进行了预测,并打印了混淆矩阵和准确率。
以下是一个代码片段:
from sklearn.linear_model import LogisticRegression from sklearn.metrics import confusion_matrix, accuracy_score lr_model = LogisticRegression() lr_model.fit(X_train, y_train) lr_preds = lr_model.predict(X_test) print(confusion_matrix(y_test, lr_preds)) print() print(accuracy_score(y_test, lr_preds))结果如下所示:
![图 7.9 – 基线模型的混淆矩阵和准确率]
图 7.9 – 基线模型的混淆矩阵和准确率
我们现在知道基线模型的准确率为 96.5%,产生了 4 个假阳性和 1 个假阴性。接下来,我们将使用 TPOT 训练一个自动化的神经网络分类器,并看看结果如何比较。
-
如前所述,使用 TPOT 训练神经网络分类器是一项艰巨的任务。因此,你可能最好切换到一个免费的 GPU 云环境,例如Google Colab。
这将确保更快的训练时间,同时你也不会让你的电脑过热。一旦进入该环境,你可以使用以下代码片段来训练基于 PyTorch 的逻辑回归模型:
from tpot import TPOTClassifier classifier_lr = TPOTClassifier( config_dict='TPOT NN', template='PytorchLRClassifier', generations=2, random_state=42, verbosity=3 ) classifier_lr.fit(X_train, y_train)这将训练模型两代。你会在训练过程中看到各种输出,如下所示:
![图 7.10 – TPOT 神经网络训练过程]
classifier_lr.fitted_pipeline_结果如下所示:
![图 7.12 – TPOT PyTorch 逻辑回归最佳流程]
from sklearn.metrics import confusion_matrix,\ accuracy_score tpot_lr_preds = classifier_lr.predict(X_test) print(confusion_matrix(y_test, tpot_lr_preds)) print() print(accuracy_score(y_test, tpot_lr_preds))结果如下所示:
![图 7.13 – PyTorch 逻辑回归模型的混淆矩阵和准确率得分]
图 7.13 – PyTorch 逻辑回归模型的混淆矩阵和准确率得分
如你所见,两代并不足以产生一个优于基线模型的结果。让我们看看使用多层感知器模型是否有所帮助。
-
我们仍然处于 Google Colab 环境中,因为在你自己的电脑上训练要慢得多(取决于你的配置)。现在的想法是使用多层感知器模型而不是逻辑回归,看看模型的变化如何影响性能。
首先,你必须修改
TPOTClassifier的template参数,如下所示:classifier_mlp = TPOTClassifier( config_dict='TPOT NN', template='PytorchMLPClassifier', generations=2, random_state=42, verbosity=3 )如你所见,我们现在使用
PytorchMLPClassifier而不是PytorchLRClassifier。要开始优化过程,只需用训练数据调用fit()方法:classifier_mlp.fit(X_train, y_train)与逻辑回归算法一样,你也会在优化过程中看到进度条:
![图 7.14 – TPOT 多层感知器训练过程]
classifier_mlp.fitted_pipeline_结果如下所示:
![图 7.16 – TPOT PyTorch 多层感知器最佳流程]
from sklearn.metrics import confusion_matrix,\ accuracy_score tpot_mlp_preds = classifier_mlp.predict(X_test) print(confusion_matrix(y_test, tpot_mlp_preds)) print() print(accuracy_score(y_test, tpot_mlp_preds))结果如下所示:
图 7.17 – PyTorch 多层感知器模型的混淆矩阵和准确率得分
如你所见,两代仍然不足以产生优于基线模型的结果,但 MLP 模型的表现优于逻辑回归模型。现在让我们看看使用自定义训练配置是否可以将准确率进一步提高。
-
最后,让我们看看如何为逻辑回归或多层感知器模型指定可能的超参数值。你所要做的就是指定一个自定义配置字典,其中包含你想要测试的超参数(如学习率、批量大小和迭代次数),并以列表的形式为这些超参数分配值。
这里有一个例子:
custom_config = { 'tpot.builtins.PytorchMLPClassifier': { 'learning_rate': [1e-1, 0.5, 1.], 'batch_size': [16, 32], 'num_epochs': [10, 15], } }现在,你可以在训练模型时使用这个
custom_config字典。以下是一个基于多层感知器模型的示例训练片段:classifier_custom = TPOTClassifier( config_dict=custom_config, template='PytorchMLPClassifier', generations=2, random_state=42, verbosity=3 ) classifier_custom.fit(X_train, y_train)如你所见,只有
config_dict参数发生了变化。一旦训练过程开始,你将在笔记本中看到类似这样的进度条:
图 7.18 – 使用神经网络的 TPOT 自定义调整
一旦训练过程完成,你应在笔记本中看到以下类似的内容:
图 7.19 – 带有自定义超参数的 TPOT 多层感知器分类器
就这么简单!为了验证,你可以通过执行以下命令来检查最佳拟合管道:
classifier_custom.fitted_pipeline_
结果如下所示:
图 7.20 – 带有自定义超参数的模型的 TPOT 最佳拟合管道
如你所见,所有超参数值都在指定的范围内,这表明自定义模型已成功训练。
这就结束了本节以及本节整体中的模型训练部分。接下来是一个对我们迄今为止所学内容的简要总结,以及对即将在后续章节中介绍内容的简要介绍。
摘要
本章在动手示例和演示方面相当密集。你或许已经学会了如何使用 TPOT 训练自动化分类管道,以及在整个过程中你可以调整什么。
现在,你应该能够使用 TPOT 训练任何类型的自动化机器学习模型,无论是回归、分类、标准分类器还是神经网络分类器。这是一个好消息,因为这是 TPOT 示例的最后一章。
在下一章第八章,TPOT 模型部署,你将学习如何将模型的预测功能封装在 REST API 中,然后将在本地和云中进行测试和部署。你还将学习部署后如何与 API 进行通信。
最后,在上一章第九章,在生产中使用部署的 TPOT 模型,你将学习如何利用部署的 API 开发有用的东西。更准确地说,你将学习如何在笔记本环境中通过向部署的 API 发起 REST 调用来进行预测,以及如何开发一个简单的 GUI 应用程序,使你的模型对最终用户更具吸引力。
和往常一样,你可以更深入地研究 TPOT,但到目前为止,你已经领先于大多数人,并且你准备好让机器学习变得有用。在那里见!
问题
-
TPOT 中关于神经网络有哪些可用的算法?
-
大约神经网络分类器训练速度比默认的 scikit-learn 分类器慢多少倍?
-
列出并简要解释使用 TPOT 和神经网络训练模型时可用的一些超参数。
-
在使用 TPOT 训练自定义神经网络模型时,能否指定自定义的超参数值范围?如果是的话,如何操作?
-
模型训练完成后,如何找到最佳拟合的流水线?
-
使用如 Google Colab 这样的 GPU 运行时在 TPOT 训练神经网络模型时有哪些优势?
-
描述为什么多层感知器模型中的单个神经元可以被视为逻辑回归。
第八章: TPOT 模型部署
在本章中,您将学习如何将任何自动化机器学习模型部署到本地主机和云端。您将了解到如果您旨在创建机器学习驱动的软件,部署步骤是必要的。假设您知道如何使用 TPOT 训练基本的回归和分类模型。不需要了解前几章(Dask 和神经网络)的主题,因为我们在这里不会涉及这些内容。
在本章中,您将了解到将模型封装在 API 中并向非数据科学家用户暴露其预测能力是多么容易。您还将了解到哪些云服务提供商最适合您免费开始。
本章将涵盖以下主题:
-
我们为什么需要模型部署?
-
介绍
Flask和Flask-RESTful -
自动化模型部署的最佳实践
-
将机器学习模型部署到本地主机
-
将机器学习模型部署到云端
技术要求
如前所述,您需要知道如何使用 TPOT 构建基本的机器学习模型。如果您对库还不够熟悉,请不要担心,我们将从头开始开发模型。如果您是 TPOT 的完全新手,请参阅第二章,深入 TPOT,第三章,使用 TPOT 探索回归,和第四章,使用 TPOT 探索分类。
本章将包含大量的代码,因此如果您遇到困难,可以参考官方 GitHub 仓库:github.com/PacktPublishing/Machine-Learning-Automation-with-TPOT/tree/main/Chapter08。
我们为什么需要模型部署?
如果您已经在费劲周折地训练和优化机器学习模型,为什么不更进一步,将其部署出来供每个人使用呢?
也许您希望将模型的预测能力集成到 Web 应用程序中。也许您是一位希望将机器学习带到 Android 和 iOS 的移动应用开发者。选项无穷无尽,但它们都有一个共同点——需要部署。
现在,机器学习模型部署与机器学习本身无关。目标是编写一个简单的 REST API(最好使用 Python,因为本书中使用的语言是 Python)并将调用predict()函数的任何形式的端点暴露给世界。您希望以 JSON 格式发送参数到您的应用程序,并将它们用作模型的输入。一旦做出预测,您只需将其返回给用户即可。
是的,这就是机器学习模型部署的全部内容。当然,事情可能会变得更加技术化,但保持简单将让我们达到 95% 的效果,而你总是可以进一步探索以获得额外的 5%。
当涉及到模型部署的技术方面时,Python 为你提供了一系列选项。你可以使用 Flask 和 Flask-RESTful、FastAPI、Django 或 Pyramid。当然,还有其他选项,但它们的“市场份额”或多或少可以忽略不计。你将在本章的下一节开始使用第一个选项。
下一个部分旨在通过几个基本的动手示例介绍这些库。之后,我们将深入了解机器学习。
介绍 Flask 和 Flask-RESTful
Flask 是一个用于构建 Web 应用的轻量级框架。它使你能够简单开始,并在需要时进行扩展。Flask-RESTful 是 Flask 的一个扩展,它允许你快速构建 RESTful API。
要开始使用这两个库,你需要安装它们。你可以在终端中执行以下行:
> pip install flask flask-restful
这就是你需要开始的地方。让我们首先探索 Flask 的基础知识:
-
信不信由你,你只需要七行代码就可以使用
Flask创建你的第一个 Web 应用程序。它可能不会做任何有用的事情,但这仍然是一个正确的方向。首先,你需要导入库并创建一个应用程序实例。然后,你需要创建一个函数,该函数返回你想要在网站上显示的内容,并用
@app.route(route_url)装饰器装饰该函数。请记住,你应该用函数应该显示结果的 URL 字符串替换route_url。如果你传递一个正斜杠(/),结果将在根页面上显示——但关于这一点,我们稍后再说。最后,你必须使用
if __name__ == '__main__'检查使 Python 文件可执行。应用程序将在本地的8000端口上运行。请参考以下代码片段以了解你的第一个
Flask应用程序:from flask import Flask app = Flask(__name__) @app.route('/') def root(): return 'Your first Flask app!' if __name__ == '__main__': app.run(host='0.0.0.0', port=8000)要运行应用程序,你必须在终端中执行 Python 文件。在我的机器上,该文件被命名为
flask_basics.py,因此要运行它,请执行以下操作:Running on http://0.0.0.0:8000/ message, you can see where the application is running, ergo which URL you need to visit to see your application. Just so you know, the 0.0.0.0 part can be replaced with localhost.Once there, you'll see the following displayed, indicating that everything worked properly: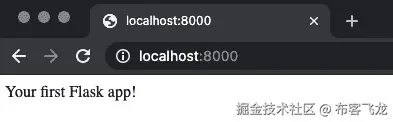Figure 8.2 – Your first Flask applicationAnd that's how easy it is to build your first web application with `Flask`. You'll learn how to make something a bit more complex next. -
到目前为止,你已经知道如何使用
Flask构建最简单的应用程序——但这不是你来的原因。我们想要构建 API 而不是应用程序,这是一个不同的故事。它们之间的区别相当明显——API 不带用户界面(除了文档页面),而 Web 应用程序则带。API 只是一个服务。实际上,你可以使用Flask直接构建 API。我们将探讨如何做到这一点,并解释为什么这不是最佳选择。首先,创建一个新的 Python 文件。这个文件将被引用为
flask_basics2.py。在里面,我们将有一个用于两种可能的 API 调用类型的单个路由。它们都有添加两个数字并返回结果的任务,但它们以不同的方式完成。让我们列出这些差异:a)
/adding(GET)依赖于之前实现的逻辑。更准确地说,当调用端点时,会发起一个 GET 请求。唯一的区别是这次,参数是通过 URL 传递的。例如,调用/adding?num1=3&num2=5应在屏幕上显示8。参数值直接从 URL 中提取。您将看到这一动作,所以一切都会立即变得清晰。b)
/adding(POST)与第一个端点非常相似,但发起的是 POST 请求。这是一种更安全的通信方法,因为参数值不是直接通过 URL 传递,而是在请求体中传递。此端点以 JSON 格式返回求和结果,因此您需要将结果包装在flask.jsonify()函数中。这两个函数旨在完成一个相同的目标 – 求两个数的和并返回结果。以下是如何实现这种逻辑的一个示例:
from flask import Flask, request, jsonify app = Flask(__name__) @app.route('/adding') def add_get(): num1 = int(request.args.get('num1')) num2 = int(request.args.get('num2')) return f'<h3>{num1} + {num2} = {num1 + num2}</h3>' @app.route('/adding', methods=['POST']) def add_post(): data = request.get_json() num1 = data['num1'] num2 = data['num2'] return jsonify({'result': num1 + num2}) if __name__ == '__main__': app.run(host='0.0.0.0', port=8000)如您所见,
add_get()函数返回一个格式为 HTML 的字符串。如果您想返回整个 HTML 文档,也可以,但这不是我们现在感兴趣的事情,所以我们不会进一步探讨。要运行应用程序,您需要在终端中执行 Python 文件。在我的机器上,该文件名为
flask_basics2.py,因此要运行它,请执行以下命令:/adding for GET first:import requests
req = requests.post(
url='http://localhost:8000/adding',
json={'num1': 3, 'num2': 5}
)
res = req.content
print(res)
If you were to run this code now, here's what you would see as the output: Figure 8.6 – The POST endpoint with parameters (Python)This is essentially a string, so some conversion to JSON will be mandatory before you can work with the returned value. More on that later, in *Chapter 9*, *Using the Deployed TPOT Model in Production*.So far, you've seen how the `Flask` library can be used to develop both web applications and web services (APIs). It's a good first option, but there's a better approach if you're only interested in building APIs – `Flask-RESTful`. Let's explore it next. -
您已经安装了
Flask-RESTful。使用它的语法略有不同。它使用get()、post()和put(),这些代表当发起特定类型的请求时会发生什么。所有 API 类都继承自
Flask-RESTful.Resource类,并且每个端点必须通过add_resource()方法手动绑定到特定的 URL 字符串。总结一下,我们将有一个
Add类,它有两个方法:get()和post()。这些方法内部的逻辑与之前相同,唯一的例外是我们不会在任何地方返回 HTML。这是整个代码片段:
from flask import Flask, request, jsonify from flask_restful import Resource, Api app = Flask(__name__) api = Api(app) class Adding(Resource): @staticmethod def get(): num1 = int(request.args.get('num1')) num2 = int(request.args.get('num2')) return num1 + num2 @staticmethod def post(): data = request.get_json() num1 = data['num1'] num2 = data['num2'] return jsonify({'result': num1 + num2}) api.add_resource(Adding, '/adding') if __name__ == '__main__': app.run(host='0.0.0.0', port=8000)Adding类内部的所有内容都在/adding端点上可用。如您所见,该 API 将在不同的端口上运行,以便于区分这个 API 和之前的那个。
如果您现在打开
http://localhost:8000/adding,您会看到以下消息:
图 8.7 – Flask-RESTful 无参数 GET
我们现在遇到了与默认FlaskAPI 相同的错误,原因是 URL 中没有给出参数值。如果您要更改它并调用http://localhost:8000/adding?num1=5&num2=10,您会在浏览器窗口中看到以下内容:
图 8.8 – Flask-RESTful 带参数 GET
如前所述,直接从浏览器与 API 通信不被认为是最佳实践,但你可以使用 GET 请求类型来做这件事。你最好使用像 Postman 这样的工具,而你已经知道如何使用它。
对于 POST 方法,你可以调用之前相同的 URL,即http://localhost:8000/adding,并在请求体中以 JSON 格式传递参数。以下是使用 Postman 进行操作的步骤:
图 8.9 – 使用 Postman 的 Flask-RESTful POST
你也可以通过 Python 来做同样的事情,但你现在应该已经知道如何做了。
你现在已经了解了使用 Python、Flask和Flask-RESTful进行 REST API 开发的基础知识。这是一个相对快速、实用的部分,作为即将到来的内容的入门。在下一节中,我们将讨论部署机器学习模型的几个最佳实践,在最后两节中,我们将探讨如何分别在本地和云中训练和部署模型。
自动化模型部署的最佳实践
自动化模型的部署与你的常规机器学习模型的部署大致相同。这归结为首先训练模型,然后以某种格式保存模型。在常规机器学习模型的情况下,你可以轻松地将模型保存为.model或.h5文件。没有理由不将 TPOT 模型也这样做。
如果你记得前面的章节,TPOT 可以将最佳管道导出为 Python 文件,这样就可以在模型未训练的情况下使用该管道进行训练,并在之后保存模型。如果模型已经训练,则只获取预测。
通过检查文件是否存在,可以确定模型是否已被训练。如果模型文件存在,我们可以假设模型已被训练,因此可以加载它并做出预测。否则,模型应该首先进行训练和保存,然后才能进行预测。
在连接到机器学习 API 时使用 POST 请求类型也是一个好主意。它比 GET 更好,因为参数值不会直接传递到 URL 中。正如你可能知道的,参数值可能是敏感的,所以尽可能隐藏它们是个好主意。
例如,你可能需要在做出预测之前通过 API 进行身份验证。很容易理解为什么直接在 URL 中发送用户名和密码凭证不是一个好主意。POST 方法可以解决这个问题,本章的其余部分将很好地利用这一点。
简而言之,在做出预测之前,你应该始终检查模型是否已训练,并在需要时进行训练。另一个要点是,在我们的情况下,POST 比 GET 更好。你现在已经了解了部署机器学习模型的一些基本最佳实践。在下一节中,我们将训练并部署模型到本地主机。
将机器学习模型部署到本地主机
在我们可以部署模型之前,我们需要先训练它。你已经知道如何使用 TPOT 进行训练的所有内容,所以我们不会在这里花费太多时间。目标是训练一个简单的 Iris 分类器,并以某种方式导出预测功能。让我们一步一步地完成这个过程:
-
像往常一样,第一步是加载库和数据集。你可以使用以下代码片段来完成此操作:
import pandas as pd df = pd.read_csv('data/iris.csv') df.head()这是前几行看起来像什么:
图 8.10 – Iris 数据集的前几行
-
下一步是将特征与目标变量分开。这次,我们不会将数据集分为训练集和测试集,因为我们不打算评估模型的性能。换句话说,我们知道模型表现良好,现在我们想在整个数据集上重新训练它。此外,目标变量中的字符串值将按照以下方式重映射为其整数表示:
a) Setosa – 0
b) Virginica – 1
c) Versicolor – 2
以下代码行执行了之前描述的所有操作:
X = df.drop('species', axis=1) y = df['species'] y = y.replace({'setosa': 0, 'virginica': 1, 'versicolor': 2}) y现在的目标变量看起来是这样的:
图 8.11 – 值重映射后的目标变量
-
下一个步骤是模型训练。我们将使用 TPOT 进行 15 分钟的模型训练。这部分你应该很熟悉,因为我们没有使用之前章节中没有使用或描述过的任何参数。
以下代码片段将在整个数据集上训练模型:
from tpot import TPOTClassifier clf = TPOTClassifier( scoring='accuracy', max_time_mins=15, random_state=42, verbosity=2 ) clf.fit(X, y)在训练过程中,你会看到许多输出,但达到 100%的准确率不应该花费太多时间,如下图所示:
图 8.12 – TPOT 训练过程
在 15 分钟的时间框架内,将经过多少代取决于你的硬件,但一旦完成,你应该看到类似以下的内容:
图 8.13 – 训练后的 TPOT 输出
-
一旦训练过程完成,你将能够访问
fitted_pipeline_属性:clf.fitted_pipeline_这是一个可以导出以供以后使用的管道对象。以下是它应该看起来像什么(请注意,你可能在你的机器上看到不同的结果):
图 8.14 – TPOT 拟合管道
-
为了演示这个管道的工作原理,请查看以下代码片段。它使用一个表示单个花种的二维输入数据数组调用
fitted_pipeline_属性的predict()函数:clf.fitted_pipeline_.predict([[5.1, 3.5, 0.2, 3.4]])结果显示在以下图中:
图 8.15 – TPOT 预测
记得我们几页前的重映射策略吗?
0表示这种物种被分类为setosa。 -
我们必须完成的最后一步是将此模型的预测能力保存到文件中。
joblib库使得这一步变得简单,因为你只需要调用dump()函数来保存模型,并调用load()函数来加载模型。这里有一个快速演示。目标是把
fitted_pipeline_属性保存到名为iris.model的文件中。你可以使用以下代码来完成:import joblib joblib.dump(clf.fitted_pipeline_, 'iris.model')就这么简单!一旦模型保存到文件中,你将看到以下输出:
![图 8.16 – 保存 TPOT 模型
![图片 B16954_08_16.jpg]
图 8.16 – 保存 TPOT 模型
为了验证模型仍然可以正常工作,你可以使用 load() 函数在新的变量中加载模型:
loaded_model = joblib.load('iris.model')
loaded_model.predict([[5.1, 3.5, 0.2, 3.4]])
上述代码的输出显示在下图中:
![图 8.17 – 保存模型的预测
![图片 B16954_08_17.jpg]
图 8.17 – 保存模型的预测
就这样,保存机器学习模型以供以后使用变得非常简单。我们现在拥有了部署此模型所需的一切,所以让我们继续下一步。
模型部署过程将与之前使用 Flask 和 Flask-RESTful 所做的非常相似。在继续逐步指南之前,你应该为你的 API 创建一个目录,并具有以下目录/文件结构:
![图 8.18 – API 目录结构
![图片 B16954_08_18.jpg]
图 8.18 – API 目录结构
如你所见,根目录被命名为 api,其中包含两个 Python 文件 —— app.py 和 helpers.py。该文件夹还有一个用于存储之前训练的模型的文件夹。
让我们一步一步地构建 API:
-
让我们从
helpers.py文件开始。这个 Python 文件的目标是从app.py中移除所有计算和数据操作。后者仅用于声明和管理 API 本身,其他所有操作都在其他地方执行。helpers.py文件将包含两个函数 ——int_to_species(in_species)和predict_single(model, X)。第一个函数的目标是反转我们之前声明的映射,并给出整数表示的实际花卉种类名称。以下是给出整数输入时返回的字符串的具体列表:
a) 0 –
setosab) 1 –
virginicac) 2 –
versicolor如果传递了其他数字,则返回一个空字符串。你可以按照以下方式找到此函数的代码:
def int_to_species(in_species): if in_species == 0: return 'setosa' if in_species == 1: return 'virginica' if in_species == 2: return 'versicolor'接下来是
predict_single(model, X)函数。该函数旨在根据模型和输入值的列表返回预测及其概率。该函数还执行以下检查:a)
X是一个列表吗?如果不是,则抛出异常。b)
X是否有四个项目(花瓣长度、花瓣宽度、花萼长度和花萼宽度)?如果不是,则抛出异常。这些检查是必需的,因为我们不希望不良或格式错误的数据进入我们的模型并使 API 崩溃。
如果所有检查都通过,预测和概率将作为字典返回给用户,并列出每个参数的输入数据。以下是实现此函数的方法:
def predict_single(model, X): if type(X) is not list: raise Exception('X must be of list data type!') if len(X) != 4: raise Exception('X must contain 4 values - \ sepal_length, sepal_width, petal_length, petal_width') prediction = model.predict([X])[0] prediction_probability =\ model.predict_proba([X])[0][prediction] return { 'In_SepalLength': X[0], 'In_SepalWidth': X[1], 'In_PetalLength': X[2], 'In_PetalWidth': X[3], 'Prediction': int_to_species(prediction), 'Probability': prediction_probability }这里是调用
predict_single()函数的一个示例:predict_single( model=joblib.load('api/model/iris.model'), X=[5.1, 3.5, 0.2, 3.4] )结果如下所示:
图 8.19 – 调用 predict_single() 函数的结果
-
现在,让我们转向
app.py。如果您从本章的开头就一直在跟进,编写这个文件将易如反掌。目标是始终加载模型,并在调用/predict端点时触发PredictSpecies类的post()方法。您将不得不自己实现这个类和方法。用户必须以 JSON 格式传递输入数据。更准确地说,每个花卉测量值都是单独传递的,因此用户总共需要指定四个参数的值。
如果一切顺利,
helpers.py中的predict_single()函数将被调用,并将结果返回给用户。让我们看看
app.py的实现:import joblib import warnings from flask import Flask, request, jsonify from flask_restful import Resource, Api from helpers import predict_single warnings.filterwarnings('ignore') app = Flask(__name__) api = Api(app) model = joblib.load('model/iris.model') class PredictSpecies(Resource): @staticmethod def post(): user_input = request.get_json() sl = user_input['SepalLength'] sw = user_input['SepalWidth'] pl = user_input['PetalLength'] pw = user_input['PetalWidth'] prediction =\ predict_single(model=model, X=[sl, sw, pl, pw]) return jsonify(prediction) api.add_resource(PredictSpecies, '/predict') if __name__ == '__main__': app.run(host='0.0.0.0', port=8000) -
您现在拥有了运行 API 所需的一切。您可以像之前使用其他 API 一样运行它,即在终端中执行以下行:
> python app.py如果一切顺利,您将看到以下消息:
图 8.20 – 运行 API
-
API 现在正在
http://localhost:8000上运行。我们将使用 Postman 应用程序来测试 API。这里是第一个示例:
图 8.21 – API 测试示例 1
如您所见,模型 100% 确信这种物种属于 setosa 类。让我们再试一个:
图 8.22 – API 测试示例 2
这具有相同的置信水平,但预测类别不同。让我们来点不一样的,传递一些与训练集不同的值:
图 8.23 – API 测试示例 3
如您所见,这次模型并不完全自信,因为输入数据与训练时看到的数据有很大不同。
到此为止,TPOT 模型部署到本地主机!本章剩下的唯一事情是将模型带到云端,使其在任何地方都可以访问。让我们接下来这么做。
将机器学习模型部署到云
云部署机器学习模型意味着创建一个云虚拟机,将我们的 API 转移到它上面,并运行它。这是一个繁琐的过程,但由于涉及许多步骤,随着重复执行会变得更容易。如果您从这个部分精确地遵循每个步骤,一切都会顺利。只需确保不要遗漏任何细节:
-
要开始,请访问
portal.aws.amazon.com/billing/signup#/start并创建一个账户(假设您还没有一个)。以下是网站目前的模样(截至 2021 年 2 月):![图 8.24 – AWS 注册网站![图片 B16954_08_24.jpg]
图 8.24 – AWS 注册网站
注册过程将花费一些时间,您将需要输入您的信用卡信息。请放心;我们将创建完全免费的虚拟机实例,所以您不会收取任何费用。
-
一旦注册过程完成,点击搜索栏中的
ubuntu:![图 8.26 – Ubuntu Server 20.04![图片 B16954_08_26.jpg]
图 8.26 – Ubuntu Server 20.04
一旦点击 选择,您将需要指定类型。如果您不想被收费,请确保选择免费版本:
![图 2.27 – Ubuntu 实例类型
![图片 B16954_08_27.jpg]
图 2.27 – Ubuntu 实例类型
然后,点击 审查和启动 按钮。您将被带到以下屏幕:
![图 2.28 – Ubuntu 实例确认
![图片 B16954_08_28.jpg]
图 2.28 – Ubuntu 实例确认
一旦点击 启动,将出现以下窗口。请确保选择相同的选项,但密钥对名称由您决定:
![图 8.29 – Ubuntu 密钥对
![图片 B16954_08_29.jpg]
图 8.29 – Ubuntu 密钥对
在输入详细信息后,点击 下载密钥对 按钮。下载完成后,您将能够点击 启动实例 按钮:
![图 8.30 – 启动 Ubuntu 实例
![图片 B16954_08_30.jpg]
图 8.30 – 启动 Ubuntu 实例
最后,完成所有操作后,您可以点击 查看实例 按钮:
![图 8.31 – 查看实例
![图片 B16954_08_31.jpg]
图 8.31 – 查看实例
您将立即看到您创建的实例。在看到实例正在运行之前可能需要一些时间,所以请耐心等待:
![图 8.32 – 运行实例
![图片 B16954_08_32.jpg]
图 8.32 – 运行实例
-
要获取连接参数,请点击实例行,并在 密钥文件 选项中选择
.ppk文件。按下 连接 按钮后,您将看到以下内容:![图 8.36 – FileZilla 主机密钥![图片 B16954_08_36.jpg]
图 8.36 – FileZilla 主机密钥
只需按 确定,您就可以开始了。连接成功,如下图所示:
![图 8.37 – FileZilla 成功连接
![图片 B16954_08_37.jpg]
图 8.37 – FileZilla 成功连接
您现在可以将 api 文件夹拖动到远程虚拟机上的 ubuntu 文件夹中,如图所示:
![图 8.38 – 将 API 数据传输到远程虚拟机
![图片 B16954_08_38.jpg]
图 8.38 – 将 API 数据传输到远程虚拟机
在进一步配置和启动 API 之前,让我们看看您如何通过终端获取连接。
-
在存储
.pem文件的新终端窗口中打开。一旦进入,执行以下命令以更改权限:TPOT_Book_KeyPair.pem with your filename and also make sure to write your instance name after ubuntu@. If you did everything correctly, you should see the following in your terminal:sudo apt-get update && sudo apt-get install python3-pip
Finally, let's install every required library. Here's the command for doing so within a virtual environment:pip3 install virtualenv
virtualenv tpotapi_env
source tpotapi_env/bin/activate
pip3 install joblib flask flask-restful sklearn tpot
There are a few steps you still need to complete before starting the API, such as managing security. -
如果现在运行 API,不会引发错误,但您将无法以任何方式访问 API。这是因为我们首先需要“修复”一些权限。简单来说,我们的 API 需要从任何地方可访问,但默认情况下并不是。
首先,导航到 网络与安全 | 安全组 侧边栏:
图 8.40 – 安全组
您应该在浏览器窗口的右上角看到 创建安全组 按钮:
图 8.41 – 创建安全组按钮
当新窗口弹出时,您必须指定一些内容。安全组名称 和 描述 字段完全是任意的。另一方面,入站规则 组不是任意的。您必须添加一个具有以下选项的新规则:
a) 类型: 所有流量
b) 源: 任何地方
参考以下图示获取更多信息:
图 8.42 – 创建安全组
在指定正确的值后,您必须滚动到屏幕底部并点击 创建安全组 选项:
图 8.43 – 验证安全组
我们还没有完成。下一步是转到侧边栏上的 网络与安全 | 网络接口 选项:
图 8.44 – 网络接口选项
一旦进入,右键单击唯一可用的网络接口(假设这是您第一次进入 AWS 控制台)并选择 更改安全组 选项:
图 8.45 – 更改安全组
整个目的就是将“从任何地方访问”的规则分配给我们的虚拟机。一旦弹出窗口,从选项下拉列表中选择之前声明的安全组:
图 8.46 – 选择安全组
添加完成后,点击 保存 按钮保存此关联:
图 8.47 – 保存安全关联
-
配置我们的虚拟机是一个相当漫长的过程,但现在您终于可以启动
Flask应用程序(REST API)了。为此,导航到/api文件夹并执行以下操作:> python3 app.py到现在为止,你应该看到一个熟悉的消息:
图 8.48 – 通过终端启动 REST API
就这样!API 现在正在运行,我们可以测试它是否正常工作。
-
在通过 Postman 发送请求之前,我们首先需要找到远程虚拟机的完整 URL。你可以通过在实例下右键单击实例并点击连接选项来找到它。在那里,你会看到SSH 客户端标签页:
图 8.49 – 虚拟机 URL
现在我们知道了完整的 URL:http://ec2-18-220-113-224.us-east-2.compute.amazonaws.com:8000/predict。从现在开始,流程与在本地主机上相同,如下图所示:
图 8.50 – 测试我们部署的 API
如你所见,连接已经建立,API 返回了与本地部署版本相同的响应。
就这样,你就有了一个将机器学习模型部署到 AWS 虚拟机的完整流程。这个过程可能相当繁琐,如果是第一次尝试,甚至可能有些棘手。随着你部署越来越多的机器学习模型,这个过程会变得越来越容易,因为流程是相同的。
如果你不想让任何人从任何地方访问你的 API,你可以玩一下权限,但这超出了本书的范围。这一章大致结束了——做得很好!接下来是所学内容的总结,然后是另一个有趣且实用的章节。
摘要
这一章是目前最长的,而且非常注重实践任务。你希望已经能够跟上并学习了如何部署使用 TPOT 构建的机器学习模型——无论是在本地还是在云端。
现在你已经能够部署任何使用 Python 构建的机器学习模型。此外,你还知道如何部署基本的 Python 网络应用程序,前提是你具备前端技术(如 HTML、CSS 和 JavaScript)的相关知识。我们没有深入这个领域,因为这不属于本书的范围。
在以下章节中第九章,在生产中使用部署的 TPOT 模型,你将学习如何围绕这个 REST API 构建一个基本的应用程序。更准确地说,你将学习如何制作一个简单且外观不错的网页界面,该界面可以根据输入数据预测花卉种类。但在那之前,你将练习使用 Python 向我们的 API 发送请求。
和往常一样,你可以自由地更详细地研究模型部署,因为 AWS 不是唯一的选择。有许多云服务提供商提供某种免费层,AWS 只是池塘中的一条鱼。
问题
-
我们为什么需要(并希望)模型部署?
-
REST API 在模型部署中扮演什么角色?
-
列举一些可以用来部署机器学习模型的 Python 库。
-
GET 和 POST 请求类型之间有什么区别?
-
Python 中
joblib库背后的基本思想是什么? -
用你自己的话解释什么是虚拟机。
-
哪个免费工具可以用来测试 REST API?
第九章:在生产中使用部署的 TPOT 模型
您已经到达了最后一章——恭喜!到目前为止,您通过解决分类和回归任务学习了 TPOT 的基础知识,了解了 TPOT 如何与 Dask 和神经网络协同工作,以及如何在本地和云端部署机器学习模型。
本章将作为甜点,因为您将学习如何与您的部署模型进行通信,以构建即使是 5 岁的孩子也能使用的东西。更具体地说,您将学习如何通过笔记本环境和简单的 GUI 网页应用程序与您的 API 进行通信。
本章将涵盖以下主题:
-
在笔记本环境中进行预测
-
开发一个简单的 GUI 网页应用程序
-
在 GUI 环境中进行预测
技术要求
这是本书的最后一章,因此假设您有一些先验知识。您需要知道如何使用 TPOT 构建基本的机器学习模型以便部署。假设您的模型已部署到在 第八章*,TPOT 模型部署*中创建的 AWS 虚拟机上。如果不是这种情况,请回顾该章节。
本章将包含大量的代码,如果您遇到困难,可以参考官方 GitHub 仓库:github.com/PacktPublishing/Machine-Learning-Automation-with-TPOT/tree/main/Chapter09。
在笔记本环境中进行预测
如果您在上一章之后休息了一天(或几天),那么您与远程虚拟机的连接可能已经结束。因此,您需要重新连接并再次启动 API。有方法可以使您的 API 总是运行,但这超出了本书的范围。此外,如果您已将 TPOT_Book_KeyPair.pem 文件移动到其他文件夹,您将需要重置权限:
-
考虑到这一点,如果您需要重置权限,请仅执行以下片段中的第一个命令行:
> chmod 400 TPOT_Book_KeyPair.pem > ssh -i "TPOT_Book_KeyPair.pem" ubuntu@ec2-18-220-113-224.us-east-2.compute.amazonaws.com > cd api > python3 app.py -
您的 API 正在运行。下一步是打开 JupyterLab 或 Jupyter Notebook 环境,并发出请求。您需要
requests库来完成此操作,以下是导入它的方法:import requests接下来,让我们声明几个变量。这些变量将保存主机名、端口和端点的值:
HOST ='http://ec2-18-220-113-224.us-east-2.compute.amazonaws.com' PORT = '8000' ENDPOINT = '/predict'从那里,我们可以轻松地将这三个变量连接成一个,形成一个 URL:
URL = f'{HOST}:{PORT}{ENDPOINT}' URL这就是它应该看起来像的样子:
![图 9.1 – URL 连接字符串
![img/B16954_09_1.jpg]
图 9.1 – URL 连接字符串
由于主机名的差异,您的操作可能略有不同。
-
接下来,我们将声明一个字典,它将作为输入数据。它将与通过 Postman 发送的上一章中的数据相同。以下是代码片段:
in_data = { 'SepalLength': 0.4, 'SepalWidth': 3.1, 'PetalLength': 0.1, 'PetalWidth': 14 }这就是我们需要进行请求的所有内容。让我们接下来这么做。
-
你可以使用
requests包中的post()函数来发送 POST 请求。需要两个参数——URL 和 JSON 格式的数据:req = requests.post(url=URL, json=in_data) req结果将在以下图中显示:
response = req.content response这就是响应的外观:
图 9.3 – API 响应作为字符串
![图片 B16954_09_3.jpg]
图 9.3 – API 响应作为字符串
如你所见,预测成功返回了,但默认情况下不是所需的格式。
-
要改变这一点,你需要将响应字符串转换为 JSON 对象。你可以使用
json包中的loads()函数来完成此操作:import json response_json = json.loads(response) response_json这里是结果:
![图 9.4 – API 响应作为 JSON 对象]
![图片 B16954_09_4.jpg]
图 9.4 – API 响应作为 JSON 对象
-
你可以像访问普通字典对象一样访问预测的类别(或任何其他属性)。以下是一个示例:
response_json['Prediction']这是返回的内容:
![图 9.5 – API 预测类别]
![图片 B16954_09_5.jpg]
图 9.5 – API 预测类别
这基本上就是你可以使用 Python 从部署的 REST API 获取预测的方法!在下一节中,你将围绕这个 API 构建一个基本的交互式网络应用程序,使其对任何人来说都极其简单易用。
开发一个简单的 GUI 网络应用程序
本节旨在展示如何使用 Flask 框架开发一个简单的网络应用程序。重点转向构建一个捕获表单数据的应用程序,然后将其传递到我们部署的机器学习 API:
-
首先,创建以下目录结构:![图 9.6 – 网络应用程序目录结构]
![图片 B16954_09_6.jpg]
图 9.6 – 网络应用程序目录结构
大部分逻辑都在
app.py中处理,而templates文件夹用于存储应用中的 HTML 文件——稍后我会详细介绍这一点。 -
这次我们将更好地组织代码,因此你需要创建一个额外的文件来存储环境变量。在根目录 (
webapp) 中创建一个名为.env的文件——并填充以下内容:SECRET_KEY=SecretKey HOST=0.0.0.0 PORT=9000 API_ENDPOINT=http://ec2-18-220-113-224.us-east-2.compute.amazonaws.com:8000/predict创建这样的单独文件被认为是开发任何类型的网络应用程序的最佳实践。
要使用这些环境变量,你需要在虚拟环境中安装一个额外的包:
> pip install python-dotenv -
现在我们来构建应用程序的基本结构。打开
app.py文件并编写以下代码:import os from flask import Flask, render_template from dotenv import load_dotenv load_dotenv('.env') app = Flask(__name__) @app.route('/') def index(): return render_template('index.html') if __name__ == '__main__': app.run(host=os.getenv('HOST'), port=os.getenv('PORT'))如果你现在运行应用程序,你不会得到错误,但屏幕上不会显示任何内容。原因是简单的——我们还没有处理
index.html文件。在我们这样做之前,让我们讨论代码中唯一可能不熟悉的部分:render_template()函数。简单地说,这个函数将显示一个 HTML 文件,而不是显示函数返回的字符串或值。有一种方法可以传递参数,但稍后再说。 -
接下来是
index.html——以下是你可以粘贴到文件中的代码:<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Iris Predictioner</title> </head> <body> <h1>Welcome to Iris Predictioner</h1> </body> </html>如果你之前没有写过一行 HTML,不要担心——它是一种简单的标记语言。把这里看到的一切都当作样板。我们感兴趣的是
<body></body>标签内的内容。如果你现在运行你的应用程序,它看起来会是这样:
图 9.7 – 爱尔兰预测应用程序(v1)
这是一个简单且极其无聊的 Web 应用程序,但至少它工作了。
-
如前所述,我们的 Web 应用程序必须以某种方式处理表单数据,因此让我们开始工作。有一个专门的包用于处理
Flask中的表单数据,称为Flask-WTF。以下是安装它的方法:forms.py file in the root directory – /webapp/forms.py. Let's take a look at the code this file contains and explain it:from flask_wtf import FlaskForm
from wtforms import FloatField, SubmitField
from wtforms.validators import DataRequired
class IrisForm(FlaskForm):
sepal_length = FloatField(
label='花瓣长度', 验证器=[DataRequired()]
)
sepal_width = FloatField(
label='花瓣宽度', 验证器=[DataRequired()]
)
petal_length = FloatField(
label='花瓣长度', 验证器=[DataRequired()]
)
petal_width = FloatField(
label='花瓣宽度', 验证器=[DataRequired()]
)
submit = SubmitField(label='预测')
Okay, so what's going on in this file? Put simply, `Flask-WTF` allows us to declare forms for `Flask` applications easily, in a class format. We can use any of the built-in field types and validators. For this simple example, we'll only need float and submit fields (for flower measurements and the submit button). Validation-wise, we only want that no fields are left blank.That's all you need to do, and `Flask` will take care of the rest. -
接下来是
app.py。需要做一些更改:-
Flask-WTF表单需要一个配置好的密钥才能工作。你可以通过访问.env文件来添加它。你声明的值完全是任意的。 -
我们现在的索引路由需要允许 POST 和 GET 方法,因为它将处理表单。在
index()函数内部,你将需要实例化之前编写的IrisForm类,并在点击提交按钮且没有验证错误时返回相关结果。你可以使用
validate_on_submit()函数进行检查。如果检查通过,输入数据将以标题格式返回(我们稍后会看到如何显示预测)。如果没有通过,则返回index.html模板。 -
现在调用
render_template()时,会传递一个参数到我们的 HTML 文件——iris_form。这给了 HTML 文件访问表单数据的能力。你将在下一分钟看到如何处理它。这就是更改后你的文件应有的样子:
import os from flask import Flask, render_template from forms import IrisForm from dotenv import load_dotenv load_dotenv('.env') app = Flask(__name__) app.config['SECRET_KEY'] = os.getenv('SECRET_KEY') @app.route('/', methods=['GET', 'POST']) def index(): iris_form = IrisForm() if iris_form.validate_on_submit(): return f''' <h3> Sepal Length: {iris_form.sepal_length.data}<br> Sepal Width: {iris_form.sepal_width.data}<br> Petal Length: {iris_form.petal_length.data}<br> Petal Width: {iris_form.petal_width.data} </h3> ''' return render_template('index.html', iris_form=iris_form) if __name__ == '__main__': app.run(host=os.getenv('HOST'), port=os.getenv('PORT'))我们几乎完成了。让我们接下来调整
index.html文件。
-
-
index.html是你需要调整以使应用程序工作的最后一个文件。我们需要的只是显示之前声明的字段的表单。同时,保护你的应用程序免受跨站请求伪造(CSRF)攻击也是强制性的。为此,你必须在表单字段之前放置一个令牌。这就是 HTML 文件应有的样子:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Iris Predictioner</title> </head> <body> <h1>Welcome to Iris Predictioner</h1> <form method="POST" action="{{ url_for('index') }}"> {{ iris_form.csrf_token }} {{ iris_form.sepal_length.label }} {{ iris_form.sepal_length(size=18) }} <br> {{ iris_form.sepal_width.label }} {{ iris_form.sepal_width(size=18) }} <br> {{ iris_form.petal_length.label }} {{ iris_form.petal_length(size=18) }} <br> {{ iris_form.petal_width.label }} {{ iris_form.petal_width(size=18) }} <br> <input type="submit" value="Predict"> </form> </body> </html>如你所见,要访问从 Python 文件发送的参数,你必须用双大括号包围代码。
-
如果你现在启动应用程序,屏幕上会显示以下内容:
图 9.8 – 爱尔兰预测应用程序
这就是你的机器学习应用的前端!它有点丑陋,但我们稍后会对其进行美化。让我们先测试一下功能。
我们不希望表单在任何一个输入值都为空的情况下被提交。如果立即按下按钮,会发生以下情况:
![图 9.9 – 爱尔兰预测应用表单验证(1)
图 9.9 – 爱尔兰预测应用表单验证(1)
验证测试 1 – 完成。让我们看看如果只有一个输入字段为空会发生什么:
![图 9.10 – 爱尔兰预测应用表单验证(2)
图 9.10 – 爱尔兰预测应用表单验证(2)
发生了同样的消息,正如你所期望的那样。为了总结,如果任何一个输入字段为空,表单将无法提交。
要继续,填写所有字段,如图所示:
![图 9.11 – 爱尔兰预测应用表单值
图 9.11 – 爱尔兰预测应用表单值
如果你现在点击按钮,你会看到以下结果:
![图 9.12 – 爱尔兰预测应用结果
图 9.12 – 爱尔兰预测应用结果
到目前为止,一切正常,但在将应用连接到我们的爱尔兰预测 API 之前,我们还需要做一步——美化。这一步是可选的,因为如果你决定立即跳到 API 连接部分,应用仍然可以工作。
为你的 Flask 应用设置适当的样式需要一点工作和重构。你可以在这里找到整个步骤列表。请注意,这本书假设没有 HTML 和 CSS 知识。你可以自由地复制粘贴这些文件的内容,但鼓励你自己进一步探索:
-
让我们从
app.py开始。我们不会返回一个包含打印为单个长字符串的输入值的H2标签,而是返回一个将显示表格的 HTML 模板。现在,我们只填写输入数据,并为预测和预测概率设置假值。这里是更改后的文件应该看起来是什么样子:
import os from flask import Flask, render_template from forms import IrisForm from dotenv import load_dotenv load_dotenv('.env') app = Flask(__name__) app.config['SECRET_KEY'] = os.getenv('SECRET_KEY') @app.route('/', methods=['GET', 'POST']) def index(): iris_form = IrisForm() if iris_form.validate_on_submit(): return render_template( 'predicted.html', sepal_length=iris_form.sepal_length.data, sepal_width=iris_form.sepal_width.data, petal_length=iris_form.petal_length.data, petal_width=iris_form.petal_width.data, prediction='Prediction', probability=100000 ) return render_template('index.html', iris_form=iris_form) if __name__ == '__main__': app.run(host=os.getenv('HOST'), port=os.getenv('PORT')) -
让我们在做这件事的同时创建一个模板文件。在
/templates目录下创建一个predicted.html文件。如前所述,这个文件将包含一个显示 API 响应的表格(一旦我们实现它)。这里是文件应该看起来是什么样子:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <link rel="stylesheet" href="{{ url_for('static', filename='css/main.css') }}"> <title>Iris Predictioner</title> </head> <body> <div class="container"> <h1>Predictions:</h1> <table> <thead> <tr><th>Attribute</th><th>Value</th></tr> </thead> <tbody> <tr><td>Sepal Length</td><td>{{ sepal_length }}</td></tr> <tr><td>Sepal Width</td><td>{{ sepal_width }}</td></tr> <tr><td>Petal Length</td>td>{{ petal_length }}</td></tr> <tr><td>Petal Width</td><td>{{ petal_width }}</td></tr> <tr><td>Prediction</td><td>{{ prediction }}</td></tr> <tr><td>Probability</td><td>{{ probability }}</td></tr> </tbody> </table> </div> </body> </html>如你所见,我们已经利用了参数传递的强大功能来显示数据在预测模型中的进出。如果你对文档头中 CSS 文件链接的问题感到好奇——现在不用担心。在处理 CSS 之前,我们还需要处理一件事。
-
最后,让我们重新格式化
index.html。这个文件只需要进行一些小的更改——几个 CSS 类和几个div元素。以下是重新格式化版本的整个代码片段:<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <link rel="stylesheet" href="{{ url_for('static', filename='css/main.css') }}"> <title>Iris Predictioner</title> </head> <body> <div class="container"> <h1>Welcome to Iris Predictioner</h1> <form method="POST" action="{{ url_for('index') }}"> {{ iris_form.csrf_token }} <div class="single-input"> {{ iris_form.sepal_length.label }} {{ iris_form.sepal_length(size=18) }} </div> <div class="single-input"> {{ iris_form.sepal_width.label }} {{ iris_form.sepal_width(size=18) }} </div> <div class="single-input"> {{ iris_form.petal_length.label }} {{ iris_form.petal_length(size=18) }} </div> <div class="single-input"> {{ iris_form.petal_width.label }} {{ iris_form.petal_width(size=18) }} </div> <input class="btn-submit" type="submit" value="Predict"> </form> </div> </body> </html> -
我们几乎完成了。到目前为止,你已经重构了所有需要重构的文件,现在你将创建一个额外的文件夹和文件。在根目录下,创建一个名为
static的文件夹。创建后,在它里面创建一个名为css的额外文件夹。这个文件夹将包含我们应用程序的所有样式。在css文件夹中,创建一个名为main.css的文件。总结一下,创建这些文件夹和文件后,你的目录结构应该如下所示:
@import url('https://fonts.googleapis.com/css2?family=Open+Sans:wght@400;600&display=swap'); * { margin: 0; padding: 0; box-sizing: border-box; font-family: 'Open Sans', sans-serif; } body { background-color: #f2f2f2; } .container { width: 800px; height: 100vh; margin: 0 auto; background-color: #ffffff; padding: 0 35px; } .container > h1 { padding: 35px 0; font-size: 36px; font-weight: 600; } .single-input { display: flex; flex-direction: column; margin-bottom: 20px; } .single-input label { font-weight: 600; } .single-input label::after { content: ":" } .single-input input { height: 35px; line-height: 35px; padding-left: 10px; } .btn-submit { width: 100%; height: 35px; background-color: #f2f2f2; font-weight: 600; cursor: pointer; border: 2px solid #dddddd; border-radius: 8px; } table { font-size: 18px; width: 100%; text-align: left; }完成了。让我们运行应用程序,看看现在的样子。
-
如果你现在重新运行应用程序,你会看到样式开始生效。以下图示显示了输入表单的外观:
图 9.14 – 样式化的 Iris 预测应用程序
应用程序现在远非完美,但至少已经是一个可展示的形式。让我们按照以下图示来完善它:
图 9.15 – 样式化的 Iris 预测应用程序(2)
最后,让我们点击预测按钮,看看另一页的样子:
图 9.16 – Iris 预测应用程序预测
在样式方面,我们可以到此为止。应用程序现在看起来相当不错,但你也可以自由地进一步调整它。
由此,你就可以看到如何构建和样式化一个围绕机器学习模型构建的Flask应用程序。下一节将连接我们的 API,使应用程序完全可用。在那里见。
在 GUI 环境中进行预测
欢迎来到本书的最后一部分。本节将把我们的简单 Web 应用程序与已部署的机器学习 API 联系起来。这非常类似于生产环境,其中你部署了一个或多个机器学习模型,而应用程序开发团队希望将其用于他们的应用程序。唯一的区别是,你既是数据科学团队也是应用程序开发团队。
再次强调,我们还需要对应用程序结构进行一些修改:
-
让我们从简单的部分开始。在根目录下,创建一个名为
predictor.py的 Python 文件。这个文件将包含一个函数,该函数实现了本章开头在笔记本环境中进行预测时讨论的逻辑。简而言之,这个函数必须向 API 发送 POST 请求,并以 JSON 格式返回响应。
这是文件中的整个代码片段:
import os import json import requests from dotenv import load_dotenv load_dotenv('.env') def predict(sepal_length, sepal_width, petal_length, petal_width): URL = os.getenv('API_ENDPOINT') req = requests.post( url=URL, json={ 'SepalLength': sepal_length, 'SepalWidth': sepal_width, 'PetalLength': petal_length, 'PetalWidth': petal_width } ) response = json.loads(req.content) return response请记住,URL 参数的值在你的机器上可能会有所不同,所以请相应地更改它。
没有必要进一步解释这个代码片段,因为它几乎与你之前看到和编写的代码相同。
-
现在我们对
app.py进行一些修改。我们将在输入字段验证后立即导入此文件并调用predict()函数。一旦返回响应,其值将作为参数传递给return语句的相应字段。这是
app.py文件的整个代码片段:import os import numpy as np from flask import Flask, render_template from forms import IrisForm from predictor import predict from dotenv import load_dotenv load_dotenv('.env') app = Flask(__name__) app.config['SECRET_KEY'] = os.getenv('SECRET_KEY') @app.route('/', methods=['GET', 'POST']) def index(): iris_form = IrisForm() if iris_form.validate_on_submit(): pred_response = predict( sepal_length=iris_form.sepal_length.data, sepal_width=iris_form.sepal_width.data, petal_length=iris_form.petal_length.data, petal_width=iris_form.petal_width.data ) return render_template( 'predicted.html', sepal_length=pred_response['In_PetalLength'], sepal_width=pred_response['In_PetalWidth'], petal_length=pred_response['In_SepalLength'], petal_width=pred_response['In_SepalWidth'], prediction=pred_response['Prediction'], probability=f"{np.round((pred_response['Probability'] * 100), 2)}%" ) return render_template('index.html', iris_form=iris_form) if __name__ == '__main__': app.run(host=os.getenv('HOST'), port=os.getenv('PORT'))如您所见,预测概率被转换为百分比并四舍五入到小数点后两位。这样做的原因只是为了在应用程序中输出更美观的格式。
-
现在是时候进行有趣的测试了。打开应用程序,在表单中输入一些数据。以下是一个示例:
图 9.17 – 爱尔兰预测应用程序最终测试
一旦你点击了预测按钮,你将在屏幕上看到以下结果:
图 9.18 – 爱尔兰预测应用程序最终结果
到此为止,你就有了一个基于部署的机器学习模型的完整且完全工作的 GUI Web 应用程序。
不包括随后的摘要,这是本章的最后一部分,也是整本书的结尾。你现在知道如何部署机器学习模型并在部署的模型周围构建简单的 Web 应用程序。恭喜!
摘要
本章属于实践性很强的章节,但我希望你已经设法跟上了。如果你做到了,你已经学到了很多——从如何在笔记本环境中进行预测到在简单和自定义构建的 Web 应用程序中进行预测。
不仅如此,你还完成了整本书。恭喜!在这九个章节中,你学到了很多。我们从机器学习的基础,通过基本的回归和分类示例开始,然后逐渐构建我们对 TPOT 的知识。你还学习了 TPOT 如何与并行训练和神经网络一起工作。但可能你获得的最重要的新技能是模型部署。没有它,你的模型就毫无用处,因为没有人可以使用它们来创造价值。
和往常一样,你可以自由探索 TPOT 以及它提供的所有惊人的功能。这本书应该为你提供一个很好的起点,因为它只用了几百页就带你从零开始构建围绕部署的自动化机器学习模型的 Web 应用程序。这确实值得骄傲!
问答
-
你可以使用哪个 Python 库向部署的 REST API 发送请求?
-
在发送 POST 请求时,数据以什么格式提供?
-
命名用于构建和操作表单的 Flask 扩展。
-
如果我们谈论的是进入机器学习模型的数据,为什么验证 Web 应用程序表单很重要?
-
你可以通过 Flask 将参数传递给 HTML 模板文件吗?如果是这样,你如何在 HTML 中显示它们的值?
-
解释将 CSS 文件链接到 Flask 应用程序的过程。
-
解释为什么将机器学习模型闲置在您的电脑上是没有意义的。
