

FastAI 深度学习秘籍(三)
原文:
annas-archive.org/md5/238a690f0344b1fc28d0f515ee7ae7ac译者:飞龙
第七章:第七章:部署与模型维护
到目前为止,在本书中你已经训练了多种 fastai 模型,包括使用表格数据集训练的模型、使用文本数据集训练的模型、推荐系统以及使用图像数据训练的模型。所有这些模型都已经在 Jupyter Notebook 环境中进行了演示。Jupyter Notebook 很适合用于训练模型并使用几个测试样本进行测试,但如果要真正让模型有用怎么办?如何使你的模型可以供其他人或应用程序使用,以实际解决问题?
将你的深度学习模型提供给其他人或应用程序的过程称为 部署。在本章中,我们将通过一些步骤,展示如何部署你的 fastai 模型。深度学习模型的工业级生产部署超出了本书的范围。在本章中,你将学习如何创建简单、独立的部署,并能够从你自己的本地系统提供服务。
本章将涉及以下步骤:
-
在本地系统上设置 fastai
-
部署一个使用表格数据集训练的 fastai 模型
-
部署一个使用图像数据集训练的 fastai 模型
-
维护你的 fastai 模型
-
测试你的知识
技术要求
在本章中,你将在本地系统上运行部署,这要求你在本地系统上安装 fastai。要在本地运行 fastai,推荐使用 Windows 或 Linux 系统,并安装 Python。虽然 fastai 也可以在 macOS 上安装,但如果你使用 Windows 或 Linux 系统进行本地安装,将能节省许多麻烦。
确保你已经克隆了本书的 GitHub 仓库 github.com/PacktPublishing/Deep-Learning-with-fastai-Cookbook,并可以访问 ch7 文件夹。该文件夹包含本章中描述的代码示例。
在本地系统上设置 fastai
在能够简单部署一个 fastai 深度学习模型的第一步是将你的本地系统设置为安装 PyTorch 和 fastai。你需要这么做,因为你将在本地系统上运行代码,调用你在本书中之前训练的模型。为了在本地系统上运行模型并进行预测,你需要安装 fastai 框架。在本节中,你将看到如何在本地系统上设置 fastai,以及如何验证你的安装。
准备工作
确保你在本地系统上安装了 Python(至少是 3.7)。
要检查 Python 的版本,可以在命令行中输入以下命令:
python –version
输出将显示你本地系统上安装的 Python 版本,如下所示:
图 7.1 – Python 版本
确保您已经将书的存储库克隆到您的本地系统上:github.com/PacktPublishing/Deep-Learning-with-fastai-Cookbook。
如何做…
要在本地系统上设置 fastai,您需要设置 PyTorch(fastai 运行的深度学习框架),然后是 fastai。要做到这一点,请按照以下步骤操作:
-
通过在本地系统的终端或命令窗口中运行以下命令,在您的本地系统上安装 PyTorch。您可以在此处找到有关在本地系统上安装 PyTorch 的完整详细信息:
pytorch.org/get-started/locally/:pip3 install torch==1.8.1+cpu torchvision==0.9.1+cpu torchaudio===0.8.1 -f https://download.pytorch.org/whl/torch_stable.html -
根据您的操作系统和典型的 Python 安装方法,按照此处的说明在本地系统上安装 fastai:
docs.fast.ai/。 -
安装完 PyTorch 和 fastai 后,通过在本地 repo 的
ch7目录中打开validate_local_setup.ipynb笔记本并运行以下单元格来验证您的安装:import fastai fastai.__version__
恭喜!你已成功在本地系统上设置了 fastai。
它是如何工作的…
您可能会问为什么有必要在本地系统上设置 fastai 来演示如何部署 fastai 模型。虽然可以在不使用本地系统的情况下部署 fastai 模型,但在本地安装 fastai 具有几个优点:
-
您可以完全控制整个环境。通过在本地安装 fastai,您可以控制整个堆栈,从 pandas 的层面到用于部署的网页的详细信息。
-
通过在本地部署 fastai 模型,您将避免可能会限制您完全理解 fastai 模型在部署时如何工作的快捷方式。您将在本章中看到的部署可能很简单,但它们是完整的。通过通过没有留下任何黑盒子的配方来工作,您将深入了解 fastai 模型在部署时真正发生的事情。
-
如果你认真对待 fastai 的使用,拥有本地安装环境会非常方便。在第一章**,快速入门 fastai中,我曾指定你需要一个云环境,像是 Gradient 或 Colab,以便进行本书中的实践部分。大多数 fastai 应用需要 GPU 才能高效训练。要在现有本地系统上设置 GPU 并不简单,除非你完全致力于通过全职工作在深度学习应用中定期使用 GPU,否则购买一个预配置有 GPU 的系统并没有太大意义。因此,使用启用 GPU 的云环境是最好的起点。然而,即便你不会在本地系统上进行模型训练,拥有一个可以运行 fastai 环境的本地系统也是非常有用的。例如,在编写本书的过程中,曾经有几次遇到 Gradient 环境的问题,而我大部分的开发工作都是在该环境中进行的。由于我本地已安装 fastai,当 Gradient 无法使用时,我依然可以在本地系统上继续编写与模型无关的代码,取得进展。
-
如果你之前没有接触过 web 应用开发,本章中的简短体验将对你有所帮助。根据我的经验,许多数据科学家对于 web 应用的工作原理一无所知,而我们大多数的工作最终都会在某种形式下通过 web 框架呈现,因此,理解 web 应用的基本工作原理对我们来说是非常重要的。通过结合 Python 的 Flask 库与基础的 HTML 和 JavaScript,我们将创建一个非常简单但完整的 web 应用,展示一些基本的 web 应用原理。如果你以前没有接触过这些原理,学会这些知识会对你非常有用。
我希望这些背景信息能够帮助你理解,在本地系统上拥有一个正常工作的 fastai 环境是多么有价值。现在你已经完成了 fastai 环境的设置,接下来的章节中,你将学会如何在本地系统上部署模型。
部署一个在表格数据集上训练的 fastai 模型
回到第三章**,训练表格数据的模型中的保存已训练的表格模型部分,你曾经练习过一个已保存的 fastai 模型。回想一下你在该部分中所经历的步骤。
首先,你按照以下方式加载了已保存的模型:
learn = load_learner('/storage/data/adult_sample/adult_sample_model.pkl')
然后你拿取了一个测试样本,并从模型中生成了该测试样本的预测:
test_sample = df_test.iloc[0]
learn.predict(test_sample)
如下截图所示,预测的输出包括了输入样本的值、预测结果以及每个结果的概率:
图 7.2 – 运行已保存的 adult_sample_model 模型进行预测的输出
在本食谱中描述的模型网页部署过程中,你将按照与我们刚刚回顾的第三章《使用表格数据训练模型》食谱中完全相同的步骤(如下所列)进行操作:
-
加载已保存的训练模型。
-
将模型应用到输入样本上。
-
获取模型的预测结果。
与第三章《使用表格数据训练模型》中所有操作都在 Jupyter notebook 环境下进行不同,在这个示例中,你将通过一个简单的网页应用程序完成这些步骤。你将能够以非常自然的方式输入新的样本并获得预测结果,预测结果会以清晰的英文语句呈现,而不是张量的形式。更棒的是,你将能够与他人分享你的网页应用程序,让他们也能使用你的模型并查看其做出的预测。简而言之,通过部署你的模型,你将其从一个只能在程序中访问的抽象编码工件转变为一个普通人也能实际使用的软件工具。
本节描述的部署过程包含一个作为 Flask 模块实现的网络服务器。Flask 是一个 Python 库,它让你可以在熟悉的 Python 环境中提供网页应用程序。在本示例中,你将启动 Flask 模块,并使用它所提供的网页来调用模型。
准备工作
确保你已经按照在本地系统上设置 fastai这一食谱中的步骤安装了 fastai,并确认你可以访问 ch7 目录下 deploy_tabular 目录中的文件。
如何操作…
要在你的系统上部署一个训练好的表格数据集模型,你将启动 Flask 服务器,并通过相关的网页来验证你是否能根据给定的输入评分参数从模型中获取预测。完成以下步骤来操作:
-
在本地系统的命令窗口/终端中,将
ch7目录下的deploy_tabular设置为当前目录。 -
在命令行/终端中输入以下命令来启动 Flask 服务器:
localhost:5000, as shown in the following screenshot:Figure 7.3 – Output when the Flask server starts -
打开浏览器窗口,并在地址栏输入以下内容:
home.html web page will be loaded in the browser, as shown in *Figure 7.4*:Figure 7.4 – home.html being server by the Flask server -
现在,选择
home.html,在此案例中,选择字段的默认值:
图 7.5 – 在 home.html 中使用默认设置生成的查询字符串
几秒钟后,show-prediction.html 网页将显示模型对 home.html 中输入的值进行预测的结果,如图 7.6所示:
图 7.6 – 模型在 show-prediction.html 中显示的预测结果
恭喜!你已成功设置了 Flask 服务器,并在简单网页部署的背景下练习了 fastai 模型的网页部署。
它是如何工作的…
当你运行这个配方时,幕后发生了很多事情。在本节中,我们将首先概述网页部署的流程,然后深入研究构成该部署的关键代码部分。
快速介绍 fastai 表格模型的网页部署工作原理
本配方中描述的网页部署与本书前面看到的配方有所不同。与其他配方(它们涉及以 Jupyter 笔记本形式呈现的单个代码文件)不同,网页部署涉及多个文件中分布的代码,如 图 7.7 所示:
图 7.7 – 使用 Flask 部署 fastai 模型的网页概述
以下是 图 7.7 中数字所标示的关键项:
-
home.html– 这是用户指定每个特征的网页,用于训练模型时使用的特征。home.html包含一组 JavaScript 函数,这些函数设置每个控件中的可用值,打包用户的输入,并调用show-prediction.html,将评分参数作为参数传递。 -
Flask
web_flask_deploy.py模块 – 一个 Python 模块,使用 Flask 库来服务构成网页部署的网页。该模块包括home.html和show-prediction.html,它们完成了网页部署的大部分工作。show-prediction.html的视图函数解析从home.html发送来的评分参数,将评分参数值组装成 DataFrame,使用包含评分参数的 DataFrame 调用训练好的模型进行预测,生成模型预测的字符串,最后触发show-prediction.html显示预测字符串。 -
fastai
adult_sample_model.pkl模型 – 这是你在 第三章 《使用表格数据训练模型》 中的 保存训练好的表格模型 配方中训练并保存的模型。web_flask_deploy.pyFlask 模块中的show-prediction.html视图函数加载此模型,并使用它对在home.html中输入的评分参数进行预测。 -
show-prediction.html– 这个网页显示模型根据在home.html中输入的评分参数所做的预测。用户阅读预测结果后,可以选择返回home.html输入另一组评分参数。
这是关于网页部署工作原理的高层次总结。接下来,我们将查看一些构成该部署的关键代码部分。
深入探索网页部署背后的代码
现在你已经了解了幕后发生的高层次过程,让我们深入探讨两段对整体 Web 部署特别重要的代码。我们将逐步解析部署中组成部分的主要代码,包括 Flask 服务器模块中的 Python 代码以及 HTML 文件中的 JavaScript 函数。
当你启动 Flask 服务器时,如食谱中的 步骤 2 所示,训练好的模型将被加载到 Python 模块中,以下是来自 Flask 服务器代码的片段:
path = Path(os.getcwd())
full_path = os.path.join(path,'adult_sample_model.pkl')
learner = load_learner(full_path)
这是该片段的关键部分:
-
path = Path(os.getcwd())– 设置path为启动 Flask 服务器的目录。代码假设模型文件位于相同的目录中。 -
full_path = os.path.join(path,'adult_sample_model.pkl')– 定义了模型的完整路径,包括文件名。 -
learner = load_learner(full_path)– 将模型加载到learner中。
当你在浏览器中访问 localhost:5000 时,将显示 home.html 页面。这个过程是如何发生的呢?在 web_flask_deploy.py Flask 模块中,home.html 控制了当 Flask 服务器运行时,你访问 localhost:5000 时发生的事情,如以下代码片段所示:
@app.route('/')
def home():
title_text = "fastai deployment"
title = {'titlename':title_text}
return render_template('home.html',title=title)
这是此视图函数的关键部分:
-
@app.route('/')– 指定当你访问localhost:5000地址时应用此视图函数。 -
return render_template('home.html',title=title)– 指定当你访问localhost:5000时显示home.html。
当 home.html 被加载时,操作从 Flask 服务器模块中的 Python 转移到 home.html 中的 HTML 和 JavaScript 的结合体。首先,调用 load_selections() 函数将值加载到网页上的控件中,如以下 HTML 语句所示:
<body onload="load_selections()">
load_selections() 函数通过指定有效值的列表填充页面上的选择控件(下拉列表),例如以下 relationship 控件的内容:
var relationship_list = [" Wife" ," Not-in-family" ," Unmarried" ," Husband" ," Own-child" ," Other-relative" ];
load_selections() 函数还包括 for 循环,这些循环将有效值列表设置到选择控件中,例如以下 for 循环填充 relationship 控件:
for(var i = 0; i < relationship_list.length; i++) {
var opt = relationship_list[i];
select_relationship.innerHTML += "<option value=\"" + opt + "\">" + opt + "</option>";
对于输入数值的控件,load_selections() 函数设置页面加载时显示的默认值。例如,以下 load_selections() 函数中的语句为 age 字段设置了默认值:
document.getElementById("age").defaultValue = 40;
一旦值被加载到控件中并且页面显示,用户可以在控件中选择与默认值不同的评分参数值。
在用户选择了评分参数的值后,用户可以选择按钮,调用 link_with_args() 函数:
<button>
<a onclick="link_with_args();" style="font-size : 20px; width: 100%; height: 100px;">Get prediction</a>
</button>
link_with_args() 函数调用 getOption() 函数,加载用户在 home.html 中选择的控件值,并用这些值构建查询字符串,如下所示,这是 getOption() 中的代码片段:
prefix = "/show-prediction/?"
window.output = prefix.concat("workclass=",workclass_string,"&age=",age_value,"&fnlwgt=",fnlwgt_value,"&education=",education_string,"&education-num=",education_num_value,"&marital-status=",marital_status_string,"&occupation=",occupation_string,"&relationship=",relationship_string,"&race=",race_string,"&sex=",sex_string,"&capital-gain=",capital_gain_value,"&capital-loss=",capital_loss_value,"&hours-per-week=",hours_per_week_value,"&native-country=",native_country_string);
document.querySelector('.output').textContent = window.output;
以下是该代码片段的关键部分:
-
prefix = "/show-prediction/?"– 指定当链接被触发时,Flask 模块中将调用哪个视图函数。 -
window.output– 指定查询字符串中包含的参数集。这个字符串由一系列键值对组成,每个值等于在home.html中对应的控件。 -
document.querySelector('.output').textContent = window.output;– 指定查询字符串将在浏览器窗口中显示。
你可能记得在这个过程中的查询字符串。在食谱的步骤 4中,当你选择 home.html 时,查询字符串会在页面底部短暂显示,随后加载 show-prediction.html。
在调用 getOption() 后,link_with_args() 函数通过以下语句触发对 show-prediction.html 的引用:
window.location.href = window.output;
通过这个语句,操作从 HTML 和 JavaScript 的世界切换回 Python,并在 Flask 服务器中调用 show-prediction.html 的视图函数。以下是该视图函数的开始部分,其中在 home.html 中输入并通过查询字符串传递的评分参数值被加载到 score_df DataFrame 中:
@app.route('/show-prediction/')
def show_prediction():
score_df = pd.DataFrame(columns=scoring_columns)
for col in scoring_columns:
print("value for "+col+" is: "+str(request.args.get(col)))
score_df.at[0,col] = request.args.get(col)
以下是该代码片段的关键部分:
-
@app.route('/show-prediction/')– 指定此视图函数适用于show-prediction.html网页。 -
score_df = pd.DataFrame(columns=scoring_columns)– 创建一个空的 DataFrame 来存储评分参数。 -
score_df.at[0,col] = request.args.get(col)– 这个语句会针对scoring_columns列表中的每一列运行。它将查询字符串中由getOption()JavaScript 函数构建并作为引用传递到show-prediction.html的值复制到score_dfDataFrame 第一行的对应列。这就是用户在home.html中输入的评分参数值如何传入 Python Flask 服务器模块的方式。
现在,评分参数已被加载到 score_df DataFrame 的第一行中,我们可以在 DataFrame 的第一行上调用模型,正如以下来自 show-prediction.html 视图函数的代码片段所示:
pred_class,pred_idx,outputs = learner.predict(score_df.iloc[0])
if outputs[0] >= outputs[1]:
predict_string = "Prediction is: individual has income less than 50k"
else:
predict_string = "Prediction is: individual has income greater than 50k"
prediction = {'prediction_key':predict_string}
return(render_template('show-prediction.html',prediction=prediction))
以下是该代码片段的关键部分:
-
pred_class,pred_idx,outputs = learner.predict(score_df.iloc[0])– 使用score_dfDataFrame 的第一行作为输入调用模型。此调用有三个输出:a)
pred_class列出了输入到模型中的评分参数。对于类别列,原始的评分参数值被替换为类别标识符。例如,native-country列中的United States被替换为40.0。这些转换与训练数据时所做的转换完全相同,正如你在 第三章*《使用表格数据训练模型》* 中所做的那样。由于 fastai 管理这些转换的方式,不像 Keras,你不需要担心在部署模型时维护管道对象并应用它——fastai 会自动处理这一切。这是 fastai 的一个巨大优势。b)
pred_idx– 预测的索引。对于此模型,预测值将为 0(表示个人收入低于 50,000)或 1(表示个人收入高于 50,000)。c)
outputs– 显示每个预测值的概率。图 7.8 显示了预测输出的示例,以及它如何对应于
pred_class、pred_idx和outputs变量:
图 7.8 – 模型预测输出示例
return(render_template('show-prediction.html',prediction=prediction))– 指定以该视图函数中设置的参数值显示show-prediction.html。
执行此操作后,页面返回到 HTML,show-prediction.html 被加载到浏览器中。以下代码片段显示了展示预测文本的 HTML:
<div class="home">
<h1 style="color: green">
Here is the prediction for the individual's income:
</h1>
<h1 style="color: green">
{{ prediction.prediction_key }}
</h1>
{{ prediction.prediction_key }} 值对应于 Flask 服务器中 show-prediction 的视图函数中设置的 predict_string 值。结果是,模型对评分参数做出的预测会被显示出来,如 图 7.9 所示:
图 7.9 – 部署模型的最终结果 – 对评分参数的预测
现在你已经看到了构成整个 fastai 模型 Web 部署流程的所有主要代码项。该流程包括以下几个步骤:
-
流程从启动 Flask 服务器开始。一旦启动了 Flask 服务器,它就准备好在
localhost:5000提供home.html。 -
当你在浏览器中访问
localhost:5000时,Flask 服务器会运行home.html的视图函数,并在浏览器中显示home.html。 -
然后流程转到
home.html中的 HTML/JavaScript,用户在此选择评分参数并点击 获取预测 按钮。 -
然后流程返回到 Flask 服务器,运行
show-prediction.html的视图函数,从模型中获取评分参数的预测,并在浏览器中展示show-prediction.html。 -
最后,流程回到
show-prediction.html,在该页面上展示模型的预测结果。 -
此时,用户可以选择
show-prediction.html,使用不同的评分参数从步骤 2重新开始整个过程。
还有更多……
本食谱中的网络部署示例仅仅触及了 Flask 的表面,它只涵盖了现代 HTML 和 JavaScript 的基本应用。本书的范围无法深入探讨如何使用 Python 开发 Web 应用,但如果你有兴趣了解更多,可以参考以下资源:
-
使用 Flask 部署深度学习模型 (
towardsdatascience.com/deploying-a-deep-learning-model-using-flask-3ec166ef59fb) 更详细地介绍了如何使用 Flask 部署深度学习模型。尽管这篇文章重点介绍的是部署 Keras 模型,而非 fastai 模型,但文章中描述的原则同样适用于这两种框架。 -
HTML5 与 CSS 的响应式网页设计 (
www.amazon.com/Responsive-Web-Design-HTML5-CSS/dp/1839211563/ref=sr_1_2?dchild=1&keywords=html5+packt&qid=1623055650&sr=8-2) 提供了现代 HTML 的广泛背景,并涉及了层叠样式表(CSS),它用于控制网页的渲染方式。 -
JavaScript 中的 Clean Code (
www.amazon.com/Clean-Code-JavaScript-reliable-maintainable/dp/1789957648/ref=sr_1_6?dchild=1&keywords=Javascript+Packt&qid=1623055616&sr=8-6) 介绍了 JavaScript 的良好编程实践。如果你正在阅读这本书,说明你对 Python 已经有了相当的掌握,应该能够轻松地掌握 JavaScript。虽然 JavaScript 在 C++和 Scala 等更高大上的语言程序员中并不总是得到应有的尊重,但事实上,JavaScript 非常灵活,学会它非常有用。
部署一个基于图像数据集训练的 fastai 模型
在使用 fastai 部署基于表格数据集训练的模型这一食谱中,我们讲解了如何部署一个基于表格数据集训练的模型。我们部署了一个根据一组被称为评分参数的特征(包括教育水平、工作类别和每周工作小时数)来预测个人是否会有超过 50,000 收入的模型。为了进行这个部署,我们需要一种方式让用户选择评分参数的值,并展示由训练好的 fastai 模型基于这些评分参数所做的预测。
在本教程中,我们将部署在第六章**,训练具有视觉数据的模型中的 使用独立视觉数据集训练分类模型 处训练的图像分类模型。此模型可以预测图像中展示的水果或蔬菜。与表格数据集模型的部署不同,部署图像数据集模型时,我们需要能够指定要进行预测的图像文件。
注意
为了简化操作,此部署使用与我们在部署基于表格数据集训练的 fastai 模型教程中相同名称的网页(home.html 和 show-prediction.html)。不过,这些网页是为图像模型部署定制的。
准备工作
确保你已经按照在本地系统上设置 fastai教程中的步骤,成功安装了 fastai。确认你可以访问 ch7 目录中的 deploy_image 目录下的文件。
如何操作……
要在本地系统上演练图像分类模型的部署,首先启动 Flask 服务器,打开浏览器中部署的 home.html 页面,选择一个图像文件进行预测,然后验证在该部署的 show-prediction.html 页面中是否显示了图像的预测结果。
按照以下步骤进行操作,以演练部署在图像数据集上训练的 fastai 模型:
-
在本地系统的命令窗口/终端中,将
ch7目录中的deploy_image目录设置为当前目录。 -
在命令行/终端输入以下命令以启动 Flask 服务器:
localhost:5000, as shown in *Figure 7.10*:Figure 7.10 – Output when the Flask server starts -
打开浏览器窗口,在地址栏输入以下内容:
home.html will be loaded in the browser, as shown in *Figure 7.11*:Figure 7.11 – home.html for the image model deployment being served by the Flask server -
现在选择
deploy_images目录中的test_images子目录。选择柠檬图像文件5_100.jpg,并关闭文件对话框,例如,在 Windows 中选择 打开。 -
当文件对话框关闭时,你选择的文件名会显示在
home.html中的 选择文件 按钮旁边,如图 7.12所示:图 7.12 – 你选择的文件名显示在 home.html 页面中
-
现在选择
show-prediction.html页面,该页面显示模型对你在home.html中选择的图像的预测结果,如图 7.13所示:
图 7.13 – 模型对图像内容的预测,显示在 show-prediction.html 页面中
恭喜!你已成功设置了 Flask 服务器并演练了 fastai 模型的 Web 部署,该模型可以预测图像中展示的物体。
工作原理……
现在你已经完成了 fastai 图像分类模型的 Web 部署,让我们来看一下幕后发生了什么。我们将从部署的概述开始,然后深入探讨图像分类模型和表格数据集模型部署之间的代码差异,正如在 《部署一个基于表格数据集训练的 fastai 模型》 配方中所描述的那样。
fastai 图像分类模型 Web 部署的工作概述
让我们回顾一下如 图 7.14 所示的端到端部署流程:
图 7.14 – 使用 Flask 部署 fastai 图像分类模型的 Web 概述
以下是 图 7.14 中数字高亮的关键项目:
-
home.html——这是用户指定要让模型对其进行预测的图像文件的网页。用于图像分类模型部署的home.html版本包含了显示文件选择对话框、打包选中文件名称并调用show-prediction.html的 HTML 和 JavaScript 函数,并将选定的图像文件名作为参数传递。 -
Flask
web_flask_deploy_image_model.py模块——这个 Python 模块使用 Flask 库来提供构成 Web 部署的网页。该模块包括home.html和show-prediction.html的视图函数。show-prediction.html的视图函数接收从home.html中选择的图像文件名称,使用该文件名调用训练好的模型进行预测,生成模型预测的字符串,并最终触发show-prediction.html显示预测字符串。 -
fastai
fruits_360may3.pkl图像分类模型——这是你在 《使用独立视觉数据集训练分类模型》 配方中训练并保存的模型,位于 第六章*,《使用视觉数据训练模型*》一章中。web_flask_deploy_image_model.pyFlask 模块中的show-prediction.html视图函数加载这个模型,然后使用它对home.html中选择的图像文件进行预测。 -
show-prediction.html——这个网页展示了模型对home.html中选择的图像文件所做的预测。在这个页面,用户可以选择home.html来选择另一张图像文件进行预测。
这就是图像分类模型 Web 部署工作的高级总结。
深入分析图像分类模型 Web 部署背后的代码
现在我们已经回顾了图像分类模型部署的整体流程,接下来让我们来看一下与我们在*《部署基于 tabular 数据集训练的 fastai 模型》*配方中涉及的 tabular 模型部署相比,图像分类模型部署的一些关键区别。以下是主要的区别:
-
home.html中的 HTML – 用于部署 tabular 数据集模型的home.html版本需要大量控件,以便用户能够指定所有必需的评分参数。用户需要能够为训练模型使用的所有特征指定值。对于图像分类模型的部署,只有一个特征——图像文件——因此我们只需要一个用于选择文件的控件。以下是文件选择控件的 HTML:<label for="image_field">Please choose an image:</label> <input type="file" id="image_field" name="image_field" accept="image/png, image/jpeg">以下是该 HTML 片段中的关键内容:
a)
input type="file"– 指定该控件用于从本地文件系统输入文件。b)
accept="image/png, image/jpeg"– 指定从此控件打开的文件对话框只允许选择具有image/png或image/jpeg内容类型的图像文件。 -
home.html中的 JavaScript – 用于部署 tabular 数据集模型的home.html版本包含三个 JavaScript 函数:a)
getOption(),用于从控件中获取值。b)
link_with_args(),用于调用getOption()并将查询字符串发送到视图函数show-prediction.html。c)
load_selections(),用于初始化控件。用于图像分类模型部署的
home.html版本不需要load_selections()(因为没有需要初始化的控件),其版本的link_with_args()与 tabular 模型部署版本相同。剩下的是getOption()函数,它与 tabular 模型部署中的版本有显著区别。以下是图像分类部署版本的getOption():function getOption() { var file_value = []; const input = document.querySelector('input'); const curFiles = input.files; if(curFiles.length === 0) { console.log("file list empty"); } else { for(const file of curFiles) { file_value.push(file.name); } } prefix = "/show-prediction/?" window.output = prefix.concat("file_name=",file_value[0]) }以下是
getOption()定义中的关键内容:a)
const input = document.querySelector('input');– 将input与文件选择器关联起来。b)
const curFiles = input.files;– 将与文件选择器关联的文件列表赋值给curFiles。c)
for(const file of curFiles) { file_value.push(file.name);}– 遍历与文件选择器关联的文件列表,并将每个文件名添加到file_value列表中。d)
window.output = prefix.concat("file_name=",file_value[0])– 使用file_value文件名列表中的第一个元素构建查询字符串。由于我们每次只对一个文件进行预测,因此查询字符串只需要一个文件名。最终生成的查询字符串类似于:/show-prediction/?file_name=5_100.jpg。 -
Flask 服务器中的
show-prediction.html视图函数 – 以下代码片段展示了图像分类 Web 部署的视图函数:@app.route('/show-prediction/') def show_prediction(): image_file_name = request.args.get("file_name") full_path = os.path.join(path,image_directory,image_file_name) img = PILImage.create(full_path) pred_class, ti1, ti2 = learner.predict(img) predict_string = "Predicted object is: "+pred_class prediction = {'prediction_key':predict_string} return(render_template('show-prediction.html',prediction=prediction))以下是定义此视图函数时的关键项:
a)
image_file_name = request.args.get("file_name")– 将image_file_name的值设置为查询字符串中的文件名。b)
full_path = os.path.join(path,image_directory,image_file_name)– 将full_path的值设置为在home.html中选择的图像文件的完整文件名。假设该文件是从运行 Flask 服务器的目录中的test_images子目录中选择的。c)
img = PILImage.create(full_path)– 为在home.html中选择的图像文件创建一个名为img的图像对象。d)
pred_class, ti1, ti2 = learner.predict(img)– 从图像分类模型中获取预测结果,预测的对象是img。pred_class包含模型对图像文件预测的类别(如 苹果 或 梨)。e)
return(render_template('show-prediction.html',prediction=prediction))– 指定显示show-prediction.html并在此视图函数中设置参数值。
现在你已经看到了在表格数据集模型部署与图像分类模型部署之间的所有主要代码差异。
还有更多内容……
在本章中,你已经看到了两个使用基于 Flask 的 Web 应用程序部署 fastai 模型的示例。这并不是你可以采用的唯一部署模型的方法。其他方法包括通过 REST API 端点部署模型(以便其他应用程序可以直接调用模型),或将模型及其依赖项封装到其他应用程序中。可以将模型和依赖项(例如所需的 Python 库)打包到 Docker 容器中,然后通过像 Kubernetes 这样的编排系统将这些容器提供给其他应用程序。
与其停留在这些一般的部署概念上,可能更有用的是回顾一些具体的快速部署 fastai 模型的方法。以下是部署 fastai 模型的一些方法示例:
-
使用 Amazon SageMaker(AWS 的机器学习环境)进行部署,具体描述请参见:
aws.amazon.com/blogs/machine-learning/building-training-and-deploying-fastai-models-with-amazon-sagemaker/。这种方法需要直接使用一些 PyTorch 代码,并且可能未在 fastai 的最新版本上进行验证。 -
使用 TorchServe 在 AWS 中部署,如此处所述:
aws.amazon.com/blogs/opensource/deploy-fast-ai-trained-pytorch-model-in-torchserve-and-host-in-amazon-sagemaker-inference-endpoint/。这种方法相比前述方法,组件较少,并且更为现代,但方法的核心似乎是重新实现 fastai 模型在 PyTorch 中的运行。 -
使用 Google Cloud Platform 部署,如此处所述:
jianjye.medium.com/how-to-deploy-fast-ai-models-to-google-cloud-functions-for-predictions-e3d73d71546b。 -
使用 Azure 部署,如此处所述:
forums.fast.ai/t/platform-azure/65527/7。
这个列表并不详尽,但它展示了可供 fastai 模型部署的各种选项。
维护你的 fastai 模型
部署一个模型并不是故事的结束。一旦你部署了一个模型,你需要维护该部署,以确保它与模型训练所使用的当前数据特征匹配。如何在生产环境中维护深度学习模型的详细描述超出了本书的范围,但值得简要提及如何在本章所描述的简单模型部署环境下维护模型。在本教程中,我们将讨论你可以采取哪些措施来维护在 部署基于表格数据集训练的 fastai 模型 中部署的表格模型。
准备工作
确保你已经按照 在本地系统上设置 fastai 这个教程的步骤完成安装,确保 fastai 已经安装在你的本地系统中。同时,确保你已经启动了用于表格模型部署的 Flask 服务器,可以通过遵循 部署基于表格数据集训练的 fastai 模型 这个教程中的 步骤 1, 2 和 3 来完成。
在这个教程中,你将对用于训练表格模型的数据进行一些基本分析,这个模型已在 部署基于表格数据集训练的 fastai 模型 这个教程中进行了部署。为了进行此分析,请确认你可以使用你选择的电子表格应用(如 Excel 或 Google Sheets)打开 adult.csv 文件,这是 ADULT_SAMPLE 数据集中的训练数据文件。如果你尚未在本地系统中拥有 adult.csv,请按照以下步骤获取该文件,并确认你可以使用电子表格应用打开它:
-
在你的 Gradient 环境中,在终端窗口输入以下命令,将
adult.csv复制到你的temp目录:cp /storage/data/adult_sample/adult.csv /notebooks/temp/adult.csv -
在你的 Gradient 环境中的 JupyterLab 中,导航到你在前一步复制
adult.csv的temp目录,右键点击adult.csv并选择 下载。 -
使用你的电子表格应用程序打开在上一步中下载的本地
adult.csv副本。图 7.15 显示了adult.csv在 Excel 中的前几行:
图 7.15 – adult.csv 在 Excel 中的前几行
注意
你可能会问,为什么我建议使用电子表格来检查此配方中的数据,而不是使用 Python?我推荐在这里使用电子表格有几个原因。首先,甚至像 Jeremy Howard 这样的权威人物都表示 Excel 是一个很棒的数据科学工具,而我恰好认为他完全正确。它灵活、轻便,并且对于在小数据集上进行简单调查,比 Python 更快。其次,Excel 帮助我调试了表格模型部署中的问题。当我第一次测试部署时,我很难理解为什么部署的模型与在 Python 笔记本中调用的模型产生不同的预测。然而,一旦我在 Excel 中检查数据,问题就显而易见了:用于训练模型的数据中的所有类别值都以空格开头。而在部署中,用户可以选择的类别值并没有以空格开头,因此模型没有将它们识别为与训练时遇到的类别值相同。Excel 给了我一个快速的方式来检测问题的根本原因。
如何操作…
为了执行一些模型维护操作,请完成以下步骤:
-
首先,仔细观察
ADULT_SAMPLE中类别值的表示方式。如果你还没有在电子表格应用程序中打开本地的adult.csv副本,现在就打开它。选择workclass列中的一个值。你是否注意到该值有任何不寻常的地方?查看其他一些类别列中的值:relationship和native-country。你会看到每个类别列中的值都以空格开头。 -
请回想,在
home.html中,用户在每个类别特征上可以选择的值是有限制的。打开表格模型部署中的home.html,查看workclass可以选择的值。图 7.16 显示了用户可以为workclass选择的值:图 7.16 – home.html 中可用的
workclass值 -
用户在
home.html中可以选择的类别列的值是通过load_selections()JavaScript 函数中的一系列列表定义的。以下是load_selections()JavaScript 函数中为workclass、relationship和native-country定义的列表:var workclass_list = [" Private" ," Self-emp-inc" ," Self-emp-not-inc" ," State-gov" ," Federal-gov" ," Local-gov" ]; var relationship_list = [" Wife" ," Not-in-family" ," Unmarried" ," Husband" ," Own-child" ," Other-relative" ]; var native_country_list = [" United-States"," Puerto-Rico"," Mexico"," Canada"," Taiwan"," Vietnam"," Philippines"];请注意,这些列表中的值每个都以一个空格开始,就像
adult.csv中对应类别列的值一样。这些列表中的值用于构建查询字符串,查询字符串又被用作输入,以从模型中获取预测,作为show-prediction.html视图函数的输入。如果home.html中的列表值定义时没有前导空格,会发生什么情况? -
假设模型的训练数据已经扩展,包括来自
adult.csv的数据,这些数据在native-country列中包含United-Kingdom值。你需要做以下操作来更新部署以适应这个变化:a) 使用新版本的
adult.csv重新训练模型,并使用learner.export()fastai API 将新的训练模型保存为pkl文件。为了本教程的目的,假设你将新的模型命名为adult_sample_model_new.pkl。b) 将更新后的
adult_sample_model_new.pkl模型文件复制到本地系统的deploy_tabular目录。c) 更新
web_flask_deploy.pyFlask 服务器模块中模型路径的定义,包含新的模型文件名:full_path = os.path.join(path, 'adult_sample_model_new.pkl')d) 更新
home.html中的native_country_list,以包括新的值:var native_country_list = [" United-States"," Puerto-Rico"," Mexico"," Canada"," Taiwan"," Vietnam"," Philippines", " United-Kingdom" ];对于任何类别列的新值,你需要采取相同的步骤来更新部署:使用更新后的训练数据集重新训练模型,将更新后的训练模型复制到部署目录,更新 Flask 服务器以加载更新后的模型,并在
home.html中更新有效的类别值列表。 -
在上一阶段,我们了解了如果数据集随着新的类别值扩展,我们需要做什么。如果数据集中添加了一个全新的列呢?就像步骤 4中描述的过程一样,你需要在包含新列的更新训练数据集上重新训练模型,将新模型复制到
deploy_tabular目录,并更新web_flask_deploy.py以加载新模型。最后,你还需要更新home.html,以便用户能够输入新列的信息。你需要进行的更新取决于新列是否在每个home.html的情况下。 -
假设你需要更新部署,以处理一个名为
years-in-job的新连续列——即记录个人在当前工作岗位上工作的年数。有效值为 0 到 45,默认值为 5。为了添加这个列,你需要对home.html进行几项更新。首先,你需要添加以下代码来定义这个新列的控制项:<p> <label for="years-in-job">years in job (0 - 45):</label> <input type="number" id="years-in-job" name="years-in-job" min="0" max="45"> </p>接下来,你需要在
load_selection()JavaScript 函数中添加以下行,以设置默认值:document.getElementById("years-in-job").defaultValue = 5;接下来,你需要在
getOption()JavaScript 函数中添加以下行,以设置将包含在查询字符串中的这个列的值:years_in_job_value = document.getElementById("years-in-job ").value;最后,你需要在用于定义
window.output的查询字符串末尾添加以下内容:,"&years-in-job=",years_in_job_value -
假设你需要更新部署,处理一个新的分类列
work-location,它指定个人当前工作的地点。该列的有效值包括remote(远程)、on-site(现场)和mixed(混合)。为了让home.html适应这个新列,首先通过添加以下代码来定义work-location列的控制:<p> Select work location: <select id="work-location"> </select> </p>接下来,向
load_selection()JavaScript 函数添加以下几行代码,以设置新列控制的值。请注意,我们假设与其他分类列一样,work-location中的值将以空格开头,因此work_location_list中的所有值都以空格开始:var select_work_location = document.getElementById("work-location"); var work_location_list = [" remote"," on-site"," mixed"]; for(var i = 0; i < work_location_list.length; i++) { var opt = work_location_list[i]; select_work_location.innerHTML += "<option value=\"" + opt + "\">" + opt + "</option>"; }接下来,向
getOption()JavaScript 函数添加以下几行代码,以设置查询字符串中包含该列的值:selectElementworklocation = \ document.querySelector('#work-location'); work_location_string =\ selectElementworklocation.options[selectElementworklocation.selectedIndex].value最后,向用于定义
window.output的查询字符串的末尾添加以下内容:,"&work-location=",work_location_string
恭喜!你已经完成了维护模型部署的一些必要操作,确保它能够适应训练数据集的变化。
它是如何工作的……
在这个食谱中,我们回顾了如何维持在表格数据上训练的模型的网络部署。我们了解了为适应训练数据集变化而调整部署的步骤。我们讨论的那些数据集变化包括现有分类列中的新值、新的连续列和新的分类列。
在工业级生产部署中,数据集的架构,即构成数据集的所有列的特征,将保存在 HTML 文件之外。例如,我们可能会将架构保存在一个单独的配置文件中,里面包含有关数据集列的信息。这样一来,home.html 中的控制和有效值就不是硬编码的,而是根据配置文件的内容动态生成。
使用这种动态设置方式,当数据集添加新列或列的有效值发生变化时,我们只需更新配置文件中的数据集架构定义,home.html 将会自动更新。为了让网络部署尽可能简单,我们将控制和有效值直接编写在 home.html 中,而不是动态生成它们。这使得 基于表格数据训练 fastai 模型的部署 食谱更易于跟随,但也意味着在 home.html 中有多个地方需要更新,以维持数据集发生变化时的部署。
还有更多内容……
在这个食谱中,我们讨论了如何处理数据集架构的变更,但我们没有讨论如何处理数据集分布的变化,或者如何监控模型以确保它随着时间的推移保持其性能。这两个问题对于维持已部署的模型至关重要,但它们超出了本书的范围。
如果你有兴趣了解更多关于在生产环境中监控模型性能的内容,这篇文章提供了一个很好的概述:christophergs.com/machine%20learning/2020/03/14/how-to-monitor-machine-learning-models/。
测试你的知识
现在你已经部署了两种 fastai 模型,并解决了与维护已部署模型相关的一些挑战,你可以尝试一些额外的部署变种,来锻炼你所学到的内容。
准备就绪
确保你已经按照在本地系统上设置 fastai教程中的步骤,在本地系统上安装了 fastai。同时,确保你已经按照部署在图像数据集上训练的 fastai 模型教程中的第 1 步、第 2 步和第 3 步,启动了 Flask 服务器以进行图像分类模型的部署。
为了在图像分类模型部署上进行实验,复制deploy_image目录。为此,将包含deploy_image的目录设置为当前目录,并运行以下命令来复制该目录及其内容,命名为deploy_image_test:
cp -r deploy_image deploy_image_test
如何做到……
你可以按照此教程中的步骤,扩展和增强你在部署在图像数据集上训练的 fastai 模型教程中遵循的模型部署,以允许用户在home.html中选择多个图像文件,并在show-prediction.html中显示所有图像的预测结果:
-
将
deploy_image_test设置为当前目录。 -
为了允许用户选择多个文件并同时显示所有文件的预测结果,你需要更新
home.html、Flask 服务器和show-prediction.html。 -
首先更新
home.html,使用户能够在文件对话框中选择多个文件。向文件对话框控件的定义中添加multiple属性,如下所示的 HTML 代码片段所示:<input type="file" multiple id="image_field" name="image_field" accept="image/png, image/jpeg">现在,用户将能够在文件对话框中选择多个文件。
-
接下来,更新
home.html中的getOption()JavaScript 函数,构建一个文件名列表,将其添加到查询字符串中,并发送回 Flask 服务器。更新后的getOption()函数如下所示:function getOption() { var file_value = []; var file_count = 0; const input = document.querySelector('input'); var file_path = input.value; const curFiles = input.files; if(curFiles.length === 0) { console.log("file list empty"); } else { for(const file of curFiles) { if (file_count == 0) { file_count = 1; file_list_prefix = "&file_name="; var file_list = file_list_prefix.concat(file.name); } else { file_list = file_list.concat("&file_name=",file.name); } file_value.push(file.name); } } prefix = "/show-prediction/?" window.output = prefix.concat("file_path=",file_path,file_list) }以下是
getOption()函数中的关键更新项:a)
var file_list = file_list_prefix.concat(file.name);– 指定如果这是第一个文件,则初始化file_list字符串。b)
file_list = file_list.concat("&file_name=",file.name);– 指定如果这不是第一个文件,将文件名添加到file_list字符串的末尾。c)
window.output = prefix.concat("file_path=",file_path,file_list)– 指定查询字符串包括file_list字符串,其中包含用户选择的所有图像文件的文件名。你已经完成了
home.html中所需的更新,以处理多个图像文件。 -
现在是时候更新 Flask 服务器了。首先,向 Flask 服务器中添加以下函数。稍后你将使用这个函数构建要发送到
show-prediction.html的参数:def package_list(key_name,list_in): i = 0 list_out = [] for element in list_in: key_value = list_in[i].strip() list_out.append({key_name:key_value}) i = i+1 return(list_out) -
接下来,更新
show-prediction.html的视图函数。首先,你需要将你在home.html的getOption()函数中构建的文件名列表转为 Python 列表。以下语句将创建一个名为image_file_name_list的列表:image_file_name_list = request.args.getlist('file_name') -
接下来,更新
show-prediction.html的视图函数,使其能够遍历image_file_name_list,为列表中的每个文件获取预测结果。将每个预测的pred_class值保存在一个名为prediction_string_list的列表中。 -
使用你在 步骤 5 中定义的
package_list函数来准备prediction_string_list,并将其发送到show-prediction.html:prediction_list = package_list("prediction_key",prediction_string_list) -
更新视图函数的
return语句,包含prediction_list:return(render_template('show-prediction.html',prediction_list=prediction_list))现在你已经完成了对 Flask 服务器的更新,以便处理多个图像文件。
-
接下来,更新
show-prediction.html,显示每个图像的预测结果:<h1 style="color: green"> Here are the predictions for the images you selected: </h1> <h1 style="color: green"> <p> {% for prediction in prediction_list %} {{prediction.prediction_key}}{% if not loop.last %}, {% endif %} {% endfor %} </p> </h1> -
现在测试是否一切正常。启动位于
deploy_image_test目录中的 Flask 服务器:python web_flask_deploy_image_model.py -
在浏览器中打开
localhost:5000来显示home.html。从deploy_image_test/test_images目录中选择4_100.jpg、5_100.jpg和26_100.jpg文件。选择这些文件后,home.html会更新,显示已选择了三个文件,如 图 7.17 所示:图 7.17 – 选择三个图像文件后的 home.html
-
选择
show-predictions.html,如 图 7.18 所示:
图 7.18 – show-prediction.html 显示多个图像的预测结果
恭喜!你已完成了一个有用的扩展,成功部署了图像分类模型。
第八章:第八章:扩展的 fastai 和部署功能
到目前为止,在本书中,你已经学习了如何使用 fastai 获取和探索数据集,如何使用表格数据、文本数据和图像数据集训练 fastai 模型,以及如何部署 fastai 模型。到目前为止,本书的重点一直是在尽可能多地展示 fastai 的功能,且主要使用 fastai 高级 API。特别是,我们强调了使用 dataloaders 对象作为定义用于训练模型的数据集的基础。在本书的这一部分,我们尽可能地遵循了理想路径。为了演示如何使用 fastai 完成任务,我们选择了最直接的方式。
在本章中,我们将从理想路径中走出一些步骤,探索 fastai 的额外功能。你将学习如何更密切地追踪模型的变化,如何控制训练过程,并且如何充分利用 fastai 提供的更多功能。我们还将介绍一些与模型部署相关的高级主题。
以下是本章将覆盖的食谱:
-
获取更多关于使用表格数据训练的模型的详细信息
-
获取更多关于图像分类模型的详细信息
-
使用增强数据训练模型
-
使用回调函数充分利用训练周期
-
使你的模型部署对他人可用
-
在图像分类模型部署中显示缩略图
-
测试你的知识
技术要求
在本章中,你将同时使用云环境和本地环境来进行模型部署:
-
确保你已完成第一章《快速入门 fastai》中的设置部分,并且拥有一个可用的 Gradient 实例或 Colab 设置。
-
确保你已完成第七章《部署与模型维护》中的在本地系统上设置 fastai的步骤,以便在本地系统上设置 fastai。
确保你已从 github.com/PacktPublishing/Deep-Learning-with-fastai-Cookbook 克隆了本书的代码仓库,并且能够访问 ch8 文件夹。这个文件夹包含了本章中描述的代码示例。
获取更多关于使用表格数据训练的模型的详细信息
在第三章《使用表格数据训练模型》中的使用 fastai 训练模型并使用精度作为度量指标的食谱中,你使用表格数据集训练了一个 fastai 模型,并使用了准确度作为评估指标。在本食谱中,你将学习如何为这个模型获取额外的指标:精确度和召回率。精确度是指真正例除以真正例加上假正例的比例。召回率是指真正例除以真正例加上假负例的比例。
这些是有用的指标。例如,在本示例中,我们正在训练的模型预测个人收入是否超过 50,000 美元。如果要尽量避免假阳性 – 即在个人收入低于 50,000 美元时预测其收入超过该金额 – 那么我们希望精确率尽可能高。本示例将向您展示如何将这些有用的指标添加到 fastai 模型的训练过程中。
准备工作
确认您可以在您的 repo 的ch8目录中打开training_with_tabular_datasets_metrics.ipynb笔记本。
如何操作…
在这个示例中,您将运行training_with_tabular_datasets_metrics.ipynb笔记本。一旦您在您的 fastai 环境中打开笔记本,请完成以下步骤:
-
运行笔记本中的单元格,直到
Define and train model单元格以导入所需的库、设置您的笔记本和准备数据集。 -
运行以下单元格以定义和训练模型:
recall_instance = Recall() precision_instance = Precision() learn = tabular_learner(dls,layers=[200,100], metrics=[accuracy,recall_instance,precision_instance]) learn.fit_one_cycle(3)本单元格中的关键项如下:
a)
recall_instance = Recall()– 定义一个召回率度量对象。请注意,如果您直接将Recall放入模型的指标列表中,将会出现错误。相反,您需要定义一个召回率度量对象,例如recall_instance,然后将该对象包含在指标列表中。有关此度量标准的更多详细信息,请参阅 fastai 文档(docs.fast.ai/metrics.html#Recall)。b)
precision_instance = Precision()– 定义一个精确率度量对象。如果您直接将Precision放入指标列表中,将会出现错误,因此您需要首先定义precision_instance对象,然后将该对象包含在模型的指标列表中。c)
metrics=[accuracy,recall_instance,precision_instance]– 指定模型将以准确率、召回率和精确率作为指标进行训练。该单元格的输出,如图 8.1所示,包括每个训练运行时的准确率以及召回率和精确率:
图 8.1 – 训练输出包括召回率和精确率
恭喜!您已经用表格数据训练了一个模型,并生成了召回率和精确率指标以用于训练过程。
工作原理…
您可能会问自己,我是如何知道您不能直接将Recall和Precision放入模型的指标列表中,并且需要先定义对象,然后将这些对象包含在指标列表中的。简单的答案是通过试错。具体来说,当我尝试直接将Recall和Precision放入模型的指标列表时,我遇到了以下错误:
TypeError: unsupported operand type(s) for *: 'AccumMetric' and 'int'
当我搜索这个错误时,我在 fastai 论坛上找到了这篇帖子:forums.fast.ai/t/problem-with-f1scoremulti-metric/63721。帖子解释了错误的原因,并指出为了解决这个问题,我需要先定义Recall和Precision对象,然后再将它们包含在 metrics 列表中。
这个经验既展示了 fastai 的一个弱点,也展示了它的一个优点。弱点是Precision和Recall的文档缺少一个重要的细节——你不能直接将它们用于 metrics 列表。优点是 fastai 论坛提供了清晰准确的解决方案,解决了像这样的疑难问题,体现了 fastai 社区的力量。
获取有关图像分类模型的更多细节
在第六章的使用简单整理视觉数据集训练分类模型食谱中,你使用CIFAR整理数据集训练了一个图像分类模型。训练和训练模型的代码很简单,因为我们利用了 fastai 中的高级结构。在本食谱中,我们将重新审视这个图像分类模型,并探索 fastai 中的技术,以获取关于模型及其表现的更多信息,包括以下内容:
-
检查 fastai 生成的数据预处理流水线
-
获取训练过程中的训练和验证损失图表
-
显示模型表现最差的图像
-
显示混淆矩阵以获取模型表现不佳的情况快照
-
将模型应用于测试集,并检查模型在测试集上的表现
在本食谱中,我们将扩展之前训练CIFAR整理数据集的食谱。通过利用 fastai 的附加功能,我们将能够更好地理解我们的模型。
做好准备
确认你可以在仓库的ch8目录中打开training_with_image_datasets_datablock.ipynb笔记本。
如何操作…
在本节中,你将运行training_with_image_datasets_datablock.ipynb笔记本。一旦你在 fastai 环境中打开了该笔记本,请完成以下步骤:
-
更新以下单元格,以确保
model_path指向你在 Gradient 或 Colab 实例中的可写目录:model_path = '/notebooks/temp' -
运行笔记本中的单元格,直到
定义 DataBlock单元格,以导入所需的库,设置你的笔记本,并加载CIFAR数据集。 -
运行以下单元格以定义一个
DataBlock对象。通过显式地定义一个DataBlock对象,我们将能够执行一些我们无法在dataloaders对象上直接执行的额外操作,比如获取流水线的摘要:db = DataBlock(blocks = (ImageBlock, CategoryBlock), get_items=get_image_files, splitter=RandomSplitter(seed=42), get_y=parent_label)以下是此单元格中的关键内容:
a)
blocks = (ImageBlock, CategoryBlock)– 指定模型的输入为图像(ImageBlock),目标为对输入图像的分类(CategoryBlock)。b)
get_items=get_image_files– 指定调用get_image_files函数来获取DataBlock对象的输入。c)
splitter=RandomSplitter(seed=42)– 指定如何从训练集中定义验证集。默认情况下,20%的训练集被随机选择构成验证集。通过为seed指定值,此调用RandomSplitter将在多次运行中产生一致的结果。有关RandomSplitter的更多细节,请参阅文档(docs.fast.ai/data.transforms.html#RandomSplitter)。d)
get_y=parent_label– 指定图像的标签(即图像所属的类别)由图像所在目录在输入数据集中的位置定义。例如,在 Gradient 上,训练集中的猫图像位于/storage/data/cifar10/train/cat目录下。 -
运行以下代码单元,使用在前一个代码单元中创建的
DataBlock对象db来定义一个dataloaders对象:dls = db.dataloaders(path/'train',bs=32)以下是此代码单元中的关键项:
a)
db.dataloaders– 指定使用DataBlock对象db来创建dataloaders对象b)
path/'train'– 指定此模型的输入仅为CIFAR数据集的训练子集。 -
运行以下代码单元来获取管道的概述:
db.summary(path/"train")让我们看一下此代码单元输出的关键部分。首先,输出展示了有关输入数据集的详细信息,包括源目录、整个数据集的大小以及训练集和验证集的大小,如下图所示:
图 8.2 – 输入数据集的概述
接下来,输出展示了 fastai 应用于单个输入样本的管道,包括样本的源目录、为该样本创建的图像对象以及样本的标签(类别),如图 8.3所示:
图 8.3 – 单个图像文件的管道概述
接下来,输出展示了 fastai 应用于构建单个批次的管道,即将从样本管道中输出的图像对象转换为张量。如图 8.4所示,32 x 32 像素的图像对象被转换为 3 x 32 x 32 的张量,其中第一维包含图像的颜色信息:
图 8.4 – 应用于单个批次的管道的概述
最后,输出展示了应用于整个批次的变换,如图 8.5所示:
图 8.5 – 应用于所有批次的流水线总结描述
-
运行以下单元格以为测试集定义一个
DataBlock对象:db_test = DataBlock(blocks = (ImageBlock, CategoryBlock), get_items=get_image_files, splitter=RandomSplitter(valid_pct=0.99,seed=42), get_y=parent_label)请注意,与训练集的
DataBlock对象不同,我们为db_test定义了一个明确的valid_pct值。我们将此值设置为 99%,因为在将测试集应用于模型时我们不会进行任何训练,因此无需将测试集的一部分用于训练。我们没有将valid_pct设置为1.0,因为这个值会在你对db_test应用汇总时产生错误。 -
运行笔记本中的单元格直到
定义并训练模型单元格以检查数据集。 -
运行以下单元格以使用
cnn_learner对象定义模型。请注意,由于你从DataBlock对象定义了一个dataloaders对象,你将获得两全其美的效果:既有DataBlock对象特有的附加功能(例如汇总),又有你在本书中大多数食谱中使用的dataloaders对象的熟悉代码模式:learn = cnn_learner(dls, resnet18, loss_func=LabelSmoothingCrossEntropy(), metrics=accuracy) -
运行以下单元格以训练模型:
learn.fine_tune(2,cbs=ShowGraphCallback())请注意
cbs=ShowGraphCallback()参数。使用该参数,训练过程的输出包括训练和验证损失的图形,如 图 8.6 所示:图 8.6 – 训练和验证损失图
该图表包含与从训练过程中默认获得的训练结果表相同的数据,如 图 8.7 所示:
图 8.7 – 训练和验证损失表
-
运行以下单元格以保存训练好的模型。我们暂时将模型的路径更新为一个在 Gradient 中可写的目录,以便我们能够保存模型:
save_path = learn.path learn.path = Path(model_path) learn.save('cifar_save_'+modifier) learn.path = save_path这个单元格中的关键项如下:
a)
save_path = learn.path– 指定将当前模型路径保存到save_path。b)
learn.path = Path(model_path)– 指定将模型路径设置为可写目录。c)
learn.save('cifar_save_'+modifier)– 保存模型。稍后我们将加载保存的模型,并使用测试集对其进行验证。d)
learn.path = save_path– 将模型的路径重置为其原始值。 -
运行以下单元格以确认训练模型的准确性表现:
learn.validate()输出中的第二个值应与在训练的最后一个时期看到的准确度相匹配,如 图 8.8 所示:
图 8.8 – 验证输出
-
运行单元格直到
检查顶级损失示例和混淆矩阵单元格。 -
运行以下单元格以查看模型损失最大的样本:
interp = ClassificationInterpretation.from_learner(learn) interp.plot_top_losses(9, figsize=(15,11))这个单元格中的关键项如下:
a)
interp = ClassificationInterpretation.from_learner(learn)– 指定interp是learn模型的解释对象b)
interp.plot_top_losses(9, figsize=(15,11))– 指定显示损失最大的九张图片输出显示了模型在预测时损失最大的图像示例,以及图像的预测内容和实际内容。你可以将这些图像视为模型预测最差的图像。图 8.9展示了输出的一个子集。例如,对于显示的第一张图像,模型预测图像包含一只鸟,而图像实际上标记为猫:
图 8.9 – 最大损失的图像示例
-
运行以下单元格以生成训练模型的混淆矩阵:
interp.plot_confusion_matrix()该单元格的输出是一个混淆矩阵,用于总结训练模型的性能,如图 8.10所示。混淆矩阵是一个N x N的矩阵,其中N是目标类别的数量。它将实际的目标类别值(纵轴)与预测值(横轴)进行比较。矩阵的对角线显示了模型做出正确预测的情况,而对角线之外的所有条目则是模型做出错误预测的情况。例如,在图 8.10所示的混淆矩阵中,在 138 个实例中,模型将一张狗的图片预测为猫,而在 166 个实例中,它将一张猫的图片预测为狗:
图 8.10 – 训练模型的混淆矩阵
-
现在你已经检查了模型在训练集上的表现,接下来让我们检查模型在测试集上的表现。为此,我们将使用测试集定义一个新的
dataloaders对象,定义一个基于该dataloaders对象的模型,加载训练模型的保存权重,然后执行与训练集上训练的模型相同的步骤来评估模型性能。首先,运行以下单元格以创建一个新的dataloaders对象dls_test,该对象是使用测试数据集定义的:dls_test = db_test.dataloaders(path/'test',bs=32) -
运行以下单元格以定义一个新的模型对象
learn_test,该对象基于你在前一步创建的dataloaders对象。注意,模型定义与在步骤 8中为训练集定义的模型完全相同,只是它使用了在前一步中用测试数据集定义的dataloaders对象dls_test:learn_test = cnn_learner(dls_test, resnet18, loss_func=LabelSmoothingCrossEntropy(), metrics=accuracy) -
运行以下单元格以加载使用训练集训练的模型的保存权重:
learn_test.path = Path(model_path) learn_test.load('cifar_save_'+modifier)以下是该单元格中的关键项:
a)
learn_test.path = Path(model_path)– 指定learn_test模型的路径更改为保存模型权重的目录,该目录在步骤 10中定义b)
learn_test.load('cifar_save_'+modifier')– 指定learn_test模型加载来自使用训练集训练的模型的权重现在我们准备好使用测试集来测试模型了。
-
运行以下单元格以查看模型在测试集上的总体准确度:
learn_test.validate()输出中的第二个值是模型在测试集上的准确度,如图 8.11所示:
图 8.11 – 在测试集上验证的输出
-
运行以下单元格以查看测试集中模型损失最大的一些图像:
interp_test = ClassificationInterpretation.from_learner(learn_test) interp_test.plot_top_losses(9, figsize=(15,11))输出显示了测试集中损失最大的一些图像示例,以及图像的预测内容和实际内容。图 8.12显示了输出的一部分:
图 8.12 – 测试集中模型表现最差的样本图像
-
运行以下单元格以获取应用于测试集的模型的混淆矩阵:
interp_test.plot_confusion_matrix()该单元格的输出是一个混淆矩阵,汇总了模型在测试集上的表现,如图 8.13所示。请注意,这个混淆矩阵中的数字比应用于训练集的模型的混淆矩阵中的数字要小:
图 8.13 – 应用在测试集上的模型的混淆矩阵
恭喜!你已经完成了图像分类模型的工作,见证了 fastai 所提供的附加信息的好处。你还学会了如何将模型应用于整个测试集,并检查模型在测试集上的表现。
它是如何工作的……
将本节中创建的模型与第六章**,使用视觉数据训练模型配方中创建的模型进行比较是很有启发性的。
以下是来自第六章**,使用视觉数据训练模型配方中的dataloaders对象的定义:
dls = ImageDataLoaders.from_folder(path, train='train', valid='test')
这里是这个配方中dataloaders对象的定义。与之前的dataloaders定义不同,这个定义使用了DataBlock对象db:
dls = db.dataloaders(path/'train',bs=32)
以下是DataBlock对象db的定义:
db = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(seed=42),
get_y=parent_label)
使用DataBlock对象定义dataloaders对象有什么好处?
首先,从DataBlock对象开始,你可以更好地控制数据集的详细设置。你可以显式定义用于定义输入数据集的函数(赋值给get_items的函数),以及用于定义标签的函数(赋值给get_y的函数)。你可能还记得,在第六章《使用视觉数据训练模型》的使用多图像分类模型与精心策划的视觉数据集训练示例中,我们利用了这种灵活性。在那个例子中,我们需要确保输入数据集排除没有注释的图像。通过在那个例子中使用DataBlock对象,我们能够定义一个自定义函数并赋值给get_items,从而排除了没有注释的图像。
其次,如果我们有一个DataBlock对象,可以利用 fastai 的一些附加功能。在这个例子中,我们能够对DataBlock对象应用summary()函数,查看 fastai 对输入数据集应用的处理流程。summary()函数不能应用于dataloaders对象,因此如果没有定义DataBlock对象,我们将错过有关数据处理流程的额外细节。
如果DataBlock对象如此有用,为什么在第六章《使用视觉数据训练模型》的使用简单的精心策划视觉数据集训练分类模型示例中没有使用它呢?在那个例子中,我们只使用了dataloaders对象(而不是从DataBlock对象开始),因为那个例子相对简单——我们不需要DataBlock对象的额外灵活性。在整本书中,我们尽可能使用 fastai 的最高级 API,包括在那个例子中。简洁性是 fastai 的一个关键优势,因此如果可以使用最高级的 API(包括直接使用dataloaders),那么保持简单并坚持使用最高级的 API 是合乎逻辑的。
使用增强数据训练模型
在前面的例子中,你了解了 fastai 提供的一些额外功能,以跟踪你的模型,并学习了如何将测试集应用于在训练集上训练的模型。在这个例子中,你将学习如何将这些技术与 fastai 使其易于融入模型训练的另一项技术结合起来:数据增强。通过数据增强,你可以扩展训练数据集,包含原始训练样本的变体,并可能提高训练模型的性能。
图 8.14 显示了对来自CIFAR数据集的图像应用增强的结果:
图 8.14 – 应用于图像的增强
你可以在这些示例中看到,应用到图像上的增强操作包括在垂直轴上翻转图像、旋转图像以及调整图像的亮度。
与之前的教程类似,本教程中我们将使用在CIFAR精选数据集上训练的图像分类模型,但本教程中我们将尝试对数据集中的图像进行增强。
准备工作
确认你能在你的仓库的ch8目录中打开training_with_image_datasets_datablock_augmented.ipynb笔记本。
如何执行...
在本教程中,你将运行training_with_image_datasets_datablock_augmented.ipynb笔记本。以下是你在本教程中将要完成的高层次概述:
-
使用未增强的数据训练模型。
-
使用增强的数据训练模型。
-
使用未增强的数据的模型对测试集进行测试。
-
使用增强数据训练的模型对测试集进行测试。
一旦你在 fastai 环境中打开了笔记本,按照以下步骤完成操作:
-
更新以下单元格,确保
model_path指向你在 Gradient 或 Colab 实例中可写的目录:model_path = '/notebooks/temp' -
运行笔记本中的单元格,直到
尝试增强训练集单元格,以导入所需的库、设置笔记本并在未增强的CIFAR数据集上训练模型。 -
运行以下单元格以创建一个新的
DataBlock对象db2,该对象包含增强功能,并定义了一个新的dataloaders对象dls2:db2 = db.new(batch_tfms=aug_transforms()) dls2 = db2.dataloaders(path/'train',bs=32)该单元格中的关键内容如下:
a)
db2 = db.new(batch_tfms=aug_transforms())– 定义了一个新的DataBlock对象db2,该对象包含由aug_transforms()定义的默认增强。有关aug_transforms()的详细信息,请参见 fastai 文档:docs.fast.ai/vision.augment.html#aug_transforms。b)
dls2 = db2.dataloaders(path/'train',bs=32)– 基于DataBlock对象db2定义了一个新的dataloaders对象dls2。现在,dls2定义了输入数据集的训练子集。 -
运行以下单元格以获取处理流程的总结:
db2.summary(path/"train")此单元格的输出为我们提供了关于应用到数据集的处理流程的详细信息。首先,输出显示了输入数据集的详细信息,包括源目录、整个数据集的大小以及训练集和验证集的大小,如图 8.15所示:
图 8.15 – 输入数据集的总结描述
接下来,输出展示了 fastai 对单个输入样本应用的处理流程,包括样本的源目录、为样本创建的图像对象以及样本的标签(类别),如图 8.16所示:
图 8.16 – 单个图像文件的管道概述描述
接下来,输出显示了 fastai 应用于构建单个批次的管道,即将从样本管道输出的图像对象转换为张量。如图 8.17所示,32 x 32 像素的图像对象被转换为 3 x 32 x 32 的张量,其中第一维包含图像的颜色信息:
图 8.17 – 应用于单个批次的管道概述描述
输出的前三部分与获取更多关于图像分类模型的细节食谱中
summary()的输出的相同部分一致。然而,最后一部分不同,它描述了在增强过程中应用于图像的变换,如图 8.18所示:图 8.18 – 应用于所有批次的管道描述(包括增强变换)
-
运行以下单元格以查看应用于数据集中图像的增强变换示例:
dls2.train.show_batch(unique=True, max_n=8, nrows=2)unique=True参数指定我们希望看到应用于单个图像的增强示例。该单元格的输出示例如图 8.19所示:请注意增强图像的变化,包括在垂直轴上翻转、亮度变化和卡车占据垂直空间的程度变化:
图 8.19 – 图像的增强版本
-
运行以下单元格来定义一个模型,以便使用增强数据集进行训练:
learn2 = cnn_learner(dls2, resnet18, loss_func=LabelSmoothingCrossEntropy(), metrics=accuracy) -
运行以下单元格来使用增强数据集训练模型:
learn2.fine_tune(2)该单元格的输出显示了训练损失、验证损失和验证准确率,如图 8.20所示:
图 8.20 – 使用增强数据集训练模型的输出
-
运行以下单元格来保存使用增强数据集训练后的模型:
save_path = learn2.path learn2.path = Path(model_path) learn2.save('cifar_augmented_save_'+modifier) learn2.path = save_path -
运行单元格直到
检查使用增强数据集训练的模型在测试集上的表现单元格,以了解使用未增强数据集训练的模型在测试数据集上进行预测的表现。 -
运行以下单元格来定义一个与测试集关联的
dataloaders对象dls_test:dls_test = db_test.dataloaders(path/'test',bs=32) -
运行以下单元格来定义
learn_augment_test模型,以便在测试数据集上进行测试:learn_augment_test = cnn_learner(dls_test, resnet18, loss_func=LabelSmoothingCrossEntropy(), metrics=accuracy) -
运行以下单元格来加载
learn_augment_test模型,并使用从增强数据集训练模型时保存的权重:learn_augment_test.path = Path(model_path) learn_augment_test.load('cifar_augmented_save_'+modifier)现在我们有一个
learn_augment_test学习器对象,它包含了使用增强数据集训练后的权重,并与测试数据集关联。 -
运行以下单元格,查看
learn_augment_test模型在测试集上的整体准确性:learn_augment_test.validate()此单元格的输出显示了该模型在测试集上的准确性,如图 8.21所示:
图 8.21 – 在增广数据集上训练的模型应用于测试集的准确性
-
运行以下单元格,获取在增广数据集上训练的模型在测试集上损失最大时的图像示例:
interp_augment_test = ClassificationInterpretation.from_learner(learn_augment_test) interp_augment_test.plot_top_losses(9, figsize=(15,11))此单元格的输出显示了在增广数据集上训练的模型在测试集上损失最大的图像。图 8.22显示了这个输出结果的示例:
图 8.22 – 模型在增广数据集上训练时损失最大的图像示例
-
运行以下单元格,查看在增广数据集上训练的模型应用于测试集的混淆矩阵:
interp_augment_test.plot_confusion_matrix()此单元格的输出是图 8.23所示的混淆矩阵:
图 8.23 – 在增广数据集上训练的模型应用于测试集的混淆矩阵
恭喜你!你已经使用增广数据集训练了一个 fastai 图像分类模型,并在测试集上进行了验证。
它是如何工作的…
在本示例中,我们详细讲解了如何在增广数据集上训练图像分类模型。我们在这个示例中使用的笔记本还包括了在非增广数据集上训练图像分类模型。现在让我们比较这两个模型的性能,看看使用增广数据集是否值得。
如果我们比较两个模型的训练结果,如图 8.24所示,训练于非增广数据集上的模型似乎表现更好:
图 8.24 – 使用和不使用增广数据训练时的结果对比
现在让我们比较这两个模型在测试数据集上的表现。图 8.25显示了在增广和非增广数据集上训练的模型应用于测试集时validate()的输出结果。再次强调,训练于非增广数据集上的模型似乎表现更好:
图 8.25 – 使用和不使用增广数据训练时validate()结果的对比
图 8.26显示了在增广数据集和非增广数据集上训练的模型应用于测试集时的混淆矩阵:
图 8.26 – 使用和不使用增强数据训练时混淆矩阵的对比
总体而言,使用增强数据集训练的模型在测试集上的表现似乎并不比使用非增强数据训练的模型更好。这可能令人失望,但没关系。
本教程的目的是向你展示如何利用 fastai 中的增强数据功能,而不是进行深入的分析以获得增强数据的最佳结果。并非所有应用都会从数据增强中受益,我们只尝试了默认的增强方法。fastai 为图像模型提供了广泛的增强选项,具体可以参考 fastai 文档:docs.fast.ai/vision.augment.html。可能这个数据集具有某些特性(例如相对较低的分辨率),导致数据增强效果不佳。也有可能默认的 fastai 增强方法中的增强操作集并不适合这个数据集,使用自定义的增强操作集可能会得到更好的结果。
aug_transforms() 这个函数是如何增强训练集中的图像的?我们可以通过对比使用非增强训练集训练的模型与使用增强数据训练的模型的流水线摘要来获得线索。图 8.27 显示了非增强型 DataBlock 对象的 summary() 输出的最后部分:
图 8.27 – 非增强型 DataBlock 对象的摘要输出
图 8.28 显示了增强型 DataBlock 对象的 summary() 输出的最后部分:
图 8.28 – 非增强型 DataBlock 对象的摘要输出
通过对比这两个模型的摘要输出部分,你可以了解在增强数据集上应用了哪些变换,如 图 8.29 所示:
图 8.29 – 在 aug_transforms() 中应用的变换
现在,你已经了解了使用增强数据集与非增强数据集训练图像分类模型之间的一些区别。
使用回调函数来最大化你的训练周期的效果
到目前为止,在本书中,我们已经通过将fit_one_cycle或fine_tune应用于学习器对象来启动 fastai 模型的训练过程,并且让训练按照指定的轮次运行。对于我们在本书中训练的许多模型,这种方法已经足够好,特别是对于每个周期需要很长时间的模型,而我们只训练一个或两个周期。但如果我们希望训练模型 10 个周期或更多呢?如果我们只是让训练过程一直运行到结束,我们将面临图 8.30中显示的问题。在图 8.30中,我们可以看到使用metric设置为accuracy训练一个表格模型 10 个周期的结果:
图 8.30 – 训练一个表格数据模型的 10 轮训练结果
这个训练过程的目标是得到一个具有最佳准确度的模型。考虑到这一目标,图 8.30中显示的结果存在两个问题:
-
最佳准确度出现在第 5 轮,但我们在训练过程结束时得到的模型是最后一轮的准确度。对于这个模型的
validate()输出,如图 8.31所示,显示该模型的准确度不是训练过程中最佳的准确度:图 8.31 – 使用 10 轮训练模型后
validate()的输出注意,如果准确度在训练结束时仍然稳步提高,则模型可能还没有过拟合,尽管你需要通过使用测试集对已训练的模型进行验证来确认这一点。
-
训练在准确度不再提高后仍然继续进行,因此浪费了训练能力。对于像这样每个周期不到一分钟就完成的训练来说,这不算什么问题。然而,想象一下,如果每个周期都需要一个小时,而你正在使用付费的 Gradient 实例进行训练,那么浪费的训练周期可能会花费大量的钱,而这些周期并没有提高模型的性能。
幸运的是,fastai 提供了解决这两个问题的方法:回调函数。你可以使用回调函数来控制训练过程,并在训练期间自动采取行动。在本节中,你将学习如何在 fastai 中指定回调函数,当模型没有进一步改善时,停止训练过程并保存训练过程中最佳的模型。你将重新回顾在第三章**,使用表格数据训练模型中的使用整理过的表格数据训练模型一节中训练的模型,但这次你将使用 fastai 回调函数来控制模型的训练过程。
准备就绪
确认你可以在你的仓库的ch8目录中打开training_with_tabular_datasets_callbacks.ipynb笔记本。
如何操作…
在这个食谱中,你将运行training_with_tabular_datasets_callbacks.ipynb笔记本。在这个食谱中,你将训练模型的三个不同变体:
-
无回调的训练
-
使用单个回调,在训练过程停止改进时结束训练
-
使用两个回调进行训练:一个用于在训练停止改进时结束训练,另一个用于保存最佳模型
一旦你在 fastai 环境中打开笔记本,完成以下步骤:
-
更新以下单元格,确保
model_path指向你在 Gradient 或 Colab 实例中可写的目录:model_path = '/notebooks/temp' -
运行笔记本中的单元格,直到
Define and train the model with no callbacks单元格,导入所需的库,设置你的笔记本,并为ADULT_SAMPLE数据集定义一个dataloaders对象。通过这种方式调用
set_seed()并在每次训练运行之前定义一个dataloaders对象,我们可以获得跨多个训练运行的一致训练结果。当我们比较有回调和没有回调的训练结果时,你将看到保持一致的训练结果的重要性。 -
运行以下单元格以定义并训练一个没有回调的模型:
%%time set_seed(dls,x=42) learn = tabular_learner(dls,layers=[200,100], metrics=accuracy) learn.fit_one_cycle(10)对
set_seed()的调用指定了与模型相关的随机种子被设置为42(一个任意值),并且结果是可重复的,这正是我们所希望的。该单元格的输出显示了每一轮的训练损失、验证损失和准确率,以及整个训练运行所花费的时间,正如图 8.32所示。请注意,训练运行进行了所有 10 轮,尽管准确率在第 2 轮之后停止改进:
图 8.32 – 使用没有回调的模型训练结果
-
运行以下单元格以获取训练模型的准确率:
learn.validate()该单元格的输出显示在图 8.33中。模型的准确率是在第 9 轮,也就是训练运行的最后一轮,达到的准确率:
图 8.33 – 使用没有回调的模型进行验证时的输出
-
运行以下单元格以定义并训练一个带有一个回调的模型——当模型的准确率不再改进时进行早停:
%%time set_seed(dls,x=42) learn_es = tabular_learner(dls,layers=[200,100], metrics=accuracy) learn_es.fit_one_cycle(10,cbs=EarlyStoppingCallback(monitor='accuracy', min_delta=0.01, patience=3))这个模型的
fit语句包括了EarlyStoppingCallback回调的定义。以下是定义回调时使用的参数:a)
monitor='accuracy'– 指定回调正在跟踪准确率指标的值。当准确率指标在指定的时间段内停止改进时,将触发该回调。b)
min_delta=0.01– 指定回调函数关注的准确率变化至少为 0.01。也就是说,如果准确率在两个周期之间的变化小于 0.01,则回调函数将忽略这种变化。c)
patience=3– 指定回调函数在准确率指标在 3 个周期内不再改善时触发。该单元格的输出显示了每个周期的训练损失、验证损失和准确率,以及训练运行所需的总时间,如 图 8.34 所示:
图 8.34 – 使用早期停止回调函数训练模型的结果
请注意,现在训练在第 5 个周期之后停止了。您可以看到回调函数跟踪的指标
accuracy在第 2 个周期之后不再改善。一旦过了另外 3 个周期(回调函数的patience参数设置为的值),训练过程将提前停止,在第 5 个周期停止,即使fit_one_cycle()调用指定了运行 10 个周期。因此,使用早期停止回调函数,我们保存了 4 个周期和约 25%的训练时间(使用早期停止回调函数为 51 秒,而没有回调函数为 68 秒)。 -
运行以下单元格以获取经过训练模型的准确率:
learn_es.validate()该单元格的输出显示在 图 8.35 中。模型的准确率是在第 5 个周期(训练运行的最后一个周期)中实现的准确率:
图 8.35 – 使用早期停止回调函数训练的模型的验证输出
-
使用早期停止回调函数,相比没有回调函数的模型,我们减少了训练时间,但训练得到的模型准确率低于训练运行期间达到的最佳准确率。让我们训练另一个模型,其中包括一个回调函数来保存最佳模型。该回调函数将确保经过训练的模型的准确率是我们从训练运行中获得的最佳结果。要做到这一点,请从运行以下单元格开始定义并训练一个包括两个回调函数的模型 – 当模型的准确率不再改善时提前停止训练,并保存最佳模型:
%%time set_seed(dls,x=42) learn_es_sm = tabular_learner(dls,layers=[200,100], metrics=accuracy) keep_path = learn_es_sm.path # set the model path to a writeable directory. If you don't do this, the code will produce an error on Gradient #learn_es_sm.path = Path('/notebooks/temp/models') learn_es_sm.path = Path(model_path) learn_es_sm.fit_one_cycle(10,cbs=[EarlyStoppingCallback(monitor='accuracy', min_delta=0.01, patience=3),SaveModelCallback(monitor='accuracy', min_delta=0.01)]) # reset the model path learn_es_sm.path = keep_path除了像 步骤 5 中指定的
EarlyStoppingCallback回调函数的定义之外,此模型的fit语句还包括一个SaveModelCallback回调函数。这里用来定义此回调函数的参数如下:a)
monitor='accuracy'– 指定SaveModelCallback回调函数跟踪准确率指标的值。当准确率达到新的最高水平时,模型将被保存。b)
min_delta=0.01– 指定回调函数关注的准确率变化至少为 0.01。请注意,该单元还包括调整模型路径为 Gradient 可写目录的语句。如果不将模型路径更改为可写目录,运行该单元时会在 Gradient 中出现错误。同时请注意,当你运行此单元时,可能会看到保存的文件不包含优化器状态的警告信息——在本教程中,你无需担心此消息。
该单元的输出显示了每轮训练损失、验证损失和准确度,以及训练运行所花费的总时间,如图 8.36所示。请注意,由于早停回调,训练在第 5 轮结束:
图 8.36 – 使用早停回调和模型保存回调训练模型的结果
-
运行以下单元以获取训练模型的准确度:
learn_es.validate()该单元的输出如图 8.37所示。模型的准确度是在第 2 轮迭代中的准确度,是训练过程中最好的准确度:
图 8.37 – 使用早停和模型保存回调训练的模型的 validate() 输出
通过使用这两个回调,我们避免了运行不会提高模型性能的迭代,并最终得到了在训练过程中最佳表现的训练模型。
恭喜!你已经成功应用了 fastai 的回调来优化训练过程,从而在训练周期中最大化你的模型表现。
它是如何工作的……
本教程演示了如何使用 fastai 的回调来控制训练过程,以便从系统的计算能力和训练时间中获得最佳结果。关于 fastai 回调,还有一些额外的细节值得回顾。在本节中,我们将深入探讨 fastai 中回调的使用方式。
set_seed() 函数并非 fastai 的默认函数
为了清楚地比较有回调和没有回调时模型的表现,我们需要控制训练运行之间的随机差异。也就是说,我们希望多次训练模型,并在不同的训练运行之间获得一致的损失和准确度。例如,如果第一次训练运行的第 1 轮准确度为 0.826271,我们希望每次后续训练运行的第 1 轮准确度完全相同。通过确保训练运行之间表现一致,我们可以进行公平对比,聚焦于回调的影响,而不是训练运行之间的随机差异。
在本配方中,我们使用了 set_seed() 函数来控制训练运行之间的随机差异。你可能已经注意到,虽然 fastai 文档中包含了一个 set_seed() 函数(docs.fast.ai/torch_core.html#set_seed),但我们在配方中并没有使用它。相反,我们使用了以下这个函数,它是从论坛讨论中分享的代码中修改过来的——github.com/fastai/fastai/issues/2832:
def set_seed(dls,x=42):
random.seed(x)
dls.rng.seed(x)
np.random.seed(x)
torch.manual_seed(x)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
if torch.cuda.is_available():
torch.cuda.manual_seed_all(x)
为什么要使用这个自定义的 set_seed() 函数,而不是 fastai 文档中提供的默认 set_seed() 函数?简单的原因是默认的 set_seed() 函数无法按预期工作——我没有得到一致的训练结果。而使用上面列出的 set_seed() 函数,我得到了稳定的一致性训练结果。
summary() 的回调部分没有包括在配方中定义的回调。
你可能会注意到,training_with_tabular_datasets_callbacks.ipynb 笔记本的末尾包含了对三个训练模型的学习者对象调用 summary() 函数的代码。这三个模型在配方中进行了训练。你可能预期,包含回调的 learn_es 和 learn_es_sm 模型的 summary() 输出中的 Callbacks 部分会列出早停和模型保存回调,但事实并非如此。图 8.38 展示了两个模型(它们显式定义了回调)的 Callbacks 部分,而这一部分与没有回调的模型的 Callbacks 部分是相同的:
图 8.38 – summary() 输出中的回调部分
图 8.38 – summary() 输出中的回调部分
为什么 summary() 输出中的 Callbacks 部分不包括模型中定义的回调?summary() 函数仅列出 fastai 本身定义的回调,而不是你自己定义的回调。
在 fastai 中,你还能做些什么与回调相关的操作?
在本配方中,我们使用了回调来确保训练过程尽可能高效,但这只是你在 fastai 中使用回调的一小部分功能。fastai 框架支持多种回调,用于控制训练过程的各个方面。事实上,在本书中,你已经接触到几种不同类型的 fastai 回调:
-
追踪回调 – 我们在本配方中使用的早停和模型保存回调就是追踪回调的例子。这类回调的文档可以在这里找到:
docs.fast.ai/callback.tracker.html。 -
使用
ShowGraphCallback回调来显示训练和验证损失的图表。进度和日志回调的文档可以在这里找到:docs.fast.ai/callback.progress.html。 -
使用
to_fp16()来指定你在该部分训练的语言模型的混合精度训练。有关混合精度训练的回调文档,请参见:docs.fast.ai/callback.fp16.html。
到目前为止,通过本书中的配方所使用的回调函数展示了使用回调函数与 fastai 结合时,你可以获得的一些强大功能和灵活性。
让你的模型部署对其他人可用
在第七章《部署和模型维护》中,你部署了几个 fastai 模型。为了获取预测结果,你将浏览器指向了localhost:5000,这会打开home.html,在这里你设置了评分参数,请求了预测,并在show-prediction.html中得到了预测结果。所有这些操作都是在本地系统上完成的。通过第七章《部署和模型维护》中的 Web 部署,你只能在本地系统上访问部署,因为localhost只在本地系统上可访问。如果你想将这些部署与朋友分享,让他们在自己的电脑上尝试你的模型,你该怎么办?
最简单的方法是使用一种叫做localhost的工具,在你的电脑上与其他电脑上的人一起工作。在这个配方中,我们将通过一些步骤来展示如何使用 ngrok 让你的部署对其他人可用。
准备工作
按照dashboard.ngrok.com/get-started中的说明设置一个免费的 ngrok 帐户,并在本地系统上设置 ngrok。记下你安装 ngrok 的目录—你将在配方中需要它。
如何实现…
借助 ngrok,你可以获得一个可以与朋友分享的 URL,这样他们就可以尝试你的 fastai 模型部署。本配方将向你展示如何分享表格模型的部署。
要分享你在第七章《部署和模型维护》中创建的部署,按照以下步骤进行:
-
将安装 ngrok 的目录设置为当前目录。
-
在命令行/终端中输入以下命令:
https Forwarding URL: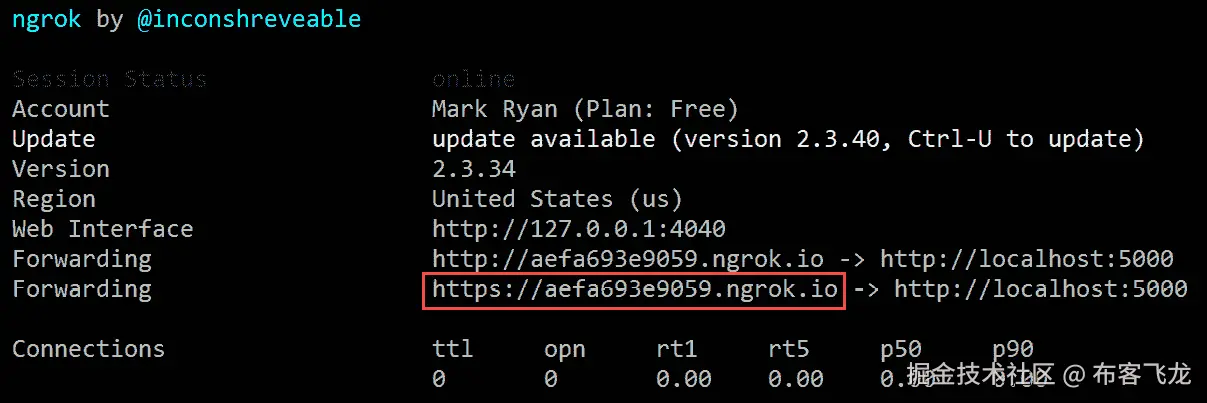Figure 8.39 – Output of ngrok -
通过将
deploy_tabular设置为当前目录并输入以下命令,启动表格模型的部署:python web_flask_deploy.py -
在另一台计算机上,打开浏览器并访问你在步骤 2中复制的
httpsForwardingURL。你应该能看到home.html,如图 8.40所示:图 8.40 – home.html
-
在
home.html中,选择Get prediction并确认你在show-prediction.html中看到了预测结果,如图 8.41所示:
图 8.41 – show-prediction.html
恭喜你!你已经成功共享了你的 fastai 模型部署,使其可以通过你分享的 ngrok 转发 URL 供其他系统的用户访问。
它是如何工作的…
当你运行 ngrok 时,它会在你的本地系统上创建一个安全隧道到localhost。当你分享 ngrok 返回的转发 URL 时,接收 URL 的人可以将浏览器指向该 URL,以查看你在本地系统上提供的内容。
当你启动 ngrok 时,你指定了 ngrok 隧道指向的端口。例如,在本教程中你输入了以下命令,指定 ngrok 转发的 URL 指向localhost:5000:
.\ngrok http 5000
现在你对 ngrok 如何方便地帮助你与其他系统上的用户分享你的模型部署有了了解。
在图像分类模型部署中显示缩略图
当你在第七章《部署和模型维护》中为图像分类模型创建部署时,缺少了一个有用的功能:显示在home.html中选择的图像的缩略图。在本教程中,你将学习如何更新home.html,以显示用户选择的图像的缩略图。
准备工作
确保你已经按照第七章《部署和模型维护》中的部署一个使用图像数据集训练的 fastai 模型教程的步骤完成了图像分类模型的部署。
如何做…
在本教程中,你将更新图像分类模型部署中的home.html,以便显示你选择的图像的缩略图。
为了进行这些更新,请按照以下步骤操作:
-
将图像分类部署的目录
deploy_image设置为当前目录。 -
通过运行以下命令,将
templates子目录设置为当前目录:cd templates -
在编辑器中打开
home.html。我喜欢使用 Notepad++(见notepad-plus-plus.org/),但你也可以使用你喜欢的编辑器。 -
更新文件对话框的控件,指定一个
onchange动作来调用getFile()JavaScript 函数。更新后,文件对话框的控件应如下所示:<input type="file" id="image_field" name="image_field" accept="image/png, image/jpeg" onchange="getFile();"> -
在
home.html中定义一个新的 JavaScript 函数getFile():<script> function getFile() { file_list = document.getElementById("image_field").files; img_f = document.createElement("img"); img_f.setAttribute("id","displayImage"); img_f.setAttribute("style","width:50px"); img_f.setAttribute("alt","image to display here"); document.body.appendChild(img_f); document.getElementById("displayImage").src = \ URL.createObjectURL(file_list[0]); } </script>以下是该函数定义中的关键内容:
a)
file_list = document.getElementById("image_field").files;– 指定file_list包含与image_field文件选择器相关联的文件列表b)
img_f = document.createElement("img");– 在页面上定义一个新的图像元素img_fc)
img_f.setAttribute("id","displayImage");– 将displayImageID 分配给新的图像元素d)
document.body.appendChild(img_f);– 将新的图像元素添加到页面底部e)
document.getElementById("displayImage").src = URL.createObjectURL(file_list[0]);– 指定在文件对话框中选择的文件会显示在新的图片元素中 -
将你的更改保存到
home.html,并通过运行以下命令将deploy_image设置为当前目录:cd .. -
通过运行以下命令启动 Flask 服务器:
python web_flask_deploy_image_model.py -
在浏览器中打开
localhost:5000来显示home.html。 -
选择
test_images目录。如果一切正常,你应该会看到页面底部显示你选择的图片的缩略图,如图 8.42所示:
图 8.42 – home.html 显示选中图片的缩略图
恭喜你!你已经更新了图像分类模型的部署,现在选择一张图片时会显示该图片的缩略图。
它是如何工作的……
在这个示例中,你看到了一个在 HTML 页面中动态创建元素的小例子。与home.html中的其他所有元素不同,当home.html首次加载时,显示缩略图的图片元素并不存在。图片元素只有在选择了图片文件并且调用getFile()函数时才会被创建。为什么我们不在文件首次加载时就像其他控件一样将图片元素硬编码在页面中呢?
如果我们将图片元素硬编码,那么当你加载home.html时,在选择图片之前,你会看到一个丑陋的缺失图片图标,原本应该显示缩略图的位置,如图 8.43所示:
图 8.43 – home.html 带有硬编码图片元素
通过在选择图片之后才动态创建图片元素,我们可以避免出现丑陋的缺失图片图标。
你可能还记得在第七章**,部署和模型维护的维护你的 fastai 模型配方中,我提到过在专业的部署中,当数据集模式出现类别列的新值或全新的列时,你不需要手动调整home.html中的控件。你可以使用本配方中描述的技术,动态创建控件,来应对home.html中大部分控件的变化,使得部署更容易适应模式变动。
测试你的知识
在本章中,我们回顾了从充分利用 fastai 提供的有关模型的信息,到将你的网页部署提供给系统外部用户的一系列主题。在本节中,你将有机会练习在本章中学到的一些概念。
探索可重复结果的价值
在使用回调最大化训练周期的效益的食谱中,你在训练每个模型之前调用了set_seed()函数。在那个食谱中,我提到这些调用是必要的,以确保多个训练周期的结果是可重复的。通过执行以下步骤亲自测试这一断言:
-
首先,复制
training_with_tabular_datasets_callbacks.ipynb笔记本。 -
通过注释掉第一次对
set_seed()的调用并重新运行整个笔记本,更新你的新笔记本。在没有回调的模型和具有早期停止回调的模型之间,fit_one_cycle()的输出有什么不同?在有早期停止回调和同时具有早期停止以及模型保存回调的模型之间,fit_one_cycle()的输出有什么不同? -
通过注释掉第二次对
set_seed()的调用并重新运行整个笔记本,更新你的新笔记本。现在,在没有回调的模型和具有早期停止回调的模型之间,fit_one_cycle()的输出有什么不同?在有早期停止回调和同时具有早期停止以及模型保存回调的模型之间,fit_one_cycle()的输出有什么不同? -
最后,再次更新你的笔记本,通过注释掉对
set_seed()的最终调用并重新运行整个笔记本。再次比较模型的结果,看看有什么变化吗?
恭喜!希望通过执行这些步骤,你能够证明可重复结果的价值。当你比较不同的模型变体,并且希望确保你在进行变体间的公平比较时,使用 fastai 中的工具来控制模型的随机初始化非常有价值,这样你就能确保多次训练运行中结果的一致性。
在你的图像分类模型部署中显示多个缩略图
在展示缩略图在你的图像分类模型部署的食谱中,你学会了如何通过展示选定用于分类的图像的缩略图来增强图像分类部署,这些内容来自第七章 部署与模型维护食谱。你可能还记得,在第七章 部署与模型维护的测试你的知识部分,你进行了一个练习,通过允许用户选择多个图像进行分类来增强图像分类模型部署。如果你想将这两个增强功能结合起来,既允许用户选择多个图像进行分类,又展示每个选定图像的缩略图,该怎么做呢?请按照以下步骤来了解如何实现:
-
确保你已经完成了第七章**“部署与模型维护”部分中的测试你的知识章节,以创建一个允许用户选择多个图像进行分类的图像分类模型部署。你将更新你在该部分完成的代码,使其显示所选图像的缩略图。
-
复制
deploy_image_test目录,创建名为deploy_image_multi_test的副本,该目录包含你创建的多图像分类部署。为此,首先将包含deploy_image_test的目录设为当前目录,并运行以下命令:cp -r deploy_image_test deploy_image_multi_test -
使
deploy_image_multi_test/templates成为当前目录。你将对该目录中的home.html文件进行更新。 -
在
home.html中,更新文件对话框控件,指定一个onchange动作来调用getFile()JavaScript 函数。更新后,文件对话框控件应如下所示:<input type="file" multiple id="image_field" name="image_field" accept="image/png, image/jpeg" onchange="getFile();"> -
在
home.html中定义一个新的 JavaScript 函数,命名为getFile()。该函数将是你在显示图像分类模型部署中的缩略图配方中定义的getFile()函数的泛化:function getFile() { img_f = []; var i = 0; var di_string = "displayImage" file_list = \ document.getElementById("image_field").files; for (file_item of file_list) { img_f[i] = document.createElement("img"); var di_1 = di_string.concat(i) img_f[i].setAttribute("id",di_1); img_f[i].setAttribute("style","width:50px"); img_f[i].setAttribute("alt","image to display here"); document.body.appendChild(img_f[i]); document.getElementById(di_1).src =\ URL.createObjectURL(file_item); i = i+1 } }这是该函数定义中的关键项目:
a)
file_list = document.getElementById("image_field").files;– 指定file_list包含与image_field文件选择器关联的文件列表。b)
var di_string = "displayImage"– 定义di_string字符串,该字符串将用作将添加到页面的图像元素 ID 的前缀。c)
for (file_item of file_list)– 指定for循环遍历file_list中的项。对于file_list中的每个项,将创建一个图像元素以显示与该项关联的图像。d)
img_f[i] = document.createElement("img");– 在页面上定义一个新的img_f[i]图像元素。e)
var di_1 = di_string.concat(i)– 使用dl_string前缀和i索引定义一个di_1字符串。例如,在循环的第一次执行中,di_1的值将是displayImage1。f)
img_f[i].setAttribute("id",di_1);– 将di_1ID 分配给img_f[i]图像元素。g)
document.body.appendChild(img_f[i]);– 将img_f[i]图像元素添加到页面的底部。h)
document.getElementById(di_1).src = URL.createObjectURL(file_item);– 指定与file_item关联的图像文件将显示在img_f[i]图像元素中。通过这些更改,用户在文件对话框中选择的文件的缩略图将显示在
home.html的底部。 -
现在测试一切是否正常。保存对
home.html的更改,将deploy_image_multi_test设为当前目录,并通过运行以下命令启动 Flask 服务器:python web_flask_deploy_image_model.py -
在浏览器中打开
localhost:5000以显示home.html。 -
选择
test_images目录。如果一切正常,你应该在页面底部看到你选择的每个图像的缩略图,如图 8.44所示:
图 8.44 – home.html 显示多个选定图像的缩略图
恭喜你!你已经结合了图像分类部署的两个增强功能,允许用户选择多个图像供模型分类,并查看他们所选图像的缩略图。
结论和 fastai 的附加资源
在本书中,你已经探索了 fastai 框架的广泛功能。通过调整书中的示例,你应该能够应用 fastai 创建深度学习模型,对各种数据集进行预测。你还将能够将你的模型部署到简单的 Web 应用程序中。
fastai 有许多超出本书内容的功能。以下是一些你可以使用的额外 fastai 资源,帮助你更深入了解该平台:
-
要更深入地了解 fastai,你可以查看该框架的在线文档(docs.fast.ai/)。
-
如果你想要一本全面的 fastai 指南,我强烈推荐 Jeremy Howard(fastai 的创始人)和 Sylvain Gugger 的杰出著作*《Deep Learning for Coders with Fastai and PyTorch》*(
www.amazon.com/Deep-Learning-Coders-fastai-PyTorch/dp/1492045527)。 -
Jeremy Howard 的 YouTube 频道(
www.youtube.com/user/howardjeremyp)是另一个关于 fastai 的优质信息来源,包括 Howard 基于 fastai 制作的深度学习课程视频*《Practical Deep Learning for Coders》*(course.fast.ai/)。 -
当你准备深入学习时,Zachary Mueller 的*《Walk with fastai》*网站(
walkwithfastai.com/)是一个非常棒的资源,它整合了 fastai 论坛(forums.fast.ai/)的许多见解,以及 Mueller 对平台的百科全书式理解。
感谢你花时间阅读本书并遵循书中的示例。我希望你觉得本书有用,并鼓励你应用所学的知识,利用 fastai 的深度学习力量做出伟大的事情。
