

持久执行引擎如Temporal和Restate用于管理分布式系统中的长期工作流。它们通过持久化状态、处理重试和容错事务来确保可靠执行,并与Kafka等事件驱动平台集成。持久执行引擎补充了流处理框架,为长期运行的业务流程提供状态管理和分布式事务处理。
作者:Kai Waehner
持久执行引擎,如 Temporal 和 Restate,正在改变开发者在分布式系统中管理长期运行的工作流和事务的方式。通过持久化工作流状态、处理重试以及支持容错事务,这些引擎确保了可靠的执行,并且擅长自动化机器对机器的交互,这与为以人为中心的工作流设计的传统 BPM 工具不同。
当与像 Apache Kafka 这样的事件驱动平台集成时,持久执行引擎开启了新的可能性。Kafka 的持久、解耦的事件存储充当了实时通信的骨干,而这些引擎编排了诸如订单处理之类的工作流,协调库存验证、支付授权和发货,即使在发生故障时也是如此。
随着持久执行引擎的采用不断增长,它们填补了传统 BPM 工具留下的重要空白,并补充了现有的流处理框架。虽然像 Kafka Streams 或 Apache Flink 这样的流处理工具为实时分析和有状态计算提供了强大的状态管理,但持久执行引擎通过在较长时间内持久化工作流状态来增强状态管理。它们是为长期运行、多步骤业务流程而专门构建的,自动处理重试、超时和分布式事务。
这篇博文探讨了持久执行引擎与诸如 Apache Kafka、Flink 和 Spark Structured Streaming 等数据流技术的集成、用例和能力,突出了它们为现代分布式企业系统创建可扩展、弹性架构的潜力。
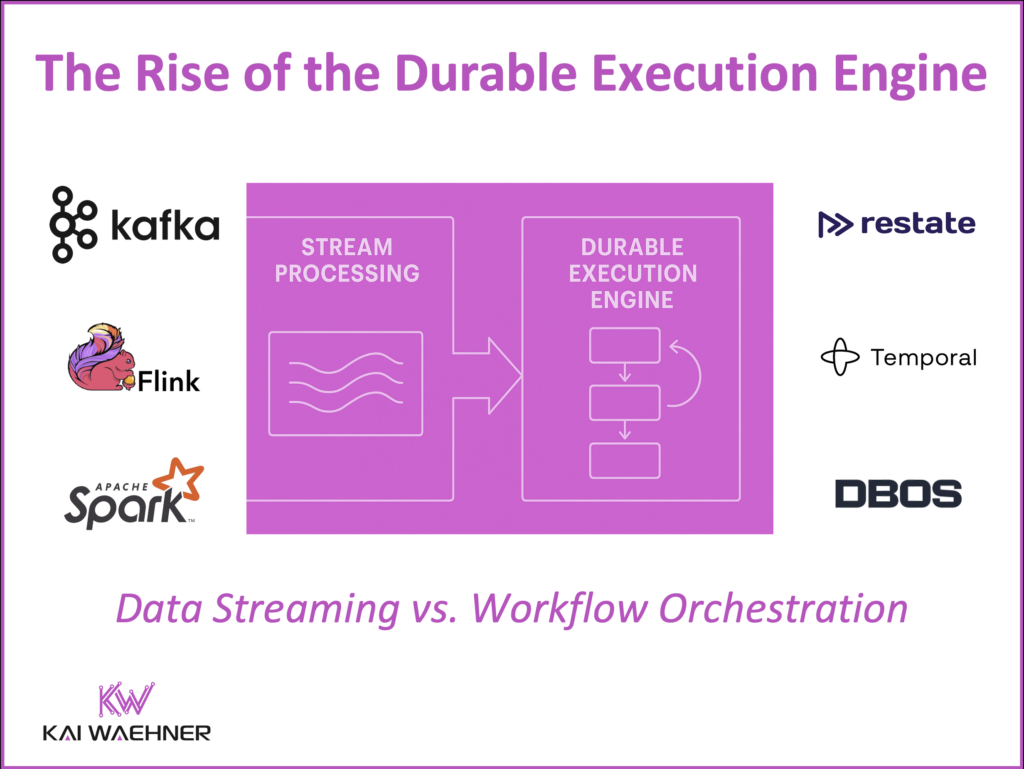
什么是持久执行引擎?
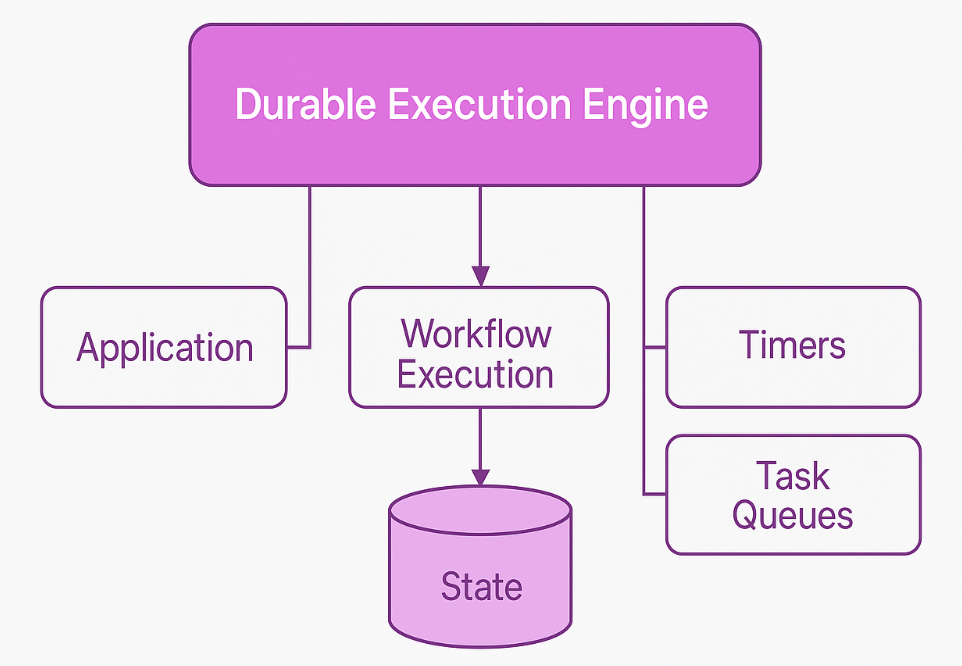
持久执行引擎确保分布式系统中工作流和流程的可靠、有状态的执行。它旨在管理长期运行、复杂或需要在重试和故障期间保持持久性的工作流。这些引擎:
- 将工作流的状态持久化到持久存储(例如,数据库)。
- 自动处理重试、超时和回滚。
- 以容错方式管理分布式事务。
例如,在一个分布式电子商务应用程序中,订单处理工作流可能涉及验证库存、保留资金和安排发货。持久执行引擎确保此过程可靠地完成,即使单个服务失败或重新启动也是如此。
主要供应商:Temporal、Restate 等
持久执行引擎的市场仍处于早期阶段,该技术正处于创新曲线的起点附近——类似于 Gartner 技术成熟度曲线的早期阶段。尽管如此新,一些有前途的供应商已经在帮助定义和塑造这个新兴类别。
Temporal 和 Restate 是这个领域中非常有趣的 emerging 供应商:
- Temporal:该开源框架提供 SDK(Java、Go、Python、Node.js)以将工作流定义为代码。Temporal 提供持久的状态管理,确保工作流在发生故障后恢复,而无需开发人员重新实现重试或检查点。
- Restate:该专有解决方案专注于为弹性流程执行提供轻量级的云原生引擎,提供用于工作流编排和状态跟踪的 API。
这两种解决方案都与现代微服务架构很好地集成,并支持诸如订单管理、欺诈检测和分布式批处理作业之类的用例。
Temporal 将其架构描述如下:使用 Temporal SDK 以您喜欢的语言构建防故障、容错的应用程序,这些 SDK 用持久的工作流、自动重试和完全的执行可见性取代了脆弱的状态机。
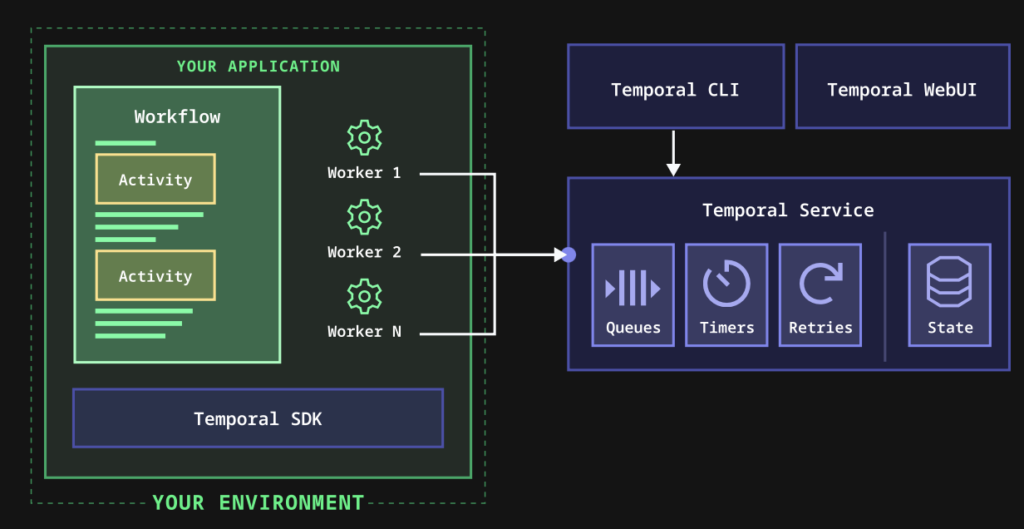
来源: Temporal
其他值得注意的工具包括 Cadence(Temporal 的开源前身)、Zeebe(由 BPM 供应商 Camunda 为云原生应用程序设计的工作流引擎)和 DBOS(一个统一的系统,集成了数据库和工作流执行功能)。
持久执行引擎与 BPM 引擎的区别
持久执行引擎与传统的业务流程管理 (BPM) 引擎有一些相似之处,但针对不同的场景进行了优化。
| 特性 | BPM 引擎 | 持久执行引擎 |
|---|---|---|
| 关注点 | 人工工作流、审批和基于表单的流程 | 针对长期运行、自动化、容错的服务编排进行了优化 |
| 持久性 | 通常仅限于任务级别的状态 | 内置,状态在故障期间保持持久 |
| 开发模型 | 可视化工作流建模 | 代码优先 |
| 可扩展性 | 有限的可扩展性 | 针对分布式、可扩展的系统进行了优化 |
| 用例示例 | 员工入职、发票审批工作流、贷款申请处理、客户投诉处理 | 电子商务中的订单履行、保险索赔处理、订阅计费和续订、物联网传感器警报工作流、金融交易结算 |
例如,Camunda 是一种 BPM 引擎,非常适合涉及人工审批步骤的工作流,例如员工入职或合规性审查。相比之下,持久执行引擎旨在协调具有复杂依赖关系的分布式微服务,其中强大的协调、重试和状态一致性至关重要。
请注意,Camunda 也支持代码集成,但 BPMN 仍然是其执行模型的核心——工作流是基于 BPMN 图定义的和执行的。代码必须与可视化流程模型保持一致,从而限制了纯代码优先的工作流设计。
Camunda 通过推出 Zeebe 提前预测了云原生架构的趋势,将水平可扩展性和事件流引入 BPM 领域——远早于“持久执行引擎”一词的出现。
像 Temporal 或 Restate 这样的持久执行引擎更进一步。它提供了对重试、超时和补偿逻辑(在工作流中稍后发生故障时撤消或调整操作的自定义步骤)的细粒度控制,以确保跨不可靠的网络和服务进行具有强大事务执行保证的有状态编排。
将持久执行引擎连接到事件驱动架构
事件驱动架构 (EDA) 是持久执行引擎的自然选择。EDA 使用事件解耦生产者和消费者,从而实现异步和反应式系统。持久执行引擎通过管理由这些事件触发的工作流的有状态编排来补充 EDA。
例如,诸如“OrderPlaced”之类的事件可以触发 Temporal 或 Restate 中的工作流来:
- 验证库存。
- 预留付款。
- 通知发货。
工作流的进度存储在持久执行引擎中,以确保它可以在服务发生故障时在任何步骤恢复。此设置确保了高容错性和运营可靠性。
Restate 在其产品描述中探讨了工作流、事件驱动的应用程序和微服务编排如何在持久执行引擎中结合在一起:
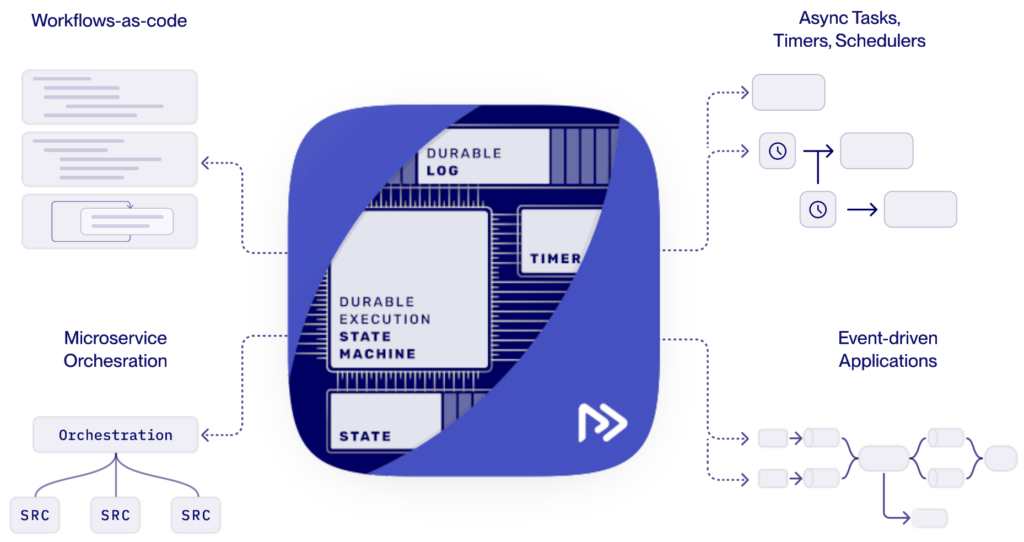
来源: Restate
Apache Kafka 的作用:真正的解耦和无缝集成
Apache Kafka 是当今大多数事件驱动架构的支柱。超过 150,000 个组织使用它来实现实时数据流和集成。它的功能使其成为与持久执行引擎配对的理想选择:
- 真正的解耦:生产者和消费者是独立的,并通过主题进行通信。这种解耦减少了相互依赖性,并实现了水平扩展,从而提高了弹性和可扩展性。
- 持久存储:Kafka 在具有保证的排序和时间戳的持久且可重放的日志中保留事件。这允许工作流异步处理事件,确保下游系统可以从延迟、故障或中断中恢复,而不会丢失数据。
- 广泛的兼容性:Kafka 通过以下方式与各种系统集成:
- Kafka Connect:用于数据库、云服务和其他系统的预构建连接器。
- Kafka Clients:适用于大多数编程语言的库。
- REST Proxy:支持与基于 HTTP 的系统集成。
- 原生中间件支持:与其他中间件和数据平台的无缝集成。
Apache Kafka 在工作流编排方面的局限性
虽然Apache Kafka 与流处理相结合,可以充当工作流引擎,但存在局限性:
- 手动状态管理:Kafka 或更一般的数据流,缺乏用于跟踪工作流状态或管理重试的内置工具。开发人员必须使用诸如 saga 编排之类的模式手动实现这些。
- 缺乏工作流语义:Kafka 主题非常适合消息传递,并作为事件的持久性层,但流处理缺乏诸如并行执行或补偿之类的内置结构。
- 代码复杂性:在 Kafka 和诸如 Kafka Streams、Flink 或 Spark Structured Streaming 之类的流处理引擎上构建功能完善的工作流引擎会增加大量的自定义开发开销。
一篇专门的博文探讨了跨行业的案例研究,以展示像 Salesforce 或 Swisscom 这样的企业如何使用 Kafka 和流处理实现有状态的工作流自动化和编排。
相比之下,持久执行引擎提供了开箱即用的这些功能,使开发人员可以专注于业务逻辑,而不是基础设施。
何时使用流处理 vs. 持久执行引擎?
虽然像 Kafka Streams、Apache Flink 或 Apache Spark 的 Structured Streaming 这样的流处理工具与持久执行引擎有一些重叠,但它们服务于不同的目的。
流处理的用例(Kafka Streams、Apache Flink、Spark Structured Streaming)
专注于转换和分析连续的数据流。通常使用流式 API 进行实时处理,但也用于某些分析批处理工作负载。非常适合以下用例:
- 实时分析(例如,支付中的欺诈检测)。
- 无状态和有状态转换(例如,在时间窗口上的聚合)。
- 事件数据的丰富(即,将实时数据流(如订单)与来自 ERP 或 CRM 的“静态”主数据结合)。
- 使用 Spark Streaming 或 Flink 的 Batch API 的批处理风格的工作负载,用于高吞吐量处理,并及时回溯以进行历史数据重放(例如,重新处理一天的交易数据以重新生成用于财务合规或审计请求的报告)
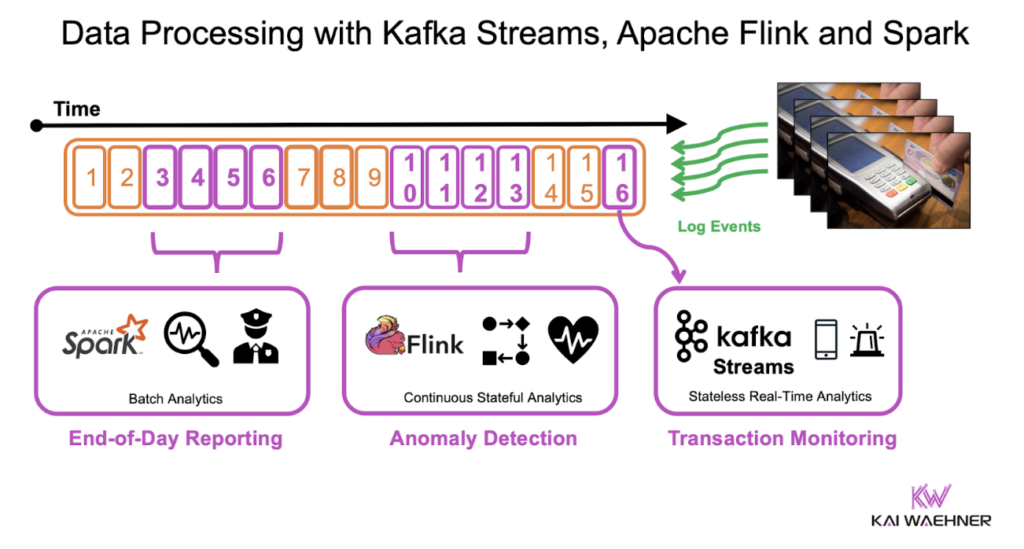
更多详细信息请参见我的文章“使用 Kafka Streams 和 Apache Flink 进行无状态 vs. 有状态流处理”。
持久执行引擎的用例(Restate、Temporal、DBOS)
管理工作流的生命周期。最适合:
- 长期运行的流程(例如,贷款审批)。
- 复杂的微服务编排和分布式事务(例如,服务到服务的调用)。
- 业务工作流的状态管理(例如,协调一个多步骤的保险索赔流程,包括审批、数据验证和第三方交互)。
有太多选择 - 流处理 vs. 持久执行引擎
如果您的主要目标是对事件流进行实时分析(例如,聚合、异常检测或丰富),那么像 Kafka Streams 或 Apache Flink 这样的工具通常是最佳选择。它们专为高吞吐量、低延迟处理而设计,并且还支持有状态、持久的计算,使其既适用于无状态操作,也适用于窗口操作。
但是,如果您需要协调长期运行的工作流、处理跨分布式系统的多步骤事务或管理重试、超时和补偿逻辑,那么持久执行引擎可能是更好的选择。这些引擎针对可靠性和业务流程连续性进行了优化,而不是流分析。
也就是说,引入其他工作流工具会增加架构的复杂性。仔细评估至关重要——在引入单独的执行引擎之前,请考虑您现有的流处理工具是否可以满足您的工作流需求。
持久执行引擎在分布式系统中崭露头角
像 Temporal 和 Restate 这样的持久执行引擎正在改变开发人员在分布式系统中构建和管理工作流的方式。这些引擎通过为分布式事务和工作流编排提供持久的状态管理,解决了传统 BPM 工具和诸如 Kafka Streams、Apache Flink 或 Spark Structured Streaming 之类的流处理框架留下的空白。
当前市场:持久执行引擎的市场还处于非常早期的阶段。人们的兴趣正在增长,但采用仍然仅限于前沿组织和早期采用者。这项技术正处于炒作周期的上升阶段,具有巨大的增长潜力。
未来趋势:预计持久执行引擎与事件驱动的数据流平台(如 Apache Kafka)的集成将更加紧密,增强的开发人员工具以及跨行业的更广泛采用。随着工具的发展以解决重叠的用例,流处理和分布式工作流编排之间的界限也可能变得模糊。
通过将持久执行引擎与事件驱动架构配对,企业可以释放新的可靠性和效率水平,使其对于下一代分布式系统而言必不可少。
