

01 背景
随着LLM模型层出不穷,同时基于Transformer、MOE架构的模型轻轻松松突破上万亿规模参数,传统的单机单卡模式已经无法满足超大模型进行训练的要求。类似大数据MapReduce思想, 模型领域也进入分布式时代,开启多机多卡进行分布式大模型的训练和推理。
并行策略实际上是三种常用的并行训练技术的组合,即数据并行(Data Parallelism)、流水线并行(Pipeline Parallelism)和张量并行(Tensor Parallelism)。 有的工作也会使用模型并行一词,它同时包括了张量并行和流水线并行。
02 数据并行
数据并行是一种提高训练吞吐量的方法,它将模型参数和优化器状态复制到多个 GPU 上,然后将训练数据平均分配到这些 GPU 上。这样,每个GPU 只需要处理分配给它的数据,然后执行前向传播和反向传播以获取梯度。当所有 GPU 都执行完毕后,该策略会将不同 GPU 的梯度进行平均,以得到整体的梯度来统一更新所有 GPU 上的模型参数。
因此,数据并行策略下,在反向传播过程中,需要对各个设备上的梯度进行AllReduce,以确保各个设备上的模型始终保持一致。
数据并行很类似spark和flink的处理方式,但是传统数据统计方法并不会占用过多资源,而在大模型时代,数据并行训练,仅仅将数据做了切割,模型在所有GPU复制了一份,导致很多冗余的问题。当数据集较大,模型较小时,由于反向过程中为同步梯度产生的通信代价较小,此时选择数据并行一般比较有优势。
02 模型并行
为解决数据并行中每块GPU中都复制了一份整个模型的权限问题,模型能不能被分割成几部分,并将这些分块分布到一个设备阵列上。每个设备只拥有模型的一部分,所有计算机设备的模型合在一起才是整个模型。模型并行又可以分成张量并行和流水线并行。
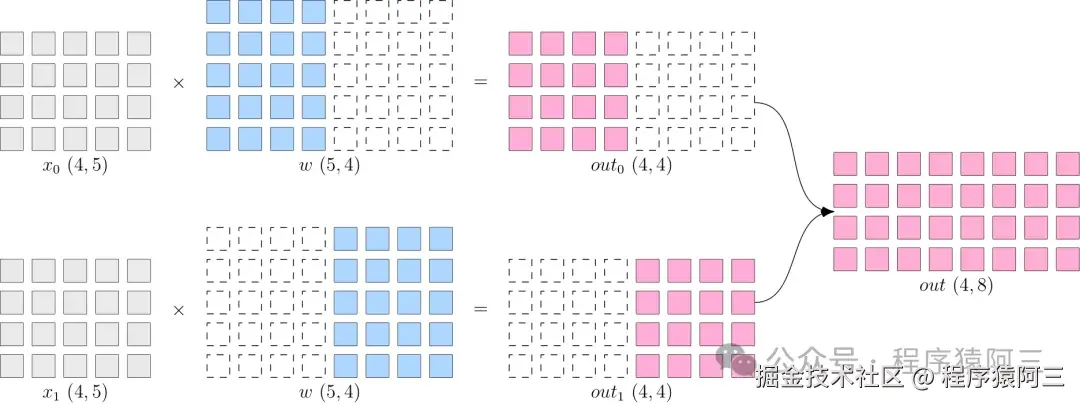
2.1 张量并行
张量并行是在一个操作中进行并行计算,如:矩阵-矩阵乘法。张量并行可以被看作是层内并行。
张量并行训练是将一个张量沿特定维度分成 N 块,每个设备只持有整个张量的 1/N,同时不影响计算图的正确性。这需要额外的通信来确保结果的正确性。
以一般的矩阵乘法为例,假设我们有 C = AB。我们可以将B沿着列分割成 [B0 B1 B2 ... Bn],每个设备持有一列。然后我们将 A 与每个设备上 B 中的每一列相乘,我们将得到 [AB0 AB1 AB2 ... ABn] 。此刻,每个设备仍然持有一部分的结果,例如,设备(rank=0)持有 AB0。为了确保结果的正确性,我们需要收集全部的结果,并沿列维串联张量。通过这种方式,我们能够将张量分布在设备上,同时确保计算流程保持正确。
模型并行的好处是,省去了多个设备之间的梯度 AllReduce;但是,由于每个设备都需要完整的数据输入,因此,数据会在多个设备之间进行广播,产生通信代价(这里指数据不会复制多份而是通过广播来传递输入数据)。
 2.2 流水并行
2.2 流水并行
流水线也是模型并行的另一种方式,是在网络各层之间并行计算,模型按层分割成若干块,每块交给一个设备,被看作是层间并行。
在前向传播过程中,每个设备中间的激活值传递给下一个阶段。在后向传播过程中,每个设备将输入张量的梯度回传给前一个阶段,如此,就可以允许设备同时计算,从而增加训练的吞吐量。
流水并行指将网络切为多个阶段,并分发到不同的计算设备上,各个计算设备之间以“接力”的方式完成训练。 这种方式有一个明显的缺点,后一个阶段需要等待前面一个阶段执行完成,导致设备容易出现空闲状态,导致计算资源浪费。
03 优化器相关并行
之前在《【小白入门篇6】常识|怎么计算模型需要的资源》文章提过,GPU需要进行存储参数包括模型本身参数、优化器状态以及激活函数的输出值、梯度等,一般情况,模型优化器状态+梯度+模型参数占用显存一半以上。能否将模型状态用分布式技术进行存储?
微软开发ZeRO是为了克服数据并行性和模型并行性的限制,同时实现两者的优点。ZeRO通过在数据并行进程中划分模型状态(参数,梯度和优化器状态),而不是复制它们,从而消除了数据并行进程中的内存冗余。它在训练期间使用动态通信计划,以在分布式设备之间共享必要的状态,以保持计算粒度和数据并行性的通信量。
ZeRO驱动的数据并行性,它允许每个设备的内存使用量随数据并行性的程度线性扩展,并产生与数据并行性相似的通信量。 ZeRO支持的数据并行性可以适合任意大小的模型,只要聚合的设备内存足够大以共享模型状态即可。
ZeRO(Zero Redundancy Optimizer)是一种用于大规模训练优化的技术,主要是用来减少内存占用。在大规模训练中,内存占用可以分为 Model States 和 Activation 两部分,而 ZeRO 主要是为了解决 Model States 的内存占用问题。
ZeRO 将模型参数分成了三个部分:Optimizer States、Gradient 和 Model Parameter。
-
Optimizer States是 Optimizer 在进行梯度更新时所需要用到的数据,例如 SGD 中的 Momentum。 -
Gradient是在反向传播后所产生的梯度信息,其决定了参数的更新方向。 -
Model Parameter则是模型参数,也就是我们在整个过程中通过数据“学习”的信息。
ZeRO-Offload和ZeRO-Stage3是DeepSpeed中的不同的Zero-Redundancy Optimization技术,用于加速分布式训练,主要区别在资源占用和通信开销方面。
-
ZeRO-Offload将模型参数分片到不同的GPU上,通过交换节点间通信来降低显存占用,但需要进行额外的通信操作,因此可能会导致训练速度的下降。 -
**
ZeRO-Stage3**将模型参数分布在CPU和GPU上,通过CPU去计算一部分梯度,从而减少显存占用,但也会带来一定的计算开销。
3.1 三个级别
ZeRO-0:禁用所有类型的分片,仅使用 DeepSpeed 作为 DDP (Distributed Data Parallel)
ZeRO-1:分割Optimizer States,减少了4倍的内存,通信容量与数据并行性相同
ZeRO-2:分割Optimizer States与Gradients,8x内存减少,通信容量与数据并行性相同
ZeRO-3:分割Optimizer States、Gradients与Parameters,内存减少与数据并行度和复杂度成线性关系。
ZeRO-Infinity:ZeRO-3的拓展。允许通过使用 NVMe 固态硬盘扩展 GPU 和 CPU 内存来训练大型模型。ZeRO-Infinity 需要启用 ZeRO-3。
04 多维度混合并行
多维混合并行指将数据并行、模型并行和流水线并行等多种并行技术结合起来进行分布式训练。代表一种混合思想。
而为了更高效地训练,可以将 PP、TP 和 DP 相结合,被业界称为 3D 并行,如下图所示。
由于每个维度至少需要 2 个 GPU,因此在这里你至少需要 8 个 GPU 才能实现完整的 3D 并行。
04 总结
说了这么多模型分布式方法,每个方法都有相应的场景。如果让开发者自主选择,固然有灵活性,但是增加学习成本。那么有没有自动方法,答案是是有,现在有一种是自动并行,自动并行的目标就是用户给定一个模型和所使用的机器资源后,能够自动地帮用户选择一个比较好或者最优的并行策略来高效执行。可以说,自动并行是分布式并行的终极目标,它能够解放工程师去手动设置分布式并行策略,而自动并行可以分为全自动并行和半自动并行模式。目前,很多的通用AI框架(如:PaddlePaddle、OneFlow、PyTorch、MindSpore、TensorFlow、JAX等)都对自动并行(全自动或半自动)进行了实现。
参考:
www.microsoft.com/en-us/resea…
zhuanlan.zhihu.com/p/598714869
learn.microsoft.com/zh-cn/azure…
datawhalechina.github.io/so-large-lm…
basicv8vc.github.io/posts/zero/
更多合集文章请关注我的公众号,一起学习一起进步:
