这一篇文章作为介绍海面渲染的提前篇,也作为第二篇的补充和修正。在第二篇中,介绍了 FFT的计算方法。然而,在深入学习了海面渲染方法时,发现了之前的一些问题。关于第二篇的内容,在这里就不回顾了,感兴趣的可以先粗略阅读。(跳转链接)
先说明第二篇存在的问题及造成该问题的原因。然后再介绍蝶形变换计算的本质和降低计算量方法。
存在的问题
第二篇提供的分析是正确的。但是实现的算法时间复杂度是O(n2log(n))。而算法的时间复杂度是可以降低到O(nlog(n))的。第二篇之所以没有意识到这个问题,是由于没有考虑到WNk的周期性。这里WNk有一个性质,即:
WNk=WNk+N
在网上公开的许多资料中,都提到了蝶形变化和比特反转。第二篇并没有提及这些内容,没有提到这些内容的原因是我认为资料中给出的介绍没有很好地解释这些内容,有的只是给了一张图,并没有解释图的含义。这里简单介绍一下比特反转,及我在学习比特翻转时发现的一些特点。
比特翻转
比特翻转就是把一个由n bit 组成的整数的比特位进行翻转,例如一个3 bit组成的整数100,经过比特翻转后变成001。
回到第二篇的递归推导。这里展示了8个数的傅立叶变换的递归计算过程。
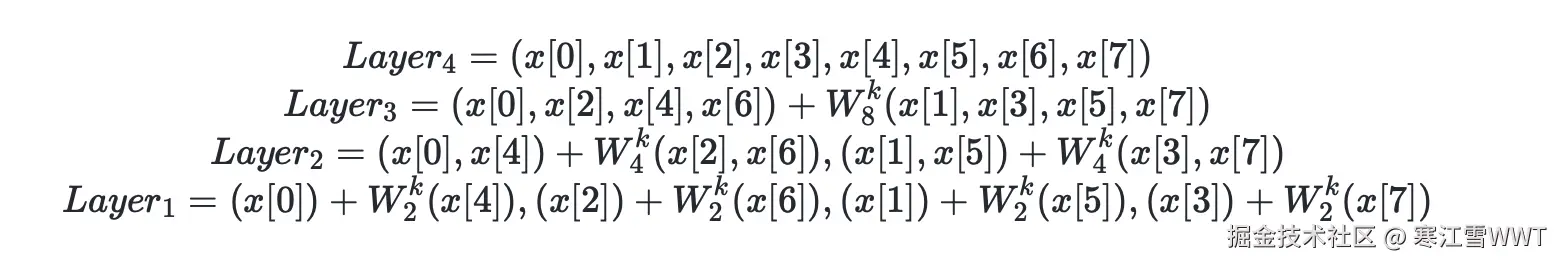
这里看最下面一层,顺序是0,4,2,6,1,5,3,7。最上一层的顺序是0,1,2,3,4,5,6,7。比特翻转的意义就是能够由最上层的下标,可以计算出最下层的下标。4的比特翻转结果是1,所以在最下一层,x[4]在下标为1的位置。比特翻转在这里就是能提前计算出输入序列在 FFT最低一层的计算中的组合方式。
不过这过计算过程,只是计算单个频率傅立叶变换的结果。即下面公式中,的某个X[i]的值,而这样的计算还有n个。
X[i]=n=0∑N−1x[n]eN−jkn2π
因此,不嫌麻烦地,我把八个数的FFT递归的每一项的计算过程都写出来。并把每一层底递归的求和结果按顺序展开,得到如下结果。从这个结果中可以总结出一些规律。
X[0]=x[0]+x[1]W80+x[2]W40+x[3]W40W80+x[4]W20+x[5]W20W80+x[6]W20W40+x[7]W20W40W80X[1]=x[0]+x[1]W81+x[2]W41+x[3]W41W81+x[4]W21+x[5]W21W81+x[6]W21W41+x[7]W21W41W81X[2]=x[0]+x[1]W82+x[2]W42+x[3]W42W82+x[4]W22+x[5]W22W82+x[6]W22W42+x[7]W22W42W82X[3]=x[0]+x[1]W83+x[2]W43+x[3]W43W83+x[4]W23+x[5]W23W83+x[6]W23W43+x[7]W23W43W83X[4]=x[0]+x[1]W84+x[2]W44+x[3]W44W84+x[4]W24+x[5]W24W84+x[6]W24W44+x[7]W24W44W84X[5]=x[0]+x[1]W85+x[2]W45+x[3]W45W85+x[4]W25+x[5]W25W85+x[6]W25W45+x[7]W25W45W85X[6]=x[0]+x[1]W86+x[2]W46+x[3]W46W86+x[4]W26+x[5]W26W86+x[6]W26W46+x[7]W26W46W86X[7]=x[0]+x[1]W87+x[2]W47+x[3]W47W87+x[4]W27+x[5]W27W87+x[6]W27W47+x[7]W27W47W87
展开之后,每一项的结果一目了然。
从比特翻转中总结出的规律
根据上文中,比特翻转的介绍及递归过程的展开结果来看。可以看出FFT和比特位有一定的关系。进一步总结,可以总结出下面的规律。
X[0]=x[0]W20W40W80+x[1]W20W40W80+x[2]W20W40W80+x[3]W20W40W80+x[4]W20W40W80+x[5]W20W40W80+x[6]W20W40W80+x[7]W20W40W80X[1]=x[0]W20W40W80+x[1]W20W40W81+x[2]W20W41W80+x[3]W20W41W81+x[4]W21W40W80+x[5]W21W40W81+x[6]W21W41W80+x[7]W21W41W81X[2]=x[0]W20W40W80+x[1]W20W40W82+x[2]W20W42W80+x[3]W20W42W82+x[4]W22W40W80+x[5]W22W40W82+x[6]W22W42W80+x[7]W22W42W82X[3]=x[0]W20W40W80+x[1]W20W40W83+x[2]W20W43W80+x[3]W20W43W83+x[4]W23W40W80+x[5]W23W40W83+x[6]W23W43W80+x[7]W23W43W83X[4]=x[0]W20W40W80+x[1]W20W40W84+x[2]W20W44W80+x[3]W20W44W84+x[4]W24W40W80+x[5]W24W40W84+x[6]W24W44W80+x[7]W24W44W84X[5]=x[0]W20W40W80+x[1]W20W40W85+x[2]W20W45W80+x[3]W20W45W85+x[4]W25W40W80+x[5]W25W40W85+x[6]W25W45W80+x[7]W25W45W85X[6]=x[0]W20W40W80+x[1]W20W40W86+x[2]W20W46W80+x[3]W20W46W86+x[4]W26W40W80+x[5]W26W40W86+x[6]W26W46W80+x[7]W26W46W86X[7]=x[0]W20W40W80+x[1]W20W40W87+x[2]W20W47W80+x[3]W20W47W87+x[4]W27W40W80+x[5]W27W40W87+x[6]W27W47W80+x[7]W27W47W87
由上,可以看到FFT的过程,就是对输入数组中每一个数乘以一个WNk。在上面的例子中,数组长度为8,比特位数为3位。下标的最高位为1的数,要乘以一个W2k,否则乘以W20(结果为1),第二位为1的,要乘以W4k,否则乘以1,第三位为1的要乘以W8k,否则要乘以1。这样就可以总结出一个规律:输入数组中每个元素的下标的比特位,决定了它应该乘的WNk还是WN0,而N从比特位的高位依次排到低位为,2,4,8……输入数组的长度保持为二的次幂,假设长度l=2n,则比特数为n。上面的例子中,比特数为3.
蝶形变换
蝶形变换的过程,正是利用了上面总结的规律进行优化计算的。由于WNk具有周期性,因此有的成积不需要多次计算,只进行一次计算复用即可。这样一维的FFT只需要O(Nlog(n))次运行即可得出结果。感兴趣的可以自己动手计算一下,感受这个过程,结合周期性去总结规律。我会在后面介绍海面渲染的文章中,讲解这个优化过程,并介绍如何利用Compute Shader优化这个计算过程。ComputeShader的计算很快,可以在帧循环中实时更新。


