- 我的环境:
- 操作系统:CentOS7
- 显卡:RTX3090
- 显卡驱动:535.154.05
- CUDA版本: 12.2
- 语言环境:Python3.10
- 编译器:Jupyter Lab
- 深度学习环境:
- torch==12.1
- torchvision==0.18.1
一、前期准备
1. 设置GPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warnings
warnings.filterwarnings("ignore")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
device(type='cuda')
2. 导入数据
import os,PIL,random,pathlib
data_dir = './data/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("/")[1] for path in data_paths]
classeNames
['shine', 'cloudy', 'rain', 'sunrise']
train_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
test_transform = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
total_data = datasets.ImageFolder("./data/",transform=train_transforms)
total_data
Dataset ImageFolder
Number of datapoints: 1125
Root location: ./data/
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=True)
RandomHorizontalFlip(p=0.5)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
total_data.class_to_idx
{'cloudy': 0, 'rain': 1, 'shine': 2, 'sunrise': 3}
3. 划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_dataset, test_dataset
(<torch.utils.data.dataset.Subset at 0x7f04a79fdd20>,
<torch.utils.data.dataset.Subset at 0x7f03beee5b40>)
batch_size = 12
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
Shape of X [N, C, H, W]: torch.Size([12, 3, 224, 224])
Shape of y: torch.Size([12]) torch.int64
二、搭建包含Backbone模块的模型
1. 模型搭建
import torch.nn.functional as F
def autopad(k, p=None):
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class Bottleneck(nn.Module):
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
class SPPF(nn.Module):
def __init__(self, c1, c2, k=5):
super().__init__()
c_ = c1 // 2
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
"""
这个是YOLOv5, 6.0版本的主干网络,这里进行复现
(注:有部分删改,详细讲解将在后续进行展开)
"""
class YOLOv5_backbone(nn.Module):
def __init__(self):
super(YOLOv5_backbone, self).__init__()
self.Conv_1 = Conv(3, 64, 3, 2, 2)
self.Conv_2 = Conv(64, 128, 3, 2)
self.C3_3 = C3(128,128)
self.Conv_4 = Conv(128, 256, 3, 2)
self.C3_5 = C3(256,256)
self.Conv_6 = Conv(256, 512, 3, 2)
self.C3_7 = C3(512,512)
self.Conv_8 = Conv(512, 1024, 3, 2)
self.C3_9 = C3(1024, 1024)
self.SPPF = SPPF(1024, 1024, 5)
self.classifier = nn.Sequential(
nn.Linear(in_features=65536, out_features=100),
nn.ReLU(),
nn.Linear(in_features=100, out_features=4)
)
def forward(self, x):
x = self.Conv_1(x)
x = self.Conv_2(x)
x = self.C3_3(x)
x = self.Conv_4(x)
x = self.C3_5(x)
x = self.Conv_6(x)
x = self.C3_7(x)
x = self.Conv_8(x)
x = self.C3_9(x)
x = self.SPPF(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = YOLOv5_backbone().to(device)
model
Using cuda device
YOLOv5_backbone(
(Conv_1): Conv(
(conv): Conv2d(3, 64, kernel_size=(3, 3), stride=(2, 2), padding=(2, 2), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(Conv_2): Conv(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_3): C3(
(cv1): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(Conv_4): Conv(
(conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_5): C3(
(cv1): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(Conv_6): Conv(
(conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_7): C3(
(cv1): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(Conv_8): Conv(
(conv): Conv2d(512, 1024, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_9): C3(
(cv1): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(SPPF): SPPF(
(cv1): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(2048, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): MaxPool2d(kernel_size=5, stride=1, padding=2, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=65536, out_features=100, bias=True)
(1): ReLU()
(2): Linear(in_features=100, out_features=4, bias=True)
)
)
2. 查看模型
import torchsummary as summary
summary.summary(model, (3, 224, 224))
----------------------------------------------------------------
Layer (type) Output Shape Param
================================================================
Conv2d-1 [-1, 64, 113, 113] 1,728
BatchNorm2d-2 [-1, 64, 113, 113] 128
SiLU-3 [-1, 64, 113, 113] 0
Conv-4 [-1, 64, 113, 113] 0
Conv2d-5 [-1, 128, 57, 57] 73,728
BatchNorm2d-6 [-1, 128, 57, 57] 256
SiLU-7 [-1, 128, 57, 57] 0
Conv-8 [-1, 128, 57, 57] 0
Conv2d-9 [-1, 64, 57, 57] 8,192
BatchNorm2d-10 [-1, 64, 57, 57] 128
SiLU-11 [-1, 64, 57, 57] 0
Conv-12 [-1, 64, 57, 57] 0
Conv2d-13 [-1, 64, 57, 57] 4,096
BatchNorm2d-14 [-1, 64, 57, 57] 128
SiLU-15 [-1, 64, 57, 57] 0
Conv-16 [-1, 64, 57, 57] 0
Conv2d-17 [-1, 64, 57, 57] 36,864
BatchNorm2d-18 [-1, 64, 57, 57] 128
SiLU-19 [-1, 64, 57, 57] 0
Conv-20 [-1, 64, 57, 57] 0
Bottleneck-21 [-1, 64, 57, 57] 0
Conv2d-22 [-1, 64, 57, 57] 8,192
BatchNorm2d-23 [-1, 64, 57, 57] 128
SiLU-24 [-1, 64, 57, 57] 0
Conv-25 [-1, 64, 57, 57] 0
Conv2d-26 [-1, 128, 57, 57] 16,384
BatchNorm2d-27 [-1, 128, 57, 57] 256
SiLU-28 [-1, 128, 57, 57] 0
Conv-29 [-1, 128, 57, 57] 0
C3-30 [-1, 128, 57, 57] 0
Conv2d-31 [-1, 256, 29, 29] 294,912
BatchNorm2d-32 [-1, 256, 29, 29] 512
SiLU-33 [-1, 256, 29, 29] 0
Conv-34 [-1, 256, 29, 29] 0
Conv2d-35 [-1, 128, 29, 29] 32,768
BatchNorm2d-36 [-1, 128, 29, 29] 256
SiLU-37 [-1, 128, 29, 29] 0
Conv-38 [-1, 128, 29, 29] 0
Conv2d-39 [-1, 128, 29, 29] 16,384
BatchNorm2d-40 [-1, 128, 29, 29] 256
SiLU-41 [-1, 128, 29, 29] 0
Conv-42 [-1, 128, 29, 29] 0
Conv2d-43 [-1, 128, 29, 29] 147,456
BatchNorm2d-44 [-1, 128, 29, 29] 256
SiLU-45 [-1, 128, 29, 29] 0
Conv-46 [-1, 128, 29, 29] 0
Bottleneck-47 [-1, 128, 29, 29] 0
Conv2d-48 [-1, 128, 29, 29] 32,768
BatchNorm2d-49 [-1, 128, 29, 29] 256
SiLU-50 [-1, 128, 29, 29] 0
Conv-51 [-1, 128, 29, 29] 0
Conv2d-52 [-1, 256, 29, 29] 65,536
BatchNorm2d-53 [-1, 256, 29, 29] 512
SiLU-54 [-1, 256, 29, 29] 0
Conv-55 [-1, 256, 29, 29] 0
C3-56 [-1, 256, 29, 29] 0
Conv2d-57 [-1, 512, 15, 15] 1,179,648
BatchNorm2d-58 [-1, 512, 15, 15] 1,024
SiLU-59 [-1, 512, 15, 15] 0
Conv-60 [-1, 512, 15, 15] 0
Conv2d-61 [-1, 256, 15, 15] 131,072
BatchNorm2d-62 [-1, 256, 15, 15] 512
SiLU-63 [-1, 256, 15, 15] 0
Conv-64 [-1, 256, 15, 15] 0
Conv2d-65 [-1, 256, 15, 15] 65,536
BatchNorm2d-66 [-1, 256, 15, 15] 512
SiLU-67 [-1, 256, 15, 15] 0
Conv-68 [-1, 256, 15, 15] 0
Conv2d-69 [-1, 256, 15, 15] 589,824
BatchNorm2d-70 [-1, 256, 15, 15] 512
SiLU-71 [-1, 256, 15, 15] 0
Conv-72 [-1, 256, 15, 15] 0
Bottleneck-73 [-1, 256, 15, 15] 0
Conv2d-74 [-1, 256, 15, 15] 131,072
BatchNorm2d-75 [-1, 256, 15, 15] 512
SiLU-76 [-1, 256, 15, 15] 0
Conv-77 [-1, 256, 15, 15] 0
Conv2d-78 [-1, 512, 15, 15] 262,144
BatchNorm2d-79 [-1, 512, 15, 15] 1,024
SiLU-80 [-1, 512, 15, 15] 0
Conv-81 [-1, 512, 15, 15] 0
C3-82 [-1, 512, 15, 15] 0
Conv2d-83 [-1, 1024, 8, 8] 4,718,592
BatchNorm2d-84 [-1, 1024, 8, 8] 2,048
SiLU-85 [-1, 1024, 8, 8] 0
Conv-86 [-1, 1024, 8, 8] 0
Conv2d-87 [-1, 512, 8, 8] 524,288
BatchNorm2d-88 [-1, 512, 8, 8] 1,024
SiLU-89 [-1, 512, 8, 8] 0
Conv-90 [-1, 512, 8, 8] 0
Conv2d-91 [-1, 512, 8, 8] 262,144
BatchNorm2d-92 [-1, 512, 8, 8] 1,024
SiLU-93 [-1, 512, 8, 8] 0
Conv-94 [-1, 512, 8, 8] 0
Conv2d-95 [-1, 512, 8, 8] 2,359,296
BatchNorm2d-96 [-1, 512, 8, 8] 1,024
SiLU-97 [-1, 512, 8, 8] 0
Conv-98 [-1, 512, 8, 8] 0
Bottleneck-99 [-1, 512, 8, 8] 0
Conv2d-100 [-1, 512, 8, 8] 524,288
BatchNorm2d-101 [-1, 512, 8, 8] 1,024
SiLU-102 [-1, 512, 8, 8] 0
Conv-103 [-1, 512, 8, 8] 0
Conv2d-104 [-1, 1024, 8, 8] 1,048,576
BatchNorm2d-105 [-1, 1024, 8, 8] 2,048
SiLU-106 [-1, 1024, 8, 8] 0
Conv-107 [-1, 1024, 8, 8] 0
C3-108 [-1, 1024, 8, 8] 0
Conv2d-109 [-1, 512, 8, 8] 524,288
BatchNorm2d-110 [-1, 512, 8, 8] 1,024
SiLU-111 [-1, 512, 8, 8] 0
Conv-112 [-1, 512, 8, 8] 0
MaxPool2d-113 [-1, 512, 8, 8] 0
MaxPool2d-114 [-1, 512, 8, 8] 0
MaxPool2d-115 [-1, 512, 8, 8] 0
Conv2d-116 [-1, 1024, 8, 8] 2,097,152
BatchNorm2d-117 [-1, 1024, 8, 8] 2,048
SiLU-118 [-1, 1024, 8, 8] 0
Conv-119 [-1, 1024, 8, 8] 0
SPPF-120 [-1, 1024, 8, 8] 0
Linear-121 [-1, 100] 6,553,700
ReLU-122 [-1, 100] 0
Linear-123 [-1, 4] 404
================================================================
Total params: 21,729,592
Trainable params: 21,729,592
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 137.59
Params size (MB): 82.89
Estimated Total Size (MB): 221.06
----------------------------------------------------------------
三、 训练模型
1. 编写训练函数
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_loss, train_acc = 0, 0
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
2. 编写测试函数
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, test_acc = 0, 0
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
3. 正式训练
import copy
def tran_my_model(train_dl, test_dl, model, loss_fn, optimizer, epochs = 40, out_best_model = "best_model.pth"):
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
lr = optimizer.state_dict()['param_groups'][0]['lr']
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss,
epoch_test_acc*100, epoch_test_loss, lr))
torch.save(model.state_dict(), out_best_model)
return [best_model, train_loss, test_loss, train_acc, test_acc]
model = YOLOv5_backbone().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr= 1e-4)
loss_fn = nn.CrossEntropyLoss()
adam_out = tran_my_model(train_dl, test_dl, model, loss_fn, optimizer, epochs = 20, out_best_model = "best_model.optim_Adam.pth")
adam_best_model, adam_train_loss, adam_test_loss, adam_train_acc, adam_test_acc = adam_out
Epoch: 1, Train_acc:62.1%, Train_loss:1.003, Test_acc:69.3%, Test_loss:0.507, Lr:1.00E-04
Epoch: 2, Train_acc:70.3%, Train_loss:0.690, Test_acc:80.0%, Test_loss:0.400, Lr:1.00E-04
Epoch: 3, Train_acc:78.1%, Train_loss:0.597, Test_acc:88.0%, Test_loss:0.374, Lr:1.00E-04
Epoch: 4, Train_acc:86.0%, Train_loss:0.375, Test_acc:90.7%, Test_loss:0.277, Lr:1.00E-04
Epoch: 5, Train_acc:85.6%, Train_loss:0.397, Test_acc:93.8%, Test_loss:0.212, Lr:1.00E-04
Epoch: 6, Train_acc:86.4%, Train_loss:0.360, Test_acc:91.6%, Test_loss:0.241, Lr:1.00E-04
Epoch: 7, Train_acc:89.7%, Train_loss:0.294, Test_acc:86.2%, Test_loss:0.352, Lr:1.00E-04
Epoch: 8, Train_acc:91.7%, Train_loss:0.260, Test_acc:94.7%, Test_loss:0.206, Lr:1.00E-04
Epoch: 9, Train_acc:91.3%, Train_loss:0.233, Test_acc:89.8%, Test_loss:0.306, Lr:1.00E-04
Epoch:10, Train_acc:92.3%, Train_loss:0.241, Test_acc:96.9%, Test_loss:0.169, Lr:1.00E-04
Epoch:11, Train_acc:91.0%, Train_loss:0.255, Test_acc:91.1%, Test_loss:0.241, Lr:1.00E-04
Epoch:12, Train_acc:91.9%, Train_loss:0.227, Test_acc:93.3%, Test_loss:0.226, Lr:1.00E-04
Epoch:13, Train_acc:94.0%, Train_loss:0.181, Test_acc:92.0%, Test_loss:0.306, Lr:1.00E-04
Epoch:14, Train_acc:92.4%, Train_loss:0.215, Test_acc:89.3%, Test_loss:0.267, Lr:1.00E-04
Epoch:15, Train_acc:95.4%, Train_loss:0.116, Test_acc:94.7%, Test_loss:0.209, Lr:1.00E-04
Epoch:16, Train_acc:94.3%, Train_loss:0.160, Test_acc:95.1%, Test_loss:0.206, Lr:1.00E-04
Epoch:17, Train_acc:95.9%, Train_loss:0.115, Test_acc:92.9%, Test_loss:0.237, Lr:1.00E-04
Epoch:18, Train_acc:94.0%, Train_loss:0.145, Test_acc:95.1%, Test_loss:0.166, Lr:1.00E-04
Epoch:19, Train_acc:94.7%, Train_loss:0.158, Test_acc:96.0%, Test_loss:0.143, Lr:1.00E-04
Epoch:20, Train_acc:96.6%, Train_loss:0.114, Test_acc:95.6%, Test_loss:0.176, Lr:1.00E-04
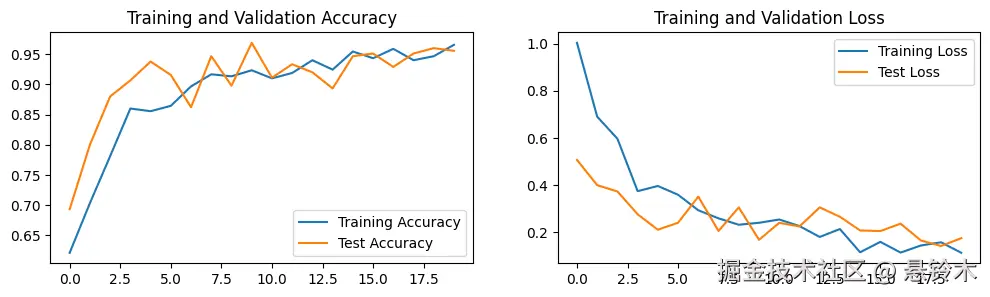
四、 结果可视化
1. Loss与Accuracy图
import matplotlib.pyplot as plt
import warnings
def plot_acc_loss(epoch_acc, epoch_loss):
warnings.filterwarnings("ignore")
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
train_acc, test_acc = epoch_acc
train_loss, test_loss = epoch_loss
epochs_range = range(len(train_acc))
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
plot_acc_loss([adam_train_acc, adam_test_acc], [adam_train_loss, adam_test_loss])
2. 模型评估
adam_best_model.load_state_dict(torch.load("best_model.optim_Adam.pth", map_location=device))
epoch_test_acc, epoch_test_loss = test(test_dl, adam_best_model, loss_fn)
epoch_test_acc, epoch_test_loss
(0.96, 0.20603143105185345)
五、 总结
- 由于对于YOLO v3和v4不了解,直接上手v5,感觉有点吃力。下一阶段需要从YOLO框架最基础的地方开始学习。


