第P8周:YOLOv5-C3模块实现
- 我的环境:
- 操作系统:CentOS7
- 显卡:RTX3090
- 显卡驱动:535.154.05
- CUDA版本: 12.2
- 语言环境:Python3.10
- 编译器:Jupyter Lab
- 深度学习环境:
- torch==12.1
- torchvision==0.18.1
一、前期准备
1. 设置GPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warnings
warnings.filterwarnings("ignore")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
device(type='cuda')
2. 导入数据
import os,PIL,random,pathlib
data_dir = './data/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("/")[1] for path in data_paths]
classeNames
['shine', 'cloudy', 'rain', 'sunrise']
train_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
test_transform = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
total_data = datasets.ImageFolder("./data/",transform=train_transforms)
total_data
Dataset ImageFolder
Number of datapoints: 1125
Root location: ./data/
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=True)
RandomHorizontalFlip(p=0.5)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
total_data.class_to_idx
{'cloudy': 0, 'rain': 1, 'shine': 2, 'sunrise': 3}
3. 划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_dataset, test_dataset
(<torch.utils.data.dataset.Subset at 0x7fa45d68f070>,
<torch.utils.data.dataset.Subset at 0x7fa45d6b7400>)
batch_size = 12
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
Shape of X [N, C, H, W]: torch.Size([12, 3, 224, 224])
Shape of y: torch.Size([12]) torch.int64
二、搭建包含C3模块的模型
1. 搭建模型

import torch.nn.functional as F
def autopad(k, p=None):
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class Bottleneck(nn.Module):
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
class model_K(nn.Module):
def __init__(self):
super(model_K, self).__init__()
self.Conv = Conv(3, 32, 3, 2)
self.C3_1 = C3(32, 64, 3, 2)
self.classifier = nn.Sequential(
nn.Linear(in_features=802816, out_features=100),
nn.ReLU(),
nn.Linear(in_features=100, out_features=4)
)
def forward(self, x):
x = self.Conv(x)
x = self.C3_1(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = model_K().to(device)
model
Using cuda device
model_K(
(Conv): Conv(
(conv): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_1): C3(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(2): Bottleneck(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(classifier): Sequential(
(0): Linear(in_features=802816, out_features=100, bias=True)
(1): ReLU()
(2): Linear(in_features=100, out_features=4, bias=True)
)
)
2. 查看模型详情
import torchsummary as summary
summary.summary(model, (3, 224, 224))
----------------------------------------------------------------
Layer (type) Output Shape Param
================================================================
Conv2d-1 [-1, 32, 112, 112] 864
BatchNorm2d-2 [-1, 32, 112, 112] 64
SiLU-3 [-1, 32, 112, 112] 0
Conv-4 [-1, 32, 112, 112] 0
Conv2d-5 [-1, 32, 112, 112] 1,024
BatchNorm2d-6 [-1, 32, 112, 112] 64
SiLU-7 [-1, 32, 112, 112] 0
Conv-8 [-1, 32, 112, 112] 0
Conv2d-9 [-1, 32, 112, 112] 1,024
BatchNorm2d-10 [-1, 32, 112, 112] 64
SiLU-11 [-1, 32, 112, 112] 0
Conv-12 [-1, 32, 112, 112] 0
Conv2d-13 [-1, 32, 112, 112] 9,216
BatchNorm2d-14 [-1, 32, 112, 112] 64
SiLU-15 [-1, 32, 112, 112] 0
Conv-16 [-1, 32, 112, 112] 0
Bottleneck-17 [-1, 32, 112, 112] 0
Conv2d-18 [-1, 32, 112, 112] 1,024
BatchNorm2d-19 [-1, 32, 112, 112] 64
SiLU-20 [-1, 32, 112, 112] 0
Conv-21 [-1, 32, 112, 112] 0
Conv2d-22 [-1, 32, 112, 112] 9,216
BatchNorm2d-23 [-1, 32, 112, 112] 64
SiLU-24 [-1, 32, 112, 112] 0
Conv-25 [-1, 32, 112, 112] 0
Bottleneck-26 [-1, 32, 112, 112] 0
Conv2d-27 [-1, 32, 112, 112] 1,024
BatchNorm2d-28 [-1, 32, 112, 112] 64
SiLU-29 [-1, 32, 112, 112] 0
Conv-30 [-1, 32, 112, 112] 0
Conv2d-31 [-1, 32, 112, 112] 9,216
BatchNorm2d-32 [-1, 32, 112, 112] 64
SiLU-33 [-1, 32, 112, 112] 0
Conv-34 [-1, 32, 112, 112] 0
Bottleneck-35 [-1, 32, 112, 112] 0
Conv2d-36 [-1, 32, 112, 112] 1,024
BatchNorm2d-37 [-1, 32, 112, 112] 64
SiLU-38 [-1, 32, 112, 112] 0
Conv-39 [-1, 32, 112, 112] 0
Conv2d-40 [-1, 64, 112, 112] 4,096
BatchNorm2d-41 [-1, 64, 112, 112] 128
SiLU-42 [-1, 64, 112, 112] 0
Conv-43 [-1, 64, 112, 112] 0
C3-44 [-1, 64, 112, 112] 0
Linear-45 [-1, 100] 80,281,700
ReLU-46 [-1, 100] 0
Linear-47 [-1, 4] 404
================================================================
Total params: 80,320,536
Trainable params: 80,320,536
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 150.06
Params size (MB): 306.40
Estimated Total Size (MB): 457.04
----------------------------------------------------------------
三、训练模型
1. 编写训练函数
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_loss, train_acc = 0, 0
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
2. 编写训练函数
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, test_acc = 0, 0
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
3. 正式训练
import copy
def tran_my_model(train_dl, test_dl, model, loss_fn, optimizer, epochs = 40, out_best_model = "best_model.pth"):
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
lr = optimizer.state_dict()['param_groups'][0]['lr']
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss,
epoch_test_acc*100, epoch_test_loss, lr))
torch.save(model.state_dict(), out_best_model)
return [best_model, train_loss, test_loss, train_acc, test_acc]
model = model_K().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr= 1e-4)
loss_fn = nn.CrossEntropyLoss()
adam_out = tran_my_model(train_dl, test_dl, model, loss_fn, optimizer, epochs = 20, out_best_model = "best_model.optim_Adam.pth")
adam_best_model, adam_train_loss, adam_test_loss, adam_train_acc, adam_test_acc = adam_out
Epoch: 1, Train_acc:76.4%, Train_loss:1.288, Test_acc:82.2%, Test_loss:0.461, Lr:1.00E-04
Epoch: 2, Train_acc:88.0%, Train_loss:0.391, Test_acc:87.1%, Test_loss:0.625, Lr:1.00E-04
Epoch: 3, Train_acc:91.8%, Train_loss:0.292, Test_acc:90.2%, Test_loss:0.365, Lr:1.00E-04
Epoch: 4, Train_acc:94.1%, Train_loss:0.207, Test_acc:91.6%, Test_loss:0.297, Lr:1.00E-04
Epoch: 5, Train_acc:97.1%, Train_loss:0.086, Test_acc:90.2%, Test_loss:0.331, Lr:1.00E-04
Epoch: 6, Train_acc:96.8%, Train_loss:0.108, Test_acc:90.2%, Test_loss:0.363, Lr:1.00E-04
Epoch: 7, Train_acc:97.8%, Train_loss:0.061, Test_acc:88.9%, Test_loss:0.321, Lr:1.00E-04
Epoch: 8, Train_acc:97.7%, Train_loss:0.064, Test_acc:88.4%, Test_loss:0.439, Lr:1.00E-04
Epoch: 9, Train_acc:98.3%, Train_loss:0.042, Test_acc:86.7%, Test_loss:0.436, Lr:1.00E-04
Epoch:10, Train_acc:98.6%, Train_loss:0.042, Test_acc:90.7%, Test_loss:0.365, Lr:1.00E-04
Epoch:11, Train_acc:98.8%, Train_loss:0.041, Test_acc:89.8%, Test_loss:0.396, Lr:1.00E-04
Epoch:12, Train_acc:98.2%, Train_loss:0.108, Test_acc:90.2%, Test_loss:0.354, Lr:1.00E-04
Epoch:13, Train_acc:98.6%, Train_loss:0.037, Test_acc:92.0%, Test_loss:0.275, Lr:1.00E-04
Epoch:14, Train_acc:98.8%, Train_loss:0.037, Test_acc:92.0%, Test_loss:0.308, Lr:1.00E-04
Epoch:15, Train_acc:98.3%, Train_loss:0.054, Test_acc:91.1%, Test_loss:0.365, Lr:1.00E-04
Epoch:16, Train_acc:98.9%, Train_loss:0.040, Test_acc:92.9%, Test_loss:0.297, Lr:1.00E-04
Epoch:17, Train_acc:99.1%, Train_loss:0.023, Test_acc:90.2%, Test_loss:0.450, Lr:1.00E-04
Epoch:18, Train_acc:96.9%, Train_loss:0.110, Test_acc:90.2%, Test_loss:0.460, Lr:1.00E-04
Epoch:19, Train_acc:98.9%, Train_loss:0.035, Test_acc:88.4%, Test_loss:0.536, Lr:1.00E-04
Epoch:20, Train_acc:98.9%, Train_loss:0.024, Test_acc:88.9%, Test_loss:0.651, Lr:1.00E-04
model = model_K().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr= 1e-4)
loss_fn = nn.CrossEntropyLoss()
sgd_out = tran_my_model(train_dl, test_dl, model, loss_fn, optimizer, epochs = 20, out_best_model = "best_model.optim_SGD.pth")
sgd_best_model, sgd_train_loss, sgd_test_loss, sgd_train_acc, sgd_test_acc = sgd_out
Epoch: 1, Train_acc:73.0%, Train_loss:0.759, Test_acc:75.6%, Test_loss:0.625, Lr:1.00E-04
Epoch: 2, Train_acc:85.9%, Train_loss:0.466, Test_acc:80.4%, Test_loss:0.523, Lr:1.00E-04
Epoch: 3, Train_acc:87.6%, Train_loss:0.400, Test_acc:82.7%, Test_loss:0.474, Lr:1.00E-04
Epoch: 4, Train_acc:87.3%, Train_loss:0.370, Test_acc:82.2%, Test_loss:0.460, Lr:1.00E-04
Epoch: 5, Train_acc:89.2%, Train_loss:0.350, Test_acc:85.8%, Test_loss:0.422, Lr:1.00E-04
Epoch: 6, Train_acc:91.6%, Train_loss:0.300, Test_acc:84.9%, Test_loss:0.408, Lr:1.00E-04
Epoch: 7, Train_acc:92.7%, Train_loss:0.257, Test_acc:84.9%, Test_loss:0.406, Lr:1.00E-04
Epoch: 8, Train_acc:93.8%, Train_loss:0.243, Test_acc:84.0%, Test_loss:0.385, Lr:1.00E-04
Epoch: 9, Train_acc:93.9%, Train_loss:0.233, Test_acc:87.1%, Test_loss:0.357, Lr:1.00E-04
Epoch:10, Train_acc:94.4%, Train_loss:0.219, Test_acc:88.0%, Test_loss:0.344, Lr:1.00E-04
Epoch:11, Train_acc:94.8%, Train_loss:0.205, Test_acc:87.1%, Test_loss:0.354, Lr:1.00E-04
Epoch:12, Train_acc:96.7%, Train_loss:0.178, Test_acc:87.6%, Test_loss:0.354, Lr:1.00E-04
Epoch:13, Train_acc:96.0%, Train_loss:0.168, Test_acc:86.7%, Test_loss:0.332, Lr:1.00E-04
Epoch:14, Train_acc:96.1%, Train_loss:0.166, Test_acc:89.3%, Test_loss:0.314, Lr:1.00E-04
Epoch:15, Train_acc:96.8%, Train_loss:0.155, Test_acc:89.3%, Test_loss:0.321, Lr:1.00E-04
Epoch:16, Train_acc:97.6%, Train_loss:0.140, Test_acc:87.1%, Test_loss:0.347, Lr:1.00E-04
Epoch:17, Train_acc:97.8%, Train_loss:0.125, Test_acc:87.6%, Test_loss:0.330, Lr:1.00E-04
Epoch:18, Train_acc:97.8%, Train_loss:0.127, Test_acc:89.8%, Test_loss:0.300, Lr:1.00E-04
Epoch:19, Train_acc:97.7%, Train_loss:0.123, Test_acc:87.6%, Test_loss:0.326, Lr:1.00E-04
Epoch:20, Train_acc:98.0%, Train_loss:0.123, Test_acc:86.7%, Test_loss:0.311, Lr:1.00E-04
四、结果可视化
1. Loss与Accuracy图
import matplotlib.pyplot as plt
import warnings
def plot_acc_loss(epoch_acc, epoch_loss):
warnings.filterwarnings("ignore")
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
train_acc, test_acc = epoch_acc
train_loss, test_loss = epoch_loss
epochs_range = range(len(train_acc))
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
plot_acc_loss([adam_train_acc, adam_test_acc], [adam_train_loss, adam_test_loss])
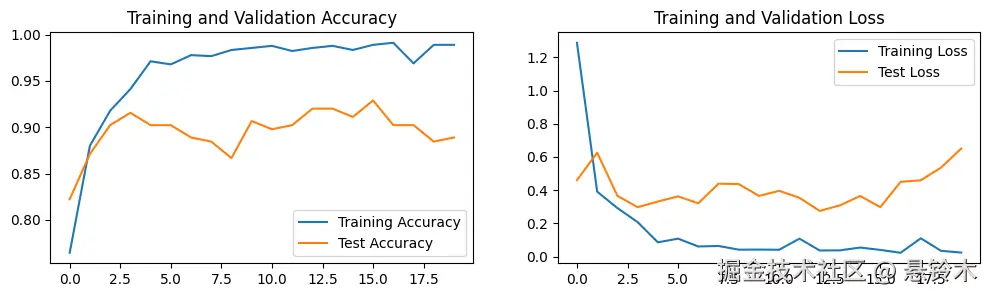
plot_acc_loss([sgd_train_acc, sgd_test_acc], [sgd_train_loss, sgd_test_loss])

五、总结
- YOLO:“You Only Look Once”
- 当优化器改为 SGD 后,并无显著改变


