

TensorFlow 深度学习入门指南(五)
十二、自编码器
假设机器学习是一块蛋糕,强化学习是蛋糕上的樱桃,监督学习是外面的糖衣,无监督学习是蛋糕本身。
—杨乐存
前面我们介绍了给定样本及其相应标签的神经网络学习算法。这类算法实际上是学习给定样本 x 的条件概率 P ( y | x )。在社交网络蓬勃发展的今天,获取海量样本数据 x 相对容易,比如照片、语音、文字,但难点在于获取这些数据对应的标签信息。例如,除了收集源语言文本,机器翻译还需要要翻译的目标语言文本数据。数据标注主要基于人类的先验知识。比如亚马逊的 Mechanical Turk 系统负责数据标注,从全球招募兼职人员完成客户数据标注任务。深度学习需要的数据规模一般都很大。这种严重依赖手工数据注释的方法非常昂贵,并且不可避免地引入了注释者的主观偏见。
对于海量的未标注数据,有没有办法从中学习到数据分布 P ( x )?这就是我们将在本章介绍的无监督学习算法。特别是,如果算法将 x 作为监督信号进行学习,这类算法称为自监督学习,本章介绍的自编码器算法就是自监督学习算法的一种。
12.1 自编码器的原理
让我们考虑一下神经网络在监督学习中的作用:
d in 是输入特征向量的长度, d out 是网络输出向量的长度。对于分类问题,网络模型将 中长度 d 的输入特征向量 x 转换为长度d*out的输出向量 o 。这个过程可以认为是一个特征约简过程,将原来的高维输入向量 x 转化为低维变量 o 。降维在机器学习中有着广泛的应用,如文件压缩和数据预处理。最常见的降维算法是主成分分析(PCA),通过对协方差矩阵进行特征分解来获得数据的主要成分,但 PCA 本质上是线性变换,提取特征的能力有限。*
那么是否可以利用神经网络强大的非线性表达能力来学习低维数据表示呢?问题的关键在于,训练神经网络一般需要一个显式的标签数据(或者有监督的信号),而无监督的数据没有额外的标签信息,只有数据 x 本身。
所以我们尝试用数据 x 本身作为监督信号来指导网络的训练,也就是希望神经网络能够学习到映射fθ:x→x。我们把网络 f θ 分成两部分。第一个子网尝试学习映射关系:,后一个子网尝试学习映射关系
,如图 12-1 所示。我们认为
是将高维输入 x 编码成低维隐变量 z (潜变量或隐变量)的数据编码过程,称为编码器网络。
被认为是数据解码的过程,将编码后的输入 z 解码成高维的 x ,称为解码器网络。
图 12-1
自编码器模型
编码器和解码器共同完成输入数据 x 的编码和解码过程。我们将整个网络模型fθ简称为自编码器。如果使用深度神经网络来参数化和
函数,则称为深度自编码器,如图 12-2 所示。
图 12-2
使用神经网络参数化的自编码器
自编码器可以将输入转换为隐藏向量 z ,通过解码器重构。我们希望解码器的输出能够完美地或者近似地恢复原始输入,也就是
,那么自编码器的优化目标可以写成:
其中代表 x 和
之间的距离测量,称为重建误差函数。最常见的测量方法是欧几里德距离的平方。计算方法如下:
原则上它等同于均方误差。自编码器网络和普通的神经网络没有本质区别,只是训练好的监督信号从标签 y 变成了自己的 x 。借助于深度神经网络的非线性特征提取能力,自编码器可以获得良好的数据表示,例如,比原始输入数据更小尺寸和维度的数据表示。这对数据和信息压缩非常有用。与 PCA 等线性方法相比,自编码器具有更好的性能,甚至可以更完美地恢复输入 x 。
在图 12-3(a) 中,第一行是从测试集中随机采样的真实 MNIST 手写数字图片,第二、第三和第四行分别使用自编码器、逻辑 PCA 和标准 PCA,使用长度为 30 的隐藏向量进行重建。在图 12-3(b) 中,第一行是真实的肖像图像,第二和第三行是基于长度为 30 的隐藏向量,使用自编码器和标准 PCA 算法恢复。可以看出,自编码器重建的图像比较清晰,复原程度高,而 PCA 算法重建的图像比较模糊。
图 12-3
自锚对 PCA [1]
12.2 亲身实践时尚 MNIST 形象重建
自编码器算法的原理非常简单,易于实现,并且训练稳定。与 PCA 算法相比,神经网络强大的表达能力可以学习输入的高层抽象隐藏特征向量 z ,也可以基于 z 重构输入。这里,我们基于时尚 MNIST 数据集执行实际的图片重建。
12.2.1 时尚 MNIST 数据集
时尚 MNIST 是一个比 MNIST 图像识别稍微复杂一点的数据集。它的环境几乎和 MNIST 一样。它包含了十种不同类型的衣服、鞋子、包包的灰度图像,图像大小为 28 × 28,共有 7 万张图片,其中 6 万张用于训练集,1 万张用于测试集,如图 12-4 所示。每一行都是一类图片。正如你所看到的,时尚 MNIST 有相同的设置,除了图片内容不同于 MNIST。大多数情况下,基于 MNIST 的原算法代码可以直接替换,无需额外修改。由于时尚 MNIST 图像识别比 MNIST 图像识别更困难,因此它可以用于测试稍微复杂一些的算法的性能。
图 12-4
时尚 MNIST 数据集
在 TensorFlow 中,加载时尚 MNIST 数据集也非常方便,可以使用 keras . datasets . Fashion _ mnist . load _ data()函数在线下载、管理和加载,如下所示:
# Load Fashion MNIST data set
(x_train, y_train), (x_test, y_test) = keras.datasets.fashion_mnist.load_data()
# Normalize
x_train, x_test = x_train.astype(np.float32) / 255., x_test.astype(np.float32) / 255.
# Only need to use image data to build data set objects, no tags required
train_db = tf.data.Dataset.from_tensor_slices(x_train)
train_db = train_db.shuffle(batchsz * 5).batch(batchsz)
# Build test set objects
test_db = tf.data.Dataset.from_tensor_slices(x_test)
test_db = test_db.batch(batchsz)
编码器
我们使用编码器将输入图片 x ∈ R 784 降维为更低维的隐藏向量 h ∈ R 20 ,使用解码器基于隐藏向量 h 重构图片。自编码器型号如图 12-5 所示。解码器由一个 3 层全连接网络组成,输出节点分别为 256、128 和 20。解码器也由三层全连接网络组成,输出节点分别为 128、256 和 784。
图 12-5
时尚 MNIST 自编码器网络架构
首先是编码器子网络的实现。使用三层神经网络将图像向量的维数从 784 降低到 256,128,并最终降低到 h_dim。每一层都使用 ReLU 激活函数,最后一层不使用任何激活函数。
# Create Encoders network, implemented in the initialization function of the autoencoder class
self.encoder = Sequential([
layers.Dense(256, activation=tf.nn.relu),
layers.Dense(128, activation=tf.nn.relu),
layers.Dense(h_dim)
])
解码器
让我们创建解码器子网。这里隐藏向量 h_dim 依次升级到 128、256、784 的长度。除了最后一层,使用 ReLU 激活功能。解码器的输出是一个长度为 784 的向量,它代表展平后的 28 × 28 大小的图片,可以通过整形操作恢复为图片矩阵,如下所示:
# Create Decoders network
self.decoder = Sequential([
layers.Dense(128, activation=tf.nn.relu),
layers.Dense(256, activation=tf.nn.relu),
layers.Dense(784)
])
自编码器
前面两个编码器和解码器的子网是在 autoencoder 类 AE 中实现的,我们同时在初始化函数中创建这两个子网。
class AE(keras.Model):
# Self-encoder model class, including Encoder and Decoder 2 subnets
def __init__(self):
super(AE, self).__init__()
# Create Encoders network
self.encoder = Sequential([
layers.Dense(256, activation=tf.nn.relu),
layers.Dense(128, activation=tf.nn.relu),
layers.Dense(h_dim)
])
# Create Decoders network
self.decoder = Sequential([
layers.Dense(128, activation=tf.nn.relu),
layers.Dense(256, activation=tf.nn.relu),
layers.Dense(784)
])
接下来,在调用函数中实现正向传播过程。输入图像首先通过编码器子网络获得隐向量 h,然后通过解码器获得重构图像。只需如下依次调用编码器和解码器的正向传播函数:
def call(self, inputs, training=None):
# Forward propagation function
# Encoding to obtain hidden vector h,[b, 784] => [b, 20]
h = self.encoder(inputs)
# Decode to get reconstructed picture, [b, 20] => [b, 784]
x_hat = self.decoder(h)
return x_hat
网络培训
自编码器的训练过程基本上与分类器的训练过程相同。通过误差函数计算重构向量与原始输入向量 x 之间的距离,然后利用 TensorFlow 的自动求导机制同时计算编码器和解码器的梯度。
首先,创建一个 autoencoder 和 optimizer 的实例,并设置一个适当的学习速率。例如:
# Create network objects
model = AE()
# Specify input size
model.build(input_shape=(4, 784))
# Print network information
model.summary()
# Create an optimizer and set the learning rate
optimizer = optimizers.Adam(lr=lr)
这里训练 100 个历元,每次通过正演计算得到重建图像向量,使用 TF . nn . sigmoid _ cross _ entropy _ with _ logits 损失函数计算重建图像与原始图像之间的直接误差。事实上,使用 MSE 误差函数也是可行的,如下所示:
for epoch in range(100): # Train 100 Epoch
for step, x in enumerate(train_db): # Traverse the training set
# Flatten, [b, 28, 28] => [b, 784]
x = tf.reshape(x, [-1, 784])
# Build a gradient recorder
with tf.GradientTape() as tape:
# Forward calculation to obtain the reconstructed picture
x_rec_logits = model(x)
# Calculate the loss function between the reconstructed picture and the input
rec_loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=x, logits=x_rec_logits)
# Calculate the mean
rec_loss = tf.reduce_mean(rec_loss)
# Automatic derivation, including the gradient of 2 sub-networks
grads = tape.gradient(rec_loss, model.trainable_variables)
# Automatic update, update 2 subnets at the same time
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 100 ==0:
# Interval print training error
print(epoch, step, float(rec_loss))
图像重建
与分类问题不同,自编码器的模型性能通常不容易量化。虽然 L 值在一定程度上可以代表网络的学习效果,但我们最终还是希望获得还原程度更高、风格更丰富的重构样本。因此,通常需要根据具体问题来讨论自编码器的学习效果。对于图像重建,它通常取决于对图像生成的人工主观评价的质量,或者使用某些图像保真度计算方法,如初始得分和 Frechet 初始距离。
为了测试图像重建的效果,我们将数据集分为训练集和测试集,其中测试集不参与训练。我们从测试集中随机抽取测试图片x∈Dtest,通过自编码器计算重建图片,然后将真实图片和重建图片保存为图片数组并可视化,以便于比较,如下所示:
# Reconstruct pictures, sample a batch of pictures from the test set
x = next(iter(test_db))
logits = model(tf.reshape(x, [-1, 784])) # Flatten and send to autoencoder
x_hat = tf.sigmoid(logits) # Convert the output to pixel values, using the sigmoid function
# Recover to 28x28,[b, 784] => [b, 28, 28]
x_hat = tf.reshape(x_hat, [-1, 28, 28])
# The first 50 input + the first 50 reconstructed pictures merged, [b, 28, 28] => [2b, 28, 28]
x_concat = tf.concat([x[:50], x_hat[:50]], axis=0)
x_concat = x_concat.numpy() * 255\. # Revert to 0~255 range
x_concat = x_concat.astype(np.uint8) # Convert to integer
save_images(x_concat, 'ae_images/rec_epoch_%d.png'%epoch) # Save picture
图像重建的效果如图 12-6 ,图 12-7 ,图 12-8 所示。每张图片左边的五列是实景图,右边的五列是对应的重建图。可以看出,在第一个历元,画面重建效果差,画面非常模糊,保真度差。随着训练的进行,重建图片的边缘越来越清晰。在第 100 个时期,重建的图像效果已经更接近真实图像。
图 12-8
第一百个纪元
图 12-7
第十纪元
图 12-6
第一纪元
这里的 save_images 函数负责合并多张图片,保存为大图。这是使用 PIL 图片库完成的。代码如下:
def save_images(imgs, name):
# Create 280x280 size image array
new_im = Image.new('L', (280, 280))
index = 0
for i in range(0, 280, 28): # 10-row image array
for j in range(0, 280, 28): # 10-column picture array
im = imgs[index]
im = Image.fromarray(im, mode='L')
new_im.paste(im, (i, j)) # Write the corresponding location
index += 1
# Save picture array
new_im.save(name)
12.3 自组装变体
总的来说,autoencoder 网络的训练相对稳定,但由于损失函数直接衡量重建样本与真实样本底层特征之间的距离,而不是评估重建样本的保真度和多样性等抽象指标,因此在一些任务上的效果很一般,例如重建图像边缘容易模糊的图像重建,保真度与真实图像相比并不好。为了学习数据的真实分布,产生了一系列自编码器变体网络:去噪自编码器。
为了防止神经网络记住输入数据的底层特征,去噪自编码器将随机噪声干扰添加到输入数据,例如将从高斯分布采样的噪声 ε 添加到输入 x :
加入噪声后,网络需要从 x 中学习数据的真实隐变量 z ,还原原始输入 x ,如图 12-9 所示。该模型的优化目标是:
图 12-9
去噪自编码器图
12.3.1 压差自编码器
自编码器网络也面临过拟合的风险。Dropout autoencoder 通过随机断开网络来降低网络的表达能力,并防止过拟合。dropout autoencoder 的实现非常简单。可以通过在网络层中插入脱落层来实现网络连接的随机断开。
12.3.2 敌方自锚
为了能够方便地从一个已知的先验分布 p ( z 中采样隐变量 z ,可以方便地使用 p ( z )来重构输入,对抗自编码器使用一个附加的鉴别器网络(discriminator,简称 D 网络)来确定降维的隐变量 z 是否是从先验分布 p ( 中采样的鉴别器网络的输出是一个属于区间[0,1]的变量,代表隐向量是否从先验分布 p ( z )中采样:所有来自先验分布 p ( z )的样本标记为真,由条件概率q*(z|x产生的样本标记为假。这样,除了重构样本,还可以约束条件概率分布 q ( x )来近似先验分布 p ( z )。*
图 12-10
对手自编自编自编自编自编自编自编自编自编自编自编自编自编自编自编自编自编自编自演
对抗式自编码器由下一章介绍的生成式对抗网络算法衍生而来。学习完对抗性生成网络后,可以加深对对抗性自编码器的理解。
12.4 可变自编码器
基本的自编码器本质上学习输入 x 和隐藏变量 z 之间的映射关系。这是一个判别模型,而不是一个生成模型。那么 autoencoder 可以调整到创成式模型来轻松生成样本吗?
已知隐变量的分布 P ( z ),如果条件概率分布 P ( z ),那么我们就可以对联合概率分布 P ( x ,z)=P(z)P(z)进行采样变型自编码器(VAE)可以实现这一目标,如图 12-11 所示。如果从神经网络的角度来理解,VAE 和之前的自编码器是一样的,非常直观,容易理解;但是 VAE 的理论推导有点复杂。接下来,我们先从神经网络的角度解释 VAE,再从概率的角度推导 VAE。
图 12-11
VAE 模型结构
从神经网络的角度来看,与自编码器模型相比,VAE 还有编码器和解码器两个子网络。解码器接受输入 x,输出是潜变量 z;解码器负责将隐变量 z 解码成重构的 x,不同的是,VAE 模型对隐变量 z 的分布有显式约束,希望隐变量 z 符合预设的先验分布 P(z)。因此,在损失函数的设计中,除了原有的重构误差项之外,还增加了对隐变量 z 分布的约束项。
VAE 原则
从概率的角度来说,我们假设任何一个数据集都是从某个分布 p ( x | z )中抽样得到的; z 是隐藏变量,代表某种内部特征,比如手写数字的图片x; z 可以表示字体大小、书写风格、粗体、斜体等设置,符合一定的先验分布 p ( z )。给定一个特定的隐藏变量 z ,我们可以从学习到的分布p(x|z)中抽取一系列样本。这些样本都具有以 z 为代表的共性。
通常假设 p ( z )遵循一个已知的分布,比如 N (0,1)。在 p ( z )已知的情况下,我们的目标是学习到一个生成概率模型p(x|z)。这里可以使用最大似然估计法:一个好的模型应该有很高的概率产生真实样本 x ∈ D 。如果我们的生成模型p(x|z)用 θ 参数化,那么我们神经网络的优化目标就是:
遗憾的是,由于 z 是连续变量,前面的积分无法转化为离散形式,很难直接优化。
另一种思路是利用变分推理的思想,我们通过分布qϕ(x)来近似 p ( z | x ,也就是我们需要最小化q**(x)和 p 之间的距离
*KL 散度 D KL 是分布 q 和 p 之间差距的度量,定义为:
严格来说,距离一般是对称的,而 KL 散度是不对称的。将 KL 发散展开为:
使用
得到
我们将定义为 L ( ϕ , θ ),那么前面的等式就变成:
其中
考虑
我们有
换句话说, L ( ϕ , θ )是 loglog p ( x )的下界,优化目标 L ( ϕ , θ )称为证据下界目标(ELBO)。我们的目标是最大化似然概率 p ( x ),或者最大化 loglog p ( x ),可以通过最大化其下界 L ( ϕ , θ )来实现。
现在我们来分析一下如何最大化 L ( ϕ , θ )函数,并将其展开得到:
所以,
(12-1)
可以用编码器网络参数化qϕ(x)函数,解码器网络参数化pθ(z)函数。目标函数 L ( θ , ϕ )可以通过计算解码器q**(x)的输出分布与先验分布 p ( z )之间的 KL 散度,以及似然概率 loglog p )来优化
特别是当q*ϕ(x)和 p ( z )都假定为正态分布时,dKL(qϕ(x)的计算
更具体地说,当qϕ(x)为正态分布 N ( μ 1 , σ 1 , p ( z )为正态分布 N (0,1),即
前面的过程使得dKL(qϕ(x)p(z)l(θ, ϕ )中的项更容易计算,而 E
因此,VAE 模型的优化目标由最大化 L ( ϕ , θ )函数转化为:
还有
第一个优化目标可以理解为约束潜变量 z 的分布,第二个优化目标可以理解为提高网络的重构效果。可以看出,经过我们的推导,VAE 模型也非常直观,易于理解。
重新参数化技巧
现在考虑在实施上述 VAE 模型时遇到的一个严重问题。从编码器的输出qϕ(x)中采样隐变量 z ,如图 12-12 左图所示。当qϕ(x)和 p ( z )均假定为正态分布时,编码器输出正态分布的均值 μ 和方差 σ 2 ,解码器的输入从 N ( 采样由于采样操作的存在,梯度传播是不连续的,VAE 网络不能通过梯度下降算法进行端到端的训练。
图 12-12
重新参数化技巧图
文献[2]提出了一种连续可导的解决方案,称为重新参数化技巧。它通过z=μ+σ⊙ε对隐变量 z 进行采样,其中和
都是连续且可微的,从而连接梯度传播。如图 12-12 右图所示, ε 变量是从标准正态分布 N (0,I)μ和 σ 由编码器网络产生。采样后的隐变量可以通过z=μ+σ⊙ε得到,保证了梯度传播的连续性。
VAE 网络模型如图 12-13 所示,输入 x 通过编码器网络qϕ(x)计算得到隐变量 z 的均值和方差,隐变量 z 通过重新参数化的技巧方法采样得到,送到解码器网络得到分布(
图 12-13
VAE 建筑模型
12.5 VAE 图像重建实践
在这一部分,我们将基于 VAE 模型重建和生成时尚 MNIST 图片。如图 12-13 所示,输入的是时尚 MNIST 图片矢量。三个全连接层后,得到隐向量 z 的均值和方差,用两个全连接层 20 个输出节点表示。FC2 的 20 个输出节点代表 20 个特征分布的均值向量 μ ,FC3 的 20 个输出节点代表 20 个特征分布的对数方差向量。通过重新参数化技巧采样获得长度为 20 的隐藏向量 z ,通过 FC4 和 FC5 重构样本图像。
作为一种生成模型,VAE 不仅可以重构输入样本,还可以单独使用解码器来生成样本。隐向量 z 由先验分布 p ( z )直接采样得到,生成的样本可以解码后生成。
图 12-14
VAE 建筑模型
VAE 模型
我们实现了 VAE 类别的编码器和解码器子网络。在初始化函数中,我们分别创建编码器和解码器所需的网络层,如下所示:
class VAE(keras.Model):
# Variational Encoder
def __init__(self):
super(VAE, self).__init__()
# Encoder
self.fc1 = layers.Dense(128)
self.fc2 = layers.Dense(z_dim) # output mean
self.fc3 = layers.Dense(z_dim) # output variance
# Decoder
self.fc4 = layers.Dense(128)
self.fc5 = layers.Dense(784)
编码器的输入首先经过共享层 FC1,然后分别经过 FC2 和 FC3 网络,得到隐向量分布的均值向量和方差的对数向量值。
def encoder(self, x):
# Get mean and variance
h = tf.nn.relu(self.fc1(x))
# Mean vector
mu = self.fc2(h)
# Log of variance
log_var = self.fc3(h)
return mu, log_var
解码器接受采样后的隐藏向量 z ,解码成图片输出。
def decoder(self, z):
# Generate image data based on hidden variable z
out = tf.nn.relu(self.fc4(z))
out = self.fc5(out)
# Return image data, 784 vector
return out
在 VAE 的正向计算过程中,首先由编码器获得输入的潜在向量 z 的分布,然后通过采样由重新参数化技巧实现的重新参数化函数获得潜在向量 z ,最后由解码器恢复重建的图像向量。实现如下:
def call(self, inputs, training=None):
# Forward calculation
# Encoder [b, 784] => [b, z_dim], [b, z_dim]
mu, log_var = self.encoder(inputs)
# Sampling - reparameterization trick
z = self.reparameterize(mu, log_var)
# Decoder
x_hat = self.decoder(z)
# Return sample, mean and log variance
return x_hat, mu, log_var
重新参数化技巧
reparameterize 函数接受均值和方差参数,通过从正态分布 N (0, I 采样得到 ε ,通过z=μ+σ⊙ε返回采样后的隐藏向量。
def reparameterize(self, mu, log_var):
# reparameterize trick
eps = tf.random.normal(log_var.shape)
# calculate standard variance
std = tf.exp(log_var)**0.5
# reparameterize trick
z = mu + std * eps
return z
网络培训
网络训练 100 个历元,每次重建样本由 VAE 模型正演计算得到。重建误差项Ez~q[log log pθ(z)】是基于交叉熵损失函数计算的。误差项dKL(qϕ(x)‖p(z))根据式(12-2)计算。
# Create network objects
model = VAE()
model.build(input_shape=(4, 784))
# Optimizer
optimizer = optimizers.Adam(lr)
for epoch in range(100): # Train 100 Epochs
for step, x in enumerate(train_db): # Traverse the training set
# Flatten, [b, 28, 28] => [b, 784]
x = tf.reshape(x, [-1, 784])
# Build a gradient recorder
with tf.GradientTape() as tape:
# Forward calculation
x_rec_logits, mu, log_var = model(x)
# Reconstruction loss calculation
rec_loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=x, logits=x_rec_logits)
rec_loss = tf.reduce_sum(rec_loss) / x.shape[0]
# Calculate KL convergence N(mu, var) VS N(0, 1)
# Refernece:https://stats.stackexchange.com/questions/7440/kl-divergence-between-two-univariate-gaussians
kl_div = -0.5 * (log_var + 1 - mu**2 - tf.exp(log_var))
kl_div = tf.reduce_sum(kl_div) / x.shape[0]
# Combine error
loss = rec_loss + 1\. * kl_div
# Calculate gradients
grads = tape.gradient(loss, model.trainable_variables)
# Update parameters
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 100 == 0:
# Print error
print(epoch, step, 'kl div:', float(kl_div), 'rec loss:', float(rec_loss))
图像生成
图像生成仅使用解码器网络。首先从先验分布 N (0, I 中采样隐藏向量,然后通过解码器得到图像向量,最后整形为图像矩阵。例如:
# Test generation effect, randomly sample z from normal distribution
z = tf.random.normal((batchsz, z_dim))
logits = model.decoder(z) # Generate pictures only by decoder
x_hat = tf.sigmoid(logits) # Convert to pixel range
x_hat = tf.reshape(x_hat, [-1, 28, 28]).numpy() *255.
x_hat = x_hat.astype(np.uint8)
save_images(x_hat, 'vae_images/epoch_%d_sampled.png'%epoch) # Save pictures
# Reconstruct the picture, sample pictures from the test set
x = next(iter(test_db))
logits, _, _ = model(tf.reshape(x, [-1, 784])) # Flatten and send to autoencoder
x_hat = tf.sigmoid(logits) # Convert output to pixel value
# Restore to 28x28,[b, 784] => [b, 28, 28]
x_hat = tf.reshape(x_hat, [-1, 28, 28])
# The first 50 input + the first 50 reconstructed pictures merged, [b, 28, 28] => [2b, 28, 28]
x_concat = tf.concat([x[:50], x_hat[:50]], axis=0)
x_concat = x_concat.numpy() * 255.
x_concat = x_concat.astype(np.uint8)
save_images(x_concat, 'vae_images/epoch_%d_rec.png'%epoch)
图片重建的效果如图 12-15 、图 12-16 和图 12-17 所示,分别显示了输入第一、第十和第 100 个历元的测试集图片得到的重建效果。每张图片左边五列是实拍图,右边五列是对应的重建效果。图像生成的效果如图 12-18 、图 12-19 和图 12-20 所示,分别显示了第一个、第十个和第 100 个历元的图像生成效果。
图 12-20
图像生成:纪元=100
图 12-19
图像生成:纪元=10
图 12-18
图像生成:纪元=1
图 12-17
图像重建:epoch=100
图 12-16
图像重建:epoch=10
图 12-15
图像重建:epoch=1
可以看出,图像重建的效果略好于图像生成,这也说明图像生成是一项更复杂的工作。虽然 VAE 模型具有生成图像的能力,但生成的效果仍然不够好,人眼仍然可以区分机器生成的图片样本和真实图片样本之间的差异。下一章将要介绍的生成式对抗网络在图像生成方面表现更好。
12.6 摘要
在这一章中,我们介绍了强大的自我监督学习算法——自编码器及其变体。我们从自编码器的原理开始,以便理解它的数学机制,然后我们通过时尚 MNIST 图像重建练习完成自编码器的实际实现。按照类似的步骤,讨论了 VAE 模型,并将其应用于时尚 MNIST 图像数据集,以演示图像生成过程。在开发机器学习或深度学习模型时,一个常见的挑战是输入数据的高维度。与传统的降维方法(例如 PCA)相比,自编码器及其变体通常在以较低的维度和大小生成数据表示方面具有更好的性能。
12.7 参考
-
G.E. Hinton,“用神经网络降低数据的维数”,2008 年。
-
D.P. Kingma 和 M. Welling,“自编码变分贝叶斯”,第二届学习表示国际会议,2014 年,ICLR,班夫,AB,加拿大,2014 年 4 月 14-16 日,会议记录,2014 年。**
十三、生成对抗网络
我不能创造的,我还没有完全理解。
理查德·费曼
在生成对抗网络(GAN)发明之前,变分自编码器被认为是理论上完整且实现简单的。使用神经网络训练时非常稳定,得到的图像更加近似,但人眼仍然可以轻松区分真实图片和机器生成的图片。
2014 年,蒙特利尔大学 yo shua beng io(2018 年图灵奖获得者)的学生 Ian Goodfellow 提出了 GAN [1],开启了深度学习最热门的研究方向之一。2014-2019 年,GAN 研究稳步推进,研究成果捷报频传。最新的 GAN 算法在图像生成上的效果已经达到了肉眼难以分辨的程度,实在令人兴奋。由于 GAN 的发明,Ian Goodfellow 被授予 GAN 之父的称号,并于 2017 年被麻省理工学院评论授予 35 名 35 岁以下创新者奖。图 13-1 从 2014 年到 2018 年,GAN 模型达到了书代的效果。可以看出,无论是画面的大小,还是画面的保真度,都有了很大的提升。 1
图 13-1
2014 年至 2018 年 GAN 生成图像效果
接下来我们就从生活中的游戏学习这个例子开始,一步步的介绍 GAN 算法的设计思路和模型结构。
13.1 游戏学习的例子
我们用一个漫画家的成长轨迹来形象地介绍甘的想法。考虑一对双胞胎兄弟,分别叫 G 和 D,G 学习如何画漫画,D 学习如何欣赏画作。两兄弟在很小的时候就学会了如何使用画笔和纸张。g 画了一幅不知名的画,如图 13-2(a) 。这个时候 D 的辨别能力不高,所以 D 觉得 G 的作品还可以,只是主角不够清晰。在 D 的指导和鼓励下,G 开始学习如何画出主体的轮廓,使用简单的色彩组合。
一年后,G 提高了绘画基本功,D 也初步掌握了通过分析名作和 G 的作品来鉴别作品的能力,此时 D 觉得 G 的作品有了主要人物,如图 13-2(b) ,但对色彩的运用还不够成熟。几年后,G 的绘画基本功已经非常扎实,可以轻松地画出主题鲜明、色彩搭配恰当、逼真度高的画作,如图 13-2(c) 所示,但 D 也观察到了 G 与其他名作的差异,提高了辨别画作的能力。这时 D 觉得 G 的绘画技巧已经成熟,但是对生活的观察还不够。g 的作品没有传达出表情,一些细节也不完美。又过了几年,G 的画技已经到了炉火纯青的地步。画作细节完美,风格迥异,栩栩如生,宛如大师级,如图 13-2(d) 。即使在这个时候,D 的辨别能力也是相当出色的。D 也很难区分 G 和其他大作。
上述画家的成长过程,其实就是一个生活中共同的学习过程,通过双方的学习和相互提高的博弈,最终达到一个平衡点。GAN 网络借鉴了游戏学习的思想,设置了两个子网络:负责生成样本的生成器 G 和负责认证的鉴别器 D。鉴别器 D 通过观察真实样本和发生器 G 产生的样本之间的差异来学习如何区分真假,其中真实样本为真,发生器 G 产生的样本为假。发电机 G 也在学习。它希望生成的样本能够被鉴别器 D 识别为真。因此,生成器 G 试图使其生成的样本被判别式 D 认为是真的,生成器 G 和判别式 D 相互博弈,共同改进,直到达到一个平衡点。此时发生器 G 产生的样本非常逼真,使得鉴别器 D 难以辨别真假。
图 13-2
画家成长轨迹速写
在最初的 GAN 论文中,Ian Goodfellow 用了另一个生动的比喻来介绍 GAN 模型:生成器网络 G 的作用是生成一系列非常逼真的假钞来试图欺骗鉴别器 D,鉴别器 D 通过学习生成器 G 生成的真钱和假钞的区别来掌握钞票鉴别方法。这两个网络在相互博弈的过程中同步,直到生成器 G 产生的假钞非常真实,连鉴别器 D 都勉强能分辨出来。
这种游戏学习的思想使得 GAN 的网络结构和训练过程与之前的网络模型略有不同。下面我们来详细介绍一下 GAN 的网络结构和算法原理。
13.2 甘原则
现在我们将正式介绍 GAN 的网络结构和训练方法。
网络结构
GAN 包含两个子网络:发生器网络(称为 G)和鉴别器网络(称为 D)。生成器网络 G 负责学习样本的真实分布,而鉴别器网络 D 负责将生成器网络生成的样本与真实样本区分开。
发电机 G ( z )发电机网络 G 类似于自编码器的解码器的作用。隐变量zpz(∙)从先验分布pz(∙)中采样。生成的样本xpG(x|z)由发电机网络 G 的参数化分布pG(x|z得到,如图 13-3 所示隐变量 z 的先验分布pz(∙)可以假设为已知分布,比如多元均匀分布 z ~ 均匀(-1,1)。
图 13-3
发电机 G
pg(x|z)可以通过深度神经网络进行参数化。如图 13-4 所示,从均匀分布pz(∙)中抽取隐变量 z ,然后从pg(x|从输入输出的角度来看,生成器 G 的作用是通过神经网络将隐向量 z 转化为样本向量 x f ,下标 f 代表伪样本。
图 13-4
转置卷积构成的生成网络
鉴频器 D ( x )鉴频器网络的作用类似于普通的二进制分类网络。它接受输入样本 x 的数据集,包括从真实数据分布pr(∙)中采样的样本xr~p*r(∙)以及从发电网络 x 中采样的伪样本 x r 和 x f 共同构成鉴别器网络的训练数据集。鉴别器网络的输出是 x 属于真实样本 P ( x 是真实的 | x )。我们将所有真实样本 x r 标注为真(1),生成网络生成的所有样本 x f 标注为假(0)。鉴频器网络 D 的预测值和标签之间的误差用于优化鉴频器网络参数,如图 13-5 所示。*
图 13-5
发电机网络和鉴别器网络
网络培训
甘游戏学习的思想体现在其训练方法上。由于生成器 G 和鉴别器 D 的优化目标不同,不能和前面的网络模型训练一样,只用一个损失函数。下面我们分别介绍一下如何训练生成器 G 和鉴别器 D。
对于鉴别器网络 D 来说,它的目标是能够区分真样本xr和假样本 x f 。以图片生成为例,其目标是最小化图片的预测值和真实值之间的交叉熵损失函数:
其中Dθ(xr代表判别网络中真实样本的输出xrDθ, θ 为判别网络的参数集, Dθ(xf)是鉴频器网络中生成样本 x f 的输出, y 是 x r 的标签。 因为真实样本被标注为真实,所以yr= 1。 y f 是生成样本的*f的标签。由于生成的样本被标注为假,yf= 0。CE 函数表示交叉熵损失函数 CrossEntropy。两个分类问题的交叉熵损失函数定义为:*
*因此,鉴频器网络 D 的优化目标是:
将 L 转换为 L ,并将其写在期望表中:
对于发生器网络 G ( z ),我们希望xf=G(z)能够很好地欺骗鉴频器网络 D,使假样本 x f 的输出尽可能接近真实标签。也就是说,在训练发生器网络时,希望鉴频器网络的输出D(G(z))尽可能接近 1,并使D(G(z))与 1 之间的交叉熵损失函数最小:
将 L 转换为 L ,并将其写在期望表中:
它可以等效地转化为:
其中 ϕ 是发电机网络 g 的参数集,可以用梯度下降算法来优化参数 ϕ 。
统一的目标函数
我们可以合并生成器和鉴别器网络的目标函数,并将其写成最小-最大博弈的形式:
(13-1)
算法如下:
| **算法 1:GAN 训练算法** | | 随机初始化参数 ***θ和ϕ*****重复****为** k 次**做**随机采样隐藏向量***z ~ p******z***(***∙***)随机抽取真实样本***x******r******~ p******r***(**)** **根据梯度下降算法更新三维网络:随机采样隐藏向量z ~ pz(∙)
根据梯度下降算法更新 G 网络:
结束于
直到训练轮数达到要求
输出:受训发电机gϕ** |
13.3 动手 DCGAN
在本节中,我们将完成卡通化身图像的实际生成。参考 DCGAN [2]的网络结构,其中鉴别器 D 由普通卷积层实现,生成器 G 由转置卷积层实现,如图 13-6 。
图 13-6
DCGAN 网络结构
13.3.1 卡通头像数据集
这里我们用的是卡通头像的数据集,总共 51223 张图片,没有标注信息。图片的主体已被裁剪、对齐并统一缩放到 96 × 96 的大小。一些样品如图 13-7 所示。
图 13-7
卡通头像数据集
对于定制数据集,需要自己完成数据加载和预处理工作。我们在这里关注 GAN 算法本身。关于自定义数据集的后续章节将详细介绍如何加载您自己的数据集。这里直接通过预先编写的 make_anime_dataset 函数获取处理后的数据集。
# Dataset path. URL: https://drive.google.com/file/d/1lRPATrjePnX_n8laDNmPkKCtkf8j_dMD/view?usp=sharing
img_path = glob.glob(r'C:\Users\z390\Downloads\faces\*.jpg')
# Create dataset object, return Dataset class and size
dataset, img_shape, _ = make_anime_dataset(img_path, batch_size, resize=64)
dataset 对象是 tf.data.Dataset 类的一个实例。已经完成了随机分散、预处理、批处理等操作,可以直接获得样本批次,img_shape 为预处理后的图像大小。
发电机
生成网络 G 由五个转置卷积层叠加而成,以实现特征图高度和宽度的逐层放大和特征图通道数的逐层减少。首先通过整形操作将长度为 100 的隐向量 z 调整为一个[ b ,1,1,100]的四维张量,并对卷积层进行转置,以便放大高度和宽度维度,减少通道数,最终得到宽度为 64,通道数为 3 的彩色图片。在每个卷积层之间插入一个 BN 层以提高训练稳定性,卷积层选择不使用偏置向量。生成器类代码实现如下:
class Generator(keras.Model):
# Generator class
def __init__(self):
super(Generator, self).__init__()
filter = 64
# Transposed convolutional layer 1, output channel is filter*8, kernel is 4, stride is 1, no padding, no bias.
self.conv1 = layers.Conv2DTranspose(filter*8, 4,1, 'valid', use_bias=False)
self.bn1 = layers.BatchNormalization()
# Transposed convolutional layer 2
self.conv2 = layers.Conv2DTranspose(filter*4, 4,2, 'same', use_bias=False)
self.bn2 = layers.BatchNormalization()
# Transposed convolutional layer 3
self.conv3 = layers.Conv2DTranspose(filter*2, 4,2, 'same', use_bias=False)
self.bn3 = layers.BatchNormalization()
# Transposed convolutional layer 4
self.conv4 = layers.Conv2DTranspose(filter*1, 4,2, 'same', use_bias=False)
self.bn4 = layers.BatchNormalization()
# Transposed convolutional layer 5
self.conv5 = layers.Conv2DTranspose(3, 4,2, 'same', use_bias=False)
发电机网络 G 的正向传播实现如下:
def call(self, inputs, training=None):
x = inputs # [z, 100]
# Reshape to 4D tensor:(b, 1, 1, 100)
x = tf.reshape(x, (x.shape[0], 1, 1, x.shape[1]))
x = tf.nn.relu(x) # activation function
# Transposed convolutional layer-BN-activation function:(b, 4, 4, 512)
x = tf.nn.relu(self.bn1(self.conv1(x), training=training))
# Transposed convolutional layer-BN-activation function:(b, 8, 8, 256)
x = tf.nn.relu(self.bn2(self.conv2(x), training=training))
# Transposed convolutional layer-BN-activation function:(b, 16, 16, 128)
x = tf.nn.relu(self.bn3(self.conv3(x), training=training))
# Transposed convolutional layer-BN-activation function:(b, 32, 32, 64)
x = tf.nn.relu(self.bn4(self.conv4(x), training=training))
# Transposed convolutional layer-BN-activation function:(b, 64, 64, 3)
x = self.conv5(x)
x = tf.tanh(x) # output x range -1~1
return x
生成的网络输出大小为[ b ,64,64,3],取值范围为 1~1。
鉴别器
鉴别器网络 D 与普通分类网络相同。它接受大小为[b,64,64,3]的图像张量,并通过五个卷积层连续提取特征。卷积层的最终输出大小为[b,2,2,1024],然后通过池层 GlobalAveragePooling2D 将特征大小转换为[b,1024],最后通过一个全连通层得到二叉分类任务的概率。鉴频器网络 D 类的代码实现如下:
class Discriminator(keras.Model):
# Discriminator class
def __init__(self):
super(Discriminator, self).__init__()
filter = 64
# Convolutional layer 1
self.conv1 = layers.Conv2D(filter, 4, 2, 'valid', use_bias=False)
self.bn1 = layers.BatchNormalization()
# Convolutional layer 2
self.conv2 = layers.Conv2D(filter*2, 4, 2, 'valid', use_bias=False)
self.bn2 = layers.BatchNormalization()
# Convolutional layer 3
self.conv3 = layers.Conv2D(filter*4, 4, 2, 'valid', use_bias=False)
self.bn3 = layers.BatchNormalization()
# Convolutional layer 4
self.conv4 = layers.Conv2D(filter*8, 3, 1, 'valid', use_bias=False)
self.bn4 = layers.BatchNormalization()
# Convolutional layer 5
self.conv5 = layers.Conv2D(filter*16, 3, 1, 'valid', use_bias=False)
self.bn5 = layers.BatchNormalization()
# Global pooling layer
self.pool = layers.GlobalAveragePooling2D()
# Flatten feature layer
self.flatten = layers.Flatten()
# Binary classification layer
self.fc = layers.Dense(1)
鉴别器 D 的正向计算过程实现如下:
def call(self, inputs, training=None):
# Convolutional layer-BN-activation function:(4, 31, 31, 64)
x = tf.nn.leaky_relu(self.bn1(self.conv1(inputs), training=training))
# Convolutional layer-BN-activation function:(4, 14, 14, 128)
x = tf.nn.leaky_relu(self.bn2(self.conv2(x), training=training))
# Convolutional layer-BN-activation function:(4, 6, 6, 256)
x = tf.nn.leaky_relu(self.bn3(self.conv3(x), training=training))
# Convolutional layer-BN-activation function:(4, 4, 4, 512)
x = tf.nn.leaky_relu(self.bn4(self.conv4(x), training=training))
# Convolutional layer-BN-activation function:(4, 2, 2, 1024)
x = tf.nn.leaky_relu(self.bn5(self.conv5(x), training=training))
# Convolutional layer-BN-activation function:(4, 1024)
x = self.pool(x)
# Flatten
x = self.flatten(x)
# Output, [b, 1024] => [b, 1]
logits = self.fc(x)
return logits
鉴频器的输出大小为[b,1]。类内部不使用 Sigmoid 激活函数,b 样本属于真实样本的概率可以通过 Sigmoid 激活函数得到。
培训和可视化
鉴别器根据公式( 13-1 ,鉴别器网络的目标是最大化函数 L ( D , G ),使真实样本预测的概率接近 1,生成样本预测的概率接近 0。我们在 d_loss_fn 函数中实现鉴别器的误差函数,将所有真实样本标记为 1,将所有生成样本标记为 0,通过最小化对应的交叉熵损失函数来最大化函数 L(D,G)。d_loss_fn 函数实现如下:
def d_loss_fn(generator, discriminator, batch_z, batch_x, is_training):
# Loss function for discriminator
# Generate images from generator
fake_image = generator(batch_z, is_training)
# Distinguish images
d_fake_logits = discriminator(fake_image, is_training)
# Determine whether the image is real or not
d_real_logits = discriminator(batch_x, is_training)
# The error between real image and 1
d_loss_real = celoss_ones(d_real_logits)
# The error between generated image and 0
d_loss_fake = celoss_zeros(d_fake_logits)
# Combine loss
loss = d_loss_fake + d_loss_real
return loss
celoss_ones 函数计算当前预测概率和标签 1 之间的交叉熵损失。代码如下:
def celoss_ones(logits):
# Calculate the cross entropy belonging to and label 1
y = tf.ones_like(logits)
loss = keras.losses.binary_crossentropy(y, logits, from_logits=True)
return tf.reduce_mean(loss)
The celoss_zeros function calculates the cross entropy loss between the current predicted probability and label 0\. The code is as follows:
def celoss_zeros(logits):
# Calculate the cross entropy that belongs to and the note is 0
y = tf.zeros_like(logits)
loss = keras.losses.binary_crossentropy(y, logits, from_logits=True)
return tf.reduce_mean(loss)
发电机发电机网络的训练目标是最小化 L ( D , G )目标函数。由于真实样本与发生器无关,误差函数只需要最小化。此时的交叉熵误差可以通过将生成的样本标记为 1 来最小化。需要注意的是,在误差反向传播的过程中,鉴别器也参与了计算图的构建,但在这个阶段只需要更新发电机网络参数。发生器的误差函数如下:
def g_loss_fn(generator, discriminator, batch_z, is_training):
# Generate images
fake_image = generator(batch_z, is_training)
# When training the generator network, it is necessary to force the generated image to be judged as true
d_fake_logits = discriminator(fake_image, is_training)
# Calculate error between generated images and 1
loss = celoss_ones(d_fake_logits)
return loss
网络训练在每个历元中,先从先验分布pz(∙)中随机采样隐向量,从真实数据集中随机采样真实图片,通过发生器和鉴频器计算鉴频器网络损耗,优化鉴频器网络参数 θ 。当训练发生器时,需要鉴别器来计算误差,但只计算发生器的梯度信息并更新 ϕ 。这里设置鉴频器训练次数 k = 5,设置发电机训练时间为 1。
首先,创建生成器网络和鉴别器网络,并分别创建相应的优化器,如下所示:
generator = Generator() # Create generator
generator.build(input_shape = (4, z_dim))
discriminator = Discriminator() # Create discriminator
discriminator.build(input_shape=(4, 64, 64, 3))
# Create optimizers for generator and discriminator respectively
g_optimizer = keras.optimizers.Adam(learning_rate=learning_rate, beta_1=0.5)
d_optimizer = keras.optimizers.Adam(learning_rate=learning_rate, beta_1=0.5)
代码的主要培训部分实现如下:
for epoch in range(epochs): # Train epochs times
# 1\. Train discriminator
for _ in range(5):
# Sample hidden vectors
batch_z = tf.random.normal([batch_size, z_dim])
batch_x = next(db_iter) # Sample real images
# Forward calculation - discriminator
with tf.GradientTape() as tape:
d_loss = d_loss_fn(generator, discriminator, batch_z, batch_x, is_training)
grads = tape.gradient(d_loss, discriminator.trainable_variables)
d_optimizer.apply_gradients(zip(grads, discriminator.trainable_variables))
# 2\. Train generator
# Sample hidden vectors
batch_z = tf.random.normal([batch_size, z_dim])
batch_x = next(db_iter) # Sample real images
# Forward calculation - generator
with tf.GradientTape() as tape:
g_loss = g_loss_fn(generator, discriminator, batch_z, is_training)
grads = tape.gradient(g_loss, generator.trainable_variables)
g_optimizer.apply_gradients(zip(grads, generator.trainable_variables))
每 100 个时期,执行一次图像生成测试。从先验分布中随机抽取隐藏向量,发送给生成器,得到生成的图片,保存为文件。
如图 13-8 所示,为 DCGAN 模型在训练过程中保存的生成图片样本。可以观察到,大部分图片主体清晰,色彩鲜艳,图片多样性丰富,生成的图片接近数据集中的真实图片。同时可以发现,生成的图片仍有少量受损,人眼无法识别图片主体。为了获得图 13-8 所示的图像生成效果,需要精心设计网络模型结构,微调网络超参数。
图 13-8
DCGAN 图像生成效果
13.4 氮化镓变体
在最初的 GAN 论文中,Ian Goodfellow 从理论层面分析了 GAN 网络的收敛性,并在多个经典图像数据集上测试了图像生成的效果,如图 13-9 所示,其中图 13-9 (a)是 MNIST 数据集,图 13-9 (b)是多伦多人脸数据集,图 13-9 (c)和图 13-9 (d)是 CIFAR1
图 13-9
原始 GAN 图像生成效果[1]
可以看出,最初的 GAN 模型在图像生成效果方面并不突出,与的差异并不明显。这个时候并没有表现出它强大的分布近似能力。然而,由于 GAN 在理论上相对较新,有许多需要改进的地方,这极大地激发了学术界的研究兴趣。在接下来的几年里,GAN 的研究如火如荼,也取得了实质性的进展。接下来,我们将介绍几种重要的 GAN 变体。
13.4.1 DCGAN
最初的 GAN 网络主要基于全连通层来实现生成器 G 和鉴别器 d,由于图片的高维性和网络参数的海量性,训练效果并不优秀。DCGAN [2]提出了用转置卷积层实现的生成器网络,和用普通卷积层实现的鉴别器网络,大大减少了网络参数的数量,大大提高了图像生成的效果,显示出 GAN 模型在图像生成方面具有优于 VAE 模型的潜力。此外,DCGAN 作者还提出了一系列经验性的 GAN 网络训练技术,这些技术被证明有利于 GAN 网络的稳定训练。我们已经使用 DCGAN 模型来完成动画化身的实际图片生成。
InfoGAN
InfoGAN [3]试图用一种无监督的方式来学习输入 x 的可解释隐向量 z 的可解释表示,即希望隐向量 z 能够对应数据的语义特征。例如,对于 MNIST 手写的数字图片,我们可以认为数字的类别、字体大小和书写风格是图片的隐藏变量。我们希望模型可以学习这些解开的可解释的特征表示方法,以便可以人工控制隐藏变量来生成指定内容的样本。对于 CelebA 名人照片数据集,希望模型可以分离发型、眼镜佩戴情况、面部表情等特征,生成指定形状的人脸图像。
解开可解释特征的好处是什么?它可以使神经网络更具可解释性。比如 z 包含了一些单独的可解释特征,那么我们只需要改变这个位置的特征就可以获得不同语义的生成数据。如图 13-10 所示,减去“戴眼镜的男人”和“不戴眼镜的男人”的隐向量,再加上“不戴眼镜的女人”的隐向量,就可以生成一张“戴眼镜的女人”的图片。
图 13-10
分离特征的示意图[3]
13.4.3 摆明
CycleGAN [4]是由朱俊彦提出的用于图像风格转换的无监督算法。因为算法清晰简单,效果更好,所以这部作品获得了很多好评。CycleGAN 的基本假设是,如果你从 A 图切换到 B 图,再从 B 图切换到 A ',那么 A '应该和 A 是同一个图,所以 CycleGAN 除了设置标准的 GAN 损失项,还增加了循环一致性损失,保证 A '尽可能接近 A。CycleGAN 图片的转换效果如图 13-11 所示。
图 13-11
图像转换效果[4]
13.4.4 WGAN
甘的训练问题一直为人诟病,容易出现训练不收敛和模式崩溃的现象。WGAN [5]从理论层面分析了原 GAN 使用 JS 散度的缺陷,并提出 Wasserstein 距离可以用来解决这个问题。在 WGAN-GP [6]中,作者提出通过添加梯度惩罚项,从工程层面很好地实现了 WGAN 算法,证实了 WGAN 训练稳定性的优势。
13.4.5 同等氮化镓
从 GAN 诞生到 2017 年底,GAN 动物园已经收集了超过 214 个 GAN 网络变种。这些 GAN 变体或多或少地提出了一些创新,但来自 Google Brain 的几位研究人员在一篇论文中提供了另一个观点[7]:没有证据表明我们测试的 GAN 变体算法一直比最初的 GAN 论文更好。在该论文中,对这些 GAN 变体进行了公正和全面的比较。在计算资源充足的情况下,发现几乎所有的 GAN 变体都可以达到相似的性能(FID 分数)。这项工作提醒业界这些 GAN 变体是否具有本质上的创新性。
甘的自我关注
注意机制在自然语言处理中得到了广泛的应用。自我注意 GAN (SAGAN) [8]借鉴注意机制,提出了一种基于自我注意机制的 GAN 变体。萨根提高了画面的保真度指数:盗梦空间得分从 36.8 提高到 52.52,弗雷歇盗梦空间距离从 27.62 提高到 18.65。从图像生成的效果来看,萨根的突破非常显著,它也激发了业界对自我关注机制的关注。
图 13-12
萨根的注意机制[8]
比根
在 SAGAN 的基础上,BigGAN [9]试图将 GAN 的训练扩展到大规模,使用正交正则化等技术来保证训练过程的稳定性。BigGAN 的意义在于启发人们 GAN 网络的训练也可以受益于大数据和大计算能力。比根影像生成的效果达到了前所未有的高度:盗梦空间评分记录提升至 166.5(提升 52.52);弗雷歇起始距离下降到 7.4,减少了 18.65。如图 13-13 所示,图像分辨率可达 512×512,图像细节极其逼真。
图 13-13
比根生成的图像
13.5 纳什均衡
现在我们从理论层面分析,通过博弈学习的训练方法,生成器 G 和判别器 D 会达到什么均衡状态。具体来说,我们将探讨以下两个问题:
-
修正 G,D 会收敛到什么最优状态D∫?
-
D 达到最优状态D∫后,G 会收敛到什么状态?
我们先通过一维正态分布的例子xrpr(∙)进行直观的解释。如图 13-14 所示,黑色虚线代表真实的数据分布pr(∙),为正态分布 N ( μ 、 σ 2 ),绿色实线代表分布xf蓝色虚线表示鉴频器的决策边界曲线。图 13-14 (a)、(b)、(c)和(d)分别表示发电机网络的学习轨迹。在初始状态下,如图 13-14 (a)所示,pg(∙)的分布与p*r(∙)有很大的不同,鉴别器很容易学习到一个清晰的判定边界,就是图 13-14(a) 中的蓝色虚线,它设定了随着生成网络的分布pg(∙)越来越接近真实分布pr(∙),鉴别器区分真假样本变得越来越困难,如图 13.14(b)(c)所示。最后,当发生器网络学习到的分布pg(∙) =pr(∙)时,从发生器网络提取的样本非常逼真,鉴别器无法区分其中的差别,即判定样本真假的概率相等,如图 13-14( d)所示。*
图 13-14
纳什均衡[1]
这个例子直观地解释了 GAN 网络的训练过程。
鉴别器状态
现在我们来推导第一个问题。回顾 GAN 的损失函数:
对于鉴别器 D,优化目标是最大化 L ( G , D )函数,需要找到以下函数的最大值:
其中 θ 为鉴频器 d 的网络参数。
让我们考虑更一般的函数 f θ 的最大值:
需要函数 f ( x )的最大值。考虑 f ( x )的导数:
设,我们可以找到 f ( x )函数的极值点:
因此,可以知道fθ函数的极值点也是:
也就是说,当鉴频器网络Dθ处于状态时, f * θ * 函数取最大值, L ( G , D )函数也取最大值。
现在回到最大化 L ( G 、 D )的问题,最大值点 L ( G 、 D )在:
这也是 D θ 的最优状态D∫。
发电机状态
在导出第二个问题之前,我们先引入另一个类似于 KL 散度的分布距离度量:JS 散度,它被定义为 KL 散度的组合:
JS 发散克服了 KL 发散的不对称性。
当 D 达到最优状态D∫时,我们来考虑一下此时 p r 和 p g 的 JS 散度:
根据 KL 散度的定义:
结合常数项,我们可以得到:
那就是:
考虑当网络达到D∫时,此时的损失函数为:
因此,当鉴频器网络达到D∫、DJS(prpG)和 L ( G 、 D
那就是:
对于发电机网络 G,考虑到 JS 发散的性质,训练目标为 L ( G , D ):
因此, L ( G ,D∫)只有在DJS(pr‖pG)= 0(此时 p
此时,发电机网络的状态G∫为:
即G∫的学习分布 p g 与真实分布 p r 一致,网络达到一个平衡点。此时:
纳什均衡点
通过前面的推导,我们可以得出结论,生成网络 G 最终会收敛到真实分布,即:pG=pr
此时生成的样本和真实样本来自同一个分布,真假难辨。鉴别器有相同的概率判断为真或假,即:
这时,损失函数是
13.6 甘训练难度
虽然 GAN 网络可以从理论层面学习数据的真实分布,但在工程实现中经常出现 GAN 网络训练困难的问题,主要体现在 GAN 模型对超参数更敏感,需要仔细选择能使模型工作的超参数。超参数设置也容易出现模式崩溃。
超参数灵敏度
超参数敏感性是指网络的结构设置、学习速率、初始化状态等超参数对网络的训练过程有较大的影响。少量的超参数调整可能会导致完全不同的网络训练结果。图 13-15 (a)显示了从 GAN 模型的良好训练中获得的生成样本。图 13-15 (b)中的网络没有使用批量归一化层等设置,导致 GAN 网络训练不稳定,无法收敛。生成的样本互不相同。真实样本差距很大。
图 13-15
超参数敏感示例[5]
为了训练好 GAN 网络,DCGAN 论文作者提出不使用池化层,不使用全连通层,多使用批量归一化层,生成网络中的激活函数要使用 ReLU。最后一层的激活函数应该是 Tanh,鉴别器网络的激活函数应该使用 LeakyLeLU 等一系列经验训练技术。然而,这些技术只能在一定程度上避免训练不稳定的现象,并没有从理论层面解释为什么会有训练困难以及如何解决训练不稳定的问题。
模型折叠
模式崩溃是指模型生成的样本单一,多样性差的现象。由于鉴别器只能识别单个样本是否是从真实分布中采样的,并且不对样本多样性施加显式约束,所以生成模型可能倾向于在真实分布的部分区间中生成少量高质量样本,而不学习所有真实分布。模型坍塌现象在 GAN 中较为常见,如图 13-16 所示。在训练过程中,通过可视化生成器网络的样本可以观察到,生成的图片类型非常单一,生成器网络总是倾向于生成某种单一风格的样本来忽悠鉴别者。
图 13-16
图像生成–模型折叠[10]
图 13-17 显示了另一个直观理解模式崩溃的例子。第一行是无模式崩溃的发电机网络的训练过程,最后一列是真实分布,即 2D 高斯混合模型。第二行显示了模型折叠的发电机网络的训练过程。最后一栏是真实分布。可以看出,真实的分布是八个高斯模型的混合。模型崩溃发生后,发电机网络总是趋向于接近真实分布的一个狭窄区间,如图 13-17 第二行的前六列所示。这个区间的样本在鉴别器中往往能以较高的概率判断为真实样本,从而欺骗鉴别器。但这种现象并不是我们希望看到的。我们希望发电机网络能近似真实分布,而不是真实分布的某一部分。
图 13-17
模型坍塌示意图[10]
那么如何解决 GAN 的训练问题,使 GAN 能像普通神经网络一样被更稳定地训练呢?WGAN 模型提供了一个解决方案。
13.7 WGAN 原则
WGAN 算法从理论层面分析了 GAN 训练不稳定的原因,并提出了有效的解决方案。那么是什么让 GAN 训练如此不稳定呢?WGAN 提出非重叠分布 p 和 q 上的 JS 散度梯度面始终为 0。如图 13-18 所示,当分布 p 和 q 不重叠时,JS 散度的梯度值始终为 0,导致梯度消失现象;所以参数长期无法更新,网络无法收敛。
图 13-18
p 和 q 分布示意图
接下来我们将详细阐述 JS 发散的缺陷以及如何解决这个缺陷。
13.7.1 JS 发散劣势
为了避免过多的理论推导,我们用一个简单的分布例子来说明 JS 发散的缺陷。考虑两个完全不重叠的分布 p 和 q(θ≠0),其中分布 p 为:
并且 q 的分布为:
其中 θ ∈ R ,当 θ = 0 时,分布 p 和 q 重叠,两者相等;当 θ ≠ 0 时,分布 p 和 q 不重叠。
让我们用 θ 来分析前面的分布 p 和 q 之间的 JS 散度的变化。根据 KL 散度和 JS 散度的定义,计算出 JS 散度DJS(p‖q)当 θ = 0:
当 θ = 0 时,两个分布完全重叠。此时 JS 散度和 KL 散度都达到最小值,为 0:
由前面的推导,我们可以得到DJS(p‖q)与 θ 的走势:
换句话说,当两个分布完全不重叠时,无论分布之间的距离如何,JS 散度都是一个恒定值 log log 2,那么 JS 散度将无法产生有效的梯度信息。当两个分布重叠时,JS 散度平滑变化,产生有效的梯度信息。当两个分布完全重合时,JS 散度取最小值 0。如图 13-19 所示,红色曲线将两个正态分布分开。由于两个分布不重叠,生成样本位置的梯度值始终为 0,生成网络的参数无法更新,导致网络训练困难。
图 13-19
JS 散度的梯度消失[5]
因此,当分布 p 和 q 不重叠时,JS 散度不能平滑地测量分布之间的距离。结果,在该位置不能产生有效的梯度信息,GAN 训练不稳定。为了解决这个问题,我们需要使用更好的分布距离度量,这样即使分布 p 和 q 不重叠,它也能平滑地反映分布之间的真实距离变化。
13.7.2 远程
WGAN 论文发现 JS 发散导致 GAN 训练不稳定,并引入了一种新的分布距离度量方法:Wasserstein 距离,也称为地球移动器距离(EM distance),它代表了将一种分布转换为另一种分布的最小成本。它被定义为:
其中∏( p , q )是由分布 p 和 q 组合而成的所有可能的联合分布的集合。对于每个可能的联合分布γ∩∏(p, q ),计算期望距离 E ( x ,y)∩γx-y不同的联合分布 γ 有不同的期望 E ( x ,y)∩γx—y】,这些期望的下确界定义为分布 p 和 q【的瓦瑟斯坦距离
继续考虑图 13-18 中的例子,我们直接给出分布 p 和 q 之间的 EM 距离的表达式:
绘制 JS 散度和 EM 距离曲线,如图 13-20 所示。可以看出,JS 散度在 θ = 0 处不连续,其他位置导数都为 0,EM 距离总能产生有效的导数信息。所以 EM 距离比 JS 散度更适合指导 GAN 网络的训练。
图 13-20
JS 散度和 EM 距离随 θ WGAN-GP 的变化曲线
考虑到几乎不可能遍历所有的联合分布 γ 来计算距离期望 E ( x ,y)∩γx—y】of‖x—y 所以计算发电机网络的分布 p g 与W(pr, p g )之间的距离是不现实的。 基于 Kantorovich-Rubinstein 对偶,WGAN 作者将直接计算的W(pr, p g )转化为:
其中 sup {∙}表示集合的上确界,fL≤K表示满足 K 阶李普希兹连续性的函数f:R→R,即
因此,我们使用判别网络Dθ(x)来参数化 f ( x )函数,在 D θ 满足 1-Lipschitz 约束的条件下,即 K = 1,此时:
因此,求解W(pr, p g )的问题可以转化为:
这是鉴别器 D 的优化目标.鉴别网络函数Dθ(x)需要满足 1-Lipschitz 约束:
在 WGAN-GP 论文中,作者提出增加梯度罚函数法来强制鉴频器网络满足一阶-Lipschitz 函数约束,并且作者发现当梯度值约束在 1 左右时工程效果更好,因此梯度罚项定义为:
因此,WGAN 鉴频器 D 的训练目标是:
其中来自于 x * r 和 x f * 的线性差:
鉴别器 D 的目标是使上述误差 L ( G , D )最小化,即迫使 EM 距离尽可能大,
接近 1。
WGAN 发电机 G 的培训目标是:
即发电机的分布pg与真实分布 p r 之间的 EM 距离尽可能小。考虑到与发电机无关,发电机的培养目标缩写为:
从实现的角度来看,鉴频器网络 D 的输出不需要添加 Sigmoid 激活函数。这是因为最初版本的鉴别器是一个二进制分类网络,增加了 Sigmoid 函数来获得属于某一类别的概率;而 WGAN 中的鉴频器用于测量发电机网络的分布 p g 与真实分布 p r 之间的电磁距离。属于实数空间,不需要添加 Sigmoid 激活函数。在计算误差函数时,WGAN 也没有对数函数。在训练 WGAN 时,WGAN 作者推荐使用 RMSProp 或 SGD 等没有动量的优化器。
WGAN 从理论层面发现了原 GAN 容易出现训练不稳定的原因,并给出了新的距离度量和工程实现方案,取得了良好的效果。WGAN 也在一定程度上缓解了模型崩溃的问题,使用 WGAN 的模型不容易出现模型崩溃。需要注意的是,WGAN 一般不会提高模型的生成效果,只是保证模型训练的稳定性。当然,训练的稳定性也是模特表现好的前提。如图 13-21 所示,DCGAN 原版在不使用 BN 层等设置的情况下,显示训练不稳定。在相同的设置下,使用 WGAN 训练鉴频器可以避免这种现象,如图 13-22 所示。
图 13-22
无 BN 层的 WGAN 发生器效应[5]
图 13-21
无 BN 层的 DCGAN 发生器效应[5]
13.8 动手操作 WGAN-GP
WGAN-GP 模型可以在原始 GAN 实现的基础上稍加修改。WGAN-GP 模型的鉴别器 D 的输出不再是样本类别的概率,输出不需要加入 Sigmoid 激活函数。同时,我们需要添加一个梯度惩罚项,如下所示:
def gradient_penalty(discriminator, batch_x, fake_image):
# Gradient penalty term calculation function
batchsz = batch_x.shape[0]
# Each sample is randomly sampled at t for interpolation
t = tf.random.uniform([batchsz, 1, 1, 1])
# Automatically expand to the shape of x, [b, 1, 1, 1] => [b, h, w, c]
t = tf.broadcast_to(t, batch_x.shape)
# Perform linear interpolation between true and false pictures
interplate = t * batch_x + (1 - t) * fake_image
# Calculate the gradient of D to interpolated samples in a gradient environment
with tf.GradientTape() as tape:
tape.watch([interplate]) # Add to the gradient watch list
d_interplote_logits = discriminator(interplate)
grads = tape.gradient(d_interplote_logits, interplate)
# Calculate the norm of the gradient of each sample:[b, h, w, c] => [b, -1]
grads = tf.reshape(grads, [grads.shape[0], -1])
gp = tf.norm(grads, axis=1) #[b]
# Calculate the gradient penalty
gp = tf.reduce_mean( (gp-1.)**2 )
return gp
WGAN 鉴频器的损耗函数计算与 GAN 不同。WGAN 直接最大化真实样本的输出值,最小化生成样本的输出值。没有交叉熵计算过程。代码实现如下:
def d_loss_fn(generator, discriminator, batch_z, batch_x, is_training):
# Calculate loss function for D
fake_image = generator(batch_z, is_training) # Generated sample
d_fake_logits = discriminator(fake_image, is_training) # Output of generated sample
d_real_logits = discriminator(batch_x, is_training) # Output of real sample
# Calculate gradient penalty term
gp = gradient_penalty(discriminator, batch_x, fake_image)
# WGAN-GP loss function of D. Here is not to calculate the cross entropy, but to directly maximize the output of the positive sample
# Minimize the output of false samples and the gradient penalty term
loss = tf.reduce_mean(d_fake_logits) - tf.reduce_mean(d_real_logits) + 10\. * gp
return loss, gp
WGAN 发生器 G 的损失函数只需要最大化鉴别器 D 中生成样本的输出值,同样没有交叉熵计算步骤。代码实现如下:
def g_loss_fn(generator, discriminator, batch_z, is_training):
# Generator loss function
fake_image = generator(batch_z, is_training)
d_fake_logits = discriminator(fake_image, is_training)
# WGAN-GP G loss function. Maximize the output value of false samples
loss = - tf.reduce_mean(d_fake_logits)
return loss
与原始 GAN 相比,WGAN 的主要训练逻辑基本相同。WGAN 的鉴频器 D 的作用是测量电磁距离。所以鉴别器越精确,对发生器越有利。对于一个步长,鉴别器 D 可以被训练多次,而发生器 G 可以被训练一次,以获得更精确的 EM 距离估计。
13.9 参考
-
I. Goodfellow、J. Pouget-Abadie、M. Mirza、B. Xu、D. Warde-Farley、S. Ozair、a .库维尔和 Y. Bengio,《生成性对抗性网络》,神经信息处理系统进展 27 ,Z. Ghahramani、M. Welling、C. Cortes、N. D. Lawrence 和 K. Q. Weinberger,Curran Associates,Inc .,2014 年,第 2672-2680 页。
-
A.拉德福德,l .梅斯和 s .钦塔拉,深度卷积生成对抗网络的无监督表示学习,2015 年。
-
X.陈,y .段,R. Houthooft,j .舒尔曼,I. Sutskever 和 P. Abbeel,“信息根:通过信息最大化生成对抗网络的可解释表示学习”,神经信息处理系统进展 29 ,D. D. Lee,M. Sugiyama,U. V. Luxburg,I. Guyon 和 R. Garnett,Curran Associates,Inc .,2016 年,第 2172-2180 页。
-
J.-Y. Zhu,T. Park,P. Isola 和 A. A. Efros,“使用循环一致对抗网络的不成对图像到图像翻译”,计算机视觉(),2017 IEEE 国际会议关于,2017。
-
米(meter 的缩写))Arjovsky,S. Chintala 和 L. Bottou,“Wasserstein 生成对抗网络”,第 34 届机器学习国际会议论文集,澳大利亚悉尼国际会议中心,2017 年。
-
I. Gulrajani,F. Ahmed,M. Arjovsky,V. Dumoulin 和 A. C .库维尔,“Wasserstein GANs 的改进训练”,神经信息处理系统进展 30 ,I. Guyon,U. V. Luxburg,S. Bengio,H. Wallach,R. Fergus,S. Vishwanathan 和 R. Garnett,Curran Associates,Inc .,2017 年,第 5767-5777 页。
-
米(meter 的缩写))Lucic、K. Kurach、M. Michalski、O. Bousquet 和 S. Gelly,《甘人生来平等吗?大规模研究”,第 32 届神经信息处理系统国际会议论文集,美国,2018。
-
H.张,I. Goodfellow,d .,A. Odena,“自我注意生成对抗网络”,第 36 届机器学习国际会议论文集,美国加州长滩,2019。
-
A.Brock,J. Donahue 和 K. Simonyan,“高保真自然图像合成的大规模 GAN 训练”,国际学习表示会议,2019。
-
长度梅茨,b .普尔,d .普法乌和 j .索尔-迪克斯坦,“展开的生成性对抗性网络”, CoRR, abs/1611.02163,2016。
图片来源: https://twitter.com/goodfellow_ian/status/1084973596236144640?lang=en
*
十四、强化学习
人工智能=深度学习+强化学习
—大卫·西尔弗
强化学习是除了监督学习和非监督学习之外的另一个机器学习领域。它主要使用智能体与环境进行交互,以便学习能够取得良好效果的策略。与监督学习不同,强化学习的动作没有明确的标签信息。它只有来自环境反馈的奖励信息。通常具有一定的滞后性,用于反映动作的“好与坏”。
随着深度神经网络的兴起,强化学习领域也蓬勃发展。2015 年,英国公司 DeepMind 提出了一种基于深度神经网络的强化学习算法 DQN,在《太空入侵者》、《砖块》、《乒乓球》等 49 款雅达利游戏中取得了人类水平的性能[1]。2017 年,DeepMind 提出的 AlphaGo 程序以 3:0 的比分击败了当时排名第一的围棋选手柯洁。同年,AlphaGo 的新版本 AlphaGo Zero 用没有任何人类知识的自玩训练 100:0 击败 alpha go[3]。2019 年,OpenAI Five 计划 2:0 击败 Dota2 世界冠军 OG 战队。虽然这个游戏的游戏规则受到限制,但是对于 Dota2 来说,它需要一个超个人的智力水平。凭借一场出色的团队合作比赛,这场胜利无疑坚定了人类对 AGI 的信念。
本章将介绍强化学习中的主流算法,包括《太空入侵者》等游戏中达到类人水平的 DQN 算法,以及 Dota2 获胜的 PPO 算法。
14.1 不久后见
强化学习算法的设计不同于传统的监督学习,包含了大量新的数学公式推导。在进入强化学习算法的学习过程之前,让我们先通过一个简单的例子来体验一下强化学习算法的魅力。
在这一部分,你不需要掌握每一个细节,但应该注重直观体验,获得第一印象。
平衡杆游戏
平衡杆游戏系统包含三个对象:滑轨、小车和杆子。如图 14-1 所示,小车可以在滑轨上自由移动,杆的一侧通过轴承固定在小车上。在初始状态下,小车位于滑轨的中心,杆立在小车上。代理通过控制小车的左右移动来控制杆的平衡。当拉杆与垂线的夹角大于一定角度或小车偏离滑轨中心一定距离后,视为比赛结束。游戏时间越长,游戏给予的奖励越多,代理的控制水平也越高。
为了简化环境的表示,我们直接将高层环境特征向量 s 作为智能体的输入。它总共包含四个高级特征,即汽车位置、汽车速度、杆角度和杆速度。代理的输出动作 a 是向左或向右移动。应用到平衡杆系统的动作会生成一个新的状态,系统也会返回一个奖励值。这个奖励值可以简单记为 1,也就是瞬间增加 1 个单位时间。在每个时间戳 t ,代理通过观察环境状态 s t 产生一个动作 a t 。环境收到动作后,状态变为st+1并返回奖励 r t 。
图 14-1
平衡杆游戏系统
健身房平台
在强化学习中,机器人可以直接与真实环境进行交互,更新的环境状态和奖励可以通过传感器获得。但是,考虑到真实环境的复杂性和实验成本,一般倾向于在虚拟软件环境中测试算法,然后考虑迁移到真实环境中。
强化学习算法可以通过大量的虚拟游戏环境进行测试。为了方便研究人员调试和评估算法模型,OpenAI 开发了一个健身房游戏交互平台。用户只需少量代码,就可以使用 Python 语言完成游戏创作和交互。很方便。
OpenAI 健身房环境包括很多简单经典的控制游戏,比如平衡杆、过山车(图 14-2 )。它还可以调用 Atari 游戏环境和复杂的 MuJoCo 物理环境模拟器(图 14-4 )。在雅达利的游戏环境中,有大家熟悉的迷你游戏,比如太空入侵者、碎砖机(图 14-3 )和赛车。这些游戏虽然规模不大,但对决策能力要求很高,非常适合评估算法的智能。
图 14-4
步行机器人
图 14-3
碎砖机
图 14-2
过山车
目前你在 Windows 平台上安装健身房环境可能会遇到一些问题,因为有些软件库对 Windows 平台并不友好。建议您使用 Linux 系统进行安装。本章用到的平衡杆游戏环境在 Windows 平台上可以完美使用,其他复杂的游戏环境就不一定了。
运行 pip install gym 命令只会安装 gym 环境的基本库,而平衡杆游戏已经包含在基本库中了。如果您需要使用 Atari 或 MuJoCo 模拟器,则需要额外的安装步骤。让我们以安装 Atari 模拟器为例:
git clone https://github.com/openai/gym.git # Pull the code
cd gym # Go to directory
pip install -e '.[all]' # Install Gym
一般来说,创建一个游戏并在健身房环境中进行交互主要包括五个步骤:
-
创建一个游戏。通过 gym.make(name)可以创建一个指定名称的游戏,并返回游戏对象 env。
-
重置游戏状态。一般游戏环境都有一个初始状态。您可以通过调用 env.reset()来重置游戏状态,并返回到游戏的初始状态观察。
-
显示游戏画面。每个时间戳的游戏画面可以通过调用 env.render()来显示,一般用于测试。在训练期间渲染图像会引入一定的计算成本,因此在训练期间可能不会显示图像。
-
与游戏环境互动。动作可以通过 env.step(action)执行,系统可以返回新的状态观察、当前奖励、游戏结束标志 done 和附加信息载体。通过循环这个步骤,你可以继续与环境互动,直到游戏结束。
-
破坏游戏。只需调用 env.close()。
下面演示了平衡杆游戏 CartPole-v1 的一段交互式代码。每次交互时,在动作空间随机采样一个动作:{left,right},与环境交互,直到游戏结束。
import gym # Import gym library
env = gym.make("CartPole-v1") # Create game environment
observation = env.reset() # Reset game state
for _ in range(1000): # Loop 1000 times
env.render() # Render game image
action = env.action_space.sample() # Randomly select an action
# Interact with the environment, return new status, reward, end flag, other information
observation, reward, done, info = env.step(action)
if done:# End of game round, reset state
observation = env.reset()
env.close() # End game environment
政策网络
我们来讨论一下强化学习中最关键的环节:如何判断和决策?我们称之为判断和决策政策。策略的输入是状态 s ,输出是具体的动作 a 或动作的分布πθ(a|s),其中 θ 是策略函数 π 的参数, π θ 神经网络 π θ 的输入是平衡杆系统的状态 s ,即一个长度为 4 的向量,输出是所有动作的概率πθ(a|s):向左的概率 P (所有行动概率之和为 1:
其中 A 是所有动作的集合。πθ网络代表代理的策略,称为策略网络。自然地,我们可以将策略函数体现为一个神经网络,它有四个输入节点,中间有多个全连接的隐含层,输出层有两个输出节点,表示这两个动作的概率分布。互动时,选择概率最高的动作:
决策的结果是,它在环境中动作,得到新的状态 s t + 1 和奖励 r t ,以此类推,直到游戏结束。
图 14-5
战略网络
我们将策略网络实现为两层全连接网络。第一层将长度为 4 的向量转换为长度为 128 的向量,第二层将长度为 128 的向量转换为 2 的向量,这是动作的概率分布。就像普通神经网络的创建过程一样,代码如下:
class Policy(keras.Model):
# Policy network, generating probability distribution of actions
def __init__(self):
super(Policy, self).__init__()
self.data = [] # Store track
# The input is a vector of length 4, and the output is two actions - left and right, specifying the initialization scheme of the W tensor
self.fc1 = layers.Dense(128, kernel_initializer='he_normal')
self.fc2 = layers.Dense(2, kernel_initializer='he_normal')
# Network optimizer
self.optimizer = optimizers.Adam(lr=learning_rate)
def call(self, inputs, training=None):
# The shape of the state input s is a vector:[4]
x = tf.nn.relu(self.fc1(inputs))
x = tf.nn.softmax(self.fc2(x), axis=1) # Get the probability distribution of the action
return x
在交互过程中,我们记录每个时间戳的状态输入st,动作分发输出 a t ,环境奖励 r t ,新状态st+1作为训练策略网络的四元组项。
def put_data(self, item):
# Record r,log_P(a|s)
self.data.append(item)
梯度更新
如果需要使用梯度下降算法优化网络,需要知道每个输入 s t 的标签信息 a t 并保证损耗值从输入到损耗连续可微。但是,强化学习并不等同于传统的监督学习,这主要体现在强化学习在每个时间戳 t 的动作 a t 并没有明确的好坏标准。奖励 r t 能在一定程度上反映动作的好坏,但不能直接决定动作的好坏。甚至有些游戏交互过程只有一个代表游戏结果的最终奖励 r t 信号,比如围棋。那么为每个状态定义一个最优动作作为神经网络输入 s * t * 的标签是否可行呢?首先是游戏中的状态总数通常是巨大的。比如围棋的总状态数大概是 10 170 。此外,很难为每个状态定义一个最佳动作。虽然有些行动短期回报低,但长期回报更好,有时甚至人类都不知道哪个行动是最好的。
因此,策略的优化目标不应该是使投入的产出 s t 尽可能接近标号动作,而是使总回报的期望值最大化。总奖励可以定义为从游戏开始到游戏结束的激励∑ r t 的总和。一个好的策略应该是能够在环境中获得总回报的最高期望值J(πθ)。根据梯度上升算法的原理,如果能找到,那么策略网络只需要跟随:
更新网络参数以最大化期望回报。
可惜总回报预期J(πθ)是游戏环境给定的。如果环境模型未知,则无法通过自动微分计算。那么即使J(πθ)的表达式未知,偏导数
是否可以直接求解?
答案是肯定的。我们这里直接给出的推导结果。具体的推导过程将在 14.3 中详细介绍:
利用前面的公式,只需要计算出,再乘以 R ( τ )就可以更新计算出
。根据
可以更新策略网络,最大化 J ( θ )函数,其中 R ( τ )为某次交互的总回报; τ 是交互轨迹s1,a1,r1, s 2 ,a2, r 2 , T 是交互的时间戳或步骤数;而log logπθ(st)是策略网络输出中 a * t * 动作的概率值的对数函数。
可通过 TensorFlow 自动微分解决。损失函数的代码实现为:
for r, log_prob in self.data[::-1]:# Get trajectory data in reverse order
R = r + gamma * R # Accumulate the return on each time stamp
# The gradient is calculated once for each timestamp
# grad_R=-log_P*R*grad_theta
loss = -log_prob * R
整个训练和更新代码如下:
def train_net(self, tape):
# Calculate the gradient and update the policy network parameters. tape is a gradient recorder
R = 0 # The initial return of the end state is 0
for r, log_prob in self.data[::-1]:# Reverse order
R = r + gamma * R # Accumulate the return on each time stamp
# The gradient is calculated once for each timestamp
# grad_R=-log_P*R*grad_theta
loss = -log_prob * R
with tape.stop_recording():
# Optimize strategy network
grads = tape.gradient(loss, self.trainable_variables)
# print(grads)
self.optimizer.apply_gradients(zip(grads, self.trainable_variables))
self.data = [] # Clear track
14.1.5 动手平衡杆游戏
我们总共训练 400 轮。在回合开始时,我们重置游戏状态,通过发送输入状态采样动作,与环境交互,记录每个时间戳的信息,直到游戏结束。
代码的交互和培训部分如下:
for n_epi in range(10000):
s = env.reset() # Back to the initial state of the game, return to s0
with tf.GradientTape(persistent=True) as tape:
for t in range(501): # CartPole-v1 forced to terminates at 500 step.
# Send the state vector to get the strategy
s = tf.constant(s,dtype=tf.float32)
# s: [4] => [1,4]
s = tf.expand_dims(s, axis=0)
prob = pi(s) # Action distribution: [1,2]
# Sample 1 action from the category distribution, shape: [1]
a = tf.random.categorical(tf.math.log(prob), 1)[0]
a = int(a) # Tensor to integer
s_prime, r, done, info = env.step(a) # Interact with the environment
# Record action a and the reward r generated by the action
# prob shape:[1,2]
pi.put_data((r, tf.math.log(prob[0][a])))
s = s_prime # Refresh status
score += r # Cumulative reward
if done: # The current episode is terminated
break
# After the episode is terminated, train the network once
pi.train_net(tape)
del tape
模型的训练过程如图 14-6 所示。横轴是训练回合数,纵轴是回合的平均返回值。可以看出,随着训练的进行,网络获得的平均回报越来越高,策略也越来越好。事实上,强化学习算法对参数极其敏感,修改随机种子会导致完全不同的性能。在实现过程中,需要仔细选择参数,以实现算法的潜力。
图 14-6
平衡杆游戏训练流程
通过这个例子,我们对强化学习算法和强化学习的交互过程有了初步的印象和了解,然后我们将对强化学习问题进行形式化描述。
14.2 强化学习问题
在强化学习问题中,具有感知和决策能力的对象称为智能体,它可以是一段算法代码,也可以是具有机械结构的机器人软硬件系统。代理通过与外部环境的交互来完成某项任务。这里的环境是指主体的行动所能影响并给予相应反馈的外部环境的总和。对于智能体来说,它通过感知环境的状态(state)来产生决策动作(action)。对于环境,它从一个初始状态 s 1 开始,通过接受智能体的动作来动态改变其状态,并给出相应的奖励信号(reward)。
我们从概率的角度描述强化学习过程。它包含以下五个基本对象:
-
状态 s 反映环境的状态特征。时间戳上的状态 t 标记为 s t 。可以是原始的视觉图像、语音波形、其他信号,也可以是经过高级抽象后的特征,比如汽车的速度、位置等。所有(有限)状态构成状态空间 s。
-
动作 a 是代理采取的动作。时间戳 t 上的状态记录为 a t ,可以是左右等离散动作,也可以是力度、位置等连续动作。所有(有限)动作构成动作空间 A 。
-
Policy π(a| s) represents the decision model of the agent. It accepts the input as the state s and gives the probability distribution p(a| s) of the action executed after the decision, which satisfies:
这种具有一定随机性的行动概率输出称为随机策略。特别是当策略模型总是输出某个动作的概率为 1,其他为 0 时,这种策略模型称为确定性策略,即:
-
奖励 r ( s , a )表示在状态 s 下接受动作 a 后环境给出的反馈信号。一般是标量值,在一定程度上反映了动作的好坏。在时间戳 t 获得的奖励记为 r t (有些资料中记为rt+1,因为奖励往往有一定的滞后性)
-
The state transition probability p(s′| s, a) expresses the changing law of the state of the environment model, that is, after the environment of the current state s accepts the action a, the probability distribution that the state changes to s′ satisfies:
主体与环境的交互过程可以用图 14-7 来表示。
图 14-7
主体与环境之间的相互作用过程
马尔可夫决策过程
代理从环境的初始状态 s 1 开始,通过策略模型π(a|s)执行一个特定的动作 a 1 。环境受动作 a 1 影响,状态 s 1 根据内部状态转移模型p(s′|s, a )变化为 s 2 。同时给出代理的反馈信号:奖励r1,由奖励函数r(s1,a1 产生。这种循环互动一直持续到游戏达到终止状态 s T 。这个过程产生一系列有序的数据:
这个序列代表了代理和环境之间的交换过程,称为轨迹,表示为 τ 。一个交互过程称为一集, T 代表时间戳(或步骤数)。有些环境有明确的终端状态。比如《太空入侵者》中的小飞机被击中游戏就结束了,而有些环境没有明确的终止标志。比如,有些游戏只要保持健康就可以无限期玩下去。此时 T 代表∞。
条件概率P(st+1|s1, s 2 ,…, s t )非常重要,但是需要多个历史状态,计算起来非常复杂。为简单起见,我们假设下一个时间戳上的状态st+1只受当前时间戳 s t 影响,与其他历史状态 s 1 、 s 2 、…、 s 无关
下一个状态 s t + 1 只与当前状态 s t 相关的性质称为马尔可夫性质,具有马尔可夫性质的序列 s 1 、 s 2 、…、 s T 称为
如果将动作 a 也考虑到状态转移概率,则马尔可夫假设也被应用:下一个时间戳的状态st+1只与当前状态 s t 相关,并且动作 a t 对当前状态执行,则条件概率变为:
我们把状态和动作的序列 s 1 , a 1 ,…, s T 称为马尔可夫决策过程(MDP)。在某些场景下,智能体只能观察到环境的部分状态,这被称为部分可观测马尔可夫决策过程(POMDP)。虽然马尔可夫假设不一定对应实际情况,但它是强化学习中大量理论推导的基石。我们将在以后的推导中看到马尔可夫性的应用。
现在让我们考虑一个确定的轨迹:
就是发生的概率P(τ):
应用马尔可夫性后,我们将前面的表达式简化为:
马尔可夫决策过程图如图 14-8 所示。
图 14-8
马尔可夫决策过程
如果可以得到环境的状态转移概率 p ( s ʹ| s , a )和报酬函数 r ( s , a ),就可以直接迭代计算价值函数。这种已知环境模型的方法统称为基于模型的强化学习。然而,现实世界中的环境模型大多是复杂和未知的。这种模型未知的方法统称为无模型强化学习。接下来主要介绍无模型强化学习算法。
目标函数
智能体每次与环境交互,都会得到一个(滞后的)奖励信号:
一个交互轨迹 τ 的累积回报称为总回报:
其中 T 是轨迹中的步数。如果只考虑sT, s t + 1 ,…, s T 从轨迹的中间状态 s t 开始的累计收益,可以记为:
在某些环境下,刺激信号是很稀疏的,比如围棋,上一步棋的刺激是 0,只有在比赛结束时才会有代表胜负的奖励信号。
因此,为了权衡短期和长期回报的重要性,可以使用随时间衰减的贴现回报(贴现回报):
其中 γ ∈ [0,1]称为折现率。可以看出,近期激励 r 1 全部用于总回报,而长期激励RT-1可以用来贡献衰减γT-2后的总回报 R ( τ )。当 γ ≈ 1 时,短期和长期奖励权重大致相同,算法更具前瞻性;当 γ ≈ 0 时,后期长期回报衰减接近 0,短期回报变得更重要。对于没有终止状态的环境,即 T = ∞,折现回报变得非常重要,因为可能增加到无穷大,对于长期奖励可以近似忽略折现回报,以方便算法实现。
我们希望找到一个策略 π ( a | s )模型,使得策略π(a|s控制下的智能体与环境相互作用产生的轨迹 τ 的总收益 R ( τ )越高越好。由于环境状态转移和策略的随机性,同样的策略模型作用于初始状态相同的环境,也可能产生完全不同的轨迹序列 τ 。因此,强化学习的目标是期望收益最大化:
训练的目标是找到一组参数 θ 所代表的策略网络πθ,使得J(πθ)最大:
其中 p ( τ )代表轨迹 τ 的分布,由状态转移概率p(s|s, a )和策略π(a|s)共同决定。策略 π 的好坏可以用J(πθ)来衡量。预期收益越大,政策越好;否则,策略越糟糕。
14.3 政策梯度法
由于强化学习的目标是找到一个最优策略πθ(s),使得期望收益 J ( θ ),这类优化问题类似于监督学习。需要用网络参数求解期望收益的偏导数,用梯度上升算法更新网络参数:
即其中 η 为学习率。
策略模型πθ(s)可以使用多层神经网络参数化πθ(s)。网络的输入是状态 s ,输出是动作 a 的概率分布。这种网络被称为政策网络。
为了优化这个网络,你只需要获得每个参数的偏导数。现在我们来推导一下
的表达式。先按轨迹分布展开:
将导数符号移动到整数符号:
添加不改变结果:
考虑:
所以:
我们可以得到:
也就是:
其中log logπθ(τ)代表轨迹的对数概率值 τ = s 1 , a 1 , s 2 , a 2 ,考虑到 R ( τ )可以通过采样得到,关键就变成了求解,我们可以分解π*θ(τ)得到:*
将日志 ∏转换为∑ 日志 ( ):
考虑到log log p(st, a t )和log log p(s1)都与 θ 无关,前面的公式变成:
可以看出,偏导数最终可以转化为log logπθ(st)即策略网络输出对网络参数 θ 的导数。与状态概率转移p(s′|s, a )无关,即不知道环境模型
即可求解。
把它分成 :
让我们直观地理解前面的公式。当某一轮的总回报 R ( τ ) > 0、和
同向时。根据梯度上升算法, θ 参数朝着增加 J ( θ )的方向更新,也朝着增加log log logπθ(st)的方向更新,这鼓励了更多这样的轨迹 τ 。当总回报 R ( * τ * ) < 0、
和
反转时,那么当 θ 参数根据梯度上升算法更新时。朝着增加 J ( θ )和减少log logπθ(st)的方向更新,即避免产生更多这样的轨迹 τ 。通过这一点,可以直观地了解网络如何自我调整以获得更大的预期回报。
有了前面的表达式,我们就可以通过 TensorFlow 的自动微分工具轻松求解
来计算
。最后,我们可以使用梯度上升算法来更新参数。策略梯度算法的一般流程如图 14-9 所示。
图 14-9
政策梯度法培训流程
14.3.1 加固算法
根据大数定律,将期望写成多个采样轨迹的平均值τN,N∈【1,N:
其中 N 为轨迹数,和
代表第 N 条轨迹的第 t 个时间戳的动作和输入状态τN。然后通过梯度上升算法更新 θ 参数。这个算法被称为加强算法[4],也是最早使用策略梯度思想的算法。
算出
更新参数
直到达到一定的训练次数
输出:策略网络(st)** |
14.3.2 对原有政策梯度法的改进
由于原有的强化算法在优化轨迹之间的方差较大,收敛速度较慢,训练过程不够平滑。我们可以利用方差缩减的思想,从因果关系和基线的角度进行改进。
因果关系。考虑到的偏导数表达式,对于时间戳为 t 的动作 a * t ,对τ*1:T—1没有影响,仅对后续轨迹τT:T有影响。所以对于πθ(sT),我们只考虑从时间戳 t 开始的累计回报R(τT:T)。
的表达式由
给出
可以写成:
其中函数代表从状态 s * t 执行 a t 动作后 π θ 的预计奖励值。Q 函数的定义也将在 14.4 节中介绍。由于只考虑从 a t 开始的轨迹τ*T:TT 所以R(τT:T的方差变小。
偏置。真实环境中的奖励rt并不是围绕 0 分布的。很多游戏的奖励都是正的,以至于 R ( τ )总是大于 0。网络倾向于增加所有采样动作的概率。未采样动作的概率相对降低。这不是我们想要的。我们希望 R ( τ )能分布在 0 附近,所以我们引入一个偏差变量 b ,叫做基线,它代表平均收益水平 R ( τ )。的表达式转换为:
考虑到因果关系,可以写成:
其中δ=R(τ)—b称为优势函数,代表当前动作序列相对于平均收益的优势。
加上 bias b 后,的值会发生变化吗?要回答问题,我们只需要考虑
能否为 0。如果是 0,那么
的值不会改变。将
展开为:
因为:
我们有:
考虑∫πθ(τ)dτ= 1,
因此,增加 bias b 并不会改变的值,但确实减少了
的方差。
14.3.3 用偏差加强算法
偏差 b 可以用蒙特卡罗方法估计:
如果考虑因果关系,那么:
偏差 b 也可以使用另一个神经网络来估计,这也是 14.5 节中介绍的行动者-评论家方法。事实上,许多政策梯度算法经常使用神经网络来估计偏差 b 。算法可以灵活调整,掌握算法思路最重要。在算法 2 中示出了具有偏差增强算法流程。
| **算法 2:用偏差加强算法流程** | | **随机初始化***θ***重复****根据策略与环境交互**(***s******t***)***,*** **生成多条轨迹**{***【τ******n*****算出** 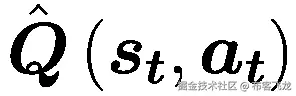**通过蒙特卡罗方法估计偏差** ***b*** ****算出** 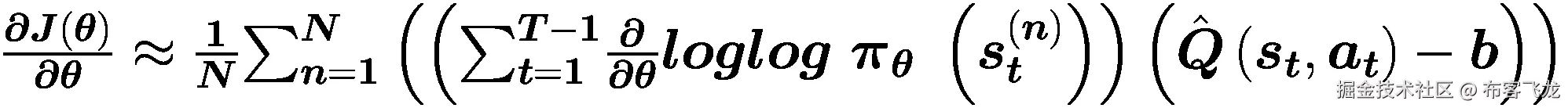更新参数
直到达到训练次数
**输出:政策网(st) |
重要性抽样
使用策略梯度法更新网络参数后,策略网络πθ(s)也发生了变化,必须使用新的策略网络进行采样。导致之前的历史轨迹数据无法重用,采样效率很低。如何提高采样效率,复用旧策略生成的轨迹数据?
在统计学中,重要抽样技术可以从另一个分布 q 估计原始分布 p 的期望值。考虑到轨迹 τ 是从原始分布 p 中采样的,我们希望估计出轨迹 τ ~ p 函数的期望Eτ∽p[f(τ)。
通过推导,我们发现 f ( τ )的期望可以不从原始分布 p 中采样,而是从另一个分布 q 中采样,只需要乘以比例。这在统计学中称为重要抽样。
设目标政策分布为pθ(τ),某个历史政策分布为,我们希望用历史采样轨迹
来估计目标政策网络的预期收益:
应用重要性抽样技术,我们可以得到:
其中代表原始分布pθ(τ)通过分布
估算的 J ( θ )的值。在近似忽略
项的假设下,认为状态 s * t * 在不同策略下出现的概率近似相等,即
,所以:
要优化的采样策略和目标策略pθ(τ)不相同的方法称为偏策略方法。相反,采样策略和要优化的目标策略是同一策略的方法称为 on-policy 方法。强化算法属于策略方法范畴。off-policy 方法可以使用历史采样数据来优化当前策略网络,这大大提高了数据利用率,但也引入了计算复杂性。特别地,当用蒙特卡罗抽样方法实施重要性抽样时,如果分布 p 和 q 之间的差值太大,期望估计就会有很大的偏差。因此,实现需要确保 p 和 q 的分布尽可能相似,例如添加 KL 散度约束来限制 p 和 q 之间的差异。
我们也称原政策梯度法的训练目标函数LPG(θ):
其中 PG 代表政策梯度,和
代表经验估计值。基于重要性抽样的目标函数称为
:
其中 IS 代表重要性抽样, θ 代表目标策略分布pθ,代表抽样策略分布
。
PPO 算法
应用重要性采样后,策略梯度算法大大提高了数据利用率,大大提高了性能和训练稳定性。比较流行的离策梯度算法有 TRPO 算法和 PPO 算法,其中 TRPO 是 PPO 算法的前身,PPO 算法可以看作是 TRPO 算法的近似简化版。
TRPO 算法为了约束目标策略 π 距离期望被用作优化问题的约束项。TRPO 算法的实现更加复杂并且计算量大。TRPO 算法的优化目标是:
PPO 算法。为了解决 TRPO 计算成本高的缺点,PPO 算法在损失函数中增加了 KL 散度约束作为惩罚项。优化目标是:
其中是指保单分布π??θ??st与
之间的距离,超参数 β 用于平衡原损失项和 KL 散度惩罚项。
自适应 KL 惩罚算法。通过设置 KL 散度的阈值 KL max 来动态调整超参数 β 。调整规则如下:如果,增加β;如果
,则减小 β 。
PPO2 算法。基于 PPO 算法,PPO2 算法调整损失函数:
误差函数的原理图如图 14-10 所示。
图 14-10
PPO2 算法误差函数示意图
14.3.6 动手 PPO
在本节中,我们实现了基于重要性采样技术的 PPO 算法,并在平衡杆游戏环境中测试了 PPO 算法的性能。
政策网。政策网络也称为行动者网络。策略网络的输入是状态 s t ,四个输入节点,输出是动作at的概率分布πθ(st),由两层全连通网络实现。
class Actor(keras.Model):
def __init__(self):
super(Actor, self).__init__()
# The policy network is also called the Actor network. Output probability p(a|s)
self.fc1 = layers.Dense(100, kernel_initializer='he_normal')
self.fc2 = layers.Dense(2, kernel_initializer='he_normal')
def call(self, inputs):
# Forward propagation
x = tf.nn.relu(self.fc1(inputs))
x = self.fc2(x)
# Output action probability
x = tf.nn.softmax(x, axis=1) # Convert to probability
return x
偏差 b 网络偏差 b 网络也叫评论家网络,或 V 值函数网络。网络的输入是状态 s t ,四个输入节点,输出是标量值 b 。使用两层全连接网络来估计 b 。代码实现如下:
class Critic(keras.Model):
def __init__(self):
super(Critic, self).__init__()
# Bias b network is also called Critic network, output is v(s)
self.fc1 = layers.Dense(100, kernel_initializer='he_normal')
self.fc2 = layers.Dense(1, kernel_initializer='he_normal')
def call(self, inputs):
x = tf.nn.relu(self.fc1(inputs))
x = self.fc2(x) # Output b's estimate
return x
接下来,完成策略网络和价值函数网络的创建,并分别创建两个优化器来优化策略网络和价值函数网络的参数。我们在 PPO 算法的主类的初始化方法中创建它。
class PPO():
# PPO algorithm
def __init__(self):
super(PPO, self).__init__()
self.actor = Actor() # Create Actor network
self.critic = Critic() # Create Critic network
self.buffer = [] # Data buffer
self.actor_optimizer = optimizers.Adam(1e-3) # Actor optimizer
self.critic_optimizer = optimizers.Adam(3e-3) # Critic optimizer
动作采样。select_action 函数可以计算当前状态的动作分布πθT7(st),并根据概率随机抽取动作,返回动作及其概率。
def select_action(self, s):
# Send the state vector to get the strategy: [4]
s = tf.constant(s, dtype=tf.float32)
# s: [4] => [1,4]
s = tf.expand_dims(s, axis=0)
# Get strategy distribution: [1, 2]
prob = self.actor(s)
# Sample 1 action from the category distribution, shape: [1]
a = tf.random.categorical(tf.math.log(prob), 1)[0]
a = int(a) # Tensor to integer
return a, float(prob[0][a]) # Return action and its probability
环境交互。在主功能中,与环境互动 500 回合。在每一轮中,策略由 select_action 函数采样并保存在缓冲池中。不时调用 agent.optimizer()函数来优化策略。
def main():
agent = PPO()
returns = [] # total return
total = 0 # Average return over time
for i_epoch in range(500): # Number of training rounds
state = env.reset() # Reset environment
for t in range(500): # at most 500 rounds
# Interact with environment with new policy
action, action_prob = agent.select_action(state)
next_state, reward, done, _ = env.step(action)
# Create and store samples
trans = Transition(state, action, action_prob, reward, next_state)
agent.store_transition(trans)
state = next_state # Update state
total += reward # Accumulate rewards
if done: # Train network
if len(agent.buffer) >= batch_size:
agent.optimize() # Optimize
break
网络优化。当缓冲池达到一定容量时,通过 optimizer()函数构造策略网络的误差和值网络的误差,优化网络的参数。先将数据按类别转换为张量类型,然后用 MC 方法计算累计回报R(τT:T)。
def optimize(self):
# Optimize the main network function
# Take sample data from the cache and convert it into tensor
state = tf.constant([t.state for t in self.buffer], dtype=tf.float32)
action = tf.constant([t.action for t in self.buffer], dtype=tf.int32)
action = tf.reshape(action,[-1,1])
reward = [t.reward for t in self.buffer]
old_action_log_prob = tf.constant([t.a_log_prob for t in self.buffer], dtype=tf.float32)
old_action_log_prob = tf.reshape(old_action_log_prob, [-1,1])
# Calculate R(st) using MC method
R = 0
Rs = []
for r in reward[::-1]:
R = r + gamma * R
Rs.insert(0, R)
Rs = tf.constant(Rs, dtype=tf.float32)
...
然后根据批量取出缓冲池中的数据。迭代训练网络十次。对于策略网络,是根据 PPO2 算法的误差函数计算的。对于价值网来说,通过均方差计算价值网的预测与R(τT:T)的距离,使网络估计的价值越来越准确。
def optimize(self):
...
# Iterate roughly 10 times on the buffer pool data
for _ in range(round(10*len(self.buffer)/batch_size)):
# Randomly sample batch size samples from the buffer pool
index = np.random.choice(np.arange(len(self.buffer)), batch_size, replace=False)
# Build a gradient tracking environment
with tf.GradientTape() as tape1, tf.GradientTape() as tape2:
# Get R(st), [b,1]
v_target = tf.expand_dims(tf.gather(Rs, index, axis=0), axis=1)
# Calculate the predicted value of v(s), which is the bias b, we will introduce why it is written as v later
v = self.critic(tf.gather(state, index, axis=0))
delta = v_target - v # Calculating advantage value
advantage = tf.stop_gradient(delta) # Disconnect the gradient
# Because TF's gather_nd and pytorch's gather function are different, it needs to be constructed
# Coordinate parameters required by gather_nd need to be constructed, indices:[b, 2]
# pi_a = pi.gather(1, a) # pytorch only need oneline implementation
a = tf.gather(action, index, axis=0) # Take out the action
# batch's action distribution pi(a|st)
pi = self.actor(tf.gather(state, index, axis=0))
indices = tf.expand_dims(tf.range(a.shape[0]), axis=1)
indices = tf.concat([indices, a], axis=1)
pi_a = tf.gather_nd(pi, indices) # The probability of action, pi(at|st), [b]
pi_a = tf.expand_dims(pi_a, axis=1) # [b]=> [b,1]
# Importance sampling
ratio = (pi_a / tf.gather(old_action_log_prob, index, axis=0))
surr1 = ratio * advantage
surr2 = tf.clip_by_value(ratio, 1 - epsilon, 1 + epsilon) * advantage
# PPO error function
policy_loss = -tf.reduce_mean(tf.minimum(surr1, surr2))
# For the bias v, it is hoped that the R(st) estimated by MC is as close as possible
value_loss = losses.MSE(v_target, v)
# Optimize policy network
grads = tape1.gradient(policy_loss, self.actor.trainable_variables)
self.actor_optimizer.apply_gradients(zip(grads, self.actor.trainable_variables))
# Optimize bias network
grads = tape2.gradient(value_loss, self.critic.trainable_variables)
self.critic_optimizer.apply_gradients(zip(grads, self.critic.trainable_variables))
self.buffer = [] # Empty trained data
训练结果。经过 500 轮训练后,我们绘制总回报曲线,如图 14-11 所示,我们可以看到,对于一个简单的游戏如平衡杆,PPO 算法显得很容易使用。
图 14-11
PPO 算法的返回曲线
14.4 价值函数法
使用策略梯度方法,通过直接优化策略网络参数,可以获得更好的策略模型。在强化学习领域,除了策略梯度法,还有一类方法是通过对价值函数建模来间接获取策略的,我们统称为价值函数法。
接下来,我们将介绍常见价值函数的定义,如何估计价值函数,以及价值函数如何帮助生成策略。
价值函数
在强化学习中,有两种类型的价值函数:状态价值函数和状态-动作价值函数,这两种函数都表示策略π下期望收益轨迹起点的定义不同。
状态值函数(简称 V 函数),定义为在策略π:
的控制下,从状态st所能获得的期望收益值
展开R(τT:T??)为:
所以:
这也被称为状态值函数的贝尔曼方程。在所有策略中,最优策略π∫是指能够获得Vπ(s)最大值的策略,即:
此时,状态值函数达到最大值:
对于最优策略,贝尔曼方程也得到满足:
该方程被称为状态值函数的贝尔曼最优方程。
考虑图 14-12 中的迷宫问题。在 3 × 4 网格中,坐标为(2,2)的网格不可通行,坐标为(4,2)的网格奖励为-10,坐标为(4,3)的网格奖励为 10。代理人可以从任何位置开始,每增加一步,奖励为-1。游戏的目标是回报最大化。对于这个简单的迷宫,可以直接画出每个位置的最优向量,即在任意起点,最优策略π∫(a|s)是确定性策略,动作如图 14-12(b) 所示。设 γ = 0.9,则:
-
从 s (4,3) 出发,即坐标(4,3),最优策略为V∫(s【4,3】)= 10
-
从 s (3,3)V∫(s【4,3】)= 1+0.9 10 = 8
从 s (2,1) 、V∫(s(2,1))= 1 0.9 1 0.921 0.931+0.9410 = 3.122
需要注意的是,状态值函数的前提是在某个策略π下,前面所有的计算都是为了计算最优策略下的状态值函数。
图 14-12
迷宫问题-V 函数
状态值函数的值反映了当前策略下状态的质量。Vπ(st)越大,当前状态的总回报预期越大。以更符合实际情况的太空入侵者游戏为例。代理人需要向飞碟、鱿鱼、螃蟹、章鱼和其他物体开火,并在击中它们时得分。同时,它必须避免被这些物体集中。红色护盾可以保护特工,但是护盾会被击中逐渐破坏。在图 14-13 中,游戏初始状态下,图中有很多物体。在一个好的政策π下,应该获得一个较大的Vπ(s)值。图 14-14 中,物体较少。再好的政策也不可能获得更大的Vπ(s)。策略的好坏也会影响Vπ(s)的值。如图 14-15 所示,一个不好的策略(比如向右移动)会导致代理被击中。因此,Vπ(s)= 0。好的政策可以击落画面中的物体,获得一定的奖励。
图 14-15
不好的政策(如向右)会结束博弈Vπ(s)= 0,好的政策还是可以获得小回报的
图 14-14
Vπ(s)在任何政策下都是小π
图 14-13
Vπ(s)在政策π下可能更大
状态-动作值函数(简称 Q 函数),定义为状态st的双重设定和动作at:
的执行在策略π的控制下所能获得的期望返回值
虽然 Q 函数和 V 函数都是预期返回值,但是 Q 函数的动作 a t 是前提条件,和 V 函数的定义不同。将 Q 函数扩展为:
所以:
因为 s t 和 a t 是固定的,r(st, a t )也是固定的。
Q 函数和 V 函数有如下关系:
即当 a t 从策略π(st)Qπ(s**t, a t 在最优策略下π∫(a|s,有如下关系:
它也表示:
此时:
前面的公式称为 Q 函数的贝尔曼最优方程。
我们定义Qπ(st, a t )和Vπ(s)为优势值函数:
表示在状态 s 中采取行动 a 超过平均水平的程度:AAπ(s, a ) > 0 表示采取行动 a 优于平均水平;否则比平均水平差。事实上,我们已经将优势价值函数的思想应用于有偏强化算法部分。
继续考虑迷宫的例子,设初始状态为s【2,1】at可右可左。对于函数Q∫(st, a t ),Q∫(s(2,1) ,右)= 1 Q∫(s(2,1) ,左)= 1 0.9 1 0.921 0.931 0.941 0.951+0.96】 我们已经计算出V∫(s(2,1) ) = 3.122,可以直观的看到它们满足V∫(st)
*
图 14-16
迷宫问题-Q 函数
以太空入侵者游戏为例,直观理解 Q 函数的概念。在图 14-17 中,图中的药剂在防护罩下面。如果你选择在这个时候开火,通常被认为是一个糟糕的行动。因此,良策π下,Qπ(s,无火)>Qπ(s,火)。如果此时在图 14-18 中选择向左移动,可能会因为时间不够错过右边的物体,所以Qπ(s,左)可能会小。如果代理向右移动并在图 14-19 中开火,Qπ(s,右)会更大。
图 14-19
在好的政策下 π ,Qπ(s,右)还是可以获得一些奖励的
图 14-18
Qπ(s,左)可能会小一些
图 14-17
Qπ(s,无火)可能比Qπ(s,无火)
在介绍了 Q 函数和 V 函数的定义后,我们将主要回答以下两个问题:
-
价值函数是如何估计的?
-
如何从价值函数推导出政策?
价值函数估计
价值函数的估计主要有蒙特卡罗方法和时间差分方法。
蒙特卡洛法
蒙特卡罗方法实际上就是通过采样策略 π ( a | s )产生的多个轨迹{ τ ( n ) }来估计 V 函数和 Q 函数。考虑一下 Q 函数的定义:
根据大数定律,可以通过抽样估算:
其中代表第 N 个采样轨迹,N∈【1, N 。每个采样轨迹的实际状态为 s ,初始动作为 a , N 为轨迹总数。V 函数可以按照同样的方法估算:
这种通过对轨迹的总收益进行采样来估计期望收益的方法被称为蒙特卡罗方法(简称 MC 方法)。
当 Q 函数或 V 函数通过神经网络参数化时,网络的输出被记录为Qπ(s, a )或Vπ(s),其真实标号被记录为蒙特卡洛估计值或
,即网络输出值与梯度下降算法用于优化神经网络。从这个角度看,价值函数的估计可以理解为一个回归问题。蒙特卡罗方法简单易行,但需要获得完整的轨迹,因此计算效率较低,在某些环境下没有明确的结束状态。
时间差异
时间差分法(简称 TD 法)利用了价值函数的贝尔曼方程性质。在计算公式中,只需要一步或多步就可以得到价值函数的误差,优化更新价值函数网络。卡罗方法计算效率更高。
回忆一下 V 函数的贝尔曼方程:
因此,TD 误差项δ=rt+γVπ(st+1)Vπ(st
其中 α ∈ [0,1]为更新步长。
Q 函数的贝尔曼最优方程是:
同样,构造 TD 误差项δ=r(st,at)+γQ∫(st+1, a
政策的改进
价值函数估计法可以得到更精确的价值函数估计,但没有直接给出政策模型。因此,需要基于价值函数间接导出策略模型。
首先看如何从 V 函数中导出策略模型:
考虑到状态空间 S 和动作空间 A 通常是巨大的,这种通过遍历来获得最优策略的方式是不可行的。那么政策模型可以从 Q 函数推导出来吗?考虑:
这样,可以通过在任何状态 s 下遍历离散动作空间 A 来选择动作。这个策略π’(s)是一个确定性的策略。因为:
所以:
即策略π’总是优于或等于策略 π ,从而实现政策改进。
确定性策略在相同的状态下产生相同的动作,所以每次交互产生的轨迹可能是相似的。政策模型总是倾向于剥削而缺乏探索,从而使得政策模型局限于局部地区,缺乏对全球状况和行动的了解。为了能够给π??’(s)确定性策略增加探索能力,我们可以让π??’(s)策略有小概率 ϵ 采用随机策略来探索未知的动作和状态。
这个政策叫做ϵ——贪婪法。它在原有策略的基础上做了少量的修改,通过控制超参数 ϵ 来平衡利用和探索,简单高效。
值函数的训练过程如图 14-20 所示。
图 14-20
价值函数法培训流程
SARSA 算法
SARSA 算法[5]用途:
估算 Q 函数的方法是,在轨迹的每一步,只有st,at, r t ,st+1,和 a t s t ,at, r t ,st+1和 a+1
*### DQN 算法
2015 年,DeepMind 提出了利用深度神经网络实现的 Q 学习[4]算法,发表在 Nature [1]上,并在 Atari 游戏环境下的 49 款迷你游戏上进行训练和学习,达到了相当于甚至优于人类的水平。人类水平的表现引起了业界和公众对强化学习研究的浓厚兴趣。
q 学习算法用途:
估算q∫(st, a t )函数并使用πϵ(st)策略获得策略改进。深度 Q 网络(DQN)使用深度神经网络参数化Q∫(st, a t )函数,并使用梯度下降算法更新 Q 网络。损失函数是:
由于既有训练目标值rt+γQθ(st+1, a 和预测值Qθ(s 并且训练数据具有很强的相关性,[1]提出了两种解决问题的措施:通过添加经验中继缓冲区来降低数据的强相关性和通过冻结目标网络技术来固定目标估计网络,稳定训练过程。
重放缓冲池相当于一个大型数据样本缓冲池。每次训练时,最新策略生成的数据对( s 、 a 、 r 、 s 、’)存储在重放缓冲池中,然后从缓冲池中随机抽取多个数据对( s 、 a 、 r 、 s 、’)进行训练。这样,可以减少训练数据的强相关性。还可以发现,DQN 算法是一种采样效率高的非策略算法。
冻结目标网络是一种训练技术。训练时,目标网络和预测网络Qθ(st, a * t )来自同一个网络,但
网络的更新频率会在Q*θ(s 这相当于
没有更新时处于冻结状态,然后在冻结结束后从Q*θ(st,at
拉最新的网络参数*
这样,训练过程可以变得更加稳定。
DQN 算法如算法 3 所示。
| **算法三:DQN 算法** | | 随机初始化***θ*****重复****复位并得到游戏初始状态** ***s*****重复**样本行动**【a】****=** ***与环境互动获得奖励 ***r*** 和状态***s***’优化 Q 网络:
【r】( a+1****)****
更新状态s←**s’
直到游戏结束
直到达到要求的训练次数
输出:策略网络(st)*********** |
14.4.6 DQN 变体
虽然 DQN 算法在雅达利游戏平台上取得了巨大突破,但后续研究发现,DQN 的 Q 值往往被高估。鉴于 DQN 算法的缺陷,人们提出了一些不同的算法。
双 DQN 在[6]中,根据损失函数:
分离并更新目标的 Q 网络和估计
网络
决斗 DQN 。[7]将网络输出分成 V ( s )和 A ( s , a ),如图 14-21 所示。然后使用:
生成 Q 函数估计值 Q ( s , a )。其余的和 DQN 保持不变。
图 14-21
DQN 网络(上)和决斗 DQN 网络(下)[7]
DQN 实践
这里我们继续实现基于平衡杆游戏环境的 DQN 算法。
Q 网。平衡杆游戏的状态是一个长度为 4 的向量。因此,Q 网络的输入被设计为四个节点。经过 256-256-2 全连接层,得到输出节点数为 2 的 Q 函数估计 Q ( s , a )的分布。网络的实现如下:
class Qnet(keras.Model):
def __init__(self):
# Create a Q network, the input is the state vector, and the output is the Q value of the action
super(Qnet, self).__init__()
self.fc1 = layers.Dense(256, kernel_initializer='he_normal')
self.fc2 = layers.Dense(256, kernel_initializer='he_normal')
self.fc3 = layers.Dense(2, kernel_initializer='he_normal')
def call(self, x, training=None):
x = tf.nn.relu(self.fc1(x))
x = tf.nn.relu(self.fc2(x))
x = self.fc3(x)
return x
重放缓冲池。DQN 算法中使用重放缓冲池来降低数据之间的强相关性。我们使用 ReplayBuffer 类中的 Deque 对象来实现缓冲池函数。训练时,最新的数据( s 、 a 、 r 、 s 、’)通过 put (transition)方法存储在 Deque 对象中,n 个数据( s 、 a 、 r 、 s 、??’)使用 sample 从 Deque 对象中随机抽取重放缓冲池的实现如下:
class ReplayBuffer():
# Replay buffer pool
def __init__(self):
# Deque
self.buffer = collections.deque(maxlen=buffer_limit)
def put(self, transition):
self.buffer.append(transition)
def sample(self, n):
# Sample n samples
mini_batch = random.sample(self.buffer, n)
s_lst, a_lst, r_lst, s_prime_lst, done_mask_lst = [], [], [], [], []
# Organize by category
for transition in mini_batch:
s, a, r, s_prime, done_mask = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
done_mask_lst.append([done_mask])
# Convert to tensor
return tf.constant(s_lst, dtype=tf.float32),\
tf.constant(a_lst, dtype=tf.int32), \
tf.constant(r_lst, dtype=tf.float32), \
tf.constant(s_prime_lst, dtype=tf.float32), \
tf.constant(done_mask_lst, dtype=tf.float32)
政策完善。这里实现了ϵ-贪婪方法。在对行动进行抽样时,有 1 个 ϵ 选择arg arg qπ(s, a )的概率,以及 ϵ 随机选择一个行动的概率。
def sample_action(self, s, epsilon):
# Send the state vector to get the strategy: [4]
s = tf.constant(s, dtype=tf.float32)
# s: [4] => [1,4]
s = tf.expand_dims(s, axis=0)
out = self(s)[0]
coin = random.random()
# Policy improvement: e-greedy way
if coin < epsilon:
# epsilon larger
return random.randint(0, 1)
else: # Q value is larger
return int(tf.argmax(out))
网络主进程。网络最多训练 10,000 轮。回合开始时,先将游戏复位得到初始状态 s ,从当前 Q 网中采样一个动作与环境交互得到数据对( s , a , r ,s′),存储在重放缓冲池中。如果当前重放缓冲池中的样本数量足够,则采样一批数据,根据 TD 误差优化 Q 网络的估计,直到比赛结束。
for n_epi in range(10000): # Training times
# The epsilon probability will also be attenuated by 8% to 1%. The more you go, the more you use the action with the highest Q value.
epsilon = max(0.01, 0.08 - 0.01 * (n_epi / 200))
s = env.reset() # Reset environment
for t in range(600): # Maximum timestamp of a round
# if n_epi>1000:
# env.render()
# According to the current Q network, extract and improve the policy.
a = q.sample_action(s, epsilon)
# Use improved strategies to interact with the environment
s_prime, r, done, info = env.step(a)
done_mask = 0.0 if done else 1.0 # End flag mask
# Save
memory.put((s, a, r / 100.0, s_prime, done_mask))
s = s_prime # Update state
score += r # Record return
if done: # End round
break
if memory.size() > 2000: # train if size is greater than 2000
train(q, q_target, memory, optimizer)
if n_epi % print_interval == 0 and n_epi != 0:
for src, dest in zip(q.variables, q_target.variables):
dest.assign(src) # weights come from Q
在训练过程中,只有 Q θ 网络会被更新,而网络会被冻结。在 Q * θ 网络多次更新后,使用下面的代码将最新的参数从 Q θ * 复制到
。
for src, dest in zip(q.variables, q_target.variables):
dest.assign(src) # weights come from Q
优化 Q 网。优化 Q 网的时候会一次训练更新十次。每次从重放缓冲池中随机取样,选择动作构造 TD 差。这里我们用平滑 L1 误差来构造 TD 误差:
在 TensorFlow 中,平滑 L1 误差可以使用 Huber 误差来实现,如下所示:
def train(q, q_target, memory, optimizer):
# Construct the error of Bellman equation through Q network and shadow network.
# And only update the Q network, the update of the shadow network will lag behind the Q network
huber = losses.Huber()
for i in range(10): # Train 10 times
# Sample from buffer pool
s, a, r, s_prime, done_mask = memory.sample(batch_size)
with tf.GradientTape() as tape:
# s: [b, 4]
q_out = q(s) # Get Q(s,a) distribution
# Because TF’s gather_nd is different from pytorch’s gather, we need to the coordinates of gather_nd, indices:[b, 2]
# pi_a = pi.gather(1, a) # pytorch only needs one line.
indices = tf.expand_dims(tf.range(a.shape[0]), axis=1)
indices = tf.concat([indices, a], axis=1)
q_a = tf.gather_nd(q_out, indices) # The probability of action, [b]
q_a = tf.expand_dims(q_a, axis=1) # [b]=> [b,1]
# Get the maximum value of Q(s',a). It comes from the shadow network! [b,4]=>[b,2]=>[b,1]
max_q_prime = tf.reduce_max(q_target(s_prime),axis=1,keepdims=True)
# Construct the target value of Q(s,a_t)
target = r + gamma * max_q_prime * done_mask
# Calcualte error between Q(s,a_t) and target
loss = huber(q_a, target)
# Update network
grads = tape.gradient(loss, q.trainable_variables)
optimizer.apply_gradients(zip(grads, q.trainable_variables))
14.5 演员-评论家方法
在引入原有的策略梯度算法时,为了减少方差,我们引入了偏差 b 机制:
其中 b 可以用蒙特卡罗方法估算。如果将 R ( τ )理解为Qπ(st, a * t )的估计值,则将偏差 b 理解为平均水平 V * π * 那么R*(τ)—b就是(近似)优势值函数Aπ(s, a )。 其中,如果偏置值函数Vπ(st)用神经网络估计,就是演员-评论家法(简称 AC 法)。策略网络πθ(st)称为 Actor,用于生成策略并与环境交互。
价值网络叫 Critic,用来评价当前状态。 θ 和 ϕ 分别是演员网和评论家网的参数。
对于演员网络πθ,目标是收益期望最大化,通过的偏导数更新策略网络的参数θ:
对于评论家网络,目标是通过 MC 方法或 TD 方法获得准确的
价值函数估计:
其中 dist(a,b)是 a 和 b 的距离测量器,比如欧几里德距离。是
的目标值。用 MC 法估算时,
用 TD 法估算时,
优势交流算法
使用优势值函数AπT5(s, a )的演员-评论家算法称为优势演员-评论家算法。这是目前使用演员-评论家思想的主流算法之一。其实演员-评论家系列算法并不一定要用优势值函数Aπ(s, a )。还有其他变种。
优势演员-评论家算法训练时,演员根据当前状态 s t 和策略 π θ 采样获得动作at,然后与环境交互获得下一个状态st+1和奖励TD 方法可以估计每一步的目标值,从而更新 Critic 网络,使价值网络的估计更接近真实环境的期望收益。
用于估计当前动作的优势值,下面的等式用于计算演员网络的梯度 info。
重复这个过程,评论家网会越来越准,演员网也会调整政策,下次做得更好。
A3C 算法
A3C 算法的全称是异步优势行动者-批评家算法。它是 DeepMind 基于优势行动者-批评家算法[8]提出的异步版本。演员-评论家网络部署在多个线程中进行同步训练,参数通过全局网络同步。。这种异步训练模式大大提高了训练效率;因此训练速度更快,算法性能更好。
如图 14-22 所示,该算法将创建一个新的全局网络和 M 个工作线程。全球网络包含演员和评论家网络,每个线程创建一个新的交互环境,演员和评论家网络。在初始化阶段,全局网络随机初始化参数 θ 和 ϕ 。Worker 中的演员-评论家网络同步地从全局网络中提取参数来初始化网络。训练时,工人中的演员-评论家网络首先从全局网络中拉取最新参数,然后最新策略πθ(stt17)将采样动作与私人环境进行交互,根据优势演员-评论家算法计算参数 θ 和 ϕ 的梯度。在完成梯度计算后,每个工人将梯度信息提交给全局网络,并使用全局网络的优化器来完成参数更新。在算法测试阶段,只有全局网络与环境交互。
图 14-22
A3C 算法
A3C 动手实践
接下来,我们实现异步 A3C 算法。像普通的 Advantage AC 算法一样,需要创建演员-评论家网络。它包含一个演员子网络和一个评论家子网络。有时演员和评论家会共享以前的网络层,以减少网络参数的数量。平衡杆游戏比较简单。我们用一个两层全连通网络来参数化 Actor 网络,另一个两层全连通网络来参数化 Critic 网络。
演员-评论家网络代码如下:
class ActorCritic(keras.Model):
# Actor-Critic model
def __init__(self, state_size, action_size):
super(ActorCritic, self).__init__()
self.state_size = state_size # state vector length
self.action_size = action_size # action size
# Policy network Actor
self.dense1 = layers.Dense(128, activation='relu')
self.policy_logits = layers.Dense(action_size)
# V network Critic
self.dense2 = layers.Dense(128, activation='relu')
self.values = layers.Dense(1)
演员-评论家正向传播过程分别计算策略分布πθ(st)和 V 函数估计Vπ(st)。代码如下:
def call(self, inputs):
# Get policy distribution Pi(a|s)
x = self.dense1(inputs)
logits = self.policy_logits(x)
# Get v(s)
v = self.dense2(inputs)
values = self.values(v)
return logits, values
工作者线程类。在 Worker 线程中,实现了与 Advantage AC 算法相同的计算过程,只是参数 θ 和 ϕ 的梯度信息不是直接用于更新 Worker 的演员-评论家网络,而是提交给全局网络进行更新。具体来说,在 Worker 类的初始化阶段,server 对象和 opt 对象分别代表全局网络模型和优化器,并创建私有 ActorCritic 类 client 和交互环境 env。
class Worker(threading.Thread):
# The variables created here belong to the class, not to the instance, and are shared by all instances
global_episode = 0 # Round count
global_avg_return = 0 # Average return
def __init__(self, server, opt, result_queue, idx):
super(Worker, self).__init__()
self.result_queue = result_queue # Shared queue
self.server = server # Central model
self.opt = opt # Central optimizer
self.client = ActorCritic(4, 2) # Thread private network
self.worker_idx = idx # Thread id
self.env = gym.make('CartPole-v0').unwrapped
self.ep_loss = 0.0
在线程运行阶段,每个线程最多与环境交互 400 轮。在该轮开始时,客户端网络采样动作用于与环境进行交互,并保存到内存对象中。回合结束,训练演员网络和评论家网络,获取参数 θ 和 ϕ 的梯度信息,调用 opt 优化器对象更新全局网络。
def run(self):
total_step = 1
mem = Memory() # Each worker maintains a memory
while Worker.global_episode < 400: # Maximum number of frames not reached
current_state = self.env.reset() # Reset client state
mem.clear()
ep_reward = 0.
ep_steps = 0
self.ep_loss = 0
time_count = 0
done = False
while not done:
# Get Pi(a|s),no softmax
logits, _ = self.client(tf.constant(current_state[None, :],
dtype=tf.float32))
probs = tf.nn.softmax(logits)
# Random sample action
action = np.random.choice(2, p=probs.numpy()[0])
new_state, reward, done, _ = self.env.step(action) # Interact
if done:
reward = -1
ep_reward += reward
mem.store(current_state, action, reward) # Record
if time_count == 20 or done:
# Calculate the error of current client
with tf.GradientTape() as tape:
total_loss = self.compute_loss(done, new_state, mem)
self.ep_loss += float(total_loss)
# Calculate error
grads = tape.gradient(total_loss, self.client.trainable_weights)
# Submit gradient info to server, and update gradient
self.opt.apply_gradients(zip(grads,
self.server.trainable_weights))
# Pull latest gradient info from server
self.client.set_weights(self.server.get_weights())
mem.clear() # Clear Memory
time_count = 0
if done: # Calcualte return
Worker.global_avg_return = \
record(Worker.global_episode, ep_reward, self.worker_idx,
Worker.global_avg_return, self.result_queue,
self.ep_loss, ep_steps)
Worker.global_episode += 1
ep_steps += 1
time_count += 1
current_state = new_state
total_step += 1
self.result_queue.put(None) # End thread
影评误差计算。当训练每个工人类时,演员和评论家网络的误差计算实现如下。这里我们用蒙特卡罗方法估计目标值,用
和
两者之间的距离作为评论家网络的误差函数值 _loss。演员网的策略损失函数 policy_loss 来自
其中由 TensorFlow 的交叉熵函数实现。各种损失函数汇总后,形成总损失函数并返回。
def compute_loss(self,
done,
new_state,
memory,
gamma=0.99):
if done:
reward_sum = 0.
else:
reward_sum = self.client(tf.constant(new_state[None, :],
dtype=tf.float32))[-1].numpy()[0]
# Calculate return
discounted_rewards = []
for reward in memory.rewards[::-1]: # reverse buffer r
reward_sum = reward + gamma * reward_sum
discounted_rewards.append(reward_sum)
discounted_rewards.reverse()
# Get Pi(a|s) and v(s)
logits, values = self.client(tf.constant(np.vstack(memory.states),
dtype=tf.float32))
# Calculate advantage = R() - v(s)
advantage = tf.constant(np.array(discounted_rewards)[:, None],
dtype=tf.float32) - values
# Critic network loss
value_loss = advantage ** 2
# Policy loss
policy = tf.nn.softmax(logits)
policy_loss = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=memory.actions, logits=logits)
# When calculating the policy network loss, the V network is not calculated
policy_loss *= tf.stop_gradient(advantage)
entropy = tf.nn.softmax_cross_entropy_with_logits(labels=policy,
logits=logits)
policy_loss -= 0.01 * entropy
# Aggregate each error
total_loss = tf.reduce_mean((0.5 * value_loss + policy_loss))
return total_loss
代理人。代理负责整个 A3C 算法的训练。在初始化阶段,代理类创建一个新的全局网络对象服务器及其优化器对象 opt。
class Agent:
# Agent, include server
def __init__(self):
# server optimizer, no client, pull parameters from server
self.opt = optimizers.Adam(1e-3)
# Sever model
self.server = ActorCritic(4, 2) # State vector, action size
self.server(tf.random.normal((2, 4)))
在训练开始时,创建每个工作者线程对象,并且开始每个线程对象与环境进行交互。当每个 Worker 对象交互时,它将从全局网络中拉出最新的网络参数,并使用最新的策略与环境进行交互,并计算自己的损失。最后,每个工人向全局网络提交梯度信息,并调用 opt 对象优化全局网络。培训代码如下:
def train(self):
res_queue = Queue() # Shared queue
# Create interactive environment
workers = [Worker(self.server, self.opt, res_queue, i)
for i in range(multiprocessing.cpu_count())]
for i, worker in enumerate(workers):
print("Starting worker {}".format(i))
worker.start()
# Plot return curver
moving_average_rewards = []
while True:
reward = res_queue.get()
if reward is not None:
moving_average_rewards.append(reward)
else: # End
break
[w.join() for w in workers] # Quit threads
14.6 摘要
本章介绍了强化学习的问题设置和基本理论,并介绍了解决强化学习问题的两大系列算法:策略梯度法和价值函数法。策略梯度法直接优化策略模型,简单直接,但采样效率低。重要抽样技术可以提高算法的抽样效率。价值函数法采样效率高,易于训练,但需要从价值函数间接推导出策略模型。最后,介绍了结合政策梯度法和价值函数法的行动者-批评家法。我们还介绍了几种典型算法的原理,并利用平衡杆游戏环境进行了算法实现和测试。
14.7 参考
-
动词 (verb 的缩写)Mnih、K. Kavukcuoglu、D. Silver、A. A .鲁苏、J. Veness、M. G. Bellemare、A. Graves、M. Riedmiller、A. K. Fidjeland、G. Ostrovski、S. Petersen、C. Beattie、A. Sadik、I. Antonoglou、H. King、D. Kumaran、D. Wierstra、S. Legg 和 D. Hassabis,“通过深度强化学习实现人类水平的控制”,《自然》, 518
-
D.Silver、A. Huang、C. J、A. Guez、L. Sifre、G. Driessche、J. Schrittwieser、I. Antonoglou、V. Panneershelvam、M. Lanctot、S. Dieleman、D. Grewe、J. Nham、N. Kalchbrenner、I. Sutskever、T. Lillicrap、M. Leach、K. Kavukcuoglu、T. Graepel 和 D. Hassabis,“利用深度神经网络和树搜索掌握围棋
-
D.Silver、J. Schrittwieser、K. Simonyan、I. Antonoglou、A. Huang、A. Guez、T. Hubert、L. Baker、M. Lai、A. Bolton、Y. Chen、T. Lillicrap、F. Hui、L. Sifre、G. Driessche、T. Graepel 和 D. Hassabis,“掌握没有人类知识的围棋游戏”,《自然》, 550,第 354-10 页 2017。
-
R.J. Williams,“联结主义强化学习的简单统计梯度跟踪算法”,机器学习, 8,第 229-256 页,1992 年 01 月 5 日。
-
G.A. Rummery 和 M. Niranjan,“使用连接主义系统的在线 Q-学习”,1994 年。
-
H.Hasselt,A. Guez 和 D. Silver,“双 Q 学习的深度强化学习”, CoRR, abs/1509.06461,2015。
-
Z.王,N. Freitas 和 M. Lanctot,“用于深度强化学习的决斗网络架构”, CoRR, abs/1511.06581,2015。
-
动词 (verb 的缩写)Mnih,A. P. Badia,M. Mirza,A. Graves,T. P. Lillicrap,T. Harley,D. Silver 和 K. Kavukcuoglu,“深度强化学习的异步方法”, CoRR, abs/1602.01783,2016。
-
C.J. C. H. Watkins 和 P. Dayan,“Q-learning”,机器学习,1992。
-
J.舒尔曼,s .莱文,p .阿贝耳,m .乔丹和 p .莫里茨,“信任区域政策优化”,第 32 届机器学习国际会议论文集,里尔,2015 年。
-
J.舒尔曼,f .沃尔斯基,p .达里瓦尔,a .拉德福德和 o .克里莫夫,“近似政策优化算法”, CoRR, abs/1707.06347,2017。**
