

Swift 和 TensorFlow 深度学习教程(二)
四、TensorFlow 基础知识
现在最重要的事情不再是争论 Swift 是否应该存在差异化编程(因为 Swift + ML 太重要了!),而是搞清楚应该在语言中落地的最佳形式!
—理查德·魏在推特上
这一简短的实用章节旨在介绍 Swift for TensorFlow 的一些深度学习特定功能。第 4.1 节介绍了张量数据结构的概念,它实质上是神经网络进行预测的基础。阅读本章后,你将能够加载数据集(第 4.2 节),编写自己的神经网络(第 4.3 节),训练你的模型并测试其准确性(第 4.4 节)。除了所有这些,在 4.5 节,你还将学习如何实现你自己的新层,激活函数,损失函数,和优化器。这将有助于原型化您的研究代码或实现深度学习算法的高级构建模块。本章要求对机器学习有所了解。我们建议您通过阅读第一章来更新您的概念。
4.1 张量
在第二章中,我们已经学习了标量、向量和矩阵的概念以及一些重要的运算。这里,我们将它们形象化以帮助我们理解,并引入张量的概念来概括它们。理解张量很重要,因为构成本书主题的神经网络本质上是操纵张量值来进行预测的。
张量是一种可以在 n 维空间中存储数值的数据结构,其中 n ≥ 0。有一些常见的张量如标量、向量和矩阵,它们的维数(称为秩)分别是零、一和二。当我们需要存储秩大于 2 的高维值时,我们使用术语张量。换句话说,张量概括了前面提到的所有低维数据结构。
TensorFlow 提供了用于初始化任意维度张量的Tensor类型。它提供了两个重要的实例计算属性,即rank和shape。rank属性返回一个代表Tensor实例维数的Int值。例如,vector 实例的rank为 1。shape属性返回一个代表每个维度中元素数量的Array值。比如一个包含三行两列的矩阵,有[4,3]的shape(程序化),数学上我们写成[4 × 3]。清单 4-1 展示了一些Tensor的例子,这些例子在图 4-1 中可以看到。
图 4-1
各种张量及其相应的秩和形状属性的可视化。在这里,每个方块包含一些数值
import TensorFlow
let scalar = Tensor<Float>(10)
let vector = Tensor<Float>(ones: [5])
let matrix = Tensor<Float>(zeros: [4, 3])
let tensor = Tensor<Float>(repeating: 2, shape: [4, 3, 2])
// Print `Tensor`s
print("scalar: \(scalar)")
print("vector: \(vector)")
print("matrix:\n\(matrix)")
print("tensor:\n\(tensor)")
print()
// Ranks
print("scalar rank: \(scalar.rank)")
print("vector rank: \(vector.rank)")
print("matrix rank: \(matrix.rank)")
print("tensor rank: \(tensor.rank)")
print()
// Shapes
print("scalar shape: \(scalar.shape)")
print("vector shape: \(vector.shape)")
print("matrix shape: \(matrix.shape)")
print("tensor shape: \(tensor.shape)")
print()
Listing 4-1Declare Tensor
instances of various dimensions
输出
scalar: 10.0
vector: [1.0, 1.0, 1.0, 1.0, 1.0]
matrix:
[[0.0, 0.0, 0.0],
[0.0, 0.0, 0.0],
[0.0, 0.0, 0.0],
[0.0, 0.0, 0.0]]
tensor:
[[[2.0, 2.0],
[2.0, 2.0],
[2.0, 2.0]],
[[2.0, 2.0],
[2.0, 2.0],
[2.0, 2.0]],
[[2.0, 2.0],
[2.0, 2.0],
[2.0, 2.0]],
[[2.0, 2.0],
[2.0, 2.0],
[2.0, 2.0]]]
scalar rank: 0
vector rank: 1
matrix rank: 2
tensor rank: 3
scalar shape: []
vector shape: [5]
matrix shape: [4, 3]
tensor shape: [4, 3, 2]
请注意,Tensor是一个泛型类型,需要我们为占位符类型Scalar传递类型。占位符类型Scalar的类型是在初始化期间在尖括号中提供的,尖括号允许我们在那个Tensor实例中存储指定Scalar类型的元素。例如,清单 4-1 中声明的所有张量对于Scalar都有一个Float类型。注意Scalar是符合TensorFlowScalar协议的Tensor的类型占位符,因为Float符合那个协议,我们可以将Scalar设置为Float类型。
在清单 4-1 中,我们声明了不同等级和形状的各种张量,然后打印出来用于演示。注意,Tensor类型有各种各样的初始化器可以灵活初始化。我们声明scalar、vector、matrix和tensor为Tensor的实例。scalar实例的rank为 0,而shape为[ ]。vector实例的rank为 1,而shape为[5]。matrix实例有 2 的rank和【4,3】的shape,即四行三列。tensor实例有 3 的rank和[4,3,2]的shape。所有这些情况都可以在图 4-1 中看到。
接下来,我们讨论 TensorFlow 中的数据集加载。
4.2 数据集加载
在撰写本文时,TensorFlow 允许加载图像和文本域中的各种数据集。但是我们会关注图像数据集。在加载这些数据集之前,您需要在 Xcode Swift 包的 Package.swift 文件中添加 swift-models 包,如下所示,或者您可以在 Xcode 项目设置中添加包 URL:
.package(name: "TensorFlowModels",
url:
"https://github.com/tensorflow/swift-models.git", .branch("master"))
如果你正在使用谷歌实验室,那么在你的 Jupyter 笔记本的顶部写下以下声明:
%install '.package(url: "https://github.com/tensorflow/swift-models", .branch("master"))' Datasets
这将加载 tensorflow/swift-models 存储库,并仅构建数据集库。但是如果你想建立其他的库,比如 TrainingLoop 和 Checkpoints,那么就把它们写在 Datasets 被写的地方,但是用一个空格分开。现在,我们可以导入数据集库,如下所示:
import Datasets
在整本书中,我们隐含地假设这个 import 语句是在我们加载任何数据集的地方编写的。现在让我们看一下与数据加载相关的一些概念。
4.2.1 时期和批次
有两个与数据集采样相关的主要概念,即时期和小批量(或简称为批量)。
批次是一组单独的数据样本,其中批次大小定义了该批次中样本的数量。例如,批量大小为 64 的一批图像(每个图像的形状为[256 × 128 × 3],其中 256 是高度(或行数),128 是宽度(或列数),3 是颜色通道数)的形状为[64 × 256 × 128 × 3]。在训练期间,一批数据样本与相应的目标标签一起通过模型进行预测(如果我们正在进行监督学习)。
epoch 是模型批量体验整个数据集的次数。单个历元包含一系列不同的多个批次(形成整个数据集),我们在训练样本批次的过程中对其进行迭代。对于随机学习,我们通常在每个历元迭代期间洗牌。
let dataset = MNIST(batchSize: 64)
let epochCount = 2
epochLoop: for (epochStep, epoch) in dataset.training.prefix(epochCount).shuffled().enumerated() {
batchLoop: for (batchStep, batch) in epoch.enumerated() {
let data = batch.data
let label = batch.label
print("epochStep: \(epochStep) | batchStep: \(batchStep) | data shape: \(data.shape) | label shape: \(label.shape)")
break epochLoop
}
}
Listing 4-2Demonstrate epochs
and batches
输出
epochStep: 0 | batchStep: 0 | data shape: [64, 28, 28, 1] | label shape: [64]
让我们来分解清单 4-2 中发生的这么多事情。首先,我们在dataset常量中加载批量为 64 个样本的MNIST数据集。然后我们宣布epochCount中的纪元数量为 2。
首先,我们有一个标记为epochLoop的纪元循环。我们使用prefix(_:)实例方法遍历dataset的training实例计算属性,该方法接受历元数(这里是epochCount,并在每个迭代步骤中依次返回一个batch数据点。在每一步,我们还用随机抽样的shuffled()实例方法打乱批次顺序。
然后我们有一个标记为batchLoop的批处理循环。我们遍历一个epoch实例中的每个batch。在batchLoop的主体中,我们从batch实例中提取data和label实例存储的属性。然后我们打印出这两者的shape以及epochLoop和batchLoop的迭代步骤。
我们在两个循环中都使用了enumerated()方法来获取序列中迭代元素的索引。我们为for-in循环定义了epochLoop和batchLoop标签,作为控制流语句的参考。你可以把epochLoop和batchLoop看作是循环的名字。如果我们简单地编写了break语句,后面没有任何带标签的循环语句,那么 epoch 循环将执行两次,batch 循环将执行一次,也就是说,这将只停止 batch 循环执行多次。通过编写break epochLoop,我们告诉编译器简单地停止 epoch 循环本身的迭代,并执行其右花括号后的代码。
这里,我们加载 MNIST 数据集(LeCun,1998),它是从 0 到 9 的手写数字(每个图像一个)及其相应标签的灰度图像的集合。它们是由不同的人写的。正如我们在前面的清单中从shape看到的,每张图像的高度和宽度都是 28 像素,只有一个颜色通道使其成为灰度。这个数据集中的每个样本都是一个表示图像像素值(如Tensor<Float>)的data和其对应的label值(如Tensor<Int32>)的元组。
机器学习算法的另一个重要部分是接下来讨论的模型定义。
4.3 定义模型
我们可以很容易地定义模型架构,其属性可以在训练过程中进行区分。TensorFlow 中定义模型的方式主要有两种,一种是使结构符合特殊协议,另一种是使用受 Keras 启发的Sequential结构。
神经网络协议
TensorFlow 提供了两种协议,即Layer和Module,用于定义神经网络。可区分的模型定义结构必须符合这些协议中的任何一个。这些协议要求我们提供模型的Input和Output类型的实现为typealias,定义callAsFunction(_:)方法,并声明至少一个Layer -或Module-符合或Sequential实例属性,其参数将在训练期间更新。
例如,让我们定义一个称为 LeNet 的卷积神经网络(LeCun 等人,1998)。
struct LeNet: Layer {
typealias Input = Tensor<Float>
typealias Output = Tensor<Float>
var convBlock = Sequential {
Conv2D<Float>(filterShape: (5, 5, 3, 6), activation: relu)
MaxPool2D<Float>(poolSize: (2, 2), strides: (2, 2))
Conv2D<Float>(filterShape: (5, 5, 6, 16), activation: relu)
MaxPool2D<Float>(poolSize: (2, 2), strides: (2, 2))
}
var flatten = Flatten<Float>()
var denseBlock = Sequential {
Dense<Float>(inputSize: 16 * 5 * 5, outputSize: 120, activation: relu)
Dense<Float>(inputSize: 120, outputSize: 84, activation: relu)
Dense<Float>(inputSize: 84, outputSize: 10, activation: identity)
}
@differentiable
func callAsFunction(_ input: Input) -> Output {
input.sequenced(through: convBlock, flatten, denseBlock)
}
}
Listing 4-3Define the LeNet model by conforming to the Layer protocol
我们使用 Swift 的关键字typealias定义了两个类型别名。这让我们可以在任何可以使用现有类型的地方使用现有类型的新名称。我们为Tensor<Float>类型定义了Input和Output类型名称。然后我们定义多个符合Layer协议的神经层,例如Flatten、Dense和Conv2D。这里,Dense是一个密集连接层(在 5.3.1 小节中解释过),Conv2D是一个卷积层(在 6.1 节中解释过),Flatten层只是对Conv2D层(这里)的输出张量进行整形,使其成为秩为 2 的批量向量。然后我们定义可微分的callAsFunction(_:)方法,它接受类型Input的输入并返回一个Output类型的值。在主体内部,我们在实例input上使用sequenced(through:)实例方法。sequenced(through:)是在Differentiable协议上定义的协议方法,因此可以被任何符合它的类型访问。它接受逗号分隔的符合Differentiable的实例,并通过它们顺序处理input。也就是说,在这里,input首先由convBlock实例处理,其输出然后由flatten处理,然后其输出最终由denseBlock处理,后者再次返回类型为Tensor<Float>的新输出。这个输出然后由这个函数返回。注意,如果函数体、闭包、计算属性或返回某个值的下标中只有一个语句,我们可以去掉return关键字。
接下来,我们解释这里使用的Sequential结构。
层的顺序
我们可以用 TensorFlow 中定义为结构的Sequential轻松定义一个多层神经网络。你可能会从 Keras 的设计中发现它的相似之处。
我们已经使用Sequential定义了清单 4-3 中的convBlock和denseBlock。这样,我们可以简单地将多个神经层传递到 Sequential,每个神经层在不同的行中,后跟左花括号。我们甚至不需要像在协议一致性中那样定义callAsFunction(_:)实例方法。对Sequential实例的输入从第一层(最靠近左花括号)到最后一层(最靠近右花括号)依次处理。如 5.3.1 小节所述,神经网络中的小序列层被称为神经块,例如,convBlock和denseBlock就是我们所说的神经块的典型例子。
加载数据集并定义模型后,现在让我们看看如何在数据集上训练模型。
4.4 培训和测试
在本节中,我们首先介绍 TensorFlow 中模型可微分参数的检查点。我们还使用定制的训练循环在 CIFAR-10 数据集上训练我们的 LeNet 模型。然后,我们再次用 Keras 风格的训练方法训练我们的模型。
4.4.1 检查点
训练神经网络是一项耗费精力和时间的任务。根据数据集和神经网络的大小,模型训练可以从几分钟到甚至几个月不等!训练找到模型的一组新参数值,对于该组新参数值,数据集具有非常低的损失值和高精度(在分类的情况下)。我们不希望我们花在训练模型上的时间被浪费。所以我们可以把最优的参数值写在磁盘上保存训练进度。这被称为检查点。当我们需要使用训练好的模型进行推理(例如,图像分类)时,我们可以简单地将参数从磁盘读入模型,并通过训练好的模型传递要分类的图像。
TensorFlow 允许我们创建模型的检查点。我们只需要使我们的模型结构符合Checkpointable协议。我们不需要写任何东西,只需要在Checkpointable后面加上左花括号和右花括号(见清单 4-4 ),所有在模型实例上可调用的方法都可以用于检查点目的。这之所以成为可能,是因为在Checkpointable协议中实现了检查点方法。
extension LeNet: Checkpointable {}
Listing 4-4Conform LeNet to the Checkpointable protocol
我们只是用扩展使LeNet符合Checkpointable!让我们声明一个目录的路径,我们希望在这个目录中读写检查点。这是通过从基础模块中定义URL实例来完成的,如清单 4-5 所示。
import Foundation
let checkpointDirectory = URL(
fileURLWithPath: "/Users/rahulbhalley/Desktop/Checkpoints",
isDirectory: true)
Listing 4-5Declare directory location for checkpointing the model
我们将isDirectory设置为true,以确保这个位置指向目录而不是任何文件。writeCheckpoint(to:name:)和readCheckpoint(from:name:)都可能抛出错误,所以我们将使用一个do - catch块进行错误处理,并用try关键字调用这些方法。我们将在下面训练模型时直接演示这一点,而不是在这里演示。
4.4.2 模型优化
让我们用随机梯度下降来训练我们的 LeNet 并节省检查点。清单 4-6 演示了培训。
// Define the default device
let device = Device.defaultXLA
// Load CIFAR 10 dataset
let dataset = CIFAR10(batchSize: 128, on: device)
// Initialize the LeNet model
var model = LeNet()
model = .init(copying: model, to: device)
// Initialize the optimizer
var optimizer = SGD(for: model, learningRate: 0.01, momentum: 0.9)
optimizer = .init(copying: optimizer, to: device)
Listing 4-6Train the LeNet model and save checkpoints
首先,我们声明一个默认的 XLA 设备,所有的处理都将在这个设备上进行。我们将 CIFAR-10 数据集加载到dataset常量中,并将其放在device上。然后我们在model变量中初始化我们的LeNet,并将其复制到device。最后,我们为model to初始化 SGD 优化器(也复制到device),使0.01的learningRate和0.9的momentum(在 5.6.2 小节中解释)。
func trainingStep(samples: Tensor<Float>, labels: Tensor<Int32>) {
// Compute gradients
let 𝛁θmodel = gradient(at: model) { model -> Tensor<Float> in
let logits = model(samples)
let loss = softmaxCrossEntropy(logits: logits, labels: labels)
return loss
}
optimizer.update(&model, along: 𝛁θmodel)
}
Listing 4-7Define one training step for the model
在清单 4-7 中,我们定义了一个函数trainingStep(samples:labels:),它接受samples和它们的labels作为参数。它为传递给model的samples计算logits,然后与labels一起用于计算 softmax 交叉熵损失。gradient(at:in:)函数将model作为at参数标签的一个参数,并接受一个闭包,该闭包计算并返回logits和labels之间的损失,这个过程在前一行中描述过。然后计算相对于model所有参数的标量损耗梯度。最后,optimizer沿着其梯度𝛁θ model的方向更新model的可微参数。这结束了一个训练步骤。
func trainingLoop(epochCount: Int = 5) {
epochLoop: for (epochStep, epoch) in dataset.training.prefix(epochCount).enumerated() {
batchLoop: for (batchStep, batch) in epoch.enumerated() {
// Get data
let samples = Tensor<Float>(copying: batch.data, to: device)
let labels = Tensor<Int32>(copying: batch.label, to: device)
// Training step
trainingStep(samples: samples, labels: labels)
}
// Print statistics
print("epoch: \(epochStep + 1)/\(epochCount)\ttest accuracy: \(testAccuracy)")
// Write checkpoint
do {
try model.writeCheckpoint(to: checkpointDirectory, name: "\(type(of: model))")
} catch {
print(error)
}
}
}
// Train the model
trainingLoop()
Listing 4-8Define a training loop executable for multiple epochs
输出
epoch: 1/5 test accuracy: 0.5064
epoch: 2/5 test accuracy: 0.5618
epoch: 3/5 test accuracy: 0.5933
epoch: 4/5 test accuracy: 0.6088
epoch: 5/5 test accuracy: 0.6187
在清单 4-8 中,我们定义了一个名为trainingLoop(epochCount:)的训练循环函数,它将历元数作为参数(默认epochCount为 5)。我们已经解释了数据采样(见 4.2 节)。对于每个batch,我们通过将采样的samples和labels传递给trainingStep(samples:labels:)函数来执行单个训练步骤。在每个epoch之后,我们在验证数据集上打印与模型准确性相关的统计数据,并且我们还将训练好的模型的参数写入到checkpointDirectory目录中,其中name是模型的类型,即 LeNet。因为检查点写入和读取方法都可能抛出错误,所以我们在一个do - catch块中使用了try语句。
var testAccuracy: Float {
let totalSamples = 10000
var correct = 0
for batch in dataset.validation {
let (data, label) = (batch.data, batch.label)
let prediction = softmax(model(data)).argmax(squeezingAxis: 1)
for index in 0..<data.shape[0] {
if prediction[index] == label[index] { correct += 1 }
}
}
return Float(correct) / Float(totalSamples)
}
Listing 4-9Define a computed property to calculate accuracy of the model on a validation set
在清单 4-9 中,我们声明了一个唯一可获取的计算属性testAccuracy,它计算validation集合上model的精度。我们将验证集中的样本总数设置为 10000,并从零个correct分类开始。遍历validation集合中的所有批次,我们生成prediction,并将其与每个对应的label进行比较,如果prediction与label匹配,则有条件地将correct变量加 1。请注意,我们在 softmax 激活的 logits 上使用argmax(squeezingAxis:)方法来获取包含具有最高值的元素的向量的索引(请记住第一章中的内容,一个独热编码向量中的每个索引都属于某个类)。最后,我们返回正确分类的分数。
对模型进行训练后,我们得到 LeNet 在 CIFAR-10 上的训练精度等于 0.6187。
4.4.3 训练循环
您可能已经注意到,定义训练步骤和循环、准确性属性以及其他内容会使程序变得稍微复杂一些。我们可以使用 swift-models 包中的 TrainingLoop 库来使我们的程序变得更小。它的灵感也来自 Keras 训练设计。训练循环目前集中在分类任务上。
让我们从头开始复制前面的程序,看看 TrainingLoop 是如何运行的。
import Datasets
import TensorFlow
import TrainingLoop
// Configurations
let epochs = 5
let device = Device.defaultXLA
// Load CIFAR 10 dataset
let dataset = CIFAR10(batchSize: 128, on: device)
// Initialize the LeNet model
var model = LeNet()
// Initialize the optimizer
var optimizer = SGD(for: model, learningRate: 0.01, momentum: 0.9)
// Train and test the model
let trainingProgress = TrainingProgress()
var trainingLoop = TrainingLoop(
training: dataset.training,
validation: dataset.validation,
optimizer: optimizer,
lossFunction: softmaxCrossEntropy,
callbacks: [trainingProgress.update])
try! trainingLoop.fit(&model, epochs: epochs, on: device)
Listing 4-10Training LeNet on MNIST with the TrainingLoop library
在清单 4-10 中,我们导入了数据集、TensorFlow 和 TrainingLoop。然后我们声明一些配置,比如将epochs设置为5,将device设置为Device.defaultXLA。数据集、模型(使用清单 4-9 中的LeNet结构)和optimizer被初始化,如清单 4-9 所示。
然后我们声明TrainingProgress类的trainingProgress实例,它跟踪与训练和测试相关的统计数据,比如损失和准确性。我们定义的下一个变量是trainingLoop,它将训练集和验证集、优化器、损失函数(这里是softmaxCrossEntropy)和回调作为参数。然后我们调用trainingLoop上的fit(_:epochs:on:)方法,将模型作为inout参数、epochs和device进行传递,我们希望对其进行训练。这将执行训练过程并实时打印统计数据,而无需编写复杂的函数。训练完成后,该模型在训练集和验证集上的精度分别为 0.5607 和 0.5625。
注意,当使用 TrainingLoop 进行训练时,我们不需要将model和optimizer复制到device;fit(_:epochs:on:)方法为我们处理这一切。另一个需要注意的重要事情是,callbacks参数在循环的各种事件的训练过程中执行一系列函数。这里,我们只传递了统计跟踪函数,但是我们将看到如何通过定义我们自己的回调函数来保存检查点!
4.5 从零开始进行研究
在本节中,我们实现了密集层、swish 激活函数、 L 、 1 损失函数和随机梯度下降优化器。这些例子演示了当某些东西还不能开箱即用时,如何实现自己的层、激活函数、损失函数和优化器,以用于研究或生产目的。这些例子也鼓励使用各种协议。我们鼓励您阅读 TensorFlow 的 API 文档 1 和代码库 2 、 3 、 4 ,以更深入地理解这些和许多其他协议。
4.5.1 层
定义新的神经层类似于我们定义自己的神经网络。我们不使用Sequential,而是让结构符合Layer或Module协议。尽管Differentiable协议可以实现与我们在 5.2 节构建线性模型时看到的相同的行为。现在,让我们通过使我们的结构符合Layer协议来定义密集层(见 5.3.1 小节)。
struct DenseLayer<Scalar: TensorFlowFloatingPoint>: Layer {
typealias Input = Tensor<Scalar>
typealias Output = Tensor<Scalar>
var weight: Tensor<Scalar>
var bias: Tensor<Scalar>
init(inputSize: Int, outputSize: Int) {
weight = Tensor<Scalar>(randomNormal: [inputSize, outputSize])
bias = Tensor(zeros: [outputSize])
}
@differentiable
func callAsFunction(_ input: Input) -> Output {
matmul(input, weight) + bias
}
}
Listing 4-11Define the
dense layer
DenseLayer是一个泛型,其Scalar类型占位符符合TensorFlowFloatingPoint,DenseLayer本身符合Layer。然后我们定义了Tensor<Scalar> type的两个类型别名,即Input和Output,在可微分的callAsFunction(_:)实例方法中我们用它们作为我们稠密层的输入和输出类型。DenseLayer还有两个Tensor<Scalar>类型的存储属性,即weight和bias,是该层的参数。DenseLayer的初始化程序接受层的输入和输出特征的数量。该信息随后用于初始化weight和bias参数属性。最后,在正向传递期间,callAsFunction(_:)接受输入,对其执行仿射变换(即,input和weight与matmul(_:_:)函数矩阵相乘,并加上bias),并返回输出。
激活功能
在对输入进行仿射变换之后,我们应用激活函数。许多激活函数分别变换张量的每个元素。图 4-2 所示的 swish 函数(Ramachandran 等人,2017)是激活函数的一个很好的例子。它由以下等式给出:
图 4-2
β = 1 及其导数(橙色)的 swish 激活函数图(蓝色)
这里, β 是一个可学习的或常数项。这一项通常设置为等于 1。因此 swish 函数变成如下:
清单 4-12 演示了如何声明自己的激活函数(这里是 swish 激活函数)。
@differentiable
func swishActivation<Scalar: TensorFlowFloatingPoint>(_ input: Tensor<Scalar>) -> Tensor<Scalar> {
input * sigmoid(input)
}
Listing 4-12Define the swish activation function
因为我们希望激活函数swishActivation(_:)是可微分的,所以我们用属性@differentiable来标记它。我们声明一个符合TensorFlowFloatingPoint的泛型类型Scalar。这个函数接受input参数并返回Tensor<Scalar>类型的输出。在swishActivation(_:)的主体中,我们将input与经过 sigmoid 函数转换的input按元素相乘,并返回输出。我们可以在任何神经层的输出之后使用这个激活函数。
损失函数
模型参数的值更新的方向由神经网络的预测(也称为 logits)和关于每个参数的相应目标(也称为标签)之间的损失梯度来引导。
在这里,我们描述如何在 TensorFlow 中实现自己的损失函数。我们展示了由以下等式给出的 L 1 损耗的简单实现。L1loss 计算逻辑和标签的每个元素之间的平均绝对误差(MAE ):
这里, y i 和 t i 分别是第 i 个索引逻辑和目标, k 是这些向量中每一个的元素个数。运算符∨。∑计算绝对值,即将向量的任何值的负号转换为正号。清单 4-13 展示了L1 损失的实现。
@differentiable(wrt: logits)
func l1Loss<Scalar: TensorFlowFloatingPoint>(
logits: Tensor<Scalar>,
labels: Tensor<Scalar>
) -> Tensor<Scalar> {
abs(labels - logits).mean()
}
Listing 4-13Define the L2 loss function
这里,l1Loss(logits:labels:)函数将logits和labels作为输入参数,并返回一个类型为Tensor<Scalar>的值,其中Scalar是一个符合TensorFlowFloatingPoint的类型占位符。这个闭包的主体计算logits和labels的对应元素之间的差,然后取其绝对值,并找到它们的平均值。
在训练期间,我们计算关于模型的每个参数的损失梯度,这给了我们最陡上升的方向。我们的目标是最小化损失函数,损失函数简单地由模型的预测和目标组成,因此我们在梯度的负方向上在参数空间中采取小的步骤。这被称为基于梯度的优化,在 5.1 节中讨论。接下来,我们看看如何在 TensorFlow 中定义我们自己的优化器。
优化器
我们可以通过使新的优化器class符合Optimizer协议来定义新的优化器。清单 4-14 通过重新定义随机梯度下降(SGD)优化器证明了这一点。
class SGDOptimizer<Model: Differentiable>: Optimizer
where Model.TangentVector: VectorProtocol & ElementaryFunctions & KeyPathIterable, Model.TangentVector.VectorSpaceScalar == Float
{
// The learning rate
var learningRate: Float
init(for model: Model, learningRate: Float) {
self.learningRate = learningRate
}
func update(_ model: inout Model, along direction: Model.TangentVector) {
model.move(along: direction.scaled(by: -learningRate))
}
required init(copying other: SGDOptimizer<Model>, to device: Device) {
learningRate = other.learningRate
}
}
Listing 4-14Define the stochastic gradient descent optimizer
优化器必须始终被定义为一个类。我们定义了符合Optimizer协议的SGDOptimizer类。我们还定义了一个符合Differentiable协议的通用类型Model。然后我们为Model定义一些条件符合。我们说Model的TangentVector必须符合VectorProtocol和ElementaryFunctions,必须是KeyPathIterable。每个协议之间的&符号(&)将所有这些协议组成一个协议。虽然这实际上并没有创建任何新的协议,但是这个协议组合表现为一个单一的协议。通过这种方式,Model符合VectorProtocol(用于向量运算等等)、ElementaryFunctions(用于算术)和KeyPathIterable(用于能够通过Model实例上的KeyPath迭代其属性)。然后我们还要求Model的TangentVector的VectorSpaceScalar(顾名思义,基本上是向量空间中的标量值)是Float类型。
我们为这个名为learningRate的类声明一个实例属性,它是优化的学习率。我们声明一个初始化器,它将Model类型的model和Float类型的learningRate作为参数。这里,传递model只是为了找到Model的类型,而不是为了在优化器中使用它。这是预期的行为。讨论请参考 GitHub 问题。 5 然后,更新实例方法简单地在相对于模型参数的损失函数的梯度的负方向上更新model。它以Model.TangentVector的inout Model和along为自变量。TangentVector存储Model的梯度。inout参数反映传递给函数的实例的变化。模型上的move(along:)实例方法在用learningRate将其缩放至较小值后,在梯度的负方向更新其参数。我们总是将实例传递给前缀为&符号的inout参数。
4.6 总结
本章重点介绍了深度学习编程,并介绍了 S4TF 的 TensorFlow 库。我们从解释如何创建张量实例开始。接下来,我们看到了如何在 TensorFlow 中加载数据集。我们还学习了如何创建深度学习模型,并对其进行训练和测试。我们还创建了模型的检查点。最后,我们学习了如何在 TensorFlow 中出于研究目的从头开始创建层、激活和损失函数以及优化器。在下一章,我们将了解神经网络的基础知识。
Footnotes 1www . tensorflow . org/swift/API _ docs
2
github。com/tensorlow/swift API
3
github。com/tensorlow/swift-models
4
5
github。com/tensorlow/swift-API/issues/656
五、神经网络
我喜欢胡说八道;它唤醒了我的脑细胞。
—苏斯博士
本章涵盖了神经网络的基础知识,也就是深度学习。我们讨论如下各种基础主题:基于梯度的输入和函数参数优化(5.1 节)、线性模型(5.2 节)、深度和密集神经网络(5.3 节)、激活函数(5.4 节)、损失函数(5.5 节)、优化(5.6 节)和正则化(5.7 节)技术。最后,我们在第 5.8 节总结了这一章。
5.1 基于梯度的优化
在这一节中,我们介绍最大值、最小值和鞍点的概念。接下来,我们介绍输入和参数优化。输入优化将用于寻找函数的最大值和最小值。另一方面,参数优化将用于使用可用的函数映射数据集来查找函数本身。这两种优化在深度学习中都扮演着重要的角色,并将贯穿全书。在这里,我们主要关注在线的基于梯度的学习策略。在第 5.6 节中介绍了用于大型深度学习模型的更有效的梯度下降方法。
我们限制自己研究无约束最优化方法,因为它简单,并且满足我们演示书中提出的深度学习方法的要求。对约束优化感兴趣的读者可以参考(Deisenroth et al .,2020)教材的第 7 章。
最大值、最小值和鞍点
这里,我们考虑一个标量函数 f : ℝ → ℝ.函数在某一点的导数有三种可能的值:正、负或零。在第一种情况下,当导数在某一点为正时,则函数随着输入的增加而增加。在第二种情况下,当导数在某一点为负时,函数的输出随着输入的增加而减少。换句话说,当输入少量增加时,导数的符号给出了函数增加的方向,可以是负的,也可以是正的。在第三种情况下,当输出不随输入的变化而变化时,那么导数在该点为零。
图 5-1
方程f(x)= 5x3+2x23x描述的函数有一个最大值和一个最小值。函数上一点的正切给出了梯度的斜率
图 5-1 为蓝色函数f(x)= 5x3+2x23x及其衍生函数f'(x)= 15x2 f 上的绿点( a ,f(a)=(3/5,1.44)和( b ,f(b)=(1/3,0.59)。)(蓝线)分别是函数的最大值和最小值。在这些点上,导数为零,即f'(a)= 0,f'(b)= 0。在水平轴上,从x= 1 开始,函数增加但缓慢减少,直到达到 x = a 。如前所述,这可以通过相同输入范围 x 中的相应红色导数线来验证;导数首先很大,但慢慢减小,直到在点 x = a 处变为零。这是函数 f ()变成零。函数上一点的正切给出了梯度的斜率。
图 5-2
任意标量函数的最大值、最小值和鞍点的可视化
同理,从 x = a 到 x = b 开始,函数递减半个距离;然后对于另一半,它的变化率增加(但仍然是负的),使得它的斜率开始接近零,导数值也是如此。
函数 f (。)在 f ( a 处具有最大值,因为该函数在 x = a 前后的输出小于点 a 处的输出。形式上, f ( a ϵ)小于f(x=a)其中 ϵ 是一个小正数。另一方面,函数的最小值位于 x = b ,即 f ( b )的值最小。因为 f ( b ϵ)的值大于 f ( b ),所以函数 f (。)在 b 处有最小值。在最后一种情况下,当在一定的输入范围内时,输出 f ( x )保持不变,然后在这些输入值处的导数保持为零,满足条件f'(xϵ)= 0。该范围内的所有点称为鞍点。简单来说,在最大值,最小值,鞍点 x ,函数 f 的导数(。)始终为零,即f'(x)= 0。
最大值、最小值和鞍点的概念(见图 5-2 )不仅仅限于一元函数,也同样适用于高维函数,尽管很难在平面上可视化(如一张纸)。
输入优化
在高中,通常遇到的数学问题如下:找出给定固定函数输出最小值和最大值的输入值。这些值分别被称为函数的最小值和最大值,如前所述。我们还知道,函数输出对输入的导数描述了输入增加时输出的变化率。
我们可以利用导数的方向信息,在数值上找到固定函数的最大值或最小值。例如,可以通过在输出相对于输入的导数的负方向上以小步长迭代地更新(或优化)输入值来找到函数的最小值(因为导数给出了函数增加最多的方向)。我们可以把基于梯度的最优化(柯西,1847)方程写成:
(5.1)
我们已经在方程 1.8 中遇到了一个更新函数参数的类似方程。这里,我们在多个步骤中迭代更新函数 f 的输入变量 x 的值。在这个等式中, η 是一个在范围(0,1)内的小正数,称为步长(或学习速率,在深度学习文献中, τ 表示时间步长,使得x(τ+1)是 x 在时间步长( τ + 1)的值
另一方面,有时我们可能需要找到一个函数的最大值。在这种情况下,我们可以简单地以小的步长在与导数相同的方向上移动输入,由下面的等式描述:
(5.2)
在基于梯度的优化中, η 项起着非常重要的作用。我们希望找到遵循输入更新的平滑轨迹的最佳输入值。因为导数在某一点上通常有一个大值,所以更新可能遵循一个不规则的轨迹,在最佳值附近表现出有弹性的行为。为了缓解这个问题,我们用 η 项缩小了导数值,这有助于按照平滑的更新轨迹更新值。
在清单 5-1 中,我们将最大化函数f(x)= 5x3+2x23x。
var x: Float = 0
let η: Float = 0.01
let maxIterations = 100
@differentiable
func f(_ x: Float) -> Float {
return 4 * pow(x, 3) + 2 * pow(x, 2) - 3 * x
}
print("Before optimization, ", terminator: "")
print("x: \(x) and f(x): \(f(x))")
Listing 5-1Declare configuration variables and function f(x) = 5x3 + 2x2 − 3x to demonstrate maxima and minima optimization
输出
Before optimization, x: 0.0 and f(x): 0.0
我们先定义前面的函数f(x)= 5x3+2x2—3x。我们通过用@differentiable属性标记它来使它可区分。然后Float类型的输入变量x的初始值被设置为 0,步长η被定义为设置为 0.01 的Float常数。我们可以看到优化前函数的输入输出值为零。
// Optimization loop
for iteration in 1...maxIterations {
/// Derivative of `f` w.r.t. `x`.
let 𝛁xF = gradient(at: x, in: { x -> Float in
return f(x)
})
// Optimization step: update `x` to maximize `f`.
x += η * 𝛁xF
}
print("After gradient ascent, ", terminator: "")
print("input: \(x) and output: \(f(x))")
Listing 5-2Find the maxima of the function f(x) = 5x3 + 2x2 − 3x
```py
**输出**
After gradient ascent, input: -0.5999994 and output: 1.4399999
清单 5-2 展示了寻找最大值的优化过程。我们迭代`maxIterations`,逐渐优化输入`x`。在每个迭代步骤中,我们计算函数`f`相对于输入`x`的导数,并将其存储在常数𝛁 `xF`中。使用`gradient(at:in:)`功能计算导数。参数标签`at`和`in`将输入`x`和一个返回标量的闭包作为参数。闭包以`x`为参数,返回`Float`计算`f(x)`。Swift 自动为我们计算出`f`相对于`x`的导数。输入`x`的优化更新步骤简单地将`η`缩放的导数加到自身上。我们可以很容易地验证优化的输入值`x`非常接近函数`f(x)`的最大值,如图 5-1 所示。
初始化可优化变量的值时必须谨慎。如果我们将`x`初始化为 1,那么就不可能找到函数 *f* ( *x* )的局部最大值,因为它的全局最大值在无穷远处。需要注意的是,在最小化的情况下,在深度学习的背景下,我们实际上希望找到函数的全局最小值(或给定数据集的最小值函数),但实际上我们只能找到与其更接近的局部最小值。所以这个函数不是一个很好的例子,但仍然展示了,在简单的标量实值空间中,当我们训练大型深度学习模型时,数百万或数十亿个变量可能会发生什么。
尽管在步长`η`前加一个负号来计算最小值很简单,但在清单 5-3 中,我们来看看 Swift 中微分闭包的优秀设计。这也可以被认为是采用 Swift 进行深度学习的动机之一。
// Optimization loop
for _ in 1...maxIterations {
/// Derivative of f w.r.t. input.
let 𝛁xF = gradient(at: x) { x in f(x) }
// Optimization step: update x to minimize f.
x.move(along: 𝛁xF.scaled(by: -η))
}
print("After gradient descent, ", terminator: "")
print("input: (x) and output: (f(x))")
Listing 5-3Find the minima of the function f(x) = 5x3 + 2x2 − 3x
**输出**
After gradient descent, input: 0.33333316 and output: -0.5925926
我们首先通过再次执行清单 5-1 将所有变量重置为初始值。注意,清单 5-3 中的大部分代码与清单 5-2 中的相似。但是我们在`gradient(at:in:)`函数中为`in`参数标签使用了尾随闭包。我们还省略了返回类型信息,因为编译器可以从上下文中推断出来,也就是说,当我们在闭包体内的`in`关键字后调用`f(x)`时,使用返回值的类型。同样,当函数只有一条语句并且返回某个值时,我们可以省略`return`关键字,使代码可读性更好。此外,闭包的主体只有一行,所以我们把它压缩成一行代码。有关函数和闭包的更多信息,请参见第 3.4 节。
最后,我们在`Float`类型上使用`move(along:)`方法。Swift 对`move(along:)`的文档描述说,“沿着给定的方向移动`self`。在黎曼几何中,这相当于指数地图,在测地曲面上沿着给定的切向量移动`self`。”Swift 类型系统中的每一个可微分类型都自动获得了`move(along:)`方法的实现。该方法将与可微分变量相关联的值`TangentVector`作为参数,并更新变量本身。这里,`f`相对于`x`的导数是𝛁 `xF`,并且具有类型`Float.TangentVector`。我们将它传递给`move(along:)`,在这里𝛁 `xF`首先被负步长`-η`缩放,以找到函数`f`的最小值。经过输入的迭代优化,我们最终近似函数的极小值接近真实极小值。
接下来,我们介绍参数优化,并解释它与输入优化有何不同和相似之处。
### 参数优化
通常,在深度学习中,我们的目的是优化可微函数。这是通过优化函数的系数(也称为*参数*)而不是输入来实现的。我们还得到一组固定的包含输入和目标对的训练数据点。这些对是从一些未知的数据生成概率分布中采样的。我们的目标是使用可用的数据集来近似这个数据生成分布。我们通过最大化函数和数据集参数的对数似然性(见 1.3 节)来做到这一点,因为数据集在统计上代表了数据生成分布。换句话说,我们在由一组可变参数和方程结构限制的函数空间中搜索一个函数,该函数是数据生成函数的良好近似,因此对于给定的一组输入,它预测的输出更接近其对应的目标值。
#### 5.1.3.1 推论
以苹果设备上的照片应用为例。Photos 应用程序使用深度学习模型来处理设备上的图像和视频,以预测对象、场景、人脸、动物等,并允许搜索带文本的媒体内容。这就叫推断。形式上,对于给定的输入样本(例如图像),预测输出(例如图像的类别)的过程被称为*推理*(或*正向传递*)。一个稍微复杂一点的推理例子是语音处理。当你对 Siri、Google Assistant 或其他语音助手说话时,你的语音会被发送到各自公司的服务器(有时在设备上)上进行处理,通过一系列部署的经过训练的自然语言处理(NLP)模型进行预测,这些模型包括但不限于语音识别、语法分析和词性标注。不同模型做出的预测代表不同的东西。例如,语音识别模型预测说出的单词序列;词性标注模型将不同的单词标记、分类或归类为名词、副词等。有趣的是,我们已经在前面的文章中看到了推理的作用。当我们在清单 5-1 、 5-2 和 5-3 中预测最优输入值的标量输出时,我们推断出了我们的模型。描述推理过程的图形见图 5-3 。

图 5-3
一种推理过程,其中输入 x 被提供给模型函数 f(.)来预测输出 y
但是在我们的模型准备好做出正确的预测之前,它必须通过接下来讨论的基于梯度的参数优化过程来训练。
#### 5.1.3.2 优化
我们首先考虑参数优化的问题陈述。正如前面已经讨论过的,我们在一个数据集中有一组输入和输出对,这些输入和输出对是从一些未知的数据分布中抽取的。设计任何机器学习算法的基本目标都是用我们选择的一些参数化密度函数(也称为*模型*)来近似真正的数据生成函数。换句话说,我们希望学习从输入到它们相应的目标值的映射。
让我们首先澄清输入和参数优化问题之间的区别。为了更清楚地区分这些问题,我们使用同一个函数 *f* (。)作为运行实例。在输入优化中,我们有一个具有固定参数集的函数,我们更新输入值,直到找到给定函数返回零输出的那个值,从而给出函数的最小值或最大值。相比之下,在参数优化中,我们在数据集中获得了一组固定的输入和目标对,以及一个我们自己选择的参数化函数,其系数可以更新。这里,我们的目标是找到一个最能代表输入和目标的映射的函数,换句话说,就是最接近数据生成函数的函数。
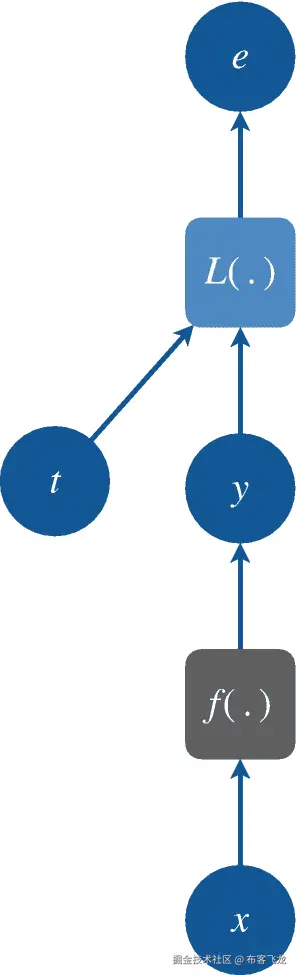
图 5-4
损失函数映射 L(y,t)其中 y = f(x)和 t 分别是预测和目标变量。最终的输出变量 e 称为误差或损失,我们希望将其最小化
乍一看,与输入优化类似,人们可能会考虑通过优化参数来解决这个问题,以便为给定数据集找到最小值函数。在最小化的情况下,可以通过迭代地进行以下更新来找到该函数,直到我们搜索的函数发出的输出值对于给定的数据集接近于零:
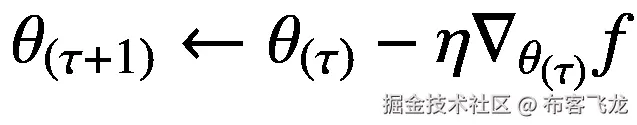
(5.3)
这里我们表示函数 *f* 的参数(。)加上一个希腊字母 *θ* (称为θ)。如果我们假设函数形式为*f*(*x*)=*ax*<sup>3</sup>+*bx*<sup>2</sup>+*CX*由系数 *a* 、 *b* 和 *c* 参数化,那么 *θ* = { *a* 前面的等式单独更新每个参数值。
请注意,等式 5.3 仅考虑输入,而不考虑其对应的目标。这仅仅意味着找到从输入到零的函数映射, *f* : *x* → 0,而我们希望近似映射 *f* : *x* → *t* ,其中 *x* 和 *t* 分别是输入和目标变量。映射*f*:*x*→*0*并不是真正想要的解决方案,因为它不代表数据集映射。
那么,我们如何找到所需的数据集映射呢?为了找到映射,我们改为在我们的方程中引入损失函数 *L* ( *f* ( *x* ), *t* )来近似未知的数据生成函数映射(见图 5-4 )。损失函数有助于学习我们的模型 *f* 的映射。),间接的。它告诉我们的模型的预测 *y* 距离给定输入 *x* 的目标 *t* 有多远。它将模型的预测值和目标值作为参数,并为变量 *e* 返回一个标量值,表示预测值和目标值之间的距离(或误差)。我们努力使用关于损失函数的每个参数的梯度信息来最小化误差项 e。如果我们通过梯度下降技术优化我们的损失函数以最小化这个误差,我们的预测将逐渐开始接近期望的目标。作为这个优化过程的结果,我们将能够自动找到数据集所表示的函数映射。换句话说,我们将能够在由模型方程描述的有限函数空间中,近似表示数据生成 PDF 的函数,从该函数中对给定数据集进行采样。
我们只需要计算损失函数相对于模型参数的偏导数,然后通过梯度下降过程迭代更新这些参数,如方程 5.4 所述。这样做,直到损失函数发出模型预测和期望目标之间的误差,对于数据集中给定的相应输入样本更接近于零:
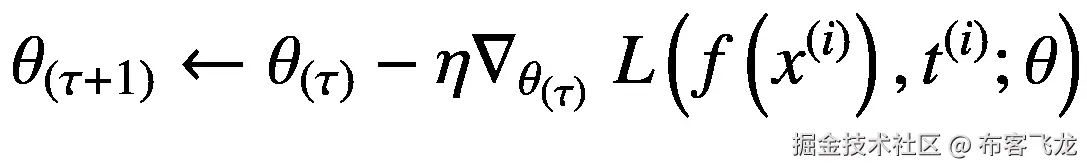
(5.4)
因为我们正在处理一个回归问题,使用一个被称为误差平方和的流行损失函数是合适的,它由方程 5.5 :
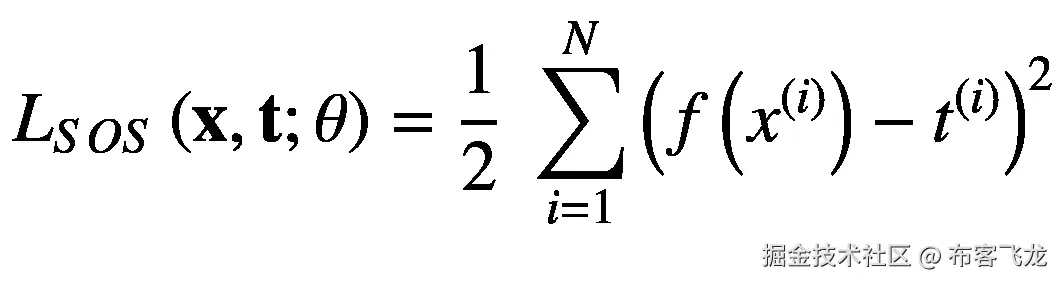
(5.5)描述
这个损失函数总是返回一个非负输出。仅当预测等于目标值时,它返回的最小值为零,这意味着预测函数完全复制了数据生成函数的映射。清单 5-4 显示了如何计算标量目标 *t* 和预测 *y* 之间的误差平方和。
```py
@differentiable
func sumOfSquaresError(_ t: Float, _ y: Float) -> Float {
0.5 * pow(t - y, 2)
}
Listing 5-4Sum of squared errors function
我们用属性@differentiable标记sumOfSquaresError(_:_:)。类似于等式 5.5 ,我们将目标t和预测y之间的差提高到 2 的幂,然后减半。
让我们在清单 5-5 中定义我们的数据生成函数。
/// Data generating function
func g(_ x: Float) -> Float {
4 * powf(x, 3) + 2 * powf(x, 2) - 3 * x
}
Listing 5-5Data-generating function g(x) = 5x3 + 2x2 − 3x
我们将模型函数声明为一个存储了可微分属性的结构,如清单 5-6 所示。
struct Function: Differentiable {
var a, b, c: Float
init() {
(a, b, c) = (1, 1, 1)
}
func callAsFunction(_ x: Float) -> Float {
a * pow(x, 3) + b * pow(x, 2) - c * x
}
}
Listing 5-6Declare a model as a Function structure
当我们对这个损失函数的输出 e (称为误差)对预测输出进行偏导数时,我们得到一个简单的偏导数如下:
(5.6)
如果我们的模型是一个深度神经网络,那么这个误差通过关于先前变量的微分链规则进一步反向传播,然后在链的更深处传播,等等。在 Swift 中,这是通过使用一种称为算法微分的更通用的偏导数计算技术来完成的(参见第 3.3 节)。
在通过损失函数进行参数优化的更有意义的问题公式化之后,参数更新方程 5.3 现在变成如下:
(5.7)
这里, L 是损失函数;并且类似于方程 5.3 ,我们更新方程 5.7 中的参数 θ 。让我们看看清单 5-7 中的参数优化。
var x: Float = 0
let η: Float = 0.01
let epochCount = 174
// Model
var f = Function()
// Dataset
let inputs = Float)
let outputs = inputs.map{ g($0) }
print("Before optimization")
dump(f)
// Optimization loop
for _ in 1...epochCount {
for (x, t) in zip(inputs, outputs) {
/// Derivative of `E` w.r.t. every differentiable parameter of `f`.
let 𝛁θE = gradient(at: f) { f -> Float in
let y = f(x)
let error = sumOfSquaresError(t, y)
return error
}
// Optimization step: update θ to minimize `error`.
f.move(along: 𝛁θE.scaled(by: -η))
}
print("After optimization")
dump(f)
Listing 5-7Find the minima function having free parameters equation f(x) = ax3 + bx2 − cx for a dataset sampled from function g(x) = 5x3 + 2x2 − 3x
```py
**输出**
Before optimization ▽ ParametersOptimization.Function
- a: 1.0
- b: 1.0
- c: 1.0 After optimization ▽ ParametersOptimization.Function
- a: 4.9880642
- b: 2.0008333
- c: -2.9924128
我们首先定义函数 *g* (。)然后对与范围[1.0,1.0]内的`inputs`相对应的`outputs`数组进行采样,其中每个连续值的差值为 0.01,构成我们的数据集。这里,`map(_:)`是一个在`Collection`协议上声明的实例方法,并采用一个闭包来应用于`Collection`实例的每个元素。
我们的目标是近似数据生成函数的映射。为了实现这一点,我们首先定义一个名为`Function`的可微分结构,它包含三个存储的属性`a`、`b`和`c,`,每个属性代表`Function`实例的一个特定系数。用于近似的函数的设计由等式*f*(*x*)=*ax*<sup>3</sup>+*bx*<sup>2</sup>-CX 描述,并已写入`callAsFunction(_:)`方法中。在这里,可以从`callAsFunction(_:)`方法中删除`@differentiable`属性的使用,因为结构本身符合`Differentiable`协议,该协议自动使该函数可区分。我们还声明了一个名为`f`的`Function`实例。
为了计算预测和目标之间的误差平方和,由方程 5.5 描述,我们将使用来自清单 5-4 的标有`@differentiable`属性的函数`sumOfSquaresError(_:_:)`。
我们将`epochCount`常量设置为 174。为了通过访问相应的输入和输出数据点进行迭代,我们在`for-in`循环中使用了`zip(_:_:)`函数。
在这个循环中,类似于前面的例子,我们计算梯度,但是这次是相对于`Function`的实例`f`的。这里,将`f`作为参数传递给`gradient(at:in:)`意味着计算误差函数相对于`f`实例的所有可微属性的偏导数。我们首先预测输出,并将其存储在不可变实例`y`中,然后传递给目标实例`t`旁边的`sumOfSquaresError(_:_:)`函数。这将返回我们的函数`f`所做预测的误差。在`gradient(at:in:)`函数的右括号之后,我们得到 e 相对于所有系数`a`、`b`和`c`的梯度,这些系数存储在类型`Function.TangentVector`的𝛁 `θE`实例中。回想一下第三章中的内容,即`TangentVector`是可微分数据类型的关联类型;这适用于所有可区分的基本类型和自定义类型。最后,我们利用存储在𝛁 `θE`中的梯度信息来更新`f`实例中的可微分属性。如前所述,这样做 174 次,最终非常接近数据生成函数 g(x)。
通过转储`f`实例的值,我们可以看到其系数的值非常接近函数 *g* ( *x* )。因此,我们在误差函数的帮助下,通过参数优化成功地近似了数据生成函数。

图 5-5
线性回归模型 y = wx + b 的计算图,其中我们还计算了损失 e = L(y,t)。(a)显式图(示出仿射变换)和(b)隐式图(假设来自(a)的操作)。在后面的图中,采用(b),我们隐含地考虑仿射变换。此后,我们将对图形中的操作进行颜色编码
接下来,我们讨论一些处理回归和分类问题的基本线性模型。
## 5.2 线性模型
线性模型是最简单的神经网络形式,可以执行回归和分类任务。尽管它们无法学习高度复杂的数据集映射,但它们确实适用于较简单的情况;由于体积小,它们处理输入的速度很快。
神经网络模型本质上是在给定输入随机变量 *x* 的情况下,对输出随机变量 *y* 的概率分布进行建模的框架,即 *P* ( *y* | *x* ),其中在给定相同样本 *x* 的情况下, *y* 必须更接近目标 *t* 。这种说法是有效的,适用于 1.2 节简要讨论的各种机器学习。
### 5.2.1 回归
回归任务与预测给定输入实值变量的输出实值变量有关。这里,输入和输出都是张量,可以有任何想要的维数。有趣的是,我们已经在前一节研究了回归。在本节中,我们将讨论各种不同容量的简单回归模型,这将进一步向我们介绍机器学习中偏差和方差的重要概念。我们将主要讨论线性和多项式模型。偏差和方差的权衡有助于我们选择模型可能的正确容量来解决给定的问题。在这里,我们介绍非常简单的回归模型,旨在预测标量输出。
#### 5.2.1.1 线性回归
我们从回归任务的最简单模型开始,称为*线性模型*(如图 5-5 所示)。它表示输入和输出实值标量之间的一元函数映射 *f* : ℝ → ℝ。顾名思义,这个模型学习了输入 *x* 和输出 *f* ( *x* )标量之间的一个线性关系,这个关系在几何上表示一个平面上的一条直线。线性模型由下面的等式给出:

(5.8)
这里,方程 5.8 描述的是二维空间(或平面)中的直线。在机器学习的上下文中,术语 *w* 和 *b* 分别称为*权重*(或*斜率*)和*偏差*(或*截距*),统称为*参数*。这个偏倚术语不应与 1.5 节中讨论的统计偏倚相混淆。
我们将线性模型拟合到方程 5.8 。参见清单 5-8 。
```py
struct LinearModel: Differentiable {
var w, b: Float
init() {
(w, b) = (1, 1)
}
func callAsFunction(_ x: Float) -> Float {
w * x + b
}
}
Listing 5-8Declare a linear model
我们已经声明了一个由权重项w和偏差项b组成的线性模型结构。接下来,我们将模型与来自数据生成函数 g 的样本进行拟合。).
import Foundation
let η: Float = 0.01
let epochCount = 174
// Model
var model = LinearModel()
// Dataset
let inputs = Float)
let outputs = inputs.map{ g($0) }
print("Before optimization")
dump(f)
// Optimization loop
for _ in 1...epochCount {
for (x, t) in zip(inputs, outputs) {
/// Derivative of `E` w.r.t. every differentiable parameter of `model`.
let 𝛁θE = gradient(at: f) { f -> Float in
let y = model(x)
let error = sumOfSquaresError(t, y)
return error
}
// Optimization step: update θ to minimize `error`.
model.move(along: 𝛁θE.scaled(by: -η))
}
print("After optimization")
dump(f)
Listing 5-9Train to fit the LinearModel to samples from function g(x)
```py
**输出**
Before optimization ▽ LinearRegression.LinearModel
- w: 1.0
- b: 1.0 After optimization ▽ LinearRegression.LinearModel
- w: 4.9880642
- b: 2.0008333
不幸的是,我们的线性模型无法近似函数 *g* (。)因为它只有两个参数,因此容量较小。现在,我们求助于更高容量的模型来学习映射。
#### 5.2.1.2 多项式回归
我们已经看到,线性模型不能很好地学习映射,因为输入和目标之间的关系不是线性的。因为函数 *g* (。)是 3 阶多项式,我们必须使用多项式函数来实验学习映射。多项式回归模型(如图 5-6 所示)也学习标量值之间的一种映射,即 *f* : ℝ → ℝ,由下式给出:

(5.9)
对于 *m* = 3,我们得到与数据函数 *g* 同阶的多项式(。)即给出如下:

(5.10)
这里, *w* <sub>0</sub> 是一个偏置项,通常写成 *b* 。偏置为 *b* 的输入始终为*x*0= 1,因此我们忽略等式中的显示。我们将它从模型定义中删除,因为它是一个冗余项,并且相对于 *b* 的偏导数始终为零。
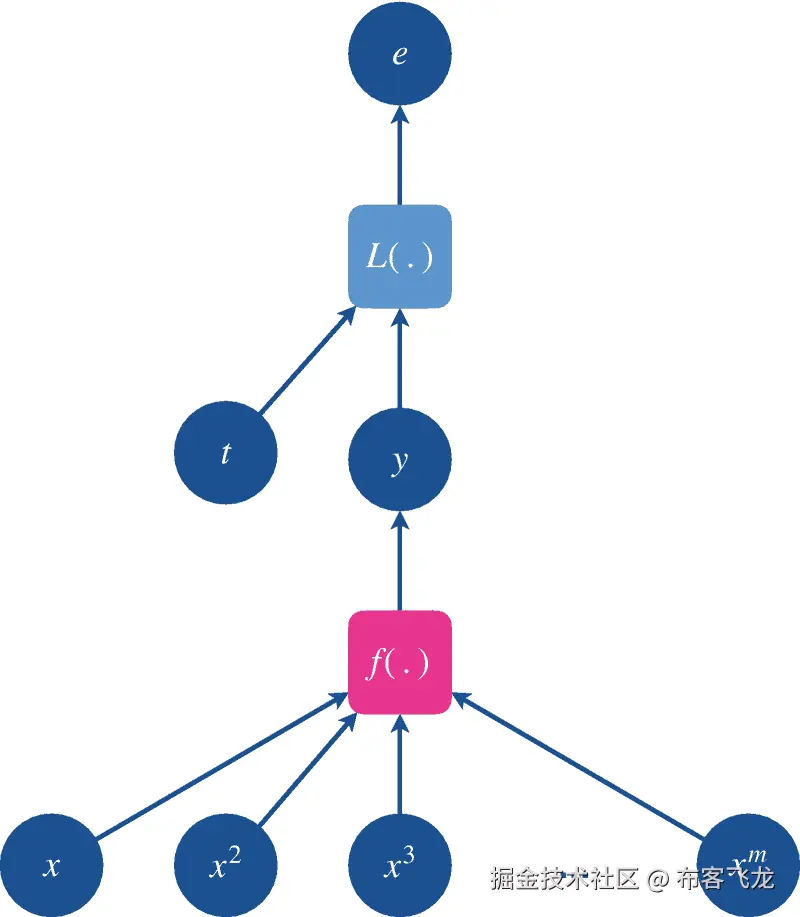
图 5-6
多项式回归模型的计算图,其中我们还计算了损失 e = L(y,t)
还要注意,线性模型是多项式模型的特例,当其阶数为 1:

多项式模型比线性模型具有优势,因为它可以具有更多的自适应参数,这给予它更多的学习能力。这意味着该模型可以更精确地近似数据生成函数。
让我们宣布我们的多项式回归模型具有选择任意顺序的灵活性。
struct PolynomialModel: Differentiable { var weights: [Float] var bias: Float = 1 @noDerivative var order: Int
init(order: Int) { weights = Array(repeating: 1, count: order) self.order = order }
@differentiable func callAsFunction(input: Float) -> Float { var output = bias for index in 0..<order { output += weights[index] * pow(x, Float(index)) } return output } }
Listing 5-10Declare a polynomial model
我们定义一个包含作为可微存储属性的`weights`数组和`bias`以及不可微存储属性的`order`的`PolynomialModel`结构。可微分的`callAsFunction(_:)`实例方法从`Float`映射到`Float`类型值。在该方法中,初始设置为等于`bias`的`output`局部变量被迭代地添加了一个加权的`input`,其中对应于来自`weights`数组的每个`weight`的`input`被赋给`weight`的`index`,因此给出了多项式方程的`result`。最后,我们从这个方法返回`output`。
我们简单地将`model`初始化为清单 5-6 中`PolynomialModel`的实例,顺序设置为 3。我们在相同的数据集上为相同的时期训练模型。通过这样做,我们能够近似数据生成函数 *g* 的系数。).这表明多项式模型比线性模型具有更大的容量,因此,它能够近似更复杂的数据生成分布。
在这里,我们可以很容易地做出原则性的猜测来尝试多项式模型,因为我们可以访问数据生成函数 *g* (。).但是在现实世界的问题中,我们实际上无法事先知道首先尝试哪种模型。我们唯一的选择是训练不同容量的多个模型,并选择一个在测试集上给出最低泛化误差的模型。一个更有原则的方法是研究解决与你相同问题的研究论文,在你的数据集上尝试这些模型,并对算法进行微小的修改,直到你得到好的结果。

图 5-7
多重回归模型的计算图,其中我们还计算了损失 e = L(y,t)
#### 5.2.1.3 多元回归
之前,我们访问了回归模型,在那里我们学习了标量输入和目标值之间的映射。但有时数据集中的输入样本可能包含多个特征,我们将其表示为向量 **x** ∈ ℝ <sup>*m*</sup> ,目标具有标量值 *t* ∈ ℝ.多元函数*f*:ℝ<sup>*m*</sup>→ℝ描述的模型称为*多元回归模型*,任务称为*多元回归*(见图 5-7 )。我们把这个模型的方程写成:

(5.12)
这里, *w* <sub>*i*</sub> 被称为权重,表示输入变量 *x* <sub>*i*</sub> 在预测正确输出中的重要性, *b* 是偏差项,其中每个变量都是标量。通过将所有输入变量及其对应的权重表示为*m*-维向量**x**=*x*<sub>1</sub>…*x*<sub>*m*</sub>和**w**=[*w*<sub>1</sub>…*w*<sub>*m*这叫做输入 **x** :</sub>

(5.14)
其中 *e* (。)是一个指数函数(见图 3-5 )。sigmoid 函数的图形呈“S”形(见图 5-8 ),很好地限定了范围(0,1)内的输出。

图 5-8
逻辑 sigmoid 激活函数(蓝色)及其导数(橙色)的图表
这个二元分类模型是一个多元函数 *f* : ℝ <sup>*m*</sup> → {0,1},写为:

(5.15)
这里,仿射变换的输入 **x** 产生标量预测 logit *y* (网络输出层中激活函数的输入),其中 *y* = **wx** + *b* 。然后,我们对这些 logit 单位应用 sigmoid 函数元素,以归一化范围(0,1)中的预测标量值。因为我们在这个模型的 logit 上应用了 sigmoid 函数,所以我们也称这个模型为*sigmoid 分类*或*逻辑回归*(一个误称,但在文献中常用)模型。处理样本以产生预测值的过程被称为*正向传播*,因为数据正通过从输入层开始到输出层的一些内部计算(仿射变换后是激活函数)被转换成有用的信息。
这些元素式函数用于限制输出逻辑单元和隐藏单元的范围(如在深度神经网络中),并被称为*激活函数*。它们有助于深度网络从输出层到输入层更好的梯度流动,使学习有效,并形成 5.4 节讨论的主题。
#### 5.2.2.2 多类分类法
在多类分类中,类似于二元分类,我们将样本标记为属于*多个*可能类别中的一个。在这里,班级不止两个。输出是一个向量,其大小与可能的标签(或目标)的数量相同。这里,标签通常用一个热点编码(也称为 1-of- *K* 编码,其中 *K* 是类的数量)来表示,这是一种表示,其中整个向量中只有单个索引的值为 1,而所有其他索引都被设置为零。假设每个指数代表某个类,值为 1 的指数就是样本所属的类。因为我们只希望标签向量的一个索引等于 1,所以我们使用 sigmoid 函数的多类推广,称为 softmax 函数,如下所示:

(5.16)
这里,为向量 **x** 的第 *i* 个索引元素计算 softmax。分子计算第 *i* 个索引值的指数,分母计算向量所有元素的指数之和。假设*y*<sub>*I*</sub>= soft max(**x**)<sub>*I*</sub>然后所有元素之和 *y* <sub>*i*</sub> ,其中 *i* = {1、…, *K* }和**y**=*y 换句话说,softmax 将向量 **x** 规格化,使得其结果向量 **y** 的所有元素之和等于 1。*
我们通过考虑从 *m-* 到 *n* 维向量的向量到向量函数**f**:ℝ<sup>*m*</sup>→ℝ<sup>*n*</sup>映射来构造多类分类器,其中 *m* 和 *n* 分别是样本特征和目标类的数量。对于一个输入样本向量**x**∈ℝ<sup>1×*m*</sup>,我们得到为对数,**w**∈ℝ<sup>m×*n*</sup>为权重,**b**∈ℝ<sup>1×*n*</sup>为然后,我们将 softmax 应用于 logits 以产生用于类预测的归一化值的向量。

图 5-9
描述前向传播的三层神经网络的计算图。灰色的圆角方形框表示任意参数化函数,也就是说,它可以是任何神经层
因为我们在该模型的逻辑上应用了 softmax 函数,所以我们也将该模型称为 *softmax 分类模型*、*多类分类器*,或者简称为 *softmax 分类器*。我们将在后面看到,类似于 softmax 分类器,密集神经网络是使用输入向量(或包含多个向量或样本的矩阵)和权重的矩阵乘法来构建的,随后添加偏置向量并应用激活函数(不仅限于 sigmoid 和 softmax ),但是对于多个层,其中前一层的输出被输入到下一层。这里,仿射变换 **xW** + **b** 是密集或全连接的层操作。
## 5.3 深度神经网络
在上一节中,我们参观了各种线性模型。这些模型的局限性在于它们只能近似样本和目标之间的线性关系。但是在现实世界中,就样本特征之间的相关性以及样本特征与目标之间的关系而言,数据集更加复杂。虽然 softmax 模型在像 MNIST 这样的小而简单的数据集上获得了很好的准确性,但我们可以做得更好。所以我们求助于非线性模型,比如深度神经网络。深度神经网络能够解决分类以及回归问题。
*深度神经网络*是一类可学习的模型,其中样本与其目标之间的映射通过称为*神经层*的一系列连锁的多个高维函数来学习。“深度”一词来自于非线性神经网络中有多个层的事实。出于同样的原因,我们将研究这种机器学习模型的领域称为“深度学习”,而不是“机器学习”。有各种各样的神经层,如密集层(接下来讨论),循环和注意层,卷积层(在第六章讨论),等等。请注意,该定义存在一个小例外,即神经网络的所有隐藏层并不总是从输入层到输出层完全链接在一起,而是链接一系列称为*神经块*的几个隐藏神经层,而其他层可能与其他更远的层有跳跃连接(见第 6.3 节)。
让我们考虑一个三层深度神经网络,可以写成**y**=**f**<sup>(3)</sup>(**f**<sup>(2)</sup>(**f**<sup>(1)</sup>(**x**))或**y**=**f**<sup>(3)</sup>∘**f**这里, **x** 是样本特征向量, **y** 是预测向量。我们将神经层表示为一个向量函数 **f** (。)其中上标的自然数是层在序列链中的位置。在这里,**f**<sup>①</sup>(。)、 **f** <sup>(2)</sup> (。),以及 **f** <sup>(3)</sup> (。)分别是*输入*、*隐藏*、*最终*(或*输出* ) *神经层*。第一层的输出**f**<sup>【1】</sup>(。)返回新的特征向量**f**<sup>(1)</sup>(**x**),该向量成为第二层 **f** <sup>(2)</sup> (。).第二层**f**(2)∘**f**<sup>(1)</sup>(**x**)的输出成为第三层 **f** <sup>(3)</sup> (。).那么最后第三层**f**<sup>(3)</sup>∘**f**<sup>(2)</sup>∘**f**<sup>(1)</sup>(**x**)的输出就是预测向量 **y** 。****
任何一层的输出都可以认为是其输入特征到一个新的维数向量所表示的不同特征的变换,例如第一层的输出特征向量 **f** <sup>(1)</sup> ( **x** )就是第二层神经网络的输入特征向量 **f** <sup>(2)</sup> (。).这里,为了清楚起见,我们省略了激活函数,但是每一层的输出都遵循激活函数的元素式应用。输入特征向量到期望输出预测向量的变换被称为*正向传播*或*正向传递*。除了跳过连接之外,所有深度神经网络都可以用这种方法来描述。
接下来,我们介绍一种最简单的深度神经网络,称为密集神经网络。
### 密集神经网络
一个*密集神经网络*,也称为*密集连接*或*全连接神经网络*,由一个以上顺序连接的密集层组成。前面讨论的 softmax 模型是只有一层的密集神经网络的特例。深度密集神经网络具有输入层、多个隐藏层和最终层,每个都是密集层类型。*密集层*是简单的矢量到矢量函数,映射到每个层的不同维度,限制是任何给定层的输出维度必须与其后续层的输入维度相匹配。密集层的输出(如图 5-10 所示)通过其输入特征向量的仿射变换进行计算,然后应用激活函数。一层的输出特征用作密集神经层的序列链中的下一层的输入特征。这个过程一直持续到我们计算出最终层的输出,预测出我们关心的结果。

图 5-10
(a)显式和(b)隐式形式的稠密层(粉红色)的计算图。这里,**y**=**f**(**x**)=**xw**+**b**其中 **x** ∈ ℝ <sup>m</sup> , **y** ∈ ℝ <sup>n</sup> , **W** ∈ ℝ <sup>m×n</sup> , **b**
让我们考虑一个***【L】***-层深度密集神经网络,其中它的每一层在前向传递期间的特征计算可以由以下等式描述:

(5.17)

(5.18)
这里, *l* = 1,…, *L* 是层索引。项 **W** <sup>( *l* )</sup> 和**b**<sup>(*l*)</sup>分别是第 *l* 层的权重矩阵和偏置向量。乘法符号(×)表示矩阵乘法。术语**x**<sup>(*l*)</sup>、**z**<sup>(*l*)</sup>和**a**<sup>(*l*)</sup>分别是 *l* 层的特征、激活和激活功能。作为特例,当 *l* = 1 时,我们得到 **x** <sup>(0)</sup> ,这是模型的输入样本特征向量。我们假设所有向量为行矩阵,以使矩阵乘法成为可能,这使得在后面的章节中使用小批量样本进行并行计算成为可能。
我们已经知道,通过密集神经网络顺序地正向传播样本特征 **x** <sup>( *l* )</sup> 来产生预测 **y** 是很简单的。该预测然后通过损失函数 *L* ( **y** , **t** )以及目标 **t** 来计算标量误差 *e* 。
接下来是计算相对于每层参数的误差梯度∂*e*/∂**w**(*l*)。这是通过执行微分的链式法则来完成的。用于 TensorFlow 的 Swift 使用反向模式算法微分来寻找损失相对于神经网络的每个参数的偏导数。还记得第 2.3.5 小节,关于任何神经层的高维参数的导数可以很容易地用雅可比矩阵表示,方法是在应用链式法则之前对它们进行整形。这为计算神经网络中的偏导数提供了一种有效且通用的方法。
接下来,我们看看一些流行的激活函数。
## 5.4 激活功能
神经网络学习映射具有小实数值的特征和目标张量,因为它们有意义地表示手边的任务。激活函数有助于维持小范围的值,使值不会不受控制地收缩或增长,否则会破坏我们预测标签分布范围内的值的目的。激活函数还有助于模型更好的泛化和更快的收敛。
激活函数用于网络的隐藏层和输出层。当应用于层中时,它们强制执行期望的概率分布。输出单元激活函数的选择基于模型的任务,而隐藏单元激活函数的选择影响神经网络的训练(或收敛)速度和性能。
为了找到更好的激活函数,已经有了很长的研究历史。我们为神经网络的输出和隐藏单元提供了各种重要的激活函数,并讨论了它们的优缺点。激活函数可以是线性的、非线性的,或者甚至是线性和非线性函数的组合。我们主要关注非线性激活函数,因为具有线性激活的神经网络可以由单层网络来描述,这使得表示能力无用。这也破坏了深度神经网络的目标,因为深度的概念是为了帮助网络学习数据集的分层和更丰富的表示。这个目的是通过使用非线性激活函数来实现的,这使得网络能够表示更大范围的函数,并且因此能够学习更复杂的非线性映射。
现在我们更深入地看看各种激活函数及其导数。
### 乙状结肠
图 5-8 中所示的 sigmoid 函数在 5.2.2 小节中引入,并由方程 5.14 给出。sigmoid 是一个标量函数,并应用于张量的元素方面,分别转换其每个元素。它只是将输入的值重新缩放到范围(0,1)。
当逻辑 sigmoid 函数应用于标量 logit 时,它学习伯努利分布,因此有助于学习执行二元分类任务。在这种情况下,输出是标量值,并且两个类 *K* = 2 中的任何一个都可以用 1 或 0 来表示,因为其概率是可能的输入类。在另一种情况下,当我们希望学习多类分类时(当一个样本属于多个类时),我们对预测向量应用 sigmoid。在这种情况下,输出是一个向量值,类用 index 表示(没有一键编码),多个元素可以是 1。
sigmoid 功能也可用于激活隐藏单元。但它不应用于隐藏图层,因为对于大值(正或负)而言,它相对于输入值(来自仿射变换的要素)的导数几乎为零。让我们仔细看看这个问题。
我们知道,在神经网络中重复应用微分链规则意味着将两个连续复合函数的偏导数相乘。现在考虑用 sigmoid 作为激活函数的多个复合神经层函数(例如,密集的)。sigmoid 激活值相对于仿射变换值∂**x**(*l*)/∂**z**<sup>(*l*)</sup>(它们是 sigmoid 的输入)的梯度将需要乘以仿射变换值相对于其权重参数矩阵∂**z**<sup>(*l*)</sup>/∂**w 的雅可比利用链式法则,我们得到下面的等式:**
****
**(5.19)**
我们知道,任意密集层的仿射变换 **z** <sup>( *l* )</sup> 是前一层的激活**x**<sup>(*l*—1)</sup>与当前层的权重矩阵**W**<sup>(*l*)</sup>的矩阵相乘,并加上一个偏置向量 **b** <sup>( *然后激活该变换,以产生激活的特征向量**x**(*l*)*</sup>。这简直就是密层操作。
让我们仔细看看前面等式中的中间项,它是激活向量 **x** <sup>( *l* )</sup> 相对于仿射变换向量**z**<sup>(*l*)</sup>:

(5.20)的梯度
这里,*σ*′(。)是由下式给出的 sigmoid 函数的导数,如图 5-8 :

(5.21)
记住:我们使用激活将输入值绑定在一个小范围内。这是因为仿射变换可以使值变大。在误差反向传播期间,我们必须通过导数激活函数来传递这些变换的特征。当我们通过 sigmoid 导数函数*’(*l*)+**b**<sup>(*l*)</sup>在方程 5.20 中输入一个大的(正的或负的)值(例如,**x**<sup>(*l*—1)</sup>×**W**<sup>【l)】),输出可以非常接近零(见图 5-8 )。也就是说,链式法则中关于仿射变换的∂**x**(*l*)</sup>/∂**z**<sup>(*l*)</sup>的激活值在乘以其他导数时给出了损失标量相对于权重矩阵的几乎为零的导数,如下所示:*
*
(5.22)

图 5-11
ReLU 激活函数(蓝色)及其导数(橙色)的图表
在训练过程中,我们使用雅可比∂*l*/∂**w**(*l*)和∂*l*/∂**b**<sup>(*l*)</sup>损失相对于每层的 *l* 参数 **W** 和 **b** 的梯度,通过基于梯度的优化来更新它们的值当激活函数相对于变换特征的梯度较小时,损失相对于参数的偏导数也较小。这意味着我们几乎没有对参数进行任何更新,因此,神经网络几乎没有学习任何东西!这被称为*消失梯度问题*。而当网络越深入,这个问题就变得严重得多。这是因为许多小值将沿深度相乘。相对于更接近损失函数的层的参数的偏导数将具有小的值,而那些远离损失函数(更接近输入层)的层可能具有零偏导数!这就是为什么使用激活函数是重要的,该激活函数允许更高的偏导数值,并且仍然将变换的特征限制在期望的小范围内。接下来,我们将看看一些更好的激活函数。
### 5.4.2 Softmax
另一个重要的激活函数是 softmax 函数,具体针对逻辑函数,由方程 5.16 给出,在第 5.2 节中介绍。
这个激活函数作用于一个向量并产生另一个向量,该向量的所有元素之和等于 1。它把每个元素(代表一个类)变成一个概率。换句话说,softmax 函数对向量进行归一化。该功能用于学习多类分类任务。
### 5.4.3 ReLU
在神经网络研究的早期,sigmoid 函数被大量用作隐藏单元的激活函数,但现在趋势已经改变。让我们来看看一个著名的激活函数叫做*整流线性单元* (ReLU) (Jarrett et al .,2009;奈尔和辛顿,2010 年;Glorot et al .,2011)由下式给出,如图 5-11 :

(5.23)
ReLU 激活作为输入特征 *x* 在范围 0,∞)内的线性函数(其输出等于其输入值),但将负值箝位为零。这个激活功能是隐藏单元的首选。还要注意,ReLU 在零输入时是不可微的。这是因为它的极限从左边接近(较低值通过加一个很小的数 *h* → 0)到零,在零,从右边接近(较高值通过减去一个很小的数 *h* → 0)到零)是不存在的;因此,ReLU 函数不是连续的。(记住一个函数必须是连续的才是可微的。)
简单来说,从左右接近的导数,以及在零点的导数,是不相等的。这使得 ReLU 在零处不连续。但是在软件实现中,为了允许梯度计算,ReLU 的导数被有意设置为等于零,以便网络可以学习。
但是梯度消失问题的解决方案呢?我们再来看 ReLU 的导函数:

(5.25)
就像 ReLU 一样,如果输入 *x* 大于零,它会发出相同的值。当输入小于零时,输出值略小于零。这样,ELU 在一定程度上缓解了死亡率上升的问题。常数项 *α* 一般设置在 0.1-0.3 之间,即α ∈ [0.1,0.3]。
ELU 函数的导数(如图 5-12 所示)如下:

图 5-12
ELU 激活函数图(蓝色)及其α = 0.2 的导数图(橙色)

(5.26)
我们可以看到,对于大于零的输入 *x* ,导数为 1。对于小于或等于零的输入,导数是输入的 ELU 加上 *α* 值。通过这种行为,我们避免了死 ReLU 问题。但是 ELU 的一个缺点是,由于指数函数 *e* <sup>*x*</sup> 的引入,ELU 在计算上比 ReLU 要昂贵一些。
### 5 . 4 . 5 leaky 注意到
*漏整流线性单元*(简称 LeakyReLU)激活函数(Maas 等人,2013)避免了 eLU 的指数项问题,由以下等式给出:

(5.27)
你可以这样写:

(5.28)
如果输入大于零,LeakyReLU 将输出设置为等于输入 *x* 。在另一种情况下,我们用小的 *α* 项(称为*负斜率*)缩放负输入,通常设置为等于 0.01:

(5.29)
查看 LeakyReLU 的导数,我们可以看到,如果输入 *x* 小于或等于零,则输出为 1,否则为 *α* 。LeakyReLU 的导数是线性的,对于零值和负值,它简单地等于 *α* (或 0.01,在我们的选择中),因此,避免了死 ReLU 问题。
请注意,与 ReLU 类似,LeakyReLU 在零处也是不可微的,但被有意设为可微的。此外,LeakyReLU 不涉及像 eLU 那样的任何指数函数计算,因此它的计算成本更低。
### 5.4.6 村庄
到目前为止讨论的所有激活都有梯度爆炸问题。最近引入的激活函数称为*比例指数线性单元* (Klambauer 等人,2017)(或简称为 SELU,如图 5-13 ),消失和爆炸梯度问题根本不可能(参见(Klambauer 等人,2017)研究的附录中的定理 2 和 3!在某些情况下,当网络的参数用 LeCun 初始化技术初始化并且网络使用 alpha dropout 时,然后在每个隐藏层中使用 SELU 激活,网络自动地自正常化。并且网络可以被认为是高斯分布。

图 5-13
SELU 激活函数(蓝色)及其导数(橙色)的图形
有趣的是,SELU 的方程式很容易理解:
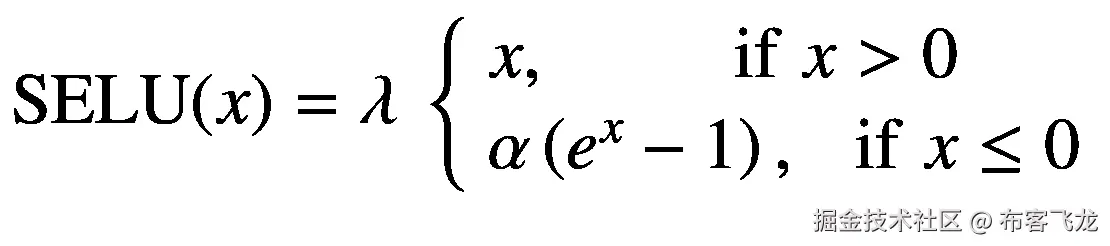
(5.30)
如果输入大于 0,则输出为输入 *x* 本身。另一方面,如果输入小于或等于 0,则输出是输入的指数乘以α*α*并减去α*α*。
alpha *α* 和 lambda λ的值呢?(Klambauer 等人,2017)的作者精确计算了它们的值如下,它们是常数:

(5.31)

(5.32)
SELU 的导数也很容易理解 1

(5.33)
对于大于 0 的输入 *x* ,导数输出为 1。对于小于或等于 0 的输入,输出是输入的指数乘以α*α*。
SELU 函数在前文讨论的条件下对神经网络进行自归一化。它还能快速收敛网络。而且根本没有渐变消失或者爆炸。
## 5.5 损失函数
在本节中,我们将探讨一些著名的损失函数,即平方和损失、sigmoid 交叉熵损失和 softmax 交叉熵损失。我们还研究了这些损失函数的导数的有趣性质。
### 平方和
观察以样本分布为条件的目标分布的概率由以下等式给出:

(5.34)
对于回归任务,我们假设目标分布是样本 **x** 的确定性函数,并添加了小的高斯噪声。我们将不进行这个损失函数的推导,但是根据这个假设,我们得到平方和损失函数如下:

(5.35)
而现在如果只有一个目标变量,那么输出也是标量,平方和损失函数变成如下:
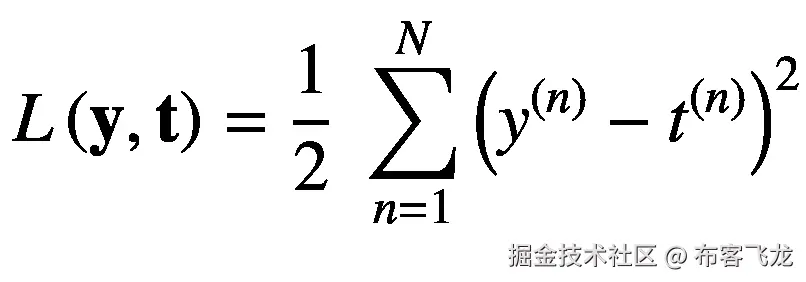
(5.36)
这里,我们假设应用在 logit *z* 、??(*n*)上的恒等(或线性)激活函数。所以误差对 logit 的偏导数简单地变成如下:

(5.37)
尽管在给定样本分布的情况下,平方和损失函数可以学习目标分布的条件映射,但是它假设目标属于高斯分布,而表示目标的类本质上是不能用该损失函数建模的二元变量。因此,对于接下来讨论的分类任务,我们求助于交叉熵损失函数。
### 5 . 5 . 2s 形交叉熵
当我们执行二元分类任务时,通过应用 sigmoid 激活函数,神经网络的输出分布被表示为伯努利分布。观察以样本为条件的类的概率由下面的等式给出:

(5.38)
观察具有模型分布 *P* ( *t* | **x** )的数据生成分布的可能性由以下等式给出:

(5.39)
当我们取这个似然函数的负对数时(5.39),我们得到由以下等式给出的两类的交叉熵损失:

(5.40)
如 1.3 节所述,我们将负对数似然性最小化,这相当于将数据分布的似然性最大化。注意,总误差只是每个预测和目标对的单个误差的总和。第 *n* 个模式(或样本)的误差相对于 logit*z*<sup>(*n*)</sup>的导数结果如下:

(5.41)
接下来,我们看看 softmax 交叉熵,它允许我们为多类分类任务的输出的多项式分布建模。
### 5.5.3 软件最大交叉熵
当我们执行多类分类任务时,通过应用 softmax 激活函数,神经网络的输出分布被表示为 Multinoulli 分布(见等式 5.16)。观察以样本为条件的类的概率由下面的等式给出:

(5.42)
观察具有模型分布的数据生成分布*P*(**t**<sup>(*n*)</sup>|**x**<sup>(*n*)</sup>)的可能性由以下等式给出:

(5.43)
当我们取似然函数的负对数时,我们得到由以下等式给出的多个类别的交叉熵损失:

(5.44)
如 1.3 节所述,我们将负对数似然性最小化,这相当于将数据分布的似然性最大化。注意,这里的总误差仅仅是预测向量和目标向量对中每个类别的单个误差之和。对于第 *n* 个模式(或样本)和第 *k* 个类,误差相对于 logit*z*??(*n*)的导数为:

【5.45】
请注意,激活和损失函数的选择非常匹配,平方和、sigmoid 和 softmax 交叉熵损失相对于其各自逻辑的偏导数具有相同的形式。
现在我们更深入地看看最常用的优化技术来训练神经网络。
## 5.6 优化
有两种类型的优化,即无约束的(基于梯度的;我们关注这个)和约束(凸优化)。我们的目标是找到函数的全局最小值,以便更好地推广到看不见的数据点,但是对于非凸函数,很难找到全局最小值。所以,在深度学习中,我们试图找到尽可能接近全局最小值(其确切值未知)的局部最小值。在凸函数的情况下,只存在一个极小值,即局部极小值等于期望的全局极小值,但这些函数的表达性较差。
### 梯度下降
通过最大化似然函数来执行参数化模型的训练。这要求我们修改模型的参数,以便模拟产生数据的分布。我们通过使用关于这些参数的损失的梯度信息更新参数值并执行梯度下降来做到这一点,如下所述。
#### 5.6.1.1 批量梯度下降
当我们考虑整个数据集来计算关于模型的损失梯度,并进一步使用它来更新参数时,这种方法被称为*批量梯度下降*。它近似于预测值和目标值之间相对于待降模型的最真实的误差梯度。
对于数据集ⅅ= {(**x**<sup>(*I*)</sup>,**t**<sup>(*I*)</sup>)},关于参数向量 *θ* 的损失由 *L* 给出。标量损失 *L* 在时间步长*相对于参数 *θ* 的梯度为。然后,该梯度可用于计算下一时间步*θ*(*τ*+1)的参数更新,其梯度下降方程如下:*
*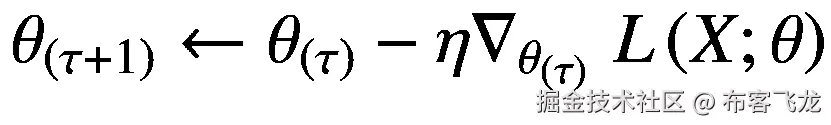*
*(5.46)*
这将在参数更新的每个时间步计算数据集中所有数据点相对于所有参数的导数。这在计算上非常昂贵,因为实际上数据集的大小可以从千兆字节到甚至千兆字节。由于物理设备(深度学习环境中的 CPU、GPU 和 TPU)的内存限制,所有数据都无法加载到内存中。为了解决这个问题,有两种方法来计算近似整个数据集的梯度,即在线梯度下降和随机梯度下降,接下来描述。
#### 5.6.1.2 在线梯度下降
实际上,真实世界的数据集非常大。并且在每个训练步骤计算整个数据集的损失梯度可能对计算要求很高。但是可以选择仅使用单个数据点的误差信息来计算梯度,该梯度可以用于更新模型的参数。对数据集中的每个数据点重复这样做可以提高模型的整体性能。这种方法称为*在线梯度下降*,在第 5.1 节中介绍。
在线梯度下降对于真实世界的应用是有用的,其中来自流的数据点可以用于改进学习系统(Bishop,2006)。这种技术可以用于生成建模,但是对于监督学习,它的标签必须提前知道。在半监督学习的情况下,模型的预测可以用作看不见的输入数据点的目标,这有望改善模型的性能。
表示第 *i* 个数据点 **x** <sup>( *i* )</sup> 为***L***<sup>(*I*)</sup>给出在时间步长 *τ* 为时损失相对于参数 *θ* 的梯度。然后,该梯度可用于计算下一时间步*θ*<sub>(*τ*+1)</sub>的参数更新,其梯度下降方程如下:

(5.47)
这里, *η* ∈ (0,1)是一个小的非零正*步长*也就是著名的*学习率*。由于梯度值可能很大,学习率用于控制所采取的更新步骤的大小。此外,损失函数的梯度给出了损失函数的标量输出值增加最多的方向。相反,负梯度给出了 *L* 下降最多的方向。因为我们希望预测值和目标值之间的误差接近于零,所以我们通过在梯度的负方向上采取小步骤来实现这一点。这就是方程 5.47 给出的梯度下降算法。
#### 5.6.1.3 随机梯度下降
*随机梯度下降* (SGD),也称为*小批量梯度下降*,采用一种激进的方法来计算梯度,结合了两者的优点。它计算一小组样本的梯度。因为数据点的小样本在统计上描述了数据集本身,所以它的梯度也大致类似于近似整个数据集的梯度。
对于一组 *m* 小批量样本(数量通常在 10 到 256 之间),随机梯度下降法计算 *m* 样本𝔻 <sup>( *i:i+m* )</sup> 的偏导数。这给出了下面的小批量随机梯度下降更新步骤:

(5.48)
这里,相对于模型的参数,为来自数据集𝔻的 *m* 个样本计算梯度,然后使用该梯度来更新其参数。尽管我们在一个序列中采样了样本的一个子集,但在实践中,我们更喜欢随机采样,以在训练时调用随机性。这也导致模型中的正则化效果。
随机梯度下降技术也比分批梯度下降技术更快地收敛模型,并且表现接近分批梯度下降技术。接下来描述的技术遵循相同的梯度下降思想,但是为了更快更好地收敛,引入了一些修改。
### 势头
用 SGD 学习可能会很慢。将学习速率设置得太低会减慢学习过程,或者甚至会使损失函数陷入局部最小值。另一方面,高学习率虽然使我们更快地降低损失,但它可能使低损失值在最优值附近振荡,甚至可能使训练发散。
动量通过考虑过去梯度的平均值来加速学习。这种方式也抑制了振荡:
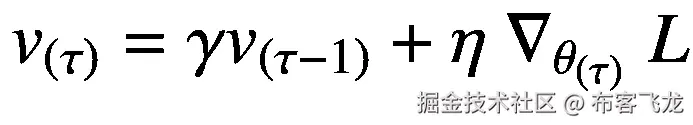
(5.49)
更新如下:
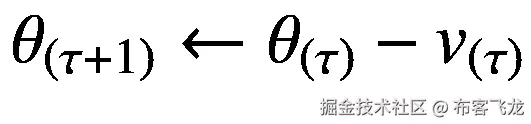
(5.50)
动量项γ的值通常选自一组值{0.5,0.9,0.999}。
接下来,我们看一些正则化技术来推广深度神经网络。
## 5.7 正规化
深度神经网络在各种情况下容易过拟合模型,例如训练样本数量少、参数数量大等。这阻止了模型很好地推广到看不见的样本。但我们可以将正则化应用于机器学习算法的不同组件,如数据集、架构、损失函数和优化方法。*正则化*是对数据、模型、损失函数或优化器进行的任何修改,以减少模型的泛化误差。我们将讨论通过改变算法的不同部分来调整模型的各种策略。
### 数据集
我们知道数据集为学习模型提供了经验。因此,数据集应该展示出我们想要很好地执行的数据的良好统计描述,也就是看不见的数据点。在这里,我们讨论两种技术来实现这一点。
#### 5.7.1.1 数据增加
由于深度神经网络具有大量可学习的参数,该模型可以很容易地根据训练集(如果它的规模很小)进行微调,因此会过拟合。概括模型的最简单方法是在非常大的数据集上对其进行训练。但是,在实践中,很难获得大的标记数据集。我们可以通过将可用样本的修改版本附加到相同的数据集来扩充数据集,而不是寻找更多的数据样本。在图像数据集的情况下,我们可以对每个样本应用以下变换(甚至随机多次),以随机大小裁剪,以一定概率水平和垂直翻转,并改变图像数据点的对比度、亮度和其他配置。(Krizhevsky 等人,2017 年)表明,数据增强有助于正则化深度神经网络(在他们的情况下,用于图像分类任务)。
#### 5.7.1.2 对抗训练
众所周知,最先进的神经网络表现得和人类一样好,在某些情况下甚至更好,例如,在图像中识别物体。虽然这些神经网络功能强大,能够很好地推广到未知样本,但它们仍然容易受到高度工程化的数据点(Szegedy 等人,2013 年)的影响,这些数据点被称为对立的例子。我们已经在 1.6.2 小节中简要理解了对立例子的概念。为了使神经网络对未知样本更加稳健,我们可以生成对立样本并将其添加到训练集中。在对立的例子上训练模型,称为*对立训练*,有助于调整神经网络,从而提高模型在测试集上的性能。
我们简单地提到一个对立样本的正反两面。在撰写本文时,谷歌搜索使用图像验证码接触敌对样本,并要求人类对图像进行分类。这样做是为了防止自动程序反复访问网站,这可能会使服务器过载。对抗性例子的一个负面用例是创建路标的对抗性样本,这些样本在人类看来很好,但却骗过了卷积网络(卷积网络处理来自自动驾驶汽车前置摄像头的图像流)。在这种情况下,对立的例子可能是致命的,例如,如果由于道路正在施工,标志牌意味着向司机发出减速信号,但汽车认为限速为 60 英里/小时,因此很可能会发生事故。
### 架构
机器学习算法的学习组件是模型。该模型非常容易过拟合数据集。为了防止这个问题,我们提出了两种技术来正则化模型。
#### 5.7.2.1 辍学单位
在任何测试集上实现良好准确性的最简单方法是通过对模型集合进行训练,并用每个模型评估每个测试样本,对每个模型的预测进行平均(分别针对每个测试样本)。(Szegedy 等人,2015 年)以六个模型的合奏赢得了 ILSVRC 竞赛。但是训练和推断许多神经网络模型对于现实世界的应用变得不切实际。
一种更简单的技术是 dropout,只需训练一个模型就可以学习指数数量的模型。 *dropout* (Srivastava 等人,2014 年)技术简单地关闭一个层的多个激活单元,在训练之前定义一些概率。这通常通过将二进制掩码(其值是从伯努利分布中随机采样的)与概率 *p* 相乘来实现,其中*p*∈【0,1】。在实践中,我们通常对隐藏层应用 dropout,并将 *p* 的值设置为 0.5 或 0.8。辍学可以被认为是以一种记忆和计算有效的方式学习一个只有一个模型的模型集合。
#### 5.7.2.2·知识蒸馏
另一种避免使用模型集合进行高精度预测的方法是使用知识提取技术。*知识* *蒸馏*的思想是将一个笨重模型(庞大的或一群模型)的知识转移到一个单一的小模型中。(Hinton 等人,2015 年)表明,如果繁琐的模型表现出良好的泛化能力,则在小模型中有可能获得良好的分类精度增益。
当小模型在与笨重模型相同的数据集上独立训练时,它具有体面的性能(小于笨重模型)。但当它使用相同的训练技术(优化器和其他超参数)使用笨重模型的预测作为软目标进行训练时,它的表现优于以前的小模型。这表明,与通过使用一般化的繁琐模型的知识来学习映射相比,小模型通过其自身从零开始准确学习数据集映射的能力更差。在小模型的知识转移中使用的损失函数包括最小化(a)由繁琐模型预测的软目标和小模型预测之间的误差,以及(b)对于给定样本,真实目标和小模型预测之间的误差。
知识提炼有利于生产中的实际应用,因为它有助于快速训练模型,该模型具有更少的推理时间,因此生产中的延迟更低,并且是轻量级的、性能更好的模型。
### 损失函数
损失函数在训练模型中起着重要的作用。它定义了学习算法要达到的目标。但是我们可以对损失函数施加一些约束,以对模型产生正则化效果。
#### 5.7.3.1 标准处罚
我们通常用大量参数训练模型。在实践中,模型的参数可能会根据训练数据集进行微调(即过拟合)以获得正确的预测。如果仔细观察单个参数,您会注意到值在正负方向变得非常大,这通常是过拟合的原因。这个问题可以通过在损失函数中对模型参数的大小施加一些约束来正则化模型来防止。深度学习使用的范数惩罚主要有两种,分别是 *L* <sup>1</sup> 和*L*2 范数惩罚。
损失函数增加的 *L* <sup>1</sup> 定额罚项写为:

(5.51)
这里,∩**w**∩<sub>1</sub>是在原损失函数 *L* ( **x** )上增加的权重参数的 *L* <sup>1</sup> 范数; *θ* 以产生修改的损失函数。术语是单个权重绝对值的总和。机构群体非常感兴趣的另一个定额罚款是我们已经在第 1.4.5 小节中讨论过的*1*2 定额罚款。有关详细信息,请参考该指南,有关这些规范重要性的详细信息,请参见第 2.1.4 小节。
### 优化
需要注意的是,如果模型训练时间较长,优化也可能导致模型过拟合。我们可以对优化技术进行修改,以减轻模型中的过拟合问题。
#### 5.7.4.1 提前停车
具有大量参数的神经网络能够过度适应训练数据集。当我们训练模型时,验证误差也随着训练误差的减小而减小。但是在迭代了多个时期之后,验证错误可能会开始增加,从而降低我们模型的性能。防止此问题的最著名、最可靠且最容易的方法是在每次验证误差减小后存储一组参数,并在满足训练终止条件时返回具有最低验证误差的模型的参数。这种技术被称为*提前停止*。当验证误差在预定数量的迭代步骤中没有进一步减小时,也可以终止训练过程。
#### 5.7.4.2 渐变剪辑
我们知道,当梯度消失或爆炸时,模型无法学习,因此无法在看不见的样本上很好地执行,并且不太通用。在第 5.4 节,我们看了一些激活函数,可以帮助减轻梯度消失和爆炸问题。在这里,我们看一个更简单的技术来缓解这个问题,而不需要对模型的架构做任何修改。我们可以通过在进行优化步骤之前对梯度向量进行一些修改来调整优化过程。
同时,深度学习社区使用的最著名的剪切梯度技术是由(Mikolov 等人,2012 年)和(Pascanu 等人,2013 年)引入的。请注意,已知这两种技术会产生类似的结果。
第一种方法(Mikolov 等人,2012 年)是在一个小批量中对所有参数的梯度进行*剪裁(或夹紧、限制),然后执行优化步骤。第二种方法(Pascanu et al .,2013)是*剪切梯度的范数*(见方程 5.52),然后执行优化步骤:*
**
*(5.52)*
这里, *v* 称为范数阈值,∇<sub>θ</sub>l 为损耗相对于模型参数的梯度。范数通常被选择为欧几里德范数,并且如果它大于阈值,我们执行梯度范数剪裁,而普通梯度剪裁被无条件地应用。在第二种方法中,您可以考虑通过以下方式更新梯度:首先对其进行归一化(即,通过欧几里德范数将其除以梯度向量距原点的长度),然后用梯度阈值项 *v* 对其进行缩放。
#### 5.7.4.3 辍学率
众所周知,基于自适应学习率的优化器能够将损失函数快速收敛到局部最小值,但它们通常会陷入鞍点,从而使优化变得困难。众所周知,具有动量的标准随机梯度下降能够找到好的局部最小值,并且不容易卡在鞍点,但是收敛损失函数非常慢。但是我们希望快速收敛到一个好的局部极小值,而不牺牲任何一个。这可以通过在基于自适应学习率的优化器上使用学习率下降(,Lin et al .,2019)来实现。
*学习率下降*的想法类似于前文讨论的单位下降。我们简单地从每层的参数样本中以概率 *p* 丢弃一组学习率。这是通过在二进制掩码(从伯努利分布采样)和该层中每个参数的学习率之间应用哈达玛乘积来实现的。
学习率下降有助于找到损失函数下降的新的随机路径,使得收敛对鞍点和不良局部最小值更鲁棒。
## 5.8 摘要
在这一章中,我们学习了与神经网络相关的各种概念,从基础开始,到高级主题结束。我们首先理解了输入和参数优化之间的区别。我们研究了与回归任务(即线性、多项式和多元回归模型)和分类任务(即二元和多类分类模型)相关的各种线性模型。然后我们理解了深度神经网络,或者更确切地说是密集神经网络。然后我们访问了各种激活函数,并对其进行了分析。我们还研究了三种常用的损失函数。然后重点介绍了不同的基于梯度的优化技术和正则化技术。
我们现在将在下一章研究卷积神经网络,它是专门为解决深度学习的计算机视觉问题而设计的。*
# 六、计算机视觉
> 所有的模型都是错的,但有些是有用的。 <sup>1</sup>
>
> *——乔治盒*
在本章中,我们将了解深度学习在计算机视觉任务中的作用。在第 6.1 节,我们讨论一种特殊的神经网络,称为卷积神经网络,旨在解决计算机视觉问题。与第五章讨论的密集神经网络相比,它有一些主要优势(第 6.2 节)。我们介绍一种减轻梯度消失问题的技术(6.3 节)。在 6.4 节中,我们实现了一个深度卷积神经网络来执行图像分类任务。最后,我们在第 6.5 节对本章和本书进行了总结。
## 6.1 卷积神经网络
在本节中,我们将讨论一类重要的神经网络,称为卷积神经网络(LeCun 等人,1989)。卷积神经网络,也称为卷积网络或简称为 ConvNet,被发明来处理具有一些空间局部信息特征的网格状数据。例如,在 2D 图像中,不同位置的小块可能包含球、脸和其他东西。诸如语音的 1D 时间序列数据可能包含不同时间帧片段中的语音。卷积网络学习许多称为过滤器的小参数张量,这些张量有助于提取基本特征。在图像环境中,特征包括边缘、曲线、对象形状、颜色渐变等,而在音频波形环境中,语音的基本特征可能包括音素、语调、音色等。

图 6-1
(a)RGB 图像和(b)双声道立体声音频张量卷积运算的摘要示意图
在第五章中,通过引入密集神经网络,我们进入了深度神经网络领域。基于密集网络的图像分类器适用于维数较小的图像数据,例如来自 MNIST 数据集的 784 维。但是当输入图像尺寸增加时,密集网络中的参数数量增长非常快。我们已经看到,密集层中的参数是从前一层中的每个单元( *m* 个单元)到当前层中的每个单元( *n* 个单元)的连接。这里,从前一层到当前层的连接总数是 *m* × *n* 。如果我们通过增加层的任何一个单元来增加层的容量,那么参数的数量会增加得非常快。例如,考虑尺寸为 32 `×` 32 `×` 3 的图像,其总共具有 3072 个特征(像素值)。现在,如果第一层有 1024 个特征单元,那么参数的总数是(3072`×`1024)+1024(额外的 1024 是偏差)= 3146752。目前,从内存的角度来看,这似乎是一个可管理的参数数量。但是,如果我们考虑一个合理大小的图像,那么参数的数量很快就达到大约 1.54 亿,确切地说是 154,141,696,这只是第一层!这是密集层的固有性质,其不允许密集神经网络随着大的输入维度大小和隐藏激活中的大量特征而缩放。在现实世界的计算机视觉应用中使用密集网络变得很困难,因为在实践中,图像数据点通常很大。卷积层通过其固有的设计(6.2 节)避开了这些问题,这促使我们在密集网络上使用卷积网络来处理大维度的数据。
与密集层中的矩阵乘法不同,卷积层使用一种称为卷积的数学运算,这使这些网络被命名为卷积神经网络。这个简单的操作是卷积网络与深度学习文献中的其他神经网络如此不同的原因。一般来说,如果网络中至少有一层使用卷积运算,则神经网络称为卷积网络(Goodfellow 等人,2016)。基于深度学习的当前研究趋势,这个定义可能并不总是有助于对网络进行分类,因为整个网络可能由不同种类的神经层组成。例如,LSTNet (Lai et al .,2018)和 Tacotron 2 (Shen et al .,2018)等网络包含卷积层和递归层,这混淆了这些网络按照此定义分类为递归网络或卷积网络。另一方面,注意机制用于密集网络(Vaswani 等人,2017)甚至卷积网络(Parmar 等人,2018;李等,2019)。我们强调,对网络的更好描述是,它由某些块组成(包含少数同构或异构类型的神经层实例),而不是基于单层操作来命名神经网络。如果一个神经网络在每一层中使用相同的操作,我们可以将该神经网络命名为以该操作为前缀的神经网络,例如卷积神经网络、循环神经网络等等。
特征和核张量具有相同的深度维度大小,但是不同的空间维度大小,其中核在空间上更小。每个内核生成一个深度维度大小为 1 的单一特征图(对于(a)以绿色阴影显示,其中灰色阴影由其他过滤器创建,对于(b)以浅绿色显示)。在(b)中,蓝色特征重叠以产生绿色输出标量特征,而在(a)中,棋盘核应用于输入特征以产生标量特征,当完全卷积时形成矩形形状。
在下文中,我们将解释卷积网络中使用的各种层,以及对数据点维度进行下采样和上采样的方法。
### 卷积层
称为*卷积层*的层的基本要求是应用卷积运算。我们首先用简单的语言(没有数学复杂性)解释卷积运算以及相关的超参数,然后给出计算输出维度大小的公式。
卷积运算是具有不同空间但相同深度维度大小的两个张量的函数。卷积操作通过将*特征*张量的空间小部分与*滤波器*张量(也称为*内核*或*参数*)重叠开始。因为两个张量的深度是相同的,所以过滤器沿着特征张量的整个深度重叠其空间维度内的所有特征值(见图 6-1 )。然后,我们在这些重叠值之间应用 Hadamard 乘积,以产生一个新的临时张量,其维数与滤波器的维数相同。现在,我们对这个临时张量中的所有值求和,以输出一个标量值。这相当于滤波器和输入特征张量重叠之间的点积运算。然后,我们在特征张量上空间地跨越(或移动)相同的滤波器,以重叠另一组值。(在图像的上下文中,stride,2)将使过滤器在 x 轴上移动 1 个像素值,在 y 轴上移动 2 个像素值,一次一个方向。但实际上,滤波器通常在所有轴上步进相同的量)。现在,我们再次取滤波张量和特征张量的重叠值的点积来生成另一个标量数。重复这个过程,直到滤波器一次跨过整个特征张量。这产生深度维度大小为 1 的特征图。我们将很快学会如何计算它的空间维度大小。这被称为*卷积运算*。换句话说,卷积是通过跨越滤波器直到整个特征张量被遍历一次,在被滤波器张量重叠的特征张量之间的点积的迭代应用。音频和图像数据点卷积运算的具体例子分别见图 6-2 和 6-3 。

图 6-2
输入 **x** 和滤波器 **f** 矢量之间的卷积运算的例子,其产生矢量 **y**
这里,滤波器首先对输入的第 0 和第 1 个索引处的值执行点积,并在输出向量的第 0 个索引处产生 0。然后,滤波器向右跨两步,再次对重叠的输入值执行点积,并在输出的第一个索引处产生 4。并且对输入的剩余值重复相同的过程。

图 6-3
输入矩阵 **X** 和滤波器矩阵 **F** 之间的卷积运算示例,其产生矩阵 **Y**
这里,filter 首先点乘左上角的 2x2 方阵,并在结果矩阵中产生标量(在(0,0)索引处)。然后,滤波器在 x 轴或 y 轴上跨两步,再次执行点积。重复这个过程,直到它卷积整个输入矩阵。
由于深度学习的想法是学习数据中复杂模式的有用表示,所以我们在卷积中不仅仅使用一个滤波器,而是使用多个滤波器。如果每个滤波器产生单个特征图,那么 *n* 个滤波器,每个滤波器对特征张量应用一个卷积运算,产生对应于每个滤波器的 *n* 个特征图。这些特征图沿着深度维度堆叠,以创建输出特征张量。输出特征张量的深度维度大小等于卷积层中的过滤器数量。
注意,从数学上讲,卷积运算只涉及一个滤波器和一个输入张量。但是在深度学习的上下文中,卷积层具有一个特征张量,并且可以具有多个滤波器,其中在特征张量和每个滤波器之间分别应用卷积运算,以产生深度维度大小与滤波器数量相同的新特征张量。
### 尺寸计算
现在我们知道了卷积运算是如何工作的。这里,我们将讨论当滤波器在给定的特征张量上卷积时,新的特征张量的输出维数的计算。
让我们从假设任意输入特征张量 t∈ℝ<sup>*a*×*b*×*c*×*d*</sup>开始,其中 *a* 、 *b* 、 *c* 和 *d* 是维度大小。对输入张量 t 的卷积运算的应用产生了另一个特征张量 t’∈ℝ<sup>*a*’×*b*’×*c*’×*d*’</sup>其中*a*’*b*’*c*’和*d*’是对应的输出维数
因为特征张量的选择是任意的,所以可以选择用 2D 音频张量、3D 图像张量或具有特定维度大小的其他张量来替换它。为了避免混淆,我们将假设图像张量 I∈ℝ<sup>*h*×*w*×*c*</sup>和音频矩阵**a**∈ℝ<sup>*t*×*c*</sup>代替任意张量 t,以更具体地理解输出张量维数的计算。这里, *h、w、c* 和 *t* 分别是高度、宽度、通道(或深度)和时间维度尺寸。
假设有两个滤波器和分别用于图像 I 和音频 A 张量,其中 F <sub>I</sub> 是 3 阶张量,**F**A 是 2 阶张量(或矩阵),并且通道 *c* 具有用于图像和音频的单独值。这里, *f* <sub>* h *</sub> 和 *f* <sub>* w *</sub> 是对应于图像张量 I 的高度 *h* 和宽度 *w* 维度尺寸的滤波器尺寸,对于音频张量 A, *f* <sub>* t *</sub> 是沿时间维度的滤波器尺寸*t 让我们也考虑卷积运算的其他超参数,例如步长大小 *s* ,零填充大小 *p* ,以及膨胀因子 *d* 。(不用担心;这些稍后解释。)因此,在定义了所有必需的术语后,使用以下公式计算输出特征张量维度大小:*

(6.1)

图 6-4
图 6-2 和 6-3 中输入周围的零填充示例。这里,(a)的零填充为 2,而(b)的零填充为 1
这里, *i* 是张量期望轴的输入维数大小, *o* 是其对应的输出维数大小。它可以是输入张量的任何维度,例如,在我们的例子中, *h* 、 *w* 或 *t* 。我们还用 *f* 指定滤波器大小,在我们的例子中,它可以是 *f* <sub>*h*</sub> , *f* <sub>*w*</sub> ,或者 *f* <sub>*t*</sub> 。影响输出尺寸大小的其他变量(或超参数)是步幅 *s* ,填充尺寸 *p* 和膨胀 *d* 。在理解输出尺寸大小的计算之前,让我们先熟悉一下这些超参数。
#### 6.1.2.1·斯特雷德
步幅 *s* 是滤波器在输入特征张量上允许的(空间或时间)方向上的移动步长(一次一个)。在图像的上下文中,如果跨距为 2,则过滤器在允许的方向(x 和 y 轴)上移动 2 个像素值,然后点乘重叠。类似地,在诸如音频的时间数据中,步长为 16 的滤波器将在时间上(在 x 轴上)移动 16 个样本,并在重叠之间取点积。所以*步幅*就是滤波器在张量上的移动步长。
#### 6.1.2.2 衬垫
另一个被称为*填充*(或*零填充*)的超参数是沿着所有深度通道的特征张量的空间或时间维度周围的零值的边界。填充 *p* 为正整数值,如图 6-4 所示。
#### 6.1.2.3 扩张
在 2015 年,(Yu 和 Koltun,2015)为卷积层引入了一个新的超参数,称为*膨胀*(也称为 *à trous 卷积*或【带孔卷积】)。没有膨胀的卷积产生的特征张量具有前一层的小感受野。*感受域*是任何先前层中负责特定特征单元预测的特征数量(见图 6-5 )。为了增加感受野,我们需要增加滤波器的大小(或滤波器中参数值的数量)。但是引入卷积层的目标之一是减少内存占用。这就是扩张卷积缓解过量内存分配问题的地方。通过在滤波器中使用*膨胀,我们可以在不增加滤波器中参数数量的情况下增加特征张量的感受域。为了在保持相同数量的参数值的同时增加感受野,我们简单地通过 *d* ∈ ℤ <sup>+</sup> 扩张来隔开参数值。通常,一个过滤器有一个膨胀;当我们增加扩张时,感受野(沿着网络深度在相应层和远处层之间)增加。扩张卷积的示例见图 6-6 。还请注意,除了内存足迹之外,膨胀在过去几年中在各种任务上取得了许多成功,例如图像分割(Yu 和 Koltun,2015 年)、原始音频波形建模(Oord 等人,2016 年 a)、记忆效率以及循环神经网络中消失和爆炸梯度问题的抑制(Chang 等人,2017 年)和关键字定位(Coucke 等人,2019 年),仅举几例。*
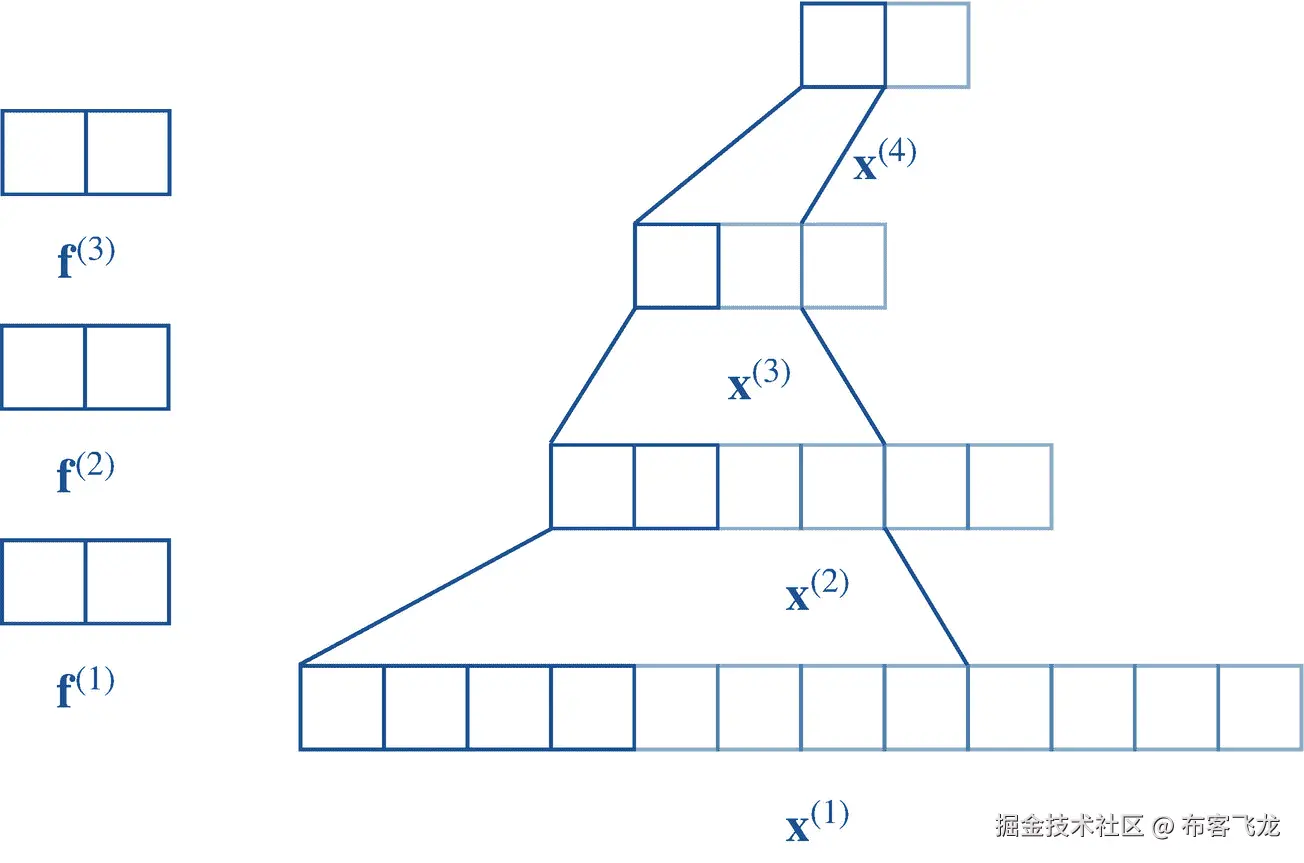
图 6-5
三层 1D 卷积网络中的感受野
所有的滤波器都是 2D 向量,并以步长 1 应用于数据。这里,阴影最后一层的 **x** <sup>(4)</sup> 特征单元的感受野对于 **x** <sup>(3)</sup> 为 2,对于**x**<sup>【2】</sup>为 4,对于 **x** <sup>(1)</sup> 为 8。

图 6-6
三层 1D 扩张卷积网络中的感受野
这里,**f**<sup>(1)</sup>**f**<sup>(2)</sup>**f**<sup>【3】</sup>的膨胀分别为 1、2、4,是 2D 向量。(过滤器中的浅色区域显示膨胀,并且只是一个空白空间,其中输入的重叠区域没有点积。)所有的过滤器对数据应用步长 1。我们在**x**<sup>【2】</sup>中用 1 个单位补零,以防止**x**<sup>【3】</sup>中分辨率大幅降低。这里,阴影化的最后一层的**x**<sup>【4】</sup>特征单元的感受野对于**x**<sup>【3】</sup>为 4,对于**x**<sup>【2】</sup>为 6,对于 **x** <sup>(1)</sup> 为 12。请注意,在非扩张卷积网络的相应层中,感受野呈指数增长。核的膨胀有效地增加了感受野,而不增加内存需求。
#### 6.1.2.4 的例子
让我们看一个音频张量的简单例子,其形状是ℝ <sup>16384×2</sup> ,其中声道 *c* 是 2,时间长度 *t* 是 16384。这是一个具有 16,384 个样本的双声道音频(或立体声音频)(一个数据点包含 16,384 个标量幅度值)。如果我们将其与形状为ℝ <sup>16×2</sup> 的滤波器矩阵 **F** 进行卷积,步长 *s* 为 4,零填充 *p* 输入张量的边界厚度为 6,膨胀 *d* 为 1,则我们得到形状为ℝ <sup>4096×1</sup> 的输出张量,计算如下:
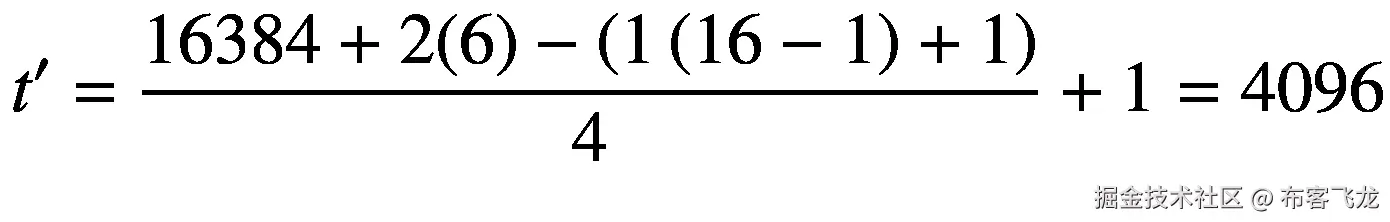
卷积后特征张量的新形状是ℝ <sup>4096×1</sup> 。因为我们只使用了一个滤波器,所以输出通道尺寸 *c* 等于 1。
类似地,也可以计算卷积输入图像张量的输出张量形状。让我们假设形状ℝ <sup>28×28×1</sup> 的灰度图像,其中通道 *c* 是 1,宽度 *w* 和高度 *h* 都是 28 像素。filter(*f*<sub>*h*</sub>、 *f* <sub>*w*</sub> )、stride *s* 、zero-padding *p* 和 exploation*d*的值分别为(5,5)、1、0 和 1。按照这种配置,卷积运算产生输出宽度 *w* 和高度 *h* 尺寸等于 24:
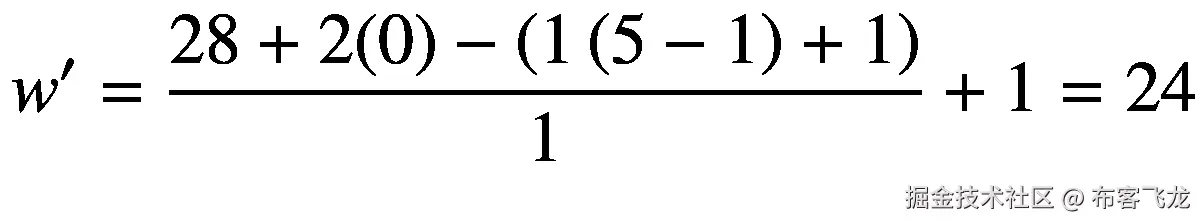
在这两个示例中,将膨胀设置为 1 与普通卷积运算相同(默认情况下,将膨胀设置为 1)。
请注意,您应该只使用那些影响特定特征尺寸的过滤器尺寸。例如,在这个公式中,一起使用 *f* <sub>*w*</sub> 和 *w* 来计算 *w* 是合适的,因为 *f* <sub>*w*</sub> 的值影响张量的宽度尺寸 *w* 而不是 *h* 。当 *f* <sub>*w*</sub> 和 *h* 是这个公式的自变量时,这个公式的一个无意义的用法就是试图计算*h*’。
在最近的深度学习模型中,自编码器中的编码器网络和生成对手网络中的鉴别器网络通常使用滤波器大小ℝ <sup>4×4</sup> 、步距(2,2)和填充 1 的卷积。这将尺寸减小了 2 倍。例如,具有指定配置的尺寸为ℝ<sup>1024×1024×*c*的图像被下采样到ℝ<sup>512×512×*c*′</sup>大小。有趣的是,当自编码器中的解码器网络和生成对抗网络中的生成器网络使用这些相同的超参数进行转置卷积运算时,我们得到了一个双维度大小的输出特征张量。也就是说,如果一幅图像的维数为ℝ <sup>512×512× *c*</sup> ,那么在应用这个转置卷积后,我们得到一个ℝ<sup>1024×1024×*c*′</sup>大小的特征张量。</sup>
实际上,大小为ℝ <sup>2×2</sup> 的滤波器也非常常用。特别是在视觉模型中,通常使用较大的过滤器尺寸和跨度会导致性能下降。值得注意的是,最近的一些研究(林等,2013;Szegedy 等人,2014 年;伊恩多拉等人,2016;Oord 等人,2016a,b,c;Springenberg 等人,2014)也使用ℝ <sup>1×1</sup> 滤波器尺寸。这乍一看似乎很奇怪,但它让网络在不改变空间维度大小的情况下学习更深层次的表示。并且还具有多个ℝ <sup>1×1</sup> 滤波器产生多个输出特征图,因此是特征张量。
还要注意,作为经验法则,当构建用于分类任务的卷积网络时,一个简单的想法是增加深度维度大小,并相应地减少空间维度大小。在到达具有少量特征单元的层之后,将卷积的特征张量整形为平坦张量,然后通过小型密集网络。这种趋势已经在深度学习文献中普遍存在(Krizhevsky 等人,2017;Simonyan 和 Zisserman,2014 年;Szegedy 等人,2015,2016;伊恩多拉等人,2016;谭和乐,2019)。
### 6.1.3 汇集层
卷积网络中常用的另一个重要层是池层。*池层*的作用是减少特征张量除深度维度尺寸外的所有维度尺寸。池进一步减少了下一层中卷积运算的计算需求,因为它的输入现在是更小的特征张量。我们已经在清单 4-3 的微型图像分类器中使用了池操作。
任何池函数都将池大小(也称为池窗口)、跨度和零填充作为其参数。使用这些参数,池化函数用单个标量值对特征张量的小边界(由池化窗口定义)中的所有标量值进行汇总。汇集函数在特征张量的每个深度索引上单独操作,这减少了时间、空间或时空维度大小,而保持深度维度大小不变。这里,池大小仅用于确定标量值在特征张量上的位置。
在深度学习文献中,我们会遇到各种各样的池操作。但这里我们讨论的是最常用的池化操作,即最大池化和平均池化。
我们知道,池函数将特征张量上的位置(由池窗口描述)中的标量值在每个深度维度中单独总结为单个标量数。在*最大池函数*的情况下,池数的值就是池窗口中的最大值。*平均池函数*通过取池窗口中所有数字的平均值来计算标量值。正如过滤器在特征张量上卷积一样,池窗口在特征张量上移动给定的步幅值,以确定要池化的值的位置。
对输入要素张量应用池函数时,以下公式计算输出要素张量的维度大小:
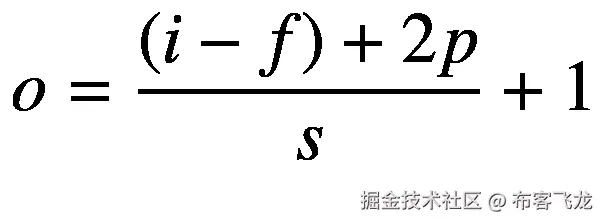
(6.2)
这里, *i* 和 *o* 为输入和输出尺寸大小。在图像特征张量 I∈ℝ<sup>*h*×*w*×*c*</sup>, *i* 可以是宽度 *w* 或高度 *h* ,而对于音频特征矩阵**a**∈ℝ<sup>*t*×*c*</sup>,*其他参数 *f* 、 *s* 和 *p* 表示池窗口大小、池窗口的步幅以及特征张量周围的零填充。请注意,该公式类似于公式 6.1 ,但是在应用卷积运算时,没有计算输出维度大小的膨胀参数。*
汇集是一个常数函数,因此不能区分,因为没有与之相关联的可调参数,关于这些参数可以获得损失梯度。(泽勒和弗格斯,2012 年)提出了一个可区分的池函数,以受益于池操作的学习。但是它并没有变得太受欢迎,在实践中也很少使用。有趣的是,(Springenberg 等人,2014 年)发现,在卷积网络中,用大步长卷积运算代替汇集运算可以实现类似的精度。这种方法使网络完全卷积,结构简单。全卷积网络比使用池操作更好的一个可能原因是,当使用池操作对特征张量进行下采样(空间)时,会发生一些信息丢失,而卷积层可以在对特征张量进行下采样时学习保留对任务重要的信息。
### 6.1.4 上采样
我们已经看到,卷积层对特征张量的空间大小进行下采样。当希望网络的输出大小小于输入大小时,这很有用。最常见的例子是图像分类(Krizhevsky 等人,2017 年),对象检测(Redmon 等人,2016 年;雷德蒙和法尔哈迪,2017,2018;Girshick 等人,2014 年;Girshick,2015),以及音频分类(Hershey 等人,2017)。但是,在某些情况下,我们需要输出大小大于输入特征张量。这些任务包括生成模型(文森特等人,2008 年;拉德福德等人,2015 年)和激活特征图可视化(泽勒和弗格斯,2014 年)。
数据点的上采样可以通过应用各种上采样层来实现,例如双三次、最近邻和其他插值,然后是卷积(Dong 等人,2014;金等人,2016 年)或转置卷积(泽勒等人,2010 年)。
#### 6.1.4.1 转置卷积层
*转置卷积*,也被称为*分数步长卷积*或*反卷积*(一个误称),在对特征张量进行上采样的同时学习自己的一组参数。它在空间上放大了特征张量,其中,就像卷积一样,输出深度维度的大小取决于所使用的滤波器的数量。转置卷积运算可以被认为是使用相同自变量(滤波器、步幅、填充和膨胀)的卷积运算的反向应用,其在空间上对特征张量进行上采样,而不是下采样。转置卷积也具有与卷积层相同的属性,即稀疏连通性、参数共享和平移等方差,这将在 6.2 节中讨论。
给定图像张量 I∈ℝ<sup>*h*×*w*×*c*</sup>的形状、滤波器和超参数,即步幅 *s* 和填充 *p* ,我们可以计算转置卷积运算的输出特征张量维数,公式如下:

(6.3)
这里, *i* 和 *o* 表示输入和输出特征张量的维数。考虑形状ℝ <sup>128×128×3</sup> 的图像张量和转置卷积运算,其中超参数滤波器大小ℝ <sup>6×6×3</sup> ,步长为(2,2),零填充为 1。当该滤波器应用于转置卷积运算时,我们得到形状ℝ <sup>256×256×1</sup> 的输出张量。类似于方程 6.2 中的公式,当适当使用该公式时,可以正确计算输入张量的任何输出维数。
#### 6.1.4.2 棋盘伪影去除
转置卷积已成功用于图像超分辨率(施等,2016a)和图像生成(等,2015)。但如果转置卷积的超参数设置不正确,可能会在生成的数据如音频(Donahue et al .,2018)或图像(Odena et al .,2016)中产生棋盘状伪影。图像中的棋盘格伪像被视为不规则的亮色像素,而在原始音频中,它可以被解释为噪声。
(Odena 等人,2016 年)的发现表明,在卷积运算之后使用简单的上采样运算完全减轻了棋盘伪影问题。虽然转置卷积比卷积方法之后的上采样操作具有更大的表示能力(Shi 等人,2016b),但是后者获得了更好的性能。结果令人震惊,因为在生成的数据点中完全消除了棋盘伪影。根据这项工作,研究人员可以专注于改进生成模型,生成实值数据点。
## 6.2 突出特点
有趣的是,卷积网络可以处理任意维数的张量。卷积网络还有许多其他重要特性。在本节中,我们将讨论这样的功能,并了解对于各种深度学习任务(主要与计算机视觉相关),卷积网络为何是比密集网络更好的选择。
### 本地连接
在第五章中讨论的密集连接层在包含参数的矩阵和输入特征向量(可视为矩阵)之间应用矩阵乘法,以产生输出特征向量。在这种情况下,输出特征向量中的每个神经元都连接到输入特征向量中的每个神经元。这使得该层非常密集,但也无法扩展到更大的输入张量和模型容量(从记忆的角度来看),如 6.1 节所述。
卷积层采用激进的方法来计算输出张量。它考虑输入特征张量和参数张量(称为核或滤波器),与输入张量相比,它们具有非常小的尺寸。当在滤波器和输入张量之间应用点积时,产生输出张量的单个神经元。换句话说,输出张量的某个单个神经元只与输入张量的一小部分相连。这被称为输出张量神经元的*感受野*。相反,在致密层的情况下,每个输出张量神经元连接到输入张量中的每个神经元。卷积的方法使得卷积层中的连通性是稀疏的(或局部的)。这也加快了计算速度。
还要注意,感受野在更近的层之间通常很小。但是当网络变得更深时,远离输入层的层中的神经元的感受野变得更大。
### 参数共享
在卷积层,在输入张量的不同位置重复使用相同的核来计算输出张量。也就是说,同一组参数在不同的输入位置之间共享。这些参数也被称为*绑定参数*,因为输入的任何位置的参数值都取决于不同位置的相同参数值。相比之下,致密层中的一组参数将输出单元连接到每个输入神经元。并且每个输出神经元都有其自己的独立参数集连接到相同的输入神经元。这反过来增加了内存需求。此外,如此密集的连接也使得计算输出的效率很低。另一方面,卷积层中的所有输出神经元具有连接到相邻输入神经元的相同的一小组参数。这些参数在输入张量的不同位置重复使用,以计算每个输出标量值(滤波器和输入张量重叠之间的点积)。参数的小尺寸和跨不同输入张量位置的共享使得计算更快并且存储更有效。
尽管与过滤器相比,真实世界的图像在空间维度尺寸上较大,但过滤器可以自动学习检测(或激活输出张量中的某些神经元)输入中的基本特征,如边缘、对比度、颜色梯度等。当在原始音频波形中使用卷积时,它可以学习诸如音色、语调、语音等特征的表示。由于约束参数,这成为可能,因为基本模式在数据的整个空间维度中是相似的,并且可以使用相同的参数在不同的位置检测。
### 翻译等值
由于参数共享,作为副作用,卷积层也是平移等变的。如果输入被 x 轴或 y 轴上的一些像素值平移并遵循卷积运算,则得到的张量将与卷积遵循相同平移运算的情况相同。例如,假设一个函数 *f* (。)将输入张量沿 y 轴平移 5 个像素,以及另一个函数 *g* (。)应用卷积。现在,由于平移等方差性质,当这些函数中的一个跟随另一个时,得到的张量将是相同的*f*(*g*(*x*)=*g*(*f*(*x*))。
考虑用卷积神经网络 *f* ()在原始音频波形 *x* 中识别一个口语单词。).让我们假设一个单词“hello”出现 2 到 3 秒。所以这个词会在这个时间段被转录为 *f* ( *x* )。然后我们用翻译函数 *g* ()将*g*(*f*(*x*))转录输出翻译成 5-6 秒。).这个翻译说这个单词在 5 到 6 秒之间被识别。在另一种情况下,假设我们将“hello”声音翻译成 5-6 秒音频波形的时间帧片段 *g* ( *x* ),然后应用卷积*f*(*g*(*x*))。现在,单词将在 5-6 秒的时间段内被转录。这意味着*f*(*g*(*x*)=*g*(*f*(*x*))并且卷积运算是平移等变的。
类似地,在图像的情况下,将图像沿着期望的轴平移一些像素并应用卷积的结果将与我们在平移函数之后应用卷积的结果相同。这表明卷积展现的平移等方差对于不同的输入特征维度大小(对于像音频或图像这样的数据)及其相应的滤波器大小仍然有效。
请注意,卷积并不等同于所有类型的平移,如缩放、旋转、扭曲等。一些研究(贾德伯格等人,2015;Sabour 等人,2017;Zhang,2019)为消除卷积网络中的这一问题做出了贡献。
## 6.3 快捷连接
我们已经讨论了具有非线性激活的深度神经网络能够学习高度复杂的数据集映射。接下来,您可能会猜测向网络中添加更多的层将有助于提高其性能(比如说,准确性)。但是,理论上是这样,但实际操作起来,这并没有看起来那么容易,就是把多层叠加起来。正如 5.4 节所讨论的,较深的网络会遇到梯度消失的问题。令人惊讶的是,它非常严重,网络越深,其性能下降越多,而越接近逻辑层的层梯度越大,学习速度越快。相比之下,越靠近输入层的层具有越小(消失)的梯度,因此学习速度越慢;有些人甚至会完全停止学习。

图 6-7
双层神经块的剩余连接
层操作的选择是任意的。第一层处理输入 **x** 并用 **a** 激活它。),而第二层首先预测输出并将其添加到该神经块的输入中,即形成快捷连接,然后应用激活以生成输出 **y** 。
但是我们希望使用更深的网络来获得更好的性能。那么如何才能规避这个问题呢?一种解决方案是使用剩余学习框架(He et al .,2016)。让我们从描述这个框架的等式来理解它:
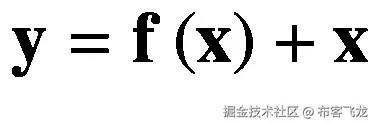
(6.4)
在方程 6.4 中, **x** 和 **y** 为输入和输出变量。这里, **f** (。)是包含一个以上神经层(通常是两个)的神经块(或复合函数)。*快捷连接*,也叫*剩余连接*,是由神经块 **f** 的输入 **x** (这里也叫*剩余*)相加而成。)至其输出 **y** 。
根据等式 6.4 ,中间输出 **f** ( **x** )的尺寸必须等于其输入 **x** 的尺寸,以便逐元素加法成为有效运算。当不是这种情况时,我们简单地将输入 **x** 投影到与 **f** ( **x** )相同的尺寸,投影参数 **W** <sub>s</sub> 如下,其中下标 *s* 代表快捷投影:

(6.5)
在神经块 **f** ()有两层,那么方程 6.4 可以写成如下,并在图 6-7 中可视化:

(6.6)
用于剩余连接的神经块中的神经层的类型是任意选择的,并且基于要执行的任务。现在,如果我们选择所有神经层作为密集层操作,那么我们可以将方程 6.4 重写如下:

(6.7)
这里,术语 **x** 、 **W** 、 **a** (。)分别是输入向量、权重矩阵和激活函数。圆括号中的上标索引表示这些元素所属的层。为了简单起见,我们省略了偏差项。注意,在任何快捷连接中,神经块的输入被添加到该块的最后(未激活的)层的输出,然后跟随该最后层的激活功能。
接下来,我们将构建自己的残差卷积网络,并训练它执行图像识别任务。
## 6.4 图像识别
在本节中,我们将构建一个深度卷积神经网络,称为残差网络(或 ResNet) (He et al .,2016),在玩具数据集上执行图像识别任务。ResNet 提出了上一节中讨论的剩余连接的概念。基于层数(例如 18、34、50、101 和 152 层),有各种 ResNet 架构。我们构建了一个 18 层深度残差网络,并在 CIFAR-10 数据集上对其进行训练,看看我们的 ResNet 是否比我们之前在第四章中训练的 LeNet 表现得更好。事实上,研究人员通常还会在 ImageNet 数据集上训练大型卷积网络,因为学习其底层映射很困难,因为有近 120 万张图像属于 1000 个类别。
旁注:虽然高速公路连接(Srivastava 等人,2015 年)被发明得更早,但它们并没有取得太大的成功,因为后来残差连接在速度、有效的更深模型训练(高达 1000 层的实验验证)以及简单的无参数操作方面胜过了它们。
现在我们来看看`ResNet18`模型的架构,它基本上有 18 个卷积层。残差块由两个卷积和批量归一化层序列组成,为简单起见,我们将其表示为`ConvBN`。残差块的输入通过第一个`ConvBN`块传递,后面是激活函数(在我们的例子中是 ReLU)。接下来,该中间输出通过另一个`ConvBN`模块,其输出与剩余模块的输入相加,并遵循激活操作。为了使剩余相加成为可能,第二个`ConvBN`模块的输出尺寸必须与剩余输入尺寸相同。换句话说,第一卷积层的输入滤波器必须等于第二卷积层的输出滤波器。如果不是这种情况,我们通过因子 2 对残差输入进行下采样,并通过名为`projection`的独立卷积层将其滤波器数量(通常是输入滤波器的两倍)与第二`ConvBN`模块的输出进行匹配。
在编程剩余块之前,让我们导入一些库。
```py
import Dispatch
import Foundation
import Datasets
import TensorFlow
import TrainingLoop
import PythonKit
let np = Python.import("numpy")
Listing 6-1Import libraries
接下来要做的事情是声明一些配置常数,例如网络的图像样本通道、CIFAR-10 数据集中的类的数量、训练模型的时期数量、样本的小批量大小,以及一些类型别名,以便于初始化将在其上执行每个训练相关操作的设备。
let inChannels: Int = 3
let classCount = 10
let epochCount = 25
let batchSize = 128
let device = Device.defaultXLA
typealias TFloat = Tensor<Float>
typealias Input = Tensor<Float>
typealias Output = Tensor<Float>
let imagenetteDataset = Imagenette(batchSize: batchSize, inputSize: .resized320, outputSize: imageSize, on: device)
Listing 6-2Initialize configuration properties, device, and type aliases for the ResNet18 model and load the CIFAR-10 dataset
网络接受的输入通道有三个,CIFAR-10 数据集的图像大小为ℝ 32×32×3 维,网络可以预测的类别数设置为 10,网络将经历数据集 50 次,每个样本为一批 128 幅图像,批维数为ℝ 128×32×32×3 。我们将device设置为 XLA 后端,默认设备将被自动选择,也就是说,如果选择了一个硬件加速器(如下所述),则为 CPU。
如果你在 Google Colaboratory 上编程,你可以选择硬件加速器为 GPU 或 TPU,方法是在菜单栏中点击运行时➤更改运行时类型,然后从弹出菜单中的硬件加速器下拉列表中选择任一设备,并点击保存按钮。现在device将自动设置为 GPU 或 TPU 加速器与 XLA 后端,ResNet18将在选定的加速器上训练。在我的实验中,我选择了 GPU。
图 6-8
残差卷积块的详细架构
输入经过卷积和批量标准化层、ReLU 激活以及另一系列卷积和批量标准化层。该输出与剩余输入相加,然后用 ReLU 激活剩余输入,给出剩余模块的最终输出。残差输入首先被投影(或下采样)到与第二批归一化层的输出相同的维度(即,输入的一半)和通道(即,输入的两倍),但是如果通道和维度相同,则它被原样传递到残差连接。
现在我们将对清单 6-3 中的ConvBN块进行编程。
struct ConvBN: Layer {
var conv: Conv2D<Float>
var norm: BatchNorm<Float>
init(
filterShape: (Int, Int, Int, Int),
strides: (Int, Int) = (1, 1),
padding: Padding = .same
) {
conv = Conv2D(filterShape: filterShape, strides: strides, padding: padding, useBias: false)
norm = BatchNorm(featureCount: filterShape.3, momentum: 0.1, epsilon: 1e-5)
}
@differentiable
func callAsFunction(_ input: Input) -> Output {
input.sequenced(through: conv, norm)
}
}
Listing 6-3Program a convolutional and batch normalization layers block
让我们从名为conv的Conv2D实例的初始化开始,它以filterShape、strides和padding作为参数。第一个自变量filterShape是四个Int值的元组,其中第一、第二、第三和第四值分别代表内核的高度、内核的宽度、内核的深度(即,输入特征图的过滤器)和内核的数量(即,输出特征图的过滤器的期望数量或深度维度大小)。第二个自变量strides是两个Int值的元组,其在第一和第二索引处分别表示在应用卷积运算之前在高度(即,垂直)和宽度(即,水平)方向上采取的步骤。第三个参数是我们已经讨论过的Padding枚举类型的padding。在 TensorFlow 中,我们不需要计算零填充并将其放在卷积或池化等层中。我们可以将padding设置为.valid或.same。两者的区别在于.same在输入周围应用零填充(如果需要)以产生与输入相同的空间或时间维度的输出,而.valid在输入周围不应用任何零填充,并且输出的空间或时间维度可能与输入的空间或时间维度相同,也可能不同。但是在我们的代码示例中,我们将主要使用Padding枚举的.same用例。最后,我们没有在我们的conv实例中使用偏差项,并将useBias参数设置为等于false。
接下来,注意批量标准化层norm采用的featureCount参数等于卷积层conv的输出滤波器数量。我们还将norm的momentum和epsilon分别设为等于0.1和0.00001。
图 6-9
18 层剩余卷积网络的详细结构
输入x∈ℝb×224×224×3经过卷积和批量归一化层和 ReLU 激活,随后是最大池操作。这里, b 是最小批量。然后,输出经过一系列八个残差块,其输出经过全局平均池操作、展平层(将多维张量转换为批量向量)和密集层,后者产生罗吉斯向量 y ∈ ℝ b×10 。
现在我们将对清单 6-4 中的剩余程序块进行编程,如图 6-8 所示。
struct ResidualBlock: Layer {
var convBN1: ConvBN
var convBN2: ConvBN
var projection: ConvBN
init(
inFilters: Int,
outFilters: Int
) {
if inFilters == outFilters {
convBN1 = ConvBN(filterShape: (3, 3, inFilters, outFilters))
convBN2 = ConvBN(filterShape: (3, 3, outFilters, outFilters))
// In this case, we don't use `projection`.
projection = ConvBN(filterShape: (1, 1, 1, 1))
} else {
convBN1 = ConvBN(filterShape: (3, 3, inFilters, outFilters), strides: (2, 2))
convBN2 = ConvBN(filterShape: (3, 3, outFilters, outFilters), strides: (1, 1))
projection = ConvBN(filterShape: (1, 1, inFilters, outFilters), strides: (2, 2))
}
}
@differentiable
func callAsFunction(_ input: Input) -> Output {
let residual = convBN1.conv.filter.shape[2] != convBN2.conv.filter.shape[3] ? projection(input) : input
let convBN1Output = relu(convBN1(input))
let convBN2Output = relu(convBN2(convBN1Output) + residual)
return convBN2Output
}
}
Listing 6-4Program a convolutional residual block and consider the downsampling for different input and output filters to it
残差块是 ResNet 模型的基本构造块。残余块的可视化和解释见图 6-8 。在清单 6-4 中,名为ResidualBlock的残差块结构有三个存储属性,即projection、convBN1和ConvBN类型的convBN2。在其初始化器中,它接受前两个Int参数,即inFilters和outFilters。初始化层时,我们检查inFilters和outFilters是否相等。如果这是真的,那么我们为convBN1和convBN2设置内核的高度和宽度等于 3 个单位。convBN1和convBN2的输入通道设置为等于inFilters和outFilters,两者的输出通道设置为等于outFilters。
两层的strides也默认为(1, 1)。在这种情况下,由于默认情况下padding为.same而strides为(1, 1),输入输出特征尺寸将相同;因此,我们不需要投影输入,我们将projection实例初始化为默认值。
当ResidualBlock的inFilters和outFilters不同时,我们将convBN1的strides设置为等于(2, 2),而对于convBN1和convBN2的其他参数与前一种情况相同。使用此strides值convBN1,输入要素的空间维度将减半。因此,我们将projection实例的所有参数设置为与convBN1相同,以将输入投射到与convBN1和convBN2序列将投射的维度相同的维度。
在callAsFunction(_:)方法的正向传递过程中,如果两个ConvBN序列的输入和输出滤波器不相同,但在其他情况下等于输入本身,我们首先将剩余输入设置为等于投影输入。然后我们应用convBN1并用relu激活它,运行通过convBN2,加上剩余输入,用relu激活它返回剩余块的输出。
清单 6-5 显示了 ResNet18 模型结构。ResNet18 模型如图 6-9 所示。
struct ResNet18: Layer {
var initialConvBNBlock = Sequential {
ConvBN(filterShape: (7, 7, inChannels, 64), strides: (2, 2))
MaxPool2D<Float>(poolSize: (3, 3), strides: (2, 2), padding: .same)
}
var block1 = Sequential {
ResidualBlock(inFilters: 64, outFilters: 64)
ResidualBlock(inFilters: 64, outFilters: 64)
}
var block2 = Sequential {
ResidualBlock(inFilters: 64, outFilters: 128)
ResidualBlock(inFilters: 128, outFilters: 128)
}
var block3 = Sequential {
ResidualBlock(inFilters: 128, outFilters: 256)
ResidualBlock(inFilters: 256, outFilters: 256)
}
var block4 = Sequential {
ResidualBlock(inFilters: 256, outFilters: 512)
ResidualBlock(inFilters: 512, outFilters: 512)
}
var globalAvgPool = GlobalAvgPool2D<Float>()
var flatten = Flatten<Float>()
var classifier: Dense<Float>
init(classCount: Int) {
classifier = Dense(inputSize: 512, outputSize: classCount)
}
@differentiable
func callAsFunction(_ input: Input) -> Output {
let initialConvBNOutput = maxPool(relu(initialConvBN(input)))
let convFeatures = initialConvBNOutput.sequenced(through: block1, block2, block3, block4)
let logits = convFeatures.sequenced(through: globalAvgPool, flatten, classifier)
return logits
}
}
Listing 6-5Define the residual convolutional network with 18 layers
如图 6-9 所示,该结构有四个块,每个块包含两个ResidualBlock,还有initialConvBN和maxPool属性,执行卷积和批量归一化以及一个最大池操作。有一个名为globalAvgPool的平均池属性和一个类型为Flatten的flatten属性。最后,我们有一个Dense类型的classifier属性用于预测logits。在正向传递中,输入张量通过initialConvBN、relu、maxPool、block1、block2、block3和block4传递。输出是输入图像的卷积特征,然后汇集、展平(即整形为批量矢量),并通过classifier层进行预测。
接下来,我们侵入Layer协议,用 NumPy 数组实现读和写检查点方法。
extension Layer {
public func writeCheckpoint(to file: String) throws {
var parameters = Array<PythonObject>()
for keyPath in self.recursivelyAllWritableKeyPaths(to: TFloat.self) {
parameters.append(self[keyPath: keyPath].makeNumpyArray())
}
np.save(file, np.array(parameters))
}
public mutating func readCheckpoint(from file: String) throws {
let parameters = np.load(file)
for (index, keyPath) in self.recursivelyAllWritableKeyPaths(to: TFloat.self).enumerated() {
self[keyPath: keyPath] = TFloat(numpy: parameters[index])!
}
}
}
Listing 6-6Implement custom checkpoint reading and writing methods on the Layer protocol using the NumPy library with Python interoperability
我们在Layer协议上声明了两个实例方法,所有符合它的类型都可以自动使用它们,即writeCheckpoint(to:)和readCheckpoint(from:)。检查点写方法声明了一个PythonObject类型的参数数组。然后我们通过可以写入的KeyPath遍历Tensor<Float>类型的所有属性。在通过调用makeNumpyArray()方法将TFloat实例转换为 NumPy 数组之后,我们将每个属性添加到parameters数组中。在循环之后,我们将 NumPy 数组类型转换参数保存到文件位置。
在检查点读取方法中,我们加载检查点文件。然后,我们递归地迭代指向TFloat类型的所有可写的KeyPath,并通过强制展开将keyPath keyPath处的符合层的实例的属性设置为等于从索引处的file加载的 NumPy 个参数。这样,我们将参数加载到我们的Layer-一致性实例中。
接下来,我们定义一个函数writeCheckpoint(_:event:)来保存训练期间每个时期结束后的检查点。我们将把它传递给数组中的参数callbacks。在训练过程中,callbacks接受一组基于特定事件调用的函数。
func writeCheckpoint<L: TrainingLoopProtocol>(_ loop: inout L, event: TrainingLoopEvent) throws {
DispatchQueue.global(qos: .userInitiated).async {
switch event {
case .epochEnd:
do {
try preTrainingModel.writeCheckpoint(to: "ResNet18.npy")
} catch {
print(error)
}
default: break
}
}
}
Listing 6-7Define a function to automatically write checkpoint during training
在清单 6-7 中,我们定义了一个占位符类型L符合TrainingLoopProtocol的函数writeCheckpoint(_:event:),它带有两个参数:inout类型的loop和TrainingLoopEvent类型的event。这个函数会抛出一个错误。如果您想在训练期间通过传递给callbacks为其他定制任务定义您的函数,您应该使用相同的参数,并在函数体内定义定制功能。
在主体内部,我们有一个包含在DispatchQueue中的switch语句,用于使用另一个线程来执行这个任务(您可能不需要编写这个语句,但是我在代码执行方面遇到了一些问题)。switch语句将事件参数与各种情况进行比较。因为我们想在每个时期结束时保存检查点,所以我们试图在event等于.epochEnd的时候写检查点。还有许多其他的event案例,你可以利用它们来定制训练循环。
// Initialize the model and optimizer
var model = ResNet18(classCount: classCount)
var optimizer = SGD(for: model, learningRate: 0.1, momentum: 0.9)
// Training setup
let trainingProgress = TrainingProgress()
var trainingLoop = TrainingLoop(
training: dataset.training,
validation: dataset.validation,
optimizer: optimizer,
lossFunction: softmaxCrossEntropy,
callbacks: [trainingProgress.update, writeCheckpoint])
// Train the model
try! trainingLoop.fit(&model, epochs: epochs, on: device)
Listing 6-8Initialize the model and optimizer, and train the model
在清单 6-8 中,我们已经用具有classCount类的ResNet18初始化了model用于预测。优化器optimizer用随机梯度下降优化器初始化,该优化器具有学习速率0.1和等于0.9的动量设置。然后分别初始化TrainingProgress和TrainingLoop实例trainingProgress和trainingLoop。对于training和validation,用datasets初始化trainingLoop,优化器被设置为等于optimizer,损失函数被设置为softmaxCrossEntropy,callbacks是包含更新方法trainingProgress.update和writeCheckpoint函数的数组。
最后,我们对model进行训练,在训练集和验证集上分别达到 0.9960 和 0.7305 的图像分类精度。我们的 ResNet18 模型的性能优于在相同数据集上训练的小 LeNet(参见第四章),后者在训练集和验证集上的精度分别仅为 0.5607 和 0.5625。
6.5 结论
在这一章中,我们研究了卷积神经网络对于处理计算机视觉问题非常有用,并且比密集网络有许多优势。我们还研究了一种减轻梯度消失问题的技术。最后,我们训练了一个深度卷积网络来对图像进行分类,其性能优于一个较小的卷积网络,表明深度非线性模型优于浅层模型。
这本书用 Swift 为 TensorFlow 介绍了深度学习学科。但我们只是触及了深度学习领域的皮毛,还有很多东西需要了解!我希望你喜欢用 Swift 语言理解和编程深度学习。直到下一次…
Footnotes 1引自(Box,1976)。
