

R 和 JavaScript 高级数据可视化(二)
四、使用 D3 实现数据可视化
到目前为止,当我们谈论用于创建数据可视化的技术时,我们一直在谈论 R。我们已经花了最后两章来探索 R 环境和学习命令行。我们讨论了 R 语言的入门主题,从数据类型、函数到面向对象编程。我们甚至讨论了如何使用 RPubs 将我们的 R 文档发布到 Web 上。
本章我们将看一个叫做 D3 的 JavaScript 库,它被用来创建交互式数据可视化。首先是一个关于 HTML、CSS 和 JavaScript 的快速入门,D3 的支持语言。然后我们将深入研究 D3,并探索如何在 D3 中制作一些更常用的图表。
初步概念
D3 是一个 JavaScript 库。具体来说,这意味着它是用 JavaScript 编写的,并嵌入在 HTML 页面中。我们可以在自己的 JavaScript 代码中引用 D3 的对象和函数。所以让我们从头开始。下一节的目的不是深入研究 HTML CSS 和 JavaScript 还有很多其他的资源,包括我参与撰写的基金会网站创建。目的是对我们将直接用 D3 处理的概念有一个非常高层次的回顾。如果你已经熟悉 HTML、CSS 和 JavaScript,你可以跳到本章的“D3 历史”部分。
超文本标记语言
HTML 是一种标记语言;事实上,它代表超文本标记语言。它是一种表示语言,由表示格式和布局的元素组成。元素包含属性,这些属性具有指定元素、标记和内容的详细信息的值。为了解释,让我们看看我们的基本 HTML 框架结构,我们将在本章的大多数例子中使用它:
<!DOCTYPE html>
<html>
<head></head>
<body></body>
</html>
让我们从第一行开始。这是告诉浏览器的渲染引擎使用什么规则集的 doctype。浏览器可以支持多个版本的 HTML,每个版本都有稍微不同的规则集。这里指定的文档类型是 HTML5 文档类型。doctype 的另一个例子是:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN"" http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd ">
这是 XHTML 1.1 的 doctype。注意,它指定了文档类型定义的 URL(.dtd)。如果我们阅读 URL 上的纯文本,我们会看到它是一个如何解析 HTML 标签的规范。W3C 在这里维护了一个文档类型列表: www.w3.org/QA/2002/04/valid-dtd-list.html 。
Modern Browser Architecture
现代浏览器由封装了特定功能的模块组成。这些模块也可以获得许可并嵌入到其他应用中:
-
它们有一个 UI 层来处理浏览器用户界面的绘制,比如窗口、状态栏和后退按钮。
-
他们有渲染引擎来解析、标记和绘制 HTML。
-
它们有一个网络层来处理检索 HTML 和页面上所有资源所涉及的网络操作。
-
他们有一个 JavaScript 引擎来解释和执行页面中的 JavaScript。
请参见图 4-1 了解该架构的图示。
图 4-1
现代浏览器架构
回到 HTML 的框架结构。下一行是<html>标签;这是文档的根级标记,包含我们将使用的所有其他 HTML 元素。请注意,文档的最后一行有一个结束标记。
接下来是<head>标签,它是一个容器,通常保存页面上没有显示的信息(例如,标题和元信息)。在<head>标签之后是<body>标签,它是一个容器,保存所有将在页面上显示的 HTML 元素,例如段落:
<p> this is a paragraph </p>
或链接:
<a href="[URL]">link text or image here</a>
或图像:
<img src="[URL]"/>
当谈到 D3 时,我们将要编写的大部分 JavaScript 将在主体部分,而大部分 CSS 将在头部分。
半铸钢ˌ钢性铸铁(Cast Semi-Steel)
CSS 代表级联样式表,用于设计网页上 HTML 元素的样式。样式表要么包含在<style>标签中,要么通过<link>标签外部链接,由样式规则和选择器组成。选择器将 web 页面上的元素作为样式的目标,样式规则定义应用什么样式。让我们看一个例子:
<style>
p{
color: #AAAAAA;
}
</style>
在前面的代码片段中,样式表在一个style标签中。p是选择器,它告诉浏览器将网页上的每个段落标记作为目标。样式规则用花括号括起来,由属性和值组成。本例将所有段落中文本的颜色设置为#AAAAAA,这是浅灰色的十六进制值。
选择器是 CSS 的真正微妙之处。这与我们相关,因为 D3 也使用 CSS 选择器来定位元素。类似于 S3/S4 类如何在 R 中相互继承,我们可以通过类或 id 使用选择器和目标元素变得非常具体,或者我们可以使用伪类来针对抽象概念,比如当元素悬停在上面时。我们可以在 DOM 中上下定位元素的祖先和后代。
Note
DOM 代表文档对象模型,是允许 JavaScript 与网页上的 HTML 元素交互的应用程序编程接口(API)。
.classname{
/* style sheet for a class*/
}
#id{
/*style sheet for an id*/
}
element:pseudo-class{
}
挽救(saving 的简写)
D3 的下一个介绍性概念是 SVG,它代表可伸缩矢量图形。SVG 是一种在浏览器中创建矢量图形的标准化方法,D3 用它来创建数据可视化。我们在 SVG 中关心的核心功能是绘制形状和文本并将它们集成到 DOM 中的能力,以便我们的形状可以通过 JavaScript 编写脚本。
Note
矢量图形是使用点和线创建的图形,这些点和线由渲染引擎进行数学计算和显示。将这种想法与位图或光栅图形进行对比,在位图或光栅图形中,像素显示是预先渲染的。向量,因为它们是简单的方程,往往规模更好,也更小。但是,它们缺乏位图或光栅图形的深度。
SVG 本质上是它自己的标记语言,有自己的 doctype。我们可以在外部.svg文件中编写 SVG,或者将 SVG 标签直接包含在我们的 HTML 中。在 HTML 页面中编写 SVG 标签允许我们通过 JavaScript 与形状进行交互。
SVG 支持预定义的形状以及画线的能力。SVG 中预定义的形状如下:
-
<rect>画矩形 -
<circle>画圆 -
<ellipse>画椭圆 -
<line>画线条;还有<polyline>和<polygon>用多个点画线
让我们看一些代码示例。如果我们将 SVG 写入 HTML 文档,我们使用<svg>标签包装我们的形状。<svg>带有xmlns和version属性。xmlns属性应该是 SVG 名称空间的路径,而version显然是 SVG 的版本:
<svg xmlns:=" http://www.w3.org/2000/svg " version="1.1">
</svg>
如果我们正在编写独立的.svg文件,我们将完整的doctype和xml标签包含到页面文件中:
<?xml version="1.0" standalone="no"?>
<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN" " http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd ">
<svg xmlns:=" http://www.w3.org/2000/svg " version="1.1">
</svg>
无论哪种方式,我们都在<svg>标签中创建我们的形状。让我们在<svg>标签中创建一些示例形状:
<svg xmlns:=" http://www.w3.org/2000/svg " version="1.1" viewBox="0 0 500 500">
<rect x="10" y="10" width="10" height="100" stroke="#000000" fill="#AAAAAA" />
<circle cx="70" cy="50" r="40" stroke="#000000" fill="#AAAAAA" />
<ellipse cx="230" cy="60" rx="100" ry="50" stroke="#000000" fill="#AAAAAA" />
</svg>
该代码产生如图 4-2 所示的形状。
图 4-2
在 SVG 中绘制的矩形、圆形和椭圆形
请注意,我们为所有形状分配了 x 和 y 坐标,在圆形和椭圆形的情况下,分配了 cx 和 cy 坐标,以及填充颜色和描边颜色。这只是最小的味道;我们也可以创建渐变和过滤器,然后将它们应用到我们的形状。我们还可以使用<text>标签创建文本,用于我们的 SVG 绘图。
让我们来看看。我们将更新前面的 SVG 代码,为每个形状添加文本标签:
<svg xmlns:=" http://www.w3.org/2000/svg " version="1.1" viewBox="0 0 500 500">
<rect x="80" y="20" width="10" height="100" stroke="#000000" fill="#AAAAAA" />
<text x="55" y="145" fill="#000000">rectangle</text>
<circle cx="170" cy="60" r="40" stroke="#000000" fill="#AAAAAA" />
<text x="150" y="145" fill="#000000">circle</text>
<ellipse cx="330" cy="70" rx="100" ry="50" stroke="#000000" fill="#AAAAAA" />
<text x="295" y="145" fill="#000000">ellipse</text>
</svg>
该代码创建如图 4-3 所示的图形。
图 4-3
带文本标签的 SVG 形状
现在,我们可以开始看到用这些基本构件创建数据可视化的可能性。因为 D3 是一个 JavaScript 库,而且我们用 D3 做的大部分工作都是在 JavaScript 中完成的,所以在我们深入研究 D3 之前,让我们先从高层次上了解一下 JavaScript。
Java Script 语言
JavaScript 是网络的脚本语言。通过将script标签内嵌在文档中或者链接到外部 JavaScript 文档,可以将 JavaScript 包含在 HTML 文档中:
<script>
//javascript goes here
</script>
<script src="pathto.js"></script>
JavaScript 可用于处理信息、对事件做出反应以及与 DOM 交互。在 JavaScript 中,我们使用关键字var创建变量。
var foo = "bar";
注意,如果我们不使用var关键字,我们创建的变量将被赋给全局范围。我们不想这样做,因为我们的全局变量可能会被网页上的其他代码覆盖。
JavaScript 看起来很像其他基于 C 的语言,因为每个表达式都以分号结尾,函数和条件体等代码块都用花括号括起来。
条件语句通常是格式如下的if-else语句:
if([condition]){
[code to execute]
}else{
[code to execute]
}
函数的格式如下:
function [function name] ([arguments]){
[code to execute]
}
在 JavaScript 中,我们通常通过引用元素的id属性来访问 DOM 元素。我们像使用getElementById()函数一样做这件事:
var header = document.getElementById("header");
前面的代码存储了对 web 页面上 ID 为header的元素的引用。然后,我们可以更新该元素的属性,包括添加新元素或完全删除该元素。
JavaScript 中的对象通常是对象文字,这意味着我们在运行时创建它们,由属性和方法组成。我们像这样创建对象文字:
var myObj = {
myProp: 20,
myfunc: function(){
}
}
我们使用点运算符引用对象的属性和方法:
myObj.myprop = 10;
看,这又快又无痛。好的,接下来是 D3!
D3 的历史
D3 代表数据驱动文档,是一个用于创建交互式数据可视化的 JavaScript 库。将成为 D3 的想法的种子始于 2009 年的 Protovis,由迈克·博斯托克、瓦迪姆·奥吉夫茨基和杰夫·赫尔在斯坦福可视化小组工作时创建。
Note
史丹福可视化小组的信息可以在它的网站上找到: http://vis.stanford.edu/ 。Protovis 的原始白皮书可在 http://vis.stanford.edu/papers/protovis 找到。
Protovis 是一个 JavaScript 库,它提供了创建不同类型可视化的接口。根名称空间是pv,它提供了一个 API 来创建条、点和区域等。像 D3 一样,Protovis 使用 SVG 来创建这些形状,但与 D3 不同,它将 SVG 调用包装在自己专有的术语中。
Protovis 在 2011 年被放弃了,所以它的创造者可以学习并专注于 D3。Protovis 和 D3 在哲学上是有区别的。Protovis 的目标是提供用于创建数据可视化的包装功能,而 D3 则通过使用现有的 web 标准和术语来简化数据可视化的创建。在 D3 中,我们在 SVG 中创建了矩形和圆形,这得益于 D3 的语法优势。
使用 D3
我们需要做的第一件事就是去 D3 网站 http://d3js.org/ ,下载最新版本(见图 4-4 )。
图 4-4
D3 主页
安装后,您可以设置一个项目。
设置项目
我们可以在页面上直接包含.js文件,就像这样:
<script src="d3.v3.js"></script>
根命名空间是d3;我们从 D3 发出的所有命令都将使用d3对象。
使用 D3
我们使用select()函数来定位特定的元素,或者使用selectAll()函数来定位所有特定的元素类型:
var body = d3.select("body");
前一行选择了body标签,并将其存储在名为body的变量中。然后,我们可以根据需要更改几何体的属性,或者向几何体添加新元素:
var allParagraphs = d3.select("body").selectAll("p");
前一行选择了body标签,然后选择了正文中的所有段落标签。
请注意,我们在第二行将两个动作链接在一起。我们选择了正文,然后选择了所有的段落,这两个动作是连在一起的。还要注意,我们使用 CSS 选择器来指定目标元素。
好了,一旦我们选择了一个元素,它现在就被认为是我们的选择,我们可以对这个选择执行操作。我们可以在选择中选择元素,就像我们在前面的例子中所做的那样。
我们可以用attr()函数更新选择的属性。attr()函数接受两个参数:第一个是属性的名称,第二个是属性的设置值。假设我们想改变当前文档的背景颜色。我们可以选择主体,并通过将它添加到我们的脚本块来设置bgcolor属性:
<script>
d3.select("body")
.attr("bgcolor", "#000000");
</script>
请注意,在前面的代码片段中,我们将链式属性函数调用带到了下一行。我们这样做是为了可读性。
真正有趣的是,因为我们在谈论 JavaScript,而函数是 JavaScript 中的一级对象,我们可以将函数作为属性值传入,这样无论它评估为什么,都成为设置的值:
<script>
d3.select("body")
.attr("bgcolor", function(){
return "#000000";
});
</script>
我们也可以使用append()函数向我们的选择添加元素。append()函数接受一个标签名作为第一个参数。它将创建指定类型的新元素,并将该新元素作为当前选择返回:
<script>
var svg = d3.select("body")
.append("svg");
</script>
前面的代码在页面主体中创建了一个新的 SVG 标记,并将该选择存储在变量svg中。
接下来,让我们用我们刚刚学到的关于 D3 的知识重新创建图 4-3 中的形状:
<script>
var svg = d3.select("body")
.append("svg")
.attr("width", 800);
var r = svg.append("rect")
.attr("x", 80)
.attr("y", 20)
.attr("height", 100)
.attr("width", 10)
.attr("stroke", "#000000")
.attr("fill", "#AAAAAA");
var c = svg.append("circle")
.attr("cx", 170)
.attr("cy", 60)
.attr("r", 40)
.attr("stroke", "#000000")
.attr("fill", "#AAAAAA");
var e = svg.append("ellipse")
.attr("cx", 330)
.attr("cy", 70)
.attr("rx", 100)
.attr("ry", 50)
.attr("stroke", "#000000")
.attr("fill", "#AAAAAA");
</script>
对于每个形状,我们向 SVG 元素添加一个新元素并更新属性。
如果我们比较这两种方法,我们可以看到我们只是在 D3 中创建了 SVG 元素,就像我们在直接标记中所做的一样。然后,我们在 SVG 元素中创建一个 SVG 矩形、圆形和椭圆形,以及我们在 SVG 标记中指定的相同属性。但是我们的 D3 例子有一个非常重要的不同:我们现在有了对页面上每个可以交互的元素的引用。
让我们来看看 D3 的交互。
绑定数据
对于数据可视化,我们与 SVG 形状最重要的交互是将数据绑定到它们。这使我们能够在形状的属性中反映这些数据。
为了绑定数据,我们简单地调用选择的data()方法:
<script>
var rect = svg
.append("rect")
.data([1,2,3]);
</script>
这相当简单。然后,我们可以通过匿名函数引用绑定的数据,并将其传递给我们的attr()函数调用。让我们看一个例子。
首先,让我们创建一个名为dataSet的数组。为了开始设想这将如何与创建数据可视化相关联,您可以将dataSet视为一个非连续值的列表,可能是一个类的测试分数或一组区域的总降雨量:
<script>
var dataSet = [ 84,62,40,109];
</script>
接下来,我们将在页面上创建一个 SVG 元素。为此,我们将选择正文并附加一个宽度为 800 像素的 SVG 元素。我们将在一个名为svg的变量中保存对这个 SVG 元素的引用:
<script>
var svg = d3
.select("body")
.append("svg")
.attr("width", 800);
</script>
这就是能够绑定数据改变事情的地方。我们将一系列命令连接在一起,这些命令将根据数据数组中存在的元素数量在 SVG 元素中创建占位符矩形。
我们将首先使用selectAll()返回对 SVG 元素中所有矩形的引用。现在还没有,但是在链执行完的时候会有。接下来,我们绑定我们的dataSet变量并调用enter()。enter()函数从绑定数据中创建占位符对象。最后,我们调用append()在enter()创建的每个占位符处创建一个矩形。
<script>
bars = svg
.selectAll("rect")
.data(dataSet)
.enter()
.append("rect");
</script>
如果我们在浏览器中查看到目前为止的工作,我们会看到一个空白页,但是如果我们在 web inspector(如 Firebug)中查看 HTML,我们会看到 SVG 元素以及创建的矩形,但是还没有指定样式或属性,类似于图 4-5 。
图 4-5
Firebug 检查界面
接下来,让我们来设计刚刚制作的矩形。我们在变量bars中有一个对所有矩形的引用,所以让我们把一堆attr()调用链接在一起来设计矩形的样式。现在,让我们使用绑定的数据来确定条形的高度。
<script>
bars
.attr("width", 15 )
.attr("height", function(x){return x;})
.attr("x", function(x){return x + 40;})
.attr("fill", "#AAAAAA")
.attr("stroke", "#000000");
</script>
完整的源代码如下所示,并做出了我们在图 4-6 中看到的形状:
图 4-6
条形图的矩形样式
<script>
var dataSet = [84,62,40,109];
var svg = d3
.select("body")
.append("svg")
.attr("width", 800);
bars = svg
.selectAll("rect")
.data(dataSet)
.enter()
.append("rect");
bars
.attr("width", 15 )
.attr("height", function(x){return x;})
.attr("x", function(x){return x + 40;})
.attr("fill", "#AAAAAA")
.attr("stroke", "#000000");
</script>
现在再看看 Firebug 或者你的浏览器的调试工具;可以看到生成的标记,如图 4-7 所示。
图 4-7
Firebug 中显示为 SVG 源代码的矩形
现在,您可以真正看到我们如何通过将数据绑定到 SVG 形状来开始用 D3 进行数据可视化。让我们把这个概念向前推进一步。
创建条形图
到目前为止,我们的示例看起来很像一个条形图的开始,因为我们有许多高度代表数据的条形。让我们给它一些结构。
首先,让我们给我们的 SVG 容器一个更具体的宽度和高度。这很重要,因为 SVG 容器的大小决定了我们用来标准化图表其余部分的比例。因为我们将在整个代码中引用这个大小,所以让我们确保将这些值抽象到它们自己的变量中。
我们将为我们的 SVG 容器定义一个高度和宽度。我们还将创建保存我们将在轴上使用的最小值和最大值的变量:分别是 0 和 109(最大的数据点)。我们还将定义一个偏移值,这样我们就可以绘制比图表略大的 SVG 容器,以给出它周围的图表边距。
<script>
var chartHeight = 460,
chartWidth = 400,
chartMin = 0,
chartMax = 109,
offset = 60
var svg = d3
.select("body")
.append("svg")
.attr("width", chartWidth)
.attr("height", chartHeight + offset);
</script>
接下来我们需要确定我们的酒吧的方向。如图 4-6 所示,这些条是从上往下画的,所以尽管它们的高度是准确的,但它们看起来是朝下的,因为 SVG 是从左上方画形状和定位形状的。因此,为了使它们的方向正确,使条形看起来像是从图表的底部向上,让我们给条形添加一个 y 属性。
y 属性应该是引用数据的函数;该函数应该从图表高度中减去条形高度值。该函数返回的值是 y 坐标中使用的值。
<script>
bars
.attr("width", 15 )
.attr("height", function(x){return x;})
.attr("y", function(x){return (chartHeight - x);})
.attr("x", function(x){return x;})
.attr("fill", "#AAAAAA")
.attr("stroke", "#000000");
</script>
这会将条形翻转到 SVG 元素的底部。我们可以在图 4-8 中看到结果。
图 4-8
条形图中的矩形不再反转
现在让我们缩放条形以适应 SVG 元素的高度。为此,我们将使用 D3 scale()函数。scale()函数用于获取一个范围内的数字,并将其转换为另一个数字范围内该数字的等效值,本质上是将值换算为等效值。
在这种情况下,我们有一个数字范围,它表示我们的dataSet数组中的值的范围,它表示条形的高度,我们希望将这些数字转换成等价的值:
<script>
var yscale = d3.scaleLinear()
.domain([chartMin,chartMax])
.range([0,(chartHeight)]);
</script>
确保将这段代码放在声明图表变量的部分之后,最好是在声明“svg”变量之前。然后,我们只需使用yscale()函数更新条形的高度和 y 属性:
<script>
bars
.attr("width", 15 )
.attr("height", function(x){ return yscale(x);})
.attr("y", function(x){return (chartHeight - yscale(x));})
.attr("x", function(x){return x;})
.attr("fill", "#AAAAAA")
.attr("stroke", "#000000");
</script>
这产生了如图 4-9 所示的图形。
图 4-9
正确缩放的条形图矩形
非常好!但到目前为止,我们只是根据高度来放置条形,而不是根据它们在数组中的位置。让我们改变这一点,使它们的数组位置更有意义,这样条形就会以正确的顺序显示。
为此,我们只需更新条形的 x 值。我们已经看到,我们可以将一个匿名函数传递给attr()函数的 value 参数。匿名函数中的第一个参数是数组中当前元素的值。如果我们在匿名函数中指定第二个参数,它将保存当前的索引号。
然后,我们可以引用该值并偏移它来放置每个条形:
<script>
bars
.attr("width", 15 )
.attr("height", function(x){ return yscale(x);})
.attr("y", function(x){return (chartHeight - yscale(x));})
.attr("x", function(x, i){return (i * 20);})
.attr("fill", "#AAAAAA")
.attr("stroke", "#000000");
</script>
这为我们提供了图 4-10 中所示的条的顺序。只需目测一下,我们就可以知道现在条形更接近于数组中数据的表示形式——不仅仅是高度,还包括数组中指定顺序的高度。
图 4-10
条形图中的矩形按照数据中的顺序排列
现在,让我们添加文本标签,以便我们可以更好地看到条形的高度所表示的值。
我们通过创建 SVG 文本元素来实现这一点,其方式与创建条的方式非常相似。我们为数据数组中的每个元素创建文本占位符,然后设置文本元素的样式。您会注意到,我们传递到 x 和 y 属性调用中的匿名函数对于文本元素和对于条形几乎是相同的,只是进行了偏移,以便文本位于每个条形的上方和中心:
<script>
svg.selectAll("text")
.data(dataSet)
.enter()
.append("text")
.attr("x", function(d, i) { return ((i * 20) + offset/4); })
.attr("y", function(x, i){return (chartHeight - yscale(x) - 24) ;})
.attr("dx", -15/2)
.attr("dy", "1.2em")
.attr("text-anchor", "middle")
.text(function(d) { return d;})
.attr("fill", "black");
</script>
该代码生成如图 4-11 所示的图表。
图 4-11
带文本标签的条形图
参见以下完整的源代码:
<html>
<head>
<title></title>
<script src="d3.js"></script>
</head>
<body>
<script>
var dataSet = [84,62,40,109];
var chartHeight = 460,
chartWidth = 400,
chartMin = 0,
chartMax = 115,
offset = 60;
var yscale = d3.scaleLinear()
.domain([chartMin,chartMax])
.range([0,(chartHeight)]);
var svg = d3
.select("body")
.append("svg")
.attr("width", chartWidth)
.attr("height", chartHeight + offset);
bars = svg
.selectAll("rect")
.data(dataSet)
.enter()
.append("rect");
bars
.attr("width", 15 )
.attr("height", function(x){ return yscale(x);})
.attr("y", function(x){return (chartHeight - yscale(x));})
.attr("x", function(x, i){return (i * 20);})
.attr("fill", "#AAAAAA")
.attr("stroke", "#000000");
svg.selectAll("text")
.data(dataSet)
.enter()
.append("text")
.attr("x", function(d, i) { return ((i * 20) + offset/4); })
.attr("y", function(x, i){return (chartHeight - yscale(x) - 24) ;})
.attr("dx", -15/2)
.attr("dy", "1.2em")
.attr("text-anchor", "middle")
.text(function(d) { return d;})
.attr("fill", "black");
</script>
</body>
</html>
最后,让我们从外部文件读入数据,而不是在页面中硬编码。
加载外部数据
首先,我们将从文件中取出数组,并将其放入自己的外部文件:sampleData.csv。sampleData.csv的内容简单如下:
84,62,40,109
接下来,我们将使用d3.text()函数加载sampleData.csv。d3.text()的工作方式是获取一个外部文件的路径,然后将它赋给一个变量(在本例中为数据)。该函数接收一个参数,该参数是外部文件的内容:
<script>
d3.text("sampleData.csv").then((data) => {});
</script>
问题是,在开始对数据进行任何制图之前,我们需要外部文件的内容。因此,在回调函数中,我们将解析文件,然后包装所有现有的功能,如下所示:
<html>
<head>
<title></title>
<script src="d3.js"></script>
</head>
<body>
<script>
d3.text("sampleData.csv").then((data) => {
var dataSet = data.split(",");
var chartHeight = 460,
chartWidth = 400,
chartMin = 0,
chartMax = 115,
offset = 60;
var yscale = d3.scaleLinear()
.domain([chartMin,chartMax])
.range([0,(chartHeight)]);
var svg = d3
.select("body")
.append("svg")
.attr("width", chartWidth)
.attr("height", chartHeight + offset);
bars = svg
.selectAll("rect")
.data(dataSet)
.enter()
.append("rect");
bars
.attr("width", 15 )
.attr("height", function(x){ return yscale(x);})
.attr("y", function(x){return (chartHeight - yscale(x));})
.attr("x", function(x, i){return (i * 20);})
.attr("fill", "#AAAAAA")
.attr("stroke", "#000000");
svg.selectAll("text")
.data(dataSet)
.enter()
.append("text")
.attr("x", function(d, i) { return ((i * 20) + offset/4); })
.attr("y", function(x, i){return (chartHeight - yscale(x) - 24) ;})
.attr("dx", -15/2)
.attr("dy", "1.2em")
.attr("text-anchor", "middle")
.text(function(d) { return d;})
.attr("fill", "black");
})
</script>
</body>
</html>
需要注意的是,如果您在本地计算机上运行这段代码,而不是在 web 服务器上运行,您将得到类似“跨源请求仅支持 HTTP”的错误。这是一种安全措施,您的浏览器使用它来防止恶意代码在您的本地计算机上运行。建议在编程时使用本地 web 服务器来解决这个问题。
回到我们的 d3.text()函数——CSV 文件不是我们唯一可以读取的格式。事实上,d3.text()只是语法糖——D3 实现XMLHttpRequest对象d3.xhr()的便利方法或特定类型包装器。
作为参考,XMLHttpRequest对象是 AJAX 事务中用来从客户端异步加载内容而无需刷新页面的对象。在纯 JavaScript 中,我们实例化 XHR 对象,传入资源的 URL,以及检索资源的方法(GET 或 POST)。我们还指定了一个回调函数,该函数将在 XHR 对象更新时被调用。在这个函数中,我们可以解析数据并开始使用它。参见图 4-12 以获得该过程的高级图。
图 4-12
XHR 交易顺序图
在 D3 里,d3.xhr()函数是 D3 对XMLHttpRequest对象的包装。它的工作方式与我们刚刚看到的d3.text()非常相似,我们传入一个资源的 URL 和一个要执行的回调函数。
D3 具有的其他特定类型的便利功能是d3.csv()、d3.json()、d3.xml()和d3.html()。
摘要
本章探讨了 D3。我们开始讲述 HTML、CSS、SVG 和 JavaScript 的介绍性概念,至少是与实现 D3 相关的内容。从那里,我们深入研究了 D3,查看了一些介绍性的概念,比如创建我们的第一个 SVG 形状,通过将这些形状制作成条形图来扩展这个想法。
D3 是制作数据可视化的极好的库。要查看完整的 API 文档,请参见 https://github.com/mbostock/d3/wiki/API-Reference 。
我们将回到 D3,但是首先,我们将探索一些我们可以创建的数据可视化,它们在 web 开发的世界中有实际的应用。我们要看的第一个是你可能在谷歌分析仪表板或类似的东西上看到过的东西:基于用户访问的数据地图。
五、可视化访问日志中的空间数据
在上一章中,我们讨论了 D3,并研究了从制作简单形状到用这些形状制作条形图的概念。在前两章中,我们深入研究了 r。现在,您已经熟悉了我们将使用的核心技术,让我们开始看一些例子,作为 web 开发人员,我们如何创建数据可视化来交流我们领域内的有用信息。
我们要看的第一个是从我们的访问日志中创建一个数据映射。
什么是数据图?
首先,让我们进行水平设置,并确保我们清楚地定义了一个数据映射。数据地图是空间领域的信息表示,是统计学和制图学的结合。数据地图是最容易理解和最广泛使用的数据可视化工具,因为它们的数据表达在我们都熟悉和使用的东西中:地图。
回想一下琼恩·雪诺在 1854 年绘制的霍乱地图第一章的讨论。这被认为是数据地图的最早例子之一,尽管有几个著名的同时代人,包括十九世纪法国工程师查尔斯·密纳德的几个。他因 1812 年拿破仑入侵俄罗斯的数据可视化而广为人知。
米纳德还创建了几个突出的数据地图。他的两个最著名的数据地图包括展示法国消费的牛的来源地区和百分比的数据地图(见图 5-1 )和展示葡萄酒从法国出口的路径和目的地的数据地图(见图 5-2 )。
图 5-2
米纳德展示葡萄酒出口路径和目的地的数据地图
图 5-1
来自 Charles Minard 的早期数据地图展示了法国的来源地区和牛的消费情况
今天,我们到处都能看到数据地图。它们可以是知识性和艺术性的表达,就像费尔南达·维埃加斯和马丁·瓦滕伯格的风地图项目(见图 5-3 )。在 http://hint.fm/wind 可以看到,风力项目展示了美国上空气流的路径和力量。
图 5-3
风地图,显示飓风桑迪登陆时各地区的风速(经费尔南达·维埃加斯和马丁·瓦滕伯格许可使用)
数据图可能很深奥,例如 energy.gov 大学提供的数据图展示了各州的能源消耗(见图 5-4 )甚至各州的可再生能源产量等概念。
图 5-4
描述 energy.gov 各州能源消耗的数据图(可在 http://energy.gov/maps/2009-energy-consumption-person 获得)
现在,您已经看到了数据地图的历史和当代示例。在本章中,您将了解如何从 web 服务器访问日志创建自己的数据映射。
访问日志
访问日志是 web 服务器保存的记录,用于跟踪请求了哪些资源。每当从服务器请求网页、图像或任何其他类型的文件时,服务器都会为该请求创建一个日志条目。每个请求都有与之相关联的某些数据点,通常是关于资源请求者的信息(例如,IP 地址和用户代理)以及诸如一天中的时间和请求了什么资源之类的一般信息。
我们来看看访问日志。一个示例条目如下所示:
msnbot-157-55-17-199.search.msn.com - - [18/Jan/2013:13:32:15 -0400] "GET /robots.txt HTTP/1.1" 404 208 "-" "Mozilla/5.0 (compatible; bingbot/2.0; + http://www.bing.com/bingbot.htm)"
这是一个样本 Apache 访问日志的片段。Apache 访问日志遵循组合日志格式,这是万维网联盟(W3C)通用日志格式标准的扩展。通用日志格式的文档可在此处找到:
www.w3.org/Daemon/User/Config/Logging.html#common-logfile-format
通用日志格式定义了以下字段,用制表符分隔:
-
远程主机的 IP 地址或 DNS 名称
-
远程用户的日志名
-
远程用户的用户名
-
日期戳
-
请求—通常包括请求方法和所请求资源的路径
-
为请求返回的 HTTP 状态代码
-
请求的资源的总文件大小
组合日志格式添加了参考和用户代理字段。组合日志格式的 Apache 文档可以在下面找到:
http://httpd.apache.org/docs/current/logs.html#combined
注意,不可用的字段由单个破折号-表示。
让我们仔细分析一下前面的日志条目:
-
第一个字段是
msnbot-157-55-17-199.search.msn.com。这是一个 DNS 名称,只是碰巧内置了 IP 地址。我们不能指望解析出这个域的 IP 地址,所以现在,就忽略这个 IP 地址。当我们开始以编程方式解析日志时,我们将使用本机 PHP 函数gethostbyname()来查找给定域名的 IP 地址。 -
接下来的两个字段,日志名和用户,是空的。
-
接下来是日戳:
[18/Jan/2013:13:32:15 -0400]。 -
日期戳之后是请求:
"GET /robots.txt HTTP/1.1"。如果你还没有从 DNS 名称中猜到,这是一个机器人,具体来说是微软的msnbot替代品:??。在这个记录中,bingbot正在请求robots.txt文件。 -
接下来是请求的 HTTP 状态:
404。显然,没有可用的robots.txt文件。 -
接下来是请求的总负载。显然 404 需要 208 字节。
-
接下来是一个破折号,表示引用地址为空。
-
最后是 useragent:
"Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)",它明确地告诉我们,它确实是一个 bot。
现在您已经有了访问日志并理解了其中的内容,您可以解析它以编程方式使用其中的每个字段。
解析访问日志
解析访问日志的过程如下:
-
读取访问日志。
-
解析它并根据存储的 IP 地址收集地理数据。
-
为我们的可视化输出我们感兴趣的字段。
-
读入这个输出并可视化。
前三步我们用 PHP,最后一步用 R。请注意,您需要运行 PHP 5.4.10 或更高版本才能成功运行以下 PHP 代码。
读取访问日志
创建一个名为parseLogs.php的新 PHP 文档,首先创建一个函数来读取文件。调用这个函数parseLog()并让它接受文件的路径:
function parseLog($file){
}
在这个函数中,您将编写一些代码来打开传入的文件进行读取,并遍历文件的每一行,直到到达文件的末尾。迭代中的每一步都将读入的行存储在变量$line中:
$logArray = array();
$file_handle = fopen($file, "r");
while (!feof($file_handle)) {
$line = fgets($file_handle);
}
fclose($file_handle);
目前为止 PHP 中相当标准的文件 I/O 功能。在这个循环中,您将对一个您将调用parseLogLine()的函数和另一个您将调用getLocationbyIP()的函数进行函数调用。在parseLogLine()中,你将拆分行并将值存储在一个数组中。在getLocationbyIP()中,你将使用 IP 地址获取地理信息。然后,您将把这个返回的数组存储在一个名为$ logArray的更大的数组中。
$lineArr = parseLogLine($line);
$lineArr = getLocationbyIP($lineArr);
$logArray[count($logArray)] = $lineArr;
不要忘记在函数的顶部创建$logArray变量。
完成的函数应该是这样的:
function parseLog($file){
$logArray = array();
$file_handle = fopen($file, "r");
while (!feof($file_handle)) {
$line = fgets($file_handle);
$lineArr = parseLogLine($line);
$lineArr = getLocationbyIP($lineArr);
$logArray[count($logArray)] = $lineArr;
}
fclose($file_handle);
return $logArray;
}
解析日志文件
接下来,您将充实parseLogLine()函数。首先,您将创建一个空函数:
function parseLogLine($logLine){
}
该函数需要一行访问日志。
请记住,访问日志的每一行都是由空格分隔的信息部分组成的。您的第一反应可能是在每个空格处拆分该行,但这会导致以意想不到的方式拆分用户代理字符串(可能还有其他字段)。
就我们的目的而言,解析该行的一个更干净的方法是使用正则表达式。正则表达式,简称 regex,是使您能够快速有效地进行字符串匹配的模式。
正则表达式使用特殊字符来定义这些模式:单个字符、字符文字或字符集。对正则表达式的深入探讨超出了本章的范围,但是阅读不同正则表达式模式的一个很好的参考是微软正则表达式快速参考,可从这里获得: http://msdn.microsoft.com/en-us/library/az24scfc.aspx 。
Grant Skinner 还提供了一个很棒的创建和调试正则表达式的工具(见图 5-5 ,这里有: https://regexr.com 。
图 5-5
格兰特·斯金纳的正则表达式工具
要使用 Grant 的工具,将顶部的模式从 JavaScript 更改为 PCRE(这是 PHP 解释正则表达式的方式)。然后将以下内容粘贴到大的“文本”框中:
114.119.143.124---[14/Jun/2021:14:21:03-0400]" GET/2007/12/your-daddy-comment-leads-to-parking-lot-attack-northwes-Florida-daily-news/HTTP/1.1 " 200 19591 "-" Mozilla/5.0(Linux;安卓 7.0;)AppleWebKit/537.36 (KHTML,喜欢壁虎)手机 Safari/537.36(兼容;PetalBot+ https://webmaster.petalsearch.com/site/petalbot )”
最后,在“表达式”框中输入以下正则表达式:^([\d.:]+)(\ s+)(\ s+)[([\ w /]+):([\ w:]+)\ s([+-]\ d { 4 })]"(。+?) (.+?) (.+?)"(\d{3}) (\d+|(?:.+?)) "([^"]|(?:.+?))" "([^"]|(?:.+?))"
单击表达式匹配将让您了解正则表达式的每个部分是如何在我们粘贴的日志条目中找到的。
转向我们的 PHP 代码,让我们定义正则表达式模式,并将其存储在一个名为$pattern的变量中。
如果你不精通正则表达式,你可以使用 Grant Skinner 的工具很容易地创建它们(参见图 5-5 )。使用此工具,您可以得出以下模式:
$pattern = '/^([\d.:]+) (\S+) (\S+) \[([\w\/]+):([\w:]+)\s([+\-]\d{4})\] "(.+?) (.+?) (.+?)" (\d{3}) (\d+|(?:.+?)) "([^"]*|(?:.+?))" "([^"]*|(?:.+?))"/';
在该工具中,您可以看到它是如何将字符串分成以下几组的(参见图 5-6 )。
图 5-6
日志文件行被分成多个组
您现在有了一个可以使用的正则表达式。让我们使用 PHP 的preg_match()函数。它将正则表达式、与之匹配的字符串和作为模式匹配输出的数组作为参数:
preg_match($pattern,$logLine,$logs);
从那里,我们可以创建一个带有命名索引的关联数组来保存我们解析的上行:
$logArray = array();
$logArray['ip'] = gethostbyname($logs[1]);
$logArray['identity'] = $logs[2];
$logArray['user'] = $logs[2];
$logArray['date'] = $logs[4];
$logArray['time'] = $logs[5];
$logArray['timezone'] = $logs[6];
$logArray['method'] = $logs[7];
$logArray['path'] = $logs[8];
$logArray['protocol'] = $logs[9];
$logArray['status'] = $logs[10];
$logArray['bytes'] = $logs[11];
$logArray['referer'] = $logs[12];
$logArray['useragent'] = $logs[13];
我们完整的parseLogLine()函数现在应该是这样的:
function parseLogLine($logLine){
$pattern = '/^([\d.:]+) (\S+) (\S+) \[([\w\/]+):([\w:]+)\s([+\-]\d{4})\] "(.+?) (.+?) (.+?)" (\d{3}) (\d+|(?:.+?)) "([^"]*|(?:.+?))" "([^"]*|(?:.+?))"/';
preg_match($pattern,$logLine,$logs);
$logArray = array();
$logArray['ip'] = gethostbyname($logs[1]);
$logArray['identity'] = $logs[2];
$logArray['user'] = $logs[2];
$logArray['date'] = $logs[4];
$logArray['time'] = $logs[5];
$logArray['timezone'] = $logs[6];
$logArray['method'] = $logs[7];
$logArray['path'] = $logs[8];
$logArray['protocol'] = $logs[9];
$logArray['status'] = $logs[10];
$logArray['bytes'] = $logs[11];
$logArray['referer'] = $logs[12];
$logArray['useragent'] = $logs[13];
return $logArray;
}
接下来,您将为getLocationbyIP()函数创建功能。
通过 IP 进行地理定位
在getLocationbyIP()函数中,您可以通过解析访问日志的一行来获取数组,并使用 IP 字段来获取地理位置。通过 IP 地址获取地理位置的方法有很多种;大多数情况下,要么调用第三方 API,要么下载预先填充了 IP 位置信息的第三方数据库。其中一些第三方是免费提供的;有些是有成本的。
出于我们的目的,您可以使用 hostip.info 上的免费 API。图 5-7 显示了 hostip.info 主页。
图 5-7
hostip.info 主页
hostip.info 服务收集来自 ISP 的地理定位信息以及来自用户的直接反馈。它公开了一个 API 和一个可供下载的数据库。
该 API 在 http://api.hostip.info/ 可用。如果没有提供参数,API 将返回客户端的地理位置。默认情况下,API 返回 XML。返回值如下所示:
<?xml version="1.0" encoding="ISO-8859-1" ?>
<HostipLookupResultSet version="1.0.1" xmlns:gml=" http://www.opengis.net/gml " xmlns:xsi=" http://www.w3.org/2001/XMLSchema-instance " xsi:noNamespaceSchemaLocation=" http://www.hostip.info/api/hostip-1.0.1.xsd ">
<gml:description>This is the Hostip Lookup Service</gml:description>
<gml:name>hostip</gml:name>
<gml:boundedBy>
<gml:Null>inapplicable</gml:Null>
</gml:boundedBy>
<gml:featureMember>
<Hostip>
<ip>71.225.152.145</ip>
<gml:name>Chalfont, PA</gml:name>
<countryName>UNITED STATES</countryName>
<countryAbbrev>US</countryAbbrev>
<!-- Co-ordinates are available as lng,lat -->
<ipLocation>
<gml:pointProperty>
<gml:Point srsName=" http://www.opengis.net/gml/srs/epsg.xml#4326 ">
<gml:coordinates>-75.2097,40.2889</gml:coordinates>
</gml:Point>
</gml:pointProperty>
</ipLocation>
</Hostip>
</gml:featureMember>
</HostipLookupResultSet>
您可以细化 API 调用。如果你只需要国家信息,你可以呼叫 http://api.hostip.info/country.php 。它返回一个带有国家代码的字符串。如果 JSON 优于 XML,可以调用 http://api.hostip.info/get_json.php ,得到如下结果:
{"country_name":"UNITED STATES","country_code":"US","city":"Chalfont, PA","ip":"71.225.152.145"}
要指定 IP 地址,添加参数?ip=xxxx,如下所示:
http://api.hostip.info/get_json.php?ip=100.43.83.146
好了,我们来编写函数吧!
我们将剔除这个函数,让它接受一个数组。我们将从数组中提取 IP 地址,将其存储在一个变量中,并将该变量连接到一个包含 hostip.info API 路径的字符串:
function getLocationbyIP($arr){
$IPAddress = $arr['ip'];
$IPCheckURL = " http://api.hostip.info/get_json.php?ip=$IPAddress ";
}
您将把这个字符串传递给本机 PHP 函数file get_contents(),并将返回值(API 调用的结果)存储在一个名为jsonResponse的变量中。您将使用 PHP json_decode()函数将返回的 JSON 数据转换成原生 PHP 对象:
$jsonResponse = file_get_contents($IPCheckURL);
$geoInfo = json_decode($jsonResponse);
接下来,从对象中提取地理位置数据,并将其添加到传递给函数的数组中。城市和州信息是由逗号和空格分隔的单个字符串(“费城,宾夕法尼亚州”),因此您需要在逗号处进行拆分,并将每个字段分别保存在数组中。
$arr['country'] = $geoInfo->{"country_code"};
$arr['city'] = explode(",",$geoInfo->{"city"})[0];
$arr['state'] = explode(",",$geoInfo->{"city"})[1];
接下来,让我们做一点错误检查,这将使后面的过程更容易。您将检查状态字符串是否有任何值;如果没有,就设置为“XX”。一旦您开始解析 r 中的数据,这将很有帮助。最后,您将返回更新后的数组:
if(count($arr['state']) < 1)
$arr['state'] = "XX";
return $arr;
完整的函数应该是这样的:
function getLocationbyIP($arr){
$IPAddress = $arr['ip'];
$IPCheckURL = " http://api.hostip.info/get_json.php?ip=$IPAddress ";
$jsonResponse = file_get_contents($IPCheckURL);
$geoInfo = json_decode($jsonResponse);
$arr['country'] = $geoInfo->{"country_code"};
$arr['city'] = explode(",",$geoInfo->{"city"})[0];
$arr['state'] = explode(",",$geoInfo->{"city"})[1];
if(count($arr['state']) < 1)
$arr['state'] = "XX";
return $arr;
}
最后,让我们创建一个函数,将处理后的数据写出到一个文件中。
输出字段
您将创建一个名为writeRLog()的函数,它接受两个参数——填充了修饰日志数据的数组和文件路径:
function writeRLog($arr, $file){
}
您需要创建一个名为writeFlag的变量,它将是一个标志,告诉 PHP 向文件中写入或追加数据。您检查文件是否存在;如果是这样,您将追加内容而不是覆盖内容。检查完毕后,打开文件:
writeFlag = "w";
if(file_exists($file)){
$writeFlag = "a";
}
$fh = fopen($file, $writeFlag) or die("can't open file");
然后遍历传入的数组;构建一个包含每个日志条目的 IP 地址、日期、HTTP 状态、国家代码、州和城市的字符串;并将该字符串写入文件。一旦遍历完数组,就关闭文件。
for($x = 0; $x < count($arr); $x++){
if($arr[$x]['country'] != "XX"){
$data = $arr[$x]['ip'] . "," . $arr[$x]['date'] . "," . $arr[$x]['status'] . "," . $arr[$x]['country'] . "," . $arr[$x]['state'] . "," . $arr[$x]['city'];
}
fwrite($fh, $data . "\n");
}
我们完成的writeRLog()函数应该是这样的:
function writeRLog($arr, $file){
$writeFlag = "w";
if(file_exists($file)){
$writeFlag = "a";
}
$fh = fopen($file, $writeFlag) or die("can't open file");
for($x = 0; $x < count($arr); $x++){
if($arr[$x]['country'] != "XX"){
$data = $arr[$x]['ip'] . "," . $arr[$x]['date'] . "," . $arr[$x]['status'] . "," . $arr[$x]['country'] . "," . $arr[$x]['state'] . "," . $arr[$x]['city'];
}
fwrite($fh, $data . "\n");
}
fclose($fh);
echo "log created";
}
添加控制逻辑
最后,您将创建一些控制逻辑来调用您刚刚创建的所有这些函数。您将声明访问日志的路径和输出平面文件的路径,调用parseLog(),并将输出发送到writeRLog()。
$logfile = "access_log";
$chartingData = "accessLogData.txt";
$logArr = parseLog($logfile);
writeRLog($logArr, $chartingData);
我们完成的 PHP 代码应该如下所示:
<html>
<head></head>
<body>
<?php
$logfile = "access_log";
$chartingData = "accessLogData.txt";
$logArr = parseLog($logfile);
writeRLog($logArr, $chartingData);
function parseLog($file){
$logArray = array();
$file_handle = fopen($file, "r");
while (!feof($file_handle)) {
$line = fgets($file_handle);
$lineArr = parseLogLine($line);
$lineArr = getLocationbyIP($lineArr);
$logArray[count($logArray)] = $lineArr;
}
fclose($file_handle);
return $logArray;
}
function parseLogLine($logLine){
$pattern = '/^([\d.:]+) (\S+) (\S+) \[([\w\/]+):([\w:]+)\s([+\-]\d{4})\] "(.+?) (.+?) (.+?)" (\d{3}) (\d+|(?:.+?)) "([^"]*|(?:.+?))" "([^"]*|(?:.+?))"/';
preg_match($pattern,$logLine,$logs);
$logArray = array();
$logArray['ip'] = gethostbyname($logs[1]);
$logArray['identity'] = $logs[2];
$logArray['user'] = $logs[2];
$logArray['date'] = $logs[4];
$logArray['time'] = $logs[5];
$logArray['timezone'] = $logs[6];
$logArray['method'] = $logs[7];
$logArray['path'] = $logs[8];
$logArray['protocol'] = $logs[9];
$logArray['status'] = $logs[10];
$logArray['bytes'] = $logs[11];
$logArray['referer'] = $logs[12];
$logArray['useragent'] = $logs[13];
return $logArray;
}
function getLocationbyIP($arr){
$IPAddress = $arr['ip'];
$IPCheckURL = "http://api.hostip.info/get_json.php?ip=$IPAddress";
$jsonResponse = file_get_contents($IPCheckURL);
$geoInfo = json_decode($jsonResponse);
$arr['country'] = $geoInfo->{"country_code"};
$arr['city'] = explode(",",$geoInfo->{"city"})[0];
$arr['state'] = explode(",",$geoInfo->{"city"})[1];
return $arr;
}
function writeRLog($arr, $file){
$writeFlag = "w";
if(file_exists($file)){
$writeFlag = "a";
}
$fh = fopen($file, $writeFlag) or die("can't open file");
for($x = 0; $x < count($arr); $x++){
if($arr[$x]['country'] != "XX"){
$data = $arr[$x]['ip'] . "," . $arr[$x]['date'] . "," . $arr[$x]['status'] . "," . $arr[$x]['country'] . "," . $arr[$x]['state'] . "," . $arr[$x]['city'];
}
fwrite($fh, $data . "\n");
}
fclose($fh);
echo "log created";
}
?>
</body>
</html>
它应该会生成一个类似如下的平面文件:
71.225.152.145,18/Jan/2013,404,US, PA,Chalfont
114.119.143.124,14/Jun/2021,200,AU,,Canberra
我们在这里制作了一个示例访问日志: https://jonwestfall.com/data/access_log 。
在 R 中创建数据映射
到目前为止,您已经解析了访问日志,清理了数据,用位置信息修饰了数据,并创建了一个包含信息子集的平面文件。下一步是可视化这些数据。
因为您正在制作地图,所以需要安装地图包。开 R;在控制台中,键入以下内容:
> install.packages('maps')
> install.packages('mapproj')
现在我们可以开始了!要在 R 脚本中引用地图包,需要通过调用library()函数将其加载到内存中:
library(maps)
library(mapproj)
接下来创建几个变量——一个指向格式化的访问日志数据;另一个是列名列表。您创建了第三个变量logData,用于保存在读取平面文件时创建的数据帧。
logDataFile <- '/Applications/MAMP/htdocs/accessLogData.txt'
logColumns <- c("IP", "date", "HTTPstatus", "country", "state", "city")
logData <- read.table(logDataFile, sep=",", col.names=logColumns)
如果您在控制台中键入 logData ,您会看到数据帧的格式如下:
> logData
IP date HTTPstatus country state city
1 100.43.83.146 25/Jan/2013 404 US NV Las Vegas
2 100.43.83.146 25/Jan/2013 301 US NV Las Vegas
3 64.29.151.221 25/Jan/2013 200 US XX (Unknown city)
4 180.76.6.26 25/Jan/2013 200 CN XX Beijing
显然,你可以从这里开始追踪几个不同的数据点。让我们首先来看一下流量来自哪些国家。
测绘地理数据
您可以从logData中提取唯一的国家名称开始。您将把它存储在一个名为country:的变量中
> country <- unique(logData$country)
如果您在控制台中键入 country ,数据如下所示:
> country
[1] US CN CA SE UA
Levels: CA CN SE UA US
这些是您从 iphost.info 获得的国家代码。R 使用不同的国家代码集,因此您需要将 iphost 国家代码转换为 R 国家代码。您可以通过对国家列表应用函数来实现这一点。
您将使用sapply()将您自己设计的匿名函数应用到国家代码列表中。在匿名函数中,您将修剪任何空白并直接替换国家代码。您将使用gsub()函数替换传入参数的所有实例。
country <- sapply(country, function(countryCode){
#trim whitespaces from the country code
countryCode <- gsub("(^ +)|( +$)", "", countryCode)
if(countryCode == "US"){
countryCode<- "USA"
}else if(countryCode == "AU"){
countryCode<- "Australia"
}}
)
您会注意到,您对每个国家代码都进行了硬编码。当然,这是一种不好的形式,一旦你深入研究了状态数据,你就会用一种非常不同的方式来处理这个问题。
如果您再次在控制台中键入 country ,您将会看到以下内容:
> country
US AU
"USA" "Australia"
接下来使用match.map()函数将国家与地图包的国家列表进行匹配。函数创建一个数字向量,其中每个元素对应世界地图上的一个国家。交叉点的元素(国家列表中的国家与世界地图中的国家相匹配)具有分配给它们的值,特别是原始国家列表中的索引号。所以对应于美国的元素有 1,对应于加拿大的元素有 2,以此类推。在没有交集的地方,元素的值为 NA。
countryMatch <- match.map("world2", country)
接下来让我们使用countryMatch列表来创建一个颜色编码的国家匹配。为此,只需应用一个检查每个元素的函数。如果不是 NA,将颜色#C6DBEF 分配给元素,这是一种很好的浅蓝色。如果元素是 NA,则将元素设置为 white 或#FFFFFF。您将把这个结果保存在一个新的列表中,您将称之为colorCountry。
colorCountry <- sapply(countryMatch, function(c){
if(!is.na(c)) c <- "#C6DBEF"
else c <- "#FFFFFF"
})
现在让我们用map()函数创建我们的第一个可视化!map()函数接受几个参数:
-
第一个是要使用的数据库的名称。数据库名称可以是
world、usa state或county;每个都包含与map()函数将要绘制的地理区域相关的数据点。 -
如果您只想绘制更大的地理数据库的子集,您可以指定一个名为
region的可选参数,该参数列出了要绘制的区域。 -
您也可以指定要使用的地图投影。一个地图投影基本上是一种在平面上表现三维弯曲空间的方式。有许多预定义的投影,R 中的
mapproj包支持许多这样的投影。对于您将要制作的世界地图,您将使用等面积投影,其标识符为“azequalarea”。有关地图投影的更多信息,请参见http://xkcd.com/977/。 -
您还可以使用
orientation参数指定地图的中心点,用纬度和经度表示。 -
最后,您将把刚刚创建的
colorCountry列表传递给col参数。
map('world', proj='azequalarea', orient=c(41,-74,0), boundary=TRUE, col=colorCountry, fill=TRUE)
这段代码生成的地图如图 5-8 所示。
图 5-8
使用世界地图的数据地图
从这张地图上,我们可以看到唯一列表中的国家为蓝色阴影,其余国家为白色。这很好,但我们可以做得更好。
添加纬度和经度
让我们从添加纬度和经度线开始,这将突出地球的曲率,并给出极点在哪里的背景。为了创建纬度和经度线,我们首先创建一个新的地图对象,但是我们将把plot设置为FALSE,这样地图就不会被绘制到屏幕上。我们将这个地图对象保存到一个名为m的变量中:
m <- map('world',plot=FALSE)
接下来我们将调用map.grid()并传入我们存储的地图对象:
map.grid(m, col="blue", label=FALSE, lty=2, pretty=TRUE)
请注意,如果您在命令窗口中一行一行地运行这段代码,那么在您输入代码时保持 Quartz 图形窗口打开是很重要的,这样 R 就可以更新图表。如果您在一行一行地输入时关闭 Quartz 窗口,您可能会得到一个错误消息,说明还没有调用plot.new。或者您可以将每一行输入到一个文本文件中,然后一次将它们复制到 R 命令行中。
现在,让我们在图表中添加一个刻度来显示
map.scale()
我们完成的 R 代码现在应该看起来像这样:
library(maps)
library(mapproj)
logDataFile <- '/Applications/MAMP/htdocs/accessLogData.txt'
logColumns <- c("IP", "date", "HTTPstatus", "country", "state", "city")
logData <- read.table(logDataFile, sep=",", col.names=logColumns)
country <- unique(logData$country)
country <- sapply(country, function(countryCode){
#trim whitespaces from the country code
countryCode <- gsub("(^ +)|( +$)", "", countryCode)
if(countryCode == "US"){
countryCode<- "USA"
}else if(countryCode == "CN"){
countryCode<- "China"
}else if(countryCode == "CA"){
countryCode<- "Canada"
}else if(countryCode == "SE"){
countryCode<- "Sweden"
}else if(countryCode == "UA"){
countryCode<- "USSR"
}
})
countryMatch <- match.map("world", country)
#color code any states with visit data as light blue
colorCountry <- sapply(countryMatch, function(c){
if(!is.na(c)) c <- "#C6DBEF"
else c <- "#FFFFFF"
})
m <- map('world',plot=FALSE)
map('world',proj='azequalarea',orient=c(41,-74,0), boundary=TRUE, col=colorCountry,fill=TRUE)
map.grid(m,col="blue", label=FALSE, lty=2, pretty=TRUE)
map.scale()
并且这段代码输出如图 5-9 所示的世界地图。
图 5-9
带有经纬线和比例尺的全球数据地图
非常好!接下来,让我们深入分析美国各州的访问情况。
显示区域数据
让我们从隔离用户数据开始;我们可以通过选择状态不等于“XX”的所有行来实现这一点。还记得我们在 PHP 中解析访问日志时将 state 列中的值设置为“XX”吗?这就是为什么。美国以外的国家没有与之相关的州数据,所以我们可以简单地只提取有州数据的行。
usData <- logData[logData$state != "XX", ]
接下来,我们需要用完整的州名替换从 hostip.info 获得的州名缩写,这样我们就可以创建一个match.map查找列表,就像我们对前面的国家数据所做的那样。
州数据的好处是,R 有一个数据集,其中包含美国所有 50 个州的名称、缩写,甚至更深奥的信息,如州的区域和命名的部门(新英格兰、中大西洋等)。有关更多信息,请在 R 控制台键入?state.name。
我们可以使用该数据集中的信息将州缩写与地图包所需的完整州名进行匹配。为此,我们使用apply()函数运行一个匿名函数,该函数遍历state.abb数据集,找到传入的州名缩写的匹配项,然后使用返回值作为索引,从state.name数据集检索完整的州名:
usData$state <- apply(as.matrix(usData$state), 1, function(s){
#trim the abbreviation of whitespaces
s <- gsub("(^ +)|( +$)", "", s)
s <- state.name[grep(s, state.abb)]
})
我们实现了与之前的国家比赛相同的功能,但更加优雅。如果我们愿意的话,我们可以回去创建我们自己的国家名称数据集,以备将来使用,从而为国家匹配提供一个类似的优雅解决方案。
现在我们有了完整的州名,我们可以提取一个唯一的州名列表,并使用该列表创建一个地图匹配列表(同样,就像我们对国家所做的一样):
states <- unique(usData$state)
stateMatch <- match.map("state", states)
使用我们的状态匹配列表,我们可以再次对其应用一个函数,该函数将在我们的匹配列表中查找不具有 NA 值的匹配元素,并将这些元素的值设置为我们漂亮的浅蓝色,而所有具有 NA 值的元素都设置为白色。我们将这个列表保存在一个名为colorMatch的变量中。
#color code any states with visit data as light blue
colorMatch <- sapply(stateMatch, function(s){
if(!is.na(s)) s <- "#C6DBEF"
else s <- "#FFFFFF"
})
然后我们可以在对map()函数的调用中使用colorMatch:
map("state", resolution = 0,lty = 0,projection = "azequalarea", col=colorMatch,fill=TRUE)
嗯,但是注意到什么了吗?只有彩色区域被绘制到舞台上,如图 5-10 所示。
图 5-10
仅显示有数据的州的数据映射
我们需要进行第二次map()调用来绘制地图的剩余部分。在这个map()调用中,我们将把add参数设置为TRUE,这将导致我们正在绘制的新地图被添加到当前地图中。在此过程中,让我们也为这张地图创建一个比例:
map("state", col = "black", fill=FALSE, add=TRUE, lty=1, lwd=1, projection="azequalarea")
map.scale()
该代码产生图 5-11 中的完成状态图。
图 5-11
已完成的状态数据映射
分发可视化
好了,现在让我们把 R 代码放在 R Markdown 文件中进行分发。让我们进入 RStudio,点击文件➤新➤ R Markdown。让我们添加一个标题,并确保我们的 R 代码包含在```r{r}标签中,并且我们的图表有指定的高度和宽度。我们完成的 R Markdown 文件应该如下所示:
Visualizing Spatial Data from Access Logs
========================================================
```r{r}
library(maps)
library(mapproj)
logDataFile <- '/Applications/MAMP/htdocs/accessLogData.txt'
logColumns <- c("IP", "date", "HTTPstatus", "country", "state", "city")
logData <- read.table(logDataFile, sep=",", col.names=logColumns)
#chart worldwide visit data
#unfortunately there is no state.name equivalent for countries so we must check
#the explicit country names. In the us states below we are able to accomplish this much
#more efficiently
country <- unique(logData$country)
country <- sapply(country, function(countryCode){
#trim whitespaces from the country code
countryCode <- gsub("(^ +)|( +$)", "", countryCode)
if(countryCode == "US"){
countryCode<- "USA"
}else if(countryCode == "CN"){
countryCode<- "China"
}else if(countryCode == "CA"){
countryCode<- "Canada"
}else if(countryCode == "SE"){
countryCode<- "Sweden"
}else if(countryCode == "UA"){
countryCode<- "USSR"
}
})
countryMatch <- match.map("world", country)
#color code any states with visit data as light blue
colorCountry <- sapply(countryMatch, function(c){
if(!is.na(c)) c <- "#C6DBEF"
else c <- "#FFFFFF"
})
m <- map('world',plot=FALSE)
map('world',proj='azequalarea',orient=c(41,-74,0), boundary=TRUE, col=colorCountry,fill=TRUE)
map.grid(m,col="blue", label=FALSE, lty=2, pretty=FALSE)
map.scale()
#isolate the US data, scrub any unknown states
usData <- logData[logData$state != "XX", ]
usData$state <- apply(as.matrix(usData$state), 1, function(s){
#trim the abbreviation of whitespaces
s <- gsub("(^ +)|( +$)", "", s)
s <- state.name[grep(s, state.abb)]
})
s <- map('state',plot=FALSE)
states <- unique(usData$state)
stateMatch <- match.map("state", states)
#color code any states with visit data as light blue
colorMatch <- sapply(stateMatch, function(s){
if(!is.na(s)) s <- "#C6DBEF"
else s <- "#FFFFFF"
})
map("state", resolution = 0,lty = 0,projection = "azequalarea", col=colorMatch,fill=TRUE)
map("state", col = "black",fill=FALSE,add=TRUE,lty=1,lwd=1,projection="azequalarea")
map.scale()
该代码产生如图 5-12 所示的输出。我还在本书的代码下载中提供了这个 R 脚本。
 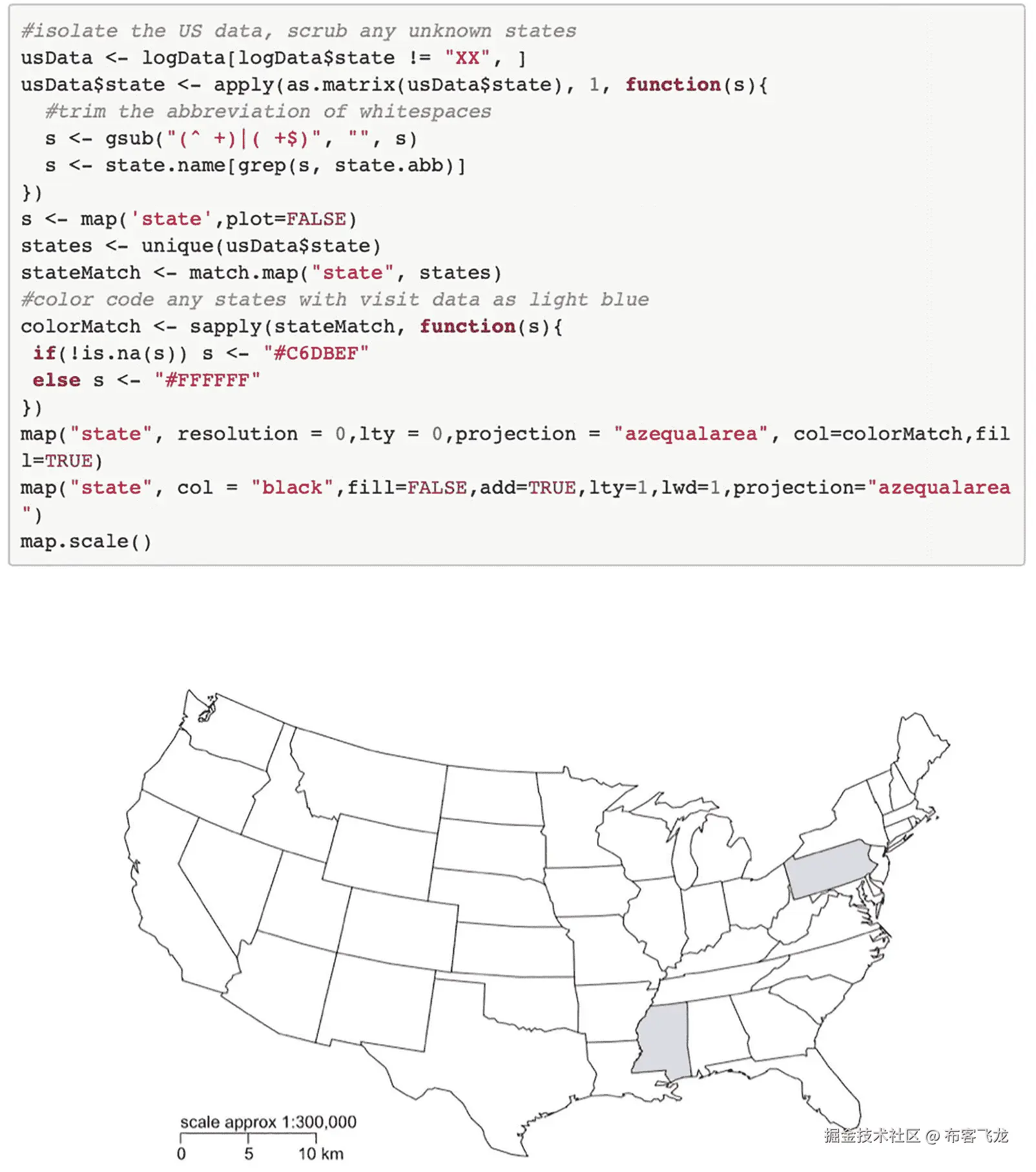
图 5-12
R Markdown 中的数据映射
## 摘要
本章讨论了解析访问日志以生成数据映射可视化。您查看了地图中的全球国家数据和更多的本地化州数据。这是您开始将使用数据应用到生活中的第一次尝试。
下一章在时序图的上下文中查看 bug backlog 数据。
# 六、可视化随着时间的推移的数据
最后一章讨论了使用访问日志来创建表示用户地理位置的数据地图。我们使用`map`和`mapproj`(用于地图投影)包来创建这些可视化。
本章探讨如何创建时间序列图表,这是一种比较数值随时间变化的图表。它们通常从左到右读取,x 轴代表某个时间度量,y 轴代表值的范围。本章讨论可视化缺陷随时间的变化。
随着时间的推移,跟踪缺陷不仅允许我们识别问题中的尖峰,还允许我们识别工作流中更大的模式,特别是当我们包括更细粒度的细节(如错误的严重性)并包括交叉引用数据(如迭代开始和结束等事件的日期)时。我们开始揭示一些趋势,比如在一个迭代中什么时候打开了 bug,什么时候打开了大部分阻塞 bug,或者什么迭代产生了最多的 bug。这种自我评估和反思让我们能够识别并关注盲点或需要改进的地方。它还允许我们在更大的范围内识别胜利,而这些胜利在没有上下文的情况下查看每日数据时可能会被错过。
一个恰当的例子:最近我们的组织设立了一个更大的团队目标,即在年底达到一定的 bug 数量,占我们在年初打开的所有 bug 的百分比。与我们的同事和我们的管理人员一起,我们指导所有的开发人员,创建过程改进,并为这个目标赢得人心。年底时,我们仍未解决的 bug 数量与我们开始时大致相同。我们感到困惑和担忧。但是当我们合计每天的数字时,我们意识到我们取得了比预期更大的成就:与前一年相比,我们实际上每年打开的错误减少了三分之一。这是一个巨大的问题,如果我们不是以批判的眼光看待这些数据,很容易被忽略。
## 收集数据
创建缺陷时间序列图的第一步是决定我们想要查看和收集数据的时间段。这意味着获取给定时间段内所有 bug 的导出。
这一步完全依赖于您可能使用的错误跟踪软件。也许您使用惠普的质量中心,因为它对您组织的其余测试需求有意义(例如能够使用 LoadRunner)。也许你使用一个托管的基于网络的解决方案,比如 Rally,因为你将缺陷管理与你的用户故事和发布跟踪捆绑在一起。也许你有自己安装的 Bugzilla,因为它是开放和免费的。
不管是哪种情况,所有的缺陷管理软件都有方法导出你当前的缺陷列表。根据所使用的缺陷跟踪软件,您可以导出到一个平面文件,比如一个逗号或者制表符分隔的文件。该软件还允许通过 API 访问其内容,因此您可以创建一个访问 API 并公开内容的脚本。
无论哪种方式,随着时间的推移,有两种重要的主要情况:
* 按日期运行的错误总数
* 按日期排列的新 bug
对于这两种情况中的任何一种,当我们从缺陷跟踪软件中导出时,我们关心的最少字段如下:
* 开业日期
* 缺陷 id
* 缺陷状态
* 缺陷的严重程度
* 缺陷的描述
导出的 bug 数据应该如下所示:
```r
Date, ID, Severity, Status, Summary
6/7/20,DE45091,Minor,Open,videos not playing
8/21/20,DE45092,Blocker,Open,alignment off
3/7/20,DE45093,Moderate,Closed,monsters attacking
让我们处理数据,以便能够可视化。
R 数据分析
第一件事是读入和排序数据。假设数据被导出到一个名为allbugs.csv的平面文件中,我们可以如下读入数据(我们已经在 http://jonwestfall.com/data/allbugs.csv 为其提供了示例数据):
bugExport <- "/Applications/MAMP/htdocs/allbugs.csv"
bugs <- read.table(bugExport, header=TRUE, sep=",")
让我们按日期排列数据框。为此,我们必须使用as.Date()函数将作为字符串读入的Date列转换为Date对象。as.Date()函数接受几个符号来表示如何读取和构造日期对象,如表 6-1 所示。
表 6-1
作为。日期( )函数符号
|标志
|
意义
|
| --- | --- |
| %m | 数字月 |
| %b | 字符串形式的月份名称,缩写 |
| %B | 字符串形式的完整月份名称 |
| %d | 数字日 |
| %a | 缩写字符串形式的工作日 |
| %A | 字符串形式的完整工作日 |
| %y | 两位数的年份 |
| %Y | 四位数的年份 |
所以对于日期"04/01/2013",我们传入"%m/%d/%Y";对于"April 01, 13",我们传入"%B %d, %Y"。您可以看到模式是如何匹配的:
as.Date(bugs$Date,"%m/%d/%y")
我们将在order()函数中使用转换后的日期,该函数返回来自bugs数据框的索引号列表,对应于数据框中值的正确排序方式:
> order(as.Date(bugs$Date,"%m/%d/%y"))
[1] 127 90 187 112 13 119 137 101 37 53 52 67 125 4 81 93 136 3 55 62 33 25 130 75 85 28
[27] 44 159 126 107 30 191 80 124 36 104 18 24 82 20 21 34 56 147 29 156 16 59 51 139 1 123
[53] 113 146 148 5 103 43 83 23 173 11 168 99 35 7 192 42 142 121 9 69 2 171 60 94 164 17
[79] 91 84 178 96 105 8 110 39 177 109 97 120 135 58 79 15 111 49 117 50 57 92 129 114 145 158
[105] 116 151 143 162 31 73 77 182 26 74 195 10 48 88 76 183 115 184 189 108 61 174 144 186 12 134
[131] 157 41 86 27 175 6 165 46 118 188 65 141 22 169 190 72 66 154 40 47 64 166 14 87 95 155
[157] 193 133 179 54 140 128 89 102 161 63 45 78 138 180 149 185 106 38 181 172 176 153 160 150 170 122
[183] 194 100 167 68 98 132 70 152 19 163 71 32 131
最后,我们将使用order()函数的结果作为bugs数据帧的索引,并将结果传回bugs数据帧:
bugs <- bugs[order(as.Date(bugs$Date," %m/%d/%y ")),]
这段代码根据在order()函数中返回的索引顺序对bugs数据帧重新排序。当我们开始分割数据时,它会很方便。数据帧现在应该是按时间顺序排列的错误列表,如下所示:
> bugs
Date ID Severity Status Summary
127 1/3/20 DE45217 Minor Open Mug of coffee empty
90 1/4/20 DE45180 Minor Closed mug of coffee destroyed
187 1/5/20 DE45277 Minor Open Zerg attack
112 1/9/20 DE45202 Blocker Closed Monkeys
13 1/12/20 DE45103 Minor Open Mug of coffee empty
119 1/13/20 DE45209 Blocker Closed The plague occurred
Let's write this newly ordered list back out to a new file that we will reference later called allbugsOrdered.csv:
write.table(bugs, col.names=TRUE, row.names=FALSE, file="allbugsOrdered.csv", quote = FALSE, sep = ",")
当我们在 D3 中查看这些数据时,这将派上用场。
计算 Bug 数量
接下来,我们将按日期计算总 bug 数。这将显示每天有多少新的 bug 被打开。
为此,我们将bugs$Date传递给table()函数,该函数在bugs数据帧中构建一个每个日期计数的数据结构:
totalBugsByDate <- table(bugs$Date)
所以totalBugsByDate的结构看起来如下:
> totalBugsByDate
1/11/21 1/12/20 1/12/21 1/13/20 1/17/21 1/18/21 1/2/21 1/21/20 1/22/20
1 1 3 1 2 1 1 1 1
1/24/20 1/24/21 1/25/20 1/27/21 1/29/21 1/3/20 1/4/20 1/5/20 1/5/21
1 1 1 1 1 1 1 1 1
1/9/20 10/1/20 10/10/20 10/15/20 10/16/20 10/18/20 10/21/20 10/25/20 10/26/20
1 1 1 1 1 2 2 1 1
10/29/20 10/30/20 10/6/20 11/17/20 11/18/20 11/19/20 11/21/20 11/23/20 11/26/20
2 1 1 1 1 1 1 1 2
11/4/20 11/8/20 12/14/20 12/15/20 12/17/20 12/21/20 12/22/20 12/23/20 12/24/20
2 1 2 1 1 1 2 1 1
12/27/20 12/29/20 12/3/20 12/31/20 2/12/21 2/13/21 2/14/20 2/15/20 2/15/21
1 1 1 1 1 1 1 1 1
2/16/20 2/22/21 2/24/20 2/25/21 2/26/21 2/28/21 2/3/21 2/4/21 2/8/21
1 2 1 1 2 1 1 1 1
3/1/20 3/1/21 3/11/21 3/14/21 3/17/21 3/2/20 3/2/21 3/22/20 3/23/21
2 1 3 1 1 1 1 2 1
3/24/20 3/25/21 3/26/20 3/28/20 3/3/21 3/31/20 3/31/21 3/6/21 3/7/20
1 1 1 1 1 1 1 1 1
3/7/21 4/12/21 4/13/20 4/15/21 4/18/21 4/19/21 4/20/20 4/25/20 4/26/21
1 1 1 1 2 1 1 1 1
4/27/20 4/29/21 4/4/20 4/5/21 4/7/20 4/8/20 5/1/20 5/10/20 5/11/21
1 1 1 3 1 2 2 1 1
5/12/20 5/14/21 5/16/21 5/17/20 5/17/21 5/2/21 5/20/20 5/20/21 5/22/20
2 1 1 1 1 1 1 2 2
5/24/21 5/25/20 5/26/21 5/27/20 5/27/21 5/28/20 5/28/21 5/29/21 5/30/20
1 1 1 1 1 1 1 2 1
5/31/20 5/6/20 5/8/20 6/11/20 6/11/21 6/14/20 6/16/21 6/2/21 6/20/20
1 1 1 1 1 1 2 1 1
6/28/20 6/3/20 6/3/21 6/4/20 6/4/21 6/6/21 6/7/20 6/7/21 6/8/21
1 1 1 1 1 1 2 1 1
6/9/21 7/14/20 7/18/20 7/2/20 7/22/20 7/23/20 7/25/20 7/28/20 7/29/20
1 1 2 1 1 1 1 1 1
7/9/20 8/10/20 8/17/20 8/2/20 8/21/20 8/22/20 8/23/20 8/24/20 8/26/20
1 1 2 1 1 1 1 2 1
8/27/20 8/28/20 8/29/20 8/3/20 8/6/20 9/10/20 9/11/20 9/14/20 9/16/20
1 1 1 1 1 1 1 1 1
9/2/20 9/21/20 9/8/20
1 1 1
让我们将这些数据绘制出来,以了解每天有多少 bug 被打开:
plot(totalBugsByDate, type="l", main="New Bugs by Date", col="red", ylab="Bugs")
这段代码创建了如图 6-1 所示的图表。
图 6-1
按日期排列的新 bug 时间序列
现在我们已经知道了每天产生多少个 bug,我们可以通过使用cumsum()函数得到一个累计总数。它获取每天打开的新 bug,并创建它们的运行总和,每天更新总数。它允许我们为一段时间内累积的 bug 计数生成一条趋势线。
> runningTotalBugs <- cumsum(totalBugsByDate)
>
> runningTotalBugs
1/11/21 1/12/20 1/12/21 1/13/20 1/17/21 1/18/21 1/2/21 1/21/20 1/22/20
1 2 5 6 8 9 10 11 12
1/24/20 1/24/21 1/25/20 1/27/21 1/29/21 1/3/20 1/4/20 1/5/20 1/5/21
13 14 15 16 17 18 19 20 21
1/9/20 10/1/20 10/10/20 10/15/20 10/16/20 10/18/20 10/21/20 10/25/20 10/26/20
22 23 24 25 26 28 30 31 32
10/29/20 10/30/20 10/6/20 11/17/20 11/18/20 11/19/20 11/21/20 11/23/20 11/26/20
34 35 36 37 38 39 40 41 43
11/4/20 11/8/20 12/14/20 12/15/20 12/17/20 12/21/20 12/22/20 12/23/20 12/24/20
45 46 48 49 50 51 53 54 55
12/27/20 12/29/20 12/3/20 12/31/20 2/12/21 2/13/21 2/14/20 2/15/20 2/15/21
56 57 58 59 60 61 62 63 64
2/16/20 2/22/21 2/24/20 2/25/21 2/26/21 2/28/21 2/3/21 2/4/21 2/8/21
65 67 68 69 71 72 73 74 75
3/1/20 3/1/21 3/11/21 3/14/21 3/17/21 3/2/20 3/2/21 3/22/20 3/23/21
77 78 81 82 83 84 85 87 88
3/24/20 3/25/21 3/26/20 3/28/20 3/3/21 3/31/20 3/31/21 3/6/21 3/7/20
89 90 91 92 93 94 95 96 97
3/7/21 4/12/21 4/13/20 4/15/21 4/18/21 4/19/21 4/20/20 4/25/20 4/26/21
98 99 100 101 103 104 105 106 107
4/27/20 4/29/21 4/4/20 4/5/21 4/7/20 4/8/20 5/1/20 5/10/20 5/11/21
108 109 110 113 114 116 118 119 120
5/12/20 5/14/21 5/16/21 5/17/20 5/17/21 5/2/21 5/20/20 5/20/21 5/22/20
122 123 124 125 126 127 128 130 132
5/24/21 5/25/20 5/26/21 5/27/20 5/27/21 5/28/20 5/28/21 5/29/21 5/30/20
133 134 135 136 137 138 139 141 142
5/31/20 5/6/20 5/8/20 6/11/20 6/11/21 6/14/20 6/16/21 6/2/21 6/20/20
143 144 145 146 147 148 150 151 152
6/28/20 6/3/20 6/3/21 6/4/20 6/4/21 6/6/21 6/7/20 6/7/21 6/8/21
153 154 155 156 157 158 160 161 162
6/9/21 7/14/20 7/18/20 7/2/20 7/22/20 7/23/20 7/25/20 7/28/20 7/29/20
163 164 166 167 168 169 170 171 172
7/9/20 8/10/20 8/17/20 8/2/20 8/21/20 8/22/20 8/23/20 8/24/20 8/26/20
173 174 176 177 178 179 180 182 183
8/27/20 8/28/20 8/29/20 8/3/20 8/6/20 9/10/20 9/11/20 9/14/20 9/16/20
184 185 186 187 188 189 190 191 192
9/2/20 9/21/20 9/8/20
193 194 195
这正是我们现在需要的,来规划 bug 积压每天增长或减少的方式。为此,让我们将runningTotalBugs传递给plot()函数。我们将类型设置为"l",以表示我们正在创建一个折线图,然后将该图命名为随时间累积的缺陷。在plot()函数中,我们还关闭了轴,这样我们就可以为这个图表绘制自定义轴。我们将希望绘制自定义轴,以便我们可以将日期指定为 x 轴标签。
为了绘制自定义轴,我们使用了axis()函数。axis()函数中的第一个参数是一个数字,它告诉 R 在哪里画轴。
-
1对应图表底部的 x 轴。 -
2在图表的左边。 -
3到图表的顶端。 -
在图表的右边。
plot(runningTotalBugs, type="l", xlab="", ylab="", pch=15, lty=1, col="red", main="Cumulative Defects Over Time", axes=FALSE)
axis(1, at=1: length(runningTotalBugs), lab= row.names(totalBugsByDate))
axis(2, las=1, at=10*0:max(runningTotalBugs))
请注意,绘图类型设置为小写 L,而不是大写 I 或 1。这段代码创建了如图 6-2 所示的时序图。
图 6-2
随着时间的推移累积的缺陷
这显示了按日期逐渐增加的 bug backlog。
到目前为止,完整的 R 代码如下:
bugExport <- "allbugs.csv"
bugs <- read.table(bugExport, header=TRUE, sep=",")
as.Date(bugs$Date,"%m/%d/%y")
order(as.Date(bugs$Date,"%m/%d/%y"))
bugs <- bugs[order(as.Date(bugs$Date," %m/%d/%y ")),]
write.table(bugs, col.names=TRUE, row.names=FALSE, file="allbugsOrdered.csv", quote = FALSE, sep = ",")
totalBugsByDate <- table(bugs$Date)
plot(totalBugsByDate, type="l", main="New Bugs by Date", col="red", ylab="Bugs")
runningTotalBugs <- cumsum(totalBugsByDate)
runningTotalBugs
plot(runningTotalBugs, type="l", xlab="", ylab="", pch=15, lty=1, col="red", main="Cumulative Defects Over Time", axes=FALSE)
axis(1, at=1: length(runningTotalBugs), lab= row.names(totalBugsByDate))
axis(2, las=1, at=10*0:max(runningTotalBugs))
让我们来看看 bug 的关键程度,它不仅显示了 bug 何时被打开,还显示了最严重(或非严重)的 bug 何时被打开。
检查错误的严重性
请记住,当我们导出 bug 数据时,我们包括了Severity字段,它指示每个 bug 的严重程度。每个团队和组织可能有自己的严重性分类,但通常包括以下内容:
-
阻塞程序是非常严重的错误,它们会阻止大量工作的启动。它们通常具有不完整的功能,或者缺少广泛使用的功能的某些部分。它们也可能是与合同或法律约束功能(如隐藏式字幕或数字版权保护)的差异。
-
中度错误是严重的错误,但没有严重到导致发布的程度。它们可能会破坏不常用功能的功能。可访问性的范围,或者一个特性被广泛使用的程度,通常是使一个 bug 成为一个阻止者或者一个关键的决定因素。
-
minor是影响极小的 bug,甚至可能不会被最终用户注意到。
为了按严重程度分类 bug,我们简单地调用table()函数,就像我们按日期分类 bug 一样,但是这次也添加了Severity列:
bugsBySeverity <- table(factor(bugs$Date),bugs$Severity)
这段代码创建了一个如下所示的数据结构:
Blocker Minor Moderate
1/11/21 0 1 0
1/12/20 0 1 0
1/12/21 1 2 0
1/13/20 1 0 0
1/17/21 2 0 0
1/18/21 0 0 1
1/2/21 0 1 0
1/21/20 1 0 0
1/22/20 1 0 0
1/24/20 0 1 0
然后我们可以绘制这个数据对象。我们这样做的方法是使用plot()函数为其中一列创建一个图表,然后使用lines()函数在图表上为其余的列绘制线条:
plot(bugsBySeverity[,3], type="l", xlab="", ylab="", pch=15, lty=1, col="orange", main="New Bugs by Severity and Date", axes=FALSE)
lines(bugsBySeverity[,1], type="l", col="red", lty=1)
lines(bugsBySeverity[,2], type="l", col="yellow", lty=1)
axis(1, at=1: length(runningTotalBugs), lab= row.names(totalBugsByDate))
axis(2, las=1, at=0:max(bugsBySeverity[,3]))
legend("topleft", inset=.01, title="Legend", colnames(bugsBySeverity), lty=c(1,1,1), col= c("red", "yellow", "orange"))
该代码生成如图 6-3 所示的图表。
图 6-3
我们的 plot()和 lines()函数按照严重性绘制了错误图表
这很好,但是如果我们想按严重性查看累积的 bug 呢?我们可以简单地使用前面的 R 代码,但是我们可以绘制出每列的累积和,而不是绘制出每列:
plot(cumsum(bugsBySeverity[,3]), type="l", xlab="", ylab="", pch=15, lty=1, col="orange", main="Running Total of Bugs by Severity", axes=FALSE)
lines(cumsum(bugsBySeverity[,1]), type="l", col="red", lty=1)
lines(cumsum(bugsBySeverity[,2]), type="l", col="yellow", lty=1)
axis(1, at=1: length(runningTotalBugs), lab= row.names(totalBugsByDate))
axis(2, las=1, at=0:max(cumsum(bugsBySeverity[,3])))
legend("topleft", inset=.01, title="Legend", colnames(bugsBySeverity), lty=c(1,1,1), col= c("red", "yellow", "orange"))
该代码生成如图 6-4 所示的图表。
图 6-4
按严重性列出的运行错误总数
添加与 D3 的交互性
前面的例子是可视化和传播关于缺陷产生的信息的好方法。但是,如果我们能更进一步,让我们可视化的消费者更深入地研究他们感兴趣的数据点,会怎么样呢?假设我们希望允许用户将鼠标悬停在时间序列中的特定点上,并查看构成该数据点的所有 bug 的列表。我们可以用 D3 做到这一点;让我们走一遍并找出方法。
首先,让我们创建一个引用了D3.js的具有基本 HTML 框架结构的新文件,并将其保存为timeseriesGranular.htm。在这个例子中,我们想要使用 D3 的旧版本——版本 3 (d3.v3.js,可以在本书的代码下载中找到),因为它比新的代码结构允许更多的灵活性和逐步构建。
<html>
<head></head>
<body>
<script src="d3.v3.js"></script>
</body>
</html>
接下来,我们在一个新的script标签中设置一些初步数据。我们创建一个对象来保存图形的边距数据以及高度和宽度。我们还创建了一个 D3 时间格式化程序,将从 string 读入的日期转换成一个本地的Date对象。
<script>
var margin = {top: 20, right: 20, bottom: 30, left: 50},
width = 960 - margin.left - margin.right,
height = 500 - margin.top - margin.bottom;
var parseDate = d3.timeFormat("%m/%d/%y").parse;
</script>
读入数据
我们添加一些代码来读入数据(之前从 R 输出的allbugsOrdered.csv文件)。回想一下,这个文件包含了按日期排序的全部 bug 数据。
我们使用d3.csv()函数来读取这个文件:
-
第一个参数是文件的路径。
-
第二个参数是读入数据后要执行的函数。正是在这个匿名函数中,我们添加了大部分功能,或者至少是依赖于要处理的数据的功能。
匿名函数接受两个参数:
-
第一个捕获任何可能发生的错误。
-
第二个是正在读入的文件的内容。
在该函数中,我们首先遍历数据的内容,并使用日期格式化程序将Date列中的所有值转换为本地 JavaScript Date对象:
d3.csv("allbugsOrdered.csv", function(error, data) {
data.forEach(function(d) {
d.Date = parseDate(d.Date);
});
});
如果我们要console.log()数据,它将是一个看起来像图 6-5 的对象数组。
图 6-5
我们的 bug 数据对象
在匿名函数中,但在循环之后,我们使用d3.nest()函数来创建一个变量,该变量保存按日期分组的 bug 数据。我们将这个变量命名为nested_data:
nested_data = d3.nest()
.key(function(d) { return d.Date; })
.entries(data);
nested_data变量现在是一个树形结构——特别是一个按日期索引的列表,每个索引都有一个 bug 列表。如果我们去console.log() nested_data,它将是一个看起来像图 6-6 的对象数组。
图 6-6
包含 bug 数据对象的数组
在页面上绘图
我们准备开始绘制页面。因此,让我们跳出回调函数,转到script标记的根,并使用之前定义的边距、宽度和高度将 SVG 标记写出到页面:
var svg = d3.select("body").append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform", "translate(" + margin.left + "," + margin.top + ")");
这是我们绘制轴和趋势线的容器。
仍然在根级别,我们为 x 轴和 y 轴添加一个 D3 scale对象,使用变量width表示 x 轴范围,使用变量height表示 y 轴范围。我们在根级别添加 x 轴和 y 轴,传入它们各自的缩放对象,并将它们定位在底部和左侧。
var xScale = d3.time.scale()
.range([0, width]);
var yScale= d3.scale.linear()
.range([height, 0]);
var xAxis = d3.svg.axis()
.scale(xScale)
.orient("bottom");
var yAxis = d3.svg.axis()
.scale(yScale)
.orient("left");
但是它们仍然没有显示在页面上。我们需要返回到我们在d3.csv()调用中创建的匿名函数,并添加我们创建的nested_data列表,作为新创建的秤的域数据:
xScale.domain(d3.extent(nested_data, function(d) { return new Date(d.key); }));
yScale.domain(d3.extent(nested_data, function(d) { return d.values.length; }));
从这里,我们需要生成轴。我们通过添加和选择一个用于通用分组的 SVG g元素,并将这个选择添加到xAxis()和yAxis() D3 函数中来实现。这也包含在加载数据时调用的匿名回调函数中。
我们还需要通过添加图表的高度来转换 x 轴,以便将其绘制在图表的底部:
svg.append("g")
.attr("transform", "translate(0," + height + ")")
.call(xAxis);
svg.append("g")
.call(yAxis)
这将创建图表的起点,其有意义的轴如图 6-7 所示。
图 6-7
时间序列开始形成;x 轴和 y 轴,但还没有线条
需要添加趋势线。回到根级别,让我们创建一个名为line的变量作为 SVG 行。假设我们已经为该行设置了data属性。我们还没有,但一会儿就会了。对于线条的 x 值,我们将有一个函数返回通过xScale刻度对象过滤的日期。对于线条的 y 值,我们将创建一个函数,返回通过yScale scale 对象运行的 bug 计数值。
var line = d3.svg.line()
.x(function(d) { return xScale(new Date(d.key)); })
.y(function(d) { return yScale(d.values.length); });
接下来,我们回到处理数据的匿名函数。在添加的轴的正下方,我们将追加一个 SVG 路径。我们设置nested_data变量作为路径的基准,新创建的line对象作为d属性。作为参考,d属性是我们指定路径描述的地方。关于d属性的文档见此处: https://developer.mozilla.org/en-US/docs/SVG/Attribute/d 。
svg.append("path")
.datum(nested_data)
.attr("d", line);
我们现在可以开始在浏览器中看到一些东西。到目前为止,代码应该是这样的:
<!DOCTYPE html>
<head>
<meta charset="utf-8">
</head>
<body>
<script src="d3.v3.js"></script>
<script>
var margin = {top: 20, right: 20, bottom: 30, left: 50},
width = 960 - margin.left - margin.right,
height = 500 - margin.top - margin.bottom;
var parseDate = d3.time.format("%m-%d-%Y").parse;
var xScale = d3.time.scale()
.range([0, width]);
var yScale = d3.scale.linear()
.range([height, 0]);
var xAxis = d3.svg.axis()
.scale(xScale)
.orient("bottom");
var yAxis = d3.svg.axis()
.scale(yScale)
.orient("left");
var line = d3.svg.line()
.x(function(d) { return xScale(new Date(d.key)); })
.y(function(d) { return yScale(d.values.length); });
var svg = d3.select("body").append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform", "translate(" + margin.left + "," + margin.top + ")");
d3.csv("allbugsOrdered.csv", function(error, data) {
data.forEach(function(d) {
d.Date = parseDate(d.Date);
});
nested_data = d3.nest()
.key(function(d) { return d.Date; })
.entries(data);
xScale.domain(d3.extent(nested_data, function(d) { return new Date(d.key); }));
yScale.domain(d3.extent(nested_data, function(d) { return d.values.length; }));
svg.append("g")
.attr("transform", "translate(0," + height + ")")
.call(xAxis);
svg.append("g")
.call(yAxis);
svg.append("path")
.datum(nested_data)
.attr("d", line);
});
</script>
</body>
</html>
该代码产生如图 6-8 所示的图形。
图 6-8
具有行数据但填充不正确的时间序列
但这并不完全正确。路径的阴影是基于浏览器对意图的最佳猜测,对其感知的封闭区域进行阴影处理。让我们使用 CSS 显式关闭阴影,改为设置路径线的颜色和宽度:
<style>
.trendLine {
fill: none;
stroke: #CC0000;
stroke-width: 1.5px;
}
</style>
我们用类trendLine为页面上的任何元素创建了样式规则。接下来,让我们在创建路径的同一个代码块中将该类添加到 SVG 路径中:
Svg.append("path")
.datum(nested_data)
.attr("d", line)
.attr("class", "trendLine");
该代码生成如图 6-9 所示的图表。
图 6-9
具有校正的线条但无样式轴的时间序列
看起来好多了!我们应该做一些小的改动,比如在 y 轴上添加文本标签,并调整轴线的宽度,使其更加整洁:
.axis path{
fill: none;
stroke: #000;
shape-rendering: crispEdges;
}
这将使我们的斧头看起来更紧。我们只需要在创建轴时将样式应用到轴上:
svg.append("g")
.attr("transform", "translate(0," + height + ")")
.call(xAxis)
.attr("class", "axis");
svg.append("g")
.call(yAxis)
.attr("class", "axis");
结果如图 6-10 所示。
图 6-10
用样式化轴更新的时间序列
到目前为止,这很好,但它没有显示出在 r 中这样做的真正好处。事实上,我们写了相当多的额外代码只是为了获得奇偶校验,甚至没有做我们在 r 中做的任何数据清理。
使用 D3 的真正好处是增加了交互性。
添加交互性
假设我们有这个新错误的时间序列,我们很好奇在二月中旬的大高峰中有什么错误。通过利用我们在 HTML 和 JavaScript 中工作的事实,我们可以通过添加一个工具提示框来扩展这一功能,该框列出了每个日期的错误。
要做到这一点,我们首先应该创建用户可以鼠标悬停的明显区域,例如每个数据点或离散日期处的红圈。要做到这一点,我们只需要在我们添加路径的地方下面创建 SVG 圆圈,在读入外部数据时触发匿名函数。我们将nested_data变量设置为圆圈的data属性,将它们设置为半径为 3.5 的红色,并将它们的 x 和 y 属性分别设置为与日期和 bug 总数相关联:
svg.selectAll("circle")
.data(nested_data)
.enter().append("circle")
.attr("r", 3.5)
.attr("fill", "red")
.attr("cx", function(d) { return xScale(new Date(d.key)); })
.attr("cy", function(d) { return yScale(d.values.length);})
这段代码更新了现有的时间序列,看起来如图 6-11 所示。这些红圈现在是焦点区域,用户可以将鼠标放在上面查看更多信息。
图 6-11
添加到线上每个数据点的圆
让我们接下来编写一个div作为工具提示,我们将显示相关的错误数据。为此,我们将创建一个新的div,就在我们在script标签的根处创建line变量的下方。我们在 D3 中再次这样做,选择body标签并给它附加一个div,给它一个类和 idtooltip——这样我们就可以对它应用tooltip样式(我们将在一分钟内创建它),这样我们就可以在本章的后面通过 ID 与它交互。我们将默认隐藏它。我们将把对这个div的引用存储在一个我们称之为tooltip的变量中。
var tooltip = d3.select("body")
.append("div")
.attr("class", "tooltip")
.attr("id", "tooltip")
.style("position", "absolute")
.style("z-index", "10")
.style("visibility", "hidden");
我们接下来需要使用 CSS 样式化这个div。我们将不透明度调整为只有 75%可见,这样当工具提示出现在趋势线上时,我们可以看到它后面的趋势线。我们对齐文本,设置字体大小,使 div 有一个白色背景,并给它圆角。
.tooltip{
opacity: .75;
text-align:center;
font-size:12px;
width:100px;
padding:5px;
border:1px solid #a8b6ba;
background-color:#fff;
margin-bottom:5px;
border-radius: 19px;
-moz-border-radius: 19px;
-webkit-border-radius: 19px;
}
接下来,我们必须向圆圈添加一个mouseover事件处理程序,用信息填充工具提示并取消隐藏工具提示。为此,我们返回到创建圆圈的代码块,并添加一个触发匿名函数的mousemove事件处理程序。
在匿名函数中,我们覆盖了工具提示的innerHTML,以显示当前红圈的日期以及与该日期相关的错误数量。然后,我们遍历 bug 列表,写出每个 bug 的 ID。
svg.selectAll("circle")
.data(nested_data)
.enter().append("circle")
.attr("r", 3.5)
.attr("fill", "red")
.attr("cx", function(d) { return xScale(new Date(d.key)); })
.attr("cy", function(d) { return yScale(d.values.length);})
.on("mouseover", function(d){
document.getElementById("tooltip").innerHTML = d.key + " " + d.values.length + " bugs<br/>";
for(x=0;x<d.values.length;x++){
document.getElementById("tooltip").innerHTML += d.values[x].ID + "<br/>";
}
tooltip.style("visibility", "visible");
})
如果我们想更进一步,我们可以为每个 bug ID 创建链接,链接到 bug 跟踪软件,列出每个 bug 的描述,如果 bug 跟踪软件有一个 API 接口,我们甚至可以有表单字段,让我们可以直接从这个工具提示更新 bug 信息。只有我们的想象力和可用的工具限制了我们将这个概念延伸到什么程度的可能性。
最后,我们向红圈添加了一个mousemove事件处理程序,这样每当用户将鼠标放在红圈上时,我们就可以根据上下文重新定位工具提示。为此,我们使用d3.mouse对象获取当前鼠标坐标。我们使用这些坐标来简单地用 CSS 重新定位工具提示。所以我们没有用工具提示覆盖红色圆圈,我们将顶部属性偏移 25 像素,将左侧属性偏移 75 像素。
svg.selectAll("circle")
.data(nested_data)
.enter().append("circle")
.attr("r", 3.5)
.attr("fill", "red")
.attr("cx", function(d) { return xScale(new Date(d.key)); })
.attr("cy", function(d) { return yScale(d.values.length);})
.on("mouseover", function(d){
document.getElementById("tooltip").innerHTML = d.key + " " + d.values.length + " bugs<br/>";
for(x=0;x<d.values.length;x++){
document.getElementById("tooltip").innerHTML += d.values[x].ID + "<br/>";
}
tooltip.style("visibility", "visible");
})
.on("mousemove", function(){
return tooltip.style("top", (d3.mouse(this)[1] + 25)+"px").style("left", (d3.mouse(this)[0] + 70)+"px");
});
当鼠标悬停在其中一个红色圆圈上时,应显示工具提示(参见图 6-12 )。
图 6-12
显示翻转的完整时间序列
完整的源代码现在应该是这样的:
<!DOCTYPE html>
<html>
<meta charset="utf-8">
<head>
<style>
body {
font: 15px sans-serif;
}
.trendLine {
fill: none;
stroke: #CC0000;
stroke-width: 1.5px;
}
.axis path{
fill: none;
stroke: #000;
shape-rendering: crispEdges;
}
.tooltip{
opacity: .75;
text-align:center;
font-size:12px;
width:100px;
padding:5px;
border:1px solid #a8b6ba;
background-color:#fff;
margin-bottom:5px;
border-radius: 19px;
-moz-border-radius: 19px;
-webkit-border-radius: 19px;
}
</style>
</head>
<body>
<script src="d3.v3.js"></script>
<script>
var margin = {top: 20, right: 20, bottom: 30, left: 50},
width = 960 - margin.left - margin.right,
height = 500 - margin.top - margin.bottom;
var parseDate = d3.time.format("%m/%d/%y").parse;
var xScale = d3.time.scale()
.range([0, width]);
var yScale = d3.scale.linear()
.range([height, 0]);
var xAxis = d3.svg.axis()
.scale(xScale)
.orient("bottom");
var yAxis = d3.svg.axis()
.scale(yScale)
.orient("left");
var line = d3.svg.line()
.x(function(d) { return xScale(new Date(d.key)); })
.y(function(d) { return yScale(d.values.length); });
var tooltip = d3.select("body")
.append("div")
.attr("class", "tooltip")
.attr("id", "tooltip")
.style("position", "absolute")
.style("z-index", "10")
.style("visibility", "hidden");
var svg = d3.select("body").append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform", "translate(" + margin.left + "," + margin.top + ")");
d3.csv("https://jonwestfall.com/data/allbugsOrdered.csv", function(error, data) {
data.forEach(function(d) {
d.Date = parseDate(d.Date);
});
nested_data = d3.nest()
.key(function(d) { return d.Date; })
.entries(data);
xScale.domain(d3.extent(nested_data, function(d) { return new Date(d.key); }));
yScale.domain(d3.extent(nested_data, function(d) { return d.values.length; }));
svg.append("g")
.attr("transform", "translate(0," + height + ")")
.call(xAxis)
.attr("class", "axis");
svg.append("g")
.call(yAxis)
.attr("class", "axis");
svg.append("path")
.datum(nested_data)
.attr("d", line)
.attr("class", "trendLine");
svg.selectAll("circle")
.data(nested_data)
.enter().append("circle")
.attr("r", 3.5)
.attr("fill", "red")
.attr("cx", function(d) { return xScale(new Date(d.key)); })
.attr("cy", function(d) { return yScale(d.values.length);})
.on("mouseover", function(d){
document.getElementById("tooltip").innerHTML = d.key + " " + d.values.length + " bugs<br/>";
for(x=0;x<d.values.length;x++){
document.getElementById("tooltip").innerHTML += d.values[x].ID + "<br/>";
}
tooltip.style("visibility", "visible");
})
.on("mousemove", function(){
return tooltip.style("top", (d3.mouse(this)[1] + 25)+"px").style("left", (d3.mouse(this)[0] + 70)+"px");
});
});
</script>
</body>
</html>
摘要
本章探索了时间序列图,既有哲学上的,也有使用它们来跟踪一段时间内的 bug 创建的上下文。我们从所选的错误跟踪软件中导出原始错误数据,并将其导入到 R 中进行清理和分析。
在 R 中,我们研究了建模和可视化数据的不同方法,研究了聚合和粒度细节,例如新的 bug 如何随着时间的推移对运行总数产生影响,或者新的 bug 是何时随着时间的推移引入的。当我们能够把我们正在看的日期联系起来时,这是特别有价值的。
然后,我们将数据读入 D3,并创建了一个交互式时间序列,使我们能够从高级趋势数据深入到所创建的每个 bug 的细节。
下一章将探讨如何创建条形图,以及如何使用它们来确定需要关注和改进的领域。
