

Python 数据分析工具包(二)
三、Python 中的正则表达式和数学
在这一章中,我们讨论 Python 中的两个模块: re ,它包含可应用于正则表达式的函数,以及 SymPy ,用于解决代数、微积分、概率和集合论中的数学问题。我们将在本章中学习的概念,如搜索和替换字符串、概率和绘制图表,将在后续章节中派上用场,我们将在后续章节中介绍数据分析和统计。
正则表达式
正则表达式是包含字符(如字母和数字)和元字符(如*和$符号)的模式。每当我们想要搜索、替换或提取具有可识别模式的数据时,都可以使用正则表达式,例如日期、邮政编码、HTML 标记、电话号码等等。通过确保用户输入的格式正确,它们还可以用于验证密码和电子邮件地址等字段。
使用正则表达式解决问题的步骤
Python 中的 re 模块提供了对正则表达式的支持,可以使用以下语句导入该模块:
import re
如果您还没有安装 re 模块,请进入 Anaconda 提示符并输入以下命令:
pip install re
一旦模块被导入,您需要遵循以下步骤。
-
定义并编译正则表达式:re 模块导入后,我们定义正则表达式并编译。搜索模式以前缀“r”开头,后跟字符串(搜索模式)。前缀“r”代表原始字符串,它告诉编译器特殊字符将按字面意思处理,而不是转义序列。请注意,前缀“r”是可选的。compile 函数将搜索模式编译成字节码,如下所示,搜索字符串(和)作为参数传递给 compile 函数。
CODE:
search_pattern=re.compile(r'and') -
在字符串中定位搜索模式(正则表达式):
在第二步中,我们尝试使用 search 方法在要搜索的字符串中定位这个模式。这个方法是对我们在上一步中定义的变量(search_pattern)调用的。
CODE:
search_pattern.search('Today and tomorrow')Output:
<re.Match object; span=(6, 9), match="and">
因为在字符串(“Today and tomorrow”)中找到了搜索模式(“and”),所以返回一个 match 对象。
快捷方式(结合步骤 2 和 3)
前面的两个步骤可以合并成一个步骤,如下面的语句所示:
代码:
re.search('and','Today and tomorrow')
使用前面定义的一行代码,我们将定义、编译和定位搜索模式这三个步骤合并为一个步骤。
延伸阅读:参考本文档,了解如何在 Python 中使用正则表达式:
https://docs.python.org/3/howto/regex.html#regex-howto
正则表达式的 Python 函数
我们使用正则表达式来匹配、拆分和替换文本,并且这些任务中的每一个都有单独的函数。表 3-1 提供了所有这些功能的列表,以及它们的用法示例。
表 3-1
在 Python 中使用正则表达式的函数
|Python 函数
|
例子
|
| --- | --- |
| re.findall( ) :搜索正则表达式的所有可能匹配项,并返回在字符串中找到的所有匹配项的列表。 | 代码:re.findall('3','98371234')输出:['3', '3'] |
| re.search( ) :搜索单个匹配项,并返回与字符串中找到的第一个匹配项相对应的 match 对象。 | 代码:re.search('3','98371234')输出:<re.Match object; span=(2, 3), match="3"> |
| re.match( ) :该功能类似于重新搜索功能。这个函数的限制是,如果模式出现在字符串的开头的*,它只返回一个匹配对象*。** | 代码:re.match('3','98371234')因为搜索模式(3)不在字符串的开头,所以 match 函数不返回对象,我们看不到任何输出。 |
| re.split( ): 在被搜索字符串中找到搜索模式的位置拆分字符串。 | 代码:re.split('3','98371234')输出:['98', '712', '4']只要找到搜索模式“3”,该字符串就会被拆分成更小的字符串。 |
| *re():*用另一个字符串或模式替换搜索模式。 | 代码:re.sub('3','three','98371234')输出:'98three712three4'字符串中的字符“3”被替换为字符串“三”。 |
延伸阅读:
了解上表中讨论的函数的更多信息:
-
搜索匹配功能:
https://docs.python.org/3.4/library/re.html#search-vs-match -
Findall 函数:
https://docs.python.org/3/library/re.html#re.findall
元字符
元字符是正则表达式中使用的具有特殊含义的字符。下面将解释这些元字符,并举例说明它们的用法。
-
点(。)元字符
这个元字符匹配一个字符,这个字符可以是一个数字、字母,甚至是它本身。
在下面的例子中,我们尝试匹配三个字母的单词(来自下面代码中逗号后面给出的列表),从两个字母“ba”开始。
CODE:
re.findall("ba.","bar bat bad ba. ban")Output:
['bar', 'bat', 'bad', 'ba.', 'ban']请注意,输出中显示的结果之一是“ba”是一个实例,其中。(点)元字符已匹配自身。
-
方括号([])作为元字符
为了匹配一组字符中的任何一个字符,我们使用方括号([ ])。在这些方括号中,我们定义了一组字符,其中一个字符必须与文本中的字符相匹配。
让我们用一个例子来理解这一点。在下面的示例中,我们尝试匹配包含字符串“ash”的所有字符串,并以下列任何字符开始-“c”、“r”、“b”、“m”、“d”、“h”或“w”。
CODE:
regex=re.compile(r'[crbmdhw]ash') regex.findall('cash rash bash mash dash hash wash crash ash')Output:
['cash', 'rash', 'bash', 'mash', 'dash', 'hash', 'wash', 'rash']请注意,字符串“ash”和“crash”不匹配,因为它们不符合标准(字符串需要以方括号中定义的字符之一开头)。
-
问号(?)元字符
当您需要匹配一个字符的最多一次出现时,使用这个元字符。这意味着我们要寻找的字符可能不在搜索字符串中,或者只出现一次。考虑下面的例子,我们试图匹配以字符“Austr”开始,以字符“ia”结束,并且以下每个字符零个或一个出现的字符串——“a”、“l”、“a”、“s”。
CODE:
regex=re.compile(r'Austr[a]?[l]?[a]?[s]?ia') regex.findall('Austria Australia Australasia Asia')Output:
['Austria', 'Australia', 'Australasia']请注意,字符串“Asia”不符合此标准。
-
星号(*)元字符
这个元字符可以匹配零个或多个给定的搜索模式。换句话说,搜索模式可能根本不会出现在字符串中,也可能出现任意次。
让我们通过一个例子来理解这一点,在这个例子中,我们试图匹配所有以字符串“abc”开头,后面跟有零个或多个数字“1”的字符串。
CODE:
re.findall("abc[1]*","abc1 abc111 abc1 abc abc111111111111 abc01")Output:
['abc1', 'abc111', 'abc1', 'abc', 'abc111111111111', 'abc']请注意,在这一步中,我们将正则表达式的编译和搜索合并在一个单独的步骤中。
-
反斜杠()元字符
The backslash symbol is used to indicate a character class, which is a predefined set of characters. In Table 3-2, the commonly used character classes are explained.
表 3-2
字符类别
|字符类
|
涵盖的字符
| | --- | --- | | \d | 匹配一个数字(0–9) | | \D | 匹配任何不是数字的字符 | | \w | 匹配字母数字字符,可以是小写字母(A–Z)、大写字母(A–Z)或数字(0–9) | | \W | 匹配任何不是字母数字的字符 | | \s | 匹配任何空白字符 | | \S | 匹配任何非空白字符 |
反斜杠符号的另一种用法:转义元字符
正如我们所见,在正则表达式中,元字符如。和*有特殊含义。如果我们想在字面上使用这些字符,我们需要通过在这些字符前面加上一个(反斜杠)符号来“转义”它们。例如,要搜索文本 W.H.O,我们需要对。(点)字符,以防止它被用作常规元字符。
CODE:
regex=re.compile(r'W\.H\.O') regex.search('W.H.O norms')Output:
<re.Match object; span=(0, 5), match='W.H.O'> -
加号(+)元字符
此元字符匹配一个或多个搜索模式。在下面的示例中,我们尝试匹配所有以至少一个字母开头的字符串。
CODE:
re.findall("[a-z]+123","a123 b123 123 ab123 xyz123")Output:
['a123', 'b123', 'ab123', 'xyz123'] -
花括号{}作为元字符
使用花括号并在花括号中指定一个数字,我们可以指定一个范围或一个数字来表示搜索模式的重复次数。
在下面的例子中,我们找出了所有格式为“xxx-xxx-xxxx”的电话号码(三个数字,接着是另一组三个数字,最后是一组四个数字,每组数字用“-”号分隔)。
CODE:
regex=re.compile(r'[\d]{3}-[\d]{3}-[\d]{4}') regex.findall('987-999-8888 99122222 911-911-9111')Output:
['987-999-8888', '911-911-9111']只有搜索字符串(
987-999-8888, 911-911-9111)中的第一个和第三个数字与模式匹配。\d 元字符代表一个数字。如果我们不知道重复次数的确切数字,但知道最大和最小重复次数,我们可以在花括号内提到上限和下限。在下面的示例中,我们搜索包含最少六个字符、最多十个字符的所有字符串。
CODE:
regex=re.compile(r'[\w]{6,10}') regex.findall('abcd abcd1234,abc$$$$$,abcd12 abcdef')Output:
['abcd1234', 'abcd12', 'abcdef'] -
美元($)元字符
如果这个元字符出现在搜索字符串的末尾,它就匹配一个模式。
在下面的例子中,我们使用这个元字符来检查搜索字符串是否以数字结尾。
CODE:
re.search(r'[\d]$','aa*5')Output:
<re.Match object; span=(3, 4), match="5">因为字符串以数字结尾,所以返回一个 match 对象。
-
脱字符(^)元字符
脱字符(^)元字符在字符串的开头查找匹配项。
在下面的例子中,我们检查搜索字符串是否以空格开头。
CODE:
re.search(r'^[\s]',' a bird')Output:
<re.Match object; span=(0, 1), match=' '>
延伸阅读:了解更多元字符: https://docs.python.org/3.4/library/re.html#regular-expression-syntax
现在让我们讨论另一个库,Sympy,它用于解决各种基于数学的问题。
使用 Sympy 解决数学问题
SymPy 是 Python 中的一个库,可用于解决各种数学问题。我们首先看一下如何在代数中使用辛函数——解方程和分解表达式。在这之后,我们将介绍集合论和微积分中的一些应用。
可以使用以下语句导入 SymPy 模块。
代码:
import sympy
如果您还没有安装 sympy 模块,请进入 Anaconda 提示符并输入以下命令:
pip install sympy
现在让我们用这个模块来解决各种数学问题,从表达式的因式分解开始。
代数表达式的因式分解
表达式的因式分解包括将表达式分解成更简单的表达式或因子。将这些因素相乘,我们得到了原始表达式。
举个例子,一个代数表达式,像x2—y2,可以因式分解为:(x-y)*(x+y)。
SymPy 为我们提供了分解表达式和扩展表达式的功能。
一个代数表达式包含在 SymPy 中被表示为“符号”的变量。在应用 SymPy 函数之前,Python 中的一个变量必须被转换成一个 symbol 对象,该对象是使用 symbols 类(用于定义多个符号)或 Symbol 类(用于定义单个符号)创建的。然后,我们导入因子和扩展函数,然后将我们需要进行因子分解或扩展的表达式作为参数传递给这些函数,如下所示。
代码:
#importing the symbol classes
from sympy import symbols,Symbol
#defining the symbol objects
x,y=symbols('x,y')
a=Symbol('a')
#importing the functions
from sympy import factor,expand
#factorizing an expression
factorized_expr=factor(x**2-y**2)
#expanding an expression
expanded_expr=expand((x-y)**3)
print("After factorizing x**2-y**2:",factorized_expr)
print("After expanding (x-y)**3:",expanded_expr)
输出:
After factorizing x**2-y**2: (x - y)*(x + y)
After expanding,(x-y)**3: x**3 - 3*x**2*y + 3*x*y**2 - y**3
解代数方程(一个变量)
代数方程包含一个表达式,带有一系列等于零的项。现在让我们使用 SymPy 中的求解函数来求解方程x25x+6 = 0。
我们从 SymPy 库中导入 solve 函数,并将我们想要求解的方程作为参数传递给这个函数,如下所示。 dict 参数以结构化格式产生输出,但是包含这个参数是可选的。
代码:
#importing the solve function
from sympy import solve
exp=x**2-5*x+6
#using the solve function to solve an equation
solve(exp,dict=True)
输出:
[{x: 2}, {x: 3}]
解联立方程(两个变量)
solve 函数也可以用来同时求解两个方程,如下面的代码块所示。
代码:
from sympy import symbols,solve
x,y=symbols('x,y')
exp1=2*x-y+4
exp2=3*x+2*y-1
solve((exp1,exp2),dict=True)
输出:
[{x: -1, y: 2}]
延伸阅读:查看更多关于求解函数的信息:
https://docs.sympy.org/latest/modules/solvers/solvers.html#algebraic-equations
求解用户输入的表达式
我们可以让用户使用 input 函数输入表达式,而不是定义表达式。问题是用户输入的内容被当作字符串处理,而 SymPy 函数无法处理这样的输入。
函数可以用来将任何表达式转换成与 SymPy 兼容的类型。注意,当输入时,用户必须输入数学运算符,如*、**,等等。例如,如果表达式是 2*x+3,用户在输入时不能跳过星号。如果用户输入 2x+3,将会产生一个错误。下面的代码块中提供了一个代码示例来演示 sympify 函数。
代码:
from sympy import sympify,solve
expn=input("Input an expression:")
symp_expn=sympify(expn)
solve(symp_expn,dict=True)
输出:
Input an expression:x**2-9
[{x: -3}, {x: 3}]
图解求解联立方程
代数方程也可以用图解法求解。如果把方程画在图上,两条线的交点代表解。
来自 sympy.plotting 模块的绘图函数可用于绘制方程,两个表达式作为参数传递给该函数。
代码:
from sympy.plotting import plot
%matplotlib inline
plot(x+4,3*x)
solve((x+4-y,3*x-y),dict=True)
输出(如图 3-1 所示)。
图 3-1
用图解联立方程
创建和操作集合
集合是唯一元素的集合,有许多操作可以应用于集合。集合用文氏图表示,文氏图描述两个或多个集合之间的关系。
SymPy 为我们提供了创建和操作集合的功能。
首先,您需要从 SymPy 包中导入 FiniteSet 类来处理集合。
代码:
from sympy import FiniteSet
现在,声明这个类的一个对象来创建一个集合,并使用您想要的集合中的数字来初始化它。
代码:
s=FiniteSet(1,2,3)
输出:
{1,2,3}
我们也可以从列表中创建一个集合,如下面的语句所示。
代码:
l=[1,2,3]
s=FiniteSet(*l)
集合的并与交
两个集合的并集是两个集合中所有不同元素的列表,而两个集合的交集包括两个集合的公共元素。
SymPy 为我们提供了一种使用并集和交集函数计算两个集合的并集和交集的方法。
我们使用 FiniteSet 类创建集合,然后对它们应用联合和相交函数,如下所示。
代码:
s1=FiniteSet(1,2,3)
s2=FiniteSet(2,3,4)
union_set=s1.union(s2)
intersect_set=s1.intersect(s2)
print("Union of the sets is:",union_set)
print("Intersection of the sets is:",intersect_set)
输出:
Union of the sets is: {1, 2, 3, 4}
Intersection of the sets is: {2, 3}
寻找一个事件的概率
事件的概率是事件发生的可能性,用数字定义。
使用集合来定义我们的事件和样本空间,我们可以在 SymPy 函数的帮助下解决概率问题。
让我们考虑一个简单的例子,其中我们发现在前十个自然数中找到 3 的倍数的概率。
为了回答这个问题,我们首先将样本空间“s”定义为一个从 1 到 10 的集合。然后,我们定义事件,用字母“a”表示,它是 3 的倍数的出现。然后,我们通过使用 len 函数,用样本空间中的元素数量来定义该事件中的元素数量,从而找到该事件的概率(‘a’)。这将在下面演示。
代码:
s=FiniteSet(1,2,3,4,5,6,7,8,9,10)
a=FiniteSet(3,6,9)
p=len(a)/len(s)
p
输出:
0.3
延伸阅读:
查看更多可对器械包执行的操作: https://docs.sympy.org/latest/modules/sets.html#compound-sets
与 SymPy: https://docs.sympy.org/latest/modules/sets.html#module-sympy.sets.sets 中的集合相关的所有信息
微积分解题
我们将学习如何使用 SymPy 计算一个函数的极限值、导数、定积分和不定积分。
函数的极限
函数的极限值 f(x)是当 x 接近某一特定值时的函数值。
例如,如果我们取函数 1/x,我们看到随着 x 的增加,1/x 的值继续减少。当 x 接近一个无限大的值时,1/x 变得更接近 0。使用 SymPy 函数- limit 计算极限值,如下所示。
代码:
from sympy import limit,Symbol
x=Symbol('x')
limit(1/x,x,0)
输出:
∞
函数的导数
函数的导数定义了该函数相对于独立变量的变化率。如果我们以距离为函数,以时间为自变量,这个函数的导数就是这个函数对时间的变化率,也就是速度。
SymPy 有一个函数, diff ,以表达式(要计算其导数)和自变量为自变量,返回表达式的导数。
代码:
from sympy import Symbol,diff
x=Symbol('x')
#defining the expression to be differentiated
expr=x**2-4
#applying the diff function to this expression
d=diff(expr,x)
d
输出:
2𝑥
```py
#### 函数的积分
函数的积分也叫做反导数。一个函数对两点的定积分,比如说“p”和“q”,就是曲线下两个极限之间的面积。对于不定积分,这些极限是没有定义的。
在 SymPy 中,可以使用 *integrate* 函数计算积分。
让我们来计算上一个例子中看到的函数的微分(2x)的不定积分。
代码:
from sympy import integrate #applying the integrate function integrate(d,x)
输出:
𝑥2
让我们使用积分函数来计算上面输出的定积分。integrate 函数接受的参数包括极限值 1 和 4(作为一个元组),以及变量(符号)“x”。
代码:
integrate(d,(x,1,4))
输出:
15
延伸阅读:查看更多关于微分、积分和计算极限的函数: [`https://docs.sympy.org/latest/tutorial/calculus.html`](https://docs.sympy.org/latest/tutorial/calculus.html)
## 摘要
1. 正则表达式是文字和元字符的组合,有多种应用。
2. 正则表达式可用于搜索和替换单词,定位系统中的文件,以及 web 爬行或抓取程序。它还可以应用于数据争论和清理操作,验证用户在电子邮件和 HTML 表单中的输入,以及搜索引擎。
3. 在 Python 中, *re* 模块提供了对正则表达式的支持。Python 中正则表达式匹配常用的函数有: *findall* 、 *search* 、 *match* 、 *split* 和 *sub* 。
4. 元字符是正则表达式中具有特殊意义的字符。每个元字符都有特定的用途。
5. 字符类(以反斜杠符号开头)用于匹配预定义的字符集,如数字、字母数字字符、空白字符等。
6. Sympy 是一个用于解决数学问题的库。Sympy 中使用的基本构建块称为“符号”,它代表一个变量。我们可以使用 Sympy 库的函数来分解或展开表达式,解方程,微分或积分函数,以及解决涉及集合的问题。
在下一章中,我们将学习另一个 Python 模块 NumPy,它用于创建数组、计算统计聚集度量和执行计算。NumPy 模块也构成了 Pandas 的主干,这是一个用于数据争论和分析的流行库,我们将在第六章中详细讨论。
## 复习练习
**问题 1**
选择不正确的陈述:
1. 即使在集合中使用,元字符也被视为元字符
2. 的。(点/点)元字符用于匹配除换行符之外的任何(单个)字符
3. 正则表达式不区分大小写
4. 默认情况下,正则表达式只返回找到的第一个匹配项
5. 以上都不是
**问题 2**
解释正则表达式的一些用例。
**问题 3**
对一个元字符进行转义的目的是什么,为此使用了哪个字符?
**问题 4**
以下语句的输出是什么?
re.findall('bond\d{1,3}','bond07 bond007 Bond 07')
**问题 5**
将下列元字符与其功能配对:
<colgroup><col class="tcol1 align-left"> <col class="tcol2 align-left"></colgroup>
| 1\. + | a.匹配零个或一个字符 |
| 2\. * | b.匹配一个或多个字符 |
| 3\. ? | c.匹配字符集 |
| 4\. [ ] | d.匹配搜索字符串末尾的字符 |
| 5\. $ | e.匹配零个或多个字符 |
| 6\. { } | f.指定时间间隔 |
**问题 6**
将以下元字符(用于字符类)与其功能匹配:
<colgroup><col class="tcol1 align-left"> <col class="tcol2 align-left"></colgroup>
| 1.\d | a.匹配单词的开头或结尾 |
| 2.\D | b.匹配除空白字符以外的任何字符 |
| 3.\S | c.匹配非数字 |
| 4.\w | d.匹配数字 |
| 5.\b | e.匹配字母数字字符 |
**问题 7**
编写一个程序,要求用户输入密码并进行验证。密码应满足以下要求:
* 长度至少应为六个字符
* 至少包含一个大写字母、一个小写字母、一个特殊字符和一个数字
**问题 8**
考虑两个表达式 y=x**2-9 和 y=3*x-11。
使用 SymPy 函数解决以下问题:
* 对表达式 x**2-9 进行因式分解,并列出其因式
* 解这两个方程
* 画出这两个方程,并用图表显示其解
* 对于 x=1,求表达式 x**2-9 的微分
* 求表达式 3*x-11 在点 x=0 和 x=1 之间的定积分
**答案**
**问题 1**
不正确的选项是选项 1 和 3。
选项 1 是不正确的,因为当元字符在集合中使用时,它不被认为是元字符,而是采用其字面意义。
选项 3 不正确,因为正则表达式区分大小写(“hat”与“HAT”不同)。
其他选项都是正确的。
**问题 2**
正则表达式的一些用例包括
1. HTML 表单中的用户输入验证。正则表达式可用于检查用户输入,并确保输入符合表单中各个字段的要求。
2. Web 爬行和 web 抓取:正则表达式通常用于从网站搜索一般信息(爬行)和从网站提取某些类型的文本或数据(抓取),例如电话号码和电子邮件地址。
3. 在您的操作系统上定位文件:使用正则表达式,您可以在您的系统上搜索文件名具有相同扩展名或遵循某种其他模式的文件。
**问题 3**
我们对元字符进行转义,以便在字面上使用它。反斜杠字符(\)符号位于要转义的元字符之前。例如,符号“*”在正则表达式中有特殊的含义。如果你想用这个字符它没有特殊的含义,你需要用\*
**问题 4**
输出
['bond07', 'bond007']
**问题 5**
1-b; 2-e; 3-a; 4-d; 5-c; 6-f
**问题 6**
1-d; 2-c; 3-b; 4-e; 5-a
**问题 7**
代码:
import re special_characters=['$','#','@','&','^','*'] while True: s=input("Enter your password") if len(s)<6: print("Enter at least 6 characters in your password") else: if re.search(r'\d',s) is None: print("Your password should contain at least 1 digit") elif re.search(r'[A-Z]',s) is None: print("Your password should contain at least 1 uppercase letter") elif re.search(r'[a-z]',s) is None: print("Your password should contain at least 1 lowercase letter") elif not any(char in special_characters for char in s): print("Your password should contain at least 1 special character") else: print("The password you entered meets our requirements") break
**问题 8**
代码:
from sympy import Symbol,symbols,factor,solve,diff,integrate,plot #creating symbols x,y=symbols('x,y') y=x2-9 y=3*x-11 #factorizing the expression factor(x2-9) #solving two equations solve((x2-9-y,3*x-11-y),dict=True) #plotting the equations to find the solution %matplotlib inline plot(x2-9-y,3x-11-y) #differentiating at a particular point diff(x**2-9,x).subs({x:1}) #finding the integral between two points integrate(3x-11,(x,0,1))
# 四、描述性数据分析基础
在前面的章节中,您已经了解了 Python 语言——语法、函数、条件语句、数据类型和不同类型的容器。您还回顾了更高级的概念,如正则表达式、文件处理以及用 Python 解决数学问题。我们的焦点现在转向这本书的核心,描述性数据分析(也称为探索性数据分析)。
在描述性数据分析中,我们借助总结、聚合和可视化等方法来分析过去的数据,以得出有意义的见解。相比之下,当我们进行预测分析时,我们试图使用各种建模技术对未来进行预测或预报。
在本章中,我们将了解各种类型的数据、如何对数据进行分类、根据数据类别执行哪些操作,以及描述性数据分析流程的工作流程。
## 描述性数据分析-步骤
图 4-1 逐步说明了描述性数据分析所遵循的方法。

图 4-1
描述性数据分析的步骤
让我们详细了解这些步骤。
1. **数据检索**:数据可以以结构化格式(如数据库或电子表格)或非结构化格式(如网页、电子邮件、Word 文档)存储。在考虑了数据的成本和结构等参数之后,我们需要弄清楚如何检索这些数据。像 Pandas 这样的库提供了以各种格式导入数据的功能。
2. **粗略的数据回顾和问题识别**:在这一步,我们对想要分析的数据形成第一印象。我们旨在了解每个单独的列或功能、数据集中使用的各种缩写和符号的含义、记录或数据代表的内容以及用于数据存储的单位。我们还需要提出正确的问题,并在进入分析的本质之前弄清楚我们需要做什么。这些问题可能包括以下内容:哪些是与分析相关的功能,各个列中是否有增加或减少的趋势,我们是否看到任何丢失的值,我们是否正在尝试开发预测并预测一个功能,等等。
3. **数据争论**:这一步是数据分析的关键,也是最耗时的活动,数据分析师和科学家大约 80%的时间都花在这上面。
由于以下任何原因,原始形式的数据通常不适合于分析:存在缺失和冗余值、异常值、不正确的数据类型、存在无关数据、使用了一个以上的测量单位、数据分散在不同的源中,以及列未被正确识别。
数据角力或 munging 是转换原始数据以使其适合数学处理和绘制图表的过程。它包括删除或替换丢失的值和不完整的条目,去除分号和逗号等填充值,过滤数据,更改数据类型,消除冗余,以及将数据与其他来源合并。
数据争论包括整理、清理和丰富数据。在数据整理中,我们识别数据集中的变量,并将它们映射到列。我们还沿着右轴组织数据,并确保行包含观察值而不是特征。将数据转换成整洁形式的目的是使数据具有便于分析的结构。数据清理包括处理缺失值、不正确的数据类型、异常值和错误输入的数据。在数据丰富中,我们可能会添加来自其他来源的数据,并创建可能有助于我们分析的新列或功能。
4. **数据探索和可视化**:准备好数据后,下一步是发现数据中的模式,总结关键特征,并理解各种特征之间的关系。有了可视化,你可以实现所有这些,并且清晰地呈现关键的发现。用于可视化的 Python 库包括 Matplotlib、Seaborn 和 Pandas。
5. **展示和发布我们的分析** : Jupyter 笔记本有两个用途,一是执行我们的代码,二是作为一个平台来提供我们分析的高级摘要。通过添加笔记、标题、注释和图像,您可以美化您的笔记本,使其更适合更广泛的受众。笔记本可以下载成各种格式,比如 PDF,以后可以与他人分享以供审阅。
我们现在继续讨论数据的各种结构和层次。
## 数据结构
我们需要分析的数据可能具有以下任何一种结构,如图 4-2 所示。

图 4-2
数据结构
## 将数据分类到不同的级别
大体上有两个层次的数据:连续的和分类的。连续数据可以进一步分为比率和区间,而分类数据可以是名义数据或顺序数据。数据等级如图 4-3 所示。

图 4-3
数据级别
以下是一些需要注意的要点:
* **分类变量的数值**:分类数据不限于非数值。例如,学生的排名可以取 1/2/3 等值,这是一个包含数字值的顺序(分类)变量的示例。然而,这些数字不具有数学意义;例如,寻找平均排名是没有意义的。
* **真零点** **的意义**:我们已经注意到区间变量没有绝对零点作为参考点,而比率变量有一个有效的零点。绝对零表示没有值。例如,当我们说像身高和体重这样的变量是比率变量时,这意味着这些变量中的任何一个值为 0 都意味着无效或不存在的数据点。对于像温度这样的间隔变量(当以摄氏度或华氏度测量时),值 0 并不意味着没有数据。0 只是温度变量可以采用的值之一。另一方面,当在开尔文温标中测量时,温度是一个比率变量,因为该温标定义了绝对零度。
* **识别区间变量**:区间变量没有绝对零度作为参考点,但是识别具有这种特征的变量可能并不明显。每当我们谈论一个数字的百分比变化时,它都是相对于它以前的值而言的。例如,通货膨胀或失业的百分比变化是以最后一个时间值作为参考点来计算的。这些是区间数据的实例。区间变量的另一个例子是在标准化考试中获得的分数,如 GRE(研究生入学考试)。最低分 260,最高分 340。评分是相对的,不是从 0 开始。与区间数据,而你可以执行加法和减法运算。不能对值进行除法或乘法运算(比率数据允许的运算)。
## 可视化不同级别的数据
每当需要分析数据时,首先要了解数据是结构化的还是非结构化的。如果数据是非结构化的,那么将它转换成具有行和列的结构化形式,这使得使用像 Pandas 这样的库进行进一步分析更加容易。有了这种格式的数据后,将每个要素或列分为四个数据级别,并相应地执行分析。
请注意,在本章中,我们仅旨在了解如何对数据集中的变量进行分类,并确定适用于每个类别的操作和绘图。第七章解释了可视化数据所需编写的实际代码。
我们看看如何对特征进行分类,并使用著名的 *Titanic* 数据集执行各种操作。数据集可以从这里导入:
[`https://github.com/DataRepo2019/Data-files/blob/master/titanic.csv`](https://github.com/DataRepo2019/Data-files/blob/master/titanic.csv)
数据集的背景信息:1912 年 4 月 15 日<sup>号,英国客轮泰坦尼克号在从南安普顿到纽约的处女航中与冰山相撞后沉没。在 2,224 名乘客中,有 1,500 人死亡,这是一场空前的悲剧。这个数据集描述了乘客的生存状态和关于他们的其他细节,包括他们的阶级、姓名、年龄和亲属数量。</sup>
图 4-4 提供了该数据集的快照。

图 4-4
泰坦尼克号数据集
表 4-1 记录了该数据集中根据数据级别分类的要素。
表 4-1
泰坦尼克号数据集——数据级别
<colgroup><col class="tcol1 align-left"> <col class="tcol2 align-left"> <col class="tcol3 align-left"></colgroup>
|
数据集中的要素
|
它代表了什么
|
数据水平
|
| --- | --- | --- |
| 乘客 Id | 乘客的身份号码 | 名义上的 |
| P 类 | 客运班(1:1 <sup>st</sup> 班;2: 2 <sup>级和</sup>级;3: 3 <sup>rd</sup> class),乘客等级被用作衡量乘客的社会经济地位 | 序数 |
| 幸存 | 存活状态(0:未存活;1:幸存) | 名义上的 |
| 名字 | 乘客姓名 | 名义上的 |
| 兄弟姐妹数 | 船上的兄弟姐妹/配偶人数 | 比例 |
| 票 | 票号 | 名义上的 |
| 小木屋 | 客舱号 | 名义上的 |
| 性 | 乘客的性别 | 名义上的 |
| 年龄 | 年龄 | 比例 |
| 烤 | 船上父母/孩子的数量 | 比例 |
| 票价 | 乘客票价(英镑) | 比例 |
| 从事 | 装运港(C 为瑟堡,Q 为皇后镇,S 为南安普敦) | 名义上的 |
现在让我们来了解一下该数据集中要素分类背后的基本原理。
1. Nominal variables: Variables like “PassengerId”, “Survived”, “Name”, “Sex”, “Cabin”, and “Embarked” do not have any intrinsic ordering of their values. Note that some of these variables have numeric values, but these values are finite in number. We cannot perform an arithmetic operation on these values like addition, subtraction, multiplication, or division. One operation that is common with nominal variables is counting. A commonly used method in Pandas, *value_counts* (discussed in the next chapter), is used to determine the number of values per each unique category of the nominal variable. We can also find the mode (the most frequently occurring value). The bar graph is frequently used to visualize nominal data (pie charts can also be used), as shown in Figure 4-5.
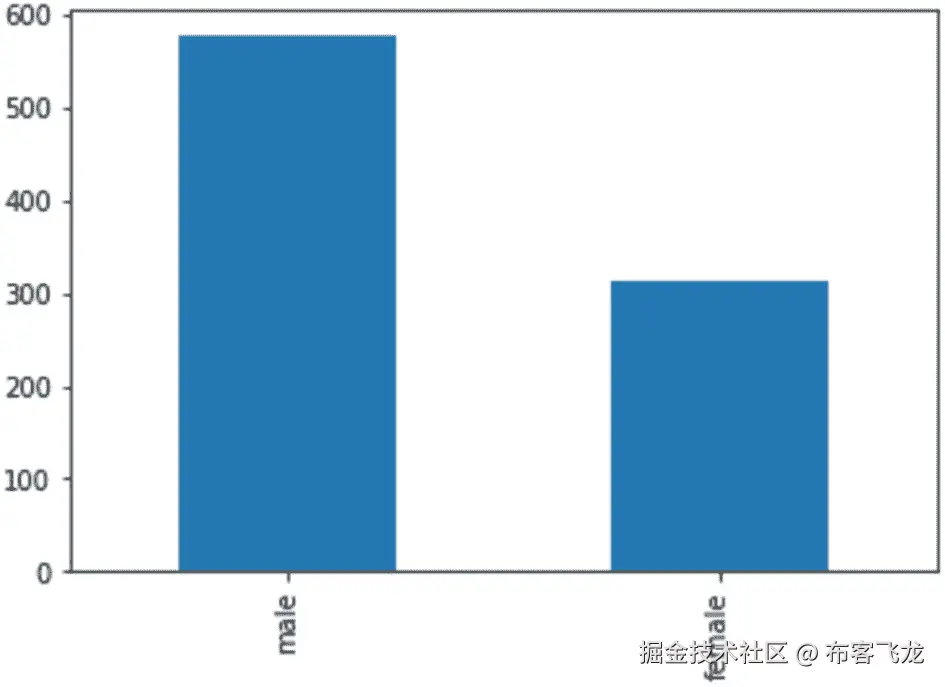
图 4-5
显示每个类别计数的条形图
2. 顺序变量:“Pclass”(或乘客等级)是一个顺序变量,因为它的值遵循一个顺序。值 1 相当于一等,2 相当于二等,依此类推。这些阶级价值观表明了社会经济地位。
我们可以找出中间值和百分位数。我们还可以计算每个类别中值的数量,计算模式,并使用条形图和饼图等图表,就像我们对名义变量所做的那样。
In Figure 4-6, we have used a pie chart for the ordinal variable “Pclass”.

图 4-6
显示每个类别的百分比分布的饼图
3. 比率数据:“年龄”和“费用”变量是比率数据的例子,以零值作为参考点。有了这种类型的数据,我们可以进行广泛的数学运算。
For example, we can add all the fares and divide it by the total number of passengers to find the mean. We can also find out the standard deviation. A histogram, as shown in Figure 4-7, can be used to visualize this kind of continuous data to understand the distribution.

图 4-7
显示比率变量分布的直方图
在前面的图中,我们查看了用于绘制单个分类变量或连续变量的图表。在下一节中,我们了解当我们有一个以上的变量或变量组合属于不同的规模或水平时,应使用哪些图表。
### 绘制混合数据
在本节中,我们将考虑三个场景,每个场景都有两个变量,它们可能属于也可能不属于同一级别,并讨论每个场景使用哪个图(使用相同的 *Titanic* 数据集)。
1. One categorical and one continuous variable: A box plot shows the distribution, symmetry, and outliers for a continuous variable. A box plot can also show the continuous variable against a categorical variable. In Figure 4-8, the distribution of ‘Age’ (a ratio variable) for each value of the nominal variable – ‘Survived’ (0 is the value for passengers who did not survive and 1 is the value for those who did).

图 4-8
箱形图,显示不同类别的年龄分布
2. Both continuous variables: Scatter plots are used to depict the relationship between two continuous variables. In Figure 4-9, we plot two ratio variables, ‘Age’ and ‘Fare’, on the x and y axes to produce a scatter plot.

图 4-9
散点图
3. Both categorical variables: Using a clustered bar chart (Figure 4-10), you can combine two categorical variables with the bars depicted side by side to represent every combination of values for the two variables.

图 4-10
簇状条形图
我们也可以使用堆积条形图来绘制两个分类变量。考虑下面的堆积条形图,如图 4-11 所示,绘制了两个分类变量——“Pclass”和“Survived”。
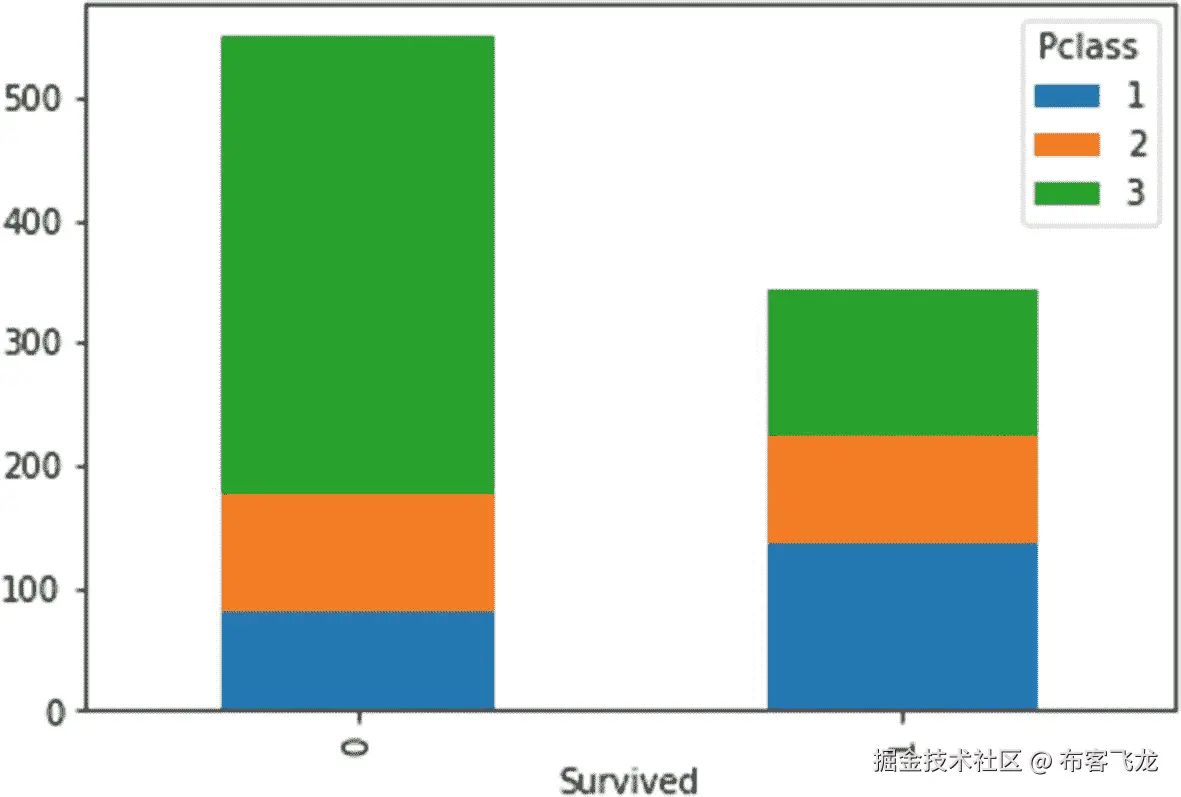
图 4-11
堆积条形图
总的来说,当您想要显示某个分类变量的不同值之间的连续变量时,您可以使用散点图来显示两个连续变量,使用堆积或簇状条形图来显示两个分类变量,以及使用箱形图。
## 摘要
1. 描述性数据分析是一个五步过程,使用过去的数据,遵循逐步的方法。这个过程的核心——数据争论——包括处理缺失值和其他异常。它还处理重组、合并和转换。
2. 数据可以根据其结构(结构化、非结构化或半结构化)或其包含的值的类型(分类或连续)进行分类。
3. 分类数据可以分为名义数据和顺序数据(取决于值是否可以排序)。连续数据可以是比率或区间类型(取决于数据是否以 0 作为绝对参考点)。
4. 可以使用的数学运算和图形绘制的种类因数据水平而异。
现在你已经对描述性数据分析过程有了一个高层次的了解,我们在下一章进入数据分析的本质。在下一章中,我们将讨论如何为我们在数据争论和准备中执行的各种任务编写代码,这一章将介绍 Pandas 库。
## 复习练习
**问题 1**
根据数据类型对下列变量进行分类。
* pH 标度
* 语言能力
* 李克特量表(用于调查)
* 工作经验
* 一天中的时间
* 社会保险号
* 距离
* 出生年
**问题 2**
按照数据分析过程中出现的顺序安排以下五个步骤。
1. 形象化
2. 分析的发布和展示
3. 导入数据
4. 数据争论
5. 问题陈述公式
**问题 3**
对于以下每个操作或统计测量,列出兼容的数据类型。
* 分开
* 添加
* 增加
* 减法
* 平均
* 中位数
* 方式
* 标准偏差
* 范围
**问题 4**
对于以下每一项,列出兼容的数据类型。
* 条形图
* 直方图
* 饼图
* 散点图
* 堆积条形图
**答案**
**问题 1**
* pH 值刻度:间隔
pH 值刻度没有绝对零点。虽然这些值可以比较,但我们无法计算比率。
* 语言能力:序数
一门语言的熟练程度有不同的等级,如“初级”、“中级”和“高级”,这些都是有序的,因此属于顺序等级。
* 李克特量表(用于调查):序数。
李克特量表常用于调查,其值有“不满意”、“满意”和“非常满意”。这些值形成了一个逻辑顺序,因此任何代表李克特量表的变量都是序数变量。
* 工作经验:比率
因为这个变量有一个绝对零点,并且可以进行算术运算,包括比率的计算,所以这个变量是一个比率变量。
* 一天中的时间:间隔
时间(12 小时制)没有绝对的零点。我们可以计算两个时间点之间的差异,但不能计算比率。
* 社会安全号码:名义上的
像社会保险号这样的标识符的值是没有顺序的,不适合数学运算。
* 距离:比率
参考点为 0,值可以加、减、乘、除,距离是一个比率变量。
* 出生年份:间隔
这样的变量没有绝对的零点。你可以计算两年之间的差异,但我们无法找出比率。
**问题 2**
正确的顺序是 3,5,4,1,2
**问题 3**
* 分部:比率数据
* 加法:比率数据、区间数据
* 乘法:比率数据
* 减法:区间数据、比率数据
* 均值:比率数据、区间数据
* 中位数:序数数据,比率数据,区间数据
* 模式:所有四个级别的数据(比率、区间、标称和序数)
* 标准差:比率和区间数据
* 范围:比率和区间数据
**问题 4**
* 箱线图:序数、比率、间隔
* 直方图:比率,间隔
* 饼图:名义值,序数
* 散点图:比率,间隔
* 堆积条形图:名义值,序数
# 五、使用 NumPy 数组
NumPy 或 Numerical Python 是一个基于 Python 的库,用于数学计算和处理数组。Python 不支持一维以上的数据结构,像列表、元组和字典这样的容器是一维的。Python 中内置的数据类型和容器不能被重构为一个以上的维度,也不适合复杂的计算。这些缺点限制了分析数据和构建模型时所涉及的一些任务,这使得数组成为一种重要的数据结构。
NumPy 数组可以被重新整形,并利用向量化的原理(其中应用于数组的操作反映在其所有元素上)。
在前一章,我们看了描述性数据分析中使用的基本概念。NumPy 是我们在数据分析中执行的许多任务不可或缺的一部分,是 Pandas 中使用的许多函数和数据类型的主干。在本章中,我们了解了如何使用各种方法创建 NumPy 数组,组合数组,对数组进行切片、整形和执行计算。
## 熟悉数组和 NumPy 函数
在这里,我们看看创建和组合数组的各种方法,以及常用的 NumPy 函数。
**导入 NumPy 包**
必须先导入 NumPy 包,然后才能使用它的函数,如下所示。NumPy 的简写符号或别名是 *np* 。
代码:
```py
import numpy as np
如果您尚未安装 NumPy,请转到 Anaconda 提示符并输入以下命令:
pip install numpy
创建数组
NumPy 中的基本单位是一个数组。在表 5-1 中,我们来看看创建数组的各种方法。
表 5-1
创建 NumPy 数组的方法
|方法
|
例子
|
| --- | --- |
| 从列表中创建数组 | 函数用来从一个列表中创建一个一维或多维数组。代码:np.array([[1,2,3],[4,5,6]])输出:array([[1, 2, 3],``[4, 5, 6]]) |
| 从一个范围创建数组 | 函数用于创建一个整数范围。代码:np.arange(0,9)``#Alternate syntax:``np.arange(9)``#Generates 9 equally spaced integers starting from 0输出:array([0, 1, 2, 3, 4, 5, 6, 7, 8]) |
| 创建一个等距数字数组 | 函数在两个极限之间创建给定数量的等距值。代码:np.linspace(1,6,5)``# This generates five equally spaced values between 1 and 6输出:array([1. , 2.25, 3.5 , 4.75, 6. ]) |
| 创建一个零数组 | 函数创建一个给定行数和列数的数组,数组中只有一个值“0”。代码:np.zeros((4,2))``#Creates a 4*2 array with all values as 0输出:array([[0., 0.],``[0., 0.],``[0., 0.],``[0., 0.]]) |
| 创建一个 1 的数组 | np.ones 函数类似于 np.zeros 函数,不同之处在于在整个数组中重复的值是“1”。代码:np.ones((2,3))``#creates a 2*3 array with all values as 1输出:array([[1., 1., 1.],``[1., 1., 1.]]) |
| 创建一个数组,其中给定的值在整个过程中重复 | 函数使用用户指定的值创建一个数组。代码:np.full((2,2),3)``#Creates a 2*2 array with all values as 3输出:array([[3, 3],``[3, 3]]) |
| 创建空数组 | 函数 np.empty 生成一个数组,没有任何特定的初始值(数组是随机初始化的)。代码:np.empty((2,2))``#creates a 2*2 array filled with random values输出:array([[1.31456805e-311, 9.34839993e+025],``[2.15196058e-013, 2.00166813e-090]]) |
| 从重复列表创建数组 | 函数从一个重复给定次数的列表中创建一个数组。代码:np.repeat([1,2,3],3)``#Will repeat each value in the list 3 times输出:array([1, 1, 1, 2, 2, 2, 3, 3, 3]) |
| 创建随机整数数组 | randint 函数(来自 np.random 模块)生成一个包含随机数的数组。代码:np.random.randint(1,100,5)``#Will generate an array with 5 random numbers between 1 and 100输出:array([34, 69, 67, 3, 96]) |
需要注意的一点是,数组是同构的数据结构,不像容器(像列表、元组、字典);也就是说,数组应该包含相同数据类型的项。例如,我们不能拥有一个同时包含整数、字符串和浮点(十进制)值的数组。虽然用不同数据类型的项定义 NumPy 数组不会在编写代码时导致错误,但应该避免这种情况。
现在我们已经了解了定义数组的各种方法,我们来看看可以对它们执行的操作,从数组的整形开始。
重塑数组
重塑数组是改变数组维数的过程。NumPy 方法“reshape”很重要,通常用于将一维数组转换为多维数组。
考虑一个包含十个元素的简单一维数组,如下面的语句所示。
代码:
x=np.arange(0,10)
输出:
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
我们可以将一维数组“x”改造成一个五行两列的二维数组:
代码:
x.reshape(5,2)
输出:
array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
作为另一个示例,考虑以下数组:
代码:
x=np.arange(0,12)
x
输出:
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
现在,应用 reshape 方法创建两个子数组——每个子数组有三行两列:
代码:
x=np.arange(0,12).reshape(2,3,2)
x
输出:
array([[[ 0, 1],
[ 2, 3],
[ 4, 5]],
[[ 6, 7],
[ 8, 9],
[10, 11]]])
经过整形的数组的维数乘积应该等于原始数组中的元素数。在这种情况下,数组(2,3,2)的维数乘以等于 12,即数组中元素的数目。如果不满足这个条件,整形就不起作用。
除了 reshape 方法,我们还可以使用 shape 属性来改变数组的形状或维度:
代码:
x.shape=(5,2)
#5 is the number of rows, 2 is the number of columns
请注意, shape 属性对原始数组进行更改,而 reshape 方法不会改变数组。
使用“拆纱”方法可以逆转整形过程:
代码:
x=np.arange(0,12).reshape(2,3,2)
x.ravel()
输出:
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
延伸阅读:查看更多关于数组创建的套路: https://numpy.org/doc/stable/reference/routines.array-creation.html#
数组的逻辑结构
用于指定点的位置的笛卡尔坐标系由一个平面组成,该平面具有两条称为“x”和“y”轴的垂直线。使用点的 x 和 y 坐标来指定点的位置。这种用轴来表示不同维度的原理也用在数组中。
一维数组有一个轴(轴=0),因为它有一个维度,如图 5-1 所示。
图 5-1
一维数组表示
二维数组的轴值为“0”表示行轴,值为“1”表示列轴,如图 5-2 所示。
图 5-2
二维数组表示形式
三维数组有三个轴,代表三个维度,如图 5-3 所示。
图 5-3
三维数组表示
扩展逻辑,具有“n”维的阵列具有“n”个轴。
请注意,前面的图表仅代表数组的逻辑结构。当涉及到内存中的存储时,数组中的元素占据连续的位置,而与维数无关。
NumPy 数组的数据类型
type 函数可以用来确定 NumPy 数组的类型:
代码:
type(np.array([1,2,3,4]))
输出:
numpy.ndarray
修改数组
数组的长度是在定义时设置的。让我们考虑下面的数组“a”:
代码:
a=np.array([0,1,2])
前面的代码语句将创建一个长度为 3 的数组。此后,数组长度不可修改。换句话说,我们不能在数组定义后添加新元素。
下面的语句将导致错误,在该语句中,我们尝试向该数组添加第四个元素:
代码:
a[3]=4
输出:
---------------------------------------------------------------------------
IndexErrorTraceback (most recent call last)
<ipython-input-215-94b083a55c38> in <module>
----> 1a[3]=4
IndexError: index 3 is out of bounds for axis 0 with size 3
---------------------------------------------------------------------------
但是,您可以更改现有元素的值。下面的语句就可以了:
代码:
a[0]=2
总之,虽然可以修改数组中现有项目的值,但不能向数组中添加新项目。
现在我们已经看到了如何定义和整形一个数组,我们来看看如何组合数组。
组合数组
组合数组有三种方法:追加、串联和堆叠。
-
追加包括将一个数组连接到另一个数组的末尾。 np.append 函数用于追加两个数组。
CODE:
x=np.array([[1,2],[3,4]]) y=np.array([[6,7,8],[9,10,11]]) np.append(x,y)Output:
array([ 1, 2, 3, 4, 6, 7, 8, 9, 10, 11]) -
串联包括沿一个轴(垂直或水平)连接数组。函数的作用是连接数组。
CODE:
x=np.array([[1,2],[3,4]]) y=np.array([[6,7],[9,10]]) np.concatenate((x,y))Output:
array([[ 1, 2], [ 3, 4], [ 6, 7], [ 9, 10]])默认情况下, concatenate 函数垂直连接数组(沿“0”轴)。如果您希望数组并排连接,则需要添加“轴”参数,其值为“1”:
CODE:
np.concatenate((x,y),axis=1)追加函数在内部使用连接函数。
-
堆叠:堆叠有垂直和水平两种,如下所述。
垂直堆叠
顾名思义,垂直堆叠将阵列一个接一个地堆叠起来。垂直堆叠的阵列的每个子阵列中的元素数量必须相同,垂直堆叠才能工作。 np.vstack 函数用于垂直堆叠。
CODE:
x=np.array([[1,2],[3,4]]) y=np.array([[6,7],[8,9],[10,11]]) np.vstack((x,y))Output:
array([[ 1, 2], [ 3, 4], [ 6, 7], [ 8, 9], [10, 11]])看看数组“x”和“y”的每个子数组中有两个元素。
水平堆叠
水平堆叠并排堆叠阵列。对于水平堆叠的每个阵列,子阵列的数量需要相同。 np.hstack 函数用于水平堆叠。
在下面的例子中,我们在每个数组中都有两个子数组,“x”和“y”。
CODE:
x=np.array([[1,2],[3,4]]) y=np.array([[6,7,8],[9,10,11]]) np.hstack((x,y))Output:
array([[ 1, 2, 6, 7, 8], [ 3, 4, 9, 10, 11]])
在下一节中,我们将研究如何使用逻辑运算符来测试 NumPy 数组中的条件。
条件测试
NumPy 使用逻辑运算符(&、|、~),以及类似于 np.any 、 np.all 和 np.where 的函数来检查条件。返回数组中满足条件的元素(或它们的索引)。
考虑以下阵列:
代码:
x=np.linspace(1,50,10)
x
输出:
array([ 1\. , 6.44444444, 11.88888889, 17.33333333, 22.77777778,
28.22222222, 33.66666667, 39.11111111, 44.55555556, 50\. ])
让我们检查以下条件,看看哪些元素满足这些条件:
-
检查所有值是否满足给定的条件:只有当数组中的所有项都满足该条件时, np.all 函数才返回值" True ",如下例所示。
CODE:
np.all(x>20) #returns True only if all the elements are greater than 20输出:
False -
检查数组中是否有任何值满足某个条件:如果有任何项满足该条件, np.any 函数返回值" True"。
CODE:
np.any(x>20) #returns True if any one element in the array is greater than 20输出:
True -
返回满足条件的项目的索引: np.where 函数返回满足给定条件的数组中的值的索引。
CODE:
np.where(x<10) #returns the index of elements that are less than 10输出:
(array([0, 1], dtype=int64),)np.where 函数对于有选择地检索或过滤数组中的值也很有用。例如,我们可以使用下面的代码语句检索那些满足条件“x < 10”的项目:
CODE:
x[np.where(x<10)]Output:
array([1\. , 6.44444444]) -
检查多个条件:
NumPy uses the following Boolean operators to combine conditions:
-
& operator(相当于 Python 中的和运算符):当所有条件都满足时返回 True:
CODE:
x[(x>10) & (x<50)] #Returns all items that have a value greater than 10 and less than 50Output:
array([11.88888889, 17.33333333, 22.77777778, 28.22222222, 33.66666667, 39.11111111, 44.55555556]) -
|操作符(相当于 Python 中的或操作符):当一组给定条件中的任意一个条件得到满足时,返回 True。
CODE:
x[(x>10) | (x<5)] #Returns all items that have a value greater than 10 or less than 5Output:
array([ 1\. , 11.88888889, 17.33333333, 22.77777778, 28.22222222, 33.66666667, 39.11111111, 44.55555556, 50\. ]) -
~运算符(相当于 Python 中的而非运算符),用于对条件求反。
CODE:
x[~(x<8)] #Returns all items greater than 8Output:
array([11.88888889, 17.33333333, 22.77777778, 28.22222222, 33.66666667, 39.11111111, 44.55555556, 50\. ])
-
我们现在继续讨论 NumPy 中的其他一些重要概念,比如广播和向量化。我们还讨论了算术运算符在 NumPy 数组中的使用。
广播、向量化和算术运算
广播
当我们说两个数组可以一起广播时,这意味着它们的维数对于对它们执行算术运算是兼容的。只要遵循广播规则,就可以使用算术运算符组合数组,下面将对此进行解释。
-
两个阵列具有相同的尺寸。
在本例中,两个数组的尺寸都是 2*6。
CODE:
x=np.arange(0,12).reshape(2,6) y=np.arange(5,17).reshape(2,6) x*yOutput:
array([[ 0, 6, 14, 24, 36, 50], [ 66, 84, 104, 126, 150, 176]]) -
其中一个数组是单元素数组。
在本例中,第二个数组只有一个元素。
CODE :
x=np.arange(0,12).reshape(2,6) y=np.array([1]) x-yOutput:
array([[-1, 0, 1, 2, 3, 4], [ 5, 6, 7, 8, 9, 10]]) -
数组和标量(单个值)组合在一起。
在本例中,变量 y 在运算中用作标量值。
CODE:
x=np.arange(0,12).reshape(2,6) y=2 x/yOutput:
array([[0\. , 0.5, 1\. , 1.5, 2\. , 2.5], [3\. , 3.5, 4\. , 4.5, 5\. , 5.5]])
我们可以使用算术运算符(+/-/*和/)或函数( np.add 、 np.subtract 、 np.multiply 和 np.divide )对数组进行加、减、乘和除操作
代码:
np.add(x,y)
#Or
x+y
输出:
array([[ 6, 8],
[11, 13]])
同样,你可以用 np.subtract (或——运算符)做减法,用 np.multiply (或*运算符)做乘法,用 np.divide (或/运算符)做除法。
延伸阅读:查看更多关于阵列广播: https://numpy.org/doc/stable/user/basics.broadcasting.html
矢量化
使用向量化的原理,您还可以方便地对数组中的每个对象应用算术运算符,而不是遍历元素,这是您对列表等容器中的项目应用运算时会做的事情。
代码:
x=np.array([2,4,6,8])
x/2
#divides each element by 2
输出:
array([1., 2., 3., 4.])
点积
我们可以得到两个数组的点积,这和两个数组相乘是不一样的。将两个数组相乘得到元素的乘积,而两个数组的点积计算元素的内积。
如果我们取两个数组,
|PQ|
|RS|
and
|UV|
|WX|
点积由下式给出
|PQ| . |UV| = |P*U+Q*VP*V+Q*X|
|R S| |WX| |R*U+S*WR*V+S*X|
将数组相乘得到以下结果:
|PQ| * |UV| = |P*U Q*V|
|R S| |WX| |R*WS*X|
如前所述,数组可以用乘法运算符(*)或 np.multiply 函数相乘。
获得点积的 NumPy 函数是 np 。打点。
代码:
np.dot(x,y)
输出:
array([[21, 24],
[47, 54]])
我们也可以把一个数组和一个标量结合起来。
在下一个主题中,我们将讨论如何获取数组的各种属性。
获取数组的属性
使用属性可以找出数组属性,如大小、维度、元素数量和内存使用情况。
考虑以下阵列:
-
属性给出了数组中元素的数量。
代码:
x.sizeOutput:
10 -
属性给出了维度的数量。
代码:
x.ndimOutput:
2 -
数组占用的内存(总字节数)可以使用 nbytes 属性来计算。
代码:
x.nbytesOutput:
40每个元素占用 4 个字节(因为这是一个 int 数组);因此,十个元素占用 40 个字节
-
这个数组中元素的数据类型可以使用 dtype 属性来计算。
代码:
x.dtypeOutput:
dtype('int32')
x=np.arange(0,10).reshape(5,2)
注意数组的类型和类型之间的区别。 type 函数给出了容器对象的类型(在本例中,类型是 ndarray ),而 dtype 是一个属性,给出了数组中单个项目的类型。
延伸阅读:了解关于 NumPy 支持的数据类型列表的更多信息:
https://numpy.org/devdocs/user/basics.types.html
转置一个数组
数组的转置是它的镜像。
考虑以下阵列:
代码:
x=np.arange(0,10).reshape(5,2)
有两种转置数组的方法:
-
我们可以用 np.transpose 的方法。
代码:
-
或者,我们可以使用 T 属性来获得转置。
代码:
np.transpose(x)
x.T
这两种方法给出相同的输出:
array([[0, 2, 4, 6, 8],
[1, 3, 5, 7, 9]])
屏蔽阵列
假设您使用一个 NumPy 数组来存储一个班级学生的考试成绩。虽然你有大多数学生的数据,但也有一些缺失值。在这种情况下,用于存储具有无效或缺失条目的数据的掩码数组非常有用。
可以通过创建“ma.masked_array”类(numpy.ma 模块的一部分)的对象来定义屏蔽数组:
代码:
import numpy.ma as ma
x=ma.masked_array([87,99,100,76,0],[0,0,0,0,1])
#The last element is invalid or masked
x[4]
输出:
Masked
两个数组作为参数传递给 ma.masked_array 类——一个包含数组中各项的值,另一个包含掩码值。掩码值“0”表示相应的项值有效,掩码值“1”表示它缺失或无效。例如,在前面的示例中,值 87、99、100 和 76 是有效的,因为它们具有掩码值“0”。第一个数组(0)中掩码值为“1”的最后一项无效。
掩码值也可以使用掩码属性来定义。
代码:
x=ma.array([87,99,100,76,0])
x.mask=[0,0,0,0,1]
要取消元素屏蔽,请为其赋值:
代码:
x[4]=82
此元素的掩码值变为 1,因为它不再有效。
现在让我们看看如何从数组中创建子集。
切片或选择数据子集
数组切片类似于 Python 中字符串和列表的切片。切片是数据结构(在本例中是数组)的子集,它可以表示一组值或单个值。
考虑以下阵列:
代码:
x=np.arange(0,10).reshape(5,2)
输出:
array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
下面给出了一些切片的例子。
-
选择第一个子数组[0,1]:
代码:
x[0]Output:
array([0, 1]) -
选择第二列:
CODE:
x[:,1] #This will select all the rows and the 2ndcolumn (has an index of 1)输出:
array([1, 3, 5, 7, 9]) -
选择第四行第一列的元素:
代码:
x[3,0]Output:
6 -
我们还可以基于以下条件创建切片:
代码:
x[x<5]Output:
array([0, 1, 2, 3, 4])
当我们分割一个数组时,原始数组没有被修改(数组的副本被创建)。
现在我们已经学习了如何创建和使用数组,接下来我们将学习 NumPy 的另一个重要应用——使用各种函数计算统计量。
获取描述性统计数据/汇总数据
NumPy 中有一些方法可以简化复杂的计算和确定聚合度量。
让我们找到该数组的集中趋势(平均值、方差、标准偏差)、总和、累积总和以及最大值的度量:
代码:
x=np.arange(0,10).reshape(5,2)
#mean
x.mean()
输出:
4.5
找出差异:
代码:
x.var() #variance
输出:
2.9166666666666665
计算标准偏差:
代码:
x.std() #standard deviation
输出:
1.707825127659933
计算每列的总和:
代码:
x.sum(axis=0) #calculates the column-wise sum
输出:
array([ 6, 15])
计算累积和:
代码:
x.cumsum()
#calculates the sum of 2 elements at a time and adds this sum to the next element
输出:
array([ 0, 1, 3, 6, 10, 15, 21, 28, 36, 45], dtype=int32)
找出数组中的最大值:
代码:
x.max()
输出:
9
在结束本章之前,让我们了解一下矩阵 NumPy 包支持的另一种数据结构。
矩阵
矩阵是二维数据结构,而数组可以由任意维数组成。
使用 np.matrix 类,我们可以使用以下语法创建一个矩阵对象:
代码:
x=np.matrix([[2,3],[33,3],[4,1]])
#OR
x=np.matrix('2,3;33,3;4,1') #Using semicolons to separate the rows
x
输出:
matrix([[ 2, 3],
[33, 3],
[ 4, 1]])
大多数可以应用于数组的函数也可以应用于矩阵。矩阵使用一些算术运算符,使矩阵运算更加直观。例如,我们可以使用*运算符来获得两个矩阵的点积,它复制了函数 np.dot 的功能。
由于矩阵只是数组的一个特例,在 NumPy 的未来版本中可能会被弃用,所以通常最好使用 NumPy 数组。
摘要
-
NumPy 是一个用于数学计算和创建数据结构(称为数组)的库,数组可以包含任意维数。
-
创建数组有多种方法,也可以改变数组的形状以添加更多的维度或更改现有的维度。
-
数组支持矢量化,这提供了一种快速直观的方法来对数组的所有元素应用算术运算符。
-
可以使用简单的 NumPy 函数计算各种统计和聚合度量,如 np.mean 、 np.var 、 np.std 等等。
复习练习
问题 1
创建以下数组:
array([[[ 1, 2, 3, 4],
[ 5, 6, 7, 8]],
[[ 9, 10, 11, 12],
[13, 14, 15, 16]],
[[17, 18, 19, 20],
[21, 22, 23, 24]]])
对前面的数组进行切片以获得以下内容:
-
第三个子阵列(17,18,19,20,21,22,23,24)中的元素
-
最后一个元素(24)
-
第二列中的元素(2,6,10,14,18,22)
-
对角线上的元素(1,10,19,24)
问题 2
使用适当的 NumPy 函数创建每个数组:
-
有七个随机数的数组
-
未初始化的 2*5 数组
-
一个数组,包含 10 个 1 到 3 之间的等距浮点数
-
所有值都为 100 的 3*3 数组
问题 3
为以下各项编写简单的代码语句:
-
创建一个数组来存储前 50 个偶数
-
计算这些数字的平均值和标准偏差
-
将此数组重塑为包含两个子数组的数组,每个子数组有五行和五列
-
计算这个重新成形的数组的维数
问题 4
计算这两种数据结构的点积:
[[ 2, 3],
[33, 3],
[ 4, 1]]
AND
[[ 2, 3, 33],
[ 3, 4, 1]]
使用
-
矩阵
-
数组
问题 5
第一部分和第二部分中编写的代码有什么不同,输出会有什么不同?
第一部分:
代码:
x=np.array([1,2,3])
x*3
第二部分:
代码:
a=[1,2,3]
a*3
答案
问题 1
-
第三个子阵列(17,18,19,20,21,22,23,24)中的元素:
代码:
x=np.arange(1,25).reshape(3,2,4)
-
最后一个元素(24):
代码:
x[2]
-
第二列中的元素(2,6,10,14,18,22):
代码:
x[2,1,3]
-
对角线上的元素(1,10,19,24):
代码:
x[:,:,1]
x[0,0,0],x[1,0,1],x[2,0,2],x[2,1,3]
问题 2
-
包含七个随机数的数组:
代码:
-
未初始化的 2*5 数组:
代码:
np.random.randn(7)
-
一个数组,包含 10 个 1 到 3 之间的等距浮点数:
代码:
np.empty((2,5))
-
所有值都为 100 的 3*3 数组:
代码:
np.linspace(1,3,10)
np.full((3,3),100)
问题 3
代码:
#creating the array of first 50 even numbers
x=np.arange(2,101,2)
#calculating the mean
x.mean()
#calculating the standard deviation
x.std()
#reshaping the array
y=x.reshape(2,5,5)
#calculating its new dimensions
y.ndim
问题 4
使用矩阵计算点积需要使用*算术运算符
代码:
x=np.matrix([[2,3],[33,3],[4,1]])
y=np.matrix([[2,3,33],[3,4,1]])
x*y
使用数组计算点积需要使用点方法。
代码:
x=np.array([[2,3],[33,3],[4,1]])
y=np.array([[2,3,33],[3,4,1]])
x.dot(y)
问题 5
产出:
-
array([3, 6, 9])数组支持矢量化,因此*运算符应用于每个元素。
-
[1, 2, 3, 1, 2, 3, 1, 2, 3]对于列表,不支持矢量化,应用*运算符只是重复列表,而不是将元素乘以给定的数字。需要一个“for”循环来对每个项目应用算术运算符。
