

Kubernetes 高级平台开发(三)
七、数据湖
数据仓库、数据集市和数据湖的概念在许多企业中已经变得司空见惯。大数据技术使组织能够收集、存储和处理不断增长的数据流。物联网、社交媒体和业务各个方面的数字化转型只会继续增加组织可用数据的数量和速度。
传统上,大数据概念侧重于为大型组织或数据收集和分析项目管理海量和各种收集数据的问题。大数据技术,特别是 Apache Hadoop 及其生态系统,使组织能够消费和存储其组织产生或相关的所有数据。然而,许多大数据解决方案是在容器和容器编排的可用性和受欢迎程度上升之前出现的,特别是 Kubernetes。过去,采用大数据技术通常意味着配置专用集群,并且通常需要一个团队来操作和维护它们。关于数据湖和数据仓库的单独一章很难触及这个充满活力的成熟生态系统的表面。以下练习旨在展示小规模的一组微小的大数据概念,利用 Kubernetes 在静态和事务性数据以及各种工作负载之间统一控制面板的优势。
所有数据都对组织有一定的价值;无论是研究地区销售报告的分析师,还是审计库存水平的采购经理,获取这一价值的成本一直是一个挑战。然而,在过去的二十年里,可用数据的数量和频率急剧增加,从消费和工业物联网到社交媒体、IT 系统和定制应用都产生了大量数据。大型组织需要解决大数据问题的解决方案。2006 年,Hadoop 项目通过将任意数量的商用服务器集群成一个大数据解决方案来解决这些问题。Hadoop 分布式文件系统(HDFS)及其 MapReduce 概念的实现允许将数据无限制地收集到巨大的“湖泊”中,并在它们的源头进行分析。对于许多组织来说,Hadoop 是一项有价值且强大的技术。然而,许多 Hadoop 功能可以在 Kubernetes 中实现,包括高度分布式工作负载、容错和自修复,以及更广泛和快速扩展的生态系统的好处。Kubernetes 不是大数据技术,但下一代支持大数据的系统可能会由此诞生。
本章并不试图说服已建立大数据管理应用的企业考虑将它们迁移到 Kubernetes 相反,目标是为在 Kubernetes 上开发的各种新应用平台中实现这些概念打下基础。
数据处理流水线
图 7-1 描绘了一个典型的数据处理流水线,包括原始和已处理数据存储、事件系统、元数据系统以及用于分析和转换的应用工作负载。本章中描述的大部分架构并不是专门为 Kubernetes 设计的,也不依赖于 Kubernetes 来运行。但是,将这些专门的集群包装在 Kubernetes 集群中可以建立统一的控制面板、网络、监控、安全策略和细粒度的资源管理,包括配置和限制存储、内存和 CPU。尽管诸如 Elasticsearch、Kafka、MQTT 和其他企业解决方案等技术需要广泛的知识来在要求苛刻的生产环境中有效地配置和管理它们,但 Kubernetes 抽象了所有人都通用的底层基础设施。
图 7-1
目标处理流水线
发展环境
本章通过包含用于对象存储的 MinIO 和作为对象元数据、原始数据仓库和已处理数据的键/值存储的 Apache Cassandra,在前面章节的基础上构建了数据处理和管理功能。
以下练习利用了第六章中提到的廉价 Hetzner 集群,包括一个用于 Kubernetes 主节点的 CX21 (2 个 vCPU/8G RAM/40G SSD)和四个用于 worker 节点的 CX41 (4 个 vCPU/16G RAM/160G SSD)实例,但任何等效的基础架构都可以容纳。此外,本章还利用了第 3 、 5 和 6 章中安装的应用和集群配置;见表 7-1 。本章在文件夹cluster-apk8s-dev5下组织新集群dev5的配置清单。
表 7-1
从前面章节收集的关键应用和配置
| |资源
|
组织
|
| --- | --- | --- |
| 第三章 | 进入证书管理器仓库监视 | 000-cluster/00-ingress-nginx``000-cluster/10-cert-manager``000-cluster/20-rook-ceph``000-cluster/30-monitoring |
| 第五章 | 命名空间动物园管理员 Kafka 蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子蚊子 | 003-data/000-namespace``003-data/010-zookeeper``003-data/020-kafka``003-data/050-mqtt |
| 第六章 | 弹性搜索 logstash(日志记录)巴拉人凯克洛克 JupyterHub | 003-data/030-elasticsearch``003-data/032-logstash``003-data/034-kibana``003-data/005-keycloak``005-data-lab/000-namespace``003-data/100-jupyterhub |
本章的剩余部分将重点介绍如何读写数据到现代概念的数据湖,数据湖是由 MinIO 实现的对象存储。MinIO 能够发出与对象(文件)的添加、状态和删除相关的事件,这使它成为任何数据处理流水线的一个引人注目的补充。最后,本章演示了应用的快速原型,该应用利用运行在 JupyterLab 实例中的基于 Python 的 Jupyter 笔记本,对 MinIO 生成的 Kafka 和 MQTT 中的对象相关事件做出反应。
作为对象存储的数据湖
事务数据库、数据仓库和数据集市都是旨在以已知的结构存储和检索数据的技术。组织经常需要存储新的和各种类型的数据,这些数据的形式通常是未知的或不适合结构化数据系统。以任何可能的形式管理无限数据的概念被称为数据湖。传统上,文件系统和块存储解决方案存储组织希望在其数据库管理系统之外收集和维护的大多数基于文件的数据。文件系统和数据块存储系统很难扩展,它们具有不同程度的容错、分布以及对元数据和分析的有限支持。
HDFS (Hadoop 分布式文件系统)一直是需要数据湖概念优势的组织的热门选择。HDFS 的设置和维护非常复杂,通常需要专用的基础架构和一名或多名专家来保持其运行和性能。
本章构建了一个带有对象存储的数据湖,用 MinIO 实现。MinIO 提供了一个与亚马逊 S3 兼容的分布式容错对象存储系统。MinIO 是水平可伸缩的,支持高达 5tb 的对象,它可以存储的对象数量没有限制。这些功能本身就满足了数据湖的基本概念要求。然而,MinIO 是可扩展的,尽管它支持事件和强大的 S3 兼容查询系统。
迷你操作员
Kubernetes 操作员是一种资源管理器,在这种情况下,安装和管理一个或多个 MinIO 集群。
Note
Kubernetes 运营商的概念产生于 2016 年。CoreOS 开始开发代表控制器的定制资源定义,旨在管理有状态应用的生命周期,并将它们称为操作符。操作员通过管理安装前和安装后的条件、监控和运行时操作,超越了 Helm 等软件包管理人员和安装人员的有限关注。操作符是定制的 Kubernetes 资源,像其他资源一样以声明方式安装,或者通过 Helm 之类的包管理器安装。收购 CoreOs 后,红帽在 2018 年发布了运营商框架 1 ,后来又与贡献者亚马逊、微软、谷歌推出了 OperatorHub 2 。
MinIO 项目提供了一个官方的 Kubernetes 运营商。以下配置安装 MinIO 操作符,管理用于声明新 MinIO 集群的新定制资源定义Tenant。
创建目录cluster-apk8s-dev5/000-cluster/22-minio以包含 MinIO 操作器安装文档。接下来,从清单 7-1 中创建一个名为README.md的文件。
# MinIO Operator Installation
see: https://github.com/minio/operator
Quick Start:
```shell script
kubectl apply -k github.com/minio/operator
Listing 7-1MinIO operator installation documentation
应用 MinIO 操作员配置:
$ kubectl apply -k github.com/minio/operator
Kubernetes 集群现在包含名称空间`minio-system`,以及名为`minio-operator`的 ServiceAccount 和部署。“操作员是 Kubernetes API 的客户端,充当定制资源的控制器,” <sup>3</sup> 在本例中,是新的资源类型`Tenant`。下一节通过声明一个`Tenant`资源来建立一个 MinIO 集群。
### 小型群集
MinIO 是一个 S3 兼容的对象存储系统,能够为平台提供一种数据湖功能。清单 7-2 中定义的小型 Minio 集群包括四个节点,支持基本级别的高可用性。`Tenant`资源描述了四个各有 10gb 的 MinIO 节点,使用在第三章中创建的`rook-ceph-block`存储类。标准存储配置将一半的可用磁盘(在本例中为永久卷)用于数据,另一半用于奇偶校验,允许在失去一个节点时进行完整的读/写活动,以及在失去两个节点时进行只读活动。这种配置对于小型开发集群或概念验证来说已经足够。
为清单 7-2 中定义的密码的用户名和密码部分生成一个大的随机字符串。此用户名和密码等同于 AWS S3 凭据,可以在任何 S3 兼容的客户端中使用,以与 MinIO 进行交互。
创建目录`cluster-apk8s-dev5/003-data/070-minio`以包含 MinIO 集群配置。接下来,从清单 7-2 中创建一个名为`90-cluster.yml`的文件。
apiVersion: v1 kind: Secret metadata: namespace: data name: minio-creds-secret type: Opaque stringData: accesskey: REPLACE_WITH_STRONG_PASSWORD secretkey: REPLACE_WITH_STRONG_PASSWORD
apiVersion: minio.min.io/v1 kind: Tenant metadata: name: minio namespace: data spec: metadata: annotations: prometheus.io/path: /minio/prometheus/metrics prometheus.io/port: "9000" prometheus.io/scrape: "true" image: minio/minio:RELEASE.2020-08-18T19-41-00Z serviceName: minio-internal-service zones: - name: "zone-0" servers: 4 volumesPerServer: 1 volumeClaimTemplate: metadata: name: miniodata spec: storageClassName: rook-ceph-block accessModes: - ReadWriteOnce resources: requests: storage: 10Gi
Secret with credentials to be used by MinIO instance.
credsSecret: name: minio-creds-secret podManagementPolicy: Parallel requestAutoCert: false certConfig: commonName: "" organizationName: [] dnsNames: [] liveness: initialDelaySeconds: 10 periodSeconds: 1 timeoutSeconds: 1
Listing 7-2MinIO cluster configuration
应用 MinIO 群集配置:
$ kubectl apply -f 90-cluster.yml
在应用了集群配置(包括`Secret`和`Tenant`资源)之后,可以在 Kubernetes 集群内的服务地址`minio-internal-service:9000`或无头服务地址`minio-hl:9000`访问 MinIO。
如清单 7-3 所示,入口配置提供对 MinIO 的外部访问。MinIO 与 AWS S3 对象存储服务兼容;因此,能够与 AWS S3 交互的现有系统可以利用新的`minio.data.dev5.apk8s.dev`作为替代端点。
接下来,从清单 7-3 中创建一个名为`50-ingress.yml`的文件。
apiVersion: networking.k8s.io/v1beta1 kind: Ingress metadata: name: minio namespace: data annotations: cert-manager.io/cluster-issuer: letsencrypt-production nginx.ingress.kubernetes.io/proxy-body-size: "0" nginx.ingress.kubernetes.io/proxy-read-timeout: "600" nginx.ingress.kubernetes.io/proxy-send-timeout: "600" spec: rules: - host: minio.data.dev5.apk8s.dev http: paths: - backend: serviceName: minio-internal-service servicePort: 9000 path: / tls: - hosts: - minio.data.dev5.apk8s.dev secretName: minio-data-tls
Listing 7-3MinIO cluster Ingress
为新的 MinIO 群集应用入口配置:
$ kubectl apply -f 50-ingress.yml
除了兼容 S3 的 API 之外,MinIO 还是一个有用且有吸引力的基于网络的用户界面,可通过位于 [`https://minio.data.dev5.apk8s.dev/`](https://minio.data.dev5.apk8s.dev/) 的网络浏览器访问。
下一节配置命令行 MinIO 客户机,用于创建存储桶、配置 MinIO 服务器和设置通知事件。
### 微型客户端
MinIO 客户端 <sup>4</sup> 是一个命令行实用程序,用于与 MinIO 集群进行交互(大部分与 AWS S3 兼容)。MinIO 客户端支持与对象存储相关的任何操作,从创建存储桶和列出对象到完整的管理和配置功能。在下一节中,MinIO 客户机用于在下面创建的存储桶上配置与对象状态相关的通知。
有关任何特定工作站的安装说明,请参考 MinIO 客户端快速入门指南。在本地工作站上安装 MinIO 客户端(mc)后,使用清单 7-3 中定义的入口主机和清单 7-2 中定义的凭证为名为`apk8s-dev5`的新集群创建一个别名:
$ mc config host add apk8s-dev5
minio.data.dev5.apk8s.dev
username password
创建桶,`upload`、`processed,`和`twitter`,在本章后面和下一章中使用:
mc mb apk8s-dev5/processed $ mc mb apk8s-dev5/twitter
列出三个新桶:
$ mc ls apk8s-dev5
MinIO 客户端可以轻松地从本地工作站或 AWS S3、谷歌云存储等复制文件。首先创建新的主机别名或列出现有别名:
$ mc config host list
MinIO 客户端是与对象存储集群进行手动交互的强大工具。为了对对象集群进行编程控制,MinIO 提供了 JavaScript、Java、Python、Golang、.NET 和 Haskell。MinIO 集群还兼容 AWS S3 API 和许多库,如 Amazon 的 Boto3 for Python、AWS。JavaScript 的 s3 类,或者 Golang 的 S3 包。Boto3 将在本章后面用于处理 CSV 文件。
下一节将利用 MinIO 发出与对象相关的事件的能力。
### 迷你活动
与对象相关的事件通知允许任意数量的服务使用这些通知并执行任务,从而为以数据为中心的平台提供了一种复杂的可扩展性。MinIO 支持配置对象状态通知给 AMQP、 <sup>5</sup> Elasticsearch、Kafka、MQTT、MySQL、NATS、 <sup>6</sup> NSQ、 <sup>7</sup> PostgreSQL、Redis 和 webhooks。 <sup>8</sup>
以下练习利用第 5 和 6 章中安装的技术,为 MinIO 配置通知 Elasticsearch、Kafka 和 MQTT 的能力。在为 Elasticsearch、Kafka 和 MQTT 配置连接设置之后,MinIO 服务器需要重新启动;但是,在此初始配置之后,在配置任意数量的通知设置时,不需要进一步重新启动。
通过请求当前配置并将其保存为 JSON 文件,开始配置 MinIO。使用前一节中安装的 MinIO 客户端命令行实用程序(`mc`)。
为 MinIO 服务器配置创建目录:
mkdir -p ./070-minio/cfg
接下来,以 JSON 文件的形式获取现有的服务器配置(上一节描述了配置`the apk8s-dev5`别名)。以下多行命令将 JSON 输出通过流水线传输到 Python,以便对其进行格式化,从而更易于编辑:
$ mc admin config get apk8s-dev5 |
python -m json.tool > config.json
在`config.json`的`"notify"`部分下,编辑 Elasticsearch、Kafka 和 MQTT 的部分以匹配清单 7-4 。
"elasticsearch": { "1": { "enable": true, "format": "namespace", "index": "processed", "url": "http://elasticsearch:9200" } }, "kafka": { "1": { "brokers": ["kafka-headless:9092"], "enable": true, "sasl": { "enable": false, "password": "", "username": "" }, "tls": { "clientAuth": 0, "enable": false, "skipVerify": false }, "topic": "upload" } }, "mqtt": { "1": { "broker": "tcp://mqtt:1883", "enable": true, "keepAliveInterval": 0, "password": "", "qos": 0, "queueDir": "", "queueLimit": 0, "reconnectInterval": 0, "topic": "processed", "username": "" } },
Listing 7-4MinIO server external connection configuration
应用编辑过的`config.json`并重启 MinIO 服务器:
mc admin service restart apk8s-dev5
MinIO 产生与对象的创建、删除和访问相关的事件通知类型,如表 7-2 所示。MinIO 支持按存储桶进行事件通知配置,并支持按事件类型、对象名前缀或对象名后缀进行细粒度过滤。
表 7-2
MinIO 支持的对象事件
<colgroup><col class="tcol1 align-left"> <col class="tcol2 align-left"></colgroup>
|
种类
|
事件
|
| --- | --- |
| 创造 | `s3:ObjectCreated:Put``s3:ObjectCreated:Post``s3:ObjectCreated:Copy``s3:ObjectCreated:CompleteMultipartUpload` |
| 删除 | `s3:ObjectRemoved:Delete` |
| 接近 | `s3:ObjectAccessed:Get``s3:ObjectAccessed:Head` |
下一节将演示在 Kubernetes 中处理对象相关事件的方法。
### 流程对象
JupyterLab,如第六章中所述,为数据科学活动提供了一个便利且高效的环境,这主要是因为它靠近集群内数据和事件源。同样,在 Kubernetes 中运行的 JupyterLab 简化了组合基于数据的事件、基于集群的数据和 Kubernetes API 的实验能力。Jupyter 笔记本是快速构建和记录复杂原型的有用工具。
以下练习构建了事件侦听器的原型,创建了一个大型 CSV 文件并将其放入 MinIO bucket,通过生成 Kubernetes 作业来压缩 CSV,并演示了如何从压缩的 CSV 中提取数据。
#### 配置通知
首先,配置 MinIO 在特定的 bucket 事件发生时通知 Kafka 和 MQTT 主题,特别是在后缀为`.csv`的`upload` bucket 中创建任何对象时,以及在后缀为`.gz`的`processed` bucket 中创建任何对象时。在本练习中,Kafka 和 MQTT 的使用只是为了说明各种事件队列:
$ mc event add apk8s-dev5/upload
arn:minio:sqs::1:kafka
--event put --suffix=".csv"
$ mc event add apk8s-dev5/processed
arn:minio:sqs::1:mqtt
--event put --suffix=".gz"
此外,配置 MinIO 在 Elasticsearch 中保留一个文档索引,描述`processed`桶中所有对象的状态:
$ mc event add apk8s-dev5/processed
arn:minio:sqs::1:elasticsearch \
#### 事件笔记本
打开一个 JupyterLab 环境并启动一个 Python 笔记本来测试由 MinIO 产生的新的 bucket 通知事件。在第一个单元格中,确保 kafka-python 库可用:
!pip install kafka-python==1.4.7
导入标准的 JSON 库来解析 MinIO 通知,从 kafka-python 库中导入 KafkaConsumer <sup>9</sup> 类,最后,从 IPython.display 中导入`clear_output`函数来帮助清除循环之间的单元格输出:
import json from kafka import KafkaConsumer from IPython.display import clear_output
将 KafkaConsumer 连接到数据名称空间中 Kafka 集群上的上传主题。将`group_id`设置为`data-bucket-processor`:
consumer = KafkaConsumer('upload', bootstrap_servers="kafka-headless.data:9092", group_id='data-bucket-processor')
最后,在消费者消息上创建一个`for`循环。循环无限继续,用当前事件替换最后一个事件:
for msg in consumer: jsmsg = json.loads(msg.value.decode("utf-8")) clear_output(True) print(json.dumps(jsmsg, indent=4))
通过从本地工作站创建一个测试 CSV 文件并上传到`upload`桶来测试事件监听器:
mc cp test.csv apk8s-dev5/upload
JupyterLab 事件笔记本现在应该显示类似于清单 7-5 的`s3:ObjectCreated:Put`事件通知。
{ "EventName": "s3:ObjectCreated:Put", "Key": "upload/test.csv", "Records": [ { "eventVersion": "2.0", "eventSource": "minio:s3", "awsRegion": "", "eventTime": "2019-12-27T08:27:40Z", "eventName": "s3:ObjectCreated:Put", "userIdentity": { "principalId": "3Fh36b37coCN3w8GAM07" }, "requestParameters": { "accessKey": "3Fh36b37coCN3w8GAM07", "region": "", "sourceIPAddress": "0.0.0.0" }, "responseElements": { "x-amz-request-id": "15E42D02F9784AD2", "x-minio-deployment-id": "0e8f8...", "x-minio-origin-endpoint": "http://10.32.128.13:9000" }, "s3": { "s3SchemaVersion": "1.0", "configurationId": "Config", "bucket": { "name": "upload", "ownerIdentity": { "principalId": "3Fh36b378GAM07" }, "arn": "arn:aws:s3:::upload" }, "object": { "key": "test.csv", "eTag": "d41d8cd98f998ecf8427e", "contentType": "text/csv", "userMetadata": { "content-type": "text/csv", "etag": "d41d8cd90998ecf8427e" }, "versionId": "1", "sequencer": "15E42D02FD98E21B" } }, "source": { "host": "0.0.0.0", "port": "", "userAgent": "MinIO (darwin" } } ] }
Listing 7-5Example bucket event notification
#### 测试数据
Python 是收集、规范化甚至生成数据的优秀工具。下面的练习生成了一个包含一百万个虚构献血者的 CSV 文件,每个献血者都包含一个假的电子邮件地址、姓名、血型、生日和州名。最后,脚本将生成的 CSV 数据上传到新 MinIO 集群上的上传桶中。
本节继续使用集群内 JupyterLab 环境;然而,这不是必需的。在 Kubernetes 集群的 JupyterLab 中创建新的 Jupyter 笔记本,或者在本地工作站上创建 Python 脚本。
示例 Python 脚本使用 Faker Python 库创建假数据,并使用 MinIO 客户端库连接到 MinIO。通过将以下 pip 安装指令添加到 Jupyter 笔记本的第一个单元,确保开发环境包含所需的依赖项:
!pip install Faker==2.0.3 !pip install minio==5.0.1
在下一个单元格中,导入以下库:
import os from faker import Faker from minio import Minio from minio.error import ResponseError
在下一个单元格中,添加以下代码以打开一个名为`donors.csv`的文件,为数据编写一个初始标题,并创建一个增量为一百万的`while`循环:
%%time fake = Faker()
f_customers = open("./donors.csv","w+") f_customers.write( "email, name, type, birthday, state\n" )
i = 0 while i < 1000000: fp = fake.profile(fields=[ "name", "birthdate", "blood_group"])
st = fake.state()
bd = fp["birthdate"]
bg = fp["blood_group"]
ml = fake.ascii_safe_email()
f_customers.write(
f'{ml},{fp["name"]},{bg},{bd},{st}\n'
)
i += 1
f_customers.close()
在 Jupyter 笔记本的最后一个单元格中,连接本章前面设置的 MinIO 集群,将新生成的`donors.csv`上传到`upload`桶中;用 MinIO 集群设置中定义的值替换**用户名**和**密码**:
Note
如果从本地工作站开发,用`'minio.data.dev5.apk8s.dev'`替换`'minio-internal-service.data:9000'`,用`secure=True`替换`secure=False`。
%%time minioClient = Minio('minio-internal-service.data:9000', access_key='username', secret_key='password', secure=False)
try: with open("./donors.csv", 'rb') as file_data: file_stat = os.stat('./donors.csv') minioClient.put_object('upload', 'donors.csv', file_data, file_stat.st_size, content_type='application/csv')
except ResponseError as err: print(err)
如果前一部分的事件笔记本正在运行,将显示一个名为`s3:ObjectCreated:CompleteMultipartUpload`的新事件,带有键`upload/donors.csv`。MinIO 集群现在拥有大约 60 兆字节的对象,包含测试数据,代表假献血者,他们的电子邮件,姓名,出生日期,血型和州。
此时,事件系统可能会触发大范围的数据处理操作。下一节使用一个定制的数据压缩应用来演示一个典型的对象处理流程。
#### 容器化应用
在 Kubernetes 上,所有工作负载都在 Pod 的一个容器中执行。最后几个练习使用一个运行 JupyterLab 容器的 Pod 来执行在 Jupyter 笔记本中编写的代码,这是一种用于实验、构建概念验证或快速原型制作的优秀方法。随着原型化过程迭代到稳定的生产系统,识别独立的工作单元,开发并将其包装在容器中,测试,版本化,并使它们可用于编排。
下面的练习在 Go 中开发了一个通用对象压缩器,构建并版本化了一个容器,并使该容器在 Docker Hub 上公开可用。在本地工作站上,确保存在 Go 版本 1.13+和 Docker 版本 19+。使用 GitLab 和 Docker Hub 上的新帐户或现有帐户(都是免费的)来存储源代码和生成的容器。
在本地工作站上为新的 Go 应用创建一个文件夹;这个例子使用了文件夹`~/workspace/apk8s/compressor`。在新文件夹中,初始化 Go 模块 <sup>10</sup> (替换为任何定制的 Git 库):
$ go mod init github.com/apk8s/compressor
Note
从 Go 1.14 开始, <sup>11</sup> Go 模块已准备好投入生产使用,并被视为 Go 的正式依赖管理系统。鼓励所有开发人员在迁移任何现有项目的同时,为新项目使用 Go 模块。
创建目录`cmd`来存储主要的 Go 源代码——这种约定通常用于表示命令行应用,而不是共享库的组件。在 cmd 目录下创建一个名为`compressor.go`的文件,并用清单 7-6 中的源代码填充它。
package main
import ( "bufio" "compress/gzip" "flag" "io" "log" "os"
minio "github.com/minio/minio-go/v6"
)
var ( endpoint = os.Getenv("ENDPOINT") endpointSSL = os.Getenv("ENDPOINT_SSL") accessKeyID = os.Getenv("ACCESS_KEY_ID") accessKeySecret = os.Getenv("ACCESS_KEY_SECRET") )
func main() { var ( fmBucket = flag.String("f", "", "From bucket.") toBucket = flag.String("t", "", "To bucket.") fmObjKey = flag.String("k", "", "From key.") ) flag.Parse()
useSSL := true
if endpointSSL == "false" {
useSSL = false
}
mc, err := minio.New(
endpoint, accessKeyID,
accessKeySecret, useSSL)
if err != nil {
log.Fatalln(err)
}
obj, err := mc.GetObject(
*fmBucket,
*fmObjKey,
minio.GetObjectOptions{},
)
if err != nil {
log.Fatalln(err)
}
log.Printf("Starting download stream %s/%s.",
*fmBucket,
*fmObjKey)
// synchronous in-memory pipe
pipeR, pipeW := io.Pipe()
// reads from object, writes to pipe
bufIn := bufio.NewReader(obj)
// gzip buffers to memory and flushes on close
gzW, err := gzip.NewWriterLevel(pipeW, 3)
if err != nil {
log.Fatalln(err)
}
go func() {
log.Printf("Compress and stream.")
n, err := bufIn.WriteTo(gzW)
if err != nil {
log.Fatalln(err)
}
gzW.Close()
pipeW.Close()
log.Printf("Compressed: %d bytes", n)
}()
// data will not be sent until gzW.Close() and
// the gzip buffer flushes
log.Print("BEGIN PutObject")
_, err = mc.PutObject(
*toBucket, *fmObjKey+".gz",
pipeR, -1, minio.PutObjectOptions{})
if err != nil {
log.Fatalln(err)
}
log.Print("COMPLETE PutObject")
}
Listing 7-6Go application: compressor
前面定义的新 Go 应用连接到一个 MinIO 集群,压缩一个对象,并将压缩后的输出放在一个单独的桶中的新对象中。这个应用只是对象处理的一个简单例子,它利用 Go 编程语言创建一个小型的、静态编译的二进制文件,不依赖于外部操作系统。
通过设置以下环境变量,在本地工作站上测试新的 compressor 应用;用本章前面定义的值替换端点、用户名和密码:
export ACCESS_KEY_ID=username $ export ACCESS_KEY_SECRET=password
编译并执行配置了桶`upload`和`processed`的 compressor 应用,以及前面部分生成并添加到 MinIO 的对象`upload/donors.csv`:
$ go run ./cmd/compressor.go -f upload -k donors.csv -t processed
在完成执行后,一个新对象包含一个名为`donors.csv.gz`的`donors.csv`的压缩版本,在`processed`桶中可用,大约 20 兆字节。此外,MinIO 向 MQTT 集群发送了一条主题为`processed`的消息,并向 Elasticsearch 索引`processed`添加了一个新文档。参见第 5 和 6 章,了解 MQTT (Mosquitto)和 Elasticsearch。
接下来,本章使用 Docker Hub 组织`apk8s`来存储和服务公共容器。为下面的练习设置一个免费的 Docker Hub 帐户或确保访问合适的容器注册表。
在代表 compressor 项目的文件夹`~/workspace/apk8s/compressor`中,创建文件`Dockerfile`并用清单 7-7 的内容填充它。
FROM golang:1.13.3 AS builder
WORKDIR /go/src
COPY . /go/src
RUN go mod download
RUN CGO_ENABLED=0
GOOS=linux
GOARCH=amd64
GO111MODULE=on
go build -ldflags "-extldflags -static"
-o /go/bin/compressor /go/src/cmd
RUN echo "nobody:x:65534:65534:Nobody:/:" > /etc_passwd
FROM scratch
ENV PATH=/bin
COPY --from=builder /etc/ssl/certs/ca-certificates.crt /etc/ssl/certs/ COPY --from=builder /etc_passwd /etc/passwd COPY --from=builder /go/bin/compressor /bin/compressor
WORKDIR /
USER nobody ENTRYPOINT ["/bin/compressor"]
Listing 7-7Dockerfile for the compressor application
新的 Dockerfile 代表了一个多阶段的构建过程。第一阶段使用名为`builder`的`golang:1.13.3`容器下载依赖项并编译静态二进制文件。构建器容器还创建了一个`/etc_passwd`文件来支持用户 Nobody 执行下面的暂存容器中的二进制文件,这被定义为 Docker 构建的第二阶段。
除了是一个很小的容器,重约 10 兆字节,这个基于`scratch`的容器(列表 7-7 )以用户`Nobody`的身份执行单个二进制文件,没有其他用户帐户,也没有操作系统。这种方法将攻击面缩小到二进制文件本身,以及用于编译它的库。允许攻击者逃离容器的利用将作为相对良性的用户`Nobody`来完成。没有完美的安全;然而,任何潜在攻击面和复杂性的减少都会减少在生产系统中运行数十万个容器的累积效应。
最后,构建、标记容器,并将其推送到 Docker Hub 或任何合适的容器注册中心:
docker push apk8s/compressor:v0.0.1
测试新容器,首先确保环境变量`ENDPOINT`、`ACCESS_KEY_ID`和`ACCESS_KEY_SECRET`仍然在当前 shell 中导出(如前面所定义的),然后执行以下命令:
ENDPOINT
-e ACCESS_KEY_ID=ACCESS_KEY_SECRET
apk8s/compressor:v0.0.1
-f=upload -k=donors.csv -t=processed
新容器已经准备好在 Kubernetes 集群中运行并处理对象,在本例中是压缩它们。然而,本练习的目标是展示开发小型、集中的应用的简易性,以及它们在基于 Kubernetes 的数据平台中所扮演的角色。下一节将演示如何构建这个(或任何)新对象处理容器的基于事件的部署的原型。
#### 程序化部署
计算集群所需状态的声明性配置是在 Kubernetes 中部署应用的惯用方法。这本书主要使用 YAML 直接定义理想状态,或者使用 Helm 间接填充和应用 YAML 模板。甚至命令式命令如`kubectl run` <sup>12</sup> 也在幕后调用声明式 API 调用。本节中的练习在 Jupyter 笔记本中开发了一个原型应用,它侦听 MinIO bucket 事件,并通过定义 Kubernetes 作业和用 Kubernetes API 应用它们来处理对象。
在将任何执行附加到事件流之前,下面的练习使用由 JupyterHub 提供的 JupyterLab 环境提供的集群内 Jupyter 笔记本来开发一个原型 Kubernetes 作业部署器。
为 Pod 中的容器指定 serviceAccount 时,Kubernetes 会将其关联的访问令牌以及集群证书 ca.crt 装入/var/run/secrets/Kubernetes . io/serviceaccount 中。未指定 service account 的 Pod 会装入运行它们的命名空间的默认服务帐户。第六章配置了一个名为 data-lab 的服务帐户和角色,它拥有对 Kubernetes API 的扩展权限,供 JupyterLab 容器使用。确保以下权限、 **pods/log** 、 **jobs** 和 **jobs/status** (如清单 7-8 所示)可用于分配给`data-lab`名称空间中`data-lab` ServiceAccount 的`data-lab`角色。
apiVersion: rbac.authorization.k8s.io/v1beta1 kind: Role metadata: name: data-lab namespace: data-lab rules:
- apiGroups: ["","batch"] resources: ["pods", "pods/log", "events", "services", "jobs", "jobs/status"] verbs: ["delete", "create", "get", "watch", "list", "endpoints", "patch", "events"]
Listing 7-8Update 005-data-lab/000-namespace/07-role.yml
参观在第六章中设置的木星实验室环境`lab.data.dev5.apk8s.dev`。在单个单元格中添加并执行以下代码示例,以测试和试验每个步骤。
添加一个单元格安装最新的 Python Kubernetes 客户端库: <sup>13</sup>
!pip install kubernetes
导入以下依赖项:
from os import path import yaml import time from kubernetes import client, config from kubernetes.client.rest import ApiException from IPython.display import clear_output
使用类`V1EnvVar` <sup>14</sup> 创建一个环境变量集合,供以后在压缩器容器中使用。用本章前面“MinIO 集群”一节中定义的值替换用户名和密码。当前集群内配置的`ENDPOINT_SSL`设置为假:
envs = [ client.V1EnvVar("ENDPOINT", "minio-internal-service.data:9000"), client.V1EnvVar("ACCESS_KEY_ID", "username"), client.V1EnvVar("ACCESS_KEY_SECRET", "password"), client.V1EnvVar("ENDPOINT_SSL", "false"), ]
使用类`V1Container,` <sup>15</sup> 配置一个容器,其中包含在前面部分构建并标记的映像`apk8s/compressor:v0.0.1`。compressor 应用需要之前配置的环境变量,以及指定要处理的桶的参数`-f`、对象键的参数`-k`和目的桶的参数`-t`:
container = client.V1Container( name="compressor", image="apk8s/compressor:v0.0.1", env=envs, args=["-f=upload", "-k=donors.csv", "-t=processed"])
使用类`V1PodTemplateSpec,`<sup>16</sup>`V1ObjectMeta,`<sup>17</sup>和`V1PodSpec,` <sup>18</sup> 配置一个 Pod 来运行之前配置的容器:
podTmpl = client.V1PodTemplateSpec( metadata=client.V1ObjectMeta( labels={"app": "compress-donors"} ), spec=client.V1PodSpec( restart_policy="Never", containers=[container]))
Kubernetes 为 Pods 提供作业资源,旨在运行到完成。只有当 Pod 返回非零值时,作业才会重新启动它。使用类别`V1Job,` <sup>19</sup> `V1ObjectMeta`和`V1JobSpec,` <sup>20</sup> 用之前配置的 Pod 配置作业:
job = client.V1Job( api_version="batch/v1", kind="Job", metadata=client.V1ObjectMeta( name="compress-donors" ), spec=client.V1JobSpec( template=podTmpl, backoff_limit=2) )
接下来,配置 Python 客户机并加载负责管理作业资源的 Kubernetes 批处理 API。方法`load_incluster_config()`将 Python 客户端配置为利用 Kubernetes 配置,该配置可用于运行当前 JupyterLab 环境的 Pod。
config.load_incluster_config() batch_v1 = client.BatchV1Api()
使用 Kubernetes 批处理 API 来应用作业配置:
resp = batch_v1.create_namespaced_job( body=job, namespace="data-lab")
在执行了前面 Jupyter 笔记本单元中的代码后,Kubernetes 在 data-lab 名称空间中创建了一个名为 compress-donors 的作业。成功执行后,作业保持完成状态。但是,任何失败都会导致两次重试,如前面使用`backoff_limit`指令配置的那样。在这两种情况下,清单 7-9 中的代码轮询已配置作业的状态,并在完成后删除它;如果作业返回错误,最终代码将显示与作业关联的 Pod 中的日志。将清单 7-9 中的代码添加到 Jupyter 笔记本的最后一个单元格中,并执行它。
completed = False
while completed == False: time.sleep(1)
try:
resp = batch_v1.read_namespaced_job_status(
name="compress-donors",
namespace="data-lab", pretty=False)
except ApiException as e:
print(e.reason)
break
clear_output(True)
print(resp.status)
if resp.status.conditions is None:
continue
if len(resp.status.conditions) > 0:
clear_output(True)
print(resp.status.conditions)
if resp.status.conditions[0].type == "Failed":
print("FAILED -- Pod Log --")
core_v1 = client.CoreV1Api()
pod_resp = core_v1.list_namespaced_pod(
namespace="data-lab",
label_selector="app=compress-donors",
limit=1
)
log_resp = core_v1.read_namespaced_pod_log(
name=pod_resp.items[0].metadata.name,
namespace='data-lab')
print(log_resp)
print("Removing Job...")
resp = batch_v1.delete_namespaced_job(
name="compress-donors",
namespace="data-lab",
body=client.V1DeleteOptions(
propagation_policy='Foreground',
grace_period_seconds=5))
break
Listing 7-9Monitor Job state and cleanup
这本书把剩下的基于事件的对象处理练习留给了读者。将本章前面定义的事件记录单与前面定义的用于处理对象的作业的编程部署结合起来。这种组合为几乎任何形式的基于事件的数据处理创建了一个原型框架,包括分析、标准化、衍生和合成数据的生成,以及内务处理任务,如前面演示的组织和压缩。
#### 无服务器对象处理
自动化前一部分开发的流程是这里简要介绍的无服务器 <sup>21</sup> (或功能即服务)技术的核心。
云供应商提供的解决方案抽象出了所有复杂的活动部分,这些部分支持任何孤立工作负载的编译、执行、缩放和错误处理,这些工作负载足够小且足够集中,可以被视为一个功能。使用 AWS Lambda、 <sup>22</sup> Azure 函数、 <sup>23</sup> 或谷歌云函数 <sup>24</sup> 构建关键业务逻辑是快速开发或寻求尽可能减少运营复杂性的小型团队的有效方法。然而,这些无服务器产品确实是以强大的供应商锁定为代价的,并且相信它们的支持产品线在未来仍然是供应商的优先选择。
在 Kubernetes 生态系统中, <sup>25</sup> 越来越多的无服务器技术提供了云本地和厂商中立的方法。Kubeless、 <sup>26</sup> OpenFaaS、 <sup>27</sup> 裂变、<sup>28</sup>Apache open whisk、 <sup>29</sup> 和 Nuclio <sup>30</sup> 都提供了非常适合公共云或定制 Kubernetes 集群的交钥匙无服务器平台。项目 Knative <sup>31</sup> 为开发新的基于无服务器的平台提供了一个灵活的组件平台。第八章展示了使用 OpenFaaS 进行无服务器风格的数据转换。
由于 Kubernetes 抽象了底层基础设施问题,MinIO 提供了对象存储和访问,再加上一个强大的无服务器平台来自动化部署和执行基于事件的对象处理,本书中描述的数据湖在为生产进行扩展时能够满足许多企业需求。
## 摘要
本章组装了一种类型的数据湖,具体来说就是上传桶,负责摄取任何形式和数量的数据 <sup>32</sup> ,具有几乎无限扩展的能力。数据湖满足了任何组织在确定任何特定目的之前获取或保留数据的愿望。数据湖不仅仅是简单的数据存储引擎;它们必须支持为各种利益相关者提供受控访问的能力,支持用于探索和分析的工具,并在需要时扩展处理能力和容量。MinIO 是在 Kubernetes 中构建数据湖的绝佳选择。MinIO 的 S3 兼容 API,以及支持各种外部系统的事件通知系统,为构建现代数据湖提供了一个广泛而强大的平台。 <sup>33</sup> 此外,本章还展示了利用集群内 Jupyter 笔记本电脑快速构建基于事件的对象处理原型的强大功能和便利性。
一旦组织、处理或转换了数据湖中的任何数据,就出现了数据仓库的概念。数据仓库是商业智能、分析和数据科学活动(包括机器学习)的关键组件。下一章用数据仓库概念叠加并扩展了本章中的功能。
<aside aria-label="Footnotes" class="FootnoteSection" epub:type="footnotes">Footnotes 1
[`https://github.com/operator-framework`](https://github.com/operator-framework)
2
[`https://operatorhub.io/`](https://operatorhub.io/)
3
[`https://kubernetes.io/docs/concepts/extend-kubernetes/operator/`](https://kubernetes.io/docs/concepts/extend-kubernetes/operator/)
4
[`https://docs.min.io/docs/minio-client-complete-guide`](https://docs.min.io/docs/minio-client-complete-guide)
5
[`www.amqp.org/`](http://www.amqp.org/)
6
[`https://nats.io/`](https://nats.io/)
7
[`https://nsq.io/`](https://nsq.io/)
8
[`www.programmableweb.com/news/what-are-webhooks-and-how-do-they-enable-real-time-web/2012/01/30`](http://www.programmableweb.com/news/what-are-webhooks-and-how-do-they-enable-real-time-web/2012/01/30)
9
[`https://kafka-python.readthedocs.io/en/master/apidoc/KafkaConsumer.html`](https://kafka-python.readthedocs.io/en/master/apidoc/KafkaConsumer.html)
10
[`https://github.com/golang/go/wiki/Modules`](https://github.com/golang/go/wiki/Modules)
11
[`https://golang.org/doc/go1.14`](https://golang.org/doc/go1.14)
12
[`https://kubernetes.io/docs/tasks/manage-kubernetes-objects/imperative-command/`](https://kubernetes.io/docs/tasks/manage-kubernetes-objects/imperative-command/)
13
[`https://github.com/kubernetes-client/python`](https://github.com/kubernetes-client/python)
14
[`https://github.com/kubernetes-client/python/blob/master/kubernetes/docs/V1EnvVar.md`](https://github.com/kubernetes-client/python/blob/master/kubernetes/docs/V1EnvVar.md)
15
[`https://github.com/kubernetes-client/python/blob/master/kubernetes/docs/V1Container.md`](https://github.com/kubernetes-client/python/blob/master/kubernetes/docs/V1Container.md)
16
[`https://github.com/kubernetes-client/python/blob/master/kubernetes/docs/V1PodTemplateSpec.md`](https://github.com/kubernetes-client/python/blob/master/kubernetes/docs/V1PodTemplateSpec.md)
17
[`https://github.com/kubernetes-client/python/blob/master/kubernetes/docs/V1ObjectMeta.md`](https://github.com/kubernetes-client/python/blob/master/kubernetes/docs/V1ObjectMeta.md)
18
[`https://github.com/kubernetes-client/python/blob/master/kubernetes/docs/V1PodSpec.md`](https://github.com/kubernetes-client/python/blob/master/kubernetes/docs/V1PodSpec.md)
19
[`https://github.com/kubernetes-client/python/blob/master/kubernetes/docs/V1Job.md`](https://github.com/kubernetes-client/python/blob/master/kubernetes/docs/V1Job.md)
20
[`https://github.com/kubernetes-client/python/blob/master/kubernetes/docs/V1JobSpec.md`](https://github.com/kubernetes-client/python/blob/master/kubernetes/docs/V1JobSpec.md)
21
[`https://martinfowler.com/articles/serverless.html`](https://martinfowler.com/articles/serverless.html)
22
[`https://aws.amazon.com/lambda/`](https://aws.amazon.com/lambda/)
23
[`https://azure.microsoft.com/en-us/services/functions/`](https://azure.microsoft.com/en-us/services/functions/)
24
[`https://cloud.google.com/functions/`](https://cloud.google.com/functions/)
25
[`https://landscape.cncf.io/format=serverless`](https://landscape.cncf.io/format%253Dserverless)
26
[`https://kubeless.io/`](https://kubeless.io/)
27
[`www.openfaas.com/`](http://www.openfaas.com/)
28
[`https://fission.io/`](https://fission.io/)
29
[`https://openwhisk.apache.org/`](https://openwhisk.apache.org/)
30
[`https://nuclio.io/`](https://nuclio.io/)
31
[`https://knative.dev/`](https://knative.dev/)
32
[`www.dataversity.net/data-lakes-101-overview/`](http://www.dataversity.net/data-lakes-101-overview/)
33
[`https://blog.minio.io/modern-data-lake-with-minio-part-1-716a49499533`](https://blog.minio.io/modern-data-lake-with-minio-part-1-716a49499533)
</aside>
# 八、数据仓库
关于数据仓库的这一章是上一章的延伸,上一章讲述了使用分布式对象存储系统 MinIO 开发现代数据湖。数据湖存储各种各样的数据形式,而数据仓库管理各种各样的数据源。数据仓库提供对数据目录、元数据、索引、键/值存储、消息队列、事件流、文档和关系数据库(包括数据湖)的访问。数据湖和数据仓库之间的界限并不总是很清楚;这本书将数据仓库的概念区分为任何包含数据的源的管理集合,这些数据是经过处理、组织、索引、编目或以其他方式有目的地标识的。
开源数据湖管理系统,如 Delta Lake <sup>1</sup> 带来了 ACID 事务、元数据、统一流和批量数据,而 Kylo <sup>2</sup> 则提供了一个健壮的用户界面,用于数据摄取、准备和发现。这些复杂的数据湖应用开始模糊一个巨大的、无形式的数据湖和组织良好的数据仓库之间的界限。然而,这些系统的结果很可能是更高层次的数据仓库概念的候选者。
数据湖在收集数据时是不加选择的;当组织获取任何类型的数据时,在使用数据的业务案例出现之前,可能会出现存储数据的需求。当了解了一组数据的价值和用途后,就可以对其进行处理、开发模式、编制属性索引、对值进行规范化,并对元数据进行编目,以供感兴趣的服务或人类分析师使用。数据仓库提供对实时事件和消息数据以及历史数据集合的访问,为决策支持系统、商业智能、分析、机器学习和推理做好准备。
## 数据和数据科学
与支持数据科学活动相关的概念非常广泛,此外还有大量技术和实现,专注于由人类或机器提供数据驱动的决策。数据平台促进了数据的接收、访问和管理,在其中,数据仓库提供了数据源、模式和元数据的目录。
在数据科学领域,机器学习活动通常会对数据提出一系列特别苛刻的要求。来自谷歌的十名研究人员撰写了一篇题为“机器学习系统中隐藏的技术债务”的研究论文。 <sup>3 支持机器学习的基础设施包括配置、数据收集、特征提取、数据验证、机器资源管理、分析工具、过程管理工具、服务基础设施和监控(见图 8-1 )。此外,许多其他数据科学活动需要大量这种资源,包括商业智能和分析。</sup>
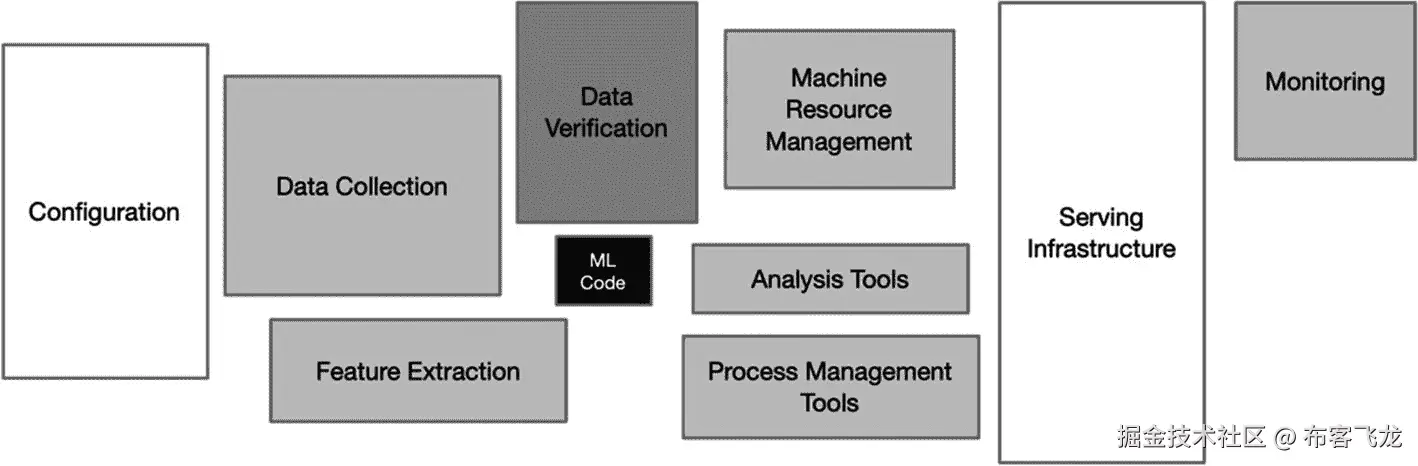
图 8-1
机器学习基础设施 <sup>3</sup>
下一节将介绍一个适中但功能强大的现代数据仓库的基础,它能够提供大多数数据科学活动(包括机器学习)所需的大部分(如果不是全部)功能。
### 数据平台
在 Kubernetes 中构建一个现代化的数据仓库提供了一个抽象的底层基础设施、一个统一的控制面板、标准化的配置管理、整体监控、基于角色的访问控制、网络策略,以及与云原生技术的快速发展前景 <sup>4</sup> 的兼容性。
本章安装并配置了三个新的数据源:MySQL <sup>5</sup> 集群,代表一个公共的 RDBMS 数据库;Apache Cassandra<sup>6</sup>作为一个宽列分布式 NoSQL 数据库;Apache Hive<sup>7</sup>能够在上一章设置的 S3 兼容对象存储之上投影一个模式。很快, <sup>8</sup> 一个针对大数据的分布式 SQL 查询引擎将这些现有的数据源绑定到一个目录中,提供模式和连接。Presto 原生支持 20 多种典型的数据应用,包括 Elasticsearch(在第六章配置)和 Apache Kafka(在第五章配置)。
编写一个本地连接并使用来自多个源的数据的应用并不罕见。但是,Presto 等技术整合和抽象了这种能力,将查询分布到集群中的工作人员,汇总结果,并监控性能。通过管理不同的连接要求和模式管理,集中访问 Presto 的巨大数据仓库减少了跨专业系统的技术债务(见图 8-2 )。
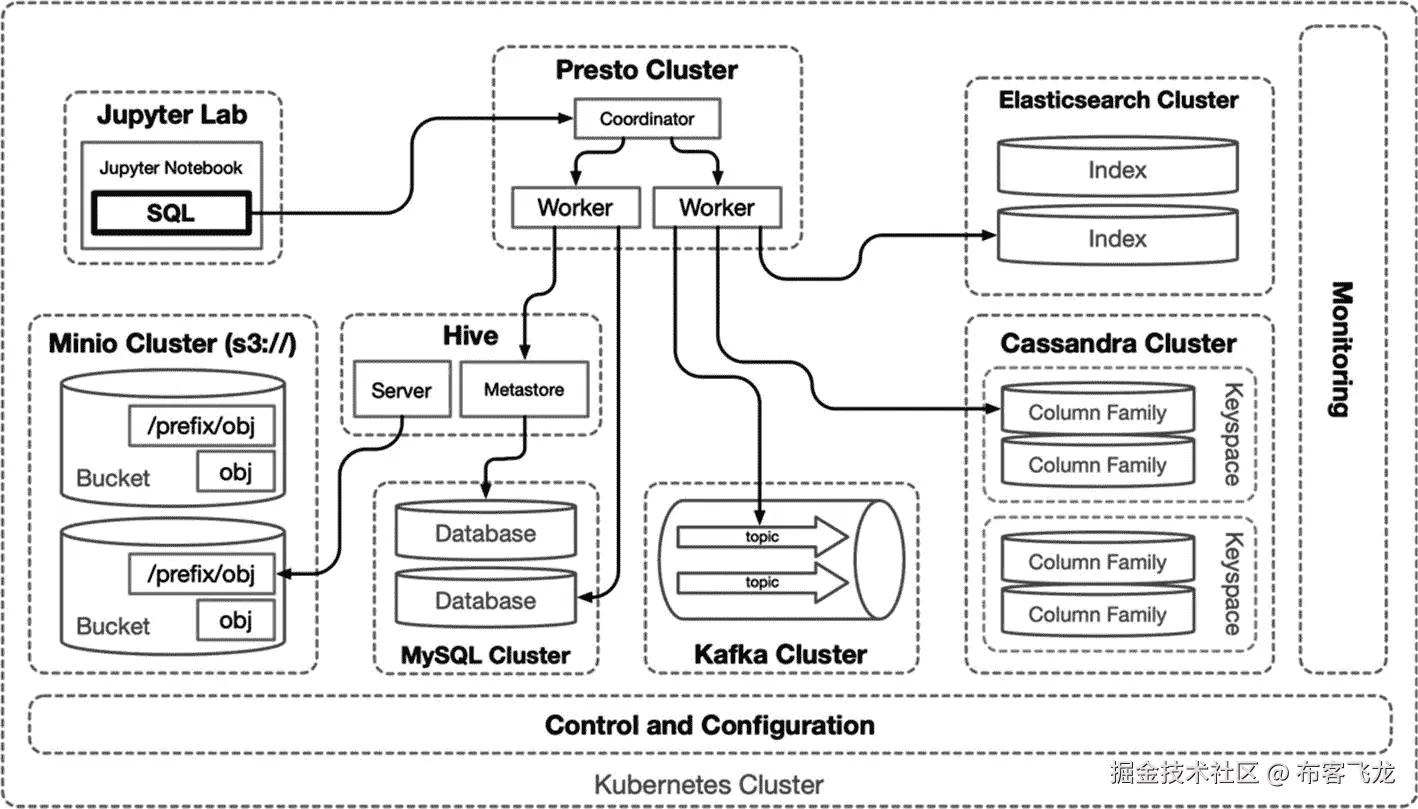
图 8-2
Presto 分布式 SQL 连接多个数据源
## 发展环境
以下练习继续利用前面章节中提到的小型集群,包括一个用于 Kubernetes 主节点的 2 vCPU/8G RAM/40G SSD 和四个用于 Kubernetes 工作节点的 4 vCPU/16G RAM/160G SSD 实例。本章中的概念和配置是按比例缩小的,以适应这个经济的实验和开发集群。
本章利用第 3 、 5 和 6 章中定义的应用和集群配置以及第七章中的新 MinIO 集群(参见表 [7-1](https://doi.org/10.1007/978-1-4842-5611-4_7Tab#1) )。本章继续在文件夹`cluster-apk8s-dev5`下组织配置清单。
## 数据和元数据源
数据仓库不仅提供对来自各种来源的历史数据的访问,而且还帮助获取、开发和描述数据集。本节将安装 MySQL,稍后 Apache Hive 将使用它来存储元数据,本书将通过在 MinIO 中的对象上投影模式来演示。此外,本章还安装了 Apache Cassandra 来进一步演示 Kubernetes 中各种数据管理系统的操作,以及利用数据仓库概念的组合效应。
### 关系型数据库
MySQL 是一个非常流行的数据库。根据 2019 年 Stack Overflow 开发者调查,54%的受访者使用 MySQL。这些结果并不令人惊讶,每天都有成千上万的网站由 MySQL 支持的内容管理系统驱动,如 WordPress 和 Drupal。 <sup>10</sup> WordPress 声称它为 35%的互联网提供动力;如果这种说法是准确的,那么可以有把握地假设所有在线数据(以网站内容表示)的很大一部分是由 MySQL 数据库提供的。
数据仓库应用 Apache Hive 需要一个数据库来存储和管理元数据。Hive 可以使用 MySQL(以及许多其他数据库)来存储元数据。对 MySQL 的平台支持既可以作为可能的数据源,也可以作为数据仓库的功能依赖(见图 8-2 )。
MySQL 以及大多数传统的数据库系统都出现在 Kubernetes 甚至云原生概念之前。用于配置和维护有状态数据库工作负载的挑战性需求的交钥匙解决方案正在快速发展。本节安装一个 MySQL Kubernetes 操作符,并定义新 MySQL 集群的期望状态。
#### MySQL 运算符
本节配置由 Presslabs 提供的稳定的、有良好文档记录的、积极维护的 MySQL Kubernetes 操作符。<sup>12</sup>MySQL 操作员定义了一个新的自定义资源,由自定义资源定义(CRD) `MysqlCluster`表示。
如果按照前面的章节,本书开发的平台在第三章定义和管理资源`CephCluster`中设置了 Rook Ceph 操作符,在第七章定义和管理资源`Tenant`中设置了 MinIO 操作符。像以前的操作符一样,新的 MySQL 操作符扩展了 Kubernetes,因此赋予了本书中开发的平台在一个或多个名称空间中快速部署和管理一个或多个 MySQL 集群的能力。
下面的配置将 MySQL 操作符安装在新的名称空间`mysql-operator`中,并且可以管理在任何名称空间中创建的`MysqlCluster`资源。在集群级别组织命名空间配置和安装文档。创建目录`cluster-apk8s-dev5/000-cluster/25-mysql-operator`来包含 MySQL 操作符名称空间配置和文档。接下来,用清单 8-1 中的内容创建一个名为`00-namespace.yml`的文件。此外,创建一个名为`README.md`的文件来记录下一步执行的 Helm 命令。
apiVersion: v1 kind: Namespace metadata: name: mysql-operator
Listing 8-1MySQL operator Namespace
应用 MySQL 操作符名称空间配置:
$ kubectl apply -f 00-namespace.yml
接下来,将 Presslabs 图表存储库添加到 Helm:
$ helm repo add presslabs
presslabs.github.io/charts
最后,安装 mysql-operator。配置操作员使用第三章中设置的 rook-ceph-block 存储类别:
$ helm install presslabs/mysql-operator
--set orchestrator.persistence.storageClass=rook-ceph-block
--name mysql-operator
--namespace mysql-operator
新的 mysql-operator 准备安装和管理 MysqlCluster 资源中定义的 mysql 集群,下一节将对此进行描述。此外,mysql-operator 将 GitHub 的 MySQL Orchestrator 公开为 mysql-operator 名称空间中的服务 mysql-operator:80。Orchestrator 是一个 MySQL 管理和可视化工具,提供拓扑发现、重构和恢复功能。 <sup>十三</sup>
通过端口转发服务并在浏览器中访问它来访问 Orchestrator:
$ kubectl port-forward service/mysql-operator
8080:80 -n mysql-operator
#### MySQL 集群
下一节定义了一个小型的双节点 MySQL 集群,在名称空间`data`中命名为`mysql`。最初,本章使用 MySQL 作为 Apache Hive 的元数据后端,后来使用 Presto 演示不同数据源之间的复杂连接。
创建目录`cluster-apk8s-dev5/003-data/080-mysql`来包含 MySQL 集群配置。接下来,从清单 8-2 中创建一个名为`90-cluster.yml`的文件。
apiVersion: v1 kind: Secret metadata: name: mysql-credentials namespace: data type: Opaque stringData: ROOT_PASSWORD: strongpassword USER: hive PASSWORD: strongpassword DATABASE: objectmetastore
apiVersion: mysql.presslabs.org/v1alpha1 kind: MysqlCluster metadata: name: mysql namespace: data spec: replicas: 2 secretName: mysql-credentials volumeSpec: persistentVolumeClaim: accessModes: ["ReadWriteOnce"] storageClassName: "rook-ceph-block" resources: requests: storage: 1Gi
Listing 8-2MySQL cluster configuration
应用 MySQL 集群配置:
$ kubectl apply -f 90-cluster.yml
### Apache 卡桑德拉
Apache Cassandra 是一个高性能、高可用性的宽列数据库。将 Cassandra 添加到本书描述的数据平台中,通过提供网络规模的数据库解决方案,完善了数据访问和存储能力。网飞是 Cassandra 更著名和公开的用户之一,“网飞在 AWS 上使用 Cassandra,作为其全球分布式流媒体产品的关键基础设施组件。”网飞公布的基准测试显示每秒超过 100 万次写入。
Cassandra 的点对点设计意味着没有主节点可以压倒或超越,从而允许 Cassandra 在数据量和速度方面进行线性扩展。这些特征提供了将大量大数据需求与高速宽列存储数据相结合的功能。
下一节配置用于在 Kubernetes 中准备和管理一个或多个 Cassandra 集群的 Rook Cassandra 操作符。
#### 卡珊德拉算子
Rook <sup>14</sup> 是一家为 Kubernetes 提供数据存储运营商的知名供应商。这本书在第三章介绍了 Rook Ceph 操作符。Rook Cassandra 操作符在 API 名称空间`cassandra.rook.io`下用新的定制资源定义`Cluster`扩展了 Kubernetes。
Rook Cassandra 操作符 <sup>15</sup> 支持集群设置,允许指定所需的 Cassandra 版本、容器映像库、注释,以及使用 Scylla、 <sup>16</sup> 的选项,这是一种用 C++编写的 Cassandra 兼容的替代方案。Scylla 声称每个节点的性能达到 1,000,000 次操作,并且能够扩展到数百个节点,99%的延迟不到 1 毫秒。Rook 与 Scylla 和 Cassandra 数据库的兼容性有助于试验这两种解决方案。此外,Rook Cassandra 操作员支持 Cassandra 物理拓扑的定义,从而能够为每个集群指定数据中心和机架配置。
创建目录`cluster-apk8s-dev5/000-cluster/23-rook-cassandra`来包含车卡珊德拉操作员配置。接下来,从清单 8-3 中创建一个名为`00-operator.yml`的文件。
apiVersion: v1 kind: Namespace metadata: name: rook-cassandra-system
apiVersion: apiextensions.k8s.io/v1beta1 kind: CustomResourceDefinition metadata: name: clusters.cassandra.rook.io spec: group: cassandra.rook.io names: kind: Cluster listKind: ClusterList plural: clusters singular: cluster scope: Namespaced version: v1alpha1 validation: openAPIV3Schema: properties: spec: type: object properties: version: type: string description: "Version of Cassandra" datacenter: type: object properties: name: type: string description: "Datacenter Name" racks: type: array properties: name: type: string members: type: integer configMapName: type: string storage: type: object properties: volumeClaimTemplates: type: object required: - "volumeClaimTemplates" placement: type: object resources:
type: object
properties:
cassandra:
type: object
sidecar:
type: object
required:
- "cassandra"
- "sidecar"
sidecarImage:
type: object
required:
- "name"
- "members"
- "storage"
- "resources"
required:
- "name"
required:
- "version"
- "datacenter"
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole
metadata: name: rook-cassandra-operator rules:
- apiGroups: [""] resources: ["pods"] verbs: ["get", "list", "watch", "delete"]
- apiGroups: [""] resources: ["services"] verbs: ["*"]
- apiGroups: [""] resources: ["persistentvolumes", "persistentvolumeclaims"] verbs: ["get", "delete"]
- apiGroups: [""] resources: ["nodes"] verbs: ["get"]
- apiGroups: ["apps"] resources: ["statefulsets"] verbs: ["*"]
- apiGroups: ["policy"] resources: ["poddisruptionbudgets"] verbs: ["create"]
- apiGroups: ["cassandra.rook.io"] resources: [""] verbs: [""]
- apiGroups: [""] resources: ["events"] verbs: ["create","update","patch"]
apiVersion: v1 kind: ServiceAccount metadata: name: rook-cassandra-operator namespace: rook-cassandra-system
kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: rook-cassandra-operator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: rook-cassandra-operator subjects:
- kind: ServiceAccount name: rook-cassandra-operator namespace: rook-cassandra-system
apiVersion: apps/v1 kind: StatefulSet
metadata: name: rook-cassandra-operator namespace: rook-cassandra-system labels: app: rook-cassandra-operator spec: replicas: 1 serviceName: "non-existent-service" selector: matchLabels: app: rook-cassandra-operator template: metadata: labels: app: rook-cassandra-operator spec: serviceAccountName: rook-cassandra-operator containers: - name: rook-cassandra-operator image: rook/cassandra:v1.1.2 imagePullPolicy: "Always" args: ["cassandra", "operator"] env: - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace
Listing 8-3Rook Cassandra operator
应用 Cassandra 运算符配置:
$ kubectl apply -f 00-operator.yml
#### 卡桑德拉星团
本节创建一个三节点 Apache Cassandra 集群,稍后用于演示 web 级宽列存储数据库和大数据系统的强大聚合,这些大数据系统用 Presto 分布式 SQL 查询引擎表示。下面的配置在数据命名空间中定义了 Kubernetes 角色、ServiceAccount 和 RoleBinding,以便在 Cassandra 集群中使用。Cassandra 集群名为 apk8s,配置在一个名为`r1`的虚拟机架中。更广泛和复杂的集群应该通过设置`nodeAffinity`、`podAffinity`、`podAntiAffinity`和`tolerations`的位置值来定义分布在 Kubernetes 集群内的多个数据中心和机架。
创建目录`cluster-apk8s-dev5/003-data/060-cassandra`来包含 Cassandra 集群配置。接下来,从清单 8-4 中创建一个名为`15-rbac.yml`的文件。
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: cassandra-member namespace: data rules:
- apiGroups: [""] resources: ["pods"] verbs: ["get"]
- apiGroups: [""] resources: ["services"] verbs: ["get","list","patch","watch"]
- apiGroups: ["cassandra.rook.io"] resources: ["clusters"] verbs: ["get"]
apiVersion: v1 kind: ServiceAccount metadata: name: cassandra-member namespace: data
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: cassandra-member namespace: data roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: cassandra-member subjects:
- kind: ServiceAccount name: cassandra-member namespace: data
Listing 8-4Rook Cassandra RBAC configuration
应用 Cassandra 集群 RBAC 配置:
$ kubectl apply -f 15-rbac.yml
接下来定义的小型 Cassandra 集群被限制在一个虚拟机架上,没有指定的 Kubernetes 节点、关联或容差。以下配置将 Cassandra 集群中的每个节点限制为一个 CPU 和 2gb 内存。
从清单 8-5 中创建一个名为`90-cluster.yml`的文件。
apiVersion: cassandra.rook.io/v1alpha1 kind: Cluster metadata: name: cassandra namespace: data spec: version: 3.11.1 mode: cassandra datacenter: name: apk8s racks: - name: r1 members: 3 storage: volumeClaimTemplates: - metadata: name: cassandra-data spec: storageClassName: rook-ceph-block resources: requests: storage: 5Gi resources: requests: cpu: 1 memory: 2Gi limits: cpu: 1 memory: 2Gi
Listing 8-5Rook Cassandra cluster configuration
应用 Cassandra 集群配置:
$ kubectl apply -f 90-cluster.yml
### Apache 蜂巢
Apache Hive 是最初由脸书开发的数据仓库软件,后来交给了 Apache 软件基金会。网飞 <sup>17</sup> 和 FINRA <sup>18</sup> 等组织使用 Hive 跨分布式存储系统查询海量结构化数据,包括 Hadoop 的 HDFS 和亚马逊 S3。Hive 通过提供标准的 SQL 接口,简化了查询大数据通常需要的复杂 MapReduce 作业。虽然 Hive 不是一个数据库,但它提供了将模式投影到存储在 HDFS 或 S3 兼容存储中的任何结构化数据上的能力。亚马逊的 AWS 提供产品 Elastic MapReduce,包括一个版本的 Hive as a service。 <sup>19</sup>
Apache Hive 使组织能够利用大量不受正式数据库管理系统管理的结构化数据、稳定的物联网数据流、从遗留系统导出的数据以及临时数据摄取。Apache Hive 通过在巨大的数据湖中提供 SQL 接口、元数据和模式,降低了执行数据科学活动的复杂性和工作负载,包括业务分析、业务智能和机器学习。
#### 容器化
本节创建一个定制的 Apache Hive 容器,该容器被配置为使用 MySQL 来存储与驻留在 S3 兼容的分布式存储系统中的对象相关的模式和元数据,例如在第七章中配置的 MinIO 集群。与许多大数据应用一样,Apache Hive 是在 Cloud-Native 和 Kubernetes 生态系统之外发展起来的,因此需要更多的努力才能将其纳入集群。下面从构建一个适用于 Kubernetes 和本地实验的定制容器开始。
创建目录`apk8s-hive`来包含新 Apache Hive Docker 容器的必要组件和配置。 <sup>20</sup> 接下来,创建目录`src`,下载并解压缩 Apache Hive 及其主依赖 Apache Hadoop:
cd apk8s-hive
$ curl -L mirror.cc.columbia.edu/pub/softwar… -o ./src/apache-hive-3.1.2-bin.tar.gz
$ curl -L archive.apache.org/dist/hadoop… -o ./src/hadoop-3.1.2.tar.gz
tar -xzvf ./src/hadoop-3.1.2.tar.gz -C ./src
接下来,通过添加 JAR 文件来扩展 Apache Hive 的功能,JAR 文件包含连接到 S3 兼容的对象存储和 MySQL 进行模式和元数据管理所需的功能:
(pwd)/src/apache-hive-3.1.2-bin/lib $ export MIRROR=repo1.maven.org/maven2
MIRROR/org/apache/hadoop/hadoop-aws/3.1.1/hadoop-aws-3.1.1.jar -o $HIVE_LIB/hadoop-aws-3.1.1.jar
MIRROR/com/amazonaws/aws-java-sdk/1.11.406/aws-java-sdk-1.11.307.jar -o $HIVE_LIB/aws-java-sdk-1.11.307.jar
MIRROR/com/amazonaws/aws-java-sdk-core/1.11.307/aws-java-sdk-core-1.11.307.jar -o $HIVE_LIB/aws-java-sdk-core-1.11.307.jar
MIRROR/com/amazonaws/aws-java-sdk-dynamodb/1.11.307/aws-java-sdk-dynamodb-1.11.307.jar -o $HIVE_LIB/aws-java-sdk-dynamodb-1.11.307.jar
MIRROR/com/amazonaws/aws-java-sdk-kms/1.11.307/aws-java-sdk-kms-1.11.307.jar -o $HIVE_LIB/aws-java-sdk-kms-1.11.307.jar
MIRROR/com/amazonaws/aws-java-sdk-s3/1.11.307/aws-java-sdk-s3-1.11.307.jar -o $HIVE_LIB/aws-java-sdk-s3-1.11.307.jar
MIRROR/org/apache/httpcomponents/httpclient/4.5.3/httpclient-4.5.3.jar -o $HIVE_LIB/httpclient-4.5.3.jar
MIRROR/joda-time/joda-time/2.9.9/joda-time-2.9.9.jar -o $HIVE_LIB/joda-time-2.9.9.jar
MIRROR/mysql/mysql-connector-java/5.1.48/mysql-connector-java-5.1.48.jar -o $HIVE_LIB/mysql-connector-java-5.1.48.jar
与许多基于 Java 的应用一样,Hive 使用 XML 文件进行配置,在本例中是 hive-site.xml。但是,将包含敏感身份验证令牌、密码和特定于环境的服务位置的配置值打包是一种反模式,会导致安全问题并限制容器的可重用性。从文件系统挂载配置文件(或者在 Kubernetes 的情况下挂载 ConfigMaps)是配置容器的标准方法,为使用容器的管理员或开发人员提供了相当大的灵活性;但是,这种方法限制了利用 Kubernetes 中现有的 Secrets 和 ConfigMap 值的能力。本节描述的技术创建了一个配置文件模板,该模板将由容器在运行时用环境变量填充。
用清单 8-6 中的内容创建一个名为`hive-site-template.xml`的文件。
Listing 8-6Apache Hive configuration template hive-site-template.xml
创建一个名为`entrypoint.sh`的 shell 脚本作为容器的初始进程。入口点脚本使用 sed 将`hive-site.xml`配置文件中的值替换为通过容器运行时传递的环境变量中的值,这在前面的部分中进行了定义。应用配置后,脚本运行实用程序`schematool`来添加任何 MySQL 数据库和 Hive 存储模式和元数据所需的表。最后,入口点脚本启动一个 Hive 服务器和一个 Hive Metastore <sup>21</sup> 服务器。
创建一个名为`entrypoint.sh`的 Bash <sup>22</sup> 脚本,将清单 8-7 中的内容用作新容器的入口点。
#!/bin/bash
provide ample time for other services to come online
sleep 10
configuration file location
HIVE_CONF="/opt/hive/conf/hive-site.xml"
template replacements
for v in
MYSQL_ENDPOINT
MYSQL_USER
MYSQL_PASSWORD
S3A_ENDPOINT
S3A_ACCESS_KEY
S3A_SECRET_KEY
S3A_PATH_STYLE_ACCESS; do
sed -i'' "s/${v}/${!v//\//\\/}/g" $HIVE_CONF
done
add metastore schema to mysql
HIVE_HOME/bin/hiveserver2 start & $HIVE_HOME/bin/hiveserver2 --service metastore
Listing 8-7Apache Hive container entrypoint.sh script
接下来,用清单 8-8 中的内容创建一个 Dockerfile。
FROM ubuntu:16.04
ENV HADOOP_HOME /opt/hadoop ENV HIVE_HOME /opt/hive ENV JAVA_HOME /usr/lib/jvm/java-8-openjdk-amd64
RUN apt-get update
&& apt-get install -y --reinstall build-essential
&& apt-get install -y
curl ssh rsync vim
net-tools openjdk-8-jdk python2.7-dev
libxml2-dev libkrb5-dev libffi-dev
libssl-dev libldap2-dev python-lxml
libxslt1-dev libgmp3-dev libsasl2-dev
libsqlite3-dev libmysqlclient-dev
ADD src/hadoop-3.1.2 /opt/hadoop ADD src/apache-hive-3.1.2-bin /opt/hive
COPY ./hive-site-template.xml /opt/hive/conf/hive-site.xml
ADD entrypoint.sh / RUN chmod 775 /entrypoint.sh
ENTRYPOINT ["/entrypoint.sh"]
EXPOSE 9083 EXPOSE 10000 EXPOSE 10002
Listing 8-8Apache Hive entrypoint.sh
确保定制的 Apache Hive 容器化项目包含前面指定的所有必要文件,如清单 8-9 所示。接下来,为本地测试构建 docker 文件中定义的容器:
. ├── Dockerfile ├── docker-compose.yml ├── entrypoint.sh ├── hive-site-template.xml └── src ├── apache-hive-3.1.2-bin ├── apache-hive-3.1.2-bin.tar.gz ├── hadoop-3.1.2 └── hadoop-3.1.2.tar.gz
Listing 8-9Apache Hive containerization files
$ docker build -t apk8s-hive-s3m:3.1.2 .
创建一个版本标记并将新容器推送到公共注册中心(或者在测试容器后创建标记,如下一节所述):
$ docker tag apk8s-hive-s3m:3.1.2
apk8s/hive-s3m:3.1.2-1.0.0
#### 本地蜂箱测试
本节通过创建一个映射到 MinIO (S3) bucket `test`的数据库和表模式来测试在上一节中构建的 Hive 容器。在第七章定义的 MinIO 集群中创建 bucket `test`。在本书的后面,Hive 用于将对象位置作为数据源进行编目,并将模式投影到它们上面。下面演示了通过在 Hive 中创建一个映射到空桶`test`的模式来创建数据源(参见图 8-3 )。
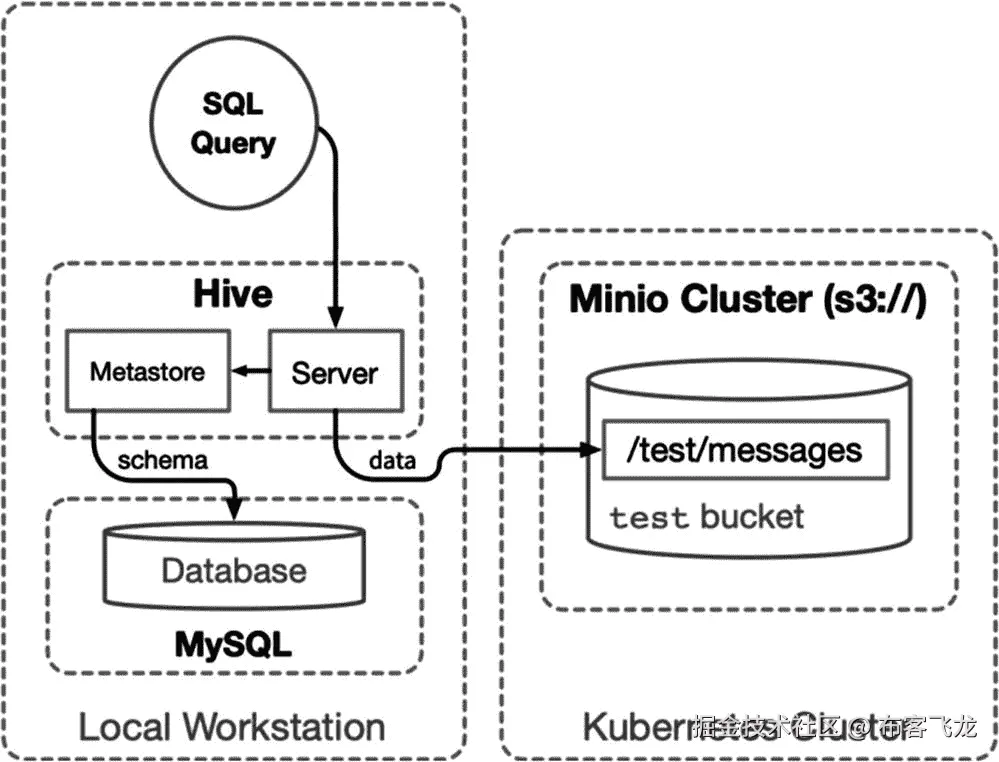
图 8-3
在本地工作站上测试配置单元
在构建新容器`apk8s-hive-s3m:3.1.2`之后,如前一节所述,创建一个 Docker Compose <sup>23</sup> 文件,用于在用于构建容器的工作站上进行本地测试。用清单 8-10 中的内容创建文件`docker-compose.yml`。将环境变量`S3A_ACCESS_KEY`和`S3A_SECRET_KEY`设置为第七章中建立的 MinIO 凭证。Docker Compose 配置定义了一个`mysql:8.0.18`数据库容器以及之前构建的 Apache Hive 容器`apk8s-hive-s3m:3.1.2`。
version: "3"
services: mysql: container_name: mysql image: mysql:8.0.18 command: --default-authentication-plugin=mysql_native_password restart: always environment: MYSQL_ROOT_PASSWORD: demo ports: - "3306:3306" hive-metastore: container_name: hive image: apk8s-hive-s3m:3.1.2 environment: MYSQL_ENDPOINT: "mysql:3306" MYSQL_USER: "root" MYSQL_PASSWORD: "demo" S3A_ENDPOINT: "obj.data.dev5.apk8s.dev" S3A_ACCESS_KEY: "miniouser" S3A_SECRET_KEY: "miniopassword" S3A_PATH_STYLE_ACCESS: "true" ports: - "9083:9083" - "10000:10000" - "10002:10002" depends_on: - mysql
Listing 8-10Apache Hive docker-compose.yml
运行新的 Docker 合成容器栈:
$ docker-compose up
启动 Docker Compose 后,新的 Apache Hive 容器连接到 MySQL,创建一个数据库和表,用于存储以后定义的模式和元数据。Apache Hive 容器公开了三个端口:HiveServer2 监听端口 10000,通过节俭/JDBC 提供 SQL 访问;Hive Metastore 侦听端口 9083,允许通过 thrift 协议访问元数据和表。Hive 在端口 10002 上提供了一个 web 接口,用于性能监控、调试和观察。
通过执行运行容器中可用的命令行应用,开始测试 Apache Hive:
$ docker exec -it hive /opt/hive/bin/hive
创建一个名为`test`的数据库:
hive> CREATE DATABASE IF NOT EXISTS test; OK
使用空桶`test`在`test`数据库中创建一个名为`message`的表(如果桶不存在,在 MinIO 中创建桶):
hive> CREATE TABLE IF NOT EXISTS test.message ( > id int, > message string > ) > row format delimited fields terminated by ',' > lines terminated by "\n" location 's3a://test/messages';
在新的`test.message`表中插入一条记录:
hive> INSERT INTO test.message > VALUES (1, "Hello MinIO from Hive");
选择从 MinIO (S3)返回的数据:
hive> SELECT * FROM test.message; OK 1 Hello MinIO from Hive
前面的测试创建了一种分布式数据库,能够从一个高度可伸缩的分布式 MinIO 对象存储系统中编目和查询数 Pb 的数据。假设指定存储桶和前缀`(/test/messages/`中的所有数据都具有相同的结构,前面的练习能够对现有数据进行建模。这个强大的概念允许组织开始收集结构化数据,并在将来需要访问时应用模式。
下一节将 Apache Hive 的强大功能引入 Kubernetes 平台,这将在本书中继续讨论。在 Kubernetes 中运行 Hive 带来了容器管理、联网、监控和数据平台内所有服务的逻辑邻近性所提供的所有优势。
## 现代数据仓库
本书将现代数据仓库和数据湖视为一个开放的(采用容器化)、云原生的平台,以 Kubernetes(容器编排)为代表的云,并将该平台视为一个不断增长的数据管理应用集合,这些应用通过 API 和图形用户界面公开,能够在其中部署业务逻辑。
许多组织和应用需要访问各种数据源,从常见的 RDBMS 数据库到分布式文档、对象和密钥存储,这是数字化转型、物联网和数据科学活动(如机器学习)趋势的结果。将不同来源的数据关联起来是一种常见的做法;然而,根据这些来源之间的关系,这一过程可能具有挑战性。将所有数据源迁移到商业数据仓库可能成本过高,带来不可接受的限制,或者导致供应商锁定。在 Kubernetes 上构建一个现代的、云原生的、厂商中立的数据仓库可能会带来新的可能性,甚至与商业应用和 PaaS 产品一起。以很少的努力和资金实现了大量的功能和灵活性,从小处着手,具有近乎无限的扩展能力。
本节将 Presto 和 Apache Hive 添加到 Kubernetes 中,在本书开发的数据平台上应用新的层。Presto 和 Hive 展示了表示和组合 MinIO (S3)、Cassandra、MySQL 等数据源的能力,创建了一个具有分布式查询执行的集中式数据访问点。
### 储备
本节将部署本章前面开发的定制 Apache Hive 容器。Hive 在 Apache Hadoop 上提供了类似 SQL 的功能,将其用途扩展到更广泛的数据分析、分析和管理应用。Hadoop 的大数据功能传统上与 Hadoop 分布式文件系统(HDFS)相关联。然而,早期开发的自定义容器扩展了 Hive,使其能够使用 S3 兼容的对象存储作为 Hadoop HDFS 的现代替代方案。Apache Hive 在一个更大的数据湖中创建了一个数据仓库,如图 8-4 所示。
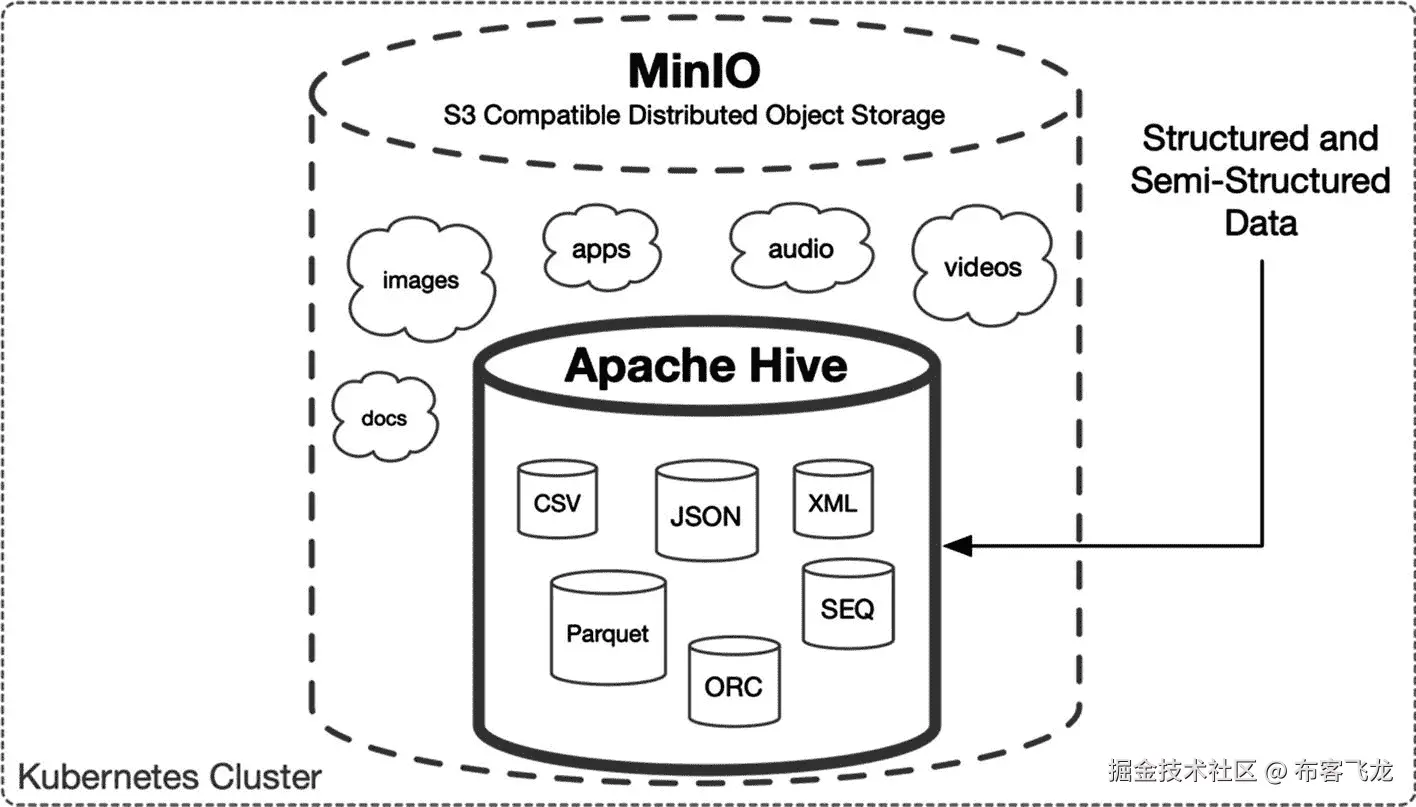
图 8-4
Apache Hive 仓库结构化和半结构化数据
#### Kubernetes 配置
下面的配置定义了一个由实现本章前面开发的定制映像`apk8s/hive-s3m:3.1.2-1.0.0`的`hive`部署支持的`hive` Kubernetes 服务。新的 Hive 容器使用 MySQL 存储模式,定义存储在 MinIO (S3)中的结构化和半结构化对象。
创建目录`cluster-apk8s-dev5/003-data/085-hive`来包含 Apache Hive Kubernetes 配置。接下来,从清单 8-11 中创建一个名为`10-service.yml`的文件。
apiVersion: v1 kind: Service metadata: name: hive namespace: data labels: app: hive spec: selector: app: hive ports: - protocol: "TCP" port: 10000 targetPort: tcp-thrift name: tcp-thrift - protocol: "TCP" port: 9083 targetPort: tcp-thrift-meta name: tcp-thrift-meta - protocol: "TCP" port: 10002 targetPort: http-hwi name: http-hwi type: ClusterIP
Listing 8-11Apache Hive Service
应用 Apache 配置单元服务配置:
$ kubectl apply -f 10-service.yml
接下来,从清单 8-12 中创建一个名为`30-deployment.yml`的文件。下面的部署将本章前面定义的环境变量`MYSQL_USER`和`MYSQL_PASSWORD`设置为 MySQL 集群配置的一部分。第七章用秘密`minio-creds-secret`配置了 MinIO,它为这个定制配置单元部署中的`S3A_ACCESS_KEY`和`S3A_SECRET_KEY`环境变量提供值。
apiVersion: apps/v1 kind: Deployment metadata: name: hive namespace: data labels: app: hive spec: replicas: 1 revisionHistoryLimit: 1 selector: matchLabels: app: hive template: metadata: labels: app: hive spec: containers: - name: hive image: apk8s/hive-s3m:3.1.2-1.0.0 imagePullPolicy: IfNotPresent env: - name: MYSQL_ENDPOINT value: "mysql:3306" - name: MYSQL_USER valueFrom: secretKeyRef: name: mysql-credentials key: USER - name: MYSQL_PASSWORD valueFrom: secretKeyRef: name: mysql-credentials key: PASSWORD - name: S3A_ENDPOINT value: "http://minio:9000" - name: S3A_ACCESS_KEY valueFrom: secretKeyRef: name: minio-creds-secret key: accesskey - name: S3A_SECRET_KEY valueFrom: secretKeyRef: name: minio-creds-secret key: secretkey - name: S3A_PATH_STYLE_ACCESS value: "true" ports: - name: tcp-thrift-meta containerPort: 9083 - name: tcp-thrift containerPort: 10000 - name: http-hwi containerPort: 10002
Listing 8-12Apache Hive Deployment
应用 Apache 配置单元部署:
$ kubectl apply -f 30-deployment.yml
#### 测试数据
正如本章前面所演示的,Apache Hive 提供了将模式投射到空存储桶上的能力,允许创建特定的但结构良好的数据集。虽然 Hive 本身不是一个数据库,但它可以在分布式对象存储上创建大规模可伸缩的基于对象的数据库,在这种情况下,是 S3 兼容的 MinIO。Hive 提供了存储支持给定类型的现有结构化和半结构化对象的模式的能力。
以下练习创建了第七章中介绍的新献血者示例数据集,由分布在一千个 CSV 文件中的一百万条记录组成。每条记录包含虚构捐赠者的电子邮件、姓名、血型、生日和州的逗号分隔值。
按照第六章中的配置运行 JupyterLab,创建一个新的 Jupyter 笔记本;在这种情况下,浏览到一个自定义的 [`https://lab.data.dev5.apk8s.dev/`](https://lab.data.dev5.apk8s.dev/) 。将下列每个代码段添加到各自的单元格中。
Note
通过将`minio-internal-service.data:9000`替换为`minio.data.dev5.apk8s.dev:443`(在第七章中设置的 MinIO 集群入口)和`secure=False`到`secure=True`,以下练习可作为普通 Python 3 脚本在本地工作站上执行。
在基于 Python 的 Jupyter 笔记本的第一个单元中,确保安装了如下的`Faker`和`minio`库:
!pip install Faker==2.0.3 !pip install minio==5.0.1
导入以下 Python 库:
import os import datetime from faker import Faker from minio import Minio from minio.error import (ResponseError, BucketAlreadyOwnedByYou, BucketAlreadyExists)
创建一个函数,返回一个元组,其中包含一条虚构的提供者信息记录:
fake = Faker()
def makeDonor(): fp = fake.profile(fields=[ "name", "birthdate", "blood_group" ])
return (
fake.ascii_safe_email(),
fp["name"],
fp["blood_group"],
fp["birthdate"].strftime("%Y-%m-%d"),
fake.state(),
)
创建一个 MinIO API 客户端并创建 bucket `exports`:
bucket = "exports" mc = Minio('minio-internal-service.data:9000', access_key='', secret_key='', secure=False)
try: mc.make_bucket(bucket) except BucketAlreadyOwnedByYou as err: pass except BucketAlreadyExists as err: pass except ResponseError as err: raise
最后,用数据时间创建一个名为的文件,包含一千个提供者记录。将文件上传到带有前缀`donors/`(例如`donors/20200205022452.csv`)的 MinIO bucket `exports`。重复这个过程 1000 次,总共有 100 万个测试记录。
for i in range(1,1001): now = datetime.datetime.now() dtstr = now.strftime("%Y%m%d%H%M%S") filename = f'donors/{dtstr}.csv' tmp_file = f'./tmp/{dtstr}.csv'
with open(tmp_file,"w+") as tf:
tf.write("email,name,type,birthday,state\n")
for ii in range(1,1001):
line = ",".join(makeDonor()) + "\n"
tf.write(line)
mc.fput_object(bucket, filename, tmp_file,
content_type='application/csv')
os.remove(tmp_file)
print(f'{i:02}: {filename}')
#### 创建模式
通过在 running Pod 中执行 Hive 命令行界面来测试新的自定义 Apache Hive 部署。
首先,在 MinIO 中创建一个名为`hive`的 bucket。
获取自定义 Apache 配置单元 Pod 名称:
$ kubectl get pods -l app=hive -n data
执行`hive`命令:
$ kubectl exec -it hive-8546649b5b-lbcrn \ /opt/hive/bin/hive -n data
从正在运行的 hive 命令中,创建一个名为`exports`的数据库:
hive> CREATE DATABASE exports;
接下来,创建表格`exports.donors`:
hive> CREATE TABLE exports.donors ( > email string, > name string, > blood_type string, > birthday date, > state string > ) > row format delimited fields terminated by ',' > lines terminated by "\n" > location 's3a://exports/donors';
本章使用一个定制的 Apache Hive 容器将模式投射到分布式对象存储上。虽然单个 Hive 容器能够通过在`hive:1000` Kubernetes 服务上公开的 ODBC/thrift 执行查询,但是直接针对 Hive 执行生产工作负载需要更大的 Hive 集群。但是,下一节使用一个 Presto 集群来执行分布式查询,并且只使用 Hive 从通过服务`hive:9083`公开的元数据服务器提供模式。
下一节将演示如何使用 Presto 连接使用 Hive 在 MinIO 分布式对象存储中收集的结构化数据,以及各种其他数据源,包括 RDBMS MySQL 和键/值数据库 Apache Cassandra。
### 很快
Presto 是本书中定义的现代数据仓库的最后一个组件。根据官网 prestodb.io 的介绍,“Presto 是一个开源的分布式 SQL 查询引擎,用于对从千兆字节到千兆字节的所有大小的数据源运行交互式分析查询。”虽然 Hive 也是一个查询海量数据的分布式 SQL 查询引擎电缆,但 Presto 连接了更广泛的数据源,包括 Apache Hive(如图 8-5 所示)。除了 Presto 的高性能查询功能,它还提供了一个数据源的中央目录。
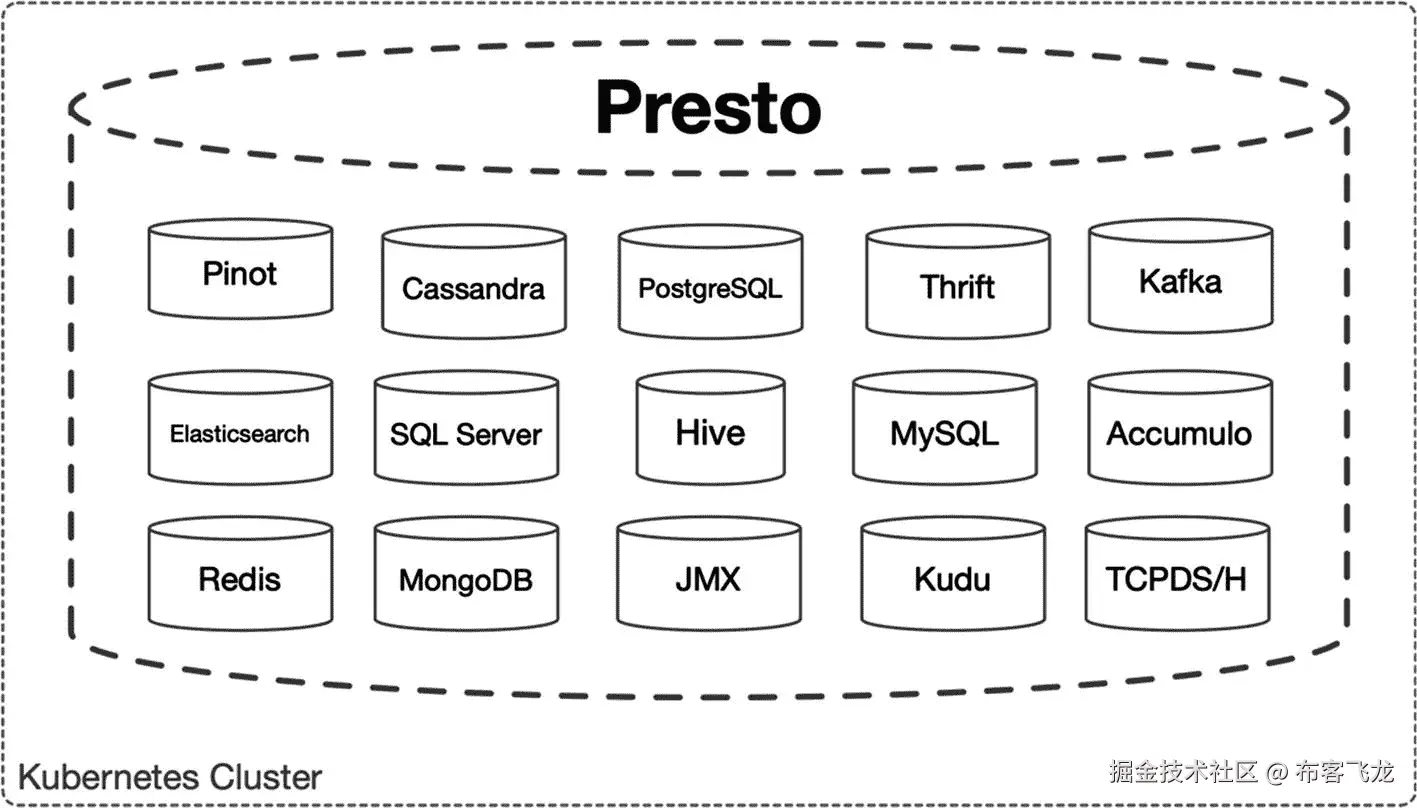
图 8-5
预先存储跨多个数据源的分布式 SQL 查询
Presto 减少了从多个来源检索数据所需的应用逻辑的数量,既通过标准的 SQL 抽象,又不需要客户端连接数据(在某些情况下被认为是反模式 <sup>24</sup> )。Presto 提供了跨所有受支持数据源的 SQL 抽象,执行分布式查询,并包括监控和可观察性。Presto 支持客户端库为 Go、 <sup>25</sup> C、 <sup>26</sup> Java、 <sup>27</sup> Node.js、 <sup>28</sup> PHP、 <sup>29</sup> Ruby、 <sup>30</sup> R、<sup>31</sup> 越来越多的基于 web 的 GUI 客户端、可视化和仪表板应用支持 Presto,包括 Apache Airflow 的创建者提供的新商业智能应用 Apache Superset(见图 8-6 )。
图 8-6
Apache 超集(图片来自 [`超集。Apache。组织`](https://superset.apache.org)
#### Kubernetes 配置
本章在 Kubernetes 中使用一个稳定的开源 Helm chart by When I Work Data 安装了一个带有两个 workers 和一个协调器的 Presto 集群。 <sup>33</sup>
创建目录`cluster-apk8s-dev5/003-data/095-presto`来包含 Presto Helm 配置和文档。接下来,用清单 8-13 中的内容创建一个名为`values.yml`的文件。此外,创建一个名为`README.md`的文件来记录下一步执行的 Helm 命令。
在 Presto 中,一个目录代表一个顶级数据源。请注意在 Helm chart configuration values . yml 的 catalog 部分中定义的四个数据源(称为连接器)。前两个数据源`obj.properties`和`hive.properties`使用 hive-hadoop2 连接器。Presto 使用 Hive 访问包含在 HDFS 或 S3 的数据文件(对象),并使用 Hive Metastore 服务访问表示数据文件的元数据和模式。`hive.properties`配置演示了定制 Apache Hive 容器(安装在前面的小节中)在 MySQL 支持的 Metastore 服务中的使用。此外,`cassandra.properties`和`mysql.properties`展示了本章配置的 MySQL 和 Apache Cassandra 的连接。
presto: environment: "production" workers: 2 logLevel: "INFO"
image: repository: "wiwdata/presto" tag: "0.217" pullPolicy: "IfNotPresent"
service: type: ClusterIP
catalog: obj.properties: | connector.name=hive-hadoop2 hive.metastore=file hive.metastore.catalog.dir=s3://metastore/ hive.allow-drop-table=true hive.s3.aws-access-key= miniobucketuserid hive.s3.aws-secret-key= miniobucketuserpassword hive.s3.endpoint=http://minio:9000 hive.s3.path-style-access=true hive.s3.ssl.enabled=false hive.s3select-pushdown.enabled=true
hive.properties: | connector.name=hive-hadoop2 hive.metastore.uri=thrift://hive:9083 hive.allow-drop-table=true hive.s3.aws-access-key= miniobucketuserid hive.s3.aws-secret-key= miniobucketuserpassword hive.s3.endpoint=http://minio:9000 hive.s3.path-style-access=true hive.s3.ssl.enabled=false
cassandra.properties: | connector.name=cassandra cassandra.contact-points=cassandra-data-r1-0,cassandra-data-r1-1,cassandra-data-r1-2
mysql.properties: | connector.name=mysql connection-url=jdbc:mysql://mysql:3306 connection-user= root connection-password= mysqlrootpassword
coordinatorConfigs: {} workerConfigs: {} environmentVariables: {} coordinatorResources: {} workerResources: {} coordinatorNodeSelector: {} workerNodeSelector: {} coordinatorTolerations: [] workerTolerations: {} coordinatorAffinity: {} workerAffinity: {}
Listing 8-13Presto Helm configuration
接下来,克隆 Presto Helm 图表库:
$ git clone git@github.com:apk8s/presto-chart.git
Note
GitHub 存储库 apk8s/presto-chart<sup>34</sup>从 wiwdata/presto-chart 派生而来,包含与 Kubernetes 1.16+兼容所需的微小更新。有关未来版本或与 Kubernetes 旧版本的兼容性,请参考上游存储库。
通过应用前面的 Helm chart 克隆,以及来自`values.yml`的自定义配置,创建一个新的 Presto 集群:
$ helm upgrade --install presto-data
--namespace data
--values values.yml
./presto-chart/presto
一旦 Helm 完成安装过程,Kubernetes 集群就包含两个 Presto worker 节点和一个 Presto 协调器。
最后,添加一个由 Helm chart 生成的新`presto-data:80`服务支持的 Kubernetes 入口配置。下面的入口使用在第五章的“数据名称空间”部分设置的秘密`sysop-basic-auth`来添加简单的基本认证安全性。从清单 8-14 中创建一个名为`50-ingress.yml`的文件。
apiVersion: networking.k8s.io/v1beta1 kind: Ingress metadata: name: presto namespace: data annotations: cert-manager.io/cluster-issuer: letsencrypt-production nginx.ingress.kubernetes.io/auth-type: basic nginx.ingress.kubernetes.io/auth-secret: sysop-basic-auth nginx.ingress.kubernetes.io/auth-realm: "Authentication Required" spec: rules: - host: presto.data.dev5.apk8s.dev http: paths: - backend: serviceName: presto-data servicePort: 80 path: / tls: - hosts: - presto.data.dev5.apk8s.dev secretName: presto-data-production-tls
Listing 8-14Presto Ingress
应用预存储入口配置:
$ kubectl apply -f 50-ingress.yml
下一节将演示如何使用 presto-python-client 库从 Jupyter 笔记本中连接到 Presto。
#### 询问
本节使用运行在 Kubernetes 集群中的基于 Python 的 Jupyter 笔记本演示了与 Presto 的交互(参见第六章)。
从 JupyterLab 环境启动一个新的 Python 3 笔记本,在各个单元格中添加并执行以下代码。从第一个单元开始,使用`pip`安装`presto-python-client`库:
!pip install presto-python-client==0.7.0
导入`prestodb`(从包`presto-python-client`)、`os`、`pandas` Python 库;创建一个新的用于执行命令的 Presto 数据库连接对象和光标,如图 8-7 所示。执行命令`SHOW CATALOGS`显示四个数据源,`cassandra`、`hive`、`mysql`和`obj`在前面章节中配置。`system`目录包含预先存储的内部配置和运行数据。
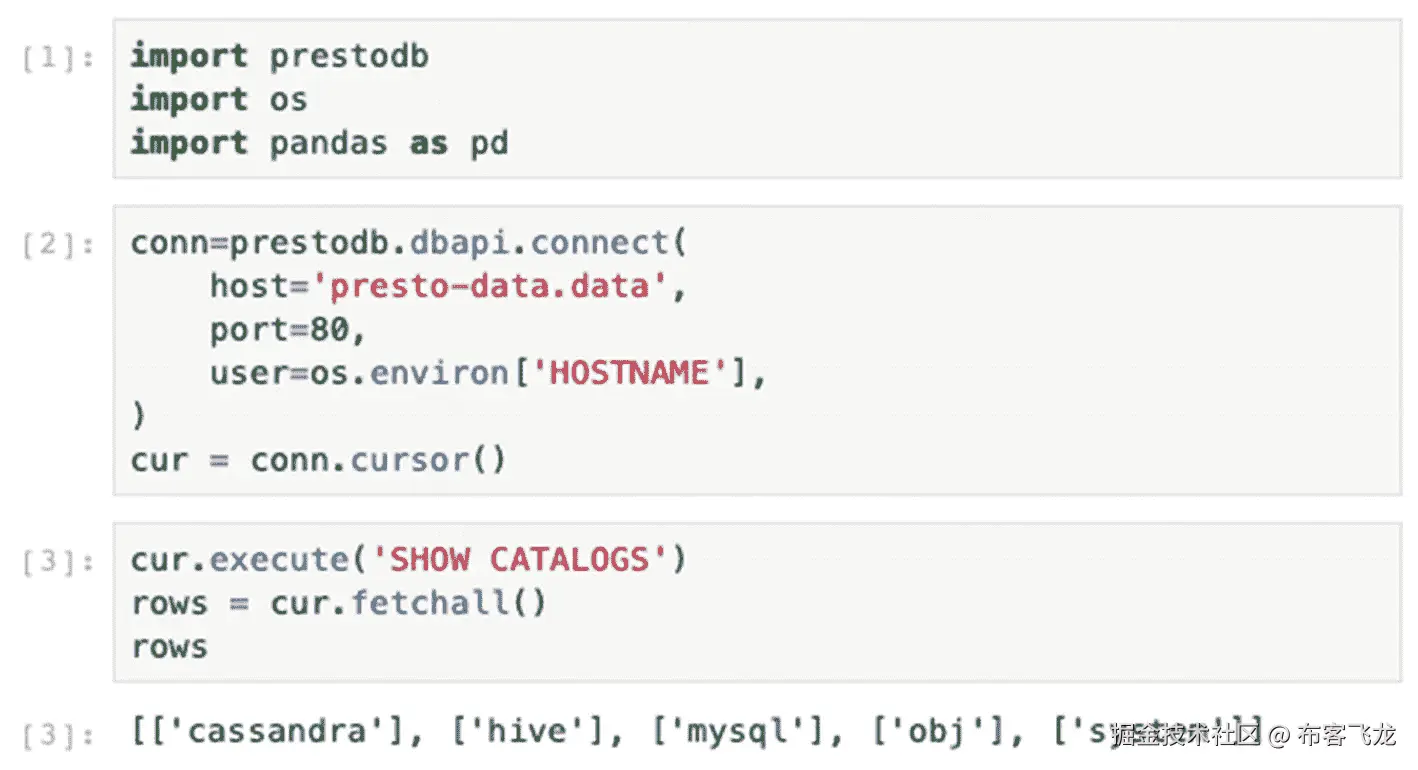
图 8-7
木星笔记本执行显示目录 presto 命令
查询`system`目录中的 Presto 节点列表,如图 8-8 所示。将 select 语句的结果与列名一起加载到 Pandas<sup>35</sup>data frame<sup>36</sup>中,为管理和显示结果集提供了一个用户界面。在执行分析和数据科学活动时,这种方法变得特别有用。Pandas 通常是 Python 数据库的核心组件,包含许多强大的数据转换和数学运算功能。
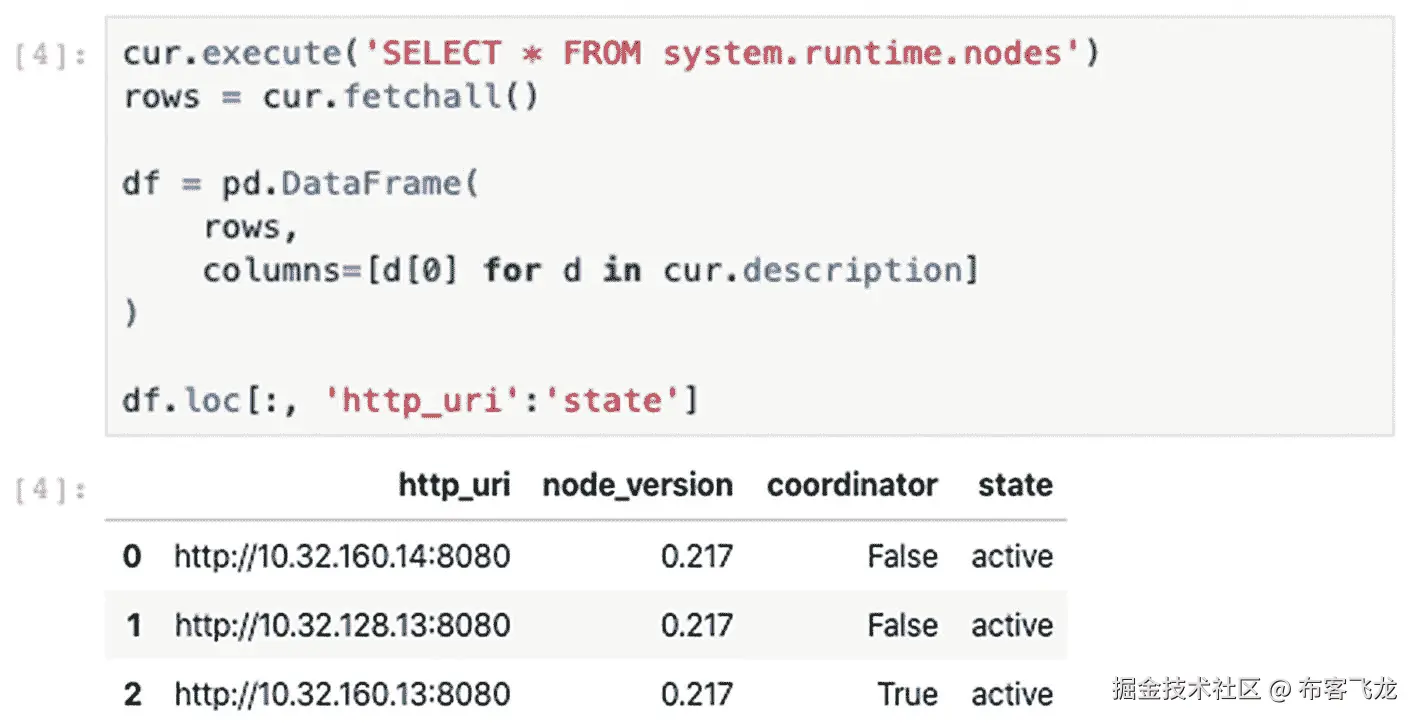
图 8-8
检索预先存储的节点列表
描述上一节中用 Apache Hive 配置的`donors`模式,如图 8-9 所示。Hive 和 Presto 完全抽象出`donors`数据集的位置和底层数据结构,在本章前面生成并上传了一千个 CSV 文件到`exports`桶。
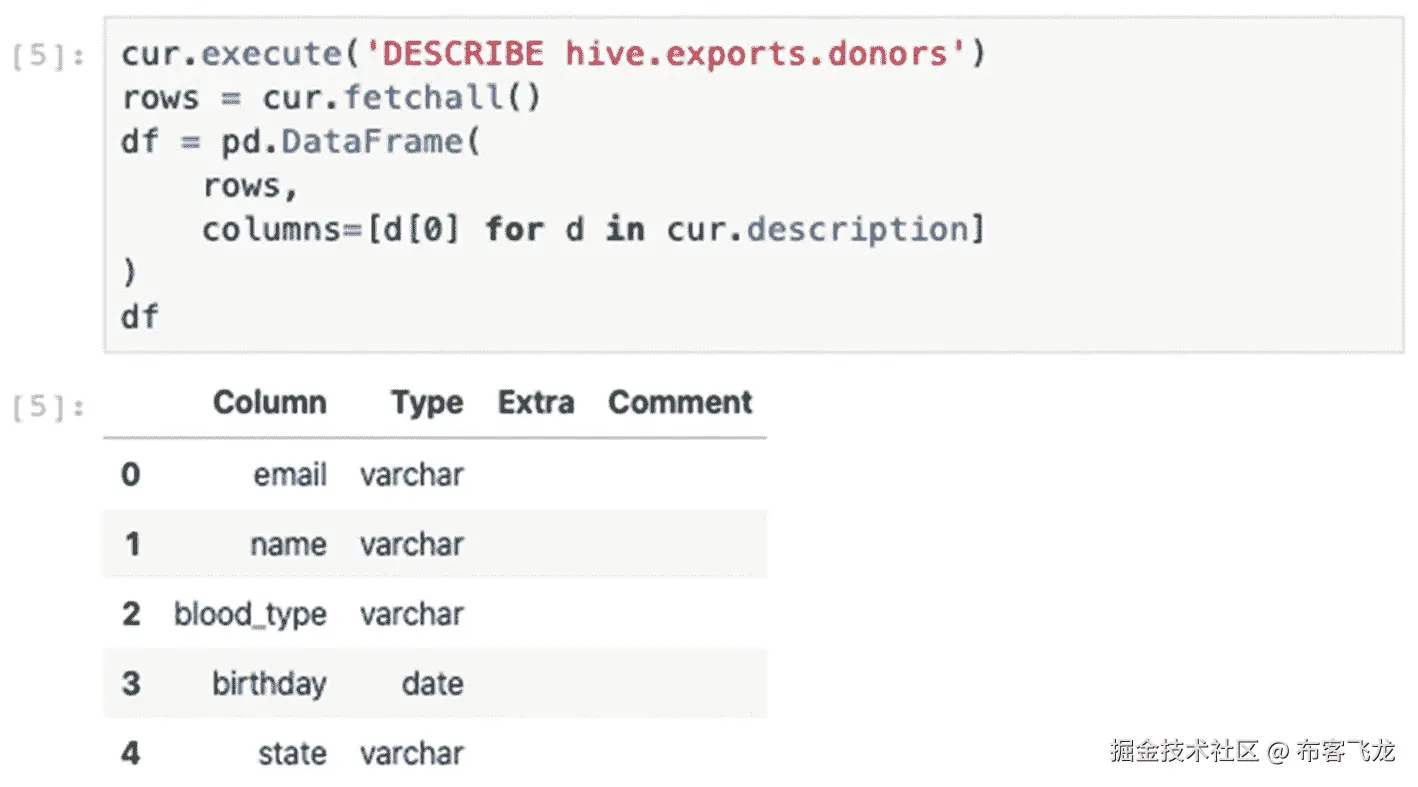
图 8-9
用 Presto 描述表格
图 8-10 描述了一个 SQL select 语句,该语句利用 Presto 扫描所有一千个 CSV 文件,查找其中`state`列的值以“新”开始的记录,并通过`state`和`blood_type`对记录进行分组,每组记录的计数。
Presto 提供了一个成熟的、文档完善的、功能全面的 SQL 接口以及几十个函数和操作符。利用 Presto 进行初始数据分析、应用数学函数和运算符、聚合等,通过利用 Presto 的分布式执行引擎来执行这些密集型任务,尤其是处理大量数据,消除了应用的操作复杂性。
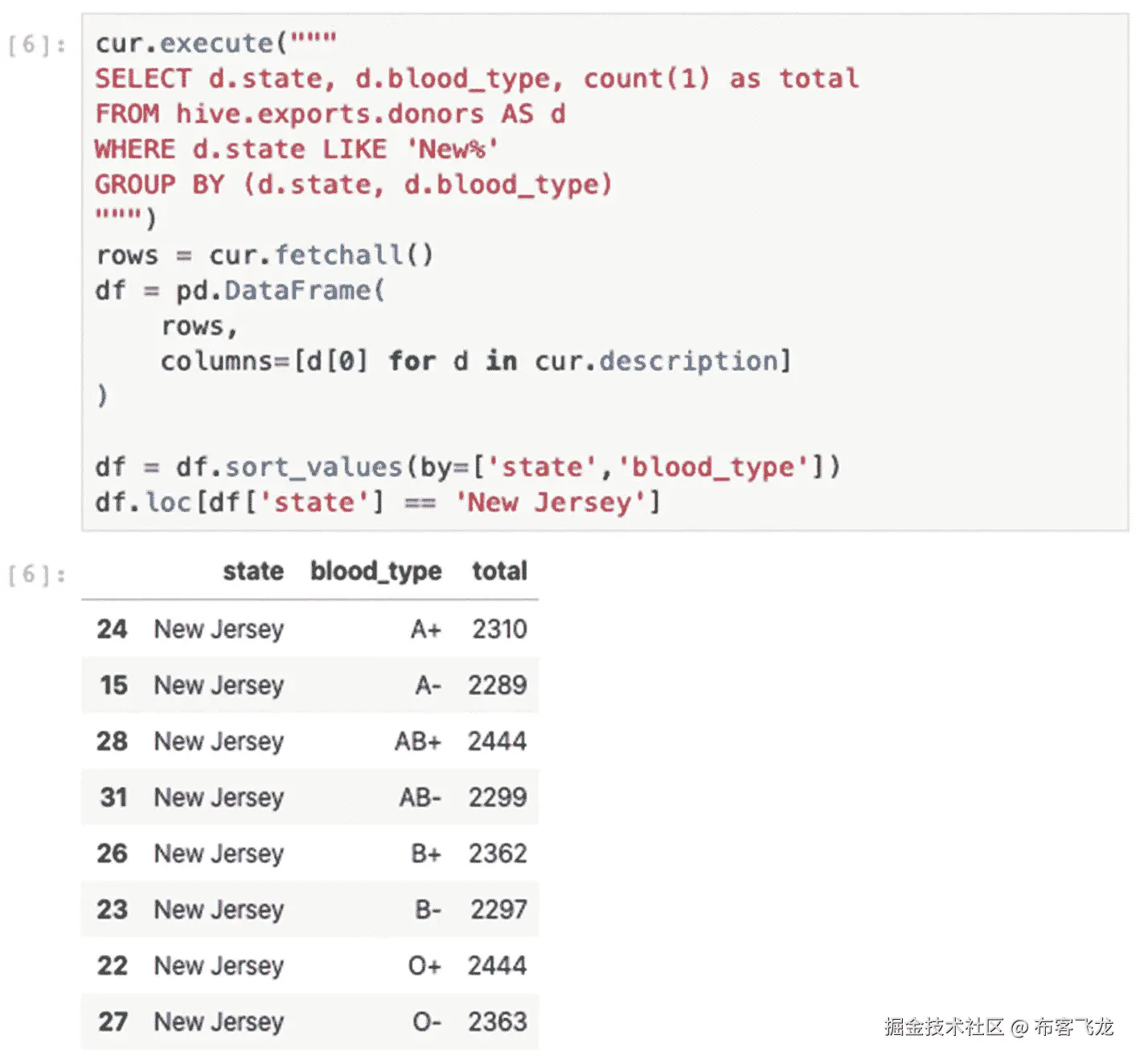
图 8-10
Presto 中的 SQL select 语句
连接不同的数据集是 Presto 的一个基本特性,也是数据仓库的核心概念。作为读者的一个练习,创建数据或将数据导入到 Apache Cassandra 或 MySQL 中,这些数据与前面使用的样本提供者数据相关。一个典型的 SQL 连接可能类似于图 8-11;在这个例子中,名为 appointment 的 Cassandra 表存在于 Keyspace lab 中,表示约会数据。
图 8-11 :使用 Presto 来 SQL 连接 Hive 和 Cassandra 数据集的示例。
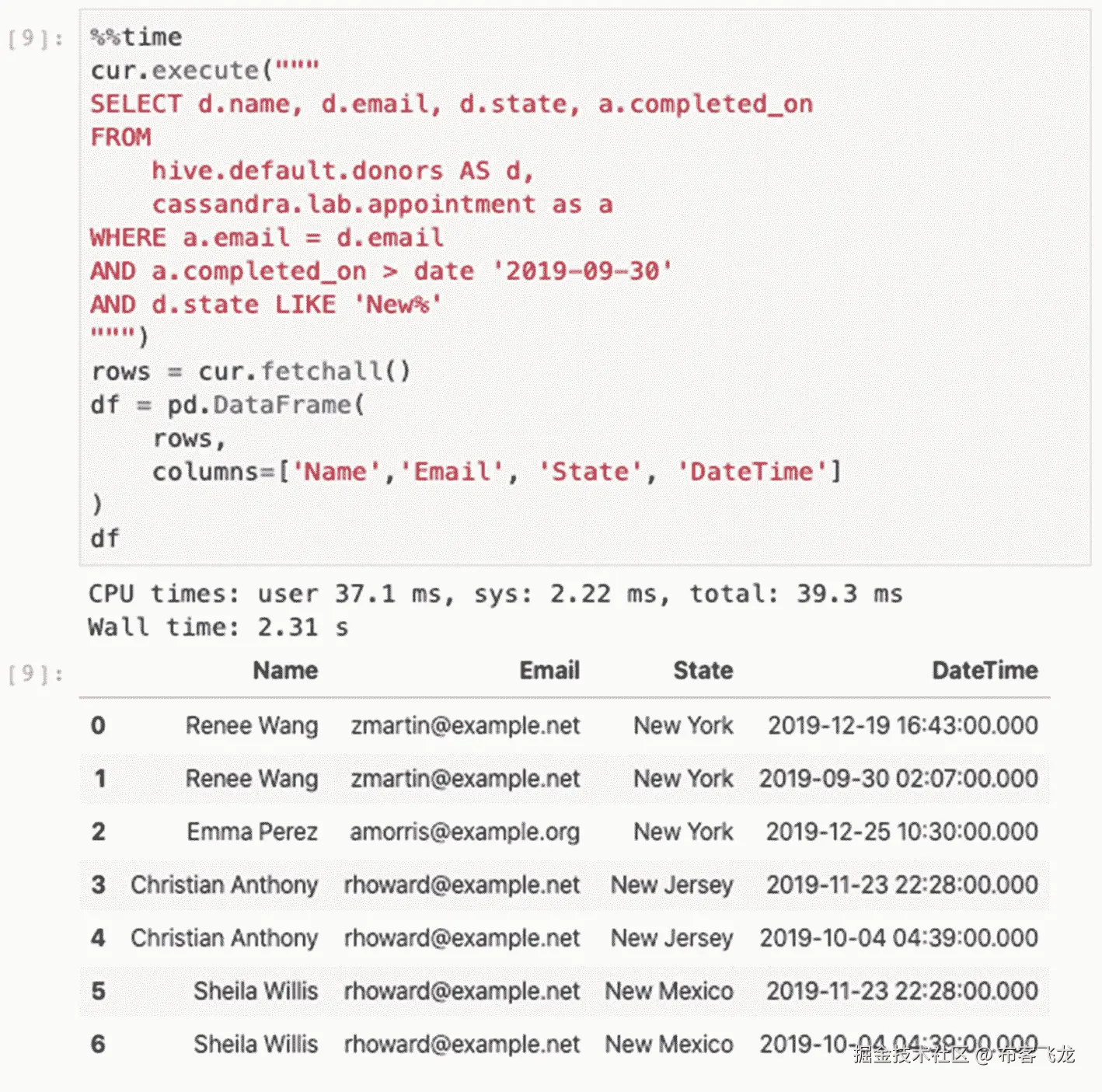
图 8-11
在 Presto 中的 SQL 连接语句
跨各种数据源连接大型数据集并对其执行操作会创建复杂的执行计划。Presto 为探索、监控和调试查询提供了一个直观的基于 web 的用户界面。上一节定义的入口配置在 [`https://presto.data.dev5.apk8s.dev`](https://presto.data.dev5.apk8s.dev) 展示 Presto UI,如图 8-12 所示。
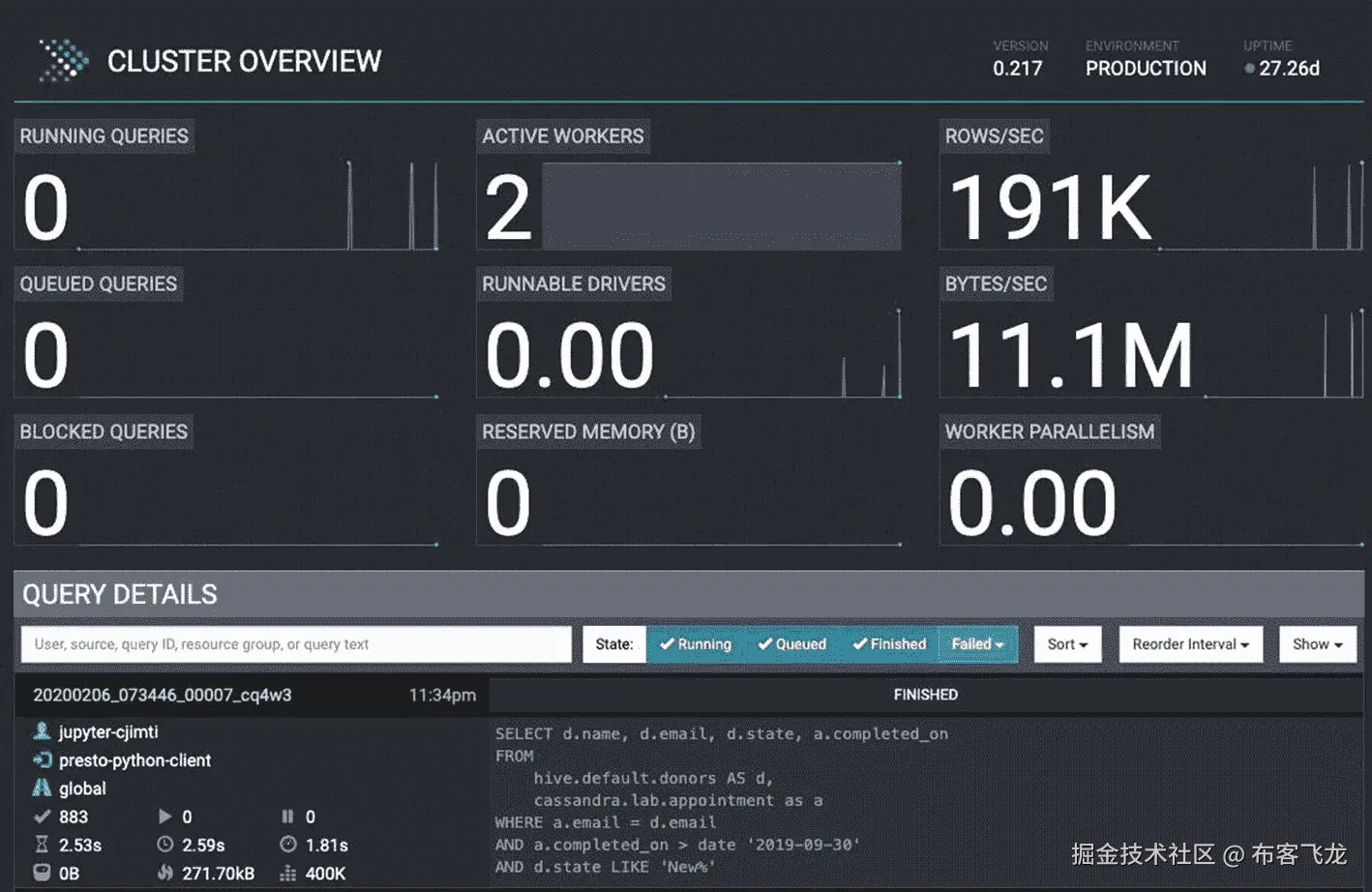
图 8-12
在 Presto 中的 SQL 连接语句
监控和可观察性对于大数据和网络规模的数据操作都至关重要。Presto web 用户界面支持深入每个查询,提供查询细节,包括资源利用、时间表、错误信息、阶段和与执行相关的任务。此外,Presto 提供了一个实时计划,如图 8-13 所示,通过网络图实时描绘了阶段之间的执行流程。
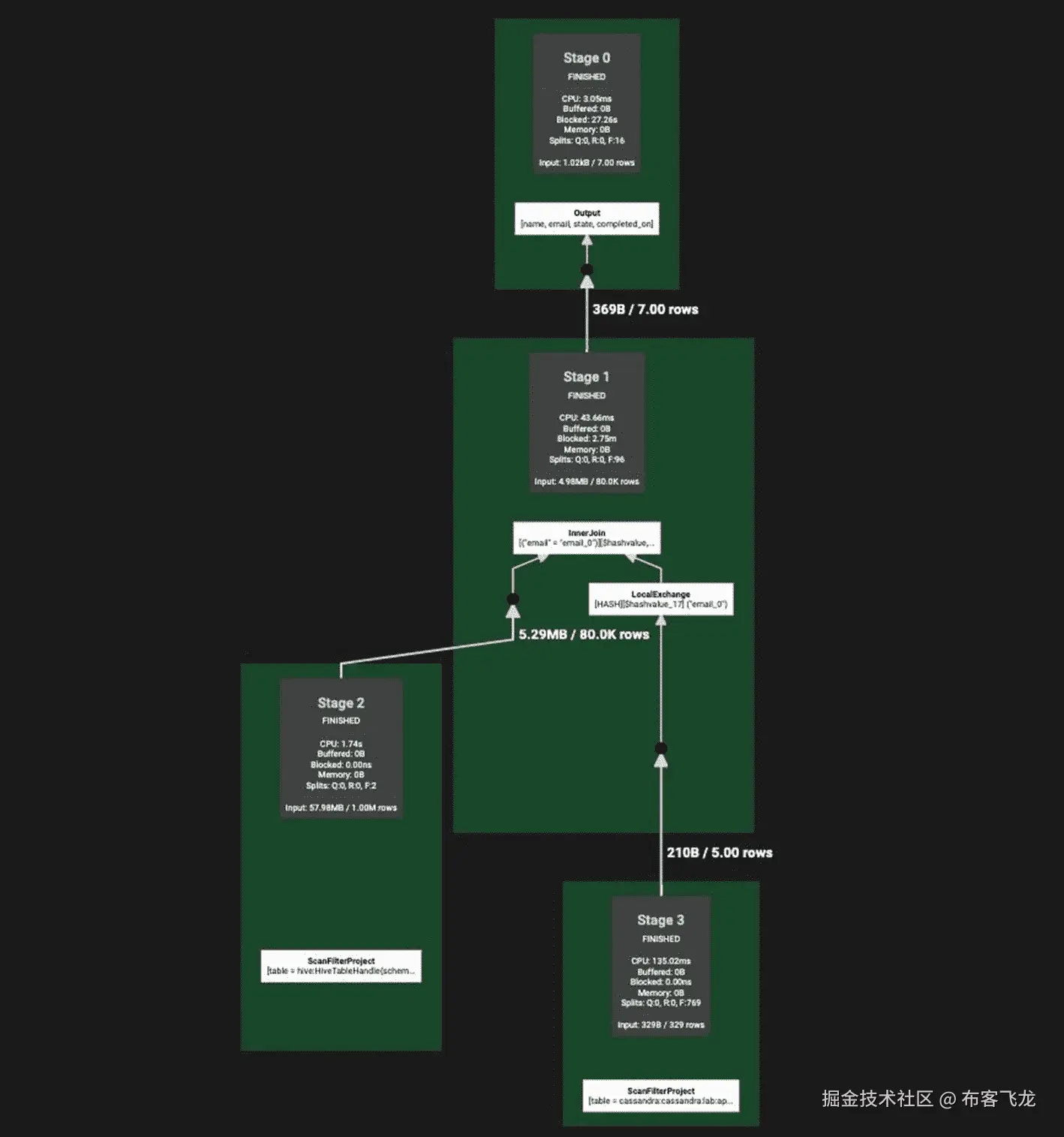
图 8-13
在 Presto 中的 SQL 连接语句
Presto 是在 Kubernetes 内部构建现代数据仓库的综合解决方案;它对一系列数据源的支持符合物联网和机器学习不断增长的需求,提供了检索、合并、关联、转换和分析无限数量和结构的数据的能力。
## 摘要
这一章,连同第六章,展示了构建在 Kubernetes 之上的数据湖和数据仓库概念的小规模表示。像 Apache Hive 和 Presto 这样的技术帮助组织处理孤立的数据管理操作;在 Kubernetes 上运行这些解决方案,通过统一底层数据和控制面板,进一步降低了这些应用在逻辑和概念上的接近程度。
本章介绍了 MySQL 集群的安装,它代表了一个非常流行的 RDBMS,Apache Cassandra 作为大数据键/值存储,Hive 公开了无限的结构化和半结构化数据对象。虽然对于一系列以数据为中心的问题领域(从机器学习到物联网)有大量的专门应用,但这本书涵盖了一套通用而全面的数据(和事件)管理解决方案。如果按照前面的章节,清单 8-15 代表了到目前为止基于 Kubernetes 的数据平台组件的当前组织的高级快照。
现在有了存储和检索几乎无限量和形式的数据的能力,下一章将通过扩展数据收集、路由、转换和处理的能力来扩展这个基于 Kubernetes 的数据平台。
./008-cluster-apk8s-dev5 ├── 000-cluster │ ├── 00-ingress-nginx │ ├── 01-helm │ ├── 10-cert-manager │ ├── 20-rook-ceph │ ├── 22-minio │ ├── 23-rook-cassandra │ ├── 25-mysql-operator │ └── 30-monitoring ├── 003-data │ ├── 000-namespace │ ├── 005-keycloak │ ├── 010-zookeeper │ ├── 020-kafka │ ├── 030-elasticsearch │ ├── 032-logstash │ ├── 034-kibana │ ├── 050-mqtt │ ├── 060-cassandra │ ├── 070-minio │ ├── 080-mysql │ ├── 085-hive │ ├── 095-presto │ └── 100-jupyterhub └── 005-data-lab └── 000-namespace
Listing 8-15Organization of Kubernetes-based data platform components
<aside aria-label="Footnotes" class="FootnoteSection" epub:type="footnotes">Footnotes 1
[`https://delta.io/`](https://delta.io/)
2
[`https://kylo.io/`](https://kylo.io/)
3
斯卡利、加里·霍尔特、丹尼尔·戈洛文、尤金·达维多夫、托德·菲利普斯、迪特马尔·埃布纳、维奈·乔杜里、迈克尔·杨、让-弗朗索瓦·克雷斯波和丹·丹尼森。“机器学习系统中隐藏的技术债务。”《神经信息处理系统的进展》28,c .科尔特斯、N. D .劳伦斯、D. D .李、m .杉山和 r .加内特编辑,2503–2511。柯伦联合公司,2015 年。 [`http://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf`](http://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf) 。
4
[`https://landscape.cncf.io/`](https://landscape.cncf.io/)
5
[`www.mysql.com/`](http://www.mysql.com/)
6
[`https://cassandra.apache.org/`](https://cassandra.apache.org/)
7
[`https://hive.apache.org/`](https://hive.apache.org/)
8
[`https://prestodb.io/`](https://prestodb.io/)
9
[`https://insights.stackoverflow.com/survey/2019#technology-_-databases`](https://insights.stackoverflow.com/survey/2019%2523technology-_-databases)
10
[`www.drupal.org/`](http://www.drupal.org/)
11
[`https://wordpress.com/activity/`](https://wordpress.com/activity/)
12
[`https://github.com/presslabs/mysql-operator`](https://github.com/presslabs/mysql-operator)
13
[`https://github.com/github/orchestrator`](https://github.com/github/orchestrator)
14
[`https://rook.io/`](https://rook.io/)
15
[`https://rook.io/docs/rook/v1.2/cassandra-cluster-crd.html`](https://rook.io/docs/rook/v1.2/cassandra-cluster-crd.html)
16
[`www.scylladb.com/`](http://www.scylladb.com/)
17
[`www.youtube.com/watch?v=Idu9OKnAOis`](http://www.youtube.com/watch%253Fv%253DIdu9OKnAOis)
18
[`https://technology.finra.org/opensource.html#bigdata`](https://technology.finra.org/opensource.html%2523bigdata)
19
[`https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-hive.html`](https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-hive.html)
20
[`https://github.com/apk8s/hive`](https://github.com/apk8s/hive)
21
[`https://cwiki.apache.org/confluence/display/Hive/AdminManual+Metastore+3.0+Administration`](https://cwiki.apache.org/confluence/display/Hive/AdminManual%252BMetastore%252B3.0%252BAdministration)
22
[`www.gnu.org/software/bash/manual/`](http://www.gnu.org/software/bash/manual/)
23
[`https://docs.docker.com/compose/`](https://docs.docker.com/compose/)
24
[`www.batey.info/cassandra-anti-pattern-distributed.html`](http://www.batey.info/cassandra-anti-pattern-distributed.html) ,
[`www.slideshare.net/chbatey/webinar-cassandra-antipatterns-45996021`](http://www.slideshare.net/chbatey/webinar-cassandra-antipatterns-45996021)
25
[`https://github.com/prestodb/presto-go-client`](https://github.com/prestodb/presto-go-client)
26
[`https://github.com/easydatawarehousing/prestoclient/tree/master/C`](https://github.com/easydatawarehousing/prestoclient/tree/master/C)
27
[`https://prestodb.io/docs/current/installation/jdbc.html`](https://prestodb.io/docs/current/installation/jdbc.html)
28
[`https://github.com/tagomoris/presto-client-node`](https://github.com/tagomoris/presto-client-node)
29
[`https://github.com/Xtendsys-labs/PhpPrestoClient`](https://github.com/Xtendsys-labs/PhpPrestoClient)
30
[`https://github.com/treasure-data/presto-client-ruby`](https://github.com/treasure-data/presto-client-ruby)
31
[`https://github.com/prestodb/RPresto`](https://github.com/prestodb/RPresto)
32
[`https://github.com/prestodb/presto-python-client`](https://github.com/prestodb/presto-python-client)
33
[`https://github.com/wiwdata/presto-chart`](https://github.com/wiwdata/presto-chart)
34
[`https://github.com/apk8s/presto-chart`](https://github.com/apk8s/presto-chart)
35
[`https://pandas.pydata.org/`](https://pandas.pydata.org/)
36
[`https://pandas.pydata.org/pandas-docs/stable/reference/frame.html`](https://pandas.pydata.org/pandas-docs/stable/reference/frame.html)
</aside>
