

Linux 内核网络教程(一)
协议:CC BY-NC-SA 4.0
零、前言
这本书引导你深入了解当前的 Linux 内核网络实现及其背后的理论。近十年来,没有关于 Linux 网络的新书问世。十年动态和快节奏的 Linux 内核开发是一段相当长的时间。有一些重要的内核网络子系统没有在任何其他书中描述;例如,IPv6、IPsec、无线(IEEE 802.11)、IEEE 802.15.4、NFC、InfiniBand 等等。关于这些子系统的实现细节,网上的信息也很少。出于所有这些原因,我写了这本书。
大约十年前,我迈出了内核编程的第一步。我是一家初创公司的开发人员,参与了一个基于 Linux 的机顶盒(STB)的 VoIP 项目。一些 USB 摄像头的 USB 堆栈出现崩溃,我们不得不钻研代码来试图找到解决方案,因为该机顶盒的供应商不想花时间来解决问题。事实上,他们并不是不想做,而是不知道怎么做。在那些日子里,几乎没有关于 USB 堆栈的文档。当年 O'Reilly 出的 Linux 设备驱动书只有第二版(第三版才加了 USB 一章)。作为一家初创公司,该项目的成功对我们来说至关重要。在解决 USB 崩溃的过程中,我学到了很多关于内核编程的知识。后来,我们有一个项目需要 NAT 穿越解决方案。用户空间解决方案太重,以至于设备很快就崩溃了。当我提出一个内核解决方案时,我的经理非常怀疑,但他们确实让我尝试了。事实证明,内核解决方案非常稳定,占用的 CPU 比用户空间解决方案少得多。从那以后,我参加了许多内核网络项目。这本书是我多年开发和研究的成果。
这本书是给谁的
本书面向从事网络相关项目的计算机专业人员,包括开发人员、软件架构师、设计人员、项目经理和首席技术官。这些项目可能涉及广泛的专业领域,如通信、数据中心、嵌入式设备、虚拟化、安全等。此外,处理网络项目或网络研究或操作系统研究的学生和学院研究人员和理论家将在本书中找到大量帮助。
这本书的结构
在第一章中,你会看到 Linux 内核和 Linux 网络栈的概述。本章的其他主题包括网络设备的实现、套接字缓冲区以及 Rx 和 Tx 路径。第一章以一个关于 Linux 内核网络开发模型的部分结束。
在第二章中,您将了解 netlink 套接字,它提供了用户空间和内核之间的双向通信机制,网络子系统和其他子系统都使用它。你还会在本章中找到一个关于通用 netlink 套接字的部分,它可以被视为高级 netlink 套接字,你会在第十二章和浏览内核网络源代码时遇到。
在第三章中,您将了解 ICMP 协议,它通过发送有关网络层(L3)的错误和控制消息来帮助保持系统正常运行。您将了解 ICMP 协议在 IPv4 和 IPv6 中的实现。
第四章深入探讨 IPv4 协议——互联网和现代生活离不开它。您将了解 IPv4 报头的结构、Rx 和 Tx 路径、IP 选项、碎片和碎片整理及其必要性,以及转发数据包,这是 IPv4 的重要任务之一。
第五章和第六章专门讨论 IPv4 路由子系统。在第五章中,您将了解路由子系统中的查找是如何执行的,路由表是如何组织的,IPv4 路由子系统中使用了哪些优化,以及 IPv4 路由缓存的移除。第六章讨论高级路由主题,如多播路由、策略路由和多路径路由。
第七章试图解释邻近的子系统。您将了解 IPv4 中使用的 ARP 协议,IPv6 中使用的 NDISC 协议,以及这两种协议之间的一些差异。您还将了解 IPv6 中的重复地址检测(DAD)机制。
第八章讨论 IPv6 协议,这似乎是解决 IPv4 地址短缺的必然方案。本章介绍了 IPv6 的实施,并讨论了 IPv6 地址、IPv6 报头和扩展报头、IPv6 中的自动配置、Rx 路径和转发等主题。它还描述了 MLD 协议。
第九章讲述了 netfilter 子系统。您将了解 netfilter 挂钩及其注册方式、连接跟踪、IP 表和网络地址转换(NAT)以及连接跟踪和 NAT 使用的回调。
第十章讨论 IPsec,它是最复杂的网络子系统之一。像 ike 协议(在用户空间中实现)和 IPsec 的加密方面的主题被简单地讨论了(完整的讨论超出了本书的范围)。您将了解 XFRM 框架,它是 Linux IPsec 子系统的基础,以及它的两个最重要的结构:XFRM 策略和 XFRM 状态。简要介绍了 ESP 协议,以及传输模式下的 IPsec Rx 路径和 Tx 路径。这一章以 XFRM 查找的一节和 NAT 穿越的一小段结束。
第十一章描述了四种第 4 层协议,从最常用的协议 UDP 和 TCP 开始,以两种较新的协议 SCTP 和 DCCP 结束。
第十二章讨论 Linux (IEEE 802.11)中的无线技术。您将了解 mac80211 子系统及其实现、各种无线网络拓扑、节能模式以及 IEEE 802.11n 和数据包聚合。本章中还有一节专门讨论无线网状网络。
第十三章深入探讨 InfiniBand 子系统,这是一项在数据中心越来越受欢迎的技术。您将了解 RDMA 堆栈组织、InfiniBand 中的寻址、InfiniBand 数据包的组织以及 RDMA API。
第十四章以对高级主题的讨论结束了这本书,例如 Linux 名称空间,特别是网络名称空间、忙轮询套接字、蓝牙子系统、IEEE 802.15.4 子系统、近场通信(NFC)子系统、PCI 子系统等等。
附录 A“Linux API”和 C,“词汇表”,为书中讨论的许多主题提供了完整的参考信息。附录 B“网络管理”提供了使用 Linux 内核网络时需要的各种工具的信息。
约定
在整本书中,我保持了一贯的风格。所有代码片段,无论是在文本段落内还是在它们自己的行上,连同库路径、shell 命令、URL 和其他与代码相关的元素,都以等宽字体设置,就像这样。新术语用斜体表示,其他强调可能用粗体表示。
一、简介
这本书讨论了 Linux 内核网络栈的实现及其背后的理论。在接下来的几页中,您将看到对网络子系统及其架构的深入而详细的分析。我不会用与网络不直接相关的主题来增加您的负担,您可能会在阅读内核网络代码时遇到这些主题(例如,锁定和同步、SMP、原子操作等等)。关于这些主题有很多资源。另一方面,专注于内核网络本身的最新资源非常少。我的意思是主要描述包在 Linux 内核网络栈中的遍历及其与各种网络层和子系统的交互——以及各种网络协议是如何实现的。
这本书也不是一个繁琐的,逐行代码演练。我重点关注每个网络层实现的本质,以及导致这种实现的理论指导方针和原则。近年来,Linux 操作系统已经证明了自己是一个成功、可靠、稳定和受欢迎的操作系统。它的受欢迎程度似乎在稳步增长,种类繁多,从大型机、数据中心、核心路由器和 web 服务器到嵌入式设备,如无线路由器、机顶盒、医疗仪器、导航设备(如 GPS 设备)和消费电子设备。许多半导体供应商使用 Linux 作为他们的板支持包(bsp)的基础。Linux 操作系统始于 1991 年一个名叫 Linus Torvalds 的芬兰学生的项目,基于 UNIX 操作系统,被证明是一个严肃可靠的操作系统,是老牌专有操作系统的竞争对手。
Linux 最初是基于 Intel x86 的操作系统,但是已经移植到非常广泛的处理器上,包括 ARM、PowerPC、MIPS、SPARC 等等。基于 Linux 内核的 Android 操作系统在今天的平板电脑和智能手机中很常见,并且似乎有可能在未来的智能电视中获得普及。除了 Android 之外,Google 还贡献了一些合并到主线内核中的内核网络特性。
Linux 是一个开源项目,因此它比其他专有操作系统更有优势:它的源代码可以在通用公共许可证(GPL)下免费获得。其他开源操作系统,如不同类型的 BSD,就没那么受欢迎了。在这种情况下,我还应该提到 OpenSolaris 项目,该项目基于通用开发和分发许可证(CDDL)。这个由 Sun 微系统公司发起的项目并没有像 Linux 那样流行。在活跃的 Linux 开发人员的大型社区中,有些人代表他们工作的公司贡献代码,有些人自愿贡献代码。所有的内核开发过程都可以通过内核邮件列表访问。有一个中央邮件列表,Linux 内核邮件列表(LKML),,许多子系统都有自己的邮件列表。贡献代码是通过向适当的内核邮件列表和维护者发送补丁来完成的,这些补丁在邮件列表中讨论。
Linux 内核网络栈是 Linux 内核的一个非常重要的子系统。很难找到一个基于 Linux 的系统,无论是台式机、服务器、移动设备还是任何其他嵌入式设备,不使用任何类型的网络。即使在机器没有任何硬件网络设备的罕见情况下,当您使用 X-Windows 时,您仍然会使用网络(可能是无意识的),因为 X-Windows 本身是基于客户机-服务器网络的。从核心路由器到小型嵌入式设备,许多项目都与 Linux 网络堆栈有关。其中一些项目处理添加特定于供应商的特性。例如,一些硬件供应商在一些网络设备中实现通用分段卸载(GSO)。GSO 是内核网络堆栈的一项网络功能,它将 Tx 路径中的一个大数据包分成较小的数据包。许多硬件供应商在其网络设备的硬件中实现校验和。校验和是一种验证数据包在传输过程中未被损坏的机制,通过计算数据包中的一些哈希并将其附加到数据包中。许多项目为 Linux 提供了一些安全性增强。有时候,这些增强需要在网络子系统中做一些改变,例如,你会在第三章中看到,当讨论 Openwall GNU/*/Linux 项目时。例如,在嵌入式设备领域,有许多基于 Linux 的无线路由器;运行 Linux 的 WRT54GL Linksys 路由器就是一个例子。还有一个开源的、基于 Linux 的操作系统,可以在这个设备(以及其他一些设备)上运行,名为 OpenWrt,拥有一个庞大而活跃的开发者社区(见https://openwrt.org/)。了解 Linux 内核网络栈是如何实现各种协议的,并熟悉其中的主要数据结构和包的主要路径,对于更好地理解它是必不可少的。
Linux 网络堆栈
根据开放系统互连(OSI)模型,有七个逻辑网络层。最低层是物理层,即硬件,最高层是应用层,用户空间软件进程在此运行。让我们来描述这七层:
- 物理层: 处理电信号和底层细节。
- 数据链路层: 处理端点之间的数据传输。最常见的数据链路层是以太网。Linux 以太网设备驱动程序位于这一层。
- 网络层: 处理包转发和主机寻址。在本书中,我讨论了 Linux 内核网络子系统最常见的网络层:IPv4 或 IPv6。Linux 还实现了其他一些不太常见的网络层,比如 DECnet,但我们不会讨论它们。
- 协议层/传输层: 处理节点间的数据发送。TCP 和 UDP 协议是最著名的协议。
- 会话层: 处理端点之间的会话。
- 表示层: 处理交付和格式化。
- 应用层: 为最终用户应用提供网络服务。
图 1-1 显示了 OSI 模型的七层。
图 1-1 。OSI 七层模型
图 1-2 显示了 Linux 内核网络栈处理的三层。此图中的 L2、L3 和 L4 层分别对应于七层模型中的数据链路层、网络层和传输层。Linux 内核栈的本质是将传入的数据包从 L2(网络设备驱动程序)传递到 L3(网络层,通常是 IPv4 或 IPv6) ,然后传递到 L4(传输层,在那里你有,例如,TCP 或 UDP 监听套接字),如果它们是用于本地传递,或者当数据包应该被转发时返回到 L2 进行传输。本地生成的传出数据包从 L4 传递到 L3,然后通过网络设备驱动程序传递到 L2 进行实际传输。沿着这条路有许多阶段,许多事情会发生。例如:
- 由于协议规则(例如,由于 IPsec 规则或 NAT 规则),数据包可以被改变。
- 该分组可以被丢弃。
- 该数据包会导致发送错误消息。
- 该分组可以被分段。
- 可以对数据包进行碎片整理。
- 应该为数据包计算校验和。
图 1-2 。Linux 内核网络层
内核不处理 L4 以上的任何层;这些层(会话层、表示层和应用层)由用户空间应用单独处理。物理层(L1)也不由 Linux 内核处理。
如果你感到不知所措,不要担心。在接下来的章节中,你将会更深入地了解这里所描述的一切。
网络设备
如图 1-2 中的所示,下层,第二层(L2)是链路层。网络设备驱动程序位于这一层。这本书不是关于网络设备驱动程序开发的,因为它关注的是 Linux 内核网络栈。我将在这里简单描述一下代表网络设备的net_device结构,以及与之相关的一些概念。为了更好地理解网络堆栈,您应该对网络设备结构有一个基本的了解。设备的参数(如 MTU 的大小,以太网设备通常为 1,500 字节)决定了数据包是否应该被分段。net_device是一个非常大的结构,由如下设备参数组成:
- 设备的 IRQ 号。
- 设备的 MTU。
- 设备的 MAC 地址。
- 设备的名称(如
eth0或eth1)。 - 设备的标志(例如,是打开还是关闭)。
- 与设备相关的多播地址列表。
promiscuity计数器(将在本节稍后讨论)。- 设备支持的功能(如 GSO 或 GRO 卸载)。
- 网络设备回调的一个对象(
net_device_opsobject),由函数指针组成,比如打开和停止一个设备,开始传输,改变网络设备的 MTU 等等。 - 一个
ethtool回调的对象,它支持通过运行命令行ethtool实用程序来获取关于设备的信息。 - 当设备支持多队列时,发送和接收队列的数量。
- 此设备上最后一次传输数据包的时间戳。
- 此设备上最后一次接收数据包的时间戳。
下面是一些net_device结构成员的定义,给你一个初步印象:
struct net_device {
unsigned int irq; /* device IRQ number */
. . .
const struct net_device_ops *netdev_ops;
. . .
unsigned int mtu;
. . .
unsigned int promiscuity;
. . .
unsigned char *dev_addr;
. . .
};
(include/linux/netdevice.h)
本书的附录 A 包含了对net_device结构及其大部分成员的详细描述。在那个附录中你可以看到irq、mtu以及本章前面提到的其他成员。
当promiscuity计数器大于 0 时,网络堆栈不会丢弃目的地不是本地主机的数据包。例如,像tcpdump和wireshark这样的数据包分析器(“嗅探器”)就使用这种方法,它们在用户空间中打开原始套接字,并希望接收这种类型的流量。它是一个计数器,而不是一个布尔值,以便能够同时打开几个嗅探器:打开每一个这样的嗅探器都会使计数器加 1。当嗅探器关闭时,promiscuity计数器减 1;如果达到 0,则不再有嗅探器运行,设备退出混杂模式。
在浏览内核联网核心源代码时,在各个地方你很可能会遇到 NAPI (New API)这个术语,这是现在大多数网络设备驱动都实现的一个特性。你应该知道它是什么,为什么网络设备驱动程序使用它。
网络设备中的新 API (NAPI)
旧的网络设备驱动程序工作在中断驱动模式下,这意味着对于每个收到的数据包,都有一个中断。事实证明,这在高负载流量下的性能方面是低效的。一种新的软件技术被开发出来,称为新 API (NAPI),现在几乎所有的 Linux 网络设备驱动程序都支持它。NAPI 最初是在 2.5/2.6 内核中引入的,后来被移植到 2.4.20 内核中。对于 NAPI,在高负载下,网络设备驱动程序工作在轮询模式,而不是中断驱动模式。这意味着每个收到的包不会触发中断。相反,数据包被缓存在驱动程序中,内核不时地轮询驱动程序以获取数据包。使用 NAPI 可以提高高负载下的性能。对于需要尽可能低的延迟并愿意为更高的 CPU 利用率付出代价的套接字应用,Linux 从内核 3.11 和更高版本添加了对套接字进行繁忙轮询的功能。这项技术将在第十四章的“忙轮询套接字”一节中讨论。
有了关于网络设备的新知识,现在是时候了解包在 Linux 内核网络栈中的遍历了。
接收和发送数据包
网络设备驱动程序的主要任务如下:
- 接收目的地为本地主机的数据包,并将它们传递到网络层(L3),然后从那里传递到传输层(L4)
- 传输本地主机生成并发送到外部的传出数据包,或者转发本地主机收到的数据包
对于每个数据包,无论是传入的还是传出的,都会在路由子系统中进行查找。基于路由子系统中的查找结果来决定是否应该转发数据包以及应该在哪个接口上发送数据包,我将在第五章和第六章中对此进行详细描述。路由子系统中的查找并不是决定数据包在网络堆栈中遍历的唯一因素。例如,网络堆栈中有五个点可以注册 netfilter 子系统(通常称为 netfilter 钩子)的回调。在执行路由查找之前,接收到的数据包的第一个 netfilter 挂钩点是 NF_INET_PRE_ROUTING。当一个包被这样一个回调处理时,这个回调由一个名为 NF_HOOK()的宏调用,它将根据这个回调的结果继续在网络堆栈中遍历(也称为verdict)。例如,如果verdict是 NF_DROP,数据包将被丢弃,如果verdict是 NF_ACCEPT,数据包将照常继续遍历。Netfilter 钩子回调由nf_register_hook()方法或nf_register_hooks()方法注册,例如,在各种 netfilter 内核模块中,你会遇到这些调用。内核 netfilter 子系统是众所周知的iptables用户空间包的基础设施。第九章描述了 netfilter 子系统和 netfilter 挂钩,以及 netfilter 的连接跟踪层。
除了 netfilter 挂钩之外,数据包遍历还会受到 IPsec 子系统的影响,例如,当它与配置的 IPsec 策略匹配时。IPsec 提供了一个网络层安全解决方案,它使用 ESP 和 AH 协议。根据 IPv6 规范,IPsec 是强制性的,而在 IPv4 中是可选的,尽管包括 Linux 在内的大多数操作系统也在 IPv4 中实现了 IPsec。IPsec 有两种操作模式:传输模式和隧道模式。它被用作许多虚拟专用网络(VPN) 解决方案、的基础,尽管也有非 IPsec VPN 解决方案。您将在第十章中了解 IPsec 子系统和 IPsec 策略,该章还讨论了通过 NAT 使用 IPsec 时出现的问题,以及 IPsec NAT 穿越解决方案。
还有其他因素会影响数据包的遍历,例如,正在转发的数据包的 IPv4 报头中的ttl字段的值。此ttl在每个转发设备中递减 1。当它达到 0 时,数据包被丢弃,并且发送回一个带有“超过 TTL 计数”代码的“超时”ICMPv4 消息。这样做是为了避免由于某些错误而导致转发数据包的无休止的旅程。此外,每次成功转发数据包并且ttl减 1 时,都应该重新计算 IPv4 报头的校验和,因为其值取决于 IPv4 报头,并且ttl是 IPv4 报头成员之一。第四章,处理 IPv4 子系统,更多的谈论这个。在 IPv6 中有一些类似的东西,但是 IPv6 报头中的跳计数器被命名为hop_limit而不是ttl。您将在第八章中了解到这一点,该章涉及 IPv6 子系统。您还将在第三章的中了解 IPv4 和 IPv6 中的 ICMP。
该书的很大一部分讨论了数据包在网络堆栈中的遍历,无论是在接收路径(Rx 路径,也称为入口流量)还是传输路径(Tx 路径,也称为出口流量)。这种遍历是复杂的,并且有许多变化:大的包在发送之前可能被分段;另一方面,应该将碎片化的数据包组装起来(在第四章的中讨论)。不同类型的数据包被不同地处理。例如,多播数据包是可以由一组主机处理的数据包(与单播数据包相反,单播数据包的目的地是指定的主机)。例如,多播可以用于流媒体应用中,以便消耗更少的网络资源。处理 IPv4 多播流量在第四章的中讨论。您还将了解主机如何加入和离开多播组;在 IPv4 中,互联网组管理协议(IGMP)协议处理多播成员资格。然而,也有主机被配置为组播路由器的情况,组播流量应该被转发而不是传送到本地主机。这些情况更加复杂,因为它们应该与用户空间多播路由守护进程一起处理,如pimd守护进程或mrouted守护进程。这些情况称为多播路由,在第六章中讨论。
为了更好地理解包遍历,您必须了解包在 Linux 内核中是如何表示的。sk_buff结构表示一个输入或输出的数据包,包括其报头(include/linux/skbuff.h)。在本书的许多地方,我将一个sk_buff对象称为 SKB,因为这是表示sk_buff对象的通用方式(SKB 代表套接字缓冲区)。套接字缓冲区(sk_buff)结构是一个很大的结构——在本章中我将只讨论这个结构的几个成员。
套接字缓冲区
sk_buff结构在附录 A 中有详细描述。当你需要了解更多关于 SKB 成员或者如何使用 SKB API 时,我推荐你参考这个附录。请注意,在使用 SKBs 时,您必须遵守 SKB API。因此,举例来说,当你想要推进skb->data指针时,你不直接这样做,而是用skb_pull_inline()方法或skb_pull()方法(你将在本节后面看到一个这样的例子)。如果您想从 SKB 获取 L4 报头(传输报头),您可以通过调用skb_transport_header()方法来完成。同样,如果您想获取 L3 报头(网络报头),您可以通过调用skb_network_header()方法来完成,如果您想获取 L2 报头(MAC 报头),您可以通过调用skb_mac_header()方法来完成。这三种方法将 SKB 作为单个参数。
下面是sk_buff结构的(部分)定义:
struct sk_buff {
. . .
struct sock *sk;
struct net_device *dev;
. . .
__u8 pkt_type:3,
. . .
__be16 protocol;
. . .
sk_buff_data_t tail;
sk_buff_data_t end;
unsigned char *head,
*data;
sk_buff_data_t transport_header;
sk_buff_data_t network_header;
sk_buff_data_t mac_header;
. . .
};
(include/linux/skbuff.h)
当网络上接收到一个数据包时,网络设备驱动程序会分配一个 SKB,通常是通过调用netdev_alloc_skb()方法(或dev_alloc_skb()方法,这是一个调用第一个参数为空的netdev_alloc_skb()方法的遗留方法)。在包遍历的过程中,有时会丢弃一个包,这是通过调用kfree_skb()或dev_kfree_skb()来实现的,这两个函数都以单个参数的形式获得一个指向 SKB 的指针。SKB 的一些成员是在链路层(L2)确定的。例如,pkt_type由eth_type_trans()方法根据目的以太网地址确定。如果这个地址是组播地址,pkt_type将被设置为 PACKET _ MULTICAST 如果该地址是广播地址,则pkt_type将被设置为 PACKET _ BROADCAST 如果这个地址是本地主机的地址,那么pkt_type将被设置为 PACKET_HOST。大多数以太网网络驱动程序在它们的 Rx 路径中调用eth_type_trans()方法。eth_type_trans()方法还根据以太网报头的ethertype设置 SKB 的protocol字段。eth_type_trans()方法还通过调用skb_pull_inline()方法将 SKB 的data指针提前 14 (ETH_HLEN),这是以太网报头的大小。这样做的原因是skb->data应该指向它当前所在的层的头。当数据包在 L2 时,在网络设备驱动程序的 Rx 路径中,skb->data指向了 L2(以太网)报头;既然数据包将被移动到第 3 层,在调用eth_type_trans()方法后,skb->data将立即指向网络(L3)报头,这在以太网报头后立即开始(见图 1-3 )。
图 1-3 。一个 IPv4 数据包
SKB 包括数据包报头(L2、L3 和 L4 报头)和数据包有效载荷。在网络堆栈中的数据包遍历中,可以添加或删除报头。例如,对于由套接字在本地生成并传输到外部的 IPv4 数据包,网络层(IPv4)会在 SKB 中添加 IPv4 报头。IPv4 报头大小最小为 20 字节。添加 IP 选项时,IPv4 报头最大可达 60 字节。IP 选项在第四章中描述,该章讨论了 IPv4 协议的实现。图 1-3 显示了一个带有 L2、L3 和 L4 报头的 IPv4 数据包的例子。图 1-3 中的例子是一个 UDPv4 包。首先是 14 字节的以太网报头(L2)。然后是最小大小为 20 字节到 60 字节的 IPv4 报头(L3 ),之后是 8 字节的 UDPv4 报头(L4)。然后是数据包的有效载荷。
每个 SKB 都有一个dev成员,它是net_device结构的一个实例。对于传入数据包,它是传入网络设备,对于传出数据包,它是传出网络设备。有时需要连接到 SKB 的网络设备来获取信息,这些信息可能会影响 SKB 在 Linux 内核网络堆栈中的遍历。例如,如前所述,网络设备的 MTU 可能需要分段。每个传输的 SKB 都有一个与之关联的sock对象(sk)。如果数据包是转发的数据包,那么sk为空,因为它不是在本地主机上生成的。
每个收到的数据包都应该由匹配的网络层协议处理程序来处理。例如,IPv4 数据包应该由ip_rcv()方法处理,IPv6 数据包应该由ipv6_rcv()方法处理。您将在第四章的中学习使用dev_add_pack()方法注册 IPv4 协议处理程序,并在第八章的中学习使用dev_add_pack()方法注册 IPv6 协议处理程序。此外,我将跟踪 IPv4 和 IPv6 中传入和传出数据包的遍历。例如,在ip_rcv()方法中,大多数情况下会执行健全性检查,如果一切正常,数据包会进入 NF_INET_PRE_ROUTING 钩子回调(如果此回调已注册),如果此钩子没有丢弃数据包,则下一步是ip_rcv_finish()方法,在路由子系统中执行查找。路由子系统中的查找建立了目的缓存条目(dst_entry对象)。在描述 IPv4 路由子系统的第五章和第六章中,您将了解到dst_entry以及与之相关的input和output回调方法。
在 IPv4 中,存在地址空间有限的问题,因为 IPv4 地址只有 32 位。组织使用 NAT(在第九章中讨论)向其主机提供本地地址,但 IPv4 地址空间仍在逐年减少。开发 IPv6 协议的主要原因之一是,与 IPv4 地址空间相比,它的地址空间非常大,因为 IPv6 地址长度为 128 位。但是 IPv6 协议不仅仅是关于更大的地址空间。IPv6 协议包含了许多变化和补充,这是多年来使用 IPv4 协议所获得的经验的结果。例如,与 IPv4 报头相比,IPv6 报头具有 40 字节的固定长度,而 IP v4 报头的长度是可变的(从最小 20 字节到 60 字节),这是由于 IP 选项可以扩展它。在 IPv4 中处理 IP 选项是复杂的,并且在性能方面相当繁重。另一方面,在 IPv6 中,您根本无法扩展 IPv6 报头(如上所述,它的长度是固定的)。取而代之的是一种扩展报头机制,它在性能方面比 IPv4 中的 IP 选项更有效。另一个显著的变化是 ICMP 协议;在 IPv4 中,它仅用于错误报告和信息性消息。在 IPv6 中,ICMP 协议用于许多其他目的:邻居发现(ND)、多播侦听发现(MLD)等等。第三章专门针对 ICMP(IP v4 和 IPv6)。IPv6 邻居发现协议在第七章的中描述,MLD 协议在第八章的中讨论,它涉及 IPv6 子系统。
如前所述,收到的数据包由网络设备驱动程序传递到网络层,即 IPv4 或 IPv6。如果数据包用于本地传送,它们将被传送到传输层(L4)以供监听套接字处理。最常见的传输协议是 UDP 和 TCP,在第十一章中讨论,其中讨论了第 4 层,即传输层。本章还介绍了两种较新的传输协议,即流控制传输协议(SCTP)和数据报拥塞控制协议(DCCP)。你会发现,SCTP 和 DCCP 都采用了一些 TCP 特性和 UDP 特性。已知 SCTP 协议与长期演进(LTE)协议结合使用;到目前为止,DCCP 还没有在更大规模的互联网环境中测试过。
本地主机生成的数据包由第 4 层套接字创建,例如 TCP 套接字或 UDP 套接字。它们是由用户空间应用用套接字 API 创建的。套接字主要有两种:数据报套接字和流套接字。这两种类型的套接字和基于 POSIX 的套接字 API 也将在第十一章中讨论,在那里您还将了解套接字的内核实现(struct socket,它提供了到用户空间的接口,struct sock,它提供了到第 3 层的接口)。本地生成的数据包被传递到网络层 L3(在第四章的【发送 IPv4 数据包】一节中描述),然后被传递到网络设备驱动程序(L2)进行传输。在有些情况下,碎片发生在第 3 层,即网络层,这也在第四章的中讨论。
每个第 2 层网络接口都有一个 L2 地址来标识它。在以太网的情况下,这是一个 48 位地址,由制造商为每个以太网网络接口分配的 MAC 地址,据说是唯一的(尽管您应该考虑到大多数网络接口的 MAC 地址可以通过用户空间命令如ifconfig或ip来更改)。每个以太网数据包都以一个 14 字节长的以太网报头开始。它由以太网类型(2 字节)、源 MAC 地址(6 字节)和目的 MAC 地址(6 字节)组成。例如,IPv4 的以太网类型值为 0x0800,IPv6 的以太网类型值为 0x86DD。对于每个传出的数据包,应该构建一个以太网报头。当用户空间套接字发送一个包时,它指定其目的地址(可以是 IPv4 或 IPv6 地址)。这不足以构建数据包,因为目的 MAC 地址应该是已知的。根据 IP 地址找到主机的 MAC 地址是相邻子系统的任务,在第七章的中讨论。邻居发现由 IPv4 中的 ARP 协议和 IPv6 中的 NDISC 协议处理。这些协议是不同的:ARP 协议依赖于发送广播请求,而 NDISC 协议依赖于发送 ICMPv6 请求,这些请求实际上是多播数据包。ARP 协议和 NDSIC 协议也在第七章中讨论。
网络堆栈应该与用户空间进行通信,以执行诸如添加或删除路由、配置邻居表、设置 IPsec 策略和状态等任务。用户空间和内核之间的通信是通过 netlink 套接字完成的,在第二章中有所描述。基于 netlink 套接字的用户空间包也在第二章的中讨论,以及通用 netlink 套接字及其优点。
无线子系统将在第十二章中讨论。如前所述,这个子系统是单独维护的;它有自己的树和自己的邮件列表。无线堆栈中有一些普通网络堆栈中不存在的独特功能,例如省电模式(当工作站或接入点进入睡眠状态时)。Linux 无线子系统还支持特殊的拓扑,,比如网状网络、自组织网络等等。这些拓扑有时需要使用特殊功能。例如,网状网络使用一种叫做混合无线网状协议(HWMP)的路由协议,在第十二章中讨论。该协议工作在第 2 层,处理 MAC 地址,与 IPV4 路由协议相反。第十二章还讨论了 mac80211 框架,无线设备驱动程序使用它。无线子系统的另一个非常有趣的特性是 IEEE 802.11n 中的块确认机制,也在第十二章中讨论过。
近年来,InfiniBand 技术在企业数据中心越来越受欢迎。InfiniBand 基于一种称为远程直接内存访问(RDMA)的技术。在版本 2.6.11 中,RDMA API 被引入到 Linux 内核中。在第十三章中,你会找到关于 Linux Infiniband 实现、RDMA API 及其基本数据结构的很好的解释。
虚拟化解决方案也变得越来越受欢迎,尤其是由于 Xen 或 KVM 等项目。此外,硬件的改进,如用于英特尔处理器的 VT-x 或用于 AMD 处理器的 AMD-V,使虚拟化更加高效。还有另一种形式的虚拟化,可能不太为人所知,但有自己的优势。这种虚拟化基于一种不同的方法:流程虚拟化。它在 Linux 中是通过名称空间实现的。Linux 目前支持六种名称空间,将来可能会有更多。名称空间特性已经被 Linux Containers ( http://lxc.sourceforge.net/)和 Userspace 中的 check point/Restore(CRIU)等项目所使用。为了支持名称空间,内核中增加了两个系统调用:unshare()和setns();六个新标志被添加到 CLONE_标志中,每个标志对应一种名称空间类型。我在第十四章中特别讨论了名称空间和网络名称空间。第十四章也讨论了蓝牙子系统,并简要介绍了 PCI 子系统,因为许多网络设备驱动程序都是 PCI 设备。我不深入研究 PCI 子系统内部,因为那超出了本书的范围。第十四章中讨论的另一个有趣的子系统是 IEEE 8012.15.4,它适用于低功耗和低成本设备。这些设备有时会与物联网* (IoT) 概念一起提及,后者涉及将支持 IP 的嵌入式设备连接到 IP 网络。事实证明,在这些设备上使用 IPv6 可能是个好主意。该解决方案被称为低功率无线个人区域网上的 IPv6(6 lowpan)。它有自己的挑战,例如扩展 IPv6 邻居发现协议以适合这种偶尔进入睡眠模式的设备(与普通 IPv6 网络相反)。IPv6 邻居发现协议的这些变化还没有实现,但是考虑这些变化背后的理论是很有趣的。除此之外,在第十四章中还有关于其他高级主题的章节,如 NFC、cgroups、Android 等等。
为了更好地理解 Linux 内核网络栈或参与其开发,您必须熟悉其开发是如何处理的。
Linux 内核网络开发模型
内核网络子系统非常复杂,它的开发相当动态。像任何 Linux 内核子系统一样,开发是由通过邮件列表(有时不止一个邮件列表)发送的git补丁完成的,这些补丁最终被该子系统的维护者接受或拒绝。出于许多原因,了解内核网络开发模型是很重要的。为了更好地理解代码,为了调试和解决基于 Linux 内核网络的项目中的问题,为了实现性能改进和优化补丁,或者为了实现新的特性,在许多情况下,您需要学习很多东西,例如:
- 如何应用补丁
- 如何阅读和解释补丁
- 如何找到可能导致给定问题的修补程序
- 如何恢复修补程序
- 如何找到与某些功能相关的补丁
- 如何将项目调整到旧的内核版本(反向移植)
- 如何将项目调整到较新的内核版本(升级)
- 如何克隆一棵树
- 如何重置一棵
git树 - 如何找出在哪个内核版本中应用了指定的
git补丁
有些情况下,您需要使用刚刚添加的新功能,为此,您需要知道如何使用最新的、前沿的树。有些情况下,当您遇到一些 bug,或者您想要向网络堆栈添加一些新功能时,您需要准备一个补丁并提交它。与内核的其他部分一样,Linux 内核网络子系统由 Linus Torvalds 开发的源代码管理(SCM)系统git管理。如果你打算为主线内核发送补丁,或者如果你的项目由git管理,你必须学会使用git工具。
有时你甚至需要安装一个git服务器来开发本地项目。即使您不打算发送任何补丁,您也可以使用git工具来检索大量关于代码和代码开发历史的信息。网上有很多关于git的资源;我推荐斯科特·沙孔的免费在线书籍 Pro Git ,在http://git-scm.com/book可以买到。如果您打算将您的补丁提交到主线,您必须遵守一些关于编写、检查和提交补丁的严格规则,这样您的补丁才会被应用。您的补丁应该符合内核编码风格,并且应该经过测试。你还需要有耐心,因为有时即使是微不足道的补丁也要过几天才能贴上。我建议学习配置一台主机,使用git send-email命令提交补丁(尽管提交补丁可以用其他邮件客户端完成,甚至是流行的 Gmail 网络邮件客户端)。网上有很多关于如何使用git准备和发送内核补丁的指南。我还建议在提交你的第一个补丁之前阅读内核树中的Documentation/SubmittingPatches和Documentation/CodingStyle。
我推荐使用以下 PERL 脚本:
scripts/checkpatch.pl检查补丁的正确性- 要找出补丁应该发给哪个维护者
最重要的信息资源之一是内核网络开发邮件列表,netdev : netdev@vger.kernel.org,存档在www.spinics.net/lists/netdev。这是一个高容量列表。大多数帖子是新代码的补丁和征求意见稿(RFC ),以及关于补丁的评论和讨论。这个邮件列表处理 Linux 内核网络堆栈和网络设备驱动程序,除了处理具有特定邮件列表和特定git存储库的子系统的情况(例如无线子系统,在第十二章中讨论)。iproute2和ethtool用户空间包的开发也在netdev邮件列表中处理。这里应该提到的是,并不是每个网络子系统都有自己的邮件列表;例如,IPsec 子系统(在第十章中讨论)没有邮件列表,IEEE 802.15.4 子系统也没有邮件列表。一些网络子系统有自己特定的git树、维护者和邮件列表,比如无线邮件列表和蓝牙邮件列表。这些子系统的维护者不时通过netdev邮件列表发送对他们的git树的请求。另一个信息来源是内核树中的Documentation/networking。它在许多文件中包含了关于各种网络主题的大量信息,但是请记住,您在那里找到的文件并不总是最新的。
Linux 内核网络子系统在两个git存储库中维护。补丁和 RFC 被发送到两个存储库的netdev邮件列表。这是两株git树:
- net:
http://git.kernel.org/?p=linux/kernel/git/davem/net.git:针对主线树中已经存在的代码进行修复 - net-next:
http://git.kernel.org/?p=linux/kernel/git/davem/net-next.git:未来内核发布的新代码
网络子系统的维护者 David Miller 不时通过 LKML 向 Linus 发送对这些git树的主线的拉请求。你应该知道,在与主线合并的过程中,有一段时间 net-next git树是关闭的,不应该发送补丁。通过netdev邮件列表发送一个通知,告知这段时间何时开始,另一个通知何时结束。
注本书基于内核 3.9。所有代码片段都来自这个版本,除非另有明确说明。内核树可以从
www.kernel.org作为一个tar文件获得。或者,您可以下载一个带有git clone的内核git树(例如,使用前面提到的git net树或git net-next树的 URL,或者其他git内核库)。互联网上有很多关于如何配置、构建和引导 Linux 内核的指南。也可以在http://lxr.free-electrons.com/在线浏览各种内核版本。这个网站让你了解每个方法和每个变量被引用的地方;此外,您可以通过点击鼠标轻松导航到 Linux 内核的以前版本。如果您正在使用您自己版本的 Linux 内核树,其中一些更改是在本地进行的,您可以在本地 Linux 机器上本地安装和配置 Linux 交叉引用服务器(LXR)。参见http://lxr.sourceforge.net/en/index.shtml。
摘要
本章是对 Linux 内核网络子系统的简短介绍。我描述了使用 Linux(一个流行的开源项目)和内核网络开发模型的好处。我还描述了网络设备结构(net_device)和套接字缓冲区结构(sk_buff),这是网络子系统的两个最基本的结构。你应该参考附录 A 中关于这些结构的几乎所有成员及其用途的详细描述。本章涵盖了与数据包在内核网络堆栈中的遍历相关的其他重要主题,例如路由子系统中的查找、碎片和碎片整理、协议处理程序注册等。其中一些协议将在后面的章节中讨论,包括 IPv4、IPv6、ICMP4 和 ICMP6、ARP 和邻居发现。几个重要的子系统,包括无线子系统、蓝牙子系统和 IEEE 812.5.4 子系统,也将在后面的章节中介绍。第二章从 netlink sockets 开始内核网络堆栈之旅,它提供了一种用户空间和内核之间的双向通信方式,这将在其他几章中讨论。
二、网络链接套接字
第一章讨论了 Linux 内核网络子系统的角色及其运行的三个层次。netlink socket 接口最早出现在 2.2 Linux 内核中,名为 AF_NETLINK socket。它是作为用户空间进程和内核之间笨拙的 IOCTL 通信方法的一种更灵活的替代方法而创建的。IOCTL 处理程序不能从内核向用户空间发送异步消息,而 netlink 套接字可以。为了使用 IOCTL,还有另一层复杂性:您需要定义 IOCTL 编号。netlink 的操作模型非常简单:您使用 socket API 在用户空间中打开并注册一个 netlink socket,这个 netlink socket 处理与内核 netlink socket 的双向通信,通常发送消息来配置各种系统设置,并从内核获得响应。
本章描述了 netlink 协议的实现和 API,并讨论了它的优点和缺点。我还谈到了新的通用 netlink 协议,讨论了它的实现及其优点,并给出了一些使用libnl库的示例。最后,我讨论了套接字监控接口。
Netlink 系列
netlink 协议是基于套接字的进程间通信(IPC)机制,基于 RFC 3549,“Linux Netlink 作为 IP 服务协议”它在用户空间和内核之间或者内核本身的某些部分之间提供了一个双向通信通道。Netlink 是标准套接字实现的扩展。netlink 协议实现主要位于net/netlink下,在这里您可以找到以下四个文件:
af_netlink.caf_netlink.hgenetlink.cdiag.c
除了它们之外,还有一些头文件。其实最常用的是af_netlink模块;它提供了 netlink 内核套接字 API,而genetlink模块提供了一个新的通用 netlink API,使用它可以更容易地创建 netlink 消息。diag监控接口模块(diag.c)提供一个 API 来转储和获取关于 netlink 套接字的信息。我将在本章后面的“套接字监控接口”一节中讨论diag模块
我应该在这里提到,理论上 netlink 套接字可以用于两个或更多用户空间进程之间的通信(包括发送多播消息),尽管这通常不被使用,也不是 netlink 套接字的最初目标。UNIX 域套接字为 IPC 提供了一个 API,它们广泛用于两个用户空间进程之间的通信。
与用户空间和内核之间的其他通信方式相比,Netlink 有一些优势。例如,当使用 netlink 套接字时,不需要轮询。一个用户空间应用打开一个 socket 然后调用recvmsg(),如果内核没有发送消息就进入阻塞状态;例如,参见iproute2包的rtnl_listen()方法(lib/libnetlink.c)。另一个优点是内核可以发起向用户空间发送异步消息,而不需要用户空间触发任何动作(例如,通过调用某个 IOCTL 或者通过写入某个sysfs条目)。另一个优点是 netlink 套接字支持多播传输。
您可以使用socket()系统调用从用户空间创建 netlink 套接字。netlink 套接字可以是 SOCK_RAW 套接字或 SOCK_DGRAM 套接字。
Netlink 套接字可以在内核或用户空间中创建;内核 netlink 套接字由netlink_kernel_create()方法创建;和用户空间 netlink 套接字由socket()系统调用创建。从用户空间或内核创建 netlink 套接字会创建一个netlink_sock对象。当从用户空间创建套接字时,它由netlink_create()方法处理。在内核中创建套接字时,由__netlink_kernel_create()处理;此方法设置 NETLINK_KERNEL_SOCKET 标志。最终,两个方法都调用__netlink_create()以公共方式分配一个套接字(通过调用sk_alloc()方法)并初始化它。图 2-1 显示了如何在内核和用户空间中创建 netlink 套接字。
图 2-1 。在内核和用户空间中创建 netlink 套接字
您可以从用户空间创建一个 netlink 套接字,方法与普通 BSD 风格的套接字非常相似,例如:socket(AF_NETLINK, SOCK_RAW, NETLINK_ROUTE)。然后你应该创建一个sockaddr_nl对象(netlink 套接字地址结构的实例),初始化它,并使用标准的 BSD 套接字 API(比如bind()、sendmsg()、recvmsg()等等)。sockaddr_nl结构表示用户空间或内核中的 netlink 套接字地址。
Netlink 套接字库为 netlink 套接字提供了一个方便的 API。我将在下一节讨论它们。
Netlink 套接字库
我推荐您使用libnl API 来开发用户空间应用,它通过 netlink 套接字发送或接收数据。libnl包是为基于 netlink 协议的 Linux 内核接口提供 API 的库集合。如前所述,iproute2包使用了libnl库。除了核心库(libnl),它还支持通用的 netlink 家族(libnl-genl)、routing 家族(libnl-route)和 netfilter 家族(libnl-nf)。这个包主要是由托马斯·格拉夫开发的。这里我还应该提到一个叫做libmnl的库,它是一个面向 netlink 开发者的极简用户空间库。libmnl库主要由 Pablo Neira Ayuso 编写,Jozsef Kadlecsik 和 Jan Engelhardt 也有贡献。(http://netfilter.org/projects/libmnl/)。
sockaddr_nl 结构
我们来看一下sockaddr_nl结构,它代表一个 netlink 套接字地址:
struct sockaddr_nl {
__kernel_sa_family_t nl_family; /* AF_NETLINK */
unsigned short nl_pad; /* zero */
__u32 nl_pid; /* port ID */
__u32 nl_groups; /* multicast groups mask */
};
(include/uapi/linux/netlink.h)
nl_family:应该一直是 AF_NETLINK。nl_pad:应始终为 0。nl_pid:netlink 套接字的单播地址。对于内核 netlink sockets ,应该是 0。用户空间应用有时会将nl_pid设置为它们的进程 id (pid)。在用户空间应用中,当您将nl_pid显式设置为 0,或者根本不设置它,然后调用bind()时,内核方法netlink_autobind()会为nl_pid赋值。它尝试分配当前线程的进程 id。如果你在用户空间中创建两个套接字,那么你要负责它们的nl_pid是唯一的,以防你不调用 bind。Netlink 套接字不仅用于网络;其他子系统,如 SELinux、audit、uevent 等,使用 netlink 套接字。rtnelink 套接字是专门用于网络的 netlink 套接字;它们用于路由消息、相邻消息、链路消息和更多网络子系统消息。nl_groups:组播组(或组播组掩码)。
下一节将讨论iproute2和旧的net-tools包。iproute2包基于 netlink 套接字,在本章后面的“在路由表中添加和删除路由条目”一节中,您将在iproute2中看到一个使用 netlink 套接字的示例。我提到net-tools包,它比较老,将来可能会被弃用,以强调作为iproute2的替代,它的功率和能力都比较低。
用于控制 TCP/IP 网络的用户空间包
有两个用户空间包用于控制 TCP/IP 网络和处理网络设备:net-tools和iproute2。iproute2包包括如下命令:
ip:用于管理网络表和网络接口tc:用于交通管制管理ss:转储套接字统计lnstat:转储 linux 网络统计bridge:用于管理网桥地址和设备
iproute2包主要基于从用户空间向内核发送请求,并通过 netlink 套接字获得回复。在iproute2中使用 IOCTLs 也有一些例外。例如,ip tuntap命令使用 IOCTLs 来添加/删除一个 TUN/TAP 设备。如果您查看 TUN/TAP 软件驱动程序代码,您会发现它定义了一些 IOCTL 处理程序,但是它不使用 rtnetlink 套接字。net-tools包基于 IOCTLs,包括如下已知命令:
ifconifgarproutenetstathostnamerarp
iproute2包的一些高级功能在net-tools包中不可用。
下一节讨论内核 netlink 套接字——通过交换不同类型的 netlink 消息来处理用户空间和内核之间的通信的核心引擎。了解内核 netlink 套接字对于理解 netlink 层提供给用户空间的接口至关重要。
内核网络链接套接字
您可以在内核网络堆栈中创建几个 netlink 套接字。每个内核套接字处理不同类型的消息:例如,应该处理 netlink_ROUTE 消息的 NETLINK 套接字在rtnetlink_net_init() : 中创建
static int __net_init rtnetlink_net_init(struct net *net) {
...
struct netlink_kernel_cfg cfg = {
.groups = RTNLGRP_MAX,
.input = rtnetlink_rcv,
.cb_mutex = &rtnl_mutex,
.flags = NL_CFG_F_NONROOT_RECV,
};
sk = netlink_kernel_create(net, NETLINK_ROUTE, &cfg);
...
}
注意,rtnetlink 套接字知道网络名称空间;网络名称空间对象(struct net)包含一个名为rtnl ( rtnetlink套接字)的成员。在rtnetlink_net_init()方法中,通过调用netlink_kernel_create()创建 rtnetlink 套接字后,将其赋给相应网络名称空间对象的rtnl指针。
让我们看看netlink_kernel_create()原型:
struct sock *netlink_kernel_create(struct net *net, int unit, struct netlink_kernel_cfg *cfg)
-
第一个参数(
net)是网络名称空间。 -
第二个参数是 netlink 协议(例如,rtnetlink 消息的 NETLINK_ROUTE,IPsec 的 NETLINK_XFRM 或审计子系统的 NETLINK_AUDIT)。有 20 多种 netlink 协议,但它们的数量被限制为 32 (MAX_LINKS)。这是创建通用 netlink 协议的原因之一,你将在本章后面看到。netlink 协议的完整列表在
include/uapi/linux/netlink.h中。 -
第三个参数是对
netlink_kernel_cfg的引用,它由创建 netlink 套接字的可选参数组成:struct netlink_kernel_cfg { unsigned int groups; unsigned int flags; void (*input)(struct sk_buff *skb); struct mutex *cb_mutex; void (*bind)(int group); }; (include/uapi/linux/netlink.h)
groups成员用于指定多播组(或多播组的掩码)。可以通过设置sockaddr_nl对象的nl_groups来加入一个组播组(也可以通过libnl的nl_join_groups()方法来完成)。然而,这样你只能加入 32 个小组。从内核版本 2.6.14 开始,可以使用 NETLINK _ ADD _ MEMBERSHIP/NETLINK _ DROP _ MEMBERSHIP 套接字选项分别加入/离开一个多播组。使用套接字选项,您可以加入更多的组。libnl的nl_socket_add_memberships()/nl_socket_drop_membership()方法使用这个套接字选项。
flags成员可以是 NL_CFG_F_NONROOT_RECV 或 NL_CFG_F_NONROOT_SEND。
设置 CFG_F_NONROOT_RECV 时,非超级用户可以绑定到多播组;在netlink_bind()中有如下代码:
static int netlink_bind(struct socket *sock, struct sockaddr *addr,
int addr_len)
{
...
if (nladdr->nl_groups) {
if (!netlink_capable(sock, NL_CFG_F_NONROOT_RECV))
return -EPERM;
}
对于非超级用户,如果没有设置 NL_CFG_F_NONROOT_RECV,那么当绑定到一个多播组时,netlink_capable()方法将返回 0,并且您将得到–EPRM 错误。
当 NL_CFG_F_NONROOT_SEND 标志被设置时,允许非超级用户发送多播。
input成员用于回调;当netlink_kernel_cfg中的input成员为空时,内核套接字将无法从用户空间接收数据(尽管从内核向用户空间发送数据是可能的)。对于 rtnetlink 内核套接字,rtnetlink_rcv()方法被声明为input回调;因此,从用户空间通过 rtnelink 套接字发送的数据将由rtnetlink_rcv()回调处理。
对于uevent内核事件,你只需要将数据从内核发送到用户空间;因此,在lib/kobject_uevent.c中,你有一个 netlink 套接字的例子,其中input回调是未定义的:
static int uevent_net_init(struct net *net)
{
struct uevent_sock *ue_sk;
struct netlink_kernel_cfg cfg = {
.groups = 1,
.flags = NL_CFG_F_NONROOT_RECV,
};
...
ue_sk->sk = netlink_kernel_create(net, NETLINK_KOBJECT_UEVENT, &cfg);
...
}
(lib/kobject_uevent.c)
netlink_kernel_cfg对象中的互斥(cb_mutex)是可选的;当没有定义互斥体时,使用默认的cb_def_mutex(互斥体结构的一个实例;参见net/netlink/af_netlink.c。事实上,大多数 netlink 内核套接字是在没有在netlink_kernel_cfg对象中定义互斥体的情况下创建的。比如前面提到的 uevent 内核 NETLINK socket(NETLINK _ ko object _ UEVENT)。此外,审计内核 netlink 套接字(NETLINK_AUDIT)和其他 NETLINK 套接字不定义互斥体。rtnetlink 套接字是一个例外,它使用rtnl_mutex。下一节讨论的通用 netlink 套接字也定义了自己的互斥锁:genl_mutex。
netlink_kernel_create()方法通过调用netlink_insert()方法在名为nl_table的表中创建一个条目。对nl_table的访问受名为nl_table_lock的读写锁保护;通过netlink_lookup()方法在该表中进行查找,指定协议和端口 id。指定消息类型的回调注册由rtnl_register()完成;在网络内核代码中有几个地方可以注册这样的回调。例如,在rtnetlink_init()中,你为一些消息注册回调,比如 RTM_NEWLINK(创建一个新链接)、RTM_DELLINK(删除一个链接)、RTM_GETROUTE(转储路由表)等等。在net/core/neighbour.c中,为 RTM_NEWNEIGH 消息(创建一个新邻居)、RTM_DELNEIGH(删除一个邻居)、RTM_GETNEIGHTBL 消息(转储邻居表)等等注册回调。我在第五章和第七章中深入讨论了这些行动。您还可以在 FIB 代码(ip_fib_init())、多播代码(ip_mr_init())、IPv6 代码和其他地方注册对其他类型消息的回调。
使用 netlink 内核套接字的第一步是注册它。我们来看看rtnl_register()方法原型:
extern void rtnl_register(int protocol, int msgtype,
rtnl_doit_func,
rtnl_dumpit_func,
rtnl_calcit_func);
第一个参数是protocol族(当你不针对某个特定协议时,是 PF _ UNSPEC);您将在include/linux/socket.h中找到所有协议族的列表。
第二个参数是 netlink 消息类型,比如 RTM_NEWLINK 或 RTM_NEWNEIGH。这些是 rtnelink 协议添加的专用 netlink 消息类型。消息类型的完整列表在include/uapi/linux/rtnetlink.h中。
最后三个参数是回调:doit、dumpit和calcit。回调是您想要执行的处理消息的动作,并且您通常只指定一个回调。
doit回调用于添加/删除/修改等动作;dumpit回调用于检索信息,calcit回调用于计算缓冲区大小。rtnetlink 模块有一个名为rtnl_msg_handlers的表。该表按协议编号进行索引。表中的每个条目本身就是一个表,按消息类型进行索引。表中的每个元素都是rtnl_link的一个实例,它是一个由这三个回调的指针组成的结构。用rtnl_register()注册回调时,将指定的回调添加到该表中。
注册回调是这样做的,比如:rtnl_register(PF_UNSPEC, RTM_NEWLINK, rtnl_newlink, NULL, NULL) in net/core/rtnetlink.c。这将在相应的rtnl_msg_handlers条目中添加rtnl_newlink作为 RTM_NEWLINK 消息的doit回调。
rtnelink 消息的发送通过rtmsg_ifinfo()完成。例如,在dev_open()中你创建了一个新链接,所以你调用了:rtmsg_ifinfo()方法中的rtmsg_ifinfo(RTM_NEWLINK, dev, IFF_UP|IFF_RUNNING);,首先调用了nlmsg_new()方法来分配一个大小合适的sk_buff。然后创建两个对象:netlink 消息头(nlmsghdr)和一个ifinfomsg对象,它位于 netlink 消息头之后。这两个对象由rtnl_fill_ifinfo()方法初始化。然后调用rtnl_notify()发送数据包;发送数据包实际上是通过通用网络链接方法nlmsg_notify()(在net/netlink/af_netlink.c中)完成的。图 2-2 显示了使用rtmsg_ifinfo()方法发送 rtnelink 消息的各个阶段。
图 2-2 。使用 rtmsg_ifinfo()方法发送 rtnelink 消息
下一节是关于 netlink 消息,它在用户空间和内核之间交换。netlink 消息总是以 netlink 消息头开始,因此学习 netlink 消息的第一步是研究 netlink 消息头格式。
Netlink 消息头
网络链接消息应该遵循 RFC 3549“作为 IP 服务协议的 Linux 网络链接”第 2.2 节“消息格式”中规定的特定格式 netlink 消息以固定大小的 netlink 报头开始,其后是有效载荷。本节描述 netlink 消息头的 Linux 实现。
netlink 报文头由include/uapi/linux/netlink.h : 中的struct nlmsghdr定义
struct nlmsghdr
{
__u32 nlmsg_len;
__u16 nlmsg_type;
__u16 nlmsg_flags;
__u32 nlmsg_seq;
__u32 nlmsg_pid;
};
(include/uapi/linux/netlink.h)
每个 netlink 数据包都以 netlink 消息头开始,用struct nlmsghdr表示。nlmsghdr的长度为 16 字节。它包含五个字段:
-
nlmsg_len是包括标题在内的消息长度。 -
nlmsg_type是报文类型;有四种基本的 netlink 报文头类型: -
NLMSG_NOOP:没有操作,消息必须被丢弃。
-
NLMSG_ERROR:出现错误。
-
NLMSG_DONE:多部分消息被终止。
-
NLMSG_OVERRUN: Overrun notification: error, data was lost.
(
include/uapi/linux/netlink.h)但是,系列可以添加他们自己的 netlink 消息头类型。例如,rtnetlink 协议族增加了 RTM_NEWLINK、RTM_DELLINK、RTM_NEWROUTE 等消息头类型(见
include/uapi/linux/rtnetlink.h)。有关 rtnelink 系列添加的 netlink 消息头类型的完整列表,以及对每种类型的详细解释,请参见:man 7 rtnetlink。注意,小于 NLMSG_MIN_TYPE (0x10)的消息类型值是为控制消息保留的,不能使用。 -
nlmsg_flags字段可以如下: -
NLM 请求:当它是一个请求消息时。
-
NLM_F_MULTI:当它是一个多部分的消息时。多部分消息用于表转储。通常消息的大小被限制为一个页面(PAGE_SIZE)。所以大消息被分成小消息,每个小消息(除了最后一个)都设置了 NLM_F_MULTI 标志。最后一条消息设置了 NLMSG_DONE 标志。
-
NLM_F_ACK:当你希望消息的接收者用 ACK 回复时。Netlink ACK 消息通过
netlink_ack()方法(net/netlink/af_netlink.c)发送。 -
NLM _ F _ 转储:检索关于表/条目的信息。
-
NLM 根:指定树根。
-
NLM_F_MATCH:返回所有匹配条目。
-
NLM_F_ATOMIC: This flag is deprecated.
以下标志是创建条目的修饰符:
-
NLM_F_REPLACE:覆盖现有条目。
-
NLM_F_EXCL:不要触摸入口,如果它存在。
-
NLM_F_CREATE:创建条目,如果它不存在。
-
NLM _ F _ 附加:将条目添加到列表末尾。
-
NLM_F_ECHO: Echo this request.
我已经展示了最常用的旗帜。完整列表见
include/uapi/linux/netlink.h。 -
nlmsg_seq是序列号(用于消息序列)。与某些第 4 层传输协议不同,序列号没有严格的强制要求。 -
nlmsg_pidis the sending port id. When a message is sent from the kernel, thenlmsg_pidis 0. When a message is sent from userspace, thenlmsg_pidcan be set to be the process id of that userspace application which sent the message.图 2-3 显示了 netlink 消息头。
图 2-3 。nlmsg 标题
报头之后是有效载荷。netlink 消息的有效载荷由一组属性组成,这些属性以类型-长度-值(TLV)格式表示。对于 TLV,类型和长度的大小是固定的(通常为 1-4 字节),而值字段的大小是可变的。TLV 表示也用于网络代码的其他地方,例如 IPv6(参见 RFC 2460)。TLV 提供了灵活性,使得将来的扩展更容易实现。属性可以嵌套,这使得复杂的属性树结构成为可能。
每个 netlink 属性头由
struct nlattr定义:struct nlattr { __u16 nla_len; __u16 nla_type; }; (include/uapi/linux/netlink.h) -
nla_len:属性的大小,以字节为单位。 -
nla_type:属性类型。例如,nla_type的值可以是 NLA_U32(用于 32 位无符号整数)、NLA _ 字符串(用于可变长度字符串)、NLA _ 嵌套(用于嵌套属性)、NLA_UNSPEC(用于任意类型和长度)等等。您可以在include/net/netlink.h中找到可用类型的列表。
每个 netlink 属性必须用一个 4 字节的边界(NLA_ALIGNTO)对齐。
每个家族可以定义一个属性验证策略,该策略表示关于接收到的属性的期望。这个验证策略由nla_policy对象表示。事实上,nla_policy struct和struct nlattr : 的内容完全一样
struct nla_policy {
u16 type;
u16 len;
};
(include/uapi/linux/netlink.h)
属性验证策略是一组nla_policy对象;这个数组由属性号索引。对于每个属性(固定长度属性除外),如果nla_policy对象中的len的值为 0,则不应该执行任何验证。如果属性是字符串类型之一(比如NLA_STRING),那么len应该是字符串的最大长度,没有终止的空字节。如果属性类型是 NLA _ 未用或未知,len应该设置为属性有效载荷的精确长度。如果属性类型是 NLA _ 标志,则不使用len。(原因是属性的存在本身就隐含了一个值true,属性的不存在隐含了一个值false)。
在内核中接收通用 netlink 消息由genl_rcv_msg()处理。如果是转储请求(当设置了NLM_F_DUMP标志时),您可以通过调用netlink_dump_start()方法来转储该表。如果不是转储请求,就用nlmsg_parse()方法解析有效负载。nlmsg_parse()方法通过调用validate_nla() ( lib/nlattr.c)来执行属性验证。如果有类型超过 maxtype 的属性,为了向后兼容,它们将被忽略。在验证失败的情况下,您不能继续执行genl_rcv_msg()中的下一步(运行doit()回调),并且genl_rcv_msg()返回一个错误代码。
下一节描述 NETLINK_ROUTE 消息,这是网络子系统中最常用的消息。
NETLINK_ROUTE 消息
rtnetlink (netlink_ROUTE)消息不限于网络路由子系统:还有相邻子系统消息、接口设置消息、防火墙消息、NETLINK 队列消息、策略路由消息和许多其他类型的 rtnetlink 消息,您将在后面的章节中看到。
NETLINK_ROUTE 消息可以分为几类:
- 链接(网络接口)
- ADDR(网络地址)
- 路由(路由消息)
- 邻居(相邻子系统消息)
- 规则(策略路由规则)
- 排队规则
- 流量类别
- 动作(数据包动作 API,见
net/sched/act_api.c) - 邻表
- 地址标签
每个系列都有三种类型的消息:用于创建、删除和检索信息。因此,对于路由消息,有用于创建路由的 RTM_NEWROUTE 消息类型、用于删除路由的 RTM_DELROUTE 消息类型和用于检索路由的 RTM_GETROUTE 消息类型。对于链接消息,除了用于创建、删除和信息检索的三种方法之外,还有用于修改链接的附加消息:RTM_SETLINK。
有些情况下会出现错误,您会发送一条错误消息作为回复。netlink 错误信息由nlmsgerr struct表示:
struct nlmsgerr {
int error;
struct nlmsghdr msg;
};
(include/uapi/linux/netlink.h)
事实上,正如你在图 2-4 中看到的,netlink 错误信息是由 netlink 信息头和错误代码组成的。当错误代码不为 0 时,导致错误的原始请求的 netlink 消息头被附加在错误代码字段之后。
图 2-4 。Netlink 错误消息
如果您发送了一个错误构造的消息(例如,nlmsg_type无效),那么会发回一个 netlink 错误消息,并且根据发生的错误设置错误代码。例如,当nlmsg_type无效时(负值,或高于允许的最大值),错误代码被设置为–EOPNOTSUPP。参见net/core/rtnetlink.c中的rtnetlink_rcv_msg()方法。在错误消息中,序列号被设置为导致错误的请求的序列号。
发送方可以请求获得 netlink 消息的 ACK。这是通过将 netlink 报文头类型(nlmsg_type)设置为 NLM_F_ACK 来实现的。当内核发送 ACK 时,它使用错误消息(该消息的 netlink 消息头类型设置为 NLMSG_ERROR ),错误代码为 0。在这种情况下,请求的原始 netlink 标头不会附加到错误消息中。具体实现参见net/netlink/af_netlink.c中的netlink_ack()方法实现。
了解了 NETLINK_ROUTE 消息后,您就可以查看使用 NETLINK_ROUTE 消息在路由表中添加和删除路由条目的示例了。
在路由表中添加和删除路由条目
在幕后,让我们看看当添加和删除路由条目时,在 netlink 协议的上下文中内核发生了什么。例如,您可以通过运行以下命令向路由表添加路由条目:
ip route add 192.168.2.11 via 192.168.2.20
该命令通过 rtnetlink 套接字从用户空间(RTM_NEWROUTE)发送 netlink 消息,用于添加路由条目。该消息由 rtnetlink 内核套接字接收,并由rtnetlink_rcv()方法处理。最终,通过调用net/ipv4/fib_frontend.c中的inet_rtm_newroute()来添加路由条目。随后,用fib_table_insert()方法完成到转发信息库(FIB)的插入,该转发信息库是路由数据库;然而,插入路由表并不是fib_table_insert()的唯一任务。您应该通知所有注册了 RTM_NEWROUTE 消息的侦听器。怎么做?当插入一个新的路由条目时,用 RTM_NEWROUTE 调用rtmsg_fib()方法。rtmsg_fib()方法构建一个 netlink 消息,并通过调用rtnl_notify() 发送它,以通知注册到 RTNLGRP_IPV4_ROUTE 组的所有侦听器。这些 RTNLGRP_IPV4_ROUTE 监听器既可以在内核中注册,也可以在用户空间中注册(就像在iproute2中一样,或者在一些用户空间路由守护进程中,比如xorp)。您将很快看到iproute2的用户空间守护进程如何订阅各种 rtnelink 多播组。
当删除一个路由条目时,会发生类似的事情。您可以通过运行以下命令提前删除路由条目:
ip route del 192.168.2.11
该命令通过 rtnetlink 套接字从用户空间(RTM_DELROUTE)发送 netlink 消息,用于删除路由条目。该消息再次由 rtnetlink 内核套接字接收,并由rtnetlink_rcv()回调处理。最终,通过调用net/ipv4/fib_frontend.c中的inet_rtm_delroute()回调来删除路由条目。随后,用调用rtmsg_fib()的fib_table_delete()从 FIB 中删除,这次是用 RTM_DELROUTE 消息。
您可以使用如下的iproute2 ip命令监控网络事件:
ip monitor route
例如,如果你打开一个终端并在那里运行ip monitor route,然后打开另一个终端并运行ip route add 192.168.1.10 via 192.168.2.200,在第一个终端上你会看到这一行:192.168.1.10 via 192.168.2.200 dev em1。当您在第二个终端上运行ip route del 192.168.1.10时,在第一个终端上将出现以下文本:Deleted 192.168.1.10 via 192.168.2.200 dev em1。
运行ip monitor route运行一个守护进程,它打开一个 netlink 套接字并订阅 RTNLGRP_IPV4_ROUTE 多播组。现在,添加/删除一个路由,如本例中所做的,将导致这样的结果:用rtnl_notify()发送的消息将被守护进程接收并显示在终端上。
您可以通过这种方式订阅其他多播组。例如,要订阅 RTNLGRP_LINK 多播组,运行ip monitor link。这个守护进程从内核接收 netlink 消息——例如,在添加/删除链接时。因此,如果您打开一个终端并运行ip monitor link,然后打开另一个终端并通过第一个终端上的vconfig add eth1 200,添加一个 VLAN 接口,您会看到这样的行:
4: eth1.200@eth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN
link/ether 00:e0:4c:53:44:58 brd ff:ff:ff:ff:ff:ff
如果您通过brctl addbr mybr在第二个终端上添加一个桥,在第一个终端上您会看到这样的行:
5: mybr: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN
link/ether a2:7c:be:62:b5:b6 brd ff:ff:ff:ff:ff:ff
您已经看到了什么是 netlink 消息以及如何创建和处理它。您已经看到了如何处理 netlink 套接字。接下来,您将了解为什么创建通用 netlink 家族(在内核 2.6.15 中引入),以及它在 Linux 中的实现。
通用网络链接协议
netlink 协议的缺点之一是协议族的数量被限制为 32 (MAX_LINKS)。这是创建通用 netlink 系列的主要原因之一——为添加更多系列提供支持。它充当 netlink 多路复用器,与单个 netlink 系列(NETLINK_GENERIC)一起工作。通用 netlink 协议基于 netlink 协议并使用其 API。
要添加 netlink 协议族,您应该在include/linux/netlink.h中添加一个协议族定义。但是有了通用的 netlink 协议,就不需要这样了。通用 netlink 协议也可用于联网以外的其他子系统,因为它提供了一个通用的通信信道。例如,它也被 acpi 子系统(参见drivers/acpi/event.c中acpi_event_genl_family的定义)、任务统计代码(参见kernel/taskstats.c)、热事件代码等等使用。
通用的 netlink 内核套接字是通过如下的netlink_kernel_create()方法创建的:
static int __net_init genl_pernet_init(struct net *net) {
..
struct netlink_kernel_cfg cfg = {
.input = genl_rcv,
.cb_mutex = &genl_mutex,
.flags = NL_CFG_F_NONROOT_RECV,
};
net->genl_sock = netlink_kernel_create(net, NETLINK_GENERIC, &cfg);
...
}
(net/netlink/genetlink.c)
注意,像前面描述的 netlink 套接字一样,通用 netlink 套接字也知道网络名称空间;网络名称空间对象(struct net)包含一个名为genl_sock(通用 netlink 套接字)的成员。如您所见,网络名称空间genl_sock指针在genl_pernet_init()方法中被赋值。
genl_rcv()方法被定义为genl_sock对象的input回调,该对象由genl_pernet_init()方法创建。因此,通过通用 netlink 套接字从用户空间发送的数据在内核中由genl_rcv()回调处理。
您可以使用socket()系统调用创建一个通用的 netlink 用户空间套接字,尽管使用libnl-genl API 会更好(在本节稍后讨论)。
创建通用 netlink 内核套接字后,立即注册控制器系列(genl_ctrl):
static struct genl_family genl_ctrl = {
.id = GENL_ID_CTRL,
.name = "nlctrl",
.version = 0x2,
.maxattr = CTRL_ATTR_MAX,
.netnsok = true,
};
static int __net_init genl_pernet_init(struct net *net) {
...
err = genl_register_family_with_ops(&genl_ctrl, &genl_ctrl_ops, 1)
...
genl_ctrl有一个固定的id0x 10(GENL_ID_CTRL);事实上,它是用固定 id 初始化的genl_family的唯一实例;所有其他实例都用GENL_ID_GENERATE作为 id 进行初始化,随后用一个动态赋值替换。
通过定义一个genl_multicast_group对象并调用genl_register_mc_group(),支持在通用 netlink 套接字中注册多播组;例如,在近场通信(NFC)子系统、?? 中,您有以下:
static struct genl_multicast_group nfc_genl_event_mcgrp = {
.name = NFC_GENL_MCAST_EVENT_NAME,
};
int __init nfc_genl_init(void)
{
...
rc = genl_register_mc_group(&nfc_genl_family, &nfc_genl_event_mcgrp);
...
}
(net/nfc/netlink.c)
多播组的名称应该是唯一的,因为它是查找的主键。
在组播组中,id也是在注册组播组时通过调用genl_register_mc_group()中的find_first_zero_bit()方法动态生成的。只有一个多播组notify_grp,它有一个固定的 ID GENL _ ID _ CTRL。
要在内核中使用通用 netlink 套接字,您应该执行以下操作:
- 创建一个
genl_family对象,并通过调用genl_register_family()注册它。 - 创建一个
genl_ops对象,并通过调用genl_register_ops()注册它。
或者,您可以调用genl_register_family_with_ops()并向其传递一个genl_family对象、genl_ops数组及其大小。该方法将首先调用genl_register_family(),然后如果成功,将为指定数组genl_ops的每个genl_ops元素调用genl_register_ops()。
genl_register_family()和genl_register_ops()以及genl_family和genl_ops在include/net/genetlink.h中定义。
无线子系统使用通用 netlink 套接字:
int nl80211_init(void)
{
int err;
err = genl_register_family_with_ops(&nl80211_fam,
nl80211_ops, ARRAY_SIZE(nl80211_ops));
...
}
(net/wireless/nl80211.c)
通用 netlink 协议由一些用户空间包使用,例如hostapd包和iw包。hostapd包 ( http://hostap.epitest.fi)为无线接入点和认证服务器提供了一个用户空间守护进程。iw包用于操作无线设备及其配置(见http://wireless.kernel.org/en/users/Documentation/iw)。
iw包基于nl80211和libnl库。第十二章更详细地讨论了nl80211。旧的用户空间无线包叫做wireless-tools ,是基于发送 IOCTLs 的。
以下是nl80211中genl_family和genl_ops的定义:
static struct genl_family nl80211_fam = {
.id = GENL_ID_GENERATE, /* don't bother with a hardcoded ID */
.name = "nl80211", /* have users key off the name instead */
.hdrsize = 0, /* no private header */
.version = 1, /* no particular meaning now */
.maxattr = NL80211_ATTR_MAX,
.netnsok = true,
.pre_doit = nl80211_pre_doit,
.post_doit = nl80211_post_doit,
};
-
name:必须是唯一的名称。 -
id:id在这种情况下是 GENL_ID_GENERATE,实际上是 0。GENL_ID_GENERATE 告诉通用 netlink 控制器,当您向genl_register_family()注册系列时,为通道分配一个唯一的通道号。genl_register_family()分配一个 id,范围为 16 (GENL_MIN_ID,即 0x10)到 1023 (GENL_MAX_ID)。 -
hdrsize:私有头的大小。 -
maxattr: NL80211_ATTR_MAX, which is the maximum number of attributes supported.nl80211_policy验证策略数组有 nl 80211 _ ATTR _ 最大元素(每个属性在数组中都有一个条目): -
netnsok:true,表示家族可以处理网络命名空间。 -
pre_doit:在doit()回调之前调用的钩子。 -
post_doit: A hook that can, for example, undo locking or any required private tasks after thedoit()callback.您可以使用
genl_ops结构添加一个或多个命令。让我们看看genl_ops struct的定义,然后看看它在nl80211中的用法:struct genl_ops { u8 cmd; u8 internal_flags; unsigned int flags; const struct nla_policy *policy; int (*doit)(struct sk_buff *skb, struct genl_info *info); int (*dumpit)(struct sk_buff *skb, struct netlink_callback *cb); int (*done)(struct netlink_callback *cb); struct list_head ops_list; }; -
cmd:命令标识符(genl_ops struct定义了一个单独的命令及其doit/dumpit处理程序)。 -
internal_flags: 家族定义使用的私有旗帜。比如在nl80211中,有很多定义内部标志的操作(比如 NL80211_FLAG_NEED_NETDEV_UP,NL80211_FLAG_NEED_RTNL 等等)。nl80211 pre_doit()和post_doit()回调根据这些标志执行动作。参见net/wireless/nl80211。 -
flags: 操作标志。值可以是以下值: -
GENL_ADMIN_PERM:设置了这个标志,就意味着操作需要 CAP_NET_ADMIN 权限;参见
net/netlink/genetlink.c中的genl_rcv_msg()方法。 -
GENL_CMD_CAP_DO:如果
genl_ops struct实现了doit()回调,则设置该标志。 -
GENL_CMD_CAP_DUMP:如果
genl_ops struct实现了dumpit()回调,则设置该标志。 -
GENL_CMD_CAP_HASPOL:如果
genl_ops struct定义了属性验证策略(nla_policy数组),则设置该标志。 -
policy: 属性验证策略将在本节稍后描述有效负载时讨论。 -
doit:标准命令回调。 -
dumpit:回拨转储。 -
done:转储完成回调。 -
ops_list:操作列表。static struct genl_ops nl80211_ops[] = { { ... { .cmd = NL80211_CMD_GET_SCAN, .policy = nl80211_policy, .dumpit = nl80211_dump_scan, }, ... }
注意,必须为genl_ops(在本例中为nl80211_ops)的每个元素指定一个doit或dumpit回调,否则函数将因-EINVAL 而失败。
genl_ops中的这个条目添加了nl80211_dump_scan()回调作为 NL80211_CMD_GET_SCAN 命令的处理程序。nl80211_policy是一个由nla_policy对象组成的数组,定义了属性的预期数据类型及其长度。
当从用户空间运行扫描命令时,例如通过iw dev wlan0 scan,您从用户空间通过通用 netlink 套接字发送一条通用 netlink 消息,其命令为 NL80211_CMD_GET_SCAN。在更新的libnl版本中,消息通过nl_send_auto_complete()方法或nl_send_auto()发送。nl_send_auto()填充 netlink 报文头中缺失的比特和片断。如果不需要任何自动消息完成功能,可以直接使用nl_send()。
消息由nl80211_dump_scan()方法处理,它是这个命令(net/wireless/nl80211.c)的dumpit回调。nl80211_ops对象中有 50 多个条目用于处理命令,包括 NL80211_CMD_GET_INTERFACE、NL80211_CMD_SET_INTERFACE、NL80211_CMD_START_AP 等等。
为了向内核发送命令,用户空间应用应该知道系列 id。系列名称在用户空间中是已知的,但是系列 id 在用户空间中是未知的,因为它只在内核运行时确定。为了获得家族 id,用户空间应用应该向内核发送一个通用的 netlink CTRL_CMD_GETFAMILY 请求。这个请求由ctrl_getfamily()方法处理。它返回家族 id 和其他信息,比如家族支持的操作。然后,用户空间可以向内核发送命令,指定它在回复中获得的家族 id。我将在下一节详细讨论这一点。
创建和发送通用网络链接消息
通用 netlink 消息以 netlink 报头开始,接着是通用 netlink 消息报头,然后是可选的用户特定报头。只有在所有这些之后,你才能找到可选的有效载荷,正如你在图 2-5 中看到的。
图 2-5 。通用网络链接消息。
这是通用 netlink 消息头:
struct genlmsghdr {
__u8 cmd;
__u8 version;
__u16 reserved;
};
(include/uapi/linux/genetlink.h)
cmd是通用的 netlink 消息类型;您注册的每个通用族都添加了自己的命令。比如上面提到的nl80211_fam家族,它添加的命令(比如 NL80211_CMD_GET_INTERFACE)就是用nl80211_commands enum来表示的。有 60 多个命令(见include/linux/nl80211.h)。version可用于版本支持。用nl80211就是 1,没有特别的意义。版本成员允许在不破坏向后兼容性的情况下更改消息的格式。reserved是为了将来使用。
通过以下方法为通用 netlink 消息分配缓冲区:
sk_buff *genlmsg_new(size_t payload, gfp_t flags)
这实际上是对nlmsg_new()的包装。
在用genlmsg_new()分配了一个缓冲区之后,调用genlmsg_put()来创建通用 netlink 头,它是genlmsghdr的一个实例。您用genlmsg_unicast()发送一个单播通用 netlink 消息,它实际上是对nlmsg_unicast()的包装。您可以用两种方式发送多播通用网络链接消息:
genlmsg_multicast():该方法将消息发送到默认的网络名称空间net_init。genlmsg_multicast_allns():该方法将消息发送到所有网络名称空间。
(本节提到的所有方法的原型都在include/net/genetlink.h中。)
您可以从用户空间创建一个通用的 netlink 套接字,如下所示:socket(AF_NETLINK, SOCK_RAW, NETLINK_GENERIC);这个调用在内核中由netlink_create()方法处理,就像普通的、非通用的 netlink 套接字一样,正如您在上一节中看到的。你可以使用 socket API 来执行进一步的调用,比如bind()和sendmsg()或者recvmsg();然而,建议使用libnl库。
libnl-genl提供通用 netlink API,用于管理控制器、系列和命令注册。使用libnl-genl,可以调用genl_connect() 来创建本地套接字文件描述符,并将套接字绑定到 NETLINK_GENERIC netlink 协议。
让我们简单地看一下,当使用libnl库和libnl-genl库通过通用 netlink 套接字向内核发送命令时,在一个简短的典型用户空间-内核会话中会发生什么。
iw包使用了libnl-genl库。当您运行类似iw dev wlan0 list的命令时,会出现以下序列(省略不重要的细节):
state->nl_sock = nl_socket_alloc()
分配一个套接字(注意这里使用的是libnl核心 API,而不是通用的 netlink 家族(libnl-genl)。
genl_connect(state->nl_sock)
用 NETLINK_GENERIC 调用socket()并在这个套接字上调用bind();genl_connect()是libnl-genl库的一个方法。
genl_ctrl_resolve(state->nl_sock, "nl80211");
此方法将通用 netlink 系列名称("nl80211")解析为相应的数字系列标识符。用户空间应用必须将它的后续消息发送到内核,指定这个 id。
genl_ctrl_resolve()方法调用genl_ctrl_probe_by_name(),它实际上用 CTRL_CMD_GETFAMILY 命令向内核发送一个通用的 netlink 消息。
在内核中,通用 netlink 控制器("nlctrl")通过ctrl_getfamily()方法处理 CTRL_CMD_GETFAMILY 命令,并将系列 id 返回给用户空间。这个 id 是在创建套接字时生成的。
注意通过运行
genl ctrl list可以使用genl(属于iproute2)的用户空间工具获得所有注册的通用 netlink 家族的各种参数(如生成 id、头大小、最大属性等)。
现在,您已经准备好学习套接字监视接口了,它可以让您获得关于套接字的信息。socket monitoring 接口用于像ss这样的用户空间工具,它显示各种套接字类型的套接字信息和统计数据,以及其他项目,您将在下一节中看到。
套接字监控接口
netlink 套接字提供了一个基于 netlink 的子系统,可以用来获取关于套接字的信息。这个特性被添加到内核中,以支持 Linux 在用户空间(CRIU)中的检查点/恢复功能。为了支持这个功能,需要关于套接字的附加数据。例如,/procfs并没有说明哪些是 UNIX 域套接字(AF_UNIX)的对等体,这些信息是检查点/恢复支持所需要的。这些额外的数据不是通过/proc导出的,对procfs条目进行修改并不总是可取的,因为这可能会破坏用户空间应用。sock_diag netlink 套接字提供了一个 API 来访问这些附加数据。这个 API 在 CRIU 项目和ss util 中都有使用。没有sock_diag,在检查点一个进程(将一个进程的状态保存到文件系统)之后,您不能重建它的 UNIX 域套接字,因为您不知道对等体是谁。
为了支持ss工具使用的监控接口,创建了一个基于 netlink 的内核套接字(NETLINK_SOCK_DIAG)。ss工具是iproute2包的一部分,它使您能够以类似于netstat的方式获得套接字统计数据。它可以显示比其他工具更多的 TCP 和状态信息。
您为sock_diag创建一个 netlink 内核套接字,如下所示:
static int __net_init diag_net_init(struct net *net)
{
struct netlink_kernel_cfg cfg = {
.input = sock_diag_rcv,
};
net->diag_nlsk = netlink_kernel_create(net, NETLINK_SOCK_DIAG, &cfg);
return net->diag_nlsk == NULL ? -ENOMEM : 0;
}
(net/core/sock_diag.c)
sock_diag模块有一个名为sock_diag_handlers的sock_diag_handler 对象表。该表由协议号索引(协议号列表见include/linux/socket.h)。
sock_diag_handler struct很简单:
struct sock_diag_handler {
__u8 family;
int (*dump)(struct sk_buff *skb, struct nlmsghdr *nlh);
};
(net/core/sock_diag.c)
每个想要向该表添加套接字监控接口条目的协议首先定义一个处理程序,然后调用sock_diag_register()、来指定其处理程序。例如,对于 UNIX 套接字,在net/unix/diag.c中有以下内容:
第一步是定义处理程序:
static const struct sock_diag_handler unix_diag_handler = {
.family = AF_UNIX,
.dump = unix_diag_handler_dump,
};
第二步是处理程序的注册:
static int __init unix_diag_init(void)
{
return sock_diag_register(&unix_diag_handler);
}
现在,with ss –x或ss --unix,您可以转储由 UNIX diag模块收集的统计数据。以非常相似的方式,还有用于其他协议的diag模块,例如 UDP ( net/ipv4/udp_diag.c)、TCP ( net/ipv4/tcp_diag.c)、DCCP ( /net/dccp/diag.c)和 AF_PACKET ( net/packet/diag.c)。
netlink 套接字本身也有一个diag模块。/proc/net/netlink条目提供了关于 netlink 套接字(netlink_sock对象)的信息,如portid、groups、套接字的 inode 号等等。如果你想知道细节,转储/proc/net/netlink由net/netlink/af_netlink.c中的netlink_seq_show()处理。有一些netlink_sock字段/proc/net/netlink没有提供——例如dst_group或dst_portid或 32 以上的组。为此,增加了 netlink 套接字监控接口(net/netlink/diag.c)。您应该能够使用iproute2的ss工具读取 netlink 套接字信息。netlink diag代码也可以构建为内核模块。
摘要
本章介绍了 netlink 套接字,它为用户空间和内核之间的双向通信提供了一种机制,并被网络子系统广泛使用。您已经看到了一些使用 netlink 套接字的例子。我还讨论了 netlink 消息,它们是如何创建和处理的。本章涉及的另一个重要主题是通用 netlink 套接字,包括它们的优点和用法。下一章将介绍 ICMP 协议,包括它在 IPv4 和 IPv6 中的使用和实现。
快速参考
我用 netlink 和通用 netlink 子系统的重要方法的简短列表来结束这一章。本章提到了其中一些:
int netlink _ rcv _ skb(struct sk _ buf * skb,int(* CB)(struct sk _ buf *, struct nlmsgid *)
此方法处理接收 netlink 消息。它是从 netlink 家族的输入回调中调用的(例如,在 rtnetlink 家族的rtnetlink_rcv()方法中,或者在sock_diag家族的sock_diag_rcv()方法中)。该方法执行健全性检查,比如确保 netlink 消息头的长度不超过允许的最大长度(NLMSG_HDRLEN)。在消息是控制消息的情况下,它还避免调用指定的回调。如果 ACK 标志(NLM_F_ACK)被置位,它通过调用netlink_ack()方法发送一个错误消息。
struct sk _ buff * netlink _ alloc _ skb(struct sock * SSK,无符号 int size, u32 dst_portid,gfp_t gfp_mask)
这个方法分配一个指定大小和gfp_mask的 size 其他参数(ssk、dst_portid)在使用内存映射 netlink IO (NETLINK_MMAP)时使用。该功能不在本章讨论,位于此:net/netlink/af_netlink.c。
结构 netlink_sock *nlk_sk(结构 sock *sk)
这个方法返回netlink_sock对象,它有一个sk作为成员,位于这里:net/netlink/af_netlink.h。
struct sock * net link _ kernel _ create(struct net * net,int unit,struct netlink_kernel_cfg *cfg)
这个方法创建一个内核 netlink 套接字。
struct nlmsg HDR * nlmsg _ HDR(const struct sk _ buf * skb)
该方法返回由skb->data指向的 netlink 消息头。
struct nlmsghdr * _ _ nlmsg _ put(struct sk _ buff * skb,u32 portid, u32 seq,int type,int len,int flags)
该方法根据指定的参数建立一个 netlink 报文头,放在skb中,位于此:include/linux/netlink.h。
struct sk_buff *nlmsg_new(size_t 有效载荷,gfp_t 标志)
该方法通过调用alloc_skb()分配一个具有指定消息有效负载的新 netlink 消息。如果指定的有效载荷为 0,则用NLMSG_HDRLEN调用alloc_skb()(在与 NLMSG_ALIGN 宏对齐后)。
int nlmsg_msg_size(int 有效载荷)
此方法返回 netlink 消息的长度(消息头长度和有效负载),不包括填充。
见 rtnl_register(int protocol,int msgtype,rtnl _ doit _ func 必须,rtnl_dumpit_func dumpit, rtnl_calcit_func calcit)
此方法用三个指定的回调注册指定的 rtnetlink 消息类型。
static int rtnetlink _ rcv _ msg(struct sk _ buf * skb,struct nlmsghdr *nlh)
此方法处理 rtnetlink 消息。
静态 int rtnl_fill_ifinfo(结构 sk_buff *skb,结构 net_device *dev, int 类型,u32 pid,u32 seq,u32 change, 无符号 int 标志,u32 ext_filter_mask)
这个方法创建了两个对象:一个 netlink 消息头(nlmsghdr)和一个ifinfomsg对象,位于 netlink 消息头之后。
void rtnl _ notify(struct sk _ buff * skb,struct net *net,u32 pid,u32 group, struct nlmsghdr *nlh,gfp_t 标志)
此方法发送 rtnetlink 消息。
int gen l _ register _ MC _ group(struct gen l _ family * family, struct gen l _ multicast _ group * grp)
该方法注册指定的多播组,通知用户空间,并在成功时返回 0 或负错误代码。指定的多播组必须有一个名称。除了具有固定 id 0x 10(GENL _ ID _ CTRL)的notify_grp之外,所有多播组的find_first_zero_bit()方法在该方法中动态生成多播组 ID。
void genl_unregister_mc_group(结构 genl_family *family, 结构 genl_multicast_group *grp)
这个方法注销指定的多播组,并通知用户空间。该组中的所有当前侦听器都会被删除。在取消注册家族之前,没有必要取消注册所有多播组—取消注册家族会导致所有分配的多播组自动取消注册。
int gen l _ register _ ops(struct gen l _ family * family,struct genl_ops *ops)
此方法注册指定的操作,并将它们分配给指定的系列。必须指定doit()或dumpit()回调,否则操作将因-EINVAL 而失败。每个命令标识符只能注册一个操作结构。如果成功,它将返回 0 或负的错误代码。
int genl _ unregister _ ops(struct genl _ family * family,struct genl_ops *ops)
此方法注销指定的操作,并从指定的系列中取消对它们的分配。该操作会一直阻止,直到当前消息处理完成,并且直到取消注册过程完成后才会再次开始。在取消注册该系列之前,不必取消注册所有操作—取消注册该系列会导致所有分配的操作自动取消注册。如果成功,它将返回 0 或负的错误代码。
int gen l _ register _ family(struct gen l _ family * family)
此方法首先验证指定的族,然后注册它。只有一个家族可以用相同的姓氏或标识符注册。家族 id 可以等于 GENL_ID_GENERATE,导致自动生成和分配唯一的 ID。
int gen l _ register _ family _ with _ ops(struct gen l _ family * family, struct genl_ops *ops,size_t n_ops)
此方法注册指定的系列和操作。只有一个家族可以用相同的姓氏或标识符注册。家族 id 可以等于 GENL_ID_GENERATE,导致自动生成和分配唯一的 ID。必须为每个注册的操作指定一个doit或dumpit回调,否则函数将失败。每个命令标识符只能注册一个操作结构。这相当于对表中的每个操作条目先调用genl_register_family(),然后调用genl_register_ops(),注意在错误路径上取消注册家族。如果成功,该方法返回 0 或负的错误代码。
int gen l _ unregister _ family(struct gen l _ family * family)
此方法注销指定的系列,并在成功时返回 0 或负错误代码。
void * genlmsg _ put(struct sk _ buff * skb,u32 portid,u32 seq, struct genl_family *family,int flags,u8 cmd)
此方法将通用 netlink 标头添加到 netlink 消息中。
int genl _ register _ family(struct genl _ family * family) int genl _ unregister _ family(struct genl _ family * family)
此方法注册/注销通用 netlink 系列。
int genl _ register _ ops(struct genl _ family * family,struct genl_ops *ops) int genl _ unregister _ ops(struct genl _ family * family,struct genl _ ops * ops)
此方法注册/注销通用 netlink 操作。
见 genl_lock(见) 见 genl_unlock(见)
该方法锁定/解锁通用网络链接互斥锁(genl_mutex)。例如在net/l2tp/l2tp_netlink.c中使用。
三、互联网控制信息协议
第二章讨论了 netlink 套接字的实现,以及 netlink 套接字如何被用作内核和用户空间之间的通信通道。本章介绍 ICMP 协议,这是一种第 4 层协议。用户空间应用可以通过使用套接字 API(最著名的例子可能是ping实用程序)来使用 ICMP 协议(发送和接收 ICMP 数据包)。本章讨论了内核如何处理这些 ICMP 数据包,并给出了一些例子。
ICMP 协议主要用作发送有关网络层(L3)的错误和控制消息的强制机制。该协议能够通过发送 ICMP 消息来获得关于通信环境中问题的反馈。这些消息提供错误处理和诊断。ICMP 协议相对简单,但对于确保正确的系统行为非常重要。ICMPv4 的基本定义在 RFC 792“互联网控制消息协议”中。这个 RFC 定义了 ICMPv4 协议的目标和各种 ICMPv4 消息的格式。我在本章中还提到了 RFC 1122(“对互联网主机—通信层的要求”),它定义了一些关于 ICMP 消息的要求;RFC 4443,它定义了 ICMPv6 协议;RFC 1812 定义了对路由器的要求。我还描述了存在哪些类型的 ICMPv4 和 ICMPv6 消息,它们是如何发送的,以及它们是如何被处理的。我将介绍 ICMP 套接字,包括为什么添加它们以及如何使用它们。请记住,ICMP 协议也用于各种安全攻击;例如,Smurf 攻击是一种拒绝服务攻击,在这种攻击中,大量带有目标受害者假冒源 IP 的 ICMP 数据包通过广播发送到使用 IP 广播地址的计算机网络。
icmpv 4
ICMPv4 消息可以分为两类:错误消息和信息消息(它们在 RFC 1812 中被称为“查询消息”)。ICMPv4 协议用于诊断工具,如ping和traceroute。著名的ping实用程序实际上是一个用户空间应用(来自iputils包),它打开一个原始套接字并发送一个 ICMP_ECHO 消息,应该得到一个 ICMP_REPLY 消息作为响应。Traceroute是一个实用程序,用于查找主机和给定目的 IP 地址之间的路径。traceroute实用程序基于为生存时间(TTL)设置不同的值,TTL 是 IP 报头中表示跳数的字段。traceroute实用程序利用了这样一个事实:当数据包的 TTL 达到 0 时,转发机器将发回 ICMP_TIME_EXCEED 消息。traceroute实用程序通过发送 TTL 为 1 的消息开始,并且随着每个接收到的代码为 ICMP_TIME_EXCEED 的 ICMP_DEST_UNREACH 作为回复,它将 TTL 增加 1 并再次发送到相同的目的地。它使用返回的 ICMP“超时”消息建立数据包经过的路由器列表,直到到达目的地,并返回 ICMP“回应回复”消息。默认情况下,Traceroute 使用 UDP 协议。ICMPv4 模块是net/ipv4/icmp.c。请注意,ICMPv4 不能构建为内核模块。
ICMPv4 初始化
ICMPv4 初始化是在启动阶段调用的inet_init()方法中完成的。inet_init()方法调用icmp_init()方法,后者又调用icmp_sk_init()方法来创建内核 ICMP 套接字以发送 ICMP 消息,并将一些 ICMP procfs变量初始化为默认值。(在本章的后面,你会遇到这些procfs变量。)
ICMPv4 协议的注册与其他 IPv4 协议的注册一样,在inet_init()中完成:
static const struct net_protocol icmp_protocol = {
.handler = icmp_rcv,
.err_handler = icmp_err,
.no_policy = 1,
.netns_ok = 1,
};
(net/ipv4/af_inet.c)
-
icmp_rcv:回调handler。这意味着,对于 IP 报头中的协议字段等于 IPPROTO_ICMP (0x1)的传入数据包,将调用icmp_rcv()。 -
该标志被设置为 1,这意味着不需要执行 IPsec 策略检查;例如,在
ip_local_deliver_finish()中没有调用xfrm4_policy_check()方法,因为设置了no_policy标志。 -
netns_ok:该标志设置为 1,表示协议知道网络名称空间。在net_device部分的附录 A 中描述了网络名称空间。对于netns_ok字段为 0 的协议,inet_add_protocol()方法将失败,错误为-EINVAL。static int __init inet_init(void) { . . . if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0) pr_crit("%s: Cannot add ICMP protocol\n", __func__); . . . int __net_init icmp_sk_init(struct net *net) { . . . for_each_possible_cpu(i) { struct sock *sk; err = inet_ctl_sock_create(&sk, PF_INET, SOCK_RAW, IPPROTO_ICMP, net); if (err < 0) goto fail; net->ipv4.icmp_sk[i] = sk; . . . sock_set_flag(sk, SOCK_USE_WRITE_QUEUE); inet_sk(sk)->pmtudisc = IP_PMTUDISC_DONT; } . . . }
在icmp_sk_init()方法中,为每个 CPU 创建一个原始 ICMPv4 套接字,并保存在一个数组中。电流sk可以通过icmp_sk(struct net *net)方法访问。这些套接字用于icmp_push_reply()方法。ICMPv4 procfs条目在icmp_sk_init()方法中初始化;我在本章中提到了它们,并在本章末尾的“快速参考”部分对它们进行了总结。每个 ICMP 数据包都以 ICMPv4 报头开始。在讨论如何接收和传输 ICMPv4 消息之前,以下部分描述了 ICMPv4 头,以便您更好地理解 ICMPv4 消息是如何构建的。
ICMPv4 报头
ICMPv4 报头由类型(8 位)、代码(8 位)、校验和(16 位)和 32 位可变部分成员(其内容根据 ICMPv4 类型和代码而变化)组成,如图 3-1 所示。在 ICMPv4 报头之后是有效载荷,它应该包括原始数据包的 IPv4 报头及其有效载荷的一部分。根据 RFC 1812,它应该包含尽可能多的原始数据报,而 ICMPv4 数据报的长度不超过 576 字节。这个大小符合 RFC 791,RFC 791 规定“所有主机必须准备好接受最多 576 个八位字节的数据报。”
图 3-1 。ICMPv4 标头
ICMPv4 报头由struct icmphdr : 表示
struct icmphdr {
__u8 type;
__u8 code;
__sum16 checksum;
union {
struct {
__be16 id;
__be16 sequence;
} echo;
__be32 gateway;
struct {
__be16 __unused;
__be16 mtu;
} frag;
} un;
};
(include/uapi/linux/icmp.h)
您将在www.iana.org/assignments/icmp-parameters/icmp-parameters.xml找到当前分配的 ICMPv4 消息类型编号和代码的完整列表。
ICMPv4 模块定义了一个名为icmp_pointers的icmp_control对象数组,该数组由 ICMPv4 消息类型索引。让我们看看icmp_control的结构定义和icmp_pointers数组:
struct icmp_control {
void (*handler)(struct sk_buff *skb);
short error; /* This ICMP is classed as an error message */
};
static const struct icmp_control icmp_pointers[NR_ICMP_TYPES+1];
NR_ICMP_TYPES 是最高的 ICMPv4 类型,为 18。
(include/uapi/linux/icmp.h)
此数组的icmp_control对象的错误字段仅对于错误消息类型为 1,如“目的地不可达”消息(ICMP_DEST_UNREACH),对于信息消息(如 echo (ICMP_ECHO))为 0(隐式)。有些处理程序被分配给多种类型。接下来,我将讨论处理程序和它们管理的 ICMPv4 消息类型。
ping_rcv()处理接收 ping 应答(ICMP_ECHOREPLY)。在 ICMP 套接字代码net/ipv4/ping.c中实现了ping_rcv()方法。在 3.0 之前的内核中,为了发送 ping,您必须在用户空间中创建一个原始套接字。当收到对 ping 的回复(ICMP_ECHOREPLY 消息)时,发送 ping 的原始套接字会对其进行处理。为了理解这是如何实现的,让我们看一看ip_local_deliver_finish(),这是一种处理传入的 IPv4 包并将它们传递给应该处理它们的套接字的方法:
static int ip_local_deliver_finish(struct sk_buff *skb)
{
. . .
int protocol = ip_hdr(skb)->protocol;
const struct net_protocol *ipprot;
int raw;
resubmit:
raw = raw_local_deliver(skb, protocol);
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot != NULL) {
int ret;
. . .
ret = ipprot->handler(skb);
. . .
(net/ipv4/ip_input.c)
当ip_local_deliver_finish()方法接收到一个 ICMP_ECHOREPLY 包时,它首先尝试将它传递给一个侦听原始套接字,该套接字将处理它。因为在用户空间中打开的原始套接字处理 ICMP_ECHOREPLY 消息,所以不需要对它做任何进一步的处理。所以当ip_local_deliver_finish()方法收到 ICMP_ECHOREPLY 时,首先调用raw_local_deliver()方法通过一个原始套接字对其进行处理,然后调用ipprot->handler(skb)(这是 ICMPv4 数据包情况下的icmp_rcv()回调)。因为数据包已经被一个原始套接字处理过了,所以没有什么要做的了。因此,通过调用 ICMP_ECHOREPLY 消息的处理程序icmp_discard()方法,数据包被无声地丢弃。
当 ICMP 套接字(“ping 套接字”)被集成到内核 3.0 中的 Linux 内核中时,这种情况被改变了。Ping 套接字将在本章后面的“ICMP 套接字(“Ping 套接字”)一节中讨论。在这个上下文中,我应该注意到,对于 ICMP 套接字,ping的发送者也可以是而不是原始套接字。例如,您可以创建这样一个套接字:socket (PF_INET, SOCK_DGRAM, PROT_ICMP)并用它来发送ping数据包。此套接字不是原始套接字。因此,echo 回复不会传递给任何原始套接字,因为没有相应的原始套接字进行侦听。为了避免这个问题,ICMPv4 模块使用ping_rcv()回调来处理接收 ICMP_ECHOREPLY 消息。ping模块位于 IPv4 层(net/ipv4/ping.c)。然而,net/ipv4/ping.c中的大部分代码是双栈代码(适用于 IPv4 和 IPv6)。因此,ping_rcv()方法也处理 IPv6 的 ICMPV6_ECHO_REPLY 消息(参见net/ipv6/icmp.c)中的icmpv6_rcv())。我将在本章的后面更多地讨论 ICMP 套接字。
icmp_discard() 是一个空的处理程序,用于不存在的消息类型(头文件中编号没有对应声明的消息类型)和一些不需要处理的消息,例如 ICMP _ TIMESTAMPREPLY。ICMP_TIMESTAMP 和 ICMP _ TIMESTAMPREPLY 消息用于时间同步;发送者在 ICMP_TIMESTAMP 请求中发送originate timestamp;接收方发送带有三个时间戳的 ICMP _ timestamp preply:时间戳请求发送方发送的起始时间戳,以及接收时间戳和发送时间戳。有比 ICMPv4 时间戳消息更常用的时间同步协议,如网络时间协议(NTP)。我还应该提到地址掩码请求(ICMP_ADDRESS ),它通常由主机发送给路由器,以便获得适当的子网掩码。收件人应该用地址掩码回复邮件来回复此邮件。过去由icmp_address()方法和icmp_address_reply()方法处理的 ICMP_ADDRESS 和 ICMP_ADDRESSREPLY 消息现在也由icmp_discard()处理。原因是有其他方法可以获得子网掩码,比如 DHCP。
icmp_unreach()处理 ICMP_DEST_UNREACH、ICMP_TIME_EXCEED、ICMP_PARAMETERPROB 和 ICMP_QUENCH 消息类型。
可以在各种条件下发送一条ICMP_DEST_UNREACH消息。本章的“发送 ICMPv4 消息:无法到达目的地”一节描述了其中的一些情况。
在两种情况下发送ICMP_TIME_EXCEEDED消息:
在ip_forward()中,每个数据包的 TTL 递减。根据 RFC 1700,IPv4 协议的建议 TTL 为 64。如果 TTL 达到 0,这表示应该丢弃数据包,因为可能存在某种循环。因此,如果 TTL 在ip_forward()中达到 0,就会调用icmp_send()方法:
icmp_send(skb, ICMP_TIME_EXCEEDED, ICMP_EXC_TTL, 0);
(net/ipv4/ip_forward.c)
在这种情况下,发送一个 ICMP_TIME_EXCEEDED 消息,代码为 ICMP_EXC_TTL,释放 SKB,InHdrErrors SNMP 计数器(IPSTATS _ MIB _ INHDRERRORS)递增,该方法返回 NET_RX_DROP。
在ip_expire()中,当一个片段超时时,会发生以下情况:
icmp_send(head, ICMP_TIME_EXCEEDED, ICMP_EXC_FRAGTIME, 0);
(net/ipv4/ip_fragment.c)
在ip_options_compile()方法或ip_options_rcv_srr()方法(net/ipv4/ip_options.c)中解析 IPv4 报头选项失败时,发送 ICMP_PARAMETERPROB 消息。这些选项是 IPv4 报头的可选可变长度字段(最多 40 个字节)。IP 选项在第四章的中讨论。
ICMP_QUENCH 消息类型实际上已被否决。根据 RFC 1812,4.3.3.3 部分(源抑制):“路由器不应该发起 ICMP 源抑制消息”,此外,“路由器可以忽略它收到的任何 ICMP 源抑制消息。”ICMP_QUENCH 消息旨在减少拥塞,但事实证明这是一个无效的解决方案。
icmp_redirect() 处理 ICMP_REDIRECT 消息;根据 RFC 1122 3.2.2.2 部分,主机不应发送 ICMP 重定向消息;重定向只能由网关发送。icmp_redirect()处理 ICMP_REDIRECT 消息。过去,icmp_redirect()调用ip_rt_redirect(),但是现在不再需要ip_rt_redirect()调用,因为协议处理程序现在可以正确地将重定向传播回路由代码。事实上,在内核 3.6 中,ip_rt_redirect()方法被移除了。因此,icmp_redirect()方法首先执行健全性检查,然后调用icmp_socket_deliver(),它将数据包传递给原始套接字并调用协议错误处理程序(如果它存在的话)。第六章更深入地讨论了 ICMP_REDIRECT 消息。
icmp_echo() 通过用icmp_reply()发送回应回复(ICMP_ECHOREPLY)来处理回应(“ping”)请求(ICMP_ECHO)。如果设置了案例net->ipv4.sysctl_icmp_echo_ignore_all,则不会发送回复。关于配置 ICMPv4 procfs条目,请参见本章末尾的“快速参考”部分,以及Documentation/networking/ip-sysctl.txt。
icmp_timestamp()通过用icmp_reply()发送 ICMP _ TIMESTAMPREPLY 来处理 ICMP 时间戳请求(ICMP_TIMESTAMP)。
在讨论通过icmp_reply()方法和icmp_send()方法发送 ICMP 消息之前,我应该描述一下在这两种方法中使用的icmp_bxm(“ICMP 构建 xmit 消息”)结构:
struct icmp_bxm {
struct sk_buff *skb;
int offset;
int data_len;
struct {
struct icmphdr icmph;
__be32 times[3];
} data;
int head_len;
struct ip_options_data replyopts;
};
skb:对于icmp_reply()方法,这个skb是请求包;icmp_param对象(icmp_bxm的实例)就是从它构建的(在icmp_echo()方法和icmp_timestamp()方法中)。对于icmp_send()方法,这个skb是由于某些条件触发发送 ICMPv4 消息的方法;在本节中,您将看到几个此类消息的示例。offset:在skb_network_header(skb)和skb->data之间的差异(偏移)。data_len: ICMPv4 数据包有效负载大小。icmph:ICMP v4 报头。times[3]:三个时间戳的数组,填入icmp_timestamp()。head_len:icmp v4 报头的大小(在icmp_timestamp()的情况下,时间戳有额外的 12 个字节)。replyopts:一个ip_options数据对象。IP 选项是 IP 报头后的可选字段,最多 40 个字节。它们支持高级功能,如严格路由/松散路由、记录路由、时间戳等。它们是用ip_options_echo()方法初始化的。第四章讨论知识产权期权。
接收 ICMPv4 消息
ip_local_deliver_finish()方法处理本地机器的数据包。当获取 ICMP 数据包时,该方法将该数据包传递给已执行 ICMPv4 协议注册的原始套接字。在icmp_rcv()方法中,首先增加InMsgs SNMP 计数器(ICMP_MIB_INMSGS)。随后,检验校验和的正确性。如果校验和不正确,两个 SNMP 计数器增加,InCsumErrors和InErrors(分别为 ICMP_MIB_CSUMERRORS 和 ICMP_MIB_INERRORS),SKB 被释放,该方法返回 0。在这种情况下,icmp_rcv()方法不会返回错误。事实上,icmp_rcv()方法总是返回 0;在校验和错误的情况下返回 0 的原因是,当接收到错误的 ICMP 消息时,除了丢弃它之外,不应该做任何特殊的事情;当协议处理程序返回否定错误时,会再次尝试处理数据包,这种情况下不需要这样做。更多细节,请参考ip_local_deliver_finish()方法的实现。然后检查 ICMP 报头,以便找到它的类型;相应的procfs消息类型计数器递增(每个 ICMP 消息类型都有一个procfs计数器),并且执行健全性检查以验证它不高于最高允许值(NR_ICMP_TYPES)。根据 RFC 1122 的第 3.2.2 节,如果收到未知类型的 ICMP 消息,它必须被无声地丢弃。因此,如果消息类型超出范围,InErrors SNMP 计数器(ICMP_MIB_INERRORS)将递增,SKB 将被释放。
如果数据包是广播或组播,并且是 ICMP_ECHO 消息或 ICMP_TIMESTAMP 消息,则通过读取变量net->ipv4.sysctl_icmp_echo_ignore_broadcasts检查是否允许广播/组播 ECHO 请求。该变量可通过写入/proc/sys/net/ipv4/icmp_echo_ignore_broadcasts经由procfs进行配置,默认情况下其值为 1。如果设置了该变量,数据包将被无声地丢弃。这是根据 RFC 1122 的 3.2.2.6 部分完成的:“发往 IP 广播或 IP 多播地址的 ICMP 回应请求可能会被无声地丢弃。”根据 RFC 的 3.2.2.8 部分,“发往 IP 广播或 IP 多播地址的 ICMP 时间戳请求消息可能会被无声地丢弃。”然后,执行检查以检测该类型是否允许广播/多播(ICMP_ECHO, ICMP_TIMESTAMP, ICMP_ADDRESS, and ICMP_ADDRESSREPLY). If it is not one of these message types, the packet is dropped and 0 is returned. Then according to its type, the corresponding entry in the icmp_pointers数组被取出,并且适当的处理程序被调用。让我们看看icmp_control调度表中的 ICMP_ECHO 条目:```sh`
static const struct icmp_control icmp_pointers[NR_ICMP_TYPES + 1] = {
...
[ICMP_ECHO] = {
.handler = icmp_echo,
},
...
}
```sh
所以当接收到 ping(消息的类型是“Echo Request”,ICMP_ECHO)时,它由`icmp_echo()`方法处理。`icmp_echo()`方法将 ICMP 头中的类型改为 ICMP_ECHOREPLY,并通过调用`icmp_reply()`方法发送回复。除了`ping`,唯一需要响应的其他 ICMP 消息是时间戳消息(ICMP _ TIMESTAMP);它由`icmp_timestamp()`方法处理,与 ICMP_ECHO 的情况非常相似,该方法将类型更改为 ICMP _ TIMESTAMPREPLY,并通过调用`icmp_reply()`方法发送回复。发送由`ip_append_data()`和`ip_push_pending_frames()`完成。接收 ping 应答(ICMP_ECHOREPLY)由`ping_rcv()`方法`.` 处理
您可以使用以下命令禁用对 pings 的回复:
```
echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all
```sh
有一些回调处理不止一种 ICMP 类型。例如,`icmp_discard()`回调处理类型不由 Linux ICMPv4 实现处理的 ICMPv4 数据包,以及 ICMP _ TIMESTAMPREPLY、ICMP_INFO_REQUEST、ICMP_ADDRESSREPLY 等消息。
发送 ICMPv4 消息:“目的地不可达”
发送 ICMPv4 消息有两种方法:第一种是`icmp_reply()`方法,它作为对 ICMP_ECHO 和 ICMP_TIMESTAMP 这两种类型的 ICMP 请求的响应发送。第二种是`icmp_send()`方法,本地机器在特定条件下发起发送 ICMPv4 消息(在本节中描述)。这两种方法最终都会调用`icmp_push_reply()`来实际发送数据包。作为对来自`icmp_echo()`方法的 ICMP_ECHO 消息的响应,调用`icmp_reply()`方法,并作为对来自`icmp_timestamp()`方法的 ICMP_TIMESTAMP 消息的响应。从 IPv4 网络堆栈中的许多地方调用`icmp_send()`方法——例如,从 netfilter、从转发代码(`ip_forward.c` ) *、*从类似`ipip`和`ip_gre`的隧道等等。
本节研究发送“目的地不可达”消息的一些情况(类型为 ICMP_DEST_UNREACH)。
代码 2: ICMP_PROT_UNREACH(协议不可达)
当 IP 报头的协议(它是一个 8 位字段)是一个不存在的协议时,ICMP _ DEST _ un reach/ICMP _ PROT _ un reach 被发送回发送方,因为这样的协议没有协议处理程序(协议处理程序数组由协议号索引,因此对于不存在的协议,将没有处理程序)。所谓*不存在的*协议,我的意思是,由于某些错误,IPv4 报头的协议号确实没有出现在协议号列表中(您可以在`include/uapi/linux/in.h` *、*中找到 IPv4 的协议号列表),或者内核是在不支持该协议的情况下构建的,因此,该协议没有被注册,并且在协议处理程序数组中没有它的条目。因为无法处理这样的数据包,所以应该向发送方回复一个“目的地不可达”的 ICMPv4 消息;ICMPv4 回复中的 ICMP_PROT_UNREACH 代码表示错误原因,“协议不可达”见下文:
```
static int ip_local_deliver_finish(struct sk_buff *skb)
{
...
int protocol = ip_hdr(skb)->protocol;
const struct net_protocol *ipprot;
int raw;
resubmit:
raw = raw_local_deliver(skb, protocol);
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot != NULL) {
...
} else {
if (!raw) {
if (xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
IP_INC_STATS_BH(net, IPSTATS_MIB_INUNKNOWNPROTOS);
icmp_send(skb, ICMP_DEST_UNREACH,ICMP_PROT_UNREACH, 0);
}
...
}
```sh
```
(net/ipv4/ip_input.c)
```sh
在这个例子中,通过协议在`inet_protos`阵列中执行查找;因为没有找到条目,这意味着该协议没有在内核中注册。
代码 3: ICMP_PORT_UNREACH(“端口不可达”)
接收 UDPv4 数据包时,会搜索匹配的 UDP 套接字。如果没有找到匹配的套接字,则检验校验和的正确性。如果它是错误的,数据包将被无声地丢弃。如果正确,则更新统计数据,并发回“目的地不可达”/“端口不可达”ICMP 消息:
```
int __udp4_lib_rcv(struct sk_buff *skb, struct udp_table *udptable, int proto)
{
struct sock *sk;
...
sk = __udp4_lib_lookup_skb(skb, uh->source, uh->dest, udptable)
...
if (sk != NULL) {
...
}
/* No socket. Drop packet silently, if checksum is wrong */
if (udp_lib_checksum_complete(skb))
goto csum_error;
UDP_INC_STATS_BH(net, UDP_MIB_NOPORTS, proto == IPPROTO_UDPLITE);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PORT_UNREACH, 0);
...
}
...
}
```sh
```
(net/ipv4/udp.c)
```sh
通过`__udp4_lib_lookup_skb()`方法执行查找,如果没有套接字,则更新统计数据,并发回一个 ICMP_PORT_UNREACH 代码为的 ICMP_DEST_UNREACH 消息。
代码 4:需要 ICMP _ FRAG _ NEEDED
当转发长度大于传出链路 MTU 的数据包时,如果 IPv4 报头(IP_DF)中的不分段(DF)位被置位,则该数据包被丢弃,并且带有 ICMP_FRAG_NEEDED 代码的 ICMP_DEST_UNREACH 消息被发送回发送方:
```
int ip_forward(struct sk_buff *skb)
{
...
struct rtable *rt; /* Route we use */
...
if (unlikely(skb->len > dst_mtu(&rt->dst) && !skb_is_gso(skb) &&
(ip_hdr(skb)->frag_off & htons(IP_DF))) && !skb->local_df) {
IP_INC_STATS(dev_net(rt->dst.dev), IPSTATS_MIB_FRAGFAILS);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_FRAG_NEEDED,
htonl(dst_mtu(&rt->dst)));
goto drop;
}
...
}
```sh
```
(net/ipv4/ip_forward.c)
```sh
代码 5: ICMP_SR_FAILED
当转发带有严格路由选项和网关设置的数据包时,会发回一条带有 ICMP_SR_FAILED 代码的“目的地不可达”消息,数据包会被丢弃:
```
int ip_forward(struct sk_buff *skb)
{
struct ip_options *opt = &(IPCB(skb)->opt);
...
if (opt->is_strictroute && rt->rt_uses_gateway)
goto sr_failed;
...
sr_failed:
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_SR_FAILED, 0);
goto drop;
}
```sh
```
(net/ipv4/ip_forward.c)
```sh
有关所有 IPv4“目的地不可达”代码的完整列表,请参见本章末尾“快速参考”部分的表 3-1 。注意,用户可以使用`iptables`拒绝目标和`--reject-with`限定符配置一些规则,这些规则可以根据选择发送“目的地不可达”消息;本章末尾的“快速参考”部分有更多信息。
`icmp_reply()`和`icmp_send()`方法都支持速率限制;他们调用`icmpv4_xrlim_allow()`,如果速率限制检查允许发送数据包(`icmpv4_xrlim_allow()`返回`true`),他们就发送数据包。这里应该提到的是,速率限制不是自动对所有类型的流量执行的。以下是不执行速率限制检查的条件:
* 消息类型未知。
* 该数据包属于 PMTU 发现。
* 该设备是一个环回设备。
* 速率掩码中没有启用 ICMP 类型。
如果所有这些条件都不匹配,则通过调用`inet_peer_xrlim_allow()`方法来执行速率限制。您可以在本章末尾的“快速参考”部分找到更多关于速率屏蔽的信息。
让我们看看`icmp_send()`方法的内部。首先,这是它的原型:
```
void icmp_send(struct sk_buff *skb_in, int type, int code, __be32 info)
```sh
skb `_in`是导致调用`icmp_send()`方法的 skb,`type`和`code`分别是 ICMPv4 消息`type`和`code`。最后一个参数`info`用于以下情况:
* 对于 ICMP_PARAMETERPROB 消息类型,它是发生解析问题的 IPv4 标头中的偏移量。
* 对于带有 ICMP_FRAG_NEEDED 代码的 ICMP_DEST_UNREACH 消息类型,它是 MTU。
* 对于带有 ICMP_REDIR_HOST 代码的 ICMP_REDIRECT 消息类型,它是发起 SKB 的 IPv4 报头中的目的地址的 IP 地址。
当进一步研究`icmp_send()`方法时,首先有一些健全性检查。那么多播/广播分组被拒绝。通过检查 IPv4 报头的`frag_off`字段来检查分组是否是片段。如果数据包被分段,则会发送一条 ICMPv4 消息,但只针对第一个分段。根据 RFC 1812 的 4.3.2.7 部分,不得因收到 ICMP 错误消息而发送 ICMP 错误消息。因此,首先执行检查以发现要发送的 ICMPv4 消息是否是错误消息,如果是,则执行另一检查以发现发起 SKB 是否包含错误 ICMPv4 消息,如果是,则该方法返回而不发送 ICMPv4 消息。此外,如果类型是未知的 ICMPv4 类型(高于 NR_ICMP_TYPES ),该方法返回时不发送 ICMPv4 消息,尽管 RFC 没有明确指定这一点。然后根据`net->ipv4.sysctl_icmp_errors_use_inbound_ifaddr`值的值确定源地址(更多细节在本章末尾的“快速参考”一节)。然后调用`ip_options_echo()`方法来复制调用 SKB 的 IPv4 报头的 IP 选项。一个`icmp_bxm`对象`(icmp_param)`正在被分配和初始化,并且在路由子系统中使用`icmp_route_lookup()`方法执行查找。然后调用`icmp_push_reply()`方法。
让我们看一下`icmp_push_reply()`方法,它实际上发送了数据包。`icmp_push_reply()`首先通过调用以下命令找到应该发送数据包的套接字:
```
sk = icmp_sk(dev_net((*rt)->dst.dev));
```sh
`dev_net()`方法返回传出网络设备的网络名称空间。(第十四章和附录 A 中讨论了`dev_net()`方法和网络名称空间。)然后,`icmp_sk()`方法获取套接字(因为在 SMP 中每个 CPU 有一个套接字)。然后调用`ip_append_data()`方法将数据包移动到 IP 层。如果`ip_append_data()`方法失败,通过增加 ICMP_MIB_OUTERRORS 计数器来更新统计数据,并且调用`ip_flush_pending_frames()`方法来释放 SKB。我在第四章的中讨论了`ip_append_data()`方法和`ip_flush_pending_frames()`方法。
既然您已经对 ICMPv4 了如指掌,那么是时候继续学习 ICMPv6 了。
ICMPv6
在网络层(L3)报告错误方面,ICMPv6 与 ICMPv4 有许多相似之处。ICMPv6 还有一些在 ICMPv4 中不执行的任务。本节讨论 ICMPv6 协议、它的新功能(在 ICMPv4 中没有实现)以及类似的功能。RFC 4443 中定义了 ICMPv6。如果您深入研究 ICMPv6 代码,您可能迟早会遇到提到 RFC 1885 的注释。事实上,RFC 1885“用于互联网协议版本 6 (IPv6)的互联网控制消息协议(ICMPv6)”是 ICMPv6 RFC 的基础。它被 RFC 2463 淘汰,而 RFC 2463 又被 RFC 4443 淘汰。ICMPv6 实现基于 IPv4,但它更复杂;本节将讨论新增的更改和内容。
根据 RFC 4443 第一部分的规定,ICMPv6 协议的下一个报头值为 58(第八章讨论了 IPv6 下一个报头)。ICMPv6 是 IPv6 不可或缺的一部分,必须由每个 IPv6 节点完全实现。除了错误处理和诊断之外,ICMPv6 还用于 IPv6 中的邻居发现(nd)协议,该协议取代并增强了 IPv4 中 ARP 的功能,还用于多播监听发现(MLD)协议,该协议是 IPv4 中 IGMP 协议的对等物,如图 3-2 中所示。
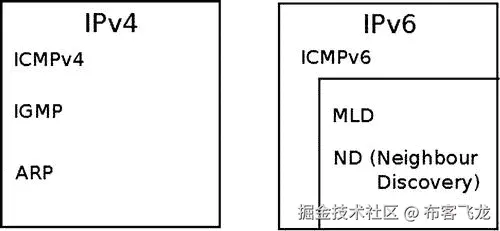
图 3-2 。IPv4 和 IPv6 中的 ICMP。IPv6 中 IGMP 协议的对应部分是 MLD 协议,IPv6 中 ARP 协议的对应部分是 nd 协议
本节介绍 ICMPv6 的实现。正如您将看到的,在处理和发送消息的方式上,它与 ICMPv4 实现有许多共同之处。甚至有在 ICMPv4 和 ICMPv6 中调用相同方法的情况(例如,`ping_rcv()`和`inet_peer_xrlim_allow()`)。有些不同,有些主题是 ICMPv6 特有的。`ping6`和`traceroute6`实用程序基于 ICMPv6,是 IPv4 的`ping`和`traceroute`实用程序的对应物(在本章开头的 ICMPv4 部分提到过)。ICMPv6 在`net/ipv6/icmp.c`和`net/ipv6/ip6_icmp.c`中实现。与 ICMPv4 一样,ICMPv6 不能作为内核模块构建。
ICMPv6 初始化
ICMPv6 初始化由`icmpv6_init()`方法和`icmpv6_sk_init()`方法完成。ICMPv6 协议的注册由`icmpv6_init()` ( `net/ipv6/icmp.c`)完成:
```
static const struct inet6_protocol icmpv6_protocol = {
.handler = icmpv6_rcv,
.err_handler = icmpv6_err,
.flags = INET6_PROTO_NOPOLICY|INET6_PROTO_FINAL,
};
```sh
`handler`回调为`icmpv6_rcv()`;这意味着对于协议字段等于 IPPROTO_ICMPV6 (58)的传入数据包,将调用`icmpv6_rcv()`。
当 INET6_PROTO_NOPOLICY 标志被设置时,这意味着不应该执行 IPsec 策略检查;例如,在`ip6_input_finish()`中没有调用`xfrm6_policy_check()`方法,因为 INET6_PROTO_NOPOLICY 标志被设置:
```
int __init icmpv6_init(void)
{
int err;
...
if (inet6_add_protocol(&icmpv6_protocol, IPPROTO_ICMPV6) < 0)
goto fail;
return 0;
}
static int __net_init icmpv6_sk_init(struct net *net)
{
struct sock *sk;
...
for_each_possible_cpu(i) {
err = inet_ctl_sock_create(&sk, PF_INET6,
SOCK_RAW, IPPROTO_ICMPV6, net);
...
net->ipv6.icmp_sk[i] = sk;
...
}
```sh
与在 ICMPv4 中一样,为每个 CPU 创建一个原始的 ICMPv6 套接字,并保存在一个数组中。当前的`sk`可以通过`icmpv6_sk()`方法访问。
ICMPv6 标题
ICMPv6 报头由`type` (8 位)`code` (8 位)`checksum` (16 位)组成,如图图 3-3 所示。
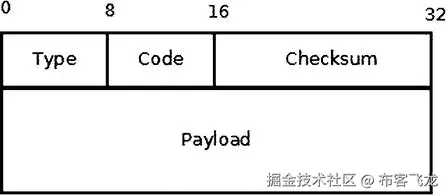
图 3-3 。ICMPv6 标头
ICMPv6 报头由`struct icmp6hdr`表示:
```
struct icmp6hdr {
__u8 icmp6_type;
__u8 icmp6_code;
__sum16 icmp6_cksum;
...
}
```sh
没有足够的空间显示`struct icmp6hdr`的所有字段,因为它太大了(它是在`include/uapi/linux/icmpv6.h`中定义的)。当类型字段的高位为 0(取值范围为 0-127)时,表示出错信息;当高位为 1(取值范围为 128 到 255)时,表示信息消息。表 3-1 根据消息的编号和内核符号显示了 ICMPv6 消息类型。
表 3-1 。ICMPv6 消息
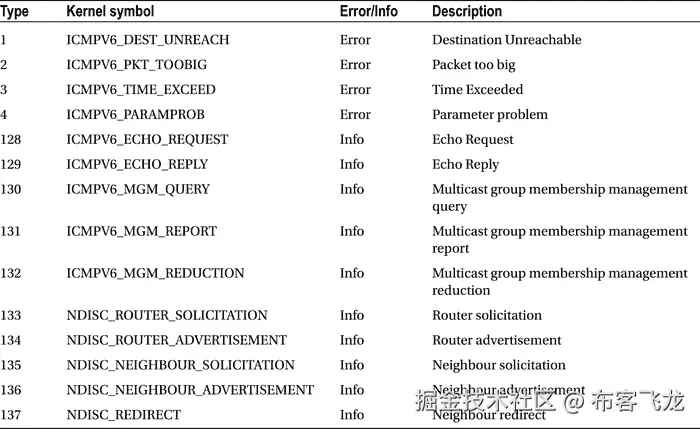
分配的 ICMPv6 类型和代码的当前完整列表可在`www.iana.org/assignments/icmpv6-parameters/icmpv6-parameters.xml`找到。
ICMPv6 执行一些 ICMPv4 没有执行的任务。例如,邻居发现是由 ICMPv6 完成的,而在 IPv4 中是由 ARP/RARP 协议完成的。多播组成员资格由 ICMPv6 结合 MLD(多播侦听程序发现)协议处理,而在 IPv4 中,这由 IGMP (Internet 组管理协议)执行。一些 ICMPv6 消息在含义上类似于 ICMPv4 消息;例如,ICMPv6 有这些消息:“无法到达目的地,”(icmp V6 _ DEST _ 未到达)、“超时”(icmp V6 _ 时间 _ 超出)、“参数问题”(ICMPV6_PARAMPROB)、“回显请求”(icmp V6 _ 回显请求),等等。另一方面,一些 ICMPv6 消息是 IPv6 独有的,例如 NDISC _ NEIGHBOUR _ SOLICITATION 消息。
接收 ICMPv6 消息
当获得一个 ICMPv6 包时,它被传递给`icmpv6_rcv()`方法,该方法只获得一个 SKB 作为参数。图 3-4 显示了接收到的 ICMPv6 消息的`Rx`路径。
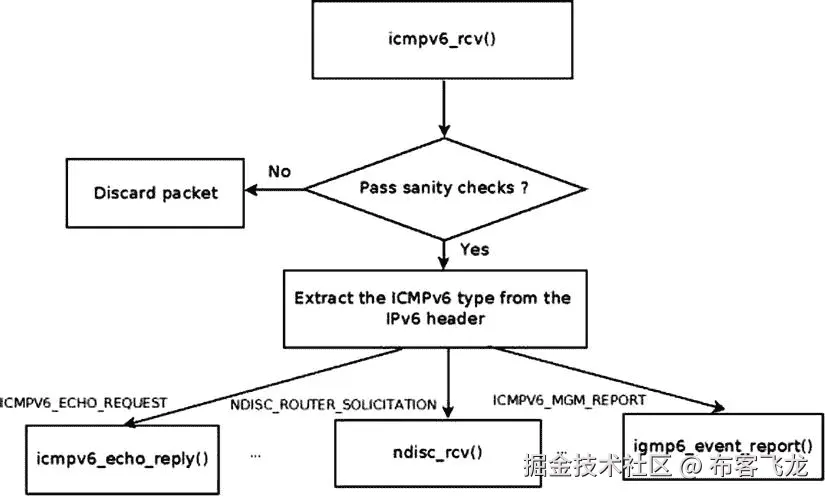
图 3-4 。ICMPv6 消息的接收路径
在`icmpv6_rcv()`方法中,在一些健全性检查之后,`InMsgs` SNMP 计数器(ICMP6_MIB_INMSGS)递增。随后,检验校验和的正确性。如果校验和不正确,则`InErrors` SNMP 计数器(ICMP6_MIB_INERRORS)递增,SKB 被释放。在这种情况下,`icmpv6_rcv()`方法不会返回错误(事实上,它总是返回 0,很像它的 IPv4 对应方法`icmp_rcv()`)。然后,读取 ICMPv6 标头以找到其类型;相应的`procfs`消息类型计数器由 ICMP6MSGIN_INC_STATS_BH 宏递增(每个 ICMPv6 消息类型都有一个`procfs`计数器)。例如,当接收到 ICMPv6 回应请求(“pings”)时,`/proc/net/snmp6/Icmp6InEchos`计数器递增,当接收到 ICMPv6 邻居请求请求时,`/proc/net/snmp6/Icmp6InNeighborSolicits`计数器递增。
在 ICMPv6 中,没有像 ICMPv4 中的`icmp_pointers`表那样的调度表。根据 ICMPv6 消息类型,在一个长的`switch(type)`命令中调用处理程序:
* “回应请求”(ICMPV6_ECHO_REQUEST)由`icmpv6_echo_reply()`方法处理。
* “回显回复”(ICMPV6_ECHO_REPLY)由`ping_rcv()`方法处理。`ping_rcv()`方法在 IPv4 `ping`模块中(`net/ipv4/ping.c`);此方法是一种双栈方法(它处理 IPv4 和 IPv6—在本章开始时讨论过)。
* 数据包太大(ICMPV6_PKT_TOOBIG)。
* 首先检查数据块区(由`skb->data`指向)是否包含一个数据块,其大小至少与 ICMP 报头一样大。这是通过`pskb_may_pull()`方法完成的。如果不满足这个条件,数据包就会被丢弃。
* 然后调用`icmpv6_notify()`方法。这个方法最终调用`raw6_icmp_error()`方法,以便注册的原始套接字将处理 ICMP 消息。
* “目的地不可达”、“超时”、“参数问题”(分别为 ICMPV6_DEST_UNREACH、ICMPV6_TIME_EXCEED、ICMPV6_PARAMPROB)也由`icmpv6_notify()`处理。
* 邻居发现(ND)消息 :
* NDISC_ROUTER_SOLICITATION:通常发送到 FF02::2 的`all-routers`组播地址的消息,由路由器广告应答。(特殊 IPv6 组播地址在第八章的中讨论)。
* NDISC_ROUTER_ADVERTISEMENT:路由器定期发送的消息,或者作为对路由器请求的即时响应。路由器通告包含用于链路确定和/或地址配置的前缀、建议的跳数限制值等等。
* NDISC _ neighbor _ SOLICITATION:IP v4 中 ARP 请求的对应方。
* NDISC _ neighbor _ ADVERTISEMENT:IP v4 中 ARP 回复的对应方。
* NDISC_REDIRECT:由路由器用来通知主机到目的地的更好的第一跳。
* 所有邻居发现(ND)消息都由邻居发现方法`ndisc_rcv()` ( `net/ipv6/ndisc.c`)处理。在第七章的中讨论了`ndisc_rcv()`方法。
* ICMPV6_MGM_QUERY(组播监听报告)由`igmp6_event_query()`处理。
* ICMPV6_MGM_REPORT(组播监听报告)由`igmp6_event_report()`处理。注意:ICMPV6_MGM_QUERY 和 ICMPV6_MGM_REPORT 在第八章中有更详细的讨论。
* 未知类型的消息以及下面的消息都由`icmpv6_notify()`方法处理:
* ICMPV6_MGM_REDUCTION:主机离开组播组时,发送 MLDv2 ICMPV6_MGM_REDUCTION 消息;参见`net/ipv6/mcast.c`中的`igmp6_leave_group()`方法。
* ICMPV6_MLD2_REPORT: MLDv2 多播侦听器报告数据包;通常与所有支持 MLDv2 的路由器多播组地址(FF02::16)的目的地址一起发送。
* ICMPV6_NI_QUERY- ICMP:节点信息查询。
* ICMPV6_NI_REPLY: ICMP 节点信息响应。
* ICMPV6_DHAAD_REQUEST: ICMP 家乡代理地址发现请求消息;请参见 RFC 6275 第 6.5 节“IPv6 中的移动性支持”
* ICMPV6_DHAAD_REPLY: ICMP 家乡代理地址发现回复消息;参见 RFC 6275 第 6.6 节。
* ICMPV6_MOBILE_PREFIX_SOL: ICMP 移动前缀请求消息格式;参见 RFC 6275 第 6.7 节。
* ICMPV6_MOBILE_PREFIX_ADV: ICMP 移动前缀广告消息格式;参见 RFC 6275 第 6.8 节。
请注意,`switch(type)`命令是这样结束的:
```
default:
LIMIT_NETDEBUG(KERN_DEBUG "icmpv6: msg of unknown type\n");
/* informational */
if (type & ICMPV6_INFOMSG_MASK)
break;
/*
* error of unknown type.
* must pass to upper level
*/
icmpv6_notify(skb, type, hdr->icmp6_code, hdr->icmp6_mtu);
}
```sh
信息消息满足条件`(type & ICMPV6_INFOMSG_MASK)`,因此它们被丢弃,而不满足该条件的其他消息(因此应该是错误消息)被传递到上层。这是根据 RFC 4443 的第 2.4 节(“消息处理规则”)完成的。
发送 ICMPv6 消息
发送 ICMPv6 消息的主要方法是`icmpv6_send()`方法。当本地计算机在本节描述的条件下开始发送 ICMPv6 消息时,将调用方法。还有一个`icmpv6_echo_reply()`方法,它仅作为对 ICMPV6_ECHO_REQUEST ("ping ")消息的响应而被调用。从 IPv6 网络栈中的许多地方调用`icmp6_send()`方法。本节看几个例子。
示例:发送“超过跃点限制时间”ICMPv6 消息
转发数据包时,每台机器都将跳数限制计数器减 1。跃点限制计数器是 IPv6 标头的一个成员,它是 IPv6 中与 IPv4 中的生存时间相对应的部分。当跳数限制计数器头的值达到 0 时,通过调用`icmpv6_send()`方法发送带有 icmp V6 _ EXC _ 跳数限制代码的 ICMPV6_TIME_EXCEED 消息,然后更新统计数据并丢弃数据包:
```
int ip6_forward(struct sk_buff *skb)
{
...
if (hdr->hop_limit <= 1) {
/* Force OUTPUT device used as source address */
skb->dev = dst->dev;
icmpv6_send(skb, ICMPV6_TIME_EXCEED, ICMPV6_EXC_HOPLIMIT, 0);
IP6_INC_STATS_BH(net,
ip6_dst_idev(dst), IPSTATS_MIB_INHDRERRORS);
kfree_skb(skb);
return -ETIMEDOUT;
}
...
}
```sh
```
(net/ipv6/ip6_output.c)
```sh
示例:发送“碎片重组时间超过”ICMPv6 消息
当一个片段超时时,通过调用`icmpv6_send()`方法:,发送回一个 ICMPV6_TIME_EXCEED 消息,消息中包含 icmp V6 _ EXC _ 片段时间代码
```
void ip6_expire_frag_queue(struct net *net, struct frag_queue *fq,
struct inet_frags *frags)
{
. . .
icmpv6_send(fq->q.fragments, ICMPV6_TIME_EXCEED, ICMPV6_EXC_FRAGTIME, 0);
. . .
}
```sh
```
(net/ipv6/reassembly.c)
```sh
示例:发送“目的地不可达”/“端口不可达”ICMPv6 消息
接收 UDPv6 数据包时,会搜索匹配的 UDPv6 套接字。如果没有找到匹配的套接字,则检验校验和的正确性。如果它是错误的,数据包将被无声地丢弃。如果正确,统计信息(UDP_MIB_NOPORTS MIB 计数器,由`/proc/net/snmp6/Udp6NoPorts`输出到`procfs`)被更新,并且一个“目的地不可到达”/“端口不可到达”的 ICMPv6 消息与`icmpv6_send()`一起被发回:
```
int __udp6_lib_rcv(struct sk_buff *skb, struct udp_table *udptable, int proto)
{
...
sk = __udp6_lib_lookup_skb(skb, uh->source, uh->dest, udptable);
if (sk != NULL) {
...
}
...
if (udp_lib_checksum_complete(skb))
goto discard;
UDP6_INC_STATS_BH(net, UDP_MIB_NOPORTS, proto == IPPROTO_UDPLITE);
icmpv6_send(skb, ICMPV6_DEST_UNREACH, ICMPV6_PORT_UNREACH, 0);
...
}
```sh
这种情况与本章前面给出的 UDPv4 示例非常相似。
示例:发送“需要碎片”ICMPv6 消息
转发数据包时,如果其大小大于传出链路的 MTU,并且 SKB 中的`local_df`位未置位,则该数据包将被丢弃,ICMPV6_PKT_TOOBIG 消息将被发送回发送方。此消息中的信息用作路径 MTU (PMTU)发现过程的一部分。
请注意,与 IPv4 中发送带有 ICMP_FRAG_NEEDED 代码的 ICMP_DEST_UNREACH 消息的并行情况相反,在这种情况下,发送回的是 ICMPV6_PKT_TOOBIG 消息,而不是“目的地不可达”(ICMPV6_DEST_UNREACH)消息。ICMPV6_PKT_TOOBIG 消息在 ICMPv6: 中有自己的消息类型号
```
int ip6_forward(struct sk_buff *skb)
{
...
if ((!skb->local_df && skb->len > mtu && !skb_is_gso(skb)) ||
(IP6CB(skb)->frag_max_size && IP6CB(skb)->frag_max_size > mtu)) {
/* Again, force OUTPUT device used as source address */
skb->dev = dst->dev;
icmpv6_send(skb, ICMPV6_PKT_TOOBIG, 0, mtu);
IP6_INC_STATS_BH(net,
ip6_dst_idev(dst), IPSTATS_MIB_INTOOBIGERRORS);
IP6_INC_STATS_BH(net,
ip6_dst_idev(dst), IPSTATS_MIB_FRAGFAILS);
kfree_skb(skb);
return -EMSGSIZE;
}
...
}
```sh
```
(net/ipv6/ip6_output.c)
```sh
示例:发送“参数问题”ICMPv6 消息
当在解析扩展标头时遇到问题时,会发回一条 ICMPV6_PARAMPROB 消息,其中包含 icmp V6 _ UNK _ 选项代码:
```
static bool ip6_tlvopt_unknown(struct sk_buff *skb, int optoff) {
switch ((skb_network_header(skb)[optoff] & 0xC0) >> 6) {
...
case 2: /* send ICMP PARM PROB regardless and drop packet */
icmpv6_param_prob(skb, ICMPV6_UNK_OPTION, optoff);
return false;
}
```sh
```
(net/ipv6/exthdrs.c)
```sh
`icmpv6_send()`方法通过调用`icmpv6_xrlim_allow()`支持速率限制。这里我应该提到,与 ICMPv4 一样,ICMPv6 不会自动对所有类型的流量执行速率限制。以下是不执行速率限制检查的条件:
* 信息性消息
* PMTU 发现
* 环回设备
如果所有这些条件都不匹配,则通过调用 ICMPv4 和 ICMPv6 共享的`inet_peer_xrlim_allow()`方法来执行速率限制。请注意,与 IPv4 不同,您不能在 IPv6 中设置速率掩码。ICMPv6 规范 RFC 4443 并没有禁止它,但它从未被实现。
让我们看看`icmp6_send()`方法的内部。首先,这是它的原型:
```
static void icmp6_send(struct sk_buff *skb, u8 type, u8 code, __u32 info)
```sh
参数和 IPv4 的`icmp_send()`方法类似,这里不再赘述。当进一步研究`icmp6_send()`代码时,您会发现一些健全性检查。通过调用`is_ineligible()`方法来检查触发消息是否为 ICMPv6 错误消息;如果是,则`icmp6_send()`方法终止。消息的长度不能超过 1280,这是 IPv6 的最小 MTU (IPV6_MIN_MTU,在`include/linux/ipv6.h`中定义)。这是根据 RFC 4443 第 2.4 (c)节完成的,该节规定每个 ICMPv6 错误消息必须包括尽可能多的 IPv6 违规(调用)数据包(导致错误的数据包),而不使错误消息数据包超过最小 IPv6 MTU。然后,通过`ip6_append_data()`方法和`icmpv6_push_pending_frame()`方法将消息传递到 IPv6 层,以释放 SKB。
现在我将转向`icmpv6_echo_reply()`方法;提醒一下,此方法是作为对 ICMPV6_ECHO 消息的响应而调用的。`icmpv6_echo_reply()`方法只获得一个参数,即 SKB。它构建了一个`icmpv6_msg`对象并将其类型设置为 ICMPV6_ECHO_REPLY。然后,它通过`ip6_append_data()`方法和`icmpv6_push_pending_frame()`方法将消息传递到 IPv6 层。如果`ip6_append_data()`方法失败,SNMP 计数器(ICMP6_MIB_OUTERRORS)递增,并且调用`ip6_flush_pending_frames()`来释放 SKB。
第七章和第八章也讨论了 ICMPv6。下一节将介绍 ICMP 套接字及其用途。
ICMP 套接字(" Ping 套接字")
Openwall GNU/*/Linux 发行版(Owl)的一个补丁添加了一种新的套接字类型(IPPROTO_ICMP ),它提供了优于其他发行版的安全性增强。ICMP 套接字启用一个`setuid-less`“ping”对于 Openwall GNU/*/Linux 来说,这是通往`setuid-less`发行版的最后一步。使用此修补程序,将使用以下内容创建一个新的 ICMPv4 ping 套接字(不是原始套接字):
```
socket(PF_INET, SOCK_DGRAM, IPPROTO_ICMP);
```sh
而不是用:
```
socket(PF_INET, SOCK_RAW, IPPROTO_ICMP);
```sh
还支持 IPPROTO_ICMPV6 套接字,这是后来在`net/ipv6/icmp.c`中添加的。使用以下内容创建新的 ICMPv6 ping 套接字:
```
socket(PF_INET6, SOCK_DGRAM, IPPROTO_ICMPV6);
```sh
而不是用:
```
socket(PF_INET6, SOCK_RAW, IPPROTO_ICMP6);
```sh
在 Mac OS X 中实现了类似的功能(非特权 ICMP );参见:`www.manpagez.com/man/4/icmp/`。
ICMP 套接字的大部分代码在`net/ipv4/ping.c`中;事实上,`net/ipv4/ping.c`中的大部分代码都是双栈的(IPv4 和 IPv6)。在 ??,只有很少的 IPv6 专用位。默认情况下,使用 ICMP 套接字是禁用的。您可以通过设置下面的`procfs`条目来启用 ICMP 套接字:`/proc/sys/net/ipv4/ping_group_range`。默认情况下,它是“1 0 ”,这意味着没有人(甚至是根用户)可以创建 ping 套接字。因此,如果您想允许一个拥有 1000 的`uid`和`gid`的用户使用 ICMP 套接字,您应该从命令行运行这个命令(具有 root 权限):`echo 1000 1000 > /proc/sys/net/ipv4/ping_group_range`,然后您可以从这个用户帐户使用 ICMP 套接字`ping`。如果您想为系统中的用户设置权限,您应该从命令行`echo 0 2147483647 > /proc/sys/net/ipv4/ping_group_range`运行。(2147483647 是 GID_T_MAX 的值;参见`include/net/ping.h`。)IPv4 和 IPv6 没有单独的安全设置;一切由`/proc/sys/net/ipv4/ping_group_range`控制。ICMP 套接字仅支持 IPv4 的 ICMP_ECHO 或 IPv6 的 ICMPV6_ECHO_REQUEST,在这两种情况下,ICMP 消息的代码都必须为 0。
`ping_supported()` helper 方法检查用于构建 ICMP 消息的参数(对于 IPv4 和 IPv6)是否有效。从`ping_sendmsg()`调用:
```
static inline int ping_supported(int family, int type, int code)
{
return (family == AF_INET && type == ICMP_ECHO && code == 0) ||
(family == AF_INET6 && type == ICMPV6_ECHO_REQUEST && code == 0);
}
```sh
```
(net/ipv4/ping.c)
```sh
ICMP 套接字将以下条目导出到 procfs:IP v4 的`/proc/net/icmp`和 IPv6 的`/proc/net/icmp6`。
有关 ICMP 套接字的更多信息,请参见`http://openwall.info/wiki/people/segoon/ping`和`http://lwn.net/Articles/420799/`。
摘要
本章讲述了 ICMPv4 和 ICMPv6 的实现。您了解了这两种协议的 ICMP 报头格式,以及使用这两种协议接收和发送消息。还讨论了 ICMPv6 的新特性,您将在接下来的章节中遇到这些新特性。使用 ICMPv6 消息的邻居发现协议在第七章中讨论,同样使用 ICMPv6 消息的 MLD 协议在第八章中讨论。下一章,第四章,讲述 IPv4 网络层的实现。
在接下来的“快速参考”一节中,我将介绍与本章中讨论的主题相关的主要方法,按照它们的上下文进行排序。本章中提到的两个表格、一些重要的相关`procfs`条目和一小段关于 ICMP 消息在`iptables reject`规则中的使用都被涵盖。
快速参考
我用一个 ICMPv4 和 ICMPv6 的重要方法的简短列表、6 个表格、一个关于`procfs`条目的部分,以及一个关于在`iptables`和`ip6tables`中使用拒绝目标来创建 ICMP“目的地不可达”消息的简短部分来结束本章。
方法
本章介绍了以下方法。
int icmp _ rcv(struct sk _ buf * skb):
此方法是处理传入 ICMPv4 数据包的主要处理程序。
extern void icmp _ send(struct sk _ buff * skb _ in,int type,int code,_ _ be32 info);
此方法发送 ICMPv4 消息。这些参数是启动 SKB、ICMPv4 消息类型、ICMPv4 消息代码和`info`(取决于类型)。
icmp6hdr *icmp6_hdr 结构(const struct sk _ buf * skb);
该方法返回指定的`skb`包含的 ICMPv6 头。
void icmp V6 _ send(struct sk _ buff * skb,u8 类型,u8 代码,_ _ u32 info);
此方法发送 ICMPv6 消息。这些参数是触发 SKB、ICMPv6 消息类型、ICMPv6 消息代码和`info`(取决于类型)。
参见 icmpv 6 _ param _ prob(struct sk _ buf * skb,u8 代码,int pos);
这个方法是`icmp6_send()`方法的一个方便版本,它所做的就是调用`icmp6_send()`,使用 ICMPV6_PARAMPROB 作为类型,使用其他指定的参数`skb`、`code`和`pos`,然后释放 SKB。
桌子
本章涵盖了以下表格。
表 3-2。ICMPv4“无法到达目的地”(ICMP _ DEST _ 无法到达)代码
|
密码
|
内核符号
|
描述
|
| --- | --- | --- |
| Zero | ICMP_NET_UNREACH | 网络不可达 |
| one | ICMP_HOST_UNREACH | 主机无法访问 |
| Two | icmp _ prot _ unregish | 协议不可达 |
| three | ICMP_PORT_UNREACH | 端口不可达 |
| four | 需要 ICMP _ FRAG _ NEEDED | 需要分段,但设置了 DF 标志。 |
| five | ICMP _ SR _ 失败 | 源路由失败 |
| six | ICMP _ NET _ 未知 | 目标网络未知 |
| seven | ICMP _ 主机 _ 未知 | 目标主机未知 |
| eight | ICMP _ 主机 _ 隔离 | 源主机被隔离 |
| nine | icmp _ net _ 是 | 目标网络被管理性禁止。 |
| Ten | icmp _ host _ 是 | 目的主机被管理性禁止。 |
| Eleven | ICMP_NET_UNR_TOS | 对于服务类型,网络不可达。 |
| Twelve | ICMP_HOST_UNR_TOS | 对于服务类型,主机不可访问。 |
| Thirteen | ICMP _ PKT _ 已过滤 | 分组过滤 |
| Fourteen | ICMP _ PREC _ 违规 | 优先违规 |
| Fifteen | ICMP _ PREC _ 截止 | 优先截止 |
| Sixteen | 编号:ICMP_UNREACH | 不可达代码的数量 |
表 3-3。ICMPv4 重定向(ICMP_REDIRECT)代码
|
密码
|
内核符号
|
描述
|
| --- | --- | --- |
| Zero | ICMP_REDIR_NET | 重定向网络 |
| one | ICMP _ REDIR _ 主机 | 重定向主机 |
| Two | icmp _ redir _ net | TOS 的重定向网络 |
| three | icmp _ redir _ hosttos | TOS 的重定向主机 |
表 3-4。ICMPv4 超时(ICMP_TIME_EXCEEDED)代码
|
密码
|
内核符号
|
描述
|
| --- | --- | --- |
| Zero | ICMP_EXC_TTL | 超过 TTL 计数 |
| one | ICMP_EXC_FRAGTIME | 碎片重组时间超过限制 |
表 3-5。ICMPv6“无法到达目的地”(icmp V6 _ DEST _ 无法到达)代码
|
密码
|
内核符号
|
描述
|
| --- | --- | --- |
| Zero | icmp V6 _ 北路由 | 没有到目的地的路线 |
| one | ICMPV6 _ ADM _ 禁止 | 与目的地的通信被行政禁止 |
| Two | ICMPV6 _ 非 _ 邻居 | 超出源地址的范围 |
| three | ICMPV6_ADDR_UNREACH | 地址无法到达 |
| four | ICMPV6_PORT_UNREACH | 端口不可达 |
注意,与 IP v4 ICMP _ DEST _ un reach/ICMP _ FRAG _ needs 对应的 ICMPV6_PKT_TOOBIG,并不是 ICMPV6_DEST_UNREACH 的代码,它本身就是一个 ICMPV6 类型。
表 3-6。ICMPv6 超时(ICMPV6_TIME_EXCEED)代码
|
密码
|
内核符号
|
描述
|
| --- | --- | --- |
| Zero | ICMPV6_EXC_HOPLIMIT | 传输中超出跳数限制 |
| one | ICMPV6_EXC_FRAGTIME | 碎片重组时间超过限制 |
表 3-7。ICMPv6 参数问题(ICMPV6_PARAMPROB)代码
|
密码
|
内核符号
|
描述
|
| --- | --- | --- |
| Zero | icmp V6 _ HDR _ 字段 | 遇到错误的标题字段 |
| one | ICMPV6_UNK_NEXTHDR | 遇到未知的下一个标头类型 |
| Two | icmp V6 _ UNK _ 选项 | 遇到未知的 IPv6 选项 |
procfs 条目
内核通过将值写入`/proc`下的条目,提供了一种从用户空间为各种子系统配置各种设置的方法。这些条目被称为`procfs`条目。所有的 ICMPv4 `procfs`条目都由`netns_ipv4`结构(`include/net/netns/ipv4.h`)中的变量表示,它是网络名称空间(`struct net`)中的一个对象。网络名称空间及其实现将在第十四章中讨论。以下是与 ICMPv4 `netns_ipv4`元素相对应的`sysctl`变量的名称、关于它们的用法的解释以及它们被初始化的默认值,还指定了在哪个方法中进行初始化。
sysctl_icmp_echo_ignore_all
当`icmp_echo_ignore_all`被设置时,回应请求(ICMP_ECHO)将不被回复。
`procfs`条目:`/proc/sys/net/ipv4/icmp_echo_ignore_all`
在`icmp_sk_init()`中初始化为 0
sysctl _ icmp _ echo _ ignore _ 广播
当接收到广播或多播回应(ICMP_ECHO)消息或时间戳(ICMP_TIMESTAMP)消息时,通过读取`sysctl_icmp_echo_ignore_broadcasts`检查广播/多播请求是否被允许。如果设置了该变量,则丢弃数据包并返回 0。
`procfs`条目:`/proc/sys/net/ipv4/icmp_echo_ignore_broadcasts`
在`icmp_sk_init()`中初始化为 1
sysctl _ icmp _ ignore _ bogus _ error _ responses
一些路由器违反 RFC1122,向广播帧发送虚假响应。在`icmp_unreach()`方法中,你检查这个标志。如果此标志设置为 TRUE,内核将不会记录这些警告("<ipv4addr>)发送了无效的 ICMP 类型。。.").</ipv4addr>
`procfs`条目:`/proc/sys/net/ipv4/icmp_ignore_bogus_error_responses`
在`icmp_sk_init()`中初始化为 1
sysctl_icmp_ratelimit
限制向特定目标发送其类型与 icmp 速率掩码(`icmp_ratemask`,见本章下文)匹配的 ICMP 数据包的最大速率。
值 0 表示禁用任何限制;否则,它是响应之间的最小间隔,以毫秒为单位。
`procfs`条目:`/proc/sys/net/ipv4/icmp_ratelimit`
在`icmp_sk_init()`中初始化为 1 * HZ
sysctl _ icmp _ 成批分配掩码
由速率受限的 ICMP 类型构成的掩码。每个位都是 ICMPv4 类型。
`procfs`条目:`/proc/sys/net/ipv4/icmp_ratemask`
在`icmp_sk_init()`中初始化为 0x1818
sysctl _ icmp _ errors _ use _ inbound _ if addr
在`icmp_send()`中检查该变量的值。如果未设置,ICMP 错误消息将与数据包将发送到的接口的主地址一起发送。设置后,icmp 消息将与接收导致 ICMP 错误的数据包的接口的主地址一起发送。
`procfs`条目:`/proc/sys/net/ipv4/icmp_errors_use_inbound_ifaddr`
在`icmp_sk_init()`中初始化为 0
 **注**更多关于 ICMP `sysctl`变量、它们的类型及其默认值,请参见
`Documentation/networking/ip-sysctl.txt`。
使用 iptables 创建“目的地不可达”信息
用户空间工具使我们能够设置规则,根据这些规则设置的过滤器来决定内核应该如何处理流量。处理`iptables`规则在 netfilter 子系统中完成,在第九章中讨论。`iptables`规则之一是`reject`规则,它丢弃数据包而不做进一步处理。当设置一个`iptables reject`目标时,用户可以使用`-j REJECT`和`--reject-with`限定符设置一个规则来发送带有各种代码的“目的地不可达”ICMPv4 消息。例如,下面的`iptables`规则将丢弃来自任何源的任何数据包,并发回“ICMP 主机被禁止”的 ICMP 消息:
```
iptables -A INPUT -j REJECT --reject-with icmp-host-prohibited
```sh
以下是用于设置 ICMPV4 消息的`--reject-with`限定符的可能值,该消息将被发送以回复发送主机:
```
icmp-net-unreachable - ICMP_NET_UNREACH
icmp-host-unreachable - ICMP_HOST_UNREACH
icmp-port-unreachable - ICMP_PORT_UNREACH
icmp-proto-unreachable - ICMP_PROT_UNREACH
icmp-net-prohibited - ICMP_NET_ANO
icmp-host-prohibited - ICMP_HOST_ANO
icmp-admin-prohibited - ICMP_PKT_FILTERED
```sh
您也可以使用`--reject-with tcp-reset`,它将发送一个 TCP RST 数据包来回复发送主机。
```
(net/ipv4/netfilter/ipt_REJECT.c)
```sh
与 IPv6 中的`ip6tables`一样,也有一个拒绝目标。例如:
```
ip6tables -A INPUT -s 2001::/64 -p ICMPv6 -j REJECT --reject-with icmp6-adm-prohibited
```sh
以下是用于设置 ICMPv6 消息的`--reject-with`限定符的可能值,该消息将被发送以回复发送主机:
```
no-route, icmp6-no-route - ICMPV6_NOROUTE.
adm-prohibited, icmp6-adm-prohibited - ICMPV6_ADM_PROHIBITED.
port-unreach, icmp6-port-unreachable - ICMPV6_NOT_NEIGHBOUR.
addr-unreach, icmp6-addr-unreachable - ICMPV6_ADDR_UNREACH.
```sh
```
(net/ipv6/netfilter/ip6t_REJECT.c)
