

Python DevOps 指南(七)
原文:
annas-archive.org/md5/68b28228356df0415ddc83eb0aaea548译者:飞龙
第十四章:机器学习运维与机器学习工程
2020 年最热门的职位之一是机器学习工程师。其他热门职位包括数据工程师、数据科学家和机器学习科学家。尽管您可以成为 DevOps 专家,但 DevOps 是一种行为,DevOps 的原则可以应用于任何软件项目,包括机器学习。让我们看看一些核心的 DevOps 最佳实践:持续集成、持续交付、微服务、基础设施即代码、监控与日志记录、以及沟通与协作。这些中哪个不适用于机器学习?
软件工程项目越复杂,而机器学习就更复杂,您就越需要 DevOps 原则。有比 API 做机器学习预测更好的微服务示例吗?在本章中,让我们深入探讨如何使用 DevOps 思维以专业且可重复的方式进行机器学习。
什么是机器学习?
机器学习是一种利用算法自动从数据中学习的方法。主要有四种类型:监督学习、半监督学习、无监督学习和强化学习。
监督学习
在监督学习中,已知并标记了正确答案。例如,如果您想要从体重预测身高,可以收集人们身高和体重的示例。身高将是目标,体重将是特征。
让我们看一个监督学习的示例:
-
25,000 个 18 岁儿童身高和体重的合成记录
摄入
**输入[0]:**
import pandas as pd
**输入[7]:**
df = pd.read_csv(
"https://raw.githubusercontent.com/noahgift/\
regression-concepts/master/\
height-weight-25k.csv")
df.head()
**输出[7]:**
| 索引 | 身高-英寸 | 体重-磅 | |
|---|---|---|---|
0 | 1 | 65.78331 | 112.9925 |
1 | 2 | 71.51521 | 136.4873 |
2 | 3 | 69.39874 | 153.0269 |
3 | 4 | 68.21660 | 142.3354 |
4 | 5 | 67.78781 | 144.2971 |
探索性数据分析(EDA)
让我们看看数据,看看可以探索什么。
散点图
在这个示例中,使用了 Python 中流行的绘图库 seaborn 来可视化数据集。如果需要安装它,您可以在笔记本中使用!pip install seaborn进行安装。您还可以在部分中使用!pip install <包名称>安装任何其他库。如果您使用的是 Colab 笔记本,则这些库已经为您安装好。查看身高/体重 lm 图(图 14-1)。
**输入[0]:**
import seaborn as sns
import numpy as np
**输入[9]:**
sns.lmplot("Height-Inches", "Weight-Pounds", data=df)
图 14-1 身高/体重 lm 图
描述性统计
接下来,可以生成一些描述性统计。
**输入[10]:**
df.describe()
**输出[10]:**
| 索引 | 身高-英寸 | 体重-磅 | |
|---|---|---|---|
数量 | 25000.000000 | 25000.000000 | 25000.000000 |
均值 | 12500.500000 | 67.993114 | 127.079421 |
标准差 | 7217.022701 | 1.901679 | 11.660898 |
最小值 | 1.000000 | 60.278360 | 78.014760 |
25% | 6250.750000 | 66.704397 | 119.308675 |
50% | 12500.500000 | 67.995700 | 127.157750 |
75% | 18750.250000 | 69.272958 | 134.892850 |
max | 25000.000000 | 75.152800 | 170.924000 |
核密度分布
密度图的分布(图 14-2)显示了两个变量之间的关系。
**In[11]:**
sns.jointplot("Height-Inches", "Weight-Pounds", data=df, kind="kde")
**Out[11]:**
图 14-2. 密度图
建模
现在让我们来审查建模过程。机器学习建模是指算法从数据中学习的过程。总体思路是利用历史数据来预测未来数据。
Sklearn 回归模型
首先,数据被提取为特征和目标,然后被分割为训练集和测试集。这允许测试集被保留以测试训练模型的准确性。
**In[0]:**
from sklearn.model_selection import train_test_split
提取并检查特征和目标
建议明确提取目标和特征变量,并在一个单元格中重塑它们。然后,您会想要检查形状,以确保它是适合使用 Sklearn 进行机器学习的正确维度。
**In[0]:**
y = df['Weight-Pounds'].values #Target
y = y.reshape(-1, 1)
X = df['Height-Inches'].values #Feature(s)
X = X.reshape(-1, 1)
**In[14]:**
y.shape
**Out[14]:**
(25000, 1)
分割数据
数据被分为 80%/20% 的比例。
**In[15]:**
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
**Out[15]:**
(20000, 1) (20000, 1)
(5000, 1) (5000, 1)
拟合模型
现在模型使用从 Sklearn 导入的 LinearRegression 算法进行拟合。
**In[0]:**
from sklearn.linear_model import LinearRegression
lm = LinearRegression()
model = lm.fit(X_train, y_train)
y_predicted = lm.predict(X_test)
打印线性回归模型的准确性
现在训练好的模型可以展示在预测新数据时的准确性。这是通过计算预测数据与测试数据的 RMSE 或均方根误差来完成的。
**In[18]:**
from sklearn.metrics import mean_squared_error
from math import sqrt
#RMSE Root Mean Squared Error
rms = sqrt(mean_squared_error(y_predicted, y_test))
rms
**Out[18]:**
10.282608230082417
绘制预测的身高与实际身高
现在让我们绘制预测的身高与实际身高(图 14-3)的图表,以查看该模型在预测中的表现如何。
**In[19]:**
import matplotlib.pyplot as plt
_, ax = plt.subplots()
ax.scatter(x = range(0, y_test.size), y=y_test, c = 'blue', label = 'Actual',
alpha = 0.5)
ax.scatter(x = range(0, y_predicted.size), y=y_predicted, c = 'red',
label = 'Predicted', alpha = 0.5)
plt.title('Actual Height vs Predicted Height')
plt.xlabel('Weight')
plt.ylabel('Height')
plt.legend()
plt.show()
图 14-3. 预测的身高与实际身高
这是一个创建机器学习模型的非常简单但又强大的实际工作流示例。
Python 机器学习生态系统
让我们快速了解一下 Python 机器学习生态系统(图 14-4)。
主要有四个领域:深度学习、sklearn、AutoML 和 Spark。在深度学习领域,最流行的框架依次是 TensorFlow/Keras、PyTorch 和 MXNet。Google 赞助 TensorFlow,Facebook 赞助 PyTorch,而 MXNet 来自亚马逊。您将会看到亚马逊 SageMaker 经常提到 MXNet。需要注意的是,这些深度学习框架针对 GPU 进行优化,使其性能比 CPU 目标提升多达 50 倍。
图 14-4. Python 机器学习生态系统
Sklearn 生态系统通常在同一个项目中同时使用 Pandas 和 Numpy。Sklearn 故意不针对 GPU,但是有一个名为 Numba 的项目专门针对 GPU(包括 NVIDIA 和 AMD)。
在 AutoML 中,Uber 的 Ludwig 和 H20 的 H20 AutoML 是两个领先的工具。两者都可以节省开发机器学习模型的时间,并且还可以优化现有的机器学习模型。
最后,有 Spark 生态系统,它建立在 Hadoop 的基础上。Spark 可以针对 GPU 和 CPU 进行优化,并通过多个平台实现:Amazon EMR、Databricks、GCP Dataproc 等。
使用 PyTorch 进行深度学习
现在定义了使用 Python 进行机器学习的生态系统,让我们看看如何将简单线性回归示例移植到 PyTorch,并在 CUDA GPU 上运行它。获取 NVIDIA GPU 的一个简单方法是使用 Colab 笔记本。Colab 笔记本是由 Google 托管的与 Jupyter 兼容的笔记本,用户可以免费访问 GPU 和张量处理单元(TPU)。您可以在GPU 中运行此代码。
使用 PyTorch 进行回归
首先,将数据转换为float32。
**In[0]:**
# Training Data
x_train = np.array(X_train, dtype=np.float32)
x_train = x_train.reshape(-1, 1)
y_train = np.array(y_train, dtype=np.float32)
y_train = y_train.reshape(-1, 1)
# Test Data
x_test = np.array(X_test, dtype=np.float32)
x_test = x_test.reshape(-1, 1)
y_test = np.array(y_test, dtype=np.float32)
y_test = y_test.reshape(-1, 1)
请注意,如果您不使用 Colab 笔记本,可能需要安装 PyTorch。此外,如果您使用 Colab 笔记本,您可以拥有 NVIDIA GPU 并运行此代码。如果您不使用 Colab,则需要在具有 GPU 的平台上运行。
**In[0]:**
import torch
from torch.autograd import Variable
class linearRegression(torch.nn.Module):
def __init__(self, inputSize, outputSize):
super(linearRegression, self).__init__()
self.linear = torch.nn.Linear(inputSize, outputSize)
def forward(self, x):
out = self.linear(x)
return out
现在创建一个启用 CUDA 的模型(假设您在 Colab 上或者有 NVIDIA GPU 的机器上运行)。
**In[0]:**
inputDim = 1 # takes variable 'x'
outputDim = 1 # takes variable 'y'
learningRate = 0.0001
epochs = 1000
model = linearRegression(inputDim, outputDim)
model.cuda()
**Out[0]:**
linearRegression(
(linear): Linear(in_features=1, out_features=1, bias=True)
)
创建随机梯度下降和损失函数。
**In[0]:**
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learningRate)
现在训练模型。
**In[0]:**
for epoch in range(epochs):
inputs = Variable(torch.from_numpy(x_train).cuda())
labels = Variable(torch.from_numpy(y_train).cuda())
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
print(loss)
# get gradients w.r.t to parameters
loss.backward()
# update parameters
optimizer.step()
print('epoch {}, loss {}'.format(epoch, loss.item()))
为了节省空间,输出被抑制了超过 1000 次运行。
**Out[0]:**
tensor(29221.6543, device='cuda:0', grad_fn=<MseLossBackward>)
epoch 0, loss 29221.654296875
tensor(266.7252, device='cuda:0', grad_fn=<MseLossBackward>)
epoch 1, loss 266.72515869140625
tensor(106.6842, device='cuda:0', grad_fn=<MseLossBackward>)
epoch 2, loss 106.6842269897461
....output suppressed....
epoch 998, loss 105.7930908203125
tensor(105.7931, device='cuda:0', grad_fn=<MseLossBackward>)
epoch 999, loss 105.7930908203125
绘制预测高度与实际高度
现在让我们绘制预测高度与实际高度的图示(图 14-5),就像简单模型一样。
**In[0]:**
with torch.no_grad():
predicted = model(Variable(torch.from_numpy(x_test).cuda())).cpu().\
data.numpy()
print(predicted)
plt.clf()
plt.plot(x_test, y_test, 'go', label='Actual Height', alpha=0.5)
plt.plot(x_test, predicted, '--', label='Predicted Height', alpha=0.5)
plt.legend(loc='best')
plt.show()
图 14-5. 预测高度与实际高度
打印 RMSE
最后,让我们打印出 RMSE 并进行比较。
**In[0]:**
#RMSE Root Mean Squared Error
rms = sqrt(mean_squared_error(x_test, predicted))
rms
**Out[0]:**
59.19054613663507
深度学习确实需要更多的代码,但其概念与 sklearn 模型相同。这里的重要一点是 GPU 正成为生产流水线中不可或缺的一部分。即使您自己不进行深度学习,了解构建基于 GPU 的机器学习模型的过程也是有帮助的。
云机器学习平台
机器学习中一个普遍存在的方面是基于云的机器学习平台。Google 提供了 GCP AI 平台(图 14-6)。
图 14-6. GCP AI 平台
GCP 平台具有许多高级自动化组件,从数据准备到数据标记。AWS 平台提供 Amazon SageMaker(图 14-7)。
图 14-7. Amazon SageMaker
SageMaker 还具有许多高级组件,包括在 spot 实例上训练和弹性预测端点。
机器学习成熟度模型
现在面临的一个重大挑战之一是意识到希望进行机器学习的公司需要进行变革。机器学习成熟度模型图表(图 14-8)展示了一些挑战和机会。
图 14-8. 机器学习成熟度模型
机器学习关键术语
让我们定义一些关键的机器学习术语,这将在本章的其余部分中非常有帮助:
机器学习
基于样本或训练数据建立数学模型的一种方法。
模型
这是机器学习应用中的产品。一个简单的例子是线性方程,即预测 X 和 Y 之间关系的直线。
特征
特征是电子表格中用作信号以创建机器学习模型的列。一个很好的例子是 NBA 球队每场比赛得分。
目标
目标是电子表格中你试图预测的列。一个很好的例子是一支 NBA 球队赛季获胜场次。
超大规模机器学习
这是根据已知的正确历史值预测未来值的机器学习类型。一个很好的例子是使用每场比赛得分特征来预测 NBA 赛季中的胜利次数。
无监督机器学习
这是一种处理未标记数据的机器学习类型。它不是预测未来值,而是通过工具如聚类来发现隐藏的模式,进而可以用作标签。一个很好的例子是创建具有类似得分、篮板、盖帽和助攻的 NBA 球员集群。一个集群可以称为“高个子顶级球员”,另一个集群可以称为“得分后卫”。
深度学习
这是一种使用人工神经网络进行监督或无监督机器学习的方法。深度学习最流行的框架是 Google 的 TensorFlow。
Scikit-learn
这是 Python 中最流行的机器学习框架之一。
熊猫
这是用于进行数据处理和分析的最流行的库之一。它与 scikit-learn 和 Numpy 配合良好。
Numpy
这是进行低级科学计算的主要 Python 库。它支持大型多维数组,并拥有大量的高级数学函数。它广泛地与 scikit-learn、Pandas 和 TensorFlow 一起使用。
第 1 级:构架、范围识别和问题定义
让我们先来看看第一层。在公司实施机器学习时,重要的是考虑需要解决的问题以及如何构架这些问题。机器学习项目失败的一个关键原因是组织在开始之前没有先提出问题。
一个很好的类比是为旧金山的一家餐馆连锁店建立移动应用程序。一个天真的方法是立即开始构建本地 iOS 和本地 Android 应用程序(使用两个开发团队)。一个典型的移动团队可能是每个应用程序三名全职开发人员。所以这意味着每个开发人员大约 20 万美元,需要聘请六名开发人员。项目的运行成本现在约为每年 120 万美元。移动应用程序每年能带来超过 120 万美元的收入吗?如果不能,是否有更简单的替代方案?也许使用现有公司的网络开发人员的移动优化 Web 应用程序会是一个更好的选择。
那么,与一家专门从事食品配送的公司合作并完全外包这项任务呢?这种方法的利弊是什么?同样的思维过程可以和应该应用于机器学习和数据科学倡议。例如,你的公司是否需要雇佣六名年薪 50 万美元的博士级机器学习研究员?还有什么替代方案?对于机器学习来说,一点点范围界定和问题定义可以大大增加成功的机会。
Level 2:数据的持续交付
文明的基础之一是运行水。罗马的高架渠道早在公元前 312 年就为城市提供了数英里的水源。运行水使得城市成功所必需的基础设施得以实现。据联合国儿童基金会估计,全球 2018 年,妇女和女童每天花费约 2 亿小时来取水。这是一个巨大的机会成本;时间不足以学习、照顾孩子、工作或放松。
一个流行的说法是“软件正在吞噬世界”。与此相关的是,未来每家公司都需要有一个机器学习和人工智能战略。其中一部分战略是更加认真地思考数据的持续交付。就像运行水一样,“运行数据”每天为您节省数小时的时间。数据湖的一个潜在解决方案如图 14-9 所示。
图 14-9. AWS 数据湖
乍看之下,数据湖可能看起来像是在寻找问题的解决方案,或者过于简单而无法做任何有用的事情。但是让我们来看看它解决的一些问题:
-
您可以在不移动数据的情况下处理数据。
-
存储数据是便宜的。
-
创建存档数据的生命周期策略是直接的。
-
创建安全并审核数据的生命周期策略是直接的。
-
生产系统与数据处理分离。
-
它可以拥有几乎无限和弹性的存储和磁盘 I/O。
这种架构的替代方案通常是一种临时混乱的等同于步行四小时到井边取水然后返回的混乱状态。安全性在数据湖架构中也是一个主要因素,就像在供水中一样。通过集中数据存储和交付的架构,防止和监控数据违规变得更加简单明了。以下是一些可能有助于防止未来数据违规的想法:
-
你的数据是否处于静态加密状态?如果是,谁拥有解密密钥?解密事件是否被记录和审计?
-
你的数据是否在离开你的网络时被记录和审计?例如,将整个客户数据库移出网络何时是一个好主意?为什么这不受监控和审计?
-
你进行定期数据安全审计吗?为什么不?
-
你是否存储个人身份信息(PII)?为什么?
-
你是否监控关键生产事件的监控?你为什么不监控数据安全事件?
我们为什么要让数据在内部网络之外流动?如果我们设计关键数据为字面上无法在主机网络之外传输的方形销钉,例如核发射代码,会怎样?让数据无法移出环境似乎是防止这些违规行为的一种可行方式。如果外部网络本身只能传输“圆销钉”数据包会怎样?此外,这可能是提供此类安全数据湖云的一个很好的“锁定”功能。
Level 3: 持续交付干净的数据
希望你能接受持续交付数据背后的理念,以及对公司的机器学习计划的成功有多么重要。持续交付数据的一个巨大改进是持续交付干净的数据。为什么要费力交付一团糟的数据?弗林特市密歇根州最近出现的污水问题让人联想起。大约在 2014 年,弗林特将水源从休伦湖和底特律河改为弗林特河。官员未能施用腐蚀抑制剂,导致老化管道中的铅渗漏到饮水供应中。这也可能导致外部水源变更引发的瘟疫,导致 12 人死亡,另有 87 人患病。
最早的数据科学成功故事之一涉及 1849-1854 年的脏水。约翰·斯诺能够使用数据可视化来识别霍乱病例的聚类(图 14-10)。这导致发现了爆发的根本原因。污水直接被泵入饮用水供应中!
图 14-10. 霍乱病例聚类
考虑以下观察:
-
为什么数据不会自动处理以“清洁”它?
-
你能够可视化具有“污水”的数据管道的部分吗?
-
公司花费了多少时间在可以完全自动化的数据清洗任务上?
Level 4: 持续交付探索性数据分析
如果你对数据科学的唯一看法是 Kaggle 项目,可能会觉得数据科学的主要目标是生成尽可能精确的预测。然而,数据科学和机器学习远不止于此。数据科学是一个多学科领域,有几种不同的视角。其中一种视角是关注因果关系。是什么潜在特征推动了模型?你能解释模型如何得出其预测吗?几个 Python 库在这方面提供了帮助:ELI5、SHAP 和 LIME。它们都致力于帮助解释机器学习模型的真实运行方式。
预测的世界观不太关注如何达到答案,而更关注预测是否准确。在一个云原生、大数据的世界中,这种方法具有优点。某些机器学习问题使用大量数据表现良好,例如使用深度学习进行图像识别。你拥有的数据和计算能力越多,你的预测准确性就会越好。
你的产品已经投入使用了吗?为什么没有?如果你建立机器学习模型,而它们没有被使用,那你建模的目的是什么?
你不知道什么?通过观察数据,你能学到什么?通常,数据科学更感兴趣的是过程而不是结果。如果你只关注预测,那么你可能会错过数据的完全不同的视角。
Level 5:传统机器学习和 AutoML 的持续交付
抗拒自动化如同人类历史的常态。卢德运动是英国纺织工人的秘密组织,他们在 1811 年到 1816 年间摧毁纺织机器,作为抗议的形式。最终,抗议者被击毙,反叛被法律和军事力量镇压,进步的道路依然前行。
如果你审视人类的历史,那些自动化取代曾由人类执行的任务的工具正在不断发展。在技术性失业中,低技能工人被取代,而高技能工人的薪水增加。一个例子是系统管理员与 DevOps 专业人员之间的对比。是的,一些系统管理员失去了工作,例如那些专注于数据中心更换硬盘等任务的工人,但是新的、薪水更高的工作,比如云架构师,也随之出现。
在机器学习和数据科学的职位招聘中,年薪通常在三十万到一百万美元之间,并不少包含着许多基本的商业规则:调整超参数,删除空值,以及将作业分发至集群。我提出的自动化定律(automator’s law)说:“如果你谈论自动化某事,它最终将会被自动化。” 关于自动机器学习(AutoML)有很多讨论,因此机器学习的大部分内容将不可避免地被自动化。
这意味着,就像其他自动化示例一样,工作的性质将发生变化。一些工作将变得更加熟练(想象一下能够每天训练数千个机器学习模型的人),而一些工作将因为机器能够做得更好而自动化(比如调整 JSON 数据结构中数值的工作,即调优超参数)。
第 6 级别:ML 操作反馈循环
为什么要开发移动应用?想必是为了让移动设备上的用户使用你的应用。那么机器学习呢?特别是与数据科学或统计学相比,机器学习的目的是创建模型并预测某些事物。如果模型没有投入生产,那它到底在做什么呢?
此外,将模型推送到生产环境是学习更多的机会。当模型真正部署到生产环境时,它是否能够准确预测新数据的情况?模型是否如预期地对用户产生影响,比如增加购买或在网站上停留的时间?只有在模型实际部署到生产环境时,才能获得这些宝贵的见解。
另一个重要的问题是可伸缩性和可重复性。一个真正技术成熟的组织可以按需部署软件,包括机器学习模型。在这里,机器学习模型的 DevOps 最佳实践同样重要:持续部署、微服务、监控和仪表化。
将更多这种技术成熟性注入到您的组织中的一个简单方法是,应用与选择云计算而不是物理数据中心相同的逻辑。租用他人的专业知识并利用规模经济。
Sklearn Flask 与 Kubernetes 和 Docker
让我们通过 Docker 和 Kubernetes 实现基于 sklearn 的机器学习模型的真实部署。
这是一个 Dockerfile。注意,它提供了一个 Flask 应用程序。Flask 应用程序将托管 sklearn 应用程序。请注意,您可能希望安装 Hadolint,这允许您对 Dockerfile 进行代码检查:https://github.com/hadolint/hadolint。
FROM python:3.7.3-stretch
# Working Directory
WORKDIR /app
# Copy source code to working directory
COPY . app.py /app/
# Install packages from requirements.txt
# hadolint ignore=DL3013
RUN pip install --upgrade pip &&\
pip install --trusted-host pypi.python.org -r requirements.txt
# Expose port 80
EXPOSE 80
# Run app.py at container launch
CMD ["python", "app.py"]
这是 Makefile,它作为应用程序运行时的中心点:
setup:
python3 -m venv ~/.python-devops
install:
pip install --upgrade pip &&\
pip install -r requirements.txt
test:
#python -m pytest -vv --cov=myrepolib tests/*.py
#python -m pytest --nbval notebook.ipynb
lint:
hadolint Dockerfile
pylint --disable=R,C,W1203 app.py
all: install lint test
这是 requirements.txt 文件:
Flask==1.0.2
pandas==0.24.2
scikit-learn==0.20.3
这是 app.py 文件:
from flask import Flask, request, jsonify
from flask.logging import create_logger
import logging
import pandas as pd
from sklearn.externals import joblib
from sklearn.preprocessing import StandardScaler
app = Flask(__name__)
LOG = create_logger(app)
LOG.setLevel(logging.INFO)
def scale(payload):
"""Scales Payload"""
LOG.info(f"Scaling Payload: {payload}")
scaler = StandardScaler().fit(payload)
scaled_adhoc_predict = scaler.transform(payload)
return scaled_adhoc_predict
@app.route("/")
def home():
html = "<h3>Sklearn Prediction Home</h3>"
return html.format(format)
# TO DO: Log out the prediction value
@app.route("/predict", methods=['POST'])
def predict():
"""Performs an sklearn prediction
input looks like:
{
"CHAS":{
"0":0
},
"RM":{
"0":6.575
},
"TAX":{
"0":296.0
},
"PTRATIO":{
"0":15.3
},
"B":{
"0":396.9
},
"LSTAT":{
"0":4.98
}
result looks like:
{ "prediction": [ 20.35373177134412 ] }
"""
json_payload = request.json
LOG.info(f"JSON payload: {json_payload}")
inference_payload = pd.DataFrame(json_payload)
LOG.info(f"inference payload DataFrame: {inference_payload}")
scaled_payload = scale(inference_payload)
prediction = list(clf.predict(scaled_payload))
return jsonify({'prediction': prediction})
if __name__ == "__main__":
clf = joblib.load("boston_housing_prediction.joblib")
app.run(host='0.0.0.0', port=80, debug=True)
这是 run_docker.sh 文件:
#!/usr/bin/env bash
# Build image
docker build --tag=flasksklearn .
# List docker images
docker image ls
# Run flask app
docker run -p 8000:80 flasksklearn
这是 run_kubernetes.sh 文件:
#!/usr/bin/env bash
dockerpath="noahgift/flasksklearn"
# Run in Docker Hub container with kubernetes
kubectl run flaskskearlndemo\
--generator=run-pod/v1\
--image=$dockerpath\
--port=80 --labels app=flaskskearlndemo
# List kubernetes pods
kubectl get pods
# Forward the container port to host
kubectl port-forward flaskskearlndemo 8000:80
#!/usr/bin/env bash
# This tags and uploads an image to Docker Hub
#Assumes this is built
#docker build --tag=flasksklearn .
dockerpath="noahgift/flasksklearn"
# Authenticate & Tag
echo "Docker ID and Image: $dockerpath"
docker login &&\
docker image tag flasksklearn $dockerpath
# Push Image
docker image push $dockerpath
Sklearn Flask 与 Kubernetes 和 Docker
您可能会问自己模型是如何创建然后“泡菜”出来的。您可以在此处查看 整个笔记本。
首先,导入一些机器学习的库:
import numpy
from numpy import arange
from matplotlib import pyplot
import seaborn as sns
import pandas as pd
from pandas import read_csv
from pandas import set_option
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import ElasticNet
from sklearn.tree import DecisionTreeRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.svm import SVR
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.ensemble import AdaBoostRegressor
from sklearn.metrics import mean_squared_error
**In[0]:**
boston_housing = "https://raw.githubusercontent.com/\
noahgift/boston_housing_pickle/master/housing.csv"
names = ['CRIM', 'ZN', 'INDUS', 'CHAS',
'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX',
'PTRATIO', 'B', 'LSTAT', 'MEDV']
df = read_csv(boston_housing,
delim_whitespace=True, names=names)
**In[0]:**
df.head()
**Out[0]:**
CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | |
|---|---|---|---|---|---|---|---|
0 | 0.00632 | 18.0 | 2.31 | 0 | 0.538 | 6.575 | 65.2 |
1 | 0.02731 | 0.0 | 7.07 | 0 | 0.469 | 6.421 | 78.9 |
2 | 0.02729 | 0.0 | 7.07 | 0 | 0.469 | 7.185 | 61.1 |
3 | 0.03237 | 0.0 | 2.18 | 0 | 0.458 | 6.998 | 45.8 |
4 | 0.06905 | 0.0 | 2.18 | 0 | 0.458 | 7.147 | 54.2 |
DIS | RAD | TAX | PTRATIO | B | LSTAT | MEDV | |
| --- | --- | --- | --- | --- | --- | --- | --- |
0 | 4.0900 | 1 | 296.0 | 15.3 | 396.90 | 4.98 | 24.0 |
1 | 4.9671 | 2 | 242.0 | 17.8 | 396.90 | 9.14 | 21.6 |
2 | 4.9671 | 2 | 242.0 | 17.8 | 392.83 | 4.03 | 34.7 |
3 | 6.0622 | 3 | 222.0 | 18.7 | 394.63 | 2.94 | 33.4 |
4 | 6.0622 | 3 | 222.0 | 18.7 | 396.90 | 5.33 | 36.2 |
EDA
这些是模型的特征:
房价中位数
查尔斯河虚拟变量(1 表示地段与河流接壤;0 表示否)
RM
每个住宅的平均房间数
TAX
完整价值的房产税率每$10,000
PTRATIO
每个住宅的平均房间数
Bk
镇上的师生比
LSTAT
% 人口低地位
MEDV
住户的房屋中位数价格(以千美元为单位)
**In[0]:**
prices = df['MEDV']
df = df.drop(['CRIM','ZN','INDUS','NOX','AGE','DIS','RAD'], axis = 1)
features = df.drop('MEDV', axis = 1)
df.head()
**Out[0]:**
CHAS | RM | TAX | PTRATIO | B | LSTAT | MEDV | |
|---|---|---|---|---|---|---|---|
0 | 0 | 6.575 | 296.0 | 15.3 | 396.90 | 4.98 | 24.0 |
1 | 0 | 6.421 | 242.0 | 17.8 | 396.90 | 9.14 | 21.6 |
2 | 0 | 7.185 | 242.0 | 17.8 | 392.83 | 4.03 | 34.7 |
3 | 0 | 6.998 | 222.0 | 18.7 | 394.63 | 2.94 | 33.4 |
4 | 0 | 7.147 | 222.0 | 18.7 | 396.90 | 5.33 | 36.2 |
建模
这是笔记本中建模的地方。一个有用的策略是始终创建四个主要部分的笔记本:
-
摄取
-
EDA
-
建模
-
结论
在这个建模部分,数据从 DataFrame 中提取并传递到 sklearn 的train_test_split模块中,该模块用于将数据拆分为训练和验证数据。
拆分数据
**In[0]:**
# Split-out validation dataset
array = df.values
X = array[:,0:6]
Y = array[:,6]
validation_size = 0.20
seed = 7
X_train, X_validation, Y_train, Y_validation = train_test_split(X, Y,
test_size=validation_size, random_state=seed)
**In[0]:**
for sample in list(X_validation)[0:2]:
print(f"X_validation {sample}")
**Out[0]:**
X_validation [ 1. 6.395 666. 20.2 391.34 13.27 ]
X_validation [ 0. 5.895 224. 20.2 394.81 10.56 ]
调整缩放的 GBM
这个模型使用了几种在许多成功的 Kaggle 项目中可以参考的高级技术。这些技术包括 GridSearch,可以帮助找到最佳的超参数。注意,数据的缩放也是必要的,大多数机器学习算法都期望进行某种类型的缩放以生成准确的预测。
**In[0]:**
# Test options and evaluation metric using Root Mean Square error method
num_folds = 10
seed = 7
RMS = 'neg_mean_squared_error'
scaler = StandardScaler().fit(X_train)
rescaledX = scaler.transform(X_train)
param_grid = dict(n_estimators=numpy.array([50,100,150,200,250,300,350,400]))
model = GradientBoostingRegressor(random_state=seed)
kfold = KFold(n_splits=num_folds, random_state=seed)
grid = GridSearchCV(estimator=model, param_grid=param_grid, scoring=RMS, cv=kfold)
grid_result = grid.fit(rescaledX, Y_train)
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))
**Out[0]:**
Best: -11.830068 using {'n_estimators': 200}
-12.479635 (6.348297) with: {'n_estimators': 50}
-12.102737 (6.441597) with: {'n_estimators': 100}
-11.843649 (6.631569) with: {'n_estimators': 150}
-11.830068 (6.559724) with: {'n_estimators': 200}
-11.879805 (6.512414) with: {'n_estimators': 250}
-11.895362 (6.487726) with: {'n_estimators': 300}
-12.008611 (6.468623) with: {'n_estimators': 350}
-12.053759 (6.453899) with: {'n_estimators': 400}
/usr/local/lib/python3.6/dist-packages/sklearn/model_selection/_search.py:841:
DeprecationWarning:
DeprecationWarning)
拟合模型
此模型使用 GradientBoostingRegressor 进行拟合。培训模型后的最后一步是拟合模型并使用设置的数据检查错误。这些数据被缩放并传递到模型中,使用“均方误差”指标评估准确性。
**In[0]:**
# prepare the model
scaler = StandardScaler().fit(X_train)
rescaledX = scaler.transform(X_train)
model = GradientBoostingRegressor(random_state=seed, n_estimators=400)
model.fit(rescaledX, Y_train)
# transform the validation dataset
rescaledValidationX = scaler.transform(X_validation)
predictions = model.predict(rescaledValidationX)
print("Mean Squared Error: \n")
print(mean_squared_error(Y_validation, predictions))
**Out[0]:**
Mean Squared Error:
26.326748591395717
评估
机器学习中较为棘手的一个方面是模型评估。这个示例展示了如何将预测和原始房屋价格添加到同一个 DataFrame 中。该 DataFrame 可用于计算差异。
**In[0]:**
predictions=predictions.astype(int)
evaluate = pd.DataFrame({
"Org House Price": Y_validation,
"Pred House Price": predictions
})
evaluate["difference"] = evaluate["Org House Price"]-evaluate["Pred House Price"]
evaluate.head()
差异显示在这里。
**Out[0]:**
原房价 | 预测房价 | 差异 | |
|---|---|---|---|
0 | 21.7 | 21 | 0.7 |
1 | 18.5 | 19 | -0.5 |
2 | 22.2 | 20 | 2.2 |
3 | 20.4 | 19 | 1.4 |
4 | 8.8 | 9 | -0.2 |
使用 Pandas 的 describe 方法是查看数据分布的好方法。
**In[0]:**
evaluate.describe()
**Out[0]:**
原始房价 | 预测房价 | 差异 | |
|---|---|---|---|
count | 102.000000 | 102.000000 | 102.000000 |
mean | 22.573529 | 22.117647 | 0.455882 |
std | 9.033622 | 8.758921 | 5.154438 |
min | 6.300000 | 8.000000 | -34.100000 |
25% | 17.350000 | 17.000000 | -0.800000 |
50% | 21.800000 | 20.500000 | 0.600000 |
75% | 24.800000 | 25.000000 | 2.200000 |
max | 50.000000 | 56.000000 | 22.000000 |
adhoc_predict
让我们测试这个预测模型,看看在反序列化后的工作流程会是什么样子。当为机器学习模型开发 Web API 时,在笔记本中测试 API 将会很有帮助。在实际笔记本中调试和创建函数比在 Web 应用中努力创建正确的函数要容易得多。
**In[0]:**
actual_sample = df.head(1)
actual_sample
**Out[0]:**
CHAS | RM | TAX | PTRATIO | B | LSTAT | MEDV | |
|---|---|---|---|---|---|---|---|
0 | 0 | 6.575 | 296.0 | 15.3 | 396.9 | 4.98 | 24.0 |
**In[0]:**
adhoc_predict = actual_sample[["CHAS", "RM", "TAX", "PTRATIO", "B", "LSTAT"]]
adhoc_predict.head()
**Out[0]:**
CHAS | RM | TAX | PTRATIO | B | LSTAT | |
|---|---|---|---|---|---|---|
0 | 0 | 6.575 | 296.0 | 15.3 | 396.9 | 4.98 |
JSON 工作流
这是笔记本中对调试 Flask 应用程序有用的一节。正如前面提到的,开发 API 代码在机器学习项目中更加直接,确保其有效,然后将该代码传输到脚本中。另一种方法是尝试在没有 Jupyter 提供的相同交互式工具的软件项目中获取准确的代码语法。
**In[0]:**
json_payload = adhoc_predict.to_json()
json_payload
**Out[0]:**
{"CHAS":{"0":0},"RM":
{"0":6.575},"TAX":
{"0":296.0},"PTRATIO":
{"0":15.3},"B":{"0":396.9},"LSTAT":
{"0":4.98}}
尺度输入
需要对数据进行缩放才能进行预测。这个工作流需要在笔记本中详细说明,而不是在网页应用中苦苦挣扎,这样调试将会更加困难。下面的部分展示了解决机器学习预测流程中这一部分的代码。然后可以将其用于在 Flask 应用程序中创建函数。
**In[0]:**
scaler = StandardScaler().fit(adhoc_predict)
scaled_adhoc_predict = scaler.transform(adhoc_predict)
scaled_adhoc_predict
**Out[0]:**
array([[0., 0., 0., 0., 0., 0.]])
**In[0]:**
list(model.predict(scaled_adhoc_predict))
**Out[0]:**
[20.35373177134412]
Pickling sklearn
接下来,我们来导出这个模型。
**In[0]:**
from sklearn.externals import joblib
**In[0]:**
joblib.dump(model, 'boston_housing_prediction.joblib')
**Out[0]:**
['boston_housing_prediction.joblib']
**In[0]:**
!ls -l
**Out[0]:**
total 672
-rw-r--r-- 1 root root 681425 May 5 00:35 boston_housing_prediction.joblib
drwxr-xr-x 1 root root 4096 Apr 29 16:32 sample_data
解析并预测
**In[0]:**
clf = joblib.load('boston_housing_prediction.joblib')
从 Pickle 中 adhoc_predict
**In[0]:**
actual_sample2 = df.head(5)
actual_sample2
**Out[0]:**
CHAS | RM | TAX | PTRATIO | B | LSTAT | MEDV | |
|---|---|---|---|---|---|---|---|
0 | 0 | 6.575 | 296.0 | 15.3 | 396.90 | 4.98 | 24.0 |
1 | 0 | 6.421 | 242.0 | 17.8 | 396.90 | 9.14 | 21.6 |
2 | 0 | 7.185 | 242.0 | 17.8 | 392.83 | 4.03 | 34.7 |
3 | 0 | 6.998 | 222.0 | 18.7 | 394.63 | 2.94 | 33.4 |
4 | 0 | 7.147 | 222.0 | 18.7 | 396.90 | 5.33 | 36.2 |
**In[0]:**
adhoc_predict2 = actual_sample[["CHAS", "RM", "TAX", "PTRATIO", "B", "LSTAT"]]
adhoc_predict2.head()
**Out[0]:**
CHAS | RM | TAX | PTRATIO | B | LSTAT | |
|---|---|---|---|---|---|---|
0 | 0 | 6.575 | 296.0 | 15.3 | 396.9 | 4.98 |
缩放输入
**In[0]:**
scaler = StandardScaler().fit(adhoc_predict2)
scaled_adhoc_predict2 = scaler.transform(adhoc_predict2)
scaled_adhoc_predict2
**Out[0]:**
array([[0., 0., 0., 0., 0., 0.]])
**In[0]:**
# Use pickle loaded model
list(clf.predict(scaled_adhoc_predict2))
**Out[0]:**
[20.35373177134412]
最后,将被 Pickle 的模型加载回来,并针对真实数据集进行测试。
练习
-
scikit-learn 和 PyTorch 之间的一些关键区别是什么?
-
什么是 AutoML 以及为什么要使用它?
-
更改 scikit-learn 模型以使用身高来预测体重。
-
在 Google Colab 笔记本中运行 PyTorch 示例,并在 CPU 和 GPU 运行时之间切换。如果有性能差异,请解释其原因。
-
什么是 EDA 以及在数据科学项目中为什么如此重要?
案例研究问题
- 前往 Kaggle 网站,选择一个流行的 Python 笔记本,并将其转换为容器化的 Flask 应用程序,该应用程序使用本章中所示的示例作为指南提供预测。现在通过托管的 Kubernetes 服务(例如 Amazon EKS)将其部署到云环境中。
学习评估
-
解释不同类型的机器学习框架和生态系统。
-
运行和调试现有的 scikit-learn 和 PyTorch 机器学习项目。
-
将 Flask scikit-learn 模型进行容器化。
-
了解生产机器学习成熟度模型。
第十五章:数据工程
数据科学可能是 21 世纪最性感的工作,但这个领域正在迅速演变成不同的职位头衔。数据科学家已经过于粗糙地描述了一系列任务。截至 2020 年,两个可以支付相同或更高工资的工作是数据工程师和机器学习工程师。
更令人惊讶的是,支持传统数据科学家所需的大量数据工程师角色。大约需要三到五名数据工程师才能支持一个数据科学家。
发生了什么?让我们从另一个角度来看待。假设我们正在为一家报纸写头条新闻,想要说一些吸引眼球的事情。我们可以说,“CEO 是富人最性感的工作。”CEO 很少,就像 NBA 明星很少,像是靠演艺为生的职业演员很少一样。每个 CEO 背后,有多少人在努力使他们成功?这个陈述与内容空洞、毫无意义,就像“水是湿的”一样。
这个陈述并不是说你不能以数据科学家的身份谋生;这更多是对这种说法背后逻辑的批评。在数据技能方面存在巨大的需求,从 DevOps 到机器学习再到沟通,都有涉及。数据科学家这个术语是模糊的。它是一种工作还是一种行为?在某种程度上,它很像 DevOps 这个词。DevOps 是一种工作,还是一种行为?
在查看职位发布数据和薪资数据时,似乎市场正在表明对数据工程和机器学习工程实际角色存在显著需求。这是因为这些角色执行可识别的任务。数据工程师的任务可能是在云中创建收集批处理和流处理数据的管道,然后创建 API 以访问该数据并安排这些作业。这项工作不是模糊的任务。它要么有效,要么无效。
同样,机器学习工程师建立机器学习模型并以可维护的方式部署它们。这个工作也不含糊。一个工程师可以做数据工程或机器学习工程,但仍然表现出与数据科学和 DevOps 相关的行为。现在是参与数据领域的激动人心时刻,因为有一些重要的机会可以建立复杂而强大的数据管道,这些管道供给其他复杂而强大的预测系统。有一句话说,“你永远不能太富有或太瘦。”同样,对于数据来说,你永远不能拥有太多的 DevOps 或数据科学技能。让我们深入一些 DevOps 风格的数据工程思想。
小数据
工具包是一个令人兴奋的概念。如果你叫水管工来你家,他们会带着工具,帮助他们比你更有效地完成任务。如果你雇用木工在你家建造东西,他们也会有一套独特的工具,帮助他们在比你更短的时间内完成任务。工具对专业人士来说至关重要,DevOps 也不例外。
在这一节中,数据工程的工具概述了它们自己。这些工具包括读写文件、使用pickle、使用JSON、写入和读取YAML文件等小数据任务。掌握这些格式对于成为能够处理任何任务并将其转化为脚本的自动化人员是至关重要的。后面还涵盖了大数据任务的工具。它讨论了与小数据使用不同的工具明显不同的工具。
什么是大数据,什么是小数据?一个简单的区分方法是笔记本电脑测试。它在你的笔记本上能运行吗?如果不能,那么它就是大数据。一个很好的例子是 Pandas。Pandas 需要的 RAM 量是数据集的 5 到 10 倍。如果你有一个 2 GB 的文件,并且你正在使用 Pandas,很可能你的笔记本无法运行。
处理小数据文件
如果 Python 有一个单一的定义特性,那将是语言中效率的不懈追求。一个典型的 Python 程序员希望编写足够的代码来完成任务,但在代码变得难以理解或简洁时停止。此外,一个典型的 Python 程序员也不愿意编写样板代码。这种环境促使有用模式的持续演变。
使用with语句来读写文件的一个活跃模式的例子。with语句处理了烦人的样板部分,即在工作完成后关闭文件句柄。with语句还在 Python 语言的其他部分中使用,使烦琐的任务不那么令人讨厌。
写一个文件
这个例子展示了使用with语句写入文件时,执行代码块后会自动关闭文件句柄。这种语法可以防止因为意外未关闭句柄而导致的 bug:
with open("containers.txt", "w") as file_to_write:
file_to_write.write("Pod/n")
file_to_write.write("Service/n")
file_to_write.write("Volume/n")
file_to_write.write("Namespace/n")
文件的输出如下所示:
cat containers.txt
Pod
Service
Volume
Namespace
读一个文件
with上下文也是推荐的读取文件的方式。注意,使用readlines()方法使用换行符返回一个惰性评估的迭代器:
with open("containers.txt") as file_to_read:
lines = file_to_read.readlines()
print(lines)
输出:
['Pod\n', 'Service\n', 'Volume\n', 'Namespace\n']
在实践中,这意味着你可以通过使用生成器表达式处理大型日志文件,而不必担心消耗机器上的所有内存。
生成器管道用于读取和处理行
这段代码是一个生成器函数,打开一个文件并返回一个生成器:
def process_file_lazily():
"""Uses generator to lazily process file"""
with open("containers.txt") as file_to_read:
for line in file_to_read.readlines():
yield line
接下来,这个生成器被用来创建一个管道,逐行执行操作。在这个例子中,将行转换为小写字符串。这里可以链式连接许多其他操作,而且非常高效,因为只使用了处理一行数据所需的内存:
# Create generator object
pipeline = process_file_lazily()
# convert to lowercase
lowercase = (line.lower() for line in pipeline)
# print first processed line
print(next(lowercase))
这是管道的输出:
pod
在实践中,这意味着那些因为太大而实际上是无限的文件,如果代码能够在找到条件时退出,则仍然可以处理。例如,也许你需要在数千兆字节的日志数据中找到一个客户 ID。生成器管道可以寻找这个客户 ID,然后在第一次出现时退出处理。在大数据的世界中,这不再是一个理论性的问题。
使用 YAML
YAML 正在成为与 DevOps 相关的配置文件的新兴标准。它是一种人类可读的数据序列化格式,是 JSON 的超集。它代表“YAML 不是一种标记语言。” 你经常会在像 AWS CodePipeline,CircleCI 这样的构建系统,或者像 Google App Engine 这样的 PaaS 提供中看到 YAML。
YAML 如此经常被使用是有原因的。需要一种配置语言,允许在与高度自动化的系统交互时进行快速迭代。无论是非程序员还是程序员都可以直观地了解如何编辑这些文件。以下是一个例子:
import yaml
kubernetes_components = {
"Pod": "Basic building block of Kubernetes.",
"Service": "An abstraction for dealing with Pods.",
"Volume": "A directory accessible to containers in a Pod.",
"Namespaces": "A way to divide cluster resources between users."
}
with open("kubernetes_info.yaml", "w") as yaml_to_write:
yaml.safe_dump(kubernetes_components, yaml_to_write, default_flow_style=False)
写入磁盘的输出如下所示:
cat kubernetes_info.yaml
Namespaces: A way to divide cluster resources between users.
Pod: Basic building block of Kubernetes.
Service: An abstraction for dealing with Pods.
Volume: A directory accessible to containers in a Pod.
结论是,它使得将 Python 数据结构序列化为易于编辑和迭代的格式变得非常简单。将此文件读回的代码仅需两行。
import yaml
with open("kubernetes_info.yaml", "rb") as yaml_to_read:
result = yaml.safe_load(yaml_to_read)
然后可以对输出进行漂亮的打印:
import pprint
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(result)
{ 'Namespaces': 'A way to divide cluster resources between users.',
'Pod': 'Basic building block of Kubernetes.',
'Service': 'An abstraction for dealing with Pods.',
'Volume': 'A directory accessible to containers in a Pod.'}
大数据
数据的增长速度比计算机处理能力的增长速度更快。更有趣的是,摩尔定律认为计算机的速度和能力每两年可以翻一番,但根据加州大学伯克利分校的 David Patterson 博士的说法,这种增长在 2015 年左右就停止适用了。CPU 速度现在每年只增长约 3%。
处理大数据的新方法是必需的。一些新方法包括使用像 GPU、张量处理单元(TPU)等 ASICs,以及云供应商提供的 AI 和数据平台。在芯片级别上,这意味着 GPU 可能是复杂 IT 过程的理想目标,而不是 CPU。通常,这个 GPU 与能够提供分布式存储机制的系统配对,该机制允许分布式计算和分布式磁盘 I/O。一个很好的例子是 Apache Spark,Amazon SageMaker 或 Google AI 平台。它们都可以利用 ASICs(GPU、TPU 等),以及分布式存储和管理系统。另一个更低级别的例子是 Amazon Spot 实例深度学习 AMIs,配有 Amazon 弹性文件系统(EFS)挂载点。
对于一个 DevOps 专业人员,这意味着几件事情。首先,这意味着在将软件交付到这些系统时需要特别注意。例如,目标平台是否有正确的 GPU 驱动程序?你是通过容器部署吗?这个系统是否将使用分布式 GPU 处理?数据主要是批处理还是流处理?提前考虑这些问题可以确保选择正确的架构。
像 AI、大数据、云或数据科学家这样的流行词存在一个问题,即它们对不同的人有不同的含义。以数据科学家为例。在一家公司,它可能意味着为销售团队生成业务智能仪表板的人,而在另一家公司,它可能意味着正在开发自动驾驶汽车软件的人。大数据也存在类似的语境问题;它可以根据你遇到的人的不同而有许多不同的含义。这里有一个考虑的定义。你是否需要不同的软件包来处理你笔记本电脑上的数据和生产环境中的数据?
一个很好的“小数据”工具的典范是 Pandas 包。根据 Pandas 包的作者,它可能需要比使用的文件大小多 5 到 10 倍的 RAM。实际上,如果你的笔记本电脑有 16 GB 的 RAM,并且打开了一个 2 GB 的 CSV 文件,那么现在就变成了一个大数据问题,因为你的笔记本电脑可能没有足够的 RAM(20 GB)来处理这个文件。相反,你可能需要重新思考如何处理这个问题。也许你可以打开数据的样本,或者截断数据以首先解决问题。
这里有一个确切问题及其解决方法的例子。假设你正在支持数据科学家,他们因为使用了对于 Pandas 来说太大的文件而经常遇到内存不足的错误。其中一个例子是来自 Kaggle 的 Open Food Facts数据集。解压后,数据集超过 1 GB。这个问题正好符合 Pandas 可能难以处理的情况。你可以做的一件事是使用 Unix 的shuf命令创建一个打乱的样本:
time shuf -n 100000 en.openfoodfacts.org.products.tsv\
> 10k.sample.en.openfoodfacts.org.products.tsv
1.89s user 0.80s system 97% cpu 2.748 total
不到两秒钟,文件就可以被削减到一个可以处理的大小。这种方法比简单地使用头或尾部更可取,因为样本是随机选择的。这对数据科学工作流程非常重要。此外,你可以检查文件的行以先了解你要处理的内容:
wc -l en.openfoodfacts.org.products.tsv
356002 en.openfoodfacts.org.products.tsv
源文件大约有 350,000 行,因此获取 100,000 个打乱的行大约占据了数据的三分之一。这个任务可以通过查看转换后的文件来确认。它显示 272 MB,大约是原始 1 GB 文件大小的三分之一:
du -sh 10k.sample.en.openfoodfacts.org.products.tsv
272M 10k.sample.en.openfoodfacts.org.products.tsv
这种大小对 Pandas 来说更容易管理,并且这个过程可以转化为一个自动化工作流程,为大数据源创建随机样本文件。这种类型的过程只是大数据要求的许多特定工作流程之一。
另一个关于大数据的定义来自麦肯锡,他们在 2011 年将大数据定义为“数据集,其大小超出典型数据库软件工具捕捉、存储、管理和分析的能力”。这个定义也是合理的,稍作修改,它不仅仅是数据库软件工具,而是任何接触数据的工具。当适用于笔记本电脑的工具(如 Pandas、Python、MySQL、深度学习/机器学习、Bash 等)因数据的规模或速度(变化率)而无法传统方式运行时,它现在是一个大数据问题。大数据问题需要专门的工具,下一节将深入探讨这个需求。
大数据工具、组件和平台
另一种讨论大数据的方式是将其分解为工具和平台。图 15-1 显示了典型的大数据架构生命周期。
图 15-1. 大数据架构
让我们讨论几个关键组件。
数据来源
一些熟悉的大数据来源包括社交网络和数字交易。随着人们将更多的对话和业务交易迁移到在线平台,数据爆炸性增长。此外,诸如平板电脑、手机和笔记本电脑等移动技术记录音频和视频,进一步创造了数据源。
其他数据来源包括物联网(IoT),包括传感器、轻量级芯片和设备。所有这些导致数据不可阻挡地增加,需要在某处进行存储。涉及数据来源的工具可能从物联网客户端/服务器系统(如 AWS IoT Greengrass)、到对象存储系统(如 Amazon S3 或 Google Cloud Storage)等广泛应用。
文件系统
文件系统在计算中发挥了重要作用。它们的实现不断演变。在处理大数据时,一个问题是有足够的磁盘 I/O 来处理分布式操作。
处理这一问题的现代工具之一是 Hadoop 分布式文件系统(HDFS)。它通过将许多服务器集群在一起来工作,允许聚合的 CPU、磁盘 I/O 和存储。实际上,这使得 HDFS 成为处理大数据的基础技术。它可以迁移大量数据或文件系统用于分布式计算作业。它还是 Spark 的支柱,可以进行流式和批量机器学习。
其他类型的文件系统包括对象存储文件系统,如 Amazon S3 文件系统和 Google Cloud 平台存储。它们允许将大文件以分布式和高可用的方式存储,或者更精确地说是 99.999999999%的可靠性。有 Python API 和命令行工具可用于与这些文件系统通信,实现简单的自动化。这些云 API 将在第十章中详细介绍。
最后,另一种需要注意的文件系统是传统的网络文件系统,或者 NFS,作为托管云服务提供。Amazon Elastic File System(Amazon EFS)是这方面的一个很好的例子。对于 DevOps 专业人员来说,一个高可用和弹性的 NFS 文件系统可以是一个非常多才多艺的工具,特别是与容器技术结合使用。图 15-2 展示了在容器中挂载 EFS 的一个示例。
图 15-2. 将 EFS 挂载在容器中
一个强大的自动化工作流程是通过构建系统(例如 AWS CodePipeline 或 Google Cloud Build)通过编程方式创建 Docker 容器。然后,这些容器被注册到云容器注册表,例如 Amazon ECR。接下来,一个容器管理系统,比如 Kubernetes,会生成挂载 NFS 的容器。这样一来,既可以享受到产生迅速的不可变容器镜像的强大功能,又可以访问到集中的源代码库和数据。这种类型的工作流程对于希望优化机器学习操作的组织来说可能是理想的。
数据存储
最终,数据需要存放在某个地方,这带来了一些令人兴奋的机会和挑战。一个新兴的趋势是利用数据湖的概念。你为什么关心数据湖?数据湖允许在存储的同一位置进行数据处理。因此,许多数据湖需要具有无限存储和提供无限计算(即在云上)。Amazon S3 通常是数据湖的常见选择。
以这种方式构建的数据湖也可以被机器学习流水线利用,该流水线可能依赖于存储在湖中的训练数据,以及训练模型。然后,可以始终对训练模型进行 A/B 测试,以确保最新模型正在改善生产预测(推断)系统,如图 15-3 所示。
图 15-3. 数据湖
其他形式的存储对于传统软件开发人员来说可能非常熟悉。这些存储系统包括关系型数据库、键/值数据库、像 Elasticsearch 这样的搜索引擎以及图数据库。在大数据架构中,每种类型的存储系统可能会发挥更具体的作用。在小规模系统中,关系型数据库可能是一个万能工具,但在大数据架构中,对于存储系统的不匹配容忍度较小。
在存储选择中出现的一个极好的不匹配例子是使用关系数据库作为搜索引擎,通过启用全文搜索功能,而不是使用专门的解决方案,比如 Elasticsearch。Elasticsearch 旨在创建可扩展的搜索解决方案,而关系数据库旨在提供引用完整性和事务。亚马逊的 CTO Werner Vogel 非常明确地指出“一个数据库规模并不适合所有人”。这个问题在图 15-4 中有所说明,该图显示每种类型的数据库都有特定的用途。
图 15-4. Amazon 数据库
选择正确的存储解决方案,包括使用哪种组合的数据库,对于任何类型的数据架构师来说都是一项关键技能,以确保系统以最佳效率运行。在考虑设计一个完全自动化和高效的系统时,应该考虑维护成本。如果滥用特定的技术选择,比如使用关系数据库作为高可用消息队列,那么维护成本可能会激增,从而带来更多的自动化工作。因此,另一个需要考虑的组成部分是维护解决方案所需的自动化工作量。
实时流式传输摄取
实时流式数据是一种特别棘手的数据类型。流本身增加了处理数据的复杂性,可能需要将流路由到系统的另一部分,该部分意图以流式处理数据。一个云端流式摄取解决方案的示例是 Amazon Kinesis Data Firehose。见图 15-5。
图 15-5. Kinesis 日志文件
下面是一个执行此操作的代码示例。请注意,Python 的asyncio模块允许高度并发的单线程网络操作。节点可以在作业农场中发出这些操作,这可能是指标或错误日志:
import asyncio
def send_async_firehose_events(count=100):
"""Async sends events to firehose"""
start = time.time()
client = firehose_client()
extra_msg = {"aws_service": "firehose"}
loop = asyncio.get_event_loop()
tasks = []
LOG.info(f"sending aysnc events TOTAL {count}",extra=extra_msg)
num = 0
for _ in range(count):
tasks.append(asyncio.ensure_future(put_record(gen_uuid_events(),
client)))
LOG.info(f"sending aysnc events: COUNT {num}/{count}")
num +=1
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
end = time.time()
LOG.info("Total time: {}".format(end - start))
Kinesis Data Firehose 通过接受捕获的数据并将其持续路由到多个目的地来工作:Amazon S3、Amazon Redshift、Amazon Elasticsearch 服务,或者像 Splunk 这样的第三方服务。使用类似 Kinesis 这样的托管服务的一个开源替代方案是使用 Apache Kafka。Apache Kafka 具有类似的原则,它作为发布/订阅架构工作。
案例研究:构建自制数据管道
在诺亚(Noah)早期担任 CTO 兼总经理的初创企业的 2000 年初期,出现了一个问题,即如何构建公司的第一个机器学习管道和数据管道。下图显示了 Jenkins 数据管道的草图(图 15-6)。
图 15-6. Jenkins 数据管道
数据管道的输入是任何需要用于业务分析或机器学习预测的数据源。这些来源包括关系数据库、Google Analytics 和社交媒体指标等等。收集作业每小时运行一次,并生成 CSV 文件,这些文件可以通过 Apache web 服务在内部使用。这个解决方案是一个引人注目且简单的过程。
这些作业本身是 Jenkins 作业,是运行的 Python 脚本。如果需要更改某些内容,更改特定作业的 Python 脚本相当简单。这个系统的另一个好处是它很容易调试。如果作业失败了,作业就会显示为失败,查看作业的输出并查看发生了什么是很简单的。
管道的最终阶段然后创建了机器学习预测和分析仪表板,通过基于 R 的 Shiny 应用程序提供仪表板服务。这种方法的简单性是这种架构的最有影响力的因素,而且作为一个额外的奖励,它利用了现有的 DevOps 技能。
无服务器数据工程
另一个新兴的模式是无服务器数据工程。图 15-7 是一个无服务器数据管道的高层架构图。
图 15-7. 无服务器数据管道
接下来,让我们看看定时 lambda 做了什么。
使用 AWS Lambda 与 CloudWatch 事件
你可以在 AWS Lambda 控制台上创建一个 CloudWatch 计时器来调用 lambda,并设置触发器,如图 15-8 所示。
图 15-8. CloudWatch Lambda 计时器
使用 Amazon CloudWatch Logging 与 AWS Lambda
使用 CloudWatch 日志记录是 Lambda 开发的一个重要步骤。图 15-9 是 CloudWatch 事件日志的一个示例。
图 15-9. CloudWatch 事件日志
使用 AWS Lambda 填充 Amazon Simple Queue Service
接下来,您希望在 AWS Cloud9 中本地执行以下操作:
-
使用 Serverless Wizard 创建一个新的 Lambda。
-
cd进入 lambda 并在上一级安装包。
pip3 install boto3 --target ../
pip3 install python-json-logger --target ../
接下来,你可以在本地测试并部署这段代码:
'''
Dynamo to SQS
'''
import boto3
import json
import sys
import os
DYNAMODB = boto3.resource('dynamodb')
TABLE = "fang"
QUEUE = "producer"
SQS = boto3.client("sqs")
#SETUP LOGGING
import logging
from pythonjsonlogger import jsonlogger
LOG = logging.getLogger()
LOG.setLevel(logging.INFO)
logHandler = logging.StreamHandler()
formatter = jsonlogger.JsonFormatter()
logHandler.setFormatter(formatter)
LOG.addHandler(logHandler)
def scan_table(table):
'''Scans table and return results'''
LOG.info(f"Scanning Table {table}")
producer_table = DYNAMODB.Table(table)
response = producer_table.scan()
items = response['Items']
LOG.info(f"Found {len(items)} Items")
return items
def send_sqs_msg(msg, queue_name, delay=0):
'''Send SQS Message
Expects an SQS queue_name and msg in a dictionary format.
Returns a response dictionary.
'''
queue_url = SQS.get_queue_url(QueueName=queue_name)["QueueUrl"]
queue_send_log_msg = "Send message to queue url: %s, with body: %s" %\
(queue_url, msg)
LOG.info(queue_send_log_msg)
json_msg = json.dumps(msg)
response = SQS.send_message(
QueueUrl=queue_url,
MessageBody=json_msg,
DelaySeconds=delay)
queue_send_log_msg_resp = "Message Response: %s for queue url: %s" %\
(response, queue_url)
LOG.info(queue_send_log_msg_resp)
return response
def send_emissions(table, queue_name):
'''Send Emissions'''
items = scan_table(table=table)
for item in items:
LOG.info(f"Sending item {item} to queue: {queue_name}")
response = send_sqs_msg(item, queue_name=queue_name)
LOG.debug(response)
def lambda_handler(event, context):
'''
Lambda entrypoint
'''
extra_logging = {"table": TABLE, "queue": QUEUE}
LOG.info(f"event {event}, context {context}", extra=extra_logging)
send_emissions(table=TABLE, queue_name=QUEUE)
This code does the following:
1. Grabs company names from Amazon DynamoDB.
2. Puts the names into Amazon SQS.
To test it, you can do a local test in Cloud9 (Figure 15-10).
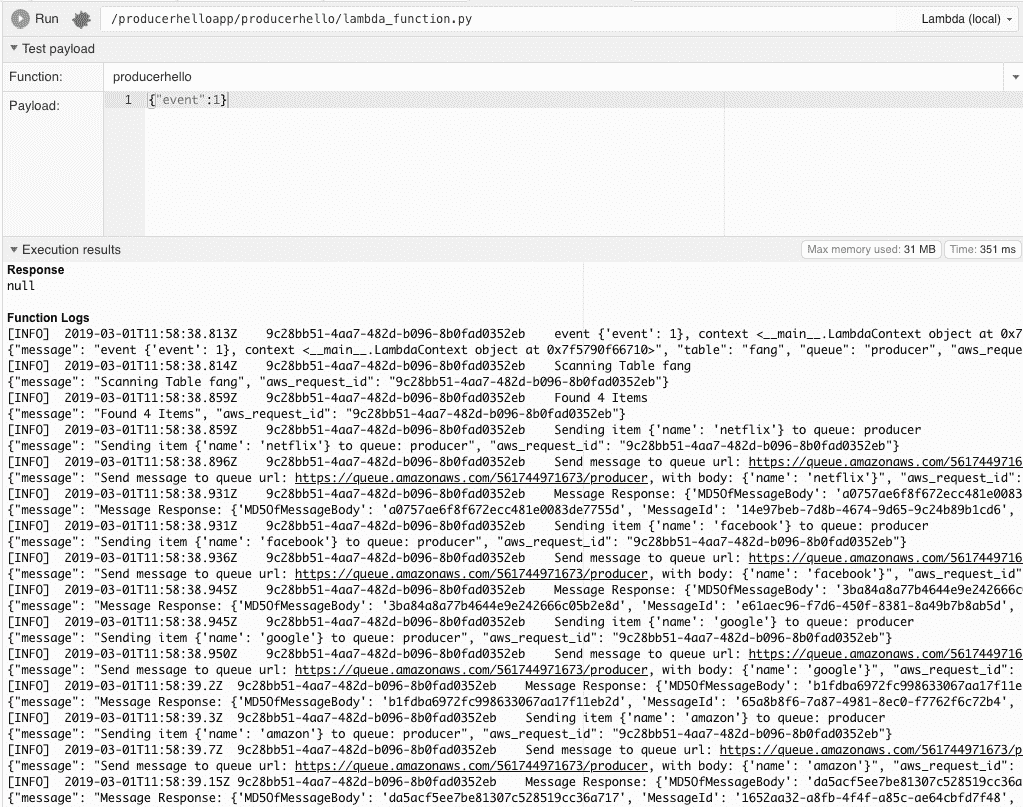
###### Figure 15-10\. Local test in Cloud9
Next you can verify messages in SQS, as shown in Figure 15-11.
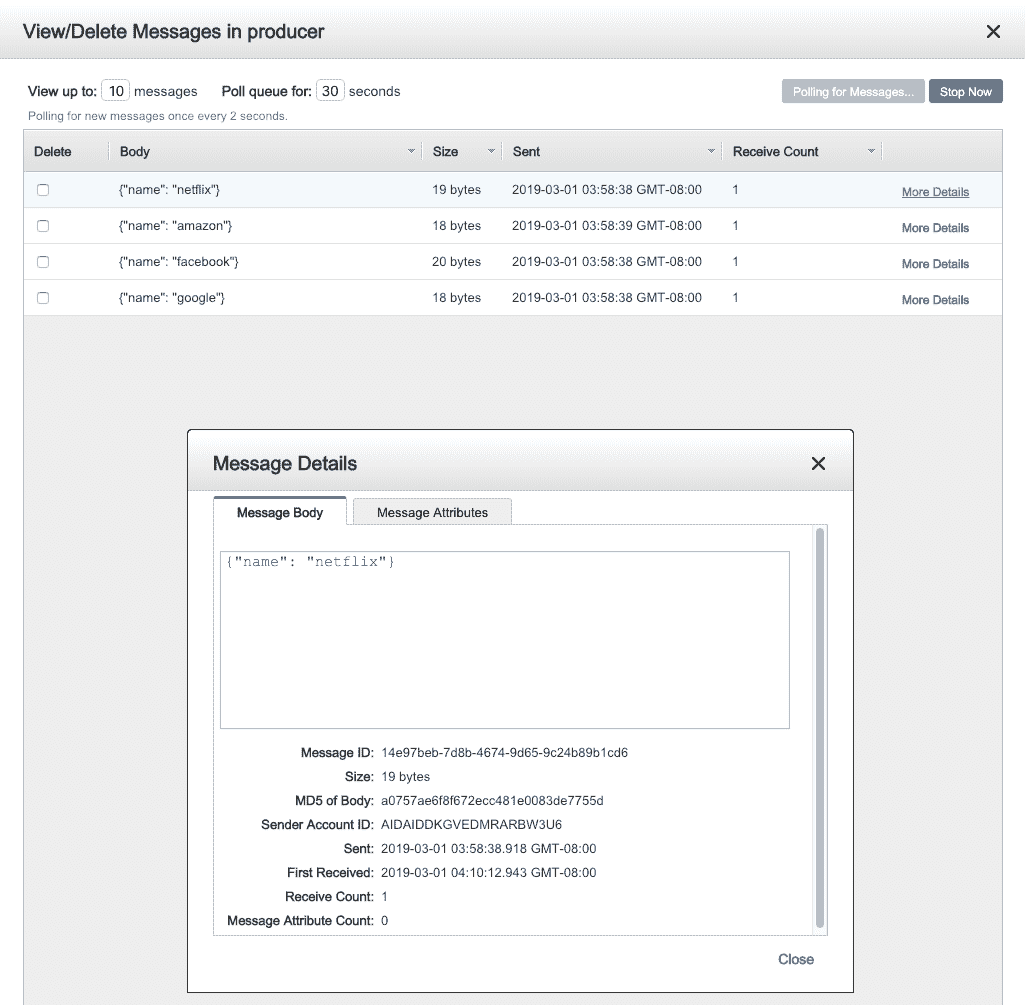
###### Figure 15-11\. SQS verification
Don’t forget to set the correct IAM role! You need to assign the lambda an IAM role that can write messages to SQS, as shown in Figure 15-12.
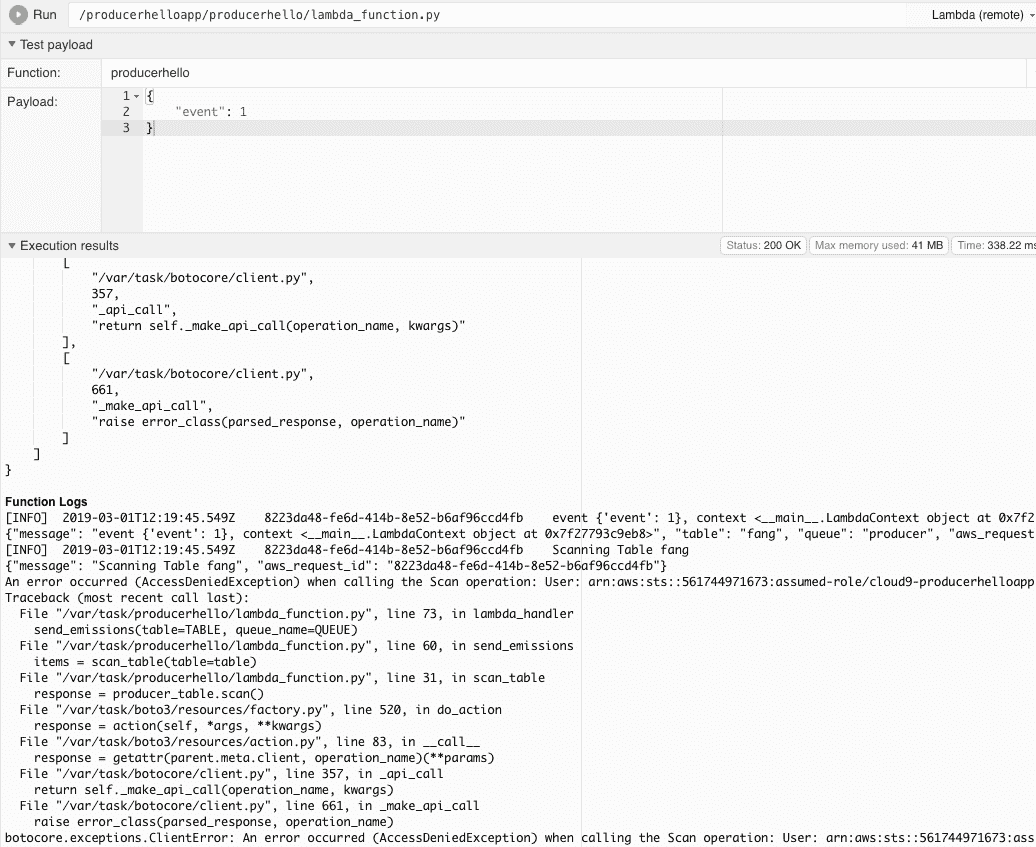
###### Figure 15-12\. Permission error
## Wiring Up CloudWatch Event Trigger
The final step to enable CloudWatch trigger does the following: enable timed execution of producer, and verify that messages flow into SQS, as shown in Figure 15-13.
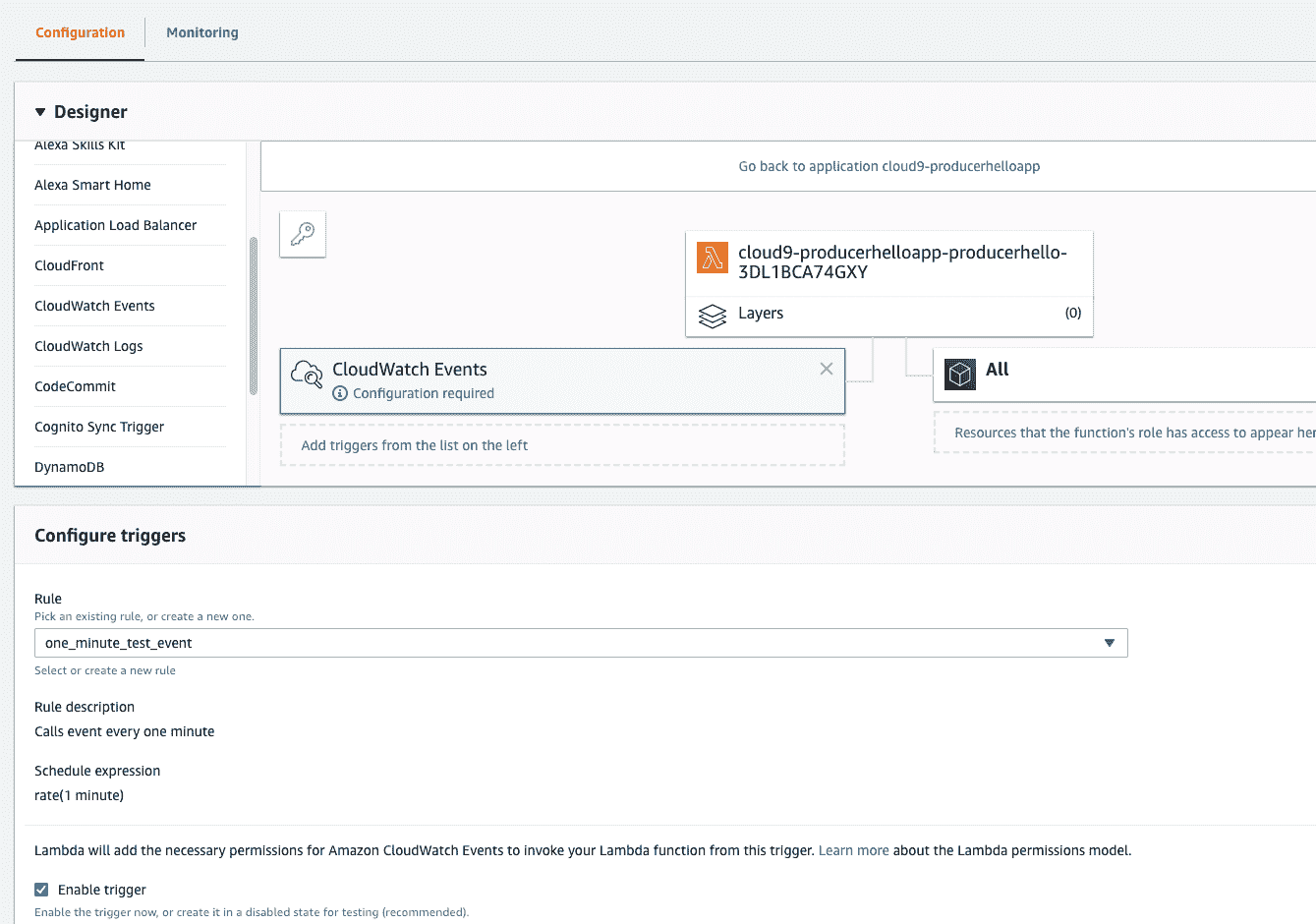
###### Figure 15-13\. Configure timer
You can now see messages in the SQS queue (Figure 15-14).
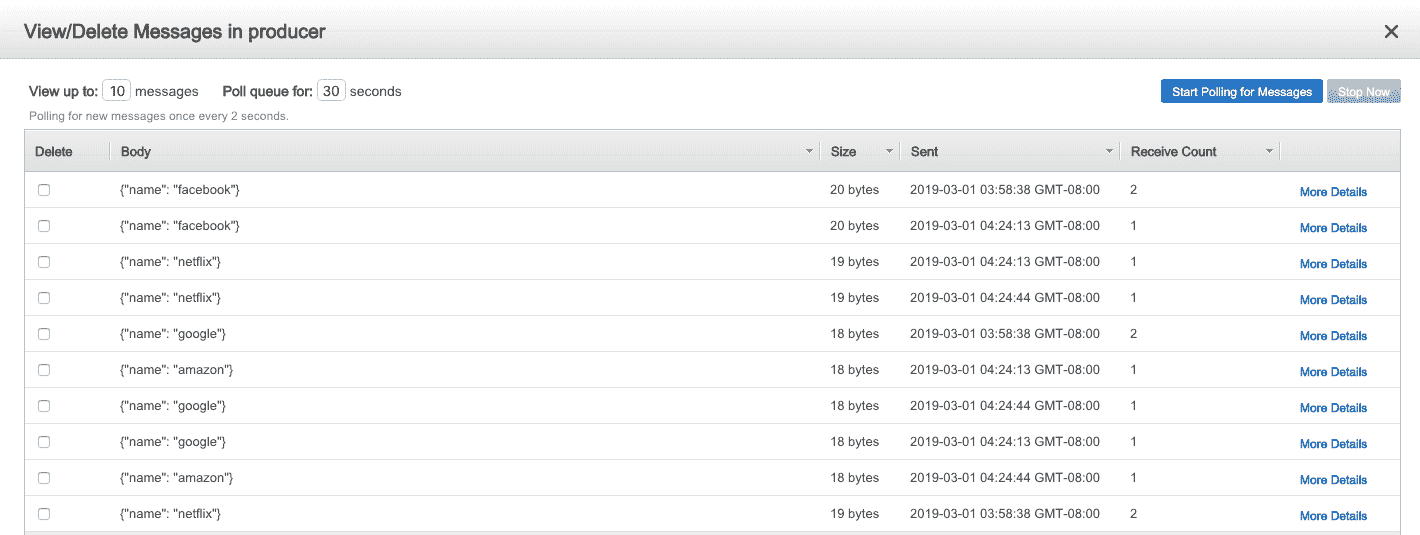
###### Figure 15-14\. SQS queue
## Creating Event-Driven Lambdas
With the producer lambda out of the way, next up is to create an event-driven lambda that fires asynchronously upon every message in SQS (the consumer). The Lambda function can now fire in response to every SQS message (Figure 15-15).
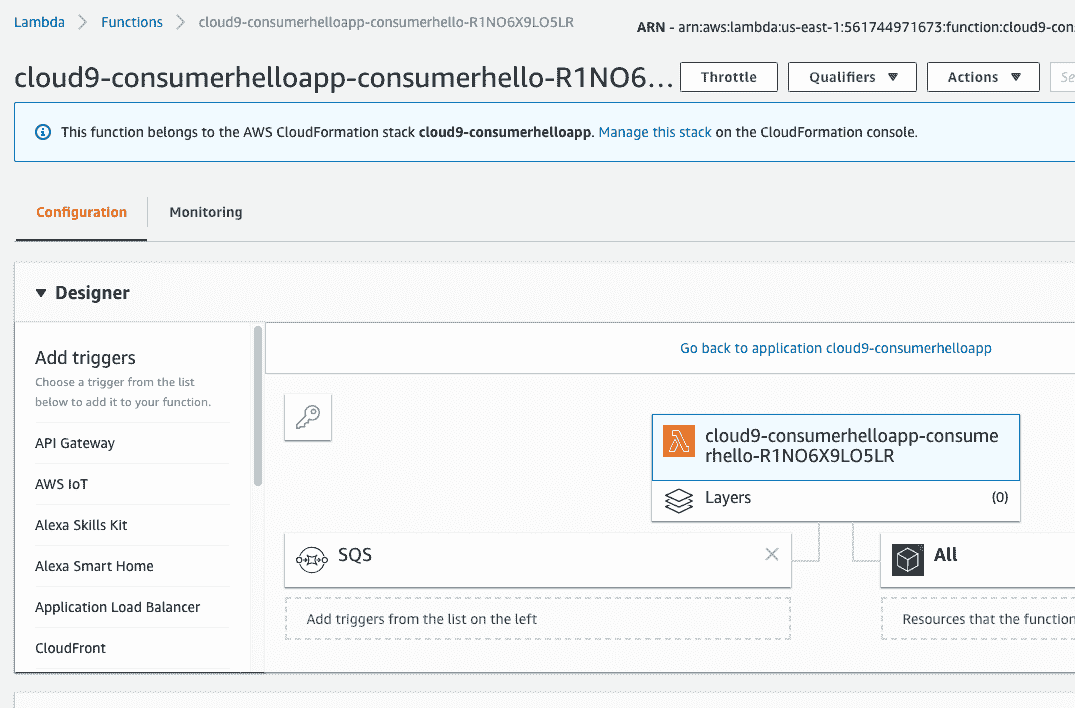
###### Figure 15-15\. Fire on SQS event
## Reading Amazon SQS Events from AWS Lambda
The only task left is to write the code to consume the messages from SQS, process them using our API, and then write the results to S3:
import json
import boto3
import botocore
#import pandas as pd
import pandas as pd
import wikipedia
import boto3
from io import StringIO
#设置日志记录
import logging
from pythonjsonlogger import jsonlogger
LOG = logging.getLogger()
LOG.setLevel(logging.DEBUG)
logHandler = logging.StreamHandler()
formatter = jsonlogger.JsonFormatter()
logHandler.setFormatter(formatter)
LOG.addHandler(logHandler)
#S3 存储桶
REGION = "us-east-1"
SQS 工具###
def sqs_queue_resource(queue_name):
"""返回一个 SQS 队列资源连接
使用示例:
在 [2] 中:queue = sqs_queue_resource("dev-job-24910")
在 [4] 中:queue.attributes
Out[4]:
{'ApproximateNumberOfMessages': '0',
'ApproximateNumberOfMessagesDelayed': '0',
'ApproximateNumberOfMessagesNotVisible': '0',
'CreatedTimestamp': '1476240132',
'DelaySeconds': '0',
'LastModifiedTimestamp': '1476240132',
'MaximumMessageSize': '262144',
'MessageRetentionPeriod': '345600',
'QueueArn': 'arn:aws:sqs:us-west-2:414930948375:dev-job-24910',
'ReceiveMessageWaitTimeSeconds': '0',
'VisibilityTimeout': '120'}
"""
sqs_resource = boto3.resource('sqs', region_name=REGION)
log_sqs_resource_msg =\
"Creating SQS resource conn with qname: [%s] in region: [%s]" %\
(queue_name, REGION)
LOG.info(log_sqs_resource_msg)
queue = sqs_resource.get_queue_by_name(QueueName=queue_name)
return queue
def sqs_connection():
"""Creates an SQS Connection which defaults to global var REGION"""
sqs_client = boto3.client("sqs", region_name=REGION)
log_sqs_client_msg = "Creating SQS connection in Region: [%s]" % REGION
LOG.info(log_sqs_client_msg)
return sqs_client
def sqs_approximate_count(queue_name):
"""Return an approximate count of messages left in queue"""
queue = sqs_queue_resource(queue_name)
attr = queue.attributes
num_message = int(attr['ApproximateNumberOfMessages'])
num_message_not_visible = int(attr['ApproximateNumberOfMessagesNotVisible'])
queue_value = sum([num_message, num_message_not_visible])
sum_msg = """'ApproximateNumberOfMessages' and\
'ApproximateNumberOfMessagesNotVisible' =\
*** [%s] *** for QUEUE NAME: [%s]""" %\
(queue_value, queue_name)
LOG.info(sum_msg)
return queue_value
def delete_sqs_msg(queue_name, receipt_handle):
sqs_client = sqs_connection()
try:
queue_url = sqs_client.get_queue_url(QueueName=queue_name)["QueueUrl"]
delete_log_msg = "Deleting msg with ReceiptHandle %s" % receipt_handle
LOG.info(delete_log_msg)
response = sqs_client.delete_message(QueueUrl=queue_url,
ReceiptHandle=receipt_handle)
except botocore.exceptions.ClientError as error:
exception_msg =\
"FAILURE TO DELETE SQS MSG: Queue Name [%s] with error: [%s]" %\
(queue_name, error)
LOG.exception(exception_msg)
return None
delete_log_msg_resp = "Response from delete from queue: %s" % response
LOG.info(delete_log_msg_resp)
return response
def names_to_wikipedia(names):
wikipedia_snippit = []
for name in names:
wikipedia_snippit.append(wikipedia.summary(name, sentences=1))
df = pd.DataFrame(
{
'names':names,
'wikipedia_snippit': wikipedia_snippit
}
)
return df
def create_sentiment(row):
"""Uses AWS Comprehend to Create Sentiments on a DataFrame"""
LOG.info(f"Processing {row}")
comprehend = boto3.client(service_name='comprehend')
payload = comprehend.detect_sentiment(Text=row, LanguageCode='en')
LOG.debug(f"Found Sentiment: {payload}")
sentiment = payload['Sentiment']
return sentiment
def apply_sentiment(df, column="wikipedia_snippit"):
"""Uses Pandas Apply to Create Sentiment Analysis"""
df['Sentiment'] = df[column].apply(create_sentiment)
return df
S3
def write_s3(df, bucket):
"""Write S3 Bucket"""
csv_buffer = StringIO()
df.to_csv(csv_buffer)
s3_resource = boto3.resource('s3')
res = s3_resource.Object(bucket, 'fang_sentiment.csv').\
put(Body=csv_buffer.getvalue())
LOG.info(f"result of write to bucket: {bucket} with:\n {res}")
def lambda_handler(event, context):
"""Lambda 的入口点"""
LOG.info(f"SURVEYJOB LAMBDA,事件 {event},上下文 {context}")
receipt_handle = event['Records'][0]['receiptHandle'] # sqs 消息
#'eventSourceARN': 'arn:aws:sqs:us-east-1:561744971673:producer'
event_source_arn = event['Records'][0]['eventSourceARN']
names = [] # 从队列中捕获
# 处理队列
for record in event['Records']:
body = json.loads(record['body'])
company_name = body['name']
# 用于处理的捕获
names.append(company_name)
extra_logging = {"body": body, "company_name":company_name}
LOG.info(f"SQS 消费者 LAMBDA,分割 arn: {event_source_arn}",
extra=extra_logging)
qname = event_source_arn.split(":")[-1]
extra_logging["queue"] = qname
LOG.info(f"尝试删除 SQS {receipt_handle} {qname}",
extra=extra_logging)
res = delete_sqs_msg(queue_name=qname, receipt_handle=receipt_handle)
LOG.info(f"删除 SQS receipt_handle {receipt_handle} 的结果为 {res}",
extra=extra_logging)
# 使用 Pandas 构建带有维基百科片段的数据框架
LOG.info(f"使用以下值创建数据框架:{names}")
df = names_to_wikipedia(names)
# 执行情感分析
df = apply_sentiment(df)
LOG.info(f"FANG 公司情感分析结果:{df.to_dict()}")
# 将结果写入 S3
write_s3(df=df, bucket="fangsentiment")
You can see that one easy way to download the files is to use the AWS CLI:
noah:/tmp $ aws s3 cp --recursive s3://fangsentiment/ .
download: s3://fangsentiment/netflix_sentiment.csv to ./netflix_sentiment.csv
download: s3://fangsentiment/google_sentiment.csv to ./google_sentiment.csv
download: s3://fangsentiment/facebook_sentiment.csv to ./facebook_sentiment.csv
好了,我们完成了什么?图 15-16 展示了我们的无服务器 AI 数据工程流水线。
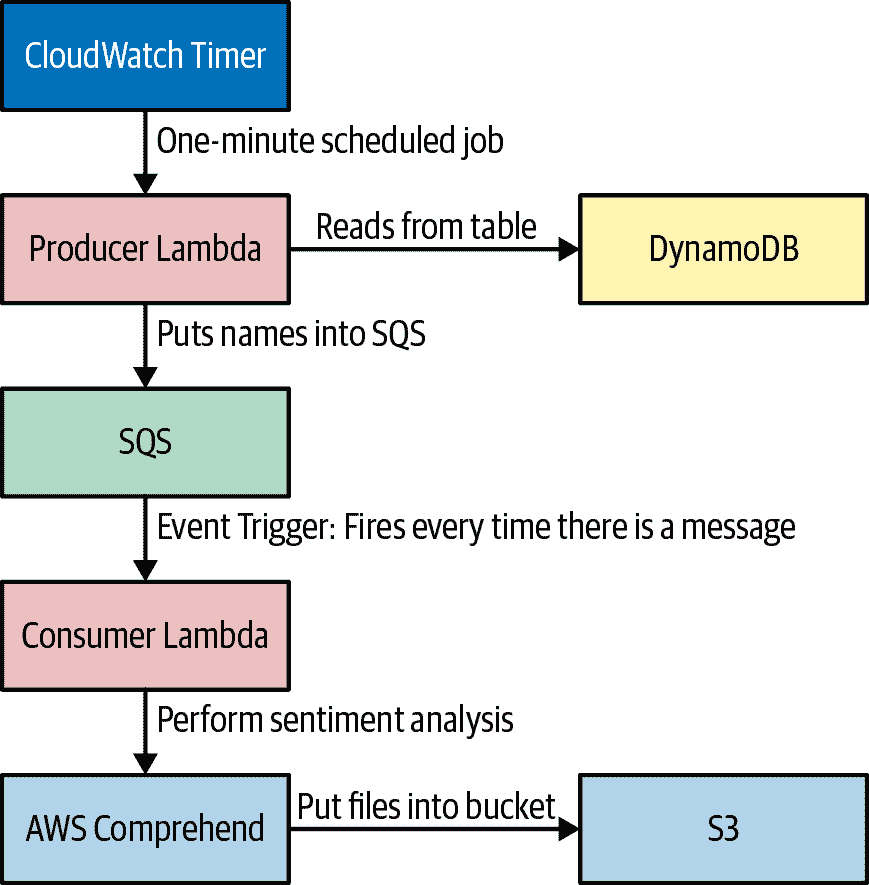
###### 图 15-16\. 无服务器 AI 数据工程流水线
# 结论
数据工程是一个不断发展的职业头衔,它极大地受益于强大的 DevOps 技能。微服务、持续交付、基础设施即代码和监控日志记录等 DevOps 最佳实践在这一类别中发挥了重要作用。通过利用云原生技术,使得复杂问题成为可能,简单问题变得无需费力。
这里有一些继续掌握数据工程技能旅程的下一步。学习无服务器技术。无论云环境是什么,都要学习!这种环境是未来,特别是数据工程非常适合抓住这一趋势。
# 练习
+ 解释 Big Data 是什么及其主要特征。
+ 使用 Python 中的小数据工具解决常见问题。
+ 解释数据湖是什么及其用途。
+ 解释不同类型用途专用数据库的适当使用案例。
+ 在 Python 中构建无服务器数据工程流水线。
# 案例研究问题
+ 使用本章展示的相同架构,构建一个端到端的无服务器数据工程管道,使用 Scrapy、Beautiful Soup 或类似的库来爬取网站,并将图像文件发送到 Amazon Rekognition 进行分析。将 Rekognition API 调用的结果存储在 Amazon DynamoDB 中。每天定时运行此作业。
