

Python Excel 指南(一)
原文:
zh.annas-archive.org/md5/4cbcfc6fe67ce954227c7b15eef2b4c0译者:飞龙
前言
Microsoft 正在运行一个 Excel 的反馈论坛UserVoice,每个人都可以提交新的想法供其他人投票。最受欢迎的功能请求是“将 Python 作为 Excel 脚本语言”,它的票数大约是第二名请求的两倍。尽管自 2015 年提出这个想法以来并没有真正发生什么,但在 2020 年底,当 Python 的创始人 Guido van Rossum 发推文说他的“退休很无聊”,并且他将加入 Microsoft 时,Excel 用户们又充满了新的希望。他的举动是否对 Excel 和 Python 的整合有任何影响,我不知道。但我确实知道,这种组合的魅力何在,以及你如何可以今天就开始使用 Excel 和 Python。这本书就是关于这个的简要概述。
Python 背后的主要推动力是我们生活在一个数据世界中的事实。如今,巨大的数据集对每个人都是可用的,而且无所不包。通常,这些数据集非常庞大,无法再适应电子表格。几年前,这可能被称为大数据,但如今,几百万行的数据集真的不算什么了。Excel 已经发展到可以应对这一趋势:它引入了 Power Query 来加载和清理那些无法适应电子表格的数据集,并且引入了 Power Pivot,一个用于对这些数据集进行数据分析并呈现结果的附加组件。Power Query 基于 Power Query M 公式语言(M),而 Power Pivot 则使用数据分析表达式(DAX)定义公式。如果你也想在 Excel 文件中自动化一些事情,那么你会使用 Excel 内置的自动化语言 Visual Basic for Applications(VBA)。也就是说,对于相对简单的任务,你最终可能会使用 VBA、M 和 DAX。其中一个问题是,所有这些语言只能在 Microsoft 世界中为你提供服务,尤其是在 Excel 和 Power BI 中(我将在第一章中简要介绍 Power BI)。
Python,另一方面,是一种通用的编程语言,已经成为分析师和数据科学家中最受欢迎的选择之一。如果你在 Excel 中使用 Python,你可以使用一种擅长于各个方面的编程语言,无论是自动化 Excel、访问和准备数据集,还是执行数据分析和可视化任务。最重要的是,你可以在 Excel 之外重复使用你的 Python 技能:如果你需要扩展计算能力,你可以轻松地将你的定量模型、仿真或机器学习应用移至云端,那里几乎没有限制的计算资源在等待着你。
为什么我写了这本书
通过我在 xlwings 上的工作,这是我们将在本书的第四部分中见到的 Excel 自动化包,我与许多使用 Python 处理 Excel 的用户保持密切联系 —— 无论是通过 GitHub 上的问题跟踪器,还是在 StackOverflow 上的问题,或者像会议和聚会这样的实际活动中。
我经常被要求推荐入门 Python 的资源。虽然 Python 的介绍确实不少,但它们往往要么太泛泛(没有关于数据分析的内容),要么太专业(完全是科学的介绍)。然而,Excel 用户往往处于中间地带:他们确实处理数据,但完全科学的介绍可能太技术化。他们也经常有特定的需求和问题,在现有的材料中找不到答案。其中一些问题是:
-
我需要哪个 Python-Excel 包来完成哪些任务?
-
-
如何将我的 Power Query 数据库连接迁移到 Python?
-
-
Python 中的 AutoFilter 或数据透视表等于 Excel 中的什么?
我写这本书是为了帮助你从零开始学习 Python,以便能够自动化你与 Excel 相关的任务,并利用 Python 的数据分析和科学计算工具在 Excel 中进行操作,而不需要任何绕道。
本书的受众
如果你是一个高级的 Excel 用户,希望用现代编程语言突破 Excel 的限制,那么这本书适合你。最典型的情况是,你每个月花数小时下载、清理和复制/粘贴大量数据到关键的电子表格中。
你应该具备基本的编程理解:如果你已经写过函数或者 for 循环(无论是哪种编程语言),并且知道什么是整数或字符串,那么会有所帮助。即使你习惯编写复杂的单元格公式或有调整过的记录的 VBA 宏经验,你也可以掌握本书。不过,并不要求你有任何 Python 特定的经验,因为我们将会介绍我们将使用的所有工具,包括 Python 自身的介绍。
如果你是一个经验丰富的 VBA 开发者,你会发现 Python 和 VBA 之间的常见比较,这将帮助你避开常见的陷阱,快速上手。
如果你是一名 Python 开发者,并且需要了解 Python 处理 Excel 应用程序和 Excel 文件的不同方式,以便根据业务用户的需求选择正确的包,那么这本书也会对你有所帮助。
本书的组织结构
在本书中,我将展示 Python 处理 Excel 的所有方面,分为四个部分:
第一部分:Python 简介
本部分首先探讨了为什么 Python 是 Excel 的理想伴侣的原因,然后介绍了本书中将要使用的工具:Anaconda Python 发行版、Visual Studio Code 和 Jupyter 笔记本。本部分还将教会你足够的 Python 知识,以便能够掌握本书的其余内容。
第二部分:pandas 介绍
pandas 是 Python 的数据分析首选库。我们将学习如何使用 Jupyter 笔记本和 pandas 组合来替换 Excel 工作簿。通常,pandas 代码既更容易维护又更高效,而且您可以处理不适合电子表格的数据集。与 Excel 不同,pandas 允许您在任何地方运行您的代码,包括云中。
第三部分:不使用 Excel 读写 Excel 文件
本部分介绍了使用以下 Python 包之一操纵 Excel 文件的方法:pandas、OpenPyXL、XlsxWriter、pyxlsb、xlrd 和 xlwt。这些包能够直接在磁盘上读取和写入 Excel 工作簿,并因此取代了 Excel 应用程序:由于不需要安装 Excel,因此它们适用于 Python 支持的任何平台,包括 Windows、macOS 和 Linux。阅读器包的典型用例是从外部公司或系统每天早晨收到的 Excel 文件中读取数据,并将其内容存储在数据库中。写入器包的典型用例是为您在几乎每个应用程序中都可以找到的着名的“导出到 Excel”按钮提供功能。
第四部分:使用 xlwings 编程 Excel 应用程序
在本部分中,我们将看到如何使用 xlwings 包将 Python 与 Excel 应用程序自动化,而不是在磁盘上读写 Excel 文件。因此,本部分需要您在本地安装 Excel。我们将学习如何打开 Excel 工作簿并在我们眼前操纵它们。除了通过 Excel 读写文件之外,我们还将构建交互式 Excel 工具:这些工具允许我们点击按钮,使 Python 执行您以前可能使用 VBA 宏执行的一些计算机密集型计算。我们还将学习如何在 Python 中编写用户定义的函数 1(UDFs),而不是 VBA 中。
非常重要的是要理解阅读和写入 Excel 文件(第三部分)与编程 Excel 应用程序(第四部分)之间的根本区别,如图 P-1 所示。
图 P-1. 读写 Excel 文件(第三部分)与编程 Excel(第四部分)
由于第三部分不需要安装 Excel,因此在 Python 支持的所有平台上都可以工作,主要是 Windows、macOS 和 Linux。然而,第四部分只能在 Microsoft Excel 支持的平台上工作,即 Windows 和 macOS,因为代码依赖于本地安装的 Microsoft Excel。
Python 和 Excel 版本
本书基于 Python 3.8,这是 Anaconda Python 发行版的最新版本附带的 Python 版本。如果你想使用更新的 Python 版本,请按照书籍首页上的说明操作,但要确保不使用旧版本。如果 Python 3.9 有变化,我会偶尔进行评论。
本书还期望你使用现代版本的 Excel,至少是 Windows 上的 Excel 2007 和 macOS 上的 Excel 2016。配有 Microsoft 365 订阅的本地安装版本的 Excel 也可以完美地工作——事实上,我甚至推荐使用它,因为它具有其他 Excel 版本中找不到的最新功能。这也是我撰写本书时使用的版本,所以如果你使用其他版本的 Excel,可能会偶尔看到菜单项名称或位置有轻微差异。
本书使用的约定
本书使用以下排版约定:
斜体
表示新术语、URL、电子邮件地址、文件名和文件扩展名。
常规宽度
用于程序清单,以及段落内引用的程序元素,如变量或函数名、数据库、数据类型、环境变量、语句和关键字。
常规宽度粗体
显示用户应该按照字面意思输入的命令或其他文本。
常规斜体
显示应由用户提供的值或由上下文确定的值替换的文本。
提示
此元素表示提示或建议。
注意
此元素表示一般说明。
警告
此元素表示警告或注意事项。
使用代码示例
我在网页上提供了额外的信息,帮助你理解这本书。确保查看,特别是如果你遇到问题时。
补充材料(代码示例、练习等)可以从github.com/fzumstein/python-for-excel下载。要下载这个配套的仓库,请点击绿色的“Code”按钮,然后选择下载 ZIP。下载后,在 Windows 上右键单击文件并选择“解压缩全部”以解压缩文件到文件夹中。在 macOS 上,只需双击文件即可解压缩。如果你知道如何使用 Git,也可以使用 Git 将仓库克隆到本地硬盘上。你可以将文件夹放在任何位置,但在本书中我偶尔会按照以下方式提及它:
C:\Users\``username``\python-for-excel
在 Windows 上简单下载并解压 ZIP 文件后,您会得到一个类似于以下结构的文件夹(请注意重复的文件夹名称):
C:\...\Downloads\python-for-excel-1st-edition\python-for-excel-1st-edition
将此文件夹的内容复制到您在 C:\Users<username>\python-for-excel 下创建的文件夹中,可能会使您更容易跟进。对于 macOS,即将文件复制到 /Users//python-for-excel。
如果您有技术问题或在使用代码示例时遇到问题,请发送电子邮件至 bookquestions@oreilly.com。
本书旨在帮助您完成工作任务。一般而言,如果本书提供了示例代码,您可以在自己的程序和文档中使用它。除非您要复制大部分代码,否则无需事先联系我们以获取许可。例如,编写一个使用本书多个代码片段的程序并不需要许可。出售或分发 O’Reilly 图书的示例代码则需要许可。通过引用本书并引用示例代码回答问题无需许可。将本书大量示例代码整合到产品文档中则需要许可。
我们感谢您的使用,但通常不需要署名。署名通常包括标题、作者、出版商和 ISBN。例如:“Python for Excel by Felix Zumstein (O’Reilly). Copyright 2021 Zoomer Analytics LLC, 978-1-492-08100-5.”
如果您认为您使用的代码示例超出了公平使用范围或上述许可的限制,请随时联系我们,邮箱为 permissions@oreilly.com。
O’Reilly 在线学习
注意
40 多年来,O’Reilly Media 提供技术和商业培训、知识和见解,帮助公司取得成功。
我们独特的专家和创新者网络通过书籍、文章和我们的在线学习平台分享他们的知识和专业知识。O’Reilly 的在线学习平台为您提供按需访问实时培训课程、深度学习路径、交互式编码环境以及来自 O’Reilly 和其他 200 多家出版商的大量文本和视频。欲了解更多信息,请访问 oreilly.com。
如何联系我们
请就本书的评论和问题联系出版商:
-
O’Reilly Media, Inc.
-
1005 Gravenstein Highway North
-
Sebastopol, CA 95472
-
800-998-9938(在美国或加拿大)
-
707-829-0515(国际或当地)
-
707-829-0104(传真)
我们为本书设有一个网页,其中列出勘误、示例和任何额外信息。您可以访问 oreil.ly/py4excel。
发送电子邮件至 bookquestions@oreilly.com 以评论或提出关于本书的技术问题。
欲了解更多关于我们的书籍、课程、会议和新闻的信息,请访问我们的网站:www.oreilly.com。
在 Facebook 上找到我们:facebook.com/oreilly。
在 Twitter 上关注我们:twitter.com/oreillymedia。
在 YouTube 上观看我们:www.youtube.com/oreillymedia。
致谢
作为初次撰写书籍的作者,我非常感激沿途得到的许多人的帮助,他们让这段旅程对我来说变得更加轻松!
在 O'Reilly,我要感谢我的编辑 Melissa Potter,在保持我积极进度和帮助我将这本书变得可读方面做得很好。我还要感谢 Michelle Smith,她与我一起工作在初步书籍提案上,以及 Daniel Elfanbaum,他从不厌倦回答我的技术问题。
非常感谢所有投入大量时间阅读我初稿的同事、朋友和客户。他们的反馈对于使书籍更易理解至关重要,一些案例研究受到了他们与我分享的真实 Excel 问题的启发。我的感谢送给 Adam Rodriguez、Mano Beeslar、Simon Schiegg、Rui Da Costa、Jürg Nager 和 Christophe de Montrichard。
我还从 O'Reilly 在线学习平台的早期发布版本的读者那里得到了有用的反馈。感谢 Felipe Maion、Ray Doue、Kolyu Minevski、Scott Drummond、Volker Roth 和 David Ruggles!
我非常幸运,这本书得到了高素质的技术审阅人员的审查,我真的很感谢他们在很大时间压力下所付出的辛勤工作。感谢你们所有的帮助,Jordan Goldmeier、George Mount、Andreas Clenow、Werner Brönnimann 和 Eric Moreira!
特别感谢 Björn Stiel,他不仅是技术审阅人员,还是我在这本书中学到许多知识的导师。这些年来,很高兴能和你一起工作!
最后但并非最不重要的,我要感谢 Eric Reynolds,在 2016 年将他的 ExcelPython 项目合并到 xlwings 代码库中。他还从头重新设计了整个包,使我早期可怕的 API 成为过去。非常感谢你!
1 Microsoft 已开始使用术语自定义函数而不是 UDF。在本书中,我将继续称它们为 UDF。
第一部分:Python 入门
第一章:为什么选择 Python 来操作 Excel?
通常,Excel 用户在遇到限制时才开始质疑他们的电子表格工具。一个经典的例子是当 Excel 工作簿包含了大量数据和公式时变得缓慢或在最坏的情况下崩溃。然而,在事情变得糟糕之前,质疑你的设置是有意义的:如果你在关键任务的工作簿上工作,其中的错误可能会导致财务或声誉损失,或者如果你每天花数小时手动更新 Excel 工作簿,那么你应该学会如何用编程语言自动化你的流程。自动化消除了人为错误的风险,并允许你将时间花在比复制/粘贴数据到 Excel 电子表格更有生产力的任务上。
在本章中,我将给出一些理由,解释为什么 Python 与 Excel 结合是一个极好的选择,以及与 Excel 内置的自动化语言 VBA 相比的优势。在介绍 Excel 作为一种编程语言并了解其特殊性之后,我将指出使 Python 与 VBA 相比如此强大的具体特性。不过,首先让我们简单地了解一下我们的两位主角的起源!
就计算机技术而言,Excel 和 Python 都已经存在了很长时间:Excel 首次于 1985 年由微软推出——这可能会让很多人感到惊讶——它只能在苹果麦金塔上使用。直到 1987 年,微软 Windows 才推出了 Excel 2.0 的第一个版本。然而微软并不是电子表格市场上的第一家公司:VisiCorp 在 1979 年推出了 VisiCalc,随后 Lotus Software 在 1983 年推出了 Lotus 1-2-3。而微软也不是首次推出 Excel:三年前,他们推出了 Multiplan,一款可在 MS-DOS 和其他一些操作系统上使用的电子表格程序,但无法在 Windows 上运行。
Python 诞生于 1991 年,仅比 Excel 晚六年。虽然 Excel 很早就流行起来了,但 Python 直到后来才在某些领域得到了采用,如 Web 开发或系统管理。2005 年,Python 开始成为科学计算的一个严肃的替代品,当时第一个数组计算和线性代数包 NumPy 首次发布。NumPy 合并了两个前身包,因此将所有关于科学计算的开发工作整合到了一个项目中。如今,它构成了无数科学包的基础,包括 2008 年推出的 pandas,它在数据科学和金融领域的广泛采用始于 2010 年之后。多亏了 pandas,Python 与 R 一起成为了数据分析、统计和机器学习等数据科学任务中最常用的语言之一。
Python 和 Excel 都是很久以前发明的事实并不是它们共同的唯一之处:Excel 和 Python 还都是一种编程语言。虽然您可能对 Python 的这一点不感到惊讶,但对于 Excel,您可能需要一些解释,我将在接下来为您解释。
Excel 是一种编程语言。
本节首先介绍 Excel 作为一种编程语言,这将帮助您理解为什么电子表格问题经常出现在新闻中。然后,我们将看看一些在软件开发社区中出现的最佳实践,这些实践可以避免许多典型的 Excel 错误。最后,我们将简要介绍 Power Query 和 Power Pivot,这两种现代 Excel 工具涵盖了我们将使用 pandas 替代的功能类型。
如果您不只是用 Excel 列出您的杂货清单,您肯定正在使用类似=SUM(A1:A4)这样的函数来对一系列单元格求和。如果您稍加思考如何工作,您会注意到一个单元格的值通常取决于一个或多个其他单元格,而这些可能又使用依赖于一个或多个其他单元格的函数,如此反复。进行这种嵌套函数调用与其他编程语言的工作方式没有什么不同,只是您在单元格中写代码而不是文本文件中。如果这还没有完全说服您:在 2020 年底,微软宣布引入 Lambda 函数,允许您在 Excel 的自有公式语言中编写可重用的函数,即不必依赖于像 VBA 这样的其他语言。根据 Brian Jones,Excel 产品负责人的说法,这是最终使 Excel 成为“真正的”编程语言的缺失部分。这也意味着 Excel 用户实际上应该被称为 Excel 程序员!
然而,Excel 程序员有一个特殊的地方:大多数都是没有计算机科学正规教育的业务用户或领域专家。他们是交易员、会计师或工程师,仅举几个例子。他们的电子表格工具旨在解决业务问题,通常忽略软件开发中的最佳实践。因此,这些电子表格工具经常在同一张表上混合输入、计算和输出,可能需要执行非明显的步骤才能正常工作,并且关键更改是没有安全网的。换句话说,这些电子表格工具缺乏坚实的应用架构,并且通常没有文档化和未经测试。有时,这些问题可能会产生灾难性后果:如果您在下单前忘记重新计算交易工作簿,可能会买入或卖出错误数量的股票,从而导致您损失资金。如果不只是您自己的资金在交易,我们可以在新闻中看到相关报道,接下来我们将看到。
Excel 在新闻中。
Excel 经常出现在新闻中,而在撰写本文期间,又有两则新闻成为头条。第一则是关于 HUGO 基因命名委员会,他们重新命名了一些人类基因,以免被 Excel 误读为日期。例如,为了防止基因MARCH1被转换成1-Mar,它被改名为MARCHF1。2 第二则新闻是,Excel 因为英格兰 16000 份 COVID-19 检测结果的延迟报告而受到指责。问题是检测结果写入的是较老的 Excel 文件格式(.xls),该格式限制了大约 65000 行数据。这意味着超出该限制的更大数据集将被简单截断。3 虽然这两则故事显示了 Excel 在当今世界的持续重要性和主导地位,但可能没有其他“Excel 事件”比伦敦鲸更为著名。
伦敦鲸是一个交易员的绰号,他的交易失误迫使摩根大通在 2012 年宣布惊人的 60 亿美元损失。灾难的根源是一个基于 Excel 的风险价值模型,该模型严重低估了他们其中一个投资组合失钱的真实风险。JPMorgan Chase & Co.管理任务组关于 2012 年 CIO 损失的报告 4(2013 年)提到,“该模型通过一系列 Excel 电子表格运行,必须通过复制和粘贴数据从一个电子表格到另一个电子表格的过程手动完成。”除了这些操作问题,他们还有一个逻辑错误:在一个计算中,他们除以一个总和而不是一个平均值。
如果您想了解更多这类故事,请查看由欧洲电子表格风险兴趣小组(EuSpRIG)维护的恐怖故事网页。
为了防止您的公司出现类似的新闻报道,让我们接下来看看几个最佳实践,可以大大提高您使用 Excel 的工作安全性。
编程最佳实践
本节将介绍您需要了解的最重要的编程最佳实践,包括关注点分离、DRY 原则、测试和版本控制。正如我们将看到的那样,当您开始将 Python 与 Excel 一起使用时,遵循这些原则将会更加容易。
关注点分离
编程中最重要的设计原则之一是关注点分离,有时也称为模块化。这意味着相关功能集应由程序的独立部分处理,以便可以轻松替换而不影响应用程序的其余部分。在最高层面上,一个应用程序通常分为以下几个层次:5
-
展示层
-
-
业务层
-
-
数据层
要解释这些层次,请考虑一个简单的货币转换器,例如在图 1-1 中显示的一个。您可以在伴侣存储库的 xl 文件夹中找到 currency_converter.xlsx Excel 文件。
这是应用程序的工作原理:在单元格 A4 和 B4 中键入金额和货币,Excel 将把它转换为美元显示在 D4 单元格中。许多电子表格应用程序都遵循这样的设计,并且每天被企业使用。让我逐层分解这个应用程序:
展示层
这是您看到并与之交互的用户界面:单元格 A4、B4 和 D4 的值及其标签共同构建了货币转换器的展示层。
业务层
这一层处理应用程序特定的逻辑:D4 单元格定义了如何将金额转换为美元。公式
=A4 * VLOOKUP(B4, F4:G11, 2, FALSE)表示金额乘以汇率。
数据层
正如名称所示,这一层负责访问数据:D4 单元格中的
VLOOKUP部分正在执行此任务。
数据层从汇率表中访问数据,该表从单元格 F3 开始,并充当这个小应用程序的数据库。如果您仔细观察,您可能会注意到单元格 D4 在所有三个层中都出现了:这个简单的应用程序在一个单元格中混合了展示、业务和数据层。
图 1-1. currency_converter.xlsx
对于这个简单的货币转换器来说,这并不一定是问题,但通常,一个开始时是小型 Excel 文件很快就会变成一个更大的应用程序。如何改善这种情况?大多数专业的 Excel 开发资源建议您为每个层次使用单独的工作表,在 Excel 的术语中通常称为输入、计算和输出。通常,这与为每个层次定义特定的颜色代码相结合,例如,所有输入单元格的蓝色背景。在第十一章中,我们将基于这些层次构建一个真实的应用程序:Excel 将作为展示层,而业务和数据层将移至 Python 中,这样可以更轻松地正确结构化您的代码。
现在您知道了关注点分离的含义,让我们了解一下 DRY 原则是什么!
DRY 原则
Hunt 和 Thomas(Pearson Education)在《实用程序员》一书中推广了 DRY 原则:不要重复自己。没有重复的代码意味着代码行数更少,错误也更少,使代码更易于维护。如果您的业务逻辑存在于单元格公式中,那么在另一个工作簿中重复使用它是几乎不可能的,因为没有机制可以实现这一点。不幸的是,这意味着启动新的 Excel 项目的常见方法是从以前的项目或模板复制工作簿。
如果你写 VBA,最常见的可重用代码片段是函数。函数使你能够从多个宏中访问同一代码块,例如。如果你有多个经常使用的函数,你可能希望在工作簿之间共享它们。在工作簿之间共享 VBA 代码的标准工具是加载项,但是 VBA 加载项缺乏分发和更新的强大方式。尽管微软推出了一个 Excel 内部加载项商店来解决这个问题,但这仅适用于基于 JavaScript 的加载项,因此对于 VBA 程序员来说并不是一个选择。这意味着,仍然很普遍地使用复制/粘贴方法与 VBA:假设你需要在 Excel 中一个三次样条函数。三次样条函数是一种根据坐标系中几个给定点插值曲线的方式,通常被固定收益交易员用来根据少数已知到期日/利率组合推导所有到期期限的利率曲线。如果你在互联网上搜索“Cubic Spline Excel”,不久就会找到一个能做你想做的事情的 VBA 代码页面。问题在于,这些函数通常是由单个人编写的,可能出于良好意图,但没有正式的文档或测试。也许它们对大多数输入有效,但对一些不常见的边缘情况呢?如果你在交易数百万的固定收益投资组合,你肯定希望有一些你知道可以信赖的东西。至少,这就是当内部审计员发现代码来源时,你会听到的意见。
Python 通过使用包管理器使得代码分发变得容易,我们将在本章的最后一节看到。然而,在那之前,让我们继续讨论测试,这是坚实软件开发的基石之一。
测试
当你告诉一个 Excel 开发者测试他们的工作簿时,他们很可能会执行一些随机检查:点击一个按钮并查看宏是否仍然执行其预期功能,或者更改一些输入并检查输出是否合理。然而,这是一种风险较高的策略:Excel 很容易引入难以察觉的错误。例如,你可以用硬编码值覆盖一个公式,或者忘记调整隐藏列中的一个公式。
当你告诉一个专业的软件开发者测试他们的代码时,他们会编写单元测试。顾名思义,这是测试程序单个组件的机制。例如,单元测试确保程序的单个函数正常工作。大多数编程语言提供一种自动运行单元测试的方法。运行自动化测试将极大增加代码库的可靠性,并相当确保在编辑代码时不会破坏当前正常运行的任何功能。
如果你看看图 1-1 中的货币转换工具,你可以编写一个测试来检查当输入为 100 欧元和 1.05 作为欧元兑美元汇率时,单元格 D4 中的公式是否正确返回 USD 105。这有什么帮助呢?假设你意外删除了包含转换公式的单元格 D4,并且不得不重新编写它:与其用汇率乘以金额,你误用了除以汇率——毕竟,处理货币可能很令人困惑。当你运行上述测试时,你会得到一个测试失败,因为 100 欧元 / 1.05 不再像测试期望的那样得到 105 美元。通过这种方式,你可以在将电子表格交给用户之前检测并修复公式。
几乎所有传统的编程语言都提供一个或多个测试框架来轻松编写单元测试,但 Excel 不行。幸运的是,单元测试的概念足够简单,并且通过将 Excel 与 Python 连接,你可以使用 Python 强大的单元测试框架。虽然本书不涉及单元测试的更深入介绍,但我邀请你阅读我的博客文章,其中我通过实际例子为你详细讲解这个主题。
单元测试通常在你将代码提交到版本控制系统时自动运行。下一节将解释版本控制系统的概念及其与 Excel 文件难以配合的原因。
版本控制
专业程序员的另一个特征是他们使用版本控制或源代码控制系统。版本控制系统(VCS)会随时间跟踪源代码的变化,允许你查看谁、何时以及为何做了变更,并允许你随时恢复到旧版本。如今最流行的版本控制系统是Git,最初是为管理 Linux 源代码而创建的,此后已占领了编程世界——甚至微软也在 2017 年采用 Git 管理 Windows 源代码。相比之下,在 Excel 的世界中,迄今为止最流行的版本控制系统是以文件夹形式存档文件,就像这样:
currency_converter_v1.xlsx currency_converter_v2_2020_04_21.xlsx currency_converter_final_edits_Bob.xlsx currency_converter_final_final.xlsx
如果,与此样本不同,Excel 开发者在文件名中坚持某种约定,这本身并没有什么问题。但是,在本地保留文件的版本历史会让您失去源代码控制的重要方面,例如更轻松的协作、同行审查、签署流程和审计日志。如果您想使工作簿更安全和稳定,您不想错过这些功能。通常情况下,专业程序员会将 Git 与像 GitHub、GitLab、Bitbucket 或 Azure DevOps 这样的基于 Web 的平台结合使用。这些平台允许您使用所谓的拉取请求或合并请求。它们允许开发人员正式请求将其更改合并到主代码库中。拉取请求提供以下信息:
-
谁是更改的作者
-
-
更改是什么时候进行的
-
-
更改的目的如何在提交消息中描述
-
-
更改的详细信息如何通过 diff 视图显示,即高亮显示新代码的绿色和删除代码的红色
这允许同事或团队负责人审查更改并发现异常。通常情况下,额外的一双眼睛能够发现一个或两个问题,或者向程序员提供宝贵的反馈。有了所有这些优势,为什么 Excel 开发者更喜欢使用本地文件系统和他们自己的命名约定,而不是像 Git 这样的专业系统呢?
-
许多 Excel 用户根本不了解 Git 或者很早就放弃了,因为 Git 学习曲线相对较陡。
-
-
Git 允许多个用户并行在本地副本上工作在同一个文件上。当所有人提交他们的工作后,Git 通常可以自动合并所有更改,无需任何手动干预。但这对 Excel 文件不适用:如果它们在分开的副本上并行更改,Git 就无法将这些更改合并回一个单一的文件中。
-
-
即使你设法处理了之前的问题,Git 对于 Excel 文件的价值远不及对文本文件:Git 无法显示 Excel 文件之间的更改,这阻碍了适当的同行审查流程。
因为所有这些问题,我们公司推出了 xltrail,一个基于 Git 的版本控制系统,它知道如何处理 Excel 文件。它隐藏了 Git 的复杂性,使业务用户感觉舒适使用它,同时还允许您连接到外部 Git 系统,例如,如果您已经在 GitHub 中跟踪您的文件。xltrail 跟踪工作簿的不同组成部分,包括单元格公式、命名区域、Power Queries 和 VBA 代码,使您能够利用版本控制的经典优势,包括同行审查。
另一个使得使用 Excel 更容易进行版本控制的选项是将你的业务逻辑从 Excel 转移到 Python 文件中,这是我们将在第十章中完成的事情。由于 Python 文件易于使用 Git 进行跟踪,你将能够完全控制你电子表格工具的最重要部分。
尽管本节称为“编程最佳实践”,但主要是指出为什么在 Excel 中遵循它们比在像 Python 这样的传统编程语言中更难。在我们把注意力转向 Python 之前,我想简要介绍一下 Power Query 和 Power Pivot,这是微软试图使 Excel 现代化的尝试。
现代 Excel
Excel 的现代时代始于 Excel 2007,当时引入了功能区菜单和新的文件格式(例如 xlsx 替代 xls)。然而,Excel 社区将现代 Excel 定义为随 Excel 2010 添加的工具:尤其是 Power Query 和 Power Pivot。它们允许您连接到外部数据源并分析无法容纳在电子表格中的大型数据。由于它们的功能与我们将在第五章中使用 pandas 进行的工作重叠,我将在本节的第一部分简要介绍它们。第二部分介绍 Power BI,这可以被描述为一个独立的商业智能应用程序,结合了 Power Query 和 Power Pivot 的功能,并具有内置的 Python 支持!
Power Query 和 Power Pivot
在 Excel 2010 中,微软引入了一个名为 Power Query 的插件。Power Query 能够连接多种数据源,包括 Excel 工作簿、CSV 文件和 SQL 数据库。它还支持连接到像 Salesforce 这样的平台,甚至可以扩展到连接没有预先支持的系统。Power Query 的核心功能是处理那些无法容纳在电子表格中的大型数据集。加载数据后,您可以执行额外的步骤来清理和操作数据,使其以可用形式出现在 Excel 中。例如,您可以将一列拆分为两列,合并两个表,或者过滤和分组数据。自 Excel 2016 起,Power Query 不再是一个插件,而是可以直接通过“数据”选项卡上的“获取数据”按钮访问。然而,Power Query 在 macOS 上仅部分可用——不过,它正在积极开发中,因此应该在未来的 Excel 发布中得到充分支持。
Power Pivot 与 Power Query 配合得天衣无缝:在使用 Power Query 获取和清洗数据后,Power Pivot 是概念上的第二步。Power Pivot 帮助你直接在 Excel 中分析和展示数据。可以将其视为传统数据透视表,类似于 Power Query,可以处理大型数据集。Power Pivot 允许你定义具有关系和层次结构的正式数据模型,并且可以通过 DAX 公式语言添加计算列。Power Pivot 也是在 Excel 2010 中引入的,但仍然是一个附加组件,目前尚不支持 macOS。
如果你喜欢使用 Power Query 和 Power Pivot,并希望在其上构建仪表板,那么值得一试 Power BI — 让我们看看为什么!
Power BI
Power BI 是一个独立应用,于 2015 年发布。这是微软对 Tableau 或 Qlik 等商业智能工具的回应。Power BI Desktop 是免费的,如果你想尝试一下,请访问Power BI 官网并下载它 — 不过需要注意的是,Power BI Desktop 仅适用于 Windows。Power BI 通过可视化交互式仪表板来理解大型数据集。其核心功能依赖于与 Excel 相同的 Power Query 和 Power Pivot 功能。商业版计划允许你在线协作和共享仪表板,但与桌面版是分开的。在本书的背景下,Power BI 之所以令人兴奋的主要原因是,自 2018 年起支持 Python 脚本。Python 不仅可以用于查询部分,还可以利用 Python 的绘图库进行可视化部分。对我来说,在 Power BI 中使用 Python 有些笨拙,但重要的是微软已经认识到 Python 在数据分析中的重要性。因此,人们对 Python 有望正式进入 Excel 持久地寄予厚望。
那么,Python 有何优点,使其进入微软的 Power BI?下一节将给出一些答案!
Python for Excel
Excel 专注于存储、分析和可视化数据。由于 Python 在科学计算领域特别强大,因此与 Excel 结合非常自然。Python 也是极少数同时吸引专业程序员和每隔几周写几行代码的初学者的语言之一。专业程序员喜欢使用 Python,因为它是一种通用编程语言,因此允许您几乎无需费力地实现任何功能。初学者喜欢 Python,因为它比其他语言更容易学习。因此,Python 既用于临时数据分析和小型自动化任务,也用于像 Instagram 后端这样的大型生产代码库。6 这也意味着,当您的基于 Python 的 Excel 工具真正受欢迎时,很容易添加一个 Web 开发人员,将您的 Excel-Python 原型转换为完整的 Web 应用程序。Python 的独特优势在于,业务逻辑部分很可能不需要重新编写,而可以直接从 Excel 原型移植到生产 Web 环境中。
在本节中,我将介绍 Python 的核心概念,并与 Excel 和 VBA 进行比较。我将涉及代码可读性、Python 的标准库和包管理器、科学计算堆栈、现代语言特性以及跨平台兼容性。让我们首先深入探讨可读性!
可读性和可维护性
如果你的代码易读,那就意味着它容易跟随和理解——尤其是对于那些没有自己编写代码的外部人员来说。这使得查找错误和维护代码变得更加容易。这就是为什么《Python 之禅》中有一句话是“可读性至关重要”。《Python 之禅》是 Python 核心设计原则的简洁总结,在下一章节我们将学习如何打印它。让我们看一下以下的 VBA 代码片段:
If``i``<``5``Then``Debug``.``Print``"i is smaller than 5"``ElseIf``i``<=``10``Then``Debug``.``Print``"i is between 5 and 10"``Else``Debug``.``Print``"i is bigger than 10"``End``If
在 VBA 中,您可以将代码片段重新格式化为以下内容,这与原来的完全等价:
If``i``<``5``Then``Debug``.``Print``"i is smaller than 5"``ElseIf``i``<=``10``Then``Debug``.``Print``"i is between 5 and 10"``Else``Debug``.``Print``"i is bigger than 10"``End``If
在第一个版本中,视觉缩进与代码逻辑对齐。这使得代码易于阅读和理解,从而更容易发现错误。在第二个版本中,对于第一次浏览代码的新开发人员可能看不到ElseIf和Else条件——如果代码是大型代码库的一部分,这显然更为真实。
Python 不接受类似第二个示例那样格式化的代码:它强制你将视觉缩进与代码逻辑对齐,以防止可读性问题。Python 之所以能做到这一点,是因为它依赖缩进来定义代码块,例如在 if 语句或 for 循环中使用。与缩进不同,大多数其他语言使用花括号,而 VBA 则使用关键字如 End If,就像我们刚刚在代码片段中看到的那样。使用缩进来定义代码块的原因是,在编程中,大部分时间都花在维护代码上,而不是最初编写代码。编写可读的代码有助于新程序员(或者是编写代码几个月后的自己)回过头去理解代码的运作方式。
我们将在第三章详细学习 Python 的缩进规则,但现在让我们继续探讨标准库:Python 开箱即用的功能。
标准库和包管理器
Python 自带丰富的功能集,由其标准库提供支持。Python 社区喜欢称其为“电池已内置”。无论您需要解压缩 ZIP 文件,读取 CSV 文件中的值,还是从互联网获取数据,Python 的标准库都可以胜任,通常只需几行代码即可完成。在 VBA 中,相同的功能需要大量代码或安装插件。而且,您在互联网上找到的解决方案通常只适用于 Windows 而非 macOS。
尽管 Python 的标准库涵盖了大量功能,但仍有一些任务在仅依赖标准库时编写起来很麻烦或者速度很慢。这就是PyPI发挥作用的地方。PyPI 是 Python 包索引的缩写,是一个巨大的仓库,任何人(包括您!)都可以上传开源 Python 包,为 Python 添加额外的功能。
PYPI VS. PYPY
PyPI 的发音是“派皮艾”,这是为了将 PyPI 与 PyPy 区分开来,PyPy 的发音是“派派”,它是 Python 的一个快速替代实现。
例如,为了更容易地从互联网上获取数据,您可以安装 Requests 包,以便获得一组强大且易于使用的命令。要安装它,您可以使用 Python 的包管理器 pip,在命令提示符或终端上运行。pip 是递归首字母缩略词,表示 pip 安装包。如果现在这听起来有点抽象,不要担心;我将在下一章详细解释它的工作原理。现在更重要的是理解为什么包管理器如此重要。其中一个主要原因是任何合理的包不仅依赖于 Python 的标准库,而且再次依赖于其他同样托管在 PyPI 上的开源包。这些依赖可能再次依赖于子依赖项等等。pip 递归检查包及其依赖项和子依赖项,并下载安装它们。pip 还可以轻松更新您的包,因此您可以保持依赖项最新。这使得遵循 DRY 原则更加容易,因为您不需要重复发明或复制/粘贴 PyPI 上已有的内容。通过 pip 和 PyPI,您还拥有一个坚实的机制来分发和安装这些依赖项,这是 Excel 传统插件所缺乏的。
开源软件(OSS)
此时,我想对开源软件说几句,因为在本节中我已经多次使用了这个词。如果软件在开源许可下分发,意味着其源代码可以免费获取,允许每个人贡献新功能、修复错误或文档。Python 本身以及几乎所有第三方 Python 包都是开源的,通常由开发者在业余时间维护。这并不总是一个理想的状态:如果您的公司依赖于某些包,您对这些包由专业程序员持续开发和维护感兴趣。幸运的是,科学计算 Python 社区已经意识到一些包太重要了,不能把它们的命运交给那些在晚上和周末工作的几个志愿者。
这就是为什么在 2012 年,NumFOCUS,一个非营利组织,成立了,以赞助科学计算领域的各种 Python 包和项目。NumFOCUS 赞助的最受欢迎的 Python 包包括 pandas、NumPy、SciPy、Matplotlib 和 Project Jupyter,但现在他们还支持来自各种其他语言,包括 R、Julia 和 JavaScript 的包。有一些大型企业赞助商,但每个人都可以作为自由社区成员加入 NumFOCUS —— 捐款可以免税。
使用 pip,您可以安装几乎任何类型的包,但对于 Excel 用户来说,最有趣的肯定是科学计算的包。让我们在下一节更多地了解使用 Python 进行科学计算!
科学计算
Python 成功的一个重要原因是它作为一种通用编程语言创建。后来添加了用于科学计算的能力,以第三方包的形式。这具有独特的优势,即数据科学家可以使用同一种语言进行实验和研究,而 Web 开发人员则可以最终围绕计算核心构建出生产就绪的应用程序。能够使用一种语言构建科学应用程序减少了摩擦、实施时间和成本。科学包如 NumPy、SciPy 和 pandas 使我们能够以非常简洁的方式制定数学问题。例如,让我们来看看根据现代投资组合理论计算投资组合方差的一个更著名的金融公式:
投资组合方差用符号表示为,其中是各个资产的权重向量,是投资组合的协方差矩阵。如果w和C是 Excel 范围,则可以在 VBA 中如下计算投资组合方差:
方差``=``Application``.``MMult``(``Application``.``MMult``(``Application``.``Transpose``(``w``),``C``),``w``)
比较这一点与 Python 中的几乎数学符号表示,假设w和C是 pandas 的 DataFrame 或 NumPy 数组(我将在第二部分正式介绍它们):
方差``=``w``.``T``@``C``@``w
但这不仅仅是美学和可读性问题:NumPy 和 pandas 在底层使用编译后的 Fortran 和 C 代码,这在处理大型矩阵时比 VBA 提供了性能提升。
在 VBA 中缺少对科学计算的支持显然是一个限制。但即使您看看核心语言特性,VBA 也已经落后了,我将在下一节中指出。
现代语言特性
自 Excel 97 以来,VBA 语言在语言特性方面没有任何重大变化。但这并不意味着 VBA 不再受支持:微软在每次 Excel 的新版本中都会发布更新,以便自动化该版本引入的新 Excel 功能。例如,Excel 2016 增加了支持自动化 Power Query 的功能。一个停止发展二十多年的语言缺少了随着年代推移在所有主要编程语言中引入的现代语言概念。例如,在 VBA 中处理错误的方式真的显得过时。如果您想在 VBA 中优雅地处理错误,就像这样:
Sub``PrintReciprocal``(``number``As``Variant``)``' 如果数字是 0 或字符串,将会发生错误``On``Error``GoTo``ErrorHandler``result``=``1``/``number``On``Error``GoTo``0``Debug``.``Print``"没有错误发生!"``Finally:``' 无论是否发生错误都会运行``If``result``=``""``Then``result``=``"N/A"``End``If``Debug``.``Print``"倒数是: "``&``result``Exit``Sub``ErrorHandler:``' 仅在发生错误时运行``Debug``.``Print``"发生了错误: "``&``Err``.``Description``Resume``Finally``End``Sub
VBA 错误处理涉及在示例中使用Finally和ErrorHandler这样的标签。您通过GoTo或Resume语句指示代码跳转到这些标签。早期,标签被认为是许多程序员所说的意大利面代码的原因:这是一种表达方式,意味着代码的流程难以跟踪,因此难以维护。这就是为什么几乎所有积极开发的语言都引入了try/catch机制——在 Python 中称为try/except——我将在第十一章中介绍它。如果您是一个熟练的 VBA 开发者,您可能也会喜欢 Python 支持类继承这一事实,这是面向对象编程中的一个特性,在 VBA 中缺少。
除了现代语言功能之外,现代编程语言还有另一个要求:跨平台兼容性。让我们看看这为何如此重要!
跨平台兼容性
即使您在运行 Windows 或 macOS 的本地计算机上开发代码,很可能最终希望在服务器或云中运行程序。服务器允许您的代码按计划执行,并使您的应用程序可以从任何您希望的地方访问,具备您需要的计算能力。事实上,在下一章中,我将向您介绍托管的 Jupyter 笔记本,展示如何在服务器上运行 Python 代码。绝大多数服务器运行 Linux,因为它是一种稳定、安全且具有成本效益的操作系统。而且由于 Python 程序在所有主要操作系统上都能无缝运行,这将大大减少从本地计算机转移到生产环境设置时的困扰。
相比之下,即使 Excel VBA 在 Windows 和 macOS 上运行,也很容易引入仅在 Windows 上运行的功能。在官方 VBA 文档或论坛上,您经常会看到类似以下代码:
Set``fso``=``CreateObject``(``"Scripting.FileSystemObject"``)
每当你使用CreateObject调用或被告知在 VBA 编辑器中转到工具 > 引用以添加引用时,你几乎总是在处理只能在 Windows 上运行的代码。如果你希望你的 Excel 文件能够跨 Windows 和 macOS 正常工作,另一个需要注意的突出领域是 ActiveX 控件。ActiveX 控件是诸如按钮和下拉菜单之类的元素,你可以将它们放在工作表上,但它们只在 Windows 上运行。如果你希望你的工作簿也能在 macOS 上运行,请务必避免使用它们!
结论
在本章中,我们遇到了 Python 和 Excel,这两种非常流行的技术已经存在了多个十年——与我们今天使用的许多其他技术相比,这是很长一段时间了。伦敦鲸鱼事件作为一个例子,展示了当你在关键任务工作簿中没有正确使用 Excel 时可能会出现多大的问题(以美元计)。这激发了我们寻找一组最佳编程实践的动力:应用关注点分离,遵循 DRY 原则,并利用自动化测试和版本控制。然后,我们研究了 Power Query 和 Power Pivot,这是微软处理比你的电子表格更大的数据的方法。然而,我认为它们通常不是正确的解决方案,因为它们将你锁定在微软世界中,并阻止你利用现代基于云的解决方案的灵活性和强大功能。
Python 具有令人信服的特性,这些特性在 Excel 中缺失:标准库、包管理器、科学计算库和跨平台兼容性。通过学习如何将 Excel 与 Python 结合使用,你可以兼顾两者的优势,并通过自动化节省时间,在遵循编程最佳实践方面减少错误,并且如果有必要,可以将你的应用程序扩展到 Excel 之外的规模。
现在你知道为什么 Python 是 Excel 的强大伴侣,是时候设置你的开发环境,开始编写你的第一行 Python 代码了!
1 你可以在Excel 博客上阅读有关 lambda 函数发布的公告。
2 James Vincent,“科学家将人类基因重新命名,以防止 Microsoft Excel 将其误读为日期”,The Verge,2020 年 8 月 6 日,
oreil.ly/0qo-n。3 Leo Kelion,“Excel:为什么使用微软工具导致 COVID-19 结果丢失”,BBC 新闻,2020 年 10 月 5 日,
oreil.ly/vvB6o。4 维基百科在其有关该案例的文章的一个脚注中链接到该文档。
5 术语来自 Microsoft 应用程序架构指南第 2 版,可在线上获取。
6 你可以在他们的工程博客上了解更多有关 Instagram 如何使用 Python 的信息。
第二章:开发环境
你可能迫不及待地想要学习 Python 的基础知识,但在此之前,你需要相应地设置你的计算机。要编写 VBA 代码或 Power Queries,只需启动 Excel 并分别打开 VBA 或 Power Query 编辑器即可。而使用 Python,则需要更多的工作。
我们将从安装 Anaconda Python 发行版开始本章。除了安装 Python 外,Anaconda 还将为我们提供 Anaconda Prompt 和 Jupyter 笔记本两个基本工具,这两个工具我们将在本书中经常使用。Anaconda Prompt 是一个特殊的命令提示符(Windows)或终端(macOS);它允许我们运行 Python 脚本和其他本书中会遇到的命令行工具。Jupyter 笔记本允许我们以交互方式处理数据、代码和图表,这使得它们成为 Excel 工作簿的一个强大替代品。在使用了一段时间的 Jupyter 笔记本后,我们将安装 Visual Studio Code(VS Code),一个功能强大的文本编辑器。VS Code 非常适合编写、运行和调试 Python 脚本,并带有集成的终端。图 2-1 总结了 Anaconda 和 VS Code 中包含的内容。
由于本书主要讲解 Excel,因此本章将重点介绍 Windows 和 macOS。然而,包括第三部分在内的一切内容也适用于 Linux。让我们开始安装 Anaconda 吧!
图 2-1. 开发环境
Anaconda Python 发行版
Anaconda 可以说是用于数据科学最流行的 Python 发行版,预装了数百个第三方包:它包括 Jupyter 笔记本和本书中将广泛使用的大多数其他包,包括 pandas、OpenPyXL 和 xlwings。Anaconda 个人版可以免费私人使用,并保证所有包都与彼此兼容。它安装在一个单独的文件夹中,并且可以轻松地卸载。安装完毕后,我们将在 Anaconda Prompt 上学习一些基本命令,并运行一个交互式的 Python 会话。然后,我们将介绍包管理器 Conda 和 pip,最后以 Conda 环境结束本节。让我们开始下载并安装 Anaconda 吧!
安装
前往Anaconda 主页并下载最新版本的 Anaconda 安装程序(个人版)。确保下载 Python 3.x 版本的 64 位图形化安装程序。1 下载完成后,双击安装程序开始安装过程,并确保接受所有默认设置。有关更详细的安装说明,请参阅官方文档。
其他 Python 发行版
尽管本书的指导假设您已安装了 Anaconda 个人版,但所展示的代码和概念也适用于任何其他 Python 安装。在这种情况下,您需要按照配套存储库中 requirements.txt 中包含的说明安装所需的依赖项。
安装了 Anaconda 后,我们现在可以开始使用 Anaconda Prompt。让我们看看这是什么以及它是如何工作的!
Anaconda Prompt
Anaconda Prompt 实际上只是在 Windows 上的命令提示符和 macOS 上的终端,已设置为使用正确的 Python 解释器和第三方包运行。Anaconda Prompt 是运行 Python 代码的最基本工具,在本书中我们将广泛使用它来运行 Python 脚本和各种由各种包提供的命令行工具。
在没有 Anaconda 的情况下使用 ANACONDA PROMPT
如果您不使用 Anaconda Python 发行版,每当我指示您使用 Anaconda Prompt 时,您将不得不使用 Windows 上的命令提示符和 macOS 上的终端。
如果您从未在 Windows 上使用过命令提示符或在 macOS 上使用过终端,不用担心:您只需要知道几个命令,这些命令将为您提供大量功能。一旦习惯了,使用 Anaconda Prompt 通常比通过图形用户界面菜单点击更快更方便。让我们开始吧:
Windows
点击“开始”菜单按钮,然后开始输入
Anaconda Prompt。在出现的条目中,选择 Anaconda Prompt,而不是 Anaconda Powershell Prompt。可以使用箭头键选择它并按 Enter 键,或者使用鼠标点击它。如果您喜欢通过“开始”菜单打开它,可以在 Anaconda3 下找到它。将 Anaconda Prompt 固定到 Windows 任务栏是一个好主意,因为您将在本书中经常使用它。Anaconda Prompt 的输入行将以(base)开头:
(base) C:\Users\felix>
macOS
在 macOS 上,您找不到名为 Anaconda Prompt 的应用程序。相反,Anaconda Prompt 指的是由 Anaconda 安装程序设置的终端,用于自动激活 Conda 环境(稍后我会详细介绍 Conda 环境):按下 Command-Space 键或打开 Launchpad,然后键入
Terminal并按 Enter 键。或者,打开 Finder 并导航到应用程序 > 实用工具,在那里您会找到可以双击的 Terminal 应用程序。一旦终端出现,它应该看起来像这样,即输入行必须以(base)开头:
(base) felix@MacBook-Pro ~ %如果你使用的是较旧版本的 macOS,它看起来会是这个样子:
(base) MacBook-Pro:~ felix$与 Windows 上的命令提示符不同,macOS 上的终端不显示当前目录的完整路径。相反,波浪符号表示主目录,通常是 /Users/。要查看当前目录的完整路径,请键入
pwd然后按 Enter 键。pwd表示打印工作目录。如果您在安装 Anaconda 后在终端中输入行不是以
(base)开头,常见原因是:如果在 Anaconda 安装过程中终端处于运行状态,您需要重新启动它。请注意,点击终端窗口左上角的红色叉号只会隐藏它而不会退出它。相反,请右键单击 dock 中的终端,选择退出,或者在终端是活动窗口时按 Command-Q 键。重新启动后,如果终端显示(base)开头的新行,表示已设置好。建议将终端固定在 dock 中,因为您将经常使用它。
在 Anaconda 提示符处,尝试执行 表 2-1 中概述的命令。我将在表后更详细地解释每个命令。
表 2-1. Anaconda 提示的命令
| 命令 | Windows | macOS |
|---|---|---|
| 列出当前目录中的文件 | dir | ls -la |
| 切换目录(相对路径) | cd path\to\dir | cd path/to/dir |
| 切换目录(绝对路径) | cd C:\path\to\dir | cd /path/to/dir |
| 切换到 D 驱动器 | D: | (不存在) |
| 切换到上级目录 | cd .. | cd .. |
| 浏览以前的命令 | ↑(上箭头) | ↑(上箭头) |
列出当前目录中的文件
在 Windows 上,输入
dir查看目录内容,然后按 Enter 键。这将打印出您当前所在目录的内容。在 macOS 上,输入
ls -la并按 Enter 键。ls是列出目录内容的缩写,-la将以长列表格式打印输出,并包括所有文件,包括隐藏文件。
切换目录
输入
cd Down并按 Tab 键。cd是改变目录的缩写。如果您在主文件夹中,Anaconda 提示应该能够自动完成到cd Downloads。如果您在不同的文件夹中,或者没有名为 Downloads 的文件夹,只需在按 Tab 键自动完成之前,开始键入前一个命令 (dir或ls -la) 中看到的一个目录名的开始部分。然后按 Enter 键以进入自动完成的目录。如果您在 Windows 上需要更改驱动器,请先输入驱动器名称,然后才能更改正确的目录:
C:\Users\felix>D:D:\>cd dataD:\data>注意,如果您从当前目录开始,使用相对路径启动路径时,需要使用一个位于当前目录中的目录或文件名,例如,
cd Downloads。如果您想要跳出当前目录,可以输入绝对路径,例如,在 Windows 上是cd C:\Users,在 macOS 上是cd /Users(请注意斜杠是在路径开头的)。
切换到上级目录
要进入父目录,即在目录层次结构中向上移动一级,请输入
cd ..,然后按 Enter 键(确保在cd和点之间有一个空格)。如果你想结合目录名称使用这个命令,例如,如果你想向上移动一级,然后切换到桌面目录,输入cd ..\Desktop。在 macOS 上,请用正斜杠替换反斜杠。
浏览之前的命令
使用向上箭头键浏览之前的命令。如果你需要多次运行相同的命令,这将节省大量击键时间。如果向上滚动太远,使用向下箭头键回滚。
文件扩展名
不幸的是,在 Windows 资源管理器或 macOS Finder 中,默认隐藏文件扩展名。这可能会使处理 Python 脚本和 Anaconda Prompt 变得更加困难,因为你需要引用包括其扩展名的文件。在处理 Excel 时,显示文件扩展名还有助于你了解你正在处理的是默认的 xlsx 文件,还是启用宏的 xlsm 文件,或任何其他 Excel 文件格式。以下是如何使文件扩展名可见的方法:
Windows
打开文件资源管理器,点击“视图”选项卡。在“显示/隐藏”组下,勾选“文件扩展名”复选框。
macOS
打开 Finder,并通过按下 Command-,(Command-逗号键) 进入偏好设置。在高级选项卡上,勾选“显示所有文件扩展名”旁边的复选框。
到此为止!你现在可以启动 Anaconda Prompt 并在所需目录中运行命令。你将立即在下一节中使用这个功能,我将向你展示如何启动交互式 Python 会话。
Python REPL:交互式 Python 会话
你可以通过在 Anaconda Prompt 上运行 python 命令来启动交互式 Python 会话:
(base) C:\Users\felix>``pythonPython 3.8.5 (default, Sep 3 2020, 21:29:08) [...] :: Anaconda, Inc. on win32 Type "help", "copyright", "credits" or "license" for more information. >>>
在 macOS 终端打印的文本略有不同,但功能基本相同。本书基于 Python 3.8 — 如果你想使用更新的 Python 版本,请确保参考书籍主页上的说明。
ANACONDA PROMPT NOTATION
今后,我将以
(base)>开头来标记 Anaconda Prompt 中输入的代码行。例如,要启动交互式 Python 解释器,我将这样写:
(base)>python而在 Windows 上看起来类似于这样:
(base) C:\Users\felix>python在 macOS 上类似这样(请记住,在 macOS 上,终端即为你的 Anaconda Prompt):
(base) felix@MacBook-Pro ~ %python
让我们玩一玩吧!请注意,在交互式会话中,>>> 表示 Python 正在等待你的输入;你无需输入这些字符。跟着我输入每一行以 >>> 开头的代码,并按 Enter 键确认:
>>>3 + 47 >>>"python " * 3'python python python '
这个交互式 Python 会话也称为 Python REPL,即读取-求值-打印循环:Python 读取你的输入,计算它,并立即打印结果,同时等待你的下一个输入。还记得我在前一章提到的 Python 之禅吗?现在你可以阅读完整版本,了解 Python 的指导原则(包括微笑)。只需在键入此行后按 Enter 运行:
>>>import this
要退出 Python 会话,请键入 quit(),然后按 Enter 键。或者,在 Windows 上按 Ctrl+Z,然后按 Enter 键。在 macOS 上,只需按 Ctrl+D — 无需按 Enter。
退出 Python REPL 后,现在是玩转 Conda 和 pip 的好时机,这两个是随 Anaconda 安装提供的包管理器。
包管理器:Conda 和 pip
在上一章中,我已经介绍了 pip,Python 的包管理器:pip 负责下载、安装、更新和卸载 Python 包及其依赖关系和子依赖关系。虽然 Anaconda 可与 pip 配合使用,但它还有一种内置的替代包管理器称为 Conda。Conda 的一个优势是它不仅可以安装 Python 包,还可以安装 Python 解释器的其他版本。简而言之:包添加了额外的功能到你的 Python 安装中,这些功能不在标准库中。pandas 是这样一个包的例子,我将在第 5 章中详细介绍它。由于它已预装在 Anaconda 的 Python 安装中,你不必手动安装它。
CONDA 与 PIP
在 Anaconda 中,你应该尽可能通过 Conda 安装所有内容,并仅在 Conda 找不到这些包时使用 pip 安装。否则,Conda 可能会覆盖之前用 pip 安装的文件。
表格 2-2 提供了你将经常使用的命令的概述。这些命令必须在 Anaconda 提示符中键入,将允许你安装、更新和卸载第三方包。
表格 2-2. Conda 和 pip 命令
| 操作 | Conda | pip |
|---|---|---|
| 列出所有已安装的包 | conda list | pip freeze |
| 安装最新的包版本 | conda install package | pip install package |
| 安装特定版本的包 | conda install package=1.0.0 | pip install package==1.0.0 |
| 更新包 | conda update package | pip install --upgrade package |
| 卸载包 | conda remove package | pip uninstall package |
例如,要查看你的 Anaconda 发行版中已有哪些包,输入以下命令:
(base)>conda list
每当本书需要一个不包含在 Anaconda 安装中的包时,我都会明确指出这一点,并向您展示如何安装它。但现在安装缺少的包可能是个好主意,这样以后就不必再处理它了。让我们首先安装 plotly 和 xlutils,这些包可以通过 Conda 获取:
(base)>conda install plotly xlutils
运行此命令后,Conda 将显示它将要执行的操作,并要求您键入 y 并按回车键确认。完成后,您可以使用 pip 安装 pyxlsb 和 pytrends,因为这些包无法通过 Conda 获取:
(base)>pip install pyxlsb pytrends
不像 Conda,当你按下回车键时,pip 会立即安装包而无需确认。
包版本
许多 Python 包经常更新,有时会引入不向后兼容的更改。这可能会破坏本书中的一些示例。我会尽力跟上这些变化,并在书的主页上发布修复内容,但你也可以创建一个使用我在写本书时使用的相同版本的包的 Conda 环境。我将在下一节介绍 Conda 环境,并在附录 A 中找到关于如何创建具有特定包的 Conda 环境的详细说明。
现在你知道如何使用 Anaconda Prompt 启动 Python 解释器并安装额外的包了。在下一节中,我会解释你的 Anaconda Prompt 开头的(base)是什么意思。
Conda 环境
你可能一直在想为什么 Anaconda Prompt 在每个输入行的开头显示 (base)。这是活跃 Conda 环境的名称。Conda 环境是一个单独的“Python 世界”,具有特定版本的 Python 和一组安装了特定版本的包。为什么需要这个?当你同时在不同项目上工作时,它们会有不同的需求:一个项目可能使用 Python 3.8 和 pandas 0.25.0,而另一个项目可能使用 Python 3.9 和 pandas 1.0.0。为 pandas 0.25.0 编写的代码通常需要更改才能运行 pandas 1.0.0,所以你不能只升级你的 Python 和 pandas 版本而不修改代码。为每个项目使用 Conda 环境确保每个项目都使用正确的依赖关系。虽然 Conda 环境是特定于 Anaconda 分发的,但该概念在每个 Python 安装下以虚拟环境的名称存在。Conda 环境更强大,因为它们使处理不同版本的 Python 本身更容易,而不仅仅是包。
在阅读本书时,你无需更改你的 Conda 环境,因为我们将始终使用默认的 base 环境。但是,当你开始构建真实项目时,最好为每个项目使用一个 Conda 或虚拟环境,以避免它们的依赖关系之间可能发生的冲突。有关处理多个 Conda 环境的所有信息都在附录 A 中解释了。在那里,你还将找到有关使用我用来撰写本书的确切软件包版本创建 Conda 环境的说明。这将使你能够在未来很多年内按原样运行本书中的示例。另一个选择是关注书的主页,以获取可能需要针对较新版本的 Python 和软件包进行的更改。
解 解决了关于 Conda 环境的谜团后,现在是介绍下一个工具的时候了,这个工具在本书中会被广泛使用:Jupyter 笔记本!
Jupyter 笔记本
在上一节中,我向你展示了如何从 Anaconda 提示符启动一个交互式的 Python 会话。如果你想要一个简单的环境来测试一些简单的东西,这是很有用的。然而,对于大多数工作,你希望一个更易于使用的环境。例如,使用 Anaconda 提示符中运行的 Python REPL 很难返回到以前的命令并显示图表。幸运的是,Anaconda 带有比只有 Python 解释器更多的东西:它还包括 Jupyter 笔记本,这已经成为在数据科学环境中运行 Python 代码的最流行方式之一。Jupyter 笔记本允许你通过将可执行的 Python 代码与格式化文本、图片和图表结合到一个在浏览器中运行的交互式笔记本中来讲述一个故事。它们适合初学者,因此在你的 Python 旅程的最初阶段特别有用。然而,它们也非也非常受欢迎,用于教学、原型设计和研究,因为它们有助于实现可重复研究。
Jupyter 笔记本已经成为 Excel 的一个严肃竞争对手,因为它们覆盖了与工作簿大致相同的用例:你可以快速准备、分析和可视化数据。与 Excel 的区别在于,所有这些都是通过编写 Python 代码而不是在 Excel 中用鼠标点击来完成的。另一个优势是,Jupyter 笔记本不会混合数据和业务逻辑:Jupyter 笔记本保存了你的代码和图表,而你通常是从外部 CSV 文件或数据库中获取数据。在你的笔记本中显示 Python 代码使得你能够很容易地看到发生了什么,而在 Excel 中,公式被隐藏在单元格的值后面。Jupyter 笔记本在本地和远程服务器上运行都很容易。服务器通常比你的本地计算机性能更强,可以完全无人值守地运行你的代码,这在 Excel 中很难做到。
在本节中,我将向您展示如何运行和导航 Jupyter 笔记本的基础知识:我们将了解笔记本单元格的内容,并看看编辑模式和命令模式之间的区别。然后我们将理解为什么单元格的运行顺序很重要,然后在结束本节之前,我们将学习如何正确关闭笔记本。让我们从我们的第一个笔记本开始吧!
运行 Jupyter 笔记本
在 Anaconda Prompt 上,切换到您的伴侣存储库的目录,然后启动 Jupyter 笔记本服务器:
(base)>cd C:\Users\``username``\python-for-excel(base)>jupyter notebook
这将自动打开您的浏览器,并显示带有目录中文件的 Jupyter 仪表板。在 Jupyter 仪表板的右上角,点击 New,然后从下拉列表中选择 Python 3(见图 2-2](#filepos133397))。
图 2-2. Jupyter 仪表板
这将在新的浏览器标签页中打开您的第一个空白 Jupyter 笔记本,如图 2-3](#filepos133850) 所示。
图 2-3. 一个空白的 Jupyter 笔记本
点击 Jupyter 标志旁边的 Untitled1 可以重命名工作簿为更有意义的名称,例如 first_notebook。图 2-3 的下部显示了一个笔记本单元格——继续下一节以了解更多信息!
笔记本单元格
在 图 2-3 中,您将看到一个空的单元格,其中有一个闪烁的光标。如果光标不闪烁,请用鼠标点击单元格的右侧,即在 In [ ] 的右侧。现在重复上一节的练习:键入 3 + 4 并通过点击顶部菜单栏中的运行按钮或更容易的方式——按 Shift+Enter 运行单元格。这将运行单元格中的代码,将结果打印在单元格下方,并跳转到下一个单元格。在这种情况下,它会插入一个空单元格,因为我们目前只有一个单元格。稍微详细解释一下:当单元格计算时,它显示 In [*],当计算完成时,星号变成一个数字,例如 In [1]。在单元格下方,您将看到相应的输出,标有相同的数字:Out [1]。每次运行一个单元格,计数器都会增加一,这有助于您查看单元格执行的顺序。在接下来的内容中,我将以这种格式展示代码示例,例如之前的 REPL 示例看起来是这样的:
In``[``1``]:``3``+``4
Out[1]: 7
这种表示法允许您在笔记本单元格中键入 3 + 4 跟随而来。通过按 Shift+Enter 运行它,您将得到我展示的输出 Out[1]。如果您在支持颜色的电子格式中阅读本书,您会注意到输入单元格使用不同颜色格式化字符串、数字等,以便更容易阅读。这被称为语法高亮显示。
CELL OUTPUT
如果单元格中的最后一行返回一个值,Jupyter 笔记本会自动在
Out [ ]下打印它。但是,当你使用In单元格下打印,而不带有Out [ ]标签。本书中的代码示例按此方式进行格式化。
单元格可以具有不同的类型,其中我们感兴趣的是两种:
代码
这是默认类型。每当你想运行 Python 代码时,请使用它。
Markdown
Markdown 是一种使用标准文本字符进行格式化的语法,可用于在笔记本中包含精美格式的解释和说明。
要将单元格类型更改为 Markdown,选择单元格,然后在单元格模式下拉菜单中选择 Markdown(参见图 2-3)。我会展示一个快捷键,用于在表 2-3 中更改单元格模式。在将空单元格更改为 Markdown 单元格后,键入以下文本,其中解释了几条 Markdown 规则:
# 这是一级标题 ## 这是二级标题 你可以使你的文本 *斜体* 或 **粗体** 或 `等宽字体`。 * 这是一个项目符号 * 这是另一个项目符号
按下 Shift+Enter 后,文本将呈现为精美格式化的 HTML。此时,你的笔记本应该看起来像图 2-4 中的内容一样。Markdown 单元格还允许你包含图片、视频或公式;请参阅Jupyter 笔记本文档。
图 2-4. 运行代码单元格和 Markdown 单元格后的笔记本
现在你已经了解了代码和 Markdown 单元格类型,是时候学习更简单的在单元格之间导航的方法了:下一节介绍了编辑和命令模式以及一些键盘快捷键。
编辑模式与命令模式
在 Jupyter 笔记本中与单元格交互时,你要么处于编辑模式,要么处于命令模式:
编辑模式
点击单元格会进入编辑模式:所选单元格周围的边框变为绿色,并且单元格内的光标在闪烁。你也可以在选定单元格时按 Enter 键,而不是点击单元格。
命令模式
要切换到命令模式,请按下
Escape键;所选单元格周围的边框将变为蓝色,且不会有任何闪烁的光标。你可以在命令模式下使用的最重要的键盘快捷键如表 2-3 所示。
表 2-3. 键盘快捷键(命令模式)
| 快捷键 | 动作 |
|---|---|
| Shift+Enter | 运行单元格(在编辑模式下也适用) |
↑(向上箭头) | 向上移动单元格选择器 |
↓(向下箭头) | 向下移动单元格选择器 |
b | 在当前单元格下方插入一个新单元格 |
a | 在当前单元格上方插入一个新单元格 |
dd | 删除当前单元格(键入两次字母d) |
m | 将单元格类型更改为 Markdown |
y | 将单元格类型更改为代码 |
知道这些键盘快捷键将允许你高效地使用笔记本,而无需经常在键盘和鼠标之间切换。在下一节中,我将向你展示使用 Jupyter 笔记本时需要注意的常见陷阱:按顺序运行单元格的重要性。
运行顺序很重要
虽然笔记本易于上手和用户友好,但如果不按顺序运行单元格,也容易陷入混乱的状态。假设你有以下笔记本单元格按顺序运行:
`In
[2]:a=1```In
[3]:a``
Out[3]: 1
In``[``4``]:``a``=``2
单元格Out[3]按预期输出值1。然而,如果现在返回并再次运行In[3],你将会陷入这种情况:
In``[``2``]:``a``=``1`In
[5]:a``
Out[5]: 2
In``[``4``]:``a``=``2
Out[5]现在显示的值为2,这可能不是你在从顶部阅读笔记本时期望的结果,特别是如果In[4]单元格更远,需要向下滚动。为防止这种情况发生,我建议你不仅重新运行单个单元格,还应该重新运行其前面的所有单元格。Jupyter 笔记本为你提供了一个简单的方法,在菜单单元格 > 运行所有上面可以实现这一点。在这些警示之后,让我们看看如何正确关闭笔记本!
关闭 Jupyter 笔记本
每个笔记本在单独的 Jupyter 内核中运行。内核是运行你在笔记本单元格中键入的 Python 代码的“引擎”。每个内核都会使用操作系统的 CPU 和 RAM 资源。因此,当你关闭一个笔记本时,应同时关闭其内核,以便资源可以被其他任务再次使用,这将防止系统变慢。最简单的方法是通过文件 > 关闭并停止关闭笔记本。如果只是关闭浏览器选项卡,内核将不会自动关闭。另外,在 Jupyter 仪表板上,你可以通过运行标签关闭正在运行的笔记本来关闭笔记本。
要关闭整个 Jupyter 服务器,请单击 Jupyter 仪表板右上角的退出按钮。如果已经关闭了浏览器,你可以在运行笔记本服务器的 Anaconda 提示符中键入两次 Ctrl+C,或者完全关闭 Anaconda 提示符。
云中的 Jupyter 笔记本
Jupyter 笔记本已经变得如此流行,以至于各种云提供商都提供它们作为托管解决方案。我在这里介绍三个免费使用的服务。这些服务的优势在于它们可以即时在任何你可以访问浏览器的地方运行,而无需在本地安装任何内容。例如,你可以在阅读前三部分的同时,在平板电脑上运行示例。但是,由于第四部分需要本地安装 Excel,所以在那里无法运行。
绑定器
Binder 是 Jupyter 笔记本背后的组织 Project Jupyter 提供的服务。Binder 旨在尝试来自公共 Git 仓库的 Jupyter 笔记本 - 你不在 Binder 本身存储任何东西,因此你不需要注册或登录即可使用它。
Kaggle 笔记本
Kaggle 是一个数据科学平台。它主办数据科学竞赛,让你轻松获取大量数据集。自 2017 年起,Kaggle 已成为谷歌的一部分。
Google Colab
Google Colab(简称 Colaboratory)是 Google 的笔记本平台。不幸的是,大多数 Jupyter 笔记本的键盘快捷键不起作用,但你可以访问你的 Google Drive 上的文件,包括 Google Sheets。
在云端运行伴随仓库的 Jupyter 笔记本最简单的方法是访问其Binder URL。你将在伴随仓库的副本上工作,所以随意编辑和打破东西!
现在您已经知道如何使用 Jupyter 笔记本工作,让我们继续学习如何编写和运行标准的 Python 脚本。为此,我们将使用 Visual Studio Code,这是一个功能强大的文本编辑器,支持 Python。
Visual Studio Code
在本节中,我们将安装和配置 Visual Studio Code(VS Code),这是来自 Microsoft 的免费开源文本编辑器。在介绍其最重要的组件后,我们将以几种不同的方式编写第一个 Python 脚本并运行它。不过,首先我将解释为什么我们将使用 Jupyter 笔记本而不是运行 Python 脚本,并且为什么我选择了 VS Code。
虽然 Jupyter 笔记本非常适合互动式工作流,如研究、教学和实验,但如果你想编写不需要笔记本的可视化能力的 Python 脚本,用于生产环境,它们就不那么理想了。此外,使用 Jupyter 笔记本管理涉及多个文件和开发者的更复杂项目也很困难。在这种情况下,你应该使用适合的文本编辑器来编写和运行经典的 Python 文件。理论上,你可以使用几乎任何文本编辑器(甚至记事本也可以),但实际上,你需要一个“理解”Python 的文本编辑器。也就是说,一个至少支持以下功能的文本编辑器:
语法高亮
根据单词表示的是否是函数、字符串、数字等,编辑器会用不同的颜色标记这些词,这样更容易阅读和理解代码。
自动补全
自动补全或 IntelliSense,正如微软所称,会自动建议文本组件,从而让您更少输入,减少错误。
而且不久之后,你会希望直接从编辑器中访问其他需求:
运行代码
在文本编辑器和外部 Anaconda Prompt(即命令提示符或终端)之间来回切换以运行代码可能会很麻烦。
调试器
调试器允许你逐行步进代码,查看发生了什么。
版本控制
如果你使用 Git 进行版本控制,直接在编辑器中处理与 Git 相关的事务是有意义的,这样你就不必在两个应用程序之间来回切换。
有一系列工具可以帮助你完成所有这些工作,如往常,每个开发人员都有不同的需求和偏好。有些人可能确实想要使用一个简单的文本编辑器,配合一个外部命令提示符。而其他人可能更喜欢集成开发环境(IDE):IDE 试图将你所需的一切都放入一个工具中,这可能会使它们变得臃肿。
我选择了 VS Code 作为本书的工具,因为它在 2015 年首次发布后迅速成为开发人员中最受欢迎的代码编辑器之一:在 StackOverflow 开发者调查 2019 中,它被评为最受欢迎的开发环境。是什么让 VS Code 成为如此受欢迎的工具呢?实质上,它是一个简易文本编辑器和完整 IDE 之间的完美结合:VS Code 是一个迷你 IDE,一切都已经包含在内,但不再多余:
跨平台
VS Code 可在 Windows、macOS 和 Linux 上运行。还有云托管版本,比如GitHub Codespaces。
集成工具
VS Code 自带调试器,支持 Git 版本控制,并且有一个集成的终端,你可以将其用作 Anaconda Prompt。
扩展
其他所有内容,比如 Python 支持,都是通过单击安装的扩展添加的。
轻量级
根据你的操作系统,VS Code 安装程序的大小仅为 50–100 MB。
Visual Studio Code 与 Visual Studio 的区别
不要将 Visual Studio Code 与 Visual Studio 混淆!虽然你可以使用 Visual Studio 进行 Python 开发(它附带了 PTVS,即 Python Tools for Visual Studio),但它是一个非常庞大的安装包,传统上是用于处理 .NET 语言,比如 C#。
要想知道你是否同意我对 VS Code 的赞美,最好的方法莫过于安装它并亲自试用一番。下一节将带你开始使用!
安装和配置
从VS Code 主页下载安装程序。有关最新的安装说明,请始终参考官方文档。
Windows
双击安装程序并接受所有默认设置。然后通过 Windows 开始菜单打开 VS Code,在那里你会在 Visual Studio Code 下找到它。
macOS
双击 ZIP 文件以解压应用程序。然后将 Visual Studio Code.app 拖放到应用程序文件夹中:现在你可以从启动台启动它了。如果应用程序没有启动,请转到系统偏好设置 > 安全性与隐私 > 通用,并选择「仍然打开」。
第一次打开 VS Code 时,它看起来像图 2-5。请注意,我已将默认的深色主题切换为浅色主题,以便更容易阅读截图。
图 2-5. Visual Studio Code
活动栏
在左侧,你会看到活动栏,从上到下的图标依次为:
-
资源管理器
-
-
搜索
-
-
源代码控制
-
-
运行
-
-
扩展
状态栏
在编辑器底部,你有状态栏。一旦配置完成并编辑一个 Python 文件,你将看到 Python 解释器显示在那里。
命令面板
你可以通过 F1 或键盘快捷键 Ctrl+Shift+P(Windows)或 Command-Shift-P(macOS)显示命令面板。如果有不确定的事情,你首先应该去命令面板,因为它可以轻松访问几乎所有你可以在 VS Code 中做的事情。例如,如果你正在寻找键盘快捷键,输入
keyboard shortcuts,选择“Help: Keyboard Shortcuts Reference”并按 Enter。
VS Code 是一个开箱即用的优秀文本编辑器,但是要使其与 Python 协同工作良好,还需要进行一些配置:点击活动栏上的 Extensions 图标,搜索 Python。安装显示 Microsoft 为作者的官方 Python 扩展。安装需要一些时间,安装完成后,可能需要点击 Reload Required 按钮完成配置 — 或者你也可以完全重新启动 VS Code。根据你的平台完成配置:
Windows
打开命令面板并输入
default shell。选择“Terminal: Select Default Shell”并按 Enter。在下拉菜单中选择 Command Prompt,并确认按 Enter。这是必需的,否则 VS Code 无法正确激活 Conda 环境。
macOS
打开命令面板并输入
shell command。选择“Shell Command: Install ‘code’ command in PATH”并按 Enter。这是必需的,这样你就可以方便地从 Anaconda Prompt(即终端)启动 VS Code。
现在 VS Code 已经安装和配置好了,让我们使用它来编写并运行我们的第一个 Python 脚本!
运行 Python 脚本
尽管你可以通过 Windows 的“开始”菜单或 macOS 的“启动台”打开 VS Code,但是通过 Anaconda Prompt 打开 VS Code 通常更快,你可以通过 code 命令启动它。因此,打开一个新的 Anaconda Prompt,并使用 cd 命令切换到你想要工作的目录,然后指示 VS Code 打开当前目录(用点表示):
(base)>cd C:\Users\``username``\python-for-excel(base)>code .
通过这种方式启动 VS Code 将会导致活动栏上的资源管理器自动显示运行 code 命令时所在目录的内容。
或者,您也可以通过 File > Open Folder 打开目录(在 macOS 上为 File > Open),但在我们在第四部分开始使用 xlwings 时,这可能会在 macOS 上引起权限错误。当您在活动栏的资源管理器上悬停文件列表时,您会看到新文件按钮出现,如 图 2-6 所示。单击新文件并命名为 hello_world.py,然后按 Enter。一旦在编辑器中打开,请写入以下代码行:
print``(``"hello world!"``)
请记住,Jupyter 笔记本方便地自动打印最后一行的返回值?当您运行传统的 Python 脚本时,您需要明确告诉 Python 要打印什么,这就是为什么在这里需要使用 print 函数的原因。在状态栏中,您现在应该看到您的 Python 版本,例如,“Python 3.8.5 64-bit (conda)”。如果单击它,命令面板将打开,并允许您选择不同的 Python 解释器(如果您有多个,包括 Conda 环境)。您的设置现在应该看起来像 图 2-6 中的设置。
图 2-6. 打开 hello_world.py 的 VS Code 界面
在运行脚本之前,请确保按下 Windows 上的 Ctrl+S 或 macOS 上的 Command-S 保存它。在 Jupyter 笔记本中,我们可以简单地选择一个单元格,然后按 Shift+Enter 运行该单元格。在 VS Code 中,您可以从 Anaconda Prompt 或点击运行按钮运行代码。从 Anaconda Prompt 运行 Python 代码是您可能在服务器上运行脚本的方式,因此了解这个过程非常重要。
Anaconda Prompt
打开 Anaconda Prompt,
cd到包含脚本的目录,然后像这样运行脚本:
(base)>cd C:\Users\``username``\python-for-excel(base)>python hello_world.pyhello world!最后一行是脚本打印的输出。请注意,如果您不在与 Python 文件相同的目录中,您需要使用完整路径到您的 Python 文件:
(base)>python C:\Users\``username``\python-for-excel\hello_world.pyhello world!Anaconda Prompt 上的长文件路径
处理长文件路径的便捷方式是将文件拖放到 Anaconda Prompt 中。这将在光标所在处写入完整路径。
VS Code 中的 Anaconda Prompt
您无需切换到 Anaconda Prompt 就能使用它:VS Code 有一个集成的终端,您可以通过键盘快捷键 Ctrl+` 或通过 View > Terminal 打开。由于它在项目文件夹中打开,您无需先更改目录:
(base)>python hello_world.pyhello world!
在 VS Code 中的运行按钮
在 VS Code 中,有一种简单的方法可以运行代码,而不必使用 Anaconda Prompt:当您编辑 Python 文件时,您将在右上角看到一个绿色的播放图标——这是运行文件按钮,如 图 2-6 所示。单击它将自动在底部打开终端并在那里运行代码。
在 VS Code 中打开文件
当你在资源管理器(活动栏)中单击文件时,VS Code 有一个不同寻常的默认行为:文件会以预览模式打开,这意味着你接下来单击的文件将替换它在标签中的位置,除非你对文件进行了一些更改。如果你想关闭单击行为(这样单击将选择文件,双击将打开它),请转到“首选项” > “设置”(在 Windows 上按 Ctrl+, 或在 macOS 上按 Command-,)并将“工作台”下拉菜单下的“列表:打开模式”设置为“双击”。
到目前为止,你已经知道如何在 VS Code 中创建、编辑和运行 Python 脚本。但是 VS Code 还可以做更多:在 附录 B 中,我解释了如何使用调试器以及如何在 VS Code 中运行 Jupyter 笔记本。
替代文本编辑器和 IDE
工具是个人的选择,仅因为本书基于 Jupyter 笔记本和 VS Code,并不意味着你不应该看看其他选项。
一些流行的文本编辑器包括:
Sublime Text
Sublime 是一个快速的商业文本编辑器。
Notepad++
Notepad++ 是免费的,已经存在很长时间,但只能在 Windows 上使用。
Vim 或 Emacs
Vim 或者 Emacs 对于初学者程序员来说可能不是最佳选择,因为它们的学习曲线陡峭,但它们在专业人士中非常受欢迎。这两款免费编辑器之间的竞争是如此激烈,以至于维基百科将其描述为“编辑器之战”。
流行的 IDE 包括:
PyCharm
PyCharm 社区版是免费且功能强大的,而专业版是商业版,增加了对科学工具和 Web 开发的支持。
Spyder
Spyder 类似于 MATLAB 的 IDE,并带有一个变量资源管理器。由于它包含在 Anaconda 分发中,你可以在 Anaconda Prompt 上运行以下命令进行尝试:
(base)>spyder。JupyterLab
JupyterLab 是由 Jupyter 笔记本团队开发的基于 Web 的 IDE,当然,它也可以运行 Jupyter 笔记本。除此之外,它还试图将你在数据科学任务中所需的一切整合到一个工具中。
Wing Python IDE
Wing Python IDE 是一个存在很长时间的 IDE。有免费的简化版本和一个商业版本称为 Wing Pro。
Komodo IDE
Komodo IDE 是由 ActiveState 开发的商业 IDE,除了 Python 之外还支持许多其他语言。
PyDev
PyDev 是基于流行的 Eclipse IDE 的 Python IDE。
结论
在本章中,我向你展示了如何安装和使用我们将要使用的工具:Anaconda Prompt、Jupyter 笔记本和 VS Code。我们还在 Python REPL、Jupyter 笔记本和 VS Code 中运行了一小部分 Python 代码。
我建议你熟悉 Anaconda Prompt,因为一旦你习惯了它,它会给你带来很大的帮助。在云端使用 Jupyter 笔记本的能力也非常方便,因为它允许你在浏览器中运行本书前三部分的代码示例。
有了一个工作的开发环境,现在你已经准备好了解接下来的章节,这里你将学到足够的 Python 知识,以便能够跟上本书的其余内容。
1 32 位系统仅存在于 Windows 中,并且已经变得很少见。找出你的 Windows 版本的简单方法是在文件资源管理器中转到 C:\驱动器。如果你可以看到 Program Files 和 Program Files (x86)文件夹,那么你使用的是 64 位版本的 Windows。如果你只能看到 Program Files 文件夹,那么你使用的是 32 位系统。
第三章:开始学习 Python
安装了 Anaconda 并且 Jupyter 笔记本已经运行起来后,你就准备好开始使用 Python 了。虽然本章不会深入探讨基础之外的内容,但它仍然涵盖了很多内容。如果你刚开始学习编程,可能需要消化的内容很多。然而,大多数概念在后面的章节中通过实际示例使用后会变得更加清晰,因此如果第一次理解不完全,也不用担心。每当 Python 和 VBA 有显著区别时,我会指出来,以确保你能够顺利从 VBA 过渡到 Python,并了解显而易见的陷阱。如果你以前没有接触过 VBA,可以忽略这些部分。
我将从 Python 的基本数据类型开始,比如整数和字符串。接下来,我会介绍索引和切片,这是 Python 中的核心概念,它让你可以访问序列的特定元素。接着是像列表和字典这样可以容纳多个对象的数据结构。我会继续介绍if语句以及for和while循环,然后介绍允许你组织和结构化代码的函数和模块。最后,我会展示如何正确格式化你的 Python 代码。到目前为止,你可能已经猜到,这一章的技术性非常强。在 Jupyter 笔记本中运行示例对于使一切更加互动和有趣是个不错的主意。你可以自己输入示例,也可以使用伴随存储库中提供的笔记本来运行它们。
数据类型
Python 和其他编程语言一样,通过为它们分配不同的数据类型来区分数字、文本、布尔值等。我们经常使用的数据类型包括整数、浮点数、布尔值和字符串。在这一部分,我将逐个介绍它们,并举几个例子。然而,要理解数据类型,首先需要解释对象是什么。
对象
在 Python 中,一切都是对象,包括数字、字符串、函数以及我们在本章中将遇到的所有内容。通过提供对一组变量和函数的访问,对象可以通过使复杂的事情变得简单和直观来帮助你。因此,在任何其他事情之前,让我先介绍一些关于变量和函数的内容!
变量
在 Python 中,变量是通过使用等号将名称分配给对象来定义的。在以下示例的第一行中,名称a被分配给对象3:
In``[``1``]:``a``=``3``b``=``4``a``+``b
Out[1]: 7
对于所有对象来说,这在 Python 中都是相同的,相比之下,VBA 更简单,你可以使用等号表示数字和字符串等数据类型,使用Set语句表示像工作簿或工作表这样的对象。在 Python 中,你可以通过将变量分配给一个新对象来简单地改变变量的类型。这被称为动态类型:
In``[``2``]:``a``=``3``print``(``a``)``a``=``"three"``print``(``a``)
3 three
与 VBA 不同,Python 是区分大小写的,所以a和A是两个不同的变量。变量名必须遵循某些规则:
-
它们必须以字母或下划线开头
-
-
它们必须由字母、数字和下划线组成
在这个关于变量的简短介绍之后,让我们看看如何进行函数调用!
函数
我将在本章后面更详细地介绍函数。现在,你只需要知道如何调用内置函数,比如我们在前面代码示例中使用的print。要调用函数,你需要在函数名后加上括号,并在括号内提供参数,这几乎相当于数学表示法:
function_name``(``argument1``,``argument2``,``...``)
现在让我们看看在对象的上下文中变量和函数是如何工作的!
属性和方法
在对象的上下文中,变量被称为属性,函数被称为方法:属性允许你访问对象的数据,而方法允许你执行操作。要访问属性和方法,你可以使用点号表示法,如myobject.attribute和myobject.method()。
让我们具体化一下:如果你编写了一个汽车赛车游戏,你很可能会使用一个表示汽车的对象。car对象可能有一个speed属性,通过car.speed可以获取当前速度,并且你可以通过调用car.accelerate(10)方法来加速汽车,这将使速度增加十英里每小时。
对象的类型及其行为由类定义,因此前面的例子需要你编写一个Car类。从Car类获取一个car对象的过程称为实例化,你可以通过调用类来实例化对象,就像调用函数一样:car = Car()。我们不会在本书中编写自己的类,但如果你对其工作原理感兴趣,请查看附录 C。
在接下来的一节中,我们将使用第一个对象方法使文本字符串变为大写,并且当我们讨论本章末尾关于datetime对象时,我们将回到对象和类的主题。现在,让我们继续讨论具有数值数据类型的对象!
数值类型
数据类型int和float分别表示整数和浮点数。要找出给定对象的数据类型,使用内置的type函数:
In``[``3``]:``type``(``4``)
Out[3]: int
In``[``4``]:``type``(``4.4``)
Out[4]: float
如果你想将数字强制转换为float而不是int,只需使用尾部的小数点或float构造函数即可:
In``[``5``]:``type``(``4.``)
Out[5]: float
In``[``6``]:``float``(``4``)
Out[6]: 4.0
最后一个示例也可以反过来使用:使用 int 构造函数,你可以将 float 转换为 int。如果小数部分不为零,它将被截断:
In``[``7``]:``int``(``4.9``)
Out[7]: 4EXCEL 单元格始终存储浮点数
当你需要从 Excel 单元格中读取一个数,并将其作为整数传递给 Python 函数时,可能需要将
float转换为int。原因是,Excel 单元格中的数字始终以浮点数形式存储,即使 Excel 显示的是整数也是如此。
Python 还有一些数值类型,本书不会使用或讨论:有 decimal、fraction 和 complex 数据类型。如果浮点数不准确是个问题(参见侧边栏),可以使用 decimal 类型获得精确的结果。不过,这类情况非常罕见。作为一个经验法则:如果 Excel 的计算结果已经足够,那就使用浮点数。
浮点数不准确
默认情况下,Excel 经常显示四舍五入的数字:在单元格中输入
=1.125-1.1,你会看到0.025。虽然这可能是你期望的结果,但这不是 Excel 内部存储的内容。将显示格式更改为至少显示 16 位小数,结果将变为0.0249999999999999。这是浮点数不准确的影响:计算机生活在一个二进制世界中,即它们只能使用 0 和 1 进行计算。某些十进制分数如0.1无法作为有限的二进制浮点数存储,这解释了减法的结果。在 Python 中,你会看到相同的效果,但 Python 不会隐藏小数部分:
In``[``8``]:``1.125``-``1.1
Out[8]: 0.02499999999999991
数学运算符
使用数值计算需要使用加号或减号等数学运算符。除了幂运算符外,如果你来自 Excel 的话,不应该有任何意外:
In``[``9``]:``3``+``4``# 求和
Out[9]: 7
In``[``10``]:``3``-``4``# 减法
Out[10]: -1
In``[``11``]:``3``/``4``# 除法
Out[11]: 0.75
In``[``12``]:``3``*``4``# 乘法
Out[12]: 12
In``[``13``]:``3``**``4``# 幂运算符(Excel 使用 3⁴)
Out[13]: 81
In``[``14``]:``3``*``(``3``+``4``)``# 使用括号
Out[14]: 21注释
在前面的例子中,我用注释描述了示例的操作(例如
# 求和)。注释有助于其他人(以及你在编写代码后的几周内)理解程序中的运行情况。最好的做法是只注释那些从代码阅读中不明显的事物:如果不确定,最好不要有注释,而不是有一个过时的注释与代码相矛盾。在 Python 中,任何以井号开头的内容都是注释,运行代码时会被忽略:
In``[``15``]:``# 这是我们之前见过的示例。``# 每行注释都必须以 # 开头``3``+``4
Out[15]: 7
In``[``16``]:``3``+``4``# 这是内联注释
Out[16]: 7大多数编辑器都有快捷键可以注释或取消注释行。在 Jupyter 笔记本和 VS Code 中,Windows 下是 Ctrl+/,macOS 下是 Command-/。请注意,在 Jupyter 笔记本的 Markdown 单元格中不接受注释——如果您以
#开头,Markdown 将把它解释为标题。
现在我们已经涵盖了整数和浮点数,让我们直接转到关于布尔值的下一节!
布尔值
Python 中的布尔类型为 True 或 False,与 VBA 完全相同。然而,布尔运算符 and、or 和 not 全部小写,而 VBA 则大写显示。布尔表达式类似于 Excel 中的工作方式,但等式和不等式运算符有所不同:
In``[``17``]:``3``==``4``# Equality (Excel uses 3 = 4)
Out[17]: False
In``[``18``]:``3``!=``4``# Inequality (Excel uses 3 <> 4)
Out[18]: True
In``[``19``]:``3``<``4``# Smaller than. Use > for bigger than.
Out[19]: True
In``[``20``]:``3``<=``4``# Smaller or equal. Use >= for bigger or equal.
Out[20]: True
In``[``21``]:``# You can chain logical expressions``# In VBA, this would be: 10 < 12 And 12 < 17``# In Excel formulas, this would be: =AND(10 < 12, 12 < 17)``10``<``12``<``17
Out[21]: True
In``[``22``]:``not``True``# "not" operator
Out[22]: False
In``[``23``]:``False``and``True``# "and" operator
Out[23]: False
In``[``24``]:``False``or``True``# "or" operator
Out[24]: True
每个 Python 对象都会评估为 True 或 False。大多数对象为 True,但有一些会评估为 False,包括 None(见侧边栏),False,0 或空数据类型,例如空字符串(我将在下一节介绍字符串)。
NONE
None是一个内置常量,代表“没有值”,根据官方文档。例如,如果函数没有显式返回任何内容,它将返回None。它还是在 Excel 中表示空单元格的良好选择,我们将在 第 III 部分 和 第 IV 部分 中看到。
若要双重检查对象是否为 True 或 False,请使用 bool 构造函数:
In``[``25``]:``bool``(``2``)
Out[25]: True
In``[``26``]:``bool``(``0``)
Out[26]: False
In``[``27``]:``bool``(``"some text"``)``# We'll get to strings in a moment
Out[27]: True
In``[``28``]:``bool``(``""``)
Out[28]: False
In``[``29``]:``bool``(``None``)
Out[29]: False
有了布尔值的支持,我们还剩下一种基本数据类型:文本数据,通常称为字符串。
字符串
如果你曾经在 VBA 中使用过超过一行的字符串,并且包含变量和文字引号,你可能希望它更加简单。幸运的是,Python 在这方面表现特别出色。字符串可以用双引号(")或单引号(')表示。唯一的条件是你必须用相同类型的引号开始和结束字符串。你可以使用 + 连接字符串或 * 重复字符串。既然我已经在前一章节的 Python REPL 中展示了重复的情况,这里是使用加号的示例:
In``[``30``]:``"一个双引号字符串。 "``+``'一个单引号字符串。'
Out[30]: '一个双引号字符串。一个单引号字符串。'
根据你想要写的内容,使用单引号或双引号可以帮助你轻松地打印文字引号,而不需要转义它们。如果你仍然需要转义字符,可以在其前面加上反斜杠:
In``[``31``]:``print``(``"不要等待! "``+``'学习如何 "说" Python。'``)
Don't wait! 学会如何 "说" Python。
In``[``32``]:``print``(``"It's easy to\"``escape``\"characters with a leading\\``."``)
It's easy to "escape" characters with a leading \.
当你将字符串与变量混合使用时,通常使用格式化字符串字面量,即 f 字符串。只需在字符串前加上 f,并在大括号中使用变量:
In``[``33``]:``# 请注意 Python 如何让你方便地在一行中为多个变量赋值``#``first_adjective``,``second_adjective``=``"free"``,``"开源的"f``"Python 是{first_adjective}和{second_adjective}。"`
Out[33]: 'Python 是免费和开源的。'
正如我在本节开头提到的,字符串与其他一切一样,它们提供一些方法(即函数)来对字符串执行操作。例如,这是如何在大写和小写字母之间转换的示例:
In``[``34``]:``"PYTHON"``.``lower``()
Out[34]: 'python'
In``[``35``]:``"python"``.``upper``()
Out[35]: 'PYTHON'获取帮助
你如何知道某些对象(如字符串)提供哪些属性以及它们的方法接受什么参数?答案有点依赖于你使用的工具:在 Jupyter 笔记本中,在输入对象后面的点后按 Tab 键,例如
"python".<Tab>。这将显示一个下拉菜单,其中包含此对象提供的所有属性和方法。如果你的光标在方法中,例如在"python".upper()的括号内部,按 Shift+Tab 可以获取该函数的描述。VS Code 会自动显示此信息作为工具提示。如果在 Anaconda Prompt 上运行 Python REPL,使用dir("python")获取可用属性,并使用help("python".upper)打印upper方法的描述。除此之外,随时查阅 Python 的在线文档总是一个好主意。如果你正在寻找像 pandas 这样的第三方包的文档,建议在PyPI上搜索它们,Python 的包索引,你将找到相应主页和文档的链接。
在处理字符串时,常见的任务是选择字符串的部分:例如,你可能想从EURUSD的汇率符号中提取USD部分。接下来的部分将展示 Python 强大的索引和切片机制,使你能够精确做到这一点。
索引和切片
索引和切片让你可以访问序列的特定元素。由于字符串是字符序列,我们可以利用它们来学习它是如何工作的。在接下来的部分中,我们将遇到额外的序列,如列表和元组,它们也支持索引和切片。
索引
图 3-1 介绍了索引的概念。Python 是从零开始索引的,这意味着序列中的第一个元素由索引0引用。负索引从-1允许你从序列的末尾引用元素。
图 3-1. 从序列的开始和结尾进行索引
VBA 开发人员的常见错误陷阱
如果你来自 VBA,索引是一个常见的错误陷阱。VBA 对于大多数集合(如
Sheets(1))使用基于一的索引,但对于数组(MyArray(0))使用基于零的索引,尽管该默认值可以更改。另一个不同之处在于,VBA 使用括号进行索引,而 Python 使用方括号。
索引的语法如下:
sequence``[``index``]
因此,你可以像这样访问字符串的特定元素:
In``[``36``]:``language``=``"PYTHON"
In``[``37``]:``language``[``0``]
Out[37]: 'P'
In``[``38``]:``language``[``1``]
Out[38]: 'Y'
In``[``39``]:``language``[``-``1``]
Out[39]: 'N'
In``[``40``]:``language``[``-``2``]
Out[40]: 'O'
你经常需要提取不止一个字符——这就是切片发挥作用的地方。
切片
如果你想从序列中获取多个元素,你可以使用切片语法,其工作方式如下:
sequence``[``start``:``stop``:``step``]
Python 使用半开区间:start索引包含在内,stop索引不包含在内。如果省略start或stop参数,它将分别包括从序列开始到结尾的所有内容。step确定方向和步长:例如,2将从左到右返回每第二个元素,-3将从右到左返回每第三个元素。默认步长为一:
In``[``41``]:``language``[:``3``]``# 同language[0:3]`
Out[41]: 'PYT'
In``[``42``]:``language``[``1``:``3``]
Out[42]: 'YT'
In``[``43``]:``language``[``-``3``:]``# 同language[-3:6]`
Out[43]: 'HON'
In``[``44``]:``language``[``-``3``:``-``1``]
Out[44]: 'HO'
In``[``45``]:``language``[::``2``]``# 每第二个元素
Out[45]: 'PTO'
In``[``46``]:``language``[``-``1``:``-``4``:``-``1``]``# 负步长从右向左移动
Out[46]: 'NOH'
到目前为止,我们只看过单个索引或切片操作,但 Python 还允许您将多个索引和切片操作链接在一起。例如,如果要从最后三个字符中获取第二个字符,可以像这样做:
In``[``47``]:``language``[``-``3``:][``1``]
Out[47]: 'O'
这与language[-2]相同,因此在这种情况下,使用链接并没有太多意义,但在下一节将介绍的列表中使用索引和切片将更有意义。
数据结构
Python 提供了强大的数据结构,使得处理对象集合非常容易。在本节中,我将介绍列表、字典、元组和集合。尽管这些数据结构各有些许不同的特性,但它们都能够容纳多个对象。在 VBA 中,您可能已经使用过集合或数组来保存多个值。VBA 甚至提供了一个名为字典的数据结构,其概念上与 Python 的字典相同。但是,它仅在 Excel 的 Windows 版本中默认可用。让我们从列表开始,这是您可能会经常使用的数据结构。
列表
列表能够容纳多个不同数据类型的对象。它们非常灵活,您会经常使用它们。您可以按以下方式创建列表:
[``element1``,``element2``,``...``]
这里有两个列表,一个是 Excel 文件名,另一个是一些数字:
In``[``48``]:``file_names``=``[``"one.xlsx"``,``"two.xlsx"``,``"three.xlsx"``]``numbers``=``[``1``,``2``,``3``]
像字符串一样,列表可以使用加号轻松连接。这也表明列表可以容纳不同类型的对象:
In``[``49``]:``file_names``+``numbers
Out[49]: ['one.xlsx', 'two.xlsx', 'three.xlsx', 1, 2, 3]
由于列表和其他所有东西一样都是对象,列表也可以将其他列表作为它们的元素。我将它们称为嵌套列表:
In``[``50``]:``nested_list``=``[[``1``,``2``,``3``],``[``4``,``5``,``6``],``[``7``,``8``,``9``]]
如果你重新排列它跨越多行,你可以轻松地识别出这是一个矩阵的非常好的表示,或者一个范围的电子表格单元格。请注意,方括号隐含允许你断开行(参见侧边栏)。通过索引和切片,你可以得到想要的元素:
In``[``51``]:``cells``=``[[``1``,``2``,``3``],``[``4``,``5``,``6``],``[``7``,``8``,``9``]]
In``[``52``]:``cells``[``1``]``# 第二行
Out[52]: [4, 5, 6]
In``[``53``]:``cells``[``1``][``1``:]``# 第二行,第二和第三列
Out[53]: [5, 6]LINE CONTINUATION
有时,一行代码可能会变得如此之长,以至于你需要将其分成两行或更多行以保持代码可读性。从技术上讲,你可以使用括号或反斜杠来断开行:
In``[``54``]:``a``=``(``1``+``2``+``3``)
In``[``55``]:``a``=``1``+``2\+``3然而,Python 的风格指南更喜欢你尽可能使用隐式换行:每当你使用包含括号、方括号或大括号的表达式时,使用它们来引入换行,而无需引入额外的字符。我将在本章末尾详细介绍 Python 的风格指南。
你可以更改列表中的元素:
In``[``56``]:``users``=``[``"Linda"``,``"Brian"``]
In``[``57``]:``users``.``append``(``"Jennifer"``)``# 通常在末尾添加``users
Out[57]: ['Linda', 'Brian', 'Jennifer']
In``[``58``]:``users``.``insert``(``0``,``"Kim"``)``# 在索引 0 处插入 "Kim"``users
Out[58]: ['Kim', 'Linda', 'Brian', 'Jennifer']
要删除一个元素,可以使用 pop 或 del。虽然 pop 是一个方法,但 del 在 Python 中实现为语句:
In``[``59``]:``users``.``pop``()``# 默认移除并返回最后一个元素
Out[59]: 'Jennifer'
In``[``60``]:``users
Out[60]: ['Kim', 'Linda', 'Brian']
In``[``61``]:``del``users``[``0``]``# del 删除指定索引处的元素
其他一些你可以使用列表做的有用的事情是:
In``[``62``]:``len``(``users``)``# 长度
Out[62]: 2
In``[``63``]:``"Linda"``in``users``# 检查 users 是否包含 "Linda"
Out[63]: True
In``[``64``]:``print``(``sorted``(``users``))``# 返回一个新的排序列表``print``(``users``)``# 原始列表不变
['Brian', 'Linda'] ['Linda', 'Brian']
In``[``65``]:``users``.``sort``()``# 对原始列表进行排序``users
Out[65]: ['Brian', 'Linda']
请注意,你也可以在字符串中使用 len 和 in:
In``[``66``]:``len``(``"Python"``)
Out[66]: 6
In``[``67``]:``"free"``in``"Python is free and open source."
Out[67]: True
要访问列表中的元素,你可以按它们的位置或索引引用它们——这并不总是实际可行的。下一节将讨论的字典允许你通过键(通常是名称)访问元素。
字典
字典将键映射到值。您将经常遇到键/值组合。创建字典的最简单方法如下:
{``key1``:``value1``,``key2``:``value2``,``...``}
虽然列表允许您按索引,即位置,访问元素,但字典允许您按键访问元素。与索引一样,键是通过方括号访问的。以下代码示例将使用货币对(键)映射到汇率(值):
In``[``68``]:``exchange_rates``=``{``"EURUSD"``:``1.1152``,``"GBPUSD"``:``1.2454``,``"AUDUSD"``:``0.6161``}
In``[``69``]:``exchange_rates``[``"EURUSD"``]``# 访问 EURUSD 汇率
Out[69]: 1.1152
下面的示例向您展示如何更改现有值并添加新的键值对:
In``[``70``]:``exchange_rates``[``"EURUSD"``]``=``1.2``# 更改现有值``exchange_rates
Out[70]: {'EURUSD': 1.2, 'GBPUSD': 1.2454, 'AUDUSD': 0.6161}
In``[``71``]:``exchange_rates``[``"CADUSD"``]``=``0.714``# 添加一个新的键值对``exchange_rates
Out[71]: {'EURUSD': 1.2, 'GBPUSD': 1.2454, 'AUDUSD': 0.6161, 'CADUSD': 0.714}
合并两个或更多字典的最简单方法是将它们解压到一个新字典中。您通过使用两个前导星号来解压字典。如果第二个字典包含来自第一个字典的键,则将从第一个字典中覆盖值。您可以通过查看GBPUSD汇率来看到这种情况发生:
In``[``72``]:``{``**``exchange_rates``,``**``{``"SGDUSD"``:``0.7004``,``"GBPUSD"``:``1.2222``}}
Out[72]: {'EURUSD': 1.2, 'GBPUSD': 1.2222, 'AUDUSD': 0.6161, 'CADUSD': 0.714, 'SGDUSD': 0.7004}
Python 3.9 引入了管道字符作为字典的专用合并操作符,这使得您可以简化先前的表达式为:
exchange_rates``|``{``"SGDUSD"``:``0.7004``,``"GBPUSD"``:``1.2222``}
许多对象都可以作为键;以下是一个带整数的示例:
In``[``73``]:``currencies``=``{``1``:``"EUR"``,``2``:``"USD"``,``3``:``"AUD"``}
In``[``74``]:``currencies``[``1``]
Out[74]: 'EUR'
通过使用get方法,字典允许您在键不存在的情况下使用默认值:
In``[``75``]:``# currencies[100]会引发异常。您可以使用任何其他不存在的键。``# 代替 100,也是一样的。``currencies``.``get``(``100``,``"N/A"``)
Out[75]: 'N/A'
在 VBA 中,字典通常可以用作Case语句的替代。前面的示例可以在 VBA 中这样写:
Select``Case``x``Case``1``Debug``.``Print``"EUR"``Case``2``Debug``.``Print``"USD"``Case``3``Debug``.``Print``"AUD"``Case``Else``Debug``.``Print``"N/A"``End``Select
现在您知道如何使用字典了,让我们继续下一个数据结构:元组。它们与列表类似,但有一个重大区别,我们将在下一节中看到。
元组
元组与列表类似,区别在于它们是不可变的:一旦创建,它们的元素就不能更改。虽然您通常可以互换使用元组和列表,但元组是在整个程序中从不更改的集合的明显选择。通过用逗号分隔值来创建元组:
mytuple``=``element1``,``element2``,``...
使用括号通常使其更易读:
In``[``76``]:``currencies``=``(``"EUR"``,``"GBP"``,``"AUD"``)
元组允许您以与列表相同的方式访问元素,但不允许更改元素。相反,连接元组将在幕后创建一个新元组,然后将您的变量绑定到此新元组:
In``[``77``]:``currencies``[``0``]``# 访问第一个元素
Out[77]: 'EUR'
In``[``78``]:``# 连接元组将返回一个新的元组。``currencies``+``(``"SGD"``,)
Out[78]: ('EUR', 'GBP', 'AUD', 'SGD')
我在附录 C 中详细解释了可变对象与不可变对象的区别,但现在让我们来看看本节的最后一个数据结构:集合。
集合
集合是没有重复元素的集合。虽然您可以用它们进行集合理论运算,在实践中它们经常帮助您获取列表或元组的唯一值。通过使用大括号来创建集合:
{``element1``,``element2``,``...``}
要获取列表或元组中的唯一对象,请使用set构造函数,如下所示:
In``[``79``]:``set``([``"USD"``,``"USD"``,``"SGD"``,``"EUR"``,``"USD"``,``"EUR"``])
Out[79]: {'EUR', 'SGD', 'USD'}
除此之外,您还可以应用集合理论操作,如交集和并集:
In``[``80``]:``portfolio1``=``{``"USD"``,``"EUR"``,``"SGD"``,``"CHF"``}``portfolio2``=``{``"EUR"``,``"SGD"``,``"CAD"``}
In``[``81``]:``# 等同于 portfolio2.union(portfolio1)``portfolio1``.``union``(``portfolio2``)
Out[81]: {'CAD', 'CHF', 'EUR', 'SGD', 'USD'}
In``[``82``]:``# 等同于 portfolio2.intersection(portfolio1)``portfolio1``.``intersection``(``portfolio2``)
Out[82]: {'EUR', 'SGD'}
要获取有关集合操作的完整概述,请参阅官方文档。在继续之前,让我们快速复习我们刚刚在表 3-1 中见过的四种数据结构。它展示了每种数据结构的一个示例,采用了我在前面段落中使用的符号,即所谓的字面量。此外,我还列出了它们的构造函数,这些构造函数提供了一种将一种数据结构转换为另一种的替代方法。例如,要将元组转换为列表,请执行以下操作:
In``[``83``]:``currencies``=``"USD"``,``"EUR"``,``"CHF"``currencies
Out[83]: ('USD', 'EUR', 'CHF')
In``[``84``]:``list``(``currencies``)
Out[84]: ['USD', 'EUR', 'CHF']
表格 3-1. 数据结构
| 数据结构 | 字面量 | 构造函数 |
|---|---|---|
| 列表 | [1, 2, 3] | list((1, 2, 3)) |
| 字典 | {"a": 1, "b": 2} | dict(a=1, b=2) |
| Tuple | (1, 2, 3) | tuple([1, 2, 3]) |
| Set | {1, 2, 3} | set((1, 2, 3)) |
到目前为止,你已经了解了所有重要的数据类型,包括基本类型如浮点数和字符串,以及数据结构如列表和字典。在下一节中,我们将继续学习控制流。
控制流
本节将介绍if语句以及for和while循环。if语句允许你仅在满足条件时执行某些代码行,而for和while循环将重复执行一段代码。在本节末尾,我还将介绍列表推导式,这是构建列表的一种方式,可以作为for循环的替代方式。我将从代码块的定义开始本节,这也是需要介绍 Python 最显著的特殊之一:显著的空白。
代码块和pass语句
代码块定义了你源代码中用于特殊用途的部分。例如,你可以使用代码块来定义程序循环的行或者它构成函数的定义。在 Python 中,你通过缩进而不是使用关键字(如 VBA 中)或者花括号(大多数其他语言中)来定义代码块。这被称为显著的空白。Python 社区已经约定使用四个空格作为缩进,但你通常会通过按 Tab 键来输入它们:Jupyter 笔记本和 VS Code 会自动将你的 Tab 键转换为四个空格。让我演示一下如何使用if语句来正式定义代码块:
if``condition``:``pass``# 什么都不做
代码块前面的行总是以冒号结束。当你不再缩进行时,代码块结束。如果你想创建一个什么都不做的虚拟代码块,你需要使用pass语句。在 VBA 中,这对应以下内容:
If``condition``Then``' 什么都不做``End``If
现在你知道如何定义代码块了,让我们在下一节开始使用它们,我将在那里适当地介绍if语句。
if语句和条件表达式
要介绍if语句,让我来重现“可读性和可维护性”中的示例,在第一章中,但这次是用 Python:
In``[``85``]:``i``=``20``if``i``<``5``:``print``(``"i is smaller than 5"``)``elif``i``<=``10``:``print``(``"i is between 5 and 10"``)``else``:``print``(``"i is bigger than 10"``)
i is bigger than 10
如果你想做和我们在第一章里做的一样,即缩进elif和else语句,你会得到SyntaxError。Python 不允许你的代码缩进与逻辑不同。与 VBA 不同的是,Python 的关键词是小写的,而不是 VBA 中的ElseIf,Python 使用elif。if语句是判断一个程序员是否新手或者已经采用 Python 风格的简单方法:在 Python 中,一个简单的if语句不需要括号,而测试一个值是否为True,你不需要显式地这样做。这就是我的意思:
In``[``86``]:``is_important``=``True``if``is_important``:``print``(``"这很重要。"``)``else``:``print``(``"这不重要。"``)
这很重要。
要检查类似列表这样的序列是否为空,使用相同的方法:
In``[``87``]:``values``=``[]``如果``values``:``print``(``f``"提供了以下数值:{values}"``)``else``:``print``(``"未提供数值。"``)
未提供数值。
来自其他语言的程序员通常会写类似if (is_important == True)或者if len(values) > 0的代码。
条件表达式,也称为三元运算符,允许你在简单的if/else语句中使用更紧凑的风格:
In``[``88``]:``is_important``=``False``print``(``"重要"``)``if``is_important``else``print``(``"不重要"``)
不重要
有了if语句和条件表达式,让我们在下一节转向for和while循环。
for和while循环
如果你需要重复做一些像打印十个不同变量的值这样的事情,最好不要把打印语句复制/粘贴十次。而是使用for循环为你做这些工作。for循环遍历序列的项目,比如列表、元组或者字符串(记住,字符串是字符序列)。作为一个介绍性的例子,让我们创建一个for循环,它将currencies列表的每个元素赋值给变量currency,然后逐个打印出来,直到列表中没有更多的元素:
In``[``89``]:``currencies``=``[``"USD"``,``"HKD"``,``"AUD"``]``for``currency``in``currencies``:``print``(``currency``)
USD HKD AUD
顺便提一下,VBA 的For Each语句与 Python 的for循环工作方式相似。前面的例子在 VBA 中可以这样写:
Dim``currencies``As``Variant``Dim``curr``As``Variant``'currency is a reserved word in VBA``currencies``=``Array``(``"USD"``,``"HKD"``,``"AUD"``)
For``Each``curr``In``currencies``Debug``.``Print``curr``Next
在 Python 中,如果你需要在 for 循环中一个计数变量,range 或 enumerate 内置函数可以帮助你。让我们先看看 range,它提供一系列数字:你可以通过提供单个 stop 参数或提供 start 和 stop 参数(带有可选的 step 参数)来调用它。与切片一样,start 包含在内,stop 是排外的,step 决定步长,其中 1 是默认值:
range``(``stop``)``range``(``start``,``stop``,``step``)
range 评估是懒惰的,这意味着如果不明确要求,你看不到它生成的序列:
In``[``90``]:``range``(``5``)
Out[90]: range(0, 5)
将 range 转换为列表可以解决这个问题:
In``[``91``]:``list``(``range``(``5``))``# stop argument
Out[91]: [0, 1, 2, 3, 4]
In``[``92``]:``list``(``range``(``2``,``5``,``2``))``# start, stop, step arguments
Out[92]: [2, 4]
大多数情况下,不需要用 list 包装 range:
In``[``93``]:``for``i``in``range``(``3``):``print``(``i``)
0 1 2
如果你在遍历序列时需要一个计数器变量,请使用 enumerate。它返回一个 (索引, 元素) 元组序列。默认情况下,索引从零开始,逐一递增。你可以像这样在循环中使用 enumerate:
In``[``94``]:``for``i``,``currency``in``enumerate``(``currencies``):``print``(``i``,``currency``)
0 美元 1 港币 2 澳大利亚元
遍历元组和集合的方式与列表相同。当你遍历字典时,Python 会遍历键:
In``[``95``]:``exchange_rates``=``{``"EURUSD"``:``1.1152``,``"GBPUSD"``:``1.2454``,``"AUDUSD"``:``0.6161``}``for``currency_pair``in``exchange_rates``:``print``(``currency_pair``)
EURUSD GBPUSD AUDUSD
使用 items 方法,你可以同时获取键和值作为元组:
In``[``96``]:``for``currency_pair``,``exchange_rate``in``exchange_rates``.``items``():``print``(``currency_pair``,``exchange_rate``)
EURUSD 1.1152 GBPUSD 1.2454 AUDUSD 0.6161
要退出循环,使用 break 语句:
In``[``97``]:``for``i``in``range``(``15``):``if``i``==``2``:``break``else``:``print``(``i``)
0 1
你可以使用 continue 语句跳过循环的剩余部分,这意味着执行将继续新的循环和下一个元素:
In``[``98``]:``for``i``in``range``(``4``):``if``i``==``2``:``continue``else``:``print``(``i``)
0 1 3
在比较 VBA 中的 for 循环与 Python 时,有一个微妙的区别:在 VBA 中,计数器变量在完成循环后会超出你的上限:
For``i``=``1``To``3``Debug``.``Print``i``Next``i``Debug``.``Print``i
这会打印:
1 2 3 4
在 Python 中,它的行为就像你可能期望的那样:
In``[``99``]:``for``i``in``range``(``1``,``4``):``print``(``i``)``print``(``i``)
1 2 3 3
要遍历序列而不是使用 for 循环,你也可以使用 while 循环在满足某个条件时运行循环:
In``[``100``]:``n``=``0``while``n``<=``2``:``print``(``n``)``n``+=``1
0 1 2增强赋值
在上一个例子中,我使用了增强赋值符号:
n += 1。这与您写n = n + 1是一样的。它也适用于我之前介绍的所有其他数学运算符;例如,减法您可以写n -= 1。
经常需要收集列表中的某些元素进行进一步处理。在这种情况下,Python 提供了一种替代循环的方式:列表、字典和集合推导式。
列表、字典和集合推导式
列表、字典和集合推导式技术上是创建相应数据结构的一种方式,但它们经常替代for循环,这就是我在这里介绍它们的原因。假设在以下 USD 货币对的列表中,您想挑选出 USD 作为第二个货币报价的那些货币。您可以写以下for循环:
In``[``101``]:``currency_pairs``=``[``"USDJPY"``,``"USDGBP"``,``"USDCHF"``,``"USDCAD"``,``"AUDUSD"``,``"NZDUSD"``]
In``[``102``]:``usd_quote``=``[]``for``pair``in``currency_pairs``:``if``pair``[``3``:]``==``"USD"``:``usd_quote``.``append``(``pair``[:``3``])``usd_quote
Out[102]: ['AUD', 'NZD']
使用列表推导式通常更容易编写。列表推导式是创建列表的简洁方式。您可以从这个示例中获取其语法,它与前面的for循环做的事情是一样的:
In``[``103``]:``[``pair``[:``3``]``for``pair``in``currency_pairs``if``pair``[``3``:]``==``"USD"``]
Out[103]: ['AUD', 'NZD']
如果没有任何条件需要满足,可以简单地省略if部分。例如,要颠倒所有货币对,使第一个货币变成第二个货币,反之亦然,可以这样做:
In``[``104``]:``[``pair``[``3``:]``+``pair``[:``3``]``for``pair``in``currency_pairs``]
Out[104]: ['JPYUSD', 'GBPUSD', 'CHFUSD', 'CADUSD', 'USDAUD', 'USDNZD']
对于字典,还有字典推导式:
In``[``105``]:``exchange_rates``=``{``"EURUSD"``:``1.1152``,``"GBPUSD"``:``1.2454``,``"AUDUSD"``:``0.6161``}``{``k``:``v``*``100``for``(``k``,``v``)``in``exchange_rates``.``items``()}
Out[105]: {'EURUSD': 111.52, 'GBPUSD': 124.54, 'AUDUSD': 61.61}
而对于集合,有集合推导式:
In``[``106``]:``{``s``+``"USD"``for``s``in``[``"EUR"``,``"GBP"``,``"EUR"``,``"HKD"``,``"HKD"``]}
Out[106]: {'EURUSD', 'GBPUSD', 'HKDUSD'}
到目前为止,您已经能够编写简单的脚本,因为您已经了解了大多数 Python 的基本构建块。在下一节中,当您的脚本开始变得更大时,您将学习如何组织您的代码以保持可维护性。
代码组织
在本节中,我们将了解如何将代码组织成可维护的结构:我将首先介绍你通常需要的所有函数细节,然后展示如何将代码分割成不同的 Python 模块。关于模块的知识将使我们能够在本节结束时研究标准库中的datetime模块。
函数
即使你只会在 Python 中写简单脚本,你仍然会经常编写函数:它们是每种编程语言中最重要的结构之一,允许你从程序的任何地方重用相同的代码行。在我们看如何调用它之前,我们将在本节开始时定义一个函数!
定义函数
要在 Python 中编写自己的函数,你必须使用关键字def,它代表函数定义。与 VBA 不同,Python 不区分函数和子程序。在 Python 中,子程序的等价物就是一个不返回任何东西的函数。Python 中的函数遵循代码块的语法,即你用冒号结束第一行,然后缩进函数体:
def``function_name``(``required_argument``,``optional_argument``=``default_value``,``...``):``return``value1``,``value2``,``...
必需参数
必需参数没有默认值。多个参数用逗号分隔。
可选参数
通过提供默认值来使参数可选。如果没有有意义的默认值,通常使用
None来使参数可选。
返回值
return语句定义函数返回的值。如果省略它,函数将自动返回None。Python 方便地允许你返回多个用逗号分隔的值。
为了能够操作一个函数,让我们定义一个能够将温度从华氏度或开尔文转换为摄氏度的函数:
In``[``107``]:``def``convert_to_celsius``(``degrees``,``source``=``"fahrenheit"``):``if``source``.``lower``()``==``"fahrenheit"``:``return``(``degrees``-``32``)``*``(``5``/``9``)``elif``source``.``lower``()``==``"kelvin"``:``return``degrees``-``273.15``else``:``return``f``"不知道如何从 {source} 转换"
我使用了字符串方法lower,它将提供的字符串转换为小写。这允许我们接受带有任何大小写的source字符串,而比较仍然有效。有了convert_to_celsius函数的定义,让我们看看如何调用它!
调用函数
正如本章开头简要提到的,通过在函数名后面添加括号并包围函数参数来调用函数:
value1``,``value2``,``...``=``function_name``(``positional_arg``,``arg_name``=``value``,``...``)
位置参数
如果你把一个值作为位置参数(
positional_arg)提供,这些值将根据它们在函数定义中的位置进行匹配。
关键字参数
通过以
arg_name=value的形式提供参数,您提供了一个关键字参数。这样做的好处是可以任意顺序提供参数。对于读者来说更加明确,有助于理解。例如,如果函数定义为f(a, b),您可以像这样调用函数:f(b=1, a=2)。这个概念在 VBA 中也存在,您可以通过像这样调用函数来使用关键字参数:f(b:=1, a:=1)。
让我们玩转convert_to_celsius函数,看看实际操作中的运作方式:
In``[``108``]:``convert_to_celsius``(``100``,``"fahrenheit"``)``# 位置参数
Out[108]: 37.77777777777778
In``[``109``]:``convert_to_celsius``(``50``)``# 将使用默认来源(fahrenheit)
Out[109]: 10.0
In``[``110``]:``convert_to_celsius``(``source``=``"kelvin"``,``degrees``=``0``)``# 关键字参数
Out[110]: -273.15
现在您已经知道如何定义和调用函数,让我们看看如何借助模块组织它们。
模块和导入语句
当您为更大的项目编写代码时,最终必须将其拆分为不同的文件,以便能够将其组织成可维护的结构。正如我们在前一章中已经看到的,Python 文件的扩展名为.py,通常将主文件称为脚本。如果您现在希望您的主脚本能够访问其他文件中的功能,首先需要导入该功能。在此上下文中,Python 源文件称为模块。要更好地了解其工作原理以及不同的导入选项,请查看伴随存储库中的文件 temperature.py,并使用 VS Code 打开它(示例 3-1)。如果您需要再次了解如何在 VS Code 中打开文件,请再次查看第二章。
示例 3-1. temperature.py
TEMPERATURE_SCALES``=``(``"fahrenheit"``,``"kelvin"``,``"celsius"``)``def``convert_to_celsius``(``degrees``,``source``=``"fahrenheit"``):``if``source``.``lower``()``==``"fahrenheit"``:``return``(``degrees``-``32``)``*``(``5``/``9``)``elif``source``.``lower``()``==``"kelvin"``:``return``degrees``-``273.15``else``:``return``f``"无法从 {source} 转换"``print``(``"这是温度模块。"``)
要能够从您的 Jupyter 笔记本中导入temperature模块,您需要确保 Jupyter 笔记本和temperature模块在同一个目录中——就像伴随存储库的情况一样。要导入,只需使用模块的名称,不需要.py扩展名。运行import语句后,您将能够通过点符号访问该 Python 模块中的所有对象。例如,使用temperature.convert_to_celsius()执行您的转换操作:
`In
[111]:import``temperature
这是温度模块。
In``[``112``]:``temperature``.``TEMPERATURE_SCALES
Out[112]: ('fahrenheit', 'kelvin', 'celsius')
In``[``113``]:temperature``.``convert_to_celsius``(``120``,``"fahrenheit"``)
Out[113]:48.88888888888889
请注意,我在TEMPERATURE_SCALES中使用了大写字母来表示它是一个常量——我将在本章末尾进一步讨论这一点。当你执行带有import temperature的单元格时,Python 将从上到下运行 temperature.py 文件。你可以很容易地看到这一点,因为导入模块将触发 temperature.py 底部的打印函数。
模块只被导入一次
如果你再次运行
import temperature单元格,你会注意到它不再打印任何东西。这是因为 Python 模块在会话中只被导入一次。如果你更改了导入模块中的代码,你需要重新启动 Python 解释器才能应用所有更改,即在 Jupyter 笔记本中,你需要点击 Kernel > Restart。
实际上,通常你不会在模块中打印任何东西。这只是为了向你展示多次导入模块的效果。通常情况下,你会在模块中放置函数和类(有关类的更多信息,请参见附录 C)。如果你不想每次使用temperature模块中的对象时都输入temperature,可以像这样更改import语句:
In``[``114``]:import``temperature``as``tp
In``[``115``]:tp``.``TEMPERATURE_SCALES
Out[115]:(fahrenheit,kelvin,celsius)`
给你的模块分配一个短的别名tp可以使其在使用时更容易,但仍然清楚对象来自哪里。许多第三方包在使用别名时建议使用特定的约定。例如,pandas 使用import pandas as pd。还有一种从另一个模块导入对象的选项:
In``[``116``]:from``temperature``import``TEMPERATURE_SCALES,``convert_to_celsius`
In``[``117``]:TEMPERATURE_SCALES
Out[117]:(fahrenheit,kelvin,celsius)`
__PYCACHE__文件夹当你导入
temperature模块时,你会发现 Python 创建了一个名为__pycache__的文件夹,其中的文件扩展名为.pyc。这些是 Python 解释器在导入模块时创建的字节编译文件。对于我们的目的,我们可以简单地忽略这个文件夹,因为这是 Python 运行代码的技术细节。
当使用from x import y语法时,你仅导入特定的对象。通过这样做,你将它们直接导入到你主脚本的命名空间中:也就是说,如果没有查看import语句,你无法知道导入的对象是在你当前的 Python 脚本还是 Jupyter 笔记本中定义的,还是来自另一个模块。这可能会导致冲突:如果你的主脚本有一个名为convert_to_celsius的函数,它会覆盖从temperature模块导入的函数。然而,如果你使用前面两种方法之一,你的本地函数和导入模块中的函数可以像convert_to_celsius和temperature.convert_to_celsius这样共存。
不要将脚本命名为现有的包名
命名 Python 文件与现有的 Python 包或模块相同是常见的错误源。如果你创建一个文件来测试一些 pandas 功能,请不要将该文件命名为 pandas.py,因为这可能会导致冲突。
现在你了解了导入机制的工作原理,让我们立即使用它来导入datetime模块!这也将使你能够学习关于对象和类的一些更多内容。
datetime 类
在 Excel 中,处理日期和时间是一种常见的操作,但它带有一些限制:例如,Excel 的时间单元格格式不支持比毫秒更小的单位,时间区域也完全不支持。在 Excel 中,日期和时间存储为称为日期序列号的简单浮点数。然后,Excel 单元格被格式化为显示日期和/或时间。例如,1900 年 1 月 1 日的日期序列号为 1,这意味着这也是你可以在 Excel 中使用的最早日期。时间被转换为浮点数的小数部分,例如,01/01/1900 10:10:00被表示为1.4236111111。
在 Python 中,要处理日期和时间,你需要导入标准库中的datetime模块。datetime模块包含同名的类,允许我们创建datetime对象。由于模块和类的名称相同可能会导致混淆,我将在本书中使用以下导入约定:import datetime as dt。这样可以很容易区分模块(dt)和类(datetime)。
到目前为止,我们大部分时间都在使用字面值来创建列表或字典等对象。字面值是指 Python 识别为特定对象类型的语法—例如列表的情况下,这可能是像[1, 2, 3]这样的东西。然而,大多数对象必须通过调用它们的类来创建:这个过程称为实例化,因此对象也称为类实例。调用一个类的方式与调用函数的方式相同,即你需要在类名后加上括号,并以与我们在函数中所做的方式相同的方式提供参数。要实例化一个datetime对象,你需要像这样调用类:
import``datetime``as``dt``dt``.``datetime``(``year``,``month``,``day``,``hour``,``minute``,``second``,``microsecond``,``timezone``)
让我们通过几个例子看看如何在 Python 中处理 datetime 对象。为了本次介绍的目的,让我们忽略时区并使用没有时区信息的 datetime 对象工作:
In``[``118``]:``# 将 datetime 模块导入为 "dt"``import``datetime``as``dt
In``[``119``]:``# 实例化一个名为 "timestamp" 的 datetime 对象``timestamp``=``dt``.``datetime``(``2020``,``1``,``31``,``14``,``30``)``timestamp
Out[119]: datetime.datetime(2020, 1, 31, 14, 30)
In``[``120``]:``# Datetime objects offer various attributes, e.g., to get the day``timestamp``.``day
Out[120]: 31
In``[``121``]:``# 两个 datetime 对象的差返回一个 timedelta 对象``timestamp``-``dt``.``datetime``(``2020``,``1``,``14``,``12``,``0``)
Out[121]: datetime.timedelta(days=17, seconds=9000)
In``[``122``]:``# 相应地,您还可以使用 timedelta 对象``timestamp``+``dt``.``timedelta``(``days``=``1``,``hours``=``4``,``minutes``=``11``)
Out[122]: datetime.datetime(2020, 2, 1, 18, 41)
要将 datetime 对象格式化为字符串,请使用 strftime 方法;要解析字符串并将其转换为 datetime 对象,请使用 strptime 函数(您可以在 datetime 文档 中找到接受的格式代码的概述):
In``[``123``]:``# 以特定方式格式化 datetime 对象``# 您也可以使用 f-string:f"{timestamp:%d/%m/%Y %H:%M}"``timestamp``.``strftime``(``"``%d``/``%m``/``%Y``%H``:``%M``"``)
Out[123]: '31/01/2020 14:30'
In``[``124``]:``# 将字符串解析为 datetime 对象``dt``.``datetime``.``strptime``(``"12.1.2020"``,``"``%d``.``%m``.``%Y``"``)
Out[124]: datetime.datetime(2020, 1, 12, 0, 0)
在这个对 datetime 模块的简短介绍之后,让我们继续本章的最后一个主题,即如何正确格式化代码。
PEP 8:Python 代码风格指南
也许你一直在想,为什么有时我会用带有下划线或全大写的变量名。这一节将通过介绍 Python 的官方风格指南来解释我的格式选择。Python 使用所谓的 Python Enhancement Proposals(PEP)来讨论引入新语言特性。其中之一,Python 代码风格指南通常用其编号来指代:PEP 8. PEP 8 是 Python 社区的一套风格建议;如果所有在同一代码上工作的人都遵循相同的风格指南,代码会变得更加可读。在开源世界尤为重要,因为许多程序员在同一项目上工作,通常彼此并不认识。Example 3-2 展示了一个简短的 Python 文件,介绍了最重要的惯例。
Example 3-2. pep8_sample.py
"""这个脚本展示了一些 PEP 8 规则。
"""``import``datetime``as``dtTEMPERATURE_SCALES``=``(``"fahrenheit"``,``"kelvin"``,``"celsius"``)class``TemperatureConverter``:pass``# 目前什么也不做 def``convert_to_celsius``(``degrees``,``source``=``"fahrenheit"``):"""这个函数将华氏度或开尔文转换为摄氏度。
"""``if``source``.``lower``()``==``"fahrenheit"``:return``(``degrees``-``32``)``*``(``5``/``9``)elif``source``.``lower``()``==``"kelvin"``:``return``degrees``-``273.15``else``:``return``f``"不知道如何从 {source} 转换"celsius=convert_to_celsius(44,source="fahrenheit")``non_celsius_scales=TEMPERATURE_SCALES[:-1]`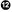`print("当前时间: "+dt.datetime.now().isoformat())print(f"摄氏度温度为: {celsius}")`
使用顶部的文档字符串解释脚本/模块的功能。文档字符串是一种特殊类型的字符串,用三个引号括起来。除了作为代码文档的字符串外,文档字符串还使得可以轻松地编写多行字符串,特别是在文本包含大量双引号或单引号时,不需要转义它们。如果您的文本包含大量的多行 SQL 查询,文档字符串非常有用,正如我们将在 第十一章 中看到的。
所有导入语句都位于文件顶部,每行一个。首先列出标准库的导入,然后是第三方包的导入,最后是自己模块的导入。本示例仅使用标准库。
使用大写字母和下划线表示常量。每行最大长度为 79 个字符。如果可能,利用括号、方括号或大括号进行隐式换行。
将类和函数与代码其余部分用两个空行分开。
尽管像
datetime这样的许多类都是小写的,但您自己的类应使用CapitalizedWords作为名称。有关类的更多信息,请参阅 附录 C。
行内注释应与代码至少用两个空格分开。代码块应缩进四个空格。
函数和函数参数应使用小写名称,并在提高可读性时使用下划线。不要在参数名和其默认值之间使用空格。
函数的文档字符串还应列出并解释函数参数。为了使示例简短,我没有在此处执行此操作,但在伴随存储库中包含的 excel.py 文件中,您将找到完整的文档字符串,并且我们将在第八章中遇到它。
在冒号周围不要使用空格。
在数学运算符周围使用空格。如果使用不同优先级的运算符,可以考虑只在优先级最低的运算符周围添加空格。因为本例中的乘法优先级最低,所以我已经在其周围添加了空格。
对变量使用小写名称。如果使用下划线可以提高可读性,则使用下划线。在赋值变量名时,使用等号周围的空格。但是,在调用带有关键字参数的函数时,不要在等号周围使用空格。
在索引和切片时,不要在方括号周围使用空格。
这是对 PEP 8 的简化总结,因此当你开始更认真地学习 Python 时,建议查看原始的 PEP 8。PEP 8 明确指出它是一种推荐,并且你自己的风格指南将优先。毕竟,一致性是最重要的因素。如果你对其他公开可用的指南感兴趣,可以看一下 Google 的 Python 风格指南,它与 PEP 8 非常接近。在实践中,大多数 Python 程序员宽松遵守 PEP 8,而忽略最大行长度 79 字符可能是最常见的错误。
由于在编写代码时可能难以正确格式化代码,因此可以自动检查代码风格。下一节将向您展示如何在 VS Code 中进行此操作。
PEP 8 和 VS Code
当使用 VS Code 时,确保你的代码符合 PEP 8 的一种简单方法是使用代码检查工具(linter)。代码检查工具会检查你的源代码是否存在语法和风格错误。在命令面板中启动(Windows 上为 Ctrl+Shift+P,macOS 上为 Command-Shift-P),搜索 Python: Select Linter。一个常用的选项是 flake8,这是 Anaconda 预装的一个包。如果启用了代码检查工具,在保存文件时,VS Code 会用波浪线下划线标出问题。将鼠标悬停在波浪线下划线上时,会显示工具提示来解释问题。你可以通过在命令面板中搜索 “Python: Enable Linting”,选择 “Disable Linting” 来关闭代码检查工具。如果你愿意,也可以在 Anaconda Prompt 上运行 flake8 命令以获取打印的报告(该命令仅在违反 PEP 8 规范时才会打印输出,因此在 pep8_sample.py 上运行时除非引入违规,否则不会打印任何内容):
(base)>cd C:\Users\``username``\python-for-excel(base)>flake8 pep8_sample.py
Python 最近通过添加对类型提示的支持,将静态代码分析推进了一步。接下来的部分将解释它们是如何工作的。
类型提示
在 VBA 中,你经常会看到每个变量都用数据类型的缩写作为前缀,比如strEmployeeName或wbWorkbookName。虽然在 Python 中没有人会阻止你这样做,但这并不常见。你也不会找到类似于 VBA 的Option Explicit或Dim语句来声明变量的类型。相反,Python 3.5 引入了一种称为类型提示的功能。类型提示也被称为类型注解,允许你声明变量的数据类型。它们是完全可选的,并不影响 Python 解释器运行代码的方式(不过,有第三方包如pydantic可以在运行时强制执行类型提示)。类型提示的主要目的是允许像 VS Code 这样的文本编辑器在运行代码之前捕捉更多的错误,而且还可以改善 VS Code 和其他编辑器的代码自动完成功能。用于类型注解代码的最流行类型检查器是 mypy,它作为 VS Code 的一个代码检查工具提供。为了感受类型注解在 Python 中的工作原理,这里有一个短小的示例,没有类型提示:
x``=``1``def``hello``(``name``):``return``f``"Hello {name}!"
再次来看类型提示:
x``:``int``=``1``def``hello``(``name``:``str``)``->``str``:``return``f``"Hello {name}!"
类型提示通常在更大的代码库中更有意义,因此在本书的剩余部分我将不会使用它们。
结论
本章是对 Python 的一个紧凑介绍。我们了解了语言的最重要的构建块,包括数据结构、函数和模块。我们还触及了 Python 的一些特殊之处,如有意义的空白和代码格式化准则,更为人熟知的是 PEP 8。作为初学者,为了继续学习这本书,你不需要了解所有细节:只需了解列表和字典、索引和切片,以及如何使用函数、模块、for循环和if语句就可以走得很远。
与 VBA 相比,我发现 Python 更一致和更强大,但同时也更容易学习。如果你是 VBA 的铁杆粉丝,并且这一章还没能说服你,那么下一部分肯定会:在那里,我将为你介绍基于数组的计算,在我们开始使用 pandas 库进行数据分析之前。让我们通过学习关于 NumPy 的一些基础知识来开始第二部分!
第二部分:pandas 入门
第四章: NumPy 基础
正如你可能从第一章中记得的那样,NumPy 是 Python 中科学计算的核心包,提供对基于数组的计算和线性代数的支持。由于 NumPy 是 pandas 的基础,我将在本章介绍其基础知识:解释了 NumPy 数组是什么之后,我们将研究向量化和广播,这两个重要概念允许你编写简洁的数学代码,并在 pandas 中再次遇到。之后,我们将看到为什么 NumPy 提供了称为通用函数的特殊函数,然后通过学习如何获取和设置数组的值以及解释 NumPy 数组的视图和副本之间的区别来结束本章。即使在本书中我们几乎不会直接使用 NumPy,了解其基础知识将使我们更容易学习下一章的 pandas。
使用 NumPy 入门
在这一节中,我们将学习一维和二维 NumPy 数组及背后的技术术语向量化、广播和通用函数。
NumPy 数组
要执行基于数组的计算,如上一章节中遇到的嵌套列表,你需要编写某种形式的循环。例如,要将一个数字添加到嵌套列表中的每个元素,可以使用以下嵌套列表推导式:
In``[``1``]:``matrix``=``[[``1``,``2``,``3``],``[``4``,``5``,``6``],``[``7``,``8``,``9``]]
In``[``2``]:``[[``i``+``1``for``i``in``row``]``for``row``in``matrix``]
Out[2]: [[2, 3, 4], [5, 6, 7], [8, 9, 10]]
这种方法不太易读,更重要的是,如果你使用大数组,逐个元素进行循环会变得非常缓慢。根据你的用例和数组的大小,使用 NumPy 数组而不是 Python 列表可以使计算速度提高几倍甚至提高到一百倍。NumPy 通过利用用 C 或 Fortran 编写的代码来实现这种性能提升——这些是编译性语言,比 Python 快得多。NumPy 数组是一种用于同类型数据的 N 维数组。同类型意味着数组中的所有元素都需要是相同的数据类型。最常见的情况是处理浮点数的一维和二维数组,如图 4-1 所示。
图 4-1 一维和二维 NumPy 数组
让我们创建一个一维和二维数组,在本章节中使用:
In``[``3``]:``# 首先,让我们导入 NumPy``import``numpy``as``np
In``[``4``]:``# 使用一个简单列表构建一个一维数组``array1``=``np``.``array``([``10``,``100``,``1000.``])
In``[``5``]:``# 使用嵌套列表构建一个二维数组``array2``=``np``.``array``([[``1.``,``2.``,``3.``],``[``4.``,``5.``,``6.``]])数组维度
重要的是要注意一维和二维数组之间的区别:一维数组只有一个轴,因此没有明确的列或行方向。虽然这类似于 VBA 中的数组,但如果你来自像 MATLAB 这样的语言,你可能需要习惯它,因为一维数组在那里始终具有列或行方向。
即使array1由整数组成,除了最后一个元素(它是一个浮点数),NumPy 数组的同质性强制数组的数据类型为float64,它能够容纳所有元素。要了解数组的数据类型,请访问其dtype属性:
In``[``6``]:``array1``.``dtype
Out[6]: dtype('float64')
由于dtype返回的是float64而不是我们在上一章中遇到的float,你可能已经猜到 NumPy 使用了比 Python 数据类型更精细的自己的数值数据类型。不过,通常这不是问题,因为大多数情况下,Python 和 NumPy 之间的不同数据类型转换是自动的。如果你需要将 NumPy 数据类型显式转换为 Python 基本数据类型,只需使用相应的构造函数(我稍后会详细说明如何从数组中访问元素):
In``[``7``]:``float``(``array1``[``0``])
Out[7]: 10.0
要查看 NumPy 数据类型的完整列表,请参阅NumPy 文档。使用 NumPy 数组,你可以编写简单的代码来执行基于数组的计算,我们接下来会看到。
矢量化和广播
如果你构建一个标量和一个 NumPy 数组的和,NumPy 将执行逐元素操作,这意味着你不必自己循环遍历元素。NumPy 社区将这称为矢量化。它允许你编写简洁的代码,几乎与数学符号一样:
In``[``8``]:``array2``+``1
Out[8]: array([[2., 3., 4.], [5., 6., 7.]])SCALAR
标量指的是像浮点数或字符串这样的基本 Python 数据类型。这是为了将它们与具有多个元素的数据结构如列表和字典或一维和二维 NumPy 数组区分开来。
当你处理两个数组时,相同的原则也适用:NumPy 逐元素执行操作:
In``[``9``]:``array2``*``array2
Out[9]: array([[ 1., 4., 9.], [16., 25., 36.]])
如果你在算术运算中使用两个形状不同的数组,NumPy 会自动将较小的数组扩展到较大的数组,以使它们的形状兼容。这称为广播:
In``[``10``]:``array2``*``array1
Out[10]: array([[ 10., 200., 3000.], [ 40., 500., 6000.]])
要执行矩阵乘法或点积,请使用@运算符:1
In``[``11``]:``array2``@``array2``.``T``# array2.T 是 array2.transpose()的快捷方式
Out[11]: array([[14., 32.], [32., 77.]])
不要被本节介绍的术语(如标量、向量化或广播)吓到!如果你曾在 Excel 中使用过数组,这些内容应该会感到非常自然,如图 4-2 所示。该截图来自于 array_calculations.xlsx,在配套库的 xl 目录下可以找到。
图 4-2. Excel 中基于数组的计算
你现在知道数组按元素进行算术运算,但如何在数组的每个元素上应用函数呢?这就是通用函数的用处所在。
通用函数(ufunc)
通用函数(ufunc)作用于 NumPy 数组中的每个元素。例如,若在 NumPy 数组上使用 Python 标准的平方根函数math模块,则会产生错误:
In``[``12``]:``import``math
In``[``13``]:``math``.``sqrt``(``array2``)``# This will raise en Error
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-13-5c37e8f41094> in <module> ----> 1 math.sqrt(array2) # This will raise en Error TypeError: only size-1 arrays can be converted to Python scalars
当然,你也可以编写嵌套循环来获取每个元素的平方根,然后从结果中再次构建一个 NumPy 数组:
In``[``14``]:``np``.``array``([[``math``.``sqrt``(``i``)``for``i``in``row``]``for``row``in``array2``])
Out[14]: array([[1. , 1.41421356, 1.73205081], [2. , 2.23606798, 2.44948974]])
在 NumPy 没有提供 ufunc 且数组足够小的情况下,这种方式可以奏效。然而,若 NumPy 有对应的 ufunc,请使用它,因为它在处理大数组时速度更快——而且更易于输入和阅读:
In``[``15``]:``np``.``sqrt``(``array2``)
Out[15]: array([[1. , 1.41421356, 1.73205081], [2. , 2.23606798, 2.44948974]])
NumPy 的一些 ufunc,例如sum,也可以作为数组方法使用:如果要对每列求和,则执行以下操作:
In``[``16``]:``array2``.``sum``(``axis``=``0``)``# 返回一个 1 维数组
Out[16]: array([5., 7., 9.])
参数axis=0表示沿着行的轴,而axis=1表示沿着列的轴,如图 4-1 所示。若省略axis参数,则对整个数组求和:
`In
[17]:array2.sum()
Out[17]: 21.0
本书后续部分还会介绍更多 NumPy 的 ufunc,因为它们可与 pandas 的 DataFrame 一起使用。
到目前为止,我们一直在处理整个数组。下一节将向你展示如何操作数组的部分,并介绍一些有用的数组构造函数。
创建和操作数组
在介绍一些有用的数组构造函数之前,我将从获取和设置数组元素的角度开始这一节,包括一种用于生成伪随机数的构造函数,您可以将其用于蒙特卡洛模拟。最后,我将解释数组的视图和副本之间的区别。
获取和设置数组元素
在上一章中,我向您展示了如何索引和切片列表以访问特定元素。当您处理像本章第一个示例中的 matrix 这样的嵌套列表时,您可以使用链式索引:matrix[0][0] 将获得第一行的第一个元素。然而,使用 NumPy 数组时,您可以在单个方括号对中为两个维度提供索引和切片参数:
numpy_array``[``row_selection``,``column_selection``]
对于一维数组,这简化为 numpy_array[selection]。当您选择单个元素时,将返回一个标量;否则,将返回一个一维或二维数组。请记住,切片表示法使用起始索引(包括)和结束索引(不包括),中间使用冒号,如 start:end。通过省略开始和结束索引,留下一个冒号,因此该冒号表示二维数组中的所有行或所有列。我在 Figure 4-3 中可视化了一些例子,但您可能也想再看看 Figure 4-1,因为那里标记了索引和轴。请记住,通过对二维数组的列或行进行切片,您最终得到的是一个一维数组,而不是一个二维列或行向量!
图 4-3. 选择 NumPy 数组的元素
运行以下代码来尝试 Figure 4-3 中展示的示例:
In``[``18``]:``array1``[``2``]``# 返回一个标量
Out[18]: 1000.0
In``[``19``]:``array2``[``0``,``0``]``# 返回一个标量
Out[19]: 1.0
In``[``20``]:``array2``[:,``1``:]``# 返回一个 2 维数组
Out[20]: array([[2., 3.], [5., 6.]])
In``[``21``]:``array2``[:,``1``]``# 返回一个 1 维数组
Out[21]: array([2., 5.])
In``[``22``]:``array2``[``1``,``:``2``]``# 返回一个 1 维数组
Out[22]: array([4., 5.])
到目前为止,我通过手动构建示例数组,即通过在列表中提供数字来完成。但是 NumPy 还提供了几个有用的函数来构建数组。
有用的数组构造函数
NumPy 提供了几种构建数组的方法,这些方法对于创建 pandas DataFrames 也很有帮助,正如我们将在 第五章 中看到的那样。一个简单创建数组的方式是使用 arange 函数。这代表数组范围,类似于我们在前一章中遇到的内置 range 函数,不同之处在于 arange 返回一个 NumPy 数组。结合 reshape 可以快速生成具有所需维度的数组:
In``[``23``]:``np``.``arange``(``2``*``5``)``.``reshape``(``2``,``5``)``# 2 行,5 列
Out[23]: array([[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]])
另一个常见的需求,例如蒙特卡洛模拟,是生成正态分布的伪随机数数组。NumPy 可以轻松实现这一点:
In``[``24``]:``np``.``random``.``randn``(``2``,``3``)``# 2 行,3 列
Out[24]: array([[-0.30047275, -1.19614685, -0.13652283], [ 1.05769357, 0.03347978, -1.2153504 ]])
其他有用的构造函数包括 np.ones 和 np.zeros,分别用于创建全为 1 和全为 0 的数组,以及 np.eye 用于创建单位矩阵。我们将在下一章再次遇到其中一些构造函数,但现在让我们学习一下 NumPy 数组视图和副本之间的区别。
视图 vs. 复制
当你切片 NumPy 数组时,它们返回视图。这意味着你在处理原始数组的子集而不复制数据。在视图上设置值也将更改原始数组:
In``[``25``]:``array2
Out[25]: array([[1., 2., 3.], [4., 5., 6.]])
In``[``26``]:``subset``=``array2``[:,``:``2``]``subset
Out[26]: array([[1., 2.], [4., 5.]])
In``[``27``]:``subset``[``0``,``0``]``=``1000
In``[``28``]:``subset
Out[28]: array([[1000., 2.], [ 4., 5.]])
In``[``29``]:``array2
Out[29]: array([[1000., 2., 3.], [ 4., 5., 6.]])
如果这不是你想要的,你需要按照以下方式更改 In [26]:
subset``=``array2``[:,``:``2``]``.``copy``()
在副本上操作将不会改变原始数组。
结论
在本章中,我向你展示了如何使用 NumPy 数组以及背后的向量化和广播表达式。抛开这些技术术语,使用数组应该感觉非常直观,因为它们紧密遵循数学符号。虽然 NumPy 是一个非常强大的库,但在用于数据分析时有两个主要问题:
-
整个 NumPy 数组都需要是相同的数据类型。例如,这意味着当数组包含文本和数字混合时,你不能执行本章中的任何算术运算。一旦涉及文本,数组将具有数据类型
object,这将不允许数学运算。 -
-
使用 NumPy 数组进行数据分析使得难以知道每列或每行指的是什么,因为通常通过它们的位置来选择列,比如在
array2[:, 1]中。
pandas 通过在 NumPy 数组之上提供更智能的数据结构来解决了这些问题。它们是什么以及如何工作将是下一章的主题。
1 如果你已经很久没有上线性代数课了,你可以跳过这个例子——矩阵乘法不是本书的基础。
