

React TypeScript Node 全栈开发(三)
原文:
zh.annas-archive.org/md5/F7C7A095AD12AA62E0C9F5A1E1F6F281译者:飞龙
第七章:学习 Redux 和 React Router
在本章中,我们将学习 Redux 和 React Router。Redux 仍然是管理 React 应用程序中共享的全局状态的最常见方法。使用 Redux 全局状态,我们可以减少大量样板代码并简化应用程序。React Router 也是管理客户端 URL 路由的最流行框架。客户端 URL 路由允许 SPA 应用程序以用户期望的经典样式 Web 应用程序的方式行为。这两种技术对于构建外观和感觉像标准 Web 应用程序的 SPA 应用程序是必不可少的。
在本章中,我们将涵盖以下主要主题:
-
学习 Redux 状态
-
学习 React Router
技术要求
您应该对使用 React 进行 Web 开发有基本的了解。我们将再次使用 Node 和 Visual Studio Code。
GitHub 存储库位于github.com/PacktPublishing/Full-Stack-React-TypeScript-and-Node。使用Chap7文件夹中的代码。
要设置本章的代码文件夹,请转到您的HandsOnTypescript文件夹并创建一个名为Chap7的新文件夹。
学习 Redux 状态
Redux 仍然是在 React 应用程序中创建和管理全局状态的最流行的企业级框架(尽管我们可以在任何 JavaScript 应用程序中使用 Redux,而不仅仅是 React)。许多新的框架已经被创建,其中一些已经获得了相当大的追随者;然而,Redux 仍然是最常用的。您可能会发现一开始很难理解 Redux。然而,一旦我们学会了它,我们将看到它的许多好处,以及为什么它经常成为大型复杂 React 应用程序的首选框架。
我们在第四章中学习了 React 状态,学习单页应用程序概念以及 React 如何实现它们,以及第五章,使用 Hooks 进行 React 开发。因此,再次强调,状态或组件的数据是 React 中所有 UI 更改的主要驱动程序。这就是为什么 React 框架的名称中有"react"一词的原因,因为它对这些状态变化做出反应(这也被称为响应式)。因此,在创建和管理状态时,我们通常希望大部分时间将本地状态与组件或组件的根父级关联起来。
基于组件的状态可能有限。有些情况下,状态不仅适用于一个组件,甚至不适用于组件层次结构。状态有时可能对多个组件或构成应用程序的其他非组件服务是必要的。除此之外,在 React 中,状态只能单向传递,从父级向子级传递作为 props。不应该向上游传递。这进一步限制了 React 中状态的使用。因此,Redux 不仅提供了一种在全局共享状态的机制,还允许根据需要从任何组件注入和更新状态。
让我们举个例子来详细说明一下。在典型的企业级应用程序中,我们总是会有身份验证。一旦用户经过身份验证,我们可能会收到关于用户的某些数据 - 例如,用户的全名、用户 ID、电子邮件等。因此,认为这些数据点可能被应用程序中的大部分组件使用并不是不合理的。因此,让每个组件调用以获取这些数据,然后在它们自己的状态中保存它,这样做将是乏味且容易出错的。这样做意味着数据会有多个副本,并且随着数据的更改,一些组件可能会保留旧版本的数据。
这种冲突可能是 bug 的来源。因此,能够在客户端的一个地方维护这些数据并与需要它的任何组件共享将是有帮助的。这样,如果这些数据有更新,我们可以确保所有组件,无论在应用程序的哪个部分,都能获得最新的有效数据。这就是 Redux 可以为我们的应用程序做的事情。我们可以把它看作是唯一的真相源。
Redux 是一个数据存储服务,它在我们的 React 应用程序中维护所有全局共享的数据。Redux 不仅提供存储本身,还提供了添加、删除和共享这些数据所需的基本功能。然而,与 React 状态的一个不同之处是,Redux 状态不一定会触发 UI 更新。如果我们希望这样做,它当然可以,但并不一定需要这样做。因此,我们应该记住这一点。
让我们看看如何设置 Redux:
- 在
Chap7文件夹中创建一个新的 React 项目,如下所示:
create-react-app redux-sample --template typescript
-
一旦我们的项目设置好了,打开它并使用命令行
cd到redux-sample文件夹。 -
我们现在将安装 Redux,实际上是几个不同的依赖项。首先,运行这个命令:
npm i redux react-redux @types/redux @types/react-redux
这个命令给我们主要的依赖项,包括 TypeScript 类型。
好的,现在我们已经完成了一些基本设置,我们需要在继续之前了解一些关于 Redux 的更多内容。Redux 使用了一对叫做 reducers 和 actions 的概念。让我们看看它们各自的作用。
Reducers 和 actions
在 Redux 中,所有数据只有一个单一的存储。因此,我们所有的全局数据都将存在于一个 Redux 对象中。现在,这种设计的问题是,由于这是全局状态,不同的应用程序功能将需要不同类型的数据,而整个数据并不总是与应用程序的所有部分相关。因此,Redux 的创建者提出了一种方案,使用 reducers 来过滤和拆分单一存储为分离的块。因此,如果组件 A 只需要特定的数据片段,它就不必处理整个存储。
这种设计是分离数据关注点的好方法。但这种设计的副作用是,我们需要一种更新相关数据部分而不影响其他部分的方法。这就是 actions 的作用。Actions 是提供特定 reducer 数据的对象。
现在我们已经对 reducers 和 actions 有了一个高层次的了解,让我们在代码中看一些例子:
-
在
src下创建一个名为store的新文件夹。 -
然后,创建一个名为
AppState.ts的文件。这个文件将存储我们的聚合 reducer 对象rootReducer,类型为AppState,它代表了全局状态。将以下代码插入文件中:
import { combineReducers } from "redux";
export const rootReducer = combineReducers({
});
export type AppState = ReturnType<typeof rootReducer>;
rootReducer代表了我们所有 reducer 的聚合对象。我们还没有任何 reducer,但是一旦我们的设置完成,我们将添加实际的 reducer。combineReducers接受我们的每个 reducer,并将它们组合成一个单一的对象。在底部,我们使用ReturnType 实用类型基于我们的rootReducer创建了一个 TypeScript 类型,然后导出了新类型AppState。
注意
实用类型只是 TypeScript 团队创建的一个帮助类,用于提供特定功能。有许多不同的实用类型,可以在这里找到列表:www.typescriptlang.org/docs/handbook/utility-types.html。
- 接下来,我们创建一个名为
configureStore.ts的文件,其中包含了 Redux 和应用程序使用的实际存储对象。它应该是这样的:
import { createStore } from "redux";
import { rootReducer } from "./AppState";
const configureStore = () => {
return createStore(rootReducer, {});
};
export default configureStore;
正如我们所看到的,Redux 的createStore方法用于基于我们的AppState对象rootReducer构建实际的存储。configureStore被导出并稍后用于执行存储的创建。
- 现在,我们必须更新我们的
index.tsx文件,调用我们的configureStore方法并为我们的应用程序初始化 Redux。像这样更新index.tsx:
import React from 'react';
import ReactDOM from 'react-dom';
import './index.css';
import App from './App';
import { Provider } from "react-redux";
import configureStore from "./store/configureStore";
import * as serviceWorker from './serviceWorker';
ReactDOM.render(
<React.StrictMode>
<Provider store={configureStore()}>
<App />
</Provider>
</React.StrictMode>,
document.getElementById('root')
);
首先,我们从react-redux中导入Provider。Provider是一个 React 组件,作为所有其他组件的父组件,并且提供我们的存储数据。此外,如所示,Provider接收了通过接受configureStore函数的返回值来初始化的存储:
// If you want your app to work offline and load faster,
// you can change
// unregister() to register() below. Note this comes with
// some pitfalls.
// Learn more about service workers:
// https://bit.ly/CRA-PWA
serviceWorker.unregister();
这些注释的代码来自create-react-app项目。这里包含它是为了完整性。好的,现在我们已经建立了 Redux 的基本设置。因此,我们的示例将继续通过创建一个调用来获取用户对象。我们将使用我们在第六章中学到的 JSONPlaceholder API,使用 create-react-app 设置我们的项目并使用 Jest 进行测试。成功登录后,它通过将用户信息放入 Redux 作为 reducer 来共享用户信息。现在让我们来做这个:
- 创建一个名为
UserReducer.ts的新文件,放在store文件夹中,像这样:
export const USER_TYPE = "USER_TYPE";
我们首先创建一个名为USER_TYPE的 action 类型的常量。这是可选的,但有助于我们避免诸如拼写错误之类的问题:
export interface User {
id: string;
username: string;
email: string;
city: string;
}
然后,我们创建一个表示我们的User的类型:
export interface UserAction {
type: string;
payload: User | null;
}
现在,按照惯例,一个 action 有两个成员:类型和有效负载。因此,我们创建了一个UserAction类型,其中包含这些成员:
export const UserReducer = ( state: User | null = null, action:
UserAction): User | null => {
switch(action.type) {
case USER_TYPE:
console.log("user reducer", action.payload);
return action.payload;
default:
return state;
}
};
然后,最后,我们创建了名为UserReducer的 reducer。reducer 始终接受state和action参数。请注意,state并不是整个状态,它只是与某个 reducer 相关的部分状态。这个 reducer 将根据action类型知道传入的state是否属于它自己。还要注意,原始状态永远不会被改变。这一点非常重要。绝对不要直接改变状态。你应该要么返回原状态,这在case default中完成,要么返回其他数据。在这种情况下,我们返回action.payload。
- 现在,我们必须回到我们的
AppState.ts文件中,添加这个新的 reducer。文件现在应该是这样的:
import { combineReducers } from "redux";
import { UserReducer } from "./UserReducer";
export const rootReducer = combineReducers({
user, which is updated by UserReducer. If we had more reducers, we would simply give them a name and add them below user with their reducer, and the combineReducers Redux function would combine all of them into a single aggregate rootReducer.
- 现在,让我们开始使用我们的新状态。像这样更新
App.tsx文件:
import React, { useState } from 'react';
import ContextTester from './ContextTester';
import './App.css';
function App() {
const [userid, setUserid] = useState(0);
const onChangeUserId = (e: React. ChangeEvent<HTMLInputElement>)
=> {
console.log("userid", e.target.value);
setUserid(e.target.value ? Number(e.target.value) : 0);
}
return (
<div className="App">
<label>user id</label>
<input value={userid} onChange={onChangeUserId} />
</div>
);
}
export default App;
我们将以userid作为参数,然后根据该 ID 从 JSON Placeholder API 中获取关联的用户。为了做到这一点,我们需要使用一些 Redux 特定的 Hooks,这样我们就可以将我们找到的用户添加到 Redux 存储中。
- 让我们像这样更新
App组件中的App.tsx:
function App() {
const [userid, setUserid] = useState(0);
dispatch. We get an instance of dispatch with the useDispatch Hook. dispatch is a Redux function that sends our action data to Redux. Redux then sends the action to each of our reducers for processing. Then the reducer that recognizes the action type accepts it as its state payload:
通过onChangeUserId处理程序,我们调用 JSONPlaceholder API。然后我们使用usersResponse响应对象从我们的网络 API 中获取结果。然后我们通过筛选从 UI 中获取的用户 ID 来获取我们想要的用户。然后我们使用 dispatch 将我们的 action 发送给我们的 reducer。还要注意onChangeUserId现在是一个异步函数:
}
return (
<div className="App">
<label>user id</label>
<input value={userid} onChange={onChangeUserId} />
</div>
);
}
这个 UI 将以userid作为输入。
现在,让我们创建一个子组件,可以显示我们所有与用户相关的数据:
- 创建一个名为
UserDisplay.tsx的新组件,并添加这段代码:
import React from 'react';
import { AppState } from './store/AppState';
import { useSelector } from 'react-redux';
const UserDisplay = () => {
useSelector Hook gets the specific user reducer. It takes a function as a parameter and this function takes the entire aggregated reducer state and only returns the user reducer. Also in this component, we are displaying the properties of our found user but taken from Redux and the user reducer. Notice also how we return null if no user is found.
- 现在,让我们将
UserDisplay组件添加到我们的App组件中:
import React, { useState } from 'react';
import './App.css';
import { useDispatch } from 'react-redux';
import { USER_TYPE } from './store/UserReducer';
UserDisplay component:
function App() {
const [userid, setUserid] = useState(0);
const dispatch = useDispatch();
const onChangeUserId = async (e:
React.ChangeEvent) => {
const useridFromInput = e.target.value ?
Number(e.target.value) : 0;
console.log("userid", useridFromInput);
setUserid(useridFromInput);
const usersResponse = await
fetch('jsonplaceholder.typicode.com/ users');
if(usersResponse.ok) {
const users = await usersResponse.json();
const usr = users.find((userItem: any) => {
return userItem && userItem.id === useridFromInput;
});
dispatch({
type: USER_TYPE,
payload: {
id: usr.id,
username: usr.username,
email: usr.email,
city: usr.address.city
}
});
}
}
No real changes up to here:
return (
<React.Fragment>
用户 ID
<input value={userid} onChange={onChangeUserId} />
在返回的 JSX UI 中使用UserDisplay,这样我们的用户信息就会显示出来。
- 现在,如果你在浏览器中加载
http://localhost:3000并在输入框中输入1,你应该会看到这个:
图 7.1 – 来自 Redux 存储的用户对象
因此,现在我们已经看到了一个简单 Redux 存储用例的示例,让我们进一步展示当我们在同一个存储中有多个 reducer 时会发生什么:
- 创建一个名为
PostDisplay.tsx的新文件,并添加以下代码。这个组件将显示来自 JSON Placeholder API 的发布评论:
import React, { useRef } from 'react';
import { AppState } from './store/AppState';
import { useSelector } from 'react-redux';
const PostDisplay = React.memo(() => {
const renderCount = useRef(0);
console.log("renders PostDisplay", renderCount. current++);
const post = useSelector((state: AppState) => state. post);
与我们之前的示例一样,这里我们使用useSelector设置我们想要的状态数据:
if(post) {
return (<React.Fragment>
<div>
<label>title:</label>
{post.title}
</div>
<div>
<label>body:</label>
{post.body}
</div>
</React.Fragment>);
} else {
return null;
}
});
export default PostDisplay
如您所见,它看起来与UserDisplay非常相似,但它显示与post相关的信息,如title和body。
- 现在,我们更新我们的 Redux 代码以添加我们的新 reducer。首先,在
store文件夹内添加一个名为PostReducer.ts的新文件,然后添加以下代码:
export const POST_TYPE = "POST_TYPE";
export interface Post {
id: number;
title: string;
body: string;
}
export interface PostAction {
type: string;
payload: Post | null;
}
export const PostReducer = ( state: Post | null = null,
action: PostAction): Post | null => {
switch(action.type) {
case POST_TYPE:
return action.payload;
default:
return state;
}
};
同样,这与UserReducer非常相似,但专注于帖子而不是用户。
- 接下来,我们想要更新
AppState.tsx文件,并将我们的新 reducer 添加到其中。添加以下代码:
import { combineReducers } from "redux";
import { UserReducer } from "./UserReducer";
import { PostReducer } from "./PostReducer";
export const rootReducer = combineReducers({
user: UserReducer,
PostReducer.
- 好的,现在我们将更新我们的
App组件,并添加特定于从 JSON Placeholder API 中查找特定帖子的代码。使用以下代码更新App:
function App() {
const [userid, setUserid] = useState(0);
const dispatch = useDispatch();
const [postid, setPostId] = useState(0);
请注意,我们没有针对任何 reducer 特定的dispatch。这是因为分派程序只是通用执行函数。该操作最终将被路由到适当的 reducer。
onChangeUserId没有改变,但出于完整性,这里显示一下:
const onChangeUserId = async (e:
React.ChangeEvent<HTMLInputElement>) => {
const useridFromInput = e.target.value ?
Number(e.target.value) : 0;
console.log("userid", useridFromInput);
setUserid(useridFromInput);
const usersResponse = await
fetch('https://jsonplaceholder.typicode.com/ users');
if(usersResponse.ok) {
const users = await usersResponse.json();
const usr = users.find((userItem: any) => {
return userItem && userItem.id === useridFromInput;
});
dispatch({
type: USER_TYPE,
payload: {
id: usr.id,
username: usr.username,
email: usr.email,
city: usr.address.city
}
});
}
}
onChangePostId是一个新的事件处理程序,用于处理与post相关的数据更改:
const onChangePostId = async (e:
React.ChangeEvent<HTMLInputElement>) => {
const postIdFromInput = e.target.value ?
Number(e.target.value) : 0;
setPostId(postIdFromInput);
const postResponse = await
fetch("https://jsonplaceholder.typicode.com/posts/"
+ postIdFromInput);
if(postResponse.ok) {
const post = await postResponse.json();
console.log("post", post);
dispatch({
type: POST_TYPE,
payload: {
id: post.id,
title: post.title,
body: post.body
}
})
}
}
OnChangePostId通过dispatch函数分派相关的action。
UI 已经稍微更新以处理新的PostDisplay组件,并将其与UserDisplay组件分开:
return (
<React.Fragment>
<div style={{width: "300px"}}>
<div className="App">
<label>user id</label>
<input value={userid} onChange={onChangeUserId} />
</div>
<UserDisplay />
</div>
<br/>
<div style={{width: "300px"}}>
<div className="App">
<label>post id</label>
<input value={postid} onChange={onChangePostId} />
</div>
<postid, you should see an interesting thing:
图 7.2 – PostDisplay 结果
请注意,在控制台中,当更新postid输入时,没有UserDisplay的日志。这表明 Redux 存储不直接连接到 React 渲染管道,只有与特定状态更改相关的组件才会重新渲染。这与 React Context 的行为不同,并且可以通过减少不需要的渲染来提高性能(我们将在下一节中讨论 Context)。
在本节中,我们了解了 Redux,这是在 React 中管理全局状态的最流行方式。在更大的应用程序中,我们经常会使用全局状态管理器,因为通常会发生大量的全局数据共享。在我们的应用程序中,我们将存储有关已登录用户和其他将在整个应用程序中共享的数据的信息,因此具有这种能力将是有价值的。
React Context
Context 是在 Hooks 之前推出的一个较新的功能。Context 不是一个单独的依赖项,而是内置到 React 核心中的。它允许类似于 Redux 的功能,即允许状态存储在单一源中,然后在组件之间共享,而无需手动通过组件层次结构传递 props。
从开发人员编码的角度来看,这种能力非常高效,因为它消除了从父级到其子级传递状态所需的大量样板代码。这是一个更大的 React 应用程序中可能的一组层次结构的可视化:
图 7.3 – React 组件层次结构
在这个示例图中,我们有一个单一的父组件,它有几个子组件,它在自己的 JSX 中使用。这些子组件也有它们自己的子组件,依此类推。因此,如果我们要为每个组件层次结构配置传递 props,那将是相当多的代码,特别是知道有些层次结涉及传递可能回调到某个任意父级的函数。这种类型的 prop 关系也会给开发人员带来额外的认知负担,因为他们需要考虑数据关系以及数据在组件之间的传递方式。
当适当时,React 上下文和 Redux 都是避免这种状态传递样板代码的好方法。对于较小的项目,上下文的简单性效果很好。然而,对于较大的项目,我建议不要使用上下文。
React 上下文可以有多个父提供者,这意味着可能有多个根上下文。对于更大的应用程序,这可能会令人困惑,并增加更多样板代码。此外,全局状态提供者的混合可能会令人困惑。如果团队决定同时使用 Context 和 Redux,那么我们何时使用每一个?如果我们现在同时使用两者,那么我们必须维护两种全局状态管理样式。
此外,与 Redux 不同,上下文没有 reducers 的概念。因此,上下文的所有用户将接收整个状态数据集,这在关注点分离方面不是一个好的实践。随着时间的推移,特定组件应处理哪个数据子集可能会变得令人困惑。
拥有所有状态数据对所有组件用户都可用的一个额外副作用是,即使组件实际上没有访问特定状态成员,任何上下文更改都会触发重新渲染。例如,假设上下文状态如下{ username, userage },而我们的组件只使用username。即使仅userage发生变化,它也会触发该组件的重新渲染。即使使用了memo(我们在第五章中介绍了memo),这也是正确的。让我们看一个演示这种效果的例子:
- 从
index.tsx中删除React.StrictMode和Provider,以避免混淆。我们稍后会把它们放回去。现在,index.tsx文件应该是这样的:
import React from 'react';
import ReactDOM from 'react-dom';
import './index.css';
import App from './App';
import { Provider } from "react-redux";
import configureStore from "./store/configureStore";
import * as serviceWorker from './serviceWorker';
ReactDOM.render(
<App />
,
document.getElementById('root')
);
同样,这些注释来自create-react-app,仅出于完整性而包含在这里:
// If you want your app to work offline and load faster,
// you can change
// unregister() to register() below. Note this comes with
// some pitfalls.
// Learn more about service workers: // https://bit.ly/CRA-PWA
serviceWorker.unregister();
You can also remove any unused imports to avoid triggering warning messages.
- 现在,创建这两个子组件,每个组件将使用我们上下文状态的一个唯一成员。首先,创建
UserAgeComp.tsx组件,并添加以下代码:
import React, { useContext } from 'react';
import { TestContext } from './ContextTester';
const UserAgeComp = () => {
const { userage } = useContext(TestContext);
return <div>
{userage}
</div>
};
export default UserAgeComp;
这段代码使用对象解构来仅使用TestContext的userage成员,通过使用稍后我们将创建的useContext Hook,并仅显示它。现在,创建UserNameComp.tsx组件,并添加以下代码:
import React, { useContext, useRef } from 'react';
import { TestContext } from './ContextTester';
const UserNameComp = React.memo(() => {
const renders = useRef(0);
username (note, I have it commented out), but before we can show the ramifications of using Context, I wanted to show this component working as expected first. So, this component has two main features. One is a ref that counts the number of times this component was rendered, and a variable called username that gets displayed. It will also log the renders count as well in order to show when a re-render is triggered.
- 现在,我们需要创建一个包含上下文的父组件。创建
ContextTester.tsx文件,并添加以下代码:
import React, { createContext, useState } from 'react';
import UserNameComp from './UserNameComp';
import UserAgeComp from './UserAgeComp';
在这里,我们使用createContext来创建我们的TestContext对象,它将保存我们的状态:
export const TestContext = createContext<{ username: string, userage: number }>({ username: "", userage:0 });
const ContextTester = () => {
const [userage, setUserage] = useState(20);
const [localState, setLocalState] = useState(0);
const onClickAge = () => {
setUserage(
userage + 1
);
}
const onClickLocalState = () => {
setLocalState(localState + 1);
}
return (<React.Fragment>
<button onClick={onClickAge}>Update age</button>
<TestContext.Provider value={{ username: "dave",
userage }}>
localState, which is incremented by the onClickLocalState handler, and the other is the renders of the two child components, UserNameComp and UserAgeComp. Notice UserNameComp, for now, lives outside of the TestContext Context component, and therefore is not affected by TestContext changes. *This is very important to note*.
- 现在,如果我们点击“更新年龄”或“更新本地状态”,你会发现
UserNameComp中的console.log语句从未执行过。该日志语句仅在页面首次加载时执行了一次,这是应该发生的,因为UserNameComp使用了memo(memo只允许在 props 更改时重新渲染)。你应该在控制台选项卡中只看到一组日志(忽略警告,因为我们很快会重新添加我们的依赖项):
图 7.4 - 上下文渲染结果
- 好的,现在,让我们强制
UserNameComp使用我们的TestContext中的username。所以现在,UserNameComp应该是这样的:
import React, { useContext, useRef } from 'react';
import { TestContext } from './ContextTester';
const UserNameComp = React.memo(() => {
const renders = useRef(0);
console.log("renders UserNameComp", renders. current++);
UserNameComp is using the username variable from the TestContext context. It never makes use of the userage variable and you will recall username has a hardcoded value so it never changes. So, theoretically, the username state of UserNameComp never changes and therefore should not cause a re-render. Now we need to place UserNameComp inside the TestContext tag as well. We are doing this because if a component needs to use a Context's state, it must be inside that Context's tag. Edit ContextTester like so:
const ContextTester = () => {
const [userage, setUserage] = useState(20);
const [localState, setLocalState] = useState(0);
const onClickAge = () => {
setUserage(
userage + 1
);
}
const onClickLocalState = () => {
setLocalState(localState + 1);
}
返回(<React.Fragment>
更新年龄
<username is hardcoded to "dave" and never changes. And as you can see, UserNameComp was moved into TestContext.
- 现在,如果我们运行这段代码,然后多次点击按钮,我们应该看到类似这样的结果:
图 7.5 - 使用上下文时的重新渲染
正如你所看到的,我们的UserNameComp组件不断重新渲染,即使我们只改变了localState变量。为什么会发生这种情况?TestContext是一个像任何其他 React 组件一样的组件。它不使用memo。因此,当父组件ContextTester重新渲染时,它也会重新渲染,这对于它的任何子组件都会产生连锁效应。这就是为什么UserNameComp不断重新渲染,尽管它从不使用userage变量。
因此,正如你所看到的,上下文在使用上有一些问题,我认为对于大型的 React 应用程序,如果你必须在这两者之间做出选择,使用 Redux 可能更好,尽管更复杂。
在本节中,我们学习了有关上下文的基础知识。上下文相对来说很容易学习和使用。对于较小的项目,它非常有效。然而,由于其简单的设计,对于更复杂的项目,更复杂的全局状态管理系统可能更可取。
学习 React Router
React Router 是 React 中最常用的路由框架。它相对来说很简单学习和使用。路由,正如我们在第四章中发现的,学习单页应用程序的概念以及 React 如何实现它们,在 Web 开发中是无处不在的。这是 Web 应用程序用户所期望的功能,因此学习如何在我们的 React 应用程序中使用它是一个要求。
在 React Router 中,路由只是包含我们自己应用程序组件的 React Router 组件,而这些组件又代表我们的屏幕。换句话说,React Router 中的路由是虚拟位置的逻辑表示(通过虚拟位置,我指的是一个仅仅是标签而不实际存在于任何服务器上的 URL)。React Router 中的“路由器”充当父组件,而我们的屏幕渲染组件充当子组件。仅仅通过阅读是有点难以理解的,所以让我们创建一个例子:
- 通过在终端中调用这个命令,在
Chap7文件夹下创建一个新的 React 项目:
create-react-app try-react-router --template typescript
- 一旦它完成了创建我们的项目,
cd进入新的try-react-outer文件夹,然后让我们添加一些包:
dom.
- 现在,让我们更新我们的
index.tsx文件,以便在我们的应用程序中包含根 React Router 组件。像这样更新index.tsx:
import React from "react";
import ReactDOM from "react-dom";
import "./index.css";
import App from "./App";
import * as serviceWorker from "./serviceWorker";
import { App component, called BrowserRouter. BrowserRouter is a bit like Redux's Provider in the sense that it is a single parent component that provides various props to child components that are relevant to doing routing. We will go over these props soon, but for now, let's finish our setup of React Router.
- 现在,由于这个工具为我们提供了路由,我们必须设置我们的个别路由。然而,由于路由最终只是代表我们屏幕的组件的容器,让我们首先创建两个屏幕。创建一个名为
ScreenA.tsx的文件,并添加以下代码:
import React from "react";
const ScreenA = () => {
return <div>ScreenA</div>;
};
export default ScreenA;
这是一个简单的组件,在浏览器中显示ScreenA。
- 现在,创建一个名为
ScreenB.tsx的文件,并添加以下代码:
import React from "react";
const ScreenB = () => {
return <div>ScreenB</div>;
};
export default ScreenB;
再次,这是一个简单的组件,在浏览器中显示ScreenB。
- 现在,让我们试试我们的路由。打开
App.tsx并添加以下代码:
import React from "react";
import "./App.css";
import { Switch, Route } from "react-router-dom";
import ScreenA from "./ScreenA";
import ScreenB from "./ScreenB";
function App() {
return (
<Switch>
<Route exact={true} path="/" component={Switch component indicates a parent that determines which route to choose by matching the browser URL to a path property of a Route instance. For example, if we start our app and go to the "/" route (the root of our application), we should see this:
图 7.6 - 路由到 ScreenA
但是,如果我们要去到路由"/b",我们应该看到ScreenB,就像这样:
图 7.7 - 路由到 ScreenB
所以,正如我在本节开头所述,React Router 路由是 React 组件。这可能看起来很奇怪,因为它们没有可见的 UI。尽管如此,它们是父组件,除了渲染它们的子组件之外,它们自己没有 UI。
现在,我们知道当我们的应用程序首次加载时,首先运行的是index.tsx文件。这也是核心 React Router 服务所在的地方。当这个服务遇到一个 URL 时,它会查看我们的App.tsx文件中定义的路由集,并选择一个匹配的路由。一旦选择了匹配的路由,就会渲染该路由的子组件。因此,例如,具有path="/b"的路由将渲染ScreenB组件。
让我们深入了解我们的路由代码的细节。如果我们回顾一下我们的路由,我们应该看到我们的第一个路由有一个叫做exact的属性。这告诉 React Router 不要使用正则表达式来确定路由匹配,而是要寻找一个精确匹配。接下来,我们看到一个叫做path的属性,这当然是我们在根域之后的 URL 路径。这个路径默认是一个"包含"路径,意味着任何包含与path属性相同值的 URL 都将被接受,并且将呈现第一个匹配的路由,除非我们包含了exact属性。
现在,你还会注意到我们有一个叫做component的属性,它当然是指要呈现的子组件。对于简单的场景,使用这个属性是可以的。但是如果我们需要向组件传递一些额外的 props 怎么办?React Router 提供了另一个叫做render的属性,它允许我们使用所谓的渲染属性。
render属性是一个以函数作为参数的属性。当父组件进行渲染时,它将在内部调用render函数。让我们看一个例子:
- 创建一个名为
ScreenC.tsx的新组件,并在其中添加以下代码:
import React, { FC } from "react";
interface ScreenCProps {
message: string;
}
const ScreenC: FC<ScreenCProps> = ({ message }) => {
return <div>{message}</div>;
};
export default ScreenC;
ScreenC组件与其他组件非常相似。但是它还接收一个叫做message的 prop,并将其用作显示。让我们看看如何通过 React Router 的render属性传递这个 prop。
- 现在让我们更新我们的
App组件,并将这个新组件作为一个路由添加进去:
import React from "react";
import "./App.css";
import { Switch, Route } from "react-router-dom";
import ScreenA from "./ScreenA";
import ScreenB from "./ScreenB";
import ScreenC from "./ScreenC";
function App() {
const renderScreenC, and it takes props as a parameter and then passes it to the ScreenC component and then returns that component. Along with passing props, we also have it passing the string "This is Screen C" into the message property. If we had tried to use the component property of Route, there would be no way to pass the message property and so we are using the render property instead.
- 接下来,我们添加一个使用
render属性的新的Route,并将其传递给renderScreenC函数。如果我们去"/c"路径,我们会看到基本上与其他屏幕相同的东西,但是有我们的消息,这是屏幕 C:
图 7.8 - 路由到 ScreenC
但是,我还包含了一个传递给组件的 props 的日志,我们可以看到诸如history、location和match成员等内容。你会记得我们的渲染函数renderScreenC,它的签名是(props:any) => { … }。这个props参数是由 React Router 服务的Route组件传递进来的。我们稍后会看一下这些路由属性。
所以,现在我们知道了如何通过使用render属性更好地控制我们的屏幕组件渲染,但是一个典型的 URL 也可以有传递数据到屏幕的参数。让我们看看如何在 React Router 中实现这一点:
- 让我们像这样更新
ScreenC的Route:
<Route path="/c/:userid" render={renderScreenC} />
userid字段现在是 URL 上的一个参数。
- 现在让我们更新我们的
ScreenC组件,接受 Route props 并处理我们的新的userid参数字段:
import React, { FC } from "react";
interface ScreenCProps {
message: string;
props) => {
return (
<div>
<div>props member without having to write them out. And now our component takes the history and match props members as its own props and it is also handling the userid field by using the match.params.userid property. Since the history object already contains location as a member, we did not add that member to our ScreenCProps interface. The screen should look like this:
图 7.9 - 带参数路由到 ScreenC
正如你所看到的,我们的userid参数的值为1。
好的,现在我们更实际地使用了 React Router,但关于 React Router 的工作方式还有另一个重要特点需要注意。React Router 基本上就像一个 URL 的堆栈。换句话说,当用户访问站点的 URL 时,他们是以线性方式进行的。他们先去 A,然后去 B,也许回到 A,然后去 C,依此类推。由此产生的结果是用户的浏览器历史可以保存为一个堆栈,用户可以前进到一个新的 URL,或者后退到先前访问过的 URL。这种浏览器行为特性在 React Router 的history对象中大多得到了维护。
所以,再次,让我们更新我们的代码,看看history对象提供的一些功能:
- 更新
ScreenC组件如下:
import React, { FC, useEffect } from "react";
interface ScreenCProps {
message: string;
history: any;
match: any;
}
const ScreenC: FC<ScreenCProps> = (props) => {
useEffect and in this function, we are waiting 3 seconds with a timer and then by using the history.push function, we are redirecting our URL to "/", which is rendered by the ScreenA component.
- 让我们在
history对象内部使用另一个函数。再次更新ScreenC,像这样:
import React, { FC } from "react";
interface ScreenCProps {
message: string;
history: any;
match: any;
}
const ScreenC: FC<ScreenCProps> = (props) => {
const history.goBack function. In order to test this code, we need to open the web page to URL localhost:3000/b first and then go to URL localhost:3000/c/2. Your screen should then look like this: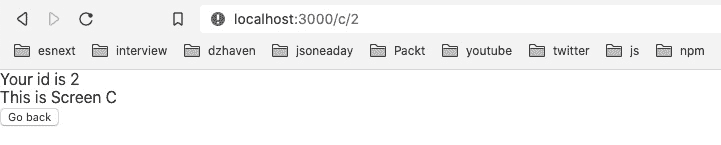Figure 7.10 – Routed to ScreenC with a Go back button
-
你可以看到我们有一个名为
"/b"的路由按钮。 -
还有一件事要回顾一下:React Router 最近添加了 Hooks 功能。因此,我们不再需要通过子组件的 props 传递路由属性;我们可以直接使用 Hooks。以下是它的样子(我已经将非 Hooks 部分作为注释保留给您):
import React, { FC } from "react";
import { useHistory, useParams } from "react-router-dom";
在这里,我们有我们的新的useHistory和useParams Hooks 导入:
interface ScreenCProps {
message: string;
history: any;
match: any;
}
const ScreenC: FC<ScreenCProps> = (props) => {
// useEffect(() => {
// setTimeout(() => {
// props.history.push("/");
// }, 3000);
// });
const history = useHistory();
const { userid } = useParams();
在这里,我们调用我们的useHistory和useParams Hooks 来获取history和userid URL 参数:
const onClickGoback = () => {
// props.history.goBack();
history.goBack();
};
return (
<div>
{/* <div>{"Your id is " + props.match.params. userid}</div>
*/}
<div>{"Your id is " + userid}</div>
<div>{props.message}</div>
<div>
<button onClick={onClickGoback}>Go back</button>
</div>
</div>
);
};
export default ScreenC;
在这里,我们使用 Hooks 对象来显示与之前相同的消息。使用起来非常简单和方便。
当然,history对象和 React Router 整体还有更多功能,但这是对这些功能的一个很好的介绍,我们将在接下来的章节中开始构建我们的应用程序时使用更多这些特性。
路由是 Web 开发的重要部分。路由帮助用户了解他们在应用程序中的位置,并提供一种上下文的感觉。路由还帮助我们作为开发人员结构化应用程序的逻辑部分,并将相关项目组合在一起。React Router 通过提供许多编程功能,使我们能够将复杂的路由集成到我们的应用程序中。
总结
本章涵盖了一些最重要的与 React 相关的框架。Redux 是一个管理全局应用程序状态的复杂工具。React Router 提供了类似经典 Web URL 的客户端 URL 管理。
使用高质量的技术,如 Redux 和 React Router,将帮助我们编写更好的代码。这反过来将帮助我们为用户提供最佳体验。
我们已经到达了重点放在客户端技术的第二部分的结尾。现在我们将开始学习第三部分的服务器端技术。
第三部分:使用 Express 和 GraphQL 理解 Web 服务开发
在本节中,我们将学习 Web 服务的作用,并了解 Express 和 GraphQL 如何帮助我们构建高性能的服务。
本节包括以下章节:
-
第八章,使用 Node.js 和 Express 学习服务器端开发
-
第九章,什么是 GraphQL?
-
第十章,使用 TypeScript 和 GraphQL 依赖项设置 Express 项目
-
第十一章, 我们将学到什么 – 在线论坛应用
-
第十二章, 为我们的在线论坛应用构建 React 客户端
-
第十三章,使用 Express 和 Redis 设置会话状态
-
第十四章, 使用 TypeORM 设置 Postgres 和存储库层
-
第十五章,添加 GraphQL 模式 – 第一部分
-
第十六章,添加 GraphQL 模式 – 第二部分
-
第十七章, 将应用部署到 AWS
第八章:学习使用 Node.js 和 Express 进行服务器端开发
在本章中,我们将学习有关 Node 和 Express 的知识。我们将了解 Node 如何帮助我们创建高性能的 Web 服务。我们还将了解 Node 和 Express 之间的关系以及如何将它们一起使用来构建我们的 Web API。
在本章中,我们将涵盖以下主要主题:
-
理解 Node 的工作原理
-
学习 Node 的能力
-
理解 Express 如何改进 Node 开发
-
学习 Express 的能力
-
使用 Express 创建 Web API
技术要求
您应该对使用 JavaScript 进行 Web 开发有基本的了解。我们将再次使用 Node 和Visual Studio Code(VSC)。
GitHub 存储库再次位于github.com/PacktPublishing/Full-Stack-React-TypeScript-and-Node。使用Chap8文件夹中的代码。
要设置本章的代码文件夹,请转到本地的HandsOnTypescript文件夹并创建一个名为Chap8的新文件夹。
理解 Node 的工作原理
Node 是世界上最流行的 JavaScript 框架之一。它被用作数百万网站的核心技术。其原因有很多。它相对容易编码。它也非常快,当与诸如集群和工作线程之类的东西一起使用时,它非常可扩展。此外,由于它使用 JavaScript,它允许仅使用一种语言创建全栈应用程序,从前端到后端。所有这些特征使 Node 成为如果你的目标是网络的话一个绝佳选择。在本节中,我们将探讨 Node 的架构以及它如何实现强大的性能。
首先,重要的是要意识到 Node 不是一个特定于服务器的框架。它实际上是一个通用的运行时环境,而不仅仅是一个 Web 服务器。Node 为 JavaScript 提供了通常不具备的功能,例如访问文件系统和接受传入的网络连接。
为了解释 Node 的工作原理,让我们以 Web 浏览器作为类比。浏览器也是我们的 JavaScript 代码(以及 HTML 和 CSS)的运行时环境。浏览器通过具有核心 JavaScript 引擎来工作,该引擎提供基本级别的 JavaScript 语言功能。这包括一个语言解释器,用于读取我们的代码以获取有效的 JavaScript,以及一个在不同设备上运行我们的代码的虚拟机。
在这个核心之上,浏览器提供了一个安全的内存容器来运行应用程序,即沙盒。但它还提供了额外的 JavaScript 功能,通常称为 Web API(不是服务器端的,而是在浏览器级别)。Web API 增强了基本的 JavaScript 引擎,提供诸如文档对象模型(DOM)访问,以便 JavaScript 代码可以访问 HTML 文档并对其进行操作。它提供了诸如 fetch 之类的调用,允许异步网络调用到其他机器,以及用于图形的 WebGL 等等。您可以在这里看到完整的列表:developer.mozilla.org/en-US/docs/Web/API。
这些功能作为额外功能提供,超出了 JavaScript“开箱即用”的功能,如果你考虑一下,这是有道理的,因为在其核心,JavaScript 只是一种语言,因此不特定于任何特定平台,甚至是网络。
Node 遵循与浏览器类似的模型,因为它也使用核心 JavaScript 引擎(来自谷歌 Chrome 的 V8 引擎),并为我们的代码提供运行时容器。然而,由于它不是浏览器,它提供了不太专注于图形显示的不同附加功能。
那么,Node 是什么?Node 是一个专注于高性能和可扩展性的通用运行时环境。您可以使用 Node 构建许多类型的应用程序,包括计算机管理脚本和终端程序。但是 Node 的扩展能力也使其非常适合作为 Web 服务器。
Node 具有许多功能,使其作为编程运行时非常有能力,但其核心是libuv。Libuv 是一个用 C 编写的 Node 服务,它与操作系统内核进行接口,并提供异步输入/输出功能。为了及时访问这些服务,libuv 使用称为事件循环的东西,我们将很快解释,以处理这些任务。在 libuv 之上,Node 有一个类似于 Chrome 扩展的插件系统。它允许开发人员使用 C++扩展 Node,并添加默认情况下不存在的高性能功能。此外,为了允许开发人员继续使用 JavaScript 调用 C++,提供了一个称为 Addons 的 JavaScript 到 C++绑定系统。让我们更深入地探讨 libuv 和事件循环。
事件循环
Node 的核心是 libuv 和事件循环。这是使其扩展的主要功能。Libuv 的主要工作是提供对底层操作系统的异步输入/输出(I/O)功能的访问(Node 支持 Linux、macOS 和 Windows)。但是,这并不总是可能的,因此它还拥有一个线程池,可以通过在线程内运行它们来有效地使同步任务异步化。但是,Node 可扩展性的核心驱动程序是异步 I/O,而不是线程。运行计时器、允许网络连接、使用操作系统套接字和访问文件系统都来自 libuv。
那么,事件循环是什么?事件循环是 libuv 中的任务运行程序,类似于 Chrome 事件循环,以迭代方式运行异步回调任务。在高层次上,它是这样工作的。
当触发某些异步任务时,它们将由事件循环执行。事件循环以阶段或集合的形式进行处理。如下图所示,它首先运行计时器,如果已经排队了任何计时器回调,则按顺序执行它们(如果没有,它稍后返回,如果计时器已完成,则排队它们的回调)。然后,它处理任何挂起的回调(操作系统设置的回调-例如 TCP 错误),以此类推,依次进行阶段处理。请注意,如果由 libuv 执行,任务本质上是异步的,但回调本身可能不是。因此,可能会阻塞事件循环,因为它不会触发队列中的下一个回调,直到当前回调返回。以下是大致显示其工作原理的图表:
图 8.1-来自 Node 文档的节点事件循环
您还可以将阶段视为异步任务及其回调的类别。
所有框架都有其优势和劣势。Node 的主要优势在于异步 I/O 绑定的可扩展性。因此,Node 最适用于需要许多同时连接的高并发工作负载。在 Node 的后续版本中,从 10.5 开始,Node 团队确实引入了工作线程,以增加运行 CPU 绑定任务的多线程能力,这些任务主要是执行长时间运算。但是,这不是 Node 的主要优势。对于计算密集型工作负载,可能有更好的选择。但由于我们在 Node 的优先级是为我们的 React 前端创建一个高度可扩展的 API,Node 对我们的需求非常适用。
在下一节中,我们将开始深入挖掘 Node,编写 Node 代码,而不使用任何包装库,如 Express 或 Koa。这不仅会让我们更清楚地了解 Node 核心的工作原理,还将帮助我们更好地理解 Node 和 Express 之间的区别。
学习 Node 的能力
在上一节中,我们对 Node 是什么以及为什么它如此强大进行了高层次的概念性概述。在本节中,我们将开始利用这种可伸缩性,通过 Node 编写代码。我们将安装 Node,设置一个项目,并开始探索 Node API。
安装 Node
在我们可以使用 Node 编写代码之前,我们需要安装它。在前几章中,您可能已经这样做了,但让我们再次回顾如何安装它,因为 Node 经常更新:
- 前往
nodejs.org。以下截图显示了本书撰写时的页面:
图 8.2 – Node 网站
对于生产使用,您可能希望选择更保守的路线,并使用npm包管理器。
- 一旦您点击您选择的版本,您将被要求保存一个与您的操作系统匹配的安装包。保存该包,然后启动它。然后您应该会看到以下屏幕:
图 8.3 – Node 设置
按照设置窗口的指导完成安装。
很好,现在我们已经安装或更新了我们的 Node 运行时和npm包管理器。如前所述,Node 不仅是一个服务器框架,还是一个完整的运行时环境,允许您编写各种不同的应用程序。例如,Node 有一个名为 REPL 的命令行界面。如果您打开命令行或终端并输入node,您将看到它转换为接受 JavaScript 命令,就像这样:
图 8.4 – Node REPL
在本书中,我们将不使用 REPL,但我在这里包含它,以便您知道它的存在,并且可能对您未来的项目有用。您可以在官方文档中了解更多关于 REPL 的信息,nodejs.org/api/repl.html#repl_design_and_features。此外,如果您好奇,undefined是因为每个命令都没有返回任何内容,在 JavaScript 中,这总是undefined。
好的,现在,让我们创建我们的第一个 Node 应用程序,并探索一些 Node 的更多特性:
-
打开 VSCode,然后打开到
Chap8文件夹的终端。 -
然后,在
Chap8文件夹中创建一个名为try-node的新文件夹。 -
现在,创建一个名为
app.js的文件。现在让我们暂时不使用 TypeScript,以便我们可以保持简单。 -
然后,在
app.js中添加一个简单的控制台消息,如下所示:
console.log("hello world");
然后运行它:
node app.js
您应该会看到以下输出:
图 8.5 – 运行 app.js
这不是一个特别有用的应用程序,但是正如您所看到的,Node 正在运行标准的 JavaScript 代码。现在,让我们做一些更有用的事情。让我们使用以下步骤访问文件系统:
- 在同一个
app.js文件中,删除控制台消息并输入以下代码:
const fs = require("fs");
您可能会对这段代码感到困惑,因为它不是当前的导入风格。但我想在这里包含它,因为很多旧的 Node 代码仍然使用这种 CommonJS 风格的语法来导入依赖项。因此,您应该对此有所了解。
- 接下来,编写以下代码来创建一个文件,然后读取其内容:
fs.writeFile("test.txt", "Hello World", () => {
fs.readFile("test.txt", "utf8", (err, msg) => {
console.log(msg);
});
});
如果您运行此代码,您将看到以下输出,并在您的try-node文件夹中创建一个名为test.txt的文件:
const fs = require("fs/promises");
(async function () {
await fs.writeFile("test-promise.txt", "Hello Promises");
const readTxt = await fs.readFile("test-promise.txt", "utf-8");
console.log(readTxt);
})();
请注意,我们正在使用 IIFE 来允许我们进行顶层等待调用。
如果您使用的是较旧版本的 Node,fs/Promises 在 11 版本之后变得稳定,因此您可以使用一个名为promisify的工具来包装回调式调用,以使它们在async await风格中工作。
尽管如此,重要的是您要了解旧的回调式调用,因为这是历史上编写 Node 代码的方式,今天可能仍然有大量的 Node 代码保持这种风格。
- 我们在代码的顶部看到,我们使用
require来进行我们的fs导入。让我们切换到更新的导入语法。我们需要做两件事:将文件扩展名从.js改为.mjs,并更新require语句如下:
import fs from "fs";
如果再次运行app.mjs,您会发现它仍然有效。我们可以在package.json中设置配置标志"type":"module",但是对于这个示例应用程序,我们没有使用npm。另外,如果我们全局设置此标志,我们将无法再使用require。这可能是一个问题,因为一些较旧的npm依赖项仍然使用require进行导入。
注意
有一个名为--experimental-modules的旧命令行标志,允许使用import,但现在已经不推荐使用,应该避免在新版本的 Node 中使用。
创建一个简单的 Node 服务器
我们了解到 Node 是基于一些较旧的 JavaScript 技术构建的,如回调和 CommonJS。Node 是在 JavaScript Promise 和 ES6 等更新版本的 JavaScript 之前创建的。尽管如此,Node 仍然运行良好,持续更新,以后,当我们添加额外的库时,我们将能够在大多数情况下使用async await和 Promise。
现在,让我们来看一个更现实的 Node 服务器示例。我们将使用npm创建一个新项目:
-
在
Chap8的根目录下,创建一个名为node-server的新文件夹。 -
进入
node-server文件夹,并使用以下命令初始化npm:
npm init
-
让我们将我们的包名称命名为
node-server,并接受其他package.json属性的默认值。 -
在根目录下创建一个名为
server.mjs的新文件,并添加以下代码:
import http from "http";
别担心,我们很快就会开始使用 TypeScript。现在,让我们保持简单,这样我们就可以专注于学习 Node。
- 我们从 Node 核心导入了
http库。然后我们使用createServer来创建一个服务器对象。请注意,我们的createServer函数接受一个函数作为参数,带有两个参数。参数req和res分别是Request和Response类型。Request对象将具有与我们的用户所做的请求相关的所有成员,而响应允许我们在发送回去之前修改我们的响应。
在我们的createServer处理程序函数的末尾,我们通过使用res.end显式结束我们的调用并返回文本。如果我们没有发送end,我们的响应将永远不会完成,浏览器上也不会出现任何内容:
const server = http.createServer((req, res) => {
console.log(req);
res.end("hello world");
});
- 最后,我们使用我们的新服务器对象来等待并监听新的请求,使用带有端口号和回调函数的
listen函数打印服务器已启动:
const port = 8000;
server.listen(port, () => {
console.log(`Server started on port ${port}`);
});
- 通过执行我们的
server.mjs脚本来运行此代码(确保使用正确的扩展名.mjs):
node server.mjs
请记住,在我们工作时,当前没有自动重新加载功能。因此,在代码更改时,我们将不得不手动停止和重新启动。随着我们继续向我们的项目添加更多功能,我们将稍后添加这个功能。
- 如果你打开浏览器到
http://localhost:8000,你应该在浏览器中看到hello world,并在控制台中看到以下内容:
图 8.7 - 第一个 node 服务器运行
终端显示了req对象及其成员。当然,我们很快将更详细地介绍Request和Response。
另一个有趣的事情是,无论我们给出什么 URL,它总是返回相同的hello world文本。这是因为我们没有实现任何路由处理。处理路由是我们必须学习的另一项内容,以便正确使用 Node。
您可以不断刷新浏览器,服务器将继续以hello world进行响应。正如您所看到的,服务器保持运行,无论我们发送多少请求,而不像典型的脚本程序一样返回并结束。这是因为事件循环,Node 的核心,是一种无限循环,将继续等待新任务并忠实地处理它们。
恭喜,您现在已经运行了您的第一个 Node 服务器!毫无疑问,这只是一个谦卑的开始,但是您现在可以进行真正的浏览器调用,我们的服务器将做出响应。所以,您已经走上了正道。
请求和响应
当来自浏览器的请求到达服务器时,所有服务器框架通常都会有两个对象:Request和Response。这两个对象代表了来自浏览器的请求的相关数据,以及将返回给它的响应。让我们从浏览器的角度来看看这些对象是由什么组成的。重新加载您的浏览器,但这次在Network选项卡上打开 Chrome 开发工具:
图 8.8 – Chrome 开发工具网络选项卡
这个视图只是从浏览器的角度来看的,在 Node 中,这些对象中有更多的信息。然而,我们需要首先了解一个网络请求由什么组成,然后才能尝试创建任何真正的网络服务器。因此,让我们列出一些更重要的项目,并描述它们的含义。
请求 URL
显然,这代表了发送到服务器的完整 URL 路径。但服务器需要知道完整路径的原因是,URL 中通常会发送大量附加信息。例如,如果我们的 URL 是http://localhost:8000/home?userid=1,实际上这里有相当多的信息。首先,我们告诉服务器我们要在home子目录中寻找网页或 API 数据。这使得服务器能够根据 URL 返回响应,只返回 HTML 页面或特定于该 URL 的数据。此外,我们传递了一个名为userid的参数(参数在问号后开始,多个参数可以用&符号分隔),服务器可以使用该参数在请求中提供唯一的数据。
请求方法
请求方法表示所谓的 HTTP 动词。动词只是一个描述,告诉服务器客户端打算执行什么操作。默认动词是 GET,这意味着,正如名称所示,浏览器想要读取一些数据。其他动词是 POST,表示创建或插入,PUT 表示更新,然后 DELETE 表示删除。在第九章,什么是 GraphQL?中,我们将看到 GraphQL 只使用 POST 方法,但这实际上不是错误,因为动词不是硬性规则,而更像是指导方针。还有一件事需要注意的是,当使用 GET 时,所需的任何参数将在 URL 中提供,就像请求 URL 的项目示例所示的那样。然而,对于 POST,参数将在请求的正文中提供。我们将在学习 Express 功能部分更详细地讨论这些差异。
状态码
所有网络请求都将返回这些代码以指示请求的结果。例如,状态码200表示成功。我不会在这里列出所有的状态码,但我们应该了解一些最常见的状态码,因为有时这可能有助于调试:
图 8.9 – 错误代码
标头
标头提供了额外的信息,充当描述或元数据。如图所示,有多种类型的标头:通用、请求、响应和实体。再次强调,我不会涵盖所有的标头,但有一些我们应该熟悉。以下是请求标头:
图 8.10 – 请求标头
以下是响应标头:
图 8.11 – 响应标头
当然,这只是干燥的信息。然而,了解制作这些请求和响应所涉及的内容有助于我们更好地理解网络的工作原理,因此编写更好的网络应用程序。现在让我们更深入地看一下路由。
路由
在某种意义上,路由有点像向服务器传递参数。当服务器看到特定的路由时,它会知道响应需要以某种特定的方式进行。响应可以是返回一些特定的数据或将数据写入数据库,但有了路由,我们可以管理服务器对每个请求的行为方式。
让我们在 Node 中进行一些路由处理:
- 像这样在
node-server项目的server.mjs文件中更新server对象:
const server = http.createServer((req, res) => {
if (req.url === "/") {
res.end("hello world");
} else if (req.url === "/a") {
res.end("welcome to route a");
} else if (req.url === "/b") {
res.end("welcome to route b");
} else {
res.end("good bye");
}
});
如你所见,我们获取req.url字段并将其与几个 URL 进行比较。对于每一个匹配的 URL,我们用一些独特的文本结束我们的响应。
- 再次运行服务器并尝试每个路由。例如,如果你的路由是
http://localhost:8000/a,那么你应该看到这个:
图 8.12 - 路由/a
- 好的,现在让我们看看如果我们收到一个 POST 请求会发生什么。像这样更新你的
createServer函数:
const server = http.createServer((req, res) => {
if (req.url === "/") {
res.end("hello world");
} else if (req.url === "/a") {
res.end("welcome to route a");
} else if (req.url === "/b") {
res.end("welcome to route b");
} else if (req.url === "/c" && req.method === "POST") {
let body = [];
req.on("data", (chunk) => {
body.push(chunk);
});
req.on("end", () => {
const params = Buffer.concat(body);
console.log("body", params.toString());
res.end(`You submitted these parameters:
${params.toString()}`);
});
} else {
res.end("good bye");
}
});
正如你所看到的,我们添加了另一个带有/c路由和POST方法类型的if else语句。你可能会惊讶地发现,为了从我们的调用中获取发布的数据,我们需要处理data事件,然后处理end事件,以便我们可以返回调用。
让我解释一下这是怎么回事。Node 是非常低级的,这意味着它不会隐藏其复杂的细节以使事情变得更容易,以便更高效。因此,当发出请求并向服务器发送一些信息时,这些数据将作为流发送。这只是意味着数据不是一次性发送的,而是分成片段发送的。Node 不会向开发人员隐藏这一事实,并使用事件系统来接收数据的块,因为一开始不清楚有多少数据要进来。然后,一旦接收完这些数据,end事件就会触发。
在这个示例中,data事件用于将我们的数据聚合到一个数组中。然后,end事件用于将该数组放入内存缓冲区,然后可以作为一个整体进行处理。在我们的情况下,它只是 JSON,所以我们将其转换为字符串。
- 为了测试这个,让我们使用
curl提交一个 POST 请求。curl只是一个命令行工具,允许我们在不使用浏览器的情况下进行 web 服务器请求。这对测试很有用。在你的终端中执行以下代码(如果你在 Windows 上,你可能需要先安装curl;在 macOS 上,它应该已经存在):
curl --header "Content-Type: application/json" --request POST --data '{"userid":"1","message":"hello"}' "http://localhost:8000/c"
你应该得到以下返回:
图 8.13 - curl POST 的结果
显然,所有这些都有效,但从开发生产力的角度来看并不理想。我们不希望在单个createServer函数中有 30 个这样的if else语句。这很难阅读和维护。我们将看到 Express 如何帮助我们避免这些问题,它提供了额外的封装来加快开发速度并提高可靠性。我们将在了解 Express 如何改进 Node 开发部分看到这一点。让我们先了解一些工具来帮助我们的 Node 编码。
调试
就像我们在 React 中看到的那样,调试器是一个非常重要的工具,可以帮助我们排除代码中的问题。当然,在 Node 的情况下,我们不能使用浏览器工具,但 VSCode 确实有一个内置的调试器,可以让我们在代码上断点并查看值。让我们来看看这个,因为我们也将在 Express 中使用它:
- 点击 VSCode 中的调试器图标,你会看到以下屏幕。在撰写本文时的当前版本中,它看起来是这样的:
图 8.14 - VSCode 调试器菜单
第一个按钮运行调试器,第二个显示终端的调试器版本。运行调试器时,通常希望查看调试器控制台,因为它可以显示运行时发生的错误。
- 运行 VSCode 调试器时,你需要点击
npm start命令:
图 8.15 - Node.js 调试器选择
- 一旦启动调试器,如果您通过单击任何行号旁边设置了断点,您将能够在那里使代码暂停。然后,您可以查看与该范围相关的值:
图 8.16 – 行视图中断
正如您所见,我们已在data事件中的第 13 行设置了断点,并且能够查看当前块。点击继续按钮或点击F5继续运行程序。
- 悬停在断点上的值是有用的,但并不是帮助调试我们的应用程序的唯一方法。我们还可以使用调试器屏幕来帮助我们了解我们在断点停止时的值是什么。看一下下面的截图:
图 8.17 – 调试窗口全景视图
看看我们的断点,截图中间。我们可以看到我们已经在end事件处理程序范围内中断。让我们看一下列出的一些功能:
-
从左上角菜单开始,称为
params和this。同样,我们正在查看end事件,这就是为什么我们只有这两个变量。 -
在中间左侧,有
params,我添加了。在这个部分中有一个加号,允许我们添加我们感兴趣的变量,当它们进入范围时,当前值将显示在那里。 -
然后,在左下角,我们看到CALL STACK。调用堆栈是我们程序正在运行的调用列表。列表将以相反的顺序显示,最后一个命令位于顶部。通常,这些调用中的许多将是来自 Node 或我们自己没有编写的其他框架的代码。
-
然后,在右下角,我们有我们的
params变量和其缓冲区被显示。 -
最后,在右上角,我们看到了调试继续按钮。左侧的第一个按钮是继续按钮,它会从上一个断点继续运行我们的应用程序。接下来是步过按钮,它将转到下一个立即行并在那里停止。接下来是步入按钮,它将在函数或类的定义内部运行。然后是步出按钮,它将使您退出并返回到父调用者。最后,方形按钮完全停止我们的应用程序。
这是对 VSCode 调试器的一个快速介绍。随着我们进入 Express,然后稍后使用 GraphQL,我们将会更多地使用它。
现在,正如您所见,每次进行任何更改时都必须手动重新启动 Node 服务有点麻烦并且会减慢开发速度。因此,让我们使用一个名为nodemon的工具,它将在保存脚本更改时自动重新启动我们的 Node 服务器:
- 通过运行以下命令全局安装
nodemon:
nodemon to our entire system. Installing it globally allows all apps to run nodemon without needing to keep installing it. Note that on macOS and Linux, you may need to prefix this command with sudo, which will elevate your rights so that you can install it globally.
- 现在,我们希望在应用程序启动时启动它。通过找到
"scripts"部分并添加一个名为"start"的子字段,然后将以下命令添加到package.json文件中:
package.json "scripts" section should look like this now:Figure 8.18 – package.json "scripts" section
- 现在,使用以下命令运行新脚本:
npm command, you need to run npm run <file name>. However, for start scripts, we can skip the run sub-command.You should see the app start up as usual.
-
现在应用程序正在运行,让我们尝试更改并保存
server.mjs文件。将listen函数中的字符串更改为The server started on port ${port}。保存此更改后,您应该看到 Node 重新启动并在终端上显示新文本。 -
package.json中的设置不会影响我们的 VSCode 调试器。因此,为了设置自动重启,我们需要进行设置。再次转到调试器菜单,点击configurations字段是一个数组,这意味着您可以继续向这个文件添加配置。但是对于我们的配置,请注意type是node,当然。我们还将name更新为"Launch node-server Program"。但是,请注意,我们将runtimeExecutable切换为nodemon而不是node,console现在是集成终端。为了在调试器中使用nodemon,我们必须切换到TERMINAL选项卡,而不是调试器控制台。 -
现在我们至少有一个
launch.json配置,我们的调试菜单将显示以下视图:
图 8.20 - 从 launch.json 调试器
如果您的下拉菜单没有显示启动 node-server 程序,请选择它,然后按播放按钮。然后,您应该再次看到调试器启动,只是这次它将自动重新启动。
- 现在,尝试进行小的更改,调试器应该会自动重新启动。我从
listen函数的日志消息中删除了T:
图 8.21 - 调试器自动重新启动
- 太好了,现在我们可以轻松地中断和调试我们的 Node 代码!
这是一次快速介绍一些将有助于我们开发和调试的工具。
在本节中,我们学习了直接使用 Node 来编写我们的服务器。我们还学习了调试和工具,以改进我们的开发流程。直接使用 Node 进行编码可能会耗费时间,也不直观。在接下来的几节中,我们将学习 Express 以及它如何帮助我们改进 Node 开发体验。
了解 Express 如何改进 Node 开发
正如我们所见,直接使用 Node 进行编码具有一种笨拙和繁琐的感觉。拥有一个更易于使用的 API 将使我们更加高效。这就是 Express 框架尝试做的事情。在本节中,我们将学习 Express 是什么,以及它如何帮助我们更轻松地为我们的 Node 应用程序编写代码。
Express 不是一个独立的 JavaScript 服务器框架。它是一个代码层,位于 Node 之上,因此使用 Node 来使使用 Node 开发 JavaScript 服务器变得更加容易和更有能力。就像 Node 一样,它有自己的核心功能,然后通过依赖包提供一些额外的功能。Express 也有其核心能力以及提供额外功能的丰富中间件生态系统。
那么,Express 是什么?根据网站的说法,Express 只是一系列中间件调用的应用程序。让我们首先通过查看图表来解释这一点:
图 8.22 - Express 请求响应流程
每当有新的服务器请求到来时,它都会沿着顺序路径进行处理。通常,您只会有一个请求,一旦请求被理解和处理,您就会得到一些响应。然而,当使用 Express 时,您可以有多个中间函数插入到过程中并进行一些独特的工作。
因此,在图 8.22中所示的示例中,我们首先看到添加了 CORS 功能的中间件,这是一种允许来自与服务器所在的 URL 域不同的 URL 域的请求的方式。然后,我们有处理会话和 cookie 的中间件。会话只是关于用户当前使用网站的唯一数据 - 例如,他们的登录 ID。最后,我们看到一个处理错误的处理程序,它将根据发生的错误确定将显示的一些唯一消息。当然,您可以根据需要添加更多的中间件。这里的关键点是 Express 以相当简单的方式使 Node 通常不具备的额外功能注入成为可能。
除了这个中间件的能力之外,Express 还为Request和Response对象添加了额外的功能,进一步增强了开发人员的生产力。我们将在下一节中查看这些功能,并进一步探索 Express。
学习 Express 的能力
Express 基本上是 Node 的中间件运行器。但是,就像生活中的大多数事情一样,简单的解释很少提供必要的信息来正确使用它。因此,在本节中,我们将探索 Express,并通过示例了解其功能。
让我们将 Express 安装到我们的node-server项目中。在终端中输入以下命令:
npm I express -S
这将给你一个更新后的package.json文件,其中有一个新的依赖项部分:
图 8.23 – 更新的 package.json
现在,在我们开始编写代码之前,我们需要了解一些事情。再次提到,Express 是 Node 的封装。这意味着 Express 已经在内部使用了 Node。因此,当我们使用 Express 编写代码时,我们不会直接调用 Node。让我们看看这是什么样子的:
- 创建一个名为
expressapp.mjs的新服务器文件,并将以下代码添加到其中:
import express from "express";
const app = express();
app.listen({ port: 8000 }, () => {
console.log("Express Node server has loaded!");
});
正如你所看到的,我们创建了一个express实例,然后在其上调用了一个名为listen的函数。在内部,express.listen函数调用了 Node 的createServer和listen函数。如果你运行这个文件,你将会看到以下日志消息:
图 8.24 – 运行 expressapp.mjs 文件
因此,现在我们有一个正在运行的 Express 服务器。但是,在添加一些中间件之前,它什么也不做。Express 的中间件运行在几个主要的伞形或部分下。有一些中间件是为整个应用程序运行的,有一些是仅在路由期间运行的,还有一些是在错误时运行的。Express 还有一些内部使用的核心中间件。当然,我们可以使用npm包提供的第三方中间件,而不是实现我们自己的中间件代码。我们已经在前一节理解 Express 如何改进 Node 开发中的图 8.22中看到了其中一些。
- 让我们从添加我们自己的中间件开始。使用以下代码更新
expressapp.mjs:
import express from "express";
const app = express();
app.use((req, res, next) => {
console.log("First middleware.");
next();
});
app.use((req, res, next) => {
res.send("Hello world. I am custom middleware.");
});
app.listen({ port: 8000 }, () => {
console.log("Express Node server has loaded!");
});
因此,对于这个第一个例子,我们决定使用app对象上的应用级中间件,通过在app对象上使用use函数。这意味着无论路由如何,对于整个应用程序的任何请求,都必须处理这两个中间件。
让我们逐个来。首先,注意所有中间件都是按照在代码中声明的顺序进行处理的。其次,除非在中间件的最后结束调用,否则我们必须调用next函数去到下一个中间件,否则处理将会停止。
第一个中间件只是记录一些文本,但第二个中间件将使用 Express 的send函数在浏览器屏幕上写入内容。send函数很像 Node 中的end函数,因为它结束了处理,但它还发送了一个text/html类型的内容类型头。如果我们使用 Node,我们将不得不自己显式地发送头。
- 现在,让我们为路由添加中间件。请注意,从技术上讲,你可以将路由(例如
/routea路由)传递给use函数。然而,最好使用router对象,并将我们的路由包含在一个容器下。在 Express 中,路由器也是中间件。让我们看一个例子:
import express from "express";
const router = express.Router();
首先,我们从express.Router类型创建了我们的新router对象:
const app = express();
app.use((req, res, next) => {
console.log("First middleware.");
next();
});
app.use((req, res, next) => {
res.send("Hello world. I am custom middleware.");
});
app.use(router);
因此,我们像之前一样将相同的一组中间件添加到了app对象中,使其在所有路由上全局运行。但是,我们还将router对象作为中间件添加到了我们的应用中。然而,路由器中间件只对定义的特定路由运行:
router.get("/a", (req, res, next) => {
res.send("Hello this is route a");
});
router.post("/c", (req, res, next) => {
res.send("Hello this is route c");
});
因此,我们再次向我们的router对象添加了两个中间件:一个用于/a路由,使用get方法函数,另一个用于/c路由,使用post方法函数。同样,这些函数代表了可能的 HTTP 动词。listen函数调用与之前相同:
app.listen({ port: 8000 }, () => {
console.log("Express Node server has loaded!");
});
现在,如果我们通过访问以下 URL 运行这段代码:http://localhost:8000/a,将会发生一个奇怪的事情。所有调用都将在那里结束,不会继续到下一个中间件。
删除发送Hello world…消息的第二个app.use调用,尝试访问http://localhost:8000/a。现在你应该看到以下消息:

图 8.25-路由/ a 的中间件
很好,那起作用了,但现在尝试使用浏览器转到http://localhost:8000/c。那起作用吗?不,它不起作用,您会得到/c路由只能是 POST 路由。如果您打开终端并运行我们在学习节点的功能部分中使用的最后一个 POST curl命令,您会看到这个:

图 8.26-路由/ c
正如您所看到的,我们收到了适当的文本消息。
- 现在,让我们添加第三方中间件。在学习节点的功能部分,我们看到了如何解析 POST 数据以及使用 Node 可能会有多么艰难。对于我们的示例,让我们使用 body parser 中间件来使这个过程更容易。更新代码如下:
import express from "express";
/c route handler so that its text message shows the value passed in the message field:
app.use((req,res,next)= > {
控制台.log("第一个中间件。");
下一个;
});
app.use(路由器);
路由器获取("/a",(req,res,next)= > {
res.send("您好,这是路由 a");
});
路由器.post("/c",(req,res,next)= > {
res.send(`您好,这是路由 c。消息是
${数据和结束。
- 现在,最后,让我们做一个错误中间件。只需在
bodyParser.json()中间件调用下面添加以下代码:
import express from "express";
import bodyParser from "body-parser";
const router = express.Router();
const app = express();
app.use(bodyParser.json());
app.use((req, res, next) => {
console.log("First middleware.");
throw new Error("A failure occurred!");
});
然后,我们从我们的第一个自定义中间件中抛出一个错误:
app.use(router);
router.get("/a", (req, res, next) => {
res.send("Hello this is route a");
});
router.post("/c", (req, res, next) => {
res.send(`Hello this is route c. Message is ${req.body. message}`);
});
app.use((err, req, res, next) => {
res.status(500).send(err.message);
});
现在,我们已经将我们的错误处理程序添加为代码中的最后一个中间件。此中间件将捕获以前未处理的所有错误并发送相同的状态和消息:
app.listen({ port: 8000 }, () => {
console.log("Express Node server has loaded!");
});
- 转到
http://localhost:8000/a,您应该看到以下消息:

图 8.27-错误消息
由于我们的顶级中间件抛出异常,所有路由都将抛出此异常,因此将被我们的错误处理程序中间件捕获。
这是 Express 框架及其功能的概述。正如您所看到的,它可以使使用 Node 变得更加简单和清晰。在下一节中,我们将看看如何使用 Express 和 Node 构建返回 JSON 的 Web API,这是 Web 的默认数据模式。
使用 Express 创建 Web API
在本节中,我们将学习有关 Web API 的知识。目前,它是提供 Web 上数据的最流行方式之一。在我们的最终应用程序中,我们将不使用 Web API,因为我们打算使用 GraphQL。但是,了解 Web API 设计是很好的,因为在互联网上,它非常常用,并且在 GraphQL 的内部也类似地工作。
什么是 Web API? API代表应用程序编程接口。这意味着这是一个编程系统与另一个系统进行交互的方式。因此,Web API 是使用 Web 技术向其他系统提供编程服务的 API。Web API 以字符串形式发送和接收数据,而不是二进制数据,通常以 JSON 格式。
所有 Web API 都将具有由 URI 表示的端点,基本上与 URL 相同。此路径必须是静态的,不得更改。如果需要更改,则预期 API 供应商将进行版本更新,保留旧的 URI 并创建由版本升级界定的新 URI。例如,如果 URI 从/api/v1/users开始,那么下一个迭代将是/api/v2/users。
让我们为演示目的创建一个简单的 Web API:
- 让我们使用以下新路由更新我们的
expressapp.mjs文件:
import express from "express";
import bodyParser from "body-parser";
const router = express.Router();
const app = express();
app.use(bodyParser.json());
app.use((req, res, next) => {
console.log("First middleware.");
/api/v1/users path. This type of pathing is fairly standard for web APIs. It indicates the version and a related container of data to query – in this case, users. For example purposes, we are using a hardcoded array of users and finding only one with a matching ID. Since id is a number and anything coming from req.query is a string, we are using == as opposed to ===. If you load the browser to the URI, you should see this:Figure 8.28 – User GET requestAs you can see, our second user, `jon`, is returned.
- 接下来,对于此中间件,我们对组进行了几乎相同的操作。请注意资源路径之间的路径设置在两者之间是一致的。这是 Web API 的一个重要特性。同样,我们从数组中获取一个项目,但在这种情况下,我们使用了 POST 方法,因此参数是从正文中获取的:
router.post("/api/v1/groups", (req, res, next) => {
const groups = [
{
id: 1,
groupname: "Admins",
},
{
id: 2,
groupname: "Users",
},
{
id: 3,
groupname: "Employees",
},
];
const group = groups.find((grp) => grp.id == req.body. groupid);
res.send(`Group ${group.groupname}`);
});
如果您运行终端命令到此 URI,您应该会看到以下内容:

图 8.29-组 POST 请求
如所示,我们返回了第一个组Admins。其余代码相同:
app.use((err, req, res, next) => {
res.status(500).send(err.message);
});
app.listen({ port: 8000 }, () => {
console.log("Express Node server has loaded!");
});
重要说明
由于 Web API 特定于 Web 技术,它支持使用所有的 HTTP 方法进行调用:GET、POST、PATCH、PUT 和 DELETE。
这是一个关于使用 Express 和 Node 构建 Web API 的快速介绍。我们现在对 Node 及其最重要的框架 Express 有了一个广泛的概述。
总结
在本章中,我们学习了 Node 和 Express。Node 是驱动网络服务器的核心服务器端技术,Express 是构建 Web 应用程序的最流行和经常使用的基于 Node 的框架。我们现在对前端和后端技术如何共同创建网站有了完整的了解。
在下一章中,我们将学习 GraphQL,这是一种非常流行且相对较新的标准,用于创建基于 Web 的 API 服务。一旦我们掌握了这个知识,我们就可以开始构建我们的项目了。
第九章:什么是 GraphQL?
在本章中,我们将学习 GraphQL,这是目前最热门的 web 技术之一。许多大公司已经采用了 GraphQL 作为他们的 API,包括 Facebook、Twitter、纽约时报和 GitHub 等公司。我们将学习 GraphQL 为什么如此受欢迎,它内部是如何工作的,以及我们如何利用它的特性。
在本章中,我们将涵盖以下主要主题:
-
理解 GraphQL
-
理解 GraphQL 模式
-
理解类型定义和解析器
-
理解查询、变异和订阅
技术要求
你应该对使用 Node 进行 web 开发有基本的了解。我们将再次使用 Node 和 Visual Studio Code。
GitHub 存储库位于github.com/PacktPublishing/Full-Stack-React-TypeScript-and-Node。使用Chap9文件夹中的代码。
要设置Chap9代码文件夹,转到你的HandsOnTypescript文件夹并创建一个名为Chap9的新文件夹。
理解 GraphQL
在本节中,我们将探讨 GraphQL 是什么,为什么它被创建以及它试图解决什么问题。了解 GraphQL 存在的根本原因很重要,因为它将帮助我们设计更好的 web API。
那么,GraphQL 是什么?让我们列举一些它的主要特点:
- GraphQL 是 Facebook 开发的数据模式标准。
GraphQL 提供了一个标准语言来定义数据、数据类型和相关数据查询。你可以把 GraphQL 大致类比为提供合同的接口。那里没有代码,但你仍然可以看到可用的类型和查询。
- GraphQL 跨平台、框架和语言运行。
当我们使用 GraphQL 创建 API 时,无论我们使用什么编程语言或操作系统,都将使用相同的 GraphQL 语言来描述我们的数据、类型和查询。在各种系统和平台上拥有一致可靠的数据表示当然对客户端和系统来说是一件好事。但对程序员来说也是有益的,因为我们可以继续使用我们正常的编程语言和选择的框架。
- GraphQL 将查询的控制权交给调用者。
在标准 web 服务中,是服务器控制返回的数据字段。然而,在 GraphQL API 中,是客户端确定他们想要接收哪些字段。这给客户端更好的控制权,减少了带宽使用和成本。
广义上说,GraphQL 端点有两个主要用途。一个是作为整合其他数据服务的网关,另一个是作为直接从数据存储接收数据并提供给客户端的主要 web API 服务。下面是一个使用 GraphQL 作为其他数据网关的图表:
图 9.1 - GraphQL 作为网关
正如你所看到的,GraphQL 作为所有客户端的唯一真相来源。它在这方面表现良好,因为它是基于标准的语言,支持各种系统。
对于我们自己的应用程序,我们将把它用作我们整个的 web API,但也可以将其与现有的 web 服务混合在一起,以便 GraphQL 仅处理正在进行的部分服务调用。这意味着你不需要重写整个应用程序。你可以逐渐有意识地引入 GraphQL,只在有意义的地方这样做,而不会干扰你当前的应用程序服务。
在这一部分,我们从概念层面上了解了 GraphQL。GraphQL 有自己的数据语言,这意味着它可以在不同的服务器框架、应用程序编程语言或操作系统上使用。这种灵活性使得 GraphQL 成为在整个组织甚至整个网络中共享数据的强大手段。在下一部分中,我们将探索 GraphQL 模式语言并了解它是如何工作的。这将帮助我们构建我们的数据模型并了解如何设置我们的 GraphQL 服务器。
理解 GraphQL 模式
正如所述,GraphQL 是一种用于为我们的实体数据提供结构和类型信息的语言。无论服务器上使用的是哪个供应商的 GraphQL 实现,我们的客户端都可以期望返回相同的数据结构。将服务器的实现细节抽象化给客户端是 GraphQL 的优势之一。
让我们创建一个简单的 GraphQL 模式并看看它是什么样子的:
-
在
Chap9文件夹中,创建一个名为graphql-schema的新文件夹。 -
在该文件夹中打开你的终端,然后运行这个命令,接受默认值:
npm init
- 现在安装这些包:
npm i express apollo-server-express @types/express
- 使用这个命令初始化 TypeScript:
tsconfig.json setting is strict.
- 创建一个名为
typeDefs.ts的新的 TypeScript 文件,并将其添加到其中:
import { gql } from "apollo-server-express";
这个导入获取了gql对象,它允许对 GraphQL 模式语言进行语法格式化和高亮显示:
const typeDefs = gql`
type User {
id: ID!
username: String!
email: String
}
type Todo {
id: ID!
title: String!
description: String
}
type Query {
getUser(id: ID): User
getTodos: [Todo!]
}
`;
这种语言相当简单,看起来很像 TypeScript。从顶部开始,首先我们有一个User实体,如type关键字所示。type是一个 GraphQL 关键字,表示正在声明某种结构的对象。正如你所看到的,User类型有多个字段。id字段的类型是ID!。ID类型是一个内置类型,表示一个唯一的值,基本上是某种 GUID。感叹号表示该字段不能为null,而没有感叹号表示它可以为null。接下来,我们看到username字段及其类型为String!,这当然意味着它是一个非空字符串类型。然后,我们有description字段,但它的类型是String,没有感叹号,所以它是可空的。
Todos类型具有类似的字段,但请注意Query类型。这表明即使查询在 GraphQL 中也是类型。因此,如果你查看两个查询,getUser和getTodos,你可以看到为什么我们创建了User和Todos类型,因为它们成为我们两个Query方法的返回值。还要注意getTodos函数返回一个非空的Todos数组,这由括号表示。最后,我们使用typeDefs变量导出我们的类型定义:
export default typeDefs;
类型定义被 Apollo GraphQL 用来描述模式文件中的模式类型。在你的服务器可以开始提供任何 GraphQL 数据之前,它必须首先有一个完整的模式文件,列出你应用程序的所有类型、它们的字段和将在其 API 中提供的查询。
另一个需要注意的是,GraphQL 有几种默认的标量类型内置到语言中。这些是Int、Float、String、Boolean和ID。正如你在模式文件中注意到的,我们不需要为这些类型创建类型标记。
在这一部分,我们回顾了一个简单的 GraphQL 模式文件是什么样子。在下一部分中,我们将深入了解 GraphQL 语言,并学习解析器是什么。
理解类型定义和解析器
在这一部分,我们将进一步探讨 GraphQL 模式,但我们也将实现解析器,这些解析器是实际工作的函数。这一部分还将向我们介绍 Apollo GraphQL 以及如何创建一个 GraphQL 服务器实例。
解析器是什么?解析器是从我们的数据存储中获取或编辑数据的函数。然后将这些数据与 GraphQL 类型定义进行匹配。
为了更深入地了解解析器的作用,我们需要继续构建我们之前的项目。让我们看看步骤:
- 安装依赖 UUID。这个工具将允许我们为我们的
ID类型创建一个唯一的 ID:
npm i uuid @types/uuid
- 创建一个名为
server.ts的新文件,它将启动我们的服务器,使用这段代码:
import express from "express";
import { ApolloServer, makeExecutableSchema } from "apollo-server-express";
import typeDefs from "./typeDefs";
import resolvers from "./resolvers";
在这里,我们导入了设置服务器所需的依赖项。我们已经创建了typeDefs文件,很快我们将创建resolvers文件。
- 现在我们创建我们的 Express 服务器
app对象:
const app = express();
makeExecutableSchema从我们的typeDefs文件和resolvers文件的组合构建了一个程序化的模式:
const schema = makeExecutableSchema({ typeDefs, resolvers });
- 最后,我们创建了一个 GraphQL 服务器的实例:
const apolloServer = new ApolloServer({
schema,
context: ({ req, res }: any) => ({ req, res }),
});
apolloServer.applyMiddleware({ app, cors: false });
context由 Express 的请求和响应对象组成。然后,我们添加了我们的中间件,对于 GraphQL 来说,就是我们的 Express 服务器对象app。cors选项表示禁用 GraphQL 作为我们的 CORS 服务器。随着我们构建应用程序,我们将在后面的章节中讨论 CORS。
在这段代码中,我们现在通过监听端口8000启动我们的 Express 服务器:
app.listen({ port: 8000 }, () => {
console.log("GraphQL server ready.");
});
listen处理程序只是记录一条消息来宣布它已经启动。
现在让我们创建我们的解析器:
- 创建
resolvers.ts文件,并将这段代码添加到其中:
import { IResolvers } from "apollo-server-express";
import { v4 } from "uuid";
import { GqlContext } from "./GqlContext";
interface User {
id: string;
username: string;
description?: string;
}
interface Todo {
id: string;
title: string;
description?: string;
}
- 由于我们使用 TypeScript,我们希望使用类型来表示我们返回的对象,这就是
User和Todo代表的。这些类型将与我们在typeDefs.ts文件中创建的同名的 GraphQL 类型相匹配:
const resolvers: IResolvers = {
Query: {
getUser: async (
obj: any,
args: {
id: string;
},
ctx: GqlContext,
info: any
): Promise<User> => {
return {
id: v4(),
username: "dave",
};
},
这是我们的第一个解析器函数,匹配getUser查询。请注意,参数不仅仅是id参数。这是来自 Apollo GraphQL 服务器的,为我们的调用添加了额外的信息。(请注意,为了节省时间,我硬编码了一个User对象。)另外,我们稍后将创建GqlContext类型,但基本上,它是一个容器,保存了我们在*第八章**中学到的请求和响应对象。
- 类似于
getUser,我们的getTodos解析器接收类似的参数,并返回一个硬编码的Todo集合:
getTodos: async (
parent: any,
args: null,
ctx: GqlContext,
info: any
): Promise<Array<Todo>> => {
return [
{
id: v4(),
title: "First todo",
description: "First todo description",
},
{
id: v4(),
title: "Second todo",
description: "Second todo description",
},
{
id: v4(),
title: "Third todo",
},
];
},
- 然后我们导出
resolvers对象:
},
};
export default resolvers;
正如你所看到的,我们的实际数据获取器只是普通的 TypeScript 代码。如果我们使用 Java 或 C#或任何其他语言,解析器也将是这些语言中的Create Read Update Delete (CRUD)操作。然后,GraphQL 服务器只是将数据实体模型转换为我们类型定义模式文件中的类型。
- 现在让我们创建我们的
GqlContext类型。创建一个名为GqlContext.ts的文件,并添加这段代码:
import { Request, Response } from "express";
export interface GqlContext {
req: Request;
res: Response;
}
这只是一个简单的 shell 界面,允许我们在 GraphQL 解析器调用中为我们的上下文提供类型安全性。正如你所看到的,这个类型包含了 Express 的Request和Response对象。
- 因此,现在我们需要将我们的代码编译成 JavaScript,因为我们使用的是 TypeScript。运行这个命令:
js versions of all the ts files.
- 现在我们可以运行我们的新代码;输入这个:
nodemon server.js
- 如果你去到 URL
http://localhost:8000/graphql,你应该会看到 GraphQL Playground 屏幕。这是 Apollo GraphQL 提供的一个查询测试页面,允许我们手动测试我们的查询。它看起来像这样:
图 9.2 - GraphQL 开发客户端
请注意,我已经运行了一个查询,它看起来像 JSON 并且在左边,结果也显示在右边,也是 JSON。如果你看左边的查询,我明确要求只返回id字段,这就是为什么只有id字段被返回。请注意,标准的结果格式是data > <function name> > <fields>。尝试运行getTodos查询作为测试。
- 另一个需要注意的是DOCS标签,它显示了所有可用的查询、变异和订阅(我们将在下一节中讨论这些)。它看起来像这样:
图 9.3 - DOCS 标签
- 最后,SCHEMA 标签显示了所有实体和查询的模式类型信息:
图 9.4 – SCHEMA 标签
如您所见,它看起来与我们的 typeDefs.ts 文件相同。
在本节中,我们通过运行一个小型的 GraphQL 服务器来查看解析器。解析器是使 GraphQL 实际运行的另一半。我们还看到了使用 Apollo GraphQL 库相对容易地运行一个小型的 GraphQL 服务器。
在下一节中,我们将更深入地研究查询,看看 mutations 和 subscriptions。
了解查询、mutations 和 subscriptions
在创建 GraphQL API 时,我们不仅想要获取数据:我们可能还想要写入数据存储或在某些数据发生变化时收到通知。在本节中,我们将看到如何在 GraphQL 中执行这两个操作。
让我们先看看如何使用 mutations 写入数据:
- 我们将创建一个名为
addTodo的 mutation,但为了使 mutation 更真实,我们需要一个临时数据存储。因此,我们将为测试目的创建一个内存数据存储。创建db.ts文件并将以下代码添加到其中:
import { v4 } from "uuid";
export const todos = [
{
id: v4(),
title: "First todo",
description: "First todo description",
},
{
id: v4(),
title: "Second todo",
description: "Second todo description",
},
{
id: v4(),
title: "Third todo",
},
];
我们刚刚将我们以前列表中的 Todos 添加到一个数组中,并将其导出。
- 现在我们需要更新我们的
typeDefs.ts文件以包含我们的新 mutation。更新如下:
import { gql } from "apollo-server-express";
const typeDefs = gql`
type User {
id: ID!
username: String!
email: String
}
type Todo {
id: ID!
title: String!
description: String
}
type Query {
getUser(id: ID): User
getTodos: [Todo!]
}
Mutation, which is where any queries that change data will reside. We also added our new mutation called addTodo.
- 现在我们想要添加我们的
addTodo解析器。将以下代码添加到您的resolvers.ts文件中:
Mutation: {
addTodo: async (
parent: any,
args: {
title: string;
description: string;
},
ctx: GqlContext,
info: any
): Promise<Todo> => {
todos.push({
id: v4(),
title: args.title,
description: args.description
});
return todos[todos.length - 1];
},
},
如您所见,我们有一个名为 Mutation 的新容器对象,里面是我们的 addTodo mutation。它具有与查询类似的参数,但此 mutation 将向 todos 数组添加一个新的 Todo。如果我们在 playground 中运行此代码,我们会看到这样:
图 9.5 – addTodo mutation 的 GraphQL playground
当我们的查询是 Query 类型时,我们可以省略查询前缀。但是,由于这是一个 mutation,我们必须包含它。如您所见,我们只返回 id 和 title,因为这是我们要求的全部内容。
现在让我们看一下订阅,这是一种在某些数据发生变化时收到通知的方式。让我们在我们的 addTodo 添加一个新的 Todo 对象时收到通知:
- 我们需要在 GraphQL 服务器的
context中添加一个PubSub类型的对象,这个对象允许我们订阅(要求在发生变化时收到通知)和发布(在发生变化时发送通知)。更新server.ts文件如下:
import express from "express";
import { PubSub type. Notice we also get createServer; we'll use that later.
- 这是我们的
pubsub对象,基于PubSub类型:
const app = express();
const pubsub = new PubSub();
- 现在我们将
pubsub对象添加到 GraphQL 服务器的context中,以便从我们的解析器中使用:
const schema = makeExecutableSchema({ typeDefs, resolvers });
const apolloServer = new ApolloServer({
schema,
context: ({ req, res }: any) => ({ req, res, pubsub }),
});
- 从 Node 直接创建一个
httpServer实例,然后在其上使用installSubscription Handlers函数。然后,当我们调用listen时,我们现在是在httpServer对象上调用listen,而不是在app对象上:
apolloServer.applyMiddleware({ app, cors: false });
const httpServer = createServer(app);
apolloServer.installSubscriptionHandlers(httpServer);
httpServer.listen({ port: 8000 }, () => {
console.log("GraphQL server ready." +
apolloServer.graphqlPath);
console.log("GraphQL subs server ready." +
apolloServer.subscriptionsPath);
});
- 现在让我们更新我们的
typeDefs.ts文件以添加我们的新 mutation。只需添加此类型:
type Subscription {
newTodo: Todo!
}
- 现在我们可以用新的订阅解析器更新我们的
resolvers.ts文件:
import { IResolvers } from "apollo-server-express";
import { v4 } from "uuid";
import { GqlContext } from "./GqlContext";
import { todos } from "./db";
interface User {
id: string;
username: string;
email?: string;
}
interface Todo {
id: string;
title: string;
description?: string;
}
NEW_TODO constant to act as the name of our new subscription. Subscriptions require a unique label, sort of like a unique key, so that they can be correctly subscribed to and published:
const resolvers: IResolvers = {
Query: {
getUser: async (
parent: any,
args: {
id: string;
},
ctx: GqlContext,
info: any
): Promise => {
return {
id: v4(),
用户名:"dave",
};
},
As you can see, nothing in our query changes, but it's included here for completeness:
getTodos: async (
parent: any,
args: null,
ctx: GqlContext,
info: any
): Promise<Array> => {
return [
{
id: v4(),
标题:"第一个待办事项",
描述:"第一个待办事项描述",
},
{
id: v4(),
标题:"第二个待办事项",
描述:"第二个待办事项描述",
},
{
id: v4(),
标题:"第三个待办事项",
},
];
},
},
Again, our query remains the same:
Mutation: {
addTodo: async (
parent: any,
args: {
标题: string;
描述: string;
},
ctx 对象,我们已将其解构为只使用 pubsub 对象,因为这是我们唯一需要的:
info: any
): Promise<Todo> => {
const newTodo = {
id: v4(),
title: args.title,
description: args.description,
};
todos.push(newTodo);
publish, which is a function to notify us when we have added a new Todo. Notice the newTodo object is being included in the publish call, so it can be provided to the subscriber later:
return todos[todos.length - 1];
},
},
Subscription: {
添加待办事项。请注意,我们的订阅 newTodo 不是一个函数。它是一个带有成员 subscribe 的对象:
},
},
};
export default resolvers;
其余部分与之前相同。
- 让我们尝试测试一下。首先,确保您已经用
tsc编译了您的代码,启动了服务器,并刷新了 playground。然后,在 playground 中打开一个新的标签页,输入这个订阅,然后点击播放按钮:
图 9.6 – 新的待办事项订阅
当您点击播放按钮时,什么也不会发生,因为还没有添加新的Todo。所以,让我们回到我们的addTodo标签页,添加一个新的Todo。一旦你做到了,回到newTodo标签页,你应该会看到这个:
图 9.7 – 新的待办事项订阅结果
正如你所看到的,这很有效,我们得到了新添加的Todo。
在本节中,我们学习了关于 GraphQL 查询、变更和订阅。我们将使用这些来构建我们的应用程序 API。因为 GraphQL 是一个行业标准,所有 GraphQL 客户端框架都可以与任何供应商的 GraphQL 服务器框架一起工作。此外,使用 GraphQL API 的客户端可以期望在服务器或供应商不同的情况下获得一致的行为和相同的查询语言。这就是 GraphQL 的力量。
总结
在本章中,我们探讨了 GraphQL 的强大和能力,这是创建 Web API 的最热门的新技术之一。GraphQL 是一种非常有能力的技术,而且,因为它是一个行业标准,我们总是可以期待在服务器、框架和语言之间获得一致的行为。
在下一章中,我们将开始整合我们迄今学到的技术,并使用 TypeScript、GraphQL 和辅助库创建一个 Express 服务器。
