

MongoDB 基础知识(四)
原文:
zh.annas-archive.org/md5/804E58DCB5DC268F1AD8C416CF504A25译者:飞龙
第七章:数据聚合
概述
本章向您介绍了聚合的概念及其在 MongoDB 中的实现。您将学习如何识别聚合命令的参数和结构,使用主要聚合阶段组合和操作数据,使用高级聚合阶段处理大型数据集,并优化和配置聚合以获得查询的最佳性能。
介绍
在之前的章节中,我们学习了与 MongoDB 交互的基础知识。通过这些基本操作(insert,update和delete),我们现在可以开始探索和操作我们的数据,就像操作任何其他数据库一样。我们还观察到,通过充分利用find命令选项,我们可以使用操作符来回答关于我们数据的更具体的问题。我们还可以在查询中进行排序、限制、跳过和投影,以创建有用的结果集。
在更简单的情况下,这些结果集可能足以回答您所需的业务问题或满足用例。然而,更复杂的问题需要更复杂的查询来解决。仅使用find命令解决这些问题将是非常具有挑战性的,并且可能需要多个查询或在客户端进行一些处理来组织或链接数据。
基本限制是当您的数据包含在两个单独的集合中。要找到正确的数据,您将不得不运行两个查询,而不是一个,将数据连接在客户端或应用程序级别。这可能看起来不是一个大问题,但随着应用程序或数据集的规模增加,性能和复杂性也会增加。在可能的情况下,最好让服务器来处理所有繁重的工作,只返回我们在单个查询中寻找的数据。这就是聚合管道的作用。
find命令。除此之外,聚合的管道结构允许开发人员和数据库分析师轻松、迭代地快速构建查询,处理不断变化和增长的数据集。如果您想在 MongoDB 中以规模完成任何重要的工作,您将需要编写复杂的多阶段聚合管道。在本章中,我们将学习如何做到这一点。
注意
在本章的整个过程中,包括的练习和活动都是针对一个场景的迭代。数据和示例都基于名为sample_mflix的 MongoDB Atlas 示例数据库。
考虑一个情景,一个电影公司正在举办年度经典电影马拉松,并试图决定他们应该播放什么电影。他们需要各种符合特定标准的热门电影来满足他们的客户群。公司已经要求你进行研究,确定他们应该展示哪些电影。在本章中,我们将使用聚合来检索给定一组复杂约束条件的数据,然后转换和操作数据,以创建新的结果,并用单个查询回答整个数据集的业务问题。这将帮助电影公司决定他们应该展示哪些电影来满足他们的客户。
值得注意的是,聚合管道足够强大,有许多方法可以完成相同的任务。本章涵盖的练习和活动只是解决所提出情景的一个解决方案,并且可以使用不同的模式来解决。掌握聚合管道的最佳方法是考虑多种方法来解决同一个问题。
聚合是新的查找
MongoDB 中的aggregate命令类似于find命令。您可以以 JSON 文档的形式提供查询的条件,并输出包含搜索结果的cursor。听起来很简单,对吧?那是因为它确实如此。尽管聚合可能变得非常庞大和复杂,但在其核心,它们是相对简单的。
聚合中的关键元素称为管道。我们将很快详细介绍它,但在高层次上,管道是一系列指令,其中每个指令的输入是前一个指令的输出。简而言之,聚合是一种以程序方式从集合中获取数据,并进行过滤、转换和连接其他集合的方法,以创建新的有意义的数据集。
聚合语法
aggregate命令与其他创建、读取、更新、删除(CRUD)命令一样,操作在集合上,如下所示:
use sample_mflix;
var pipeline = [] // The pipeline is an array of stages.
var options = {} // We will explore the options later in the chapter.
var cursor = db.movies.aggregate(pipeline, options);
聚合使用了两个参数。pipeline参数包含了查找、排序、投影、限制、转换和聚合数据的所有逻辑。pipeline参数本身作为 JSON 文档数组传递。您可以将其视为要发送到数据库的一系列指令,然后在最终阶段之后产生的数据存储在cursor中返回给您。管道中的每个阶段都是独立完成的,依次进行,直到没有剩余的阶段。第一个阶段的输入是集合(在上面的示例中是movies),每个后续阶段的输入是前一个阶段的输出。
第二个参数是options参数。这是可选的,允许您指定配置的细节,比如聚合应该如何执行或者在调试和构建管道过程中需要的一些标志。
aggregate命令中的参数比find命令中的参数少。我们将在本章的最后一个主题中介绍options,所以现在我们可以通过完全排除options来简化我们的命令,如下所示:
var cursor = db.movies.aggregate(pipeline);
在上面的示例中,我们首先将管道保存为变量,而不是直接将管道写入命令中。聚合管道可能会变得非常庞大,在开发过程中难以解析。将管道(甚至管道的大部分)分开为单独的变量以提高代码清晰度有时可能会有所帮助。虽然建议这样做,但这种模式完全是可选的,类似于以下内容:
var cursor = db.movies.aggregate([])
建议您在代码或文本编辑器中跟随这些示例,保存您的脚本,然后将其复制粘贴到 MongoDB shell 中。例如,假设我们创建了一个名为aggregation.js的文件,内容如下:
var MyAggregation_A = function() {
print("Running Aggregation Script Ch7.1");
var pipeline = [];
// This next line stores our result in a cursor.
var cursor = db.movies.aggregate(pipeline);
// This line will print the next iteration of our cursor.
printjson(cursor.next())
};
MyAggregation_A();
然后,将此代码直接复制到 MongoDB shell 中,将返回以下输出:
图 7.1:聚合结果(为简洁起见输出被截断)
我们可以看到,在定义了MyAggregation_A.js函数之后,我们只需要再次调用该函数即可查看我们聚合的结果(在本例中是电影列表)。您可以一遍又一遍地调用这个函数,而无需每次都写整个管道。
通过以这种方式构建聚合,您将不会丢失任何聚合。它还有一个额外的好处,可以让您将所有聚合作为函数交互地加载到 shell 中。但是,如果您愿意,也可以将整个函数复制粘贴到 MongoDB shell 中,或者直接交互输入。在本章中,我们将两种方法混合使用。
聚合管道
如前所述,聚合中的关键元素是管道,它是对初始集合执行的一系列指令。您可以将数据视为流经此管道的水,在每个阶段进行转换和过滤,直到最终作为结果倒出管道的末端。
在下图中,橙色块代表聚合管道。管道中的每个块都被称为聚合阶段:
图 7.2:聚合管道
关于聚合的一点需要注意的是,虽然管道始终以一个集合开始,但使用某些阶段,我们可以在管道中进一步添加集合。我们将在本章后面讨论加入集合。
大型多阶段管道可能看起来令人生畏,但是如果您了解命令的结构以及可以在给定阶段执行的各个操作,那么您可以轻松地将管道分解为较小的部分。在本主题中,我们将探讨聚合管道的构建,比较使用find实现的查询与使用aggregate创建的查询,并识别一些基本操作符。
管道语法
聚合管道的语法非常简单,就像aggregate命令本身一样。管道是一个数组,数组中的每个项都是一个对象:
var pipeline = [
{ . . . },
{ . . . },
{ . . . },
];
数组中的每个对象代表整个管道中的单个阶段,阶段按其数组顺序(从上到下)执行。每个阶段对象采用以下形式:
{$stage : parameters}
该阶段代表我们要对数据执行的操作(如limit或sort),参数可以是单个值或另一个对象,具体取决于阶段。
管道可以通过两种方式传递,可以作为保存的变量,也可以直接作为命令。以下示例演示了如何将管道作为变量传递:
var pipeline = [
{ $match: { "location.address.state": "MN"} },
{ $project: { "location.address.city": 1 } },
{ $sort: { "location.address.city": 1 } },
{ $limit: 3 }
];
然后,在 MongoDB shell 中键入db.theaters.aggregate(pipeline)命令将提供以下输出:
MongoDB Enterprise atlas-nb3biv-shard-0:PRIMARY> var pipeline = [
... { $match: { "location.address.state": "MN"} },
... { $project: { "location.address.city": 1 } },
... { $sort: { "location.address.city": 1 } },
... { $limit: 3 }
... ];
MongoDB Enterprise atlas-nb3biv-shard-0:PRIMARY>
MongoDB Enterprise atlas-nb3biv-shard-0:PRIMARY> db.theaters.aggregate(pipeline)
{ "_id" : ObjectId("59a47287cfa9a3a73e51e94f"), "location" : { "address" : { "city" : "Apple Valley" } } }
{ "_id" : ObjectId("59a47287cfa9a3a73e51eb8f"), "location" : { "address" : { "city" : "Baxter" } } }
{ "_id" : ObjectId("59a47286cfa9a3a73e51e833"), "location" : { "address" : { "city" : "Blaine" } } }
MongoDB Enterprise atlas-nb3biv-shard-0:PRIMARY>
直接将其传递到命令中,输出如下:
MongoDB Enterprise atlas-nb3biv-shard-0:PRIMARY> db .theaters.aggregate([
... ... { $match: { "location.address.state": "MN"} },
... ... { $project: { "location.address.city": 1 } },
... ... { $sort: { "location.address.city": 1 } },
... ... { $limit: 3 }
... ... ]
... );
{ "_id" : ObjectId("59a47287cfa9a3a73e51e94f"), "location" : { "address" : { "city" : "Apple Valley" } } }
{ "_id" : ObjectId("59a47287cfa9a3a73e51eb8f"), "location" : { "address" : { "city" : "Baxter" } } }
{ "_id" : ObjectId("59a47286cfa9a3a73e51e833"), "location" : { "address" : { "city" : "Blaine" } } }
MongoDB Enterprise atlas-nb3biv-shard-0:PRIMARY>
如您所见,使用任一方法都会得到相同的输出。
创建聚合
让我们开始探索管道本身。将以下代码粘贴到 MongoDB shell 中,将帮助我们获取明尼苏达州(MN)所有剧院的列表:
var simpleFind = function() {
// Find command using filter, project, sort and limit.
print("Find Result:")
db.theaters.find(
{"location.address.state" : "MN"},
{"location.address.city" : 1})
.sort({"location.address.city": 1})
.limit(3)
.forEach(printjson);
}
simpleFind();
这将给我们以下输出:
MongoDB Enterprise atlas-nb3biv-shard-0:PRIMARY> simpleFind();
Find Result:
{
"_id" : ObjectId("59a47287cfa9a3a73e51e94f"),
"location" : {
"address" : {
"city" : "Apple Valley"
}
}
}
{
"_id" : ObjectId("59a47287cfa9a3a73e51eb8f"),
"location" : {
"address" : {
"city" : "Baxter"
}
}
}
{
"_id" : ObjectId("59a47286cfa9a3a73e51e7e2"),
"location" : {
"address" : {
"city" : "Blaine"
}
}
}
这个语法现在应该看起来非常熟悉。这是一个非常简单的命令,让我们看看涉及的步骤:
-
匹配剧院收集以获取
MN(明尼苏达州)州内所有剧院的列表。 -
只投影剧院所在的城市。
-
按
city名称对列表进行排序。 -
将结果限制为前
三个剧院。
让我们将此命令重建为聚合。如果一开始看起来有点令人生畏,不要担心。我们将逐步进行解释:
var simpleFindAsAggregate = function() {
// Aggregation using match, project, sort and limit.
print ("Aggregation Result:")
var pipeline = [
{ $match: { "location.address.state": "MN"} },
{ $project: { "location.address.city": 1 } },
{ $sort: { "location.address.city": 1 } },
{ $limit: 3 }
];
db.theaters.aggregate(pipeline).forEach(printjson);
};
simpleFindAsAggregate();
您应该看到以下输出:
图 7.3:聚合结果(为简洁起见输出被截断)
如果您运行这两个函数,将会得到相同的结果。请记住,find和aggregate命令都返回一个游标,但我们在最后使用.forEach(printjson);将它们打印到控制台以便理解。
如果您观察前面的示例,应该能够从find中匹配出大部分相同的功能。project、sort和limit都以 JSON 文档的形式存在,就像在find命令中一样。这些的唯一显着差异是它们现在是数组中的文档,而不是函数。我们管道开头的$match阶段相当于我们的过滤文档。因此,让我们逐步分解它:
- 首先,搜索剧院收集,以查找与州
MN匹配的文档:
{ $match: { "location.address.state": "MN"} },
- 将此剧院列表传递到第二阶段,该阶段仅投影所选州内剧院所在的城市:
{ $project: { "location.address.city": 1 } },
- 然后将这个城市(和 ID)列表传递到
sort阶段,按城市名称按字母顺序排序数据:
{ $sort: { "location.address.city": 1 } },
- 最后,列表传递到
limit阶段,仅输出前三个条目:
{ $limit: 3 }
相当简单,对吧?您可以想象这个管道在生产中可能会变得多么庞大和复杂,但它的一个优点是能够将大型管道分解为较小的子部分或单个阶段。通过逐个和顺序地查看阶段,看似难以理解的查询可以变得相当简单。同样重要的是要注意,步骤的顺序与阶段本身一样重要,不仅在逻辑上,而且在性能上也是如此。$match和$project阶段首先执行,因为这些将在每个阶段减少结果集的大小。虽然不适用于每种类型的查询,但通常最好的做法是尽早尝试减少您正在处理的文档数量,忽略任何会给服务器增加过大负载的文档。
尽管管道结构本身很简单,但是需要更复杂的阶段和运算符来完成高级聚合,并对其进行优化。在接下来的几个主题中,我们将看到许多这样的内容。
练习 7.01:执行简单的聚合
在开始这个练习之前,让我们回顾一下介绍中概述的电影公司,该公司每年都会举办经典电影马拉松。在以前的几年里,他们在最终手工合并所有数据之前,对几个子类别使用了手动流程。作为这项任务的初始研究的一部分,您将尝试将他们的一个较小的手动流程重新创建为 MongoDB 聚合。这个任务将使您更熟悉数据集,并为更复杂的查询打下基础。
您决定重新创建的流程如下:
“返回按 IMDb 评分排序的前三部爱情类型电影,并且只返回 2001 年之前发布的电影”
可以通过执行以下步骤来完成:
-
将您的查询转换为顺序阶段,这样您就可以将其映射到聚合阶段:限制为三部电影,仅匹配爱情电影,按 IMDb 评分排序,并且仅匹配 2001 年之前发布的电影。
-
尽可能简化您的阶段,通过合并重复的阶段来简化。在这种情况下,您可以合并两个匹配阶段:限制为三部电影,按 IMDb 评分排序,并匹配 2001 年之前发布的爱情电影。
重要的是要记住,阶段的顺序是至关重要的,除非我们重新排列它们,否则将产生错误的结果。为了演示这一点,我们将暂时保留它们的错误顺序。
- 快速查看电影文档的结构,以帮助编写阶段:
db.movies.findOne();
文档如下所示:
图 7.4:查看文档结构(输出被截短以保持简洁)
对于这个特定的用例,您将需要imdb.rating、released和genres字段。现在您知道您要搜索什么,可以开始编写您的管道了。
- 创建一个名为
Ch7_Activity1.js的文件,并添加以下基本阶段:limit以将输出限制为三部电影,sort以按其评分对其进行排序,并且match以确保您只找到 2001 年之前发布的爱情电影:
// Ch7_Exercise1.js
var findTopRomanceMovies = function() {
print("Finding top Classic Romance Movies...");
var pipeline = [
{ $limit: 3 }, // Limit to 3 results.
{ $sort: {"imdb.rating": -1}}, // Sort by IMDB rating.
{ $match: {. . .}}
];
db.movies.aggregate(pipeline).forEach(printjson);
}
findTopRomanceMovies();
$match运算符的功能与find命令中的过滤参数非常相似。您可以简单地传入两个条件而不是一个。
- 对于
早于 2001 年的条件,使用$lte运算符:
// Ch7_Exercise1.js
var findTopRomanceMovies = function() {
print("Finding top Classic Romance Movies...");
var pipeline = [
{ $limit: 3 }, // Limit to 3 results.
{ $sort: {"imdb.rating": -1}}, // Sort by IMDB rating.
{ $match: {
genres: {$in: ["Romance"]}, // Romance movies only.
released: {$lte: new ISODate("2001-01-01T00:00: 00Z") }}},
];
db.movies.aggregate(pipeline).forEach(printjson);
}
findTopRomanceMovies();
因为genres字段是一个数组(电影可以属于多种类型),您必须使用$in运算符来查找包含您所需值的数组。
- 现在运行这个管道;您可能会注意到它不返回任何文档:
MongoDB Enterprise atlas-nb3biv-shard-0:PRIMARY> findTopRomanceMovies();
Finding top Classic Romance Movies...
MongoDB Enterprise atlas-nb3biv-shard-0:PRIMARY>
是否可能没有文档满足这个查询?当然,可能没有电影满足所有这些要求。然而,正如你可能已经猜到的那样,在这里并非如此。正如前面所述,导致产生误导结果的是管道的顺序。因为你的限制阶段是管道中的第一个阶段,你只能查看三个文档,后续阶段没有足够的数据来找到匹配。因此,记住这一点总是很重要:
在编写聚合管道时,操作的顺序很重要。
因此,重新排列它们,确保你只在管道的末尾限制你的文档。由于命令的类似数组结构,这是相当容易的:只需剪切限制阶段,然后粘贴到管道的末尾。
- 安排阶段,使限制发生在最后,不会产生不正确的结果:
// Our new pipeline.
var pipeline = [
{ $sort: {"imdb.rating": -1}}, // Sort by IMDB rating.
{ $match: {
genres: {$in: ["Romance"]}, // Romance movies only.
released: {$lte: new ISODate("2001-01-01T00:00: 00Z") }}},
{ $limit: 3 }, // Limit to 3 results (last stage)
];
- 在更改后重新运行这个查询。这次,文档被返回:
图 7.5:有效文档返回的输出(为简洁起见,输出被截断)
这是编写聚合管道的挑战之一:这是一个迭代过程,当处理大量复杂文档时可能会很麻烦。
缓解这一痛点的一种方法是在开发过程中添加简化数据的阶段,然后在最终查询中删除这些阶段。在这种情况下,你将添加一个阶段,只投影你正在查询的数据。这将使你更容易判断你是否捕捉到了正确的条件。在这样做时,你必须小心,不要影响查询的结果。我们将在本章后面更详细地讨论这个问题。现在,你可以简单地在最后添加投影阶段,以确保它不会干扰你的查询。
- 在管道的末尾添加一个投影阶段来帮助调试你的查询:
var pipeline = [
{ $sort: {"imdb.rating": -1}}, // Sort by IMDB rating.
{ $match: {
genres: {$in: ["Romance"]}, // Romance movies only.
released: {$lte: new ISODate("2001-01-01T00:00:00Z") }}},
{ $limit: 3 }, // Limit to 3 results.
{ $project: { genres: 1, released: 1, "imdb.rating": 1}}
];
- 再次运行这个查询,你会看到一个更短、更容易理解的输出,如下面的代码块所示:
图 7.6:前面片段的输出
如果你是从桌面上的文件运行代码,请记住,你可以直接将整个代码片段(如下所示)复制并粘贴到你的 shell 中:
// Ch7_Exercise1.js
var findTopRomanceMovies = function() {
print("Finding top Classic Romance Movies...");
var pipeline = [
{ $sort: {"imdb.rating": -1}}, // Sort by IMDB rating.
{ $match: {
genres: {$in: ["Romance"]}, // Romance movies only.
released: {$lte: new ISODate("2001-01-01T00:00: 00Z") }}},
{ $limit: 3 }, // Limit to 3 results.
{ $project: { genres: 1, released: 1, "imdb.rating": 1}}
];
db.movies.aggregate(pipeline).forEach(printjson);
}
findTopRomanceMovies();
输出应该如下:
图 7.7:2001 年之前发布的经典浪漫电影排行榜
你还可以看到返回的每部电影都是浪漫类别的,2001 年之前发布的,并且具有较高的 IMDb 评分。因此,在这个练习中,你成功地创建了你的第一个聚合管道。现在,让我们拿刚刚完成的管道,努力改进一下。当你相信你已经完成了一个管道时,询问自己通常是有帮助的:
“我能减少通过管道传递的文档数量吗?”
在下一个练习中,我们将尝试回答这个问题。
练习 7.02:聚合结构
把管道想象成一个多层漏斗。它从顶部开始变宽,向底部变窄。当你把文档倒入漏斗顶部时,有很多文档,但随着你向下移动,这个数字在每个阶段都在减少,直到只有你想要的文档在底部输出。通常,实现这一点的最简单方法是先进行匹配(过滤)。
在这个管道中,你将对集合中的所有文档进行排序,并丢弃不匹配的文档。你目前正在对不需要的文档进行排序。交换这些阶段:
- 交换
match和sort阶段以提高管道的效率:
var pipeline = [
{ $match: {
genres: {$in: ["Romance"]}, // Romance movies only.
released: {$lte: new ISODate("2001-01-01T00:00: 00Z") }}},
{ $sort: {"imdb.rating": -1}}, // Sort by IMDB rating.
{ $limit: 3 }, // Limit to 3 results.
{ $project: { genres: 1, released: 1, "imdb.rating": 1}}
];
另一个需要考虑的事情是,虽然你有一个符合条件的电影列表,但你希望你的结果对你的用例有意义。在这种情况下,你希望你的结果对查看这些数据的电影公司有意义和用处。他们可能最关心电影的标题和评分。他们可能还希望看到电影是否符合他们的要求,所以最后让我们将这些投影出来,丢弃所有其他属性。
- 在投影阶段添加电影
title字段。你的最终聚合应该是这样的:
// Ch7_Exercise2.js
var findTopRomanceMovies = function() {
print("Finding top Classic Romance Movies...");
var pipeline = [
{ $match: {
genres: {$in: ["Romance"]}, // Romance movies only.
released: {$lte: new ISODate("2001-01-01T00:00: 00Z") }}},
{ $sort: {"imdb.rating": -1}}, // Sort by IMDB rating.
{ $limit: 3 }, // Limit to 3 results.
{ $project: { title: 1, genres: 1, released: 1, "imdb.rating": 1}}
];
db.movies.aggregate(pipeline).forEach(printjson);
}
findTopRomanceMovies();
- 通过复制并粘贴 步骤 2 中的代码重新运行你的管道。你应该看到排名前两的电影是
傲慢与偏见和阿甘正传:
图 7.8:前面片段的输出
如果你看到这些结果,你刚刚优化了你的第一个聚合管道。
正如你所看到的,聚合管道是灵活、强大且易于操作的,但你可能会认为对于这种用例来说似乎有点过于复杂,可能大多数情况下一个简单的 find 命令就能解决问题。的确,聚合管道并不是每个简单查询都需要的,但你只是刚刚开始。在接下来的几节中,你将看到 aggregate 命令提供了 find 命令所不具备的功能。
数据操作
我们大部分的活动和示例都可以归结为以下几点:在一个集合中有一个或多个文档应该以一种简单易懂的格式返回一些或所有文档。在本质上,find 命令和聚合管道只是关于识别和获取正确的文档。然而,聚合管道的能力要比 find 命令更加强大和广泛。
使用管道中一些更高级的阶段和技术可以让我们转换我们的数据,衍生新的数据,并在更广泛的范围内生成见解。聚合命令的这种更广泛的实现比仅仅将一个 find 命令重写为一个管道更为常见。如果你想要回答复杂的问题或从你的数据中提取最大可能的价值,你需要知道如何实现聚合管道的聚合部分。
毕竟,我们甚至还没有开始聚合任何数据。在这个主题中,我们将探讨如何开始转换和聚合你的数据的基础知识。
分组阶段
正如你从名称中期望的那样,$group 阶段允许你根据特定条件对文档进行分组(或聚合)。虽然有许多其他阶段和方法可以使用 aggregate 命令来完成各种任务,但是 $group 阶段是最强大查询的基石。以前,我们能够返回的最重要的数据单元是一个文档。我们可以对这些文档进行排序,通过直接比较文档来获得洞察力。然而,一旦我们掌握了 $group 阶段,我们就能够通过将文档聚合成大的逻辑单元来增加我们查询的范围到整个集合。一旦我们有了更大的分组,我们可以像在每个文档基础上一样应用我们的过滤、排序、限制和投影。
$group 阶段的最基本实现只接受一个 _id 键,其值为一个表达式。这个表达式定义了管道将文档分组在一起的条件。这个值成为了新生成的文档的 _id,每个唯一的 _id 会生成一个文档。例如,以下代码将按照电影的评分对其进行分组,为每个评分类别输出一个记录:
var pipeline = [
{$group: {
_id: "$rated"
}}
];
db.movies.aggregate(pipeline).forEach(printjson);
结果输出将如下所示:
图 7.9:前面片段的结果输出
在我们的 $group 阶段中,你可能会注意到的第一件事是 rated 字段之前的 $ 符号。如前所述,我们的 _id 键的值是一个表达式。在聚合术语中,表达式可以是文字,表达式对象,运算符或字段路径。在这种情况下,我们传递了一个字段路径,它告诉管道应该访问输入文档中的哪个字段。在 MongoDB 中,你可能已经遇到过字段路径,也可能没有。
你可能会想为什么我们不能像在 find 命令中那样传递字段名。这是因为在聚合时,我们需要告诉管道我们想要访问当前正在聚合的文档的字段。$group 阶段将 _id: "$rated" 解释为等同于 _id: "$$CURRENT.rated"。这可能看起来很复杂,但它表明对于每个文档,它将适合与具有相同(当前)文档的 "rated" 键的组匹配。在下一节的实践中,这将变得更清晰。
到目前为止,按单个字段分组已经很有用,可以得到唯一值的列表。然而,这并没有告诉我们更多关于我们的数据。我们想要了解这些不同的组更多信息;例如,每个组中有多少个标题?这就是我们的累加表达式会派上用场的地方。
累加器表达式
$group 命令可以接受不止一个参数。它还可以接受任意数量的其他参数,格式如下:
field: { accumulator: expression},
让我们将这个分解成它的三个组件:
-
field将为每个组定义我们新计算的字段的键。 -
accumulator必须是一个受支持的累加器运算符。这些是一组运算符,就像你可能已经使用过的其他运算符一样 - 例如$lte- 除了,正如名称所示,它们将在属于同一组的多个文档之间累积它们的值。 -
在这种情况下,
expression将作为输入传递给accumulator运算符,告诉它应该累积每个文档中的哪个字段。
在前面的示例基础上,让我们确定每个组中电影的总数:
var pipeline = [
{$group: {
_id: "$rated",
"numTitles": { $sum: 1},
}}
];
db.movies.aggregate(pipeline).forEach(printjson);
从中可以看出,我们可以创建一个名为 numTitles 的新字段,该字段的值是每个组的文档总和。这些新创建的字段通常被称为累积结果迄今为止的 1。在 MongoDB shell 中运行这个命令将给我们以下结果:
图 7.10:前面片段的输出
同样,我们可以累积给定字段的值,而不仅仅是在每个文档上累积 1。例如,假设我们想要找到每部电影在一个评级中的总运行时间。我们按 rating 字段分组,并累积每部电影的运行时间:
var pipeline = [
{$group: {
_id: "$rated",
"sumRuntime": { $sum: "$runtime"},
}}
];
db.movies.aggregate(pipeline).forEach(printjson);
记住,我们必须在运行时间字段前加上 $ 符号,告诉 MongoDB 我们正在引用我们正在累积的每个文档的运行时间值。我们的新结果如下:
图 7.11:前面片段的输出
虽然这是一个简单的例子,但你可以看到,只需一个聚合阶段和两个参数,我们就可以开始以令人兴奋的方式转换我们的数据。几个累加器运算符可以组合和层叠,以生成关于组的更复杂和有见地的信息。我们将在接下来的示例中看到其中一些运算符。
重要的是要注意,我们不仅可以使用累加器运算符作为我们的表达式。我们还可以使用其他几个有用的运算符,在累积数据之后对数据进行转换。假设我们想要得到每个组的标题的平均运行时间。我们可以将我们的 $sum 累加器更改为 $avg,这将返回每个组的平均运行时间,因此我们的管道变为如下:
var pipeline = [
{$group: {
_id: "$rated",
"avgRuntime": { $avg: "$runtime"},
}}
];
db.movies.aggregate(pipeline).forEach(printjson);
然后我们的输出变为:
图 7.12:基于评分的平均运行时间值
在这种情况下,这些平均运行时间值并不特别有用。让我们添加另一个阶段来投影运行时间,使用$trunc阶段,给我们一个整数值:
var pipeline = [
{$group: {
_id: "$rated",
"avgRuntime": { $avg: "$runtime"},
}},
{$project: {
"roundedAvgRuntime": { $trunc: "$avgRuntime"}
}}
];
db.movies.aggregate(pipeline).forEach(printjson);
这将为我们提供一个更加格式良好的结果,就像这样:
{ "_id" : "PG-13", "avgRuntime" : 108 }
本节演示了如何将分组阶段与运算符、累加器和其他阶段结合起来,以帮助操纵我们的数据来回答更广泛的业务问题。现在,让我们开始聚合并将这个新阶段付诸实践。
练习 7.03:操纵数据
在之前的情景中,你已��习惯了数据的形状,并将客户的一个手动流程重新创建为一个聚合管道。作为经典电影马拉松的前奏,电影公司决定尝试为每种流派运行一部电影(直到马拉松结束每周一部),他们希望最受欢迎的流派最后播放,以此来烘托活动气氛。然而,他们有一个问题。这些周的时间表已经被规定,这意味着经典电影将不得不适应时间表中的空档。因此,为了实现这一目标,他们必须知道每种流派中最长电影的长度,包括每部电影的预告片时间。
注意
在这种情况下,热门程度是由IMDb 评分定义的,而预告片在任何电影之前都会播放 12 分钟。
目标可以总结如下:
“仅针对 2001 年之前的电影,找到每种流派的平均热门程度和最大热门程度,按热门程度对流派进行排序,并找到每种流派中最长电影的调整(包括预告片)运行时间。”
将查询转换为顺序阶段,以便你可以映射到你的聚合阶段:
-
匹配 2001 年之前发布的电影。
-
找到每种流派的平均热门程度。
-
按热门程度对流派进行排序。
-
输出每部电影的调整后的运行时间。
由于你对分组阶段有了更多了解,利用你的新知识详细说明这一步骤:
-
匹配 2001 年之前发布的电影。
-
按照它们的第一个流派对所有电影进行分组,并累积平均和最大的 IMDb 评分。
-
按每种流派的平均热门程度进行排序。
-
将调整后的运行时间投影为
total_runtime。
以下步骤将帮助你完成这个练习。
- 首先创建你的聚合大纲。创建一个名为
Ch7_Exercise3.js的新文件:
// Ch7_Exercise3.js
var findGenrePopularity = function() {
print("Finding popularity of each genre");
var pipeline = [
{ $match: {}},
{ $group: {}},
{ $sort: {}},
{ $project: {}}
];
db.movies.aggregate(pipeline).forEach(printjson);
}
findGenrePopularity();
- 一次填写一个步骤,从
$match开始:
{ $match: {
released: {$lte: new ISODate("2001-01-01T00:00: 00Z") }}},
这类似于练习 7.01,执行简单的聚合,在那里你匹配了 2001 年之前发布的所有文档。
- 对于
$group阶段,首先为每个输出文档确定你的新id:
{ $group: {
_id: {"$arrayElemAt": ["$genres", 0]},
}},
$arrayElemAt从数组中取出指定索引处的元素(在这种情况下是 0)。对于这种情况,假设数组中的第一个流派是电影的主要流派。
接下来,在结果中指定你需要的新计算字段。记住使用累加器运算符,包括$avg(平均)和$max(最大)。记住,在accumulator中,因为你在引用一个变量,你必须在字段前加上$符号:
{ $group: {
_id: {"$arrayElemAt": ["$genres", 0]},
"popularity": { $avg: "$imdb.rating"},
"top_movie": { $max: "$imdb.rating"},
"longest_runtime": { $max: "$runtime"}
}},
- 填写
sort字段。现在你已经定义了你的计算字段,这很简单:
{ $sort: { popularity: -1}},
- 要获得调整后的运行时间,使用
$add运算符并添加12(分钟)。你添加 12 分钟是因为客户(电影公司)已经告诉你这是每部电影播放前预告片的长度。一旦你有了调整后的运行时间,你将不再需要longest_runtime:
{ $project: {
_id: 1,
popularity: 1,
top_movie: 1,
adjusted_runtime: { $add: [ "$longest_runtime", 12 ] } } }
- 还要添加一个
$。你最终的聚合管道应该是这样的:
var findGenrePopularity = function() {
print("Finding popularity of each genre");
var pipeline = [
{ $match: {
released: {$lte: new ISODate("2001-01-01T00:00:00Z") }}},
{ $group: {
_id: {"$arrayElemAt": ["$genres", 0]},
"popularity": { $avg: "$imdb.rating"},
"top_movie": { $max: "$imdb.rating"},
"longest_runtime": { $max: "$runtime"}
}},
{ $sort: { popularity: -1}},
{ $project: {
_id: 1,
popularity: 1,
top_movie: 1,
adjusted_runtime: { $add: [ "$longest_runtime", 12 ] } } }
];
db.movies.aggregate(pipeline).forEach(printjson);
}
findGenrePopularity();
如果你的结果是正确的,你的前几个文档应该如下:
图 7.13:返回的前几个文档
输出显示,黑色电影、纪录片和短片是最受欢迎的,我们还可以看到每个类别的平均运行时间。在下一个练习中,我们将根据特定要求从每个类别中选择一个标题。
练习 7.04:从每个电影类别中选择标题
您现在已经回答了客户提出的问题。但是,这个结果对于他们来说并没有帮助选择特定的电影。他们必须执行不同的查询,以获取每个流派的电影列表,并从中选择要展示的最佳电影。此外,您还了解到最大的时间段可用为 230 分钟。您将修改此查询,以为电影公司提供每个类别的推荐标题。以下步骤将帮助您完成此练习:
- 首先,增加第一个匹配以过滤掉不适用的电影。过滤掉超过 218 分钟(230 加上预告片)的电影。还要过滤掉评分较低的电影。首先,您将获得评分超过 7.0 的电影:
{ $match: {
released: {$lte: new ISODate("2001-01-01T00:00:00Z") },
runtime: {$lte: 218},
"imdb.rating": {$gte: 7.0}
}
},
- 为了获得每个类别的推荐标题,使用我们组阶段中的
$first累加器来获取每个流派的顶级文档(电影)。为此,您首先需要按评分降序排序,确保第一个文档也是评分最高的。在初始的sort 阶段:
{ $sort: {"imdb.rating": -1}},
- 现在,在组阶段中添加
$first累加器,添加您的新字段。还添加recommended_rating和recommended_raw_runtime字段以便使用:
{ $group: {
_id: {"$arrayElemAt": ["$genres", 0]},
"recommended_title": {$first: "$title"},
"recommended_rating": {$first: "$imdb.rating"},
"recommended_raw_runtime": {$first: "$runtime"},
"popularity": { $avg: "$imdb.rating"},
"top_movie": { $max: "$imdb.rating"},
"longest_runtime": { $max: "$runtime"}
}},
- 确保将此新字段添加到最终的投影中:
{ $project: {
_id: 1,
popularity: 1,
top_movie: 1,
recommended_title: 1,
recommended_rating: 1,
recommended_raw_runtime: 1,
adjusted_runtime: { $add: [ "$longest_runtime", 12 ] } } }
您的新最终查询应该如下所示:
// Ch7_Exercise4js
var findGenrePopularity = function() {
print("Finding popularity of each genre");
var pipeline = [
{ $match: {
released: {$lte: new ISODate("2001-01-01T00:00:00Z") },
runtime: {$lte: 218},
"imdb.rating": {$gte: 7.0}
}
},
{ $sort: {"imdb.rating": -1}},
{ $group: {
_id: {"$arrayElemAt": ["$genres", 0]},
"recommended_title": {$first: "$title"},
"recommended_rating": {$first: "$imdb.rating"},
"recommended_raw_runtime": {$first: "$runtime"},
"popularity": { $avg: "$imdb.rating"},
"top_movie": { $max: "$imdb.rating"},
"longest_runtime": { $max: "$runtime"}
}},
{ $sort: { popularity: -1}},
{ $project: {
_id: 1,
popularity: 1,
top_movie: 1,
recommended_title: 1,
recommended_rating: 1,
recommended_raw_runtime: 1,
adjusted_runtime: { $add: [ "$longest_runtime", 12 ] } } }
];
db.movies.aggregate(pipeline).forEach(printjson);
}
findGenrePopularity();
- 执行此操作,您的前两个结果文档应该看起来像下面这样:
图 7.14:前两个结果文档
您可以看到,通过对管道进行一些添加,您已经提取出了评分最高和最长的电影,为客户创造了额外的价值。
在本主题中,我们看到了如何查询数据,然后对结果进行排序、限制和投影。我们还看到,通过使用更高级的聚合阶段,我们可以完成更复杂的任务。数据被操纵和转换以创建新的、有意义的文档。这些新的阶段使用户能够回答更广泛、更困难的业务问题,并获得有价值的数据洞察。
处理大型数据集
到目前为止,我们一直在处理相对较少的文档。movies集合中大约有 23,500 个文档。这对于人类来说可能是一个相当大的数字,但对于大型生产系统来说,您可能会处理数百万而不是数千的规模。到目前为止,我们也一直严格专注于一次处理单个集合,但如果我们的聚合范围扩大到包括多个集合呢?
在第一个主题中,我们简要讨论了在开发管道时如何使用投影阶段来创建更易读的输出,并简化调试结果。但是,我们没有涵盖在处理更大规模的数据集时如何提高性能,无论是在开发过程中还是在最终的生产就绪查询中。在本主题中,我们将讨论在处理大型多集合数据集时需要掌握的一些聚合阶段。
使用$sample 进行抽样
学习如何处理大型数据集的第一步是了解$sample。这个阶段简单而有用。$sample的唯一参数是您的样本期望大小。这个阶段会随机选择文档(最多达到您指定的大小)并将它们传递到下一个阶段:
{ $sample: {size: 100}}, // This will reduce the scope to 100 random docs.
通过这样做,您可以显著减少通过管道的文档数量。主要是有两个原因。第一个原因是在处理庞大数据集时加快执行时间,尤其是在微调或构建聚合时。第二个原因是对于可以容忍结果中缺少文档的查询用例。例如,如果您想返回某个流派的任意五部电影,您可以使用$sample:
var findWithSample = function() {
print("Finding all documents WITH sampling")
var now = Date.now();
var pipeline = [
{ $sample: {size: 100}},
{ $match: {
"plot": { $regex: /around/}
}}
];
db.movies.aggregate(pipeline)
var duration = Date.now() - now;
print("Finished WITH sampling in " + duration+"ms");
}
findWithSample();
执行新的findWithSample()函数后,将获得以下结果:
Finding all documents WITH sampling
Finished WITH sampling in 194ms
你可能会想为什么不直接使用$limit命令来实现在管道的某个阶段减少文档数量的相同结果。主要原因是$limit始终遵守文档的顺序,因此每次返回相同的文档。然而,重要的是要注意,在某些情况下,当你不需要$sample的伪随机选择时,最好使用$limit。
让我们看看$sample的实际应用。这是一个查询,用于在plot字段中搜索特定关键字的所有电影,分别使用和不使用$sample实现:
var findWithoutSample = function() {
print("Finding all documents WITHOUT sampling")
var now = Date.now();
var pipeline =[
{ $match: {
"plot": { $regex: /around/}
}},
]
db.movies.aggregate(pipeline)
var duration = Date.now() - now;
print("Finished WITHOUT sampling in " + duration+ "ms");
}
findWithoutSample();
前面的例子并不是衡量性能的最佳方式,有更好的方法来分析管道的性能,比如Explain。然而,由于我们将在本书的后面部分涵盖这些内容,这将作为一个简单的例子。如果你运行这个小脚本,你将始终得到以下结果:
Finding all documents WITHOUT sampling
Finished WITHOUT sampling in 862ms
这两个命令的输出的简单比较如下:
Finding all documents WITH sampling
Finished WITH sampling in 194ms
Finding all documents WITHOUT sampling
Finished WITHOUT sampling in 862ms
通过抽样,性能得到了显著改善。然而,这是因为我们只查看了 100 个文档。更可能的是,在这种情况下,我们希望在match语句之后对结果进行抽样,以确保我们不会在第一个阶段排除所有结果。在大多数情况下,在处理执行时间显著的大型数据集时,你可能希望在构建管道时从开始进行抽样,并在查询最终确定后移除抽样。
使用$lookup 连接集合
抽样可能在针对大型集合开发查询时对你有所帮助,但在生产查询中,你有时需要编写跨多个集合操作的查询。在 MongoDB 中,使用$lookup聚合步骤进行这些集合连接。
这些连接可以通过以下聚合轻松理解:
var lookupExample = function() {
var pipeline = [
{ $match: { $or: [{"name": "Catelyn Stark"}, {"name": "Ned Stark"}]}},
{ $lookup: {
from: "comments",
localField: "name",
foreignField: "name",
as: "comments"
}},
{ $limit: 2},
];
db.users.aggregate(pipeline).forEach(printjson);
}
lookupExample();
在我们尝试运行之前,让我们先分析一下。首先,我们对users集合运行了$match,只获取了两个名为Ned Stark和Catelyn Stark的用户。一旦我们有了这两条记录,我们执行我们的查找。$lookup的四个参数如下:
-
from:我们要连接到当前聚合的集合。在这种情况下,我们将comments连接到users。 -
localField:我们将用来连接本地集合中文档的字段名称(我们正在对其进行聚合的集合)。在这种情况下,是我们用户的名称。 -
foreignField:链接到from集合中的localField的字段。它们可能有不同的名称,但在这种情况下,它是相同的字段:name。 -
as:这是我们新连接的数据将被标记的方式。
在这个例子中,查找使用我们用户的名称,搜索comments集合,并将具有相同名称的任何评论添加到原始用户文档的新数组字段中。这个新数组被称为comments。通过这种方式,我们可以获取另一个集合中所有相关文档的数组,并将它们嵌入到我们原始文档中,以便在聚合的其余部分中使用。
如果我们按照现有的管道运行,输出的开头将看起来像这样:
图 7.15:运行管道后的输出(为简洁起见截断)
由于输出非常大,前面的截图只显示了comments数组的开头部分。
在这个例子中,用户发表了许多评论,因此嵌入的数组变得相当庞大且难以查看。这个问题是引入$unwind运算符的一个很好的地方,因为这些连接通常会导致大量相关文档的数组。$unwind是一个相对简单的阶段。它会从输入文档中解构一个数组字段,以输出数组中每个元素的新文档。例如,如果你展开这个文档:
{a: 1, b: 2, c: [1, 2, 3, 4]}
输出将是以下文档:
{"a" : 1, "b" : 2, "c" : 1 }
{"a" : 1, "b" : 2, "c" : 2 }
{"a" : 1, "b" : 2, "c" : 3 }
{"a" : 1, "b" : 2, "c" : 4 }
我们可以添加这个新的阶段到我们的连接中,然后尝试运行它:
var lookupExample = function() {
var pipeline = [
{ $match: { $or: [{"name": "Catelyn Stark"}, {"name": "Ned Stark"}]}},
{ $lookup: {
from: "comments",
localField: "name",
foreignField: "name",
as: "comments"
}},
{ $unwind: "$comments"},
{ $limit: 3},
];
db.users.aggregate(pipeline).forEach(printjson);
}
lookupExample();
我们将看到如下输出:
图 7.16:上述片段的输出(为简洁起见而截断)
我们可以看到每个用户有多个文档,每个评论都有一个单独的文档,而不是一个嵌入式数组。有了这种新格式,我们可以添加更多阶段来操作我们的新文档集。例如,我们可能希望过滤掉对特定电影的任何评论,或者按日期对评论进行排序。$lookup和$unwind的组合对于在单个聚合中跨多个集合回答复杂问题是一个强大的组合。
使用$out和$merge输出您的结果
假设在过去的一周里,我们一直在一个大型的多阶段聚合管道上工作。我们一直在调试、抽样、过滤和测试我们的管道,以解决一个具有挑战性和复杂业务问题的巨大数据集。最后,我们对我们的管道感到满意,我们想要执行它,然后保存结果以供后续分析和展示。
我们可以运行查询并将结果导出到新的格式。然而,这意味着如果我们想对结果集进行后续分析,就需要重新导入结果。
我们可以将输出保存在一个数组中,然后重新插入到 MongoDB 中,但这意味着需要将所有数据从服务器传输到客户端,然后再从客户端传输回服务器。
幸运的是,从 MongoDB 4.2 版本开始,我们提供了两个聚合阶段来解决这个问题:$out和$merge。这两个阶段都允许我们将管道的输出写入一个集合以供以后使用。重要的是,整个过程都在服务器上进行,这意味着所有数据都不需要通过网络传输到客户端。可以想象,在创建了一个复杂的聚合查询之后,您可能希望每周运行一次,并通过将数据写入集合来创建结果的快照。
让我们看看这两个阶段的语法,以及它们的最基本形式,然后我们可以比较它们的功能:
// Available from v2.6
{ $out: "myOutputCollection"}
// Available from version 4.2
{ $merge: {
// This can also accept {db: <db>, coll: <coll>} to merge into a different db
into: "myOutputCollection",
}}
正如您所看到的,没有任何可选参数的语法几乎是相同的。然而,在其他方面,这两个命令是不同的。$out非常简单;唯一需要指定的参数是期望的输出集合。它要么创建一个新的集合,要么完全替换现有的集合。$out还有一些约束条件,而$merge没有。例如,$out必须输出到与聚合目标相同的数据库。
在 MongoDB 4.2 服务器上运行时,$merge可能是更好的选择。然而,在本书的范围内,我们将使用 MongoDB 的免费版,它运行的是 MongoDB 4.0。因此,在这些示例中,我们将更多地关注$out阶段。
$out的语法非常简单。唯一的参数是我们想要输出结果的集合。以下是一个带有$out的管道的示例:
var findTopRomanceMovies = function() {
var pipeline = [
{ $sort: {"imdb.rating": -1}}, // Sort by IMDB rating.
{ $match: {
genres: {$in: ["Romance"]}, // Romance movies only.
released: {$lte: new ISODate("2001-01-01T00:00: 00Z") }}},
{ $limit: 5 }, // Limit to 5 results.
{ $project: { title: 1, genres: 1, released: 1, "imdb.rating": 1}},
{ $out: "movies_top_romance"}
];
db.movies.aggregate(pipeline).forEach(printjson);
}
findTopRomanceMovies();
通过运行这个管道,您将不会收到任何输出。这是因为输出已经重定向到我们想要的集合中:
MongoDB Enterprise atlas-nb3biv-shard-0:PRIMARY> findTopRomanceMovies();
MongoDB Enterprise atlas-nb3biv-shard-0:PRIMARY>
我们可以看到,一个新的集合被我们的结果创建了:
MongoDB Enterprise atlas-nb3biv-shard-0:PRIMARY> show collections
comments
movies
movies_top_romance
sessions
theaters
users
如果我们在新的集合上运行一个查找,我们可以看到我们的聚合结果现在存储在其中:
MongoDB Enterprise atlas-nb3biv-shard-0:PRIMARY> db.movies_top_romance.findOne({})
{
"_id" : ObjectId("573a1399f29313caabceeead"),
"genres" : [
"Drama",
"Romance"
],
"title" : "Pride and Prejudice",
"released" : ISODate("1996-01-14T00:00:00Z"),
"imdb" : {
"rating" : 9.1
}
}
通过将结果放入一个集合中,我们可以存储、共享和更新新的复杂聚合结果。我们甚至可以对这个新集合运行进一步的查询和聚合。$out是一个简单但强大的聚合阶段。
练习 7.05:列出评论最多的电影
电影公司希望了解哪些电影从用户那里获得了最多的评论。然而,鉴于数据库中有很多评论(以及您倾向于使用您新学到的技能),您决定在开发此管道时,只使用评论的样本。从这个样本中,您将找出最受关注的电影,并将这些文档与movies集合中的文档结合起来,以获取有关电影的更多信息。公司还要求您的最终交付成果是一个包含输出文档的新集合。鉴于您现在已经了解了$merge阶段,这个要求应该很容易满足。
您收集到的一些额外信息是,他们希望结果尽可能简单,并且希望知道电影的标题和评分。此外,他们希望看到评论最多的前五部电影。
在这个练习中,您将帮助电影公司获取用户评论最多的电影列表。执行以下步骤完成这个练习:
- 首先,概述管道中的阶段;它们按以下顺序出现:
在构建管道时,对comments集合进行$sample。
$group评论按其所针对的电影分组。
$sort结果按总评论数排序。
$limit结果为评论最多的前五部电影。
$lookup与每个文档匹配的电影。
$unwind电影数组,以保持结果文档简单。
$project只有电影标题和评分。
$merge结果到一个新的集合中。
尽管这可能看起来有很多阶段,但每个阶段都相对简单,整个过程可以从头到尾逻辑地跟随。
- 创建一个名为
Ch7_Exercise5.js的新文件,并编写您的管道框架:
// Ch7_Exercise5.js
var findMostCommentedMovies = function() {
print("Finding the most commented on movies.");
var pipeline = [
{ $sample: {}},
{ $group: {}},
{ $sort: {}},
{ $limit: 5},
{ $lookup: {}},
{ $unwind: },
{ $project: {}},
{ $out: {}}
];
db.comments.aggregate(pipeline).forEach(printjson);
}
findMostCommentedMovies();
- 在决定样本大小之前,您应该了解
comments集合有多大。对comments集合运行count:
MongoDB Enterprise atlas-nb3biv-shard-0:PRIMARY> db.comments.count()
50303
- 在开发过程中对集合进行大约百分之十的抽样。将本练习的样本大小设置为
5000:
{ $sample: {size: 5000}},
- 现在您已经完成了较容易的步骤,填写
$group语句,将评论按其关联的电影分组,累积每部电影的评论总数:
{ $group: {
_id: "$movie_id",
"sumComments": { $sum: 1}
}},
- 接下来,添加
sort,使具有最高sumComments值的电影排在第一位:
{ $sort: { "sumComments": -1}},
- 在构建管道时,定期运行部分完成的管道非常重要,以确保您看到预期的结果。由于您正在抽样,每次运行管道时结果都不会相同。以下输出只是一个例子:
{ $lookup: {
from: "movies",
localField: "_id",
foreignField: "_id",
as: "movie"
}},
重新运行此代码,现在您可以看到一个带有所有电影详细信息的movie数组嵌入其中:
{ $unwind: "$movie" },
{ $project: {
"movie.title": 1,
"movie.imdb.rating": 1,
"sumComments": 1,
}}
- 您的数据现在已经完整,但您仍然需要将此结果输出到一个集合中。在最后添加
$out步骤:
{ $out: "most_commented_movies" }
您最终的代码应该看起来像这样:
// Ch7_Exercise5.js
var findMostCommentedMovies = function() {
print("Finding the most commented on movies.");
var pipeline = [
{ $sample: {size: 5000}},
{ $group: {
_id: "$movie_id",
"sumComments": { $sum: 1}
}},
{ $sort: { "sumComments": -1}},
{ $limit: 5},
{ $lookup: {
from: "movies",
localField: "_id",
foreignField: "_id",
as: "movie"
}},
{ $unwind: "$movie" },
{ $project: {
"movie.title": 1,
"movie.imdb.rating": 1,
"sumComments": 1,
}},
{ $out: "most_commented_movies" }
];
db.comments.aggregate(pipeline).forEach(printjson);
}
findMostCommentedMovies();
运行此代码。如果一切顺利,您将在 shell 中看不到管道的任何输出,但您应该能够使用find()检查您新创建的集合并查看您的结果。请记住,由于抽样阶段,结果每次都不会相同:
图 7.20:前面片段的结果(为简洁起见截断输出)
通过本主题学到的新阶段,我们现在拥有了在更大、更复杂的数据集上执行聚合的良好基础。而且,更重要的是,我们现在能够有效地在多个集合之间进行数据连接。通过这样做,我们可以扩大我们的查询范围,从而满足更广泛的用例。
通过out阶段,我们可以存储聚合的结果。这使用户可以通过常规的 CRUD 操作快速探索结果,并且可以轻松地保持更新结果。unwind 阶段还使我们能够将查找操作中的连接文档分开成单独的文档,以便将其馈送到后续的管道阶段中。
通过结合所有这些阶段,我们现在能够创建跨大型多集合数据集进行操作的广泛新聚合。
从您的聚合中获得最大收益
在过去的三个主题中,我们已经了解了聚合的结构以及构建复杂查询所需的关键阶段。我们可以使用给定的条件搜索大型多集合数据集,操纵数据以创建新的见解,并将结果输出到新的或现有集合中。
这些基础将使您能够解决聚合管道中遇到的大多数问题。然而,还有一些其他阶段和模式可以让您从聚合中获得最大收益。我们不会在本书中涵盖所有这些内容,但在本主题中,我们将讨论一些可以帮助您微调管道的技巧,以及一些我们到目前为止还没有涵盖的其他技巧。我们将使用Explain来分析您的聚合选项。
调整您的管道
在早期的主题中,我们通过输出聚合之前和之后的时间来计算我们的管道的执行时间。这是一种有效的技术,你可能经常在客户端或应用程序端计时你的 MongoDB 查询。然而,这只能给我们一个大致的持续时间,并且只告诉我们响应到达客户端所花费的总时间,而不是服务器执行管道所花费的时间。MongoDB 为我们提供了一个很好的学习方式,可以准确地了解它是如何执行我们请求的查询的。这个功能被称为Explain,是检查和优化我们的 MongoDB 命令的常规方式。
然而,有一个问题。Explain目前不支持聚合的详细执行计划,这意味着在优化管道时其使用受到限制。Explain和执行计划将在本书的后面更详细地介绍。由于我们不能依赖Explain来分析我们的管道,因此更加重要的是仔细构建和规划我们的管道,以提高聚合的性能。虽然没有一种适用于任何情况的单一正确方法,但有一些启发式方法通常会有所帮助。我们将通过一些示例来介绍其中的一些方法。MongoDB 在幕后进行了大量的性能优化,但这些仍然是要遵循的良好模式。
尽早过滤,经常过滤
聚合管道的每个阶段都会对输入进行一些处理。这意味着输入越重要,处理就越大。如果您正确设计了管道,那么这种处理对于您要返回的文档是不可避免的。您所能做的就是确保您只处理您想要返回的文档。
实现这一点的最简单方法是添加或移动过滤文档的管道阶段。我们在之前的情景中已经用$match和$limit做过这个操作。确保这一点的常见方法是将管道中的第一个阶段设置为$match,这样可以只匹配后续管道中需要的文档。让我们通过以下管道示例来理解这一点,其中管道没有按预期执行设计:
var badlyOrderedQuery = function() {
print("Running query in bad order.")
var pipeline = [
{ $sort: {"imdb.rating": -1}}, // Sort by IMDB rating.
{ $match: {
genres: {$in: ["Romance"]}, // Romance movies only.
released: {$lte: new ISODate("2001-01-01T00:00:00Z") }}},
{ $project: { title: 1, genres: 1, released: 1, "imdb.rating": 1}},
{ $limit: 1 }, // Limit to 1 result.
];
db.movies.aggregate(pipeline).forEach(printjson);
}
badlyOrderedQuery();
输出将如下所示:
MongoDB Enterprise atlas-nb3biv-shard-0:PRIMARY> badlyOrderedQuery();
Running query in bad order.
{
"_id" : ObjectId("573a1399f29313caabceeead"),
"genres" : [
"Drama",
"Romance"
],
"title" : "Pride and Prejudice",
"released" : ISODate("1996-01-14T00:00:00Z"),
"imdb" : {
"rating" : 9.1
}
}
一旦你正确地排序了管道,它将如下所示:
var wellOrderedQuery = function() {
print("Running query in better order.")
var pipeline = [
{ $match: {
genres: {$in: ["Romance"]}, // Romance movies only.
released: {$lte: new ISODate("2001-01-01T00:00:00Z") }}},
{ $sort: {"imdb.rating": -1}}, // Sort by IMDB rating.
{ $limit: 1 }, // Limit to 1 result.
{ $project: { title: 1, genres: 1, released: 1, "imdb.rating": 1}},
];
db.movies.aggregate(pipeline).forEach(printjson);
}
wellOrderedQuery();
这将导致以下输出:
图 7.21:前面片段的输出(为简洁起见而截断)
从逻辑上讲,这个改变意味着我们首先要做的是在对它们进行排序之前获取所有符合条件的文档列表,然后我们取前五个并且只投影这五个文档。
这两个管道都输出相同的结果,但第二个更加健壮且易于理解。你可能不会总是看到这种改变带来显著的性能提升,特别是在较小的数据集上。然而,这是一个很好的实践,因为它将帮助你创建逻辑、高效和简单的管道,可以更容易地进行修改或扩展。
使用你的索引
索引是 MongoDB 查询性能的另一个关键因素。本书在第九章“性能”中更深入地介绍了索引及其创建。在创建聚合时,你需要记住的是,在使用$sort和$match等阶段时,你要确保你正在操作的是正确索引的字段。使用索引的概念将会变得更加明显。
考虑期望的输出
改进你的管道最重要的方法之一是计划和评估它们,以确保你得到了解决业务问题的期望输出。如果你在创建一个精心调整的管道时遇到困难,可以问自己以下问题:
-
我是否输出了所有数据来解决我的问题?
-
我是否只输出了解决问题所需的数据?
-
我是否能够合并或删除任何中间步骤?
如果你已经评估了你的管道,调整了它,但仍然觉得它过于复杂或低效,你可能需要对数据本身提出一些问题。聚合是否困难是因为设计了错误的查询,甚至是问了错误的问题?或者,也许这是数据形状需要重新评估的一个迹象。
聚合选项
修改管道是你在处理聚合时可能会花费大部分时间的地方,对于初学者来说,你可能只需编写管道就能实现大部分目标。正如本章前面提到的,可以传递多个选项到aggregate命令中以配置其操作。我们不会深入探讨这些选项,但了解它们是有帮助的。以下是包含一些选项的聚合示例:
var options = {
maxTimeMS: 30000,
allowDiskUse: true
}
db.movies.aggregate(pipeline, options);
要指定这些选项,需要在管道数组之后传递第二个参数给命令。在这种情况下,我们称之为options。一些需要注意的选项包括以下内容:
-
maxTimeMS:MongoDB 在终止操作之前可以处理的时间量。本质上是聚合的超时时间。默认值为0,这意味着操作不会超时。 -
allowDiskUse:聚合管道中的阶段可能只使用最大数量的内存,这使得处理大型数据集变得具有挑战性。通过将此选项设置为true,MongoDB 可以写临时文件以处理更多的数据。 -
bypassDocumentValidation:这个选项专门用于将使用$out或$merge写入集合的管道。如果将此选项设置为true,则不会对从该管道写入集合的文档进行文档验证。 -
comment:这个选项只是用于调试,允许指定一个字符串来帮助在解析数据库日志时识别这个聚合。 -
现在让我们进行一个练习,将我们到目前为止学到的概念付诸实践。
练习 7.06:查找获奖纪录片
在看到前几个练习中实现的聚合管道的结果以及它们为电影公司带来的价值后,公司的一些内部工程师尝试自己编写了一些新的聚合。电影公司要求您审查这些管道,以协助他们内部工程师的学习过程。您将使用前面的一些技术和您对最后三个主题中聚合的理解来修复一个管道。这个简单管道的目标是获取一份评分很高的纪录片清单。
对于这种情况,您还将在假设集合中有大量数据的情况下进行工作。给您要审查的管道如下。此练习的目的是找到一些获奖纪录片,并列出获奖最多的电影:
var findAwardWinningDocumentaries = function() {
print("Finding award winning documentary Movies...");
var pipeline = [
{ $sort: {"awards.wins": -1}}, // Sort by award wins.
{ $match: {"awards.wins": { $gte: 1}}},
{ $limit: 20}, // Get the top 20 movies with more than one award
{ $match: {
genres: {$in: ["Documentary"]}, // Documentary movies only.
}},
{ $project: { title: 1, genres: 1, awards: 1}},
{ $limit: 3},
];
var options = { }
db.movies.aggregate(pipeline, options).forEach(printjson);
}
findAwardWinningDocumentaries();
可以通过以下步骤实现结果:
- 首先,合并两个
$match语句,并将match移到管道的顶部:
var pipeline = [
{ $match: {
"awards.wins": { $gte: 1},
genres: {$in: ["Documentary"]},
}},
{ $sort: {"awards.wins": -1}}, // Sort by award wins.
{ $limit: 20}, // Get the top 20 movies.
{ $project: { title: 1, genres: 1, awards: 1}},
{ $limit: 3},
];
- 不再需要在开头使用
sort,因此可以将其移动到倒数第二步:
var pipeline = [
{ $match: {
"awards.wins": { $gte: 1},
genres: {$in: ["Documentary"]},
}},
{ $limit: 20}, // Get the top 20 movies.
{ $project: { title: 1, genres: 1, awards: 1}},
{ $sort: {"awards.wins": -1}}, // Sort by award wins.
{ $limit: 3},
];
- 不再需要两个限制。删除第一个:
var pipeline = [
{ $match: {
"awards.wins": { $gte: 1},
genres: {$in: ["Documentary"]},
}},
{ $project: { itle: 1, genres: 1, awards: 1}},
{ $sort: {"awards.wins": -1}}, // Sort by award wins.
{ $limit: 3},
];
- 最后,将投影移到最后三个文档:
var pipeline = [
{ $match: {
"awards.wins": { $gte: 1},
genres: {$in: ["Documentary"]},
}},
{ $sort: {"awards.wins": -1}}, // Sort by award wins.
{ $limit: 3},
{ $project: { title: 1, genres: 1, awards: 1}},
];
- 这已经看起来好多了。您被告知集合非常庞大,因此还要为聚合添加一些选项:
var options ={
maxTimeMS: 30000,
allowDiskUse: true,
comment: "Find Award Winning Documentary Films"
}
db.movies.aggregate(pipeline, options).forEach(printjson);
- 运行完整查询:
var findAwardWinningDocumentaries = function() {
print("Finding award winning documentary Movies...");
var pipeline = [
{ $match: {
"awards.wins": { $gte: 1},
genres: {$in: ["Documentary"]},
}},
{ $sort: {"awards.wins": -1}}, // Sort by award wins.
{ $limit: 3},
{ $project: { title: 1, genres: 1, awards: 1}},
];
var options ={
maxTimeMS: 30000,
allowDiskUse: true,
comment: "Find Award Winning Documentary Films"
}
db.movies.aggregate(pipeline, options).forEach(printjson);
}
findAwardWinningDocumentaries();
因此,您的结果应如下所示:
图 7.22:获奖纪录片清单(为简洁起见截断)
有了这个,您已根据您的电影公司的要求检索了获奖纪录片清单。我们在本主题中看到,为了从聚合中获得最大价值,您需要设计、测试和不断重新评估您的管道。然而,先前列出的启发式只是设计有用的聚合的一小部分模式,因此建议您进行其他模式和程序的研究。
我们还看到了如何向aggregate命令传递一些选项,以帮助我们处理特定用例或处理可能需要更长时间的大型数据集。
活动 7.01:将聚合实践应用到实践中
在前几个练习中,电影公司对您使用聚合管道从数据中提取的见解印象深刻。然而,公司在管理不同的查询和将数据组合成有意义的结果方面遇到了麻烦。他们决定他们想要一个单一的、统一的聚合,总结他们即将举办的电影马拉松活动的基本信息。
您的目标是设计、测试和运行一个聚合管道,以创建这个统一视图。您应确保聚合的最终输出回答以下业务问题:
-
对于每种流派,哪部电影获得了最多的奖项提名,假设它们至少赢得了其中一项提名?
-
对于这些电影中的每一部电影,在每部电影之前都有 12 分钟的预告片,它们的附加运行时间是多少?
-
关于这部电影的用户评论的例子。
-
因为这是一场经典的电影马拉松,只有在 2001 年之前发布的电影才有资格。
-
在所有流派中,列出获奖次数最多的所有流派。
您可以以任何方式完成此活动,但请尽量专注于创建一个简单而高效的聚合管道,以便将来进行调整或修改。有时最好尝试并决定输出文档可能是什么样子,然后从那里开始向后工作。
请记住,在测试时,您也可以选择使用$sample阶段来加快查询速度,但在最终解决方案中必须删除这些步骤。
为了保持所需的输出简单,将结果限制为此场景的三个文档。
以下步骤将帮助您完成此任务:
-
过滤掉在 2001 年之前未发布的任何文件。
-
筛选掉没有至少一次获奖的文件。
-
按奖项提名对文件进行排序。
-
将文档分组成流派。
-
获取每个组的第一部电影。
-
获取每个组的获奖总数。
-
与
comments集合连接,获取每部电影的评论列表。 -
使用投影将每部电影的评论数量减少到一个。(提示:使用
$slice运算符来减少数组长度。) -
将每部电影的播放时间追加 12 分钟。
-
按获奖总数对结果进行排序。
-
限制三个文件。
期望的输出如下:
图 7.23:执行活动步骤后的最终输出
注意
可以通过此链接找到此活动的解决方案。
摘要
在本章中,我们已经涵盖了您需要了解、编写、理解和改进 MongoDB 聚合的所有基本组件。这种新功能将帮助您回答关于数据的更复杂和困难的问题。通过创建多阶段的管道,连接多个集合,您可以将查询范围扩大到整个数据库,而不仅仅是单个集合。我们还看了如何将结果写入新集合,以便进一步探索或操纵数据。
在最后一节中,我们介绍了确保编写的管道具有可扩展性、可读性和性能的重要性。通过专注于这些方面,您的管道将继续在未来提供价值,并可以作为进一步聚合的基础。
然而,我们在这里所涵盖的只是您可以通过聚合功能实现的开始。重要的是要不断探索、实验和测试您的管道,以真正掌握这项 MongoDB 技能。
在下一章中,我们将介绍如何在 Node.js 中使用 MongoDB 作为后端创建应用程序。即使您不是开发人员,这也将让您深入了解 MongoDB 应用程序的构建方式,以及对构建和执行动态查询的更深入理解。
第八章:在 MongoDB 中编写 JavaScript 代码
概述
在本章中,您将学习如何使用 Node.js 驱动程序阅读、理解和创建简单的 MongoDB 应用程序。这些应用程序将帮助您以编程方式获取、更新和创建 MongoDB 集合中的数据,以及处理错误和用户输入。在本章结束时,您将能够创建一个简单的基于 MongoDB 的应用程序。
介绍
到目前为止,我们直接使用 mongo shell 与 MongoDB 数据库进行了交互。这些直接的交互快速、简单,是学习或实验 MongoDB 功能的绝佳方式。然而,在许多生产情况下,将是软件代替用户连接到数据库。MongoDB 是一个很好的存储和查询数据的地方,但通常,它最重要的用途是作为大规模应用程序的后端。这些应用程序通常在某些条件或用户界面触发后以编程方式写入、读取和更新数据。
要将您的软件与数据库连接,通常会使用一个库(通常由数据库创建者提供)称为驱动程序。这个驱动程序将帮助您连接、分析、读取和写入数据库,而无需为简单操作编写多行代码。它提供了常见用例的函数和抽象,以及用于处理从数据库中提取的数据的框架。MongoDB 为不同的编程语言提供了几种不同的驱动程序,其中最流行的(也是我们将在本章中探讨的)是 Node.js 驱动程序(有时称为 Node)。
要将这与现实生活联系起来,想想您的在线购物体验。第一次从网站购买产品时,您必须输入所有的账单和送货细节。然而,如果您已经注册了一个账户,第二次去结账时,所有的细节都已经保存在网站上。这是一个很好的体验,而且在许多网站上,这是通过 Web 应用程序查询后端数据库来实现的。MongoDB 是可以支持这些应用程序的一个这样的数据库。
MongoDB 取得如此出色的增长和采用的主要原因之一是其成功说服软件开发人员选择它作为其应用程序的数据库。其中很大一部分说服力来自于 MongoDB 与 Node 的良好集成。
Node.js 已经成为基于 Web 的应用程序的主要语言之一,我们将在本章后面学习。然而,现在知道 Node 和 MongoDB 集成的便利性对两种技术都非常有益就足够了。这种共生关系还导致了大量成功的 Node/MongoDB 实现,从小型移动应用到大规模 Web 应用。在展示 MongoDB 驱动程序时,选择 Node.js 是首选。
根据您的工作角色,您可能负责编写针对 MongoDB 运行的应用程序,或者期望偶尔编写一行代码。然而,无论您的编程水平或专业责任如何,了解应用程序如何使用驱动程序与 MongoDB 集成将非常有价值。大多数 MongoDB 生产查询是由应用程序而不是人运行的。无论您是数据分析师、前端开发人员还是数据库管理员,您的生产环境很可能会使用 MongoDB 驱动程序之一。
注意
在本章的整个持续时间内,包括的练习和活动都是对一个情景的迭代。数据和示例都基于名为sample_mflix的 MongoDB Atlas 示例数据库。
在本章的整个持续时间内,我们将按照一个基于理论情景的一系列练习。这是我们在第七章“聚合”中涵盖的情景的扩展。
在第七章“聚合”中构建场景的基础上,一个电影公司正在举办年度经典电影马拉松,并希望决定他们的放映计划应该是什么,他们需要满足特定标准的各种受欢迎的电影来满足他们的客户群。在探索数据并协助他们做出业务决策后,您为他们提供了新的见解。电影公司对您的建议感到满意,并决定让您参与他们的下一个项目。该项目涉及创建一个简单的 Node.js 应用程序,允许他们的员工查询电影数据库,而无需了解 MongoDB 并对应该在电影院放映哪些电影进行投票。在本章的过程中,您将创建此应用程序。
连接到驱动程序
在高层次上,使用 Node.js 驱动程序与 MongoDB 的过程类似于直接连接 shell。您将指定 MongoDB 服务器 URI、几个连接参数,并且可以对集合执行查询。这应该都很熟悉;主要区别在于这些指令将以 JavaScript 而不是 Bash 或 PowerShell 编写。
Node.js 简介
由于本章的目标不是学习 Node.js 编程,我们将简要介绍基础知识,以确保我们可以创建我们的 MongoDB 应用程序。Node.js 中的js代表JavaScript,因为 JavaScript 是 Node.js 理解的编程语言。JavaScript 通常在浏览器中运行。但是,您可以将 Node.js 视为在计算机上执行 JavaScript 文件的引擎。
在本章的过程中,您将编写 JavaScript(.js)语法,并使用 Node.js 执行它。虽然您可以使用任何文本编辑器编写 JavaScript 文件,但建议使用可以帮助您进行语法高亮和格式化的应用程序,例如Visual Studio Code或Sublime。
首先,让我们看一些示例代码:
// 1_Hello_World.js
var message = "Hello, Node!";
console.log(message);
让我们详细定义前面语法中的每个术语:
-
var关键字用于声明一个新变量;在本例中,变量名为message。 -
=符号将此变量的值设置为一个名为Hello, Node!的字符串。 -
在每个语句的末尾使用分号(
;)。 -
console.log(message)是用于输出message值的函数。
如果您熟悉编程基础知识,您可能已经注意到我们不必将message变量显式声明为string。这是因为 JavaScript 是动态类型的,这意味着您不必显式指定变量类型(数字、字符串、布尔值等)。
如果您对编程基础知识不太熟悉,本章中的一些术语可能会使您感到困惑。因为这不是一本 JavaScript 编程书,这些概念不会被深入讨论。本章的目标是了解驱动程序如何与 MongoDB 交互;Node.js 的具体内容并不重要。尽管本章试图保持编程概念简单,但如果有什么复杂的地方,不要担心。
让我们尝试运行代码示例,将该代码保存到名为1_Hello_World.js的文件中,保存到我们当前的目录中,然后使用以下命令在我们的终端或命令提示符中运行该命令:
> node 1_Hello_World.js
您将看到一个看起来像这样的输出:
Section1> node 1_Hello_World.js
Hello, Node!
Section1>
如您所见,运行 Node.js 脚本非常简单,因为无需构建或编译,您可以编写代码并使用node调用它。
var关键字将信息存储在变量中,并在代码中稍后更改。但是,还有另一个关键字const,用于存储不会更改的信息。因此,在我们的示例中,我们可以用const关键字替换我们的var关键字。作为最佳实践,您可以将任何不会更改的内容声明为const:
// 1_Hello_World.js
const message = "Hello, Node!";
console.log(message);
现在,让我们考虑函数和参数的结构。就像在 mongo shell 中的前几章查询的结构一样。首先,让我们考虑定义函数的以下示例:
var printHello = function(parameter) {
console.log("Hello, " + parameter);
}
printHello("World")
以下是我们将在本章后面遇到的一些代码类型的预览。您可能会注意到,尽管这是一个更复杂的代码片段,但与您在早期章节(第四章,查询文档,特别是)学到的 CRUD 操作有一些共同的元素,例如find命令的语法和 MongoDB URI:
// 3_Full_Example.js
const Mongo = require('mongodb').MongoClient;
const server = 'mongodb+srv://username:password@server- abcdef.gcp.mongodb.net/test?retryWrites=true&w=majority'
const myDB = 'sample_mflix'
const myColl = 'movies';
const mongo = new Mongo(server);
mongo.connect(function(err) {
console.log('Our driver has connected to MongoDB!');
const database = mongo.db(myDB);
const collection = database.collection(myColl);
collection.find({title: 'Blacksmith Scene'}).each(function(err, doc) {
if(doc) {
console.log('Doc returned: ')
console.log(doc);
} else {
mongo.close();
return false;
}
})
})
开始时可能有点令人生畏,但随着我们深入探讨本章,这将变得更加熟悉。正如我们之前提到的,即使它们看起来有些不同,您应该能够从 mongo shell 中识别出一些元素。代码中映射到 mongo shell 元素的一些元素如下:
-
collection对象,就像 shell 中的db.collection。 -
在我们的
collection之后使用find命令,就像在 shell 中一样。 -
我们
find命令中的参数是一个文档过滤器,这正是我们在 shell 中使用的。
在 Node.js 中,函数声明是使用function(parameter){…}函数完成的,它允许我们创建可以多次运行的较小、可重用的代码片段,例如find()或insertOne()函数。定义函数很容易;您只需使用function关键字,后跟函数的名称、括号中的参数和大括号来定义此函数的实际逻辑。
这是定义函数的代码。请注意,有两种方法可以做到这一点:您可以将函数声明为变量,也可以将函数作为参数传递给另一个函数。我们将在本章后面详细介绍这一点:
// 4_Define_Function.js
const newFunction = function(parameter1, parameter2) {
// Function logic goes here.
console.log(parameter1);
console.log(parameter2);
}
获取 Node.js 的 MongoDB 驱动程序
安装 Node.js 的 MongoDB 驱动程序最简单的方法是使用npm。npm,或 node 包管理器,是一个用于添加、更新和管理 Node.js 程序中使用的不同包的包管理工具。在这种情况下,您要添加的包是 MongoDB 驱动程序,因此在存储脚本的目录中,在您的终端或命令提示符中运行以下命令:
> npm install mongo --save
安装包后可能会看到一些输出,如下所示:
图 8.1:使用 npm 安装 MongoDB 驱动程序
就这么简单。现在,让我们开始针对 MongoDB 进行编程。
数据库和集合对象
在使用 MongoDB 驱动程序时,您可以使用三个主要组件进行大多数操作。在后面的练习中,我们将看到它们如何组合在一起,但在那之前,让我们简要介绍每个组件及其目的。
MongoClient是您在代码中必须创建的第一个对象。这代表您与 MongoDB 服务器的连接。将其视为 mongo shell 的等价物;您传入数据库的 URL 和连接参数,它将为您创建一个连接供您使用。要使用MongoClient,您必须在脚本顶部导入模块:
// First load the Driver module.
const Mongo = require('MongoDB').MongoClient;
// Then define our server.
const server = 'mongodb+srv://username:password@server- abcdef.gcp.mongodb.net/test?retryWrites=true&w=majority';
// Create a new client.
const mongo = new Mongo(server);
// Connect to our server.
mongo.connect(function(err) {
// Inside this block we are connected to MongoDB.
mongo.close(); // Close our connection at the end.
})
接下来是database对象。就像 mongo shell 一样,一旦建立连接,您可以针对服务器中的特定数据库运行命令。这个数据库对象还将确定您可以针对哪些集合运行查询:
…
mongo.connect(function(err) {
// Inside this block we are connected to MongoDB.
// Create our database object.
const database = mongo.db(«sample_mflix»);
mongo.close(); // Close our connection at the end.
})
…
在(几乎)每个基于 MongoDB 的应用程序中使用的第三个基本对象是collection对象。正如在 mongo shell 中一样,大多数常见操作将针对单个集合运行:
…
mongo.connect(function(err) {
// Inside this block we are connected to MongoDB.
// Create our database object.
const database = mongo.db("sample_mflix");
// Create our collection object
const collection = database.collection("movies");
mongo.close(); // Close our connection at the end.
})
…
database和collection对象表达了与直接连接 mongo shell 相同的概念。在本章中,MongoClient仅用于创建和存储与服务器的连接。
重要的是要注意,这些对象之间的关系是MongoClient对象可以创建多个database对象,而database对象可以创建多个用于运行查询的collection对象:
图 8.2:驱动程序实体关系
上图是对前面段落中描述的实体关系的可视化表示。这里有一个MongoClient对象对应多个database对象,每个database对象可能有多个用于运行查询的collection对象。
连接参数
在编写代码之前,了解如何建立到MongoClient的连接是很重要的。创建新客户端时只有两个参数:服务器的 URL 和任何额外的连接选项。如果需要创建客户端,连接选项是可选的,如下所示:
const serverURL = 'mongodb+srv://username:password@server- abcdef.gcp.mongodb.net/test';
const mongo = new Mongo(serverURL);
mongo.connect(function(err) {
// Inside this block we are connected to MongoDB.
mongo.close(); // Close our connection at the end.
})
注意
callback. We will cover these in detail later in this chapter. For now, it is enough to use this pattern without having a more in-depth understanding.
与 mongo shell 一样,serverURL支持所有 MongoDB URI 选项,这意味着您可以在连接字符串本身中指定配置,而不是在第二个可选参数中;例如:
const serverURL = 'mongodb+srv://username:password@server- abcdef.gcp.mongodb.net/test?retryWrites=true&w=majority';
为了简化这个字符串,可以在创建客户端时在第二个参数中指定许多这些 URI 选项(以及其他选项,例如 SSL 设置);例如:
const mongo = new Mongo(serverURL, {
sslValidate: false
});
mongo.connect(function(err) {
// Inside this block we are connected to MongoDB.
mongo.close(); // Close our connection at the end.
})
与 mongo shell 一样,有许多配置选项,包括 SSL、身份验证和写入关注选项。然而,大部分超出了本章的范围。
注意
请记住,您可以在 cloud.mongodb.com 的用户界面中找到 Atlas 的完整连接字符串。您可能希望复制此连接字符串,并在所有脚本中使用它作为serverURL。
让我们通过练习学习如何与 Node.js 驱动程序建立连接。
练习 8.01:使用 Node.js 驱动程序创建连接
在开始这个练习之前,回顾一下介绍部分中概述的电影公司。您可能还记得电影公司希望有一个 Node.js 应用程序,允许用户查询和更新电影数据库中的记录。为了实现这一点,您的应用程序首先需要建立与服务器的连接。可以通过执行以下步骤来完成:
- 首先,在您当前的工作目录中,创建一个名为
Exercise8.01.js的新 JavaScript 文件,并在您选择的文本编辑器(Visual Studio Code、Sublime 等)中打开它:
> node Exercise8.01.js
```
1. 通过将以下行添加到文件顶部,将 MongoDB 驱动程序库(如本章前面所述)导入到您的脚本文件中:
```js
const MongoClient = require('mongodb').MongoClient;
```
注意
如果您在本章早期没有安装 npm MongoDB 库,现在应该运行`npm install mongo --save`在命令提示符或终端中进行安装。在与您的脚本相同的目录中运行此命令。
1. 创建一个包含您的 MongoDB 服务器的 URL 的新变量:
```js
const url = 'mongodb+srv://username:password@server- abcdef.gcp.mongodb.net/test';
```
1. 创建一个名为`client`的新`MongoClient`对象,使用`url`变量:
```js
const client = new MongoClient(url);
```
1. 使用以下方式打开到 MongoDB 的连接`connect`函数:
```js
client.connect(function(err) {
…
})
```
1. 在连接块中添加一个`console.log()`消息,以确认连接已打开:
```js
console.log('Connected to MongoDB with NodeJS!');
```
1. 最后,在连接块的末尾,使用以下语法关闭连接:
```js
client.close(); // Close our connection at the end.
```
您的完整脚本应如下所示:
```js
// Import MongoDB Driver module.
const MongoClient = require('mongodb').MongoClient;
// Create a new url variable.
const url = 'mongodb+srv://username:password@server- abcdef.gcp.mongodb.net/test';
// Create a new MongoClient.
const client = new MongoClient(url);
// Open the connection using the .connect function.
client.connect(function(err) {
// Within the connection block, add a console.log to confirm the connection
console.log('Connected to MongoDB with NodeJS!');
client.close(); // Close our connection at the end.
})
```
使用`node Exercise8.01.js`执行代码后,将生成以下输出:
```js
Chapter8> node Excercise8.01.js
Connected to MongoDB with NodeJS!
Chapter8>
```
在这个练习中,您使用 Node.js 驱动程序建立了与服务器的连接。
# 执行简单查询
现在我们已经连接到 MongoDB,可以对数据库运行一些简单的查询。在 Node.js 驱动程序中运行查询与在 shell 中运行查询非常相似。到目前为止,您应该熟悉 shell 中的`find`命令:
```js
db.movies.findOne({})
以下是驱动程序中find命令的语法:
collection.find({title: 'Blacksmith Scene'}).each(function(err, doc) { … }
正如您所看到的,一般结构与您在 mongo shell 中执行的find命令相同。在这里,我们从数据库对象中获取一个集合,然后针对该集合运行带有查询文档的find命令。这个过程本身很简单。主要的区别在于我们如何构造我们的命令以及如何处理驱动程序返回的结果。
在编写 Node.js 应用程序时,一个关键的问题是确保您的代码以一种易于修改、扩展或理解的方式编写,无论是将来您自己还是其他专业人士可能需要在应用程序上工作。
创建和执行 find 查询
将Exercise 8.01中的代码,使用 Node.js 驱动程序创建连接,作为参考,因为它已经包含了连接:
const MongoClient = require('mongodb').MongoClient;
// Replace this variable with the connection string for your server, provided by MongoDB Atlas.
const url = 'mongodb+srv://username:password@server-abcdef.gcp.mongodb.net/test';
const client = new MongoClient(url);
client.connect(function(err) {
console.log('Connected to MongoDB with NodeJS!');
// OUR CODE GOES BELOW HERE
// AND ABOVE HERE
client.close();
})
我们的查询逻辑将在这里添加:
// OUR CODE GOES BELOW HERE
// AND ABOVE HERE
现在,我们已经连接到了 MongoDB 服务器。但是,还有两个重要的对象——db和collection。让我们创建我们的数据库对象(用于sample_mflix数据库),如下所示:
// OUR CODE GOES BELOW HERE
const database = client.db("sample_mflix")
// AND ABOVE HERE
现在我们有了我们的database对象。在 mongo shell 中发送查询时,您必须将文档作为命令的过滤器传递给您的文档。这在 Node.js 驱动程序中也是一样的。您可以直接传递文档。但是,建议将过滤器单独定义为变量,然后再分配一个值。您可以在以下代码片段中看到差异:
// Defining filter first.
var filter = { title: 'Blacksmith Scene'};
database.collection("movies").find(filter).toArray(function(err, docs) { });
// Doing everything in a single line.
database.collection("movies").find({title: 'Blacksmith Scene'}).toArray(function(err, docs) {});
与 mongo shell 一样,您可以将空文档作为参数传递以查找所有文档。您可能还注意到我们的find命令末尾有toArray。这是因为,默认情况下,find命令将返回一个游标。我们将在下一节中介绍游标,但与此同时,让我们看看这个完整脚本会是什么样子:
const MongoClient = require('mongodb').MongoClient;
// Replace this variable with the connection string for your server, provided by MongoDB Atlas.
const url = 'mongodb+srv://mike:password@myAtlas- fawxo.gcp.mongodb.net/test?retryWrites=true&w=majority'
const client = new MongoClient(url);
client.connect(function(err) {
console.log('Connected to MongoDB with NodeJS!');
const database = client.db("sample_mflix");
var filter = { title: 'Blacksmith Scene'};
database.collection("movies").find(filter).toArray(function(err, docs) {
console.log('Docs results:');
console.log(docs);
});
client.close();
})
如果您将此修改后的脚本保存为2_Simple_Find.js并使用命令node 2_Simple_Find.js运行它,将会得到以下输出:
图 8.3:上述片段的输出(为简洁起见而截断)
上述输出与通过 mongo shell 而不是驱动程序执行的 MongoDB 查询的输出非常相似。在通过驱动程序执行查询时,我们已经了解到,尽管语法可能与 mongo shell 不同,但查询及其输出中的基本元素是相同的。
使用游标和查询结果
在前面的示例中,我们使用toArray函数将我们的查询输出转换为一个可以用console.log输出的数组。当处理少量数据时,这是一种简单的处理结果的方法;然而,对于较大的结果集,您应该使用游标。您应该对游标有一定的了解,这是从第五章,插入、更新和删除文档中的 mongo shell 查询中得到的。在 mongo shell 中,您可以使用it命令来遍历游标。在 Node.js 中,有许多访问游标的方式,其中三种更常见的模式如下:
toArray:这将获取查询的所有结果并将它们放入一个单一的数组中。这很容易使用,但当您期望从查询中获得大量结果时,效率不是很高。在以下代码中,我们针对电影集合运行find命令,然后使用toArray将数组中的第一个元素记录到控制台中:
database.collection("movies").find(filter).toArray(function(err, docsArray) {
console.log('Docs results as an array:');
console.log(docsArray[0]); // Print the first entry in the array.
});
```
+ `each`:这将逐个遍历结果集中的每个文档。如果您想要检查或使用结果中的每个文档,这是一个很好的模式。在以下代码片段中,我们针对电影集合运行`find`命令,使用`each`记录返回的每个文档,直到没有文档为止:
```js
database.collection("movies").find(filter).each(function(err, doc) {
if(doc) {
console.log('Current doc');
console.log(doc);
} else {
client.close(); // Close our connection.
return false; // End the each loop.
}
});
```
当没有更多文档返回时,文档将等于`null`。因此,每次检查新文档时,检查文档是否存在(使用`if(doc)`)是很重要的。
+ `next`:这将允许你访问结果集中的下一个文档。如果你只想要一个单独的文档或结果的子集,而不必遍历整个结果,这是最好的模式。在下面的代码片段中,我们对电影集合运行了一个`find`命令,使用`next`获取返回的第一个文档,然后将该文档输出到控制台:
```js
database.collection("movies").find(filter).next(function(err, doc) {
console.log("First doc in the cursor");
console.log(doc);
});
```
因为`next`一次只返回一个文档,在这个例子中,我们运行了三次来检查前三个文档。
在本章的示例、练习和活动中,我们将学习这三种方法是如何被使用的。然而,需要注意的是还有其他更高级的模式。
你也可以通过在`find(…)`之后放置这些命令来实现相同的`sort`和`limit`功能,这应该是你在 shell 中以前查询时熟悉的:
```js
database.collection("movies").find(filter).limit(5).sort([['title', 1]]).next (function(err, doc) {…}
练习 8.02:构建一个 Node.js Driver 查询
在这个练习中,你将在练习 8.01的场景上进行构建,使用 Node.js Driver 创建连接,这允许你连接到 mongo 服务器。如果你要交付一个 Node.js 应用程序,允许电影院员工查询和对电影投票,你的脚本将需要根据给定的条件查询数据库,并以易于阅读的格式返回结果。对于这种情况,你必须获取以下查询的结果:
查找两部浪漫类电影,只投影每部电影的标题。
你可以通过执行以下步骤在 Node.js 中实现这一点:
-
创建一个名为
Exercise8.02.js的新的 JavaScript 文件。 -
为了不必从头开始重写所有内容,将
Exercise8.01.js的内容复制到你的新脚本中。否则,在你的新文件中重写连接代码。 -
为了保持代码整洁,创建新的变量来存储
databaseName和collectionName。记住,由于这些在整个脚本中不会改变,你必须使用const关键字将它们声明为常量:
const databaseName = "sample_mflix";
const collectionName = "movies";
```
1. 现在,创建一个新的`const`来存储我们的查询文档;你应该熟悉从之前的章节中创建这些:
```js
const query = { genres: { $all: ["Romance"]} };
```
1. 定义好所有的变量后,创建我们的数据库对象:
```js
const database = client.db(databaseName);
```
现在,你可以使用以下语法发送你的查询。使用`each`模式,传递一个回调函数来处理每个文档。如果这看起来奇怪,不要担心;你将在接下来的部分中详细了解这个。记得使用`limit`只返回两个文档和`project`只输出`title`,因为它们是我们场景的要求:
```js
database.collection(collectionName).find(query).limit(2).project({title: 1}).each(function(err, doc) {
if(doc) {
} else {
client.close(); // Close our connection.
return false; // End the each loop.
}
});
```
1. 在你的回调函数中,使用`console.log`输出我们的查询返回的每个文档:
```js
if(doc){
console.log('Current doc');
console.log(doc);
}
```
你的最终代码应该像这样:
```js
const MongoClient = require('mongodb').MongoClient;
const url = 'mongodb+srv://username:password@server- abcdef.gcp.mongodb.net/test';
const client = new MongoClient(url);
const databaseName = "sample_mflix";
const collectionName = "movies";
const query = { genres: { $all: ["Romance"]} };
// Open the connection using the .connect function.
client.connect(function(err) {
// Within the connection block, add a console.log to confirm the connection
console.log('Connected to MongoDB with NodeJS!');
const database = client.db(databaseName);
database.collection(collectionName).find(query).limit(2).project({title: 1}).each(function(err, doc) {
if(doc) {
console.log('Current doc');
console.log(doc);
} else {
client.close(); // Close our connection.
return false; // End the each loop.
}
});
})
```
1. 现在,使用`node Exercise8.02.js`运行脚本。你应该得到以下输出:
```js
Connected to MongoDB with NodeJS!
Our database connected alright!
Current doc
{ _id: 573a1390f29313caabcd548c, title: 'The Birth of a Nation' }
Current doc
{ _id: 573a1390f29313caabcd5b9a, title: "Hell's Hinges" }
```
在这个练习中,你构建了一个 Node.js 程序,对 MongoDB 执行查询,并将结果返回到控制台。虽然这是一个小步骤,我们可以很容易地在 mongo shell 中完成,但这个脚本将作为更高级和交互式的 Node.js 应用程序的基础。
# 在 Node.js 中的回调和错误处理
所以,我们已经成功打开了与 MongoDB 的连接并运行了一些简单的查询,但可能有一些代码元素看起来不太熟悉;例如,这里的语法:
```js
.each(function(err, doc) {
if(doc) {
console.log('Current doc');
console.log(doc);
} else {
client.close(); // Close our connection.
return false; // End the each loop.
}
});
这就是所谓的MongoClient,一旦它完成了自己的内部逻辑,它应该执行我们作为第二个参数传递的函数中的代码。第二个参数被称为回调。回调是额外的函数(代码块),作为参数传递给另一个首先执行的函数。
回调允许您指定仅在函数完成后执行的逻辑。我们必须在 Node.js 中使用回调的原因是 Node.js 是异步的,这意味着当我们调用诸如connect之类的函数时,它不会阻塞执行。脚本中的下一个内容将被执行。这就是为什么我们使用回调的原因:确保我们的下一步等待连接完成。除了回调之外,还有其他现代模式可以用来替代回调,例如promises和await/async。但是,考虑到本书的范围,我们将只在本章中涵盖回调,并学习如何处理驱动程序返回的错误。
Node.js 中的回调
回调通常在视觉上令人困惑且难以概念化;但是,从根本上讲,它们非常简单。回调是作为第二个函数的参数提供的函数,这允许两个函数按顺序运行。
不使用回调函数(或任何其他同步模式),两个函数将在彼此之后立即开始执行。使用驱动程序时,这会创建错误,因为第二个函数可能依赖于第一个函数在开始之前完成。例如,在连接建立之前,您无法查询数据。让我们来看一下回调的分解:
图 8.4:回调的分解
现在,将此与我们的find查询代码进行比较:
图 8.5:MongoDB 回调的分解
您可以看到,相同的结构存在,只是回调函数的参数不同。您可能想知道我们如何知道在特定回调中使用哪些参数。答案是,我们传递给回调函数的参数由我们提供回调函数的第一个函数确定。也许这是一个令人困惑的句子,但它的意思是:当将函数 fA 作为参数传递给第二个函数 fB 时,fA 的参数由 fB 提供。让我们再次检查我们的实际示例,以确保我们理解这一点:
database.collection(collectionName).find(query).limit(2).project({title: 1}).each (function(err, doc) {
if(doc) {
console.log('Current doc');
console.log(doc);
} else {
client.close(); // Close our connection.
return false; // End the each loop.
}
});
因此,我们的回调函数function(err, doc) { … }作为参数提供给驱动程序函数each。这意味着each将为结果集中的每个文档运行我们的回调函数,为每次执行传递err(错误)和doc(文档)参数。以下是相同的代码,但添加了一些日志以演示执行顺序:
console.log('This will execute first.')
database.collection(collectionName).find(query).limit(2).project({title: 1}).each (function(err, doc) {
console.log('This will execute last, once for each document in the result.')
if(doc) {
} else {
client.close(); // Close our connection.
return false; // End the each loop.
}
});
console.log('This will execute second.');
如果我们使用node 3_Callbacks.js运行此代码,我们可以在输出中看到执行顺序:
Connected to MongoDB with NodeJS!
This will execute first.
This will execute second.
This will execute last, once for each doc.
This will execute last, once for each doc.
This will execute last, once for each doc.
回调有时是复杂的模式,需要熟悉,并且越来越多地被更高级的 Node.js 模式(例如promises和async/await)所取代。熟悉这些模式的最佳方法是使用它们,因此如果您对它们还不太熟悉,不用担心。
Node.js 中的基本错误处理
当我们检查回调时,您可能已经注意到我们尚未描述的参数:err。在 MongoDB 驱动程序中,大多数在 mongo shell 中可能返回错误的命令也可以在驱动程序中返回错误。在回调的情况下,err参数将始终存在;但是,如果没有错误,则err的值为null。在 NodeJS 中捕获异步代码中的错误的“错误优先”模式是标准做法。
例如,假设您创建了一个应用程序,将用户的电话号码输入客户数据库,两个不同的用户输入相同的电话号码。当您尝试运行插入时,MongoDB 将返回重复键错误。此时,作为 Node.js 应用程序的创建者,您有责任正确处理该错误。要检查查询中的任何错误,我们可以检查err是否不为null。您可以使用以下语法轻松检查:
database.collection(collectionName).find(query).limit(2).project({title: 1}).each (function(err, doc) {
if(err) {
console.log('Error in query.');
console.log(err);
client.close();
return false;
}
else if(doc) {
console.log('Current doc');
console.log(doc);
} else {
client.close(); // Close our connection.
return false; // End the each loop.
}
});
您可能会注意到,这与我们在使用each时检查是否有更多文档时使用的语法相同。类似于我们检查查询的错误,我们的客户端中的connect函数也会向我们的callback函数提供一个错误,这在运行任何进一步的逻辑之前应该进行检查:
// Open the connection using the .connect function.
client.connect(function(err) {
if(err) {
console.log('Error connecting!');
console.log(err);
client.close();
} else {
// Within the connection block, add a console.log to confirm the connection
console.log('Connected to MongoDB with NodeJS!');
client.close(); // Close our connection at the end.
}
})
注意
在尝试使用参数之前,最好使用回调来检查传递的参数。在find命令的情况下,这意味着检查是否有错误并检查是否返回了文档。在针对 MongoDB 编写代码时,最好验证从数据库返回的所有内容,并记录错误以进行调试。
但我们不仅可以在回调中验证代码的准确性。我们还可以检查非回调函数,以确保一切顺利,例如当我们创建我们的database对象时:
const database = client.db(databaseName);
if(database) {
console.log('Our database connected alright!');
}
根据您尝试使用 MongoDB 实现的目标,您的错误处理可能像前面的示例那样简单,或者您可能需要更复杂的逻辑。但是,在本章的范围内,我们只会看一下基本的错误处理。
练习 8.03:使用 Node.js 驱动程序进行错误处理和回调
在Exercise 8.02中,构建 Node.js 驱动程序查询,您创建了一个成功连接到 MongoDB 服务器并生成查询结果的脚本。在这个练习中,您将向您的代码添加错误处理——这意味着如果出现任何问题,它可以帮助您识别或修复问题。您将通过修改查询来测试此处理,以使其失败。您可以通过以下步骤在 Node.js 中实现这一点:
-
创建一个名为
Exercise8.03.js的新 JavaScript 文件。 -
为了不必从头开始重写所有内容,将
Exercise8.02.js的内容复制到您的新脚本中。否则,在新文件中重写连接和查询代码。 -
在连接回调中,检查
err参数。如果您有错误,请确保使用console.log输出它:
client.connect(function(err) {
if(err) {
console.log('Failed to connect.');
console.log(err);
return false;
}
// Within the connection block, add a console.log to confirm the connection
console.log('Connected to MongoDB with NodeJS!');
```
1. 在运行查询之前添加一些错误检查,以确保数据库对象已成功创建。如果您有错误,请使用`console.log`输出它。使用`!`语法来检查某些东西是否不存在:
```js
const database = client.db(databaseName);
if(!database) {
console.log('Database object doesn't exist!');
return false;
}
```
1. 在`each`回调中,检查`err`参数,确保每个文档都没有错误地返回:
```js
database.collection(collectionName).find(query).limit(2).project({title: 1}).each(function(err, doc) {
if(err) {
console.log('Query error.');
console.log(err);
client.close();
return false;
}
if(doc) {
console.log('Current doc');
console.log(doc);
} else {
client.close(); // Close our connection.
return false; // End the each loop.
}
});
```
此时,您的整个代码应该如下所示:
```js
const MongoClient = require('mongodb').MongoClient;
const url = 'mongodb+srv://username:password@server- fawxo.gcp.mongodb.net/test?retryWrites=true&w=majority';
const client = new MongoClient(url);
const databaseName = "sample_mflix";
const collectionName = "movies";
const query = { genres: { $all: ["Romance"]} };
// Open the connection using the .connect function.
client.connect(function(err) {
if(err) {
console.log('Failed to connect.');
console.log(err);
return false;
}
// Within the connection block, add a console.log to confirm the connection
console.log('Connected to MongoDB with NodeJS!');
const database = client.db(databaseName);
if(!database) {
console.log('Database object doesn't exist!');
return false;
}
database.collection(collectionName).find(query).limit(2).project({title: 1}).each(function(err, doc) {
if(err) {
console.log('Query error.');
console.log(err);
client.close();
return false;
}
if(doc) {
console.log('Current doc');
console.log(doc);
} else {
client.close(); // Close our connection.
return false; // End the each loop.
}
});
})
```
1. 在添加错误之前,使用 node `Exercise8.03.js`运行脚本。您应该会得到以下输出:
```js
Connected to MongoDB with NodeJS!
Current doc
{ _id: 573a1390f29313caabcd548c, title: 'The Birth of a Nation' }
Current doc
{ _id: 573a1390f29313caabcd5b9a, title: "Hell's Hinges" }
```
1. 修改查询以确保产生错误:
```js
const query = { genres: { $thisIsNotAnOperator: ["Romance"]} };
```
1. 使用 node `Exercise8.03.js`运行脚本。您应该会得到以下输出: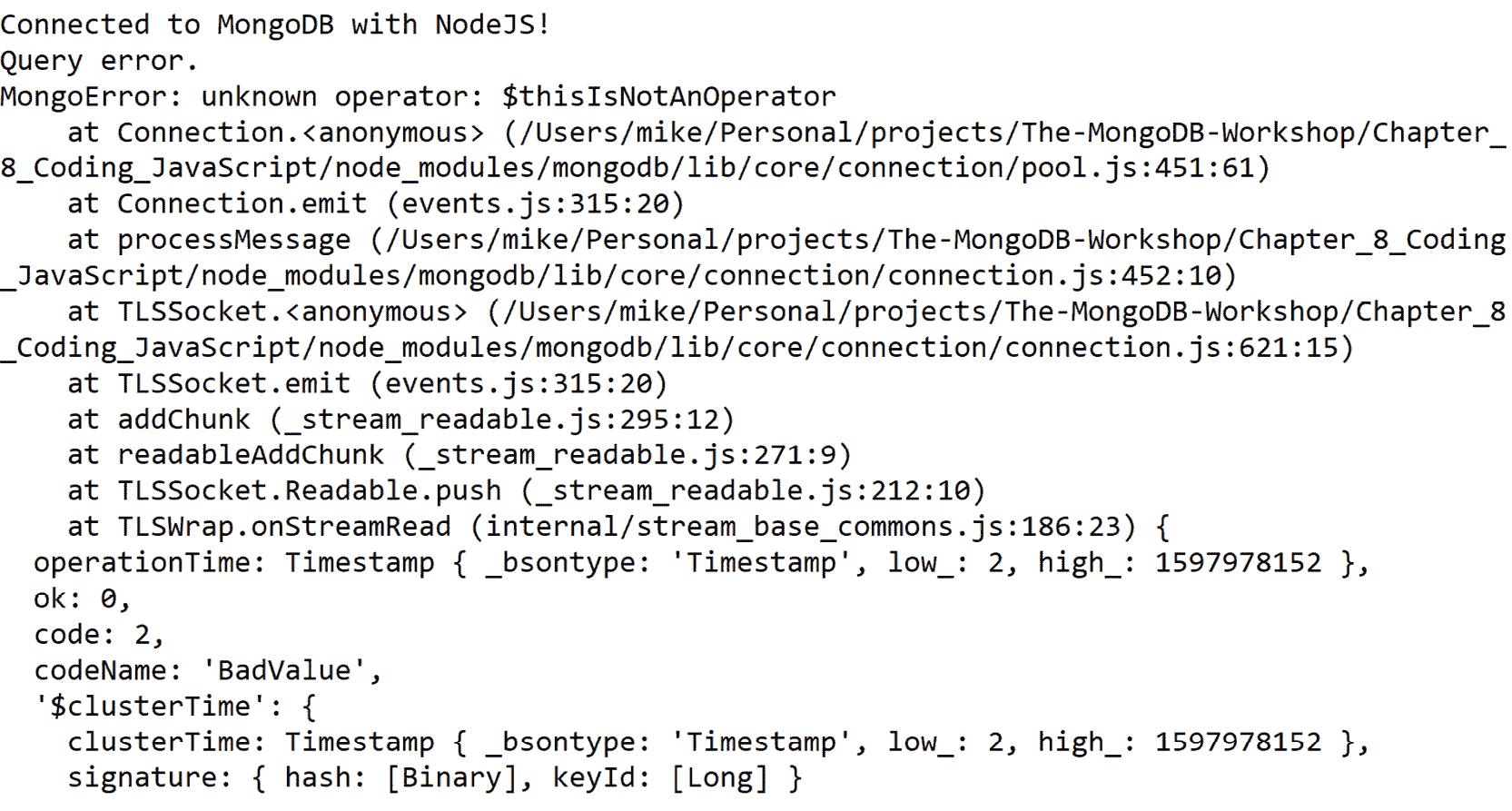
图 8.6:脚本运行后的输出(为简洁起见进行了截断)
在这个练习中,您扩展了您的 Node.js 应用程序,以便在 Node.js 环境中运行 MongoDB 查询时捕获和处理可能遇到的错误。这将使您能够创建更健壮、容错和可扩展的应用程序。
# 高级查询
在上一节中,我们连接到了 MongoDB 服务器,查询了一些数据,输出了它,并处理了我们遇到的任何错误。但是,如果应用程序或脚本只能执行读取操作,那么它的实用性将受到限制。在本节中,我们将在 MongoDB 驱动程序中应用`write`和`update`操作。此外,我们将研究如何使用函数语法为我们的最终应用程序创建可重用的代码块。
## 使用 Node.js 驱动程序插入数据
与 mongo shell 类似,我们可以使用`insertOne`或`insertMany`函数将数据写入我们的集合。这些函数在集合对象上调用。我们需要将单个文档传递给这些函数,或者在`insertMany`的情况下,需要传递文档数组。以下是一个包含如何使用带有回调的`insertOne`和`insertMany`的代码片段。到目前为止,您应该能够认识到这是一个不完整的代码片段。要执行以下代码,您需要添加我们在本章前面学到的基本连接逻辑。现在这应该看起来非常熟悉:
```js
database.collection(collectionName).insertOne({Hello: "World"}, function(err, result) {
// Handle result.
})
database.collection(collectionName).insertMany([{Hello: "World"}, {Hello: "Mongo"}], function(err, result) {
// Handle result.
})
与find一样,我们将回调传递给这些函数以处理操作的结果。插入操作将返回一个错误(可能为null)和一个结果,其中详细说明了插入操作的执行方式。例如,如果我们要构建在先前练习的结果之上,并记录insertMany操作的结果,那么将产生以下输出:
database.collection(collectionName).insertOne({Hello: "World"}, function(err, result) {
console.log(result.result);
client.close();
})
我们可能会在输出中看到一个像图 8.7那样的result对象。
注意
我们只输出了整个result对象的一个子集,其中包含有关我们操作的更多信息。例如,我们正在记录result.result,这是整个result对象中的一个子文档。这仅适用于本示例的范围。在其他用例中,您可能需要更多关于操作结果的信息:
图 8.7:显示整个结果对象的子集的输出
使用 Node.js 驱动程序更新和删除数据
使用驱动程序更新和删除文档遵循与insert函数相同的模式,其中collection对象通过回调传递,检查错误,并分析操作的结果。所有这些函数都将返回一个结果文档。但是,在这三个操作之间,结果文档中包含的格式和信息可能会有所不同。让我们看一些示例。
以下是一些示例代码的示例(也建立在我们之前的连接代码之上),用于更新文档。我们可以使用updateOne或updateMany:
database.collection(collectionName).updateOne({Hello: "World"}, {$set: {Hello : "Earth"}}, function(err, result) {
console.log(result.modifiedCount);
client.close();
})
如果我们运行这段代码,我们的输出结果可能如下所示:
Connected to MongoDB with NodeJS!
1
现在,让我们看一个删除文档的示例。与我们的其他函数一样,我们可以使用deleteOne或deleteMany。请记住,此代码片段作为我们为Exercise 8.03创建的较大代码的一部分存在,Node.js 驱动程序中的错误处理和回调:
database.collection(collectionName).deleteOne({Hello: "Earth"}, function(err, result) {
console.log(result.deletedCount);
client.close();
})
如果我们运行这段代码,我们的输出将如下所示:
Connected to MongoDB with NodeJS!
1
正如您所看到的,所有这些操作都遵循类似的模式,并且在结构上非常接近您将发送到 mongo shell 的相同命令。主要区别在于回调,我们可以在操作结果上运行自定义逻辑。
编写可重用的函数
到目前为止,在我们的示例和练习中,我们总是执行单个操作并输出结果。但是,在更大,更复杂的应用程序中,您将希望在同一程序中运行许多不同的操作,具体取决于上下文。例如,在您的应用程序中,您可能希望多次运行相同的查询并比较各自的结果,或者您可能希望根据第一个查询的输出修改第二个查询。
这就是我们将创建自己的函数的地方。您已经编写了一些函数用作回调,但在这种情况下,我们将编写可以随时调用的函数,无论是用于实用程序还是保持代码清晰和分离。让我们看一个例子。
让我们通过以下代码片段更好地理解这一点,该代码片段运行了三个非常相似的查询。这些查询之间唯一的区别是每个查询中的一个参数(评分):
database.collection(collectionName).find({name: "Matthew"}).each(function(err, doc) {});
database.collection(collectionName).find({name: "Mark"}).each(function(err, doc) {});
database.collection(collectionName).find({name: "Luke"}).each(function(err, doc) {})
让我们尝试用一个函数简化和清理这段代码。我们使用与变量相同的语法声明一个新函数。因为这个函数不会改变,我们可以将它声明为const。对于函数的值,我们可以使用我们在之前的示例中(本章早期的回调部分的示例)已经熟悉的语法:
const findByName = function(name) {
}
现在,让我们在花括号之间为这个函数添加逻辑:
const findByName = function(name) {
database.collection(collectionName).find({name: name}).each(function(err, doc) {})
}
但是有些地方不太对。我们在创建数据库对象之前引用了数据库对象。我们将不得不将该对象作为参数传递给这个函数,所以让我们调整我们的函数来做到这一点:
const findByName = function(name, database) {
database.collection(collectionName).find({name: name}).each(function(err, doc) {})
}
现在,我们可以用三个函数调用来替换我们的三个查询:
const findByName = function(name, database) {
database.collection(collectionName).find({name: name}).each(function(err, doc ) {})
}
findByName("Matthew", database);
findByName("Mark", database);
findByName("Luke", database);
在本章中,为了简单起见,我们不会过多地讨论创建模块化、功能性的代码。但是,如果您想进一步改进这段代码,您可以使用数组和for循环来为每个值运行函数,而不必调用它三次。
练习 8.04:使用 Node.js 驱动程序更新数据
考虑介绍部分的情景,您已经从起点取得了相当大的进展。您的最终应用程序需要能够通过运行更新操作向电影添加投票。但是,您还没有准备好添加这个逻辑。不过,为了证明您能够做到这一点,编写一个脚本,更新数据库中的几个不同文档,并创建一个可重用的函数来实现这一点。在这个练习中,您需要更新chapter8_Exercise4集合中的以下名称。您将使用这个唯一的集合来确保在更新期间不会损坏其他活动的数据:
Ned Stark to Greg Stark, Robb Stark to Bob Stark, and Bran Stark to Brad Stark.
您可以通过执行以下步骤在 Node.js 中实现这一点:
- 首先,确保正确的文档存在以进行更新。直接使用 mongo shell 连接到服务器,并执行以下代码片段来检查这些文档:
db.chapter8_Exercise4.find({ $or: [{name: "Ned Stark"}, {name: "Robb Stark"}, {name: "Bran Stark"}]});
```
1. 如果前面查询的结果为空,请使用此片段添加要更新的文档:
```js
db.chapter8_Exercise4.insert([{name: "Ned Stark"}, {name: "Bran Stark"}, {name: "Robb Stark"}]);
```
1. 现在,要创建脚本,请退出 mongo shell 连接,并创建一个名为`Exercise8.04.js`的新 JavaScript 文件。这样您就不必从头开始重写所有内容,只需将`Exercise8.03.js`的内容复制到新脚本中。否则,请在新文件中重写连接代码。如果您从*Exercise 8.03*,*使用 Node.js 驱动程序处理错误和回调*中复制了代码,则删除查找查询的代码。
1. 将集合从电影更改为`chapter8_Exercise4`:
```js
const collectionName = "chapter8_Exercise4";
```
1. 在脚本开始之前,在连接之前,创建一个名为`updateName`的新函数。这个函数将以数据库对象、客户端对象以及`oldName`和`newName`作为参数:
```js
const updateName = function(client, database, oldName, newName) {
}
```
1. 在`updateName`函数中,添加运行更新命令的代码,该命令将更新包含名为`oldName`的字段的文档,并将该值更新为`newName`:
```js
const updateName = function(client, database, oldName, newName) {
database.collection(collectionName).updateOne({name: oldName}, {$set: {name: newName}}, function(err, result) {
if(err) {
console.log('Error updating');
console.log(err);
client.close();
return false;
}
console.log('Updated documents #:');
console.log(result.modifiedCount);
client.close();
})
};
```
1. 现在,在连接回调中,运行您的新函数三次,分别为要更新的三个名称运行一次:
```js
updateName(client, database, "Ned Stark", "Greg Stark");
updateName(client, database, "Robb Stark", "Bob Stark");
updateName(client, database, "Bran Stark", "Brad Stark");
```
1. 此时,您的整个代码应该如下所示:
```js
const MongoClient = require('mongodb').MongoClient;
const url = 'mongodb+srv://mike:password@myAtlas-fawxo.gcp.mongodb.net/test?retryWrites=true&w=majority';
const client = new MongoClient(url);
const databaseName = "sample_mflix";
const collectionName = "chapter8_Exercise4";
const updateName = function(client, database, oldName, newName) {
database.collection(collectionName).updateOne({name: oldName}, {$set: {name: newName}}, function(err, result) {
if(err) {
console.log('Error updating');
console.log(err);
client.close();
return false;
}
console.log('Updated documents #:');
console.log(result.modifiedCount);
client.close();
})
};
// Open the connection using the .connect function.
client.connect(function(err) {
if(err) {
console.log('Failed to connect.');
console.log(err);
return false;
}
// Within the connection block, add a console.log to confirm the connection
console.log('Connected to MongoDB with NodeJS!');
const database = client.db(databaseName);
if(!database) {
console.log('Database object doesn't exist!');
return false;
}
updateName(client, database, "Ned Stark", "Greg Stark");
updateName(client, database, "Robb Stark", "Bob Stark");
updateName(client, database, "Bran Stark", "Brad Stark");
})
```
1. 使用`node Exercise8.04.js`运行脚本。您应该会得到以下输出:
```js
Connected to MongoDB with NodeJS!
Updated documents #:
1
Updated documents #:
1
Updated documents #:
1
```
在过去的四个部分中,您已经学会了如何创建一个连接到 MongoDB 的 Node.js 脚本,运行易于使用的函数进行查询,并处理我们可能遇到的任何错误。这为您搭建了一个基础,可以用它来构建许多脚本,以使用您的 MongoDB 数据库执行复杂的逻辑。然而,在我们迄今为止的示例中,我们的查询参数总是硬编码到我们的脚本中,这意味着我们的每个脚本只能满足特定的用例。
这并不理想。像 Node.js 驱动程序这样的强大之处之一是能够拥有一个解决大量问题的单个应用程序。为了扩大我们脚本的范围,我们将接受用户输入来创建动态查询,能够解决用户的问题,而无需重写和分发我们程序的新版本。在本节中,我们将学习如何接受用户输入、处理它,并从中构建动态查询。
注意
在大多数大型、生产就绪的应用程序中,用户输入将以**图形用户界面**(**GUI**)的形式出现。这些 GUI 将简单的用户选择转换为复杂的、相关的查询。然而,构建 GUI 是非常棘手的,超出了本书的范围。
## 从命令行读取输入
在本节中,我们将从命令行获取输入。幸运的是,Node.js 为我们提供了一些简单的方法来从命令行读取输入并在我们的代码中使用它。Node.js 提供了一个名为 `readline` 的模块,它允许我们向用户请求输入、接受输入,然后使用它。您可以通过在文件顶部添加以下行来将 `readline` 加载到您的脚本中。在使用 `readline` 时,您必须始终创建一个接口:
```js
const readline = require('readline');
const interface = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
现在,我们可以要求用户输入一些内容。 readline 为我们提供了多种处理输入的方式。然而,现在最简单的方法是使用 question 函数,就像这里的例子一样:
interface.question('Hello, what is your name? ', (input) => {
console.log(`Hello, ${input}`);
interface.close();
});
注意
${input} 语法允许我们在字符串中嵌入一个变量。在使用时,请确保使用反引号,`(如果您不确定在标准 QWERTY 键盘上哪里可以找到它,它与1键左侧的~符号共享一个键。)
如果我们运行这个示例,我们将得到类似这样的输出:
Chapter_8> node example.js
Hello, what is your name? Michael
Hello, Michael
如果你想创建一个更长的提示,最好使用console.log来输出大部分输出,然后只提供一个较小的readline问题。例如,假设我们在询问用户输入之前发送了一条长消息。我们可以将其定义为变量,并在询问问题之前记录它:
const question = "Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum?"
interface.question(question, (input) => {
console.log(`Hello, ${input}`);
interface.close();
});
通过这种方式,我们可以轻松地修改和在多个输入中重用我们的消息。
注意
在 Node.js 中处理输入有许多不同的库和模块。然而,为了简化,我们将在本章中使用readline。
创建交互式循环
因此,我们有一种简单的方法来询问用户问题并接受他们的输入。然而,如果每次我们想要使用它时都必须从命令行运行我们的应用程序,那么它不会非常有用。如果我们能运行一次程序,并根据不同的输入执行多次运行,那将更加有用。
为此,我们可以创建一个交互式循环,即应用程序将持续请求输入,直到满足退出条件。为了确保循环持续,我们可以将提示语句放置在一个调用自身的函数中,这将使代码块内的代码一直运行,直到所述的退出条件变为true。这将为我们代码的用户提供更好的体验。以下是使用我们之前提到的readline实现交互式循环的示例:
const askName = function() {
interface.question("Hello, what is your name?", (input) => {
if(input === "exit") {
return interface.close(); // Will kill the loop.
}
console.log(`Hello, ${input}`);
askName();
});
}
askName(); // First Run.
注意这里的退出条件:
if(input === "exit") {
return interface.close(); // Will kill the loop.
}
确保在任何循环中都设置退出条件至关重要,因为这允许用户退出应用程序。否则,他们将永远被困在循环中,这可能会消耗计算机的资源。
注意
在编写代码中的循环时,你可能会不小心创建一个没有退出条件的无限循环。如果确实发生了这种情况,你可能不得不终止你的 shell 或 Terminal。你可以尝试Ctrl+C,或在 macOS 上使用Cmd+C退出。
如果你运行前面的示例,你将能够在退出之前多次回答问题;例如:
Chapter_8> node examples.js
Hello, what is your name?Mike
Hello, Mike
Hello, what is your name?John
Hello, John
Hello, what is your name?Ed
Hello, Ed
Hello, what is your name?exit
练习 8.05:在 Node.js 中处理输入
对于这个练习,你将创建一个小的 Node.js 应用程序,允许你询问用户的姓名。你可以将此视为一个基本的登录系统。此应用程序应在交互式循环中运行;用户的选择如下:
-
login(询问并存储用户的姓名) -
who(输出用户的姓名) -
exit(结束应用程序)
通过执行以下步骤创建此应用程序:
-
创建一个名为
Exercise8.05.js的新 JavaScript 文件。 -
导入
readline模块:
const readline = require('readline');
const interface = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
```
1. 定义选择和用户变量。
1. 现在,定义一个名为`login`的新函数,该函数接受用户作为参数。该函数首先询问用户并将其存储在变量中:
```js
const login = function() {
interface.question("Hello, what is your name?", (name) => {
user = name;
prompt();
});
}
```
1. 创建一个名为`who`的新函数,该函数输出`user`:
```js
const who = function () {
console.log(`User is ${user}`);
prompt();
}
```
1. 创建一个输入循环,条件是选择不等于退出:
```js
const prompt = function() {
interface.question("login, who OR exit?", (input) => {
if(input === "exit") {
return interface.close(); // Will kill the loop.
}
prompt();
});
}
```
1. 之后,使用 if 关键字检查他们的选择是否匹配 "`login`"。如果找到匹配项,则运行 `login` 函数:
```js
if(input === "login") {
login();
}
```
1. 接着,使用 if 关键字检查他们的选择是否匹配 "`who`"。如果找到匹配项,则打印出 `user` 变量:
```js
if(input === "who") {
who();
}
```
你的最终代码应该大致如下所示:
```js
const readline = require('readline');
const interface = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
var choice;
var user;
var cinema;
const login = function() {
interface.question("Hello, what is your name?", (name) => {
user = name;
prompt();
});
}
const who = function () {
console.log(`User is ${user}`)
prompt();
}
const prompt = function() {
interface.question("login, who OR exit?", (input) => {
if(input === "exit") {
return interface.close(); // Will kill the loop.
}
if(input === "login") {
login();
}
if(input === "who") {
who();
}
});
}
prompt();
```
1. 通过运行 `node Exercise8.05.js` 并输入一些内容来执行代码。现在,你应该能够与应用程序进行交互了。以下是一个示例:
```js
Chapter_8> node .\Exercise8.06.js
login, who OR exit?login
Hello, what is your name?Michael
login, who OR exit?who
User is Michael
login, who OR exit?exit
```
在这个练习中,您创建了一个基本的交互式应用程序,使用 Node.js 让用户从三个输入中进行选择,并相应地输出结果。
## 活动 8.01:创建一个简单的 Node.js 应用程序
您已被一家电影公司聘请,创建一个应用程序,允许客户列出所选类别中评分最高的电影。客户应该能够提供一个类别,并在命名的命令行列表中提供响应。他们还需要提供他们最喜欢的电影的详细信息,以便在收藏字段中捕获。最后,完成所有这些后,客户应该能够`退出`应用程序,如下所示:
+ `"列表"`:询问用户一个流派,然后查询该流派中排名前五的电影,输出`ID`、`标题`和`favourite`字段。
+ `"favourite"`:询问用户一个电影 ID,然后更新该电影的收藏字段。
+ `"退出"`:退出交互循环和应用程序。
此活动旨在创建一个小型的 Node.js 应用程序,向用户公开一个交互式输入循环。在此循环中,用户可以通过流派查询数据库中的信息,并通过 ID 更新记录。您还需要确保处理可能出现的用户输入错误。
您可以通过多种方式完成此目标,但请记住我们在本章中学到的内容,并尝试创建简单、易于使用的代码。
以下高级步骤将帮助您完成此任务:
1. 导入`readline`和 MongoDB 库。
1. 创建您的`readline`接口。
1. 声明您将需要的任何变量。
1. 创建一个名为列表的函数,它将为给定流派获取排名前五的最高评分电影,返回`标题`、`收藏`和`ID`字段。
注意
您将需要在此函数中询问类别。查看*练习 8.05*,*在 Node.js 中处理输入*中的登录方法,以获取更多信息。
1. 创建一个名为`favourite`的函数,它将通过标题更新文档,并向文档添加一个名为`favourite`的键,其值为`true`。(提示:在此函数中,您将需要使用与列表函数相同的方法询问标题。)
1. 创建 MongoDB 连接、数据库和集合。
1. 基于用户输入创建一个交互式 while 循环。如果您不确定如何做到这一点,请参考我们在*练习 8.05*,*在 Node.js 中处理输入*中的提示函数。
1. 在交互循环中,使用 if 条件来检查输入。如果找到有效输入,则运行相关函数。
1. 请记住,您需要通过每个函数传递数据库和客户端对象,包括每次调用`prompt()`。要测试您的输出,请运行以下命令:
`列表`
`恐怖`
`favourite`
`列表`
`退出`
预期输出如下:
注意
您可能会注意到输出中标题`Nosferatu`出现了两次。如果查看`_id`值,您会发现这实际上是两部具有相同标题的不同电影。在 MongoDB 中,您可能有许多不同的文档,它们在字段中共享相同的值。
图 8.8:最终输出(为简洁起见截断)
注意
此活动的解决方案可通过此链接找到。
# 总结
在本章中,我们已经介绍了创建使用 Node.js 驱动程序的 MongoDB 应用程序所必需的基本概念。使用这些基础知识,可以创建大量脚本来执行对数据库的查询和操作。我们甚至学会了处理错误和创建交互式应用程序。
尽管您可能不需要在日常工作职责中编写或阅读这些应用程序,但对这些应用程序是如何构建的有深入的理解,可以让您独特地了解 MongoDB 开发以及您的同行可能如何与您的 MongoDB 数据交互。
然而,如果你想增加对于 MongoDB 的 Node.js 驱动的专业知识,这只是个开始。有许多不同的模式、库和最佳实践可以用来开发针对 MongoDB 的 Node.js 应用程序。这只是你 Node.js 之旅的开始。
在下一章中,我们将深入探讨如何提高 MongoDB 交互的性能,并创建高效的索引来加快查询速度。我们还将介绍另一个有用的功能,即使用 `explain` 并且如何最好地解释其输出。
