

Kali Linux 数字取证(二)
原文:
annas-archive.org/md5/8FE31A420313B3F8EBAD75F795E950BF译者:飞龙
第七章:使用 Volatility 进行内存取证
在前几章中,我们看了各种类型的内存。这包括 RAM 和交换或分页文件,它是硬盘驱动器上的一个区域,虽然速度较慢,但作为 RAM。我们还讨论了 RAM 易失性的问题,这意味着当 RAM 芯片不再有电荷或电流时,RAM 中的数据很容易丢失。由于 RAM 上的数据最易失性,因此在易失性顺序中排名较高,并且必须作为高优先级的取证对象进行获取和保留。
许多类型的数据和取证物品驻留在 RAM 和分页文件中。正如前面讨论的,登录密码、用户信息、运行和隐藏进程,甚至加密密码只是在进行 RAM 分析时可以找到的许多有趣数据类型之一,进一步增加了对内存取证的需求。
在本章中,我们将看看功能强大的 Volatility 框架及其在内存取证中的许多用途。
关于 Volatility 框架
Volatility 框架是一个开源的、跨平台的、事件响应框架,提供了许多有用的插件,可以从内存快照(也称为内存转储)中为调查人员提供丰富的信息。Volatility 的概念已经存在了十年,除了分析运行和隐藏进程之外,还是恶意软件分析的一个非常受欢迎的选择。
要创建内存转储,可以使用 FTK imager、CAINE、Helix 和LiME(Linux Memory Extractor 的缩写)等多种工具来获取内存图像或内存转储,然后通过 Volatility 框架中的工具进行调查和分析。
Volatility 框架可以在支持 Python 的任何操作系统(32 位和 64 位)上运行,包括:
-
Windows XP,7,8,8.1 和 Windows 10
-
Windows Server 2003,2008,2012/R2 和 2016
-
Linux 2.6.11 - 4.2.3(包括 Kali、Debian、Ubuntu、CentOS 等)
-
macOS Leopard(10.5.x)和 Snow Leopard(10.12.x)
Volatility 支持多种内存转储格式(32 位和 64 位),包括:
-
Windows 崩溃和休眠转储(Windows 7 及更早版本)
-
VirtualBox
-
VMWare
.vmem转储 -
VMware 保存状态和挂起转储—
.vmss/.vmsn -
原始物理内存—
.dd -
通过 IEEE 1394 FireWire 直接物理内存转储
-
专家证人格式(EWF)—
.E01 -
QEMU(快速模拟器)
Volatility 甚至允许在这些格式之间进行转换,并自称能够完成类似工具的所有任务。
下载用于 Volatility 的测试图像
在本章中,我们将使用一个名为cridex.vmem的 Windows XP 图像,可以直接从github.com/volatilityfoundation/volatility/wiki/Memory-Samples下载。
选择带有描述列的链接,恶意软件 - Cridex,下载cridex.vmem图像:
此页面上还有许多其他图像可供分析。为了练习使用 Volatility 框架并进一步提高您的分析技能,您可能希望下载尽可能多的图像,并使用 Volatility 中提供的各种插件。
图像位置
正如我们将很快看到的,Volatility 框架中的所有插件都是通过终端使用的。为了使访问图像文件更加方便,不必指定图像的冗长路径,我们已将cridex.vmem图像移动到桌面:
我们还可以将目录更改为桌面,然后从那里运行 Volatility 框架及其插件。为此,我们打开一个新的终端并输入以下命令:
cd Desktop
我们还可以查看桌面的内容,以确保cridex.vmem文件存在,方法是输入ls -l:
在 Kali Linux 中使用 Volatility
要启动 Volatility Framework,请单击侧边栏底部的所有应用程序按钮,然后在搜索栏中键入volatility:
单击 Volatility 图标会在终端中启动程序。当 Volatility 启动时,我们看到正在使用的版本是2.6,并为我们提供了使用选项:
要获得所有插件的完整列表,打开一个单独的终端并运行volatility -h命令,而不是不得不滚动到您用于运行 Volatility 插件命令的终端的顶部:
以下截图显示了 Volatility Framework 中许多插件的片段:
在执行分析时,此列表非常有用,因为每个插件都带有自己的简短描述。以下截图显示了help命令的片段,其中提供了imageinfo插件的描述:
在 Volatility 中使用插件的格式是:
volatility -f [filename] [plugin] [options]
如前一节所示,要使用imageinfo插件,我们将键入:
volatility -f cridex.vmem imageinfo
在 Volatility 中选择配置文件
所有操作系统都将信息存储在 RAM 中,但是根据所使用的操作系统,它们可能位于内存中的不同位置。在 Volatility 中,我们必须选择最能识别操作系统类型和服务包的配置文件,以帮助 Volatility 识别存储工件和有用信息的位置。
选择配置文件相对简单,因为 Volatility 会使用imageinfo插件为我们完成所有工作。
imageinfo插件
此插件提供有关所使用的图像的信息,包括建议的操作系统和Image Type (Service Pack),使用的Number of Processors,以及图像的日期和时间。
使用以下命令:
volatility -f cridex.vmem imageinfo
imageinfo输出显示Suggested Profile(s)为WinXPSP2x86和WinXPSP3x86:
-
WinXP:Windows XP
-
SP2/SP3:Service Pack 2/Service Pack 3
-
x86:32 位架构
图像类型或服务包显示为3,表明这是一个将用作案例配置文件的 Windows XP,Service Pack 3,32 位(x86)操作系统:
选择了配置文件后,我们现在可以继续使用 Volatility 插件来分析cridex.vmem图像。
进程识别和分析
为了识别和链接连接的进程,它们的 ID,启动时间和内存映像中的偏移位置,我们将使用以下四个插件来开始:
-
pslist -
pstree -
psscan -
psxview
pslist命令
此工具不仅显示所有运行中的进程列表,还提供有用的信息,如进程 ID(PID)和父进程 ID(PPID),还显示进程启动的时间。在本节显示的截图中,我们可以看到System,winlogon.exe,services.exe,svchost.exe和explorer.exe服务都是首先启动的,然后是reader_sl.exe,alg.exe,最后是wuauclt.exe。
PID 标识进程,PPID 标识进程的父进程。查看pslist输出,我们可以看到winlogon.exe进程的PID为608,PPID为368。services.exe和lsass.exe进程的 PPID(在winlogon.exe进程之后)都是608,表明winlogon.exe实际上是services.exe和lsass.exe的 PPID。
对于那些对进程 ID 和进程本身不熟悉的人,快速的谷歌搜索可以帮助识别和描述信息。熟悉许多启动进程也很有用,以便能够快速指出可能不寻常或可疑的进程。
还应该注意进程的时间和顺序,因为这些可能有助于调查。在下面的截图中,我们可以看到几个进程,包括explorer.exe、spoolsv.exe和reader_sl.exe,都是在02:42:36 UTC+0000同时启动的。我们还可以看到explorer.exe是reader_sl.exe的 PPID。
在这个分析中,我们可以看到有两个wuauclt.exe的实例,其父进程是svchost.exe。
使用的pslist命令如下:
volatility --profile=WinXPSP3x86 -f cridex.vmem pslist
pstree 命令
另一个可以用来列出进程的进程识别命令是pstree命令。该命令显示与pslist命令相同的进程列表,但缩进也用于标识子进程和父进程。
在下面的截图中,列出的最后两个进程是explorer.exe和reader_sl.exe。explorer.exe没有缩进,而reader_sl有缩进,表明sl_reader是子进程,explorer.exe是父进程:
psscan 命令
查看运行进程列表后,我们通过输入以下命令运行psscan命令:
volatility --profile=WinXPSP3x86 -f cridex.vmem psscan
psscan命令显示了可以被恶意软件使用的非活动甚至隐藏的进程,如 rootkits,这些进程以逃避用户和杀毒程序的发现而闻名。
pslist和psscan命令的输出应该进行比较,以观察任何异常情况:
psxview 插件
与psscan一样,psxview插件用于查找和列出隐藏进程。然而,使用psxview,会运行各种扫描,包括pslist和psscan。
运行psxview插件的命令如下:
volatility --profile=WinXPSP3x86 -f cridex.vmem psxview
分析网络服务和连接
Volatility 可以用于识别和分析活动的、终止的和隐藏的连接,以及端口和进程。所有协议都受支持,Volatility 还显示了进程使用的端口的详细信息,包括它们启动的时间。
为此,我们使用以下三个命令:
-
connections -
connscan -
sockets
连接命令
connections命令列出了当时的活动连接,显示了本地和远程 IP 地址以及端口和 PID。connections命令仅用于 Windows XP 和 2003 服务器(32 位和 64 位)。connections命令的使用如下:
volatility --profile=WinXPSP3x86 -f cridex.vmem connections
connscan 命令
connections命令在那个时候只显示了一个活动连接。要显示已终止的连接列表,使用connscan命令。connscan命令也仅适用于 Windows XP 和 2003 服务器(32 位和 64 位)系统:
volatility --profile=WinXPSP3x86 -f cridex.vmem connscan
使用connscan命令,我们可以看到相同的本地地址之前连接到另一个带有 IP125.19.103.198:8080的远程地址。1484的Pid告诉我们,连接是由explorer.exe进程建立的(如之前使用pslist命令显示的)。
可以使用 IP 查找工具和网站(例如whatismyipaddress.com/ip-lookup)获取有关远程地址的更多信息:
通过点击“获取 IP 详细信息”按钮,我们得到以下结果,包括 ISP 名称、洲和国家详情,以及显示设备大致位置的地图:
sockets 插件
sockets插件可用于提供额外的连接信息监听套接字。尽管 UDP 和 TCP 是以下截图中输出的唯一协议,但sockets命令支持所有协议:
DLL 分析
DLL(动态链接库)是特定于 Microsoft 的,包含可以同时供多个程序使用的代码。检查进程的运行 DDL 和文件和产品的版本信息可能有助于相关进程。还应分析进程和 DLL 信息,因为它们与用户帐户相关。
对于这些任务,我们可以使用以下插件:
-
verinfo -
dlllist -
getsids
verinfo 命令
此命令列出了有关PE(可移植可执行文件)文件的版本信息(verinfo)。此文件的输出通常非常冗长,因此可以在单独的终端中运行,如果调查人员不希望不断滚动当前终端以查看过去的插件命令列表和输出。
verinfo命令的使用如下:
volatility --profile=WinXPSP3x86 -f cridex.vmem verinfo
dlllist插件
dlllist插件列出了内存中那个时间运行的所有 DLL。DLL 由可以同时供多个程序使用的代码组成。
dlllist命令的使用如下:
volatility --profile=WinXPSP3x86 -f cridex.vmem dlllist
getsids命令
所有用户还可以通过安全标识符(SID)得到唯一标识。getsids命令按照进程启动的顺序有四个非常有用的项目(参考pslist和pstree命令的截图)。
getsids命令输出的格式为:
[Process] (PID) [SID] (User)
例如,列表中的第一个结果列出了:
System (4) : S – 1 – 5- 18 (User)
-
System:进程 -
(4):PID -
S - 1 - 5- 18:SID -
用户:本地系统
如果 SID 中的最后一个数字在 500 范围内,这表示具有管理员特权的用户。例如,S – 1 – 5- 32-544(管理员)。
getsids命令的使用如下:
volatility --profile=WinXPSP3x86 -f cridex.vmem getsids
向下滚动getsids输出,我们可以看到一个名为Robert的用户,其 SID 为S-1-5-21-79336058(非管理员),已启动或访问explorer.exe,PID 为1484:
注册表分析
在注册表中可以找到有关每个用户、设置、程序和 Windows 操作系统本身的信息。甚至可以在注册表中找到哈希密码。在 Windows 注册表分析中,我们将使用以下两个插件。
-
hivescan -
hivelist
hivescan 插件
hivescan插件显示了可用注册表蜂巢的物理位置。
运行hivescan的命令如下:
**volatility --profile=WinXPSP3x86 -f cridex.vmem hivescan**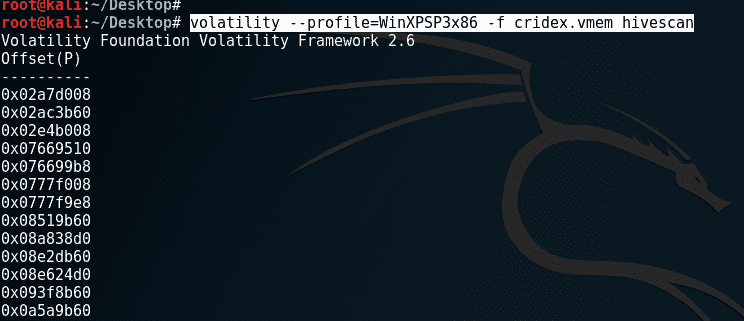 # hivelist 插件 对于有关注册表蜂巢和 RAM 内位置的更详细(和有用的)信息,可以使用`hivelist`插件。`hivelist`命令显示`虚拟`和`物理`地址的详细信息,以及更易读的纯文本名称和位置。 运行`hivelist`的命令如下: ``` volatility --profile=WinXPSP3x86 -f cridex.vmem hivelist ``` 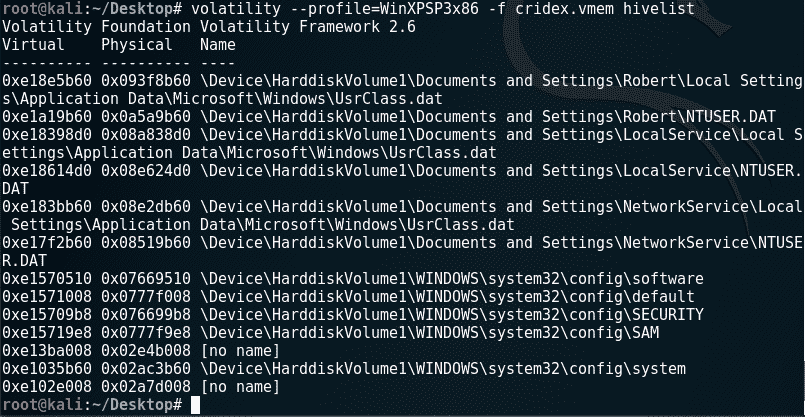 # 密码转储 使用`hivelist`插件还列出了**安全帐户管理器**(**SAM**)文件的位置,如下截图所示。`SAM`文件包含 Windows 机器用户名的哈希密码。`SAM`文件的路径如下截图所示为`Windows\system32\config\SAM`。在 Windows 中,系统开启时用户无法访问此文件。这可以进一步用于使用`wordlist`和密码破解工具(如**John the Ripper**,也可在 Kali Linux 中使用)破解`SAM`文件中的哈希密码:  # 事件时间线 Volatility 可以生成一个带有时间戳的事件列表,这对于任何调查都是必不可少的。为了生成这个列表,我们将使用`timeliner`插件。 # 时间线插件 `timeliner`插件通过提供图像获取时发生的所有事件的时间线来帮助调查人员。尽管我们对这种情况发生了什么有所了解,但许多其他转储可能会非常庞大,更加详细和复杂。 `timeliner`插件按时间分组详细信息,并包括进程、PID、进程偏移、使用的 DDL、注册表详细信息和其他有用信息。 要运行`timeliner`命令,我们输入以下内容: ``` volatility --profile=WinXPSP3x86 -f cridex.vmem timeliner ``` 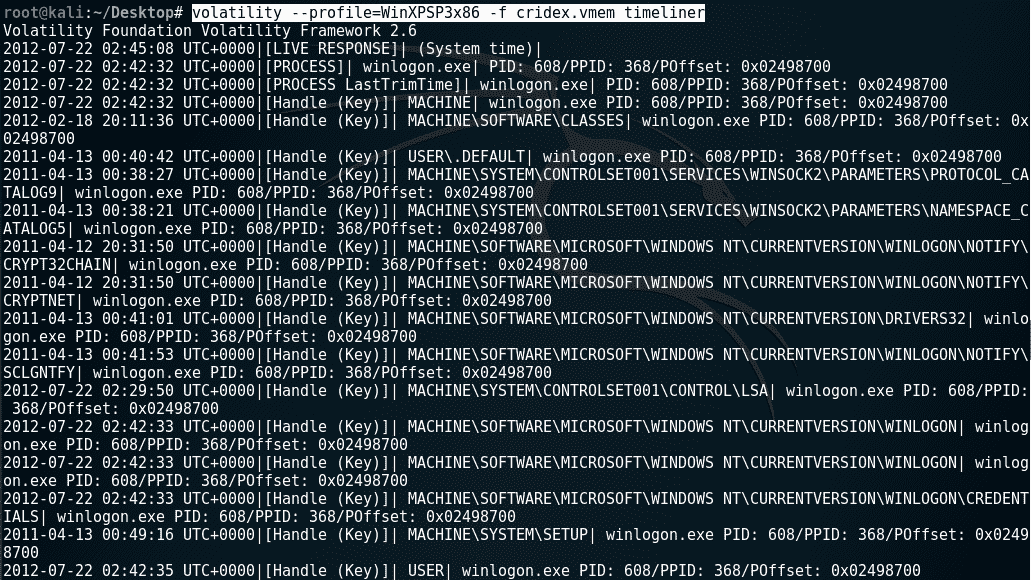 以下是`timeliner`命令的片段,当进一步滚动其输出时: 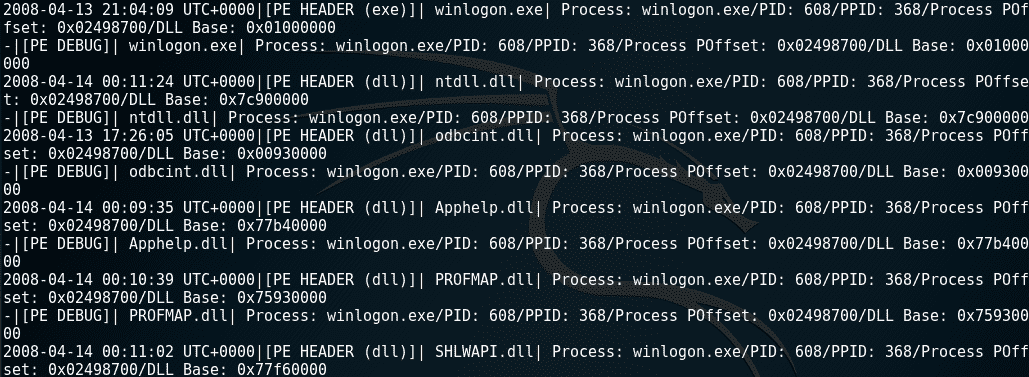 # 恶意软件分析 在 Volatility 令人印象深刻的插件阵容中,还有`malfind`插件。 正如其名称所示,`malfind`插件用于查找,或者至少指引调查人员找到可能已经注入到各种进程中的恶意软件的线索。`malfind`插件的输出可能特别冗长,因此应该在单独的终端中运行,以避免在审查其他插件命令的输出时不断滚动。 运行`malfind`的命令如下: ``` volatility --profile=WinXPSP3x86 -f cridex.vmem malfind ``` 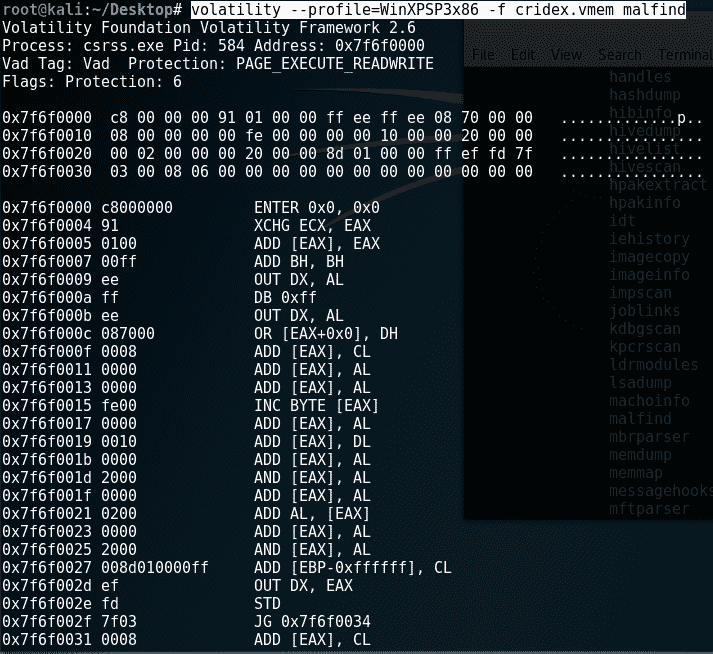 `malfind`插件也可以直接在进程上使用`-p`开关运行。 正如我们发现的那样,`winlogon.exe`被分配了 PID`608`。要在 PID`608`上运行`malfind`,我们输入: ``` volatility --profile=WinXPSP3x86 -f cridex.vmem malfind -p 608 ```  # 总结 在本章中,我们使用了 Volatility Framework 中的许多可用插件进行内存取证和分析。在使用 Volatility 的工作中,首先也是最重要的一步是选择 Volatility 在整个分析过程中将使用的配置文件。这个配置文件告诉 Volatility 正在使用的操作系统类型。一旦选择了配置文件,我们就能够成功地使用这个多功能工具进行进程、网络、注册表、DLL 甚至恶意软件分析。正如我们所看到的,Volatility 可以在数字取证中执行几个重要的功能,并且应该与我们之前使用的其他工具一起使用,以进行深入和详细的取证分析和调查。 一定要下载更多公开可用的内存映像和样本,以测试您在这个领域的技能。尽可能多地尝试各种插件,并当然,一定要记录您的发现并考虑在线分享。 在我们的下一章中,我们将转向另一个功能强大的工具,它可以从获取到报告的所有工作。让我们开始使用 Autopsy—The Sleuth Kit®。 # 第八章:Autopsy - The Sleuth Kit Autopsy 和 The Sleuth Kit 是相辅相成的。两者都是由 Brian Carrier 创建的。The Sleuth Kit 是一套功能强大的 CLI 取证工具,而 Autopsy 是坐落在 The Sleuth Kit 之上的 GUI,并通过 Web 浏览器访问。The Sleuth Kit 支持磁盘映像文件类型,包括 RAW(DD),EnCase(.01)和**高级取证格式**(**AFF**)。 The Sleuth Kit 使用命令行界面工具执行以下任务: + 查找和列出分配的和未分配的(已删除)文件,甚至是被 rootkits 隐藏的文件 + 显示 NTFS **备用数据流**(**ADS**),文件可以隐藏在其他文件中 + 按类型列出文件 + 显示元数据信息 + 时间线创建 Autopsy 可以在法庭模式下从 Live CD/USB 上运行,作为实时分析的一部分,也可以在专用机器上用于死亡模式后期分析。 本章将涵盖以下主题: + 在 Autopsy 中使用的示例图像文件 + 使用 Autopsy 进行数字取证 + 在 Autopsy 中创建一个新案例 + 使用 Autopsy 进行分析 + 在 Autopsy 中重新打开案例 # 介绍 Autopsy - The Sleuth Kit Autopsy 提供对来自 The Sleuth Kit 的各种调查命令行工具的 GUI 访问,包括文件分析,图像和文件哈希,已删除文件恢复和案例管理等功能。安装 Autopsy 可能会有问题,但幸运的是,它已内置在 Kali Linux 中,并且非常容易设置和使用。 尽管 Autopsy 浏览器基于 The Sleuth Kit,但在使用 Windows 版本与 Linux 版本时,Autopsy 的功能有所不同。Kali Linux 中 The Sleuth Kit 和 Autopsy 2.4 提供的一些官方功能包括: + **图像分析**:分析目录和文件,包括文件排序,恢复已删除的文件和预览文件 + **文件活动时间线**:根据文件的时间戳创建时间线,包括写入、访问和创建时间 + **图像完整性**:创建使用的图像文件的 MD5 哈希,以及单个文件 + **哈希数据库**:将未知文件(如疑似恶意的`.exe`文件)的数字哈希或指纹与 NIST **国家软件参考库**(**NSRL**)中的文件进行匹配 + **事件排序器**:按日期和时间排序显示事件 + **文件分析**:分析整个图像文件以显示目录和文件信息和内容 + **关键字搜索**:允许使用关键字列表和预定义表达式列表进行搜索 + **元数据分析**:允许查看文件的元数据详细信息和结构,这对数据恢复至关重要 # Autopsy 中使用的示例图像文件 用于分析的图像文件可以在[`dftt.sourceforge.net/`](http://dftt.sourceforge.net/)上公开下载。 我们将使用的文件是 JPEG 搜索测试#1(Jun'04),如下面的屏幕截图所示:  该图像包含几个更改扩展名的文件以及其中的其他文件,如下面的下载描述所示: 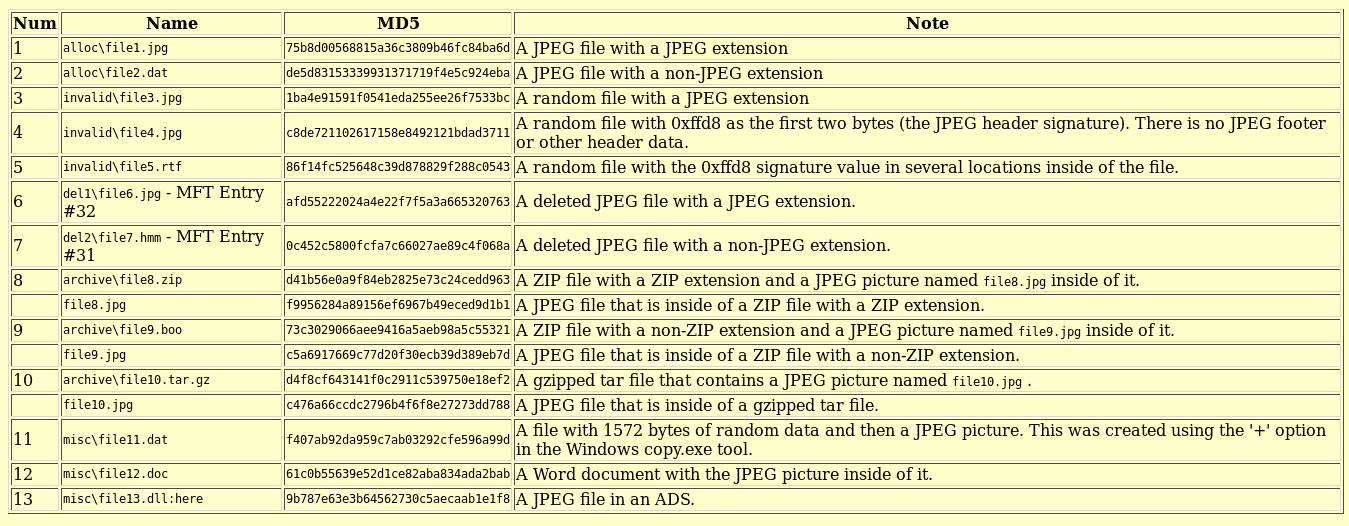 请务必注意下载示例文件的位置,因为稍后会需要它。 调查硬盘和设备时,务必遵循适当的获取程序,并使用经过预先测试的写阻塞器,以避免篡改原始证据。 # 使用 Autopsy 进行数字取证 现在我们已经下载了示例图像文件(或者甚至是我们自己的法庭获取的图像),让我们通过使用 Autopsy 浏览器进行分析,首先熟悉启动 Autopsy 的不同方法。 # 启动 Autopsy Autopsy 可以通过两种方式启动。第一种方法是使用应用程序菜单,单击应用程序| 11-取证|尸检:  或者,我们可以单击显示应用程序图标(侧边菜单中的最后一项)并在屏幕顶部中间的搜索栏中键入`autopsy`,然后单击尸检图标:  一旦点击了尸检图标,就会打开一个新的终端,显示程序信息以及打开尸检法医浏览器的连接详细信息。 在下面的屏幕截图中,我们可以看到版本号列为 2.24,`证据保险箱`文件夹的路径为`/var/lib/autopsy`: 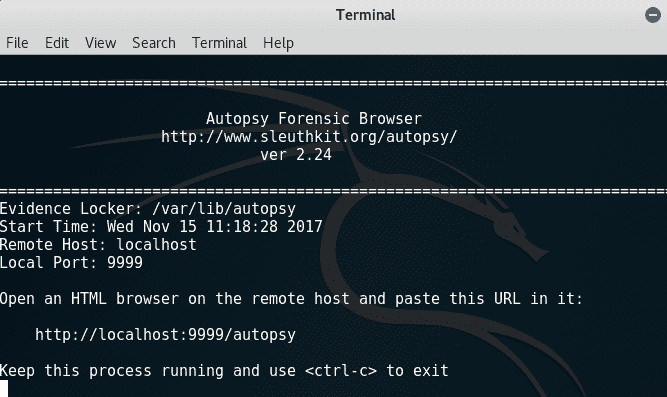 要打开 Autopsy 浏览器,请将鼠标放在终端中的链接上,然后右键单击并选择“打开链接”,如下面的屏幕截图所示:  # 创建新案例 要创建新案例,请按照给定的步骤操作: 1. 打开尸检法医浏览器后,调查员将看到三个选项。 1. 单击“新案例”: 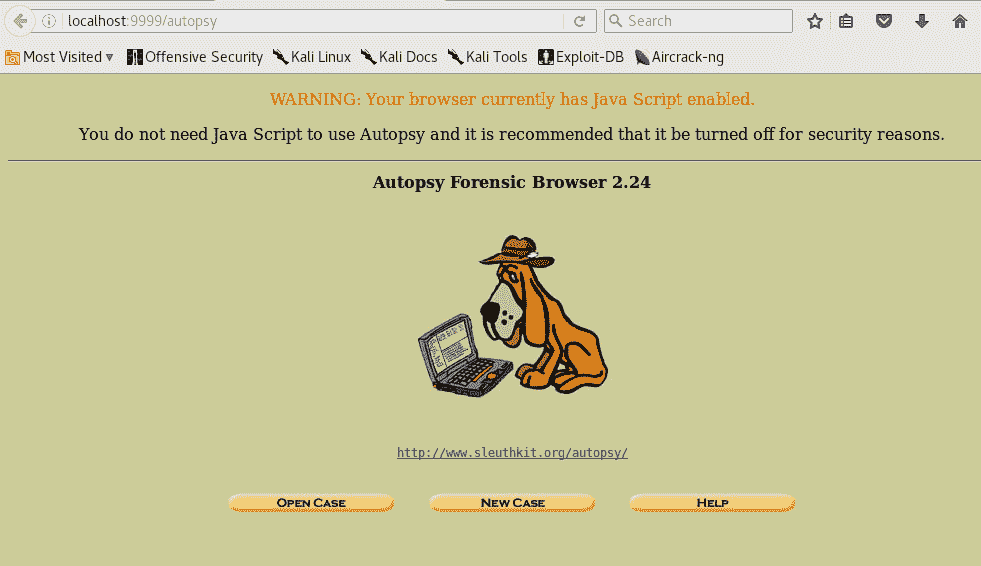 1. 输入案例名称、描述和调查员名称的详细信息。对于案例名称,我输入了`SP-8-dftt`,因为它与图像名称(`8-jpeg-search.dd`)非常匹配,我们将在此调查中使用。输入所有信息后,单击“新案例”: 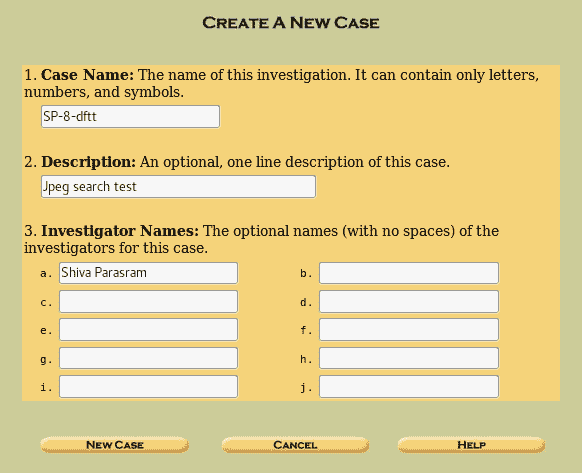 有几个调查员名称字段可用,因为可能有几个调查员一起工作的情况。 案例目录和配置文件的位置将显示并显示为已创建。重要的是要注意案例目录的位置,如屏幕截图所示:案例目录(/var/lib/autopsy/SP-8-dftt/)已创建。单击“添加主机”继续: 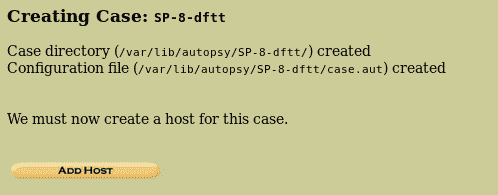 1. 输入主机名(正在调查的计算机的名称)和主机描述的详细信息。 1. 可选设置: + 时区:如果未指定,默认为本地设置 + 时间偏移调整:添加一个以秒为单位的值来补偿时间差异 + 警报哈希数据库路径:指定已知恶意哈希的创建数据库的路径 + 忽略哈希数据库路径:指定已知良好哈希的创建数据库的路径,类似于 NIST NSRL:  1. 单击“添加主机”按钮继续。 1. 添加主机并创建目录后,我们通过单击“添加图像”按钮添加要分析的法医图像:  1. 单击“添加图像文件”按钮添加图像文件:  1. 要导入图像进行分析,必须指定完整路径。在我的机器上,我将图像文件(`8-jpeg-search.dd`)保存到`桌面`文件夹中。因此,文件的位置将是`/root/Desktop/ 8-jpeg-search.dd`。 对于导入方法,我们选择符号链接。这样,可以将图像文件从当前位置(`桌面`)导入到证据保险箱,而不会出现与移动或复制图像文件相关的风险。 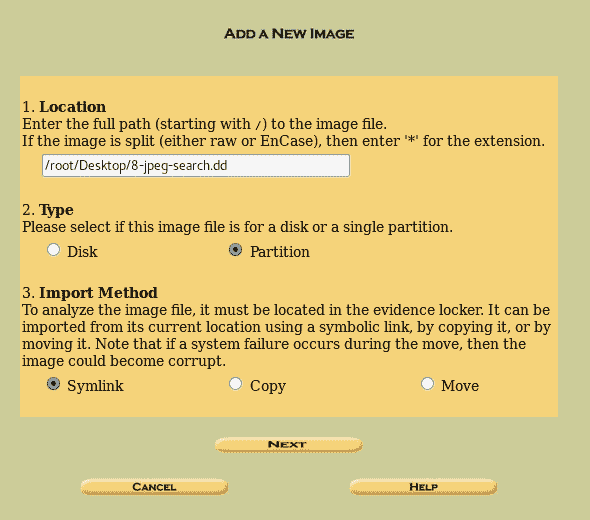 1. 如果出现以下错误消息,请确保指定的图像位置正确,并且使用正斜杠(`/`): 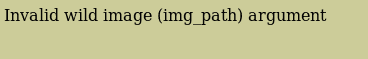 1. 单击**下一步**后,将显示图像文件详细信息。要验证文件的完整性,请选择计算此图像的哈希值的单选按钮,并选择导入后验证哈希值的复选框。 1. 文件系统详细信息部分还显示图像是 ntfs 分区的。 1. 单击“添加”按钮继续: 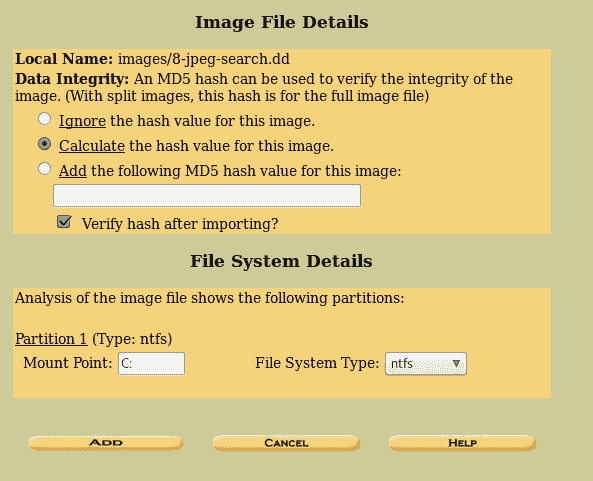 1. 单击前面屏幕截图中的“添加”按钮后,尸检将计算 MD5 哈希并将图像链接到证据保险箱。按“确定”继续:  1. 此时,我们几乎准备好分析图像文件了。如果在画廊区域列出了任何之前调查中的多个案例,一定要选择`8-jpeg-search.dd`文件和案例: 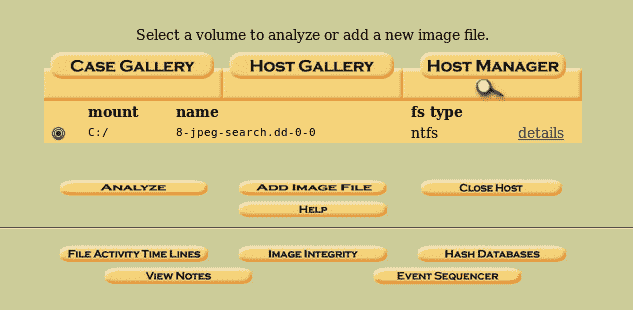 1. 在继续之前,我们可以点击“图像详情”选项。该屏幕提供了图像名称、卷 ID、文件格式、文件系统等详细信息,并允许提取 ASCII、Unicode 和未分配数据以增强和加快关键字搜索。点击浏览器中的返回按钮返回上一个菜单,并继续分析:  1. 在点击“分析”按钮开始我们的调查和分析之前,我们还可以通过点击“图像完整性”按钮创建 MD5 哈希来验证图像的完整性:  还有其他选项,如文件活动时间线、哈希数据库等。我们可以随时返回这些选项进行调查。 1. 点击“图像完整性”按钮后,将显示图像名称和哈希值。点击“验证”按钮验证 MD5 哈希:  1. 验证结果显示在 Autopsy 浏览器窗口的左下角: 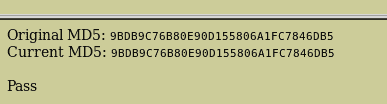 1. 我们可以看到我们的验证成功了,结果中显示了匹配的 MD5 哈希。点击“关闭”按钮继续。 1. 开始我们的分析,我们点击分析按钮:  # 使用 Autopsy 进行分析 现在我们已经创建了我们的案例,添加了适当目录的主机信息,并添加了我们获取的图像,我们可以进行分析了。 点击“分析”按钮(参见上一个截图)后,我们将看到几个选项以开始我们的调查:  点击图像详情选项卡,查看图像的详细信息。在下面的片段中,我们可以看到卷序列号和操作系统(版本)列为 Windows XP: 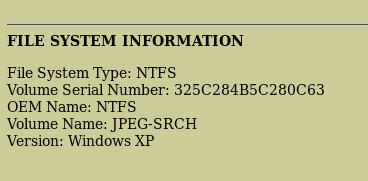 接下来,点击“文件分析”选项卡。这种模式打开为文件浏览模式,允许检查图像中的目录和文件。图像中的目录默认列在主视图区域中:  在文件浏览模式中,目录列出为当前目录指定为`C:/`。 对于每个目录和文件,都有显示该项的写入、访问、更改和创建时间的字段,以及其大小和元数据: + 写入:文件上次写入的日期和时间 + 访问:文件上次访问的日期和时间(只有日期是准确的) + 更改:文件的描述数据修改的日期和时间 + 创建:文件创建的日期和时间 + META:描述文件和文件信息的元数据:  为了完整性,可以通过点击“生成文件的 MD5 列表”按钮生成所有文件的 MD5 哈希。 调查人员还可以通过点击“添加注释”按钮对文件、时间、异常等进行注释:  左侧窗格包含我们将使用的四个主要功能: + **目录搜索**:允许搜索目录 + **文件名搜索**:允许通过 Perl 表达式或文件名搜索文件 + **所有已删除的文件**:搜索已删除的文件 + **展开目录**:展开所有目录以便查看内容  通过点击 EXPAND DIRECTORIES,所有内容都可以在左窗格和主窗口内轻松查看和访问。目录旁边的+表示可以进一步展开以查看子目录(++)及其内容:  要查看已删除的文件,我们点击左窗格中的 ALL DELETED FILES 按钮。已删除的文件标记为红色,并且遵循相同的格式:写入、访问、更改和创建时间。 从下面的截图中,我们可以看到图像包含两个已删除的文件:  我们还可以通过点击其 META 条目查看有关此文件的更多信息。通过查看文件的元数据条目(最右侧的最后一列),我们还可以查看文件的十六进制条目,即使扩展名已更改,也可以了解真实的文件扩展名。 在上述截图中,第二个已删除的文件(`file7.hmm`)具有一个奇特的文件扩展名`.hmm`。 点击 META 条目(31-128-3)以查看元数据: 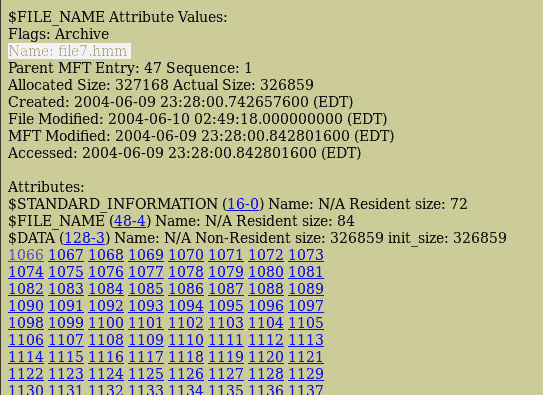 在属性部分,点击标有 1066 的第一个簇以查看文件的头部信息: 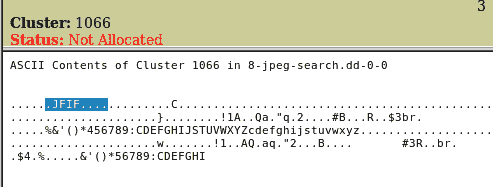 我们可以看到第一个条目是**.JFIF**,这是**JPEG 文件交换格式**的缩写。这意味着`file7.hmm`文件是一个图像文件,但其扩展名已更改为`.hmm`。 # 文件排序 检查每个文件的元数据可能在大型证据文件中不太实际。对于这种情况,可以使用 FILE TYPE 功能。此功能允许检查现有(已分配)、已删除(未分配)和隐藏文件。点击 FILE TYPE 选项卡继续:  点击按类型对文件进行分类(将默认选项保持不变),然后点击 OK 开始排序过程:  排序完成后,将显示结果摘要。在下面的片段中,我们可以看到有五个 Extension Mismatches:  要查看排序后的文件,我们必须手动浏览到`output`文件夹的位置,因为 Autopsy 2.4 不支持查看排序后的文件。要显示此位置,请点击左窗格中的 View Sorted Files:  `output`文件夹的位置将根据用户在首次创建案例时指定的信息而有所不同,但通常可以在`/var/lib/autopsy///output/sorter-vol#/index.html`找到。 打开`index.html`文件后,点击 Extension Mismatch 链接:  列出的五个扩展名不匹配的文件应该通过查看元数据内容进行进一步检查,并由调查人员添加注释。 # 在 Autopsy 中重新打开案例 案例通常是持续进行的,可以通过启动 Autopsy 并点击 OPEN CASE 来轻松重新开始:  在 CASE GALLERY 中,请确保选择正确的案例名称,然后继续您的检查:  # 总结 在本章中,我们使用 Autopsy Forensic Browser 和 The Sleuth Kit 进行取证。与单个工具相比,Autopsy 具有案例管理功能,并支持各种类型的文件分析,搜索和对分配的、未分配的和隐藏文件进行排序。Autopsy 还可以对文件和目录级别进行哈希处理,以保持证据的完整性。 接下来,我们使用另一个非常强大的 GUI 工具**Xplico**对互联网和网络遗物进行分析。请参阅第九章,*使用 Xplico 进行网络和互联网捕获分析*。 # 第九章:使用 Xplico 进行网络和互联网捕获分析 Xplico 是一个开源的 GUI **网络取证分析工具**(**NFAT**),专注于从网络和互联网捕获中提取数据。 使用 Xplico 的实时获取功能直接获取网络和互联网流量捕获,也可以使用 Kali Linux 中的工具,如 Wireshark 和 Ettercap。这些网络获取文件保存为`.pcap`或**数据包捕获**文件,然后上传到 Xplico 并使用其 IP 解码器和解码器管理器组件进行自动解码。 我们可以使用 Xplico 调查的一些协议包括但不限于: + **传输控制协议**(**TCP**) + **用户数据报协议**(**UDP**) + **超文本传输协议**(**HTTP**) + **文件传输协议**(**FTP**) + **微型文件传输协议**(**TFTP**) + **会话初始协议**(**SIP**) + **邮局协议**(**POP**) + **互联网地图访问协议**(**IMAP**) + **简单邮件传输协议**(**SMTP**) 网络和互联网数据包捕获中包含的数据,甚至包括实时获取,可能包含以下内容: + 诸如浏览的网站之类的**HTTP**流量 + 电子邮件 + Facebook 聊天 + RTP 和 VoIP + 打印文件 使用**安全套接字层**(**SSL**)加密的流量目前无法在 Xplico 中查看。 # 所需软件 Xplico 配有许多 Linux 版本。根据使用的 Kali 版本,Xplico 通常需要一些更新才能运行。对于本章,我建议使用 Kali Linux 2016.1 或 2016.2。我还建议在使用 Xplico 时在虚拟环境中使用 Kali,因为错误地更新 Kali 可能会*破坏*它。用户还可以在更新 Kali Linux 之前使用快照功能,该功能保存了机器的当前工作状态,可以在发行版中断时轻松恢复到该状态。 可以从[`cdimage.kali.org/kali-2016.1/`](https://cdimage.kali.org/kali-2016.1/)下载 Kali Linux 2016.1。 可以从[`cdimage.kali.org/kali-2016.2/`](https://cdimage.kali.org/kali-2016.2/)下载 Kali Linux 2016.2。 如果在更新 Kali 或运行 Xplico 时遇到困难(有时会发生),可以考虑在虚拟环境中下载并运行 DEFT Linux 8.2。初学者可能会发现在 DEFT Linux 中使用 Xplico 可能更容易,因为有 GUI 菜单项来启动 Apache 和 Xplico 服务选项,而在 Kali Linux 中必须在终端中键入这些选项。 可以从[`na.mirror.garr.it/mirrors/deft/`](http://na.mirror.garr.it/mirrors/deft/)下载 DEFT Linux 8.2。 # 在 Kali Linux 中启动 Xplico 更新 Kali 很简单,因为在不同版本(2016.x 和 2017.x)中更新时,命令保持不变。 在新的终端中,我们输入`apt-get update`并按*Enter*。如果前者无法成功运行,则可能需要使用`sudo apt-get update`命令来提供管理员权限。 然后,我们尝试通过输入`apt-get install xplico`(或`sudo apt-get install xplico`)来安装 Xplico:  如果遇到错误,如下图所示,我们必须首先更新 Kali Linux 存储库,然后再次运行`apt-get update`命令。要更新源列表,请键入`leafpad /etc/apt/sources.list`命令,这将打开文件供我们编辑:  在文件顶部,输入以下存储库位置: ``` deb https://http.kali.org/kali kali-rolling main non-free contrib ``` 输入存储库位置后,单击“文件”,然后单击“保存”,然后关闭列表。 确保删除文本前面的任何`#`符号,因为这会忽略后面的任何文本。 关闭列表文件后,返回到终端,再次运行`apt-get update`命令:  Kali 更新后,运行`apt-get install xplico`命令。在提示时确保按*Y*继续:  安装 Xplico 后,我们必须启动 Apache 2 和 Xplico 服务。在终端中,输入以下两个命令: + `service apache2 start` + `service xplico start`  完成这些步骤后,现在可以通过单击应用程序| 11-取证| xplico 来访问 Xplico:  浏览器窗口立即打开,显示 URL`localhost:9876/users/login`。 # 在 DEFT Linux 8.2 中启动 Xplico 如前所述,DEFT Linux 8.2 应作为虚拟主机运行。这个过程不像安装 Kali Linux 那样复杂(如第二章中所述,*安装 Kali Linux*),因为 DEFT 可以用作实时取证获取分发。 一旦 DEFT Linux ISO 映像被下载(从[`na.mirror.garr.it/mirrors/deft/`](http://na.mirror.garr.it/mirrors/deft/)),打开 VirtualBox,单击“新建”,然后输入以下详细信息: + 名称:`Deft 8.2` + 类型:Linux + 版本:Ubuntu(64 位)(验证输入的详细信息是否与屏幕截图中的相匹配)  现在,在填写适当的信息之后,请按照以下步骤进行: 1. 分配 4GB 或更多的 RAM。 1. 保留“现在创建虚拟硬盘”的默认选项,然后单击“创建”。 1. 保留 VDI(VirtualBox 磁盘映像)的默认选项,然后单击“下一步”。 1. 保留动态分配的默认选项,单击下一步,然后单击创建。 1. 单击 VirtualBox Manager 屏幕上的绿色启动箭头以启动 VM。 在提示选择启动磁盘时,单击浏览文件夹图标,浏览到下载的 DEFT Linux 8.2 ISO 映像,然后单击“开始”:  这将带用户到 DEFT 启动画面。选择英语作为语言,然后选择 DEFT Linux 8 实时:  DEFT Linux 引导并加载桌面后,单击左下角的 DEFT 菜单按钮,然后单击服务菜单,然后单击“启动 Apache”。重复此过程以到达服务菜单,然后单击“启动 Xplico”:  最后,通过单击 DEFT 按钮,然后转到 DEFT 菜单,跨到网络取证,然后单击 Xplico 来启动 Xplico:  这将带我们到与 Kali Linux 中相同的 Xplico Web 界面 GUI:  # 使用 Xplico 进行数据包捕获分析 无论是使用 Kali Linux 还是 DEFT Linux,在本章中,我们将使用可以在[`wiki.xplico.org/doku.php?id=pcap:pcap`](http://wiki.xplico.org/doku.php?id=pcap:pcap)下载的公开可用的样本数据包捕获(.pcap)文件。 所需的文件是: + DNS + MMS + Webmail:Hotmail/Live + HTTP(web) + SIP 示例 1 我们还需要从 Wireshark 样本捕获页面[`wiki.wireshark.org/SampleCaptures`](https://wiki.wireshark.org/SampleCaptures)获取一个 SMTP 样本文件。 # 使用 Xplico 进行 HTTP 和 web 分析 在这个练习中,我们上传了 HTTP(web)(`xplico.org_sample_capture_web_must_use_xplico_nc.cfg.pcap`)样本数据包捕获文件。 对于这个 HTTP 分析,我们使用 Xplico 搜索与 HTTP 协议相关的工件,如网站的 URL、图像和可能的与浏览器相关的活动。 一旦 Xplico 启动,使用以下凭据登录: + 用户名:`xplico` + 密码:`xplico` 然后我们从左侧菜单中选择新案例,并选择上传 PCAP 捕获文件按钮,因为我们将上传文件而不是执行实时捕获或获取。对于每个案例,我们还必须指定案例名称:  在下面的截图中,我已经为案例名称输入了`HTTP-WEB`。点击“创建”继续。案例 HTTPWEB 现在已经创建。点击 HTTPWEB 继续到会话屏幕:  现在我们通过点击左侧菜单中的“新会话”选项为我们的案例创建一个新的会话:  我们为会话命名并点击“创建”继续:  我们已经创建了名为 HTTPWEB 的新会话:  一旦我们输入了案例和会话的详细信息,我们将看到 Xplico 界面主窗口,其中显示了在我们上传和解码`.pcap`文件后找到的各种可能的证据类别,包括 HTTP、DNS、Web Mail 和 Facebook 等: 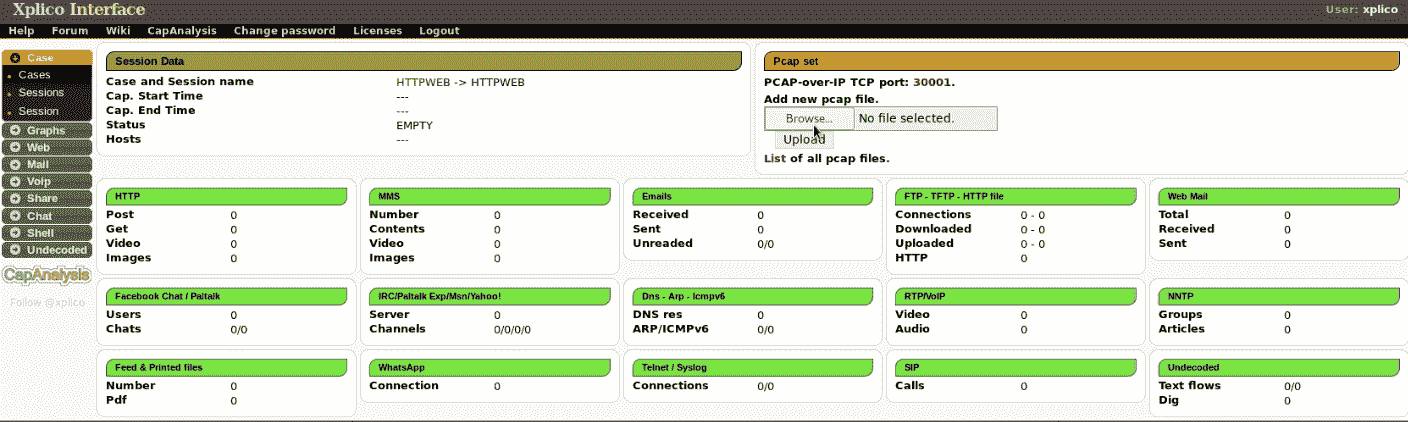 要上传我们的`.pcap`文件,点击右上角的 Pcap 设置区域中的“浏览...”按钮,选择下载的(`xplico.org_sample_capture_web_must_use_xplico_nc.cfg.pcap`)`.pcap`文件,然后点击“上传”按钮开始 Xplico 中的解码过程: 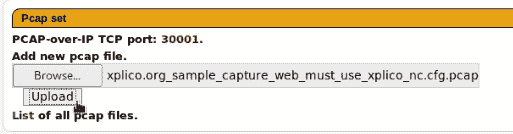 解码过程可能需要一段时间,具体取决于`.pcap`文件的大小,因为这个过程将`.pcap`文件解码为 Xplico 内部易于搜索的类别。一旦完成,会话数据区域的“状态”字段将显示“解码完成”,还会显示案例和会话名称以及**捕获**(**Cap**)的开始和结束时间: 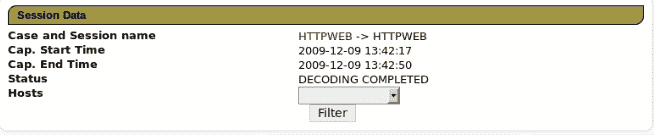 解码完成后,结果将显示在各个类别区域。在下面的截图中,我们可以看到“未解码”类别下有一个文本流的条目: 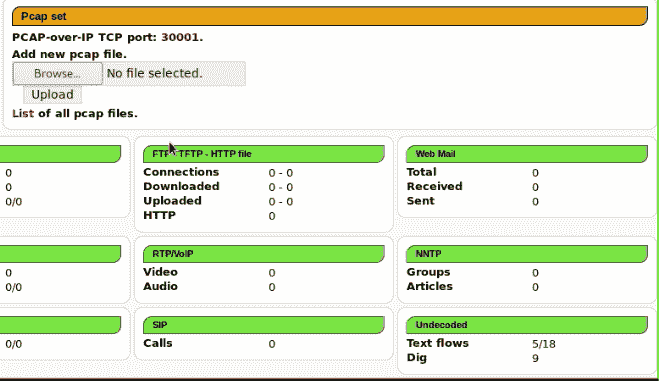 要分析解码后的结果,我们使用 Xplico 界面极左侧的菜单。由于我们在“未解码”类别中列出了结果,点击菜单中的“未解码”,它会展开为 TCP-UDP 和 Dig 子菜单。点击 TCP-UDP 子菜单以进一步探索: 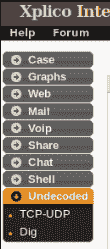 TCP-UDP 选项显示目标 IP、端口、日期和时间、连接持续时间,以及包含更多细节的信息文件。标记为红色的目标 IP 条目可以点击并进一步探索: 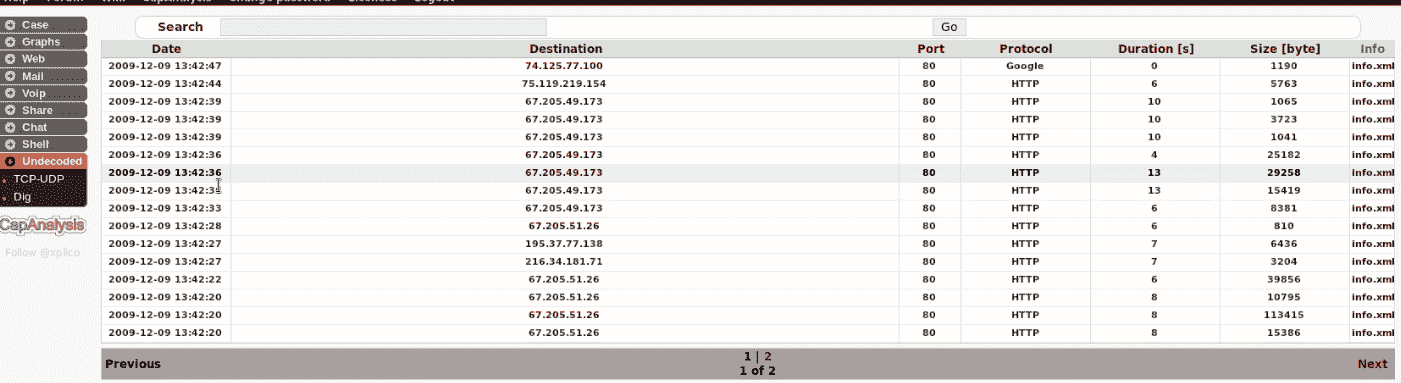 如果我们点击第一个目标 IP 条目`74.125.77.100`,将提示我们将此条目的信息详细保存在一个文本文件中: 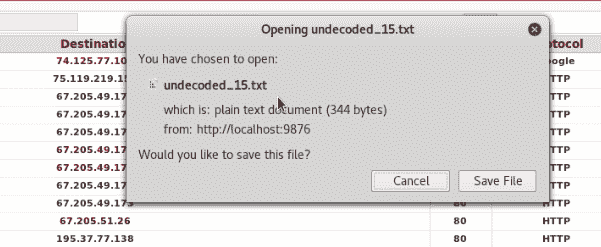 要查看文件的内容,我们可以直接从保存的位置打开它,或者使用`cat`命令通过终端显示内容,输入`cat /root/Downloads/undecoded_15.txt`: 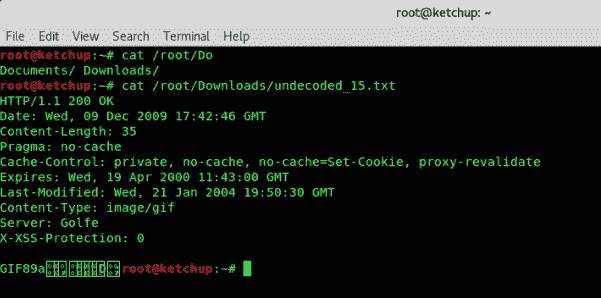 在前面的终端窗口中显示的结果表明,于 2009 年 12 月 9 日(星期三)查看或下载了一个`.gif`图像。 我们还可以点击“信息.xml”链接,以获取更多信息: 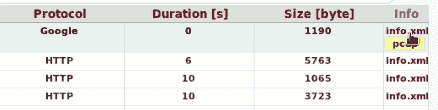 信息.xml 显示了源 IP 地址和目标 IP 地址以及端口号。现在我们可以探索所有目标 IP 地址及其各自的“信息.xml”文件,以收集更多案例信息: 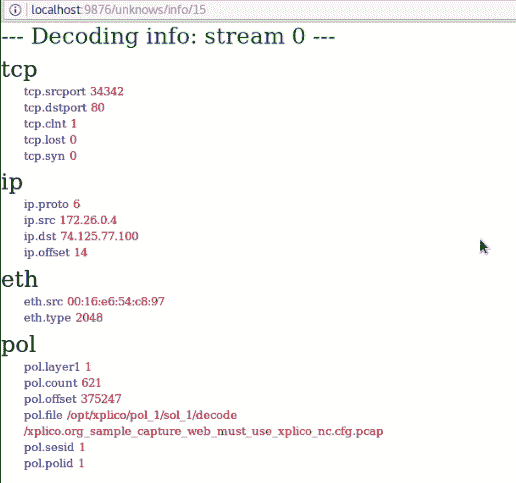 让我们回到左侧的“未解码”菜单,点击 Dig 子菜单进一步探索我们的捕获文件:  在前面的截图中,Dig 子菜单显示了通过 HTTP 连接查看的几个图像证据,包括`.gif`、`.tif`和`.jpg`格式以及日期。 这些图像应该作为我们案例发现的一部分进行查看和记录: 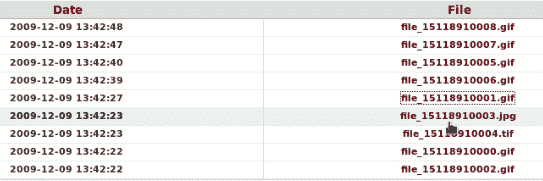 # 使用 Xplico 进行 VoIP 分析 许多组织甚至普通终端用户主要为了减少语音和多媒体通信会话的成本而实施或使用**VoIP**(**IP 电话**)解决方案,否则需要使用付费电话线。要使用 VoIP 服务,我们必须使用**SIP**(**会话初始化协议**)。 在这个练习中,我们将使用 SIP 示例 1(`freeswitch4560_tosipphone_ok.pcap`)数据包捕获文件来分析 VoIP 服务,如果有的话。 与我们之前的 HTTP 网页分析一样,必须使用相关细节为新案例和会话创建新案例和会话: + 案例名称:`SIP_Analysis` + 会话名称:`Sip_File` 创建案例和会话后,浏览要上传的`.pcap`文件(`freeswitch4560_tosipphone_ok.pcap`),然后单击上传开始解码过程:  文件解码后,我们可以看到右下角 Calls 类别中列出了 2 个结果:  要开始探索和分析 VoIP 通话的详细信息,请单击左侧菜单上的 VoIP 选项:  单击 Sip 子菜单,我们将看到通话的详细信息。我们可以看到从`“Freeswitch”`拨打电话到`Freeswitch`:  单击持续时间详情(`0:0:19`)进行进一步分析和探索: 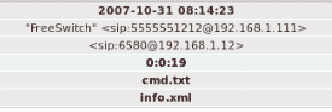 让我们首先单击`cmd.txt`查看信息文件和日志: 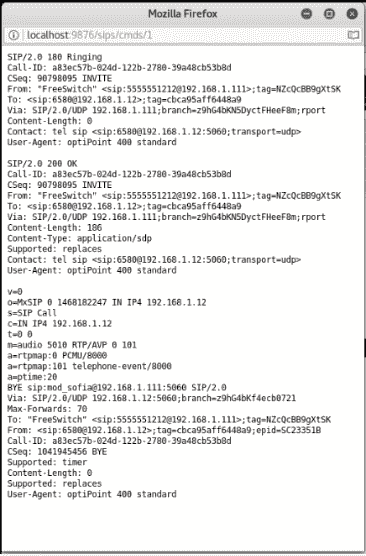 在上一张截图中,我们可以看到对话中的号码、日期、时间和持续时间的详细信息。还有一个选项可以在任一端播放对话:  # 使用 Xplico 进行电子邮件分析 电子邮件使用不同的协议发送和接收电子邮件,具体取决于发送、接收和存储/访问电子邮件的方法。使用的三种协议是: + **简单邮件传输协议**(**SMTP**) + **邮局协议**(**POP3**) + **Internet 消息访问协议**(**IMAP**) SMTP 使用端口`25`,用于发送电子邮件。 POP3 使用端口`110`,用于通过从电子邮件服务器下载电子邮件到客户端来检索电子邮件。 Microsoft Outlook 是 POP3 客户端的一个例子。 IMAP4 使用端口`143`,类似于 POP3,它检索电子邮件但在服务器上保留电子邮件的副本,并可以通过 Web 浏览器随时访问,通常称为 Webmail。 Gmail 和 Yahoo 是 Webmail 的例子。 在这个练习中,我们将使用两个示例文件: 第一个文件是 Webmail:Hotmail/Live `.pcap`文件(`xplico.org_sample_capture_webmail_live.pcap`),可从[`wiki.xplico.org/doku.php?id=pcap:pcap`](http://wiki.xplico.org/doku.php?id=pcap:pcap)下载。 第二个是`smtp.pcap`文件,可从[`wiki.wireshark.org/SampleCaptures`](https://wiki.wireshark.org/SampleCaptures)下载。 对于第一个`.pcap`文件(Webmail:Hotmail/Live)的分析,我已创建了一个带有以下详细信息的案例: + 案例名称:`Webmail_Analysis` + 会话名称:`WebmailFile`  如果我们仔细查看解码结果,我们可以看到现在有几个填充的类别,包括 HTTP、DNS -ARP - ICMP v6 和 FTP - TFTP - HTTP 文件: + HTTP 类别:  + Dns -Arp - Icmpv6 类别:  + FTP - TFTP - HTTP 文件: 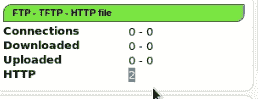 现在我们已经知道存在哪些工件,让我们现在使用左侧菜单来进一步分析结果。 单击左侧的图表菜单会显示域信息,包括主机名,**CName**(**规范名称**)条目,主机的 IP 地址,以及每个条目的`info.xml`文件,以获取更详细的源和地址信息:  第一个条目(`spe.atdmt.com`)的`info.xml`文件(如下截图所示)显示,本地 IP(`ip.src`)为`10.0.2.15`,连接到具有 IP(`ip.dst`)为`194.179.1.100`的主机(也在 IP 字段的上一个截图中显示): 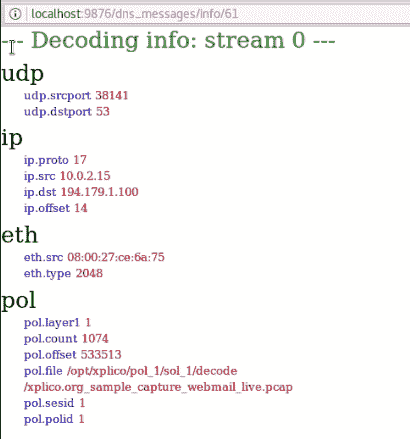 接下来,我们转到 Web 菜单,然后到站点子菜单。显示了访问的网页列表以及访问的日期和时间。我们可以看到前三个条目属于域`mail.live.com`,第四个和第五个属于`msn.com`: 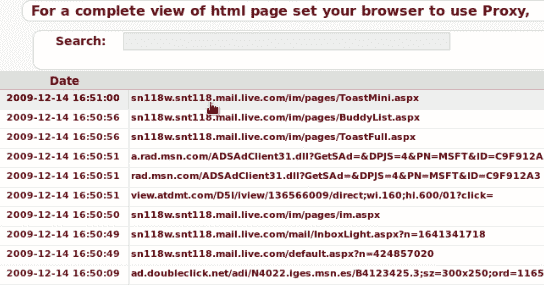 通过单击`info.xml`,我们可以检查第一个站点条目。在 HTTP 部分下,我们可以看到使用了 Mozilla Firefox 浏览器,并访问了`sn118w.snt118.mail.live.com`主机: 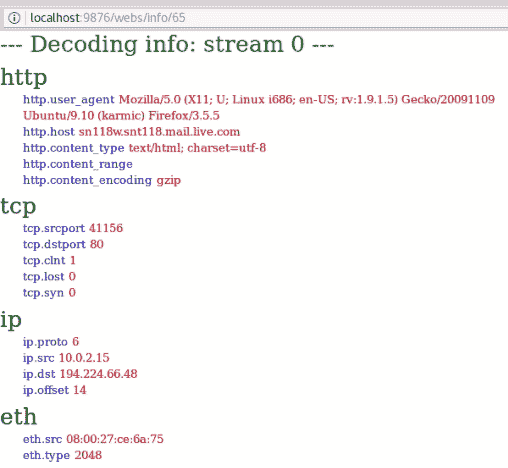 关闭`info.xml`文件并选择图像按钮,然后单击“Go”以显示找到的任何图像:  图像搜索结果显示了找到的几个图像和图标。单击列表以查看图像。 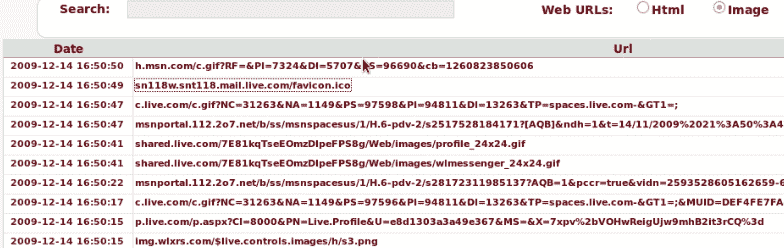 我们还可以通过返回左侧的 Web 菜单,然后点击图像子菜单来查看找到的图像。这会呈现给我们一个图形化的图像组,其中包含到其各自页面的链接: > 向下滚动到左侧的主菜单,单击共享菜单,然后单击 HTTP 文件子菜单。在这里,我们看到两个可以通过单击其`info.xml`文件进一步调查的项目:  通过单击`abUserTile.gif`的`info.xml`文件,我们可以看到这是从主机`194.224.66.18`访问的: 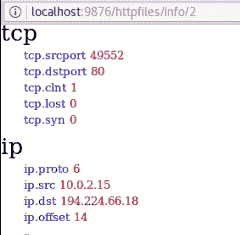 在未解码菜单和 HTTP 子菜单中,我们还有关于目标 IP`194.224.66.19`的 HTTP 信息。尝试通过单击`info.xml`文件进一步探索:  # 使用 Wireshark 示例文件进行 SMTP 练习 在此示例中,我们使用了从本节开始的 Wireshark 示例链接下载的 SMTP 示例捕获文件。 我已经创建了一个案例,其中包含以下细节,如下截图的会话数据部分所示: + 案例名称:SMTP + 会话名称:`SMTPfile` 屏幕右下角我们可以看到在邮件类别的未读字段中有一个项目: 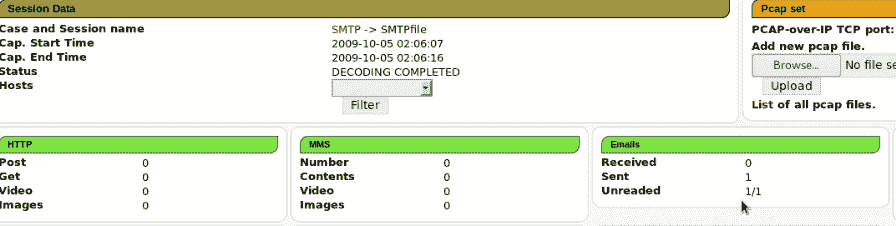 知道我们正在分析和调查电子邮件,我们可以直接转到界面左侧的邮件菜单和电子邮件子菜单。这显示我们发送了一个没有主题的电子邮件,发件人是`gurpartap@patriots.in`,收件人是`raj_deo2002in@yahoo.co.in`。单击-(无主题)-字段以进一步检查电子邮件:  单击-(无主题)-字段后,我们现在可以看到电子邮件的内容: 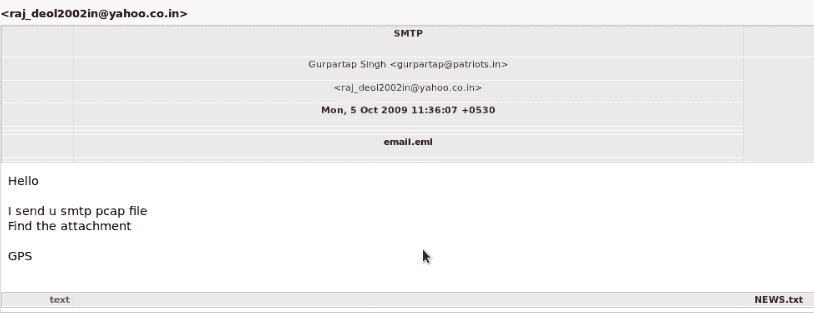 # 总结 我希望你和我一样喜欢本章的练习。虽然我们中的一些人可能由于更新和存储库问题而在运行 Xplico 时遇到困难,但我鼓励你在 DEFT Linux 8.2 上尝试 Xplico,因为 Xplico 可以是一个非常有用的 GUI 工具,用于解码互联网和网络流量。正如我们在本章中所看到和做的,Xplico 可以用于 HTTP、VoIP 和电子邮件分析,还可以执行 MMS、DNS、Facebook 和 WhatsApp 聊天分析。我鼓励你尝试从 Xplico 和 Wireshark 样本捕获页面下载和分析更多样本文件,以便更熟悉使用 Xplico 进行分析和审查。 让我们现在转向另一个全能调查工具,数字取证框架,也被称为 DFF。见你在第十章,*使用 DFF 揭示证据*。 # 第十章:使用 DFF 揭示证据 欢迎来到最后一章;你成功了。我们将使用的最后一个工具是**数字取证框架**(**DFF**)。DFF 使用模块化模型在一个简单和用户友好的图形用户界面中执行图像的自动化分析。DFF 支持多种图像文件格式,包括`.dd`、`.raw`、`.img`、`.bin`、E01、EWF 和 AFF。模块可以应用于使用嵌入式查看器查看各种文件格式,包括视频、音频、PDF、文档、图像和注册表文件。 DFF 还支持以下内容: + 浏览器历史分析 + 文件恢复 + 元数据和 EXIF 数据分析 + 内存/RAM 分析 将所有这些功能集成到一个 GUI 中,可以轻松调查和分析获取的图像。在本章的练习中,我们将使用已经获取并可供下载的图像。这并不意味着我们应该只使用一个工具(如 DFF)进行分析。我建议至少使用两种工具进行所有调查任务,以便可以比较结果,增加调查的准确性和完整性。 请记住,在获取自己的图像时,始终确保通过使用写入阻断器和哈希工具来维护设备和证据的完整性。同样重要的是,除非情况需要,否则我们只能使用取证副本来保留证据。 让我们看看本章将涵盖的主题: + 安装 DFF + 启动 DFF GUI + 使用 DFF 恢复已删除的文件 + 使用 DFF 进行文件分析 # 安装 DFF 要使用 DFF 进行调查,我们首先需要 Kali Linux 2016.1 ISO 镜像。我选择使用 64 位版本,并在 VirtualBox 中作为虚拟主机运行。 可以从[`www.kali.org/downloads/`](https://www.kali.org/downloads/)下载 Kali Linux 2016.1 ISO 镜像: 1. 安装 Kali 2016.1 作为虚拟主机后,我们可以使用`uname -a`命令查看版本详细信息:  1. 要开始安装 DFF,我们首先需要使用 Kali Sana 中使用的存储库更新`sources.list`。虽然在上一章中我们直接浏览到了`sources.list`文件,但是我们还可以使用终端以两种其他方式执行此任务。 在新的终端中,我们可以输入以下内容: ``` echo "deb http://old.kali.org/kali sana main non-free contrib" > /etc/apt/sources.list ```  或者,我们可以使用第二种方法,输入以下内容: ``` nano /etc/apt/sources.list ```  然后是存储库的详细信息: ``` deb http://http.kali.org/kali kali-rolling main contrib non-free deb src http://http.kali.org/kali kali-rolling main contrib non-free deb http://http.kali.org/kali sana main contrib ``` 1. 然后,按*Ctrl* + *X*退出,按*Y*保存更改到`sources.list`文件中:  1. 接下来,我们通过输入`apt-get update`来更新 Kali: 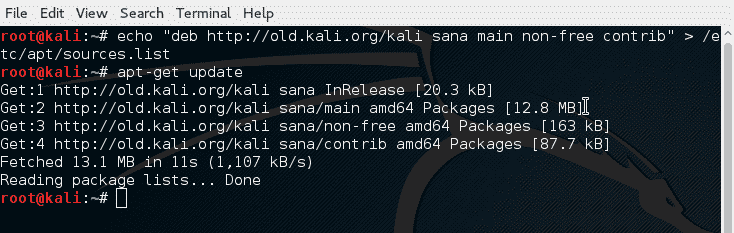 1. 现在,我们通过输入以下内容来安装高级取证格式库: ``` apt-get install libafflib0 ```  如前面的屏幕截图所示,按*Y*继续。这是一个相当冗长的过程,因为它安装了几个取证工具的组件,包括 Autopsy、Sleuthkit、Bulk_extractor 和 DFF,如下一张屏幕截图所示: 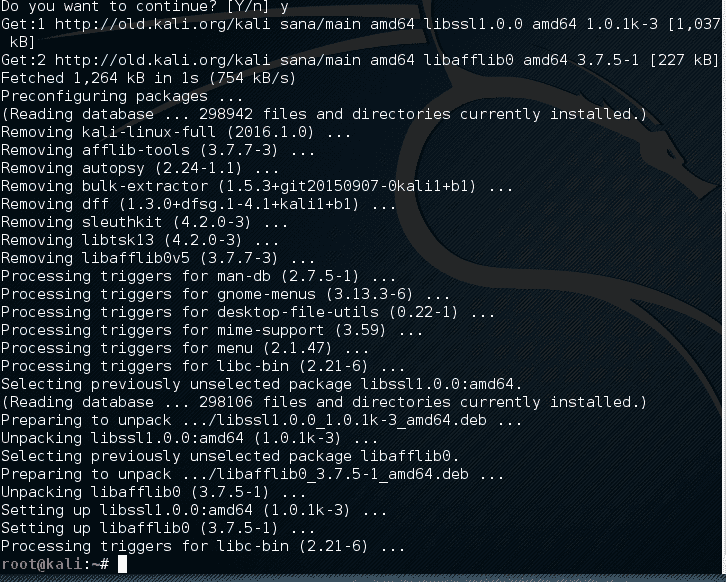 1. 安装库成功后,我们可以通过输入以下内容来安装 DFF: ``` apt-get install dff ``` 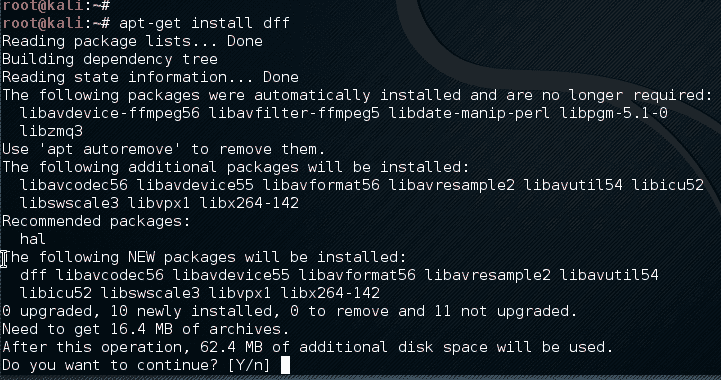 1. 按*Y*继续,以允许安装 DFF 1.3.3 继续: 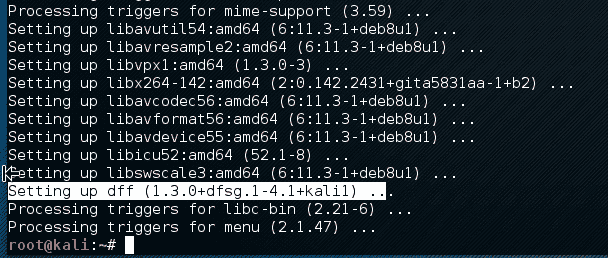 1. 为了确保 DFF 已成功安装,我们可以在终端中输入`dff`,这将加载 DFF 中可用的模块:  一旦显示`欢迎使用数字取证框架`横幅,这意味着我们的 DFF 安装成功。现在我们可以通过运行 DFF GUI 来开始我们的调查:  # 启动 DFF GUI 现在我们已经安装了 DFF,我们可以首先验证 DFF 的版本,还可以使用 CLI 查看 DFF 中的一些命令: 1. 要查看已安装的 DFF 版本,在新的终端中,输入`dff -v`。在下面的屏幕截图中,我们可以看到版本是 1.3.0:  1. 要查看可用选项,我们输入`dff -h`:  1. 要启动图形界面,我们输入`dff -g`:  1. 也可以通过单击应用程序 | 取证 | dff gui 来启动图形界面:  1. 使用任一方法打开后,我们将看到 DFF GUI:  # 使用 DFF 恢复已删除的文件 在本练习中,我们将使用使用 DD 创建的一个非常小的`.raw`图像。这个文件大约 6MB,可以在[`dftt.sourceforge.net/test7/index.html`](http://dftt.sourceforge.net/test7/index.html)上公开获取: 1. 单击 ZIP 文件进行下载并将其提取到默认位置。提取后,文件名显示为`7-ntfs-undel.dd`。在导入图像之前,花点时间观察主窗口区域条目旁的图标。逻辑文件字段的图标是一个带有一丝蓝色的白色文件夹:  在接下来的步骤中,当我们添加图像时,文件夹图标上会出现蓝色加号。 1. 要在 DFF 中打开我们下载的 DD 图像,单击文件 | 打开证据或单击打开证据按钮,如下图所示:  1. 在选择证据类型框中,确保选中了 RAW 格式选项,并且在下拉框中选择了文件选项。单击绿色加号(+)以浏览`7-ntfs-undel.dd`文件。单击确定以继续:  在 DFF 的左窗格和主窗口中,观察逻辑文件图标旁边的加号。这告诉我们,虽然大小、标签和路径没有条目,但图像已成功添加,我们可以浏览逻辑文件部分:  1. 在左窗格中,单击逻辑文件类别。在主窗口中,显示图像名称:  1. 在主窗口中双击图像名称。在应用模块框中,单击是:  应用模块后,在左窗格的逻辑文件下显示图像名称(`7-ntfs-undel.dd`):  1. 单击左窗格中图像名称左侧的加号,展开菜单并查看图像内容。展开后,我们可以看到有两个文件夹,即`NTFS`和`NTFS 未分配`:  红色标记的条目(`dir1`和`$Orphans`)是已删除的文件。 1. 要查看文件内容,双击主窗口中的`NTFS`条目:  1. 单击`frag1.dat`已删除文件。右窗格显示有关文件的信息,包括以下内容: + 名称:`frag1.dat` + 节点类型:已删除文件 + 生成者:ntfs + 创建时间:2004-02-29 20:00:17 + 文件访问时间:2004-02-29 20:00:17 + 文件修改时间:2004-02-29 20:00:17 + MFT 修改时间:2004-02-29 20:00:17  1. 让我们检查另一个已删除的文件。单击`mult1.dat:ADS`流并查看其详细信息: 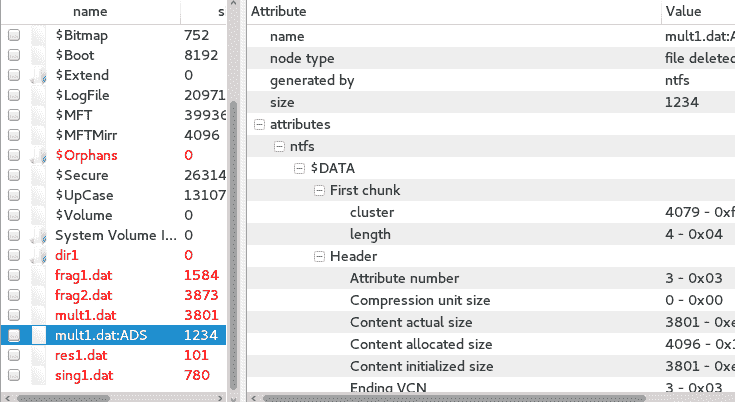 根据[`dftt.sourceforge.net/test7/index.html`](http://dftt.sourceforge.net/test7/index.html)上的文件列表,该图像包含 11 个已删除的文件,包括`mult1.dat:ADS`,其中包含 NTFS 备用数据流中的隐藏内容。DFF 已找到所有 11 个文件。请访问前面的网站或查看下面的截图以查看已删除文件的名称进行比较: 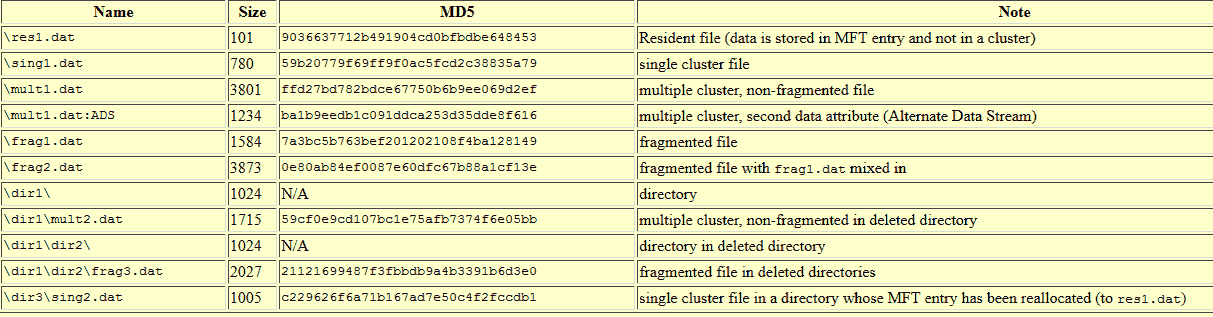 # 使用 DFF 进行文件分析 现在我们已经查看了文件恢复过程,让我们继续使用 DFF 来检查一个内容更多的图像文件。 在这个练习中,我们将使用另一个公开可用的图像,名为*JPEG 搜索测试#1(Jun'04)*。可以在[`dftt.sourceforge.net/test8/index.html`](http://dftt.sourceforge.net/test8/index.html)下载 ZIP 文件: 1. 下载 ZIP 文件后,将其解压到默认位置。解压后的文件名为`8-jpeg-search.dd`。 1. 通过重复上一个练习中的步骤,在 DFF 中打开证据文件: 1. 通过点击“应用程序”|“取证”|“ddf gui”来启动 DFF。 1. 点击“打开证据”按钮。 1. 浏览到`8-jpeg-search.dd`图像文件(如下截图所示)。 1. 点击“确定”:  1. 点击左窗格中的逻辑文件,然后在主窗口中双击文件名(`8-jpeg-search.dd`):  1. 在应用模块框中,当提示应用 NTFS 模块到节点时选择“是”:  1. 点击左窗格中的加号(+),旁边是逻辑文件,展开菜单。 1. 点击`8-jpeg-search.dd`文件名旁边的加号(+)以展开菜单。 在这个练习中,我们还发现了两个名为`NTFS`和`NTFS 未分配`的 NTFS 文件夹:  1. 点击左窗格中的`NTFS`以查看子文件夹和文件(显示在主窗口中):  1. 点击`alloc`文件夹查看其内容。在`alloc`文件夹中,主窗口中有两个带有彩色图标的文件: + `file1.jpg` + `file2.dat` 1. 如果尚未选择,请点击`file1.jpg`:  1. 在右侧的属性列中,向下滚动到类型字段。请注意以下属性值,如下截图所示: + 魔术:JPEG 图像数据,JFIF 标准 1.01 + 魔术 mime:image/jpeg 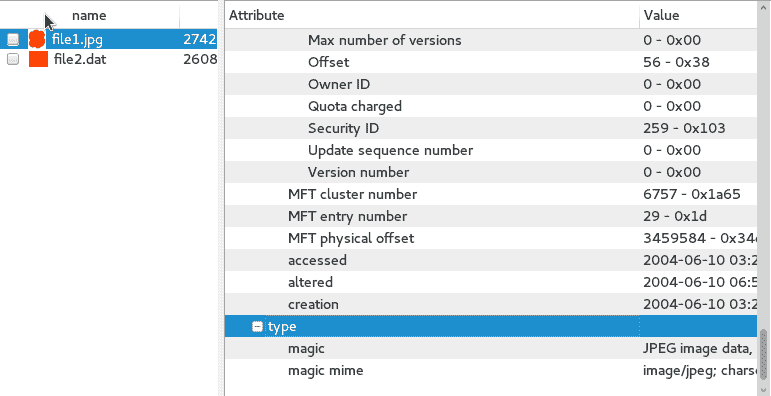 1. 双击`file1.jpg`,在提示应用图片模块到节点时点击“是”,这将允许我们查看图片:  预览窗口打开,显示图像,并在图像下方显示文件路径为`/逻辑文件/8-jpeg-search.dd/NTFS/alloc/file1.jpg`:  1. 通过点击“打开证据”按钮下的“浏览器”按钮返回到 DFF 浏览器界面:  1. 点击`file2.dat`并向下滚动到类型属性,并注意魔术和魔术 mime 值: + 魔术:JPEG 图像数据,JFIF 标准 1.01 + 魔术 mime:image/jpeg 请注意,即使`file2`的扩展名是`.dat`,DFF 也读取了头文件,并将文件的真实类型列为 JPEG/JFIF 文件: >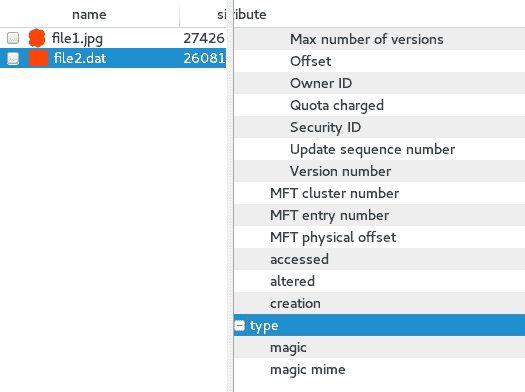 1. 双击`alloc`文件夹中的`file2.dat`(在`file1.jpg`文件下),在提示应用图片模块时点击“是”:  1. 单击“浏览”按钮返回 DFF 界面。在左侧窗格中单击`del1`文件夹以查看其内容。在`del1`文件夹中有一个名为`file6.jpg`的单个文件,在属性列中列为已删除,如下截图所示。属性列中值得注意的值包括: + 名称:`file6.jpg` + 节点类型:已删除 + magic: JPEG 图像数据,JFIF 标准。 + magic mime: image/jpeg; 1. 双击`file6.jpg`并应用模块以预览文件(确保单击“浏览”按钮返回 DFF 浏览器界面):  1. 在左侧窗格中单击`del2`文件夹。主窗口显示一个带有奇怪扩展名`file7.hmm`的单个文件。属性列将文件列为已删除;但是,类型属性显示如下内容:  1. 双击`file7.hmm`文件并应用图片模块以预览`.jpg`图像:  # 总结 恭喜,您已经到达了结尾。在这最后一章中,我们看了非常多功能的 DFF。使用 DFF,我们进行了文件恢复,文件夹探索,文件分析,并且还能够使用各种模块预览文件。 重要的是要记住,尽管 DFF 可以执行多项任务,但应该使用在前几章中使用的其他工具来验证发现的准确性。在调查过程中,记录您的步骤也很重要,以防必须重新创建调查过程或重迹您的步骤。 我本人,审阅者,编辑以及整个 Packt 家族代表,感谢您购买本书。请务必查看[`www.packtpub.com/`](https://www.packtpub.com/)上提供的其他优秀书籍。
