

GPU并行处理
前言
本文为《CUDA与TensorRT部署学习笔记》系列中并行处理与GPU体系架构篇。本文主要从GPU与CPU并行处理的异同、CPU的优化方式、GPU的特点方面进行学习记录。
Goal: 理解CPU和GPU并行处理上的不同,以及影响并行处理的基本因素
1 关键字理解
-
Latency(延迟) :完成一个指令所需的时间。
大白话理解
它表示执行一项任务所需的时间,就像是从你说了做一件事情,中间所花费的时间。 -
Memory Latency(内存延迟) :CPU/GPU 从内存获取数据所需的等待时间。(CPU优化的主要方向)
大白话理解
像你想要从柜子里拿一本书,但是得等一会儿,这个等待的时间就是内存延迟。CPU 或 GPU 也需要等待数据从内存中读取。 -
Throughput(吞吐量) : 单位时间内可以执行的指令数。(GPU并行处理的优化的主要方向)
大白话理解
每秒钟可以处理多少事情,就像是工厂生产线一样,吞吐量高表示工厂效率高。 -
Multi-threading(多线程) : 多线程处理。
大白话理解
像有很多人同时在工作,每个人独立处理不同的任务,这样整体的工作效率就提高了。
2 GPU与CPU并行处理的异同
2.1 CPU 目标:减少 Memory Latency(内存延迟)
CPU 的主要目标是尽量减少从内存获取数据所需的等待时间,也就是减少内存延迟。
大白话理解
好比在烹饪中,为了更高效地使用食材,尽量减少等待取材的时间。CPU 也是尽量缩短等待数据的时间,以便更迅速地进行计算。
2.2 GPU 目标:提高 Throughput(吞吐量)
GPU 的主要目标是提高单位时间内可以执行的指令数,也就是提高吞吐量。
大白话理解
想象有一大堆相似的任务,比如清理一大片地方。为了尽快完成,你需要让所有人一起协同工作。GPU 就像是一个高效的清理团队,通过同时处理很多任务,提高了整体的效率。
2.3 总结
- CPU 更关注单个任务的速度,尽量减少每个任务的等待时间,使得单个任务执行得更快。
- GPU 更关注同时处理多个任务,以提高整体的效率,尽量在单位时间内完成更多的任务。
3 CPU的优化方式
3.1 memory latency是什么?
-
内存延迟是指从启动对内存中的字节或字的请求到被处理器检索之间的时间。如果数据不在处理器的高速缓存中,则需要更长的时间来获取它。因此,延迟是衡量内存速度的基本指标:延迟越短,读取操作越快。
-
内存延迟对计算机的性能有很大的影响。内存潜伏时间越短,处理器可以更快地访问数据,从而提高计算机的性能。
简单来说
它是从内存获取数据所需的等待时间。
-
cache hit
cache hit是指当CPU需要读取或写入某个数据时,能够在缓存中找到这个数据的情况。缓存是一种比内存更快但容量更小的存储器,它可以暂时存放CPU最近访问过或即将访问的数据,从而提高CPU的运行速度。
大白话理解
cache hit就像是你去图书馆借书,发现你想要的书就在你手边的书架上,你就不用跑到其他地方去找了,这样就节省了时间和精力。相反,如果你想要的书不在你手边的书架上,你就要去其他地方找,这就叫做cache miss,也就是缓存未命中。
-
cache miss
cache miss是指当CPU需要读取或写入某个数据时,不能够在缓存中找到这个数据的情况。cache miss会导致额外的延迟,并降低系统的运行效率。因此,减少cache miss是优化计算机系统性能的关键。stall状态指的是CPU Core由于没有数据,在等待数据的到来的状态。
cache miss的原因有以下几种:
- 强制性cache miss:当CPU第一次访问某个数据时,缓存中肯定没有这个数据,所以必然发生cache miss,这种情况无法避免。
- 容量性cache miss:当缓存中的数据超过了缓存的容量时,需要替换掉一些旧的数据,如果后续CPU又访问了被替换掉的数据,就会发生cache miss,这种情况可以通过增加缓存的容量或者优化缓存的替换策略来减少。
- 冲突性cache miss:当缓存中的不同位置映射到同一个内存地址时,就会发生冲突,导致一些数据被频繁地替换,从而发生cache miss,这种情况可以通过增加缓存的关联度或者改变缓存的映射方式来减少。
-
Computer Memory Hierarchy(计算机内存层次结构)
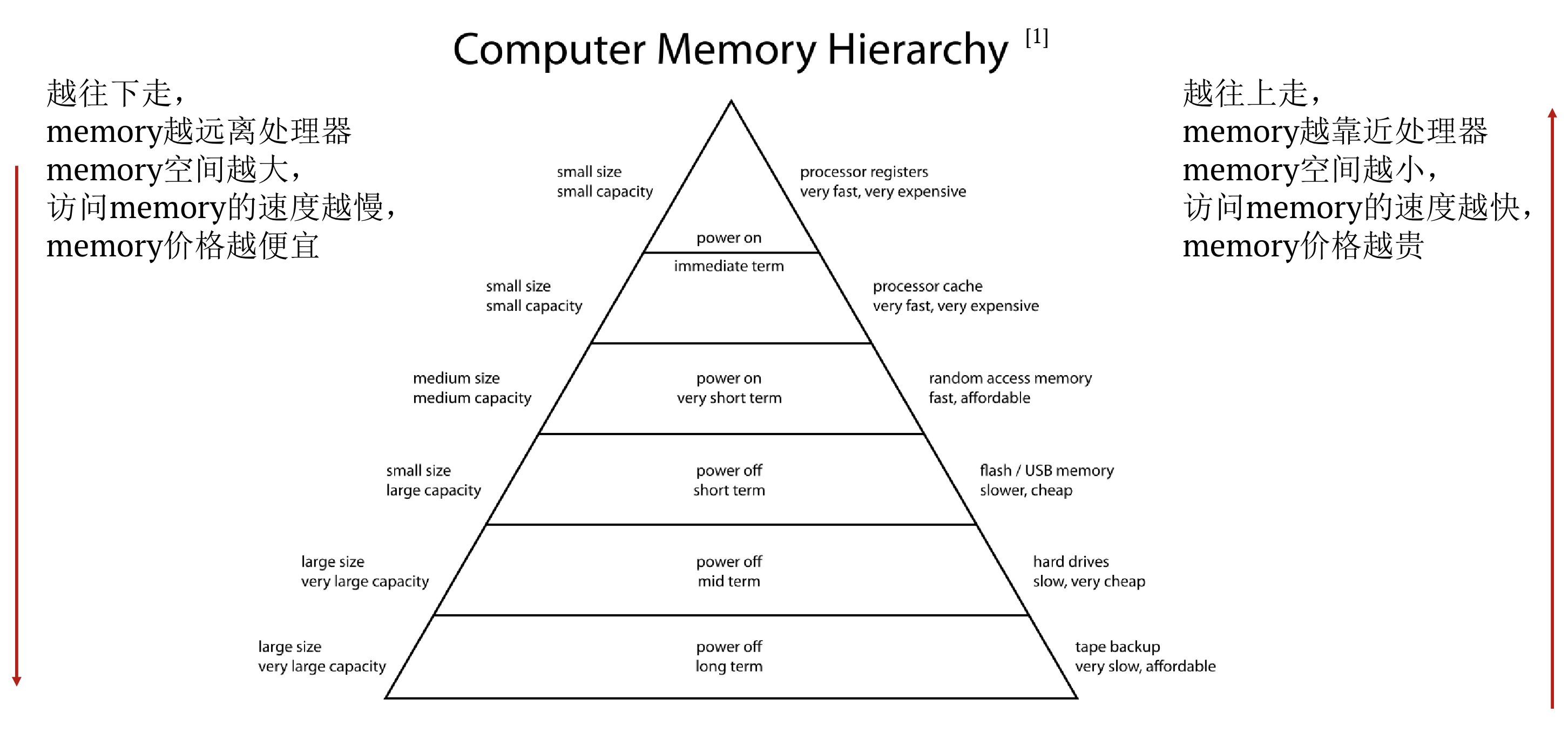
3.2 CPU是如何进行优化的?
以下是几种优化方式:
- Pipeline
- cache hierarchy
- Pre-fetch
- Branch-prediction
- Multi-threading
3.2.1 Pipeline (流水线执行)
Pipeline是一种提高throughput的一种优化的方式。
-
CPU instruction pipeline(CPU流水线执行)
- IF: Instruction fetch:把指令从memory中取出来
- ID: Instruction decode:把取出来的指令给解码成机器可以识别的信号
- OF: Operand fetch:把数据从memory中取出来放到register中
- EX: Execution:使用ALU(负责运算的unit)来进行计算
- WB: write back:把计算完的结果写回register

通过并行的方式多个指令的执行,这样就能提高单位时间内执行的指令需要的时间。
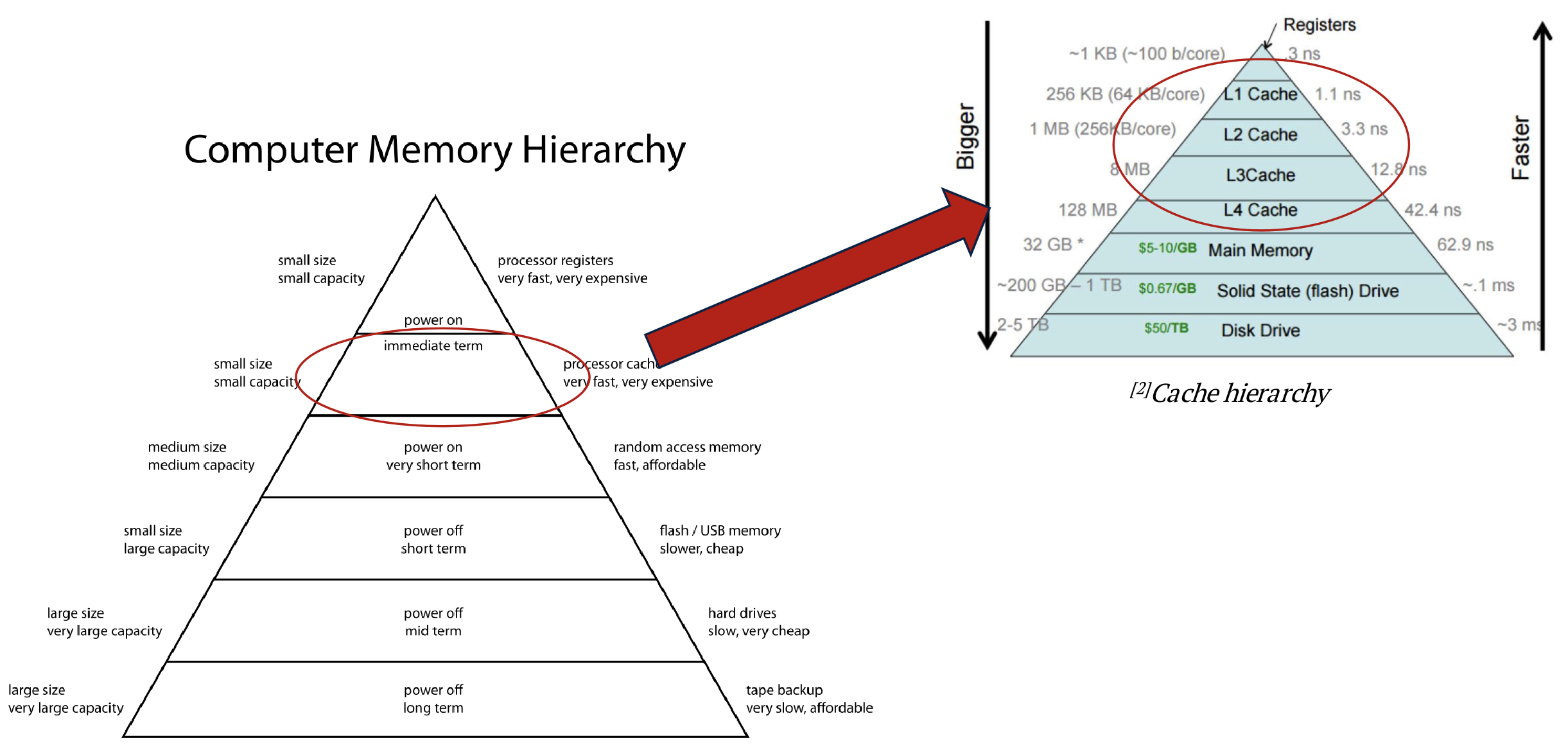
3.2.2 cache hierarchy (多级缓存)
cache hierarchy是减少memory latency的一种优化方式。
采用多级缓存的方式,一层一层往下找,这样速度就会快很多。
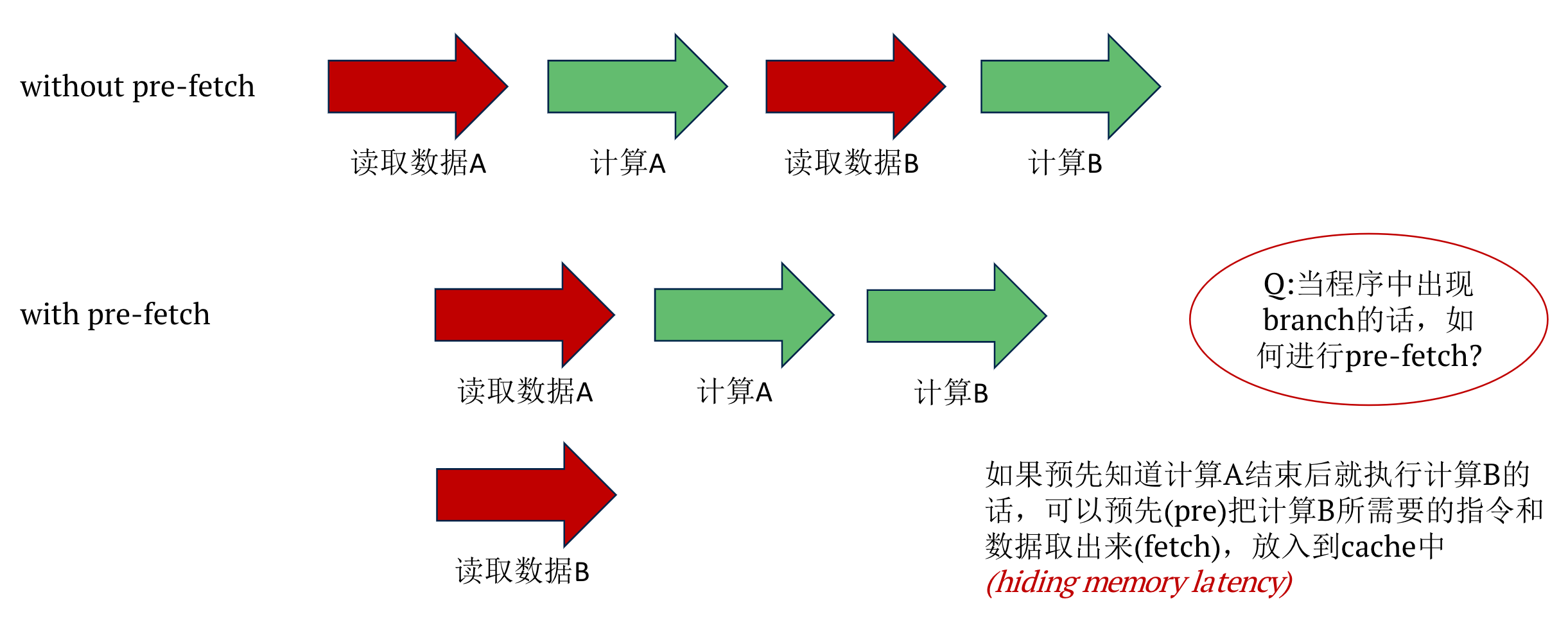
3.2.3 Pre-fetch
Pre-fetch是一种减少memory latency的一种优化的优化方式。(提前取数)
当没有prefetch得时候读A然后读B。
如果有可以在读取A的时候读B。
3.2.4 Branch-prediction(分支预测)
Branch-prediction就是根据以往的branch得走向,去预测下一次branch的走向。CPU硬件上有专门负责分支预测的Unit。
举个例子:
while(i< 100){
sum += a[i];
1 ++;
}
因为以往一直都是true,所以预测下一次循环也是true,那么先把数据取出来进行pipeline。如果预测失败,rollback回去就好了。
3.2.5 Multi-threading(多线程)
-
Multi-threading可以充分利用计算资源的一种技术。
-
Multi-threading让因为数据依赖或者cache miss而stall的core去做一些其他的事情。
由于存在stall,所以可以让它去做一些其他的指令。
-
Multi-threading可以提高throughput的一种技术。
3.2.6 总结
(1)减少memory latency
- cache hierarchy
- pre-fetch
- branch prediction
(2)提高throuphput
- pipeline
- multi-threading
但是:由于CPU处理的大多数都是一些复杂逻辑的计算,有大量的分支以及难以预测的分支方向,所以增加core的数量,增加线程数而带来的throughput的收益往往并不是那么高。
因此: 去掉复杂的逻辑计算,去掉分支,把大量的简单运算放在一起的话,是不是就可以最大化的提高throughput呢?
答案是yes,这个就是GPU所做的事情。(GPU诞生背景)
4 GPU的特点
4.1 GPU包含以下主要特点
(1)multi-threading技术
(2)大量的core,可以支持大量的线程
- CPU并行处理的threads数量规模:数十个
- GPU并行处理的threads数量规模:数千个
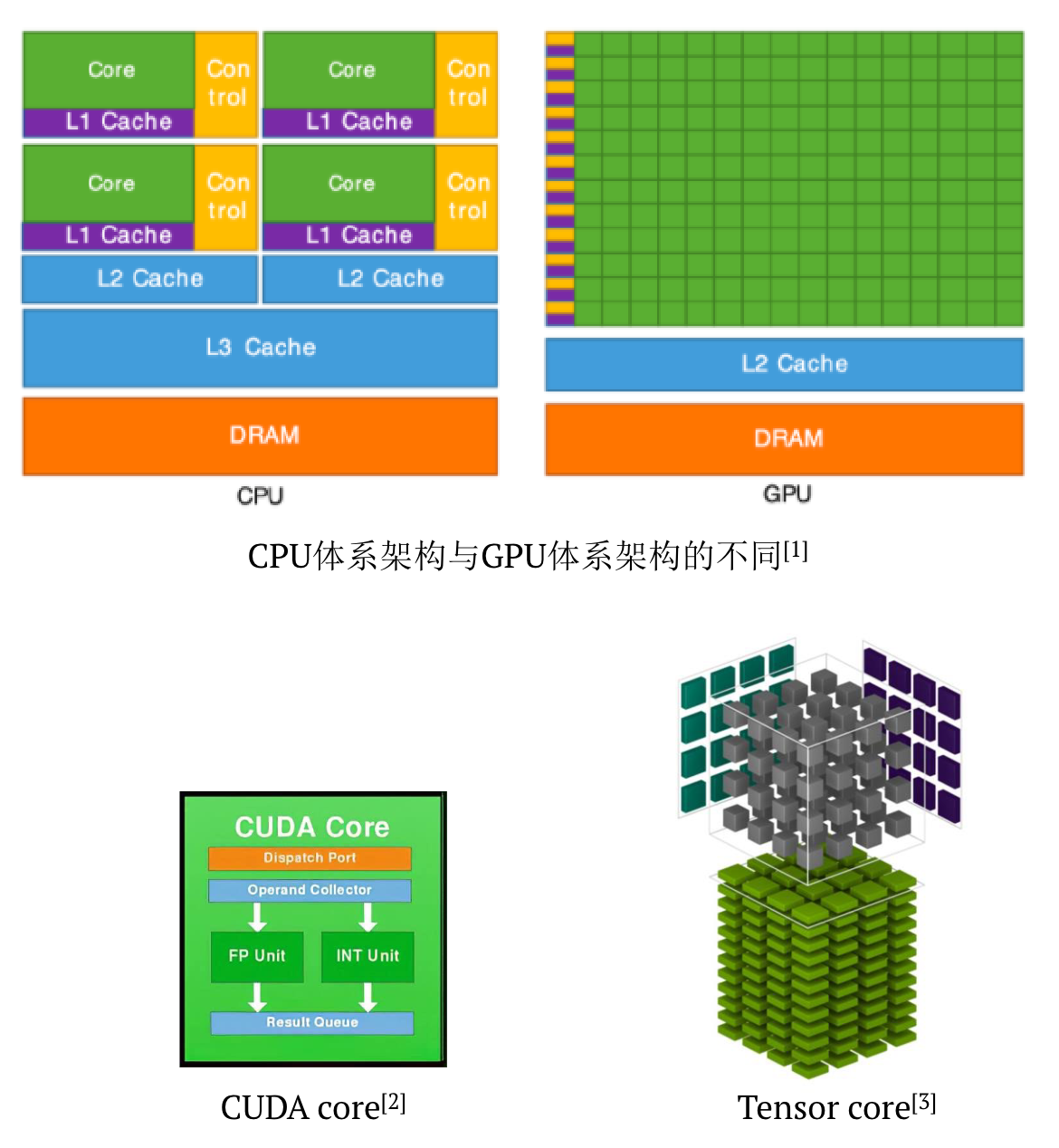
(3)每一个core负责的运算逻辑十分simple
-
CUDA core:
- D = A * B + C
-
Tensor core:
- 4x4x4的matrix calculation
- D = A * B + C
cpu处理逻辑非常复杂,但是GPU运算非常简单。
(4)SIMT
-
SISD
SISD 是 Single Instruction, Single Data 的缩写,意思是 单指令单数据。在这种情况下,CPU 一次只能执行一条指令,并且每条指令只能操作一个数据。
SISD是最简单的模型,就像一个人在做一件事情,每次只能处理一个数据,按照一定的顺序执行一系列的指令,不能同时做多件事情。
例如,你在做一道数学题,你只能按照题目的要求,一步一步地计算,不能同时处理多个数字或公式。
-
SIMD
SIMD 是 Single Instruction, Multiple Data 的缩写,意思是 单指令多数据。
SIMD是一种利用数据并行性的模型,就像一个人在做多件相同的事情,每次可以处理多个数据,但是每个数据都要执行相同的指令,不能执行不同的指令。
例如,你在给一堆照片调整亮度,你可以一次调整多张照片,但是每张照片都要用同样的方法和参数,不能根据照片的不同而采用不同的方法或参数。
-
SIMT
SIMT 是 Single Instruction, Multiple Thread 的缩写,意思是 单指令多线程。
SIMT是一种结合了SIMD和多线程的模型,就像多个人在做多件相同的事情,每个人可以处理一个或多个数据,但是每个数据都要执行相同的指令,不能执行不同的指令。
例如,你在给一堆照片添加水印,你可以让多个人一起工作,每个人负责一张或多张照片,但是每张照片都要用同样的水印和位置,不能根据照片的不同而改变水印或位置。
(5)由于GPU的throughput(吞吐量)非常的高,所以相比与CPU,cache miss所产生的latency对性能的影响比较小
吞吐量(throughput)是指单位时间内系统能够处理的数据量。延迟(latency)是指系统处理请求所需的时间。如果一个系统每秒处理的数据量非常多,那么即使 cache miss 发生了,对整体性能的影响也不会很大。因为 cache miss 的延迟只是其中很小一部分。
大白话理解
一个快递员,他每天要送很多的快递,有些快递是在他的车上,有些快递是在他的仓库里。如果他要送的快递在车上,他就可以直接拿出来送,这样很快;如果他要送的快递在仓库里,他就要先开车回仓库,再拿出来送,这样就慢一些。这个过程就像是缓存命中和缓存未命中。但是,如果这个快递员每天能送很多的快递,那么即使有些快递要回仓库拿,也不会影响他的总体效率,因为他的送货速度很高。这个速度就像是吞吐量。
(6)GPU主要负责的任务是大规模计算(图像处理、深度学习等等),所以一旦fetch好了数据以后,就会一直连续处理,并且很少cache miss
GPU的主要工作是同时处理很多的数据,比如图像上的每个像素,或者深度学习中的每个参数,这些数据都是相互独立的,不需要等待其他数据的结果。所以,GPU只要一次性把所有需要的数据从内存中读取到缓存中,就可以不断地进行计算,不需要再去内存中找数据,这样就避免了缓存未命中的情况。
大白话理解
一个厨师,他要做很多份相同的菜,每份菜都需要用到同样的食材,比如鸡蛋、面粉、油等。如果他一开始就把所有需要的食材都准备好,放在手边,就可以连续地做菜,不需要再去冰箱或柜子里找食材,这样就节省了时间和精力。这个过程就像是GPU的工作方式。相反,如果他每做一份菜,就要去找一次食材,就会浪费很多时间,这就像是缓存未命中。
4.2 CPU和GPU的分工区别
4.2.1 CPU
- 适合复杂逻辑的运算
- 优化方向在于减少memory latency
- 相关的技术有,cache hierarchy, pre-fetch, branch-prediction, multi-threading
- 不同于GPU,CPU硬件上有复杂的分支预测器去实现branch-prediction
- 由于CPU经常处理复杂的逻辑,过大的增大core的数量并不能很好的提高throughput
4.2.2 GPU
- 适合简单单一的大规模运算。比如说科学计算,图像处理,深度学习等等
- 优化方向在于提高throughput
- 相关的技术有,multi-threading,warp schedular
- 不同于CPU,GPU硬件上有复杂的warp schedular去实现多线程的multi-threading
- 由于GPU经常处理大规模运算,所以在throughput很高的情况下,GPU内部的memory latency上带来的性能损失不是那么明显,然而CPU和GPU间通信时所产生的memory latency需要重视
