1、调包方式
1.1 代码
split_input = "共和国成立仪式于2020年在人民大会堂召开"
split_result = jieba.cut(split_input, HMM=False)
print(list(split_result))
split_result = jieba.cut(split_input, HMM=True)
print(list(split_result))
1.2 结果

2、手工计算
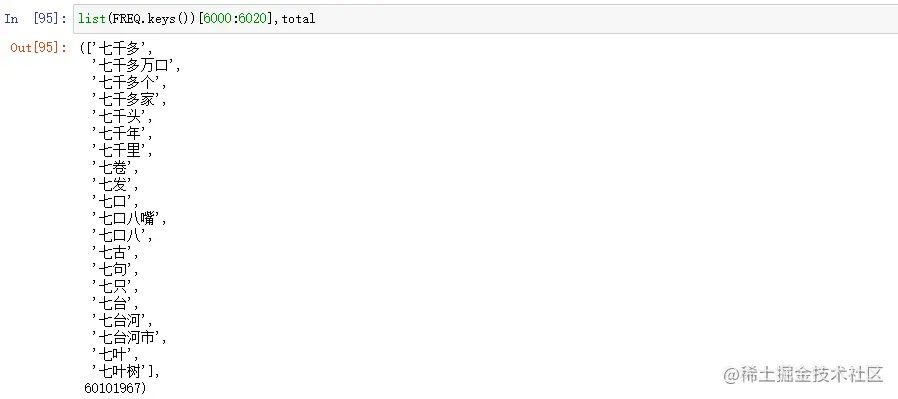
2.1 读取字典
import marshal
with open("C:\\Users\\AppData\\Local\\Temp\\jieba.cache", 'rb') as cf:
FREQ,total = marshal.load(cf)
list(FREQ.keys())[6000:6020],total
2.2 正则表达式拆分为list
import re
re_han=re.compile('([一-鿕a-zA-Z0-9+#&\\._%\\-]+)')
re_skip=re.compile('([一-鿕a-zA-Z0-9+#&\\._%\\-]+)')
blocks = re_han.split(split_input)
blocks
blk = "共和国成立仪式于2020年在人民大会堂召开"

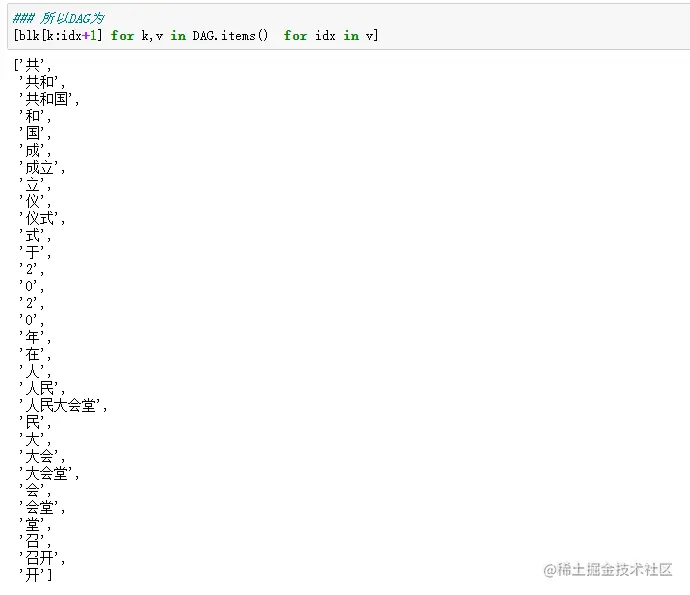
2.3 建立DAG图
def get_DAG(FREQ, sentence):
DAG = {}
N = len(sentence)
for k in range(N):
tmplist = []
i = k
frag = sentence[k]
while i < N and frag in FREQ:
if FREQ[frag]:
tmplist.append(i)
i += 1
frag = sentence[k:i + 1]
if not tmplist:
tmplist.append(k)
DAG[k] = tmplist
return DAG
DAG = get_DAG(FREQ,blk)
DAG
[blk[k:idx+1] for k,v in DAG.items() for idx in v]

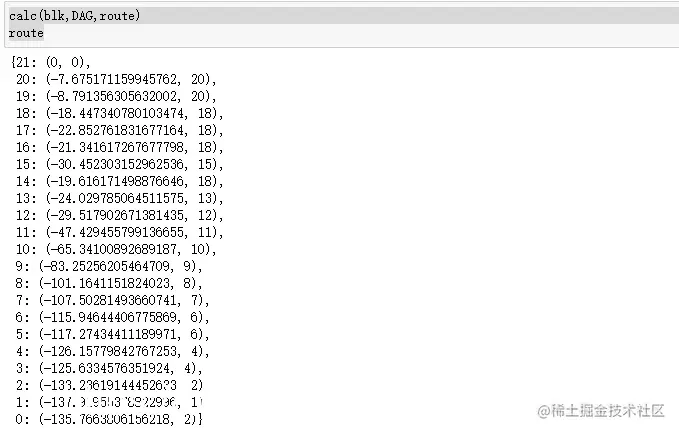
2.4 建立route概率图
route={}
import numpy as np
log = np.log
def calc(sentence, DAG, route):
N = len(sentence)
route[N] = (0, 0)
logtotal = log(total)
for idx in range(N - 1, -1, -1):
route[idx] = max((log(FREQ.get(sentence[idx:x + 1]) or 1) -
logtotal + route[x + 1][0], x) for x in DAG[idx])
calc(blk,DAG,route)
route
2.5 生成切分结果
def generate_result(route,sentence):
x = 0
N = len(sentence)
buf = ''
re_eng = re.compile("[a-zA-Z0-9]")
while x < N:
y = route[x][1] + 1
l_word = sentence[x:y]
if re_eng.match(l_word) and len(l_word) == 1:
buf += l_word
x = y
else:
if buf:
yield buf
buf = ''
yield l_word
x = y
if buf:
yield buf
buf = ''
results = generate_result(route,blk)
list(results)



