一、概述
高斯网络是一种特殊的概率图模型,它的随机变量的概率分布是连续的高斯分布,而不是普通概率图模型的离散分布。高斯网络可以进一步划分为有向图和无向图两种类型,其中,有向图被称为高斯贝叶斯网络(Gaussian Bayesian Network,GBN),而无向图则被称为高斯马尔可夫网络(Gaussian Markov Network,GMN)。
概率图模型的分类大致如下:
PGM⎩⎨⎧→discrete{BayesianNetworkMarkovNetwork→continuousGaussianNetwork{GaussianBayesianNetworkGaussianMarkovNetwork
高斯网络概率图中的每个节点xi都服从高斯分布,即xi∼N(μi,Σi),而对于概率图的随机变量x=(x1x2⋯xp)T(假设有p个节点),也服从参数为μ和Σ的高斯分布:
P(x)=(2π)p/2∣Σ∣1/21exp{−21(x−μ)TΣ−1(x−μ)}
对于方差矩阵Σ,定义:
Σ=[σij]=⎣⎡σ11σ21⋮σp1σ12σ22⋮σp2⋯⋯⋱⋯σ1pσ2p⋮σpp⎦⎤p×p
由方差矩阵我们可以表示全局独立性:
xi⊥xj⇔σij=0
对于方差矩阵Σ的逆,我们定义其为Λ,叫做精度矩阵(precision matrix)或者信息矩阵(information matrix),即Λ=Σ−1=[λij]。通过精度矩阵我们可以表示条件独立性:
xi⊥xj∣x−{xi,xj}⇔λij=0
在本文中只介绍高斯网络有向图和无向图的表示方法,不介绍其他的一些推断的方法。
二、高斯贝叶斯网络
1.有向概率图模型的因子分解
GBN作为一种有向概率图模型,同样服从有向图的因子分解:
P(x1,x2,⋯,xp)=i=1∏pP(xi∣xparent(i))
2.线性高斯模型
GBN从局部来看是一个线性高斯模型,举例来说,就是下面两个两个随机变量之间满足线性关系,同时包含一定的噪声,噪声服从高斯分布:
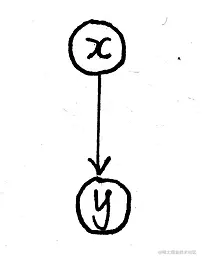
其概率表示如下:
P(x)=N(x∣μx,Σx)P(y∣x)=N(y∣Ax+b,Σy)
3.类比线性动态系统
对于GBN是线性高斯模型这一点可以类比之前讲过的线性动态系统(Linear Dynamic System,LDS),参考链接:卡尔曼滤波
LDS是一种特殊的GBN,它的概率图模型如下:
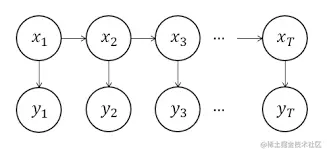
在LDS中每个节点都只有一个父亲节点,其概率为:
xt=A⋅xt−1+B+εyt=C⋅xt+D+δε∼N(0,Q)δ∼N(0,R)
写成条件概率的形式就是:
P(zt∣zt−1)∼N(A⋅zt−1+B,Q)P(xt∣zt)∼N(C⋅zt+D,R)z1∼N(μ1,Σ1)
LDS 的假设是相邻时刻的变量之间的依赖关系,因此是一个局域模型,而GBN每⼀个节点的父亲节点不⼀定只有⼀个,因此可以看成是⼀个全局的模型。
4.高斯贝叶斯网络的表示
在GBN中,对于每一个节点,其概率可以写成以下标准形式:
P(xi∣xparent(i))=N(xi∣μi+wiTxparent(i),σi2)
在上面的式子中,将xparent(i)当做向量来使用。另外我们也可以将随机变量写成等式的形式:
xi=μi+j∈xparent(i)∑wij(xj−μj)+σiεi,εi∼N(0,1)
也就是:
xi−μi=j∈xparent(i)∑wij(xj−μj)+σiεi,εi∼N(0,1)
这里将每个随机变量都减去了它的均值,是为了简化模型和计算上的方便。接着定义以下向量和矩阵:
μ=(μ1μ2⋯μp)TW=[wij]ε=(ε1ε2⋯εp)TS=diag(σi)
然后将前面的式子写成向量形式:
x−μ=W(x−μ)+Sε
整理一下,也就有:
x−μ=(I−W)−1Sε
因此协方差矩阵就可以写成:
Σ=Cov(x)=Cov(x−μ)
三、高斯马尔可夫网络
1.高斯贝叶斯网络的表示
对于无向图的高斯网络,其概率可以表示为:
P(x)=Z1i=1∏pnodepotentialψi(xi)i,j∈x∏pedgepotentialψi,j(xi,xj)
而对于多维高斯分布的概率表达形式:
P(x)=(2π)p/2∣Σ∣1/21exp{−21(x−μ)TΣ−1(x−μ)}
我们可以根据上式进行整理来探索上述两个不同的概率公式之间的联系:
P(x)∝exp{−21(x−μ)TΣ−1(x−μ)}=exp{−21(x−μ)TΛ(x−μ)}=exp{−21(xTΛ−μTΛ)(x−μ)}=exp⎩⎨⎧−21(xTΛx−标量μTΛx−标量xTΛμ+μTΛμ)⎭⎬⎫=exp⎩⎨⎧−21(xTΛx−2μTΛx+与x无关μTΛμ)⎭⎬⎫∝exp⎩⎨⎧−二次21xTΛx+一次(Λμ)Tx⎭⎬⎫
经过一番整理我们发现P(x)所正比于的函数中包含一个二次项和一个一次项。这里我们将Λμ记作h,称为potential vector,即:
h=Λμ=⎝⎛h1h2⋮hp⎠⎞
从exp{−21xTΛx+(Λμ)Tx}这个式子中我们可以得到与xi和xi,xj相关的项,下面的结果通过展开这个式子就可以轻易得到:
xi:−21xi2λii+hixixi,xj:−21(λijxixj+λjixjxi)=−λijxixj
这些相关项可以分别对应节点势能和边势能,从而将两个公式联系起来。此外,在一个GMN中,如果两个节点之间没有边,那么它们之间的λij就为0。这表明xi,xj的相关项构成的势函数只与λij有关,从而可以推导出条件独立性:
xi⊥xj∣x−{xi,xj}⇔λij=0
我们之前的讨论是为了阐明以下观点:一个多维高斯分布对应一个GMN。在学习这个多维高斯分布时,我们不仅可以学习到这个分布的参数,同时也可以学习到这个GMN的结构。这是因为,如果我们学习到λij=0,那么这就意味着在概率图上,对应的两个节点之间没有边。
2.其他性质
对于无向图高斯网络来说,除了满足全局独立性和条件独立性以外,还满足另外一个性质,也就是:
对于任意一个无向图中的节点xi,满足:
xi∣x−{xi}∼N(∑j=iλiiλijxj,σiiλii−1)
也就是说xi可以表示为无向图中跟它有连接的xj(因为没有连接的xj对应的λij=0的线性组合。
上述性质的得出是根据x=(xix−{xi})=(xaxb)来求解条件概率分布,而求解高斯分布的条件概率分布的方法在之前的课程中已经介绍过了,参考链接:高斯分布。
“本文正在参加 人工智能创作者扶持计划”


