一、简介
- 为什么需要降维
数据的维度过高容易造成维数灾难(Curse of Dimensionality)。.
维数灾难:通常是指在涉及到向量的计算的问题中,随着维数的增加,计算量呈指数倍增长的一种现象。
这里可以举两个几何的例子来看一下维数过高的影响:
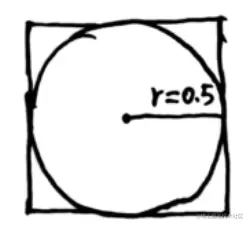
上图表示一个多维空间(以二维为例),则其中图形的体积有如下关系:
V超立方体 =1V超球体 =K⋅0.5DD→∞limV超球体 =0
上式也就表明当数据的维度过高时,数据主要存在于空间的边边角角的地方,这也就造成了数据的稀疏性。
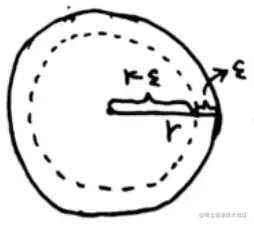
上图也表示一个多维空间 (以二维为例),则其中图形的体积有如下关系:
V外 =K⋅1D=KV环形带 =V外 −V内 =K−K⋅(1−ε)DV外 V环形带 =KK−K⋅(1−ε)D=1−(1−ε)DD→∞limV外 V环形带 =D→∞lim1−(1−ε)D=1
可以看到当数据的维度过高时,数据主要存在于球壳上,类似于人的大脑皮层。
2. 降维的方法
降维可以作为一种防止过拟合的方式,其具体的方法包含下列几种:

特征选择是一种直接剔除主观认为不重要的特征的过程。
本文接下来的部分主要介绍主成分分析(PCA)。
二、样本均值与样本方差
- 概述
假设有以下数据:
xi∈Rp,i=1,2,⋯,NX=(x1,x1,⋯,xN)T=⎝⎛x1Tx2T⋮xNT⎠⎞=⎝⎛x11x21⋮xN1x12x22⋮xN2⋯⋯⋱⋯x1px2p⋮xNp⎠⎞N×p
- 样本均值与样本方差
以下定义了数据的样本均值与样本方差:
Sample Mean :xp×12=N1i=1∑NxiSampleCovariance:Sp×p=N1i=1∑N(xi−x2)(xi−x2)T
接下来需要对样本均值与样本方差进行一些变换来获得其另一种表示形式:
规定向量1N=⎝⎛11⋮1⎠⎞N×1x2=N1i=1∑Nxi=N1XT(x1x2⋯xN)⎝⎛11⋮1⎠⎞=N1XT1NS=N1i=1∑N(xi−x2)(xi−x2)T上式中(x1−x2x2−x2⋯xN−x2)=(x1x2⋯xN)−(x2x2⋯x2)=XT−x2(11⋯1)=XT−x21NT=XT−N1XT1N1NT=XT(IN−N11N1NT)则S=N1XTH(IN−N11N1NT)(IN−N11N1NT)TX(H称为中心矩阵,centeringmatrix)=N1XTHHTX
中心矩阵H具备以下性质:
(1) HT=HHT=(IN−N11N1NT)T=IN−N11N1NT=H (2) Hn=HH2=H⋅H=(IN−N11N1NT)(IN−N11N1NT)=IN−N21N1NT+N211N1NT1N1NT=IN−N2⎝⎛11⋮1⎠⎞(11⋯1)+N21⎝⎛11⋮1⎠⎞(11⋯1)⎝⎛11⋮1⎠⎞(11⋯1)=IN−N2⎣⎡11⋮111⋮1⋯⋯⋱⋯11⋮1⎦⎤N×N+N21⎣⎡11⋮111⋮1⋯⋯⋱⋯11⋮1⎦⎤N×N⎣⎡11⋮111⋮1⋯⋯⋱⋯11⋮1⎦⎤N×N=IN−N2⎣⎡11⋮111⋮1⋯⋯⋱⋯11⋮1⎦⎤N×N+N21⎣⎡NN⋮NNN⋮N⋯⋯⋱⋯NN⋮N⎦⎤N×N=IN−N2⎣⎡11⋮111⋮1⋯⋯⋱⋯11⋮1⎦⎤N×N+N1⎣⎡11⋮111⋮1⋯⋯⋱⋯11⋮1⎦⎤N×N=IN−N11N1NT=H
因此最终可以得到
x2=N1XT1NS=N1XTHX
三、主成分分析的思想
总结起来就是:
一个中心:PCA是对原始特征空间的重构,将原来的线性相关的向量转换成线性无关的向量;
两个基本点:最大投影方差和最小重构距离,这是本质相同的两种方法,在接下来的部分将具体介绍。
PCA首先要将数据中心化(即减去均值)然后投影到一个新的方向上,这个新的方向即为重构的特征空间的坐标轴,同时也要保证投影以后得到的数据的方差最大,即最大投影方差,这样也保证了数据的重构距离最小。
四、最大投影方差
假设投影方向为 u ,由于我们只关注投影的方向,因此将 u 的模设置为 1 ,即 uTu=1 ,则 中心化后的数据在 u 方向上的投影为 (xi−x2)Tu ,是一个标量。按照最大投影方差的思想,我们定义损失函数如下:
J(u)=N1i=1∑N((xi−xˉ)Tu)2=i=1∑NN1uT(xi−xˉ)(xi−xˉ)Tu=uTS[N1i=1∑N(xi−xˉ)(xi−xˉ)T]u=uTSu
因此该问题就转换为以下最优化问题:
{u^=uargmaxuTSu s.t. uTu=1
然后使用拉格朗日乘子法进行求解:
L(u,λ)=uTSu+λ(1−uTu)∂u∂L=2Su−2λu=0S 特征向量 u= 特征值 λu
最后解得符合条件的向量是协方差矩阵 S 的特征向量。如果想要降到 q 维( q<p) ,则只需要将对应特征值最大的前 q 个特征向量取出来作为投影方向然后获得数据在这些方向上的投影 即为重构的坐标,即:
⎝⎛x1Tx2T⋮xNT⎠⎞N×p(u1u2⋯uq)p×q=⎣⎡x1Tu1x2Tu1⋮xNTu1x1Tu2x2Tu2⋮xNTu2⋯⋯⋱⋯x1Tuqx2Tuq⋮xNTuq⎦⎤N×q
特征向量表示投影变换的方向,特征值表示投影变换的强度。通过降维,我们希望减少冗余信息, 提高识别的精度,或者希望通过降维算法来寻找数据内部的本质结构特征。找最大的特征值是因为,在降维之后要最大化保留数据的内在信息,并期望在所投影的维度上的离散最大。
五、最小重构距离
最小重构距离是另一种求解的方法,其本质上和最大投影方差是相同的。
我们知道有 p 个投影方向符合条件,因此原来的数据可以表示为以下形式,降维的数据也就是舍弃掉第 q+1 到第 p 这几个方向上的信息。
原来的中心化了的数据xi−x2=k=1∑p((xi−x2)Tuk)uk降维的数据x^i=k=1∑q((xi−x2)Tuk)uk(u1到up分别对应从大到小的特征值)
因此重构距离也就是指 xi−x^i ,本着最小化重构距离的思想我们可以设置新的损失函数如下:
J=N1i=1∑N∥∥(xi−x2)−x^i∥∥2=N1i=1∑N∥∥k=q+1∑p((xi−x2)Tuk)uk∥∥2=N1i=1∑Nk=q+1∑p((xi−x2)Tuk)2=k=q+1∑pukTSukN1i=1∑N((xi−x2)Tuk)2=k=q+1∑pukTSuk s.t. ukTuk=1
然后就可以转化为以下最优化问题:
{u^=argmin∑k=q+1pukTSuk s.t. ukTuk=1
显然这里的每个 uk 是可以单独求解的,最终也可以解得 uk 是协方差矩阵 S 的特征向量,只不过这里的 uk 是对应特征值较小的几个特征向量。
六、SVD角度看PCA和PCoA
协方差矩阵 S 的特征分解:
S=GKGT, 其中 GTG=I,K=⎣⎡k1k2⋱kp⎦⎤,k1≥k2≥⋯≥kp
将 X 中心化的结果 HX 做奇异值分解:
HX=UΣVT, 其中 ⎩⎨⎧UN×N 是正交矩阵 Vp×p 是正交矩阵 ΣN×p 是对角矩阵
接下里可以做以下变换:
Sp×p=XTHX=XTHTHX=VΣTUTUΣVT=VΣTΣVT(VΣTΣVT 是 S 的特征值分解, ΣTΣ 即为 K 。 )
接下来我们构造矩阵 TN×N :
TN×N=HXXTHT=UΣVTVΣTUT=UΣΣTUT(UΣΣTUT 是 T 的特征值分解, ΣΣT 为特征值矩阵。 )
对比 Sp×p 和 TN×N ,我们可以发现:
①将 S 进行特征分解然后得到投影的方向,也就是主成分,然后矩阵 HXV 即为重构坐标系的坐标矩阵;
②将 T 进行特征分解可以直拉获得坐标矩阵 UΣ 。
(注意应保证 S 和 T 特征分解得到的特征向量是单位向量。)
关于为什么将 T 进行特征分解可以直接获得坐标矩阵,现做以下解释:
坐标矩阵HXV=UΣVTV=UΣ也就是说UΣ即为坐标矩阵接着TUΣ=UΣΣTUTUΣ=UΣ(ΣTΣ)也就是说UΣ是T的特征向量组成的矩阵
使用 T 进行特征分解的方法叫做主坐标分析 (Principal Co-ordinates Analysis,PCoA) 。
这两种方法都可以得到主成分,但是由于方差矩阵是 p×p 的,而 T 是 N×N 的,所以对样本量较少的时候可以采用 PCOA的方法。
七、概率PCA(p-PCA)
- 概述
假设有以下数据:
x∈Rp,z∈Rq,q<p
其中 x 是原始数据, z 是降维后的数据,可以将 z 看做隐变量 (latent variable), x 看做观测变量 (observed variable),则p-PCA就可以看做生成模型。
x 和 z 满足以下关系:
⎩⎨⎧z∼N(0q×1,Iq×q)x=Wz+μ+εε∼N(0p×1,σ2Ip×p)
这是一个线性高斯模型,其中 ε 是噪声, ε 与 z 是独立的。求解这个模型要经过两个阶段:
①inference: 求 P(z∣x)
②learning: 使用EM算法求解参数 W、μ,σ2 。
x 的生成过程如下:
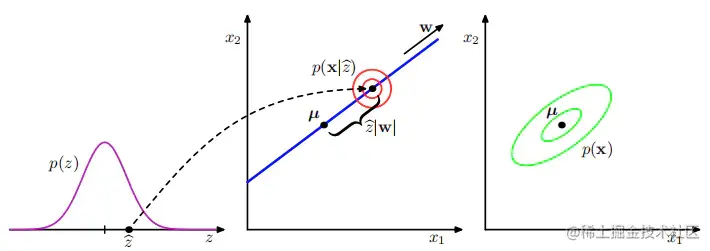
上图中数据空间为二维,潜在空间为一维。一个观测数据点 x 的生成方式为: 首先从潜在变量 的先验分布 p(z) 中抽取一个潜在变量的值 z^ ,然后从一个各向同性的高斯分布 (用红色圆圈 表示) 中抽取一个 x 的值,这个各向同性的高斯分布的均值为 Wz^+μ ,协方差为 σ2I 。绿色椭圆画出了边缘概率分布 p(x) 的密度轮廓线。
2. 推断 (inference)
求解 P(z∣x) 的过程如下:
P(z)→P(x∣z)→P(x)→P(z∣x)
- 求 P(x∣z)
E[x∣z]=E[Wz+μ+ε]=Wz+μ+0=Wz+μVar[x∣z]=Var[Wz+μ+ε]=σ2I⇒x∣z∼N(Wz+μ,σ2I)
E[x]=E[Wz+μ+ε]=E[Wz+μ]+E[ε]=μVar[x]=Var[wz+μ+ε]=Var[Wz]+Var[ε]=WWT+σ2I⇒x∼N(μ,WWT+σ2I)
其中,Var[Wz]=WWT是因为z的均值为0,则方差自然是W方了
- 求 P(z∣x)
该问题和高斯分布(1.intro_math)中第六部分的问题是类似的。
(xz)∼N([μ0],[WWT+σ2IΔTΔI])Δ=Cov(x,z)=E[(x−μ)(z−0)T]=E[(Wz+μ+ε−μ)zT]=E[(Wz+ε)zT]=E[WzzT+εzT]=E[WzzT]+E[εzT]=WE[zzT]+E[ε]E[zT]=WE[(z−0)(z−0)T]+0==WVar[z]=W 因此 (xz)∼N([μ0],[WWT+σ2IWTWI])
利用高斯分布中第五部分的公式可以求解 P(z∣x) :
P(z∣x)∼N(WT(WWT+σ2I)−1(x−μ),I−WT(WWT+σ2I)−1W)
- 学习(learning)
使用EM算法求解,这里不做展示,后续章节会讲解。
八、小结
降维是解决维度灾难和过拟合的重要方法,除了直接的特征选择外,我们还可以采用算法的途径对特征进行筛选,线性的降维方法以 PCA 为代表,在 PCA 中,我们只要直接对数据矩阵进行中心化然后求奇异值分解或者对数据的协方差矩阵进行分解就可以得到其主要维度。非线性学习的方法如流形学习将投影面从平面改为超曲面。


