

导读
背景请参考 Nodejs 服务端框架调研 内容。简单说就是笔者想找一个合适的做 BFF 的 Nodejs 框架。
Eggjs(后文简称 Egg) 在国内的使用率还是比较高的,可以参考 如何获取 cnpm 的 packages 下载量 中的数据,在 cnpm 上,Eggjs 的下载量是 Nestjs 的 1.57 倍,而在 npm 上,后者是前者的近 28 倍,这差距着实有些惊人啊。
如果不研究下 Eggjs 的话,难免就有种「外国的月亮比较圆」的偏见了。所以今天就来研究下 Eggjs。
设计原则
引用一段 官网文档 中笔者认为最具有代表性的描述:
Egg 奉行『约定优于配置』,按照一套统一的约定进行应用开发,团队内部采用这种方式可以减少开发人员的学习成本,开发人员不再是『钉子』,可以流动起来。没有约定的团队,沟通成本是非常高的,比如有人会按目录分栈而其他人按目录分功能,开发者认知不一致很容易犯错。
这个初衷还是很有意义的,毕竟在绝大多数情况下,自由与可控总是存在矛盾的,忘记是哪个大神说过的一句话,大意是:「软件设计是一件妥协的艺术」。不过这样设计,马上就会面临两个问题,一个是扩展性,一个是学习成本。
Egg 主要用「插件」和「中间件」来解决扩展性的问题。由于 Egg 的底层是 Koa,所以在中间件上也采用了「洋葱圈模型」,这点就不细展开了,有兴趣的话可以查看 文档。
而插件更能体现 Egg 的设计思想,后文会有较详细的展开。这里我们要先说另一个概念:加载器(Loader)。Loader 是 Egg 底层架构的具体实现,所以理解起来还是有一定复杂度和难度的。我们需要进行一些铺垫。
目录结构
在说 Loader 之前,我们要先来看一下 Egg 规定的目录结构:
egg-project
├── package.json
├── app.js (可选)
├── agent.js (可选)
├── app
| ├── router.js
│ ├── controller
│ ├── service (可选)
│ ├── middleware (可选)
│ ├── schedule (可选)
│ ├── public (可选)
│ ├── view (可选)
│ └── extend (可选)
├── config
└── test
以上是简化的结构,完整结构以及各自功能,详见 文档。整个框架的流转链路大致为:
middleware(入)=> router => controller => service => plugin => middleware(出)
说明
这个链路非常不严谨,但是为了能够更好的理解 Egg 的底层原理,我们姑且先将其简化成这个样子。extend、schedule、public、view 等属于「枝杈」类的内容,而非「主干」,可以暂时忽略。
只要按照这个目录结构,往里面写内容,Egg 就知道把该内容当做「链路」中的特定模块进行解析。比如在 controller 下写了一个 A,Egg 就大概知道 A 会被 router 加载,可能会调用 service。这种行为有很强的可预测性,强可预测性就意味着可以自动化的实现其逻辑,从而提升了开发人员的效率。
强可预测性,恰恰是靠「约定」实现的。也就是说:如果你只要按照我们的约定来做,你就能省时省力,提高开发效率。如果大家都按照我们的约定来做,那世界将变成美好的人间……
加载器(Loader)
趁热打铁,现在我们可以简单的将 Egg 的设计理念理解为:约定 = 目录结构,下面就要引出 Loader 的概念了。Loader 的作用就是,正确解析目录结构,然后在正确的时间,正确的地点,调用正确的模块。说的宏观一点,就是 Egg 设计原则的具体代码实现。如果想了解更多内容,可以查看 文档。
有了前面的铺垫,Loader 几句话就能解释清楚了,下面我们再来看看另一个核心的概念:插件(Plugin)。
插件(Plugin)
先来回答一个问题:有了 middleware 了,为什么还需要 plugin?
我们引用 文档原文 来回答这个问题:
我们在使用 Koa 中间件过程中发现了下面一些问题:
- 中间件加载其实是有先后顺序的,但是中间件自身却无法管理这种顺序,只能交给使用者。这样其实非常不友好,一旦顺序不对,结果可能有天壤之别。
- 中间件的定位是拦截用户请求,并在它前后做一些事情,例如:鉴权、安全检查、访问日志等等。但实际情况是,有些功能是和请求无关的,例如:定时任务、消息订阅、后台逻辑等等。
- 有些功能包含非常复杂的初始化逻辑,需要在应用启动的时候完成。这显然也不适合放到中间件中去实现。
综上所述,我们需要一套更加强大的机制,来管理、编排那些相对独立的业务逻辑。
文档回答的已经很清楚了。接下来我们再来关注一下 plugin 的具体加载机制,我们还是引用一下文档内容:
一个插件其实就是一个『迷你的应用』,和应用(app)几乎一样:
- 它包含了 Service、中间件、配置、框架扩展等等。
- 它没有独立的 Router 和 Controller。
- 它没有 plugin.js,只能声明跟其他插件的依赖,而不能决定其他插件的开启与否。
他们的关系是:
- 应用可以直接引入 Koa 的中间件。
- 当遇到上一节提到的场景时,则应用需引入插件。
- 插件本身可以包含中间件。
- 多个插件可以包装为一个上层框架。
我们来提炼一下关键词:
- 『迷你的应用』,和应用(app)几乎一样。意味着直接就可以用 Loader 来解析 plugin 了,完美复用;
- 没有 router、controller、plugin.js,基本就说明了如何开发一个 plugin 了,通过查看 文档 我们也能映证这一点。
小结
Egg 的设计原则大概就分析到这,线条比较粗,好多细节刻意的忽略了,不过这样更有利于快速理解核心概念。接下来我们更具体一些,来看一下一些重要的概念,比如 Controller、Service 等。这些概念对于后端同学来说,接受起来比较容易,但是对于前端转后端的同学来说,还是需要一些扫盲科普的。
基础概念
Egg 的 MVC
下面的内容,主要针对「纯前端」同学,讲的会尽量通俗,所以在严谨性上可能会有所欠缺,各位看官请多包涵。
上文已经通过文字简单描述了 Egg 整个框架的逻辑流转链路,现在我们来看下更完整的版本:
这个图已经把 Egg 当中各个模块之间的关系表示的非常清楚了,虽然有些地方不是特别准确,比如 MVC 之间的流转,但很明显能够体现其 MVC 模型的本质,对此我们大可不必太较真。
MVC 在这里就不做扫盲了,这个模型的实现千奇百怪,不过以笔者目前的阅历,见得较多的还是 Controller - Service 模型。
由于现在前后端分离是主流,所以后端的 View 层几乎消失了,只需要提供 API,也就是 router + controller 即可。
又因为 Nodejs 普遍作为 BFF 层使用,直接操作数据库的场景其实不多,更可能是调用其他微服务,进行接口整合之类的业务,所以 Model 层的抽象也相对没有那么实用了(其实还是挺有用的)。这时候承载复杂逻辑的 Service 层的内容就变得多了起来。
所以在前后端分离和微服务的大环境背景下,Controller - Service 模型就成为了自然而然的选择。所以接下来我们只挑重要的几个概念来研究下,剩下的分支概念可以后续慢慢了解。
Middleware
上文提到了 Koa 的洋葱圈模型,这里引用一下官网的动图,来看下到底为啥叫「洋葱」。
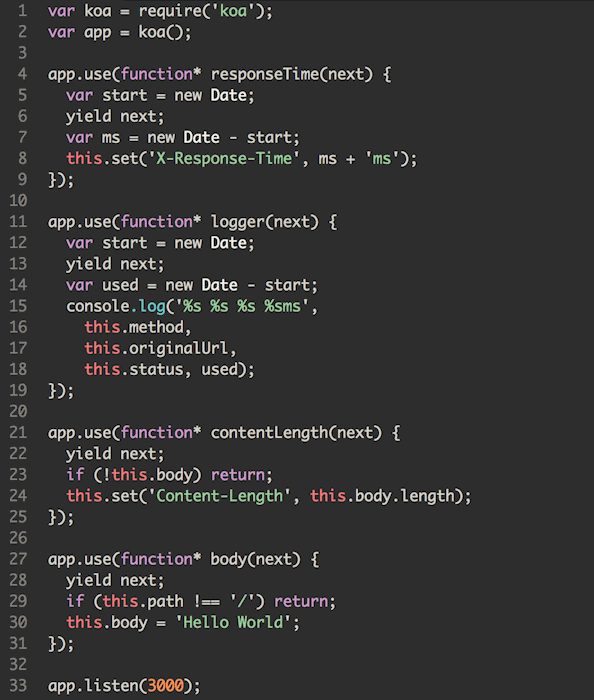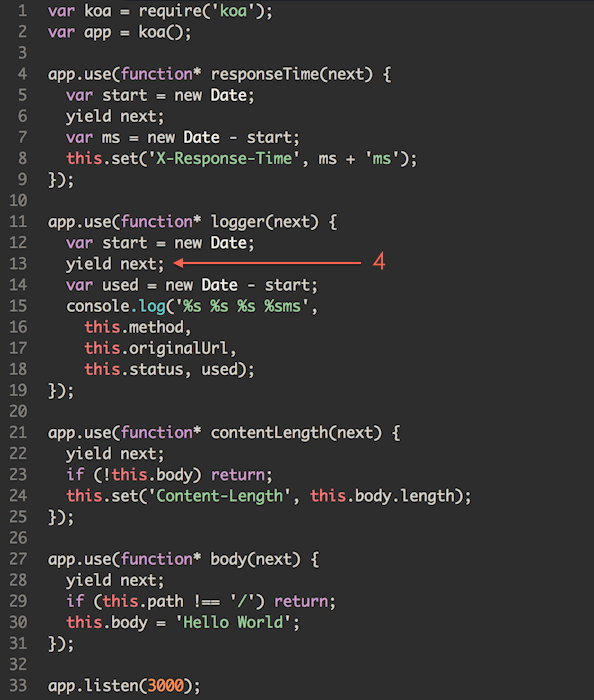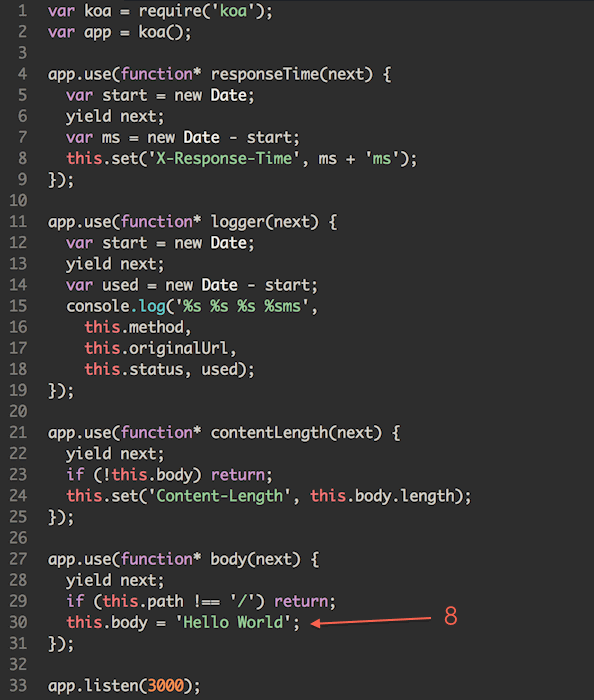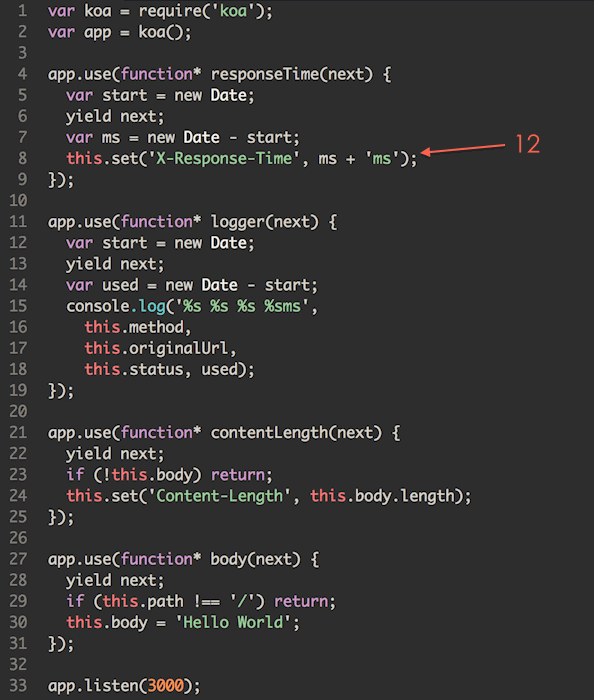
有点「栈」的意思,一个个进,再一个个出,后进先出,大家意会。以上代码是 Koa1 的写法,还有 yield 呢,早就过时了,在 Egg 里,中间件的代码是这个样子:
// app/middleware/gzip.js
const isJSON = require('koa-is-json');
const zlib = require('zlib');
async function gzip(ctx, next) {
await next();
// 后续中间件执行完成后将响应体转换成 gzip
let body = ctx.body;
if (!body) return;
if (isJSON(body)) body = JSON.stringify(body);
// 设置 gzip body,修正响应头
const stream = zlib.createGzip();
stream.end(body);
ctx.body = stream;
ctx.set('Content-Encoding', 'gzip');
}
关键就是那句 await next(),这是洋葱芯儿。在它之前的逻辑属于「入栈」阶段,之后的逻辑属于「出栈」阶段,两个阶段就给洋葱加了一层皮。
再来看下中间件的使用,最常用的就是在应用中使用中间件,只需要在 config 中配置一下:
// config.default.js
module.exports = {
// 配置需要的中间件,数组顺序即为中间件的加载顺序
middleware: ['gzip'],
// 配置 gzip 中间件的配置
gzip: {
threshold: 1024, // 小于 1k 的响应体不压缩
},
};
这时候中间件就会按照数组的顺序执行,排越前,所处洋葱圈越外。除此之外还有在框架和插件中使用,这里就不赘述了,看 文档 即可。
Controller
Router 实在没什么好说的,就是把 URL 分发给不同 Controller 而已,本质就是一个映射配置文件。所以我们直接来看 Controller,文档 写的很好,直接引用:
简单的说 Controller 负责解析用户的输入,处理后返回相应的结果,例如
- 在 RESTful 接口中,Controller 接受用户的参数,从数据库中查找内容返回给用户或者将用户的请求更新到数据库中。
- 在 HTML 页面请求中,Controller 根据用户访问不同的 URL,渲染不同的模板得到 HTML 返回给用户。
- 在代理服务器中,Controller 将用户的请求转发到其他服务器上,并将其他服务器的处理结果返回给用户。
框架推荐 Controller 层主要对用户的请求参数进行处理(校验、转换),然后调用对应的 service 方法处理业务,得到业务结果后封装并返回:
- 获取用户通过 HTTP 传递过来的请求参数。
- 校验、组装参数。
- 调用 Service 进行业务处理,必要时处理转换 Service 的返回结果,让它适应用户的需求。
- 通过 HTTP 将结果响应给用户。
说的再直白点,实现 Controller 拢共分 3 步:
- 第一步:把入参处理成 service 想要的;
- 第二步:调用 service,得到返回值;
- 第三步:把 service 返回的结果处理成业务想要的;
职责非常明确,就是处理 service 的入参和出参。几乎所有 MVC 框架当中的 Controller 都是如此定义的,是不是很简单?简单就对了,因为简单,所以健壮。
Service
下面很自然的就引出了 Service,还是引用一下 文档原文:
简单来说,Service 就是在复杂业务场景下用于做业务逻辑封装的一个抽象层,提供这个抽象有以下几个好处:
- 保持 Controller 中的逻辑更加简洁。
- 保持业务逻辑的独立性,抽象出来的 Service 可以被多个 Controller 重复调用。
- 将逻辑和展现分离,更容易编写测试用例,测试用例的编写具体可以查看这里。
使用场景
- 复杂数据的处理,比如要展现的信息需要从数据库获取,还要经过一定的规则计算,才能返回用户显示。或者计算完成后,更新到数据库。
- 第三方服务的调用,比如 GitHub 信息获取等。
说白了,就是一种分层、解耦的设计思想。理论上,每个 Service 都可以是一个「纯函数」,而且承载的都是核心的业务逻辑。这样做的结果就是可以保证核心逻辑的稳定性和健壮性,无论 Router 和 Controller 层如何变动,最复杂的核心代码可以不用动,大大增加了项目的可维护性。这也正是 MVC 理论的设计初衷。
总结
在搜集资料的过程中,网上骂 Egg 的挺多的,个人觉得是有点过了,尤其是把 Egg 跟 Nestjs 对比的时候,感觉骂 Egg 就是政治正确一样。
不过话说回来,笔者对于团队是否选择 Egg,还是持保留态度,原因之一就是它对 TS 的支持,TS 是笔者的一个强需求。虽然 Egg 也有 TS 的模板,但是那些网上诟病的评论,还是多少有些影响的。
后来阿里又出了 Midway,底层是 Egg,号称是:
Midway 基于 TypeScript 开发,结合了
面向对象(OOP + Class + IoC)与函数式(FP + Function + Hooks)两种编程范式,并在此之上支持了 Web / 全栈 / 微服务 / RPC / Socket / Serverless 等多种场景,致力于为用户提供简单、易用、可靠的 Node.js 服务端研发体验。
简单看了下文档,起码从语法上来看,很像 Nestjs。这起码证明,起码在语法上,Nestjs 是一个先行者,是被借鉴者,有一定的先进性。
一方面 Midway 的使用量还比较少,而且疑似大量参考 Nestjs 的设计。再加上 Nestjs 在 npm 下载量上的绝对领先,还是用 TS 写的,笔者大概率还是会选择 Nestjs。唯一需要担心的,可能就是学习成本了。不过这种装饰器的写法和 IoC 的思路还是值得学习的,有比较大的可复用性,可以积累,不会浪费。据说玩熟了之后,可以无缝切换 Sprint。咱也不知道,咱也不敢问啊~
最后说一嘴,Egg 的文档有的内容还是不错的。比如笔者在阅读 核心功能文档 的过程中,从「单元测试」、「应用部署」、「多进程模型和进程间通讯」、「安全」这几个模块,收获了很多关键认知,强烈推荐大家读一下。
Design is there to enable you to keep changing the software easily in the long term. -- Kent Beck
软件设计是为了「长期」更加容易地适应未来的变化。
