持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第9天,点击查看活动详情
GR-GAN是北京邮电大学学者们发表的一篇文本生成图像的论文,文章被ICME(B类会议,IEEE International Conference on Multimedia & Expo)2022录用
论文地址:arxiv.org/abs/2205.11…
代码地址:github.com/BoO-18/GR-G…
本博客是精读这篇论文的报告,包含一些个人理解、知识拓展和总结。
一、原文摘要
一个好的文本到图像模型不仅要生成高质量的图像,还要确保文本和生成的图像之间的一致性。以前的模型无法同时很好地满足以上两个条件。为了有效缓解这一问题,本文提出了一种渐进细化生成对抗网络模型(GR-GAN)。GRG模块设计用于生成从低分辨率到高分辨率的图像,相应的文本约束从粗粒度(句子)到细粒度(单词)逐级进行,ITM模块设计用于提供相应阶段在句子图像级和单词区域级的图像-文本匹配损失。我们还引入了一种新的度量交叉模型距离(CMD),用于同时评估图像质量和图像文本一致性。实验结果表明,GR-GAN的性能明显优于以前的模型,并且在FID和CMD方面都达到了新的水平。
二、为什么提出GR-GAN
- 当前的多级网络生成从低分辨率到高分辨率图像时,未考虑相应细粒度的语言约束;不同分辨率的图像应该与不同粒度的文本描述对应,即低分辨率图像用粗粒度的语言文本对应表达,高分辨率的图像可以用细粒度文本更好的描述;
- 当前的评估指标都无法同时评估图像质量和图像文本一致性,R精度虽然可以一定程度上评估,但存在严重过拟合现象。
三、GR-GAN
3.1、整体框架
GRGAN模型整体框架图如下:
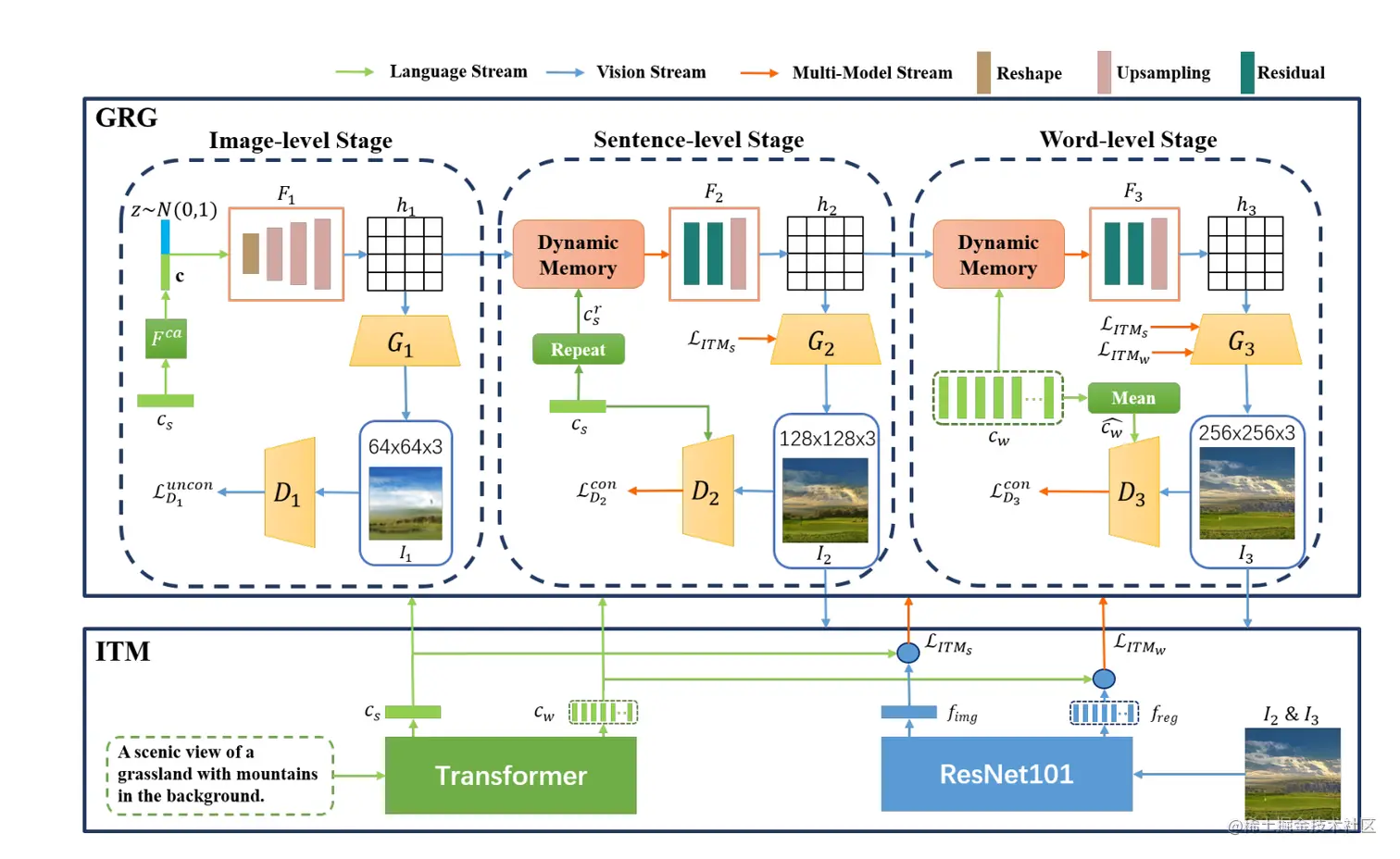 可以看到模型的上层为GRG(Gradual Refinement Generator)模块,下层为ITM(Image-Text Matcher)模块。GRG模块包括三层生成器和三层鉴别器,ITM模型包括两部分,一部分用于对文本描述和生成的图像进行编码,另一部分提供图像和文本之间不同粒度的相似度。
可以看到模型的上层为GRG(Gradual Refinement Generator)模块,下层为ITM(Image-Text Matcher)模块。GRG模块包括三层生成器和三层鉴别器,ITM模型包括两部分,一部分用于对文本描述和生成的图像进行编码,另一部分提供图像和文本之间不同粒度的相似度。
3.2、逐步求精生成器:GRG
如上图所示GRG模块有三个层次:图像初始化阶段、句子级细化阶段、单词级细化阶段
3.2.1、图像初始化阶段
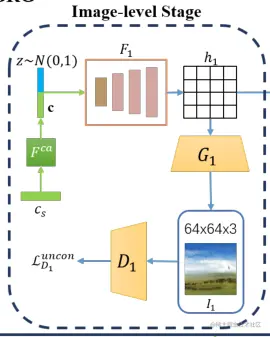 图像初始化阶段,如图所示从左边看起,cs为文本输入,经过CA阶段(用的是StackGAN的那一套)将文本转换为条件向量c,然后加入噪声,输入到F1,F1主要通过重塑、上采样等步骤对特征进行变换得到图像特征h1,生成器G1利用h1生成64*64尺寸的图像,而鉴别器D1判别该小尺寸图像是否为真。第一阶段的无条件损失函数如下:
LD1uncon=LG1uncon=−21Ex1∼ data [log(D(x1))]−21Ex1∼G1[1−log(D(x1))]−21Ex1∼G1[log(D(x1))]
图像初始化阶段,如图所示从左边看起,cs为文本输入,经过CA阶段(用的是StackGAN的那一套)将文本转换为条件向量c,然后加入噪声,输入到F1,F1主要通过重塑、上采样等步骤对特征进行变换得到图像特征h1,生成器G1利用h1生成64*64尺寸的图像,而鉴别器D1判别该小尺寸图像是否为真。第一阶段的无条件损失函数如下:
LD1uncon=LG1uncon=−21Ex1∼ data [log(D(x1))]−21Ex1∼G1[1−log(D(x1))]−21Ex1∼G1[log(D(x1))]
3.2.2、句子级细化阶段
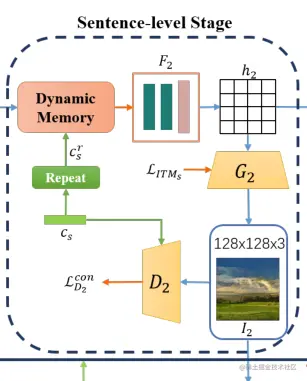 句子级细化阶段再次引入句子级特征cs,句子级特征原本是R1×N,经过一层repeat重复置为RL×N然后,使用动态存储器(用的DMGAN的那一套)将其与图像特征h1融合,如等式所示:TR−S=FDM(h1,csr),得到TR−S,然后将其输入进F2,F2通过残差和上采样过程,得到图像特征h2,生成器G2利用h2生成128*128尺寸的图像,而鉴别器D2判别该小尺寸图像是否为真,损失函数如下(注意此时的鉴别器已经是有条件判断,采用的是有条件损失):
LD2con=LG2con=−21Ex2∼ data [log(D(x2,cs))]−21Ex2∼G2[1−log(D(x2,cs))]−21Ex2∼G2[log(D(x2,cs))]
作者在第二层开始加入了ITM的文本-图像一致性损失,第二层添加用于句子级-图像的一致性损失,以加强在此阶段对图像和句子之间整体一致性的限制。损失由ITM模型计算,将在3.3中讲到,添加后的损失函数公式如下:LG2−totalcon=LG2con+λ2LITMs
句子级细化阶段再次引入句子级特征cs,句子级特征原本是R1×N,经过一层repeat重复置为RL×N然后,使用动态存储器(用的DMGAN的那一套)将其与图像特征h1融合,如等式所示:TR−S=FDM(h1,csr),得到TR−S,然后将其输入进F2,F2通过残差和上采样过程,得到图像特征h2,生成器G2利用h2生成128*128尺寸的图像,而鉴别器D2判别该小尺寸图像是否为真,损失函数如下(注意此时的鉴别器已经是有条件判断,采用的是有条件损失):
LD2con=LG2con=−21Ex2∼ data [log(D(x2,cs))]−21Ex2∼G2[1−log(D(x2,cs))]−21Ex2∼G2[log(D(x2,cs))]
作者在第二层开始加入了ITM的文本-图像一致性损失,第二层添加用于句子级-图像的一致性损失,以加强在此阶段对图像和句子之间整体一致性的限制。损失由ITM模型计算,将在3.3中讲到,添加后的损失函数公式如下:LG2−totalcon=LG2con+λ2LITMs
3.2.3、单词级细化阶段
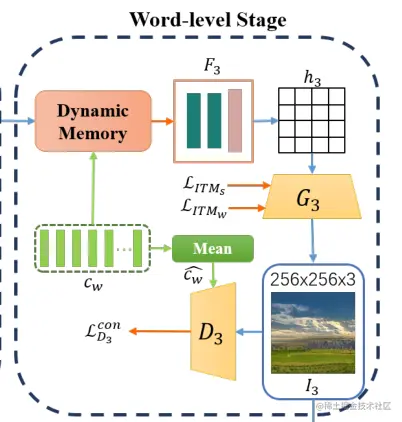 单词级细化阶段与3.2.2类似,将生成的句子级蹄子cw输入到动态存储器当中与图像特征融合然后输入到F3中,F3通过残差和上采样生成图像特征h3,生成器G3利用h2生成128*128尺寸的图像,而鉴别器D3判别该小尺寸图像是否为真,损失函数如下:(此时的鉴别器也是有条件鉴别,且此时引入的也是单词级条件)
LD3con=LG3con=−21Ex3∼ data [log(D(x3,cw))]−21Ex3∼G3[1−log(D(x3,cw))]−21Ex3∼G3[log(D(x3,cw))]
单词级细化阶段与3.2.2类似,将生成的句子级蹄子cw输入到动态存储器当中与图像特征融合然后输入到F3中,F3通过残差和上采样生成图像特征h3,生成器G3利用h2生成128*128尺寸的图像,而鉴别器D3判别该小尺寸图像是否为真,损失函数如下:(此时的鉴别器也是有条件鉴别,且此时引入的也是单词级条件)
LD3con=LG3con=−21Ex3∼ data [log(D(x3,cw))]−21Ex3∼G3[1−log(D(x3,cw))]−21Ex3∼G3[log(D(x3,cw))]
在第三层,作者进一步加入了单词级-图像的一致性损失,进一步加强对图像和描述之间细粒度一致性的约束,同样加入后的生成器总损失如下:
LG3−totalcon=LG3con+λ1LITMs+λ2LITMs
3.3、图像文本匹配器:ITM
 ITM模型是由Transformer和ResNet101构建的一致性约束模型,该模型基于CLIP参数进行训练。其主要做的事情就是将文本编码形成句子级特征cs和单词级特征cw,然后提取图像区域特征 freg和图像整体特征 fimg,为GRG模型中用作一致性损失的图像和文本描述计算句子图像级相似度和词区域级相似度:\mathcal{L}{1}^{s}=-\sum{i=1}^{M} \log \frac{\gamma \exp \left(R\left(I_{i}, S_{i}\right)\right)}{\sum_{i=1}^{M} \gamma \exp \left(R\left(I_{i}, S_{j}\right)\right)}其中R(I_i,S_j)是图像句子对(I_i,S_j)的匹配分数,{L}{2}^{s}可通过替换等式的分母获得,然后计算单词区域对的匹配分数来获得L^w_1和L^w_2,∗∗最后ITM总损失如下∗∗:\begin{aligned}
\mathcal{L}{I T M} &=\lambda_{1} \mathcal{L}{I T M{s}}+\lambda_{2} \mathcal{L}{I T M{w}}
&=\lambda_{1}\left(\mathcal{L}{1}^{s}+\mathcal{L}{2}^{s}\right)+\lambda_{2}\left(\mathcal{L}{1}^{w}+\mathcal{L}{2}^{w}\right)
\end{aligned}$
ITM模型是由Transformer和ResNet101构建的一致性约束模型,该模型基于CLIP参数进行训练。其主要做的事情就是将文本编码形成句子级特征cs和单词级特征cw,然后提取图像区域特征 freg和图像整体特征 fimg,为GRG模型中用作一致性损失的图像和文本描述计算句子图像级相似度和词区域级相似度:\mathcal{L}{1}^{s}=-\sum{i=1}^{M} \log \frac{\gamma \exp \left(R\left(I_{i}, S_{i}\right)\right)}{\sum_{i=1}^{M} \gamma \exp \left(R\left(I_{i}, S_{j}\right)\right)}其中R(I_i,S_j)是图像句子对(I_i,S_j)的匹配分数,{L}{2}^{s}可通过替换等式的分母获得,然后计算单词区域对的匹配分数来获得L^w_1和L^w_2,∗∗最后ITM总损失如下∗∗:\begin{aligned}
\mathcal{L}{I T M} &=\lambda_{1} \mathcal{L}{I T M{s}}+\lambda_{2} \mathcal{L}{I T M{w}}
&=\lambda_{1}\left(\mathcal{L}{1}^{s}+\mathcal{L}{2}^{s}\right)+\lambda_{2}\left(\mathcal{L}{1}^{w}+\mathcal{L}{2}^{w}\right)
\end{aligned}$
3.4、定量指标:CMD
作者提出了一种跨模型距离(CMD),通过将图像和文本信息映射成多模态语义分布,同时评估图像质量和图像文本一致性。CMD定义如下:
CMD=Dis(f,r)+∣Dis(f,l)−Dis(r,l)∣,其中∣Dis(f,l)−Dis(r,l)∣表示的是图像与文本的一致性距离,简称ITDis,ITDis越小,图像文本一致性越好
四、实验
4.1、实验设置
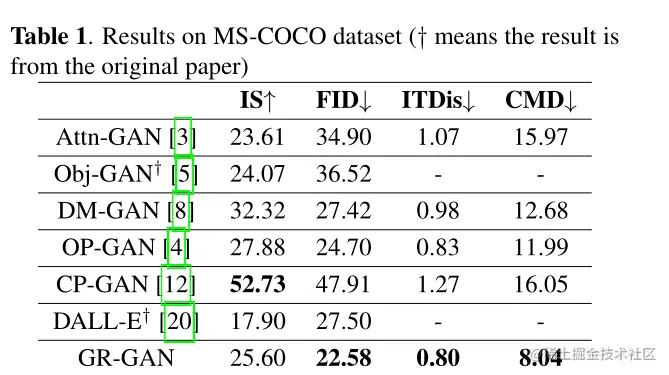
- 数据集:MS-COCO
- 定量指标:IS、FID、ITDis、CMD
- 参数设置:学习率0.0002,epoch轮数300,λ1=4 and λ2= 1
4.2、实验结果

4.3、一些定性实验
作者在AttnGAN和DM-GAN上做了一些定性实验,并且对本GR-GAN在GRG、ITM上做了一些消融实验。如下表,具体请看原文,此处不再赘述。
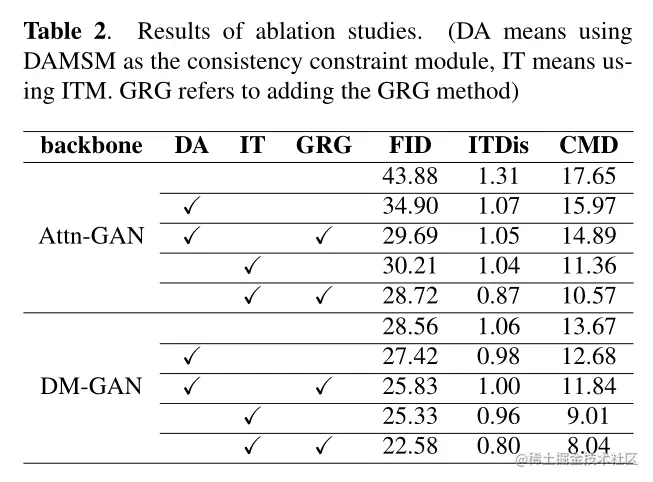
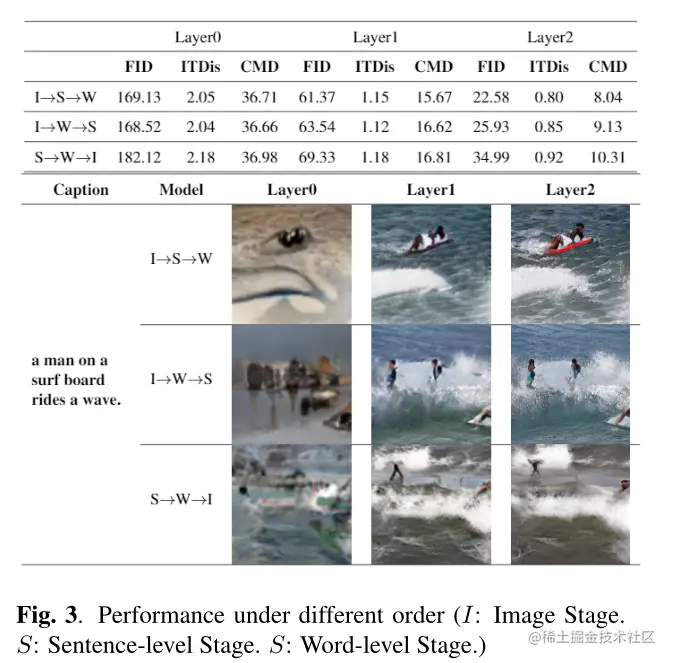
创新点与总结
- 作者提出了一种渐进细化生成对抗网络(GR-GAN),包括渐进细化生成器(GRG)和图像文本匹配器(ITM),GRG逐步合成基于文本描述的图像,ITM利用从粗粒度到细粒度的相应文本约束,为各个阶段提供不同级别的图像文本匹配损失;
- 提出了一种新的文本到图像度量CMD,它可以同时评估图像质量和图像文本的一致性。它更适合于评估文本到图像的任务;
- GR-GAN显著优于以前的模型,并在FID和CMD上实现了新的SOTA。
最后
💖 个人简介:人工智能领域研究生,目前主攻文本生成图像(text to image)方向
🔥 限时免费订阅:文本生成图像T2I专栏
🎉 支持我:点赞👍+收藏⭐️+留言📝


