本文已参与「新人创作礼」活动,一起开启掘金创作之路。
声明: 本文图文均来源于www.kalmanfilter.net/,如有侵权请联系删除。
本文由微信公众号【DeepDriving】整理,由于全文内容较多所以分成3部分发出来。关注公众号【DeepDriving】,后台回复关键字【卡尔曼滤波器】可获取全文PDF。
一个简单的例子
估计金条的重量
我们先从一个简单的例子开始,在这个例子中我们将会去估计一个静态系统,所谓静态系统就是在一定的时间内其状态不会改变的系统。
在这个例子中,我们将估计一个金条的重量。首先假设我们使用的是一个无偏差的秤,也就是没有系统误差,但是测量值是包含随机误差的。这里的系统就是金条,系统的状态就是金条的重量。系统的动态模型是恒定的,因为我们假设金条的重量在短时间内不会发生变化。为了估计系统的状态,我们可以进行多次测量,然后对测量值求平均。
经过N次测量,估计值xN,N是之前所有测量值的平均值:
x^N,N=N1(z1+z2+…+zN−1+zN)=N1n=1∑N(zn)
在上式中,
- x表示金条重量的真实值;
- zn表示第n次的测量值;
- x^n,n表示第n次对x的估计值,估计是在采用了第n次的测量值zn后做出的;
- x^n,n−1表示之前对x的估计值,是在第n−1次时采用了测量值zn−1后做出的;
- x^n+1,n表示对x未来状态的估计值,这个估计是在第n次时得到测量值zn后做出的,也就是说x^n+1,n是一个预测状态值。由于在本例中动态模型是恒定的,所以有xn+1,n=xn,n。
对上式进行一些数学变换:
x^N,N=N1n=1∑N(zn)=N1(n=1∑N−1(zn)+zN)=N1n=1∑N−1(zn)+N1zN=N1N−1N−1n=1∑N−1(zn)+N1zN=NN−1N−11n=1∑N−1(zn)+N1zN=NN−1x^N−1,N−1+N1zN=x^N−1,N−1−N1x^N−1,N−1+N1zN=x^N−1,N−1+N1(zN−x^N−1,N−1)
通过前面的知识,我们知道x^N−1,N−1是第N−1次时对x的估计值,现在我们需要基于x^N−1,N−1在第N次时对状态x进行预测从而得到x^N,N−1。由于是一个静态系统,所以有x^N,N−1=x^N−1,N−1,那么上式就可以写为
x^N,N=x^N,N−1+N1(zn−x^N,N−1)
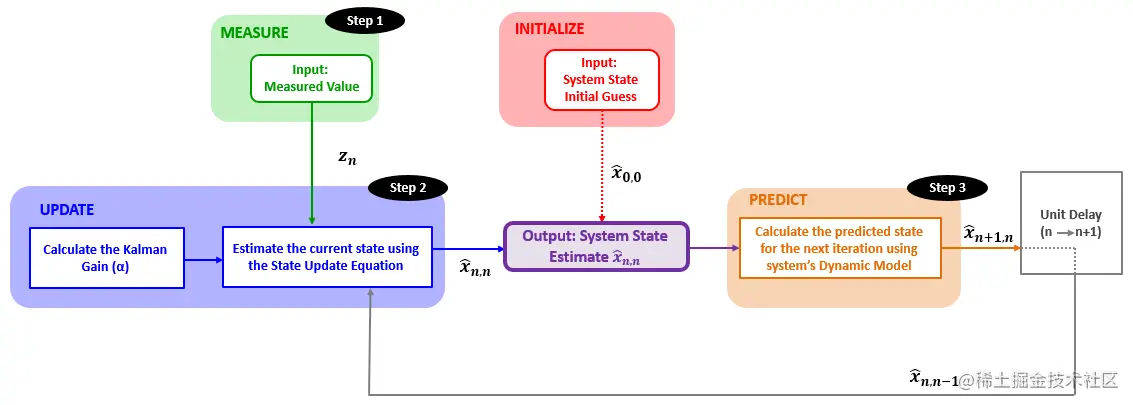
上面这个公式是卡尔曼滤波器的5个方程之一,被称为状态更新方程,它的含义如下:

在本例中,系数N1是一个特定的值。在卡尔曼滤波器中,这个系数被称为卡尔曼增益(Kalman Gain),记作Kn,其下标n表示卡尔曼增益会随着迭代而变化。在深入卡尔曼滤波器之前,我们先用αn代替Kn,那么状态更新方程可以写为
x^n,n=x^n,n−1+αn(zn−x^n,n−1)
这里的(zn−x^n,n−1)被称为测量残差,也叫更新项。更新意味着包含了新的信息,也就是新的测量值。
在本例中,系数N1会随着N的变大而变小。那么怎么理解这个状态更新方程呢?在开始的时候,我们没有足够的信息来估计金条的重量,只能基于测量值对状态做出估计,也就是更多地采用测量值。随着迭代次数增多,系数N1越来越小,每次的测量值的权重也就越来越小,当迭代次数足够多的时候,新的测量值对估计值的影响已经可以忽略不计了。
在状态更新方程中,我们还需要有一个初始值。在本例中,在进行第一次测量前我们可以通过猜测来粗略估计一下金条的重量,这个初始猜测(Initial Guess)值也就是第一个估计值。在这个特定的例子中,初始猜测值可以是任何值,因为α1=1,初始猜测值在第一次迭代时就被消掉了。
根据状态更新方程,估计算法的流程如下图所示:
我们对金条进行10次称重,然后根据上面的估计算法对金条的重量做出估计,得到的结果如下表所示:
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|
| αn | 1 | 21 | 31 | 41 | 51 | 61 | 71 | 81 | 91 | 101 |
| zn | 1030 | 989 | 1017 | 1009 | 1013 | 979 | 1008 | 1042 | 1012 | 1011 |
| xn,n^ | 1030 | 1009.5 | 1012 | 1011.25 | 1011.6 | 1006.17 | 1006.13 | 1010.87 | 1011 | 1011 |
| xn+1,n^ | 1030 | 1009.5 | 1012 | 1011.25 | 1011.6 | 1006.17 | 1006.13 | 1010.87 | 1011 | 1011 |
将这些数据可视化:
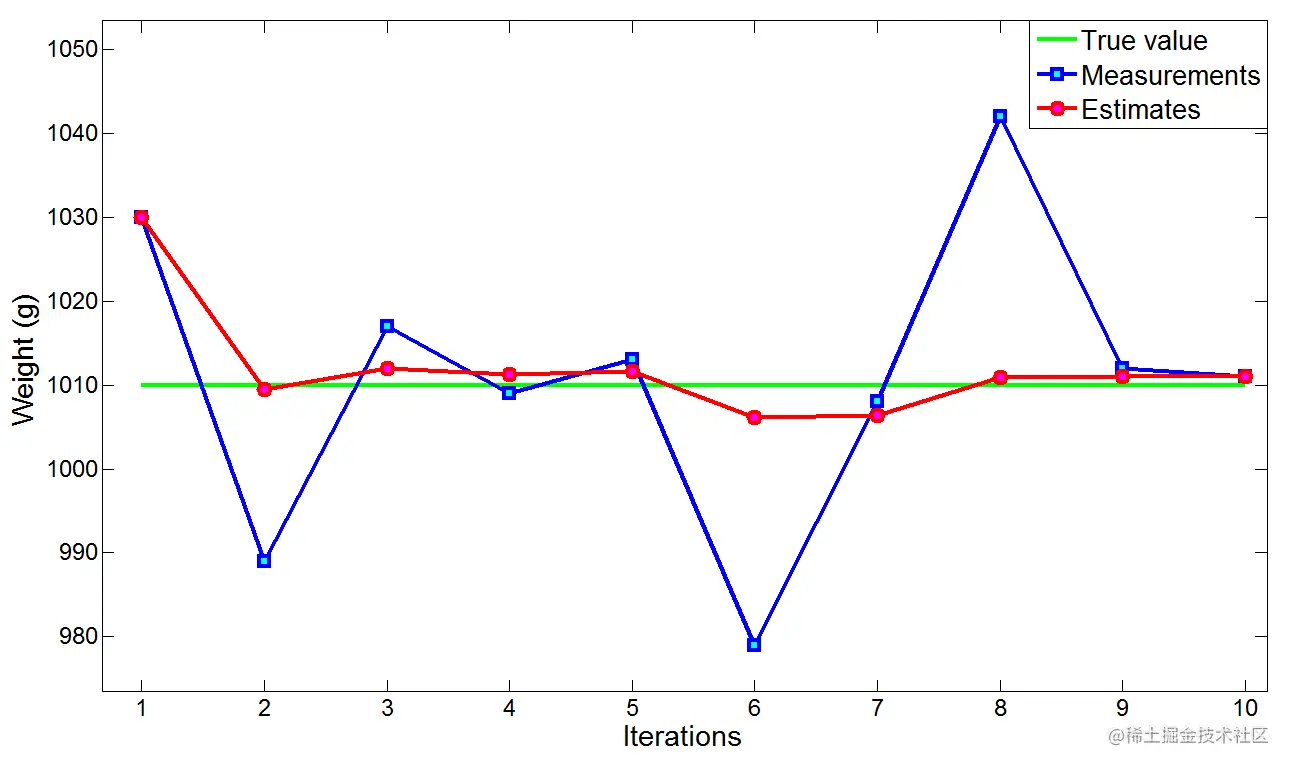
可以看到,我们的估计算法可以很好地对测量数据进行平滑滤波,并且朝着真值方向逐渐收敛。
一维卡尔曼滤波器
在前面称金条重量的例子中,我们通过多次测量然后求平均的方法去估计金条的重量。通过对数据的可视化可以方便地看到,测量值存在随机测量误差。通常我们用方差σ2来描述这种随机误差,测量误差的方差实际上就是测量的不确定度,一般由测量设备的生产厂商提供。在一些文献中,测量的不确定度也称为测量误差,我们用r来表示。估计值与真实值之间的差别被称为估计误差,可以看到,随着测量次数的增加,估计误差越来越小最后收敛为零。实际中我们并不知道估计误差到底是多少,但是我们可以知道估计值的不确定度,这个不确定度我们用p来表示。
前面介绍了状态更新方程,在卡尔曼滤波器中,系数αn是在每一次迭代过程中动态计算的,被称为卡尔曼增益,用Kn来表示。卡尔曼增益方程的表达式如下:
Kn=UncertaintyinEstimate+UncertaintyinMeasurementUncertaintyinEstimate=pn,n−1+rnpn,n−1
其中,pn,n−1是外推的估计不确定度 ,rn是当前的测量不确定度。可以知道,卡尔曼增益的值域为0≤Kn≤1。卡尔曼增益这个公式是怎么来的呢?接下来我们详细推导一下。
给定当前的测量值zn和先前的估计值x^n,n−1,我们的目的是要找到一组参数将zn和x^n,n−1组合到一起得到当前最优的估计值x^n,n,也就是需要给它们赋予最优的权重:
x^n,n=kzn+(1−k)x^n,n−1
这个最优状态估计的方差为
pn,n=k2rn+(1−k)2pn,n−1
因为我们是要找一个最优估计,那么就希望pn,n最小,也就是要找到一个k值,使得pn,n最小。为了找到这个k值,我们对pn,n求关于k的导数,并且设导数为零:
dkdpn,n=2krn−2(1−k)pn,n−1=0
可得
krn=pn,n−1−kpn,n−1
kpn,n−1+krn=pn,n−1
k=pn,n−1+rnpn,n−1
到这里,一维卡尔曼增益的公式就推导出来了!
让我们重写一下状态更新方程
x^n,n=x^n,n−1+Kn(zn−x^n,n−1)=(1−Kn)x^n,n−1+Knzn
可以看到,卡尔曼增益Kn就是一个赋给测量值的权重,而(1−Kn)则是赋给估计值的权重。当测量的不确定度很小而估计的不确定度很大的时候,卡尔曼增益接近于1,此时测量值的权重很大,相当于更相信测量值;反之,当测量的不确定度很大而估计的不确定度很小的时候,卡尔曼增益接近于0,此时估计值的权重很大,相当于更相信估计值。
下面的公式是估计不确定度的更新方程:
pn,n= (1−Kn)pn,n−1
其中,Kn是卡尔曼增益;pn,n−1是在先前滤波器估计期间计算的估计不确定度;pn,n是当前状态估计的不确定度。这个方程用于更新当前状态估计的不确定度,也叫做协方差更新方程。从这个公式可以知道,由于(1−Kn)≤1,估计值的不确定度将会随着迭代次数的增加而变得越来越小。
在这个例子中,我们采用的系统动态模型是恒定模型,所以状态外推方程为
xn+1,n=xn,n
同样的,估计不确定度外推方程(也叫作协方差外推方程)为
pn+1,n=pn,n
下面的表格对一维卡尔曼滤波器的5个方程进行了总结(针对恒定模型):
| 方程表达式 | 方程名 |
|---|
| x^n,n= x^n,n−1+Kn(zn−x^n,n−1) | 状态更新方程 |
| xn+1,n=xn,n | 状态外推方程 |
| Kn=pn,n−1+rnpn,n−1 | 卡尔曼增益方程 |
| pn,n= (1−Kn)pn,n−1 | 协方差更新方程 |
| pn+1,n=pn,n | 协方差外推方程 |
卡尔曼滤波器算法的框图如下所示:
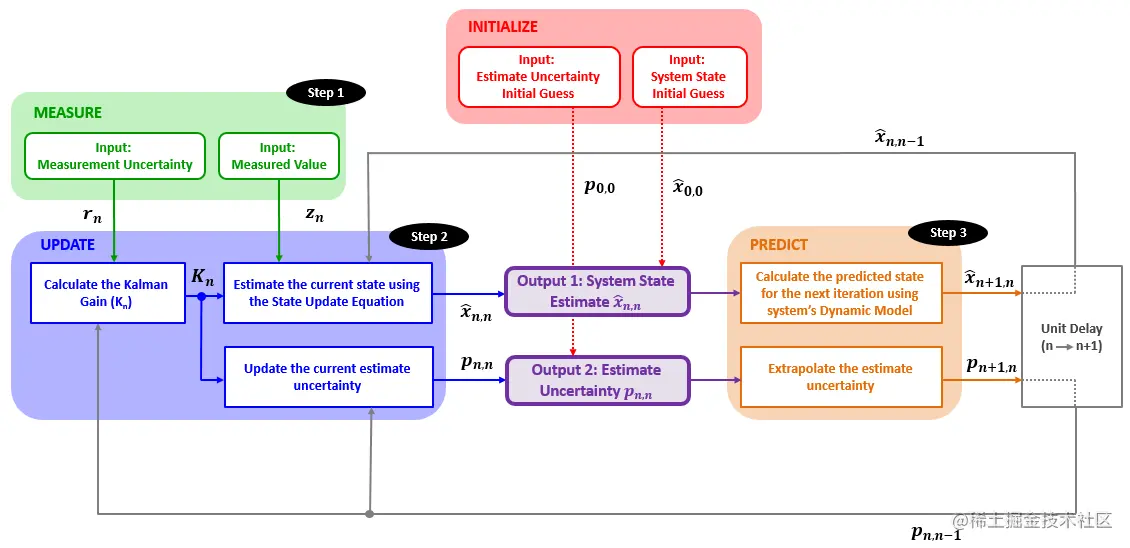
我们来梳理一下算法的流程:
-
步骤0: 初始化
卡尔曼滤波器需要初始化两个参数:系统状态x^1,0和状态的不确定度p1,0。初始化完成后,滤波器将会基于这个初始状态去做预测。
-
步骤1: 测量
测量会给系统提供两个参数:系统状态的测量值zn和测量的不确定度rn。
-
步骤2: 状态更新
状态更新过程的输入为:
- 测量值zn
- 测量的不确定度rn
- 先前的系统状态估计值x^n,n−1
- 先前估计的不确定度pn,n−1
基于这些输入数据,状态更新过程将会计算卡尔曼增益Kn,然后提供两个输出:
- 当前的系统状态估计x^n,n
- 当前状态估计的不确定度pn,n
-
步骤3: 预测
预测过程基于系统的动态模型将当前系统状态和当前系统状态估计的不确定度外推到下一个系统状态。本次迭代预测过程的输出,在滤波器的下一次迭代过程中就变成了先前的系统状态估计和估计的不确定度了。


