本文已参与「新人创作礼」活动,一起开启掘金创作之路。
声明: 本文图文均来源于www.kalmanfilter.net/,如有侵权请联系删除。
本文由微信公众号【DeepDriving】整理,由于全文内容较多所以分成3部分发出来。关注公众号【DeepDriving】,后台回复关键字【卡尔曼滤波器】可获取全文PDF。
背景知识
在介绍卡尔曼滤波器之前,我们先来学习一些跟数学相关的基础知识。
均值与期望值
均值(Mean)和期望值(Expected Value)是两个相似但不相同的概念。假如我们有2枚5分的硬币和3枚10分的硬币,很容易可以算出它们的均值:
Vmean=N1n=1∑NVn=51(5+5+10+10+10)=8分
上面的结果不能称为期望值,因为系统的状态不是隐式的并且我们用了全部的5枚硬币来计算均值。
现在假设一个人连续测5次体重,得到的结果分别为:79.8千克、80千克、 80.1千克、79.8千克、80.2千克,体重秤自身的随机测量误差导致每次的测量值都不同。我们并不知道真实的体重到底是多少,因为这是一个隐式变量,但是我们可以对5次的测量结果求平均值来估计出一个相对准确的体重值:
W=N1n=1∑NWn=51(79.8+80+80.1+79.8+80.2)=79.98千克
上面这个平均值就可以称为是隐式变量体重的期望值。
均值通常使用希腊字母μ来表示,期望值则用字母E来表示。
方差与标准差
方差(Variance)用来衡量一组数据的离散程度,即样本数据与均值之间的偏差;标准差(Standard Deviation)是方差的平方根,一般用希腊字母σ来表示,并将方差表示为σ2。
假设有两支高中篮球队队员的身高如下表所示:
| 队员1 | 队员2 | 队员3 | 队员4 | 队员5 | 平均值 |
|---|
| A队 | 1.89m | 2.1m | 1.75m | 1.98m | 1.85m | 1.914m |
| B队 | 1.94m | 1.9m | 1.97m | 1.89m | 1.87m | 1.914m |
我们想比较一下这两个篮球队队员的身高数据。首先,从上表中可以知道两个队的平均身高是一样的。更进一步地,我们可以比较它们的方差和标准差。用x表示身高,μ表示身高的平均值,根据方差和标准差的计算公式
σ2=N1n=1∑N(xn−μ)2
σ=N1n=1∑N(xn−μ)2
求得A队身高的方差σA2=0.014m2,标准差σA=0.12m;B队身高的方差σB2=0.0013m2,标准差σB=0.036m。从两队身高的方差可以知道,A队队员身高的差异性更大一些。
假如我们要计算所有高中篮球队所有队员身高的均值和方差,这将会是一个很难完成的任务,因为需要从每个学校的每个队员那里统计数据。不过我们可以收集一个比较大的数据集,然后通过这个数据集来估计所有队员身高的均值和方差。比如,我们可以随机收取100个队员的身高数据,这个数据集足以对所有队员身高的均值和方差进行准确的估计。需要注意的是,这时计算方差的公式与上面的略有不同,除数是N−1而不是N:
σ2=N−11n=1∑N(xn−μ)2
系数N−1被称为贝塞尔校正(Bessel's correction),详细的数学证明可以参考这篇文章。
正态分布
许多自然现象都遵循正态分布(Normal Distribution)的规律。还是以篮球运动员的身高为例,如果我们随机抽取队员的身高建立一个大的数据集,并绘制出身高数值与其出现频次的图表,我们将会得到一个类似下图的钟型曲线:
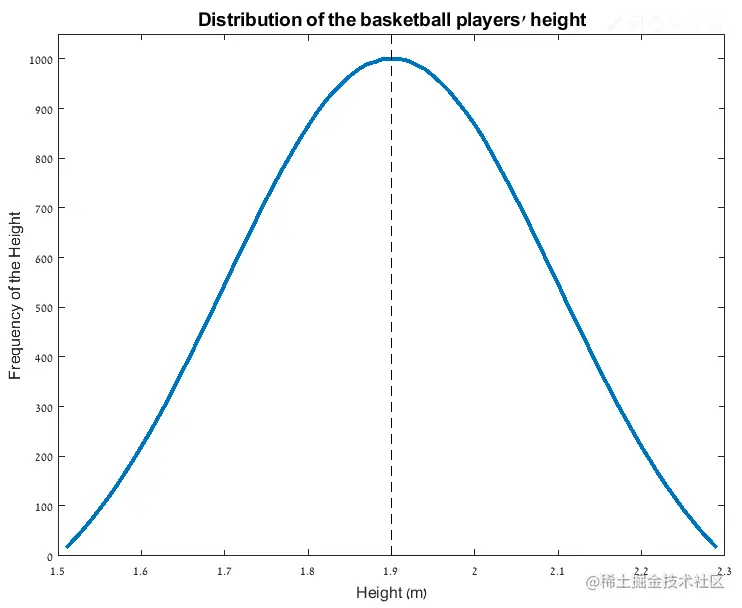
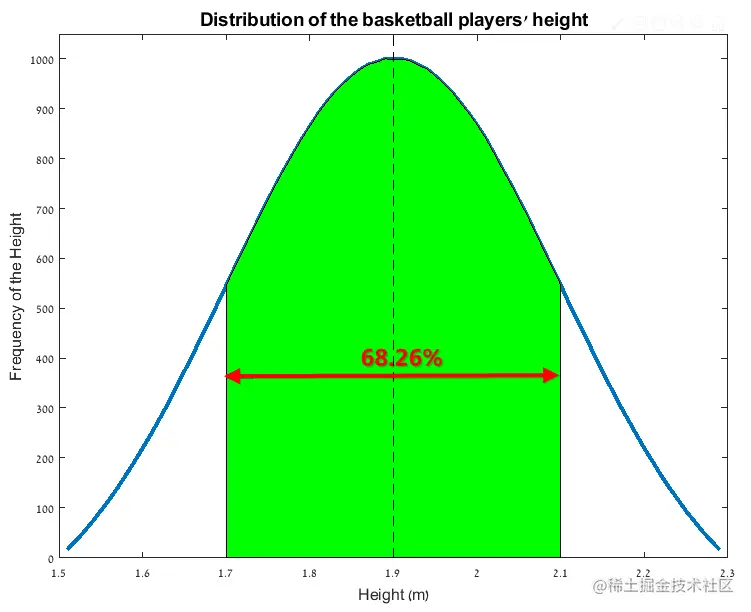
可以看到这条曲线是以均值1.9m为中心的对称曲线,并且均值附近的数值出现的次数远高于远端数值出现的次数。这组数据的标准差为0.2m,如下图所示,有68.26%的值位于距均值一个标准差的范围内(1.7m~2.1m):
正态分布又被称为高斯分布,其公式如下:
f(x;μ,σ2)=2πσ21e2σ2−(x−μ)2
上面的曲线被称为是正态分布的概率密度函数(Probability Density Function,PDF)。
测量误差通常是符合正态分布的,所以我们在设计卡尔曼滤波器的时候会假设测量误差是呈正态分布的。
随机变量
如果用测速枪测量一辆行驶中的车辆的车速,那么测速枪的测量值是一个随机变量,测量的结果呈正态分布。随机变量可以是连续的,也可以是离散的,所有测量值都是连续随机变量。
估计、准确度与精确度
估计(Estimate)是对系统隐式状态的一次估算。比如飞机的真实位置对于观察者来说是一个隐式的状态值,我们可以用雷达等传感器来进行测量并通过多传感器融合及跟踪算法来提升估计的准确度。测量或者计算出的参数都是估计值。
准确度(Accuracy)用来表示测量值与真实值的接近程度。
精确度(Precision)用来表示测量结果的再现性。
估计需要考虑系统的准确性与精确性,下图说明了准确度与精确度的关系:
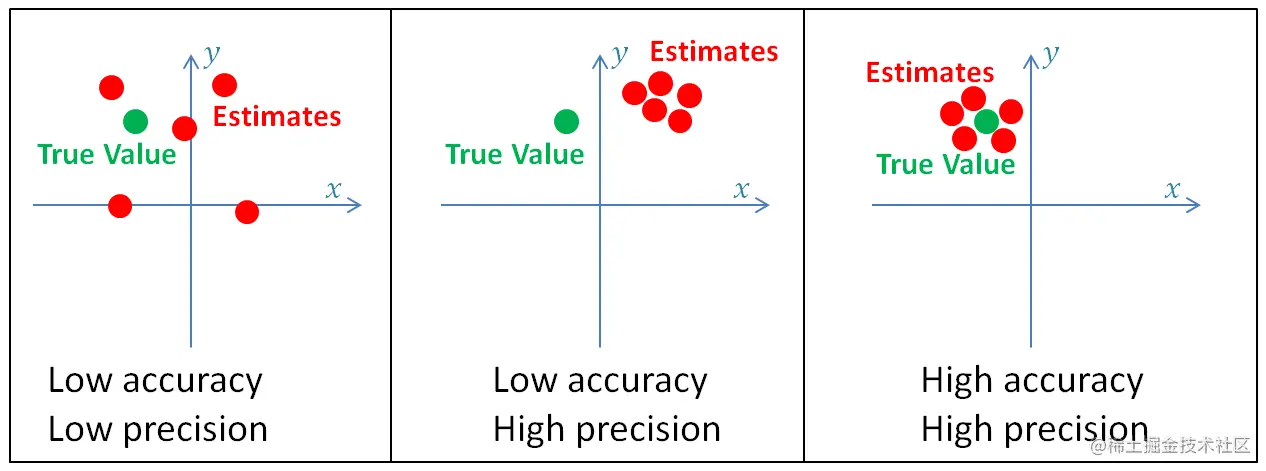
高精确度系统的测量值的方差小(低的不确定度),反之,低精确度系统的测量值的方差大(高的不确定度),方差是由随机测量误差造成的。
低准确度的系统被称为有偏系统,因为其测量值总会存在一个内在的系统误差(偏差)。
对测量值进行平均或平滑处理可以显著地降低方差的影响。比如,如果我们使用带有随机测量误差的温度计来测量温度,测量误差将会导致测量值可能高于或者低于真实值。我们可以进行多次测量并对其求平均值,这个估计值将会接近真实值,测量次数越多,估计值就越接近真实值。但如果温度计本身有偏差,那么估计值会有一个固定的系统误差。
下图从统计学的角度描述了测量值:
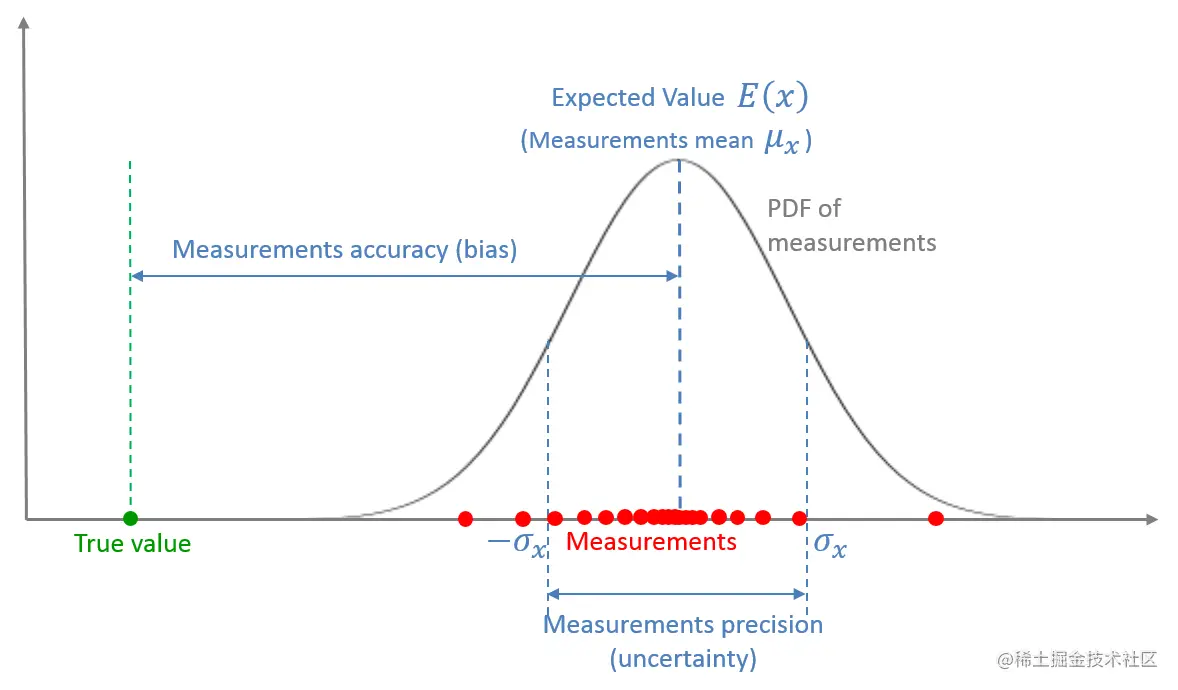
- 测量值是一个由概率密度函数描述的随机变量;
- 测量值的均值即为随机变量的期望值;
- 测量值的均值与真实值之间的偏移被称为偏差或者系统测量误差,用来表示测量的准确度;
- 测量值分布的离散程度为测量值的精确度,又称为测量噪声(
measurement noise)、随机测量误差(random measurement error)或者测量不确定度(measurement uncertainty)。
协方差与协方差矩阵
协方差用来衡量两个随机变量x和y的联合变化程度,表示的是两个变量的总体的误差,这与方差不同,方差只表示一个变量误差。方差可以看成是协方差的一种特殊情况,即两个变量是一样的。如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。如果两个变量的变化趋势相反,即其中一个大于自身的期望值,而另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。如果x与y是统计独立的,那么二者之间的协方差就是0。随机变量x与y的协方差计算公式如下:
σ(x,y)=N−11n=1∑N(xn−μx)(yn−μy)
其中,μx和μy分别为随机变量x与y的平均值。
对于一个含有k个元素的向量x
[x1x2x3…xk]T
其协方差矩阵为
COV(x)=E⎝⎛⎣⎡(x1−μx1)2(x2−μx2)(x1−μx1)⋮(xk−μxk)(x1−μx1)(x1−μx1)(x2−μx2)(x2−μx2)2⋮(xk−μxk)(x2−μx2)⋯⋯⋱⋯(x1−μx1)(xk−μxk)(x2−μx2)(xk−μxk)⋮(xk−μxk)2⎦⎤⎠⎞=E⎝⎛⎣⎡(x1−μx1)(x2−μx2)⋮(xk−μxk)⎦⎤[(x1−μx1)(x2−μx2)⋯(xk−μxk)]⎠⎞=E((x−μx)(x−μx)T)
基本的期望运算规则
随机变量X的期望E(X)等于它的平均值:
E(X)=μX
一些基本的期望运算规则如下:
| 规则 | 备注 |
|---|
| E(X)=μX=∑xp(x) | p(x)是x的概率 |
| E(a)=a | a为常数 |
| E(aX)=aE(X) | a为常数 |
| E(a±X)=a±E(X) | a为常数 |
| E(a±bX)=a±bE(X) | a,b为常数 |
| E(X±Y)=E(X)±E(Y) | Y为另一个随机变量 |
| E(XY)=E(X)E(Y) | 如果X和Y相互独立 |
将随机变量X和Y的方差分别记为V(X)和V(Y),它们的协方差记为COV(X,Y),下面是一些基本的运算规则:
| 规则 | 备注 |
|---|
| V(a)=0 | a为常数 |
| V(a±X)=V(X) | a为常数 |
| V(X)=E(X2)−μX2 | |
| COV(X,Y)=E(XY)−μXμY | |
| COV(X,Y)=0 | 如果X和Y相互独立 |
| V(aX)=a2V(X) | a为常数 |
| V(X±Y)=V(X)+V(Y)±2COV(X,Y) | |
| V(XY)=V(X)V(Y) | |
下面是对几个公式的证明:
(1).
V(X)=E((X−μX)2)=E(X2−2XμX+μX2)=E(X2)−E(2XμX)+E(μX2)=E(X2)−2μXE(X)+μX2=E(X2)−2μXμX+μX2=E(X2)−μX2
(2).
COV(X,Y)=E((X−μX)(Y−μY))=E(XY−XμY−YμX+μXμY)=E(XY)−E(XμY)−E(YμX)+E(μXμY)=E(XY)−μYE(X)−μXE(Y)+E(μXμY)=E(XY)−μYμX−μXμY+μXμY=E(XY)−μXμY
(3).
V(aX)=E((aX)2)−(aμX)2=E(a2X2)−a2μX2=a2E(X2)−a2μX2=a2(E(X2)−μX2)=a2V(X)
(4).
V(X±Y)=E((X±Y)2)−(μX±μY)2=E(X2±2XY+Y2)−(μX2±2μXμY+μy2)=E(X2)−μX2+E(Y2)−μY2±2(E(XY)−μXμY)=V(X)+V(Y)±2(E(XY)−μXμY)=V(X)+V(Y)±2COV(X,Y)
矩阵乘积迹的微分
这里我们将对两个公式进行证明。
(1).
dAd(tr(AB))=BT
证明:
给定两个矩阵A(m×n)和B(n×m),它们的乘积为
AB=⎣⎡a11⋮am1⋯⋱⋯a1n⋮amn⎦⎤⎣⎡b11⋮bn1⋯⋱⋯b1m⋮bnm⎦⎤=⎣⎡∑i=1na1ibi1⋮∑i=1namibi1⋯⋱⋯∑i=1na1ibim⋮∑i=1namibim⎦⎤
矩阵AB的迹tr(AB)为它的主对角线元素之和:
tr(AB)=i=1∑na1ibi1+⋯+i=1∑namibim=i=1∑nj=1∑majibij
对迹tr(AB)求微分
∂A∂tr(AB)=⎣⎡∂a11∂(∑i=1n∑j=1majibij)⋮∂am1∂(∑i=1n∑j=1majibij)⋯⋱⋯∂a1n∂(∑i=1n∑j=1majibij)⋮∂amn∂(∑i=1n∑j=1majibij)⎦⎤=⎣⎡b11⋮b1m⋯⋱⋯bn1⋮bnm⎦⎤=BT
(2).
dAd(tr(ABAT))=2AB
其中B为对称矩阵。
证明:
给定两个矩阵A(m×n)和B(n×m),
ABAT=⎣⎡a11⋮am1⋯⋱⋯a1n⋮amn⎦⎤⎣⎡b11⋮bn1⋯⋱⋯b1n⋮bnn⎦⎤⎣⎡a11⋮a1n⋯⋱⋯am1⋮amn⎦⎤=⎝⎛⎣⎡∑i=1na1ibi1⋮∑i=1namibi1⋯⋱⋯∑i=1na1ibin⋮∑i=1namibin⎦⎤⎠⎞⎣⎡a11⋮a1n⋯⋱⋯am1⋮amn⎦⎤=⎣⎡∑j=1n∑i=1na1ibija1j⋮∑j=1n∑i=1namibija1j⋯⋱⋯∑j=1n∑i=1na1ibijamj⋮∑j=1n∑i=1namibijamj⎦⎤
矩阵ABAT的迹tr(ABAT)是它的主对角线元素之和:
tr(ABAT)=j=1∑ni=1∑na1ibija1j+⋯+j=1∑ni=1∑namibijamj=k=1∑mj=1∑ni=1∑nakibijakj
对迹tr(ABAT)求微分
∂A∂tr(ABAT)=⎣⎡∂a11∂(∑k=1n∑j=1n∑i=1nakibijakj)⋮∂am1∂(∑k=1n∑j=1n∑i=1nakibijakj)⋯⋱⋯∂a1n∂(∑k=1n∑j=1n∑i=1nakibijakj)⋮∂amn∂(∑k=1n∑j=1n∑i=1nakibijakj)⎦⎤=⎣⎡∑j=1nb1ja1j+∑i=1na1ibi1⋮∑j=1nb1jamj+∑i=1namibi1⋯⋱⋯∑j=1nbnja1j+∑i=1na1ibin⋮∑j=1nbnjamj+∑i=1namibin⎦⎤=⎣⎡∑j=1na1jb1j⋮∑j=1namjb1j⋯⋱⋯∑j=1na1jbnj⋮∑j=1namjbnj⎦⎤+⎣⎡∑i=1na1ibi1⋮∑i=1namibi1⋯⋱⋯∑i=1na1ibin⋮∑i=1namibin⎦⎤=⎣⎡a11⋮am1⋯⋱⋯a1n⋮amn⎦⎤⎣⎡b11⋮b1n⋯⋱⋯bn1⋮bnn⎦⎤+⎣⎡a11⋮am1⋯⋱⋯a1n⋮amn⎦⎤⎣⎡b11⋮bn1⋯⋱⋯b1n⋮bnn⎦⎤=ABT+AB
因为矩阵B是对称矩阵,所以B=BT,可得
∂A∂tr(ABAT)=ABT+AB=AB+AB=2AB 

