

这是我参与「第四届青训营 」笔记创作活动的第8天
Presto 架构原理与优化介绍
大数据与OLAP的演进
大数据
关于大数据概念,这里参考马丁·希尔伯特的总结:大数据其实是在2000年后,因为信息化的快速发展。信息交换、信息存储、信息处理三个方面能力的大幅增长而产生的数据。
Hadoop
Hadoop是基于廉价机器的存算分离的大规模分布式处理系统
- 谷歌在2003、2004年发布Google File System论文、MapReduce论文
- 2008年,Hadoop成为apache顶级项目
OLAP
OLAP是对业务数据执行多维分析,并提供复杂计算,趋势分析和复杂数据建模的能力。是许多商务智能(BI)应用程序背后的技术
Mapreduce
Mapreduce代表了抽象的物理执行模型,使用门槛较高。
与Mapreduce Job相比,OLAP引擎常通过SQL的形势,为数据分析、数据开发人员提供统一的逻辑描述语言,实际的物理执行由具体的引擎进行转换和优化。
常见的OLAP引擎
- 预计算引擎:Kylin,Druid
- 批式处理引擎:Hive, Spark
- 流式处理引擎:Flink
- 交互式处理引擎:Presto,Clickhouse,Doris
Presto设计思想
Presto 最初是由Facebook研发的构建于Hadoop/HDFS系统之上的PB级交互式分析引擎,其具有如下的特点:
- 多租户任务的管理与调度
- 多数据源联邦查询
- 支持内存化计算
- Pipeline式数据处理
OLAP的核心概念
维度(Dimension) :维度是描述与业务主题相关的一组属性,单个属性或属性集合可以构成一个维。如时间、地理位置、年龄和性别等都是维度。
维的层次(Level of Dimension) :一个维往往可以具有多个层次,例如时间维度分为年、季度、月和日等层次,地区维可以是国家、地区、省、市等层次。这里的层次表示数据细化程度,对应概念分层。后面介绍的上卷操作就是由低层概念映射到高层概念。概念分层除了可以根据概念的全序和偏序关系确定外,还可以通过对数据进行离散化和分组实现。
维的成员(Member of Dimension) :若维是多层次的,则不同的层次的取值构成一个维成员。部分维层次同样可以构成维成员,例如“某年某季度”、“某季某月”等都可以是时间维的成员。
度量(Measure) :表示事实在某一个维成员上的取值。例如开发部门汉族男性有39人,就表示在部门、民族、性别三个维度上,企业人数的事实度量。
OLAP的基本操作
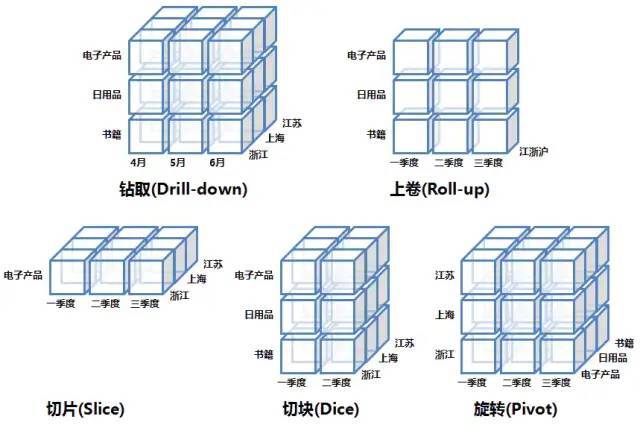
OLAP的操作是以查询——也就是数据库的SELECT操作为主,但是查询可以很复杂,比如基于关系数据库的查询可以多表关联,可以使用COUNT、SUM、AVG等聚合函数。OLAP正是基于多维模型定义了一些常见的面向分析的操作类型是这些操作显得更加直观。
OLAP的多维分析操作包括:钻取(Drill-down)、上卷(Roll-up)、切片(Slice)、切块(Dice)以及旋转(Pivot),下面还是以数据立方体为例来逐一解释下:
钻取(Drill-down) :在维的不同层次间的变化,从上层降到下一层,或者说是将汇总数据拆分到更细节的数据,比如通过对2010年第二季度的总销售数据进行钻取来查看2010年第二季度4、5、6每个月的消费数据,如上图;当然也可以钻取浙江省来查看杭州市、宁波市、温州市……这些城市的销售数据。
上卷(Roll-up) :钻取的逆操作,即从细粒度数据向高层的聚合,如将江苏省、上海市和浙江省的销售数据进行汇总来查看江浙沪地区的销售数据,如上图。
切片(Slice) :选择维中特定的值进行分析,比如只选择电子产品的销售数据,或者2010年第二季度的数据。
切块(Dice) :选择维中特定区间的数据或者某批特定值进行分析,比如选择2010年第一季度到2010年第二季度的销售数据,或者是电子产品和日用品的销售数据。
旋转(Pivot) :即维的位置的互换,就像是二维表的行列转换,如图中通过旋转实现产品维和地域维的互换。
Presto基础原理和概念
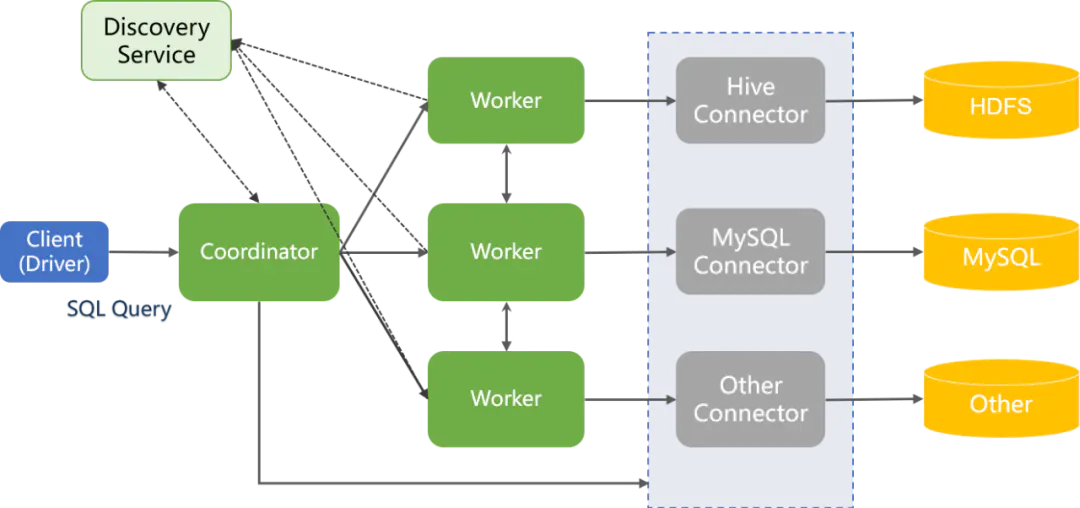
- Coordinator:解析SQL语句、生成执行计划、分发执行任务给Worker节点
- Worker:执行 Task处理数据、与其他Worker交互传输数据。
- Connector:一个Connector代表一种数据源。可以认为Connector是由Presto提供的适配多数据源的统一接口
- Catalog:管理元信息与实际数据的映射关系
Query
- Query:基于SQL parser后获得的执行计划
- Stage:根据是否需要shuffle将Query拆分成不同的subplan,每一个subplan便是一个stage
- Fragment:基本等价于Stage,属于在不同阶段的称呼,在本门课程可以认为两者等价
- Task:单个Worker节点上的最小资源管理单元:在一个节点上,一个Stage只有一个Task,一个Query可能由多个Task
- Pipeline:Stage按照LocalExchange切分成若干Operator集合,每个Operator集合定义一个Pipeline
- Driver:Pipeline的可执行实体,Pipeline和Driver的关系可类比程序和进程,是最小的执行单元,通过火山迭代模型执行每一个Operator
- Spilt:输入数据描述,数量上和Driver一一对应,不仅代表实际数据源spilt,也代表了不同stage传输的数据
- Operator:最小的物理算子
数据传输
- Exchange:表示不同Stage间的数据传输,大多数意义下等价于Shuffle
- LocalExchange:Stage内的rehash操作,常用于提高并行处理数据的能力(Task在Presto中只是最小的容器,而不是最小的执行单元)。LocalExchange的默认数值是16。
-
如何衡量某个任务某个Stage的真实并行度?
- 在不同的Pipeline下Split(Driver)的数目之和。
核心组件架构
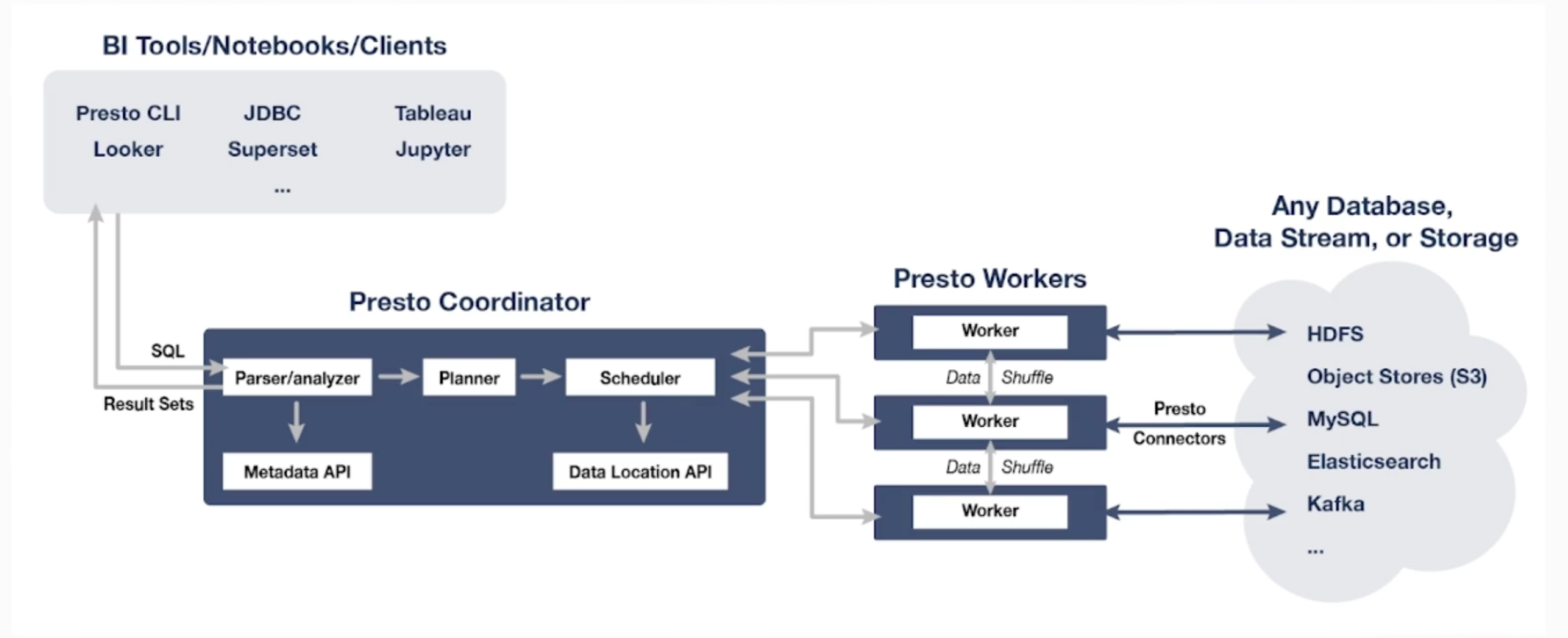
服务发现 Discovery Service
- Worker 配置文件配置 Discovery Service 地址
- Worker 节点启动后会向 Discovery Service 注册
- Coordiantor 从 Discovery Service 获取 Worker 的地址
Presto重要机制
多租户资源管理
Case
假设某个用户提交一个sql : 提交方式:Presto-cli 提交用户: zhangyanbing 提交SQL : select customer_ type, avg( cost) as a from test_ table group by customer_ type order by a limit 10;
Resouurce Group
- 类似Yarn多级队列的资源管理方式
- 基于CPU、MEMORY、SQL执行数进行资源使用量限制
- 优点:轻量的Query级别的多级队列资源管理模式
- 缺点:存在一定滞后性,只会对Group中正在运行的SQL进行判断
多租户下的任务调度
Stage调度
AllAtOnceExecutionPolicy:延迟点,会存在任务空跑
PhasedExecutionPolicy:有一定延迟、节省部分资源
典型的应用场景(join查询)
- Build端:右表构建用户join的hashtable
- Probe端:对用户左表数据进行探查,需要等待build端完成
Build端构建hashtable端时,probe端是一直在空跑的
Task调度
Task的数量如何确定:
- Source:根据数据meta决定分配多少个节点
- Fixed:hash partition count确定,如集群节点数量、
- Sink:汇聚结果,一台机器
- Scaled:无分区限制,可拓展,如write数据
- Coordinator_Only:只需要coordinator参与
选择什么样的节点(调度方式有那些):
- HARD_AFFINITY:计算、存储local模式,保障计算与存储在同一个节点,减少数据传输
- SOFT_AFFINITY:基于某些特定算法,如一致性HASH函数,常用于缓存场景,保证相似的Task调度到同一个Worker
- NO_PREFERENCE:随机选取,常用于普通的纯计算Task
Split调度
FIFO(先进先出) :顺序执行,绝对公平
优先级调度:快速响应
- 按照固定的时间片,轮询Split处理数据,处理1s,再重新选择一个Split执行。
- Split间存在优先级
MultilevelSplitQueue
- 5个优先级level理论上分配的时间占比为168421(2-based)
优势
- 优先保证小query快速执行
- 保障大queue存在固定比例的时间片,不会被完全饿死
内存计算
pipeline化的数据处理
- pipeline的引入更好的实现算子间的并行
- 语义上保证了每个task内的数据流式处理
Back Pressure Mechanism
- 控制split生成流程
- 控制operator的执行
- targetConcurrency auto-scale-out:定时检查,如果OutPutBuffers使用率低于0.5(下游消费较快,需要提高生产速度),并发度+1
- sink.max-buffer-size 写入 buffer 的大小控制:
exchange.max-buffer-size读取buffer的大小控制
达到最大值时operator会进入阻塞状态
多数据源联邦查询
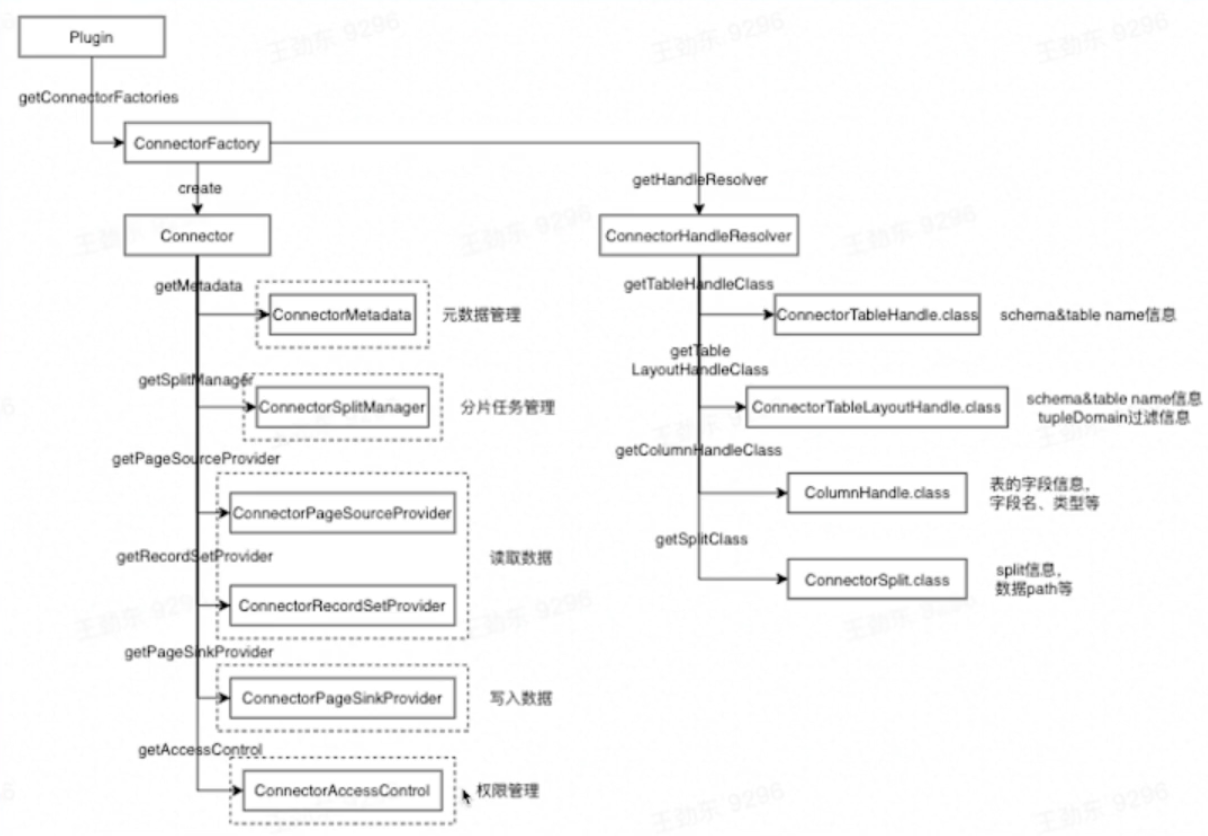
将各个数据源进行统一的抽象,最后由presto server进行统一的物理执行
局限性:
1.元数据管理与映射(每个connector管理一套元数据服务)
2.谓词下推
3.数据源分片
