逻辑回归
一、矢量理解
好好利用Python的Numpy模块的线性代数库、数值线性代数库。
1. 样例
-
简化累加:
- hθ(x)=j=0∑nθjxj=θTx.本质就是行向量乘列向量会得到一个数而非矩阵。
- Python语句如何表示?
-
简化梯度下降中的θ迭代:
-
θj:=θj−αm1∑i=1m(hθ(x(i))−y(i))xj(i)( for all j )
-
计算过程:
θ0θ1θ2:=θ0−αm1i=1∑m(hθ(x(i))−y(i))x0(i):=θ1−αm1i=1∑m(hθ(x(i))−y(i))x1(i):=θ2−αm1i=1∑m(hθ(x(i))−y(i))x2(i)
第 i 个样例的输出只有 y(i)一个,所以没有下标
-
简化思想:[重点在向量和常数相乘]
θ:=θ−αδ
其中 ,α为 学习率,δ=m1∑i=1m(hθ(x(i))−y(i))x(i),此处的 x(i)是一个向量,内含第 i 行数据中的 n + 1 (x0=1)个特征:
x0(i),x1(i),x2(i),......,xn(i),也即x(i)=⎣⎡x0(i)x1(i)x2(i)⎦⎤.
所以可以得出 δ 也是一个向量, δ=⎣⎡δ0δ1δ2⎦⎤,δ0=m1∑i=1m(hθ(x(i))−y(i))x0(i)
二、分类
-
概念:预测的值 y 是一个既定值(即预先知道结果是哪几种)。
-
例子:
- 邮件分类:垃圾/正常
- 线上交易:账户是否正常
- 肿瘤:良性/恶性
一般 “坏” 就是 阳性(positive), 也由 1 表示。
1. 分类中的线性回归
-
例子:肿瘤大小判断良性恶性
-
设定阈值来判别,生成一元函数,通过 x 对 y 的映射值是否大于 0.5 来判别其是否为良性
-
第一种情况
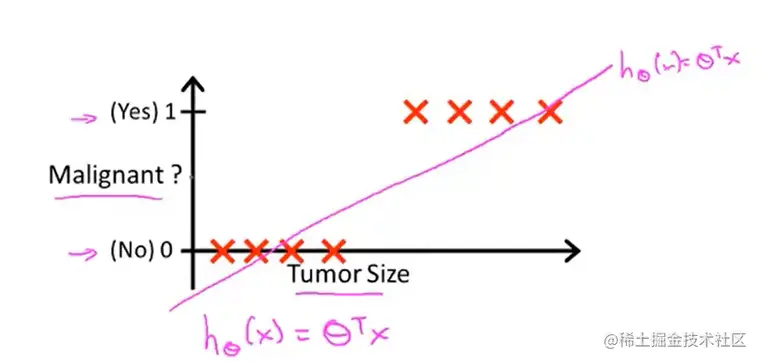
可以将此条线性直线的 对应 y = 0.5 的 x 值作为阈值,当 x >= 0.5 ,则为 y = 1, 阳 —— 恶性。
-
第二种情况
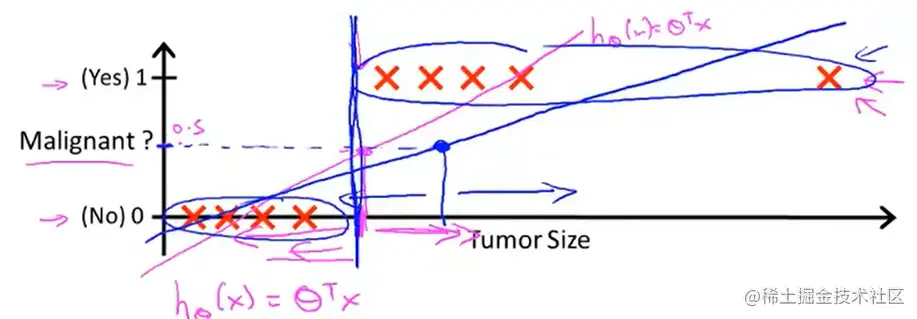
直线会因为一个噪声点而向平行于x轴的方向偏移,那么此时取 y = 0.5 对应的 x 只作为阈值的话,中间部分的点大部分都会判断为 y = 0,阴性,显然不正确。
可以看出线性回归并不适合于分类。而且如果 映射出来的 y 非常大,而对应的范围有十分有限的时候,这种假设就没有必要。
2. 假设陈述
-
问题背景:
需要将 hθ(x)的值限定在 [0, 1] 范围内,需要另外一种假设函数(非线性)。
hθ(x) = g(θTx),也就是利用向量乘法简化计算。
-
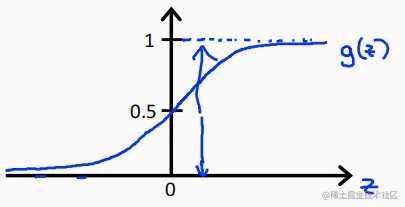
Sigmoid函数:
-
g(z) = 1 / (1 + e−z)。
-
图像如下:
-
输出解释
-
给出 在 输出为 x 的条件下,y = 1 的概率, θ 指的是模型的拟合数据。
例如,若x=[x0x1],hθ(x)=0.7,则表明 当 肿瘤尺寸为 x1的情况下,其为恶性的概率为 0.7.后面会继续讨论二分类模型的输出,一般是将概率较大者作为结果输出。
-
对于二分类问题:
- P( y = 0 | x, θ) + P( y = 1 | x, θ) = 1
- 移项可得:P( y = 0 | x, θ) = 1 - P( y = 1 | x, θ)
3. 决策界限
-
什么时候将 y 预测为 0 或 1?
-
思想:直接使用概率代替输出。预测 y = 1 的概率大于等于 0.5 ,则输出 y = 1,否则 y = 0。而使 y = 1 的概率为 0.5 的这个 z = θTx取值就是决策边界。如下:
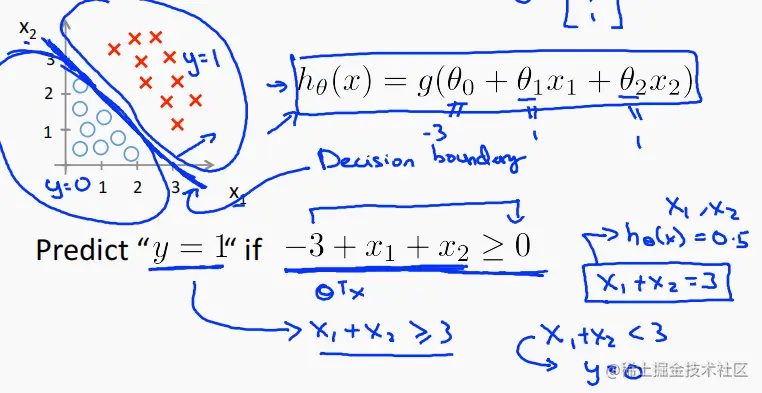
也就是 由 g 值 反推 x 的取值方式。就像上面说的,要取 y = 1作为输出,则 取 y = 1 的概率要 P(y = 1 |x;θ)> = 0.5。从而将 g = 0.5 作为界限, 而 g(z) = 1 / (1 + e−z),当且仅当 z = θTx = 0 时, g = 0.5。 所以直接 令θTx = 0 即可解出决策界限。
-
注意:决策边界是与数据集无关的,它只与假设函数有关。因为输入集中的 x 是不变的,θ 才是我们不断假设和解错的对象,也是假设函数得来源。
-
例子:[都是根据 θ值进行绘制的]
-
线性决策边界
hθ(x)=g(θ0+θ1x1+θ2x2),决策边界分析方式如上。
-
环状(非线性)
hθ(x)=g(θ0+θ1x1+θ2x2+θ3x12+θ4x22),决策边界的分析方式如上。

4. 代价函数
-
数据集
{(x(1),y(1)),(x(2),y(2)),(x(3),y(3)),......(x(m),y(m))},一共有 m 个样例,其中 x ∈ x=⎣⎡x0x1x2...xn⎦⎤,x0=1,y属于{0,1}
-
假设函数
将 z = θTx代入 g(z) = sigmoid(z) 中可得:hθ(x)=1+e−θTx1
-
如何选择θ?
-
代价函数:J(θ)=m1∑i=1mCost(hθ(x(i)),y(i))
-
Cost 函数的一般映射:
Cost(hθ(x),y)={−log(hθ(x))−log(1−hθ(x)) if y=1 if y=0,可以从图像上来理解
三、模型优化
1. 简化代价函数和梯度下降
-
逻辑回归的一般代价函数:
J(θ)=m1∑i=1mCost(hθ(x(i)),y(i))Cost(hθ(x),y)={−log(hθ(x))−log(1−hθ(x)) if y=1 if y=0 ,此处的 y 的值只能为 0 或 1。
-
如何用一个式子来替换上面 Cost 分段函数?
- 等式形式:Cost(h0(x),y)=−ylog(h0(x))−((1−y)logy(1−hθ(x))。
- 同理,利用(x1−a1)(x2−a2)......(xn−an)=0可以将任意段分段函数用一个式子表示。(当然此处的 x 一定要为整数)
- 推广:J(θ)=m1i=1∑mCost(hθ(x(i)),y(i))=−m1[i=1∑my(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))]
-
逻辑回归梯度下降
Gradient descent algorithm
J(θ)=−m1[∑i=1my(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))]
Want minθJ(θ):
Repeat{θj:=θj−α∑i=1m(hθ(x(i))−y(i))xj(i).(利用整个数据集来同时更新所有θ)
同样应该使用 矩阵 - 向量 来简化计算
-
注意:
因为假设函数不同,所以线性回归和逻辑回归之间并没有关系。
逻辑回归也可以使用特征缩放来预处理数据
2. 高级优化
主要来探寻更适合于 logistic regression 的迭代方法,这些方法也应更适合于之后的庞大特征数据集。
-
梯度下降分析
-
过程
给定 θ 利用代价函数算出 J(θ),利用偏导数来迭代 θ。
-
特点
求导过程运算量大,收敛慢,但是算法简单。
-
另外的一些迭代算法
- Conjugate gradient
- BFGS
- L-BFGS
这些算法的一些优点:① 不用选择学习率 α ② 迭代时间通常比梯度下降要高;缺点就是比较复杂。
-
举例
3. 多元分类 —— 一对多
不同与之前的logistic regression 输出只有两个值,这里的多元分类要对应 3 个 及以上。
-
引言
-
应用举例:
邮件标签:工作、朋友、家庭、爱好
医疗诊断:健康、受凉、流感
天气:晴朗、多云、雨天、下雪
-
处理思想:
将多元分类分为若干个二元分类的子问题(是或不是,类似于决策树)
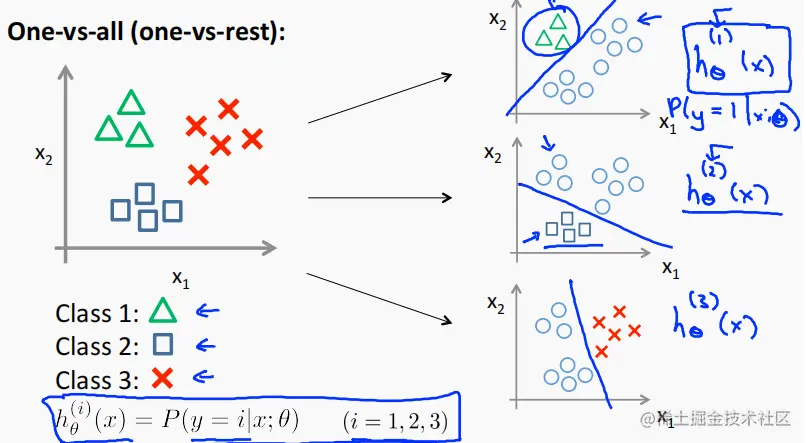
也就是对每一个特征进行 “是” 或 “不是”的假设,分别计算其概率。
-
处理步骤:
- 训练一个逻辑回归分类器 hθ(i)(x),对每个 i 值分类 进行 y = i的概率预测
- 对输入值 x 使用该分类器得出结果,并将概率最大值 i 作为最终结果 输出


